第8讲、Multi-Head Attention 的核心机制与实现细节
🤔 为什么要有 Multi-Head Attention?
单个 Attention 机制虽然可以捕捉句子中不同词之间的关系,但它只能关注一种角度或模式。
Multi-Head 的作用是:
多个头 = 多个视角同时观察序列的不同关系。
例如:
- 一个头可能专注主语和动词的关系;
- 另一个头可能专注宾语和介词;
- 还有的可能学习句法结构或时态变化。
这些头的表示最终会被拼接(concatenate)后再线性变换整合成更丰富的上下文表示。
🔍 技术深入:Multi-Head Attention 计算过程
Multi-Head Attention 的计算过程如下:
- 对输入 X 进行线性变换得到 Q、K、V 矩阵
- 将 Q、K、V 分割成 h 个头
- 每个头独立计算 Attention
- 拼接所有头的输出
- 最后进行一次线性变换
# 伪代码实现
def multi_head_attention(X, h=8):# 线性变换获得 Q, K, VQ = X @ W_q # [batch_size, seq_len, d_model]K = X @ W_kV = X @ W_v# 分割成多头Q_heads = split_heads(Q, h) # [batch_size, h, seq_len, d_k]K_heads = split_heads(K, h)V_heads = split_heads(V, h)# 每个头独立计算 attentionattn_outputs = []for i in range(h):attn_output = scaled_dot_product_attention(Q_heads[:, i], K_heads[:, i], V_heads[:, i])attn_outputs.append(attn_output)# 拼接所有头的输出concat_output = concatenate(attn_outputs) # [batch_size, seq_len, d_model]# 最后的线性变换output = concat_output @ W_oreturn output
🧮 如何判断多少个头(h)?
Transformer 默认将 d_model(模型维度)均分给每个头。
设:
d_model = 512:模型的总嵌入维度h = 8:头数
那么每个头的维度为:
d_k = d_model // h = 512 // 8 = 64
一般要求:
⚠️
d_model必须能被h整除。
📊 参数计算
Multi-Head Attention 中的参数量:
- 输入投影矩阵:3 × (d_model × d_model) = 3d_model²
- 输出投影矩阵:d_model × d_model = d_model²
总参数量:4 × d_model²
例如,当 d_model = 512 时,参数量约为 100 万。
📌 头的数量怎么选?
头数 h | 每头维度 d_k | 适用情境 |
|---|---|---|
| 1 | 全部 | 基线,最弱(没多视角) |
| 4 | 中等 | 小模型,如 tiny Transformer |
| 8 | 64 | 标准配置,如原始 Transformer |
| 16 | 更细粒度 | 大模型中常见,如 BERT-large |
实际训练中:
- 小任务(toy 或翻译教学):用 2 或 4 个头就够了。
- 真实 NLP 任务:建议使用 8 个头(Transformer-base 规范)。
- 太多头而模型参数不足时,效果可能反而下降(每头维度太小)。
📈 头数与性能关系
研究表明,头数与模型性能并非简单的线性关系:
- 头数过少:无法捕捉多种语言模式
- 头数适中:性能最佳
- 头数过多:每个头的维度变小,表达能力下降

🔬 实验发现
Michel et al. (2019) 的研究《Are Sixteen Heads Really Better than One?》发现:
- 在训练好的模型中,并非所有头都同等重要
- 大多数情况下,可以剪枝掉一部分头而不显著影响性能
- 不同层的头有不同的作用,底层头和顶层头往往更为重要
💡 Multi-Head Attention 的优势
- 并行计算:所有头可以并行计算,提高训练效率
- 多角度表示:捕捉不同类型的依赖关系
- 信息冗余:多头提供冗余信息,增强模型鲁棒性
- 注意力分散:防止单一头过度关注某些模式
🧠 总结一句话
Multi-Head 的本质是多角度捕捉词与词的关系,提升模型对上下文的理解能力。头数越多,观察角度越多,但每个头的维度会减小,需注意平衡。
📊 Attention 可视化
不同头学习到的注意力模式各不相同。以下是一个英语句子在 8 头注意力机制下的可视化示例:

可以看到:
- 头1:关注相邻词的关系
- 头2:捕捉主语-谓语关系
- 头3:识别句法结构
- 头4:连接相关实体
- 其他头:各自专注于不同的语言特征
这种多角度的观察使得 Transformer 能够全面理解文本的语义和结构。
🖥️ Streamlit 交互式可视化案例
想要直观地理解 Multi-Head Attention?以下是一个使用 Streamlit 构建的交互式可视化案例,让你可以实时探索不同头的注意力模式:
import streamlit as st
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import seaborn as sns
from transformers import BertTokenizer, BertModel# 页面设置
st.set_page_config(page_title="Multi-Head Attention 可视化", layout="wide")
st.title("Multi-Head Attention 可视化工具")# 加载预训练模型
@st.cache_resource
def load_model():tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese', output_attentions=True)return tokenizer, modeltokenizer, model = load_model()# 用户输入
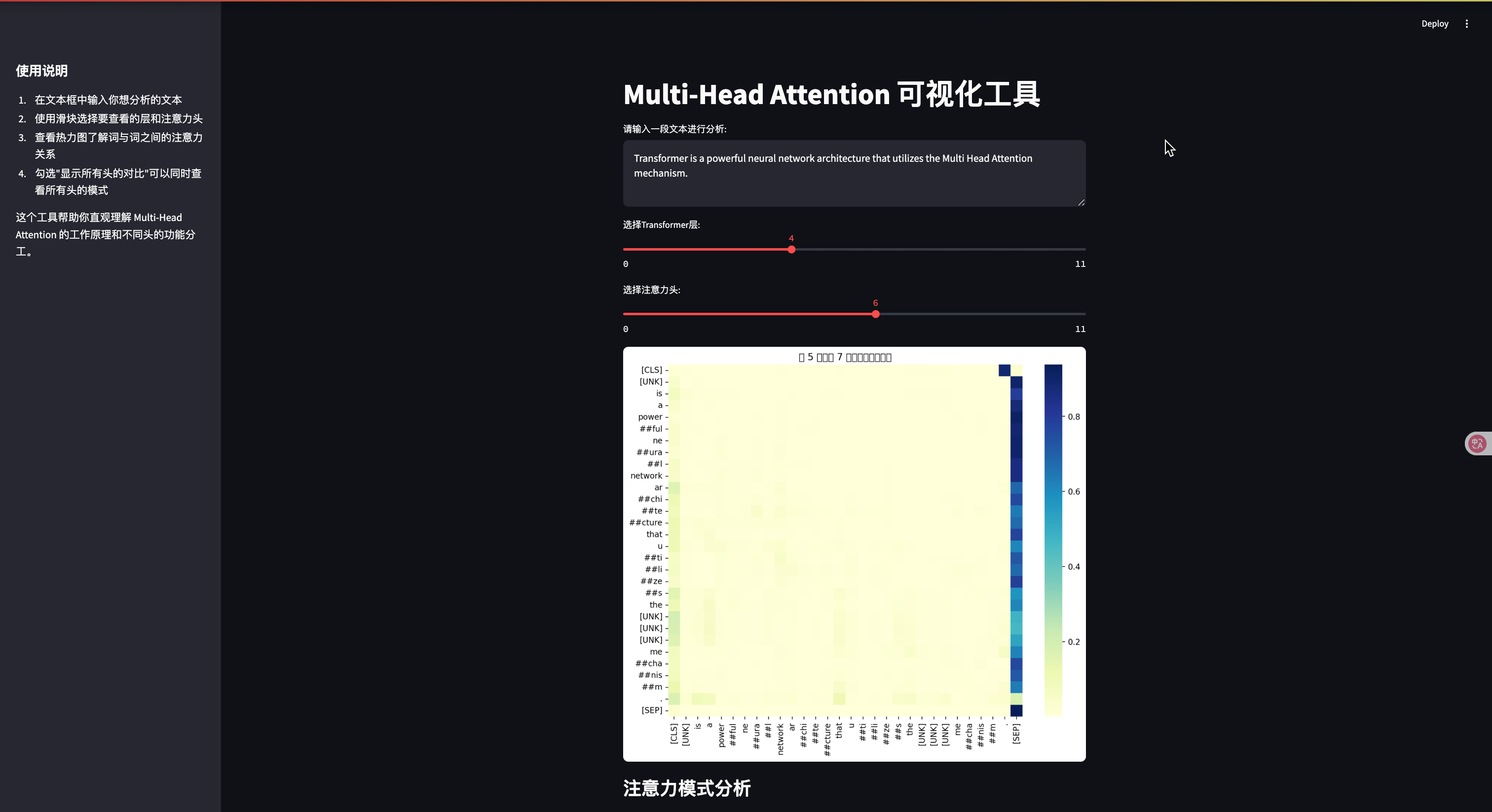
user_input = st.text_area("请输入一段文本进行分析:", "Transformer是一种强大的神经网络架构,它使用了Multi-Head Attention机制。",height=100)# 处理文本
if user_input:# 分词并获取注意力权重inputs = tokenizer(user_input, return_tensors="pt")outputs = model(**inputs)# 获取所有层的注意力权重attentions = outputs.attentions # tuple of tensors, one per layer# 选择层layer_idx = st.slider("选择Transformer层:", 0, len(attentions)-1, 0)# 获取选定层的注意力权重layer_attentions = attentions[layer_idx].detach().numpy()# 获取头数num_heads = layer_attentions.shape[1]# 选择头head_idx = st.slider("选择注意力头:", 0, num_heads-1, 0)# 获取选定头的注意力权重head_attention = layer_attentions[0, head_idx]# 获取标记tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])# 可视化fig, ax = plt.subplots(figsize=(10, 8))sns.heatmap(head_attention, xticklabels=tokens, yticklabels=tokens, cmap="YlGnBu", ax=ax)plt.title(f"第 {layer_idx+1} 层,第 {head_idx+1} 个头的注意力权重")st.pyplot(fig)# 显示注意力模式分析st.subheader("注意力模式分析")# 计算每个词的平均注意力avg_attention = head_attention.mean(axis=0)top_indices = np.argsort(avg_attention)[-3:][::-1]st.write("这个注意力头主要关注的词:")for idx in top_indices:st.write(f"- {tokens[idx]}: {avg_attention[idx]:.4f}")# 添加交互式功能if st.checkbox("显示所有头的对比"):st.subheader("所有头的注意力对比")# 为每个头创建一个小型热力图# 计算行列数以适应任意数量的头num_cols = 4num_rows = (num_heads + num_cols - 1) // num_cols # 向上取整fig, axes = plt.subplots(num_rows, num_cols, figsize=(15, 3*num_rows))axes = axes.flatten()for h in range(num_heads):sns.heatmap(layer_attentions[0, h], xticklabels=[] if h < (num_heads-num_cols) else tokens, yticklabels=[] if h % num_cols != 0 else tokens, cmap="YlGnBu", ax=axes[h])axes[h].set_title(f"头 {h+1}")# 隐藏未使用的子图for h in range(num_heads, len(axes)):axes[h].axis('off')plt.tight_layout()st.pyplot(fig)# 添加解释st.markdown("""### 如何解读这个可视化:- 颜色越深表示注意力权重越高- 纵轴代表查询词(当前词)- 横轴代表键词(被关注的词)- 每个头学习不同的关注模式通过调整滑块,你可以探索不同层和不同头的注意力模式,观察模型如何理解文本中的关系。""")# 运行说明
st.sidebar.markdown("""
## 使用说明1. 在文本框中输入你想分析的文本
2. 使用滑块选择要查看的层和注意力头
3. 查看热力图了解词与词之间的注意力关系
4. 勾选"显示所有头的对比"可以同时查看所有头的模式这个工具帮助你直观理解 Multi-Head Attention 的工作原理和不同头的功能分工。
""")# 代码说明
with st.expander("查看完整代码实现"):st.code("""
import streamlit as st
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import seaborn as sns
from transformers import BertTokenizer, BertModel# 页面设置
st.set_page_config(page_title="Multi-Head Attention 可视化", layout="wide")
st.title("Multi-Head Attention 可视化工具")# 加载预训练模型
@st.cache_resource
def load_model():tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')model = BertModel.from_pretrained('bert-base-chinese', output_attentions=True)return tokenizer, modeltokenizer, model = load_model()# 用户输入和可视化逻辑
# ...此处省略,与上面代码相同
""")### 🚀 如何运行这个可视化工具1. 安装必要的依赖:
```bash
pip install streamlit torch transformers matplotlib seaborn
-
将上面的代码保存为
attention_viz.py -
运行 Streamlit 应用:
streamlit run attention_viz.py

这个交互式工具让你可以:
- 输入任意文本并查看注意力分布
- 选择不同的 Transformer 层和注意力头
- 直观对比不同头学习到的不同模式
- 分析哪些词获得了最高的注意力权重
通过这个可视化工具,你可以亲自探索 Multi-Head Attention 的工作原理,加深对这一机制的理解。
相关文章:

第8讲、Multi-Head Attention 的核心机制与实现细节
🤔 为什么要有 Multi-Head Attention? 单个 Attention 机制虽然可以捕捉句子中不同词之间的关系,但它只能关注一种角度或模式。 Multi-Head 的作用是: 多个头 多个视角同时观察序列的不同关系。 例如: 一个头可能专…...

【发票提取表格】批量PDF电子发票提取明细保存到Excel表格,批量提取ODF电子发票明细,行程单明细,单据明细保存到表格,使用步骤、详细操作方法和注意事项
在日常办公中,我们常常会面临从大量 PDF 电子发票、ODF 电子发票、行程单及各类单据中提取明细,并整理到 Excel 表格的艰巨任务。手动操作不仅耗时费力,还极易出错。以下为您详细介绍其使用步骤、操作方法、注意事项及应用场景。 一、适用场…...
React中startTransition的使用
// 引入 React 的 Hook API:useState 管理状态、useTransition 处理非紧急更新、useMemo 缓存计算结果 import { useState, useTransition, useMemo } from react;/*** List 组件:* 根据输入的 query 动态渲染一个包含 10000 条数据的列表*/ function Li…...
)
Reactor (epoll实现基础)
Reactor 是什么? Reactor 网络模型是一种高性能的事件驱动模型,广泛应用于网络编程中。它通过 I/O 多路复用技术,实现了高效的事件处理和系统吞吐量的优化。 核心概念 Reactor 模型_的核心是事件驱动,即当 I/O 事件准备就绪时_…...

php fiber 应用
参考 基于 PHP Fiber(纤程)的游戏开发分析-腾讯云开发者社区-腾讯云PHP 8.1 引入的 Fibers 为游戏开发带来新机遇,能管理渲染、物理计算等任务且不阻塞主线程。它支持并发,提升效率,简单易用,但也有局限&a…...

前端扫盲HTML
文章目录 下载、安装、运行第一个代码(hello world)创建代码文件编辑代码(hello world)HTML常见标签注释标签标题标签段落标签换行标签格式化标签图片标签表格标签列表标签表单标签下拉菜单无语义标签 参考文档 下载、安装、运行第…...

RAG与微调:企业知识库落地的技术选型
从本质上看,RAG是"让模型查阅外部知识",而微调是"让模型学会并内化知识"。这一根本差异决定了它们在不同场景下的适用性。 技术选型的关键依据 场景RAG微调说明模型定制化需求❌✅微调更适合塑造特定风格、口吻和人格特征硬件资源…...

Linux安全篇 --firewalld
一、Firewalld 防火墙概述 1、Firewalld 简介 firewalld 的作用是为包过滤机制提供匹配规则(或称为策略),通过各种不同的规则告诉netfilter 对来自指定源、前往指定目的或具有某些协议特征的数据包采取何种处理方式为了更加方便地组织和管理防火墙,firewalld 提供…...

关于Android Studio for Platform的使用记录
文章目录 简单介绍如何使用配置导入aosp工程配置文件asfp-config.json 简单介绍 Android Studio for Platform是google最新开发,用来阅读aosp源码的工具 详细的资料介绍: https://developer.android.google.cn/studio/platform 将工具下载下来直接点击…...

搜索引擎工作原理|倒排索引|query改写|CTR点击率预估|爬虫
写在前面 使用搜索引擎是我们经常做的事情,搜索引擎的实现原理。 什么是搜索引擎 搜索引擎是一种在线搜索工具,当用户在搜索框输入关键词时,搜索引擎就会将与该关键词相关的内容展示给用户。比较大型的搜索引擎有谷歌,百度&…...

【找工作系列①】【大四毕业】【复习】巩固JavaScript,了解ES6。
文章目录 前言Tasks:复习笔记:JavaScript是什么?JavaScript有什么用或者换句话说 是做什么的?JavaScript由哪几部分组成?BOM?DOM?html文件中script标签放在哪里?🧩 1. **放在 ****<head>**** 中**✅ 优点&…...

Oracle 11.2.0.4 pre PSU Oct18 设置SSL连接
Oracle 11.2.0.4 pre PSU Oct18 设置SSL连接 1 说明2 客户端配置jdk环境3服务器检查oracle数据库补丁4设置ssla 服务器配置walletb 上传测试脚本和配置文件到客户端c 服务器修改数据库侦听和sqlnet.orad 修改客户端的sqlnet.ora和tnsnames.ora的连接符e 修改java代码的数据连接…...
)
本地部署开源网盘系统 kiftd 并实现外部访问(Linux 版本)
kiftd 是一款专为个人、团队及小型组织设计的开源网盘系统,兼具便捷性、跨平台兼容性与丰富的功能,成为替代传统文件共享工具的理想选择。 本文将详细介绍如何在 Linux 系统本地部署 kiftd 并结合路由侠实现外网访问本地部署的 kiftd 。 第一步&#x…...

ECS/GEM是半导体制造业的标准通信协议中host和equipment的区别是什么,在交互过程中,如何来定位角色谁为host,谁为equipment
文章目录 一、角色定义与核心区别1. Host(主机)2. Equipment(设备)3. Host与Equipment的核心区别 二、交互过程中的角色定位1. 交互方向2. 控制层级3. 交互过程中角色的定位方法3.1. 通信发起方向3.2. 协议功能与状态管理3.3. 物理…...

5000 字总结CSS 中的过渡、动画和变换详解
CSS 中的过渡、动画和变换详解 一、CSS 过渡(Transitions) 1. 基本概念 CSS 过渡是一种平滑改变 CSS 属性值的机制,允许属性值在一定时间内从一个值逐渐变化到另一个值,从而创建流畅的动画效果。过渡只能用于具有中间值的属性&…...
)
2025年渗透测试面试题总结-安恒[实习]安全工程师(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 安恒[实习]安全工程师 一面 1. 自我介绍 2. 前两段实习做了些什么 3. 中等难度的算法题 4. Java的C…...

WebXR教学 09 项目7 使用python从0搭建一个简易个人博客
WebXR教学 09 项目7 使用python从0搭建一个简易个人博客(1) 前期设计规划 功能 呈现个人博客文章 技术选型 HTMLCSSJSPythonFlask 环境准备 VS Code Python3.8 代码实现 包 # 创建虚拟环境(-m 会先将模块所在路径加入 sys.path,更适…...
--异常处理,命名空间,多继承与虚继承)
c++从入门到精通(五)--异常处理,命名空间,多继承与虚继承
异常处理 栈展开过程: 栈展开过程沿着嵌套函数的调用链不断查找,直到找到了与异常匹配的catch子句为止;也可能一直没找到匹配的catch,则退出主函数后查找过程终止。栈展开过程中的对象被自动销毁。 在栈展开的过程中,…...

开源安全大模型Foundation-Sec-8B实操
一、兴奋时刻 此时此刻,晚上22点55分,从今天早上6点左右开始折腾,花费了接近10刀的环境使用费,1天的休息时间,总算是把Foundation-Sec-8B模型跑起来了,中间有两次胜利就在眼前,但却总在远程端口转发环节出问题,让人难受。直到晚上远程Jupyter访问成功那一刻,眉开眼笑,…...

现代优化算法全解析:禁忌搜索算法、模拟退火算法、遗传算法、蚁群优化算法、人工神经网络
现代优化算法全解析:禁忌搜索算法、模拟退火算法、遗传算法、蚁群优化算法、人工神经网络 引言:为什么需要优化算法? 在当今这个数据驱动的时代,优化算法已成为计算机科学、工程设计、人工智能等领域的核心工具。无论是训练神经…...

Docker常见命令解读
上图是对docker常见命令的一个图解,方便大家理解,下面,我将对这些命令做一些解释。 一、镜像生命周期管理 1. 镜像构建(Build) docker build -t my-image . # 根据Dockerfile构建镜像 Dockerfile:…...

为什么 Docker 建议关闭 Swap
在使用 Docker 时,关闭系统 Swap(交换分区) 是一个常见的推荐做法,尤其是在生产环境中。虽然 Docker 不强制要求禁用 Swap,但出于性能、稳定性、可控性和资源管理的目的,通常建议这样做。 为什么 Docker 建…...

TIFS2024 | CRFA | 基于关键区域特征攻击提升对抗样本迁移性
Improving Transferability of Adversarial Samples via Critical Region-Oriented Feature-Level Attack 摘要-Abstract引言-Introduction相关工作-Related Work提出的方法-Proposed Method问题分析-Problem Analysis扰动注意力感知加权-Perturbation Attention-Aware Weighti…...

WPS PPT设置默认文本框
被一个模板折磨了好久,每次输入文本框都是很丑的24号粗体还有行标,非常恶心,我甚至不知道如何描述自己的问题,非常憋屈,后来终于知道怎么修改文本框了。这种软件操作问题甚至不知道如何描述问题本身,非常烦…...

支持selenium的chrome driver更新到136.0.7103.94
最近chrome释放新版本:136.0.7103.94 如果运行selenium自动化测试出现以下问题,是需要升级chromedriver才可以解决的。 selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only su…...

“下一辆车还买小米”
大家好,我是小悟。 就在5月13日,江西上饶德兴街头,一辆紫色小米SU7 Max停在路边,却遭遇了一场堪比灾难片的意外。 一辆满载货物的大货车因手刹故障溜坡,径直撞向SU7,两车从两米高的落差坠落,货…...

opencv4.11生成ArUco标记 ArUco Marker
从opencv4.7开始aruco有了一些变化 以下是opencv4.11生成ArUco标记的小例子 #include <iostream> #include <opencv2/opencv.hpp> #include <opencv2/objdetect/aruco_detector.hpp>int main() {cv::Mat markerImage;cv::aruco::Dictionary dictionary cv…...

从辅助到协作:GitHub Copilot的进化之路
如果说现代程序员的标配工具除了VS Code、Stack Overflow之外,还有谁能入选,那一定是GitHub Copilot。从2021年首次亮相,到如今深度集成进开发者日常流程,这个“AI编程助手”已经不只是写几行自动补全代码的小帮手了,而…...
功能详解(实战部分))
QMK 宏(Macros)功能详解(实战部分)
QMK 宏(Macros)功能详解(实战部分) 一、宏的基本概念与作用 宏(Macros)是 QMK 固件中一项强大的功能,它允许您在按下单个按键时执行多个按键操作。通过宏,您可以: 输入常用短语或文本执行复杂的按键组合自动化重复性操作触发系统功能或快捷键🔔 安全提示:虽然可以…...

SVN 版本控制入门指南
SVN 版本控制系统详细入门指南 一、SVN 基础概念详解 1. 什么是版本控制? 版本控制是一种记录文件变化的系统,可以: 追踪文件的修改历史查看每次修改的内容恢复到任意历史版本协调多人协作开发 2. SVN 核心概念 2.1 仓库(Re…...

6to4、6over4的类比解释
本文由deepseek生成,特此声明 1. 6to4:自动的“快递中转站” 类比场景: 假设你住在一个偏远的小镇(IPv6网络),周围被大海(IPv4互联网)包围,你想给另一个偏远小镇&#…...

跨国应用程序的数据存储方案常见的解决方案
一、数据隐私与合规性 跨国数据存储方案必须遵守不同国家和地区的数据隐私法律和规定,例如: GDPR(欧盟一般数据保护条例)CCPA(加利福尼亚消费者隐私法案)各国的本地数据存储法规解决方案: 采用本地化存储:在不同国家或地区设立数据存储中心,以遵循当地的法律和隐私要…...
)
JSP链接MySQL8.0(Eclipse+Tomcat9.0+MySQL8.0)
所用环境 Eclipse Tomcat9.0 MySQL8.0.21(下载:MySQL Community Server 8.0.21 官方镜像源下载 | Renwole) mysql-connector-java-8.0.21(下载:MySQL :: Begin Your Download) .NET Framework 4.5.2(下…...
基于KAN+Transformer的专业领域建模方法论
一、专业领域KAN方法创新路径 1. 领域函数分解策略 数学建模:针对专业领域特性设计专用基函数组合 医学影像:采用小波变换基函数分解图像特征 class WaveletKAN(nn.Module): def __init__(self): self.wavelet_basis nn.Par…...

Go语言 Gin框架 使用指南
Gin 是一个用 Go (Golang) 编写的 Web 框架。 它具有类似 martini 的 API,性能要好得多,多亏了 httprouter,速度提高了 40 倍。 如果您需要性能和良好的生产力,您一定会喜欢 Gin。Gin 相比于 Iris 和 Beego 而言,更倾向…...

内容安全:使用开源框架Caffe实现上传图片进行敏感内容识别
上传图片进行敏感内容识别 预览效果 环境准备 Ubuntu 16.04python 2.7.12caffe 1.0.0 安装调试环境: sudo apt-get update sudo apt-get install -y --no-install-recommends build-essential cmake git wget libatlas-base-dev libboost-all-dev libgflags-dev sudo apt-g…...
策略)
缓慢变化维度(SCD)策略
缓慢变化维度(SCD)策略 缓慢变化维度(SCD)策略是数据仓库中处理维度属性随时间变化的核心技术,根据业务需求的不同,主要分为以下类型: 1. SCD Type 0(固定维度) 定义&a…...

【Mysql】详解InnoDB存储引擎以及binlog,redelog,undolog+MVCC
1.InnoDB存储引擎 在Mysql中,InnoDB存储引擎是默认的,也是我们最常用的一个存储引擎,其中分为内存结构和磁盘结构两大部分,整体架构图如下: 1.1Buffer Pool Buffer pool(缓存区)是Mysql内存的一个主要区域࿰…...

面向对象详解和JVM底层内存分析
神速熟悉面向对象 表格结构和类结构 我们在现实生活中,思考问题、发现问题、处理问题,往往都会用“表格”作为工具。实际上,“表格思维”就是一种典型的面向对象思维。 实际上,互联网上所有的数据本质上都是“表格”。我们在这里…...
:内存和地址、指针变量和地址、指针变量类型的意义、指针运算)
C语言指针深入详解(一):内存和地址、指针变量和地址、指针变量类型的意义、指针运算
目录 一、内存和地址 (一)内存 (二)如何理解编址 二、指针变量和地址 (一)取地址操作符(&) (二)指针变量和解引用操作符(*)…...

MATLAB中进行深度学习网络训练的模型评估步骤
文章目录 前言环境配置一、基础性能评估二、高级评估指标三、模型解释与可视化四、交叉验证与模型选择五、部署前的优化 前言 在 MATLAB 中进行深度学习网络训练后的模型评估是确保模型性能和可靠性的关键环节。以下是详细的评估步骤和方法。 环境配置 MATLAB下载安装教程&…...

30、WebAssembly:古代魔法——React 19 性能优化
一、符文编译术(编译优化) 1. 语言选择与量子精简 // Rust编译优化 cargo build --target wasm32-wasi --release 魔法特性: • 选择低运行时开销语言(如Rust/C),编译后文件比Swift小4倍 • --rel…...

Python集合运算:从基础到进阶全解析
Python基础:集合运算进阶 文章目录 Python基础:集合运算进阶一、知识点详解1.1 集合运算(运算符 vs 方法)1.2 集合运算符优先级1.3 集合关系判断方法1.4 方法对比 二、说明示例2.1 权限管理系统2.2 数据去重与差异分析2.3 数学运算…...

【开源Agent框架】Suna架构设计深度解析与应用实践
一、项目基本介绍 Suna是一款全栈开源的通用型AI代理系统,其名称源自日语"砂"的发音,寓意如流沙般渗透到各类数字任务中。项目采用Apache 2.0协议,由Kortix AI团队维护,核心开发者包括Adam Cohen Hillel等三位主要贡献者。 技术架构全景 系统由四大核心组件构…...

C++类与对象--2 对象的初始化和清理
C面向对象来源于生活,每个对象都有初始化设置和销毁前的清理数据的设置。 2.1 构造函数和析构函数 (1)构造函数 初始化对象的成员属性不提供构造函数时,编译器会提供不带参数的默认构造函数,函数实现是空的构造函数不…...
)
计网| 网际控制报文协议(ICMP)
目录 网际控制报文协议(ICMP) 一、ICMP 基础特性 二、ICMP 报文分类及作用 差错报告报文 询问报文 网际控制报文协议(ICMP) ICMP(Internet Control Message Protocol,网际控制报文协议)是 …...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

printf耗时高的原因
背景:设备升级初始化失败。具体表现为:app在启动dsp后,需在15秒内与其建立连接以确认通信成功,但当前未能在此时间限制内完成连接。 排查过程:通过在初始化过程中添加耗时打印,发现各阶段耗时虽不高&#…...

20250517 我设想一个空间,无限大,空间不与其中物质进行任何作用,甚至这个空间能容纳可以伸缩的空间
1.我设想一个空间,无限大,空间不与其中物质进行任何作用,甚至这个空间能容纳可以伸缩的空间 您设想的这个空间具有一些有趣的特点: 无限大:空间本身没有边界或限制,理论上可以容纳无限多的物质或结构。非…...
)
GO语言学习(二)
GO语言学习(二) method(方法) 这一节我们介绍一下GO语言的面向对象,之前我们学习了struct结构体,现在我们来解释一下方法method主要是为了简化代码,在计算同类时,使用函数接收方法…...