TIFS2024 | CRFA | 基于关键区域特征攻击提升对抗样本迁移性
Improving Transferability of Adversarial Samples via Critical Region-Oriented Feature-Level Attack
- 摘要-Abstract
- 引言-Introduction
- 相关工作-Related Work
- 提出的方法-Proposed Method
- 问题分析-Problem Analysis
- 扰动注意力感知加权-Perturbation Attention-Aware Weighting
- 区域 ViT 关键检索-Region ViT-Critical Retrieval
- 损失函数-Loss Functions
- 实验-Experiments
- 讨论-Discussion
- 结论-Conclusion

论文链接
本文 “Improving Transferability of Adversarial Samples via Critical Region-Oriented Feature-Level Attack” 提出基于关键区域的特征级攻击(CRFA)方法提升对抗样本迁移性,包括扰动注意力感知加权(PAW)和区域 ViT 关键检索(RVR)。PAW 通过生成近似注意力图加权对抗扰动,减少对模型注意力的改变,提升跨模型迁移性,尤其是在攻击多目标图像时效果显著;RVR 搜索对 ViT 输出有重要影响的关键 patch,引入 ViT 先验知识,提高对抗样本在 ViT 上的跨架构迁移性。实验表明,CRFA 生成的对抗样本在 CNN 和 ViT 模型上,相比现有特征级攻击方法,愚弄率分别提高了 19.9% 和 25.0% ,视觉质量更优,验证了该方法的有效性。
摘要-Abstract
Deep neural networks (DNNs) have received a lot of attention because of their impressive progress in computer vision. However, it has been recently shown that DNNs are vulnerable to being spoofed by carefully crafted adversarial samples. These samples are generated by specific attack algorithms that can obfuscate the target model without being detected by humans. Recently, feature-level attacks have been the focus of research due to their high transferability. Existing state-of-the-art feature-level attacks all improve the transferability by greedily changing the attention of the model. However, for images that contain multiple target class objects, the attention of different models may differ significantly. Thus greedily changing attention may cause the adversarial samples corresponding to these images to fall into the local optimum of the surrogate model. Furthermore, due to the great structural differences between vision transformers (ViTs) and convolutional neural networks (CNNs), adversarial samples generated on CNNs with feature-level attacks are more difficult to successfully attack ViTs. To overcome these drawbacks, we perform the Critical Region-oriented Feature-level Attack (CRFA) in this paper. Specifically, we first propose the Perturbation Attention-aware Weighting (PAW), which destroys critical regions of the image by performing feature-level attention weighting on the adversarial perturbations without changing the model attention as much as possible. Then we propose the Region ViT-critical Retrieval (RVR), which enables the generator to accommodate the transferability of adversarial samples on ViTs by adding extra prior knowledge of ViTs to the decoder. Extensive experiments demonstrate significant performance improvements achieved by our approach, i.e., improving the fooling rate by 19.9% against CNNs and 25.0% against ViTs as compared to state-of-the-art feature-level attack method.
深度神经网络(DNNs)因其在计算机视觉领域取得的显著进展而备受关注。然而,最近研究表明,DNNs容易受到精心制作的对抗样本的欺骗。这些样本由特定的攻击算法生成,能够迷惑目标模型且不易被人类察觉。近年来,特征级攻击因其较高的迁移性成为研究热点。现有的前沿特征级攻击方法均通过贪婪地改变模型的注意力来提高迁移性。然而,对于包含多个目标类对象的图像,不同模型的注意力可能存在显著差异。因此,贪婪地改变注意力可能会导致对应这些图像的对抗样本陷入代理模型的局部最优解。此外,由于视觉 Transformer(ViTs)和卷积神经网络(CNNs)在结构上存在巨大差异,通过特征级攻击在 CNNs 上生成的对抗样本更难成功攻击 ViTs。为克服这些缺点,本文提出了基于关键区域的特征级攻击(CRFA)。具体而言,我们首先提出了扰动注意力感知加权(PAW)方法,该方法通过对对抗扰动进行特征级注意力加权来破坏图像的关键区域,同时尽可能不改变模型的注意力。然后,我们提出了区域 ViT 关键检索(RVR)方法,通过向解码器添加 ViTs 的额外先验知识,使生成器能够适应对抗样本在 ViTs 上的迁移性。大量实验表明,我们的方法在性能上有显著提升,与最先进的特征级攻击方法相比,对 CNNs 的愚弄率提高了19.9%,对 ViTs 的愚弄率提高了25.0%.
引言-Introduction
这部分内容主要介绍了研究背景和动机,具体如下:
- DNNs的广泛应用与安全问题:近年来,DNNs 在图像分类、分割、检索等众多视觉任务中得到广泛应用且表现出色。随着物联网、软件开发等领域对安全问题的深入探索,DNNs 的鲁棒性备受关注。研究发现,DNNs 易受对抗样本欺骗,这些样本由恶意添加的精心设计的扰动产生,难以被察觉却能使模型输出错误结果。因此,对抗攻击在人脸识别、工业系统、自动驾驶等领域受到高度关注,同时也为神经网络的可解释性和鲁棒性研究提供了思路。
- 对抗攻击的分类:根据攻击者对模型信息的获取程度,对抗攻击可分为白盒攻击和黑盒攻击。白盒攻击中攻击者能获取目标模型的结构和参数;而在现实应用中,DNNs 多部署在黑盒环境下,目标模型未知,所以黑盒攻击更具实际意义。黑盒攻击又可大致分为基于查询的攻击和基于迁移的攻击。基于查询的攻击通过向目标模型发送查询获取概率向量或硬标签来生成对抗样本,但在现实中大量查询往往受限。基于迁移的攻击则利用对抗样本的跨模型迁移性,在代理模型上生成对抗样本并直接攻击目标模型,受到越来越多的关注 。
- 现有攻击方法的局限性与特征级攻击的发展:传统攻击方法(如 FGSM、PGD、BIM 等)生成的对抗样本在代理模型上常出现过拟合问题,导致跨模型迁移性受限。以往方法通过在对抗样本优化过程中添加额外操作来缓解过拟合,也有一些方法在特征空间设计对抗扰动,即特征级攻击。特征级攻击利用模型内部特征信息,由于影响图像类别的关键特征在不同模型间有较高重叠,该方法在提高对抗样本跨模型迁移性方面展现出潜力。早期特征级攻击(如 NRDM、TAP)不加区分地扭曲目标模型内部特征,过度强调非关键特征,使生成的对抗样本易陷入代理模型的局部最优,阻碍了迁移性。近期的一些方法(如 FIA、NAA)虽提出了衡量特征重要性的方法,但对于包含多个目标对象的图像,不同模型的注意力差异较大,修改后的注意力区域可能与目标模型不匹配,导致对抗样本攻击失败。
- 本文的研究内容与贡献:为缓解当前特征级攻击的不足,本文提出了 PAW 方法,通过用生成的近似注意力图对对抗扰动进行加权,显著提高对抗样本的跨模型迁移性,尤其是在攻击多目标图像时效果明显。同时,提出 RVR 方法,通过搜索对 ViTs 输出有重要影响的图像关键 patch 并将其作为加权项,提高对抗样本在 ViTs 上的跨架构迁移性。综合实验证实,本文提出的 CRFA 方法能兼顾对抗样本在 CNNs 和 ViTs 上的迁移性,与现有最先进的特征级攻击方法相比,对 CNNs 和 ViTs 的愚弄率分别提高了19.9%和25.0%.
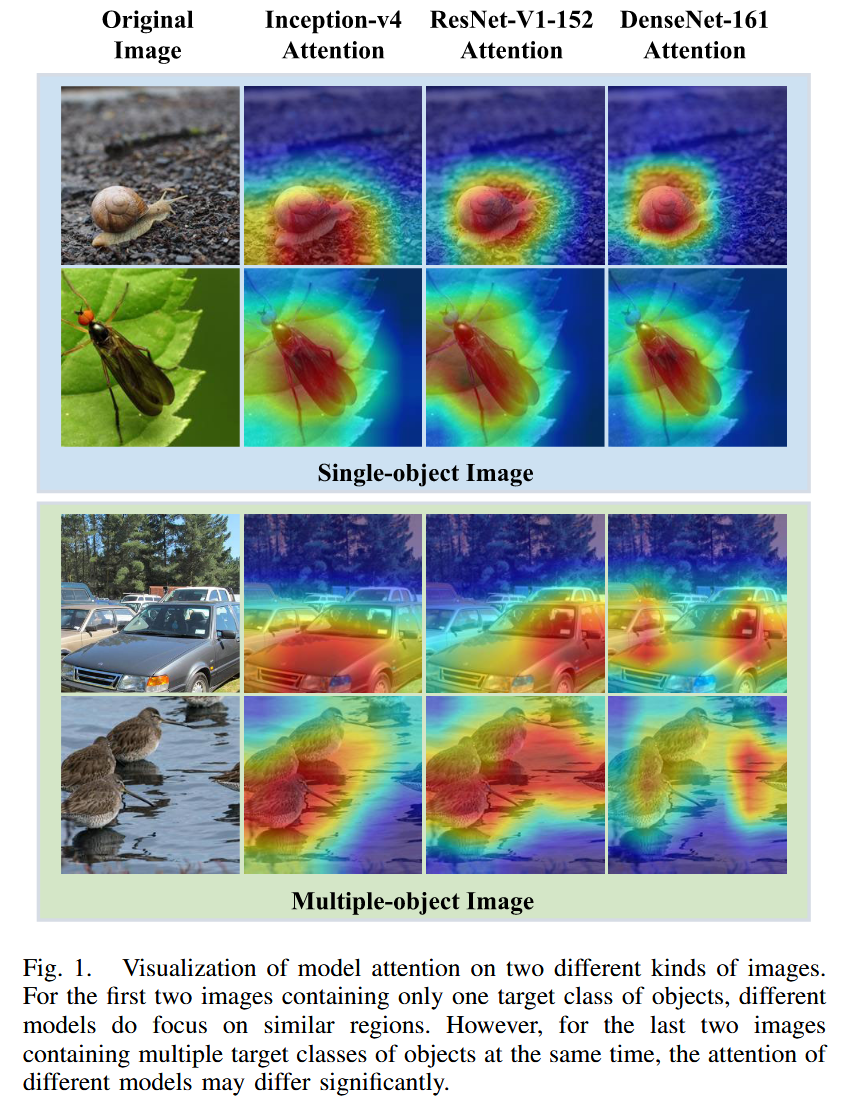
图1. 两种不同类型图像上模型注意力的可视化。前两张图像仅包含一个目标类别的对象,不同模型确实聚焦于相似区域。然而,对于最后两张同时包含多个目标类别的图像,不同模型的注意力可能存在显著差异。
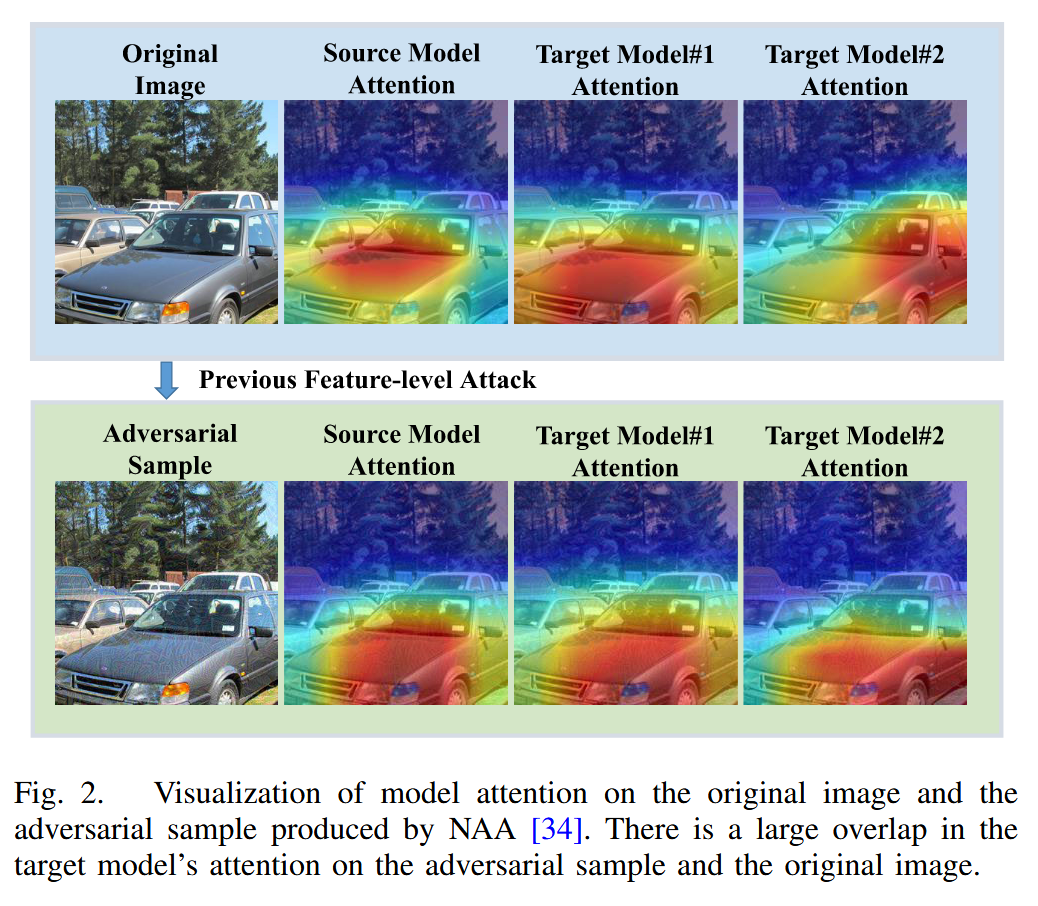
图2. 原图像以及由神经元归因攻击(NAA)方法生成的对抗样本上的模型注意力可视化。目标模型对对抗样本和原图像的注意力存在很大重叠。
相关工作-Related Work
该部分主要回顾了与深度神经网络对抗攻击相关的研究工作,包括白盒攻击、黑盒攻击和特征级攻击,具体内容如下:
- 对抗攻击场景分类:根据攻击者获取目标模型信息的程度,攻击场景分为白盒攻击和黑盒攻击。白盒攻击中攻击者可获取模型结构、训练参数和防御方法等所有信息;黑盒攻击则需要攻击者通过间接方式实施攻击。
- 白盒攻击:在白盒攻击设置下,基于梯度的攻击是最常见的方法。例如,快速梯度符号法(FGSM)通过用损失函数的梯度符号正向更新良性图像,并使用步长控制扰动的 L ∞ L_{\infty} L∞ 范数来生成对抗样本;迭代快速梯度符号法(I - FGSM)是 FGSM 的迭代版本;投影梯度下降法(PGD)通过固定次数的 FGSM 迭代或直到出现误分类来生成对抗样本;Carlini 和 Wagner 攻击(C&W)通过优化降低损失函数并引入超参数 κ κ κ 控制攻击强度来生成对抗样本。
- 黑盒攻击:在实际任务中,目标模型通常是未知的,白盒攻击因高度依赖梯度信息难以在现实中部署,因此黑盒攻击近年来受到越来越多的关注。黑盒攻击大致可分为基于查询的攻击和基于迁移的攻击。基于查询的攻击通过不断向目标模型发出查询以获取硬标签或输出概率向量来生成对抗样本,但在现实中大量查询不被允许,查询成本与对抗样本数量大致呈线性关系,存在实际限制。基于迁移的攻击利用对抗样本的跨模型迁移性,使用在已知的代理模型上精心制作的对抗样本来攻击未知结构和参数的目标模型。许多工作通过设计梯度更新方法(如动量迭代法(MIM)、Nesterov迭代法(NIM))避免对抗样本因贪婪迭代陷入局部最优,还有一些工作通过变换输入图像(如多样输入法(DIM)、平移不变法(TIM))来减轻过拟合程度,基于对象的多样输入(ODI)通过将输入图像投影到 3D 表面进行攻击,Zhang 等人利用额外的增强路径来扩展输入图像的多样性,这些基于变换的攻击可以灵活地与其他攻击方法结合。
- 特征级攻击:考虑到白盒攻击在现实中的不适用性,本文旨在增强黑盒设置下对抗样本的迁移性。特征级攻击通过关注模型的内部特征层来进一步提高对抗样本的迁移性。例如,TAP 通过最大化对抗样本与原始图像在代理模型特定特征层上的距离来生成对抗样本;NRDM 借鉴此思想生成在不同视觉任务中具有高迁移性的对抗样本。然而,这些早期特征级攻击方法简单地贪婪破坏代理模型的内部特征,容易使对抗样本陷入局部最优。后续的 FDA 使用通道的平均激活值来衡量不同特征的重要性,但仅根据是否大于平均激活值将特征分为正负两类;FIA 通过计算反向传播梯度和激活值的乘积获得特征重要性图,通过破坏在模型决策中起关键作用的特征来生成对抗样本;NAA 使用集成梯度来进一步提高对抗样本的迁移性,以应对 FIA 可能出现的梯度饱和问题。特征级攻击生成的对抗样本的高迁移性是基于不同模型之间关键特征的共享,但对于包含多个目标类对象的图像,不同模型的关注区域往往不同,改变后的关注区域可能与目标模型重叠,从而降低对抗样本的跨模型迁移性。此外,视觉 Transformer(ViTs)在视觉任务中表现出色且比传统 CNNs 更具鲁棒性,由于 CNNs 和 ViTs 之间的结构差异,在 CNNs 上生成的对抗样本往往难以迁移到 ViTs 上。现有基于迁移的黑盒对抗攻击分别考虑 CNNs 和 ViTs,没有致力于减少两种不同架构之间攻击有效性的差异。本文提出的 RVR 方法通过让生成器更关注对 ViTs 输出类别有显著影响的 patch,在不影响对 CNNs 攻击成功率的情况下,尽可能提高对抗样本在 ViTs 上的迁移性。
提出的方法-Proposed Method
问题分析-Problem Analysis
这部分主要分析了基于迁移的黑盒对抗攻击中存在的问题,并提出了本文的解决思路,具体内容如下:
- 对抗样本的定义与条件:将用于图像分类任务的深度神经网络表示为函数 f θ ( x ) f_{\theta}(x) fθ(x),其中 θ \theta θ 代表模型参数, x x x 是原始输入图像,其真实标签为 t t t,函数输出是对应输入图像 x x x 的概率向量, f θ ( x ) [ c ] f_{\theta}(x)[c] fθ(x)[c] 表示 x x x 属于类别 c c c 的输出 logit 值 。对抗样本 x a d v = x + δ x^{adv}=x+\delta xadv=x+δ 通过在输入图像 x x x 上叠加精心设计的对抗扰动 δ \delta δ 得到,需满足两个条件:一是 a r g m a x c f θ ( x a d v ) [ c ] ≠ t \underset{c}{arg max } f_{\theta}\left(x^{adv}\right)[c] \neq t cargmaxfθ(xadv)[c]=t,即让分类器输出错误标签;二是 ∥ δ ∥ p ≤ ϵ \| \delta\| _{p} \leq \epsilon ∥δ∥p≤ϵ,使用 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束扰动,使对抗样本具有实际意义。
- 以往特征级攻击的问题:基于迁移的黑盒对抗攻击的核心是在代理模型上生成具有高迁移性的对抗样本。然而,以往大多数特征级攻击严重依赖代理模型对单个输入图像的梯度信息,这使得生成的对抗样本容易过度拟合代理模型,在不同模型间的迁移性受限。
- 本文的解决思路:本文采用基于生成器的方法,学习从输入图像到对抗样本的直接映射。这种映射是基于训练数据分布进行学习的,而非针对单个图像,从而有效缓解了过拟合问题。此外,在生成器的优化过程中,添加特定的先验知识,帮助生成器更加关注对 CNNs 和 ViTs 输出类别影响较大的敏感区域,进而提升对抗样本的跨模型迁移性。
扰动注意力感知加权-Perturbation Attention-Aware Weighting
这部分主要介绍了扰动注意力感知加权(PAW)方法,旨在提升多目标图像对抗样本的跨模型迁移性,具体内容如下:
- 方法提出的背景:对于包含多个目标类对象的图像,不同模型的注意力区域差异显著。以往特征级攻击通过贪婪地改变代理模型的注意力区域来生成对抗样本,这会使对应这些图像的对抗样本陷入局部最优,影响其迁移性。因此,PAW 方法摒弃直接破坏代理模型内部特征的方式,采用基于近似注意力图对扰动进行加权的策略,让生成器聚焦关键区域的同时尽量不改变模型注意力。
- 计算特征重要性图和注意力图:
- 用空间池化梯度计算特征图 A k c ( x ) A_{k}^{c}(x) Akc(x) 的重要性图 α k c ( x ) [ t ] \alpha_{k}^{c}(x)[t] αkc(x)[t],公式为 α k c ( x ) [ t ] = 1 M ∑ i ∑ j ∂ f θ ( x ) [ t ] ∂ A k c ( x ) [ i , j ] \alpha_{k}^{c}(x)[t]=\frac{1}{M} \sum_{i} \sum_{j} \frac{\partial f_{\theta}(x)[t]}{\partial A_{k}^{c}(x)[i, j]} αkc(x)[t]=M1∑i∑j∂Akc(x)[i,j]∂fθ(x)[t],其中 M M M 是限制重要性图值范围的放缩因子, α k c ( x ) [ t ] \alpha_{k}^{c}(x)[t] αkc(x)[t] 表示第 k k k 层第 c c c 个特征图对于真实标签 t t t 的重要性图。
- 为了对与原始输入图像大小相同的对抗扰动进行元素级加权,通过 Ω k t ( x ) = U p s a m p l e ( ∑ c ( A k c ( x ) ⋅ α k c ( x ) [ t ] ) ) \Omega_{k}^{t}(x)=Upsample\left(\sum_{c}\left(A_{k}^{c}(x) \cdot \alpha_{k}^{c}(x)[t]\right)\right) Ωkt(x)=Upsample(∑c(Akc(x)⋅αkc(x)[t])) 计算注意力图。具体操作是先将神经元激活值 A k c ( x ) A_{k}^{c}(x) Akc(x) 与注意力权重 α k c ( x ) [ t ] \alpha_{k}^{c}(x)[t] αkc(x)[t] 相乘,再对同一层的所有特征图进行通道维度的求和,最后通过上采样操作得到注意力图。与传统方法不同,这里去除了 ReLU 函数操作,保留负注意力权重,使生成器能更好地区分图像中的非关键区域,生成更精细的对抗扰动。
- 生成近似注意力图和加权对抗扰动:使用包含编码器和两个解码器的生成器 G G G。编码器 ϵ \epsilon ϵ 将输入图像 x x x 映射为潜在代码 z = E ( x ) z = E(x) z=E(x), z z z 分别输入到解码器 D 1 D_{1} D1 和 D 2 D_{2} D2。 D 1 D_{1} D1 在注意力图 Ω k t ( x ) \Omega_{k}^{t}(x) Ωkt(x) 的监督下生成近似注意力图 Ω ~ k t ( x ) = D 1 ( z ) \tilde{\Omega}_{k}^{t}(x)=D_{1}(z) Ω~kt(x)=D1(z), D 2 D_{2} D2 负责生成原始对抗扰动 δ = D 2 ( z ) \delta = D_{2}(z) δ=D2(z)。通过公式 δ ′ = δ ⋅ Ω ~ k t ( x ) ∗ α + δ = δ ( 1 + Ω ~ k t ( x ) ∗ α ) \delta'=\delta \cdot \tilde{\Omega}_{k}^{t}(x) * \alpha+\delta=\delta\left(1+\tilde{\Omega}_{k}^{t}(x) * \alpha\right) δ′=δ⋅Ω~kt(x)∗α+δ=δ(1+Ω~kt(x)∗α) 计算注意力加权后的对抗扰动 δ ′ \delta' δ′,其中 α \alpha α 是预定义的超参数,用于控制加权强度。这样在反向传播时,关键区域中被扰动像素的梯度会乘以较大权重,非关键区域的梯度乘以较小权重,使生成器在优化过程中更关注不同模型间共享的关键区域,有效破坏图像中高注意力区域,显著提升多目标图像对抗样本的跨模型迁移性。
区域 ViT 关键检索-Region ViT-Critical Retrieval
这部分主要介绍了区域 ViT 关键检索(RVR)方法,目的是提升对抗样本在视觉 Transformer(ViTs)上的跨架构迁移性,具体内容如下:
- 方法提出的背景:ViTs 在图像识别任务中表现出色,但相比传统卷积神经网络(CNNs)具有更强的鲁棒性。由于两者结构差异显著,基于 CNNs 生成的对抗样本难以成功攻击 ViTs。对于特征级攻击而言,贪婪地改变 CNNs 代理模型的注意力会导致对抗样本在 ViTs 上的跨架构迁移性较差,因为 ViTs 和 CNNs 的关键区域并不共享。所以,需要在生成器优化过程中引入 ViTs 的先验知识来解决这一问题。
- 搜索ViT关键区域:定义在 Imagenet1k 上预训练的 ViT 分类器为函数 F ( x ) F(x) F(x),以 ViT-B/16 为例,它将图像分割成 196 个 patch 作为输入,这些 patch 包含图像的所有信息,但不同 patch 对识别任务的贡献不同。通过计算 patch 对真实标签概率的边际贡献来衡量其重要性,定义二元掩码 M M M 并初始化为全1,某 patch 集合 s s s 的边际贡献公式为 φ s = F ( x ) [ t ] − F ( x ⊙ M s ) [ t ] \varphi_{s}=F(x)[t]-F\left(x \odot M_{s}\right)[t] φs=F(x)[t]−F(x⊙Ms)[t],其中 M s M_{s} Ms 是将集合 s s s 中的 patch 全部设为 0 后的二元掩码。
- 具体检索过程:从原始输入图像 x i n i t x_{init} xinit 开始,遍历图像中的196个 patch,分别计算每个 patch 的边际贡献。选择边际贡献最大的 patch,更新掩码 M M M(将该 patch 所在区域设为0),并用更新后的掩码与当前图像 x x x 相乘来更新图像。若当前图像 x x x 仍能使 F ( x ) F(x) F(x) 正确分类,则继续遍历未被选择的 patch,重新计算边际贡献并更新图像,直到模型误分类或所有 patch 都被视为关键区域,最终得到二元掩码 M M M,其中元素值为 0 的区域就是对 ViTs 输出有显著影响的关键区域。
- 计算最终对抗扰动和样本:得到关键区域后,对对抗扰动进行加权计算。在 PAW 得到的对抗扰动 δ ′ \delta' δ′ 基础上,通过 δ ′ ′ = δ ′ ⊙ ( 1 − M ) ⋅ β + δ ′ \delta''=\delta' \odot(1 - M) \cdot \beta+\delta' δ′′=δ′⊙(1−M)⋅β+δ′ 计算最终的对抗扰动 δ ′ ′ \delta'' δ′′ ,其中 β \beta β 是控制加权强度的放缩因子,可随生成器训练过程不断优化。最后,通过 x a d v = x + ϵ ⋅ t a n h ( δ ′ ′ ) x^{adv}=x+\epsilon \cdot tanh (\delta^{\prime \prime}) xadv=x+ϵ⋅tanh(δ′′) 得到最终的对抗样本,其中 ϵ \epsilon ϵ 是超参数,与 t a n h ( ⋅ ) tanh (\cdot) tanh(⋅) 函数一起将对抗扰动限制在 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束内。

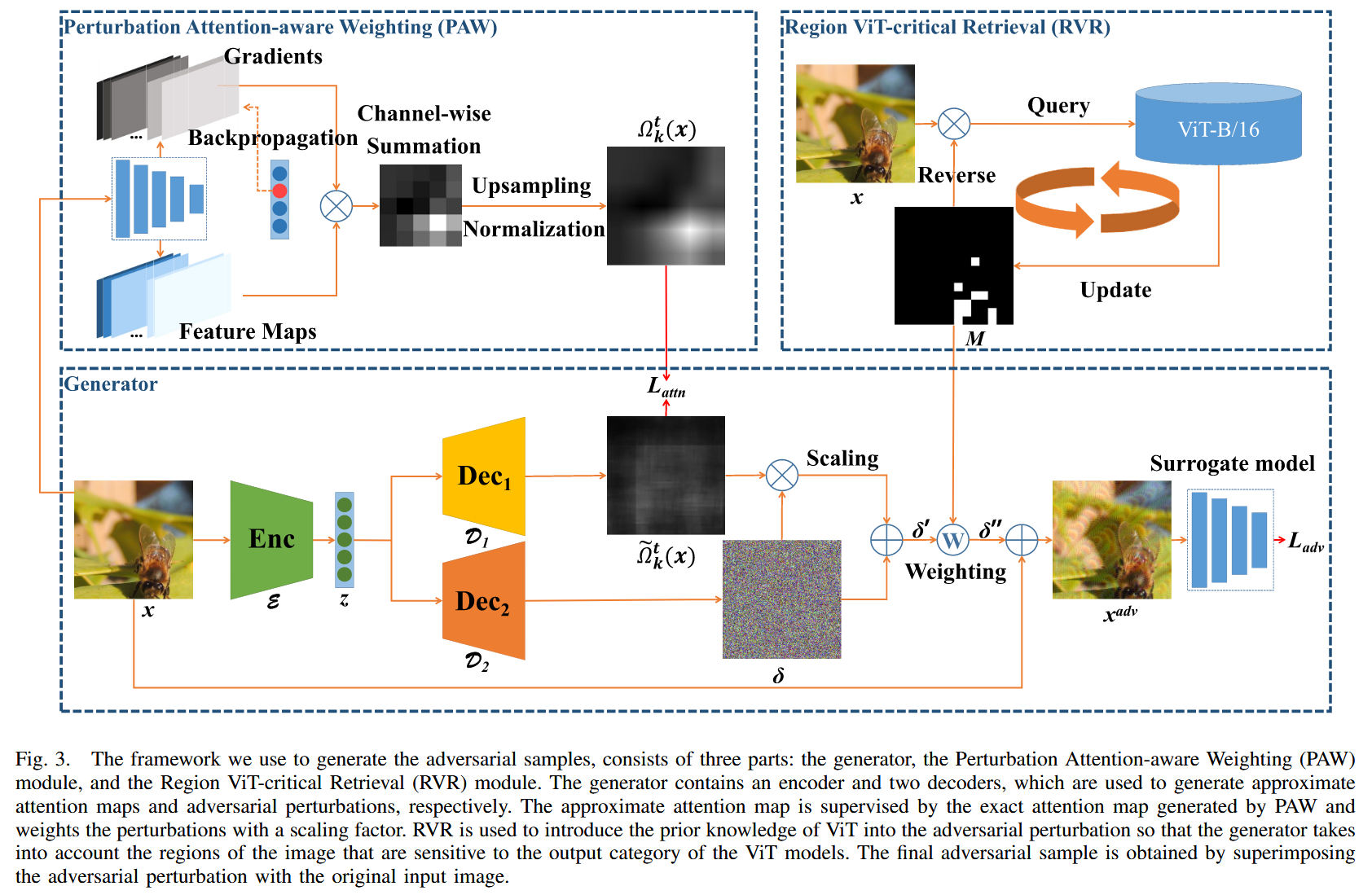
图3. 我们用于生成对抗样本的框架由三个部分组成:生成器、扰动注意力感知加权(PAW)模块和区域 ViT 关键检索(RVR)模块。生成器包含一个编码器和两个解码器,分别用于生成近似注意力图和对抗扰动。近似注意力图由 PAW 生成的精确注意力图进行监督,并使用缩放因子对扰动进行加权。RVR 用于将 ViT 的先验知识引入对抗扰动中,以便生成器考虑图像中对 ViT 模型输出类别敏感的区域。最终的对抗样本是通过将对抗扰动与原始输入图像叠加得到的。
损失函数-Loss Functions
这部分内容介绍了在生成对抗样本过程中使用的损失函数,包括对抗损失、注意力损失以及总体损失,具体如下:
- 对抗损失(Adversarial Loss):非目标对抗攻击旨在生成能被目标模型误分类的对抗样本。在基于迁移的黑盒攻击中,需要一个代理模型 f θ f_{\theta} fθ 来监督生成器 S S S 的训练过程。在每次迭代时,生成器尝试最小化对抗样本对应真实标签 t t t 的输出概率,因此对抗损失函数定义为 L a d v = f θ ( x a d v ) [ t ] \mathcal{L}_{adv}=f_{\theta}\left(x^{adv}\right)[t] Ladv=fθ(xadv)[t]. 通过最小化这个损失函数,促使生成器生成的对抗样本更易被目标模型误分类,从而实现对抗攻击的目的。
- 注意力损失(Attention Loss):在提出的 PAW 方法中,使用解码器 D 2 D_{2} D2 生成的近似注意力图来替代从公式计算得到的精确注意力图 Ω k t ( x ) \Omega_{k}^{t}(x) Ωkt(x),对对抗扰动进行加权。为了保证近似注意力图能较好地逼近精确注意力图,需要用精确注意力图 Ω ( x ) t \Omega_{(x)}^{t} Ω(x)t 来监督生成器的训练过程。因此,注意力损失函数被定义为 L a t t n = ∥ D 1 ( z ) − Ω k t ( x ) ∥ 2 \mathcal{L}_{attn }=\left\| \mathcal{D}_{1}(z)-\Omega_{k}^{t}(x)\right\| _{2} Lattn=∥D1(z)−Ωkt(x)∥2,该损失函数衡量了生成器生成的近似注意力图 D 1 ( z ) \mathcal{D}_{1}(z) D1(z) 与精确注意力图 Ω k t ( x ) \Omega_{k}^{t}(x) Ωkt(x) 之间的差异,通过最小化这个差异,使生成器生成更准确的近似注意力图,进而提升对抗样本的质量和迁移性。
- 总体损失(Overall Loss):将对抗损失和注意力损失结合起来,得到总体损失函数 L = L a d v + λ L a t t n \mathcal{L}=\mathcal{L}_{adv}+\lambda \mathcal{L}_{attn } L=Ladv+λLattn,其中 λ \lambda λ 是一个超参数,用于控制注意力损失与对抗损失的相对重要程度。在训练过程中,通过调整 λ \lambda λ 的值,可以平衡对抗损失和注意力损失对生成器训练的影响,使得生成器在生成对抗样本时,既能有效地使目标模型误分类(通过对抗损失),又能保证近似注意力图的准确性(通过注意力损失),从而提高对抗样本的性能。在推理阶段,训练好的生成器 G G G 可以将任何输入图像映射为相应的对抗样本,并用于攻击任何黑盒模型。
实验-Experiments
这部分主要通过一系列实验验证了基于关键区域的特征级攻击(CRFA)方法的有效性,具体内容如下:
-
实验设置
- 生成器实现:采用包含编码器和两个解码器的残差网络架构。编码器将原始输入图像映射为潜在代码,两个解码器分别用于生成颜色初始对抗扰动图像和灰度近似注意力图,最终结合二者得到最终对抗扰动。
- 数据集:生成器在 ImageNet 验证集上训练,使用 NIPS 2017 对抗竞赛数据集进行测试,以保证与之前工作对比的公平性。
- 目标模型:选择 9 个 CNN 模型、6 个 ViT 模型,还纳入了新的卷积模型和自监督学习训练的 ViT 模型,以及基于多层感知器的 Mixer-B 模型,全面评估方法的性能。
- 基线方法:选取 4 种特征级攻击方法(FDA、NRDM、FIA、NAA)和 2 种常用方法(MIM、DIM)作为基线,用于对比验证 CRFA 的有效性。
- 评估指标:使用愚弄率衡量攻击效果,即被目标模型分类为与原始输入图像不同类别的对抗样本占所有对抗样本的比例。
- 参数设置:对 PAW 中的放缩因子 α \alpha α、总体损失中的 λ \lambda λ 等参数进行设置,并对基线方法的相关参数也进行设定,确保实验的一致性和可比性。
-
迁移性比较
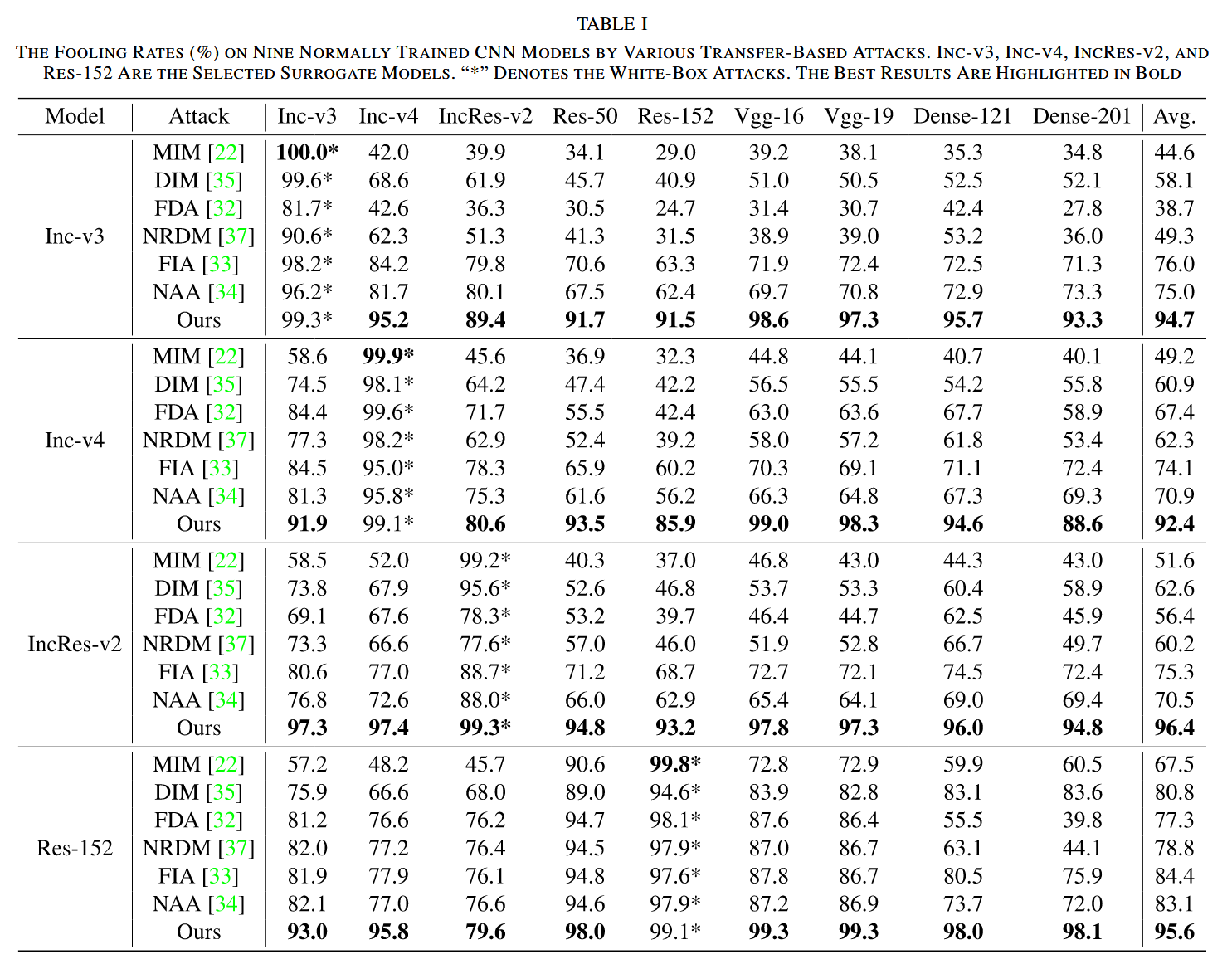
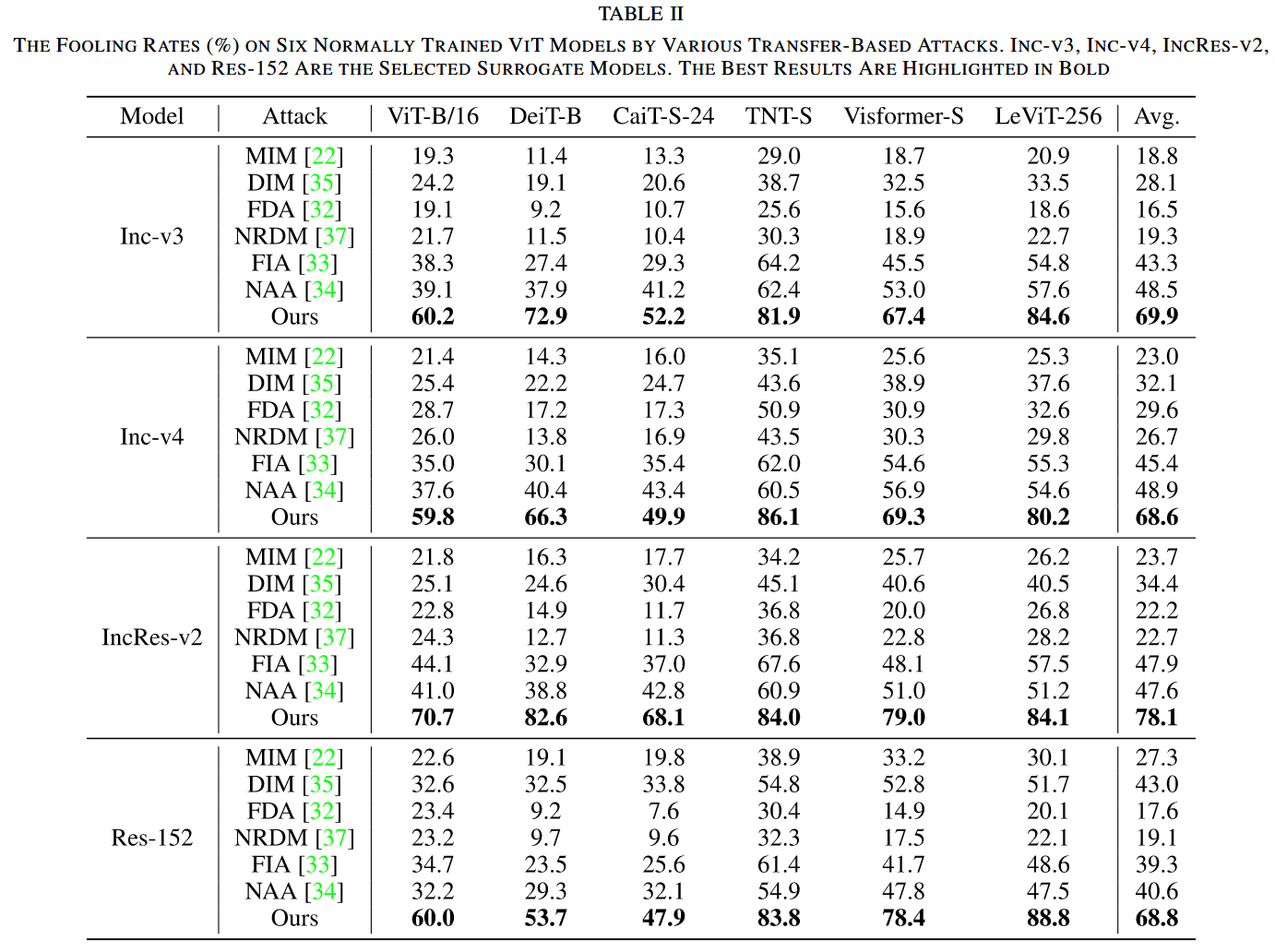
- 跨模型迁移性:以 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 为代理模型攻击其他 CNN 目标模型。结果显示,早期的 MIM 在白盒设置下愚弄率高,但在目标模型上攻击效果衰减严重;DIM 通过输入变换提升了性能,但在简单结构代理模型上生成的对抗样本跨模型迁移性仍不佳;FDA 和 NRDM 表现优于 MIM,但未达预期;NAA 和 FIA 有较大改进,但攻击多目标图像时效果不佳。相比之下,CRFA 在所有目标模型上表现优异,愚弄率比 NAA 和 FIA 分别提高 19.9% 和 17.3%,且在更复杂代理模型上生成的对抗样本迁移性更强。
表1. 展示了各种基于迁移的攻击方法对九个正常训练的 CNN 模型的愚弄率(%)。Inception-V3(Inc-v3)、Inception-V4(Inc-v4)、Inception-Resnet-V2(IncRes-v2)和ResNet-V1-152(Res-152)被选作代理模型。“*”表示白盒攻击。最佳结果以粗体突出显示。
- 跨架构转迁移性:用在 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 上生成的对抗样本攻击 6 种常见 ViT 模型。MIM 对 ViTs 的平均愚弄率低于 30.0%,DIM 表现稍好但仍低于 43.0%,早期特征级攻击如 FDA 在 ViTs 上迁移性差,NAA 在 ViTs 上的最大平均愚弄率仅 48.9%。而 CRFA 在所有 ViT 目标模型上表现最优,最大平均愚弄率超 78.1%,且对抗样本跨架构迁移性与代理模型复杂度正相关。
表2. 展示了各种基于迁移的攻击方法对六个正常训练的 ViT 模型的愚弄率(%)。Inception-V3(Inc-v3)、Inception-V4(Inc-v4)、Inception-Resnet-V2(IncRes-v2)和ResNet-V1-152(Res-152)被选作代理模型。最佳结果以粗体突出显示。
- 跨模型迁移性:以 Inc-v3、Inc-v4、IncRes-v2 和 Res-152 为代理模型攻击其他 CNN 目标模型。结果显示,早期的 MIM 在白盒设置下愚弄率高,但在目标模型上攻击效果衰减严重;DIM 通过输入变换提升了性能,但在简单结构代理模型上生成的对抗样本跨模型迁移性仍不佳;FDA 和 NRDM 表现优于 MIM,但未达预期;NAA 和 FIA 有较大改进,但攻击多目标图像时效果不佳。相比之下,CRFA 在所有目标模型上表现优异,愚弄率比 NAA 和 FIA 分别提高 19.9% 和 17.3%,且在更复杂代理模型上生成的对抗样本迁移性更强。
-
注意力可视化:通过可视化分析发现,CRFA 能在不显著改变模型注意力的情况下成功攻击图像,有效缓解了特征级攻击中因代理模型和目标模型注意力差异导致的过拟合问题,使生成器更关注代理模型感兴趣的图像区域,提升对抗样本跨模型迁移性。
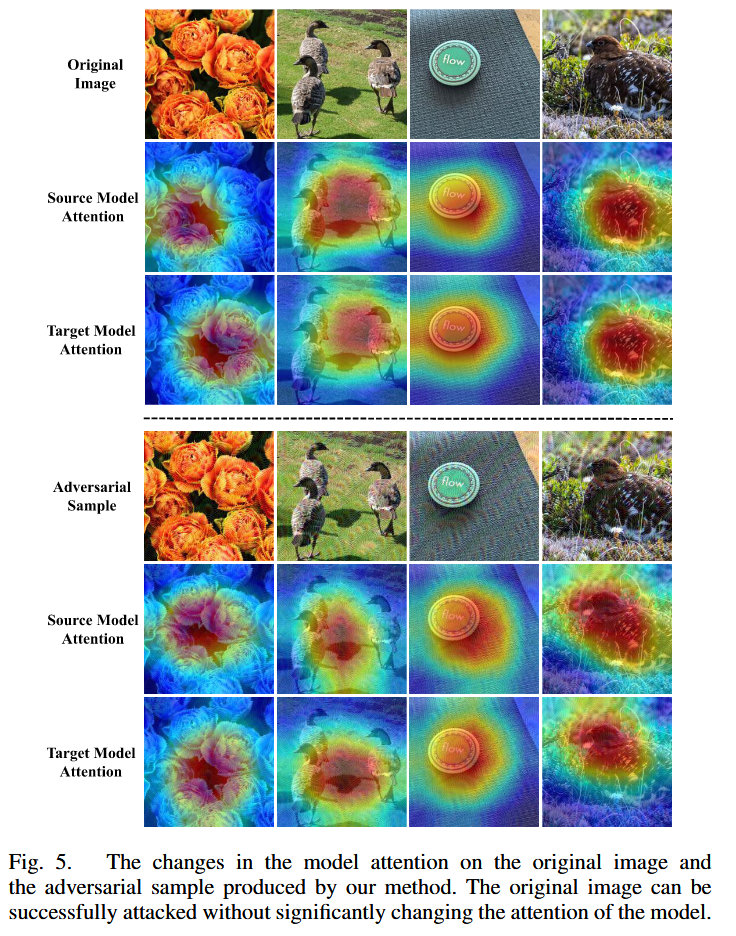
图5. 模型对原始图像的注意力以及由我们的方法生成的对抗样本的注意力的变化情况。原始图像能够在不显著改变模型注意力的情况下被成功攻击。 -
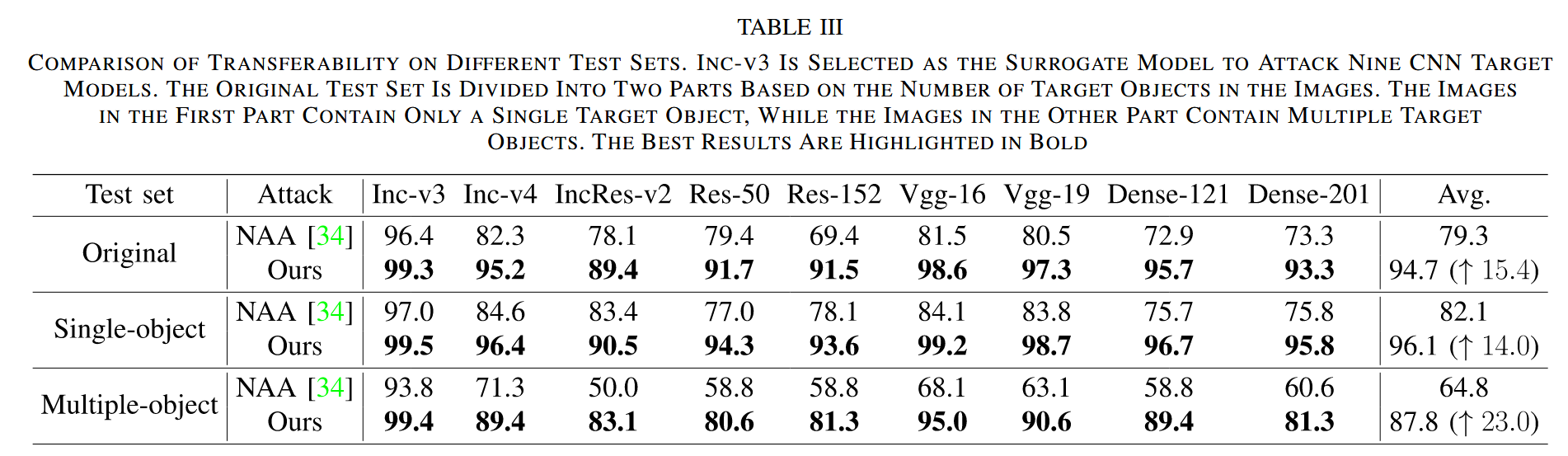
不同测试集迁移性:从原始测试集中选取多目标图像构成多目标集,其余构成单目标集,以 Inc-v3 为代理模型攻击 9 个 CNN 目标模型,并与 NAA 对比。结果表明,在单目标集上,两种方法的愚弄率都有所提高,NAA 提升更明显;在多目标集上,两种方法愚弄率均下降,但 NAA 下降显著,CRFA 在多目标集上的平均愚弄率比 NAA 高 23.0%,在原始测试集上高 15.4%,证明 CRFA 在攻击多目标图像时优势明显。
表3. 不同测试集上的迁移性比较。选择 Inception-V3(Inc-v3)作为代理模型,对九个 CNN 目标模型进行攻击。原始测试集根据图像中目标对象的数量分为两部分。第一部分的图像仅包含一个目标对象,而另一部分的图像包含多个目标对象。最佳结果以粗体突出显示。
-
攻击先进模型:对两种新卷积模型、四种自监督学习的 ViT 模型和一种多层感知器模型进行攻击实验。结果显示,早期特征级攻击方法如 FDA 平均愚弄率约 25%,FIA 和 NAA 虽有改进但仍低于 50%,CRFA 在所有选定目标模型上表现更优,对 RepLKNet-B 的愚弄率比 FIA 和 NAA 提高超 25%,表明该方法对先进模型同样有效。
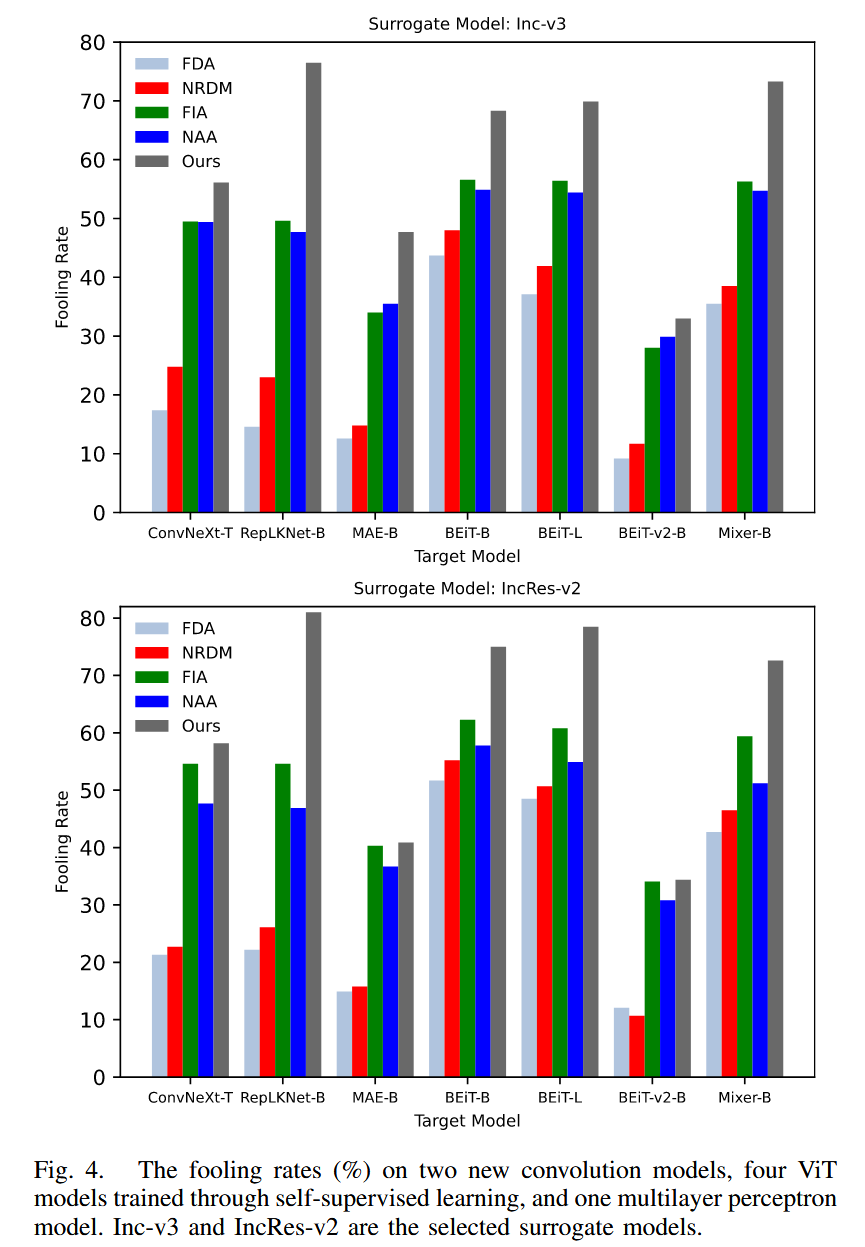
图4. 针对两种新型卷积模型、四种通过自监督学习训练的视觉Transformer(ViT)模型以及一种多层感知器模型的愚弄率(%)。Inception-V3(Inc-v3)和 Inception-Resnet-V2(IncRes-v2)被选为代理模型。 -
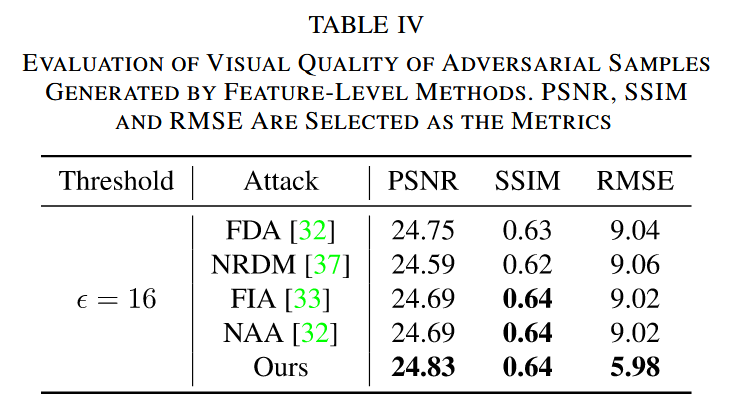
视觉质量评估:使用 PSNR、SSIM 和 RMSE 指标评估对抗样本视觉质量。在相同 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束下,CRFA 生成的对抗样本在 PSNR 和 SSIM 性能相当的情况下,RMSE 更小,视觉质量更优。
表4. 特征级方法生成的对抗样本视觉质量评估。选用峰值信噪比(PSNR)、结构相似性指数(SSIM)和均方根误差(RMSE)作为评估指标。
-
消融研究
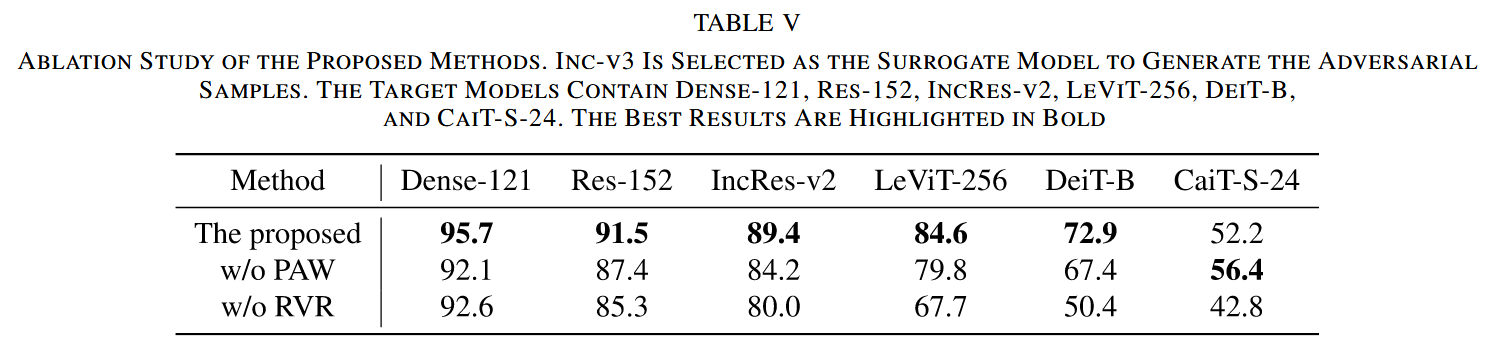
- PAW 的影响:去除 PAW 后,对抗样本在CNN目标模型上的愚弄率从92.2%降至87.9%,在多数ViT目标模型上愚弄率也下降,表明PAW能有效提升跨模型迁移性,并有助于平衡RVR,减轻对抗样本在ViTs上的过拟合。
- RVR 的影响:去除 RVR 后,对抗样本在所有选定目标模型上的愚弄率均下降,在 ViTs 上下降更明显,表明 RVR 通过添加 ViTs 先验知识,显著提升了跨架构迁移性,同时也能缓解对抗样本在 CNNs 上的过拟合,提升跨模型迁移性。
表5. 所提出方法的消融研究。选择Inception-V3(Inc-V3)作为代理模型来生成对抗样本。目标模型包括DenseNet-121(Dense-121)、ResNet-152(Res-152)、Inception-ResNet-V2(IncRes-V2)、LeViT-256(LEVIT-256)、DeiT-B(DEIT-B)和CaiT-S-24(CAIT-S-24)。最佳结果以粗体突出显示。
-
参数影响:研究 PAW 中 α \alpha α 和总体损失中 λ \lambda λ 对愚弄率的影响。发现 α \alpha α 在1-2.5之间时,对抗样本愚弄率大致相同, α \alpha α 为 3 时愚弄率下降,因此将 α \alpha α 设为 2; λ \lambda λ 过小时,生成器过度关注基本对抗损失,导致近似注意力图保真度差,对抗样本迁移性不佳; λ \lambda λ 过大时,会使对抗样本在代理模型注意力上过拟合,同样降低迁移性,所以选择 λ = 5 \lambda = 5 λ=5 平衡对抗损失和注意力损失。
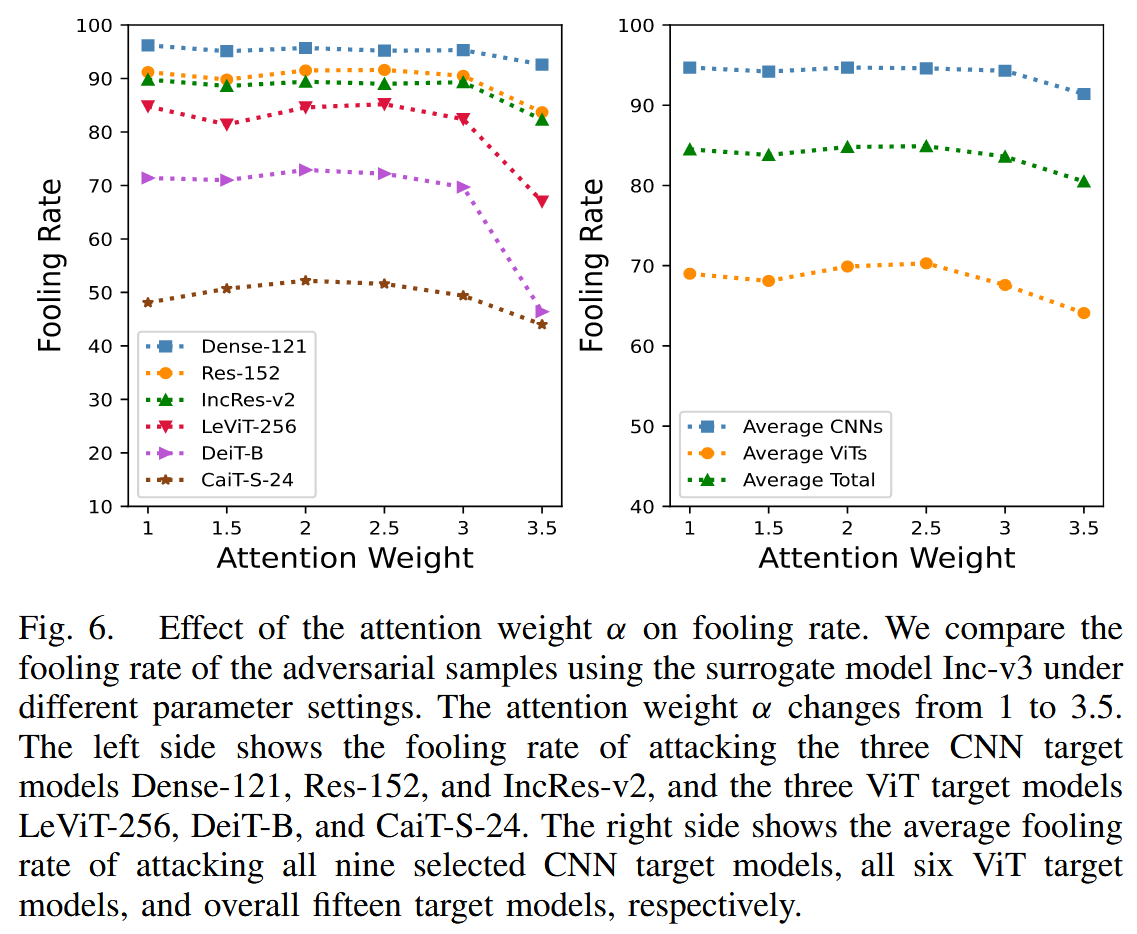
图6. 注意力权重 α α α 对愚弄率的影响。我们比较了使用代理模型 Inception-v3 在不同参数设置下对抗样本的愚弄率。注意力权重 α α α 在 1 到 3.5 之间变化。左侧展示了攻击三个卷积神经网络(CNN)目标模型(Dense-121、Res-152和Inception-ResNet-v2)以及三个视觉Transformer(ViT)目标模型(LeViT-256、DeiT-B和CaiT-S-24)的愚弄率。右侧分别展示了攻击所有九个选定的 CNN 目标模型、所有六个 ViT 目标模型以及总共十五个目标模型的平均愚弄率。
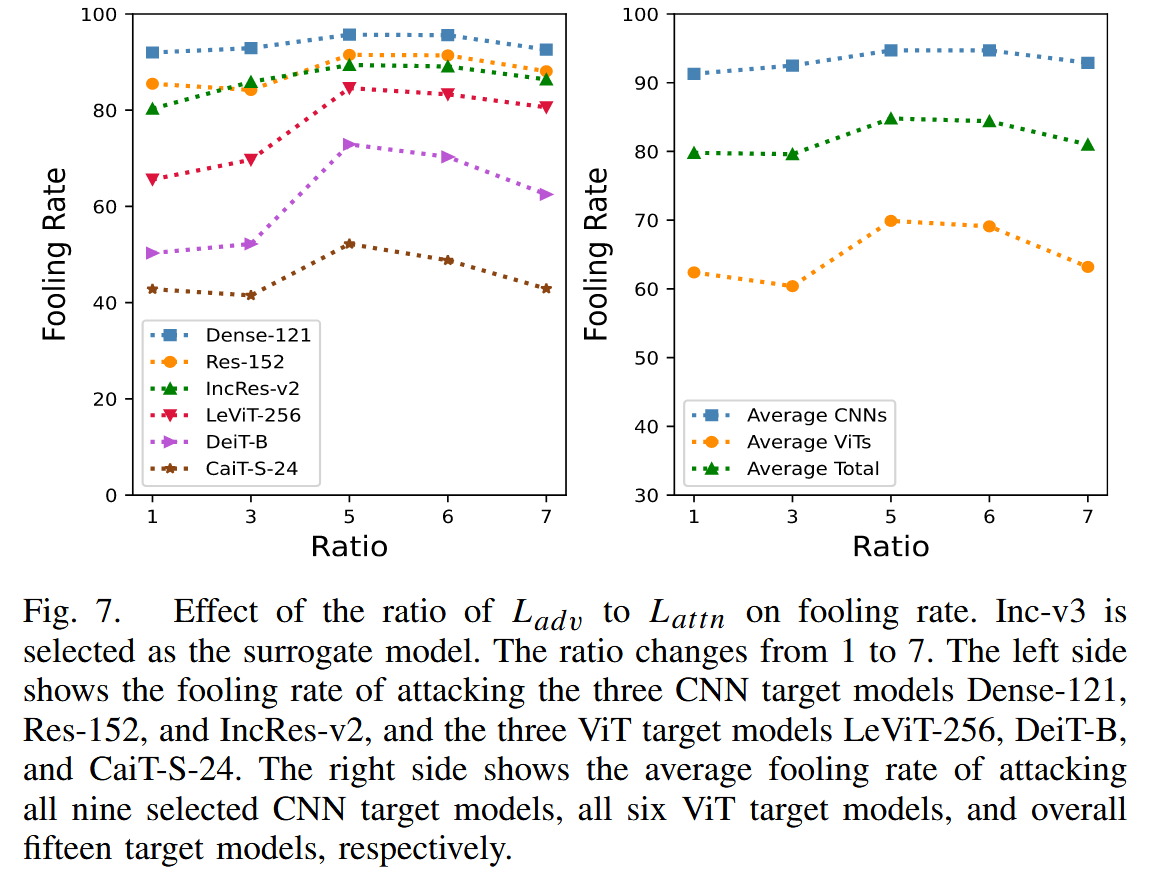
图7. 对抗损失 L a d v L_{adv} Ladv 与注意力损失 L a t t n L_{attn} Lattn 的比率对愚弄率的影响。选取 Inception-v3 作为代理模型。该比率在 1 到 7 之间变化。左侧展示了攻击三个卷积神经网络(CNN)目标模型(DenseNet-121、ResNet-152 和 Inception-ResNet-v2)以及三个视觉 Transformer(ViT)目标模型(LeViT-256、DeiT-B和CaiT-S-24)的愚弄率。右侧分别展示了攻击所有九个选定的 CNN 目标模型、所有六个 ViT 目标模型以及总共十五个目标模型的平均愚弄率。
讨论-Discussion
这部分内容主要围绕研究过程中发现的问题展开讨论,并针对这些问题提出潜在的解决思路,具体内容如下:
- 多目标图像模型注意力差异及潜在防御机制:研究揭示了不同模型在处理包含多个目标类对象的图像时,注意力存在显著差异。这种差异使得以往的特征级攻击方法性能欠佳,因为改变模型注意力的方式可能导致对抗样本陷入局部最优。基于此发现,文章提出了一种潜在的对抗防御机制。该机制通过引入额外网络或进行模型微调,使模型注意力在目标对象间尽可能均匀地分散。这样做的好处是,既可以维持模型训练后的分类性能,又能防止对抗样本使模型注意力偏离目标对象,进而降低模型对攻击的敏感性,提高防御能力。
- RVR 方法的局限性与改进方向:文中提出的 RVR 方法虽然能有效增强对抗样本对 ViTs 的迁移性,但存在一定的局限性。RVR 在选择对 ViTs 输出有重要影响的 patch 时,没有对这些 patch 进行区分。这意味着所有被选中的 patch 在指导生成对抗样本时被同等对待,忽略了不同 patch 可能具有不同重要性的情况。为了进一步提升对抗样本的迁移性,文章指出需要设计一种更复杂、更精细的检索算法。这种算法能够为不同的 patch 分配不同的权重,使生成器可以更好地学习 ViTs 的先验知识,从而在生成对抗样本时更有针对性地对关键区域进行扰动,达到增强迁移性的目的。
结论-Conclusion
这部分内容总结了本文提出的方法、实验验证结果以及研究意义,具体如下:
- 提出的方法:提出了扰动注意力感知加权(PAW)和区域 ViT 关键检索(RVR)两种方法。PAW 通过使用近似注意力图对对抗扰动进行加权,有效缓解了以往特征级攻击在代理模型上的过拟合问题。它让生成器在不显著改变模型注意力的情况下,更聚焦于图像的关键区域,进而显著提升了对抗样本在卷积神经网络(CNNs)上的迁移性。RVR 则是通过向解码器添加视觉Transformer(ViTs)的先验知识,具体是搜索对 ViTs 输出有重要影响的关键 patch,并将其作为加权项与对抗扰动相乘,使得对抗样本能够更好地适应 ViTs,提升了在 ViTs 上的迁移性 。
- 实验验证结果:经过大量实验验证,基于 PAW 和 RVR 构建的关键区域导向的特征级攻击(CRFA)方法,在性能上优于现有的最先进的特征级攻击方法。在针对 CNNs 的攻击实验中,CRFA 生成的对抗样本愚弄率相比现有方法提高了19.9%;在针对 ViTs 的攻击实验中,愚弄率提高了25.0%。这充分证明了 CRFA 方法在提升对抗样本迁移性方面的有效性和优越性。
- 研究意义:本文的研究成果对于理解和应对深度神经网络的对抗攻击具有重要意义。PAW 和 RVR 为提升对抗样本在不同类型模型(CNNs 和 ViTs)上的迁移性提供了有效的解决方案,有助于深入研究神经网络的脆弱性和安全性,也为后续相关研究和应用奠定了基础。
相关文章:

TIFS2024 | CRFA | 基于关键区域特征攻击提升对抗样本迁移性
Improving Transferability of Adversarial Samples via Critical Region-Oriented Feature-Level Attack 摘要-Abstract引言-Introduction相关工作-Related Work提出的方法-Proposed Method问题分析-Problem Analysis扰动注意力感知加权-Perturbation Attention-Aware Weighti…...

WPS PPT设置默认文本框
被一个模板折磨了好久,每次输入文本框都是很丑的24号粗体还有行标,非常恶心,我甚至不知道如何描述自己的问题,非常憋屈,后来终于知道怎么修改文本框了。这种软件操作问题甚至不知道如何描述问题本身,非常烦…...

支持selenium的chrome driver更新到136.0.7103.94
最近chrome释放新版本:136.0.7103.94 如果运行selenium自动化测试出现以下问题,是需要升级chromedriver才可以解决的。 selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only su…...

“下一辆车还买小米”
大家好,我是小悟。 就在5月13日,江西上饶德兴街头,一辆紫色小米SU7 Max停在路边,却遭遇了一场堪比灾难片的意外。 一辆满载货物的大货车因手刹故障溜坡,径直撞向SU7,两车从两米高的落差坠落,货…...

opencv4.11生成ArUco标记 ArUco Marker
从opencv4.7开始aruco有了一些变化 以下是opencv4.11生成ArUco标记的小例子 #include <iostream> #include <opencv2/opencv.hpp> #include <opencv2/objdetect/aruco_detector.hpp>int main() {cv::Mat markerImage;cv::aruco::Dictionary dictionary cv…...

从辅助到协作:GitHub Copilot的进化之路
如果说现代程序员的标配工具除了VS Code、Stack Overflow之外,还有谁能入选,那一定是GitHub Copilot。从2021年首次亮相,到如今深度集成进开发者日常流程,这个“AI编程助手”已经不只是写几行自动补全代码的小帮手了,而…...
功能详解(实战部分))
QMK 宏(Macros)功能详解(实战部分)
QMK 宏(Macros)功能详解(实战部分) 一、宏的基本概念与作用 宏(Macros)是 QMK 固件中一项强大的功能,它允许您在按下单个按键时执行多个按键操作。通过宏,您可以: 输入常用短语或文本执行复杂的按键组合自动化重复性操作触发系统功能或快捷键🔔 安全提示:虽然可以…...

SVN 版本控制入门指南
SVN 版本控制系统详细入门指南 一、SVN 基础概念详解 1. 什么是版本控制? 版本控制是一种记录文件变化的系统,可以: 追踪文件的修改历史查看每次修改的内容恢复到任意历史版本协调多人协作开发 2. SVN 核心概念 2.1 仓库(Re…...

6to4、6over4的类比解释
本文由deepseek生成,特此声明 1. 6to4:自动的“快递中转站” 类比场景: 假设你住在一个偏远的小镇(IPv6网络),周围被大海(IPv4互联网)包围,你想给另一个偏远小镇&#…...

跨国应用程序的数据存储方案常见的解决方案
一、数据隐私与合规性 跨国数据存储方案必须遵守不同国家和地区的数据隐私法律和规定,例如: GDPR(欧盟一般数据保护条例)CCPA(加利福尼亚消费者隐私法案)各国的本地数据存储法规解决方案: 采用本地化存储:在不同国家或地区设立数据存储中心,以遵循当地的法律和隐私要…...
)
JSP链接MySQL8.0(Eclipse+Tomcat9.0+MySQL8.0)
所用环境 Eclipse Tomcat9.0 MySQL8.0.21(下载:MySQL Community Server 8.0.21 官方镜像源下载 | Renwole) mysql-connector-java-8.0.21(下载:MySQL :: Begin Your Download) .NET Framework 4.5.2(下…...
基于KAN+Transformer的专业领域建模方法论
一、专业领域KAN方法创新路径 1. 领域函数分解策略 数学建模:针对专业领域特性设计专用基函数组合 医学影像:采用小波变换基函数分解图像特征 class WaveletKAN(nn.Module): def __init__(self): self.wavelet_basis nn.Par…...

Go语言 Gin框架 使用指南
Gin 是一个用 Go (Golang) 编写的 Web 框架。 它具有类似 martini 的 API,性能要好得多,多亏了 httprouter,速度提高了 40 倍。 如果您需要性能和良好的生产力,您一定会喜欢 Gin。Gin 相比于 Iris 和 Beego 而言,更倾向…...

内容安全:使用开源框架Caffe实现上传图片进行敏感内容识别
上传图片进行敏感内容识别 预览效果 环境准备 Ubuntu 16.04python 2.7.12caffe 1.0.0 安装调试环境: sudo apt-get update sudo apt-get install -y --no-install-recommends build-essential cmake git wget libatlas-base-dev libboost-all-dev libgflags-dev sudo apt-g…...
策略)
缓慢变化维度(SCD)策略
缓慢变化维度(SCD)策略 缓慢变化维度(SCD)策略是数据仓库中处理维度属性随时间变化的核心技术,根据业务需求的不同,主要分为以下类型: 1. SCD Type 0(固定维度) 定义&a…...

【Mysql】详解InnoDB存储引擎以及binlog,redelog,undolog+MVCC
1.InnoDB存储引擎 在Mysql中,InnoDB存储引擎是默认的,也是我们最常用的一个存储引擎,其中分为内存结构和磁盘结构两大部分,整体架构图如下: 1.1Buffer Pool Buffer pool(缓存区)是Mysql内存的一个主要区域࿰…...

面向对象详解和JVM底层内存分析
神速熟悉面向对象 表格结构和类结构 我们在现实生活中,思考问题、发现问题、处理问题,往往都会用“表格”作为工具。实际上,“表格思维”就是一种典型的面向对象思维。 实际上,互联网上所有的数据本质上都是“表格”。我们在这里…...
:内存和地址、指针变量和地址、指针变量类型的意义、指针运算)
C语言指针深入详解(一):内存和地址、指针变量和地址、指针变量类型的意义、指针运算
目录 一、内存和地址 (一)内存 (二)如何理解编址 二、指针变量和地址 (一)取地址操作符(&) (二)指针变量和解引用操作符(*)…...

MATLAB中进行深度学习网络训练的模型评估步骤
文章目录 前言环境配置一、基础性能评估二、高级评估指标三、模型解释与可视化四、交叉验证与模型选择五、部署前的优化 前言 在 MATLAB 中进行深度学习网络训练后的模型评估是确保模型性能和可靠性的关键环节。以下是详细的评估步骤和方法。 环境配置 MATLAB下载安装教程&…...

30、WebAssembly:古代魔法——React 19 性能优化
一、符文编译术(编译优化) 1. 语言选择与量子精简 // Rust编译优化 cargo build --target wasm32-wasi --release 魔法特性: • 选择低运行时开销语言(如Rust/C),编译后文件比Swift小4倍 • --rel…...

Python集合运算:从基础到进阶全解析
Python基础:集合运算进阶 文章目录 Python基础:集合运算进阶一、知识点详解1.1 集合运算(运算符 vs 方法)1.2 集合运算符优先级1.3 集合关系判断方法1.4 方法对比 二、说明示例2.1 权限管理系统2.2 数据去重与差异分析2.3 数学运算…...

【开源Agent框架】Suna架构设计深度解析与应用实践
一、项目基本介绍 Suna是一款全栈开源的通用型AI代理系统,其名称源自日语"砂"的发音,寓意如流沙般渗透到各类数字任务中。项目采用Apache 2.0协议,由Kortix AI团队维护,核心开发者包括Adam Cohen Hillel等三位主要贡献者。 技术架构全景 系统由四大核心组件构…...

C++类与对象--2 对象的初始化和清理
C面向对象来源于生活,每个对象都有初始化设置和销毁前的清理数据的设置。 2.1 构造函数和析构函数 (1)构造函数 初始化对象的成员属性不提供构造函数时,编译器会提供不带参数的默认构造函数,函数实现是空的构造函数不…...
)
计网| 网际控制报文协议(ICMP)
目录 网际控制报文协议(ICMP) 一、ICMP 基础特性 二、ICMP 报文分类及作用 差错报告报文 询问报文 网际控制报文协议(ICMP) ICMP(Internet Control Message Protocol,网际控制报文协议)是 …...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

printf耗时高的原因
背景:设备升级初始化失败。具体表现为:app在启动dsp后,需在15秒内与其建立连接以确认通信成功,但当前未能在此时间限制内完成连接。 排查过程:通过在初始化过程中添加耗时打印,发现各阶段耗时虽不高&#…...

20250517 我设想一个空间,无限大,空间不与其中物质进行任何作用,甚至这个空间能容纳可以伸缩的空间
1.我设想一个空间,无限大,空间不与其中物质进行任何作用,甚至这个空间能容纳可以伸缩的空间 您设想的这个空间具有一些有趣的特点: 无限大:空间本身没有边界或限制,理论上可以容纳无限多的物质或结构。非…...
)
GO语言学习(二)
GO语言学习(二) method(方法) 这一节我们介绍一下GO语言的面向对象,之前我们学习了struct结构体,现在我们来解释一下方法method主要是为了简化代码,在计算同类时,使用函数接收方法…...
)
神经网络与深度学习第六章--循环神经网络(理论)
#第六章-循环神经网络 前馈神经网络的缺点: ①信息的传递是单向的。前馈神经网络可以看作一个复杂的函数,每次的输入都是独立的,即网络的输出只依赖于当前的输入。前馈神经网络是一种静态网络,没有记忆能力,就无法模拟…...

第三十五节:特征检测与描述-ORB 特征
1. 引言:为什么需要ORB? 在计算机视觉领域,特征检测与描述是许多任务(如图像匹配、目标跟踪、三维重建等)的核心基础。传统的算法如SIFT(尺度不变特征变换)和SURF(加速稳健特征)因其优异的性能被广泛应用,但它们存在两个显著问题: 专利限制:SIFT和SURF受专利保护,…...

重庆 ICPC 比赛游记
2025.5.9 比赛前一天晚上,激动地睡不着觉,起来收拾了好多东西。(其实就四本书,剩下的全是零食……关键在于这四本书基本没用。) 2025.5.10 学校丧心病狂的让我们 6:20 到校门口集合坐车(据说是怕赶不上比…...

二进制与十进制互转的方法
附言: 在计算机科学和数字系统中,二进制和十进制是最常见的两种数制。二进制是计算机内部数据存储和处理的基础,而十进制则是我们日常生活中最常用的数制。因此,掌握二进制与十进制之间的转换方法对于计算机学习者和相关领域的从业者来说至关…...

咖啡叶子病害检测数据集VOC+YOLO格式1468张4类别均为单叶子
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1468 标注数量(xml文件个数):1468 标注数量(txt文件个数):1468 …...

JDBC实现模糊、动态与分页查询的详解
文章目录 一. 模糊查询1. Mysql的写法2. JDBC的实现 二. 动态条件查询1. 创建生成动态条件查询sql的方法2. 完整的动态条件查询类以及测试类 三. 分页查询1. 什么是分页查询?2. 分页查询的分类3. MySQL的实现4. JDBC实现4.1. 创建page页4.2. 分页的实现 本章来讲一下…...

golang读、写、复制、创建目录、删除、重命名,文件方法总结
文章目录 一、只读文件二、写入文件三、复制文件四、创建目录五、删除目录/文件五、重命名文件 一、只读文件 file, err : os.Open("./main.go")defer file.Close() //打开文件一定要关闭关闭文件if err ! nil {fmt.Println("文件打开失败", err)}/*方案一…...

信贷域——互联网金融业务
摘要 本文深入探讨了信贷域全托与半托业务的定义、特点、适用场景及注意事项,并分析了互联网金融核心信息流的多个方面,包括资金流、信息流、风险流、合规流、物流、技术流和商流,还阐述了金融系统“断直连”业务的相关内容,以及…...

计算机操作系统概要
不谋万世者,不⾜谋⼀时。不谋全局者 ,足谋⼀域 。 ——陈澹然《寤⾔》《迁都建藩议》 操作系统 一.对文件简单操作的常用基础指令 ls ls 选项 目录或⽂件名:罗列当前⽬录下的⽂件 -l:以长格式显示⽂件和⽬录的详细信息 -a 或 --all&…...

gRPC开发指南:Visual Studio 2022 + Vcpkg + Windows全流程配置
前言 gRPC作为Google开源的高性能RPC框架,在微服务架构中扮演着重要角色。本文将详细介绍在Windows平台下,使用Visual Studio 2022和Vcpkg进行gRPC开发的完整流程,包括环境配置、项目搭建、常见问题解决等实用内容。 环境准备 1. 安装必要组…...

MATLAB安装常见问题及解决办法
MATLAB安装失败 安装MATLAB时可能会遇到失败的情况,通常是由于系统环境不兼容或安装文件损坏。确保系统满足MATLAB的最低要求,并重新下载安装文件。如果问题仍然存在,可以尝试以管理员身份运行安装程序。 许可证激活问题 在激活MATLAB许可证时,可能会遇到激活失败或无法…...

英语学习5.17
attract 👉 前缀:at-(朝向) 👉 含义:吸引(朝某处拉) 例句:The flowers attract bees. (花吸引蜜蜂。) distract 👉 前缀ÿ…...

深入解析 React 的 useEffect:从入门到实战
文章目录 前言一、为什么需要 useEffect?核心作用: 二、useEffect 的基础用法1. 基本语法2. 依赖项数组的作用 三、依赖项数组演示1. 空数组 []:2.无依赖项(空)3.有依赖项 四、清理副作用函数实战案例演示1. 清除定时器…...

Scrapy进阶实践指南:从脚本运行到分布式爬取
Scrapy作为Python生态中最强大的爬虫框架之一,其官方文档的"Common Practices"章节总结了多个高频使用场景的解决方案。本文将深入解析如何通过脚本控制爬虫、多爬虫协同工作、分布式部署策略以及反反爬技巧,帮助开发者突破基础使用限制。 一…...
TCP、UDP协议)
(面试)TCP、UDP协议
TCP(传输控制协议)和UDP(用户数据报协议)是互联网核心的传输层协议,负责应用程序之间的数据传输。它们在设计目标、特性和适用场景上有显著差异: TCP:面向连接,可靠的,速…...
的处理与效率提升)
数据库blog1_信息(数据)的处理与效率提升
🌿信息的处理 🍂实际中离不开信息处理 ● 解决问题的建模 任何对问题的处理都可以看作数据的输入、处理、输出。 eg.一个项目中,用户点击信息由前端接收传递到后端处理后返回结果eg.面对一个问题,我们在搜集信息后做出处理与分析…...
:受身形)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(23):受身形
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(23):受身形 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)うけみけい 受身形1、グループ2、グループ3、グループ(2) か ~かどうか1、か2、かどうか3、单词(1)日语(2)日语片假名单词4、相近词练习5、单词…...

kubernetes的Service与服务发现
kubernetes的Service与服务发现 1 Service1.1 Service概念1.2 Service类型1.2.1 ClusterIP1.2.2 NodePort1.2.3 LoadBalancer1.2.4 ExternalName1.2.5 Headless 2 CoreDNS2.1 CoreDNS概念2.2 CoreDNS插件架构2.3 CoreDNS在kubernetes下的工作原理2.4 Pod上的DNS解析策略 3 Ingr…...

python打卡day28
类的简单复习 知识点回顾: 类的定义pass占位语句类的初始化方法类的普通方法类的继承:属性的继承、方法的继承 类就是对属性和方法的封装,一个常见的类的定义包括了: 关键字class类名语法固定符号冒号(:)一个初始化函数__init__(…...

【学习心得】英伟达的诸多显卡性能对比
型号 CUDA核心 显存容量 算力(FP32/TFLOPS) A100 6912 HBM2e/80G 19.49 A800 6912 HBM2e/80G 19.49 H100 14592 HBM3/80G 51.22 H800 14592 HBM3/80G 51.22 T4 4352 GDDR6/16G 8.14 P40 3840 GDDR5/24G 11.76 L40 18176 G…...

使用Pinia持久化插件-persist解决刷新浏览器后数据丢失的问题
文章目录 一、现象二、原因三、解决:使用Pinia持久化插件-persist安装persistpinia中使用persist插件在创建定义状态时配置持久化 四、参考资料 一、现象 登录成功后,能正常看到文章分类的数据,但只要刷新浏览器就提示服务异常 二、原因 P…...

mysql中4种扫描方式和聚簇索引非聚簇索引【爽文一篇】
目录 一 mysql的聚簇索引&非聚簇索引 1.1 数据表 1.2 聚簇索引 1.3 非聚簇索引 1.4 覆盖索引 二 mysql的4种扫描查询 2.1 全表扫描 2.2 索引扫描 2.3 覆盖索引扫描 2.4 回表扫描 2.5 总结 三 mysql的回表查询详解 3.1 回表查询 一 mysql的聚簇索引&非聚簇…...