GpuGeek 网络加速:破解 AI 开发中的 “最后一公里” 瓶颈
摘要:网络延迟在AI开发中常被忽视,却严重影响效率。GpuGeek通过技术创新,提供学术资源访问和跨国数据交互的加速服务,助力开发者突破瓶颈。
目录
一、引言:当算力不再稀缺,网络瓶颈如何破局?
二、GpuGeek 网络加速核心优势解析
2.1 学术资源加速引擎:20 + 核心站点一键直达
2.2 全球节点布局:构建低延迟算力网络
2.3 弹性计费与智能调度:成本效率双平衡
三、网络加速实战指南:从配置到调优全流程
3.1 快速上手:3 步激活加速服务
3.2 高级技巧:定制化加速策略
3.3 典型场景优化方案
3.4 网络加速的重要性
四、网络加速赋能多元 AI 场景
4.1 高校科研:让文献与代码触手可及
4.2 企业开发:突破跨境协作壁垒
4.3 个人开发者:轻量化加速体验
五、经典代码案例及解释
5.1 代码案例1:使用TensorFlow构建简单的卷积神经网络(CNN)进行图像分类
5.2 代码案例2:使用PyTorch进行模型微调
5.3 代码案例3:使用OpenCV进行图像预处理
5.4 代码案例4:使用TensorFlow构建并训练一个循环神经网络(RNN)进行文本生成
5.5 代码案例5:使用PyTorch进行Transformer模型的微调
5.6 代码案例6:使用OpenCV和TensorFlow进行实时图像识别
六、总结:重新定义 AI 开发的 “网络效率”
6.1 附录:常见问题解答(FAQ)
6.2 写在最后
一、引言:当算力不再稀缺,网络瓶颈如何破局?
在 AI 开发的全流程中,算力资源的重要性已被广泛认知,但网络延迟导致的效率损耗却常被忽视。从 GitHub 代码拉取的龟速加载,到 Hugging Face 模型下载的反复中断,再到跨国协作时的镜像传输卡顿,网络问题正成为开发者的 “隐性成本黑洞”。GpuGeek 平台针对这一痛点推出的网络加速功能,通过技术创新实现了学术资源访问、跨国数据交互的效率跃升,成为 AI 开发者突破瓶颈的关键利器。

二、GpuGeek 网络加速核心优势解析
2.1 学术资源加速引擎:20 + 核心站点一键直达
GpuGeek 专为 AI 研发场景优化网络链路,内置的学术加速通道覆盖 Google Scholar、GitHub、Hugging Face、ArXiv 等 20 + 国际核心学术站点。开发者无需复杂配置,通过 SSH 命令即可激活加速服务:
# 临时加速通道(24小时有效)
ssh -L 8080:github.com:443 speedup.gpugeek.com
# 永久加速配置(控制台提交工单添加目标域名)
平台采用智能路由算法,动态选择最优节点,实测 GitHub 代码克隆速度提升 300%,Hugging Face 模型下载耗时缩短 60%。支持按需购买流量包,未使用流量自动冻结,避免资源浪费。

2.2 全球节点布局:构建低延迟算力网络
依托香港、达拉斯、庆阳、宿迁四大核心数据中心,GpuGeek 形成 “本地接入 + 跨境优化” 的全球算力网络:
- 就近接入:国内用户访问海外站点时,流量经香港节点中转,延迟从平均 300ms 降至 80ms 以下;
- 跨境加速:海外节点与国内集群通过专属链路互联,跨国模型镜像拉取速度提升 5 倍,10GB 级数据集传输耗时从 2 小时压缩至 20 分钟;
- 合规性保障:内置数据加密与访问审计模块,支持跨境数据权限可视化配置,满足科研数据合规传输要求。
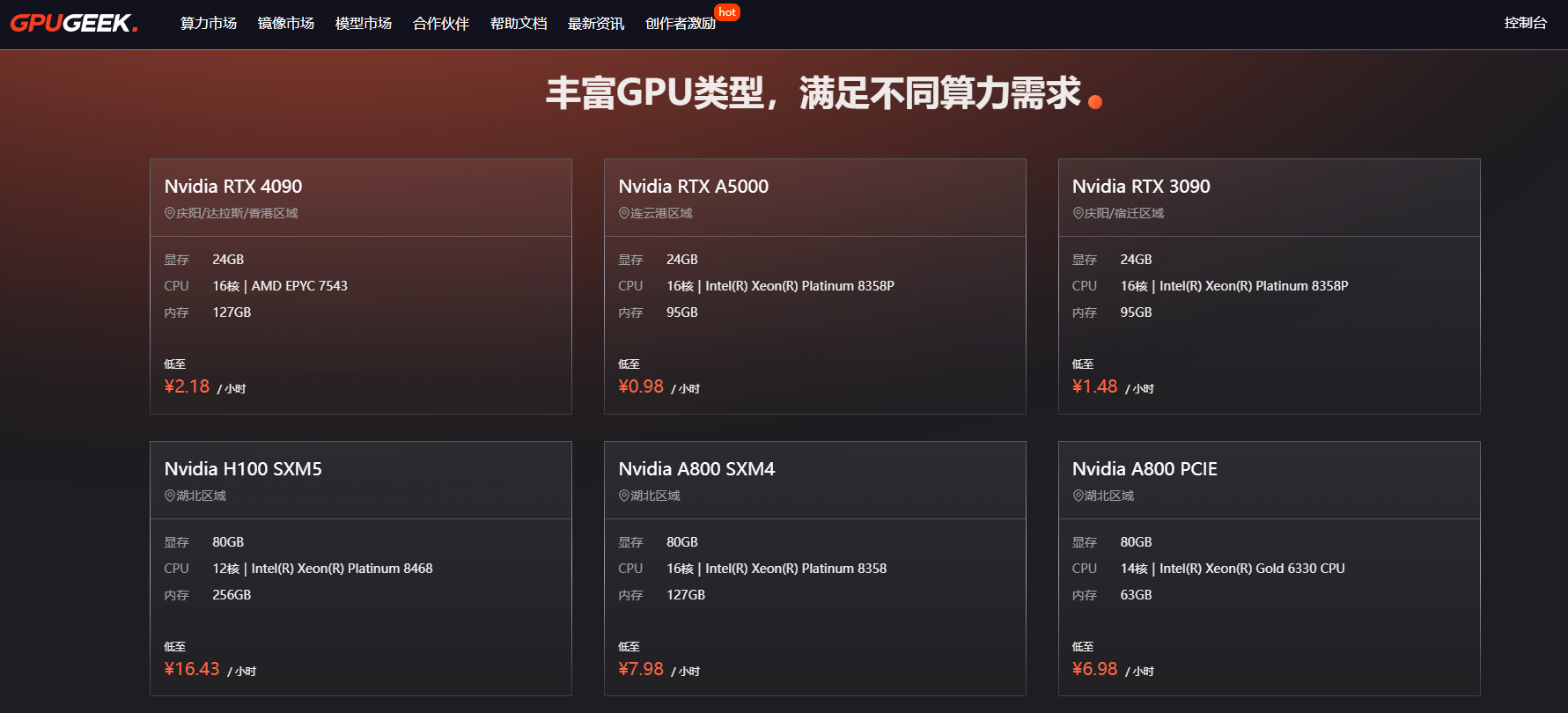
2.3 弹性计费与智能调度:成本效率双平衡
区别于传统云平台的固定带宽收费模式,GpuGeek 提供动态加速策略:
- 按实际加速流量计费,单价低至 0.1 元 / GB,无保底消费;
- 支持竞价模式获取闲置加速资源,成本最高可降低 70%;
- 智能识别访问峰值,自动扩容带宽资源,避免突发流量导致的链路拥塞。
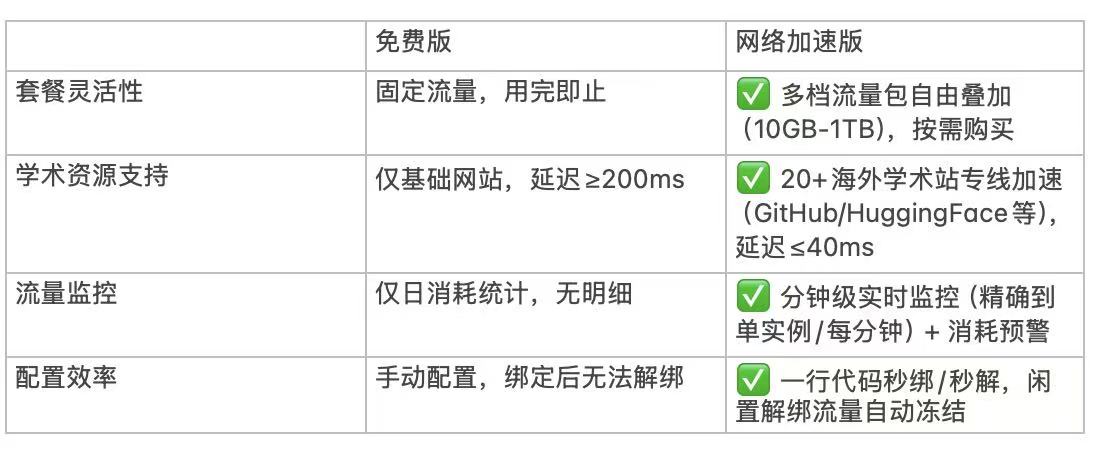
三、网络加速实战指南:从配置到调优全流程
3.1 快速上手:3 步激活加速服务
- 控制台配置:进入 GpuGeek 管理后台(GpuGeek官网注册入口),在 “网络加速” 模块选择目标站点(如github.com),勾选 “启用学术加速”;
- 实例关联:在创建 GPU 实例时,选择已配置加速策略的网络模板,支持批量绑定多实例;
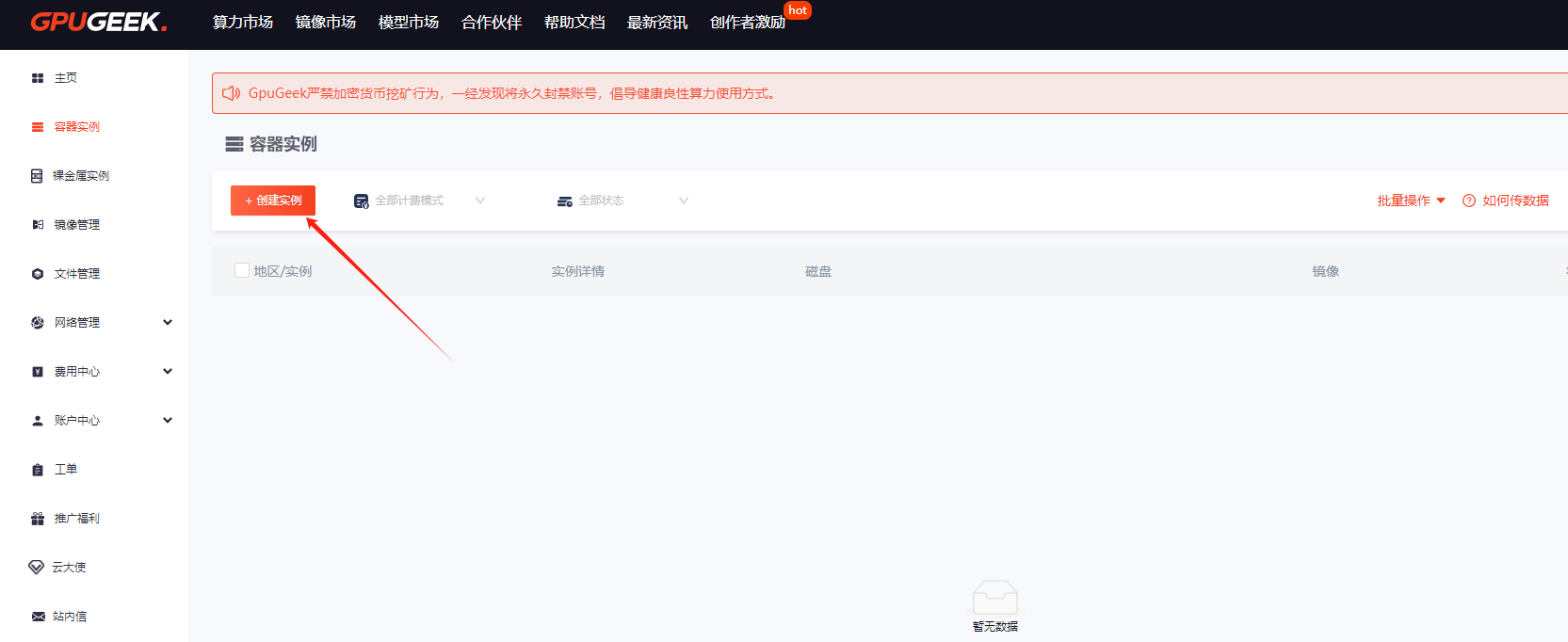 选择需要的计费模式、配置、卡、数据盘大小以及镜像等,核查配置后点击【创建实例】
选择需要的计费模式、配置、卡、数据盘大小以及镜像等,核查配置后点击【创建实例】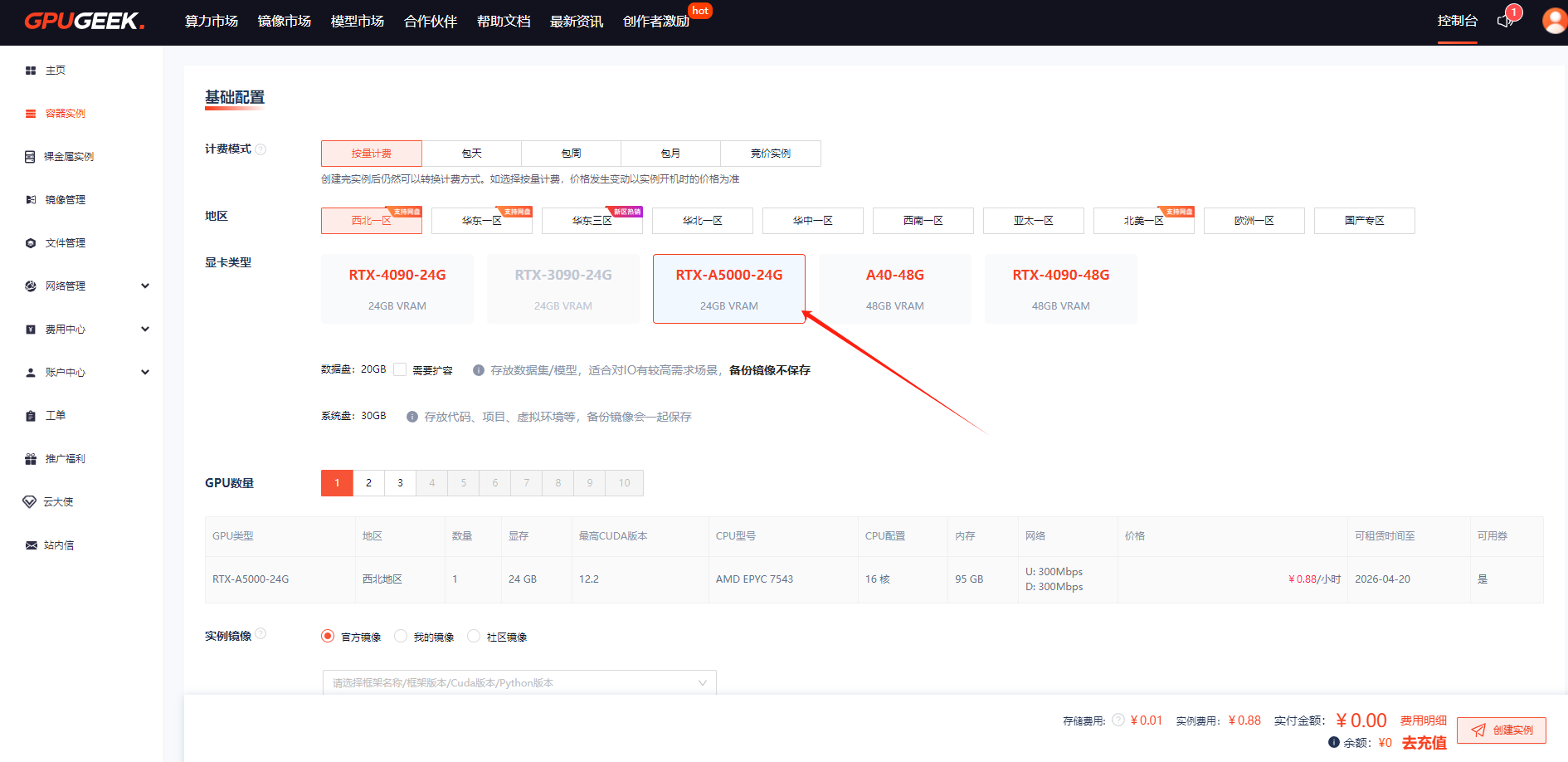
- 效果验证:通过
speedtest.gpugeek.com实时监测下载速度,对比加速前后的 Ping 值与吞吐量。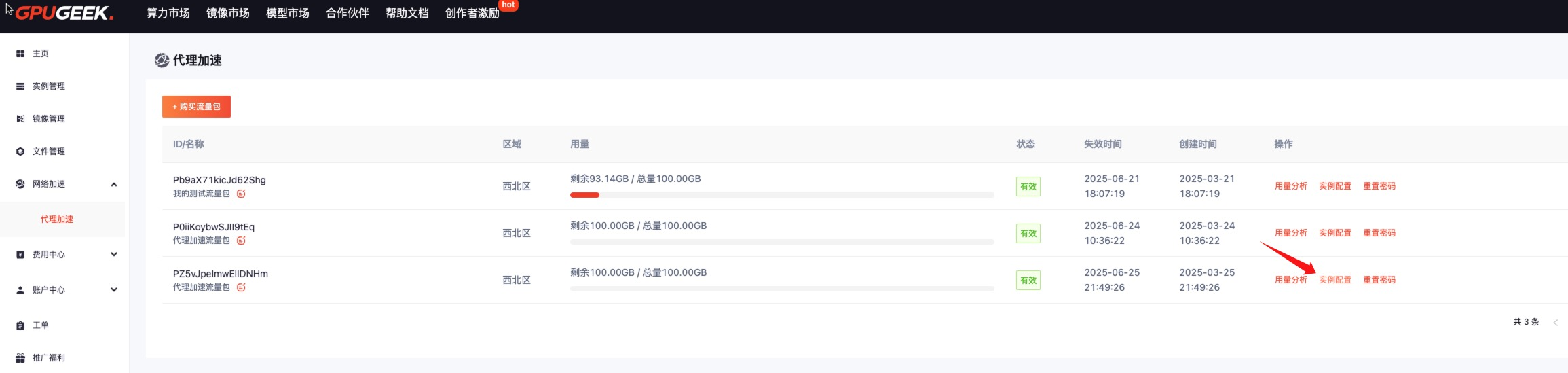
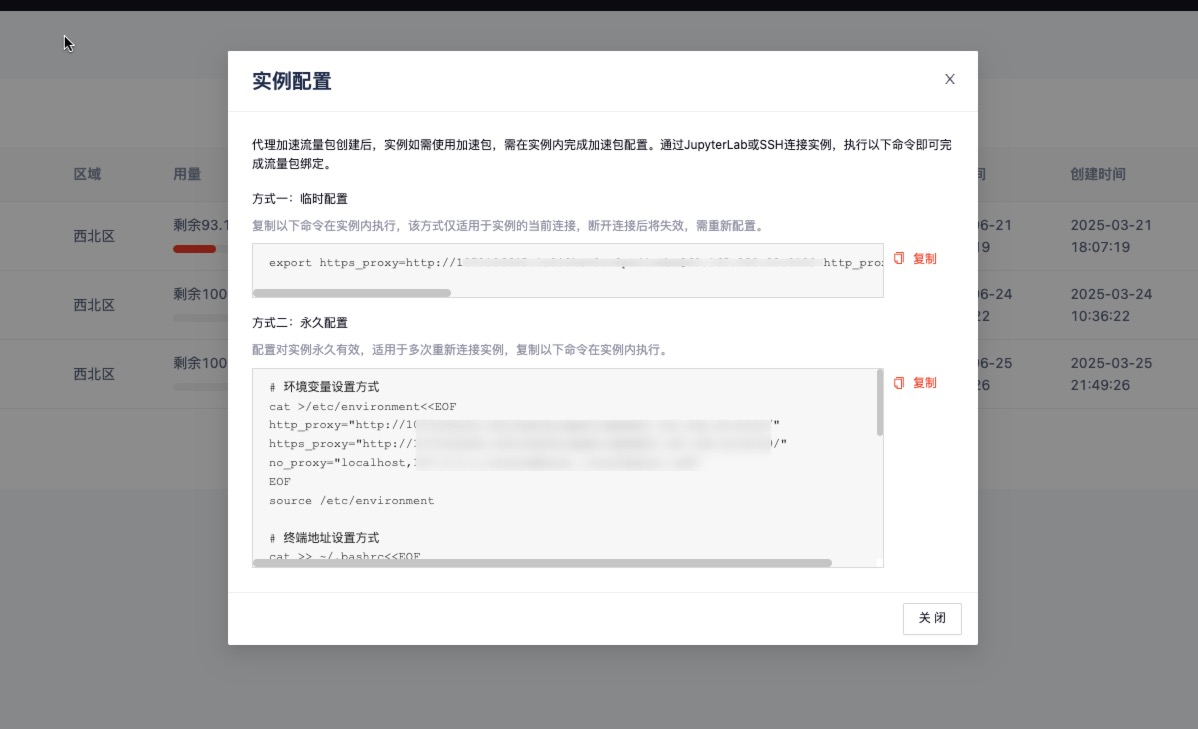
-
提示:当前可用加速地址如下,若如下地址中若存在您所需的加速地址,可在GpuGeek控制台 提交工单,内容填写需要新增加速的域名或者地址后,平台评估域名或地址合规后将进行新增加速地址。
3.2 高级技巧:定制化加速策略
- 多站点分组管理:按 “代码托管”“模型仓库”“文献数据库” 创建加速分组,针对性分配带宽资源;
- 本地 DNS 优化:在实例内修改
/etc/resolv.conf,指向 GpuGeek 专属 DNS 服务器(223.5.5.5),提升域名解析效率; - 流量监控与预警:通过 API 接口获取实时流量数据,设置阈值触发邮件预警,避免超量消费。
3.3 典型场景优化方案
| 应用场景 | 加速配置建议 | 实测效果 |
|---|---|---|
| 大规模代码拉取 | 启用 GitHub 专属加速通道 | 1GB 代码库拉取耗时 < 3 分钟 |
| 预训练模型下载 | 绑定 Hugging Face 节点集群 | 10GB 模型下载速度 > 50MB/s |
| 跨国协同开发 | 选择 “香港 + 达拉斯” 双节点链路 | 远程调试延迟 < 50ms |
3.4 网络加速的重要性
在深度学习和模型开发过程中,网络如同连接各个环节的桥梁,其速度和稳定性对整个流程的效率有着深远的影响。在数据传输方面,无论是将海量的训练数据从存储设备传输到计算节点,还是将训练好的模型部署到推理服务器,数据传输速度都至关重要。假设在训练一个大型的自然语言处理模型时,训练数据量达到数 TB 甚至更大,若网络传输速度缓慢,仅数据传输这一环节就可能耗费数天的时间,大大延长了模型的训练周期。而在模型推理阶段,实时性要求较高的应用场景,如自动驾驶中的实时目标检测、智能客服的即时响应等,快速的数据传输能够确保模型及时获取输入数据并返回准确的推理结果,提升用户体验。如果网络延迟过高,数据传输出现卡顿,可能导致自动驾驶系统的决策延迟,增加交通事故的风险;对于智能客服来说,延迟的响应可能会让用户感到不满,影响用户对服务的满意度。此外,在与外部资源交互时,如从 Github 获取开源代码、从学术数据库下载相关文献等,网络速度也直接影响着开发的进度和效率。如果网络不稳定,频繁出现连接中断或下载失败的情况,会严重干扰开发者的工作节奏,降低开发效率 。

四、网络加速赋能多元 AI 场景
4.1 高校科研:让文献与代码触手可及
某 985 高校 AI 实验室使用 GpuGeek 加速后,师生访问 Google Scholar 的文献下载速度从 10KB/s 提升至 2MB/s,GitHub 上的协同代码提交冲突率下降 40%。通过课程专属镜像与加速策略绑定,实验环境部署时间从 4 小时缩短至 20 分钟,算力资源利用率提升 65%。
4.2 企业开发:突破跨境协作壁垒
某金融科技公司在开发智能风控模型时,通过 GpuGeek 海外节点加速访问彭博终端数据接口,实时数据流延迟从 1.2 秒降至 0.3 秒,模型推理响应时间优化 30%。结合竞价实例的弹性加速方案,月度网络成本降低 55%。
4.3 个人开发者:轻量化加速体验
独立开发者通过 GpuGeek 的免费加速额度(新用户赠送 5GB 流量),可快速完成 Stable Diffusion 模型下载与调试,避免因网络问题导致的开发中断。平台支持的本地环境镜像(如 PyTorch 2.3+CUDA 12.4 预配置),进一步将环境搭建时间压缩至 5 分钟以内。
五、经典代码案例及解释

5.1 代码案例1:使用TensorFlow构建简单的卷积神经网络(CNN)进行图像分类
import tensorflow as tf
from tensorflow.keras import layers, models# 构建CNN模型
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 打印模型结构
model.summary()解释:此代码使用TensorFlow构建了一个简单的卷积神经网络(CNN),适用于图像分类任务。模型包含多个卷积层和池化层,用于提取图像特征,最后通过全连接层输出分类结果。model.compile用于配置模型的优化器、损失函数和评估指标,model.summary打印模型的结构和参数信息。
5.2 代码案例2:使用PyTorch进行模型微调
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision.models import resnet50# 加载预训练的ResNet50模型
model = resnet50(pretrained=True)# 冻结所有参数
for param in model.parameters():param.requires_grad = False# 替换最后的全连接层以适应新的分类任务
num_classes = 10
model.fc = torch.nn.Linear(model.fc.in_features, num_classes)# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)# 数据加载和预处理
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)# 训练模型
for epoch in range(5):model.train()for images, labels in train_loader:optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()解释:此代码展示了如何使用PyTorch对预训练的ResNet50模型进行微调。首先加载预训练模型并冻结其所有参数,然后替换最后的全连接层以适应新的分类任务。定义损失函数和优化器后,对模型进行训练。通过微调,可以在特定数据集上快速获得性能较好的模型。
5.3 代码案例3:使用OpenCV进行图像预处理
import cv2
import numpy as np# 读取图像
image = cv2.imread('example.jpg')# 调整图像大小
resized_image = cv2.resize(image, (224, 224))# 转换颜色空间为灰度
gray_image = cv2.cvtColor(resized_image, cv2.COLOR_BGR2GRAY)# 对图像进行归一化
normalized_image = gray_image / 255.0# 显示处理后的图像
cv2.imshow('Processed Image', normalized_image)
cv2.waitKey(0)
cv2.destroyAllWindows()解释:此代码使用OpenCV库对图像进行预处理。首先读取图像,然后调整其大小为224×224像素,接着将图像转换为灰度图像,并对像素值进行归一化处理,使其范围在[0,1]之间。这些预处理步骤有助于提高图像数据的质量,为后续的深度学习模型训练做好准备。
5.4 代码案例4:使用TensorFlow构建并训练一个循环神经网络(RNN)进行文本生成
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense# 示例文本数据
text = "Hello, this is a sample text for training an RNN model. It will generate new text based on the training data."# 文本预处理
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text])
total_words = len(tokenizer.word_index) + 1# 创建输入序列
input_sequences = []
for line in text.split('.'):token_list = tokenizer.texts_to_sequences([line])[0]for i in range(1, len(token_list)):n_gram_sequence = token_list[:i+1]input_sequences.append(n_gram_sequence)# 填充序列
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))# 创建输入和标签
X, y = input_sequences[:,:-1], input_sequences[:,-1]
y = tf.keras.utils.to_categorical(y, num_classes=total_words)# 构建RNN模型
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(SimpleRNN(150))
model.add(Dense(total_words, activation='softmax'))# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# 训练模型
model.fit(X, y, epochs=100, verbose=1)# 生成新文本
def generate_text(seed_text, next_words, max_sequence_len):for _ in range(next_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')predicted = model.predict(token_list, verbose=0)predicted_word_index = np.argmax(predicted, axis=1)[0]for word, index in tokenizer.word_index.items():if index == predicted_word_index:output_word = wordbreakseed_text += " " + output_wordreturn seed_textprint(generate_text("Hello", 5, max_sequence_len))解释:
-
文本预处理:使用
Tokenizer将文本转换为单词索引序列,然后生成输入序列。通过pad_sequences将所有序列填充到相同的长度。 -
模型构建:构建一个简单的RNN模型,包含嵌入层、RNN层和全连接层。嵌入层将单词索引映射到固定大小的密集向量,RNN层负责学习序列中的模式,全连接层输出每个单词的概率分布。
-
模型训练:使用
categorical_crossentropy作为损失函数,adam作为优化器,训练模型。 -
文本生成:通过给定的种子文本,模型预测下一个单词,逐步生成新文本。
5.5 代码案例5:使用PyTorch进行Transformer模型的微调
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader, Dataset# 示例数据
texts = ["This is a positive review.", "This is a negative review."]
labels = [1, 0] # 1 for positive, 0 for negative# 数据集类
class TextDataset(Dataset):def __init__(self, texts, labels, tokenizer, max_len):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]encoding = self.tokenizer.encode_plus(text,max_length=self.max_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 加载预训练的BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')# 创建数据集和数据加载器
dataset = TextDataset(texts, labels, tokenizer, max_len=128)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)# 定义优化器和损失函数
optimizer = optim.Adam(model.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()# 微调模型
model.train()
for epoch in range(3):for batch in dataloader:input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['labels']outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossoptimizer.zero_grad()loss.backward()optimizer.step()# 评估模型
model.eval()
with torch.no_grad():for batch in dataloader:input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['labels']outputs = model(input_ids, attention_mask=attention_mask)logits = outputs.logitspredictions = torch.argmax(logits, dim=1)print(f"Predicted: {predictions}, Actual: {labels}")解释:
-
数据预处理:使用
BertTokenizer对文本进行分词和编码,创建自定义的数据集类TextDataset,并使用DataLoader加载数据。 -
模型加载和配置:加载预训练的BERT模型
BertForSequenceClassification,并定义优化器和损失函数。 -
微调模型:对模型进行训练,通过反向传播更新模型参数。
-
模型评估:在评估模式下,对模型进行评估,输出预测结果和实际标签。

5.6 代码案例6:使用OpenCV和TensorFlow进行实时图像识别
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import load_model# 加载预训练的模型
model = load_model('path_to_your_model.h5')# 定义图像预处理函数
def preprocess_image(image):image = cv2.resize(image, (224, 224))image = image.astype('float32') / 255.0image = np.expand_dims(image, axis=0)return image# 打开摄像头
cap = cv2.VideoCapture(0)# 循环读取摄像头帧
while True:ret, frame = cap.read()if not ret:break# 预处理图像processed_frame = preprocess_image(frame)# 使用模型进行预测predictions = model.predict(processed_frame)predicted_class = np.argmax(predictions, axis=1)[0]# 在图像上显示预测结果cv2.putText(frame, f'Predicted Class: {predicted_class}', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)# 显示图像cv2.imshow('Real-Time Image Recognition', frame)# 按下'q'键退出if cv2.waitKey(1) & 0xFF == ord('q'):break# 释放摄像头并关闭窗口
cap.release()
cv2.destroyAllWindows()解释:
-
模型加载:加载预训练的深度学习模型,用于图像识别。
-
图像预处理:定义一个函数
preprocess_image,对摄像头捕获的图像进行预处理,包括调整大小、归一化和扩展维度。 -
实时图像捕获:使用OpenCV打开摄像头,循环读取每一帧图像。
-
模型预测:对每一帧图像进行预处理后,使用模型进行预测,并将预测结果显示在图像上。
-
显示和退出:使用OpenCV显示图像,并在按下'q'键时退出程序。
这些代码案例涵盖了从基础到高级的深度学习应用,帮助你更好地理解和应用这些技术。
六、总结:重新定义 AI 开发的 “网络效率”
GpuGeek 的网络加速功能不仅解决了 “能不能访问” 的基础问题,更通过精细化的流量管理、全球化的节点布局、智能化的成本控制,构建了一套适配 AI 开发全流程的网络解决方案。当算力与网络效率形成协同,开发者得以彻底摆脱基础设施的桎梏,将精力聚焦于算法创新与模型优化。
立即体验 GpuGeek 网络加速,注册即享 20GB 免费加速流量,解锁丝滑代码拉取与模型下载体验:
GpuGeek官网地址
在 AI 开发的竞速赛中,网络加速已成为决定胜负的关键赛道。GpuGeek 用技术创新证明:当每一个数据请求都能以最优路径抵达,AI 的无限可能正从这里开始。
6.1 附录:常见问题解答(FAQ)
Q1:如何避免训练任务被竞价实例中断?
A1:使用--checkpoint-interval 300参数每5分钟保存检查点,任务中断后可通过gpugeek job resume <job_id>自动恢复。
Q2:是否支持私有化部署?
A2:企业版支持本地化部署,最低配置为8卡A100集群。
Q3:如何优化跨国数据传输成本?
A3:启用跨区域数据同步功能,香港与法兰克福节点间传输免费,其他区域按0.01元/GB计费。
Q4:已经释放的实例还能找回数据吗?
您好,实例释放后无法找回数据。
Q5:服务器CPU跑满了怎么办?
首先要查看是哪些进程/应用在消耗 CPU。
Q6:JupyterLab打不开是怎么回事?
通过镜像导入功能导入的镜像,默认不会安装 jupyterlab,如果需要安装 jupyterlab,请自行安装配置。
官方镜像中默认吧 jupyterlab 安装到了 base 虚拟环境中,如果您对 base 虚拟环境做了修改,比如修改 python 版本、安装其它包导致与 jupyterlab 冲突,卸载 jupyter、误操作等,会引起已安装的 jupyter 损坏,从而导致无法访问到 jupyter,下面给出排查和解决方法。
# 1. 先查看 base 环境中的 Python 版本是否与实例创建时,选择的镜像中的Python版本是否一致。
(base) root@492132307857413:/# python -V
Python 3.10.10# 2. 使用 `pip list | grep jupyter` 命令来查看当前安装的 jupyter 是否缺少某个包,与下面做对比
(base) root@492132307857413:/# pip list | grep jupyter
jupyter_client 8.6.0
jupyter_core 5.5.0
jupyter-events 0.9.0
jupyter-lsp 2.2.0
jupyter_server 2.11.1
jupyter_server_terminals 0.4.4
jupyterlab 4.0.8
jupyterlab-language-pack-zh-CN 4.0.post3
jupyterlab-pygments 0.2.2
jupyterlab_server 2.25.0#3. 如果缺少某个包,则通过 pip install 包名 进行安装,例如缺少 jupyter_core 组件,则使用如下命令进行安装
(base) root@492132307857413:/# pip install jupyter_core#4. 安装完成后使用如下命令重启 jupyterlab
(base) root@492132307857413:/# supervisord ctl restart jupyterlab#5. 然后查看 jupyterlab 运行状态,如果状态为 Running 则正常,然后去控制台进行访问
(base) root@492132307857413:/# supervisord ctl status jupyterlab
jupyterlab Running pid 40, uptime 0:15:43#如果为其它状态则提交工单让技术进行排查
Q7:为什么我不能调用GPU?
在进行深度学习训练时发现没有使用 GPU,可以尝试以下步骤进行故障排查和解决:
1.确保可以通过 nvidia-smi 命令看到 GPU 信息
nvidia-smi
2.检查当前代码运行的实例环境中已正确安装了您代码所使用的框架,(如TensorFlow、PyTorch等)支持GPU
TensorFlow框架检查
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
PyTorch框架检查
import torch
print(torch.cuda.is_available())
3.检查安装的CUDA版本是否与您的深度学习框架版本兼容
官方所提供的镜像,包含了框架、CUDA、Python版本,并且都是框架官方所支持的版本)。
如果您在官方镜像中又安装了其它版本的框架,那么请检查下对应框架的官方对于您所安装的框架版本对当前的CUDA版本兼容性。
查看CUDA版本
nvcc -V
4.在训练代码中显性指定GPU设备
TensorFlow框架
with tf.device('/GPU:0'):model.fit(...)
PyTorch框架
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 确保数据也被发送到GPU
inputs, labels = data[0].to(device), data[1].to(device)
5.设置环境变量 对于某些框架,可能需要设置环境变量来指示使用GPU;例如,对于CUDA,可以设置:
export CUDA_VISIBLE_DEVICES=0
Q8:实例通过镜像还原后SSH、JupyterLab无法连接?
实例通过镜像还原后,如果无法连接 SSH 或 JupyterLab,建议您先重启下实例,重启成功后再进行尝试连接,重启后如果还是无法连接,麻烦创建工单让技术排查具体问题。
如果还原镜像选择的是导入的自定义镜像,那么自定义镜像中默认不会安装 JupyterLab ,但是 SSH 应该正常使用,如果 SSH 也无法正常使用,同样去创建工单让技术排查具体问题。
Q9:HuggingFace缓存
默认HuggingFace的缓存模型会保存在/root/.cache目录,可以通过以下方式将模型的缓存保存到数据盘,具体方法为:
#终端中执行:
export HF_HOME=/gz-data/hf-cache/#或者Python代码中执行:
import os
os.environ['HF_HOME'] = '/gz-data/hf-cache/'
6.2 写在最后
如果你是一名 AI 开发者,或是正在从事与深度学习、大模型开发相关的工作,不妨尝试使用 GpuGeek 平台。相信它会为你的工作带来全新的体验和高效的解决方案,助力你在 AI 领域取得更大的突破和成就 。
相关文章:

GpuGeek 网络加速:破解 AI 开发中的 “最后一公里” 瓶颈
摘要: 网络延迟在AI开发中常被忽视,却严重影响效率。GpuGeek通过技术创新,提供学术资源访问和跨国数据交互的加速服务,助力开发者突破瓶颈。 目录 一、引言:当算力不再稀缺,网络瓶颈如何破局? …...

关于 Web安全:1. Web 安全基础知识
一、HTTP/HTTPS 协议详解 1. HTTP协议基础 什么是 HTTP? HTTP(HyperText Transfer Protocol)是互联网中浏览器和服务器之间传输数据的协议,基于请求-响应模式。它是一个无状态协议,意思是每次请求都是独立的&#x…...

debugfs:Linux 内核调试的利器
目录 一、什么是 debugfs?二、debugfs 的配置和启用方式2.1 内核配置选项2.2 挂载 debugfs2.3 Android 系统中的 debugfs 三、debugfs 的典型应用场景3.1 调试驱动开发3.2 内核子系统调试3.3 性能分析 四、常见 debugfs 子目录与功能示例4.1 /sys/kernel/debug/trac…...
)
Spyglass:跨时钟域同步(同步使能)
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 简介 同步使能方案主要用于数据信号跨时钟域同步,该方案将一个控制信号同步至目标时钟域并用其作为数据信号的捕获触发器的使能信号,如图1所示…...

安装Minikube
环境 CentOS7 参考 minikube start | minikube 创建虚拟机,参考 模拟Gitlab安装-CSDN博客 下载二进制包 curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64 报错不能解析host,配置host 下载成功 安装 sudo install minikube-linux-am…...

图像锐化调整
一、背景介绍 之前找多尺度做对比度增强时候,发现了一些锐化相关算法,正好本来也要整理锐化,这里就直接顺手对之前做过的锐化大概整理了下,方便后续用的时候直接抓了。 这里整理的锐化主要是两块:一个是参考论文&#…...

【CanMV K230】AI_CUBE1.4
《k230-AI 最近小伙伴有做模型的需求。所以我重新捡起来了。正好把之前没测过的测一下。 这次我们用的是全新版本。AICUBE1.4.dotnet环境9.0 注意AICUBE训练模型对硬件有所要求。最好使用独立显卡。 有小伙伴说集显也可以。emmmm可以试试哈 集显显存2G很勉强了。 我们依然用…...

STM32外设AD-定时器触发 + DMA读取模板
STM32外设AD-定时器触发 DMA读取模板 一,方法思路二,定时器基础与配置1,定时器时钟源 (Clock Source)2,预分频器 (Prescaler - PSC)3,自动重装载寄存器 (Auto-Reload Register - ARR) / 周期 (Period)4,触…...

数据库故障排查指南:从入门到精通
1. 常见数据库故障类型 1.1 连接故障 数据库连接超时连接池耗尽网络连接中断认证失败1.2 性能故障 查询执行缓慢内存使用过高CPU使用率异常磁盘I/O瓶颈1.3 数据故障 数据不一致数据丢失数据损坏事务失败2. 故障排查流程 2.1 初步诊断 -- 检查数据库状态SHOW STATUS;SHOW PRO…...

【AT32】 AT32 移植 Freemodbus 主站
基于野火开发板 at32f437zgt6芯片 和at32 官方开发工具 移植了网上一套开源的freemodbus 主站 这里对modbus 协议不做过多的讲解 主要已实现代码为主 AT32 Work Bench 参考之前我之前的配置 与stm32cubemx软件差不多 注意485芯片的收发脚配置即可 AT32 IDE 说实话这软件太垃…...

内网环境下如何使用ntpdate实时同步时间
背景介绍 NTP(Network Time Protocol)是一种网络协议,用于同步计算机系统的时间。ntpdate是一个用于手动同步时间的命令行工具,它可以从指定的NTP服务器获取当前时间并更新本地系统时间。 ntpdate 服务介绍 功能:ntp…...

python版本管理工具-pyenv轻松切换多个Python版本
在使用python环境开发时,相信肯定被使用版本所烦恼,在用第三方库时依赖兼容的python版本不一样,有没有一个能同时安装多个python并能自由切换的工具呢,那就是pyenv,让你可以轻松切换多个Python 版本。 pyenv是什么 p…...

工商总局可视化模版 – 基于ECharts的大数据可视化HTML源码
概述 在大数据时代,数据可视化已成为各行各业进行数据分析和决策的重要工具。幽络源今天为大家带来一款基于ECharts的工商总局数据可视化HTML模版,帮助开发者快速搭建专业级工商广告数据展示平台。这款模版设计规范,功能完善,适合…...

计算机网络 : 网络基础
计算机网络 : 网络基础 目录 计算机网络 : 网络基础引言1. 网络发展背景2. 初始协议2.1 初始协议2.2 协议分层2.2.1 软件分层的好处2.2.2 OSI七层模型2.2.3 TCP/IP五层(四层)模型 2.3 TCP/IP协议2.3.1TCP/IP协议与操作系统的关系&…...

eSwitch manager 简介
eSwitch manager 的定义和作用 eSwitch manager 通常指的是能够配置和管理 eSwitch(嵌入式交换机)的实体或接口。在 NVIDIA/Mellanox 的网络架构中,Physical Function(PF)在 switchdev 模式下充当 eSwitch manager&am…...

物联网技术在银行安全用电系统中的应用与实践研究
摘要 随着金融科技的快速发展,银行业电子设备数量激增,用电安全管理问题日益突出。本文基于2019年农业银行与2020年中国邮政储蓄银行发布的安全用电相关政策,分析了银行场景下存在的五大用电安全隐患,提出以物联网技术为核心的安…...

589. N叉树的前序遍历迭代法:null指针与栈的巧妙配合
一、题目描述 给定一个N叉树的根节点,返回其节点值的前序遍历结果。前序遍历的定义是:先访问根节点,再依次遍历每个子节点(从左到右)。例如,对于如下N叉树: 1/ | \3 2 4 / \ 5 6前序遍历结果…...

【洗车店专用软件】佳易王洗车店多项目会员管理系统:一卡多用扣次软件系统实操教程 #扣次洗车管理软件
一、软件试用版资源文件下载说明 (一)若您想体验软件功能,可通过以下方式获取软件试用版资源文件: 访问头像主页:进入作者头像主页,找到第一篇文章,点击文章最后的卡片按钮,即可了解…...

小红书笔记详情接口如何调用?实操讲解。
调用小红书笔记详情接口通常需要经过申请权限、构建请求、发送请求并处理响应等步骤,以下是详细的实操讲解: 一、申请接口权限 注册小红书开放平台账号 访问小红书开放平台官网/第三方开放平台,按照提示完成注册流程,提供必要的…...

leetcode 57. Insert Interval
题目描述 代码:由于intervals已经按照左端点排序,并且intervals中的区间全部不重叠,那么可以断定intervals中所有区间的右端点也已经是有序的。先二分查找intervals中第一个其右端点>newInterval左端点的区间。然后按照类似于56. Merge In…...

杰理ac696配置mic
省电容mic有概率不出声解决办法如下...

COMSOL随机参数化表面流体流动模拟
基于粗糙度表面的裂隙流研究对于理解地下水的流动、污染物传输以及与之相关的地质灾害(如滑坡)等方面具有重要意义。本研究通过蒙特卡洛方法生成随机表面形貌,并利用COMSOL Multiphysics对随机参数化表面的微尺度流体流动进行模拟。 参数化…...

Linux远程连接服务
远程连接服务器简介 远程连接服务器通过文字或图形接口方式来远程登录系统,让你在远程终端前登录linux主机以取得可操作主机接口(shell),而登录后的操作感觉就像是坐在系统前面一样。 远程连接服务器的功能 分享主机的运算能力 远…...

用Python绘制梦幻星空
用Python绘制梦幻星空 在这篇教程中,我们将学习如何使用Python创建一个美丽的星空场景。我们将使用Python的图形库Pygame和随机库来创建闪烁的星星、流星和月亮,打造一个动态的夜空效果。 项目概述 我们将实现以下功能: 创建深蓝色的夜…...

EWOMAIL
1、错误 Problem: problem with installed package selinux-policy-targeted-3.14.3-41.el8.noarch package fail2ban-server-1.0.2-3.el8.noarch requires (fail2ban-selinux if selinux-policy-targeted), but none of the providers can be installed - package fail2ban-…...
)
网安面试经(1)
1.说说IPsec VPN 答:IPsec VPN是利用IPsec协议构建的安全虚拟网络。它通过加密技术,在公共网络中创建加密隧道,确保数据传输的保密性、完整性和真实性。常用于企业分支互联和远程办公,能有效防范数据泄露与篡改,但部署…...
)
【每天一个知识点】意图传播(Intent Propagation)
在人工智能(AI)快速发展的背景下,自然语言处理(NLP)已成为推动智能系统理解与生成自然语言的核心技术。其中,“意图识别”作为人机交互的关键步骤,已被广泛应用于智能客服、对话系统、语音助手等场景。而“意图传播”(Intent Propagation)作为更深层的机制,逐渐成为当…...
)
【串流VR手势】Pico 4 Ultra Enterprise 在 SteamVR 企业串流中无法识别手势的问题排查与解决过程(Pico4UE串流手势问题)
写在前面的话 此前(用Pico 4U)接入了MRTK3,现项目落地需要部署,发现串流场景中,Pico4UE的企业串流无法正常识别手势。(一体机方式部署使用无问题) 花了半小时解决,怕忘,…...

工具:shell命令提示符自定义之显示GIT当前分支
1 背景 在命令行操作,每次想查看当前分支都要手动执行命令(git branch)太麻烦了,想着在命令提示符上面显示当前分支,很直观也很方便 2 实现 编辑 vim ~/.bashrc 文件,添加如下内容 function update_prom…...
)
现代计算机图形学Games101入门笔记(十四)
Irradiance 微小的能量/微小的面积 用Irradiance解释能量大小解释冬夏 Intensity没变,但是Irradiance是衰减的,外圈面积变大,单位面积上接受的能量就变小了。 入射进来 离开 这里就是从某个方向来了一个能量,经过反射,…...

前端开发笔记与实践
一、Vue 开发规范与响应式机制 1. 组件命名规范 自定义组件使用大驼峰命名法(如 MyComponent),符合 Vue 官方推荐,便于与原生 HTML 元素区分。 2. Proxy vs defineProperty 特性Proxy(Vue3)Object.defi…...

机器学习知识自然语言处理入门
一、引言:当文字遇上数学 —— 自然语言的数字化革命 在自然语言处理(NLP)的世界里,计算机要理解人类语言,首先需要将文字转化为数学向量。早期的 One-Hot 编码如同给每个词语分配一个唯一的 “房间号”,例…...

泰迪杯特等奖案例深度解析:基于多级二值化与CNN回归的车牌识别系统设计
(第八届泰迪杯数据挖掘挑战赛特等奖案例全流程拆解) 一、案例背景与核心挑战 1.1 行业痛点与场景需求 在智慧交通与无感支付场景中,车牌识别是核心环节。传统车牌识别系统在复杂光照、污损车牌、多角度倾斜等场景下存在显著缺陷。根据某智慧油站2024年运营数据显示,高峰期…...
开发 python高级应用5:crawl4ai 如何建立一个全面的知识库 第一步找分类)
ai agent(智能体)开发 python高级应用5:crawl4ai 如何建立一个全面的知识库 第一步找分类
让我们充分利用爬虫功能建立自己丰富的知识库, 第一步找分类 以下是一个层次分明、覆盖全面的知识库分类体系,分为9大主类、43个子类,并融入交叉学科和新兴领域设计: 一、经济与商业 宏观经济(全球经济/国家政策&a…...
)
Solon Ai Flow 编排开发框架发布预告(效果预览)
Solon Ai 在推出 Solon Ai Mcp 后,又将推出 Solon Ai Flow。 1、Solon Ai Flow 是个啥? Solon Ai Flow 是一个智能体编排开发框架。它是框架!不是工具,不是产品(这与市面上流行的工具和产品,有较大差别&a…...
)
【言语】刷题5(填空)
front:刷题5 第一个词排除人迹罕至 人迹罕至:很少有人去的地方。指偏僻荒涼的地方。(荒郊野岭既视感的一个词) 第二个空锁定B,太贴合语义了 第三个空排除一文不值,百无一用,现在这题已经可以过了…...

技术解码 | 腾讯云SRT弱网优化
随着互联网基础设施和硬件设备的不断发展。广大直播观众对于直播观看的清晰度,延时等方面的体验要求越来越高,直播也随之进入了低延迟高码率的时代,直播传输技术也面临着越来越高的要求和挑战。 腾讯视频云为此在全链路上针对流媒体传输不断深…...

“分布形态“
一、分布形态的基础分类 1、正态分布(对称分布) (1)特征:钟型曲线,均值=中位数=众数;约68%数据在μσ范围内,95%在μ2σ内。 (2)应用:身高、体重、测量误差等自然现象。 (3)重要性:多数统计方法(如T检验、方差分析)假设数据正态性。 2、偏态分布 (1)左偏(负…...

Android minSdk从21升级24后SO库异常
问题 minSdk从21调整到24后: java.nio.file.NoSuchFileException: /data/app/~~Z9s2NfuDdclOUwUBLKnk0A/com.rs.unity- Bg31QvFwF4qsCwv2XCqT-w/split_config.arm64_v8a.apkjava.nio.file.NoSuchFileException: /data/app/~~Z9s2NfuDdclOUwUBLKnk0A/com.rs.unity-…...
stack(栈))
C#进阶(2)stack(栈)
前言 我们前面介绍了ArrayList,今天就介绍另一种数据结构——栈。 这是栈的基本形式,博主简单画了一下,你看个意思就行,很明显,这种数据有一种特征:先进后出。因为先进来的数据会在下面,下面是密闭的,所以只能取后面进来的。 C#为我们封好了这种数据结构,我们不用担…...

Linux du 命令终极指南:从基础到精通
文章目录 Linux du 命令终极指南:从基础到精通du 命令简介常用参数详解常见用法示例查看当前目录总大小查看当前目录及其子目录占用空间只显示当前目录总占用空间查看目录下每个文件和子目录的大小查看某目录深度为 1 的大小分布查看某目录并排除日志文件查看多个目…...

【Linux网络】数据链路层
数据链路层 用于两个设备(同一种数据链路节点)之间进行传递。 认识以太网 “以太网” 不是一种具体的网络,而是一种技术标准;既包含了数据链路层的内容,也包含了一些物理层的内容。例如:规定了网络拓扑结…...

水库雨水情测报与安全监测系统解决方案
一、方案概述 本水库雨水情测报与安全监测解决方案的核心目标在于利用尖端的技术手段,确保对水库雨水情势以及大坝安全状况的持续监控和及时预警,从而为水库的稳定运行提供坚实的支持和保障。该方案严格遵循“统筹协调、因库制宜、实用有效、信息共享”的…...

Shotcut:免费开源的视频编辑利器
Shotcut是一款功能强大且完全免费的开源视频编辑软件,专为需要高效、灵活视频编辑的用户设计。它支持多种常见视频格式,如MP4、AVI、MOV等,并提供了丰富的视频编辑功能,满足用户在不同场景下的需求。无论是初学者还是专业人士&…...

学习海康VisionMaster之直方图工具
一:进一步学习了 今天学习下VisionMaster中的直方图工具:就是统计在ROI范围内进行灰度级分布的统计 二:开始学习 1:什么是直方图工具? 直方图工具针对输入灰度图像的指定ROI区域,输出该区域的图像灰度直方…...

AI 笔记 -基于retinaface的FPN上采样替换为CARAFE
上采样替换为CARAFE 引言内容感知特征重组(CARAFE)公式化核预测模块 引言 简介:CARAFE(Content-Aware ReAssembly of FEatures),是用于增强卷积神经网络特征图的上采样方法,论文被 ICCV 2019 接…...

Visual Studio 2022 中添加“高级保存选项”及解决编码问题
文章目录 一、背景二、方法方法一:通过菜单栏手动添加(推荐)方法二:通过拖拽快速添加(替代方案) 三、验证与使用四、补充说明五、所能解决的问题 一、背景 VS 在开发cmake项目的过程中,可能会遇…...

SQLMesh 增量模型从入门到精通:5步实现高效数据处理
本文深入解析 SQLMesh 中的增量时间范围模型,介绍其核心原理、配置方法及高级特性。通过实际案例说明如何利用该模型提升数据加载效率,降低计算资源消耗,并提供配置示例与最佳实践建议,帮助读者在实际项目中有效应用这一强大功能。…...

嵌入式开发书籍推荐
嵌入式开发是将计算机技术、微电子技术与各行业应用相结合的综合技术,学习过程中需要多方面知识储备。以下精选书籍,从基础到进阶,助你系统掌握嵌入式开发知识。 基础理论类 《计算机组成原理》(唐朔飞版)࿱…...

实变函数 第二章 点集
2 点集 2.1 欧式空间 2.1.1 度量空间、欧式空间 Definition \textbf{Definition} Definition 度量空间 (距离空间) 若 ∀ x , y ∈ X : ∃ d : ( x , y ) → R \forall x,y\in X:\exists d:(x,y)\to\mathbb{R} ∀x,y∈X:∃d:(x,y)→R,满足: d ( x , y…...