pytorch 14.3 Batch Normalization综合调参实践
文章目录
- 一、Batch Normalization与Batch_size综合调参
- 二、复杂模型上的Batch_normalization表现
- 1、BN对复杂模型(sigmoid)的影响
- 2、模型复杂度对模型效果的影响
- 3、BN对复杂模型(tanh)的影响
- 三、包含BN层的神经网络的学习率优化
- 1.学习率敏感度
- 2.学习率学习曲线
- 3.不同学习率下不同模型优化效果
- 四、带BN层的神经网络模型综合调整策略总结
一、Batch Normalization与Batch_size综合调参
我们知道,BN是一种在长期实践中被证明行之有效的优化方法,但在使用过程中首先需要知道,BN的理论基础(尽管不完全正确)是以BN层能够有效预估输入数据整体均值和方差为前提的,如果不能尽可能的从每次输入的小批数据中更准确的估计整体统计量,则后续的平移和放缩也将是有偏的。而由小批数据估计整体统计量的可信度其实是和小批数据本身数量相关的,如果小批数据数量太少,则进行整体统计量估计时就将有较大偏差,此时会影响模型准确率。
因此,一般来说,我们在使用BN时,至少需要保证小批数据量(batch_size)在15-30以上,才能进行相对准确的预估。此处我们适当调整小批数据量参数,再进行模型计算。
# 进行数据集切分与加载
# 设置batch_size为50
train_loader, test_loader = split_loader(features, labels, batch_size=50)
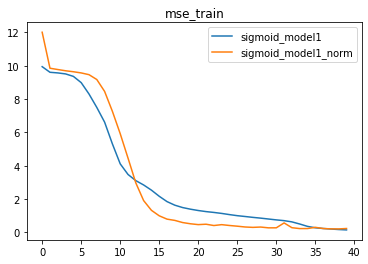
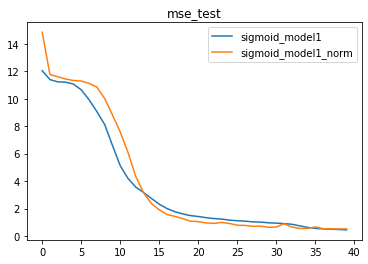
我们发现,当提升batch_size之后,带BN层的模型效果有明显提升,相比原始模型,带BN层的模型拥有更快的收敛速度。
二、复杂模型上的Batch_normalization表现
1、BN对复杂模型(sigmoid)的影响
一般来说,BN方法对于复杂模型和复杂数据会更加有效,换而言之,很多简单模型是没必要使用BN层(徒增计算量)。对于上述net_class1来说,由于只存在一个隐藏层,因此也不会存在梯度不平稳的现象,而BN层的优化效果也并不明显。接下来,我们尝试构建更加复杂的模型,来测试BN层的优化效果。
从另一个角度来说,其实我们是建议更频繁的使用更加复杂的模型并带上BN层的,核心原因在于,复杂模型带上BN层之后会有更大的优化空间。
接下来,我们尝试设置更加复杂的数据集,同时增加模型复杂度,测试在更加复杂的环境下BN层表现情况。
此处我们创建满足 y = 2 x 1 2 − x 2 2 + 3 x 3 2 + x 4 2 + 2 x 5 2 y=2x_1^2-x_2^2+3x_3^2+x_4^2+2x_5^2 y=2x12−x22+3x32+x42+2x52的回归类数据集。
# 设置随机数种子
torch.manual_seed(420) # 创建最高项为2的多项式回归数据集
features, labels = tensorGenReg(w=[2, -1, 3, 1, 2], bias=False, deg=2)# 进行数据集切分与加载
train_loader, test_loader = split_loader(features, labels, batch_size=50)
接下来,我们同时创建Sigmoid1-4,并且通过对比带BN层的模型和不带BN层的模型来进行测试。
# class1对比模型
# 设置随机数种子
torch.manual_seed(24) # 实例化模型
sigmoid_model1 = net_class1(act_fun= torch.sigmoid, in_features=5)
sigmoid_model1_norm = net_class1(act_fun= torch.sigmoid, in_features=5, BN_model='pre')# 创建模型容器
model_ls1 = [sigmoid_model1, sigmoid_model1_norm]
name_ls1 = ['sigmoid_model1', 'sigmoid_model1_norm']# 核心参数
lr = 0.03
num_epochs = 40# 模型训练
train_ls1, test_ls1 = model_comparison(model_l = model_ls1, name_l = name_ls1, train_data = train_loader,test_data = test_loader,num_epochs = num_epochs, criterion = nn.MSELoss(), optimizer = optim.SGD, lr = lr, cla = False, eva = mse_cal)# class2对比模型
# 设置随机数种子
torch.manual_seed(24) # 实例化模型
sigmoid_model2 = net_class2(act_fun= torch.sigmoid, in_features=5)
sigmoid_model2_norm = net_class2(act_fun= torch.sigmoid, in_features=5, BN_model='pre')# 创建模型容器
model_ls2 = [sigmoid_model2, sigmoid_model2_norm]
name_ls2 = ['sigmoid_model2', 'sigmoid_model2_norm']# 核心参数
lr = 0.03
num_epochs = 40# 模型训练
train_ls2, test_ls2 = model_comparison(model_l = model_ls2, name_l = name_ls2, train_data = train_loader,test_data = test_loader,num_epochs = num_epochs, criterion = nn.MSELoss(), optimizer = optim.SGD, lr = lr, cla = False, eva = mse_cal)# class3对比模型
# 设置随机数种子
torch.manual_seed(24) # 实例化模型
sigmoid_model3 = net_class3(act_fun= torch.sigmoid, in_features=5)
sigmoid_model3_norm = net_class3(act_fun= torch.sigmoid, in_features=5, BN_model='pre')# 创建模型容器
model_ls3 = [sigmoid_model3, sigmoid_model3_norm]
name_ls3 = ['sigmoid_model3', 'sigmoid_model3_norm']# 核心参数
lr = 0.03
num_epochs = 40# 模型训练
train_ls3, test_ls3 = model_comparison(model_l = model_ls3, name_l = name_ls3, train_data = train_loader,test_data = test_loader,num_epochs = num_epochs, criterion = nn.MSELoss(), optimizer = optim.SGD, lr = lr, cla = False, eva = mse_cal)# class4对比模型
# 设置随机数种子
torch.manual_seed(24) # 实例化模型
sigmoid_model4 = net_class4(act_fun= torch.sigmoid, in_features=5)
sigmoid_model4_norm = net_class4(act_fun= torch.sigmoid, in_features=5, BN_model='pre')# 创建模型容器
model_ls4 = [sigmoid_model4, sigmoid_model4_norm]
name_ls4 = ['sigmoid_model4', 'sigmoid_model4_norm']# 核心参数
lr = 0.03
num_epochs = 40# 模型训练
train_ls4, test_ls4 = model_comparison(model_l = model_ls4, name_l = name_ls4, train_data = train_loader,test_data = test_loader,num_epochs = num_epochs, criterion = nn.MSELoss(), optimizer = optim.SGD, lr = lr, cla = False, eva = mse_cal)
# 训练误差
plt.subplot(221)
for i, name in enumerate(name_ls1):plt.plot(list(range(num_epochs)), train_ls1[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train_ls1')plt.subplot(222)
for i, name in enumerate(name_ls2):plt.plot(list(range(num_epochs)), train_ls2[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train_ls2')plt.subplot(223)
for i, name in enumerate(name_ls3):plt.plot(list(range(num_epochs)), train_ls3[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train_ls3')plt.subplot(224)
for i, name in enumerate(name_ls4):plt.plot(list(range(num_epochs)), train_ls4[i], label=name)
plt.legend(loc = 1)
plt.title('mse_train_ls4')
# 训练误差
plt.subplot(221)
for i, name in enumerate(name_ls1):plt.plot(list(range(num_epochs)), test_ls1[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test_ls1')plt.subplot(222)
for i, name in enumerate(name_ls2):plt.plot(list(range(num_epochs)), test_ls2[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test_ls2')plt.subplot(223)
for i, name in enumerate(name_ls3):plt.plot(list(range(num_epochs)), test_ls3[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test_ls3')plt.subplot(224)
for i, name in enumerate(name_ls4):plt.plot(list(range(num_epochs)), test_ls4[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test_ls4')
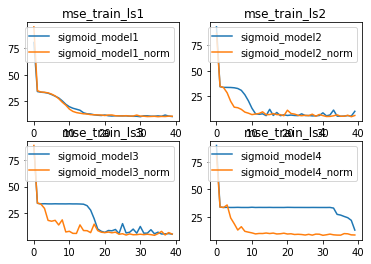
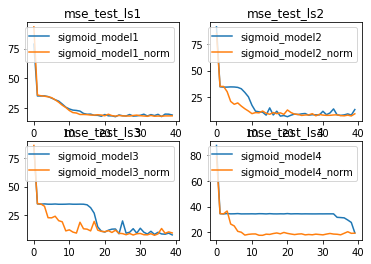
由此,我们可以清楚的看到,BN层对更加复杂模型的优化效果更好。换而言之,越复杂的模型对于梯度不平稳的问题就越明显,因此BN层在解决该问题后模型效果提升就越明显。
2、模型复杂度对模型效果的影响
并且,针对复杂数据集,在一定范围内,伴随模型复杂度提升,模型效果会有显著提升。但是,当模型太过于复杂时,仍然会出现模型效果下降的问题。
for i, name in enumerate(name_ls1):plt.plot(list(range(num_epochs)), test_ls1[i], label=name)
for i, name in enumerate(name_ls2):plt.plot(list(range(num_epochs)), test_ls2[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test')
for i, name in enumerate(name_ls2):plt.plot(list(range(num_epochs)), test_ls2[i], label=name)
for i, name in enumerate(name_ls4):plt.plot(list(range(num_epochs)), test_ls4[i], label=name)
plt.legend(loc = 1)
plt.title('mse_test')
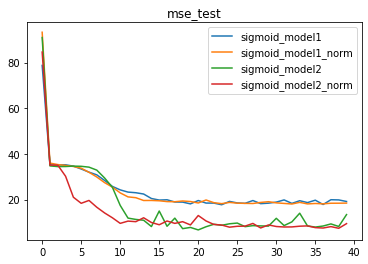
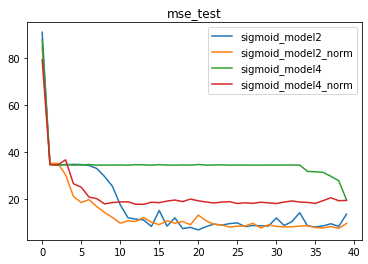
3、BN对复杂模型(tanh)的影响
对于Sigmoid来说,BN层能很大程度上缓解梯度消失问题,从而提升模型收敛速度,并且小幅提升模型效果。而对于激活函数本身就能输出Zero-Centered结果的tanh函数,BN层的优化效果会更好。
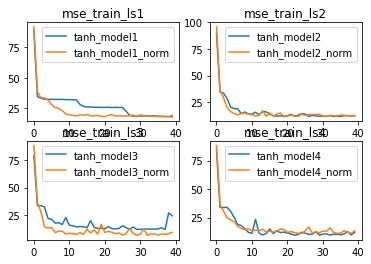
训练结果:
测试结果:
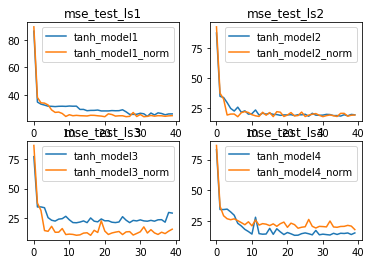
相比Sigmoid,使用tanh激活函数本身就是更加复杂的一种选择,因此,BN层在tanh上所表现出的更好的优化效果,也能看成是BN在复杂模型上效果有所提升。
三、包含BN层的神经网络的学习率优化
1.学习率敏感度
学习率lr对复杂模型(tanh)的影响
# 学习率 0.1
# 学习率 0.03
# 学习率 0.01
# 学习率 0.005
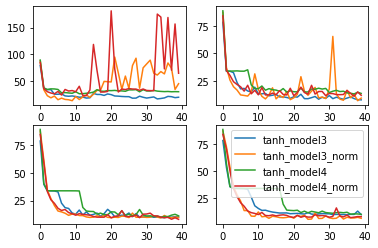
能够看出,随着学习率逐渐变化,拥有BN层的模型表现出更加剧烈的波动,这也说明拥有BN层的模型对学习率变化更加敏感。
2.学习率学习曲线
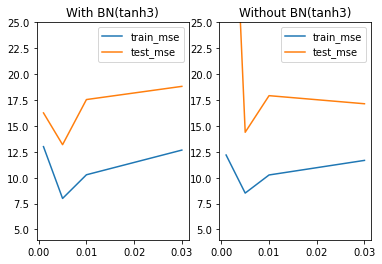
对于学习率的调整,一般都会出现倒U型曲线。我们能够发现,在当前模型条件下,学习率为0.005左右时模型效果较好。当然,我们这里也只取了四个值进行测试,也有可能最佳学习率在0.006或者0.0051,关于学习率参数的调整策略(LR-scheduler),我们将在下一节进行详细介绍,本节我们将利用此处实验得到的0.005作为学习率进行后续实验。
tanh_model3在不同学习率lr下的loss值
3.不同学习率下不同模型优化效果
既然学习率学习曲线是U型曲线,那么U型的幅度其实就代表着学习率对于该模型的优化空间,这里我们可以通过简单实验,来观测不同模型的U型曲线的曲线幅度。首先,对于tanh2来说,带BN层的模型学习率优化效果比不带BN层学习率优化效果更好。
# 设置随机数种子
torch.manual_seed(24) # 实例化模型
tanh_model3 = net_class3(act_fun= torch.tanh, in_features=5)
tanh_model3_norm = net_class3(act_fun= torch.tanh, in_features=5, BN_model='pre')
tanh_model4 = net_class4(act_fun= torch.tanh, in_features=5)
tanh_model4_norm = net_class4(act_fun= torch.tanh, in_features=5, BN_model='pre')# 创建模型容器
model_l = [tanh_model3, tanh_model3_norm, tanh_model4, tanh_model4_norm]
name_l = ['tanh_model3', 'tanh_model3_norm', 'tanh_model4', 'tanh_model4_norm']# 核心参数
lr = 0.001
num_epochs = 40# 模型训练 tanh_model3
train_l001, test_l001 = model_comparison(model_l = model_l, name_l = name_l, train_data = train_loader,test_data = test_loader,num_epochs = num_epochs, criterion = nn.MSELoss(), optimizer = optim.SGD, lr = lr, cla = False, eva = mse_cal)
lr_l = [0.03, 0.01, 0.005, 0.001]
train_ln = [train_l03[1:,-5:].mean(), train_l01[1:,-5:].mean(), train_l005[1:,-5:].mean(), train_l001[1:,-5:].mean()]
test_ln = [test_l03[1:,-5:].mean(), test_l01[1:,-5:].mean(), test_l005[1:,-5:].mean(), test_l001[1:,-5:].mean()]
train_l = [train_l03[0:,-5:].mean(), train_l01[0:,-5:].mean(), train_l005[0:,-5:].mean(), train_l001[0:,-5:].mean()]
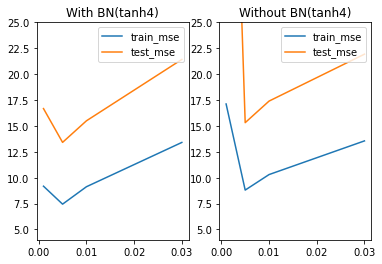
test_l = [test_l03[0:,-5:].mean(), test_l01[0:,-5:].mean(), test_l005[0:,-5:].mean(), test_l1[0:,-5:].mean()]plt.subplot(121)
plt.plot(lr_l, train_ln, label='train_mse')
plt.plot(lr_l, test_ln, label='test_mse')
plt.legend(loc = 1)
plt.ylim(4, 25)
plt.title('With BN(tanh3)')plt.subplot(122)
plt.plot(lr_l, train_l, label='train_mse')
plt.plot(lr_l, test_l, label='test_mse')
plt.legend(loc = 1)
plt.ylim(4, 25)
plt.title('Without BN(tanh3)')
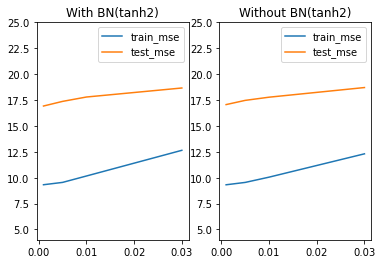
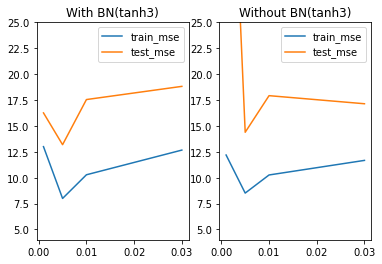
四、带BN层的神经网络模型综合调整策略总结
最后,我们总结下截至目前,针对BN层的神经网络模型调参策略。
- 简单数据、简单模型下不用BN层,加入BN层效果并不显著;
- BN层的使用需要保持running_mean和running_var的无偏性,因此需要谨慎调整batch_size;
- 学习率是重要的模型优化的超参数,一般来说学习率学习曲线都是U型曲线;
- 从学习率调整角度出发,对于加入BN层的模型,学习率调整更加有效;对于带BN层模型角度来说,BN层能够帮助模型拓展优化空间,使得很多优化方法都能在原先无效的模型上生效;
- 对于复杂问题,在计算能力能够承担的范围内,应当首先构建带BN层的复杂模型,然后再试图进行优化,就像上文所述,很多优化方法只对带BN层的模型有效;
其他拓展方面结论:
- 关于BN和Xavier/Kaiming方法,一般来说,使用BN层的模型不再会用参数初始化方法,从理论上来看添加BN层能够起到参数初始化的相等效果;(另外,带BN层模型一般也不需要使用Dropout方法)
- 本节尚未讨论ReLU激活函数的优化,相关优化方法将放在后续进行详细讨论,但需要知道的是,对于ReLU叠加的模型来说,加入BN层之后能够有效缓解Dead
ReLU Problem,此时无须刻意调小学习率,能够在收敛速度和运算结果间保持较好的平衡。- BN层是目前大部分深度学习模型的标配,但前提是你有能力去对其进行优化;
相关文章:

pytorch 14.3 Batch Normalization综合调参实践
文章目录 一、Batch Normalization与Batch_size综合调参二、复杂模型上的Batch_normalization表现1、BN对复杂模型(sigmoid)的影响2、模型复杂度对模型效果的影响3、BN对复杂模型(tanh)的影响 三、包含BN层的神经网络的学习率优化…...

供应链安全检测系列技术规范介绍之一|软件成分分析
软件成分分析的概念及意义 软件成分分析Software Compostition Analysis(SCA)是一种用于管理开源组件应用安全的方法。软件成分分析系统可以快速跟踪和分析应用软件的开源组件,发现相关组件、支持库以及它们之间直接和间接依赖关系࿰…...

pytorch 15.1 学习率调度基本概念与手动实现方法
文章目录 一、学习率对模型训练影响 二、学习率调度基本概念与手动实现方法1.模型调度基本概念2.手动实现学习率调度3.常用学习率调度思路 从本节开始,我们将介绍深度学习中学习率优化方法。学习率作为模型优化的重要超参数,在此前的学习中,我…...

c++ 类的语法4
测试析构函数、虚函数、纯虚函数: void testClass5() {class Parent {public:Parent(int x) { cout << "Parent构造: " << x << endl; }~Parent() {cout << "调用Parent析构函数" << endl;}virtual string toSt…...
)
品铂科技在UWB行业地位综述(2025年更新)
一、行业领先地位 国内UWB领域头部企业 在2025年中国UWB企业综合实力排行榜中位列第一,技术研发、市场份额及行业影响力均处于领先地位。连续多年获评中国物联网产业联盟“中国最有影响力物联网定位企业”。 2.全球技术竞争力 .2016年IPSN微软国际室内…...

muduo库EventLoop模块详解
muduo库EventLoop模块深度解析 EventLoop是muduo网络库实现Reactor模型的核心调度中枢,负责驱动整个事件循环机制,协调Poller、Channel、TimerQueue等组件的工作。其设计遵循"One Loop Per Thread"原则。 一、核心职责与设计思想 1. 核心职责…...
 错误)
循环导入(Circular Import) 错误
ImportError: cannot import name event_type_data_tree from partially initialized module routers.ticket (most likely due to a circular import) (E:\ai12345\backend\app\routers\ticket.py) 这是什么错,中文回答 这个错误是 循环导入(Circular …...

基于大数据的租房信息可视化系统的设计与实现【源码+文档+部署】
课题名称 基于大数据的租房信息可视化系统的设计与实现 学 院 专 业 计算机科学与技术 学生姓名 指导教师 一、课题来源及意义 租房市场一直是社会关注的热点问题。随着城市化进程的加速,大量人口涌入城市,导致租房需求激增。传统的租…...

奥运数据可视化:探索数据讲述奥运故事
在数据可视化的世界里,体育数据因其丰富的历史和文化意义,常常成为最有吸引力的主题之一。今天我要分享一个令人着迷的奥运数据可视化项目,它巧妙地利用交互式图表和动态动画,展现了自1896年至今奥运会的发展历程和各国奥运成就的…...

linux环境下 安装svn并且创建svn版本库详细教程
一、安装SVN 通过yum安装Subversion 在Linux系统中执行以下命令安装: yum install subversion -y 安装完成后,验证版本: svnserve --version 二、创建版本库 选择存储路径并创建目录 通常将版本库放在/var/svn或/usr/local/…...

STM32控制电机
初始化时钟:在 STM32 的程序中,初始化系统时钟,一般会使用 RCC(Reset and Clock Control)相关函数来配置时钟。例如,对于 STM32F103 系列,可能会使用 RCC_APB2PeriphClockCmd 函数来使能 GPIO 和…...

Ubuntu 更改 Nginx 版本
将 1.25 降为 1.18 先卸载干净 # 1. 完全卸载当前Nginx sudo apt purge nginx nginx-common nginx-core# 2. 清理残留配置 sudo apt autoremove sudo rm -rf /etc/apt/sources.list.d/nginx*.list修改仓库地址 # 添加仓库(通用稳定版仓库) codename$(…...

微服务初步学习
系统架构演变过程 一、单体架构 前后端都在一个项目中,包括我们现在的前后端分离开发,都可以看作是一个单体项目。 二、集群架构 把一个服务部署多次,可以解决服务不够的问题,但是有些不必要的功能也跟着部署多次。 三、垂直架…...

旧 docker 版本通过 nvkind 搭建虚拟多节点 gpu 集群的坑
踩坑 参考nvkind教程安装到Setup这一步,由于docker版本较旧,–cdi.enabled 和 config 参数执行不了 手动修改 /etc/docker/daemon.json 配置文件 "features": {"cdi": true}手动修改 /etc/nvidia-container-runtime/config.toml 配…...

Fabric 服务端插件开发简述与聊天事件监听转发
原文链接:Fabric 服务端插件开发简述与聊天事件监听转发 < Ping通途说 0. 引言 以前写过Spigot的插件,非常简单,仅需调用官方封装好的Event类即可。但Fabric这边在开发时由于官方文档和现有互联网资料来看,可能会具有一定的误…...

Wise Disk Cleaner:免费系统清理工具,释放空间,提升性能
Wise Disk Cleaner是一款功能强大且完全免费的系统清理工具,专为帮助用户清理系统中的无用文件和垃圾文件而设计。它能够有效释放磁盘空间,提高系统运行速度,确保电脑始终保持最佳性能。无论是日常维护还是深度清理,Wise Disk Cle…...

排序算法之高效排序:快速排序,归并排序,堆排序详解
排序算法之高效排序:快速排序、归并排序、堆排序详解 前言一、快速排序(Quick Sort)1.1 算法原理1.2 代码实现(Python)1.3 性能分析 二、归并排序(Merge Sort)2.1 算法原理2.2 代码实现…...

主打「反激进」的一汽丰田,靠稳扎稳打的技术实现突围
文/王俣祺 导语:今年的上海车展,当新势力都在用“1000TOPS算力”“激光雷达矩阵”等参数堆砌着一个个技术神话的时候,一汽丰田却选择了一条不同的路——用“反激进”的技术哲学,在电动化和智能化的大风向中,构建独特的…...

变量赋值和数据类型
对象 Python是面相对象的编程语言,在Python一些都是对象,对象由标识、类型、值三部分组成,本质上来讲,系统分配一块内存,这块内存中存储了特定了的值,还支持特定类型的相关操作。 标识:即对象…...

【笔记】cri-docker.service和containerd
cri-docker.service 和 containerd 都是 Kubernetes 支持的容器运行时组件,但它们的架构、功能定位及与 Docker 的关系有显著差异。以下是它们的核心区别和关联: 1. 功能定位 组件核心角色是否直接支持 CRIcontainerd轻量级容器运行时,直接管…...

技术文章:解决汇川MD500系列变频器干扰问题——GRJ9000S EMC滤波器的应用
1. 引言 汇川MD500系列变频器(Variable Frequency Drive, VFD)以其高性能、宽功率范围(0.4kW-500kW)和灵活的控制方式,广泛应用于工业自动化领域,如风机、水泵、传送带和压缩机等。然而,MD500系…...

频域中的反射-信号完整性分析
频域中的反射: 频域与时域的桥梁是傅里叶变换,一个周期信号可以拆分为许多个正弦波。所谓从频域中看信号,看到的可以是很多个频域中的点,也可以是许多个正弦波。 所以在大家眼中看到的信号如图4-13所示。我们可以将该信号分解为图4-14所示信号。 让我们来思考下面这个问题:…...

window nvidia-smi命令 Failed to initialize NVML: Unknown Error
如果驱动目录下的可以执行,那可能版本原因 "C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi"复制"C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi.exe"替换 C:\Windows\System32\nvidia-smi.exe 或者 把C:\Windows\System3…...

ubuntu 20.04 更改国内镜像源-阿里源 确保可用
镜像源是跟linux版本一一对应的,查询自己系统的版本号: 命令:lsb_release -a macw:~$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.6 LTS Release: 20.04 Codename: focal macw:~$…...
如何在Linux 系统中下载、安装)
Elasticsearch 学习(一)如何在Linux 系统中下载、安装
目录 一、Elasticsearch 下载二、使用 yum、dnf、zypper 命令下载安装三、使用 Docker 本地快速启动安装(ESKibana)【测试推荐】3.1 介绍3.2 下载、安装、启动3.3 访问3.4 修改配置,支持ip访问 官网地址: https://www.elastic.co/…...

PYTHON训练营DAY27
装饰器 编写一个装饰器 logger,在函数执行前后打印日志信息(如函数名、参数、返回值) logger def multiply(a, b):return a * bmultiply(2, 3) # 输出: # 开始执行函数 multiply,参数: (2, 3), {} # 函数 multiply 执行完毕&a…...
)
Shell脚本日志输出完整指南(AI)
一、基础日志输出方法 1. 标准输出与错误重定向 在Shell脚本中,可以使用重定向操作符将命令输出记录到日志文件: >:覆盖写入文件>>:追加写入文件2>:重定向错误输出&>:同时重定向标准…...
 - 创建文件、打开文件、写入数据、追加数据、读取数据、创建目录、删除目录)
node.js文件系统(fs) - 创建文件、打开文件、写入数据、追加数据、读取数据、创建目录、删除目录
注意:以下所有示例均是异步语法! 注意:以下所有示例均是异步语法! 创建文件 node.js 允许我们在计算机本地创建文件,例如创建一个 word 文件: // 引入核心模块(fs) var fs require(fs)// API fs.writeF…...

关于如何本地启动xxl-job,并且整合SpringBoot
1. 本地安装xxl-job并启动 拉取xxl-job的代码 git clone gitgithub.com:xuxueli/xxl-job.git配置xxl-job数据库 拉取代码后,代码的doc/db目录下有官方配置好的sql脚本,执行里面的sql脚本至本地数据库 3. 修改xxl-job默认的数据库配置 spring.dataso…...

基于Unity的简单2D游戏开发
基于Unity的简单2D游戏开发 摘要 本文围绕基于Unity的简单2D游戏开发进行深入探讨,旨在分析其开发过程中的技术架构与实现策略。通过文献综述与市场分析,研究发现,近年来Unity引擎因其优秀的跨平台特性及可视化编程理念,成为2D游戏开发的主要工具。文章首先梳理了游戏开发的…...
_cat: /usr/include/cudnn_version.h: 没有那个文件或目录)
在服务器上安装AlphaFold2遇到的问题(3)_cat: /usr/include/cudnn_version.h: 没有那个文件或目录
[rootlocalhost ~]# cat /usr/include/cudnn_version.h cat: /usr/include/cudnn_version.h: 没有那个文件或目录这个错误表明系统找不到 cudnn_version.h 头文件,说明 cuDNN 的开发文件(头文件)没有正确安装。以下是完整的解决方案ÿ…...

Java生产环境设限参数教学
哈哈,这个问题问得好!咱们用开餐厅的比喻来理解生产环境的四大必须设限参数,保证你听完再也不会忘!(搓手手) 1. 堆内存上限:-Xmx(厨房的最大容量) 问题:想象…...

武汉火影数字全息剧秀制作:科技与艺术的梦幻联动
全息剧秀是通过全息投影技术、多媒体互动技术、舞台表演艺术等元素深度融合的新型演出形式。 随着科技的不断进步,投影技术的更加成熟,全息剧秀作为演艺行业的创新力量,正以其独特的魅力和无限的潜力,为观众带来全新的视听盛宴。 …...

MySQL锁机制详解与加锁流程全解析
一、MySQL锁机制全景图 1.1 锁类型体系 #mermaid-svg-czUB6iJgmHuOPdN1 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-czUB6iJgmHuOPdN1 .error-icon{fill:#552222;}#mermaid-svg-czUB6iJgmHuOPdN1 .error-text{f…...

云轴科技ZStack官网上线Support AI,智能助手助力高效技术支持
5月16日,云轴科技ZStack在官网(www.zstack.io)正式上线ZStack Support AI智能助手。该系统是ZStack应用人工智能于技术支持服务领域的重要创新,基于自研ZStack AIOS平台智塔及LLMOPS技术打造。 ZStack Support AI定位为智能客服&…...
)
深度学习笔记23-LSTM实现火灾预测(Tensorflow)
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者: 一、前期准备 1.导入数据 import pandas as pd import numpy as npdf_1 pd.read_csv("D:\TensorFlow1\woodpine2.csv") df_1import matplotlib.pyplot as…...
详解)
单例模式(Singleton Pattern)详解
单例模式(Singleton Pattern)详解 1. 定义与核心目标 单例模式是一种创建型设计模式,确保一个类只有一个实例,并提供全局访问点。核心目标: 控制实例数量:防止重复创建对象,节省资源。统一管理共享资源:如配置管理、数据库连接池、日志处理器等。2. 实现方式及对比 (…...

IntelliJ IDEA打开项目后,目录和文件都不显示,只显示pom.xml,怎样可以再显示出来?
检查.idea文件夹 如果项目目录中缺少.idea文件夹,可能导致项目结构无法正确加载。可以尝试删除项目根目录下的.idea文件夹,然后重新打开项目,IDEA会自动生成新的.idea文件夹和相关配置文件,从而恢复项目结构。 问题解决࿰…...

LongRefiner:解决长文档检索增强生成的新思路
大语言模型与RAG的应用越来越广泛,但在处理长文档时仍面临不少挑战。今天我们来聊聊一个解决这类问题的新方法——LongRefiner。 背景问题:长文档处理的两大难题 使用检索增强型生成(RAG)系统处理长文档时,主要有两个…...

Tcping详细使用教程
Tcping详细使用教程 下载地址 https://download.elifulkerson.com/files/tcping/0.39/在windows环境下安装tcping 在以上的下载地中找到exe可执行文件,其中tcping.exe适用于32位Windows系统,tcping64.exe适用于64位Windows操作系统。 其实tcping是个…...

Java + 鸿蒙双引擎:ZKmall开源商城如何定义下一代B2C商城技术标准?
在 B2C 电商领域持续革新的当下,技术架构的优劣成为决定商城竞争力的核心要素。ZKmall开源商城以其创新融合的 Java 与鸿蒙双引擎,为下一代 B2C 商城技术标准勾勒出全新蓝图,在性能、兼容性、拓展性等关键维度实现了重大突破。 一、Java 技术…...

华为云Flexus+DeepSeek征文|基于Dify平台tiktok音乐领域热门短视频分析Ai agent
前言 在当今数字化快速发展的时代,人工智能技术尤其是大模型的应用,正逐渐成为推动各行业创新与变革的关键力量。大模型凭借其强大的语言理解、生成和逻辑推理能力,为企业和开发者提供了全新的解决方案和应用可能性。然而,将这些…...

排序算法之线性时间排序:计数排序,基数排序,桶排序详解
排序算法之线性时间排序:计数排序、基数排序、桶排序详解 前言一、计数排序(Counting Sort)1.1 算法原理1.2 代码实现(Python)1.3 性能分析1.4 适用场景 二、基数排序(Radix Sort)2.1 算法原理2…...

HarmonyOS 开发之 —— 合理使用动画与转场
HarmonyOS 开发之 —— 合理使用动画与转场 谢谢关注!! 前言:上一篇文章主要介绍HarmonyOs开发之———UIAbility进阶:https://blog.csdn.net/this_is_bug/article/details/147976323?spm=1011.2415.3001.10575&sharefrom=mp_manage_link 在移动应用开发中,动画与转…...

网络流量分析 | NetworkMiner
介绍 NetworkMiner 是一款适用于Windows(也适用于Linux/Mac)的开源网络取证分析工具。它可被用作被动网络嗅探器/数据包捕获工具,也可被用于检测操作系统、会话、主机名、开放端口等,还能被用于解析pcap文件进行离线分析。点击此…...

EtherCAT转ProfiNet智能网关选型策略匹配S7-1500与CX5140通讯需求的关键参数对比
一、案例背景 随着新能源行业的迅猛发展,锂电池生产制造企业面临着日益激烈的市场竞争和不断增长的生产需求。某锂电池生产企业在扩大产能的过程中,新建了一条锂电池生产线。该生产线采用了倍福CX5140PLC作为EtherCAT协议主站,控制着涂布机、…...

适合学校使用的桌面信息看板,具有倒计时、桌面时钟、课程表、天气预报、自动新闻联播、定时关机、消息通知栏、随机点名等功能。
简介 教育时钟(Education Clock) 是一款致力于帮助学习者科学规划学习时间、提高学习效率的开源工具。由 Return-Log 团队开发,适配多平台(Windows、Mac、Linux),界面简洁直观,操作便捷。通过设…...

兰亭妙微设计:为生命科技赋予人性化的交互语言
在医疗科技日新月异的今天,卓越的硬件性能唯有匹配恰如其分的交互语言,方能真正发挥价值。作为专注于医疗UI/UX设计的专业团队,兰亭妙微设计(www.lanlanwork.com)始终相信:每一处像素的排布,都应…...
)
redis数据结构-12(配置 RDB 快照:保存间隔和压缩)
配置 RDB 快照:保存间隔和压缩 Redis 持久性对于确保在服务器重启或发生故障时数据不会丢失至关重要。虽然 Redis 以其内存中数据存储而闻名,但它提供了将数据持久化到磁盘的机制。本章节重点介绍其中一种机制:Redis 数据库 (RDB…...

SG7050VAN差分晶振,X1G0042810033,EPSON爱普生以太网6G晶振
产品简介 SG7050VAN差分晶振,X1G0042810033,EPSON爱普生以太网6G晶振,日本EPSON爱普生株式会社,进口晶振型号:SG7050VAN,编码为:X1G0042810033,频率为:156.250000 MHz,小体积晶振尺…...