【PmHub后端篇】PmHub 中缓存与数据库一致性的实现方案及分析
在软件开发项目中,缓存的使用十分普遍。缓存作为一种存储机制,能够暂时保存数据,从而加速数据的读取和访问。然而,当数据同时存在于缓存和数据库中时,如何保证两者的数据一致性成为了一个关键问题。在 PmHub 项目中,同样面临着这样的挑战,下面将详细介绍 PmHub 中保证缓存和数据库一致性的相关内容。
1 缓存的重要性
缓存可分为本地缓存和分布式缓存。本地缓存如 JDK 自带的 HashMap 和 ConcurrentHashMap,以及 Ehcache、Guava Cache、Spring Cache、Caffeine 等常见的本地缓存框架;分布式缓存如常用的 Redis,它可以单机或者集群部署在不同的服务器上。本地缓存与应用处于同一位置,而分布式缓存独立部署在不同服务器。无论是哪种缓存,其核心目的都是用空间换时间,通过存储可能重复使用或计算的数据,减少数据的重新获取或计算时间。
2 缓存一致性问题
导致缓存和数据库数据不一致的原因主要有以下几点:
- 缓存过期:缓存中的数据存在生命周期,过期后若未及时更新,会出现数据不一致情况。
- 写操作延迟:执行写操作时,数据库更新和缓存更新时间不同步,可能导致缓存中的数据不一致。
- 并发操作:多个并发操作同时进行,会出现竞态条件,从而导致缓存和数据库数据不一致。
- 缓存失效策略不当:使用不当的缓存失效策略,会使缓存中的数据无法及时更新,造成不一致。
- 网络延迟或故障:网络延迟或故障会导致缓存服务器和数据库之间通信出现问题,进而导致数据不一致。
3 常见的解决不一致问题的方案
- Cache Aside 模式:在读写操作中使用该模式,确保在写操作后及时失效缓存中的数据。
- 分布式锁:在并发写操作时使用分布式锁,保证同时只有一个操作能够更新缓存和数据库,避免竞态条件。
- 双写一致性:在写操作时同时更新数据库和缓存,以确保数据的一致性。
- 延迟双删:在写操作时,先删除缓存中的数据,更新数据库后,再次删除缓存中的数据,确保缓存中数据的一致性。
- 版本控制:在缓存和数据库中使用版本号或时间戳,确保数据更新时的一致性检查。
- 监控和告警:对缓存和数据库中的数据进行监控,发现不一致时及时告警并处理。
4 常见缓存更新策略
| 模式名称 | 描述 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| Cache Aside Pattern (旁路缓存模式) | 读取数据时先检查缓存,缓存未命中则从数据库读取并更新缓存。写入数据时先更新数据库,然后使缓存失效。 | - 读取性能高 - 实现简单 | - 首次请求数据一定不在缓存问题 - 写操作较频繁的话会导致缓存中数据被频繁删除,会影响缓存命中率 | 数据读取频率高,写入频率较低的场景 |
| Read/Write Through Pattern (读写穿透模式) | 所有的读写操作都通过缓存进行,缓存负责同步数据库。 | - 数据一致性好 - 实现了读写操作的统一 | - 实现复杂 - 依赖缓存的高可用性 | 数据读取和写入频率均较高的场景 |
| Write Behind Pattern (异步缓存写入) | 写操作首先更新缓存,然后异步地将数据写入数据库。 | - 写操作性能高 - 减少数据库压力 | - 存在数据丢失的风险 - 数据一致性较差 | 写操作频繁,且对实时一致性要求不高的场景 |
4 Cache Aside 模式
4.1 Cache Aside 模式概述
读取数据时先检查缓存,缓存未命中则从数据库读取并更新缓存;写入数据时先更新数据库,然后使缓存失效。
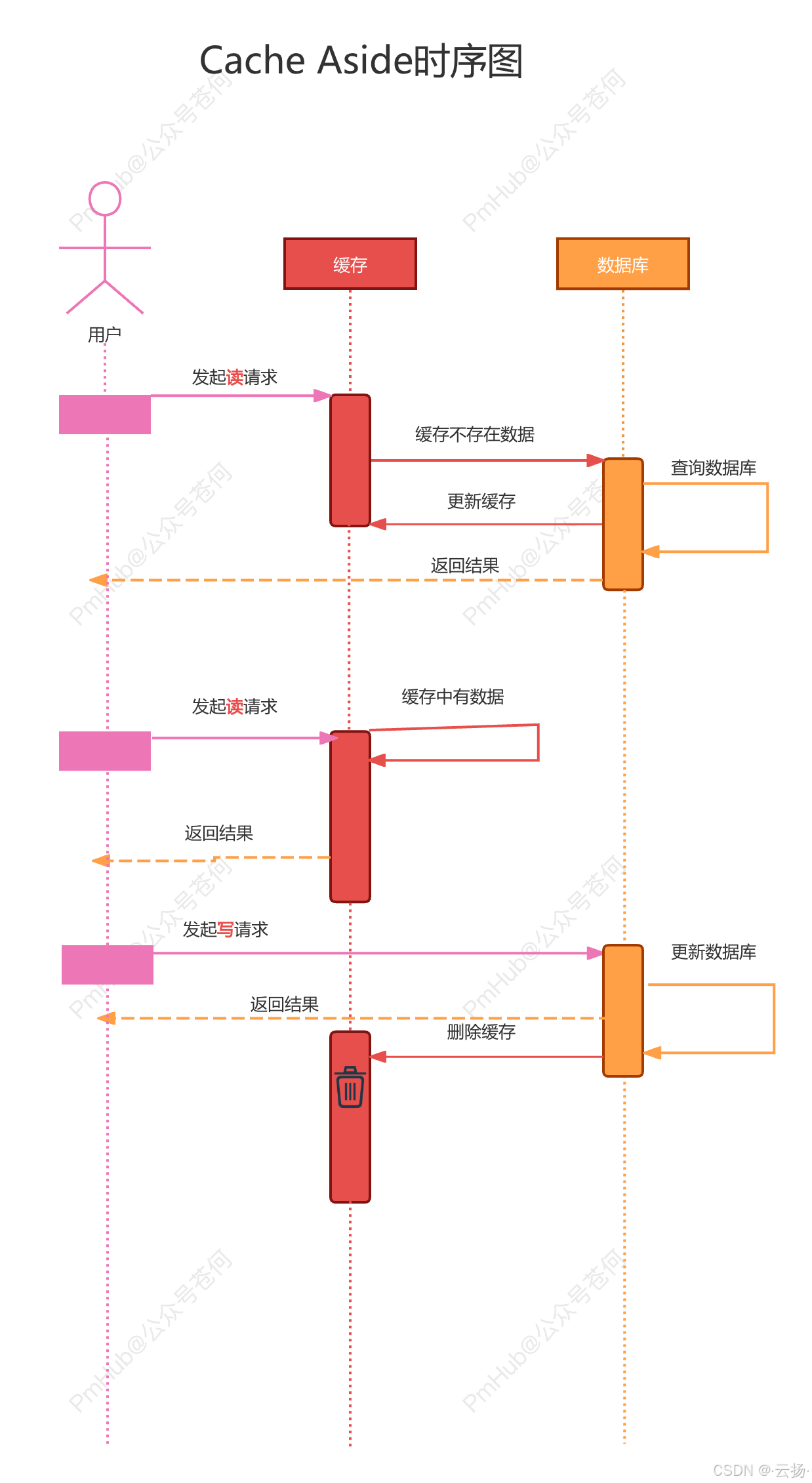
4.2 Cache Aside 模式优点
- 读取性能高:缓存命中时可直接从缓存读取数据,显著减少数据库访问压力。
- 实现简单:模式逻辑清晰,容易理解和实现。
- 灵活性强:程序员可根据需要灵活控制缓存的更新和失效策略,适应不同应用场景和需求。
- 缓存利用率高:只有在缓存未命中时才从数据库读取数据并更新缓存,避免不必要的数据冗余。
4.3 Cache Aside 模式局限
- 写操作较慢:每次写操作都需更新数据库并使缓存失效,操作过程较长,导致写操作性能较低。
- 数据一致性挑战:在高并发环境下,缓存和数据库之间容易出现数据不一致的情况,如缓存失效不及时或更新顺序问题。
- 缓存预热问题:初始时缓存为空,第一次读取时会有较大延迟,因此建议将热点数据直接放入缓存。
- 复杂的失效策略:程序员需要设计合理的缓存失效策略,增加了实现和维护的复杂性。
- 过期数据风险:若没有合适的失效机制,缓存中可能存在过期数据,返回错误或过时的信息给用户。
5 PmHub 中的实践
5.1 PmHub 中的数据读取
先查询缓存,若有数据则直接返回,若无则去数据库查询,然后写入缓存。例如根据键名查询参数配置信息即采用此方式:com.laigeoffer.pmhub.system.service.impl.SysConfigServiceImpl#selectConfigByKey。
/*** 根据键名查询参数配置信息* 查询逻辑:* 1. 优先从Redis缓存中获取配置值* 2. 缓存未命中时查询数据库* 3. 将数据库查询结果写入缓存(缓存穿透保护)* 4. 最终未找到配置时返回空字符串** @param configKey 参数key* @return 参数键值,未找到时返回空字符串*/@Overridepublic String selectConfigByKey(String configKey) {// 从Redis获取缓存值(使用系统配置专用前缀)String configValue = Convert.toStr(redisService.getCacheObject(getCacheKey(configKey)));// 命中缓存直接返回if (StringUtils.isNotEmpty(configValue)) {return configValue;}// 构造查询条件对象SysConfig config = new SysConfig();config.setConfigKey(configKey);// 查询数据库配置信息SysConfig retConfig = configMapper.selectConfig(config);// 数据库查询结果处理if (StringUtils.isNotNull(retConfig)) {// 更新缓存(设置永不过期)redisService.setCacheObject(getCacheKey(configKey), retConfig.getConfigValue());return retConfig.getConfigValue();}// 未找到配置时返回空字符串return StringUtils.EMPTY;}
5.2 PmHub 中的数据更新
更新数据时,先更新数据库信息,然后删除缓存信息,例如在批量删除参数信息的场景中即采用此方式:com.laigeoffer.pmhub.system.service.impl.SysConfigServiceImpl#deleteConfigByIds。
/*** 批量删除参数信息* 删除逻辑:* 1. 遍历所有待删除配置ID* 2. 对每个配置执行:* - 校验是否为内置参数(禁止删除内置配置)* - 执行数据库删除* - 清理对应Redis缓存* 3. 遇到内置参数时抛出业务异常终止操作** @param configIds 需要删除的参数ID数组* @throws ServiceException 当尝试删除内置参数时抛出*/@Overridepublic void deleteConfigByIds(Long[] configIds) {// 遍历所有待删除配置IDfor (Long configId : configIds) {// 获取完整配置信息(用于后续校验和缓存清理)SysConfig config = selectConfigById(configId);// 内置参数校验(UserConstants.YES 表示内置系统参数)if (StringUtils.equals(UserConstants.YES, config.getConfigType())) {throw new ServiceException(String.format("内置参数【%1$s】不能删除 ", config.getConfigKey()));}// 执行数据库删除configMapper.deleteConfigById(configId);// 清理对应的Redis缓存(避免脏数据残留)redisService.deleteObject(getCacheKey(config.getConfigKey()));}}
6 总结
本文围绕软件开发中缓存使用展开,阐述缓存重要性,分析缓存与数据库数据不一致原因,介绍常见解决不一致的方案和缓存更新策略,展示PmHub项目中数据读取和更新实践,为确保数据一致性提供参考。
7 参考链接
- PmHub如何保证缓存和数据库的一致性
- 项目仓库(GitHub):https://github.com/laigeoffer/pmhub
- 项目仓库(码云):https://gitee.com/laigeoffer/pmhub (国内访问速度更快)
相关文章:

【PmHub后端篇】PmHub 中缓存与数据库一致性的实现方案及分析
在软件开发项目中,缓存的使用十分普遍。缓存作为一种存储机制,能够暂时保存数据,从而加速数据的读取和访问。然而,当数据同时存在于缓存和数据库中时,如何保证两者的数据一致性成为了一个关键问题。在 PmHub 项目中&am…...

Verilog HDL 语言整理
Verilog HDL 语言 Verilog HDL 简介 硬件描述语言Hardware Description Language是一种用形式化方法即文本形式 来描述和设计数字电路和数字系统的高级模块化语言 Verilog HDL(Hardware Description Language)是一种硬件描述语言,用于建模…...

[250516] OpenAI 升级 ChatGPT:GPT-4.1 及 Mini 版上线!
目录 ChatGPT 迎来重要更新:GPT-4.1 和 GPT-4.1 mini 正式上线用户如何访问新模型?技术亮点与用户体验优化 ChatGPT 迎来重要更新:GPT-4.1 和 GPT-4.1 mini 正式上线 OpenAI 宣布在 ChatGPT 平台正式推出其最新的 AI 模型 GPT-4.1 和 GPT-4.…...

R语言学习--Day03--数据清洗技巧
在一般情况下,我们都是在数据分析的需求前提下去选择使用R语言。而实际上,数据分析里,百分之八十的工作,都是在数据清洗。并不只是我们平时会提到的异常值处理或者是整合格式,更多会涉及到将各种各样的数据整合&#x…...

文件系统交互实现
关于之前的搭建看QT控件文件系统的实现-CSDN博客,接下来是对本程序的功能完善,我想着是这样设计的,打开一个目录以后,鼠标选中一个项可以是目录,也可以是文件,右键可以出现一个菜单选择操作,比如…...

SqlHelper 实现类,支持多数据库,提供异步操作、自动重试、事务、存储过程、分页、缓存等功能。
/// <summary> /// SqlHelper 实现类,支持多数据库,提供异步操作、自动重试、事务、存储过程、分页、缓存等功能。 /// </summary> public class SqlHelper : IDbHelper {private readonly IDbConnectionFactory _connectionFactory;private…...

DevExpressWinForms-RichEditControl-基础应用
RichEditControl-基础应用 在企业级WinForms应用开发中,富文本编辑与文档处理是常见需求。DevExpress WinForms的RichEditControl作为一款功能强大的富文本编辑控件,提供了媲美Microsoft Word的文档处理能力,支持复杂格式编辑、打印导出、界…...

Elasticsearch 索引副本数
作者:来自 Elastic Kofi Bartlett 解释如何配置 number_of_replicas、它的影响以及最佳实践。 更多阅读:Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica 想获得 Elastic 认证?查看下一期 Elasticsearc…...

RabbitMQ 扇形交换器工作原理详解
目录 一、扇形交换器简介二、扇形交换器工作原理2.1 消息广播机制2.2 路由键的忽略三、代码示例3.1 生产者代码3.2 消费者代码四、实际应用场景4.1 日志收集系统4.2 实时通知系统4.3 事件驱动架构五、总结在 RabbitMQ 的众多交换器类型中,扇形交换器(Fanout Exchange)是一种…...

IDEA中springboot项目中连接docker
具体内容如下: 1、在Linux中安装docker 使用安装命令: apt-get install docker.io 还有一个是更新软件并安装docker: sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io 运行docker systemctl start …...

arxiv等开源外文书数据的获取方式
一、一些基本说明 开放API接口文档:https://info.arxiv.org/help/api/user-manual.html#2-api-quickstart研究领域分类说明文档:https://arxiv.org/category_taxonomy 二、基于url接口方式检索并获取数据 本质是get方式,在url中传检索参数…...

ChatGPT再升级!
近日,OpenAI 正式发布 GPT-4.1 和轻量级版本 GPT-4.1mini,并已全面上线 ChatGPT 平台,迅速引发全球 AI 圈热议,标志着 ChatGPT 在智能化和效率上再登新高峰。 GPT-4.1 是为编程与任务处理优化的高性能模型。相较前作 GPT-4o&#…...

23、电网数据管理与智能分析 - 负载预测模拟 - /能源管理组件/grid-data-smart-analysis
76个工业组件库示例汇总 电网数据管理与智能分析组件 1. 组件概述 本组件旨在模拟一个城市配电网的运行状态,重点关注数据管理、可视化以及基于模拟数据的智能分析,特别是负载预测功能。用户可以通过界面交互式地探索电网拓扑、查看节点状态、控制时间…...

#跟着若城学鸿蒙# web篇-获取定位
前言 在业务中,某些网页上需要获取用户的地理位置,然后按照用户搜索的兴趣点与用户的距离远近进行排序,这就需要h5能够获取到用户的位置。 由于 web 组件基于Chromium M114 版本开发,前端就可以使用navigator.geolocation.getC…...

前端批量下载文件打包为zip
多文件需要一次性下载为zip文件 这是近期遇到的一个需求,本身是多文件上传的,下载时单个下载太慢又繁杂,用户希望能一次性批量下载,就选择了jszip import axios from "axios" import JSZip from "jszip" im…...

Vue百日学习计划Day9-15天详细计划-Gemini版
重要提示: 番茄时钟: 每个番茄钟为25分钟学习,之后休息5分钟。每完成4个番茄钟,进行一次15-30分钟的长休息。灵活性: JavaScript 的概念较多,尤其是 this、原型链、闭包和异步编程,可能需要更多…...

MySQL8.x新特性:与mysql5.x的版本区别
MySQL8.x新特性 1.与mysql5.x的区别:MySQL8.x新特性:与mysql5.x的版本区别-CSDN博客 2.窗口函数(Window Functions):MySQL8.x新特性:窗口函数(Window Functions)-CSDN博客 引言 …...
)
RabbitMQ 消息模式实战:从简单队列到复杂路由(三)
精准投递:路由模式 路由模式详解 路由模式是 RabbitMQ 中一种功能强大且灵活的消息传递模式,它在发布订阅模式的基础上,引入了路由键(Routing Key)的概念,实现了消息的精准路由和分发 。在路由模式中&…...

STM32 定时器主从模式配置解析
STM32 定时器主从模式配置解析 下面这两行代码是配置STM32定时器主从模式的关键设置 代码功能解析 TIM_SelectInputTrigger(TIM3, TIM_TS_TI2FP2); // 选择从模式输出的触发源 TIM_SelectSlaveMode(TIM3, TIM_SlaveMode_Reset); // 选择从模式1. TIM_SelectInputTrigger(T…...

Leetcode76覆盖最小子串
覆盖最小子串 代码来自b站左程云 class Solution {public String minWindow(String str, String tar) {char[] s str.toCharArray();char[] t tar.toCharArray();int[] cnt new int[256];for (char cha : t) { cnt[cha]--;}int len Integer.MAX_VALUE;int debt t.length…...

Perl语言深度考查:从文本处理到正则表达式的全面掌握
阅读原文 前言:为什么Perl依然值得学习? "这个脚本用Perl写只需要5分钟!"——在当今Python大行其道的时代,你依然能在不少企业的运维部门听到这样的对话。Perl作为一门有着30多年历史的语言,凭借其强大的文…...

idea中Lombok失效的解决方案
Lombok 是一个 Java 库,旨在通过注解简化 Java 代码的编写,减少样板代码,提高开发效率。它通过自动生成常见的代码(如 getter、setter、构造函数等)来减少开发者的手动编码工作。 一般Lombok失效有四步排查方案&#…...

【LeetCode 热题 100】动态规划 系列
📁 70. 爬楼梯 状态标识:爬到第i层楼梯时,有多少种方法。 状态转移方程:dp[i] dp[i-1] dp[i-2],表示从走一步和走两步的方式。 初始化:dp[1] 1 , dp[2] 2。 返回值:dp[n],即走到…...

刷leetcodehot100返航版--双指针5/16
for (int i 0, j 0; i < n; i ) { while (j < i && check(i, j)) j ; // 具体问题的逻辑 } 常见问题分类: (1) 对于一个序列,用两个指针维护一段区间 (2) 对于两个序列,维护某种次序,比如归并排序中…...

DAY24元组和OS模块
元组 元组的特点: 有序,可以重复,这一点和列表一样元组中的元素不能修改,这一点非常重要,深度学习场景中很多参数、形状定义好了确保后续不能被修改。 很多流行的 ML/DL 库(如 TensorFlow, PyTorch, Num…...

CSS:三大特性
文章目录 一、层叠性二、继承性三、优先级 一、层叠性 二、继承性 可以在MDN网站上查看属性是否可以被继承 例如color 三、优先级...
)
Cross-Site Scripting(XSS)
1. XSS介绍 跨站脚本攻击(Cross-Site Scripting)简称XSS,人们经常将跨站脚本攻击(Cross Site Scripting)缩写为CSS,但这会与层叠样式表(Cascading Style Sheets,CSS)的缩…...

掌握HTML文件上传:从基础到高级技巧
HTML中input标签的上传文件功能详解 一、基础概念 1. 文件上传的基本原理 在Web开发中,文件上传是指将本地计算机中的文件(如图片、文档、视频等)传输到服务器的过程。HTML中的<input type"file">标签是实现这一功能的基础…...

WebRTC中的几个Channel
一、我指的是谁? 以视频为例,常见的有:MediaChannel、VideoMediaChannel、WebRtcVideoChannel、BaseChannel、VideoChannel,那么,为什么要这么多Channel,只写一个叫做SuperChannel行不行(很多程…...

【设计模式】- 行为型模式1
模板方法模式 定义了一个操作中的算法骨架,将算法的一些步骤推迟到子类,使得子类可以不改变该算法结构的情况下重定义该算法的某些步骤 【主要角色】: 抽象类:给出一个算法的轮廓和骨架(包括一个模板方法 和 若干基…...

容器化-k8s-使用和部署
一、K8s 使用 1、基本概念 集群: 由 master 节点和多个 slaver 节点组成,是 K8s 的运行基础。节点: 可以是物理机或虚拟机,是 K8s 集群的工作单元,运行容器化应用。Pod: K8s 中最小的部署单元,一个 Pod 可以包含一个或多个紧密相关的容器,这些容器共享网络和存储资源。…...
)
黑马k8s(九)
1.Pod-生命周期概述 2.Pod生命周期-创建和终止 3.Pod生命周期-初始化容器...

Android trace中CPU的RenderThread与GPU
Android trace中CPU的RenderThread与GPU RenderThread是系统的GPU绘制线程,GPU渲染就是通常所谓的硬件加速,如果应用关闭硬件加速,就没有了RenderThread,只有UI Thread,即Android主线程。 Android GPU渲染SurfaceFlin…...
容器知识)
测试工程师如何学会Kubernetes(k8s)容器知识
Kubernetes(K8s)作为云原生时代的关键技术之一,对于运维工程师、开发工程师以及测试工程师来说,都是一门需要掌握的重要技术。作为一名软件测试工程师,学习Kubernetes是一个有助于提升自动化测试、容器化测试以及云原生应用测试能力的重要过程…...

接触感知 钳位电路分析
以下是NG板接触感知电路的原理图。两极分别为P3和P4S,电压值P4S < P3。 电路结构分两部分,第一部分对输入电压进行分压钳位。后级电路使用LM113比较器芯片进行电压比较,输出ST接触感知信号。 钳位电路输出特性分析 输出电压变化趋势&a…...

码蹄集——圆包含
MT1181 圆包含 输入2个圆的圆心的坐标值(x,y)和半径,判断断一个圆是否完全包含另一个圆,输出YES或者NO。另:内切不算做完全包含。 格式 输入格式:输入整型,空格分隔。 每行输入一组…...

ConcurrentSkipListMap的深入学习
目录 1、介绍 1.1、线程安全 1.2、有序性 1.3、跳表数据结构 1.4、API 提供的功能 1.5、高效性 1.6、应用场景 2、数据结构 2.1、跳表(Skip List) 2.2、节点类型: 1.Node 2.Index 3.HeadIndex 2.3、特点 3、选择层级 3.1、随…...

ProfibusDP主站转modbusTCP网关接DP从站网关通讯案例
ProfibusDP主站转modbusTCP网关接DP从站网关通讯案例 在工业自动化领域,Profibus DP和Modbus TCP是两种常见的通信协议。Profibus DP广泛应用于过程自动化、工厂自动化等场景,而Modbus TCP则常见于楼宇自动化、能源管理等领域。由于设备和系统之间往往存…...

第一次做逆向
题目来源:ctf.show 1、下载附件,发现一个exe和一个txt文件 看看病毒加没加壳,发现没加那就直接放IDA 放到IDA找到main主函数,按F5反编译工具就把他还原成类似C语言的代码 然后我们看逻辑,将flag.txt文件的内容进行加…...

【项目】自主实现HTTP服务器:从Socket到CGI全流程解析
00 引言 在构建高效、可扩展的网络应用时,理解HTTP服务器的底层原理是一项必不可少的技能。现代浏览器与移动应用大量依赖HTTP协议完成前后端通信,而这一过程的背后,是由网络套接字驱动的请求解析、响应构建、数据传输等一系列机制所支撑…...

AI最新资讯,GPT4.1加入网页端、Claude 3.7 Sonnet携“极限推理”发布在即
目录 一、GPT4.1加入网页端二、Claude 3.7 Sonnet携“极限推理”发布在即三、这项功能的关键特点1、双模式操作2、可视化思考过程3、可控的思考预算4、性能提升 四、Claude制作SVG图像1、Prompt提示词模板2、demo:技术路线图**Prompt提示词:**3、甘特图4…...
)
Android 中使用通知(Kotlin 版)
1. 前置条件 Android Studio:确保使用最新版本(2023.3.1)目标 API:最低 API 21,兼容 Android 8.0(渠道)和 13(权限)依赖库:使用 WorkManager 和 Notificatio…...

在 Kotlin 中,什么是解构,如何使用?
在 Kotlin 中,解构是一种语法糖,允许将一个对象分解为多个独立的变量。 这种特性可以让代码更简洁、易读,尤其适用于处理数据类、集合(如 Pair、Map)或其他结构化数据。 1 解构的核心概念 解构通过定义 componentN()…...
)
apisix透传客户端真实IP(real-ip插件)
文章目录 apisix透传客户端真实IP需求和背景apisix real-ip插件为什么需要 trusted_addresses?安全架构的最佳实践 示例场景apisix界面配置 apisix透传客户端真实IP 需求和背景 当 APISIX 前端有其他反向代理(如 Nginx、HAProxy、云厂商的 LBÿ…...

初学者如何用 Python 写第一个爬虫?
初学者如何用 Python 写第一个爬虫? 一、爬虫的基本概念 (一)爬虫的定义 爬虫,英文名为 Web Crawler,也被叫做网络蜘蛛、网络机器人。想象一下,有一个勤劳的小蜘蛛,在互联网这个巨大的蜘蛛网中…...
)
基于MNIST数据集的手写数字识别(CNN)
目录 一,模型训练 1.1 数据集介绍 1.2 CNN模型层结构 1.3 定义CNN模型 1.4 神经网络的前向传播过程 1.5 数据预处理 1.6 加载数据 1.7 初始化 1.8 模型训练过程 1.9 保存模型 二,模型测试 2.1 定义与训练时相同的CNN模型架构 2.2 图像的预处…...
篇三:阅读与注释 QPlainTextEdit,给出源代码)
QT6 源(103)篇三:阅读与注释 QPlainTextEdit,给出源代码
(10)关于文本处理的内容很多,来不及全面阅读、思考与整理。先给出类的继承图: (11)本源代码来自于头文件 qplaintextedit . h : #ifndef QPLAINTEXTEDIT_H #define QPLAINTEXTEDIT_H#include &…...

yocto5.2开发任务手册-7 升级配方
此文为机器辅助翻译,仅供个人学习使用,如有翻译不当之处欢迎指正 7 升级配方 随着时间的推移,上游开发者会为图层配方构建的软件发布新版本。建议使配方保持与上游版本发布同步更新。 虽然有多种升级配方的方法,但您可能需要先…...

LangPDF: Empowering Your PDFs with Intelligent Language Processing
LangPDF: Empowering Your PDFs with Intelligent Language Processing Unlock Global Communication: AI-Powered PDF Translation and Beyond In an interconnected world, seamless multilingual document management is not just an advantage—it’s a necessity. LangP…...
 和 P2P(点对点网络) 的详细对比)
DDS(数据分发服务) 和 P2P(点对点网络) 的详细对比
1. 核心特性对比 维度 DDS P2P 实时性 微秒级延迟,支持硬实时(如自动驾驶) 毫秒至秒级,依赖网络环境(如文件传输) 架构 去中心化发布/订阅模型,节点自主发现 完全去中心化,节…...