ConcurrentSkipListMap的深入学习
目录
1、介绍
1.1、线程安全
1.2、有序性
1.3、跳表数据结构
1.4、API 提供的功能
1.5、高效性
1.6、应用场景
2、数据结构
2.1、跳表(Skip List)
2.2、节点类型:
1.Node
2.Index
3.HeadIndex
2.3、特点
3、选择层级
3.1、随机化
3.2、期望高度
3.3、保持平衡性
3.4、简单性
3.5、性能分析
4、层级遍历
4.1、层级引用的结构
4.2、查找过程
5、线程安全的实现
5.1、分段锁机制
5.2、无锁读操作
5.3、随机化和跳表结构
5.4、操作的原子性
5.5、自然的排序和查找性能
6、排序目的
6.1、数据检索
6.2、导航操作
6.3、高效性
6.4、灵活性
7、并发控制机制
7.1、CAS(Compare-And-Swap)
7.2、版本标记
7.3、无阻塞设计
7.4、辅助删除
7.5、寻找前驱节点
7.6、弱一致性
8、常用方法
8.1、put方法
8.2、get操作
8.3、remove操作
8.4、迭代器实现
一种高效的线程安全有序映射,适合在高并发环境中使用。其结合了跳表的优点,提供了很好的查找、插入、删除性能,并且支持无锁读取,适合需要频繁读写的多线程应用场景。
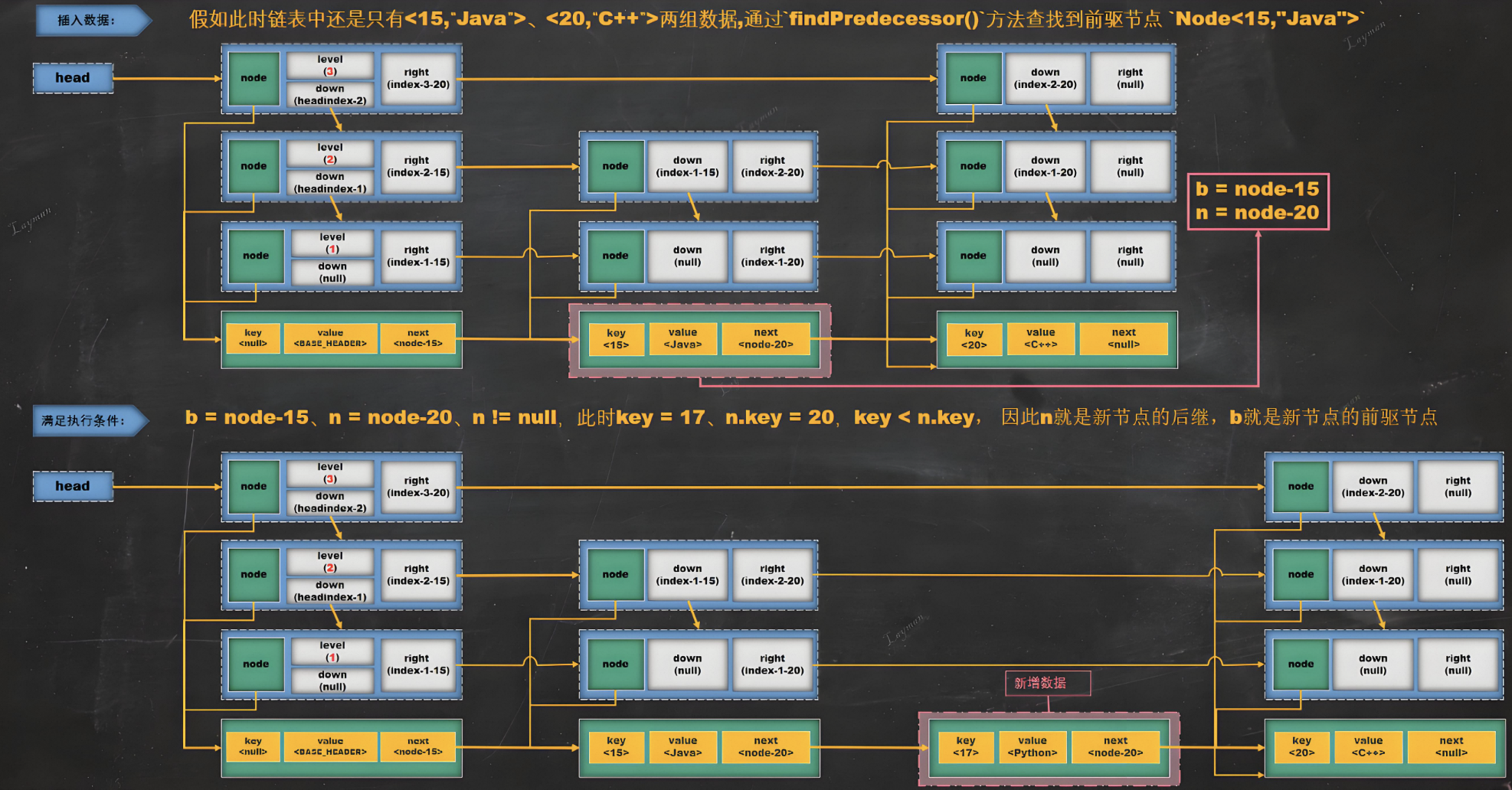
与其他map相比如下图所示:
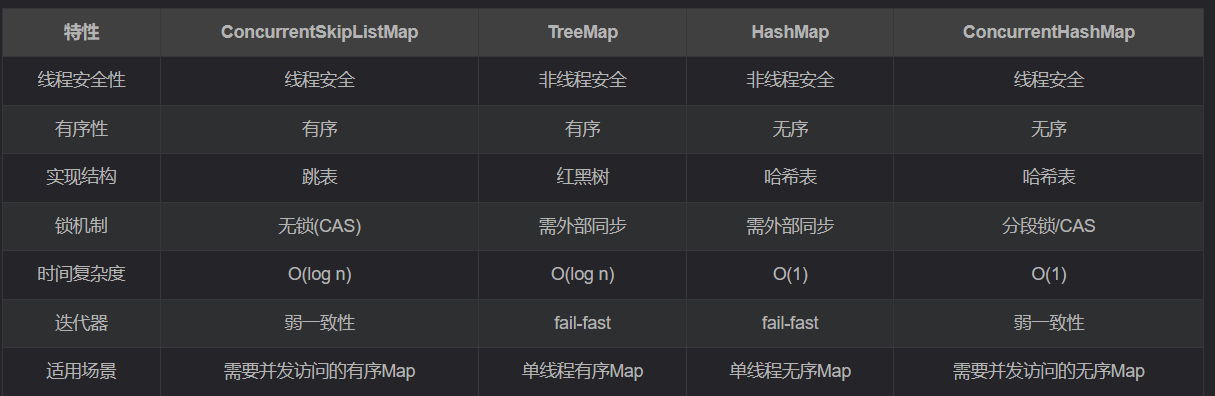
它是唯一一个同时提供线程安全和有序性的Map实现。
1、介绍
是 Java 提供的一个并发集合类,属于java.util.concurrent包。它实现了ConcurrentNavigableMap接口,并且是一个线程安全的、有序的、跳表(Skip List)数据结构。
如下图所示:
以下是 ConcurrentSkipListMap 的主要作用和特点:
1.1、线程安全
是一个支持并发访问的集合类,多个线程可以同时进行读和写操作,而不需要显式的同步。这就意味着,当多个线程同时访问这个映射时,不会导致数据不一致或抛出异常。
1.2、有序性
根据键的自然顺序或根据构造时提供的比较器(Comparator)来维护元素的顺序。它能有效地执行一些有序操作,如范围查询、排序等。
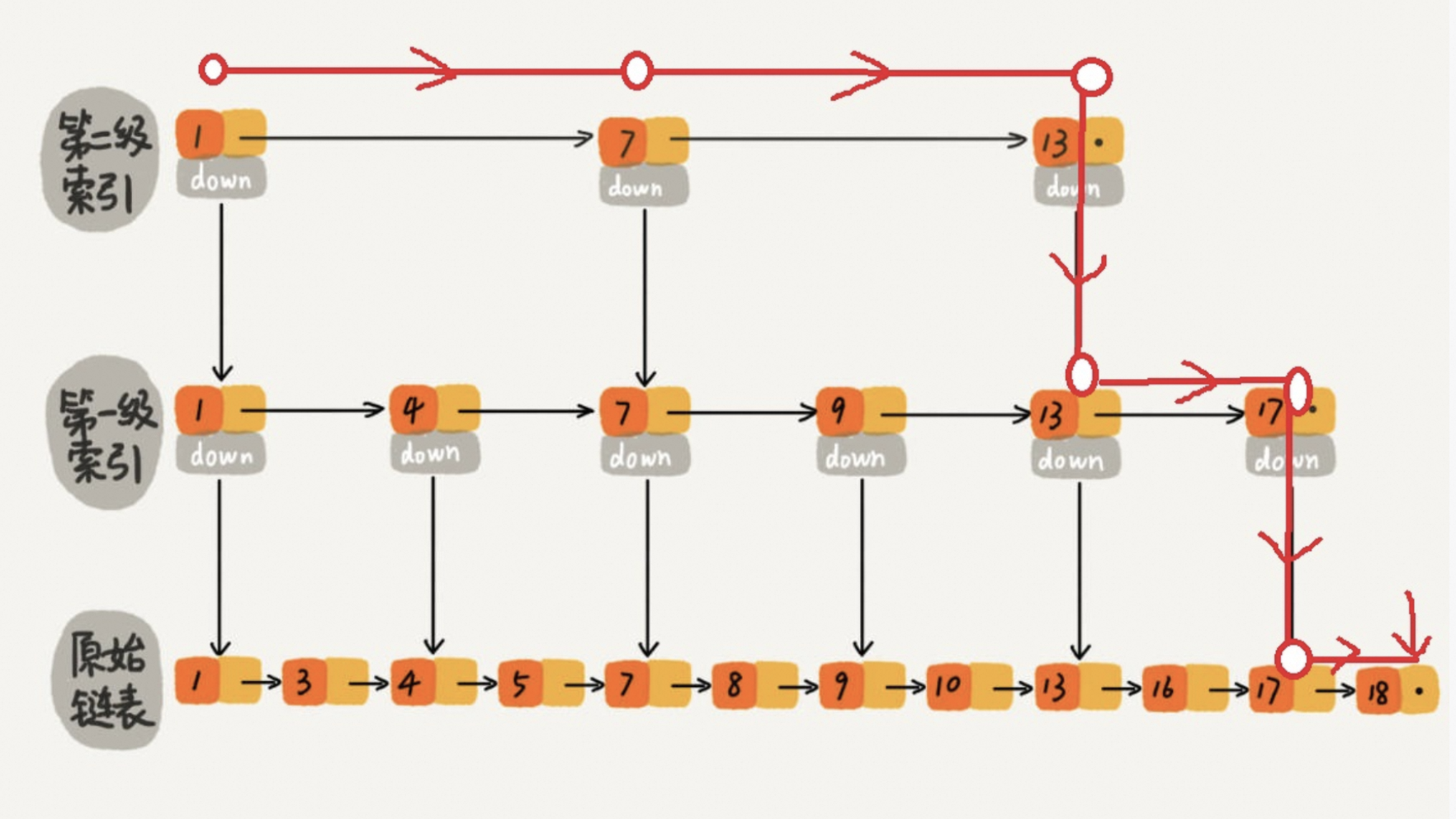
1.3、跳表数据结构
跳表是一种随机化的数据结构,具有多层级(linked lists)的有序列表。查找、插入和删除的时间复杂度平均为 O(log n),同时跳表在并行环境中表现良好。这使得 ConcurrentSkipListMap 在大规模并发访问的情况下迁移期间性能良好。
如下图所示:
1.4、API 提供的功能
- 由于实现了
NavigableMap接口,ConcurrentSkipListMap提供了一些有用的方法:- 导航方法:如
lowerKey(),higherKey(),floorKey(),ceilingKey()等,这些方法允许对键进行导航操作。 - 集合视图:可以获取键集、值集合和条目集的视图。
- 范围操作:支持范围查询,可以方便地获取某个范围内的元素。
- 导航方法:如
1.lowerKey(K key)
-
功能:返回严格小于给定键的最大键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.lowerKey(4); // 返回32.higherKey(K key)
-
功能:返回严格大于给定键的最小键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.higherKey(2); // 返回33.floorKey(K key)
-
功能:返回小于或等于给定键的最大键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.floorKey(3); // 返回34.ceilingKey(K key)
-
功能:返回大于或等于给定键的最小键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.ceilingKey(2); // 返回31.5、高效性
由于基于跳表,ConcurrentSkipListMap 在高并发情况下提供了优良的性能。此外,由于它采用了分段锁的机制,允许多个线程进行同时的插入和查询操作。
1.6、应用场景
根据ConcurrentSkipListMap的特性,以下场景特别适合使用它:
1、需要线程安全且有序的Map实现时:
如果应用需要在多线程环境下维护一个按键排序的映射。
2、需要高效的范围查询操作时:
支持高效的范围操作,如subMap、headMap、tailMap等,这在需要按范围获取数据的场景中非常有用。
3、需要按键的顺序进行并发迭代时:
迭代器按键的顺序遍历元素,这在需要有序处理数据的并发场景中很有价值。
4、需要线程安全但又不希望有锁带来的阻塞时:
ConcurrentSkipListMap的无锁设计避免了线程阻塞,提供了更好的并发性能。
5、读操作明显多于写操作,且需要有序性的场景:
虽然ConcurrentSkipListMap的写操作比ConcurrentHashMap慢,但在读多写少且需要有序性的场景中,它是最佳选择。
ConcurrentSkipListMap特别适合用在对性能和线程安全性有严格要求的应用场景中,例如:- 在线交易处理
- 实时数据监控
- 需要频繁插入、删除和查找操作的多线程环境
示例代码:
以下是 ConcurrentSkipListMap 的简单示例:
import java.util.concurrent.ConcurrentSkipListMap;public class ConcurrentSkipListMapExample {public static void main(String[] args) {ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();// 添加元素map.put(3, "Three");map.put(1, "One");map.put(2, "Two");// 获取元素System.out.println(map.get(2)); // 输出: Two// 遍历元素map.forEach((key, value) -> {System.out.println(key + ": " + value);});// 使用导航方法System.out.println("Lowest key: " + map.firstKey()); // 输出: 1System.out.println("Highest key: " + map.lastKey()); // 输出: 3}
}
总结
ConcurrentSkipListMap 是一个高效、线程安全的有序映射实现, 适合在高并发环境下使用,支持快速的查找、插入、删除和有序访问操作。由于其优秀的性能特性,适用于多种需要处理并发数据的场景。
2、数据结构
基于 跳表(Skip List)数据结构实现的。核心思想是以空间换时间,通过构建多层索引,使得查找、插入和删除操作的平均时间复杂度降低到O(log n)。
没有初始化容量,和HashMap对比:

2.1、跳表(Skip List)
跳表是一种基于链表的分层的动态数据结构,旨在高效地实现有序映射和集合操作。它结合了链表和二分搜索的优点,使用多级索引来加速查找、插入和删除操作。
如图所示:
具体来讲,跳表由多个层级的有序链表组成,其中每一层都是底层链表的一个子集。
2.2、节点类型:
ConcurrentSkipListMap 的节点主要由 Node, Index, HeadIndex 构成。

如下图所示:
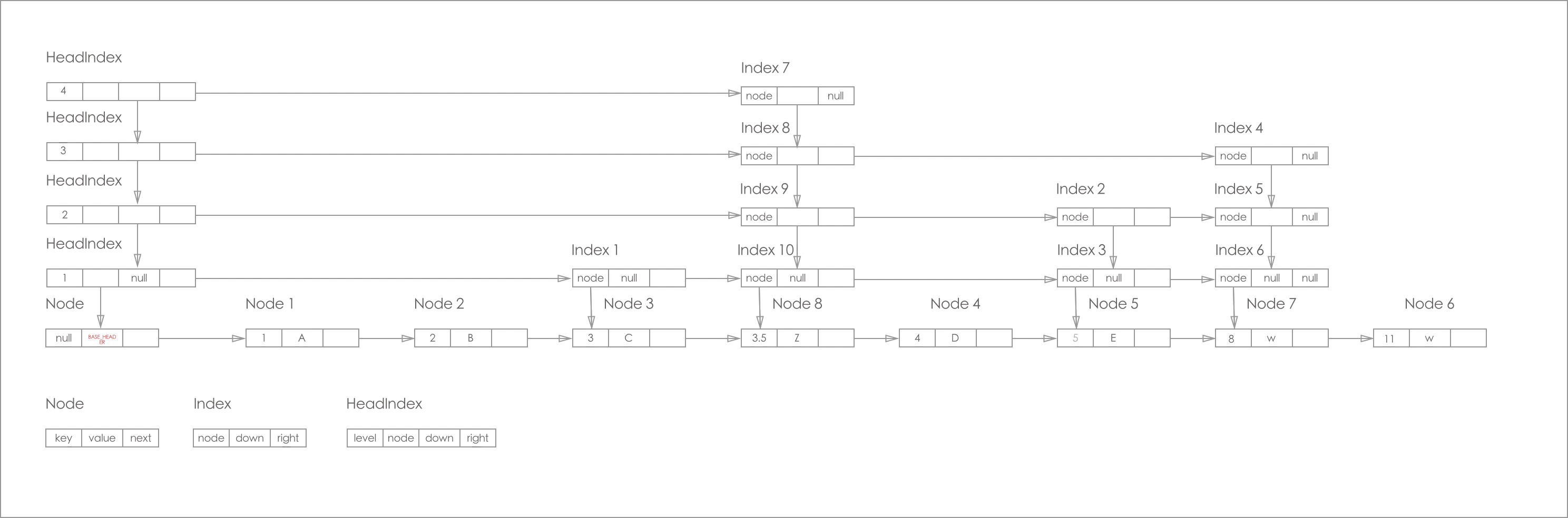
具体简化如下图所示:
head ---> Index ---> Index ---> null| | |v v v
head ---> Index ---> Index ---> null| | |v v v
head ---> Node ----> Node ----> Node ----> null
1.Node
基础节点,构成底层有序链表,包含key、value和next引用。
/*** 最上层链表的头指针head*/private transient volatile HeadIndex<K, V> head;/* ---------------- 普通结点Node定义 -------------- */static final class Node<K, V> {final K key;volatile Object value;volatile Node<K, V> next;// ...}
2.Index
索引节点,构成上层快速路径,包含node引用和right、down引用。
/* ---------------- 索引结点Index定义 -------------- */static class Index<K, V> {final Node<K, V> node; // node指向最底层链表的Node结点final Index<K, V> down; // down指向下层Index结点volatile Index<K, V> right; // right指向右边的Index结点// ...}
3.HeadIndex
头索引节点,是Index的特殊子类,维护索引层链接。
/* ---------------- 头索引结点HeadIndex -------------- */static final class HeadIndex<K, V> extends Index<K, V> {final int level; // 层级// ...}
}
VarHandle:JDK 9+使用VarHandle替代Unsafe进行CAS操作。
如下图所示:
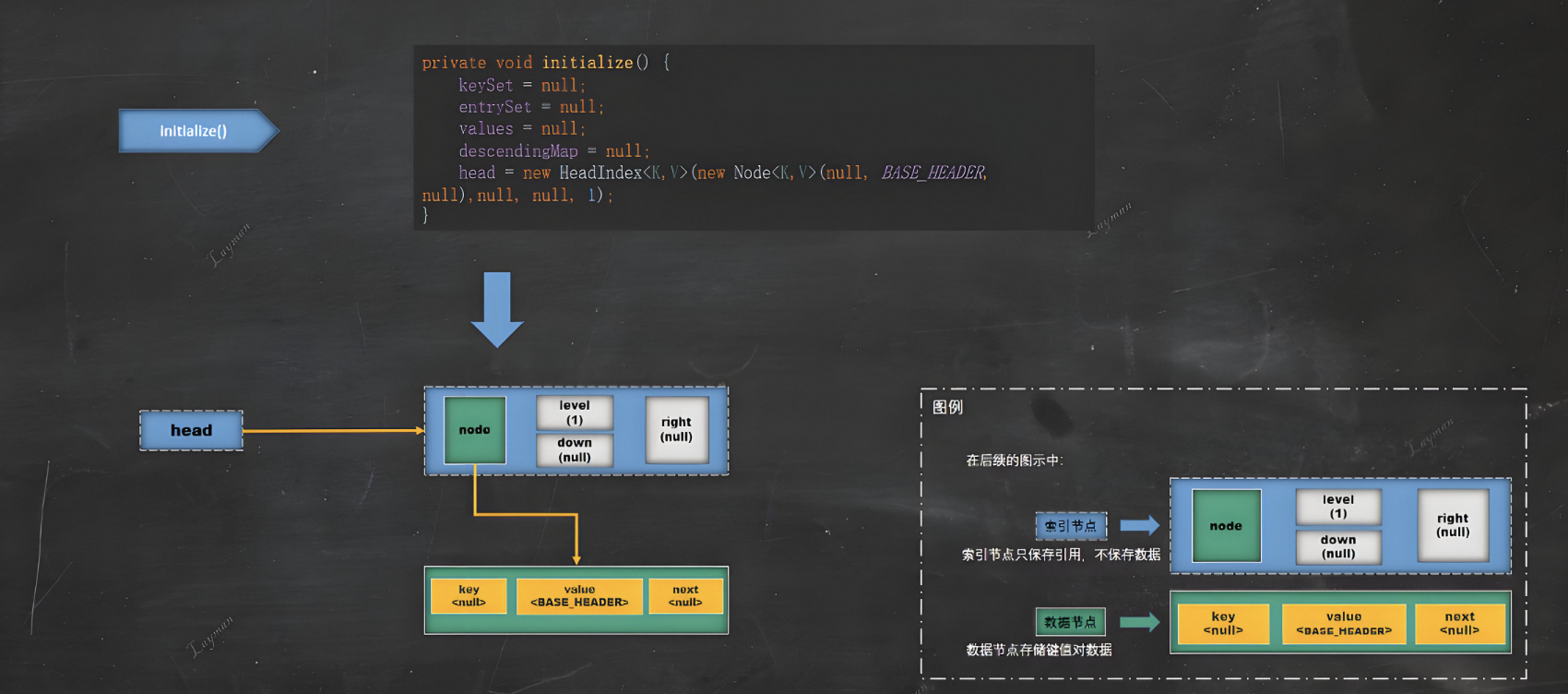
2.3、特点
1、层级结构:
跳表有多层,每层包含一些节点。最底层是包含所有元素的有序链表。每向上增加一层,节点的数量通常会减少。
最下面那层是Node层(数据节点)层, 上面几层都是Index(索引)层。
所有层的节点都有指向它们下层节点的引用,允许快速搜索。从纵向链表来看, 最左边的是 HeadIndex 层, 右边的都是Index 层, 且每层的最底端都是对应Node, 纵向上的索引都是指向最底端的Node。
2、随机化:
新插入的节点会随机选择层级。通常,选定层级的概率是
0.5,这意味着大约一半的节点会出现在上一层中。
这种随机化使跳表在平均情况下表现出 O(log n) 的查找、插入和删除时间复杂度。
3、有序性:
每一层链表都是有序的,因此从最上层开始,可以通过向前跳过多个节点(即 "跳")来快速找到目标节点。这样可以有效减少查找时间。
3、选择层级
在跳表(Skip List)中,新插入节点选择层级的概率是 0.5(即每次向上一层的概率是 50%)是基于特定的设计思想,目的是为了实现平衡性和高效性。
这个设计选择有以下几点原因和好处:
3.1、随机化
均匀分布:
通过使用 0.5 的概率,能够使得节点在各个层级之间的分布较为均匀。这种随机化过程中,较少的节点会在较高的层级上存储,从而有效地减少了第一个层级中节点的数量,使得每一层的链表都保持相对高效的空间利用和查询时间。
3.2、期望高度
1、跳表的高度:
跳表的平均高度(h)是对数级的。如果每个节点上升一层的概率是 0.5,那么插入 n 个节点后,跳表的高度是 O(logn)O(logn)。这意味着大部分的节点都在较低的层级,只有少数节点会在较高的层级出现,使得整个数据结构在平均情况下保持高效。
最早有31层,
-
Integer.numberOfTrailingZeros(random)返回random二进制表示中最低位1之前0的个数。 -
由于
int是 32 位,最多可能有 31 个连续的0(因为至少需要 1 个1),所以层级上限是31 + 1 = 32。但实际实现中会限制为31,避免极端情况。
// 伪代码:随机生成层级
int random = ThreadLocalRandom.current().nextInt();
int level = Integer.numberOfTrailingZeros(random) + 1;3.3、保持平衡性
自调整能力: 随机化算法特性提供了一种自适应的能力,无需对跳表进行显式的平衡调整。它通过随机选择的方式,减少了过多的链表在某个层级的集中程度,从而实现了良好的负载均衡,这在其他数据结构中通常需要额外的维护工作(例如 AVL 树或红黑树的旋转)。
3.4、简单性
使用固定的概率,如 0.5,使得跳表的实现简单且易于理解。在插入节点时,只需一段简单的代码来决定节点的层高。
具体计算:
假设有 n 个节点,如果每个节点都有 0.5 的概率在每层存在,那么期望一个节点在某一层的出现概率是 1/2^h,其中 h 是层数。
通过这种方式,可以保证跳表的高度不至于过高,从而确保了查找、插入和删除操作的对数时间复杂度。
跳表的查询、插入和删除操作的平均时间复杂度为 O(log n),这依赖于节点层级的随机分布。
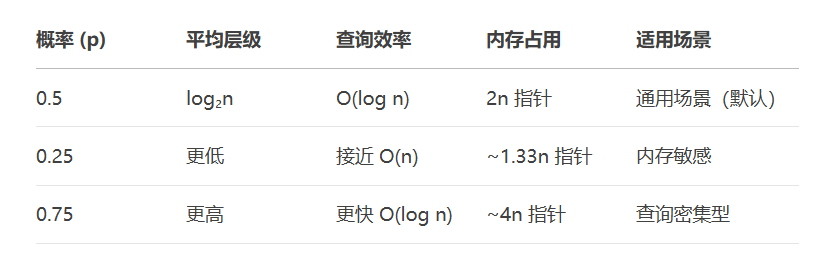
-
概率 p = 0.5 时,跳表的层级分布最均衡:
-
第 1 层包含所有节点(100%)
-
第 2 层约 50% 的节点
-
第 3 层约 25% 的节点(即 0.5²)
-
第 k 层约 n/2^k 个节点
这种分布能保证 查询路径长度 ≈ log₂n,与平衡二叉树的性能相当。
-
过高(如 0.75)会导致高层级节点过多,增加并发冲突;过低(如 0.25)会减少跳跃性,退化成链表。
3.5、性能分析
由于这种概率分布,跳表能够以 O(logn)的时间复杂度进行查找、插入和删除,这使得它在高并发或需要动态修改集合的场景中表现优异。
小结
将新插入节点选定层级的概率设为 0.5 是一种简化且有效的随机化策略,保证了跳表在保持有序性的同时,还能在高效性和均衡性之间取得良好的平衡。
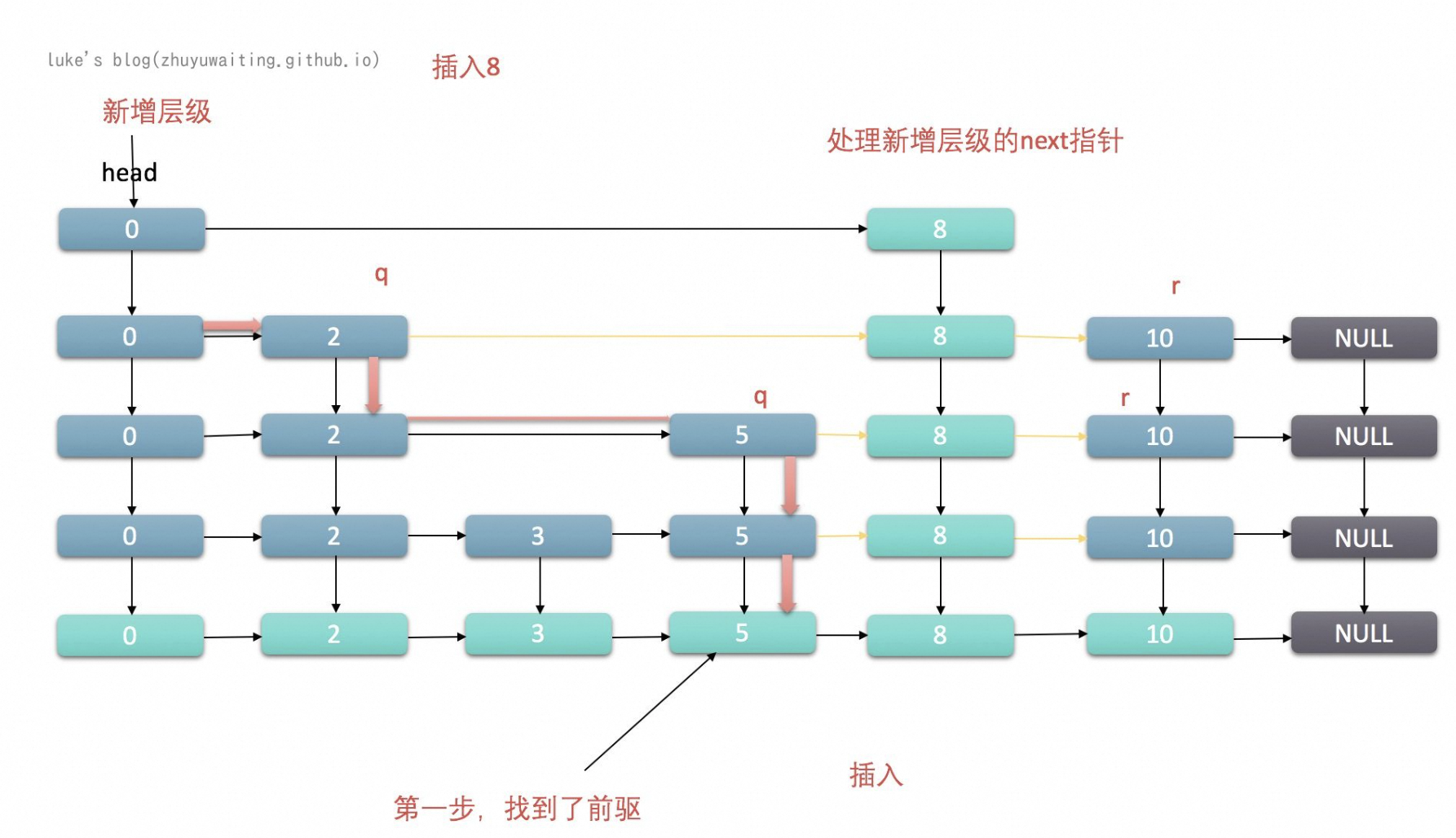
4、层级遍历
在跳表 (Skip List) 的实现中,层级的引用通常是 单向的,并且在查找时,通常是 从高层遍历开始,逐层向下查找。
如下图所示:
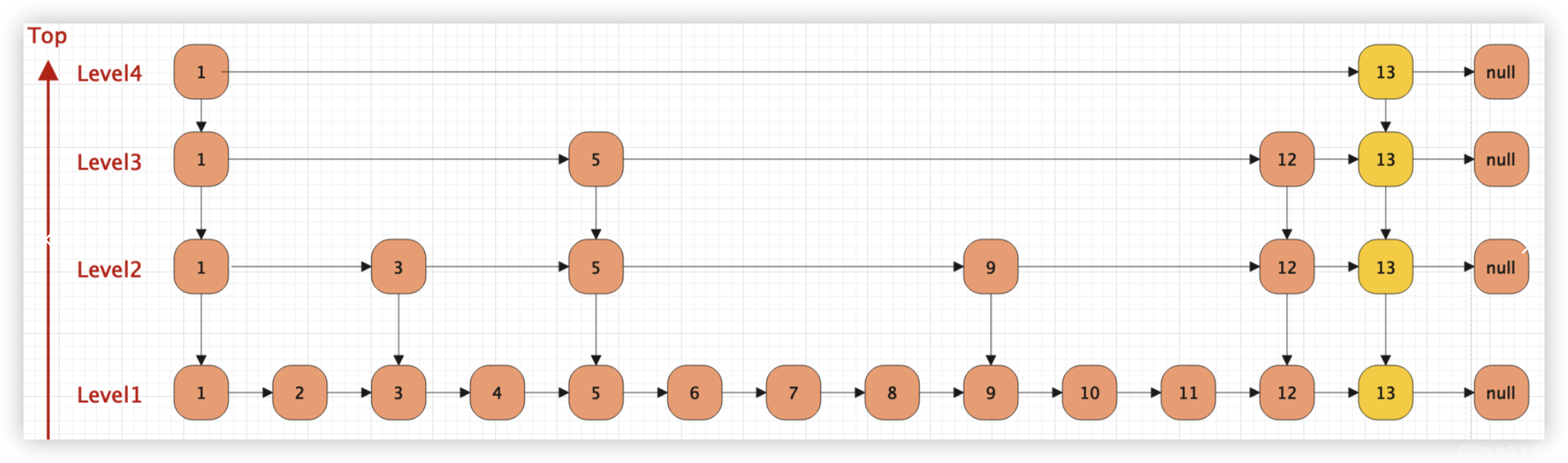
4.1、层级引用的结构
1、单向引用:
在跳表的每一层中,节点之间的指针仅指向下一层的节点。这意味着每个节点在同一层中只保持指向下一个节点的引用,因此它是单向的。在跳表中,尽管有多个层,但是节点在每层之间的访问是单向的,即只能向右查找,不能向左查找。
2、跨层引用:
每个节点不仅在其所在层中保持对下一个节点的引用,还可能在更高层级中保持对其他节点的引用。这样,节点在不同层之间的连接仍然是单向的,但可以在高层直接访问更远的节点。
4.2、查找过程
如下图所示:
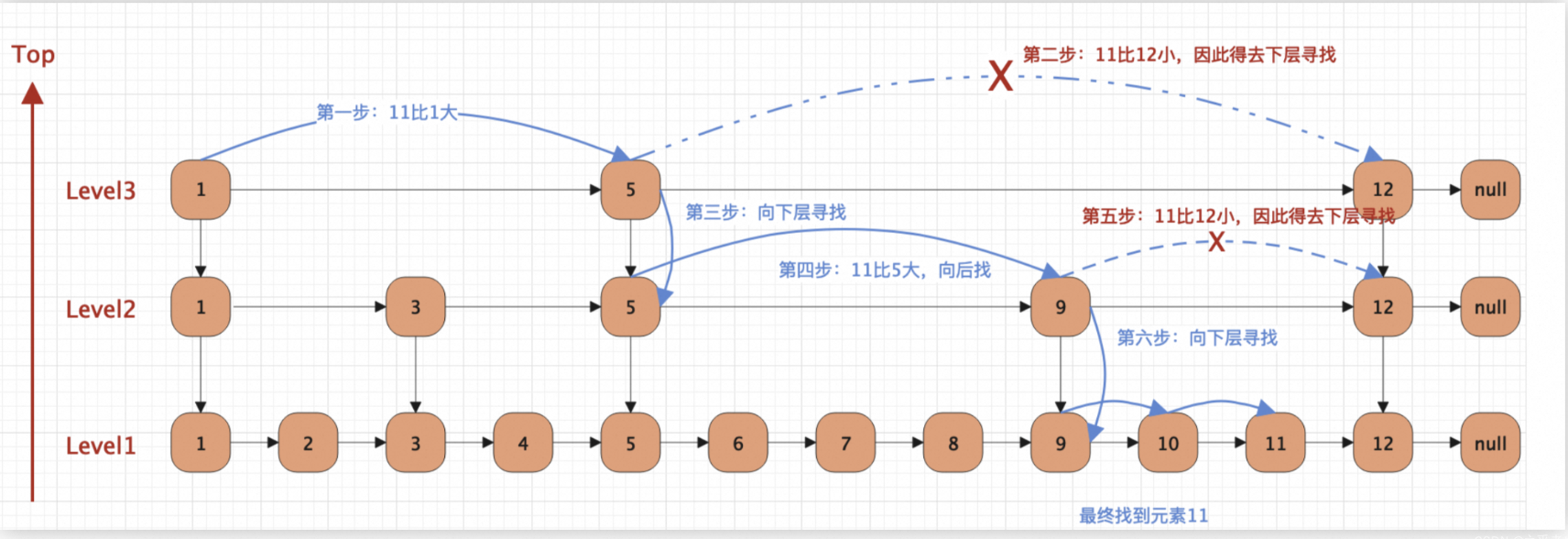
1、从高层开始查找:
查找操作通常从跳表的最高层开始。如果当前节点的下一个节点的值大于所需查找的值,则向下移动到下一层;如果下一个节点的值小于或等于所需查找的值,则向右移动到下一个节点。
这种方式利用了高层节点分布稀疏的特性,可以快速缩小查找范围。因为高层的节点数量相对较少,可以“跳过”较大的值范围。
2、逐层向下:
当在某一层遇到节点的值大于目标值时,就会向下层下降,继续此过程,直到找到目标节点或达到底层为止。在底层时,通常会完成最后的查找,因为底层包含所有的值。
总结
层级引用:
在跳表中,层级的引用是单向的。
查找顺序:
查找时是从高层开始,并逐层向下移动,这样可以加速查找过程,提升效率。通过利用高层的节点稀疏性,可以迅速导航到可能包含目标值的区域,从而实现均匀的查找时间。
5、线程安全的实现
5.1、分段锁机制
部分锁定:
采用了一种分段锁的机制,在对跳表中的某些部分进行操作时只会锁定相关节点,而不会锁定整个数据结构的所有部分。
这种方法提高了并发性,因为它允许多个线程同时访问不同部分的跳表。
节点锁:
跳表中的每个节点都维护一个锁,多个线程可以同时获取不同节点的锁来进行操作,而不必等待其他线程完成对不同节点的操作。这样,读操作与写操作之间不会发生严重的竞争。
5.2、无锁读操作
Optimistic Concurrency Control:
实现了一种无锁的读操作机制,读取操作通常无需加锁,这大大提高了读取的性能。
基础数据结构:
读操作可以仅通过检查节点的引用和数据来完成,不需要进行复杂的锁定,从而降低了延迟。
5.3、随机化和跳表结构
跳表的设计:
跳表本身通过概率方法(例如 0.5 的概率选择层级)使得结构在某种程度上是随机化的,减少了集中的竞争风险。随即的层级产生了自然的分布,减少了热点。
5.4、操作的原子性
原子更新:
对于插入、删除和查找操作,在内部使用原子性的方法来保证这些操作的原子特性。此操作包括对于节点的添加和删除确保数据结构的一致性。
Compare-And-Swap (CAS):
在某些实现细节中,ConcurrentSkipListMap 可能使用底层的 Compare-And-Swap 操作来确保对节点的更改是安全的,这种操作是原子性的,并能够有效防止数据竞争。
5.5、自然的排序和查找性能
排序:
由于 ConcurrentSkipListMap 维护了节点的顺序结构以及通过跳表保证了高效的查找操作,使得在多线程场景中,正好可以利用这些性能,减少了潜在的锁竞争带来的影响。
示例:
以下示例演示了如何使用 ConcurrentSkipListMap 在多线程环境中安全地操作有序映射,特别是执行插入、删除和遍历操作。
import java.util.concurrent.ConcurrentSkipListMap;public class ConcurrentSkipListMapExample {public static void main(String[] args) {// 创建一个并发跳表ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();// 启动多个线程,同时对跳表进行插入操作Thread writer1 = new Thread(() -> {for (int i = 1; i <= 5; i++) {map.put(i, "Value " + i);System.out.println("Writer 1: Inserted (" + i + ", Value " + i + ")");}});Thread writer2 = new Thread(() -> {for (int i = 6; i <= 10; i++) {map.put(i, "Value " + i);System.out.println("Writer 2: Inserted (" + i + ", Value " + i + ")");}});// 启动多个线程,同时对跳表进行读取操作Thread reader = new Thread(() -> {for (int i = 1; i <= 10; i++) {String value = map.get(i);System.out.println("Reader: Retrieved (" + i + ", " + value + ")");}});// 启动线程writer1.start();writer2.start();reader.start();// 等待线程完成try {writer1.join();writer2.join();reader.join();} catch (InterruptedException e) {e.printStackTrace();}// 最后展示跳表的内容System.out.println("Final map contents: " + map);}
}
6、排序目的
ConcurrentSkipListMap 之所以实现有序性,主要有以下几点原因:
6.1、数据检索
有序数据结构支持高效地访问元素。可以快速找到最大、最小值,或者某个范围内的所有元素。
6.2、导航操作
有序集合支持各种导航操作,如查找小于某个值的最大元素、查找大于某个值的最小元素、获取指定范围内的所有元素等。
6.3、高效性
跳表在保持有序性的同时,可以支持快速的插入和删除,以及在并发环境中的高效访问。
6.4、灵活性
允许用户自定义排序策略(通过提供比较器),使得可以根据应用的需求选择不同的排序逻辑。
代码如下所示:
import java.util.Comparator;
import java.util.concurrent.ConcurrentSkipListMap;public class CustomSortingExample {public static void main(String[] args) {// 创建一个自定义比较器的ConcurrentSkipListMapComparator<String> customComparator = (s1, s2) -> {// 按字符串长度排序,长度相同则按字母顺序int lengthCompare = Integer.compare(s1.length(), s2.length());return lengthCompare != 0 ? lengthCompare : s1.compareTo(s2);};ConcurrentSkipListMap<String, Integer> map = new ConcurrentSkipListMap<>(customComparator);// 添加元素map.put("apple", 1);map.put("banana", 2);map.put("pear", 3);map.put("orange", 4);map.put("kiwi", 5);// 输出结果将按自定义顺序排列System.out.println("Sorted map: " + map);// 输出: Sorted map: {kiwi=5, pear=3, apple=1, banana=2, orange=4}}
}总结
一个有序的多级链表结构,通过随机化技术来高效地实现元素查找、插入和删除操作。它支持对数据的快速检索和有序访问,因此广泛应用于需要维护和操作有序集合的多线程环境。这使得成为 Java 中一个非常强大的并发映射实现。
7、并发控制机制
ConcurrentSkipListMap采用了无锁并发控制机制,主要包括以下几个方面:
7.1、CAS(Compare-And-Swap)
使用UNSAFE.compareAndSwapObject()/VarHandle.compareAndSet()原子更新引用,主要用于节点链接、断开和值更新,确保在多线程环境下对共享引用的安全更新。
CAS是无锁算法的核心,它是一种原子操作,比较内存位置的当前值与预期值,只有当它们相同时才将该位置更新为新值。
代码示例如下:
// 使用Unsafe类的CAS操作
boolean casNext(Node<K,V> cmp, Node<K,V> val) {return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}// JDK 9+使用VarHandle
private static final VarHandle NEXT;
static {try {NEXT = MethodHandles.lookup().findVarHandle(Node.class, "next", Node.class);} catch (ReflectiveOperationException e) {throw new ExceptionInInitializerError(e);}
}boolean casNext(Node<K,V> cmp, Node<K,V> val) {return NEXT.compareAndSet(this, cmp, val);
}
7.2、版本标记
使用节点引用的低位比特作为标记(marked bit),节点删除时先标记引用,再实际删除,防止并发问题,这种两阶段删除确保了并发安全。
代码示例:
// 标记节点已删除
static <K,V> Node<K,V> markNode(Node<K,V> n) {return (n == null) ? null : new Node<K,V>(n.key, n.value, n, null);
}// 检查节点是否已标记删除
static <K,V> boolean isMarker(Node<K,V> n) {return (n != null && n.next == n);
}
7.3、无阻塞设计
所有操作均不使用阻塞锁,冲突时使用重试而非阻塞等待,确保系统整体进展,防止死锁和优先级倒置。
读取-复制-写入模式:
修改操作不直接修改现有结构,而是创建新节点,通过CAS操作将新节点链接到正确位置。
// 添加新节点的简化示例
Node<K,V> newNode = new Node<K,V>(key, value, null);
for (;;) {Node<K,V> next = pred.next;if (next != null && next.key.compareTo(key) < 0) {pred = next;continue;}newNode.next = next;if (pred.casNext(next, newNode))break;
}
7.4、辅助删除
线程在发现已标记为删除的节点时会帮助完成物理删除,保证即使标记节点的线程失败,节点最终也会被删除,分摊了删除工作,防止删除节点堆积。
// 帮助删除已标记节点的简化示例
if (n != null && n.isMarked()) {pred.casNext(n, n.next); // 尝试物理删除continue; // 重试
}
7.5、寻找前驱节点
findPredecessor方法是核心操作,用于定位操作点,从最高层开始,通过索引层快速接近目标位置,处理并跳过已标记删除的节点。
7.6、弱一致性
迭代器反映创建时的部分快照状态,不抛出ConcurrentModificationException,size()方法可能不准确,返回估计值。
这些机制共同作用,确保了ConcurrentSkipListMap在高并发环境下的安全性和高性能。
8、常用方法
8.1、put方法
put方法是ConcurrentSkipListMap的核心写操作,它的实现体现了跳表的并发插入算法:
public V put(K key, V value) {if (value == null)throw new NullPointerException();return doPut(key, value, false);
}private V doPut(K key, V value, boolean onlyIfAbsent) {Node<K,V> z; // 新增节点if (key == null)throw new NullPointerException();Comparator<? super K> cmp = comparator;// 外层循环,处理重试outer: for (;;) {// 查找插入位置的前驱节点Node<K,V> b = findPredecessor(key, cmp);Node<K,V> n = b.next;// 内层循环,处理同一位置的冲突for (;;) {if (n != null) {Node<K,V> f = n.next;// 如果b不再是n的前驱,说明有并发修改,重试if (n != b.next)continue outer;// 如果n已被标记删除,帮助删除并重试if (f != null && f.value == n)continue outer;// 比较键,决定是继续查找还是更新现有节点int c = cpr(cmp, key, n.key);if (c > 0) {b = n;n = f;continue;}// 找到相同的键,更新值if (c == 0) {if (onlyIfAbsent || n.casValue(n.value, value))return n.value;continue outer; // CAS失败,重试}}// 准备插入新节点z = new Node<K,V>(key, value, n);if (!b.casNext(n, z))continue outer; // CAS失败,重试break;}// 成功插入节点后,随机决定是否需要增加索引层int rnd = ThreadLocalRandom.nextSecondarySeed();if ((rnd & 0x80000001) == 0) { // 大约有1/4的概率需要建索引int level = 1, max;while (((rnd >>>= 1) & 1) != 0)++level;// 创建并链接索引节点Index<K,V> idx = null;HeadIndex<K,V> h = head;if (level <= (max = h.level)) {for (int i = 1; i <= level; ++i)idx = new Index<K,V>(z, idx, null);}else { // 需要增加层级level = max + 1;Index<K,V>[] idxs = new Index[level+1];for (int i = 1; i <= level; ++i)idxs[i] = idx = new Index<K,V>(z, idx, null);// 尝试增加层级,可能会失败并重试for (;;) {h = head;int oldLevel = h.level;if (level <= oldLevel)break;HeadIndex<K,V> newh = new HeadIndex<K,V>(h.node, h, null, level);if (casHead(h, newh)) {// 成功增加层级,设置新层的链接h = newh;idx = idxs[level];for (int i = level; i > oldLevel; --i) {Index<K,V> ni = idxs[i];Index<K,V> pi = h;// 设置每层的右侧链接for (;;) {Index<K,V> r = pi.right;if (r != null && r.node.key != null &&cpr(cmp, r.node.key, key) < 0) {pi = r;continue;}ni.right = r;if (pi.casRight(r, ni))break;}}break;}}}// 设置现有层级的索引链接for (int i = 1; i <= max && i <= level; ++i) {Index<K,V> ni = idxs[i];for (;;) {Index<K,V> pi = findPredecessorIndex(key, i, cmp);Index<K,V> r = pi.right;if (r != null && r.node.key != null &&cpr(cmp, r.node.key, key) < 0)continue; // 右侧节点小于key,继续查找ni.right = r;if (pi.casRight(r, ni))break; // 成功链接}}}return null; // 新增节点,返回null}
}
源码分析:
1、put操作首先调用doPut方法,该方法同时处理put和putIfAbsent操作。
2、查找过程从findPredecessor开始,该方法从最高索引层开始,逐层下降,最终定位到底层链表的合适位置。
3、在找到位置后,检查是否已存在相同键的节点:
如果存在,则尝试更新值。
如果不存在,则创建新节点并插入。
4、插入新节点后,随机决定是否需要为该节点创建索引层。
5、如果需要创建索引,会根据随机数决定索引的层数,并将索引节点链接到对应层。
6、如果新索引的层数超过当前最高层,则增加整个跳表的高度。
整个过程不使用锁,而是通过CAS操作和重试机制保证线程安全。
8.2、get操作
get方法是ConcurrentSkipListMap的核心读操作,它利用跳表的多层索引结构快速定位元素:
public V get(Object key) {return doGet(key);
}private V doGet(Object key) {if (key == null)throw new NullPointerException();Comparator<? super K> cmp = comparator;// 从最高层开始查找outer: for (;;) {// 获取当前最高层的头索引HeadIndex<K,V> h = head;Index<K,V> q = h;Index<K,V> r;// 从最高层开始,逐层向下查找for (;;) {// 在当前层向右查找while ((r = q.right) != null) {Node<K,V> n = r.node;K k = n.key;if (n.value == null) { // 节点已被删除if (!q.unlink(r))break; // 帮助删除失败,重新开始continue;}// 比较键,决定是继续向右还是向下int c = cpr(cmp, key, k);if (c > 0) {q = r; // 继续向右continue;}else if (c == 0) {return n.value; // 找到匹配的键,返回值}else // c < 0,当前位置的键大于目标键,停止向右break;}// 到达当前层的尽头或找到大于目标键的位置// 如果有下一层,继续向下查找Index<K,V> d = q.down;if (d != null) {q = d;continue;}// 已到达最底层,开始在链表中查找break;}// 在底层链表中查找Node<K,V> b = q.node;Node<K,V> n = b.next;while (n != null) {K k = n.key;if (n.value == null) { // 节点已被删除n = n.next;continue;}// 比较键,决定是继续查找还是返回结果int c = cpr(cmp, key, k);if (c > 0) {b = n;n = n.next;}else if (c == 0) {return n.value; // 找到匹配的键,返回值}else // c < 0,未找到匹配的键break;}return null; // 未找到匹配的键,返回null}
}
源码分析:
get操作首先调用doGet方法
1、从最高索引层开始,利用索引结构快速定位到目标位置附近。
2、在每一层中,向右查找直到找到大于或等于目标键的位置。
3、如果找到等于目标键的节点,直接返回其值,否则,继续向下一层查找,直到到达底层链表。4、在底层链表中线性查找目标键,如果找到匹配的键,返回其值;否则返回null。
整个过程不需要加锁,是一个纯读操作。
get操作充分利用了跳表的多层索引结构,使得查找操作的平均时间复杂度为O(log n),这与红黑树等平衡树结构相当。由于不需要加锁,多个线程可以同时进行读操作,提供了极高的并发读取性能。
8.3、remove操作
remove方法是ConcurrentSkipListMap的核心删除操作,它实现了无锁的并发删除算法:
public V remove(Object key) {return doRemove(key, null);
}final V doRemove(Object key, Object value) {if (key == null)throw new NullPointerException();Comparator<? super K> cmp = comparator;// 外层循环,处理重试outer: for (;;) {// 查找要删除节点的前驱节点Node<K,V> b = findPredecessor(key, cmp);Node<K,V> n = b.next;// 内层循环,处理同一位置的冲突for (;;) {if (n == null)return null; // 未找到要删除的节点Node<K,V> f = n.next;// 如果b不再是n的前驱,说明有并发修改,重试if (n != b.next)continue outer;// 如果n已被标记删除,帮助删除并重试if (f != null && f.value == n)continue outer;// 比较键,决定是继续查找还是删除当前节点int c = cpr(cmp, key, n.key);if (c < 0)return null; // 未找到要删除的节点if (c > 0) {b = n;n = f;continue; // 继续查找}// 找到匹配的键,检查值是否也匹配(用于removeValue操作)if (value != null && !value.equals(n.value))return null;// 尝试将节点的值设为null,标记为已删除if (!n.casValue(n.value, null))continue outer; // CAS失败,重试// 尝试物理删除节点(更新前驱节点的next引用)if (!n.casNext(f, new Node<K,V>(n.key, null, f, n)))findNode(n.key); // 帮助完成删除// 物理删除成功,可能需要删除索引节点findPredecessor(key, cmp); // 清理索引// 如果没有其他线程在使用索引,可能需要降低跳表高度if (head.right == null && head.down != null) {HeadIndex<K,V> d = head.down;if (d.right == null && d.down != null)casHead(head, d); // 尝试降低高度}return (V)n.value; // 返回被删除的值}}
}
源码分析:
remove操作首先调用doRemove方法,该方法同时处理remove和removeValue操作
1、查找过程从findPredecessor开始,定位到要删除节点的前驱节点
2、找到要删除的节点后,执行两阶段删除:
3、首先使用CAS操作将节点的值设为null,标记为逻辑删除
4、然后尝试物理删除节点,更新前驱节点的next引用
5、如果物理删除成功,还需要清理索引节点
6、如果跳表的高度过高(顶层索引为空),可能需要降低跳表高度
整个过程不使用锁,而是通过CAS操作和重试机制保证线程安全
remove操作的关键在于它的两阶段删除设计:先逻辑删除(标记节点),再物理删除(移除链接)。这种设计确保了在并发环境下的安全删除,即使有其他线程同时访问被删除的节点,也不会导致不一致状态。
8.4、迭代器实现
ConcurrentSkipListMap的迭代器实现提供了弱一致性的保证,不会抛出ConcurrentModificationException:
public Set<K> keySet() {KeySet<K> ks = keySet;return (ks != null) ? ks : (keySet = new KeySet<K>(this));
}public Collection<V> values() {Values<V> vs = values;return (vs != null) ? vs : (values = new Values<V>(this));
}public Set<Map.Entry<K,V>> entrySet() {EntrySet<K,V> es = entrySet;return (es != null) ? es : (entrySet = new EntrySet<K,V>(this));
}// KeySet迭代器
static final class KeyIterator<K,V> extends Iter<K,V> implements Iterator<K> {public K next() {Node<K,V> n = advance();return n.key;}
}// Values迭代器
static final class ValueIterator<K,V> extends Iter<K,V> implements Iterator<V> {public V next() {Node<K,V> n = advance();return n.value;}
}// EntrySet迭代器
static final class EntryIterator<K,V> extends Iter<K,V> implements Iterator<Map.Entry<K,V>> {public Map.Entry<K,V> next() {Node<K,V> n = advance();return new AbstractMap.SimpleImmutableEntry<K,V>(n.key, n.value);}
}// 基础迭代器类
abstract static class Iter<K,V> {Node<K,V> next; // 下一个要返回的节点Node<K,V> lastReturned; // 最后一个返回的节点V nextValue; // 缓存的下一个值Iter(ConcurrentSkipListMap<K,V> map) {// 初始化,找到第一个有效节点Node<K,V> n = map.findFirst();next = n;nextValue = (n == null) ? null : n.value;}public final boolean hasNext() {return next != null;}// 获取下一个有效节点final Node<K,V> advance() {Node<K,V> n = next;if (n == null)throw new NoSuchElementException();lastReturned = n;// 查找下一个有效节点Node<K,V> f = n.next;for (;;) {if (f == null) {next = null;nextValue = null;break;}V v = f.value;if (v != null) { // 找到有效节点next = f;nextValue = v;break;}// 跳过已删除的节点f = f.next;}return n;}public final void remove() {Node<K,V> l = lastReturned;if (l == null)throw new IllegalStateException();map.remove(l.key);lastReturned = null;}
}
源码分析:
1、ConcurrentSkipListMap提供了三种视图:keySet、values和entrySet,每种视图都有对应的迭代器。
2、所有迭代器都继承自基础迭代器类Iter,共享核心逻辑。
3、迭代器在创建时会找到第一个有效节点作为起点。
4、advance()方法负责查找下一个有效节点,跳过已删除的节点。
5、迭代器支持remove操作,但实际上是调用map的remove方法,而不是直接修改结构。
6、迭代器提供弱一致性保证,可能看不到迭代过程中的并发修改。
不会抛出ConcurrentModificationException,即使在迭代过程中有其他线程修改了map。
ConcurrentSkipListMap的迭代器设计体现了并发集合的一个重要特性:弱一致性。这种设计在保证安全性的同时,提供了更好的并发性能,但使用者需要了解其语义,不能期望看到所有的最新修改。
小结
通过分段锁、无锁读取、内部节点锁、跳表的设计和原子操作等机制,有效确保了在高并发环境下的线程安全。
参考文章:
1、JUC并发集合-ConcurrentSkipListMap_concurrentskiplistmap在微服务中的用法-CSDN博客
2、ConcurrentSkipListMap 图解_concurrentskiplistmap.headmap-CSDN博客
相关文章:

ConcurrentSkipListMap的深入学习
目录 1、介绍 1.1、线程安全 1.2、有序性 1.3、跳表数据结构 1.4、API 提供的功能 1.5、高效性 1.6、应用场景 2、数据结构 2.1、跳表(Skip List) 2.2、节点类型: 1.Node 2.Index 3.HeadIndex 2.3、特点 3、选择层级 3.1、随…...

ProfibusDP主站转modbusTCP网关接DP从站网关通讯案例
ProfibusDP主站转modbusTCP网关接DP从站网关通讯案例 在工业自动化领域,Profibus DP和Modbus TCP是两种常见的通信协议。Profibus DP广泛应用于过程自动化、工厂自动化等场景,而Modbus TCP则常见于楼宇自动化、能源管理等领域。由于设备和系统之间往往存…...

第一次做逆向
题目来源:ctf.show 1、下载附件,发现一个exe和一个txt文件 看看病毒加没加壳,发现没加那就直接放IDA 放到IDA找到main主函数,按F5反编译工具就把他还原成类似C语言的代码 然后我们看逻辑,将flag.txt文件的内容进行加…...

【项目】自主实现HTTP服务器:从Socket到CGI全流程解析
00 引言 在构建高效、可扩展的网络应用时,理解HTTP服务器的底层原理是一项必不可少的技能。现代浏览器与移动应用大量依赖HTTP协议完成前后端通信,而这一过程的背后,是由网络套接字驱动的请求解析、响应构建、数据传输等一系列机制所支撑…...

AI最新资讯,GPT4.1加入网页端、Claude 3.7 Sonnet携“极限推理”发布在即
目录 一、GPT4.1加入网页端二、Claude 3.7 Sonnet携“极限推理”发布在即三、这项功能的关键特点1、双模式操作2、可视化思考过程3、可控的思考预算4、性能提升 四、Claude制作SVG图像1、Prompt提示词模板2、demo:技术路线图**Prompt提示词:**3、甘特图4…...
)
Android 中使用通知(Kotlin 版)
1. 前置条件 Android Studio:确保使用最新版本(2023.3.1)目标 API:最低 API 21,兼容 Android 8.0(渠道)和 13(权限)依赖库:使用 WorkManager 和 Notificatio…...

在 Kotlin 中,什么是解构,如何使用?
在 Kotlin 中,解构是一种语法糖,允许将一个对象分解为多个独立的变量。 这种特性可以让代码更简洁、易读,尤其适用于处理数据类、集合(如 Pair、Map)或其他结构化数据。 1 解构的核心概念 解构通过定义 componentN()…...
)
apisix透传客户端真实IP(real-ip插件)
文章目录 apisix透传客户端真实IP需求和背景apisix real-ip插件为什么需要 trusted_addresses?安全架构的最佳实践 示例场景apisix界面配置 apisix透传客户端真实IP 需求和背景 当 APISIX 前端有其他反向代理(如 Nginx、HAProxy、云厂商的 LBÿ…...

初学者如何用 Python 写第一个爬虫?
初学者如何用 Python 写第一个爬虫? 一、爬虫的基本概念 (一)爬虫的定义 爬虫,英文名为 Web Crawler,也被叫做网络蜘蛛、网络机器人。想象一下,有一个勤劳的小蜘蛛,在互联网这个巨大的蜘蛛网中…...
)
基于MNIST数据集的手写数字识别(CNN)
目录 一,模型训练 1.1 数据集介绍 1.2 CNN模型层结构 1.3 定义CNN模型 1.4 神经网络的前向传播过程 1.5 数据预处理 1.6 加载数据 1.7 初始化 1.8 模型训练过程 1.9 保存模型 二,模型测试 2.1 定义与训练时相同的CNN模型架构 2.2 图像的预处…...
篇三:阅读与注释 QPlainTextEdit,给出源代码)
QT6 源(103)篇三:阅读与注释 QPlainTextEdit,给出源代码
(10)关于文本处理的内容很多,来不及全面阅读、思考与整理。先给出类的继承图: (11)本源代码来自于头文件 qplaintextedit . h : #ifndef QPLAINTEXTEDIT_H #define QPLAINTEXTEDIT_H#include &…...

yocto5.2开发任务手册-7 升级配方
此文为机器辅助翻译,仅供个人学习使用,如有翻译不当之处欢迎指正 7 升级配方 随着时间的推移,上游开发者会为图层配方构建的软件发布新版本。建议使配方保持与上游版本发布同步更新。 虽然有多种升级配方的方法,但您可能需要先…...

LangPDF: Empowering Your PDFs with Intelligent Language Processing
LangPDF: Empowering Your PDFs with Intelligent Language Processing Unlock Global Communication: AI-Powered PDF Translation and Beyond In an interconnected world, seamless multilingual document management is not just an advantage—it’s a necessity. LangP…...
 和 P2P(点对点网络) 的详细对比)
DDS(数据分发服务) 和 P2P(点对点网络) 的详细对比
1. 核心特性对比 维度 DDS P2P 实时性 微秒级延迟,支持硬实时(如自动驾驶) 毫秒至秒级,依赖网络环境(如文件传输) 架构 去中心化发布/订阅模型,节点自主发现 完全去中心化,节…...

TC8:SOMEIP_ETS_029-030
SOMEIP_ETS_029: echoUINT8Array16Bitlength 目的 检查当method echoUINT8Array16BitLength的参数中长度字段为16bit时,SOME/IP协议层是否能对参数进行序列化和反序列化。 对于可变长度的数组而言,必须用长度字段表示数组长度。否则接收方无法判断有效数据。 SOMEIP_ETS_02…...

Elasticsearch索引全生命周期管理指南之一
#作者:猎人 文章目录 一、索引常规操作二、索引mapping和别名管理 一、索引常规操作 索引数据特点: 索引中的数据随着时间,持续不断增长 按照时间序列划分索引的好处&挑战: 按照时间进行划分索引,会使得管理更加…...

本土DevOps革命:Gitee如何撬动中国企业的数字化转型新动能
在数字化浪潮席卷全球的背景下,中国企业正面临前所未有的转型压力与机遇。随着《数据安全法》和《个人信息保护法》的全面实施,以及信创产业政策的深入推进,研发工具链的自主可控已成为关乎企业核心竞争力的战略命题。在这一关键赛道上&#…...

ARM服务器解决方案
ARM服务器解决方案已成为异构计算领域的重要技术路径,其核心优势与多元化场景适配性正加速产业渗透。以下为关键要点分析: 一、核心优势与架构设计 能效比优化 ARM架构基于RISC指令集,单节点功耗可控制在15W以下,较x86架构能效…...

【暗光图像增强】【基于CNN的方法】2020-AAAI-EEMEFN
EEMEFN:Low-Light Image Enhancement via Edge-Enhanced Multi-Exposure Fusion Network EEMEFN:基于边缘增强多重曝光融合网络的低光照图像增强 AAAI 2020 论文链接 0.论文摘要 本研究专注于极低光照条件下的图像增强技术,旨在提升图像亮度…...

嵌入式EasyRTC音视频实时通话SDK在工业制造领域的智能巡检/AR协作等应用
一、背景 在数字化浪潮席卷全球的当下,远程监控与驾驶技术已深度渗透至工业巡检、智能交通等核心领域。然而,传统方案普遍面临实时性瓶颈、高延迟传输及交互体验匮乏等痛点,严重制约行业智能化转型。EasyRTC作为前沿的实时音视频通信技术&am…...
)
uniapp-商城-58-后台 新增商品(属性子级的添加和更新)
前面对父级属性的添加进行了分析,这里再来继续做属性子级的数据添加,包含页面逻辑以及后台处理的逻辑。当然这里还是在前面的云对象的方式进行的。 本文介绍了在云对象green-mall-sku中添加子级属性的实现过程。首先,通过updateChild接口处理…...

基于springboot+vue的机场乘客服务系统
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7数据库工具:Navicat12开发软件:eclipse/myeclipse/ideaMaven包:Maven3.3.9 系统展示 用户管理 航班信…...

npm和nvm和nrm有什么区别
npm 全称:Node Package Manager。 作用: 包管理:用于安装、共享、分发代码,管理项目依赖关系。项目管理:创建和管理 package.json 文件,记录项目依赖和配置信息。脚本执行:运行项目中的脚本&…...
)
几种排序方式的C语言实现(冒泡、选择、插入、希尔等)
## 分类 存储器类型: - 内排序(数据规模小 内存) - 外排序(数据库 磁盘) 是否基于元素之间的比较 - 基数排序 - 其他排序:冒泡、选择、插入、快速、归并、希尔、堆…… 时间复杂度 - O&#…...

【MATLAB例程】线性卡尔曼滤波的程序,三维状态量和观测量,较为简单,可用于理解多维KF,附代码下载链接
本文所述代码实现了一个 三维状态的扩展卡尔曼滤波 (Extended Kalman Filter, EKF) 算法。通过生成过程噪声和观测噪声,对真实状态进行滤波估计,同时对比了滤波前后状态量的误差和误差累积分布曲线。 文章目录 简介运行结果MATLAB源代码 简介 代码分为以…...

芯片测试之X-ray测试
原理: X-ray是利用阴极射线管产生高能量电子与金属靶撞击,在撞击过程中,因电子突然减速,其损失的动能会以X-Ray形式放出。而对于样品无法以外观方式观测的位置,利用X-Ray穿透不同密度物质后其光强度的变化,…...

机器学习中的特征工程:解锁模型性能的关键
在机器学习领域,模型的性能往往取决于数据的质量和特征的有效性。尽管深度学习模型在某些任务中能够自动提取特征,但在大多数传统机器学习任务中,特征工程仍然是提升模型性能的关键环节。本文将深入探讨特征工程的重要性、常用方法以及在实际…...
 | 第七章|神经网络(1))
【学习笔记】机器学习(Machine Learning) | 第七章|神经网络(1)
机器学习(Machine Learning) 简要声明 基于吴恩达教授(Andrew Ng)课程视频 BiliBili课程资源 文章目录 机器学习(Machine Learning)简要声明 机器学习之深度学习神经网络入门一、神经网络的起源与发展二、神经元模型(…...

反向传播算法:神经网络的核心优化方法,一文打通任督二脉
搞神经网络训练,**反向传播(Backpropagation)**是最核心的算法。 没有它,模型就只能瞎猜参数,训练基本白搭。 这篇文章不整公式推导,不搞花架子,咱就把最关键的几个问题讲明白: 反向传播到底是干啥的? 它是怎么一步步更新参数的? 哪些坑你必须避免? 一、反向传播是…...

neo4j框架:java安装教程
安装使用neo4j需要事先安装好java,java版本的选择是一个犯难的问题。本文总结了在安装java和使用Java过程中遇到的问题以及相应的解决方法。 Java的安装包可以在java官方网站Java Downloads | Oracle 中国进行下载 以java 8为例,选择最后一行的x64 compr…...

基于React的高德地图api教程007:椭圆的绘制、编辑和删除
文章目录 7、椭圆绘制7.1 绘制椭圆7.1.1 设置圆心7.1.2 确定短半轴7.1.3 确定长半轴7.1.4 实时显示椭圆形状7.2 修改椭圆7.2.1 修改椭圆属性信息7.2.2 修改椭圆形状7.3 删除椭圆7.4 定位椭圆7.5 代码下载7.07、椭圆绘制 7.1 绘制椭圆 7.1.1 设置圆心 第一次点击地图设置圆心…...

Python多线程实战:提升并发效率的秘诀
一、前言:为什么需要多任务处理? 在实际开发中,我们经常需要让程序同时执行多个任务,例如: 同时下载多个文件;在后台运行耗时计算的同时保持界面响应;并发处理网络请求等。 Python 提供了多种…...

将嵌入映射到 Elasticsearch 字段类型:semantic_text、dense_vector、sparse_vector
作者: Andre Luiz 讨论如何以及何时使用 semantic_text、dense_vector 或 sparse_vector,以及它们与嵌入生成的关系。 通过这个自定进度的 Search AI 实践学习亲自体验向量搜索。你可以开始免费云试用,或者在本地机器上尝试 Elastic。 多年来…...
)
RabbitMQ 消息模式实战:从简单队列到复杂路由(四)
模式对比与选择 各模式特点对比 简单队列模式:结构最为简单,生产者直接将消息发送到队列,消费者从队列中获取消息,实现一对一的消息传递。其优势在于易于理解和实现,代码编写简单,适用于初学者和简单业务…...

OpenCV CUDA模块中矩阵操作------归一化与变换操作
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 OpenCV 的 CUDA 模块中,normalize 和 rectStdDev 函数用于对矩阵进行归一化处理和基于积分图计算矩形区域的标准差。 函数介绍 …...

1Panel应用推荐:Beszel轻量级服务器监控平台
1Panel(github.com/1Panel-dev/1Panel)是一款现代化、开源的Linux服务器运维管理面板,它致力于通过开源的方式,帮助用户简化建站与运维管理流程。为了方便广大用户快捷安装部署相关软件应用,1Panel特别开通应用商店&am…...

谷歌地图代理 | 使用 HTML 和矢量模式 API 更轻松地创建 Web 地图
在过去的一年里,谷歌对 Maps JavaScript API 进行了两项重要更新,以便更轻松地采用我们最新、最好的地图:HTML 地图和矢量模式 API。今天谷歌地图亚太区最大代理商之一的 Cloud Ace云一 为大家介绍一下更新的具体内容。 联系我们 - Cloud Ac…...

最新开源 TEN VAD 与 Turn Detection 让 Voice Agent 对话更拟人 | 社区来稿
关键词:对话式 AI | 语音智能体 | Voice Agent | VAD | 轮次检测 | 声网 | TEN GPT-4o 所展示对话式 AI 的新高度,正一步步把我们在电影《Her》中看到的 AI 语音体验变成现实。AI 的语音交互正在变得更丰富、更流畅、更易用,成为构建多模态智…...

「Mac畅玩AIGC与多模态40」开发篇35 - 用 Python 开发服务对接 SearxNG 与本地知识库
一、概述 本篇介绍如何使用 Python 构建一个集成本地聚合搜索引擎 SearxNG 与本地知识库的双通道服务接口,返回标准结构化 JSON 数据,并用于对接智能体插件系统。该接口适用于本地 Agent 应用开发与 Dify 插件集成场景。 二、目标说明 使用 Flask 实现…...

【Boost搜索引擎】构建Boost站内搜索引擎实践
目录 1. 搜索引擎的相关宏观原理 2. 正排索引 vs 倒排索引 - 搜索引擎具体原理 3. 编写数据去标签与数据清洗的模块 Parser 去标签 编写parser 用boost枚举文件名 解析html 提取title 编辑 去标签 构建URL 将解析内容写入文件中 4. 编写建立索引的模块 Index 建…...

记参加一次数学建模
题目请到全国大学生数学建模竞赛下载查看。 注:过程更新了很多文件,所有这里贴上的有些内容不是最新的(而是草稿)。 注:我们队伍并没有获奖,文章内容仅供一乐。 从这次比赛,给出以下赛前建议 …...

【gRPC】HTTP/2协议,HTTP/1.x中线头阻塞问题由来,及HTTP/2中的解决方案,RPC、Protobuf、HTTP/2 的关系及核心知识点汇总
HTTP/2协议特点 gRPC基于HTTP/2协议,原因: 多路复用:允许在同一个TCP连接上并行传输多个请求和响应,即多个gRPC调用可以通过同一个连接同时进行,避免了HTTP/1.x中常见的线头阻塞问题,减少了连接建立和关闭…...

mac中加载C++动态库文件
前言 需要再mac系统下运行C开发的程序,通过摸索,初步实现了一版,大致记录下 1. 前提准备 安装OpenCV 使用Homebrew安装OpenCV: brew install opencv确认安装路径: brew --prefix opencv默认路径为/opt/homebrew/…...

Apollo Client 1.6.0 + @RefreshScope + @Value 刷新问题解析
问题描述 在使用 Apollo Client 1.6.0 结合 Spring Cloud 的 RefreshScope 和 Value 注解时,遇到以下问题: 项目启动时第一次属性注入成功后续配置变更时,Value 属性会刷新,但总是刷新为第一次的旧值,而不是最新的配…...

大语言模型 09 - 从0开始训练GPT 0.25B参数量 补充知识之数据集 Pretrain SFT RLHF
写在前面 GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,…...

文本分类任务Qwen3-0.6B与Bert:实验见解
文本分类任务Qwen3-0.6B与Bert:实验见解 前言 最近在知乎上刷到一个很有意思的提问Qwen3-0.6B这种小模型有什么实际意义和用途。查看了所有回答,有人提到小尺寸模型在边缘设备场景中的优势(低延迟)、也有人提出小模型只是为了开…...

Mysql、Oracle、Sql Server、达梦之间sql的差异
1:分页查询 Sql Server: <bind name"startRow" value"(page - 1) * limit 1"/> <bind name"endRow" value"page * limit"/> SELECT *FROM (SELECT ROW_NUMBER() OVER (<if test"sortZd!…...

STM32外设AD-DMA+定时读取模板
STM32外设AD-DMA定时读取模板 一,方法引入二,CubeMX配置三,变量声明四,代码实现 (单通道) 一,方法引入 轮询法虽然简单,但 CPU 一直在忙着等待,效率太低。为了让 CPU 能在 ADC 转换的同时处理其…...

SQL里where条件的顺序影响索引使用吗?
大家好,我是锋哥。今天分享关于【SQL里where条件的顺序影响索引使用吗?】面试题。希望对大家有帮助; SQL里where条件的顺序影响索引使用吗? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 在 SQL 查询中,W…...

Java 接口中实现异步处理的方法
在Java中,接口本身不能直接实现逻辑(接口中的方法默认是抽象的,JDK 8+允许通过default方法提供非抽象实现,但通常不用于复杂的异步处理)。异步处理的逻辑需要在实现接口的类中通过多线程、异步框架或回调机制来实现。以下是几种常见的在接口实现类中实现异步处理<...