Ascend的aclgraph(九)AclConcreteGraph:e2e执行aclgraph
1回顾
前面的几章内容探讨了aclgraph运行过程中的涉及到的关键模块和技术。本章节将前面涉及到的模块串联起来,对aclgraph形成一个端到端的了解。
先给出端到端运行的代码,如下:
import torch
import torch_npu
import torchair
import logging
from torchair import logger
logger.setLevel(logging.INFO)
torch._logging.set_logs(dynamo=logging.DEBUG,aot=logging.DEBUG,output_code=True,graph_code=True)# Patch方式实现集合通信入图(可选)
from torchair import patch_for_hcom
patch_for_hcom()# 定义模型Model
class Model(torch.nn.Module):def __init__(self):super().__init__()def forward(self, x, y):return torch.add(x, y)# 实例化模型model
model = Model().npu()# 获取TorchAir提供的默认npu backend,自行配置config功能
config = torchair.CompilerConfig()
config.mode = "reduce-overhead"
npu_backend = torchair.get_npu_backend(compiler_config=config) // 关注点1# 使用npu backend进行compile
opt_model = torch.compile(model, backend=npu_backend) // 关注点2# 使用编译后的model去执行
x = torch.randn(2, 2).npu()
y = torch.randn(2, 2).npu()
out = opt_model(x, y) // 关注点3
pring(out)
config.mode = "reduce-overhead"配置了aclgraph的模式。该代码在CANN8.1rc1(https://www.hiascend.com/document/detail/zh/canncommercial/81RC1/quickstart/index/index.html),torch_npu插件版本 7.0.0(https://www.hiascend.com/document/detail/zh/Pytorch/700/configandinstg/instg/insg_0004.html)以后的版本上aclgraph模式才得以支持,是可以运行起来的。
关注上述代码的3个主要部分。
2 torchair.get_npu_backend
def get_npu_backend(*, compiler_config: CompilerConfig = None, custom_decompositions: Dict = {}):if compiler_config is None:compiler_config = CompilerConfig()decompositions = get_npu_default_decompositions()decompositions.update(custom_decompositions)add_npu_patch(decompositions, compiler_config)return functools.partial(_npu_backend, compiler_config=compiler_config, decompositions=decompositions)
从Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?中可知。该函数最终返回的是_npu_backend在固定参数compiler_config和decompositions下返回的一个新的函数。
def _npu_backend(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor],compiler_config: CompilerConfig = None, decompositions: Dict = {}):if compiler_config is None:compiler_config = CompilerConfig()compiler = get_compiler(compiler_config)input_dim_gears = dict()for i, t in enumerate(example_inputs):dim_gears = get_dim_gears(t)if dim_gears is not None:input_dim_gears[i - len(example_inputs)] = dim_gearsfw_compiler, inference_compiler, joint_compiler = _wrap_compiler(compiler, compiler_config)fw_compiler = _set_gear_to_compiler(fw_compiler, compiler_config, input_dim_gears)inference_compiler = _set_gear_to_compiler(inference_compiler, compiler_config, input_dim_gears)partition_fn = _get_partition_fn(compiler_config)if compiler_config.experimental_config.aot_config_enable_joint_graph:output_loss_index = int(compiler_config.experimental_config.aot_config_output_loss_index.value)return aot_module_simplified_joint(gm, example_inputs,compiler=joint_compiler, decompositions=decompositions,output_loss_index=output_loss_index)keep_inference_input_mutations = bool(compiler_config.experimental_config.keep_inference_input_mutations)# TO DO: fix me in masterif compiler_config.mode.value == "reduce-overhead":keep_inference_input_mutations = Falselogger.debug(f"To temporarily avoid some precision problem in AclGraph, "f"keep_inference_input_mutations config is set to {keep_inference_input_mutations}.")return aot_module_simplified(gm, example_inputs, fw_compiler=fw_compiler, bw_compiler=compiler,decompositions=decompositions, partition_fn=partition_fn,keep_inference_input_mutations=keep_inference_input_mutations,inference_compiler=inference_compiler)_npu_backend中最终返回的是aot_module_simplified。_npu_backend的解析请参照Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?和Ascend的aclgraph(二)_npu_backend中还有些什么秘密?。
aot_module_simplified 作用在前文中可知是:通常用于简化将一个 PyTorch 模型准备好进行 AOT 编译的过程,简单理解就是AOT编译前的预操作。
写个示例:
import torch
from torch.compile import aot_module_simplified# 假设有一个简单的模型
class SimpleModel(torch.nn.Module):def forward(self, x):return torch.relu(x)model = SimpleModel()# 使用 aot_module_simplified 进行 AOT 编译
compiled_model = aot_module_simplified(model)# 现在可以使用 compiled_model 进行推理
input_tensor = torch.randn(5)
output_tensor = compiled_model(input_tensor)
print(output_tensor)
在这个示例中,compiled_model 就是经过 aot_module_simplified 编译优化后的模型。你可以像使用普通 PyTorch 模型那样调用它的方法来进行推理。
回到代码中的关注1,那么npu_backend 返回的就是一个可以执行的model对象torch.nn.Module
接着看关注2。
3 torch.compile(model, backend=npu_backend)
通过Ascend的aclgraph(二)_npu_backend中还有些什么秘密?可知backend是一个回调函数(可调用的对象)
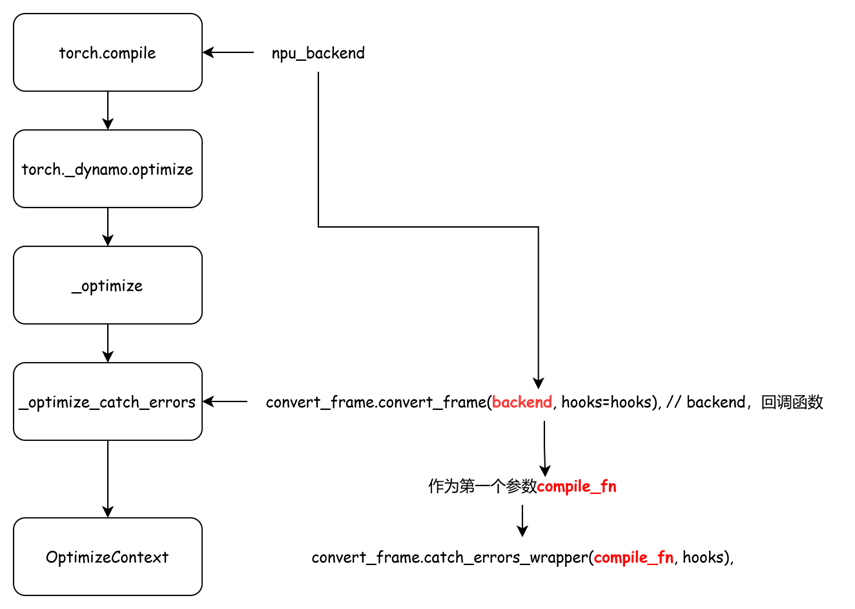
def _optimize(rebuild_ctx: Callable[[], Union[OptimizeContext, _NullDecorator]],backend="inductor",*,nopython=False,guard_export_fn=None,guard_fail_fn=None,disable=False,dynamic=None,
) -> Union[OptimizeContext, _NullDecorator]:# 中间代码省略...return _optimize_catch_errors(convert_frame.convert_frame(backend, hooks=hooks), // backend,回调函数hooks,backend_ctx_ctor,dynamic=dynamic,compiler_config=backend.get_compiler_config()if hasattr(backend, "get_compiler_config")else None,rebuild_ctx=rebuild_ctx,)# ---------------------------------------------------------------------------------------------------------------------------------------
def _optimize_catch_errors(compile_fn,hooks: Hooks,backend_ctx_ctor=null_context,export=False,dynamic=None,compiler_config=None,rebuild_ctx=None,
):return OptimizeContext(convert_frame.catch_errors_wrapper(compile_fn, hooks), // 回调函数backend_ctx_ctor=backend_ctx_ctor,first_ctx=True,export=export,dynamic=dynamic,compiler_config=compiler_config,rebuild_ctx=rebuild_ctx,)
上述这些 ,都是pytorch代码中的标准流程。在npu上却有些不一样。
3.1 npu上的torch._dynamo.optimize
首先还是从代码torch.compile开始
def compile(model: Optional[Callable] = None, *, # Module/function to optimizefullgraph: builtins.bool = False, #If False (default), torch.compile attempts to discover compileable regions in the function that it will optimize. If True, then we require that the entire function be capturable into a single graph. If this is not possible (that is, if there are graph breaks), then this will raise an error.dynamic: Optional[builtins.bool] = None, # dynamic shapebackend: Union[str, Callable] = "inductor", # backend to be usedmode: Union[str, None] = None, # Can be either "default", "reduce-overhead", "max-autotune" or "max-autotune-no-cudagraphs"options: Optional[Dict[str, Union[str, builtins.int, builtins.bool]]] = None, # A dictionary of options to pass to the backend. Some notable ones to try out aredisable: builtins.bool = False) # Turn torch.compile() into a no-op for testing-> Callable:# 中间代码省略... return torch._dynamo.optimize(backend=backend, nopython=fullgraph, dynamic=dynamic, disable=disable)(model) compile中调用的是torch._dynamo.optimize函数。而npu上的torch._dynamo.optimize是被重新赋值的。
函数调用流程如下:

def patch_dynamo_optimize():src_optimize = optimizedef npu_optimize(*args, **kwargs):backend = Noneif 'backend' in kwargs.keys():backend = kwargs['backend']elif len(args) == 1:backend = args[0]backend_name = Noneif isinstance(backend, str):backend_name = backendelif isinstance(backend, _TorchCompileWrapper):backend_name = backend.compiler_nameif backend_name == 'npu':# Init torchair ahead of running model._get_global_npu_backend()return src_optimize(*args, **kwargs)torch._dynamo.optimize = npu_optimize
可以看到,torch._dynamo.optimize = npu_optimize已经被重新赋值了。依旧从代码的角度,看下是如何一步步执行下去的。
_get_global_npu_backend返回的是torchair.get_npu_backend()获取的对象,和关注点1加粗样式调用的接口相同,但是这里却是没有传入congfig参数,一切都是默认的。
def _get_global_npu_backend():global _global_npu_backendif _global_npu_backend is not None:return _global_npu_backendif 'torchair' not in sys.modules:raise AssertionError("Could not find module torchair. ""Please check if torchair is removed from sys.modules." + pta_error(ErrCode.NOT_FOUND))import torchair_global_npu_backend = torchair.get_npu_backend()return _global_npu_backend
接下来调用的函数是src_optimize,而src_optimize是通过_dynamo.py中的optimize赋值的。
src_optimize = optimize
看下完整的optimize函数
def optimize(backend="inductor",*,nopython=False,guard_export_fn=None,guard_fail_fn=None,disable=False,dynamic=None,
):"""The main entrypoint of TorchDynamo. Do graph capture and callbackend() to optimize extracted graphs.Args:backend: One of the two things:- Either, a function/callable taking a torch.fx.GraphModule andexample_inputs and returning a python callable that runs thegraph faster.One can also provide additional context for the backend, liketorch.jit.fuser("fuser2"), by setting the backend_ctx_ctor attribute.See AOTAutogradMemoryEfficientFusionWithContext for the usage.- Or, a string backend name in `torch._dynamo.list_backends()`nopython: If True, graph breaks will be errors and there willbe a single whole-program graph.disable: If True, turn this decorator into a no-opdynamic: If True, upfront compile as dynamic a kernel as possible. If False,disable all dynamic shapes support (always specialize). If None, automaticallydetect when sizes vary and generate dynamic kernels upon recompile.Example Usage::@torch._dynamo.optimize()def toy_example(a, b):..."""其中backend的注释
backend:可以是以下两种情况之一:
- 要么,它是一个函数或可调用对象,接收一个 torch.fx.GraphModule 和 example_inputs,并返回一个能够更快执行该计算图的 Python 可调用对象。
你也可以通过设置 backend_ctx_ctor 属性,为 backend 提供额外的上下文信息,例如:torch.jit.fuser(“fuser2”)。
使用方式请参见:AOTAutogradMemoryEfficientFusionWithContext。- 要么,它是一个字符串,表示后端名称,这个名称必须在 torch._dynamo.list_backends() 返回的列表中。
当前npu下,属于第一种情况的backend。补充完整调用栈:
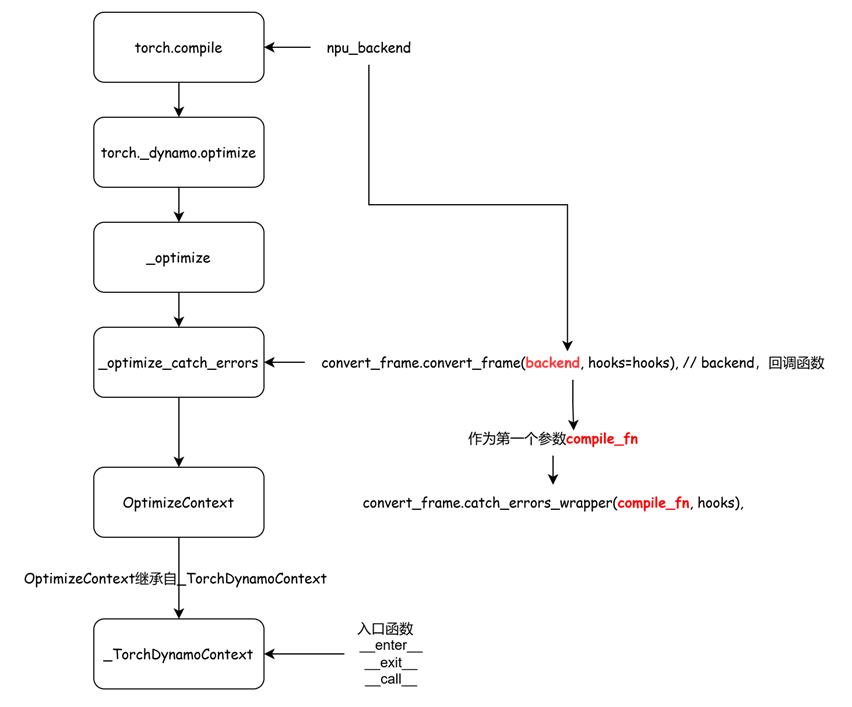
optimize最终使能到的对象是_TorchDynamoContext。
torch._dynamo.optimize的流程就走完了。再回到
return torch._dynamo.optimize(backend=backend, nopython=fullgraph, dynamic=dynamic, disable=disable)(model)
关注最后一个参数model,意思也就是给_TorchDynamoContext传入参数model,会触发调用_TorchDynamoContext的__call__方法。由于例子中的Model()是个fn, torch.nn.Module对象,因此走到下面的代码分支
... 省略
if isinstance(fn, torch.nn.Module):mod = fn new_mod = OptimizedModule(mod, self)# Save the function pointer to find the original callable while nesting# of decorators.new_mod._torchdynamo_orig_callable = mod.forward# when compiling torch.nn.Module,# provide public api OptimizedModule.get_compiler_config()assert not hasattr(new_mod, "get_compiler_config")new_mod.get_compiler_config = get_compiler_configreturn new_mod
... 省略
返回的是一个OptimizedModule实例对象。
new_mod = OptimizedModule(mod, self)
特别要注意OptimizedModule对象,实例创建的过程其实包含一段执行逻辑,先看流程图
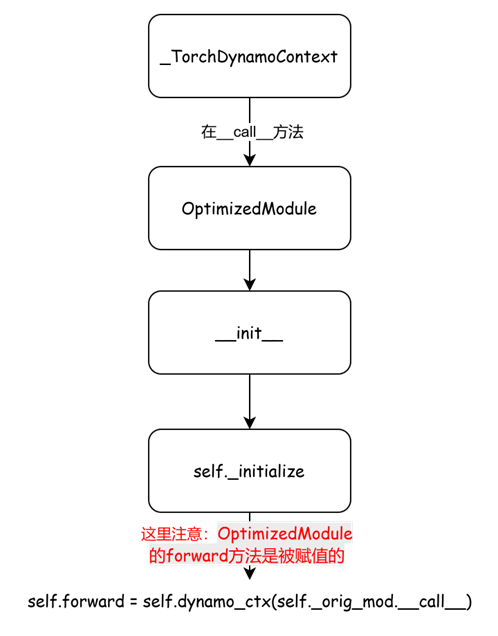
再给出代码:
class OptimizedModule(torch.nn.Module):"""Wraps the original nn.Module object and later patches itsforward method to optimized self.forward method."""_torchdynamo_orig_callable: Callable[..., Any]get_compiler_config: Callable[[], Any]def __init__(self, mod: torch.nn.Module, dynamo_ctx):super().__init__()# Installs the params/bufferself._orig_mod = modself.dynamo_ctx = dynamo_ctxself._initialize()def _initialize(self):# Do this stuff in constructor to lower overhead slightlyif isinstance(self._orig_mod.forward, types.MethodType) and trace_rules.check(self._orig_mod.forward):# This may be a torch.nn.* instance in trace_rules.py which# won't trigger a frame evaluation workaround to add an extra# frame we can captureself.forward = self.dynamo_ctx(external_utils.wrap_inline(self._orig_mod))else:# Invoke hooks outside of dynamo then pickup the inner frameself.forward = self.dynamo_ctx(self._orig_mod.__call__)if hasattr(self._orig_mod, "_initialize_hook"):self._forward = self.forwardself.forward = self._call_lazy_check
而self.forward = self.dynamo_ctx(self._orig_mod.__call__)这行代码会去执行_TorchDynamoContext原的__call__函数的,逻辑是如下。
OptimizedModule的构造函数种,mod就是传入的mode对象,而dynamo_ctx是_TorchDynamoContext。
self._orig_mod = mod
self.dynamo_ctx = dynamo_ctx
那么self.dynamo_ctx(self._orig_mod.__call__),意思也就是调用_TorchDynamoContext的
__call__函数,然后参数是mode的__call__对象。
也就是说,_TorchDynamoContext的__call__函数被执行了2遍。最终__call__函数返回的是_fn函数。
@functools.wraps(fn)
def _fn(*args, **kwargs):if is_fx_tracing():if config.error_on_nested_fx_trace:raise RuntimeError("Detected that you are using FX to symbolically trace ""a dynamo-optimized function. This is not supported at the moment.")else:return fn(*args, **kwargs)if is_jit_tracing():if config.error_on_nested_jit_trace:raise RuntimeError("Detected that you are using FX to torch.jit.trace ""a dynamo-optimized function. This is not supported at the moment.")else:return fn(*args, **kwargs)cleanups = [enter() for enter in self.enter_exit_hooks]prior = set_eval_frame(callback)try:return fn(*args, **kwargs)finally:set_eval_frame(prior)for cleanup in cleanups:cleanup()always_optimize_code_objects[fn.__code__] = True... 省略 ...return _fn
读到这里,也就是说torch.compile返回的就是_fn函数。
4 opt_model(x, y)
现在走到关注点3,到模型执行部分,调用的是_fn函数,
@functools.wraps(fn)
def _fn(*args, **kwargs):if is_fx_tracing():if config.error_on_nested_fx_trace:raise RuntimeError("Detected that you are using FX to symbolically trace ""a dynamo-optimized function. This is not supported at the moment.") else:return fn(*args, **kwargs)if is_jit_tracing():if config.error_on_nested_jit_trace:raise RuntimeError("Detected that you are using FX to torch.jit.trace ""a dynamo-optimized function. This is not supported at the moment.") else:return fn(*args, **kwargs)cleanups = [enter() for enter in self.enter_exit_hooks]prior = set_eval_frame(callback)try: return fn(*args, **kwargs)finally:set_eval_frame(prior)for cleanup in cleanups:cleanup()
函数种fn是 Model对象
<bound method Module._wrapped_call_impl of Model()>
接下来执行的时候,会触发回调函数的调用。具体是如何触发的呢?
首先是:prior = set_eval_frame(callback),这句代码的意思,就是给frame设置了callback函数,该callback函数是convert_frame.convert_frame(backend, hooks=hooks),具体参见:Ascend的aclgraph(三)TorchDynamo。
4.1 设置set_eval_frame的callback
set_eval_frame是个pybind函数,最终执行调用的是c++(pytorch/torch/csrc/dynamo
/eval_frame.c)的是set_eval_frame函数,
static PyObject* set_eval_frame(PyObject* new_callback,PyThreadState* tstate,PyObject* module) {// Change the eval frame callback and return the old one// - None: disables TorchDynamo// - False: run-only mode (reuse existing compiles)// - Python callable(): enables TorchDynamoPyObject* old_callback = eval_frame_callback_get();// owned by callerPy_INCREF(old_callback);if (old_callback != Py_None && new_callback == Py_None) {decrement_working_threads(tstate, module);} else if (old_callback == Py_None && new_callback != Py_None) {increment_working_threads(tstate, module);}Py_INCREF(new_callback);Py_DECREF(old_callback);// Set thread local callback. This will drive behavior of our shim, if/when it// is installed.eval_frame_callback_set(new_callback);return old_callback;
}
接着调用eval_frame_callback_set,
void eval_frame_callback_set(PyObject* obj) {PyThread_tss_set(&eval_frame_callback_key, obj);
}
PyThread_tss_set可以认为是eval_frame_callback_key是key,obj是value。eval_frame_callback_key是个静态全局变量。
4.2 执行fn(*args, **kwargs)
Ascend的aclgraph(三)TorchDynamo中有提到,通过 CPython 提供的_PyInterpreterState_SetEvalFrameFunc()函数把CPython中用于执行字节码的默认函数给替换为custom_eval_frame_shim()。 在执行用户想要编译的函数时便会进入_custom_eval_frame_shim().
注意:小编看看的的代码中是dynamo_custom_eval_frame_shim(因为版本原因,小编是最新的main分支)。整体逻辑如下:
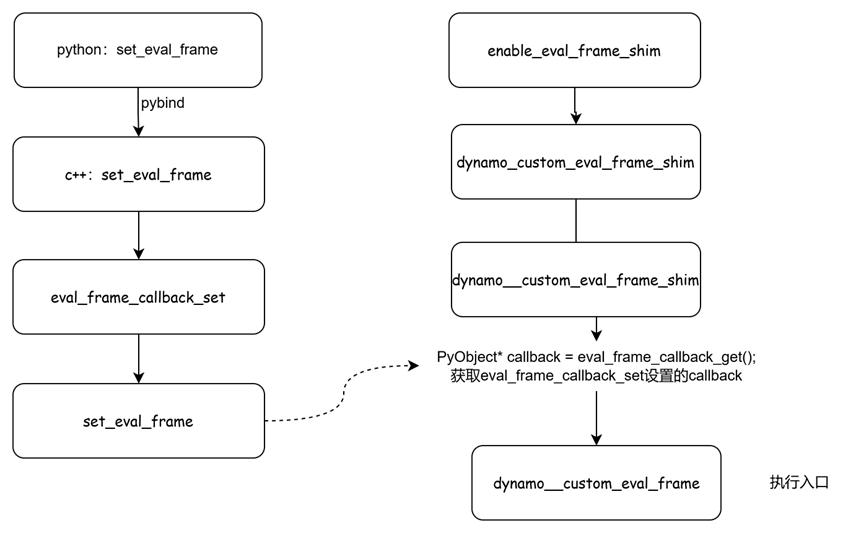
最终调用执行的函数就是dynamo__custom_eval_frame。该函数在https://github.com/pytorch/pytorch/blob/main/torch/csrc/dynamo/eval_frame_cpp.cpp中实现,如下:
/ frame and callback are borrowed references.
// Returns new reference.
PyObject* dynamo__custom_eval_frame(PyThreadState* tstate,THP_EVAL_API_FRAME_OBJECT* frame,int throw_flag,PyObject* callback_py) {
#if IS_PYTHON_3_11_PLUSDEBUG_TRACE("begin %s %s %i %i",get_frame_name(frame),PyUnicode_AsUTF8(F_CODE(frame)->co_filename),F_CODE(frame)->co_firstlineno,_PyInterpreterFrame_LASTI(frame));
#elseDEBUG_TRACE("begin %s %s %i %i %i",get_frame_name(frame),PyUnicode_AsUTF8(F_CODE(frame)->co_filename),frame->f_lineno,frame->f_lasti,frame->f_iblock);
#endifif (throw_flag) {// When unwinding generators, eval frame is called with throw_flag ==// true. Frame evaluation is supposed to continue unwinding by propagating// the exception. Dynamo doesn't really know how to do this, nor does it// really want to do this, because there's unlikely any code to capture// (you're going to immediately quit out of the frame, perhaps running// some unwinding logic along the way). So we just run the default// handler in this case.//// NB: A previous version of this patch returned NULL. This is wrong,// because returning NULL is *different* from unwinding an exception.// In particular, you will not execute things like context manager// __exit__ if you just return NULL.//// NB: It's /conceivable/ that you might want to actually still call the// Dynamo callback when throw_flag == TRUE, to give Dynamo a chance to// do any stack unwinding code. But this is not really useful because// (1) Dynamo doesn't actually know how to do stack unwinding, so it would// immediately skip the frame, and (2) even if it did, this would only// be profitable if there was tensor code in the unwinding code. Seems// unlikely.DEBUG_TRACE("throw %s", get_frame_name(frame));return dynamo_eval_frame_default(tstate, frame, throw_flag);}py::handle callback(callback_py);// callback to run on recursively invoked framespy::handle recursive_callback = callback; // borrowedPyCodeObject* cached_code = nullptr; // borrowedconst char* trace_annotation = "";PyObject* eval_result = nullptr; // strong reference// exit functionsauto eval_default = [&]() {eval_frame_callback_set(recursive_callback.ptr());eval_result = dynamo_eval_frame_default(tstate, frame, throw_flag);if (!callback.is(recursive_callback)) {// NB: Only set the callback if it's different than the recursive// callback! Setting the callback is dangerous in the case that `frame`// also sets the eval frame callback. This happens in some functions in// eval_frame.py. These functions should be skipped with DEFAULT recursive// action, so we won't accidentally overwrite the callback.eval_frame_callback_set(callback.ptr());}};// NOTE: In 3.12+, the frame evaluation function (callee) is responsible for// clearing/popping the frame, meaning that unless we default evaluate the// original frame, we are responsible for clearing it - via// clear_old_frame_if_python_312_plus.auto eval_custom = [&]() {eval_frame_callback_set(recursive_callback.ptr());DEBUG_NULL_CHECK(cached_code);eval_result = dynamo_eval_custom_code(tstate, frame, cached_code, trace_annotation, throw_flag);if (!callback.is(recursive_callback)) {eval_frame_callback_set(callback.ptr());}clear_old_frame_if_python_312_plus(tstate, frame);};auto fail = [&]() { clear_old_frame_if_python_312_plus(tstate, frame); };ExtraState* extra = get_extra_state(F_CODE(frame));if (callback.is(py::bool_(false)) && extra == nullptr) {DEBUG_TRACE("skip (run only with empty cache) %s", get_frame_name(frame));eval_default();return eval_result;}// create cacheif (extra == nullptr) {extra = init_and_set_extra_state(F_CODE(frame));}// Get recursive actionFrameExecStrategy strategy = extra_state_get_exec_strategy(extra);recursive_callback =_callback_from_action(recursive_callback, strategy.recursive_action);// Skip this frameif (strategy.cur_action == SKIP) {DEBUG_TRACE("skip %s", get_frame_name(frame));eval_default();return eval_result;}// default and run-only mode require guard evalstd::unique_ptr<FrameLocalsMapping> locals =std::make_unique<FrameLocalsMapping>(frame);PyObject* backend = get_backend(callback.ptr()); // borrowed// We don't run the current custom_eval_frame behavior for guards.// So we temporarily set the callback to Py_None to drive the correct behavior// in the shim.eval_frame_callback_set(Py_None);DEBUG_CHECK(PyDict_CheckExact(frame->f_globals));DEBUG_CHECK(PyDict_CheckExact(frame->f_builtins));_PytorchRecordFunctionState* rf =_pytorch_record_function_enter(cache_lookup_profiler_str);PyObject* maybe_cached_code = nullptr;lookup(extra,locals.get(),backend,&maybe_cached_code,&trace_annotation,is_skip_guard_eval_unsafe);_pytorch_record_function_exit(rf);// A callback of Py_False indicates "run only" mode, the cache is checked,// but we never compile.bool run_only =strategy.cur_action == RUN_ONLY || callback.is(py::bool_(false));if (run_only) {DEBUG_TRACE("In run only mode %s", get_frame_name(frame));}if (maybe_cached_code == nullptr) {// guard eval failed, keep propagatingfail();return eval_result;} else if (maybe_cached_code != Py_None) {cached_code = (PyCodeObject*)maybe_cached_code;// used cached versionDEBUG_TRACE("cache hit %s", get_frame_name(frame));eval_custom();return eval_result;}// cache missDEBUG_TRACE("cache miss %s", get_frame_name(frame));if (is_skip_guard_eval_unsafe) {PyErr_SetString(PyExc_RuntimeError,"Recompilation triggered with skip_guard_eval_unsafe stance. ""This usually means that you have not warmed up your model ""with enough inputs such that you can guarantee no more recompilations.");fail();return eval_result;}if (run_only) {eval_default();return eval_result;}// call callbackCacheEntry* cache_entry = extract_cache_entry(extra);FrameState* frame_state = extract_frame_state(extra);py::object callback_result;FrameExecStrategy new_strategy;bool apply_to_code = false;PyObject* guarded_code = nullptr;try {callback_result = dynamo_call_callback(callback, frame, locals.get(), cache_entry, frame_state);new_strategy =callback_result.attr("frame_exec_strategy").cast<FrameExecStrategy>();apply_to_code = callback_result.attr("apply_to_code").cast<bool>();guarded_code = callback_result.attr("guarded_code").ptr();} catch (py::error_already_set& e) {// internal exception, returning here will leak the exception into user// code this is useful for debugging -- but we dont want it to happen// outside of testing NB: we intentionally DO NOT re-enable custom// behavior to prevent cascading failure from internal exceptions. The// upshot is if Dynamo barfs, that's it for Dynamo, even if you catch the// exception inside the torch.compile block we won't try to Dynamo// anything else.fail();e.restore();return eval_result;}// recursive frame actionif (strategy.recursive_action == DEFAULT) {// old recursive action overrides new recursive actionrecursive_callback = _callback_from_action(recursive_callback, new_strategy.recursive_action);}// possibly apply frame strategy to future frames with same code objectif (apply_to_code) {if (new_strategy.cur_action != DEFAULT) {DEBUG_TRACE("create action: %d\n", new_strategy.cur_action);}if (new_strategy.recursive_action != DEFAULT) {DEBUG_TRACE("create recursive action: %d\n", new_strategy.recursive_action);}extra_state_set_exec_strategy(extra, new_strategy);}if (guarded_code != Py_None) {DEBUG_TRACE("create cache %s", get_frame_name(frame));// NB: We could use extract_cache_entry to get the cache_entry, but// extract_cache_entry returns a borrowed reference. Modifying a borrowed// reference seems wrong. Therefore, we directly access the// extra->cache_entry. extra wont be NULL here.CacheEntry* new_cache_entry =create_cache_entry(extra, guarded_code, backend);// Update the existing cache_entry on the extra object. This extra object// is sitting on the extra scratch space, we are just changing the// cache_entry ptr. As a result, extra now becomes the owner of CacheEntry// object. This will be cleaned up when set_extra_state is called.// Re-enable custom behaviorcached_code = CacheEntry_get_code(new_cache_entry),trace_annotation = CacheEntry_get_trace_annotation(new_cache_entry);eval_custom();} else {eval_default();}return eval_result;
}
整个函数很长,但基本逻辑与Ascend的aclgraph(三)TorchDynamo中讲的一样,这里引用过来:
在_custom_eval_frame函数中,会先通过lookup函数检查cache中是否有已编译代码,若存在则直接调用eval_custom_code函数执行,从而避免重复编译相同函数。若cache未命中,则通过call_callback调用回调函数进行编译,并通过set_extra()将编译结果保存在PyFrameObject中,最后调用eval_custom_code继续进行执行。而这里的回调函数也即前面在torch._dynamo.optimize传入的回调函数:convert_frame.convert_frame(backend, hooks=hooks)(包含编译入口compile_fn)。
打开日志可以看到具体的编译过程。
V0515 09:03:05.795000 281473434236992 torch/_dynamo/convert_frame.py:254] skipping because no torch.* dispatch_call /usr/local/python3.10.17/lib/python3.10/bdb.py 118
V0515 09:03:05.795000 281473434236992 torch/_dynamo/convert_frame.py:254] skipping because no torch.* break_anywhere /usr/local/python3.10.17/lib/python3.10/bdb.py 251
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] torchdynamo start compiling forward /home/torchair/test.py:19, stack (elided 5 frames):
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] File "/home/torchair/test.py", line 37, in <module>
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] print(opt_model(x, y))
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] File "/usr/local/python3.10.17/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] return self._call_impl(*args, **kwargs)
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] File "/usr/local/python3.10.17/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1541, in _call_impl
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] return forward_call(*args, **kwargs)
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] File "/usr/local/python3.10.17/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 451, in _fn
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] return fn(*args, **kwargs)
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] File "/usr/local/python3.10.17/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1532, in _wrapped_call_impl
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] return self._call_impl(*args, **kwargs)
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] File "/usr/local/python3.10.17/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1541, in _call_impl
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0] return forward_call(*args, **kwargs)
V0515 09:03:05.802000 281473434236992 torch/_dynamo/convert_frame.py:652] [0/0]
I0515 09:03:05.806000 281473434236992 torch/_dynamo/logging.py:55] [0/0] Step 1: torchdynamo start tracing forward /home/torchair/test.py:19
V0515 09:03:05.809000 281473434236992 torch/fx/experimental/symbolic_shapes.py:1980] [0/0] create_env
V0515 09:03:05.814000 281473434236992 torch/_dynamo/symbolic_convert.py:699] [0/0] [__trace_source] TRACE starts_line /home/torchair/test.py:19 in forward (Model.forward)
V0515 09:03:05.814000 281473434236992 torch/_dynamo/symbolic_convert.py:699] [0/0] [__trace_source] def forward(self, x, y):
V0515 09:03:07.619000 281473434236992 torch/_dynamo/symbolic_convert.py:699] [0/0] [__trace_source] TRACE starts_line /home/torchair/test.py:20 in forward (Model.forward)
V0515 09:03:07.619000 281473434236992 torch/_dynamo/symbolic_convert.py:699] [0/0] [__trace_source] return torch.add(x, y)
V0515 09:03:07.620000 281473434236992 torch/_dynamo/symbolic_convert.py:725] [0/0] TRACE LOAD_GLOBAL torch []
V0515 09:03:07.622000 281473434236992 torch/_dynamo/symbolic_convert.py:725] [0/0] TRACE LOAD_ATTR add [PythonModuleVariable(<module 'torch' from '/usr/local/python3.10.17/lib/python3.10/site-packages/torch/__init__.py'>)]
V0515 09:03:07.625000 281473434236992 torch/_dynamo/symbolic_convert.py:725] [0/0] TRACE LOAD_FAST x [TorchInGraphFunctionVariable(<built-in method add of type object at 0xffffa30bf048>)]
V0515 09:03:07.625000 281473434236992 torch/_dynamo/symbolic_convert.py:725] [0/0] TRACE LOAD_FAST y [TorchInGraphFunctionVariable(<built-in method add of type object at 0xffffa30bf048>), LazyVariableTracker()]
V0515 09:03:07.626000 281473434236992 torch/_dynamo/symbolic_convert.py:725] [0/0] TRACE CALL_FUNCTION 2 [TorchInGraphFunctionVariable(<built-in method add of type object at 0xffffa30bf048>), LazyVariableTracker(), LazyVariableTracker()]
V0515 09:03:07.627000 281473434236992 torch/_dynamo/output_graph.py:1959] [0/0] create_graph_input L_x_ L['x']
V0515 09:03:07.629000 281473434236992 torch/_dynamo/variables/builder.py:1873] [0/0] wrap_to_fake L['x'] (2, 2) StatefulSymbolicContext(dynamic_sizes=[<DimDynamic.STATIC: 2>, <DimDynamic.STATIC: 2>], constraint_sizes=[None, None], view_base_context=None, tensor_source=LocalSource(local_name='x', cell_or_freevar=False), shape_env_to_source_to_symbol_cache={}) <class 'torch.Tensor'>
V0515 09:03:07.635000 281473434236992 torch/_dynamo/output_graph.py:1959] [0/0] create_graph_input L_y_ L['y']
V0515 09:03:07.636000 281473434236992 torch/_dynamo/variables/builder.py:1873] [0/0] wrap_to_fake L['y'] (2, 2) StatefulSymbolicContext(dynamic_sizes=[<DimDynamic.STATIC: 2>, <DimDynamic.STATIC: 2>], constraint_sizes=[None, None], view_base_context=None, tensor_source=LocalSource(local_name='y', cell_or_freevar=False), shape_env_to_source_to_symbol_cache={}) <class 'torch.Tensor'>
V0515 09:03:07.645000 281473434236992 torch/_dynamo/symbolic_convert.py:725] [0/0] TRACE RETURN_VALUE None [TensorVariable()]
I0515 09:03:07.645000 281473434236992 torch/_dynamo/logging.py:55] [0/0] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
V0515 09:03:07.646000 281473434236992 torch/_dynamo/symbolic_convert.py:2267] [0/0] RETURN_VALUE triggered compile
V0515 09:03:07.646000 281473434236992 torch/_dynamo/output_graph.py:871] [0/0] COMPILING GRAPH due to GraphCompileReason(reason='return_value', user_stack=[<FrameSummary file /home/torchair/test.py, line 20 in forward>], graph_break=False)
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] TRACED GRAPH
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] ===== __compiled_fn_0 =====
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] /usr/local/python3.10.17/lib/python3.10/site-packages/torch/fx/_lazy_graph_module.py class GraphModule(torch.nn.Module):
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] def forward(self, L_x_ : torch.Tensor, L_y_ : torch.Tensor):
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] l_x_ = L_x_
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] l_y_ = L_y_
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code]
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] # File: /home/torchair/test.py:20 in forward, code: return torch.add(x, y)
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] add = torch.add(l_x_, l_y_); l_x_ = l_y_ = None
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code] return (add,)
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code]
V0515 09:03:07.649000 281473434236992 torch/_dynamo/output_graph.py:1157] [0/0] [__graph_code]
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] Tabulate module missing, please install tabulate to log the graph in tabular format, logging code instead:
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] TRACED GRAPH
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] ===== __compiled_fn_0 =====
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] /usr/local/python3.10.17/lib/python3.10/site-packages/torch/fx/_lazy_graph_module.py class GraphModule(torch.nn.Module):
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] def forward(self, L_x_ : torch.Tensor, L_y_ : torch.Tensor):
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] l_x_ = L_x_
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] l_y_ = L_y_
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph]
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] # File: /home/torchair/test.py:20 in forward, code: return torch.add(x, y)
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] add = torch.add(l_x_, l_y_); l_x_ = l_y_ = None
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph] return (add,)
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph]
V0515 09:03:07.653000 281473434236992 torch/_dynamo/output_graph.py:1163] [0/0] [__graph]
V0515 09:03:07.656000 281473434236992 torch/_dynamo/output_graph.py:1164] [0/0] [__graph_sizes] TRACED GRAPH TENSOR SIZES
V0515 09:03:07.656000 281473434236992 torch/_dynamo/output_graph.py:1164] [0/0] [__graph_sizes] ===== __compiled_fn_0 =====
V0515 09:03:07.656000 281473434236992 torch/_dynamo/output_graph.py:1164] [0/0] [__graph_sizes] l_x_: (2, 2)
V0515 09:03:07.656000 281473434236992 torch/_dynamo/output_graph.py:1164] [0/0] [__graph_sizes] l_y_: (2, 2)
V0515 09:03:07.656000 281473434236992 torch/_dynamo/output_graph.py:1164] [0/0] [__graph_sizes] add: (2, 2)
V0515 09:03:07.656000 281473434236992 torch/_dynamo/output_graph.py:1164] [0/0] [__graph_sizes]
I0515 09:03:07.658000 281473434236992 torch/_dynamo/logging.py:55] [0/0] Step 2: calling compiler function functools.partial(<function _npu_backend at 0xfffddf6fedd0>, compiler_config=<torchair.configs.compiler_config.CompilerConfig object at 0xffffa3937e50>, decompositions={<OpOverload(op='npu_define.allgather', overload='default')>: <function allgather_decomposition at 0xfffddf03f130>, <OpOverload(op='_c10d_functional.all_to_all_single', overload='default')>: <function decomp_c10d_functional_all_to_all_single at 0xfffddf731510>})
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs] TRACED GRAPH
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs] ===== Forward graph 0 =====
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs] /usr/local/python3.10.17/lib/python3.10/site-packages/torch/fx/_lazy_graph_module.py class <lambda>(torch.nn.Module):
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs] def forward(self, arg0_1: "f32[2, 2]", arg1_1: "f32[2, 2]"):
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs] # File: /home/torchair/test.py:20 in forward, code: return torch.add(x, y)
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs] add: "f32[2, 2]" = torch.ops.aten.add.Tensor(arg0_1, arg1_1); arg0_1 = arg1_1 = None
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs] return (add,)
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs]
I0515 09:03:07.717000 281473434236992 torch/_functorch/_aot_autograd/dispatch_and_compile_graph.py:109] [0/0] [__aot_graphs]
[INFO] TORCHAIR(9569,python):2025-05-15 09:03:07.720.050 [npu_fx_compiler.py:324]9569 compiler inputs
[INFO] TORCHAIR(9569,python):2025-05-15 09:03:07.720.361 [npu_fx_compiler.py:326]9569 input 0: FakeTensor(..., device='npu:0', size=(2, 2))
[INFO] TORCHAIR(9569,python):2025-05-15 09:03:07.720.982 [npu_fx_compiler.py:326]9569 input 1: FakeTensor(..., device='npu:0', size=(2, 2))
[INFO] TORCHAIR(9569,python):2025-05-15 09:03:07.721.521 [npu_fx_compiler.py:327]9569 graph: graph():%arg0_1 : [num_users=1] = placeholder[target=arg0_1]%arg1_1 : [num_users=1] = placeholder[target=arg1_1]%add : [num_users=1] = call_function[target=torch.ops.aten.add.Tensor](args = (%arg0_1, %arg1_1), kwargs = {})return (add,)
I0515 09:03:07.745000 281473434236992 torch/_dynamo/logging.py:55] [0/0] Step 2: done compiler function functools.partial(<function _npu_backend at 0xfffddf6fedd0>, compiler_config=<torchair.configs.compiler_config.CompilerConfig object at 0xffffa3937e50>, decompositions={<OpOverload(op='npu_define.allgather', overload='default')>: <function allgather_decomposition at 0xfffddf03f130>, <OpOverload(op='_c10d_functional.all_to_all_single', overload='default')>: <function decomp_c10d_functional_all_to_all_single at 0xfffddf731510>})
I0515 09:03:07.753000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2806] [0/0] produce_guards
V0515 09:03:07.754000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['x'].size()[0] 2 None
V0515 09:03:07.754000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['x'].size()[1] 2 None
V0515 09:03:07.754000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['x'].stride()[0] 2 None
V0515 09:03:07.755000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['x'].stride()[1] 1 None
V0515 09:03:07.755000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['x'].storage_offset() 0 None
V0515 09:03:07.756000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['y'].size()[0] 2 None
V0515 09:03:07.756000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['y'].size()[1] 2 None
V0515 09:03:07.756000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['y'].stride()[0] 2 None
V0515 09:03:07.757000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['y'].stride()[1] 1 None
V0515 09:03:07.757000 281473434236992 torch/fx/experimental/symbolic_shapes.py:2988] [0/0] track_symint L['y'].storage_offset() 0 None
V0515 09:03:07.759000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['x'].size()[0] == 2
V0515 09:03:07.759000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['x'].size()[1] == 2
V0515 09:03:07.760000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['x'].stride()[0] == 2
V0515 09:03:07.760000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['x'].stride()[1] == 1
V0515 09:03:07.761000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['x'].storage_offset() == 0
V0515 09:03:07.762000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['y'].size()[0] == 2
V0515 09:03:07.762000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['y'].size()[1] == 2
V0515 09:03:07.763000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['y'].stride()[0] == 2
V0515 09:03:07.763000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['y'].stride()[1] == 1
V0515 09:03:07.764000 281473434236992 torch/fx/experimental/symbolic_shapes.py:3138] [0/0] Skipping guard L['y'].storage_offset() == 0
V0515 09:03:07.764000 281473434236992 torch/_dynamo/guards.py:1076] [0/0] [__guards] GUARDS:
V0515 09:03:07.765000 281473434236992 torch/_dynamo/guards.py:1085] [0/0] [__guards] hasattr(L['x'], '_dynamo_dynamic_indices') == False # return torch.add(x, y) # ome/torchair/test.py:20 in forward
V0515 09:03:07.768000 281473434236992 torch/_dynamo/guards.py:1085] [0/0] [__guards] hasattr(L['y'], '_dynamo_dynamic_indices') == False # return torch.add(x, y) # ome/torchair/test.py:20 in forward
V0515 09:03:07.770000 281473434236992 torch/_dynamo/guards.py:1085] [0/0] [__guards] utils_device.CURRENT_DEVICE == None # _dynamo/output_graph.py:430 in init_ambient_guards
V0515 09:03:07.772000 281473434236992 torch/_dynamo/guards.py:1085] [0/0] [__guards] ___check_current_backend(281468843512288) # _dynamo/output_graph.py:436 in init_ambient_guards
V0515 09:03:07.773000 281473434236992 torch/_dynamo/guards.py:1085] [0/0] [__guards] check_tensor(L['x'], Tensor, DispatchKeySet(PrivateUse1, BackendSelect, ADInplaceOrView, AutogradPrivateUse1), torch.float32, device=0, requires_grad=False, size=[2, 2], stride=[2, 1]) # return torch.add(x, y) # ome/torchair/test.py:20 in forward
V0515 09:03:07.775000 281473434236992 torch/_dynamo/guards.py:1085] [0/0] [__guards] check_tensor(L['y'], Tensor, DispatchKeySet(PrivateUse1, BackendSelect, ADInplaceOrView, AutogradPrivateUse1), torch.float32, device=0, requires_grad=False, size=[2, 2], stride=[2, 1]) # return torch.add(x, y) # ome/torchair/test.py:20 in forward
[INFO] TORCHAIR(9569,python):2025-05-15 09:03:08.055.789 [fx2acl_converter.py:148]9569 Success to capture fx graph[id: 281468755723648] and start to run AclGraph[id: 281468838205920].
模型的最终输出:
tensor([[-1.4626, 1.1921],[ 1.8496, -0.7179]], device='npu:0')
5 小结
经过总体9篇的介绍,相信大家已经对AclConcreteGraph中的成图有个大概的了解。剩下就剩一个遗留问题,就是GeConcreteGraph,顺便看看GeConcreteGraph与AclConcreteGraph之间的差别。
相关文章:
AclConcreteGraph:e2e执行aclgraph)
Ascend的aclgraph(九)AclConcreteGraph:e2e执行aclgraph
1回顾 前面的几章内容探讨了aclgraph运行过程中的涉及到的关键模块和技术。本章节将前面涉及到的模块串联起来,对aclgraph形成一个端到端的了解。 先给出端到端运行的代码,如下: import torch import torch_npu import torchair import log…...

2025 OceanBase 开发者大会全议程指南
5 月 17 日,第三届 OceanBase 开发者大会将在广州举办。 我们邀请数据库领军者与AI实践先锋,与开发者一起探讨数据库与 AI 协同创新的技术趋势,面对面交流 OceanBase 在 TP、AP、KV 及 AI 能力上的最新进展,深度体验“打破技术栈…...

【深度学习之四】知识蒸馏综述提炼
知识蒸馏综述提炼 目录 知识蒸馏综述提炼 前言 参考文献 一、什么是知识蒸馏? 二、为什么要知识蒸馏? 三、一点点理论 四、知识蒸馏代码 总结 前言 知识蒸馏作为一种新兴的、通用的模型压缩和迁移学习架构,在最近几年展现出蓬勃的活力…...

Java大师成长计划之第23天:Spring生态与微服务架构之服务发现与注册中心
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4-turbo模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在微服务架构中,服务发现…...

list简单模拟实现
成员变量迭代器(重点)ListIterator运算符重载begin、end 插入、删除inserterase头插、尾插、头删、尾删 operator->const_iterator拷贝构造operator析构函数完整代码 由于前面已经模拟实现了vector,所以这里关于一些函数实现就不会讲的过于…...

undefined reference to `typeinfo for DeviceAllocator‘
出现“undefined reference to typeinfo”链接错误的原因及解决方法如下: class DeviceAllocator { public:explicit DeviceAllocator(DeviceType device_type){};virtual void* allocate(size_t n) 0;virtual void deallocate(void* p) 0;~DeviceAllocator() d…...
)
动态规划问题 -- 多状态模型(买股票的最佳时机II)
目录 动态规划分析问题五步曲题目概述利用状态机推导状态转移方程式代码编写 动态规划分析问题五步曲 不清楚动态规划分析问题是哪关键的五步的少年们可以移步到 链接: 动态规划算法基础 这篇文章非常详细的介绍了动态规划算法是如何分析和解决问题的 题目概述 链接: 买股票的最…...

【落羽的落羽 C++】进一步认识模板
文章目录 一、非类型模板参数二、模板的特化1. 函数模板特化2. 类模板特化 三、模板的编译分离 一、非类型模板参数 模板参数可以分为类型参数和非类型参数。我们之前使用的都是类型参数,即出现在模板参数列表中,跟在class或typename之类的参数类型名称…...

Java爬虫能处理京东商品数据吗?
Java爬虫完全可以处理京东商品数据。通过Java爬虫技术,可以高效地获取京东商品的详细信息,包括商品名称、价格、图片、描述等。这些信息对于市场分析、选品上架、库存管理和价格策略制定等方面具有重要价值。以下是一个完整的Java爬虫示例,展…...

#跟着若城学鸿蒙# web篇-初探
前言 先看下官方介绍,这里总结了比较重要的几点Web组件基础:加载与渲染网页全面解析Web组件是现代应用开发中不可或缺的重要元素,它允许开发者在原生应用中无缝集成Web内容。本文将全面介绍Web组件的基本功能,包括多种内容加载方…...

Top-p采样:解锁语言模型的创意之门
Top - p采样 是什么:核采样:排序,累计到0.7,随机选择 在自然语言生成和大规模语言模型推理中,Top - p采样(又叫核采样,Nucleus Sampling)是一种基于累积概率的采样策略。 Top - p介…...

周赛好题推荐
这周周赛很有质量的,上了一个很有意思的数学题目,推了半天..... 给定一个区间[l,r],求出区间内所有满足x mod 2^i !k的所有正整数(最后全部进行异或) 首先我们不妨先算出[l,r]区间所有数字的异或,然后在算…...

【RabbitMQ】实现RPC通信的完整指南
文章目录 RPC 通信创建相关队列客户端代码声明队列发送请求接收响应完整代码 服务端代码设置同时只能获取一个消息接收消息完整代码 运行程序启动客户端启动服务端 RPC 通信 RPC (Remote Procedure Call), 即远过程调用。它是一种通过网络从远程计算机上请求服务,而…...

CK3588下安装linuxdeployqt qt6 arm64
参考资料: Linux —— linuxdeployqt源码编译与打包(含出错解决) linux cp指令报错:cp: -r not specified; cp: omitting directory ‘xxx‘(需要加-r递归拷贝) CMake Error at /usr/lib/x86_64…...
)
滑动窗口之二(优先队列)
原本滑动窗口的板子用的是数组和双指针模拟,我嫌麻烦还不好懂找了双端队列。但其实还是不太好使,比如今天的这道题就处理起来很麻烦。但是如果用优先队列的话就可以一直保证整个窗口是有序的,只需判断一下是否在窗口内即可。但是!…...

小刚说C语言刷题—1088求两个数M和N的最大公约数
1.题目描述 求两个正整数 M 和 N 的最大公约数(M,N都在长整型范围内) .输入 输入一行,包括两个正整数。 输出 输出只有一行,包括1个正整数。 样例 输入 45 60 输出 15 2.参考代码(C语言版) #include <stdio.h> …...

pytorch训练可视化工具---TensorBoard
一、目的:为什么使用 TensorBoard 调控模型 使用 TensorBoard 可以帮我们: 实时查看 loss / acc 曲线 → 判断是否过拟合、欠拟合; 对比不同模型或超参数的效果; 可视化模型结构 → 帮助调试模型设计; 查看权重/梯…...

丝杆升降机限位失灵深度剖析:从故障机理到智能监测方案
在工业自动化与精密机械传动领域,丝杆升降机凭借高精度、大推力的特性,成为产线设备的核心执行部件。然而,限位系统的可靠性直接决定设备安全运行与生产连续性。本文将从技术原理、故障诊断到智能监测方案,系统性解析丝杆升降机限…...

系统集成项目管理工程师学习笔记
第九章 项目管理概论 1、项目基本要素 项目基础 项目是为创造独特的产品、服务或成果而进行的临时性工作。 项目具有临时性、独特性、渐进明细的特点。项目的“临时性”是指项目只有明确的起点和终点。“临时性”并一定意味着项目的持续时间短。 项目可宣告结束的情况&…...

RDD的自定义分区器-案例
对电商订单数据进行处理,订单数据包含用户 ID 和订单金额,不同地区的用户有不同的 ID 范围。我们会按照地区对订单数据进行分区,这样做能让相同地区的订单数据处于同一分区,便于后续按地区进行统计金额分析。 订单数据如下&#x…...
)
牛客网NC231954:斐波那契数列 (简单的数列问题)
牛客网NC231954:斐波那契数列 (简单的数列问题) 题目描述 本题要求我们计算斐波那契数列的第n项,斐波那契数列定义如下: f(1) 1f(2) 1f(n) f(n-1) f(n-2),当n ≥ 3 给定整数n,求f(n)的值。 算法思路 斐波那契…...

中国近代史3
辛亥革命 1.同盟会:建立 1905年,东京,第一个全国性的资产阶级革命政党;同盟会纲领“驱除鞑虏,恢复中华,建立民国,平均地权” “民族”“民生”“民权” 2.武昌起义 ①爆发:1911.10…...

晶振的核心参数
目录 1.简介 2.晶振核心参数详解 3.晶振的抖动(jitter) 4.抖动的三种测量方式 5.抖动的其他资料 1.简介 再看一些晶振的手册时,经常遇到一些类似或相近的参数,今天借此机会,做一个小姐。 2.晶振核心参数详解 1…...

北京孙河傲云源墅:限量典藏的主城墅居臻品
在限墅令的背景下,北京主城的墅居产品日益稀缺,而傲云源墅作为孙河墅区的杰出之作,凭借其独特的价值,成为了众多高端置业者的理想选择。 傲云源墅所处的孙河地区,是北京公认的高价值板块。其地位在 2025 年孙河 2902 …...

驱动-Linux定时-timer_list
了解内核定时相关基础知识 文章目录 简要介绍timer_list 特点API 函数实验测试程序 - timer_mod.c编译文件-Makefile实验验证 注意事项总结 简要介绍 硬件为内核提供了一个系统定时器来计算流逝的时间(即基于未来时间点的计时方式, 以当前时刻为计时开始…...

从理论到实战:模糊逻辑算法的深度解析与应用实践
从理论到实战:模糊逻辑算法的深度解析与应用实践 一、模糊逻辑的核心概念与数学基础 模糊逻辑(Fuzzy Logic)是一种处理不确定性的数学工具,其核心思想是将传统布尔逻辑的“非黑即白”扩展为连续的隶属度函数。例如,在…...

涨薪技术|0到1学会性能测试第65课-SQL捕获阻塞事件
前面的推文我们掌握了JVM调优技术。今天给大家分享MS SQL数据库监控与调优技术。后续文章都会系统分享干货,带大家从0到1学会性能测试。 01SQL捕获阻塞事件 在SQL Server 2005之前的版本,分析哪些进程产生阻塞以及哪些进程被阻塞,都需要使用脚…...

SQL实战:06交叉日期打折问题求解
文章目录 概述题目:交叉打折问题求解题解第一步:使用滑动窗口统计当前活动前的最大结束日期步骤二:拆分出交叉部分步骤三:计算每次活动的持续天数步骤四:分组统计最终结果完整SQL 概述 最近刷题时遇到一些比较有意思的…...
)
Linux云计算训练营笔记day09(MySQL数据库)
Linux云计算训练营笔记day09(MySQL数据库) 目录 Linux云计算训练营笔记day09(MySQL数据库)外键约束数据的导入和导出数据的导出数据的导入 DQL 数据查询语言查指定字段查所有字段where 过滤条件and 和 orin 和 not inbetween...an…...

docker 学习记录
docker pull nginx docker 将本地nginx快照保存到当前文件夹下 docker save -o nginx.tar nginx:latestdocker 将本地nginx 加载 docker load -i nginx.tar docker运行nginx在80端口 docker run --name dnginx -p 80:80 -d nginxredis启动 docker run --name mr -p 6379:6379 -…...

Kind方式部署k8s单节点集群并创建nginx服务对外访问
资源要求 请准备好doker环境,尽量用比较新的版本。我的docker环境如下 docker 环境: Docker version 20.10.21, build 20.10.21-0ubuntu1~18.04.3 安装kind kind表现上就是一个二进制程序,下载对应版本并增加执行权限即可: cu…...

Da14531蓝牙特征值1读没有回调解决
一. 我们调试中发现user_peripheral.c中的回调,一直都没有回调。(大家可以通过打印去排查) void user_catch_rest_hndl(ke_msg_id_t const msgid, void const *param, ke_task_id_t const dest_id, ke_task_id_t const src_id) { //此处省…...
投稿咨询)
journal of Electronic Imaging(JEI)投稿咨询
研究生投的第二篇论文-CV方向,由于太菜了,到处被拒,最后选择了Journal of Electronic Imaging(JEI) 审稿了三个月,最近突然变了状态,之前催稿说才一个审稿人,这样子是不是要被拒了,有没有知道的…...

upload-labs靶场通关详解:第6-9关
目录 第六关:大小写绕过 一、分析源代码 二、解题思路 三、解题步骤 第七关:空格绕过 一、分析源代码 二、解题思路 三、解题步骤 第八关:点号绕过 一、分析源代码 二、解题思路 三、解题步骤 第九关:::$DATA字符串绕…...
)
算法图表总结:查找、排序与递归(含 Mermaid 图示)
算法图表总结:查找、排序与递归(含 Mermaid 图示) 分类标签:算法、数据结构、Mermaid、技术图表 关键词: 算法可视化、Mermaid 图表、数据结构、二分查找、快速排序、递归树 摘要: 本文通过 Mermaid 图表…...

在文件检索方面doris和elasticsearch的区别
apache Doris 与 Elasticsearch 在文件检索领域的差异源于技术架构与定位目标的本质区别,以下从核心维度对比分析二者的技术特性: 一、 架构设计与定位差异 维度Apache DorisElasticsearch核心架构分布式 MPP 列式分析引擎,面向 OLAP 优化分布式倒排索…...

linux系统服务
Linux 系统服务(System Services) 是在后台持续运行的进程(守护进程,即 daemon),用于提供核心功能或支持其他应用程序(如网络管理、日志记录、定时任务等)。它们通常在系统启动时自动…...

大语言模型三大演进方向:记忆增强、工具集成与多模态突破
目录 一、方向演进:从通用模型到记忆增强系统 1.1 技术瓶颈分析 1.2 记忆增强技术路径 1.3 企业级应用架构 二、工具调用:从语言理解到行动执行 2.1 工具调用协议演进 2.2 工具编排范式比较 三、多模态突破:跨模态统一建模 3.1 多模态架构演进 3.2 医学多模态应用…...
)
嵌入式学习笔记DAY21(双向链表、Makefile)
一、双向链表 1.概念 双向链表(Doubly Linked List) 是一种链式数据结构,每个节点包含 两个指针(前驱指针 prev 和后继指针 next),分别指向 前一个节点 和 后一个节点,形成双向连接。 头节点&…...

Vue 学习随笔系列二十三 -- el-date-picker 组件
el-date-picker 组件 文章目录 el-date-picker 组件el-date-picker 只有某些日期可选 el-date-picker 只有某些日期可选 <template><div><el-form ref"form" size"mini":model"form" :rules"rules"label-width"8…...
)
IEEE出版|连续多年稳定检索|第三届信号处理与智能计算国际学术会议(SPIC2025)
【重要信息】 会议官网: www.ic-spic.com 会议日期:2025年11月28-30日 会议地点:中国 广州 截稿日期:2025年11月10日 接受或拒绝通知日期:提交后7个工作日 【征稿主题】 人工智能和机器学习 计算机系统和架构 …...

用Python代码绘制动态3D爱心效果
引言 介绍Python在创意编程中的应用,特别是如何通过简单的代码实现视觉上的美感。引出本文将分享的爱心代码,并简要说明其实现原理。 爱心代码的基本实现 展示一个简单的Python代码示例,使用字符画的方式在控制台中绘制一个爱心图案。 pr…...

牛客网刷题:NC208813求逆序数
牛客网刷题:NC208813求逆序数 问题描述 在排序和数据结构分析中,逆序数是一个重要的概念。对于一个数列来说,如果一对数的前后位置与大小顺序相反(即前面的数大于后面的数),那么它们就称为一个逆序对。一个…...

Day 21 训练
Day 21 训练 常见的降维算法数据预处理无监督降维PCA(主成分分析)主成分分析(PCA)作用和优势应用场景t-SNE(t-分布随机邻域嵌入)t-SNE(t-分布随机邻域嵌入)为什么 t-SNE 特别适用于高…...

1267, “Illegal mix of collations (latin1_swedish_ci,IMPLICIT
python 执行数据迁移报错 mysql : 1267, "Illegal mix of collations (latin1_swedish_ci,IMPLICIT 解决方法: 替换TABLE 后面的表名为你自己的表名,mysql 黑窗口执行。 以下是我的表名,仅作参考 ALTER TABLE book CONVERT TO CHARACTE…...
、异步等待和直接join)
【C#】Thread.Join()、异步等待和直接join
JogThread.Join() 是 .NET 中 System.Threading.Thread 类的一个方法,用来让当前调用线程暂停执行,直到目标线程(这里是 JogThread)终止为止。以下是它的核心语义和你在 UI 代码里需要注意的几个相关知识点。 1. Thread.Join() 的…...

Malformed input or input contains unmappable characters解决
JDK 17 文件上传编码异常解决方案技术文档 1. 问题背景 在 JDK 17 环境下,文件上传过程中可能抛出 Malformed input or input contains unmappable characters 错误。此问题通常由以下原因触发: 文件路径/名称包含非 ASCII 字符(如中文、日…...

PYTHON训练营DAY26
一、函数 (一)不带参数的函数 # 定义一个简单的问候函数 def greet():"""打印一句问候语。"""message "大家好!欢迎学习Python函数定义!"print(message)greet()(二&#x…...

奇变偶不变,符号看象限
三角函数诱导公式口诀详解:奇变偶不变,符号看象限 口诀解析 1. 口诀含义 奇变偶不变: 奇/偶:指角度加减的是π/2(90)的奇数倍还是偶数倍 奇数倍(如π/2, 3π/2)→ 函数名改变&…...
)
基于SpringBoot的家政服务系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...