第28周——InceptionV1实现猴痘识别
前言
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
一、前期准备
1.检查GPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasetsimport os,PIL,pathlibdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")device2.查看数据
import os,PIL,random,pathlibdata_dir = 'data/45-data/'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[2] for path in data_paths]
classeNames二、构建模型
1.划分数据集
total_datadir = 'data/45-data'train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_datatrain_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_datasettrain_size,test_sizebatch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)breakShape of X [N, C, H, W]: torch.Size([32, 3, 224, 224]) Shape of y: torch.Size([32]) torch.int64
2.创建模型
import torch
import torch.nn as nn
import torch.nn.functional as Fclass inception_block(nn.Module):def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):super().__init__()# 1x1 conv branchself.branch1 = nn.Sequential(nn.Conv2d(in_channels, ch1x1, kernel_size=1),nn.BatchNorm2d(ch1x1),nn.ReLU(inplace=True))# 1x1 -> 3x3 conv branchself.branch2 = nn.Sequential(nn.Conv2d(in_channels, ch3x3red, kernel_size=1),nn.BatchNorm2d(ch3x3red),nn.ReLU(inplace=True),nn.Conv2d(ch3x3red, ch3x3, kernel_size=3, padding=1),nn.BatchNorm2d(ch3x3),nn.ReLU(inplace=True))# 1x1 -> 5x5 conv branchself.branch3 = nn.Sequential(nn.Conv2d(in_channels, ch5x5red, kernel_size=1),nn.BatchNorm2d(ch5x5red),nn.ReLU(inplace=True),nn.Conv2d(ch5x5red, ch5x5, kernel_size=5, padding=2),nn.BatchNorm2d(ch5x5),nn.ReLU(inplace=True))# 3x3 pool -> 1x1 conv branchself.branch4 = nn.Sequential(nn.MaxPool2d(kernel_size=3, stride=1, padding=1),nn.Conv2d(in_channels, pool_proj, kernel_size=1),nn.BatchNorm2d(pool_proj),nn.ReLU(inplace=True))def forward(self, x):return torch.cat([self.branch1(x),self.branch2(x),self.branch3(x),self.branch4(x)], dim=1) # 沿通道维度拼接class InceptionV1(nn.Module):def __init__(self, num_classes=1000):super().__init__()# 初始卷积层self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)self.maxpool1 = nn.MaxPool2d(3, stride=2, padding=1)self.conv2 = nn.Conv2d(64, 64, kernel_size=1)self.conv3 = nn.Conv2d(64, 192, kernel_size=3, padding=1)self.maxpool2 = nn.MaxPool2d(3, stride=2, padding=1)# Inception 模块self.inception3a = inception_block(192, 64, 96, 128, 16, 32, 32) # 输出通道: 64+128+32+32=256self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64) # 输出: 128+192+96+64=480self.maxpool3 = nn.MaxPool2d(3, stride=2, padding=1)self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64) # 192+208+48+64=512self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64) # 160+224+64+64=512self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64) # 128+256+64+64=512self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64) # 112+288+64+64=528self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128) # 256+320+128+128=832self.maxpool4 = nn.MaxPool2d(3, stride=2, padding=1)self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128) # 256+320+128+128=832self.inception5b = nn.Sequential(inception_block(832, 384, 192, 384, 48, 128, 128), # 384+384+128+128=1024nn.AdaptiveAvgPool2d((1, 1)), # 自适应池化到1x1nn.Dropout(0.4))# 分类器self.classifier = nn.Linear(1024, num_classes) # 输入特征数必须匹配池化后的通道数def forward(self, x):# 输入形状: [32, 3, 224, 224]x = F.relu(self.conv1(x)) # -> [32, 64, 112, 112]x = self.maxpool1(x) # -> [32, 64, 56, 56]x = F.relu(self.conv2(x)) # -> [32, 64, 56, 56]x = F.relu(self.conv3(x)) # -> [32, 192, 56, 56]x = self.maxpool2(x) # -> [32, 192, 28, 28]x = self.inception3a(x) # -> [32, 256, 28, 28]x = self.inception3b(x) # -> [32, 480, 28, 28]x = self.maxpool3(x) # -> [32, 480, 14, 14]x = self.inception4a(x) # -> [32, 512, 14, 14]x = self.inception4b(x) # -> [32, 512, 14, 14]x = self.inception4c(x) # -> [32, 512, 14, 14]x = self.inception4d(x) # -> [32, 528, 14, 14]x = self.inception4e(x) # -> [32, 832, 14, 14]x = self.maxpool4(x) # -> [32, 832, 7, 7]x = self.inception5a(x) # -> [32, 832, 7, 7]x = self.inception5b(x) # -> [32, 1024, 1, 1]x = torch.flatten(x, 1) # -> [32, 1024]x = self.classifier(x) # -> [32, num_classes]return x# 测试代码
if __name__ == "__main__":model = InceptionV1(num_classes=1000)dummy_input = torch.randn(32, 3, 224, 224) # 匹配输入形状[N, C, H, W]=[32,3,224,224]output = model(dummy_input)print("Output shape:", output.shape) # 应输出 torch.Size([32, 1000])
from torchsummary import summary
model=InceptionV1().to(device)
# 将模型移动到GPU(如果可用)summary(model, (3, 224, 224))
print(model)Output shape: torch.Size([32, 1000]) ----------------------------------------------------------------Layer (type) Output Shape Param # ================================================================Conv2d-1 [-1, 64, 112, 112] 9,472MaxPool2d-2 [-1, 64, 56, 56] 0Conv2d-3 [-1, 64, 56, 56] 4,160Conv2d-4 [-1, 192, 56, 56] 110,784MaxPool2d-5 [-1, 192, 28, 28] 0Conv2d-6 [-1, 64, 28, 28] 12,352BatchNorm2d-7 [-1, 64, 28, 28] 128ReLU-8 [-1, 64, 28, 28] 0Conv2d-9 [-1, 96, 28, 28] 18,528BatchNorm2d-10 [-1, 96, 28, 28] 192ReLU-11 [-1, 96, 28, 28] 0Conv2d-12 [-1, 128, 28, 28] 110,720BatchNorm2d-13 [-1, 128, 28, 28] 256ReLU-14 [-1, 128, 28, 28] 0Conv2d-15 [-1, 16, 28, 28] 3,088BatchNorm2d-16 [-1, 16, 28, 28] 32ReLU-17 [-1, 16, 28, 28] 0Conv2d-18 [-1, 32, 28, 28] 12,832BatchNorm2d-19 [-1, 32, 28, 28] 64ReLU-20 [-1, 32, 28, 28] 0MaxPool2d-21 [-1, 192, 28, 28] 0Conv2d-22 [-1, 32, 28, 28] 6,176BatchNorm2d-23 [-1, 32, 28, 28] 64ReLU-24 [-1, 32, 28, 28] 0inception_block-25 [-1, 256, 28, 28] 0Conv2d-26 [-1, 128, 28, 28] 32,896BatchNorm2d-27 [-1, 128, 28, 28] 256ReLU-28 [-1, 128, 28, 28] 0Conv2d-29 [-1, 128, 28, 28] 32,896BatchNorm2d-30 [-1, 128, 28, 28] 256ReLU-31 [-1, 128, 28, 28] 0Conv2d-32 [-1, 192, 28, 28] 221,376BatchNorm2d-33 [-1, 192, 28, 28] 384ReLU-34 [-1, 192, 28, 28] 0Conv2d-35 [-1, 32, 28, 28] 8,224BatchNorm2d-36 [-1, 32, 28, 28] 64ReLU-37 [-1, 32, 28, 28] 0Conv2d-38 [-1, 96, 28, 28] 76,896BatchNorm2d-39 [-1, 96, 28, 28] 192ReLU-40 [-1, 96, 28, 28] 0MaxPool2d-41 [-1, 256, 28, 28] 0Conv2d-42 [-1, 64, 28, 28] 16,448BatchNorm2d-43 [-1, 64, 28, 28] 128ReLU-44 [-1, 64, 28, 28] 0inception_block-45 [-1, 480, 28, 28] 0MaxPool2d-46 [-1, 480, 14, 14] 0Conv2d-47 [-1, 192, 14, 14] 92,352BatchNorm2d-48 [-1, 192, 14, 14] 384ReLU-49 [-1, 192, 14, 14] 0Conv2d-50 [-1, 96, 14, 14] 46,176BatchNorm2d-51 [-1, 96, 14, 14] 192ReLU-52 [-1, 96, 14, 14] 0Conv2d-53 [-1, 208, 14, 14] 179,920BatchNorm2d-54 [-1, 208, 14, 14] 416ReLU-55 [-1, 208, 14, 14] 0Conv2d-56 [-1, 16, 14, 14] 7,696BatchNorm2d-57 [-1, 16, 14, 14] 32ReLU-58 [-1, 16, 14, 14] 0Conv2d-59 [-1, 48, 14, 14] 19,248BatchNorm2d-60 [-1, 48, 14, 14] 96ReLU-61 [-1, 48, 14, 14] 0MaxPool2d-62 [-1, 480, 14, 14] 0Conv2d-63 [-1, 64, 14, 14] 30,784BatchNorm2d-64 [-1, 64, 14, 14] 128ReLU-65 [-1, 64, 14, 14] 0inception_block-66 [-1, 512, 14, 14] 0Conv2d-67 [-1, 160, 14, 14] 82,080BatchNorm2d-68 [-1, 160, 14, 14] 320ReLU-69 [-1, 160, 14, 14] 0Conv2d-70 [-1, 112, 14, 14] 57,456BatchNorm2d-71 [-1, 112, 14, 14] 224ReLU-72 [-1, 112, 14, 14] 0Conv2d-73 [-1, 224, 14, 14] 226,016BatchNorm2d-74 [-1, 224, 14, 14] 448ReLU-75 [-1, 224, 14, 14] 0Conv2d-76 [-1, 24, 14, 14] 12,312BatchNorm2d-77 [-1, 24, 14, 14] 48ReLU-78 [-1, 24, 14, 14] 0Conv2d-79 [-1, 64, 14, 14] 38,464BatchNorm2d-80 [-1, 64, 14, 14] 128ReLU-81 [-1, 64, 14, 14] 0MaxPool2d-82 [-1, 512, 14, 14] 0Conv2d-83 [-1, 64, 14, 14] 32,832BatchNorm2d-84 [-1, 64, 14, 14] 128ReLU-85 [-1, 64, 14, 14] 0inception_block-86 [-1, 512, 14, 14] 0Conv2d-87 [-1, 128, 14, 14] 65,664BatchNorm2d-88 [-1, 128, 14, 14] 256ReLU-89 [-1, 128, 14, 14] 0Conv2d-90 [-1, 128, 14, 14] 65,664BatchNorm2d-91 [-1, 128, 14, 14] 256ReLU-92 [-1, 128, 14, 14] 0Conv2d-93 [-1, 256, 14, 14] 295,168BatchNorm2d-94 [-1, 256, 14, 14] 512ReLU-95 [-1, 256, 14, 14] 0Conv2d-96 [-1, 24, 14, 14] 12,312BatchNorm2d-97 [-1, 24, 14, 14] 48ReLU-98 [-1, 24, 14, 14] 0Conv2d-99 [-1, 64, 14, 14] 38,464BatchNorm2d-100 [-1, 64, 14, 14] 128ReLU-101 [-1, 64, 14, 14] 0MaxPool2d-102 [-1, 512, 14, 14] 0Conv2d-103 [-1, 64, 14, 14] 32,832BatchNorm2d-104 [-1, 64, 14, 14] 128ReLU-105 [-1, 64, 14, 14] 0inception_block-106 [-1, 512, 14, 14] 0Conv2d-107 [-1, 112, 14, 14] 57,456BatchNorm2d-108 [-1, 112, 14, 14] 224ReLU-109 [-1, 112, 14, 14] 0Conv2d-110 [-1, 144, 14, 14] 73,872BatchNorm2d-111 [-1, 144, 14, 14] 288ReLU-112 [-1, 144, 14, 14] 0Conv2d-113 [-1, 288, 14, 14] 373,536BatchNorm2d-114 [-1, 288, 14, 14] 576ReLU-115 [-1, 288, 14, 14] 0Conv2d-116 [-1, 32, 14, 14] 16,416BatchNorm2d-117 [-1, 32, 14, 14] 64ReLU-118 [-1, 32, 14, 14] 0Conv2d-119 [-1, 64, 14, 14] 51,264BatchNorm2d-120 [-1, 64, 14, 14] 128ReLU-121 [-1, 64, 14, 14] 0MaxPool2d-122 [-1, 512, 14, 14] 0Conv2d-123 [-1, 64, 14, 14] 32,832BatchNorm2d-124 [-1, 64, 14, 14] 128ReLU-125 [-1, 64, 14, 14] 0inception_block-126 [-1, 528, 14, 14] 0Conv2d-127 [-1, 256, 14, 14] 135,424BatchNorm2d-128 [-1, 256, 14, 14] 512ReLU-129 [-1, 256, 14, 14] 0Conv2d-130 [-1, 160, 14, 14] 84,640BatchNorm2d-131 [-1, 160, 14, 14] 320ReLU-132 [-1, 160, 14, 14] 0Conv2d-133 [-1, 320, 14, 14] 461,120BatchNorm2d-134 [-1, 320, 14, 14] 640ReLU-135 [-1, 320, 14, 14] 0Conv2d-136 [-1, 32, 14, 14] 16,928BatchNorm2d-137 [-1, 32, 14, 14] 64ReLU-138 [-1, 32, 14, 14] 0Conv2d-139 [-1, 128, 14, 14] 102,528BatchNorm2d-140 [-1, 128, 14, 14] 256ReLU-141 [-1, 128, 14, 14] 0MaxPool2d-142 [-1, 528, 14, 14] 0Conv2d-143 [-1, 128, 14, 14] 67,712BatchNorm2d-144 [-1, 128, 14, 14] 256ReLU-145 [-1, 128, 14, 14] 0inception_block-146 [-1, 832, 14, 14] 0MaxPool2d-147 [-1, 832, 7, 7] 0Conv2d-148 [-1, 256, 7, 7] 213,248BatchNorm2d-149 [-1, 256, 7, 7] 512ReLU-150 [-1, 256, 7, 7] 0Conv2d-151 [-1, 160, 7, 7] 133,280BatchNorm2d-152 [-1, 160, 7, 7] 320ReLU-153 [-1, 160, 7, 7] 0Conv2d-154 [-1, 320, 7, 7] 461,120BatchNorm2d-155 [-1, 320, 7, 7] 640ReLU-156 [-1, 320, 7, 7] 0Conv2d-157 [-1, 32, 7, 7] 26,656BatchNorm2d-158 [-1, 32, 7, 7] 64ReLU-159 [-1, 32, 7, 7] 0Conv2d-160 [-1, 128, 7, 7] 102,528BatchNorm2d-161 [-1, 128, 7, 7] 256ReLU-162 [-1, 128, 7, 7] 0MaxPool2d-163 [-1, 832, 7, 7] 0Conv2d-164 [-1, 128, 7, 7] 106,624BatchNorm2d-165 [-1, 128, 7, 7] 256ReLU-166 [-1, 128, 7, 7] 0inception_block-167 [-1, 832, 7, 7] 0Conv2d-168 [-1, 384, 7, 7] 319,872BatchNorm2d-169 [-1, 384, 7, 7] 768ReLU-170 [-1, 384, 7, 7] 0Conv2d-171 [-1, 192, 7, 7] 159,936BatchNorm2d-172 [-1, 192, 7, 7] 384ReLU-173 [-1, 192, 7, 7] 0Conv2d-174 [-1, 384, 7, 7] 663,936BatchNorm2d-175 [-1, 384, 7, 7] 768ReLU-176 [-1, 384, 7, 7] 0Conv2d-177 [-1, 48, 7, 7] 39,984BatchNorm2d-178 [-1, 48, 7, 7] 96ReLU-179 [-1, 48, 7, 7] 0Conv2d-180 [-1, 128, 7, 7] 153,728BatchNorm2d-181 [-1, 128, 7, 7] 256ReLU-182 [-1, 128, 7, 7] 0MaxPool2d-183 [-1, 832, 7, 7] 0Conv2d-184 [-1, 128, 7, 7] 106,624BatchNorm2d-185 [-1, 128, 7, 7] 256ReLU-186 [-1, 128, 7, 7] 0inception_block-187 [-1, 1024, 7, 7] 0 AdaptiveAvgPool2d-188 [-1, 1024, 1, 1] 0Dropout-189 [-1, 1024, 1, 1] 0Linear-190 [-1, 1000] 1,025,000 ================================================================ Total params: 7,012,472 Trainable params: 7,012,472 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.57 Forward/backward pass size (MB): 69.61 Params size (MB): 26.75 Estimated Total Size (MB): 96.93 ---------------------------------------------------------------- InceptionV1((conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))(maxpool1): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(conv2): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))(conv3): Conv2d(64, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool2): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception3a): inception_block((branch1): Sequential((0): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(96, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(192, 16, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception3b): inception_block((branch1): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(256, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 96, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(maxpool3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception4a): inception_block((branch1): Sequential((0): Conv2d(480, 192, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(480, 96, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(96, 208, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(208, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(480, 16, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(16, 48, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(480, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4b): inception_block((branch1): Sequential((0): Conv2d(512, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(112, 224, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4c): inception_block((branch1): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(512, 24, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(24, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4d): inception_block((branch1): Sequential((0): Conv2d(512, 112, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(112, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(512, 144, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(144, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(144, 288, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(512, 64, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception4e): inception_block((branch1): Sequential((0): Conv2d(528, 256, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(528, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(528, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(528, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(maxpool4): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)(inception5a): inception_block((branch1): Sequential((0): Conv2d(832, 256, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(832, 160, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(160, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(832, 32, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(32, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(inception5b): Sequential((0): inception_block((branch1): Sequential((0): Conv2d(832, 384, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True))(branch2): Sequential((0): Conv2d(832, 192, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(4): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch3): Sequential((0): Conv2d(832, 48, kernel_size=(1, 1), stride=(1, 1))(1): BatchNorm2d(48, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(48, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True))(branch4): Sequential((0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)(1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1))(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)))(1): AdaptiveAvgPool2d(output_size=(1, 1))(2): Dropout(p=0.4, inplace=False))(classifier): Linear(in_features=1024, out_features=1000, bias=True) )
3.编译及训练模型
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_lossdef test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_lossepochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')三、结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率from datetime import datetime
current_time = datetime.now() # 获取当前时间epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()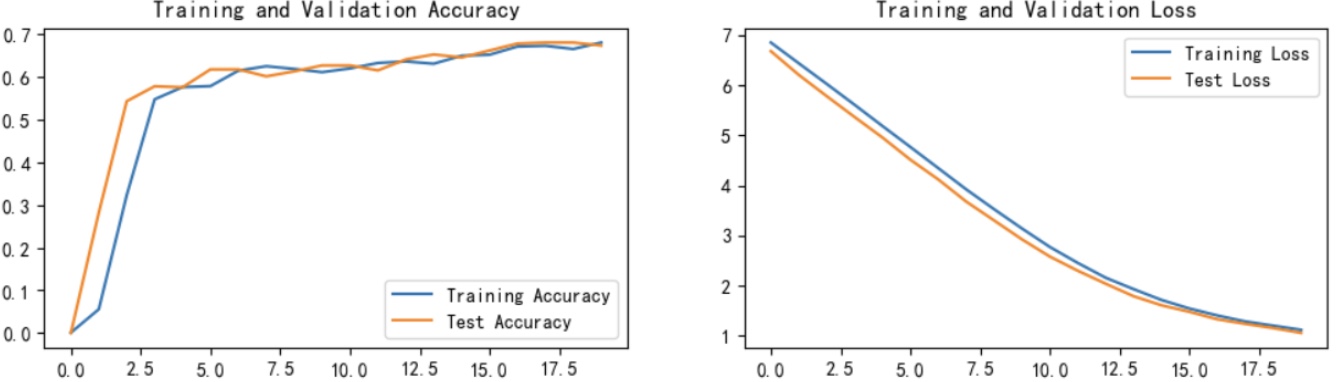
四、总结
其主要优点在于通过并行使用不同尺寸的卷积核(1×1、3×3、5×5)以及引入1×1卷积进行降维,在有效提升特征提取能力的同时大幅减少了计算量和参数数量,表现出较高的计算效率和良好的实际性能。然而,InceptionV1的网络结构较为复杂,不易手工实现与调试,且固定的卷积核组合在适应不同任务时灵活性不足。此外,虽然其参数量较小,但多分支结构在某些硬件平台上部署并不友好,后续版本也对其做了进一步优化。因此,InceptionV1是一种在性能与效率之间取得良好平衡的网络结构,但在实际应用中仍存在一定的改进空间。
相关文章:

第28周——InceptionV1实现猴痘识别
前言 🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 一、前期准备 1.检查GPU import torch import torch.nn as nn import torchvision.transforms as transforms import torchvision from torchvision im…...

云上玩转 Qwen3 系列之三:PAI-LangStudio x Hologres构建ChatBI数据分析Agent应用
本文详细介绍了如何使用 LangStudio 和 Qwen3 构建基于 MCP 协议的 Hologres ChatBI 智能 Agent 应用。该应用通过将 Agent、MCP Server 等技术和阿里最新的推理模型 Qwen3 编排在一个应用流中,为大模型提供了 MCPOLAP 的智能数据分析能力,使用自然语言即…...

Android开发-在应用之间共享数据
在Android系统中,应用之间的隔离机制(沙箱机制)保障了系统的安全性与稳定性。然而,在实际开发中,我们经常需要实现跨应用的数据共享,例如: 从一个应用向另一个应用传递用户信息;多个…...

MySQL-数据库分布式XA事务
准备 innodb存储引擎开启支持分布式事务 set global innodb_support_axonMySQL数据库XA事务的SQL语法如下: XA {START| BEGIN} xid {JOIN | RESUME} XA END xid {SUSPEND [ FOR MIGRATE]} XA PREPARE xid XA COMMIT xid [ONE PHASE] XA ROLLBACK xid XA RECOVER 完…...

如何快速入门-衡石科技分析平台
快速指南 创建管理员账号 按照文档安装成功之后,假设安装所在服务器 IP 是<Server IP>,端口是<Server Port>,则可以通过浏览器访问http://<Server IP>:<Server Port>/ 访问衡石分析平台,如果正常&a…...

20250515通过以太网让VLC拉取视熙科技的机芯的rtsp视频流的步骤
20250515通过以太网让VLC拉取视熙科技的机芯的rtsp视频流的步骤 2025/5/15 20:26 缘起:荣品的PRO-RK3566适配视熙科技 的4800W的机芯。 1080p出图预览的时候没图了。 通过105的机芯出图确认 荣品的PRO-RK3566 的硬件正常。 然后要确认 视熙科技 的4800W的机芯是否出…...

OpenCV CUDA模块中矩阵操作-----矩阵最大最小值查找函数
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在OpenCV的CUDA模块中,矩阵最大最小值查找操作用于快速获取矩阵中的全局最小值、最大值及其位置。这些函数对于图像处理任务特别有用…...
——案例:海报的透视变换)
OpenCv高阶(4.0)——案例:海报的透视变换
文章目录 前言一、工具函数模块1.1 图像显示函数1.2 保持宽高比的缩放函数1.3 坐标点排序函数 二、透视变换核心模块2.1 四点透视变换实现 三、主流程技术分解3.1 图像预处理3.2 轮廓检测流程3.3 最大轮廓处理 四、后处理技术4.1 透视变换4.2 形态学处理 五、完整代码总结 前言…...
)
JavaScriptWeb API (DOM和BOM操作)
Web API (基础部分) 作用: 使用 JS 去操作 html 和浏览器 分类: DOM 和 BOM DOM: 操作 HTML 文档的 APIBOM: 操作浏览器的 API DOM(文档对象模型) 是用来呈现以及与任意 HTML 或 XML 文档进行交互的 API 作用: 开发网页内容特效和实现用户交互 动态创建 HTML 元素改变 HTML…...

AM-Thinking-v1论文解读:以32B规模推进推理前沿
《AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale》论文解读 一、引言 过去半年,大型语言模型(LLMs)在推理领域(如数学问题求解和代码生成)取得了显著进展,扩大了其在现实场景中的应…...

Spark--RDD中的转换算子
1、算子的简单介绍 Transformation(转换)算子:根据数据集创建一个新的数据集,计算后返回一个新RDD,例如一个rdd进行map操作后生了一个新的rdd。 Action(动作)算子:对rdd结果计算后返回一个数值value给驱动程序(driver),例如collect算子将数据集的所有元素收集完成返回给驱动程…...

【文件上传漏洞】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文件上传漏洞 定义客户端js检测 服务器检测后缀黑名单白名单 检测内容其他 定义 文件上传漏洞是指用户上传了一个可执行的脚本文件,并通过此脚本文件获得了执行服…...

electron进程通信
electron进程通信 模式 1:渲染器进程到主进程(单向) send和on 1.渲染器进程调用方法 click setTitle2.预加载进程暴露setTile方法 setTitle: (title) > ipcRenderer.send(set-title, title),3.主进程监听到方法 ipcMain.on(set-title…...

[C++面试] lambda面试点
一、入门 1、什么是 C lambda 表达式?它的基本语法是什么? Lambda 是 C11 引入的匿名函数对象,用于创建轻量级的可调用对象。 [捕获列表] (参数列表) mutable(可选) 异常声明(可选) -> 返回…...

【愚公系列】《Manus极简入门》040-科技与组织升级顾问:“项目掌舵人”
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

2505C++,py和go调用雅兰亭库的协程工具
原文 神算调用C 一般调用pybind11封装的C库实现神算调用C库,pybind11封装c的接口很简单. 创建一个py_example.cpp文件 #include <pybind11/pybind11.h> #include <string> namespace py pybind11; PYBIND11_MODULE(py_example, m) {m.def("hello", …...

题解:P12207 [蓝桥杯 2023 国 Python B] 划分
链接 题目描述 给定 40 个数,请将其任意划分成两组,每组至少一个元素。每组的权值为组内所有元素的和。划分的权值为两组权值的乘积。请问对于以下 40 个数,划分的权值最大为多少。 5160 9191 6410 4657 7492 1531 8854 1253 4520 9231126…...

英迈国际Ingram Micro EDI需求分析
Ingram Micro(英迈国际)成立于1979年,是全球领先的技术和供应链服务提供商,总部位于美国加州尔湾。公司致力于连接全球的技术制造商与渠道合作伙伴,业务涵盖IT分销、云服务、物流和供应链优化等多个领域。Ingram Micro…...

【Linux】网络基础与socket编程基础
一.网络发展 计算机的出现是在网络之前的。而网络产生之初就是为了解决局部计算机无法交互的问题。所以,网络在诞生之初,最先出现的就是我们的局域网LAN,用来结局局部多台计算机的通信问题。 而随着时间的推移,局域网已经不能满…...

漂亮的收款打赏要饭网HTML页面源码
这是一款专为个人收款及接受打赏设计的HTML页面,其设计简洁且美观。 下载地址:漂亮的收款打赏要饭网HTML页面源码 备用地址:漂亮的收款打赏要饭网HTML页面源码...

【图书推荐】几本人工智能实用性图书
《OpenCV计算机视觉开发实践:基于Python》 《OpenCV计算机视觉开发实践:基于Python》【摘要 书评 试读】- 京东图书 《PyTorch深度学习与计算机视觉实践》 《PyTorch深度学习与计算机视觉实践(人工智能技术丛书)》(王晓华)【摘要 书评 试读…...

uniapp+vite+cli模板引入tailwindcss
目前vitecli方式用的都是官方提供的模板,vite版本还是4.14版本,较旧,而tailwindcss已经有了4版本,实际发现引入最新版会报错,因而继续使用3.3.5版本 pnpm install tailwindcss3.3.5 uni-helper/vite-plugin-uni-tail…...

【使用 C# 获取 USB 设备信息及进行通信】
文章目录 使用 C\# 获取 USB 设备信息及进行通信为什么需要获取 USB 设备信息?方法一:使用 C\# 库 (推荐)1. HidSharp2. LibUsbDotNet 方法二:直接调用 Windows API (P/Invoke)理解设备通信协议 (用于数据交换)总结 使用 C# 获取 USB 设备信息…...
)
Spring Cloud探索之旅:从零搭建微服务雏形 (Eureka, LoadBalancer 与 OpenFeign实战)
引言 大家好!近期,我踏上了一段深入学习Spring Cloud构建微服务应用的旅程。我从项目初始化开始,逐步搭建了一个具备服务注册与发现、客户端负载均衡以及声明式服务调用功能的基础微服务系统。本文旨在记录这一阶段的核心学习内容与实践成果…...

四维时空数据安全传输新框架:压缩感知与几何驱动跳频
四维时空数据安全传输新框架:压缩感知与几何驱动跳频 1. 引言 1.1 研究背景 随着三维感知技术(如激光雷达、超宽带定位)与动态数据流(如无人机集群、工业物联网)的快速发展,四维时空数据(三维…...

CSS相关知识补充
:root伪类 css自定义变量和var()引用自定义变量 https://developer.mozilla.org/zh-CN/docs/Web/CSS/var 在 SCSS 中,变量的声明和使用是用 $ 符号,比如: $primary-color: #ff5722;.button {color: $primary-color; }SCSS 里没有 var() 这…...

DeepSeek 赋能物联网:从连接到智能的跨越之路
目录 一、引言:物联网新时代的开启二、DeepSeek 技术揭秘2.1 DeepSeek 是什么2.2 DeepSeek 技术优势 三、DeepSeek 与物联网的融合之基3.1 物联网发展现状与挑战3.2 DeepSeek 带来的变革性突破 四、DeepSeek 在物联网的多元应用场景4.1 智慧电力:开启能源…...

谷歌量子计算机:开启计算新纪元
量子计算的黎明 原始尺寸更换图片 在科技迅猛发展的时代,量子计算作为前沿领域,正逐渐崭露头角,吸引着全球无数科研人员与科技巨头的目光。它宛如一把开启未来科技大门的钥匙,为解决诸多复杂难题提供了前所未有的可…...

桃芯ingchips——windows HID键盘例程无法同时连接两个,但是安卓手机可以的问题
目录 环境 现象 原理及解决办法 环境 PC:windows11 安卓:Android14 例程使用的是HID Keyboard,板子使用的是91870CQ的开发板,DB870CC1A 现象 连接安卓手机时并不会出现该现象,两个开发板都可以当做键盘给手机发按…...
)
AMC8 -- 2009年真题解析(中文解析)
Problem 1 Answer: E 中文解析: Bridget最后有4个,给了Cassie3个, 则给Cassie之前有7个。在此之前给了一半的苹果给Ann, 那么在给Anna之前,他有7*214个苹果。 因此答案是E。 Problem 2 Answer: D 中文解析࿱…...

深入解析CountDownLatch的设计原理与实现机制
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、概述 CountDownLatch是Java并发包(java.util.concurrent)中用于协调多线程同步的核心工具类,其设计目标是允许一个或…...

缓存的相关内容
缓存是一种介于数据永久存储介质与数据应用之间数据临时的存储介质 实用化保存可以有效地减少低俗数据读取的次数 (例如磁盘IO), 提高系统性能 缓存不仅可以用于提高永久性存储介质的数据读取效率,还可以提供临时的数据存储空间 spring boot中提供了缓存技术, 方便…...

JVM方法区核心技术解析:从方法区到执行引擎
方法区 方法区的内部结构 在经典方法区设计中,主要存储以下核心数据内容: 一、类型信息 方法区维护的类型信息包含以下要素: 类全称标识 类名称(含完整包路径)直接父类的完全限定名(包含完整包路径&am…...

AIbase推出全球MCP Server集合平台 收录超12万个MCP服务器客户端
2025年,AI领域迎来了一项重要的技术进展——MCP(Model Context Protocol,模型上下文协议)的广泛应用。全球MCP Server集合平台AIbase(https://mcp.aibase.cn/)应运而生,为AI开发者提供了一站式的MCP服务器和客户端整合…...

Python训练打卡Day22
复习日: 1.标准化数据(聚类前通常需要标准化) scaler StandardScaler() X_scaled scaler.fit_transform(X) StandardScaler() :这部分代码调用了 StandardScaler 类的构造函数。在Python中,当你在类名后面加上括号…...

【ALINX 实战笔记】FPGA 大神 Adam Taylor 使用 ChipScope 调试 AMD Versal 设计
本篇文章来自 FPGA 大神、Ardiuvo & Hackster.IO 知名博主 Adam Taylor。在这里感谢 Adam Taylor 对 ALINX 产品的关注与使用。为了让文章更易阅读,我们在原文的基础上作了一些灵活的调整。原文链接已贴在文章底部,欢迎大家在评论区友好互动。 在上篇…...

【数据结构入门训练DAY-35】棋盘问题
本次训练聚焦于使用深度优先搜索(DFS)算法解决棋盘上的棋子摆放问题。题目要求在一个可能不规则的nn棋盘上摆放k个棋子,且任意两个棋子不能位于同一行或同一列。输入包括棋盘大小n和棋子数k,以及棋盘的形状(用#表示可放…...
深度学习中的损失函数优化技巧)
张 提示词优化(相似计算模式)深度学习中的损失函数优化技巧
失函数的解释 损失函数代码解析 loss = -F.log_softmax(logits[...

Elasticsearch 常用语法手册
🧰 Elasticsearch 常用语法手册 📚 目录 索引操作文档操作查询操作聚合查询健康与状态查看常见问题与注意事项 🔹 索引操作 查询全部索引 GET _search创建索引 PUT /es_db创建索引并设置分片数和副本数 PUT /es_db {"settings&quo…...

华宇TAS应用中间件与亿信华辰多款软件产品完成兼容互认证
近日,华宇TAS应用中间件与亿信华辰多款产品成功通过兼容互认证测试,双方产品在功能协同、性能优化及高可用性等维度实现全面适配,将为用户提供更加稳定、高效、安全的国产化解决方案。 此次认证也标志着华宇在国产化生态适配领域再添重要里程…...

AI大模型从0到1记录学习numpy pandas day24
第 1 章 环境搭建 1.1 Anaconda 1.1.1 什么是Anaconda Anaconda官网地址:https://www.anaconda.com/ 简单来说,Anaconda Python 包和环境管理器(Conda) 常用库 集成工具。它适合那些需要快速搭建数据科学或机器学习开发环境的用…...

开源GPU架构RISC-V VCIX的深度学习潜力测试:从RTL仿真到MNIST实战
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。 一、开篇:AI芯片架构演变的三重挑战 (引述TPUv4采用RISC-V的行业案…...

VirtualiSurg使用SenseGlove触觉手套开发XR手术培训体验
虚拟现实和虚拟现实触觉 作为一个领先的培训平台,VirtualiSurg自2017年以来一直利用扩展现实(XR)和触觉技术,为全球医疗保健行业提供个性化的数据驱动学习解决方案。它们使医疗专业人员能够协作学习和培训,提高他们的技能,让他们…...

AbstractErrorController简介-笔记
1. AbstractErrorController简介 org.springframework.boot.autoconfigure.web.servlet.error.AbstractErrorController 是 Spring Boot 提供的一个用于处理 HTTP 错误(如 404、500 等)的抽象类,用于自定义错误响应的逻辑。它是 Spring Boot…...

next.js实现项目搭建
一、创建 Next.js 项目的步骤 1、安装 npx create-next-applatest # 或 yarn create next-app # 或 pnpm create next-app 按照交互式提示配置你的项目: 输入项目名称 选择是否使用 TypeScript 选择是否启用 ESLint 选择是否启用 Tailwind CSS 选择是否使用 s…...

使用GoLang版MySQLDiff对比表结构
概述 下载地址: https://github.com/camry/mysqldiff/ 编译安装 git clone https://github.com/camry/mysqldiff.git go env -w GOPROXYhttps://goproxy.cn,direct go env -w GOPRIVATE*.corp.example.com go build .\mysqldiff.go执行对比 ./mysqldiff --sourc…...

git工具使用详细教程-------命令行和图形化工具
下载 git下载地址:https://git-scm.com/downloads TortoiseGit(图形化工具)下载地址:https://tortoisegit.org/download/ 认识git结构 工作区:存放代码的地方 暂存区:临时存储,将工作区的代码…...

失控的产品
大部分程序员很难有机会做一个新的产品,绝大多时候去一家新公司也都是在旧产品上修修补补。 笔者还是很幸运得到了开发新品的机会,从2023年开始做,中间经历了许多磕磕碰碰。 有的小伙伴从中离开,偶尔又加入1~2个人,但…...

区块链blog1__合作与信任
🍂我们的世界 🌿不是孤立的,而是网络化的 如果是单独孤立的系统,无需共识,而我们的社会是网络结构,即结点间不是孤立的 🌿网络化的原因 而目前并未发现这样的理想孤立系统,即现实中…...
)
ES常识9:如何实现同义词映射(搜索)
在 Elasticsearch(ES)中实现同义词映射(如“美丽”和“漂亮”),核心是通过 同义词过滤器(Synonym Token Filter) 在分词阶段将同义词扩展或替换为统一词项,从而让搜索时输入任意一个…...