【数据处理】Python对CMIP6数据进行插值——详细解析实现(附源码)
目录
- Python对CMIP6数据进行插值
- 一、引言
- 代码概览
- 思维导图
- 二、数据预处理
- 三、数据区域裁剪
- 四、插值
- (一) 垂直插值
- (二) 水平插值
- 五、保存插值好的文件
- 六、文件合并与气候态计算
- 七、代码优化技巧
- 八、多线程处理
- 九、全部代码
Python对CMIP6数据进行插值
写在前面—为什么要写这篇博客?
小编最近接触到一个气候方面的项目,然后需要利用到CMIP6数据,需要对其进行数据插值,小编也是第一次接触这个数据,所以就想着学习一下如何利用Python对数据进行插值。在对数据插值之前,我们首先要了解一下我们的数据是什么样子的,也就是对CMIP6数据以及nc文件有个简单的了解。对源数据有个
简单了解之后,我们就可以选择合适的方法对数据进行插值。
一、引言
在气候科学和地球数据分析中,数据插值是一项基础且关键的任务。由于不同模型或观测数据的空间分辨率、层次结构存在差异,将数据统一到标准网格是后续分析的前提。本文结合一个实际的气候数据处理项目,详细介绍如何利用Python实现数据插值。
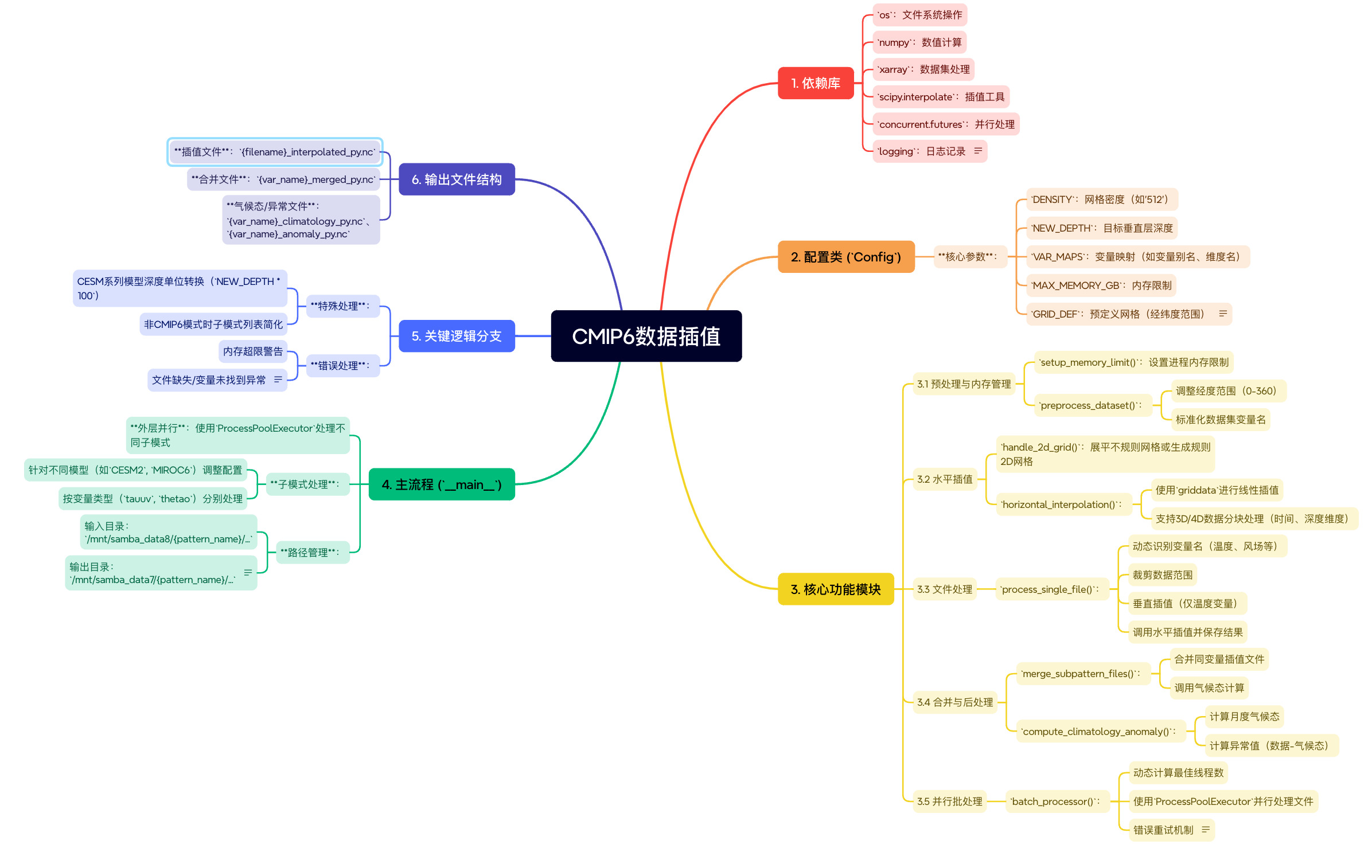
代码概览
代码主要功能包括:
- 数据预处理:调整经度范围、识别关键变量。
- 数据区域裁剪: 裁剪目标区域的数据。
- 垂直插值:将数据插值到指定深度层次。
- 水平插值:将数据映射到规则网格。
- 多线程处理:加速大规模文件处理。
- 文件合并与气候态计算:生成时间序列完整的数据集及异常分析。
思维导图
二、数据预处理
要想做好数据预处理,首先就要先了解CMIP6数据以及NC文件,关于CMIP6数据以及NC文件的的介绍可以参考:
- 【数据处理】 深入解析CMIP6数据与NetCDF(NC)文件:从入门到精通玩转NC文件!
- 【数据处理】NetCDF 文件:从入门到精通
原始数据可能包含不规则网格或非标准变量名,预处理阶段需解决以下问题:
- 变量识别:不同的模式可能有不同的变量名,因此我们在处理数据之前,首先要识别变量名称。本次数据处理用的变量名称主要有
thetao,lon,lat,time,level; 因此我们首先根据先验知识定义了一个变量别名表,如下所示:
VAR_MAPS = {'thetao': ['votemper', 'thetao', 'pottmp', 'TEMP'],'tauu': ['tauu', 'sozotaux', 'uflx', 'TAUX'],'tauv': ['tauv', 'sometauy', 'vflx', 'TAUY'],'lon': ['lon', 'longitude', 'nav_lon', 'LONN359_360'],'lat': ['lat', 'latitude', 'nav_lat', 'LAT'],'lev': ['lev', 'depth', 'deptht', 'level', 'olevel', 'LEV1_13'],'time': ['time', 'TIME', 'time_counter'],
}
- 查找变量:根据预定义的变量别名表(如
thetao可能对应votemper、TEMP等),动态匹配数据中的变量名。
keys = list(ds.variables.keys())
# 示例:动态识别变量名
var = next((v for v in keys if v in config.VAR_MAPS['var']), None)
lon_var = next((v for v in keys if v in config.VAR_MAPS['lon']), None)
lat_var = next((v for v in keys if v in config.VAR_MAPS['lat']), None)
time_var = next((v for v in keys if v in config.VAR_MAPS['time']), None)
lev_var = next((v for v in keys if v in config.VAR_MAPS['lev']), None)
- 经度标准化:将经度范围从[-180°, 180°]转换为[0°, 360°],避免插值时的边界问题。
if lon_var and ds[lon_var].min() < 0:ds[lon_var] = xr.where(ds[lon_var] < 0, ds[lon_var] + 360, ds[lon_var])
三、数据区域裁剪
我们在插值的时候可能并不需要全球的区域,所以我们可以进行区域裁剪来降低计算量,具体实现如下:
lon_mask = (ds[lon_var] >= config.LON_RANGE.start) & (ds[lon_var] <= config.LON_RANGE.stop)
lat_mask = (ds[lat_var] >= config.LAT_RANGE.start) & (ds[lat_var] <= config.LAT_RANGE.stop)
mask = (lon_mask & lat_mask).compute() # 显式计算布尔掩码
ds_cropped = ds.where(mask, drop=True)
四、插值
(一) 垂直插值
利用xarray的interp方法,将数据插值到预设深度(如5m、20m等):
ds_vert = ds.interp({lev_var: config.NEW_DEPTH}, method='linear')
(二) 水平插值
使用scipy.interpolate.griddata实现二维网格插值,支持不规则网格数据:
- 输入:原始经纬度(展平为1D数组)及对应的变量值。 由于不同的模式经纬度的构造方式可能不一致,所以在正式插值之前要先把原始数据的经纬度进行预处理,具体如下:
def handle_2d_grid(lon: np.ndarray, lat: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:"""处理不规则网格展平(兼容2D非正交网格)"""if len(lon.shape) > 1:lon = lon.flatten()lat = lat.flatten()else:lat_2d, lon_2d = np.meshgrid(lat, lon, indexing='ij')lon, lat = lon_2d.flatten(), lat_2d.flatten()return lon, lat
- 目标网格:根据配置生成规则网格(如180*360)。 具体如下:
target_lon = config.GRID_DEF[config.DENSITY]['lon']
target_lat = config.GRID_DEF[config.DENSITY]['lat']
grid_lon, grid_lat = np.meshgrid(target_lon, target_lat)
- 插值方法:采用线性插值。
new_data = griddata((src_lon, src_lat), current_data.flatten(), (grid_lon, grid_lat), method='linear')
五、保存插值好的文件
保存为netcdf文件,具体代码如下:
coords = {'time': ds[time_var].values,'lev': config.NEW_DEPTH,'lat': config.GRID_DEF[config.DENSITY]['lat'],'lon': config.GRID_DEF[config.DENSITY]['lon'],}
dims = ['time', 'lev', 'lat', 'lon']
output_ds = xr.Dataset({var: (dims, interp_data)},coords=coords)# 保存文件 ----------------------------------------------------------
output_path = os.path.join(output_dir, f"{os.path.splitext(file_name)[0]}{config.INTER_NAME}{config.SUFFIX}.nc")
output_ds.to_netcdf(output_path)
output_ds.close() # 显式关闭输出数据集
六、文件合并与气候态计算
- 文件合并:将插值后的文件按时间维度拼接,生成完整数据集并保存。
datasets = [xr.open_dataset(file) for file in filtered_files]
combined_ds = xr.concat(datasets, dim='time').sortby('time')
# 保存合并文件
merged_path = os.path.join(merged_output_dir, f"{var_name}{config.MERGE_NAME}{config.SUFFIX}.nc")
combined_ds.to_netcdf(merged_path)
combined_ds.close()
- 气候态计算:选定起止时间,按月计算多年平均气候态,并生成异常数据(实际值减气候态)。
# 选择指定时间范围内的数据
ds = ds.sel(time=slice(start_date, end_date))
# 计算气候态(按月平均)
climatology = ds.groupby('time.month').mean(dim='time')
# 计算异常
anomaly = ds.groupby('time.month') - climatology
# 保存结果
climatology_path = os.path.join(output_dir, f"{var_name}{config.CLIMA_NAME}{config.SUFFIX}.nc")
anomaly_path = os.path.join(output_dir, f"{var_name}{config.ANOMALY_NAME}{config.SUFFIX}.nc")
climatology.to_netcdf(climatology_path)
anomaly.to_netcdf(anomaly_path)
七、代码优化技巧
- 内存优化:分块读取数据(
xarray的chunks参数)减少内存占用。
with xr.open_dataset(file_path, chunks={'time': 1}) as ds:
- 异常处理:捕获并记录处理失败的文件,支持重试机制。
- 日志记录:通过
logging模块记录运行状态,便于调试。
八、多线程处理
通过concurrent.futures.ProcessPoolExecutor实现多进程并行处理,显著提升大量文件的处理效率:
- 动态线程数:根据CPU核心数、内存限制和文件数量自动调整线程数。
- 内存管理:使用
resource模块限制进程内存,避免系统崩溃。
# 设置内存限制(单位:GB)
resource.setrlimit(resource.RLIMIT_AS, (config.MAX_MEMORY_GB * 1024**3,))
九、全部代码
import os
import time
import logging
import numpy as np
import xarray as xr
from scipy.interpolate import griddata
from scipy.interpolate import NearestNDInterpolator
# from xesmf import Regridder
import concurrent.futures
import sys
import warnings
from typing import List, Tuple, Dict
import resource
from concurrent.futures import ProcessPoolExecutor
import logging
import sys
# 配置日志记录
logging.basicConfig(level=logging.INFO,format='%(asctime)s [%(levelname)s] %(message)s',handlers=[logging.FileHandler("data_inter.log"),logging.StreamHandler()]
)
logger = logging.getLogger(__name__)# 配置参数(可抽离为单独配置文件)
class Config:"""全局配置参数类"""DENSITY = '512'NEW_DEPTH = np.array([5.0, 20.0, 40.0, 60.0, 90.0, 120.0, 150.0])# NEW_DEPTH = np.array([5.0, 20.0])VAR_MAPS = {'var': ['votemper', 'thetao', 'pottmp', 'TEMP', 'tauu', 'sozotaux', 'uflx', 'TAUX', 'tauv', 'sometauy', 'vflx', 'TAUY'],'thetao': ['votemper', 'thetao', 'pottmp', 'TEMP'],'tauu': ['tauu', 'sozotaux', 'uflx', 'TAUX'],'tauv': ['tauv', 'sometauy', 'vflx', 'TAUY'],'lon': ['lon', 'longitude', 'nav_lon', 'LONN359_360'],'lat': ['lat', 'latitude', 'nav_lat', 'LAT'],'lev': ['lev', 'depth', 'deptht', 'level', 'olevel', 'LEV1_13'],'time': ['time', 'TIME', 'time_counter'],'start_dates': {'ORAS5': '1958-01-01','CMIP6': '1850-01-01','GODAS': '1980-01-01','SODA': '1871-01-01', },'end_dates': {'ORAS5': '1979-12-31','CMIP6': '2014-12-31','GODAS': '2021-12-31','SODA': '1979-12-31'}}MAX_MEMORY_GB = 1024 # 最大内存限制SUFFIX = '_py'INTER_NAME = '_interpolated'MERGE_NAME = '_merged'ANOMALY_NAME = '_anomaly'CLIMA_NAME = '_climatology'# 定义经度和纬度范围LON_RANGE = slice(0, 360) # 经度范围LAT_RANGE = slice(-90, 90) # 纬度范围start = LAT_RANGE.startend = LAT_RANGE.stopnum = end-5GRID_DEF = {'512': {'lon': np.linspace(0, 360, 180),'lat': np.concatenate((np.linspace(start, -6, num),np.linspace(-5, 5, 21),np.linspace(6, end, num)))},'25': {'lon': np.linspace(0, 360, 144),'lat': np.linspace(-90, 90, 72),},'55': {'lon': np.linspace(0, 360, 72),'lat': np.linspace(-90, 90, 36),},'11': {'lon': np.linspace(0, 360, 360),'lat': np.linspace(-90, 90, 180),},}warnings.filterwarnings('ignore')def handle_2d_grid(lon: np.ndarray, lat: np.ndarray) -> Tuple[np.ndarray, np.ndarray]:"""处理不规则网格展平(兼容2D非正交网格)"""if len(lon.shape) > 1:lon = lon.flatten()lat = lat.flatten()else:lat_2d, lon_2d = np.meshgrid(lat, lon, indexing='ij')lon, lat = lon_2d.flatten(), lat_2d.flatten()return lon, latdef setup_memory_limit(config: Config):"""设置进程内存限制"""try:mem_limit = config.MAX_MEMORY_GB * 1024 ** 3resource.setrlimit(resource.RLIMIT_AS,(mem_limit, mem_limit))logger.info(f"内存限制设置为 {config.MAX_MEMORY_GB}GB")except ValueError as e:logger.warning(f"内存限制设置失败: {str(e)}")def preprocess_dataset(ds: xr.Dataset, config: Config) -> xr.Dataset:"""跳过坐标重命名,仅处理经度范围"""print("开始进行数据预处理...")try:# 直接查找原始经度变量并标准化范围keys = list(ds.variables.keys())lon_var = next((v for v in keys if v in config.VAR_MAPS['lon']), None)if lon_var and ds[lon_var].min() < 0:ds[lon_var] = xr.where(ds[lon_var] < 0, ds[lon_var] + 360, ds[lon_var])print("数据预处理完成。")return dsexcept Exception as e:logger.error(f"预处理失败: {str(e)}")raisedef merge_subpattern_files(sub_pattern_dir: str, merged_output_dir: str, var_name: str, config: Config) -> None:"""合并指定目录下所有包含特定变量的 *_interp.nc 文件"""# 获取所有待合并文件files = [os.path.join(sub_pattern_dir, f)for f in sorted(os.listdir(sub_pattern_dir))if f.endswith(f'{config.INTER_NAME}{config.SUFFIX}.nc')]if not files:raise FileNotFoundError(f"无待合并文件于目录: {sub_pattern_dir}")# 筛选包含目标变量的文件filtered_files = []for file in files:with xr.open_dataset(file) as ds:if var_name in list(ds.variables.keys()):filtered_files.append(file)if not filtered_files:raise ValueError(f"目录 {sub_pattern_dir} 中无 {var_name} 变量文件")# 合并文件datasets = [xr.open_dataset(file) for file in filtered_files]combined_ds = xr.concat(datasets, dim='time').sortby('time')# 保存合并文件merged_path = os.path.join(merged_output_dir, f"{var_name}{config.MERGE_NAME}{config.SUFFIX}.nc")combined_ds.to_netcdf(merged_path)combined_ds.close()print(f"{var_name} 合并完毕,保存至: {merged_path}")compute_climatology_anomaly(merged_path, merged_output_dir, var_name, config)def compute_climatology_anomaly(merged_path: str, output_dir: str, var_name: str, config: Config) -> None:"""计算气候态和异常"""with xr.open_dataset(merged_path) as ds:start_date, end_date = config.VAR_MAPS['start_dates'][pattern_name], config.VAR_MAPS['end_dates'][pattern_name]ds = ds.sortby('time')# 选择指定时间范围内的数据ds = ds.sel(time=slice(start_date, end_date))# 计算气候态(按月平均)climatology = ds.groupby('time.month').mean(dim='time')# 计算异常anomaly = ds.groupby('time.month') - climatology# 保存结果climatology_path = os.path.join(output_dir, f"{var_name}{config.CLIMA_NAME}{config.SUFFIX}.nc")anomaly_path = os.path.join(output_dir, f"{var_name}{config.ANOMALY_NAME}{config.SUFFIX}.nc")climatology.to_netcdf(climatology_path)anomaly.to_netcdf(anomaly_path)def horizontal_interpolation(data: np.ndarray, src_lon: np.ndarray,src_lat: np.ndarray, config: Config) -> np.ndarray:"""支持三维和四维数据的水平插值"""target_lon = config.GRID_DEF[config.DENSITY]['lon']target_lat = config.GRID_DEF[config.DENSITY]['lat']grid_lon, grid_lat = np.meshgrid(target_lon, target_lat)print("src_lon:", src_lon.shape, "src_lat:", src_lat.shape)print("开始水平插值...")final_data = []for time_idx in range(data.shape[0]):print(f"处理时间步 {time_idx + 1}/{data.shape[0]}")if data.ndim == 4:# 温度数据分块处理lev_data = []for depth_idx in range(data.shape[1]):current_data = data[time_idx, depth_idx, ...].flatten()new_data = griddata((src_lon, src_lat),current_data,(grid_lon, grid_lat),method='linear')lev_data.append(new_data)print(config.var_type, config.pattern_name, config.sub_pattern_name, time_idx, depth_idx, new_data.shape, np.nanmin(new_data), np.nanmax(new_data))print()final_data.append(lev_data)else:# 处理风数据current_data = data[time_idx, ...].flatten()new_data = griddata((src_lon, src_lat),current_data,(grid_lon, grid_lat),method='linear')print(config.var_type, config.pattern_name, config.sub_pattern_name, time_idx, new_data.shape, np.nanmin(new_data), np.nanmax(new_data))print()final_data.append(new_data)final_data = np.array(final_data)return final_datadef process_single_file(file_info: Tuple[str, str, str, str, Config]) -> bool:"""直接通过原始变量名提取数据"""file_name, input_dir, output_dir, pattern, config = file_infofile_path = os.path.join(input_dir, file_name)try:with xr.open_dataset(file_path, chunks={'time': 1}) as ds:# ds = preprocess_dataset(ds)print(ds)keys = list(ds.variables.keys())print(keys)# 动态识别原始变量名 -------------------------------------------------# 1. 查找目标变量var = next((v for v in keys if v in config.VAR_MAPS['var']), None)if not var:raise ValueError("未找到温度变量(thetao)")is_temp_var = var in config.VAR_MAPS['thetao']# 2. 查找经纬度变量lon_var = next((v for v in keys if v in config.VAR_MAPS['lon']), None)if lon_var and ds[lon_var].min() < 0:ds[lon_var] = xr.where(ds[lon_var] < 0, ds[lon_var] + 360, ds[lon_var])lat_var = next((v for v in keys if v in config.VAR_MAPS['lat']), None)time_var = next((v for v in keys if v in config.VAR_MAPS['time']), None)# 4. 查找垂直层变量if is_temp_var:lev_var = next((v for v in keys if v in config.VAR_MAPS['lev']), None)if not lev_var:raise ValueError("缺失垂直维度")ds_vert = ds.interp({lev_var: config.NEW_DEPTH},method='linear',kwargs={'fill_value': 'extrapolate'})else:ds_vert = dsds = ds_vert# 3. 裁剪数据lon_mask = (ds[lon_var] >= config.LON_RANGE.start) & (ds[lon_var] <= config.LON_RANGE.stop)lat_mask = (ds[lat_var] >= config.LAT_RANGE.start) & (ds[lat_var] <= config.LAT_RANGE.stop)mask = (lon_mask & lat_mask).compute() # 显式计算布尔掩码ds_cropped = ds.where(mask, drop=True)ds_vert = ds_cropped# 5. 水平插值(使用原始经纬度)src_lon = ds_vert[lon_var].valuessrc_lat = ds_vert[lat_var].valuesdata = ds_vert[var].valuessrc_lon, src_lat = handle_2d_grid(src_lon, src_lat)print("ds_vert:", data.shape)interp_data = horizontal_interpolation(data, src_lon, src_lat, config)print(type(interp_data), type(ds_vert))# 构建动态输出数据集if is_temp_var:coords = {'time': ds[time_var].values,'lev': config.NEW_DEPTH,'lat': config.GRID_DEF[config.DENSITY]['lat'],'lon': config.GRID_DEF[config.DENSITY]['lon'],}dims = ['time', 'lev', 'lat', 'lon']else:coords = {'time': ds[time_var].values,'lat': config.GRID_DEF[config.DENSITY]['lat'],'lon': config.GRID_DEF[config.DENSITY]['lon'],}dims = ['time', 'lat', 'lon']output_ds = xr.Dataset({var: (dims, interp_data)},coords=coords)# 保存文件 ----------------------------------------------------------output_path = os.path.join(output_dir, f"{os.path.splitext(file_name)[0]}{config.INTER_NAME}{config.SUFFIX}.nc")output_ds.to_netcdf(output_path)output_ds.close() # 显式关闭输出数据集del ds, output_ds # 主动释放内存return Trueexcept Exception as e:logger.error(f"处理失败 {file_path}: {str(e)}", exc_info=True)return Falsedef batch_processor(input_dir: str, merged_dir: str, output_dir: str,pattern: str, max_workers: int, config: Config) -> None:"""安全批处理控制器"""setup_memory_limit(config)if not os.path.exists(output_dir):os.makedirs(output_dir)print(f"输出目录 {output_dir} 不存在,已创建。")if not os.path.exists(merged_dir):os.makedirs(merged_dir)print(f"合并目录 {merged_dir} 不存在,已创建。")files = [ ffor f in sorted(os.listdir(input_dir))if f.endswith('.nc') and not f.startswith('._')]ds0 = xr.open_dataset(os.path.join(input_dir, files[0]), chunks={'time': 1})ds1 = xr.open_dataset(os.path.join(input_dir, files[-1]), chunks={'time': 1})keys0 = list(ds0.variables.keys())keys1 = list(ds1.variables.keys())var_name0 = next((v for v in keys0 if v in config.VAR_MAPS['var']), None)var_name1 = next((v for v in keys1 if v in config.VAR_MAPS['var']), None)total_files = len(files)print(f"发现 {total_files} 个待处理文件。")# 自动计算最佳线程数cpu_count = os.cpu_count() or 1safe_workers = min(cpu_count * 2, # 超线程优化max_workers or 64, # 默认上限64len(files),(config.MAX_MEMORY_GB * 1024) // 2 # 每个进程约2GB内存)print(f"使用 {safe_workers} 个工作线程。")# 使用进程池+重试机制with concurrent.futures.ProcessPoolExecutor(max_workers=safe_workers) as executor:futures = {executor.submit(process_single_file, (f, input_dir, output_dir, pattern, config)): f for f in files}completed_files = 0for future in concurrent.futures.as_completed(futures):completed_files += 1print(f"已完成 {completed_files}/{total_files} 个文件的处理。")file_path = futures[future]try:result = future.result()if not result:logger.warning(f"需重试文件: {file_path}")# 加入重试队列except Exception as e:logger.error(f"执行异常: {file_path} - {str(e)}")print("主处理流程完成,开始合并文件...")try:merge_subpattern_files(output_dir, merged_dir, var_name0, config)if var_name1 != var_name0:merge_subpattern_files(output_dir, merged_dir, var_name1, config)except Exception as e:logger.error(f"合并失败: {str(e)}", exc_info=True)if __name__ == "__main__":# 配置日志记录(确保多进程安全)logger = logging.getLogger(__name__)def process_subpattern(var_type: str, sub_pattern_name: str, pattern_name: str) -> None:"""处理单个子模式的独立函数(每个进程独立配置)"""local_config = Config()local_config.DENSITY = '512'local_config.sub_pattern_name = sub_pattern_namelocal_config.var_type = var_typelocal_config.pattern_name = pattern_name# CESM系列需要特殊处理深度(不影响其他进程)if sub_pattern_name in ['CESM2', 'CESM2-WACCM']:local_config.NEW_DEPTH = local_config.NEW_DEPTH * 100try:batch_processor(input_dir=f"/mnt/samba_data8/{pattern_name}/{pattern_name}_{var_type}/{sub_pattern_name}",output_dir=f"/mnt/samba_data7/{pattern_name}/{local_config.DENSITY}{local_config.INTER_NAME}/{var_type}/{sub_pattern_name}",merged_dir=f"/mnt/samba_data7/{pattern_name}/{local_config.DENSITY}{local_config.MERGE_NAME}/{var_type}/{sub_pattern_name}",pattern=pattern_name,max_workers=4, # 调整内层并行度config=local_config)except Exception as e:logger.error(f"处理失败 {sub_pattern_name}/{var_type}: {str(e)}", exc_info=True)raise# 原始配置sub_pattern_names = ['ACCESS-CM2', 'ACCESS-ESM1-5', 'BCC-CSM2-MR', 'CAMS-CSM1-0', 'CanESM5-1','CMCC-CM2-SR5', 'E3SM-1-1', 'EC-Earth3', 'EC-Earth3-CC', 'FGOALS-f3-L','FGOALS-g3', 'FIO-ESM-2-0', 'INM-CM4-8', 'INM-CM5-0', 'NorESM2-LM','CESM2-WACCM-FV2', 'CNRM-ESM2-1', 'GISS-E2-1-G', 'CMCC-ESM2', 'EC-Earth3-Veg','NESM3', 'EC-Earth3-Veg-LR', 'CAS-ESM2-0', 'CanESM5', 'CIESM', 'GFDL-CM4','GFDL-ESM4', 'NorESM2-MM', 'CNRM-CM6-1', 'MCM-UA-1-0', 'MPI-ESM1-2-HR','MPI-ESM1-2-LR', 'CanESM5-CanOE', 'SAM0-UNICON', 'E3SM-1-0', 'HadGEM3-GC31-LL','UKESM1-0-LL', 'IPSL-CM6A-LR', 'KIOST-ESM', 'HadGEM3-GC31-MM', 'MRI-ESM2-0','MIROC6', 'MIROC-ES2L', 'CESM2', 'CESM2-WACCM']pattern_name = 'CMIP6'if pattern_name != 'CMIP6':sub_pattern_names = ['']var_types = ['tauuv', 'thetao']# 创建外层进程池(根据系统资源调整max_workers)with ProcessPoolExecutor(max_workers=45) as executor:futures = []# 生成所有任务for var_type in var_types:for sub_pattern_name in sub_pattern_names:future = executor.submit(process_subpattern,var_type,sub_pattern_name,pattern_name)futures.append(future)# 等待并处理结果for future in concurrent.futures.as_completed(futures):try:future.result()except Exception as e:logger.error(f"子任务异常: {str(e)}")logger.info("所有子模式处理完成")
相关文章:
)
【数据处理】Python对CMIP6数据进行插值——详细解析实现(附源码)
目录 Python对CMIP6数据进行插值一、引言代码概览思维导图 二、数据预处理三、数据区域裁剪四、插值(一) 垂直插值(二) 水平插值 五、保存插值好的文件六、文件合并与气候态计算七、代码优化技巧八、多线程处理九、全部代码 Pytho…...

worldquant rank函数
https://support.worldquantbrain.com/hc/en-us/community/posts/13869304934935-%E6%80%8E%E6%A0%B7%E7%90%86%E8%A7%A3rank%E5%87%BD%E6%95%B0 链接。进的话可以填我的邀请码JS34795我可以带你 现在学习rank函数 我们所说的做多和做空 首先,当我们讨论Long和S…...

工业4.0神经嫁接术:ethernet ip转profinet协议通信步骤图解
在现代工业自动化领域,不同品牌的设备和协议之间的兼容性问题一直是个挑战。我们的包装线项目就遇到了这样的难题:需要将Rockwell Allen-Bradley的EtherNet/IP伺服系统与西门子PLC的PROFINET主站进行无缝对接。为了解决这一问题,我们采用了et…...

数据库——数据操作语言DML
(2)数据操作语言DML 简称DML——Data Manipulation Language用来对数据库中表的记录进行更新关键字:insert,delete,update A、 插入表记录 向表中插入数据 格式:insert into 表名(字段1,字段2,字段3……) values(值1,值2,值3);…...

文件防泄密的措施有哪些?
文件防泄密措施需要从技术、管理和物理三个层面综合施策,以下为常见措施分类整理: 一、技术防护措施 华途加密技术 文件加密:使用AES、RSA等算法对敏感文件加密。 传输加密:通过SSL/TLS、VPN保障传输安全,禁止明文传…...
)
C++ Mac 打包运行方案(cmake)
文章目录 背景动态库梳理打包方案静态库处理动态库处理(PCL库)编译链接动态库后处理逻辑 批量信任 背景 使用C编写的一个小项目,需要打包成mac下的可执行文件(免安装版本),方便分发给其他mac执行,需要把项目的动态库都…...

数学复习笔记 10
前言 我觉得数学的高分乃至满分属于那些,聪明,坚韧,勇敢,细致的人。我非常惭愧自己不是这样的人,我在生活中发现了这样的同学,和他们交流的时候我常常感到汗流浃背,因为他们非常扎实的基础知识…...

Oracle-相关笔记
Oracle Database Online Documentation 11g 连接 WinR sqlplus username/passwordhostname:port/service_namesqlplus user02/123456192.xxx:1521/orclsqlplus / as sysdba #SQL*Plus 終端编码使用UTF-8 chcp 65001#打开SQL*Plus程序 sqlplus /nolog#使用dba角色登录(用 1.…...

mac安装cast
背景 pycharm本地运行脚本时提示cast没有安装 问题原因 脚本尝试调用cast命令(以太坊开发工具foundry中的子命令),但您的系统未安装该工具。 从日志可见,错误发生在通过sysutil.py执行shell命令时。 解决方案 方法1…...

CodeEdit:macOS上一款可以让Xcode退休的IDE
CodeEdit 是一款轻量级、原生构建的代码编辑器,完全免费且开源。它使用纯 swift 实现,而且专为 macOS 设计,旨在为开发者提供更高效、更可靠的编程环境,同时释放 Mac 的全部潜力。 Stars 数21,719Forks 数1,081 主要特点 macOS 原…...

opencv4.11编译Debug提示缺少python312_d.lib或python3*_d.lib的解决办法
前言 当我们编译OpenCV 4.11的时候可能会遇到提示缺少库文件,这个时候我们可以下载Python源码编译这个lib。 也可以下载我上传的版本(python312_d.lib),但是如果是其他版本需要自己编译。编译步骤如下,大概几分钟搞定…...

html的鼠标点击事件有哪些写法
在HTML中,鼠标点击事件的实现方式多样,以下从基础语法到现代实践为您详细梳理: 一、基础写法:直接内联事件属性 在HTML标签内通过on前缀事件属性绑定处理函数,适合简单交互场景: <!-- 单击事件 -->…...

深度解析物理机服务器故障修复时间:影响因素与优化策略
一、物理机故障修复的核心影响因素 物理机作为企业 IT 基础设施的核心载体,其故障修复效率直接关系到业务连续性。故障修复时间(MTTR)受多重因素交叉影响: 1. 故障类型的复杂性 硬件级故障: 简单故障:内存…...

蓝桥杯 2024 C++国 B最小字符串
P10910 [蓝桥杯 2024 国 B] 最小字符串 题目描述 给定一个长度为 N N N 且只包含小写字母的字符串 S S S,和 M M M 个小写字母 c 1 , c 2 , ⋯ , c M c_1, c_2, \cdots, c_M c1,c2,⋯,cM。现在你要把 M M M 个小写字母全部插入到字符串 S S S 中&…...

解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-docker MCP解析
解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-docker MCP解析 这里面有很重要的原因其中一个很其中一个原因是因为如果你使用docker的方式,你可以在虚拟环境下就类似于这个沙箱的这个机制可以进行隔离。这对于安全,…...
全部被“重置连接”或超时)
访问 Docker 官方镜像源(包括代理)全部被“重置连接”或超时
华为云轻量应用服务器(Ubuntu 系统) 遇到的问题是: 🔒 访问 Docker 官方镜像源(包括代理)全部被“重置连接”或超时了,说明你这台服务器的出境网络对这些国外域名限制很严格,常见于华…...
从原理到实战)
前馈神经网络回归(ANN Regression)从原理到实战
前馈神经网络回归(ANN Regression)从原理到实战 一、回归问题与前馈神经网络的适配性分析 在机器学习领域,回归任务旨在建立输入特征与连续型输出变量之间的映射关系。前馈神经网络(Feedforward Neural Network)作为最基础的神经网络架构&a…...

RNN/LSTM原理与 PyTorch 时间序列预测实战
🕰️ RNN / LSTM 原理与 PyTorch 时间序列预测实战 在处理时间序列数据、语音信号、文本序列等连续性强的问题时,循环神经网络(RNN)及其改进版本 LSTM(长短期记忆网络)是最常见也最有效的模型之一。本文将深入讲解 RNN 和 LSTM 的核心原理,并通过 PyTorch 实现一个时间…...

Docker容器镜像与容器常用操作指南
一、镜像基础操作 搜索镜像 docker search <镜像名>在Docker Hub中查找公开镜像,例如: docker search nginx拉取镜像 docker pull <镜像名>:<标签>从仓库拉取镜像到本地,标签默认为latest: docker pull nginx:a…...

1:OpenCV—图像基础
OpenCV教程 头文件 您只需要在程序中包含 opencv2/opencv.hpp 头文件。该头文件将包含应用程序的所有其他必需头文件。因此,您不再需要费心考虑程序应包含哪些头文件。 例如 - #include <opencv2/opencv.hpp>命名空间 所有 OpenCV 类和函数都在 cv 命名空…...
)
测试--BUG(软件测试⽣命周期 bug的⽣命周期 与开发产⽣争执怎么办)
1. 软件测试的⽣命周期 软件测试贯穿于软件的整个⽣命周期,针对这句话我们⼀起来看⼀下软件测试是如何贯穿软件的整个⽣命周期。 软件测试的⽣命周期是指测试流程,这个流程是按照⼀定顺序执⾏的⼀系列特定的步骤,去保证产品质量符合需求。在软…...

基于大模型预测围术期麻醉苏醒时间的技术方案
目录 一、数据收集与处理(一)数据来源(二)数据预处理二、大模型构建与训练(一)模型选择(二)模型训练三、围术期麻醉苏醒时间预测(一)术前预测(二)术中动态预测四、并发症风险预测(一)风险因素分析(二)风险预测模型五、基于预测制定手术方案(一)个性化手术规划…...
阅读与注释 QPlainTextEdit,其继承于QAbstractScrollArea,属性学习与测试)
QT6 源(101)阅读与注释 QPlainTextEdit,其继承于QAbstractScrollArea,属性学习与测试
(1) (2) (3)属性学习与测试 : (4) (5) 谢谢...

电池组PACK自动化生产线:多领域电池生产的“智能引擎”
在电池产业蓬勃发展的当下,电池组PACK自动化生产线凭借其高效、精准、智能的优势,成为众多电池生产领域的核心装备。它广泛适用于数码电池、工具电池、储能电池、电动车电池以及动力电池的生产,有力推动了相关产业的升级与发展。 数码电池领…...

生成式AI在编程中的应用场景:从代码生成到安全检测
引言 生成式AI正在深刻改变软件开发的方式,从代码编写到测试、文档和维护,AI技术正在为每个环节带来革命性的变革。本文将深入探讨生成式AI在编程中的主要应用场景,分析其优势与局限性,并展望未来发展趋势。 主要应用场景 1. 代…...
安全体系》)
安全牛报告解读《低空经济发展白皮书(3.0)安全体系》
一、概述 《低空经济发展白皮书(3.0)安全体系》由粤港澳大湾区数字经济研究院(IDEA研究院)发布,旨在构建低空经济安全发展的系统性框架,解决规模化低空飞行中的安全挑战。核心目标是明确安全体系需覆盖的飞…...

“2W2H”分析方法
“2W2H”是一种常用的分析方法,它通过回答**What(是什么)、Why(为什么)、How(怎么做)、How much(多少)**这四个问题来全面了解和分析一个事物或问题。这种方法可以帮助你…...

【数据挖掘笔记】兴趣度度量Interest of an association rule
在数据挖掘中,关联规则挖掘是一个重要的任务。兴趣度度量是评估关联规则的重要指标,以下是三个常用的兴趣度度量:支持度、置信度和提升度。 支持度(Support) 计算方法 支持度表示包含项集的事务占总事务的比例&…...

ArcGIS Pro调用多期历史影像
一、访问World Imagery Wayback,基本在我国范围 如下图: 二、 放大到您感兴趣的区域 三、 查看影像版本信息 点击第二步的按钮后,便可跳转至World Imagery (Wayback 2025-04-24)的相关信息。 四 、点击上图影像版本信息,页面跳转…...

Web3.0:互联网的去中心化未来
随着互联网技术的不断发展,我们正站在一个新时代的门槛上——Web3.0时代。Web3.0不仅仅是一个技术升级,它更是一种全新的互联网理念,旨在通过去中心化技术重塑网络世界。本文将深入探讨Web3.0的核心概念、技术基础、应用场景以及它对未来的深…...

java17
1.常见API之BigDecimal 底层存储方式: 2.如何分辨过时代码: 有横线的代码表示该代码已过时 3.正则表达式之字符串匹配 注意:如果X不是单一字符,需要加[]中括号 注意:1.想要表达正则表达式里面的.需要\\. 2.想要表…...

游戏引擎学习第283天:“让‘Standing-on’成为一个更严谨的概念
如果同时使用多个OpenGL上下文,并且它们都有工作负载,GPU或GPU驱动程序如何决定调度这些工作?我注意到Windows似乎优先处理活动窗口的OpenGL上下文(即活动窗口表现更好),挺有意思的…… 当多个OpenGL上下文…...

小白上手RPM包制作
目录 rpm常用命令 安装环境-Ruby 安装环境-fpm 关于服务器 打包-打包二进制工程 .fpm配置文件 打包-打没有文件的包 RPM 包微调 命令行参数 fpm --help RPM 签名 打包-制作NGINX的RPM包 关于rpmbuild 简单使用 打包之前的准备工作 rpmbuild 打包 - sniproxy …...

电商热销榜的5种实现方案
文章目录 1. MySQL 聚合查询:传统统计法2. Redis Sorted Set:内存排行榜3. Elasticsearch 实时聚合:搜索专家4. 缓存异步更新:榜单的幕后推手5. 大数据离线批处理:夜间魔法师 博主介绍:全网粉丝10w、CSDN合…...

车载诊断进阶篇 --- 车载诊断概念
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

AD 多层线路及装配图PDF的输出
装配图的输出: 1.点开‘智能PDF’ 2. 设置显示顶层: 设置显示底层: 多层线路的输出 同样使用‘智能PDF’...

FramePack - 开源 AI 视频生成工具
🎬 项目简介 由开发者 lllyasviel 创建的一个轻量级动画帧处理工具库,专门用于游戏开发、动画制作和视频处理中的帧序列打包与管理。该项目采用高效的算法实现,能够显著提升动画资源的处理效率。 此 AI 视频生成项目,旨在通过低显…...

“this”这个关键字
一、什么是“this”? 简单来说,“this”是每个非静态成员函数隐含的指针,它指向调用该成员函数的那个对象本身。 换句话说,当你调用对象的方法时,编译器会自动传入一个指针,指向你调用的“那个对象”&…...
+Gazebo+rqt下,无法显示仿真无人机的相机图像)
问题处理——在ROS2(humble)+Gazebo+rqt下,无法显示仿真无人机的相机图像
文章目录 前言一、问题展示二、解决方法:1.下载对应版本的PX42.下载对应版本的Gazebo3.启动 总结 前言 在ROS2的环境下,进行无人机仿真的过程中,有时需要调取无人机的相机图像信息,但是使用rqt,却发现相机图像无法显示…...
)
广度和深度优先搜索(BFS和DFS)
1. 广度和深度优先搜索(BFS和DFS) 1.1. Python实现BFS和DFS from collections import dequeclass Graph:"""无向图类,支持添加边,并实现了 BFS(广度优先搜索)和 DFS(深度优先搜…...

React和Vue在前端开发中, 通常选择哪一个
React和Vue的选择需结合具体需求: 选React的场景 大型企业级应用,需处理复杂状态(如电商、社交平台)团队熟悉JavaScript,已有React技术栈积累需要高度灵活的架构(React仅专注视图层,可自由搭配…...
和ref()函数详解))
Vue3学习(组合式API——reactive()和ref()函数详解)
目录 一、reactive()函数。 (1)介绍与使用。 (2)简单案例演示。 二、ref()函数。 (1)介绍与使用。 (2)简单案例演示。 <1>ref()函数获取响应式对象的本质与底层。 <2>基…...
二叉排序树)
数据结构 -- 树形查找(一)二叉排序树
二叉排序树 二叉排序树的定义 二叉排序树,又称二叉查找树 一棵二叉树或者是空二叉树,或者是具有以下性质的二叉树: 左子树上所有结点的关键字均小于根结点的关键字 右子树上所有结点的关键字均大于根结点的关键字 左子树和右子树又各是…...

【实战教程】从零实现DeepSeek AI多专家协作系统 - Spring Boot+React打造AI专家团队协作平台
🚀 本项目是DeepSeek大模型应用系列的V3版本,基于V1和V2版本的功能进行全面升级,引入了多智能体协作机制! 系列教程推荐阅读顺序: 【V1版本】零基础搭建DeepSeek大模型聊天系统 - Spring BootReact完整开发指南【V2版本…...

React事件机制
React事件机制 React 的事件机制是其实现高效、跨浏览器交互的核心系统,它通过 合成事件(SyntheticEvent)、事件委托(Event Delegation)、事件冒泡(Bubbling) 和 事件派发(Dispatch…...
)
LeetCode 45. 跳跃游戏 II(中等)
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返回到达 nums[n - 1] 的最…...

LeetCode 热题 100 437. 路径总和 III
LeetCode 热题 100 | 437. 路径总和 III 大家好,今天我们来解决一道经典的二叉树问题——路径总和 III。这道题在 LeetCode 上被标记为中等难度,要求计算二叉树中节点值之和等于给定目标值 targetSum 的路径数目。 问题描述 给定一个二叉树的根节点 ro…...

力扣.1471数组的k个最强值,力扣.1471数组的k个最强值力扣1576.替换所有的问号力扣1419.数青蛙编辑力扣300.最长递增子序列
目录 力扣.1471数组的k个最强值 力扣1576.替换所有的问号 力扣1419.数青蛙编辑 力扣300.最长递增子序列 力扣.1471数组的k个最强值 class Solution {public static int[] getStrongest(int[] arr,int k) {if(karr.length){return arr;}int []retnew int[k];int narr.lengt…...

使用itextsharp5.0版本来合并多个pdf文件并保留书签目录结构
using System; using System.Collections.Generic; using System.IO; using iTextSharp.text; using iTextSharp.text.pdf;public class PdfMergeUtility {/// <summary>/// 合并多个PDF文件并保留书签目录结构/// </summary>/// <param name"inputFiles&q…...

2025-5-15Vue3快速上手
1、setup和选项式API之间的关系 (1)vue2中的data,methods可以与vue3的setup共存 (2)vue2中的data可以用this读取setup中的数据,但是反过来不行,因为setup中的this是undefined (3)不建议vue2和vue3的语法混用…...