电商热销榜的5种实现方案
文章目录
- 1. MySQL 聚合查询:传统统计法
- 2. Redis Sorted Set:内存排行榜
- 3. Elasticsearch 实时聚合:搜索专家
- 4. 缓存+异步更新:榜单的幕后推手
- 5. 大数据离线批处理:夜间魔法师
博主介绍:全网粉丝10w+、CSDN合伙人、华为云特邀云享专家,阿里云专家博主、星级博主,51cto明日之星,热爱技术和分享、专注于Java技术领域
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
在电商平台中,展示“热销榜”是常见功能:哪些商品卖得最火?不同场景下有不同的实现思路。下面我们用幽默轻松的方式,介绍五种实现方案,包括它们的适用场景、优劣势以及技术选型建议,并附上简洁的代码示例。
1. MySQL 聚合查询:传统统计法
场景与原理:最直观的方法是直接用 MySQL 在订单表或销售记录表上做 GROUP BY 聚合,统计各商品销量后排序。比如:
SELECT product_id, SUM(quantity) AS total_sales
FROM order_items
WHERE order_date BETWEEN '2025-05-01' AND '2025-05-15'
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 10;
-
适用场景:数据量较小或业务量不大时,可以用这种「直接查」的方式,开发成本最低。适合中小型电商、离峰时间定时统计等场景。
-
优势:实现简单,代码容易理解;数据高度一致(强一致性)。使用索引、分区、物化视图等还能做一定优化。
-
劣势:面对海量数据时十分“煎熬”。例如,假设平台有50万用户、500万商品,如果订单行为记录有数亿条,对整个表做统计查询会非常耗时。查询太慢,写入时还可能因为锁表或锁行影响并发(例如点赞时需要更新计数列,会造成写冲突)。总之,用一个大锅把所有数据煮在一起再端出来,性能瓶颈明显。
-
技术建议:如果使用此方案,应尽量限制统计范围(如时间范围、热门品类)。可以考虑把历史数据分表分库,或者提前把每日/每月统计结果预先汇总到一个汇总表。还可以在业务角度做缓存——比如每天晚上离峰期预先统计好第二天的榜单,缩短展示延迟。
-
示例代码:下面用 Python 演示通过数据库查询热销榜(伪代码):
import mysql.connectorconn = mysql.connector.connect(host='db', database='shop', user='root', password='secret') cursor = conn.cursor() # 查询过去一周每个商品的总销量,取前10 cursor.execute("""SELECT product_id, SUM(quantity) AS total_salesFROM order_itemsWHERE order_date BETWEEN %s AND %sGROUP BY product_idORDER BY total_sales DESCLIMIT 10 """, ('2025-05-08', '2025-05-15')) for product_id, total in cursor.fetchall():print(product_id, total)这段代码直观易懂,但当
order_items表有数亿条记录时,查询很可能超时。
2. Redis Sorted Set:内存排行榜
场景与原理:Redis 的有序集合(ZSet)非常适合排行榜场景。可以把每个商品作为成员(member),销量作为分值(score),每次订单时用 ZINCRBY 更新分值,展示榜单时用 ZREVRANGE(按分值降序)取 TopN。这样排行榜信息都在内存中,查询极快。
ZINCRBY sales_rank 1 product_12345 # 商品ID为product_12345,销量加1
ZINCRBY sales_rank 2 product_67890 # 另一个商品销量加2
ZREVRANGE sales_rank 0 9 WITHSCORES # 获取销量最高的前10个商品及销量
-
适用场景:适合需要实时更新和查询的排行榜,比如秒杀活动、游戏积分榜、热销榜等。只要内存够用,Redis 的性能非常高,可以毫秒级完成更新和排序操作。
-
优势:读写速度快(Redis 基于内存),支持原子更新,无需复杂锁;获取 TopN 非常高效(底层跳表实现)。能方便地实现日榜、周榜、月榜等不同时间段的排行榜(只需按日期拆分不同的 ZSet key)。
-
劣势:数据是存内存的,需要足够内存存储排行数据。如果商品和时间维度很多,ZSet 的 key 数量会成倍增加,每次更新也要遍历多个 key(例如日榜、周榜、月榜都要加分);而且内存数据易丢失(需要持久化方案)。Redis 也不适合超大数据量的全量统计。
-
技术建议:适合对实时性要求高、单机数据量可控的场景。可结合定时持久化或 AOF 保存防止数据丢失。为节省内存,只存需要排行榜的热门商品,其他商品不入 Redis。榜单长度一般固定在 TopN,因此 Memory 不会“特别大”。
-
示例代码:下面用 Python 和
redis-py演示排行榜更新与查询:import redisr = redis.Redis(host='localhost', port=6379, db=0) # 模拟订单发生时更新排行榜 product_id = "product_12345" r.zincrby("sales_rank", 1, product_id) # 商品销量 +1 r.zincrby("sales_rank", 1, "product_67890") # 获取销量榜前10 top10 = r.zrevrange("sales_rank", 0, 9, withscores=True) for rank, (prod, score) in enumerate(top10, 1):print(rank, prod.decode(), int(score))上面示例中,
sales_rank是一个 ZSet 键,每个成员是商品ID,分值是累计销量。执行zincrby后,zrevrange能迅速返回前十。
3. Elasticsearch 实时聚合:搜索专家
场景与原理:Elasticsearch (ES) 作为分布式实时搜索引擎,也可用于排行查询。思路有两种:一是将商品信息及其实时销量作为文档存入 ES,并按销量字段排序;二是将每笔订单记录入 ES,然后用聚合(terms + sum)查询各商品销量。例如,使用聚合查询求前10销量商品:
GET /orders/_search
{"size": 0,"aggs": {"top_products": {"terms": {"field": "product_id","order": { "total_sales": "desc" },"size": 10},"aggs": {"total_sales": { "sum": { "field": "quantity" } }}}}
}
-
适用场景:适合需要复杂实时查询和分析的场景。Elasticsearch 是分布式、实时的搜索和分析引擎,可以水平扩展到集群,支持全文检索、过滤、聚合等多种能力。用于热销榜时,如果数据量较大,ES 可以并行聚合分片数据,返回结果。它的实时性比传统数据库要好一些。
-
优势:内置强大的聚合功能,可用来统计和排序;水平扩展容易加节点;结合 Kibana 等工具,可做可视化分析。对于数据量大、并发查询高的场景,分布式 ES 比单机 MySQL 更具吞吐。
-
劣势:ES 资源消耗大,需要更多内存和 CPU。“处理大量数据时可能会出现性能问题”,配置和调优复杂;数据一致性为近实时,写入到可查询需要一个小延迟;针对排行榜这种频繁更新分值的场景,每次写入文档后都需要刷新索引,消耗较大。此外,ES 专为搜索设计,用于高频率更新排名时并不是最优选择。StackOverflow 上就有人提到“对 ES 来说,每次更新都要重新计算排名,没办法做到排行”。
-
技术建议:若已有 ES 平台,可方便地扩展出排行榜功能。可将订单日志同步到 ES,并周期性运行聚合查询(近实时)。或者在商品索引中增加销量字段,每次订单后更新文档,但要注意批量刷新策略来减少开销。适合需要全文搜索与排行融合的场景,否则纯排行需求下,可以优先考虑 Redis 或缓存方案。
-
示例代码:下面示例用 ES 的 JSON 查询语言,统计各商品总销量并按降序取前10(相当于前面示例中的聚合查询):
GET /orders/_search {"size": 0,"aggs": {"top_products": {"terms": {"field": "product_id","order": { "total_sales": "desc" },"size": 10},"aggs": {"total_sales": { "sum": { "field": "quantity" } }}}} }上述查询返回了按销量排序的前 10 个
product_id。在实际代码中,可以使用官方客户端发起此查询。例如使用 Python 的elasticsearch库:from elasticsearch import Elasticsearches = Elasticsearch(["http://localhost:9200"]) res = es.search(index="orders", body={"size": 0,"aggs": {"top_products": {"terms": {"field": "product_id", "order": {"total_sales": "desc"}, "size": 10},"aggs": {"total_sales": {"sum": {"field": "quantity"}}}}} }) top = res['aggregations']['top_products']['buckets'] for bucket in top:print(bucket['key'], bucket['total_sales']['value'])需要注意的是,如果订单数量极大,上述聚合也会很耗时。一般可将 ES 用作对 MySQL 的补充分析,而非单纯排行榜的主要存储。
4. 缓存+异步更新:榜单的幕后推手
场景与原理:实时性需求高,但数据库写入慢时,可采用「写一遍缓存、后台慢慢同步」的方式。具体做法是:用户下单时,先更新缓存中的排行榜(如 Redis ZSet),并异步将增量消息发到消息队列;后台消费者接收消息后再更新关系型数据库或持久化存储。这样,排行榜可立即反馈给用户(低延迟),而数据库更新则异步执行,削峰填谷。
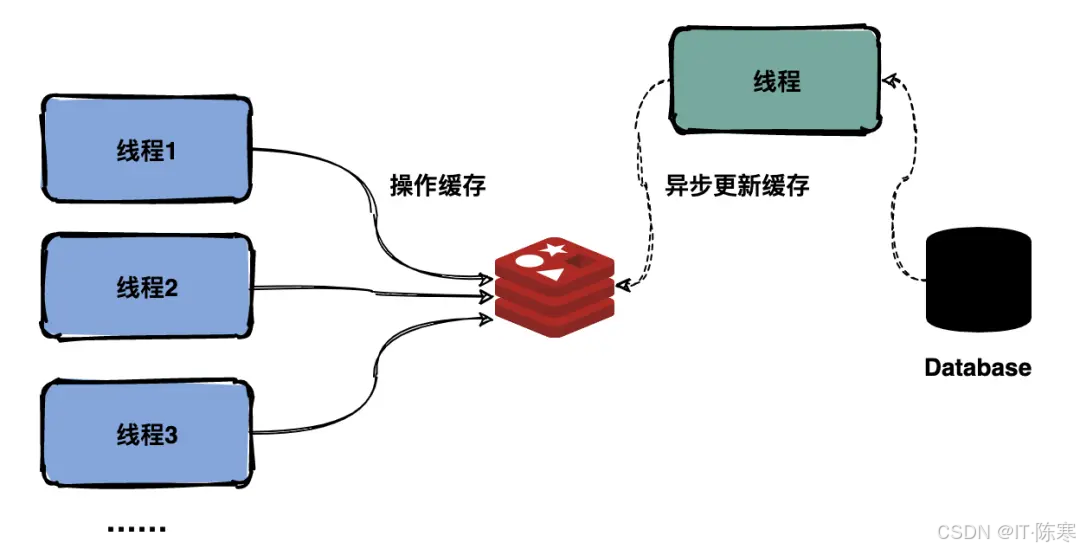
-
适用场景:适合对读高峰性能要求严格,而对最终一致性要求稍松的场景(例如排行榜不是严格金融账本)。当订单并发猛增时(秒杀场景),通过消息队列缓冲可平滑流量,避免 DB 瞬时写爆表。
-
优势:读操作(排行榜查询)都落在缓存层,速度飞快;写操作先写缓存,不阻塞用户流程;消息队列可应对突发流量,将写压力抛给后台,有一定的降峰功能;系统整体更解耦、灵活。
-
劣势:弱一致性:缓存与数据库之间可能存在短暂数据不一致,需要考虑延时刷新和缓存失效策略;系统复杂度提高,需要额外维护消息队列和后台服务;需要保证消息投递与消费的可靠性。
-
技术建议:常见做法是使用 Redis 作为排行榜缓存,RabbitMQ/Kafka 等消息中间件接收“销售事件”消息,后台服务消费后更新 MySQL 或 Elasticsearch。建议给“热Key”操作加分使用异步方式,防止缓存击穿或数据库死锁。
-
示例代码:下面用 Python 演示一个简化的异步更新流程(伪代码)。假设我们有一个消费订单的函数,当订单到来时我们更新 Redis 并发送消息到队列:
import redis, json import pika # RabbitMQ 客户端示例# 初始化 Redis 和消息队列(RabbitMQ) r = redis.Redis(host='localhost', port=6379, db=0) conn = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = conn.channel() channel.queue_declare(queue='sales_updates')def on_order_created(order):# 订单生成时更新缓存排行榜pid = order['product_id']qty = order['quantity']r.zincrby("sales_rank", qty, pid) # Redis 内存排行加分# 异步发消息给后台处理持久化msg = json.dumps({"product_id": pid, "increment": qty})channel.basic_publish(exchange='', routing_key='sales_updates', body=msg)# 后台消费者示例(可运行在另一个进程或服务) def process_sales_update(ch, method, properties, body):data = json.loads(body)pid = data['product_id']inc = data['increment']# 这里调用数据库接口,更新订单表或商品销量表update_database_sales(pid, inc)ch.basic_ack(delivery_tag=method.delivery_tag)在这个例子里,
on_order_created表示一个订单生产事件:它将销量更新到 Redis 排行榜,同时将消息放入sales_updates队列。后台有一个监听该队列的服务,异步处理并更新数据库。这样用户侧不会被数据库的锁或延迟拖慢。
5. 大数据离线批处理:夜间魔法师
场景与原理:当订单数据量极大(数亿、数十亿条)且对实时性要求不高时,可以使用大数据技术(如 Apache Spark、Flink 等)离线批处理生成热销榜。思路是把所有订单数据(日志、HDFS、数据湖或数据库快照)作为输入,通过分布式计算,按商品汇总销量,然后排序输出 TopN。因为是离线统计,往往在业务低峰期(如半夜)跑批任务,第二天再展示榜单。
-
适用场景:适合数据规模特别大或计算非常复杂的情况。例如电商全站级别的统计分析、定期报表、整站销量排行等。利用 Spark 或 Flink 的强大并行能力,可以在处理数十亿条记录后,快速生成榜单。
-
优势:可处理海量数据,横向扩容能力强;开发模型相对灵活,可合并多种数据源(订单库、点击流日志等),实现更复杂的统计。结果离线生成,数据库和应用不受高峰压力。
-
劣势:非实时,通常需要几分钟到几小时的延迟,不适合需要分钟级更新的榜单;需要运维大数据平台,学习成本和资源成本都较高;调度和监控复杂。
-
技术建议:可使用 Spark SQL、Flink 批处理等。将订单数据按时间分区存储(如 Parquet),定时触发批作业。注意采用适当的分区和聚合策略(如使用
groupBy+sum操作然后orderBy+limit)来获取 TopN。处理完后将榜单写入缓存或数据库,供服务端读取展示。 -
示例代码:以下是用 PySpark 简单演示的示例,假设有一张订单数据表,列有
product_id和quantity:from pyspark.sql import SparkSession from pyspark.sql.functions import desc, sum as _sumspark = SparkSession.builder.appName("HotProducts").getOrCreate() # 读取订单数据(例如已缓存为 Parquet 或从数据库导入) orders = spark.read.parquet("hdfs://.../data/orders.parquet") # 计算各商品总销量,取前10 top10 = (orders.groupBy("product_id").agg(_sum("quantity").alias("total_sales")).orderBy(desc("total_sales")).limit(10)) top10.show()这段代码将在整个集群上并行运行,对巨量订单数据分区聚合后输出前10名热销商品。生产环境中,可以把结果保存到 Hive 表或 NoSQL 存储,定时更新排行榜。
综上所述,不同的技术方案各有千秋:MySQL 聚合法简单但对海量场景“骨感”;Redis ZSet实时快速但占内存、易失效;Elasticsearch搜索力强、分布式友好,但更新开销大、配置复杂;缓存+异步方案读写分离、降峰有奇效;大数据离线能扛海量,但要等批作业完成。根据业务需求(实时性、数据量、成本等)权衡取舍,才能设计出既酷炫又靠谱的电商热销榜。
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
相关文章:

电商热销榜的5种实现方案
文章目录 1. MySQL 聚合查询:传统统计法2. Redis Sorted Set:内存排行榜3. Elasticsearch 实时聚合:搜索专家4. 缓存异步更新:榜单的幕后推手5. 大数据离线批处理:夜间魔法师 博主介绍:全网粉丝10w、CSDN合…...

车载诊断进阶篇 --- 车载诊断概念
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

AD 多层线路及装配图PDF的输出
装配图的输出: 1.点开‘智能PDF’ 2. 设置显示顶层: 设置显示底层: 多层线路的输出 同样使用‘智能PDF’...

FramePack - 开源 AI 视频生成工具
🎬 项目简介 由开发者 lllyasviel 创建的一个轻量级动画帧处理工具库,专门用于游戏开发、动画制作和视频处理中的帧序列打包与管理。该项目采用高效的算法实现,能够显著提升动画资源的处理效率。 此 AI 视频生成项目,旨在通过低显…...

“this”这个关键字
一、什么是“this”? 简单来说,“this”是每个非静态成员函数隐含的指针,它指向调用该成员函数的那个对象本身。 换句话说,当你调用对象的方法时,编译器会自动传入一个指针,指向你调用的“那个对象”&…...
+Gazebo+rqt下,无法显示仿真无人机的相机图像)
问题处理——在ROS2(humble)+Gazebo+rqt下,无法显示仿真无人机的相机图像
文章目录 前言一、问题展示二、解决方法:1.下载对应版本的PX42.下载对应版本的Gazebo3.启动 总结 前言 在ROS2的环境下,进行无人机仿真的过程中,有时需要调取无人机的相机图像信息,但是使用rqt,却发现相机图像无法显示…...
)
广度和深度优先搜索(BFS和DFS)
1. 广度和深度优先搜索(BFS和DFS) 1.1. Python实现BFS和DFS from collections import dequeclass Graph:"""无向图类,支持添加边,并实现了 BFS(广度优先搜索)和 DFS(深度优先搜…...

React和Vue在前端开发中, 通常选择哪一个
React和Vue的选择需结合具体需求: 选React的场景 大型企业级应用,需处理复杂状态(如电商、社交平台)团队熟悉JavaScript,已有React技术栈积累需要高度灵活的架构(React仅专注视图层,可自由搭配…...
和ref()函数详解))
Vue3学习(组合式API——reactive()和ref()函数详解)
目录 一、reactive()函数。 (1)介绍与使用。 (2)简单案例演示。 二、ref()函数。 (1)介绍与使用。 (2)简单案例演示。 <1>ref()函数获取响应式对象的本质与底层。 <2>基…...
二叉排序树)
数据结构 -- 树形查找(一)二叉排序树
二叉排序树 二叉排序树的定义 二叉排序树,又称二叉查找树 一棵二叉树或者是空二叉树,或者是具有以下性质的二叉树: 左子树上所有结点的关键字均小于根结点的关键字 右子树上所有结点的关键字均大于根结点的关键字 左子树和右子树又各是…...

【实战教程】从零实现DeepSeek AI多专家协作系统 - Spring Boot+React打造AI专家团队协作平台
🚀 本项目是DeepSeek大模型应用系列的V3版本,基于V1和V2版本的功能进行全面升级,引入了多智能体协作机制! 系列教程推荐阅读顺序: 【V1版本】零基础搭建DeepSeek大模型聊天系统 - Spring BootReact完整开发指南【V2版本…...

React事件机制
React事件机制 React 的事件机制是其实现高效、跨浏览器交互的核心系统,它通过 合成事件(SyntheticEvent)、事件委托(Event Delegation)、事件冒泡(Bubbling) 和 事件派发(Dispatch…...
)
LeetCode 45. 跳跃游戏 II(中等)
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返回到达 nums[n - 1] 的最…...

LeetCode 热题 100 437. 路径总和 III
LeetCode 热题 100 | 437. 路径总和 III 大家好,今天我们来解决一道经典的二叉树问题——路径总和 III。这道题在 LeetCode 上被标记为中等难度,要求计算二叉树中节点值之和等于给定目标值 targetSum 的路径数目。 问题描述 给定一个二叉树的根节点 ro…...

力扣.1471数组的k个最强值,力扣.1471数组的k个最强值力扣1576.替换所有的问号力扣1419.数青蛙编辑力扣300.最长递增子序列
目录 力扣.1471数组的k个最强值 力扣1576.替换所有的问号 力扣1419.数青蛙编辑 力扣300.最长递增子序列 力扣.1471数组的k个最强值 class Solution {public static int[] getStrongest(int[] arr,int k) {if(karr.length){return arr;}int []retnew int[k];int narr.lengt…...

使用itextsharp5.0版本来合并多个pdf文件并保留书签目录结构
using System; using System.Collections.Generic; using System.IO; using iTextSharp.text; using iTextSharp.text.pdf;public class PdfMergeUtility {/// <summary>/// 合并多个PDF文件并保留书签目录结构/// </summary>/// <param name"inputFiles&q…...

2025-5-15Vue3快速上手
1、setup和选项式API之间的关系 (1)vue2中的data,methods可以与vue3的setup共存 (2)vue2中的data可以用this读取setup中的数据,但是反过来不行,因为setup中的this是undefined (3)不建议vue2和vue3的语法混用…...

Kafka消费者分组机制深度解析
一、集群协调者 1.1 GroupCoordinator的元数据管理 每个Broker内置的GroupCoordinator实例通过哈希算法确定消费者组的归属权。其内存模型维护三个核心数据结构: 成员注册表:采用跳表结构存储消费者ID与心跳时间戳,支持快速查询和过期检测…...

Python 类变量与实例变量完全指南:区别、使用场景及常见陷阱
类变量与实例变量的区别总结 代码示例 class Example:class_var "我是类变量,所有实例共享我" # 类变量def __init__(self, name):self.name name # 实例变量,每个实例独有def modify_class_var(self, new_value):Example.class_var ne…...

Ubuntu Linux bash的相关默认配置文件内容 .profile .bashrc, /etc/profile, /etc/bash.bashrc等
文章目录 文件的source顺序/etc/profile:系统级配置/etc/bash.bashrc:bash终端的系统级配置~/.profile:用户级配置~/.bashrc bash:终端的主要配置~/.bash_logout:bash终端登出时清理 建议的额外配置: 安装 …...

redis解决常见的秒杀问题
title: redis解决常见的秒杀问题 date: 2025-03-07 14:24:13 tags: redis categories: redis的应用 秒杀问题 每个店铺都可以发布优惠券,保存到 tb_voucher 表中;当用户抢购时,生成订单并保存到 tb_voucher_order 表中。 订单表如果使用数据…...

Springboot3自定义starter笔记
场景:抽取聊天机器人场景,它可以打招呼。 效果:任何项目导入此 starter 都具有打招呼功能,并且问候语中的人名需要可以在配置文件中修改。 创建自定义 starter 项目,引入 spring-boot-starter 基础依赖。 <dependen…...
基本概念)
Modern C++(一)基本概念
1、基本概念 1.1、注释 注释在翻译阶段3会被替换为单个空白字符从程序中移除 1.2、名字与标识符 标识符是一个由数字、下划线、大小写字符组成的任意长度序列。有效的标识符首个字符必须是以A-Z、a-z、下划线开头,。有效的标识符其他字符可以是0-9、A-Z、a-z、下…...

Apache HttpClient 5 用法-Java调用http服务
Apache HttpClient 5 核心用法详解 Apache HttpClient 5 是 Apache 基金会推出的新一代 HTTP 客户端库,相比 4.x 版本在性能、模块化和易用性上有显著提升。以下是其核心用法及最佳实践: 一、添加依赖 Maven 项目: <dependency><…...
)
Python中plotext 库详细使用(命令行界面中直接绘制各种图形)
更多内容请见: python3案例和总结-专栏介绍和目录 文章目录 plotext概述1.1 plotext介绍1.2 安装二、基本用法2.1 简单绘图2.2 散点图2.3 折线图2.4 条形图2.5 直方图2.6 标题和坐标轴标签2.7 网格和坐标轴2.8 颜色和样式2.9 多图叠加三、高级功能3.1 多图绘制3.2 对数坐标3.3…...

【Java Web】速通JSON
参考笔记:JavaWeb 速通JSON_java webapi调用传json与head-CSDN博客 目录 1.JSON基本介绍 2.JSON串的格式 3.JSON在客户端/浏览器的使用 3.1 JavaScript对象和JSON串的相互转换 3.2 案例演示 4.JSON在服务端的使用 4.1 基本说明 4.2 应用场景 4.2.1 JSON字…...

Ubuntu 20.04 LTS 中部署 网页 + Node.js 应用 + Nginx 跨域配置 的详细步骤
Ubuntu 20.04 LTS 中部署 网页 Node.js 应用 Nginx 跨域配置 的详细步骤 一、准备工作1、连接服务器2、更新系统 二、安装 Node.js 环境1、安装 Node.js 官方 PPA(用于获取最新稳定版):2、安装 Node.js 和 npm(LTS 长期支持版本…...

java中XML的使用
文章目录 什么是XML特点XML作用XML的编写语法基本语法特殊字符编写 约束XML的书写格式DTD文档schema文档属性命名空间XML命名空间的作用 解析XML的方法DOM解析XMLDOM介绍DOM解析包:org.w3c.dom常用接口DOM解析包的使用保存XML文件添加DOM节点修改/删除DOM节点 S…...

Spark SQL 之 Analyzer
Spark SQL 之 Analyzer // Special case for Project as it supports lateral column alias.case p: Project =>val resolvedNoOuter = p.projectList.map(resolveExpressionByPlanChildren(_, p...

Java - Junit框架
单元测试:针对最小的功能单元(方法),编写测试代码对该功能进行正确性测试。 Junit:Java语言实现的单元测试框架,很多开发工具已经集成了Junit框架,如IDEA。 优点 编写的测试代码很灵活,可以指某个测试方法…...

麒麟系统ARM64架构部署mysql、jdk和java项目
麒麟系统ARM64架构部署mysql、jdk和java项目 一、mysql8的安装 操作步骤: 先下载mysql安装包 下载地址:https://downloads.mysql.com/archives/community/ 由于官网里,mysql5.7以及更低版本不支持arm版本的,只能安装mysql8。…...

修复“ImportError: DLL load failed while importing lib: 找不到指定的程序”笔记
#工作记录 一、问题描述 在运行CosyVoice_For_Windows项目时,出现以下报错: Traceback (most recent call last): File "D:\ProgramData\anaconda3\envs\CosyVoice\Lib\pydoc.py", line 457, in safeimport module __import__(path) …...

vllm量化03—INT4 W4A16
本系列基于Qwen2.5-7B,学习如何使用vllm量化,并使用benchmark_serving.py、lm_eval 测试模型性能和评估模型准确度。 测试环境为: OS: centos 7 GPU: nvidia l40 driver: 550.54.15 CUDA: 12.3本文是该系列第3篇——INT4 W4A16 一、量化 f…...

VScode各文件转化为PDF的方法
文章目录 代码.py文件.ipynb文本和代码夹杂的文件方法 1:使用 VS Code 插件(推荐)步骤 1:安装必要插件步骤 2:安装 `nbconvert`步骤 3:间接导出(HTML → PDF)本文遇见了系列错误:解决方案:问题原因步骤 1:降级 Jinja2 至兼容版本步骤 2:确保 nbconvert 版本兼容替代…...

AI日报 · 2025年5月15日|GPT-4.1 登陆 ChatGPT
AI日报 2025年5月15日|GPT-4.1 登陆 ChatGPT 1、OpenAI 在 ChatGPT 全面开放 GPT-4.1 与 GPT-4.1 mini 北京时间 5 月 14 日晚,OpenAI 在官方 Release Notes 中宣布:专为复杂代码与精细指令场景打造的 GPT-4.1 正式加入 ChatGPT࿰…...

高效管理多后端服务:Nginx 配置与实践指南
在现代的 Web 开发和运维中,一个系统往往由多个后端服务组成,每个服务负责不同的功能模块。例如,一个电商网站可能包括用户服务、订单服务和支付服务,每个服务都运行在独立的服务器或容器中。为了高效地管理这些服务并提供统一的访…...
)
从代码学习深度学习 - 实战 Kaggle 比赛:图像分类 (CIFAR-10 PyTorch版)
文章目录 前言1. 读取并整理数据集1.1 读取标签文件1.2 划分训练集和验证集1.3 整理测试集1.4 执行数据整理2. 图像增广2.1 训练集图像变换2.2 测试集(和验证集)图像变换3. 读取数据集3.1 创建 Dataset 对象3.2 创建 DataLoader 对象4. 定义模型4.1 获取 ResNet-18 模型4.2 损…...

什么是路由器环回接口?
路由器环回接口(LoopbackInterface)是网络设备中的一种逻辑虚拟接口,不依赖物理硬件,但在网络配置和管理中具有重要作用。以下是其核心要点: 一、基本特性 1.虚拟性与稳定性 环回接口是纯软件实现的逻辑接口&#x…...

【高频面试题】LRU缓存
文章目录 1 相关前置知识(OS)2 面试题 16.25. LRU 缓存2.1 题面2.2 示例2.3 解法1 (双端队列哈希表)思路 2.4 解法2思路 3 参考 1 相关前置知识(OS) 为什么需要页面置换算法:当进程运行时&…...

Golang
本文来源 :腾讯元宝 Go语言(又称Golang)是由Google开发的一种现代编程语言,自2009年发布以来,因其简洁性、高性能和内置并发支持而广受欢迎。以下是关于Go语言的核心特点和优势的总结: 1. 核心特点…...

20250515配置联想笔记本电脑IdeaPad总是使用独立显卡的步骤
20250515配置联想笔记本电脑IdeaPad总是使用独立显卡的步骤 2025/5/15 19:55 百度:intel 集成显卡 NVIDIA 配置成为 总是用独立显卡 百度为您找到以下结果 ?要将Intel集成显卡和NVIDIA独立显卡配置为总是使用独立显卡,可以通过以下步骤实现?ÿ…...

『已解决』Python virtualenv_ error_ unrecognized arguments_--wheel-bundle
📣读完这篇文章里你能收获到 🐍 了解 virtualenv 参数错误的原因及解决方案📦 学习如何正确配置 Python 虚拟环境 文章目录 前言一、问题描述1.1 错误现象1.2 影响范围 二、问题分析2.1 根本原因 三、解决方案3.1 兼容处理3.2 完整解决方案 …...

使用 Apache POI 生成 Word 文档
创建一个包含标题、段落和表格的简单文档。 步骤 1:添加依赖 确保你的项目中已经添加了 Apache POI 的依赖。如果你使用的是 Maven,可以在 pom.xml 中添加以下内容: <dependency><groupId>org.apache.poi</groupId>...

表记录的检索
1.select语句的语法格式 select 字段列表 from 表名 where 条件表达式 group by 分组字段 [having 条件表达式] order by 排序字段 [asc|desc];说明: from 子句用于指定检索的数据源 where子句用于指定记录的过滤条件 group by 子句用于对检索的数据进行分组 ha…...

【PX4飞控】在 Matlab Simulink 中使用 Mavlink 协议与 PX4 飞行器进行交互
这里列举一些从官网收集的比较有趣或者实用的功能。 编写 m 脚本与飞行器建立 UDP 连接,并实时可视化 Mavlink 消息内容,或者读取脚本离线分析数据。不光能显示 GPS 位置或者姿态等信息的时间曲线,可以利用 Matlab Plot 功能快速定制化显示一…...
整合scRNA-seq 和空间转录组学揭示了子宫内膜癌中 MDK-NCL 依赖性免疫抑制环境)
文章复现|(1)整合scRNA-seq 和空间转录组学揭示了子宫内膜癌中 MDK-NCL 依赖性免疫抑制环境
https://www.frontiersin.org/journals/immunology/articles/10.3389/fimmu.2023.1145300/full 目标:肿瘤微环境(TME)在子宫内膜癌(EC)的进展中起着重要作用。我们旨在评估EC的TME中的细胞群体。 方法:我们从GEO下载了EC的单细胞RNA测序(scRNA-seq)和空…...

自用Vscode 配置c++ debug环境
前言 使用vscode配置c debug环境的好处 1、可以借助vscode方便轻量的扩展和功能 2、避免了传统使用gdb 复杂按键以及不够直观的可视化 3、方便一次运行,断点处查看变量,降低找bug难度 4、某大公司项目采用类似配置,经过实践检验 配置c运行环…...

STM32单片机内存分配详细讲解
单片机的内存无非就两种,内部FLASH和SRAM,最多再加上一个外部的FLASH拓展。在这里我以STM32F103C8T6为例子讲解FLASH和SRAM。 STM32F103C8T6具有64KB的闪存和20KB的SRAM。 一. Flash 1.1 定义 非易失性存储器,即使在断电后,其所…...

从算力困境到创新突破:GPUGEEK如何重塑我的AI开发之旅
目录 从算力困境到创新突破:GPUGEEK如何重塑我的AI开发之旅开发者的算力挣扎:一个不得不面对的现实AI算力市场的尴尬现状:为什么我们需要另辟蹊径1. 资源分配失衡与价格壁垒2. 技术门槛与环境复杂性 GPUGEEK深度剖析:不只是又一个…...

基于OpenCV的人脸微笑检测实现
文章目录 引言一、技术原理二、代码实现2.1 关键代码解析2.1.1 模型加载2.1.2 图像翻转2.1.3 人脸检测 微笑检测 2.2 显示效果 三、参数调优建议四、总结 引言 在计算机视觉领域,人脸检测和表情识别一直是热门的研究方向。今天我将分享一个使用Python和OpenCV实现…...