Oracle-相关笔记
Oracle Database Online Documentation 11g
连接
Win+R
sqlplus username/password@hostname:port/service_namesqlplus user02/123456@192.xxx:1521/orclsqlplus / as sysdba#SQL*Plus 終端编码使用UTF-8
chcp 65001#打开SQL*Plus程序
sqlplus /nolog#使用dba角色登录(用
1.sqlplus / as sysdba 这是典型的操作系统认证,不需要listener进程
2.sqlplus sys/oracle 这种连接方式只能连接本机数据库,同样不需要listener进程
3.sqlplus sys/oracle@orcl 这种方式需要listener进程处于可用状态。最普遍的通过网络连接。)conn sys/123456@QJJK AS SYSDBASID
SID 是 Oracle 数据库实例的唯一标识符,用于区分同一主机上的多个数据库实例。
Oracle 中的 SID(System Identifier) 是用于标识一个数据库实例的唯一名称,通常在单实例数据库环境中使用。
一个服务器可以创建多个Oracle实例来区分业务。例如,一个服务器可以同时运行 ORCL, TESTDB, FINANCE 等多个实例,它们互不干扰、各自管理自己的数据库。
每个 Oracle 数据库实例都有一个唯一的 SID。
SELECT instance_name FROM v$instance;
SID和用户的关系:
用户属于SID下的。
🔹 3. 一个 SID 中可以有多个用户
常见用户:
SYS、SYSTEM、HR、SCOTT、自定义的业务用户等。每个用户拥有独立的权限、对象、空间。
Java驱动
- Oracle 19c: 推荐使用
ojdbc8或更高版本。 - Oracle 12c: 使用
ojdbc7或ojdbc8。 - Oracle 11g: 使用
ojdbc6或ojdbc7。
SELECT * FROM v$version;
用户相关
创建用户
create user USER99 identified by "123456" default tablespace USERS temporary tablespace TEMP profile DEFAULT; # 创建用户
-- 创建用户USER99,密码是123456
create user USER99identified by "123456"default tablespace USERS -- 指定用户的默认表空间为 USERStemporary tablespace TEMP -- 指定用户的临时表空间为 TEMPprofile DEFAULT; -- 指定用户的资源限制和密码管理策略为 DEFAULT 配置文件-- 授予连接权限:允许用户连接到数据库
grant connect to USER99; -- 授予 DBA 角色的权限:
grant dba to USER99;-- 授予资源权限:允许用户创建表、序列等对象。
grant resource to USER99;-- 授予用户 无限制表空间 权限:授予此权限的用户可以在任何表空间中使用无限空间,意味着他们不受表空间的存储配额限制
grant unlimited tablespace to USER99;删除用户
DROP USER 用户名 [CASCADE];
CASCADE表示会删除用户及其所有对象(包括表、视图、存储过程等)。- 如果没有加
CASCADE,Oracle 会报错,提示该用户拥有对象无法删除。
存储过程
零基础学SQL(十二、存储过程)_sql创建存储过程-CSDN博客
完成指定功能的一段sql的集合,可以看作一个方法使用。
比如我写过的这个,查询前一天的异常数量,并将异常数量汇总到STATISTICS_LOG表中:
CREATE OR REPLACE PROCEDURE "PROC_CAL_SERVER_STATUS_LOG"
AS
TYPE TYPE_ARRAY IS TABLE OF VARCHAR2(20) INDEX BY BINARY_INTEGER;DATA_DATE NUMBER;
--定义当前日期
V_CUR_DATE VARCHAR2(20);
V_CUR_NUM INT;
V_EXE_SQL VARCHAR2(255);
V_TYPE VARCHAR2(20);--定义一个数组
TYPES TYPE_ARRAY;V_SOFTWAEW_TYPE VARCHAR2(20);
V_TOTAL_TYPE VARCHAR2(50);
V_SELECT_SQL VARCHAR2(255);
BEGIN--给数组赋值TYPES(1):= 'SERVER_STATUS';TYPES(2):= 'SOFTWARE_STATUS';TYPES(3):= 'DEVICE_STATUS';TYPES(4):= 'DBTABLE_STATUS';TYPES(5):= 'FOLDER_STATUS';TYPES(6):= 'SWICHER_STATUS';TYPES(7):= 'SWICHER_LINE_STATUS';TYPES(8):= 'SIG_STATUS';TYPES(9):= 'TEM_HUM_STATUS';TYPES(10):= 'ACU_STATUS';-- 前一天日期V_CUR_DATE := TO_CHAR(SYSDATE-1,'YYYYMMDD');-- 遍历TYPES数组FOR i IN 1..TYPES.COUNT LOOP--当前V_TYPE := TYPES(i);V_TOTAL_TYPE := TYPES(i) || '_LOG';-- 给V_SELECT_SQL赋值V_SELECT_SQL := 'SELECT COUNT(*) FROM '|| V_TOTAL_TYPE ||' WHERE RUN_STATUS = ''异常'' and status_time >= trunc(sysdate-1) and status_time < trunc(sysdate)';DBMS_OUTPUT.put_line(V_SELECT_SQL);-- 执行sql语句,并将结果赋值给V_CUR_NUMEXECUTE IMMEDIATE V_SELECT_SQL INTO V_CUR_NUM;V_EXE_SQL := 'INSERT INTO STATISTICS_LOG(STATUS_TIME, NUM, DEVICE_TYPE) VALUES(TO_DATE(' || '''' || V_CUR_DATE || '''' || ',''yyyyMMdd''), '|| V_CUR_NUM || ',' || '''' || V_TYPE || '''' || ')';EXECUTE IMMEDIATE V_EXE_SQL;END LOOP;COMMIT;
END;
TYPE TYPE_ARRAY IS TABLE OF VARCHAR2(20) INDEX BY BINARY_INTEGER;是声明了一个 PL/SQL 中的关联数组类型(Associative Array Type),其键是BINARY_INTEGER类型,值是VARCHAR2(20)类型。这种类型通常用于在 PL/SQL 中创建临时的索引数组,可以通过整数索引进行访问。在你的代码中,TYPES就是这样一个关联数组。
--创建了一个存储过程,可以打印当前时间
CREATE OR REPLACE PROCEDURE MY_PRO_TEST ASV_CUR_DATE VARCHAR2(20);V_SELECT_SQL VARCHAR2(255);
BEGINV_SELECT_SQL := 'SELECT TO_CHAR(SYSDATE, ''YYYY-MM-DD HH24:MI:SS'') FROM dual';EXECUTE IMMEDIATE V_SELECT_SQL INTO V_CUR_DATE;DBMS_OUTPUT.put_line(V_CUR_DATE);
end;-- 将30天以前的日志清除,防止表数据量过大
CREATE OR REPLACE PROCEDURE CLEAR_LOG
AS
BEGINDELETE * FROM ACU_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;DELETE * FROM DBTABLE_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;DELETE * FROM DEVICE_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;DELETE * FROM SIG_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;DELETE * FROM SERVER_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;DELETE * FROM SWICHER_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;DELETE * FROM SWICHER_LINE_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;DELETE * FROM TEM_HUM_STATUS_LOG WHERE STATUS_TIME < SYSDATE - 30;
COMMIT;
END定时任务
Oracle定时任务 - 乐子不痞 - 博客园
--创建
DECLARExxxjobid number;
BEGINDBMS_JOB.SUBMIT(JOB => xxxjobid,WHAT => 'begin 存储过程名; end; 或者 SQL语句;',NEXT_DATE => sysdate+3/(24*60),/**初次执行时间,当前时间的3分后*/interval => '' /**每次执行的间隔时间*/);
commit;
end;--查询定时任务
SELECT * FROM DBA_JOBS;
SELECT * FROM USER_JOBS;举例:
CREATE OR REPLACE PROCEDURE MY_PRO_TEST AS
BEGININSERT INTO MY_TEST(MY_TIME) VALUES(sysdate);
end;DECLAREprintTime NUMBER;
BEGINDBMS_JOB.SUBMIT(JOB => printTime,WHAT => 'begin my_pro_test; end;',INTERVAL =>'TRUNC(SYSDATE+1)' );COMMIT;
END;每天凌晨12点执行上面那个定时任务。
序列
用于11g中id自增:
-- 创建一个序列
CREATE SEQUENCE seq_init_adsb_part_id START WITH 1 INCREMENT BY 1 NOCACHE;-- 创建触发器自动填充 ID
CREATE OR REPLACE TRIGGER trg_init_adsb_part_idBEFORE INSERT ON init_adsb_partFOR EACH ROWWHEN (NEW.id IS NULL)
BEGINSELECT seq_init_adsb_part_id.NEXTVAL INTO :NEW.id FROM dual;
END;SELECT * from user_sequences; -- **修改序列的last_number值
DROP SEQUENCE sys_user_seq;create sequence USER05.sys_user_seq
minvalue 1
maxvalue 9999999999999999999999999999
start with 105
increment by 1
nocache;导入导出
exp导出的话,如果表没有分配存储空间,会漏掉:
查询尚未分配存储空间的数据表,在 Oracle 数据库中,当创建表时,可能没有立即分配存储空间,而是在插入数据时自动分配。
select 'alter table '||table_name||' allocate extent;' from user_tables WHERE SEGMENT_CREATED='NO';然后上面命令执行完,将每个结果运行,给没有分配存储空间的表分配存储空间,再exp导出
导出cmd命令行:
只导出USER02的:
exp user01/123456@192.168.31.47:1521/QJJK owner=user01 file=E:\ljl\notes\work\linjl\user01.dmp log=E:\ljl\notes\work\linjl\user01_export_log.log导入命令行命令:
imp USER011/123456@192.168.31.47:1521/QJJK file=E:\ljl\notes\work\linjl\user01.dmp fromuser=USER01 touser=USER011表空间
Managing Database Storage Structures
数据库被划分为多个称为表空间的逻辑存储单元,这些单元将相关的逻辑结构(例如表、视图和其他数据库对象)分组。例如,可以将所有应用程序对象分组到单个表空间中,以简化维护操作。
表空间由一个或多个物理数据文件组成。分配给表空间的数据库对象存储在该表空间的物理数据文件中。
当您创建 Oracle 数据库时,一些表空间已经存在,例如SYSTEM和SYSAUX。
表空间提供了一种在存储上物理定位数据的方法。定义组成表空间的数据文件时,需要指定这些文件的存储位置。例如,您可以将某个表空间的数据文件位置指定为指定的主机目录(即某个磁盘卷)或指定的 Oracle 自动存储管理磁盘组。分配给该表空间的任何模式对象都将位于指定的存储位置。表空间还提供备份和恢复的单元。Oracle 数据库的备份和恢复功能使您能够在表空间级别进行备份或恢复。
| 表空间 | 描述 |
|---|---|
| 此表空间包含 Oracle 数据库附带的示例模式。这些示例模式为示例提供了一个通用平台。Oracle 文档和培训资料包含基于这些示例模式的示例。 | |
| 此表空间在创建数据库时自动创建。Oracle 数据库使用它来管理数据库。它包含数据字典,即一组用于特定数据库的只读引用的表和视图。它还包含各种包含数据库管理信息的表和视图。这些信息都包含在 | |
| 这是表空间的辅助表空间 表 安装期间用作默认表空间的组件 | |
| 此表空间存储处理 SQL 语句时生成的临时数据。例如,此表空间可用于查询排序。每个数据库都应该有一个临时表空间,并分配给用户作为其临时表空间。在预配置的数据库中,此 | |
| 这是数据库用来存储撤消信息的撤消表空间。请参阅“管理撤消数据”以了解 Oracle 数据库如何使用撤消表空间。每个数据库都必须有一个撤消表空间。 | |
| 此表空间用于存储永久用户对象和数据。与 |
自动扩展表空间
您可以将表空间设置为在达到其大小限制时自动扩展指定量。如果未启用自动扩展功能,则当表空间达到其临界阈值或警告阈值时,您会收到警报。临界阈值和警告阈值参数具有默认值,您可以随时更改这些默认值。这些参数还会针对接近其指定大小限制的自动扩展表空间生成警报。您可以通过手动增加表空间大小来应对大小警报。您可以通过增加一个或多个表空间数据文件的大小,或向表空间添加另一个数据文件来实现。
-- 此条SQL可以非常直观的看到数据库中各个表空间的实时使用率情况
selecta.tablespace_name, -- 表空间名称total, -- 总大小(MB)free, -- 空闲大小(MB)total - free as used, -- 已用大小(MB)ROUND(free / total * 100, 2) AS "FREE%",ROUND((total - free) / total * 100, 2) AS "USED%"from (select tablespace_name, sum(bytes) / 1024 / 1024 as totalfrom dba_data_filesgroup by tablespace_name) a,(select tablespace_name, sum(bytes) / 1024 / 1024 as freefrom dba_free_spacegroup by tablespace_name) b
where a.tablespace_name = b.tablespace_name
order by a.tablespace_name;SELECTfile_id,file_name,tablespace_name,autoextensible,bytes / 1024 / 1024 AS size_mb,maxbytes / 1024 / 1024 AS max_size_mb
FROMdba_data_files
ORDER BYtablespace_name, file_id;| 字段名 | 含义说明 |
|---|---|
file_id | 数据文件编号 |
file_name | 数据文件的路径和文件名 |
tablespace_name | 所属的表空间名称 |
autoextensible | 是否开启了自动扩展(YES/NO) |
size_mb | 当前文件大小(单位 MB) |
max_size_mb | 最大可扩展至的大小(单位 MB) |
优化器
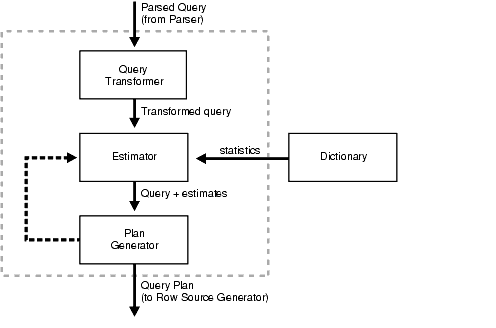
本章讨论SQL处理、优化方法以及查询优化器(通常称为优化器)如何选择特定的计划来执行SQL。
Oracle优化器就是用来确定如何执行SQL才是最优的。
优化器是内置软件,可确定执行 SQL 语句的最有效方法。
优化器操作
数据库可以通过多种方式执行SQL语句,例如全表扫描、索引扫描、嵌套循环和哈希连接。
优化器在确定执行计时会考虑与查询中的对象和条件相关的许多因素。此确定是SQL处理中的重要步骤,并且会极大地影响执行时间。
优化器在不同版本的Oracle数据库之间做出的决策可能有所不同。在较新的版本中,优化器可能会做出不同的决策,因为可以获得更准确的信息。
当用户提交SQL语句执行时,优化器执行以下步骤:
1、优化器根据可用的访问路径和提示为 SQL 语句生成一组潜在计划。
2、优化器根据数据字典中的统计信息估算每个计划的成本。统计信息包括语句访问的表、索引和分区的数据分布和存储特性信息。
3、这cost是一个预估值,与使用特定计划执行语句所需的预期资源使用量成比例。优化器会根据预估的计算机资源(包括 I/O、CPU 和内存)来计算访问路径和连接顺序的成本。
成本较高的串行计划比成本较低的串行计划执行时间更长。使用并行计划时,资源使用量与运行时间没有直接关系。
优化器比较各个计划并选择成本最低的计划。
优化器的输出是一个执行计划,它描述了最佳的执行方法。该计划展示了 Oracle 数据库执行 SQL 语句所使用的步骤组合。每个步骤要么从数据库中物理检索行,要么为发出语句的用户准备行。
全表扫描
这种类型的扫描会读取表中的所有行,并过滤掉那些不符合选择条件的行。在全表扫描期间,表中所有位于扫描高水位线。高水位线表示已用空间量,或已格式化为接收数据的空间量。检查每一行以确定其是否满足语句的WHERE子句。
当 Oracle 数据库执行全表扫描时,会按顺序读取数据块。由于数据块相邻,数据库可以进行大于单个数据块的 I/O 调用,以加快读取速度。读取调用的大小范围从一个数据块到初始化参数指定的数据块数。DB_FILE_MULTIBLOCK_READ_COUNT使用多块读取,数据库可以非常高效地执行全表扫描。数据库每个块仅读取一次。
1、为什么全表扫描在访问大量数据时速度更快
当访问表中的大部分数据块时,全表扫描比索引范围扫描的开销更小。全表扫描可能会使用较大的 I/O 调用,而较少的大型 I/O 调用比多次较小的 I/O 调用开销更小。
2、当优化器使用全表扫描时
在以下任一情况下,优化器都会使用全表扫描:
2.1、缺少索引
如果查询无法使用现有索引,也就是索引失效。则使用全表扫描。例如,如果查询中索引列上使用了函数,则优化器无法使用索引,而是使用全表扫描。
如果您需要使用索引进行不区分大小写的搜索,则要么不允许搜索列中出现大小写混合的数据,要么在搜索列上创建基于函数的索引,例如UPPER( )。请参阅“使用基于函数的索引来提高性能”。last_name
2.2、大量数据
如果优化器认为查询需要表中的大多数块,那么它会使用全表扫描,即使索引可用。
2.3、小表
如果表中包含的DB_FILE_MULTIBLOCK_READ_COUNT高水位线以下的块少于数据库可以在单个 I/O 调用中读取的块,则全表扫描可能比索引范围扫描更便宜,无论访问的表或存在的索引的比例如何。
2.4、高度并行
如果表的并行度较高,优化器会倾向于进行全表扫描而非范围扫描。请检查表DEGREE中的列以确定并行度。ALL_TABLES
执行计划
EXPLAIN PLAN FOR
SELECT *
FROM INIT_ADSB_PART
WHERE nowtim BETWEEN TO_DATE('2025-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS')AND TO_DATE('2025-01-01 00:01:10', 'YYYY-MM-DD HH24:MI:SS');SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);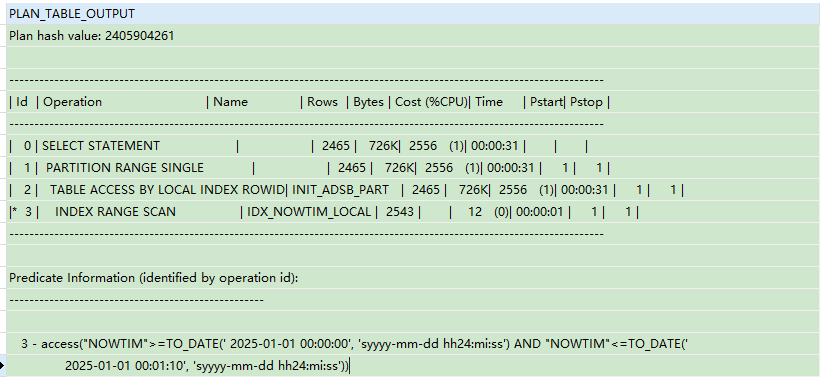
执行顺序说明(从最底层往上看):
-
Step 3 - INDEX RANGE SCAN(IDX_NOWTIM_LOCAL)
-
使用本地索引
IDX_NOWTIM_LOCAL扫描符合时间范围的记录。 -
索引范围条件是:
NOWTIM >= TO_DATE('2025-01-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND NOWTIM <= TO_DATE('2025-01-01 00:01:10', 'YYYY-MM-DD HH24:MI:SS') -
命中数据行数预估:
2543
-
-
Step 2 - TABLE ACCESS BY LOCAL INDEX ROWID
-
使用从索引中获取的
ROWID回到表中获取完整数据行。 -
表是分区表,每个分区都有独立的 ROWID 空间(因此叫 LOCAL)。
-
命中数据行:
2465(比索引少可能是过滤了无效数据)
-
-
Step 1 - PARTITION RANGE SINGLE
-
表示只访问了第一个分区(Pstart=1, Pstop=1)。
-
分区裁剪已成功。
-
意味着 Oracle 根本没去看其它分区。
-
-
Step 0 - SELECT STATEMENT
-
汇总所有结果。
-
分区
文章:
Oracle分区表详解(Oracle Partitioned Tables)_oracle 分区表-CSDN博客
分区允许将表、索引或索引组织表细分为更小的部分,其中每个数据库对象的部分称为一个分区。每个分区都有自己的名称,并且可以选择具有自己的存储特性。
Oracle 中的分区(Partitioning)是一种将大型表或索引划分为多个更小、更易于管理的部分的技术。它是优化大数据量表性能、可维护性和可扩展性的强大手段。
分区表:逻辑上是一个表,物理上被拆分成多个段(segment),称为分区(partition)。
每个分区可以存放一部分数据,Oracle 在访问数据时可以通过分区“跳过不相关的分区”,这叫分区裁剪(partition pruning),可以显著提高查询效率。
| 分区类型 | 说明 | 示例 |
|---|---|---|
范围分区 (RANGE) | 按值范围划分 | 按日期:2023-01-01~2023-01-31 |
列表分区 (LIST) | 按固定值划分 | 按地区:北京、上海 |
哈希分区 (HASH) | 按哈希算法自动分布 | 数据均匀分散处理 |
复合分区 (RANGE-HASH, RANGE-LIST) | 先按一种方式分,再在每个分区中再细分 | 范围 + 哈希 |
何时考虑分区
当单表数据量随着时间变的越来越大时,会给数据的管理和查询带来不便。我们可以考虑对表进行分区,利用分区表特性将数据分成小块存储,可以大幅提升查询性能,管理便捷性及数据的可用性。
-
数据量大于 几百万行时可以考虑分区。
-
大于 2 GB 的表。
-
包含历史数据的表,其中新数据被添加到最新的分区中。一个典型的例子是历史表,其中只有当前月份的数据可更新,而其他 11 个月的数据是只读的。
-
查询条件中涉及时间、地域、ID 等字段时,可考虑使用分区提升性能。
-
分区字段应该常作为查询条件(WHERE),否则难以裁剪。
- 表中有大量的历史数据,数据存在明显的时间顺序
一般是定时任务+存储过程来创建未来的分区,这个月定时任务触发存储过程创建下个月的分区。
分区的操作
-- 增加分区
ALTER TABLE INIT_ADSB_PART
ADD PARTITION p_202505 VALUES LESS THAN (TO_DATE('2025-06-01', 'YYYY-MM-DD'));-- 删除分区 该操作会删除 p_202501 分区中的所有数据,谨慎操作。
ALTER TABLE INIT_ADSB_PART
DROP PARTITION p_202501;-- 查看分区信息
SELECT TABLE_NAME, PARTITION_NAME, HIGH_VALUE
FROM USER_TAB_PARTITIONS
WHERE TABLE_NAME = 'INIT_ADSB_PART';
已有数据分区
由于表已经有数据,不能直接给普通表加分区,所以我们需要 新建分区表 + 数据迁移。
-- 创建一个新的分区表(例:按月分区)
CREATE TABLE INIT_ADSB_PART (ID NUMBER,NOWTIM DATE,OTHER_COLS VARCHAR2(100),...
)
PARTITION BY RANGE (NOWTIM) (PARTITION p_202501 VALUES LESS THAN (TO_DATE('2025-02-01', 'YYYY-MM-DD')),PARTITION p_202502 VALUES LESS THAN (TO_DATE('2025-03-01', 'YYYY-MM-DD')),PARTITION p_202503 VALUES LESS THAN (TO_DATE('2025-04-01', 'YYYY-MM-DD')),PARTITION p_max VALUES LESS THAN (MAXVALUE)
);-- 把原表数据迁移过去
INSERT /*+ APPEND */ INTO INIT_ADSB_PART
SELECT * FROM INIT_ADSB;-- 可选:校验数据是否一致
SELECT COUNT(*) FROM INIT_ADSB;
SELECT COUNT(*) FROM INIT_ADSB_PART;
每个
PARTITION表示一个数据分区,Oracle 会根据NOWTIM值将数据自动插入到对应分区:
分区名 包含的数据范围(NOWTIM) p_202501< 2025-02-01 p_202502≥ 2025-02-01 且 < 2025-03-01 p_202503≥ 2025-03-01 且 < 2025-04-01 p_max≥ 2025-04-01
ALTER TABLE INIT_ADSB_PART
ADD PARTITION p_202505 VALUES LESS THAN (TO_DATE('2025-06-01', 'YYYY-MM-DD'));
分区的优势
分区裁剪:指的是 Oracle 优化器在执行 SQL 查询时,根据 WHERE 条件,只扫描符合条件的分区,而跳过其他无关分区,从而大幅提升性能。
分区修剪通常可以将查询性能提高几个数量级。例如,假设某个应用程序包含一个Orders包含订单历史记录的表,并且该表已按周分区。请求一周订单的查询只会访问该Orders表的一个分区。如果该Orders表包含两年的历史数据,那么该查询只需访问一个分区,而不是 104 个分区。仅仅因为分区修剪,这个查询的执行速度就有可能提高 100 倍。
索引
Oracle 的 索引(Index) 是一种提高查询性能的数据结构,它类似于书的目录,可以加快数据检索的速度,但也会占用额外空间,并在插入、更新、删除时增加维护成本。
索引的作用
-
加快 SELECT 查询,特别是 WHERE 条件、JOIN、ORDER BY。
-
避免全表扫描(Full Table Scan)。
-
用于约束(如主键、唯一键)实现。
索引类型
| 类型 | 说明 |
|---|---|
| B树索引(默认) | 最常见,高效处理大部分查询类型。 |
| 位图索引 | 适合低基数字段(如性别、状态码等)。常用于数据仓库。 |
| 唯一索引 | 不允许重复值,常用于主键/唯一约束。 |
| 函数索引 | 对表达式/函数结果创建索引,例如 UPPER(name)。 |
| 组合索引 | 多个列联合创建索引,列顺序影响使用效率。 |
| 反向键索引 | 将列值反转后再建索引,适用于热点插入减少争用(如递增主键)。 |
| 分区索引 | 用于分区表的索引,可以是局部或全局。 |
| 不可见索引 | 索引存在但不参与优化器计算,便于测试删除效果。 |
| 域索引 | 针对 BLOB、CLOB 或文本字段,用于全文搜索(如 Oracle Text)。 |
1、分区索引分为本地索引和全局索引
本地索引是对单个分区的,每个分区索引只指向一个表分区,全局索引则不然,一个分区所引能指向n个表分区,同时,一个表分区,也可能指向n个索引分区,对分区表中的某个分区TRUNCATE或者MOVE、SHRINK等,可能会影响到n个全局索引分区,正因为这一点,本地索引具有更高的可用性。
在 Oracle 分区表中,本地索引(Local Index)是一种每个分区都有自己对应子索引段的索引。它的索引结构是按照表的分区方式同步划分的,也就是说:一个分区对应一个索引分区。
-- 假设你的表 INIT_ADSB_PART 分为 3 个分区:
INIT_ADSB_PART(分区表)
├── p_202501
├── p_202502
└── p_max-- 如果你创建了一个本地索引:
CREATE INDEX IDX_ADSB_NOWTIM_LOCAL
ON INIT_ADSB_PART(NOWTIM)
LOCAL;-- 它在物理上等价于创建了 3 个索引段:
IDX_ADSB_NOWTIM_LOCAL(本地索引)
├── IDX_ADSB_NOWTIM_LOCAL_p_202501
├── IDX_ADSB_NOWTIM_LOCAL_p_202502
└── IDX_ADSB_NOWTIM_LOCAL_p_max每个分区索引 只维护自己分区的数据,这样当你查询涉及一个时间段时,Oracle 能:直接跳过不相关的分区(分区裁剪);只扫描对应分区内的索引段,提高性能。索引的操作
-- 创建普通 B 树索引
CREATE INDEX idx_emp_name ON emp(name);-- 创建组合索引
CREATE INDEX idx_emp_dept_sal ON emp(deptno, sal);-- 创建函数索引
CREATE INDEX idx_upper_name ON emp(UPPER(name));-- 创建唯一索引
CREATE UNIQUE INDEX idx_emp_id ON emp(empno);
-- 删除索引
DROP INDEX idx_nowtim;-- 查询表的索引
SELECT index_name, table_name, uniqueness, status
FROM user_indexes
WHERE table_name = 'INIT_ADSB';SELECT i.index_name,i.table_name,i.uniqueness,i.status,c.column_name
FROM user_indexes iJOIN user_ind_columns c ON i.index_name = c.index_name
WHERE i.table_name = 'INIT_ADSB_PART';uniqueness
说明:表示索引的唯一性。该字段可以有两种值:
UNIQUE:表示该索引是唯一索引,保证索引列中的值唯一。
NONUNIQUE:表示该索引是非唯一索引,允许索引列中的值重复。索引失效
查看索引是否生效
-
EXPLAIN PLAN FOR ...用来生成 SQL 查询的执行计划(存入PLAN_TABLE中)。 -
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);是用来查看刚才那条 SQL 的执行计划。
EXPLAIN PLAN FOR
SELECT * FROM INIT_ADSB WHERE nowtim BETWEEN TO_DATE('2025-04-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND TO_DATE('2025-04-01 00:00:10', 'YYYY-MM-DD HH24:MI:SS');SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);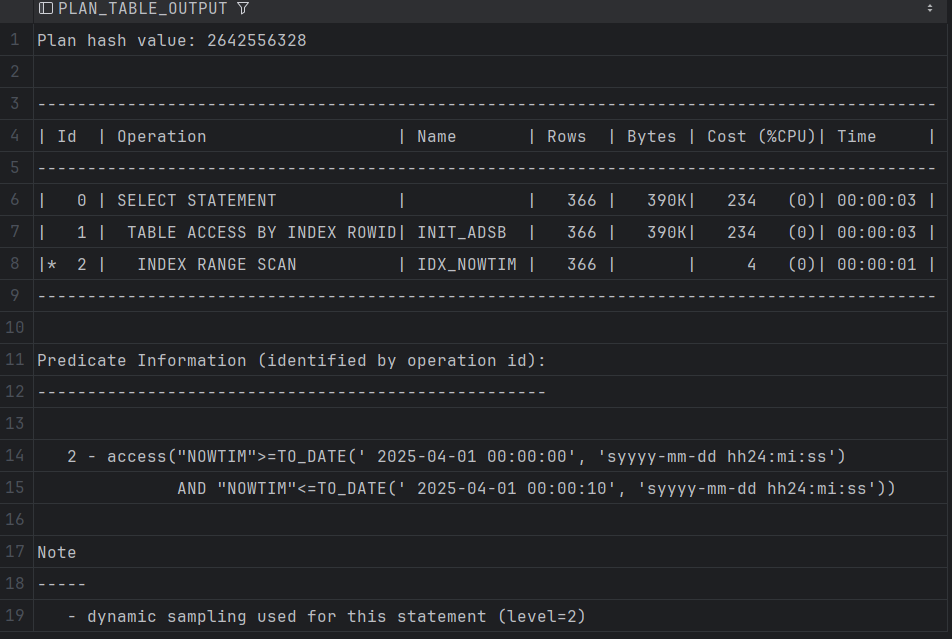
索引和分区
| 是否建分区 | 是否建索引 | 是否必要 | 适用情况 |
|---|---|---|---|
| 否 | 是 | 可行,但不适合海量数据 | 小表、低并发场景 |
| 是 | 否 | 查询会慢,不推荐 | 理论上可行但性能差 |
| 是 | 是 | ✅ 最佳实践 | 大数据量、时间序列型查询场景 |
CREATE TABLE INIT_ADSB_PART (ID NUMBER,NOWTIM DATE,OTHER_COLS VARCHAR2(100)
)
PARTITION BY RANGE (NOWTIM) (PARTITION p202504 VALUES LESS THAN (TO_DATE('2025-05-01', 'YYYY-MM-DD')),PARTITION p202505 VALUES LESS THAN (TO_DATE('2025-06-01', 'YYYY-MM-DD')),PARTITION pmax VALUES LESS THAN (MAXVALUE)
);CREATE INDEX idx_nowtim_local ON INIT_ADSB_PART (NOWTIM) LOCAL;
在 Oracle 中,当你同时使用了分区和索引(尤其是本地索引)后,查询的过程一般如下:
Oracle 执行流程如下:
-
分区裁剪(Partition Pruning):
-
Oracle 首先根据
WHERE条件中的NOWTIM值判断哪些分区可能包含匹配数据; -
例如:
NOWTIM BETWEEN '2025-04-01' AND '2025-04-02',只会命中某个具体的分区,比如p202504。
-
-
访问目标分区(Partition Access):
-
Oracle 只访问匹配的分区,而不是整个表(这就是分区带来的性能优势);
-
如果你使用了
LOCAL索引,这些索引是按分区建立的子索引,只会读取目标分区的索引。
-
-
索引查找(Index Access):
-
Oracle 使用目标分区的本地索引(如果存在)进行范围扫描,如
INDEX RANGE SCAN; -
然后定位到具体的数据块读取行(即
TABLE ACCESS BY INDEX ROWID)。
-
-
返回结果。
Oracle体系结构
Oracle体系结构(14)——Oracle 的数据文件(Data files)与表空间管理_oracle datafile-CSDN博客
Oarcle 数据库真正存放数据的是数据文件,表空间(tablespaces)实际上是一个逻辑的概念,在物理上并不存在。表空间具有如下特点:
(1)一个数据库可以包含多个表空间,一个表空间只能属于一个数据库;
(2)一个表空间包含多个数据文件,一个数据文件只能属于一个表空间。
批量操作
// 在Oracle中想要批量操作某个表的话,可以使用以下方式,
// 但是会报无效字符(the error occurred while setting parameters)
<foreach collection="equipinfos" item="e" separator=";" close=";">update local_equipinfo<set><if test="e.chuSelfCode != null">chu_self_code = #{e.chuSelfCode},</if><if test="e.selfCode != null">self_code = #{e.selfCode},</if></set>where ID = #{e.id}
</foreach>// 解决方式:使用begin end;将要执行批量操作的sql语句包装成sql语句块。// 但是要注意:在Oracle中,当使用PL/Sql语句块执行更新操作时(其他的还不知道),返回值为-1是正常的。begin
<foreach collection="equipinfos" item="e" separator=";" close=";">update local_equipinfo<set><if test="e.chuSelfCode != null">chu_self_code = #{e.chuSelfCode},</if><if test="e.selfCode != null">self_code = #{e.selfCode},</if></set>where ID = #{e.id}</foreach>
end;批量插入
<insert id="batchInsert" >begin<foreach collection="equipmentCountInfoList" item="eci" separator=";" close=";">insert into equipment_count_info<trim prefix="(" suffix=")" suffixOverrides=",">id,<if test="eci.equipmentCode != null and eci.equipmentCode != ''">equipment_code,</if><if test="eci.countPos != null">count_pos,</if><if test="eci.countTime != null">count_time,</if><if test="eci.countTaskId != null and eci.countTaskId != ''">count_task_id,</if><if test="eci.countUser != null">count_user,</if><if test="eci.countComm != null">count_comm,</if><if test="eci.scanCode != null">scan_code,</if><if test="eci.countCabiCode != null">count_cabi_code,</if><if test="eci.countCabiName != null">count_cabi_name,</if><if test="eci.countStatus != null">count_status,</if></trim><trim prefix="values (" suffix=")" suffixOverrides=",">equipment_count_info_seq.nextval,<if test="eci.equipmentCode != null and eci.equipmentCode != ''">#{eci.equipmentCode},</if><if test="eci.countPos != null">#{eci.countPos},</if><if test="eci.countTime != null">#{eci.countTime},</if><if test="eci.countTaskId != null and eci.countTaskId != ''">#{eci.countTaskId},</if><if test="eci.countUser != null">#{eci.countUser},</if><if test="eci.countComm != null">#{eci.countComm},</if><if test="eci.scanCode != null">#{eci.scanCode},</if><if test="eci.countCabiCode != null">#{eci.countCabiCode},</if><if test="eci.countCabiName != null">#{eci.countCabiName},</if><if test="eci.countStatus != null">#{eci.countStatus},</if></trim></foreach>end;</insert><insert id="insertBatch">INSERT INTO MATERIAL (ID, MATERIAL_NAME, MODEL, CLASS_ID, UNIT, NUM, UPDATE_TIME, UNIT_CODE, STORE_CODE, PRICE)SELECT MATERIAL_SEQUENCE.nextval ID,A.MATERIAL_NAME,A.MODEL,A.CLASS_ID,A.UNIT,A.NUM,A.UPDATE_TIME,A.UNIT_CODE,A.STORE_CODE,A.PRICEFROM (<foreach collection="materialDtoList" item="material" index="index" separator="UNION ALL">select#{material.materialName} MATERIAL_NAME,#{material.model} MODEL,#{material.classId} CLASS_ID,#{material.unit} UNIT,<choose><when test="material.num != null and material.num != ''">#{material.num} NUM,</when><otherwise>0 NUM,</otherwise></choose>sysdate UPDATE_TIME,#{material.unitCode} UNIT_CODE,#{material.storeCode} STORE_CODE,#{material.price} PRICEfrom dual</foreach>) A</insert>private void myBatchInsertEquipCountInfo(List<EquipmentCountInfo> equipmentCountInfoList) {Connection connection = null;PreparedStatement preparedStatement = null;try {// 1. 连接到数据库connection = DriverManager.getConnection(dataUrl, dataUser, dataPwd);connection.setAutoCommit(false);// 2. 创建一个PreparedStatement,包含要执行的插入SQL语句String insertSQL = "INSERT INTO equipment_count_info " +"(ID, equipment_code, count_pos, count_time, count_task_id, " +"count_user, count_comm, scan_code, count_cabi_code, count_cabi_name, count_status) " +"VALUES " +"(equipment_count_info_seq.nextval, ?, ?, ?, ?, ?, ?, ?, ?, " +"?, ?)";preparedStatement = connection.prepareStatement(insertSQL);// 3. 创建要插入的数据列表// 假设你有一个List<YourEntity> entities 包含要插入的数据// 4. 遍历数据列表,将数据添加到批处理中for (EquipmentCountInfo entity : equipmentCountInfoList) {int num = 1;preparedStatement.setString(num++, getValueOrNullString(entity.getEquipmentCode()));preparedStatement.setString(num++, getValueOrNullString(entity.getCountPos()));preparedStatement.setDate(num++, (java.sql.Date) entity.getCountTime());preparedStatement.setString(num++, getValueOrNullString(entity.getCountTaskId()));preparedStatement.setString(num++, getValueOrNullString(entity.getCountUser()));preparedStatement.setString(num++, getValueOrNullString(entity.getCountComm()));preparedStatement.setString(num++, getValueOrNullString(entity.getScanCode()));preparedStatement.setString(num++, getValueOrNullString(entity.getCountCabiCode()));preparedStatement.setString(num++, getValueOrNullString(entity.getCountCabiName()));preparedStatement.setString(num++, getValueOrNullString(entity.getCountStatus()));preparedStatement.addBatch();}// 5. 执行批处理插入操作int[] batchResult = preparedStatement.executeBatch();// 6. 处理批处理的结果// batchResult 数组包含了每个插入语句的执行结果,通常返回1表示成功,返回-2表示成功但没有行数返回。// 7. 提交事务connection.commit();} catch (SQLException e) {// 处理异常e.printStackTrace();try {if (connection != null) {connection.rollback(); // 如果发生异常,回滚事务}} catch (SQLException rollbackException) {rollbackException.printStackTrace();}} finally {// 8. 关闭连接和PreparedStatementtry {if (preparedStatement != null) {preparedStatement.close();}if (connection != null) {connection.close();}} catch (SQLException closeException) {closeException.printStackTrace();}}}一些SQL
查询 Oracle 中表 INIT_ADSB_PART 在 USERS 表空间上的 物理存储分配情况,包括每个 extent 的文件号、起始块号和大小(以字节为单位)。
SELECT segment_name, tablespace_name, file_id, block_id, bytes
FROM dba_extents
WHERE segment_name = 'INIT_ADSB_PART' AND tablespace_name = 'USERS';| SEGMENT_NAME | TABLESPACE_NAME | FILE_ID | BLOCK_ID | BYTES |
|---|---|---|---|---|
| INIT_ADSB_PART | USERS | 5 | 12345 | 65536 |
| INIT_ADSB_PART | USERS | 5 | 12445 | 65536 |
| ... | ... | ... | ... | ... |
这些表示该表在数据文件中使用的物理空间情况。
字段名 含义说明 SEGMENT_NAME对象名称(如表、索引名)。这里是 'INIT_ADSB_PART'表TABLESPACE_NAME表所在的表空间名。这里是 'USERS'FILE_ID表空间中数据文件的 ID(对应数据文件 *.dbf文件)BLOCK_ID该 extent 的起始块号(在该文件中的起始逻辑块编号) BYTES此 extent 的大小,单位是 字节
一些问题
cx_Oracle.DatabaseError: ORA-01688: 表 LIN.INIT_ADSB_DAY_PART 分区 SYS_P48 无法通过 1024 (在表空间 USERS 中) 扩展
表示 表 LIN.INIT_ADSB_DAY_PART 的某个分区(SYS_P48)尝试扩展(写入更多数据)时失败了,因为所在的表空间 USERS 没有足够的空间可用(无法分配 1024 个 Oracle 块大小的空间)。
表空间对应的数据文件达到了最大大小,无法继续扩展写入了。
相关文章:

Oracle-相关笔记
Oracle Database Online Documentation 11g 连接 WinR sqlplus username/passwordhostname:port/service_namesqlplus user02/123456192.xxx:1521/orclsqlplus / as sysdba #SQL*Plus 終端编码使用UTF-8 chcp 65001#打开SQL*Plus程序 sqlplus /nolog#使用dba角色登录(用 1.…...

mac安装cast
背景 pycharm本地运行脚本时提示cast没有安装 问题原因 脚本尝试调用cast命令(以太坊开发工具foundry中的子命令),但您的系统未安装该工具。 从日志可见,错误发生在通过sysutil.py执行shell命令时。 解决方案 方法1…...

CodeEdit:macOS上一款可以让Xcode退休的IDE
CodeEdit 是一款轻量级、原生构建的代码编辑器,完全免费且开源。它使用纯 swift 实现,而且专为 macOS 设计,旨在为开发者提供更高效、更可靠的编程环境,同时释放 Mac 的全部潜力。 Stars 数21,719Forks 数1,081 主要特点 macOS 原…...

opencv4.11编译Debug提示缺少python312_d.lib或python3*_d.lib的解决办法
前言 当我们编译OpenCV 4.11的时候可能会遇到提示缺少库文件,这个时候我们可以下载Python源码编译这个lib。 也可以下载我上传的版本(python312_d.lib),但是如果是其他版本需要自己编译。编译步骤如下,大概几分钟搞定…...

html的鼠标点击事件有哪些写法
在HTML中,鼠标点击事件的实现方式多样,以下从基础语法到现代实践为您详细梳理: 一、基础写法:直接内联事件属性 在HTML标签内通过on前缀事件属性绑定处理函数,适合简单交互场景: <!-- 单击事件 -->…...

深度解析物理机服务器故障修复时间:影响因素与优化策略
一、物理机故障修复的核心影响因素 物理机作为企业 IT 基础设施的核心载体,其故障修复效率直接关系到业务连续性。故障修复时间(MTTR)受多重因素交叉影响: 1. 故障类型的复杂性 硬件级故障: 简单故障:内存…...

蓝桥杯 2024 C++国 B最小字符串
P10910 [蓝桥杯 2024 国 B] 最小字符串 题目描述 给定一个长度为 N N N 且只包含小写字母的字符串 S S S,和 M M M 个小写字母 c 1 , c 2 , ⋯ , c M c_1, c_2, \cdots, c_M c1,c2,⋯,cM。现在你要把 M M M 个小写字母全部插入到字符串 S S S 中&…...

解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-docker MCP解析
解密企业级大模型智能体Agentic AI 关键技术:MCP、A2A、Reasoning LLMs-docker MCP解析 这里面有很重要的原因其中一个很其中一个原因是因为如果你使用docker的方式,你可以在虚拟环境下就类似于这个沙箱的这个机制可以进行隔离。这对于安全,…...
全部被“重置连接”或超时)
访问 Docker 官方镜像源(包括代理)全部被“重置连接”或超时
华为云轻量应用服务器(Ubuntu 系统) 遇到的问题是: 🔒 访问 Docker 官方镜像源(包括代理)全部被“重置连接”或超时了,说明你这台服务器的出境网络对这些国外域名限制很严格,常见于华…...
从原理到实战)
前馈神经网络回归(ANN Regression)从原理到实战
前馈神经网络回归(ANN Regression)从原理到实战 一、回归问题与前馈神经网络的适配性分析 在机器学习领域,回归任务旨在建立输入特征与连续型输出变量之间的映射关系。前馈神经网络(Feedforward Neural Network)作为最基础的神经网络架构&a…...

RNN/LSTM原理与 PyTorch 时间序列预测实战
🕰️ RNN / LSTM 原理与 PyTorch 时间序列预测实战 在处理时间序列数据、语音信号、文本序列等连续性强的问题时,循环神经网络(RNN)及其改进版本 LSTM(长短期记忆网络)是最常见也最有效的模型之一。本文将深入讲解 RNN 和 LSTM 的核心原理,并通过 PyTorch 实现一个时间…...

Docker容器镜像与容器常用操作指南
一、镜像基础操作 搜索镜像 docker search <镜像名>在Docker Hub中查找公开镜像,例如: docker search nginx拉取镜像 docker pull <镜像名>:<标签>从仓库拉取镜像到本地,标签默认为latest: docker pull nginx:a…...

1:OpenCV—图像基础
OpenCV教程 头文件 您只需要在程序中包含 opencv2/opencv.hpp 头文件。该头文件将包含应用程序的所有其他必需头文件。因此,您不再需要费心考虑程序应包含哪些头文件。 例如 - #include <opencv2/opencv.hpp>命名空间 所有 OpenCV 类和函数都在 cv 命名空…...
)
测试--BUG(软件测试⽣命周期 bug的⽣命周期 与开发产⽣争执怎么办)
1. 软件测试的⽣命周期 软件测试贯穿于软件的整个⽣命周期,针对这句话我们⼀起来看⼀下软件测试是如何贯穿软件的整个⽣命周期。 软件测试的⽣命周期是指测试流程,这个流程是按照⼀定顺序执⾏的⼀系列特定的步骤,去保证产品质量符合需求。在软…...

基于大模型预测围术期麻醉苏醒时间的技术方案
目录 一、数据收集与处理(一)数据来源(二)数据预处理二、大模型构建与训练(一)模型选择(二)模型训练三、围术期麻醉苏醒时间预测(一)术前预测(二)术中动态预测四、并发症风险预测(一)风险因素分析(二)风险预测模型五、基于预测制定手术方案(一)个性化手术规划…...
阅读与注释 QPlainTextEdit,其继承于QAbstractScrollArea,属性学习与测试)
QT6 源(101)阅读与注释 QPlainTextEdit,其继承于QAbstractScrollArea,属性学习与测试
(1) (2) (3)属性学习与测试 : (4) (5) 谢谢...

电池组PACK自动化生产线:多领域电池生产的“智能引擎”
在电池产业蓬勃发展的当下,电池组PACK自动化生产线凭借其高效、精准、智能的优势,成为众多电池生产领域的核心装备。它广泛适用于数码电池、工具电池、储能电池、电动车电池以及动力电池的生产,有力推动了相关产业的升级与发展。 数码电池领…...

生成式AI在编程中的应用场景:从代码生成到安全检测
引言 生成式AI正在深刻改变软件开发的方式,从代码编写到测试、文档和维护,AI技术正在为每个环节带来革命性的变革。本文将深入探讨生成式AI在编程中的主要应用场景,分析其优势与局限性,并展望未来发展趋势。 主要应用场景 1. 代…...
安全体系》)
安全牛报告解读《低空经济发展白皮书(3.0)安全体系》
一、概述 《低空经济发展白皮书(3.0)安全体系》由粤港澳大湾区数字经济研究院(IDEA研究院)发布,旨在构建低空经济安全发展的系统性框架,解决规模化低空飞行中的安全挑战。核心目标是明确安全体系需覆盖的飞…...

“2W2H”分析方法
“2W2H”是一种常用的分析方法,它通过回答**What(是什么)、Why(为什么)、How(怎么做)、How much(多少)**这四个问题来全面了解和分析一个事物或问题。这种方法可以帮助你…...

【数据挖掘笔记】兴趣度度量Interest of an association rule
在数据挖掘中,关联规则挖掘是一个重要的任务。兴趣度度量是评估关联规则的重要指标,以下是三个常用的兴趣度度量:支持度、置信度和提升度。 支持度(Support) 计算方法 支持度表示包含项集的事务占总事务的比例&…...

ArcGIS Pro调用多期历史影像
一、访问World Imagery Wayback,基本在我国范围 如下图: 二、 放大到您感兴趣的区域 三、 查看影像版本信息 点击第二步的按钮后,便可跳转至World Imagery (Wayback 2025-04-24)的相关信息。 四 、点击上图影像版本信息,页面跳转…...

Web3.0:互联网的去中心化未来
随着互联网技术的不断发展,我们正站在一个新时代的门槛上——Web3.0时代。Web3.0不仅仅是一个技术升级,它更是一种全新的互联网理念,旨在通过去中心化技术重塑网络世界。本文将深入探讨Web3.0的核心概念、技术基础、应用场景以及它对未来的深…...

java17
1.常见API之BigDecimal 底层存储方式: 2.如何分辨过时代码: 有横线的代码表示该代码已过时 3.正则表达式之字符串匹配 注意:如果X不是单一字符,需要加[]中括号 注意:1.想要表达正则表达式里面的.需要\\. 2.想要表…...

游戏引擎学习第283天:“让‘Standing-on’成为一个更严谨的概念
如果同时使用多个OpenGL上下文,并且它们都有工作负载,GPU或GPU驱动程序如何决定调度这些工作?我注意到Windows似乎优先处理活动窗口的OpenGL上下文(即活动窗口表现更好),挺有意思的…… 当多个OpenGL上下文…...

小白上手RPM包制作
目录 rpm常用命令 安装环境-Ruby 安装环境-fpm 关于服务器 打包-打包二进制工程 .fpm配置文件 打包-打没有文件的包 RPM 包微调 命令行参数 fpm --help RPM 签名 打包-制作NGINX的RPM包 关于rpmbuild 简单使用 打包之前的准备工作 rpmbuild 打包 - sniproxy …...

电商热销榜的5种实现方案
文章目录 1. MySQL 聚合查询:传统统计法2. Redis Sorted Set:内存排行榜3. Elasticsearch 实时聚合:搜索专家4. 缓存异步更新:榜单的幕后推手5. 大数据离线批处理:夜间魔法师 博主介绍:全网粉丝10w、CSDN合…...

车载诊断进阶篇 --- 车载诊断概念
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界噪音的通透淡然。 生活中有两种人,一种人格外在意别人的眼光;另一种人无论…...

AD 多层线路及装配图PDF的输出
装配图的输出: 1.点开‘智能PDF’ 2. 设置显示顶层: 设置显示底层: 多层线路的输出 同样使用‘智能PDF’...

FramePack - 开源 AI 视频生成工具
🎬 项目简介 由开发者 lllyasviel 创建的一个轻量级动画帧处理工具库,专门用于游戏开发、动画制作和视频处理中的帧序列打包与管理。该项目采用高效的算法实现,能够显著提升动画资源的处理效率。 此 AI 视频生成项目,旨在通过低显…...

“this”这个关键字
一、什么是“this”? 简单来说,“this”是每个非静态成员函数隐含的指针,它指向调用该成员函数的那个对象本身。 换句话说,当你调用对象的方法时,编译器会自动传入一个指针,指向你调用的“那个对象”&…...
+Gazebo+rqt下,无法显示仿真无人机的相机图像)
问题处理——在ROS2(humble)+Gazebo+rqt下,无法显示仿真无人机的相机图像
文章目录 前言一、问题展示二、解决方法:1.下载对应版本的PX42.下载对应版本的Gazebo3.启动 总结 前言 在ROS2的环境下,进行无人机仿真的过程中,有时需要调取无人机的相机图像信息,但是使用rqt,却发现相机图像无法显示…...
)
广度和深度优先搜索(BFS和DFS)
1. 广度和深度优先搜索(BFS和DFS) 1.1. Python实现BFS和DFS from collections import dequeclass Graph:"""无向图类,支持添加边,并实现了 BFS(广度优先搜索)和 DFS(深度优先搜…...

React和Vue在前端开发中, 通常选择哪一个
React和Vue的选择需结合具体需求: 选React的场景 大型企业级应用,需处理复杂状态(如电商、社交平台)团队熟悉JavaScript,已有React技术栈积累需要高度灵活的架构(React仅专注视图层,可自由搭配…...
和ref()函数详解))
Vue3学习(组合式API——reactive()和ref()函数详解)
目录 一、reactive()函数。 (1)介绍与使用。 (2)简单案例演示。 二、ref()函数。 (1)介绍与使用。 (2)简单案例演示。 <1>ref()函数获取响应式对象的本质与底层。 <2>基…...
二叉排序树)
数据结构 -- 树形查找(一)二叉排序树
二叉排序树 二叉排序树的定义 二叉排序树,又称二叉查找树 一棵二叉树或者是空二叉树,或者是具有以下性质的二叉树: 左子树上所有结点的关键字均小于根结点的关键字 右子树上所有结点的关键字均大于根结点的关键字 左子树和右子树又各是…...

【实战教程】从零实现DeepSeek AI多专家协作系统 - Spring Boot+React打造AI专家团队协作平台
🚀 本项目是DeepSeek大模型应用系列的V3版本,基于V1和V2版本的功能进行全面升级,引入了多智能体协作机制! 系列教程推荐阅读顺序: 【V1版本】零基础搭建DeepSeek大模型聊天系统 - Spring BootReact完整开发指南【V2版本…...

React事件机制
React事件机制 React 的事件机制是其实现高效、跨浏览器交互的核心系统,它通过 合成事件(SyntheticEvent)、事件委托(Event Delegation)、事件冒泡(Bubbling) 和 事件派发(Dispatch…...
)
LeetCode 45. 跳跃游戏 II(中等)
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向后跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返回到达 nums[n - 1] 的最…...

LeetCode 热题 100 437. 路径总和 III
LeetCode 热题 100 | 437. 路径总和 III 大家好,今天我们来解决一道经典的二叉树问题——路径总和 III。这道题在 LeetCode 上被标记为中等难度,要求计算二叉树中节点值之和等于给定目标值 targetSum 的路径数目。 问题描述 给定一个二叉树的根节点 ro…...

力扣.1471数组的k个最强值,力扣.1471数组的k个最强值力扣1576.替换所有的问号力扣1419.数青蛙编辑力扣300.最长递增子序列
目录 力扣.1471数组的k个最强值 力扣1576.替换所有的问号 力扣1419.数青蛙编辑 力扣300.最长递增子序列 力扣.1471数组的k个最强值 class Solution {public static int[] getStrongest(int[] arr,int k) {if(karr.length){return arr;}int []retnew int[k];int narr.lengt…...

使用itextsharp5.0版本来合并多个pdf文件并保留书签目录结构
using System; using System.Collections.Generic; using System.IO; using iTextSharp.text; using iTextSharp.text.pdf;public class PdfMergeUtility {/// <summary>/// 合并多个PDF文件并保留书签目录结构/// </summary>/// <param name"inputFiles&q…...

2025-5-15Vue3快速上手
1、setup和选项式API之间的关系 (1)vue2中的data,methods可以与vue3的setup共存 (2)vue2中的data可以用this读取setup中的数据,但是反过来不行,因为setup中的this是undefined (3)不建议vue2和vue3的语法混用…...

Kafka消费者分组机制深度解析
一、集群协调者 1.1 GroupCoordinator的元数据管理 每个Broker内置的GroupCoordinator实例通过哈希算法确定消费者组的归属权。其内存模型维护三个核心数据结构: 成员注册表:采用跳表结构存储消费者ID与心跳时间戳,支持快速查询和过期检测…...

Python 类变量与实例变量完全指南:区别、使用场景及常见陷阱
类变量与实例变量的区别总结 代码示例 class Example:class_var "我是类变量,所有实例共享我" # 类变量def __init__(self, name):self.name name # 实例变量,每个实例独有def modify_class_var(self, new_value):Example.class_var ne…...

Ubuntu Linux bash的相关默认配置文件内容 .profile .bashrc, /etc/profile, /etc/bash.bashrc等
文章目录 文件的source顺序/etc/profile:系统级配置/etc/bash.bashrc:bash终端的系统级配置~/.profile:用户级配置~/.bashrc bash:终端的主要配置~/.bash_logout:bash终端登出时清理 建议的额外配置: 安装 …...

redis解决常见的秒杀问题
title: redis解决常见的秒杀问题 date: 2025-03-07 14:24:13 tags: redis categories: redis的应用 秒杀问题 每个店铺都可以发布优惠券,保存到 tb_voucher 表中;当用户抢购时,生成订单并保存到 tb_voucher_order 表中。 订单表如果使用数据…...

Springboot3自定义starter笔记
场景:抽取聊天机器人场景,它可以打招呼。 效果:任何项目导入此 starter 都具有打招呼功能,并且问候语中的人名需要可以在配置文件中修改。 创建自定义 starter 项目,引入 spring-boot-starter 基础依赖。 <dependen…...
基本概念)
Modern C++(一)基本概念
1、基本概念 1.1、注释 注释在翻译阶段3会被替换为单个空白字符从程序中移除 1.2、名字与标识符 标识符是一个由数字、下划线、大小写字符组成的任意长度序列。有效的标识符首个字符必须是以A-Z、a-z、下划线开头,。有效的标识符其他字符可以是0-9、A-Z、a-z、下…...

Apache HttpClient 5 用法-Java调用http服务
Apache HttpClient 5 核心用法详解 Apache HttpClient 5 是 Apache 基金会推出的新一代 HTTP 客户端库,相比 4.x 版本在性能、模块化和易用性上有显著提升。以下是其核心用法及最佳实践: 一、添加依赖 Maven 项目: <dependency><…...