构建RAG混合开发---PythonAI+JavaEE+Vue.js前端的实践
写在前文:之所以设计这一套流程,是因为 Python在前沿的科技前沿的生态要比Java好,而Java在企业级应用层开发比较活跃;
毕竟许多企业的后端服务、应用程序均采用Java开发,涵盖权限管理、后台应用、缓存机制、中间件集成及数据库交互等方面。但是现在的AI技术生态发展得很快,而Python在科研(数据科学/机器学习领域)语言,在这方面有天然的优势;所以为了接入大模型LLMs,选择用Python接入大模型LLMs,然后通过FastAPI发布HTTP接口,让Java层负责与前端Vue.js应用及Python流接口进行交互,这样的话,前端直接访问Java应用,企业应用只需要保持现有生态即可,当前的权限、后台应用、缓存、中间件等流程都不用再Python端再次开发,省去了很多工作;
整个流程如下: python负责和模型交互---Java作为中间层负责和前端Vue以及Python流接口交互-----Vue负责展示;
技术体系
PythonAI端:
- LLM模型:本地ChatOllama+Qwen VLLm+Qwen、本地通过HF的Transformer加载- Embedding向量:OllamaEmbedding + nomic-embed-text:latest- 向量库FAISS:使用本地版本的Faiss库- 检索优化:混合(二阶段)检索:similarity_score_threshold相似性打分(向量检索)+BM25(关键字)检索构成的混合检索 结合 FlashRank重排序优化检索继续优化,多阶段检索:多查询检索(LLM扩展)、混合检索(向量检索+BM25关键字检索)、重排序优化、LLM压缩;---之所以不使用多查询LLM扩展和LLM压缩,是因为性能问题---在使用LLM压缩时,最好结合微调效果会好很多,不然可能会排除掉一些问题和答案关联性不强但实际上是一一对应的问题答案;使用单独使用混合检索的时候满足绝大多数情况;- 重排序:离线的FlashRankRerank+默认ms-marco-MultiBERT-L-12模型
- 流输出:使用StreamingResponse包装结合yield关键字;
- 性能优化:调用astream的异步执行方法/如果要使用stream同步方法,那么使用iterate_in_threadpool转异步/也可以使用async+with来管理异步执行
JavaAI端:
- 核心:Springboot
- 请求流接口:WebClient
- 返回流结果:Flux前端:vue3+vite构建项目核心接口主要包含下面的功能:
Python的流输出:Python通过yield定义一个生成器函数(可以不间断的返回数据),然后通过“StreamingResponse”包装后流式返回;
---注意:return是一次性返回;
Java请求流接口:在Java端我们使用WebClient请求Python的流接口;
Java流输出:将结果转为Flux类型的数据返回到前端页面;
--- 此时这两个接口,都是可以直接通过浏览器访问接口查看效果
--- 如果使用Postman,必须返回标准的SSE格式的数据,不然是看不到效果的;
SSE数据格式:每个数据块以"data: "开头,结尾加两个换行符
PythonAI ---- 本文主要是本地Ollama加载模型
下一篇更新:云服务通过VLLm部署模型,然后本地使用OpenAI加载云端的VLLm模型;以及“使用HuggingFace的原生Transformer加载LLM”
流式输出核心代码
主要是通过yield定义一个生成器函数,再通过StreamingResponse包装返回,注意设置media_type="text/event-stream;charset=utf-8"
def llm_astream(self, faiss_query):from fastapi.concurrency import iterate_in_threadpoolsync_generator = self.chain.astream(faiss_query)# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 转换为异步async for chunk in iterate_in_threadpool(sync_generator):# yield chunk.content# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符# yield f"data: {chunk.content}\n\n" # 使用String字符串返回import json# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n" # # 如果 chain.stream 本身是异步生成器,直接使用:# async for chunk in self.chain.stream(faiss_query):# yield chunk.content@app.get("/stream")
async def llm_stream(query: str):from starlette.responses import StreamingResponsereturn StreamingResponse( # 使用StreamingResponse包装,流返回retriever.llm_astream(query),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8)注意:此种方法可以使用浏览器看到效果;但是用Postman---如果不是标准的SSE格式数据就看不到效果;
注意:我们返回数据时一定要返回SSE格式的数据,不然Java端要报错“java.lang.NullPointerException: The mapper [xxxxxxx$$Lambda$880/0x0000000801118d08] returned a null value”;
SSE标准格式,返回JSON格式版本:yield f"data: {json.dumps({'content': chunk.content})}\n\n"
Java端使用“ServerSentEvent”事件接收;
SSE标准格式,返回字符串格式版本:yield f"data: {chunk.content}\n\n"
Java端使用“String”事件接收;
完整的代码
下面关于检索优化、构建链、llm交互、rag知识入库、向量库、Ollama加载云端API等...技术知识见我之前发的几篇文章;---- 安装了依赖以后,可以直接运行下面代码;
请求地址:http://localhost:8000/astream?query=xxxxx
---还可以访问stream接口看看使用异步协程、同步返回的不同效果;
"""检索agent"""
import asynciofrom langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from langserve import add_routesdef log_retrieved_docs(ctx):# print(f"[{ctx['msgid']}] [{ctx['query']}] Retrieved documents:[{ctx['content']['content']}]")print(f"Retrieved documents:[{ctx}]")return ctx # 确保返回原数据继续链式传递class RetrieverLoad:def __init__(self):print("加载向量库...")from langchain_ollama import OllamaEmbeddingsself.faiss_persist_directory = 'faiss路径'self.embedding = OllamaEmbeddings(model='nomic-embed-text:latest')self.faiss_index_name = 'faiss_index名称'self.faiss_vector_store = self.load_embed_store()self.llm = ChatOllama(model="qwen2.5:3b")self.prompt = ChatPromptTemplate.from_template(retriver_template)self.retriever = self.retriever()self.chain = self.llm_chain()def load_embed_store(self):return FAISS.load_local(self.faiss_persist_directory,embeddings=self.embedding,index_name=self.faiss_index_name, # 需与保存时一致allow_dangerous_deserialization=True)def retriever(self, score_threshold: float = 0.5, k: int = 5):sst_retriever = self.faiss_vector_store.as_retriever(search_type='similarity_score_threshold',search_kwargs={"score_threshold": score_threshold, "k": k})# 初始化BM25检索# (使用公共方法获取文档)documents = list(self.faiss_vector_store.docstore._dict.values())from langchain_community.retrievers import BM25Retrieverbm25_retriever = BM25Retriever.from_documents(documents,k=20, # 返回数量k1=1.5, # 默认1.2,增大使高频词贡献更高b=0.8 # 默认0.75,减小以降低文档长度影响)# 混合检索:BM25+embedding的from langchain.retrievers import EnsembleRetrieverensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, sst_retriever],weights=[0.3, 0.7])# 混合检索后 重排序# 构建压缩管道:重排序 + 内容提取from flashrank import Rankerfrom langchain_community.document_compressors import FlashrankRerankflashrank_rerank = FlashrankRerank(client=Ranker(cache_dir='D://A4Project//LLM//flash_rankRerank//'),top_n=8)# 三阶段检索:粗检索、重排序、内容压缩from langchain.retrievers import ContextualCompressionRetrieverbase_retriever = ContextualCompressionRetriever(# step1. 粗检索---30% BM25+70% Embedding向量检索base_retriever=ensemble_retriever,# step2. 重排序---FlashRankbase_compressor=flashrank_rerank)# step3、内容压缩---LLM---部分场景不推荐使用LLM内容压缩,压缩可能会删除RAG里面原本Q&A对应但是答案中不包含问题,导致关联性小的数据;而且很影响性能# from langchain.retrievers.document_compressors import LLMChainExtractor# # 重排序后 压缩上下文# compressor_prompt = """# 鉴于以下问题和内容,提取与回答问题相关的背景*按原样*的任何部分。如果上下文都不相关,则返回{no_output_str}。# 记住,*不要*编辑提取上下文的部分。# 问题: {{question}}# 内容: {{context}}# 提取相关部分:# """# from langchain_core.prompts import PromptTemplate# compressor_prompt_template = PromptTemplate(# input_variables=['question', 'context'],# template=compressor_prompt.format(no_output_str='NO_OUTPUT'))# compressor = LLMChainExtractor.from_llm(prompt=compressor_prompt_template, llm=self.llm)# # compressor = LLMChainExtractor.from_llm(llm=self.llm)# pipeline_retriever = ContextualCompressionRetriever(# base_retriever=base_retriever,# base_compressor=compressor# )return base_retrieverdef llm_chain(self):# 处理检索结果的函数(将文档列表转换为字符串)from langchain_core.runnables import RunnableLambda# process_docs = RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs]))from langchain_core.runnables import RunnablePassthroughprompt = """请根据以下内容回答问题,内容中如果没有的那就回答“请咨询人工...”,内容中如果有其他不相干的内容,直接删除即可。内容:{content}问题:{query}回答:"""prompt_template = ChatPromptTemplate.from_template(prompt)from operator import itemgetterchain = (# RunnableLambda(log_retrieved_docs) | # 直接打印传递进来的参数{# 这个content和query会继续往下传递,直到prompt --->{content}、{query}"content": RunnableLambda(lambda x: x["query"]) # 必须,不然要报错“TypeError: Expected a Runnable, callable or dict.Instead got an unsupported type: <class 'str'”| self.retriever # 检索# | RunnableLambda(log_retrieved_docs) # 打印出检索到的文档,检索后未处理# 先检索再处理文档| RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs])),# | process_docs # 先检索再处理文档 --- 和上面方法二选一# | RunnableLambda(log_retrieved_docs), # 打印出检索后的文档 --- 这里传递的仅仅是检索到的内容且预处理后的内容"query": itemgetter("query"), # 直接传递用户原始问题"msgid": RunnableLambda(lambda x: x["msgid"]), # 显示传递msgid --- 和itemgetter同样的效果}| RunnableLambda(log_retrieved_docs) # 传递的是前面整个content、query、msgid的值到日志中| prompt_template # 组合成完整 prompt| self.llm # 传给大模型生成回答# | RunnableLambda(log_retrieved_docs) # 传递的是LLM生成的内容 --- 但是在这一步以后,系统会同步返回---不推荐在这里打印日志)return chainasync def llm_invoke(self, query):return self.chain.invoke(query)async def retriever_stream(self, query):return self.retriever.stream(query)async def llm_astream(self, query: str, msgid: str):# 直接使用astream 异步执行chunks = []result = ""async for chunk in self.chain.astream({"query": query, "msgid": msgid}):chunks.append(chunk.content)result += chunk.content# yield chunk.content# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符import json# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"print(f"query:{query} msgid:{msgid} llm:{result}")# # 如果 chain.stream 本身是异步生成器,直接使用:# async for chunk in self.chain.stream(query):# yield chunk.contentasync def llm_stream(self, query):from fastapi.concurrency import iterate_in_threadpool# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 转换为异步async for chunk in iterate_in_threadpool(self.chain.stream(query)):# yield chunk.content# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符import json# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"# # 如果 chain.stream 本身是异步生成器,直接使用:# async for chunk in self.chain.stream(query):# yield chunk.contentfrom fastapi import FastAPIapp = FastAPI(title='ruozhiba', version='1.0.0', description='ruozhiba检索')
# 添加 CORS --- 跨域 中间件
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(CORSMiddleware,allow_origins=["*"], # 允许所有来源,生产环境建议指定具体域名allow_credentials=True, # 允许携带凭证(如cookies)allow_methods=["*"], # 允许所有HTTP方法(可选:["GET", "POST"]等)allow_headers=["*"], # 允许所有HTTP头
)
# 同步返回
@app.get("/invoke")
async def llm_invoke(query: str):results = await retriever.llm_invoke(query)return {"results": results.content}@app.get("/retriever")
async def retriever_stream(query: str):return await retriever.retriever_stream(query)# 流式输出——异步执行
@app.get("/astream")
async def astream(query: str, msgid: str):from starlette.responses import StreamingResponseprint(f"请求开始:query:{query} msgid:{msgid}")return StreamingResponse(retriever.llm_astream(query, msgid),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8)# 流式输出——同步执行
@app.get("/stream")
async def llm_stream(query: str):from starlette.responses import StreamingResponsereturn StreamingResponse(retriever.llm_stream(query),media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8)
if __name__ == '__main__':# asyncio.run(main())import uvicornretriever = RetrieverLoad()uvicorn.run(app, host='localhost', port=8000)JavaAI
引入依赖
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.1</version><relativePath/> <!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency></dependencies>返回Flux流 --- 测试
---浏览器访问就可以看到流效果...但是中文的话,会是乱码;
@GetMapping(value = "/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> chat() {
// Thread.sleep()会阻塞线程,改用Flux.interval实现非阻塞延迟:return Flux.interval(Duration.ofMillis(100)) // 每100ms生成一个数字.map(i -> "消息:" + i) // 转换为消息字符串.take(10); // 限制总数量为10000条
// return Flux.create(emitter -> {
// // 模拟数据流
// for (int i = 0; i < 10000; i++) {
// emitter.next("Message " + i);
// try {
// Thread.sleep(100); // 模拟延迟
// } catch (InterruptedException e) {
// emitter.error(e);
// }
// }
// emitter.complete();
// });}解决中文乱码问题
如果不使用Filter,那么在返回前端页面的时候会是中文乱码;
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class FluxPreProcessorFilter implements Filter {@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)throws IOException, ServletException {response.setCharacterEncoding("UTF-8");chain.doFilter(request, response);}
}结合Python流接口
初始化WebClient
private final WebClient webClient;public ChatMsgController(WebClient.Builder webClientBuilder) {this.webClient = webClientBuilder.clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(30)) // 第一次请求可以设置长点.compress(false) // 关闭压缩(如果开启可能缓冲)))// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)// 网上说:必须设置为JSON格式;初始设置MediaType.TEXT_EVENT_STREAM_VALUE会导致请求失败,必须使用APPLICATION_JSON_VALUE// 实际测试,与这无关
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000") // python项目地址.build();}接收String流
public Flux<Object> stream(String query) {return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().bodyToFlux(String.class).doOnError(e->System.err.println("发生错误: " + e.getMessage()));}接收JSON流
public Flux<String> stream(String query) {return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().bodyToFlux(ServerSentEvent.class)// 解析为标准的SSE事件.mapNotNull(ServerSentEvent::data) // 提取标准的SEE数据格式的 数据部分.doOnError(e->System.err.println("发生错误: " + e.getMessage())).map(Object::toString); // 返回是否需要根据情况来定 --- 如果不需要,返回“Flux<Object>”即可}日志&错误处理
public Flux<String> stream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);return webClient.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 请求失败返回错误。// 状态码 --- 当未请求成功时的异常.onStatus(HttpStatusCode::isError, response -> {log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class).log() // 打印日志.doOnNext(data -> System.out.println("接收到数据块:" + data)) // 打印接收到的数据.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常}移除多余的前缀
@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);return webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve().onStatus(HttpStatusCode::isError, response -> {log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class) // 转为String// 移除多余的Python返回的前缀; --- 因为我们返回给前端的也是SSE数据格式,所以返回的数据也是默认会有data:.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", "")) .doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常.map(Object::toString);}保存历史记录
public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);Flux<String> dataFlux = webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 通过cache()共享数据流,单独订阅以保存数据,避免重复请求,确保保存操作仅触发一次。// 必须开启,不然在后续执行"dataFlux.collectList()/ dataFlux.reduce"会再次发起请求// 不开启cache的话---相当于前端请求一次,后端发起了三次请求.cache().doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常.map(Object::toString);// 单独订阅以收集并保存数据 --- 下面是测试方法,二选一// 使用.collectList() 收集成一个完整的 List<String>,打印出来的list是一个chunk,["你好", ",世界", "!"]// 自己拼装ListdataFlux.collectList() //.flatMap(list -> {String join = String.join("", list);log.info("触发collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);return Mono.just(join);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("collectList保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("collectList数据已保存。msgid:{},query:{}", msgid, query));// 使用reduce,合并ChunkdataFlux.reduce((a, b) -> a + b).flatMap(list -> {log.info("触发reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);return Mono.just(list);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("reduce保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("reduce数据已保存。msgid:{},query:{}", msgid, query));return dataFlux;}完整代码
SpringBoot启动---浏览器请求
@RestController
@RequestMapping("/ai")
@CrossOrigin("*")
@Slf4j
public class ChatMsgController {private final WebClient webClient;public ChatMsgController(WebClient.Builder webClientBuilder) {this.webClient = webClientBuilder.clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(60)).compress(false) // 关闭压缩(如果开启可能缓冲)))
// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)// ⚠️ 必须设置为JSON格式;初始设置MediaType.TEXT_EVENT_STREAM_VALUE会导致请求失败,必须使用APPLICATION_JSON_VALUE
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000").build();}@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)public Flux<String> astream(@PathVariable("query") String query) {String msgid = UUID.randomUUID().toString().replace("-", "");log.info("请求开始。msgid:{},query:{}", msgid, query);Flux<String> dataFlux = webClient.get().uri("/astream?query={query}&msgid={msgid}", query, msgid).accept(MediaType.TEXT_EVENT_STREAM).retrieve()// 请求失败返回错误。// 状态码 --- 当未请求成功时的异常.onStatus(HttpStatusCode::isError, response -> {log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class) // 转为String
// .bodyToFlux(ServerSentEvent.class) // 解析为标准的SSE事件
// .mapNotNull(ServerSentEvent::data) // 提取标准的SEE数据格式的 数据部分.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", ""))
// .log() // 打印日志 --- 这个日志是一个chunk一个chunk打印的.cache()// 通过cache()共享数据流,单独订阅以保存数据,避免重复请求,确保保存操作仅触发一次。必须开启,不然在后续执行"dataFlux.collectList()/ dataFlux.reduce"会再次发起请求---相当于前端请求一次,后端发起了三次请求
// .doOnNext(data -> System.out.println("接收到数据块:" + data)) // 打印接收到的数据.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常.map(Object::toString);// 单独订阅以收集并保存数据// 使用.collectList() 收集成一个完整的 List<String>,打印出来的list是一个chunk,["你好", ",世界", "!"]// 自己拼装ListdataFlux.collectList() //.flatMap(list -> {String join = String.join("", list);log.info("触发collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);return Mono.just(join);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("collectList保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("collectList数据已保存。msgid:{},query:{}", msgid, query));// 使用reduce,合并ChunkdataFlux.reduce((a, b) -> a + b).flatMap(list -> {log.info("触发reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);return Mono.just(list);}).subscribeOn(Schedulers.boundedElastic()).subscribe(null,error -> log.error("reduce保存失败。msgid:{},query:{}", msgid, query, error),() -> log.info("reduce数据已保存。msgid:{},query:{}", msgid, query));return dataFlux;}
}Test/Main启动
public class StreamApiClient {public void streamData(String query) {
// WebClient client = WebClient.create("http://localhost:8000");WebClient client = WebClient.builder().clientConnector(new ReactorClientHttpConnector(HttpClient.create().responseTimeout(Duration.ofSeconds(10))
// .compress(false) // 关闭压缩(如果开启可能缓冲)))
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE).baseUrl("http://localhost:8000").build();Flux<String> stream = client.get().uri("/stream?query={query}", query).accept(MediaType.TEXT_EVENT_STREAM).retrieve().onStatus(HttpStatusCode::isError, response -> { // 请求失败返回错误System.out.println("错误状态码: " + response.statusCode());return response.bodyToMono(String.class).flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));}).bodyToFlux(String.class)
// .log()
// .doOnNext(data -> System.out.println("接收到数据块:" + data)).doOnError(e -> System.err.println("发生错误: " + e.getMessage()));stream.subscribe(chunk -> System.out.println("Received chunk: " + chunk),error -> System.err.println("Error: " + error),() -> System.out.println("Stream completed"));}public static void main(String[] args) throws InterruptedException {StreamApiClient streamApiClient = new StreamApiClient();streamApiClient.streamData("五块能娶几个老婆");Thread.sleep(40000); // 可以适当提升时间,不然可能程序还没得到返回就结束了,看不到效果}
}Vue前端
前端使用vue3+vite构建
创建项目
HBuilderX创建

使用命令创建
npm create vite@latest my-vue-app -- --template vue # 创建项目
cd my-vue-app # 进入到项目中
npm install # 安装依赖
npm run dev # 运行dev环境项目<!-- 其中: -->
<!-- index.html 主要是标签---包含标签页itme样式; -->
<!-- src/App.vue ---主页访问,系统 import HelloWorld from './components/HelloWorld.vue'导入了HelloWorld.vue -->
<!-- src/components/HelloWorld.vue ---刚开始是广告页,可以修改内容 -->
<!-- 所以启动成功后,访问"http://localhost:3000/index"会直接进入HelloWorld.vue; -->
<!-- 我们现在只需要修改HelloWorld.vue即可 -->修改HelloWorld.vue
<template><div><input v-model="query" placeholder="输入查询内容" class="query-input" /><button @click="startStream" class="action-button start-button">调用Java接收流</button><button @click="chatStream" class="action-button start-button">调用Chat接口测试</button><button @click="pythonStream" class="action-button start-button">调用python接口</button><button @click="closeStream" class="action-button stop-button">停止接收</button><div class="result-container"><pre class="response-data">{{ responseData }}</pre><div>这个数据来源于App的MSG组件:{{msg}}</div></div></div>
</template>
<script setup>
import { ref, onBeforeUnmount } from 'vue'// Props 定义
const props = defineProps({msg: String
})// 响应式数据
const query = ref('为什么砍头不找死刑犯来演')
const responseData = ref('')
const eventSource = ref(null)// 方法
const pythonStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8000/astream?query=${encodeURIComponent(query.value)}&msgid=123456`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {const data = JSON.parse(event.data)responseData.value += data.content + "\n"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const chatStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8080/ai/chat`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {responseData.value += event.data + "\n"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const startStream = () => {closeStream()responseData.value = ''const url = `http://localhost:8080/ai/astream/${encodeURIComponent(query.value)}`eventSource.value = new EventSource(url)eventSource.value.onmessage = (event) => {responseData.value += event.data + "-"}eventSource.value.onerror = (error) => {console.warn("EventSource warn:", error)closeStream()}
}const closeStream = () => {if (eventSource.value) {eventSource.value.close()eventSource.value = null}
}// 生命周期钩子
onBeforeUnmount(() => {closeStream()
})
</script><style scoped>.container {max-width: 600px;margin: 50px auto;padding: 20px;border-radius: 10px;box-shadow: 0 4px 8px rgba(0, 0, 0, .1);background-color: #fff;}.query-input {width: calc(100% - 22px);padding: 10px;margin-bottom: 15px;border: 1px solid #ccc;border-radius: 5px;font-size: 16px;}.action-button {padding: 10px 20px;margin-right: 10px;border: none;border-radius: 5px;cursor: pointer;font-size: 16px;transition: all .3s ease;}.start-button {background-color: #4CAF50;color: white;}.stop-button {background-color: #f44336;color: white;}.start-button:hover {background-color: #45a049;}.stop-button:hover {background-color: #e53935;}.result-container {margin-top: 20px;padding: 15px;background: #f9f9f9;border-radius: 5px;overflow-x: auto;}.response-data {white-space: pre-wrap;word-wrap: break-word;font-size: 14px;color: #333;}
</style>请求测试
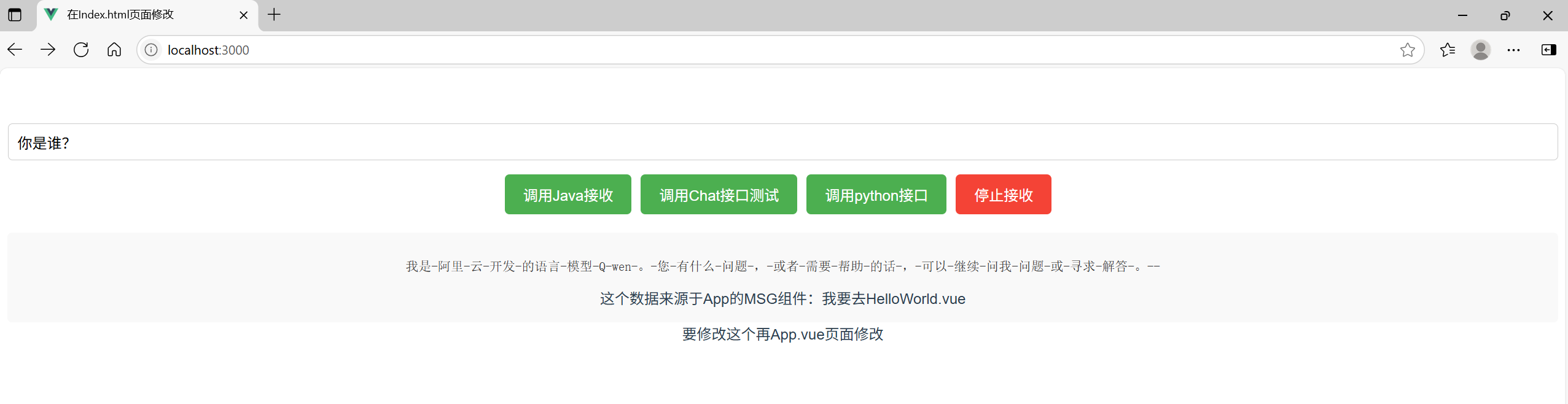
相关文章:

构建RAG混合开发---PythonAI+JavaEE+Vue.js前端的实践
写在前文:之所以设计这一套流程,是因为 Python在前沿的科技前沿的生态要比Java好,而Java在企业级应用层开发比较活跃; 毕竟许多企业的后端服务、应用程序均采用Java开发,涵盖权限管理、后台应用、缓存机制、中间件集成…...

游戏引擎学习第280天:精简化的流式实体sim
回顾并为今天的内容做铺垫 今天的任务是让之前关于实体存储方式的改动真正运行起来。我们现在希望让实体系统变得更加真实和实用,能够支撑我们游戏实际所需的功能。这就要求我们对它进行更合理的实现和调试。 昨天我们基本让代码编译通过了,但实际上还…...

小程序映射逻辑处理
onLoad: function (options) { // 如果直接从options获取数据 this.setData({ jielunpin:发羽音, birthStr: 1944-01-01 }); // 处理诊断结论 this.processJielunpin(); // 添加一个处理诊断结论的函数 processJielunpin: function() { // 获取jielunpin和birthSt…...

亚马逊,temu测评采购低成本养号策略:如何用一台设备安全批量管理买家账号
只要能够巧妙规避平台的检测和风控措施,测评便可安全进行。 自养号测评,它更便于卖家掌控,且能降低风险。现在很多卖家都是自己养号,自己养号都是精养,不是自动的机刷,买家账号掌握在自己手里,更…...
)
TCP实现安全传输的核心机制 + TCP的报文讲解(全程图文讲解)
目录 一、TCP的协议和数据报格式 二、TCP常见的核心机制 1. 确认应答 2. 超时重传 3. 连接管理 三次握手(建立连接) 四次挥手(断开连接) 常见的状态和整体的传输流程 4. 滑动窗口 5. 流量控制 6. 拥塞控制 7. 延迟应…...

【测试工具】selenium和playwright如何选择去构建自动化平台
构建UI自动化平台服务,在底层选择自动化框架,selenium和playwright这两个如何选择 在构建UI自动化平台服务时,选择底层自动化框架(如 Selenium 和 Playwright)是一个非常关键的决策,直接影响平台的性能、可…...

ES常识8:ES8.X如何实现热词统计
文章目录 一、数据采集与存储设计1. 确定需记录的字段2. 设计搜索日志索引 二、数据写入与采集三、热门搜索词统计(核心逻辑)1. 基础版:近 7 天热门搜索词(按出现次数排序)2. 进阶版:加权热门词(…...

可解释性AI 综述《Explainable AI for Industrial Fault Diagnosis: A Systematic Review》
一、研究背景与动因(Background & Motivation) 随着工业4.0与工业5.0的发展,工业生产越来越依赖自动化与智能化手段,以实现高效、预测性维护与运行优化。在这一背景下,人工智能(AI)与机器学…...

数据可视化-----子图的绘制及坐标轴的共享
目录 绘制固定区域的子图 (一)、绘制单子图 subplot()函数 Jupyter Notebook的绘图模式 (二)、多子图 subplots()--可以在规划好的所有区域中一次绘制多个子图 (三)、跨行跨列 subplot2grid()---将整…...

nginx 配置
proxy_pass 结尾斜杠规则 不带斜杠:保留原始请求路径。 location /api {proxy_pass http://backend; # 转发到 http://backend/api }带斜杠:剥离 location 匹配的路径前缀。 location /api/ {proxy_pass http://backend/; # 转发到 http://back…...
》)
《从零开始入门递归算法:搜索与回溯的核心思想 + 剑指Offer+leetcode高频面试题实战(含可视化图解)》
一.递归 1.汉诺塔 题目链接:面试题 08.06. 汉诺塔问题 - 力扣(LeetCode) 题目解析:将A柱子上的盘子借助B柱子全部移动到C柱子上。 算法原理:递归 当A柱子上的盘子只有1个时,我们可以直接将A上的盘子直…...

船舶制造业数字化转型:驶向智能海洋新航道
在全球海洋经济蓬勃发展的当下,船舶制造业作为海洋产业的重要支柱,正面临着前所未有的机遇与挑战。船舶制造周期长、技术复杂,从设计图纸到最终交付,涉及成千上万的零部件和复杂的工艺流程,传统制造模式已难以满足市场…...

SpringBoot 自动装配流程
Spring Boot 的自动装配(Auto Configuration)是其最核心的特性之一,它让你能“开箱即用”,极大简化了配置。下面是 Spring Boot 自动装配的整体流程(从启动到生效) 的详细解析: ✅ 一、整体流程…...
)
Vue 3 实现后端 Excel 文件流导出功能(Blob 下载详解)
💡 本文以告警信息导出为例,介绍 Vue 3 中如何通过 Axios 调用后端接口并处理文件流,实现 Excel 自动下载功能。 📑 目录 一、前言 二、后端接口说明 三、前端实现思路 四、导出功能完整代码 五、常见问题处理 六、效果展示 …...

基于IBM BAW的Case Management进行项目管理示例
说明:使用IBM BAW的难点是如何充分利用其现有功能根据实际业务需要进行设计,本文是示例教程,因CASE Manager使用非常简单,这里重点是说明如何基于CASE Manager进行项目管理,重点在方案设计思路上,其中涉及的…...

《Python星球日记》 第78天:CV 基础与图像处理
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、计算机视觉(CV)简介1. 什么是计算机视觉?2. 计算机视觉的应用场景3. 图像的基本属性a》像素(Pixel)b》通道(Channel)c》分辨率(Res…...

Google DeepMind 推出AlphaEvolve
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

Flink 1.13.2 日志配置优化:保留最近 7 天日志文件
Flink 1.13.2 日志配置优化:保留最近 7 天日志文件 在使用 Apache Flink 1.13.2 进行流处理任务时,合理的日志配置对于作业的监控、调试和故障排查至关重要。本文将介绍如何通过修改log4j.properties文件,将 Flink 的默认日志配置升级为保留最近 7 天的日志文件配置,并解决…...
)
【优化算法】协方差矩阵自适应进化策略(Covariance Matrix Adaptation Evolution Strategy,CMA-ES)
CMA-ES(Covariance Matrix Adaptation Evolution Strategy)算法是一种无导数、基于多元正态分布的迭代优化方法,通过自适应地调整搜索分布的均值、协方差矩阵和步长,能够高效地解决非线性、非凸的连续优化问题。 算法以最大似然和…...

基于Leaflet和天地图的免费运动场所WebGIS可视化-以长沙市为例
目录 前言 一、免费运动场所数据整理 1、本地宝数据简介 2、Java后台数据解析 二、Leaflet前端地图展示 1、基础数据准备 2、具体位置及属性标记 三、成果展示 1、空间位置分布 2、东风路立交桥运动公园 3、芙蓉区花侯路浏阳河大桥下方 4、梅岭国际小区 5、湖南大学…...

399. 除法求值
https://leetcode.cn/problems/evaluate-division/description/?envTypestudy-plan-v2&envIdtop-interview-150思路:读完题后我们可以发现这题的考察已经很明确了就是考我们矩阵,我们将矩阵构建出来后,这题就变成可达性分析题了。 所以解…...
)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示(实操部分)
QMK固件OLED显示屏配置教程:从零开始实现个性化键盘显示 📢 前言: 作为一名键盘爱好者,近期研究了QMK固件的OLED显示屏配置,发现网上的教程要么太过复杂,要么过于简单无法实际操作。因此决定写下这篇教程,从零基础出发,带大家一步步实现键盘OLED屏幕的配置与个性化显示…...

深度解析 Meta 开源 MR 项目《North Star》:从交互到渲染的沉浸式体验设计
🌌 一、项目概览:什么是 North Star? North Star 是由 Meta 官方推出并开源 的一款面向 Meta Quest 平台 的混合现实(MR)视觉演示项目。它不仅上线了 Horizon Store,更以完整的技术栈与高质量内容向开发者展示了如何在 VR/MR 设备上实现“视觉上限”和“交互潜力”的结…...

使用VS Code通过SSH编译Linux上的C++程序
引言 在软件开发领域,跨平台开发是一项常见需求。特别是对于C开发者来说,有时需要在Windows环境下编写代码,但却需要在Linux环境中编译和运行。这种情况在系统编程、嵌入式开发或高性能计算领域尤为常见。 Visual Studio Code (VS Code) 提…...

Datawhale 5月llm-universe 第2次笔记
第二章 使用 LLM API 开发应用 名词解释 Temperature 参数/场景低 Temperature(0 ~ 0.3)高 Temperature(0.7 ~ 1.0)输出特点保守、稳定、可预测创造性强、多样化、不可预测语言模型行为更少的随机性,倾向于选择高概…...

【Vue】CSS3实现关键帧动画
关键帧动画 两个重点keyframesanimation子属性 实现案例效果展示: 两个重点 keyframes 和 animation 作用:通过定义关键帧(keyframes)和动画(animation)规则,实现复杂的关键帧动画。 keyframes 定义动画的关键帧序列…...

Spring 模拟转账开发实战
一、转账业务场景分析 转账是金融类应用的核心场景之一,涉及付款方扣减金额和收款方增加金额两个关键操作。在开发中需解决以下问题: 业务层与数据层解耦:通过分层架构(Service 层调用 Dao 层)实现逻辑分离。数据库事…...

Baklib内容中台赋能资源管理升级
内容中台驱动管理升级 在数字化转型进程中,企业级内容管理工具的效能直接影响资源协同效率。以全渠道资源整合为核心的内容中台,通过集中化处理文档、FAQ及社区论坛等非结构化数据,有效解决信息孤岛问题。例如,某金融集团通过部署…...
——排序)
数据结构(九)——排序
一、排序的基本概念 1.排序:重新排列表中的元素,使表中的元素满足按关键字有序 2.稳定性:Ri和Rj相对位置保持不变 3.内部排序:指在排序期间元素全部存在内存中的排序(比较和移动),如插入排序…...
)
MinerU安装(pdf转markdown、json)
在Windows上安装MinerU,参考以下几个文章,可以成功安装,并使用GPU解析。 整体安装教程: MinerU本地化部署教程——一款AI知识库建站的必备工具 其中安装conda的教程: 一步步教你在 Windows 上轻松安装 Anaconda以及使…...

Spring框架核心技术深度解析:JDBC模板、模拟转账与事务管理
一、JDBC模板技术:简化数据库操作 在传统JDBC开发中,繁琐的资源管理和重复代码一直是开发者的痛点。Spring框架提供的 JDBC模板(JdbcTemplate) 彻底改变了这一现状,它通过封装底层JDBC操作,让开发者仅需关注SQL逻辑&a…...

LCD电视LED背光全解析:直下式 vs 侧光式、全局调光 vs 局部调光与HDR体验
Abstract: This article explores the various types of LED backlighting used in televisions and monitors. It categorizes backlight systems based on structural design—direct-lit and edge-lit—as well as by dimming technology—global dimming and local dimmin…...

ET EntityRef EntityWeakRef 类分析
EntityRef EntityWeakRef 相同点 也是这两个的作用:这两个都是用来表示一个实体引用。一般来说使用一个对象,直接持有对象就可以,但是如果对象来自于对象池,这个时候直接持有对象不合适,对象可能已经被对象池回收&…...
)
Python----神经网络(基于DNN的风电功率预测)
一、基于DNN的风电功率预测 1.1、背景 在全球能源转型的浪潮中,风力发电因其清洁和可再生的特性而日益重要。然而,风力发电功率的波动性给电网的稳定运行和能源调度带来了挑战。准确预测风力发电机的功率输出,对于优化能源管理、提高电网可靠…...

Web前端入门:JavaScript 的应用领域
截至目前,您应该对前端的 HTML CSS 应该有了很清楚的认知,至少实现一个静态网页已经完全不在话下了。 当然,CSS 功能绝不止这些,一些不太常用的 CSS 相关知识,后续将通过案例进行分享。 那么咱们接下来看看 JavaScrip…...
,实现多台电脑共享鼠标和键盘(支持window系统))
实用工具:微软软件PowerToys(完全免费),实现多台电脑共享鼠标和键盘(支持window系统)
实用工具:微软软件 PowerToys 让多台电脑共享鼠标和键盘 在如今的数字化办公与生活场景中,我们常常会面临同时使用多台电脑的情况。例如,办公时可能一台电脑用于处理工作文档,另一台用于运行专业软件或查看资料;家庭环…...
:移情阶段评分体系构建与实战案例解析)
精益数据分析(61/126):移情阶段评分体系构建与实战案例解析
精益数据分析(61/126):移情阶段评分体系构建与实战案例解析 在创业的移情阶段,如何科学评估用户需求的真实性与紧迫性,是决定后续产品方向的关键。今天,我们结合《精益数据分析》中的评分框架,…...

面试题:介绍一下JAVA中的反射机制
什么是反射机制? Java反射机制是指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性。这种动态获取的信息以及动态调用对象的方法的功能称为Java语言的…...

yarn任务筛选spark任务,判断内存/CPU使用超过限制任务
yarn任务筛选spark任务,判断内存/CPU使用超过限制任务 curl -s “http://it-cdh-node01:8088/ws/v1/cluster/apps?statesRUNNING” | jq ‘select(.apps.app[].applicationType “SPARK”) | .apps.app[].id’ | xargs -I {} curl -s “http://it-cdh-node01:808…...
-004)
ArcGIS Pro地块图斑顺序编号(手绘线顺序快速编号)-004
ArcGIS全系列实战视频教程——9个单一课程组合系列直播回放_arcgis初学者使用视频-CSDN博客 4大遥感软件!遥感影像解译!ArcGISENVIErdaseCognition_遥感解译软件-CSDN博客 今天介绍一下在ArcGIS Pro地块图斑顺序编号(手绘线顺序快速编号&am…...

红黑树解析
目录 一、引言 二、红黑树的概念与性质 2.1 红黑树的概念 2.2 红黑树的性质 三、红黑树的节点定义与结构 3.1 节点定义 四、红黑树的插入操作 4.1 插入步骤 4.2 插入代码实现 五、红黑树的验证 5.1 验证步骤 5.2 验证代码实现 六、红黑树迭代器的实现 6.1 迭代器的…...

在线文档管理系统 spring boot➕vue|源码+数据库+部署教程
📌 一、项目简介 本系统采用Spring Boot Vue ElementUI技术栈,支持管理员和员工两类角色,涵盖文档上传、分类管理、公告发布、员工资料维护、部门岗位管理等核心功能。 系统目标是打造一个简洁高效的内部文档管理平台,便于员工…...

Python3 简易DNS服务器实现
使用Python3开发一个简单的DNS服务器,支持配置资源记录(RR),并能通过dig命令进行查询。 让自己理解DNS原理 实现方案 我们将使用socketserver和dnslib库来构建这个DNS服务器。dnslib库能帮助我们处理DNS协议的复杂细节。 1. 安装依赖 首先确保安装了d…...

雾锁王国开服联机教程-专用服务器
一。阿里云服务器搭建 服务器地址:1分钟畅玩!一键部署联机服务器 《雾锁王国(Enshrouded)》融合了生存、制作以及动作 RPG 战斗,游戏背景设定在了一个基于体素构筑的辽阔大陆。无论是攀登山脉还是跨越沙漠࿰…...

鸿蒙OSUniApp 开发的一键分享功能#三方框架 #Uniapp
使用 UniApp 开发的一键分享功能 在移动应用开发中,分享功能几乎是必不可少的一环。一个好的分享体验不仅能带来更多用户,还能提升产品的曝光度。本文将详细讲解如何在 UniApp 框架下实现一个简单高效的一键分享功能,适配多个平台。 各平台分…...

Hive PredicatePushDown 谓词下推规则的计算逻辑
1. PredicatePushDown 谓词下推 谓词下推的处理顺序是先处理子节点的操作,子节点都处理完,然后处理父节点。 select web_site_sk from (select web_site_sk,web_name from web_site where web_cityPleasant Hill ) t where web_name <> site_…...

2024东北四省ccpc
F题 解题思路 数论 有限小数的条件 p q \frac{p}{q} qp 在 k k k 进制下是有限小数,当且仅当 q q q 的所有质因数都是 p p p 或 k k k 的质因数。 即,若 q q q 的质因数分解为 q ∏ i p i a i q \prod_{i} p_i^{a_i} q∏ipiai&#x…...
)
【C语言】初阶数据结构相关习题(二)
🎆个人主页:夜晚中的人海 今日语录:知识是从刻苦劳动中得来的,任何成就都是刻苦劳动的结果。——宋庆龄 文章目录 🎄一、链表内指定区间翻转🎉二、从链表中删去总和值为零的节点🚀三、链表求和&…...

DeepSeek执行流程加速指南:跨框架转换与编译优化的核心策略全解析
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
)
解决 Conda 安装 PyTorch 1.1.0 报错:excluded by strict repo priority(附三种解决方案)
# 💥解决 Conda 安装 PyTorch 1.1.0 报错问题:excluded by strict repo priority在使用旧版本 PyTorch(例如 1.1.0)时,有些开发者会遇到以下 conda 安装报错:LibMambaUnsatisfiableError: package pytorch-…...