第九讲 | 模板进阶
模板进阶
- 一、非类型模板参数
- 1、模板参数的分类
- 2、应用场景
- 3、array
- 4、注意
- 二、模板的特化
- 1、概念
- 2、函数模板特化
- 3、类模板特化
- (1)、全特化:全部模板参数都特化成具体的类型
- (2)、偏/半特化:部分模板参数特化成具体的类型,还可以是对参数的进一步限制
- (3)、priority_queue中使用类模板特化
- 三、typename的特性
- 四、模板的分离编译
- 五、模板的优缺点
一、非类型模板参数
1、模板参数的分类
- 模板参数分为非类型模板参数和类型模板参数:
-
类型模板参数:出现在模板参数列表中,跟在class或者typename之后的参数类型名称。我们之前定义的都是类型模板参数。
-
非类型模板参数:常量作为类(函数)模板的参数,在类(函数)模板中可将该参数当成常量来使用。
2、应用场景
为什么要有非类型模板参数?
例如,定义一个静态的栈。静态栈需要确定大小,假设两个栈分别是10、100个空间,但是静态栈不能同时做到一个是10个,一个是100个,宏常量只能是一个大小;与typedef是一样的道理,只能保证是一个类型。若将N改成100#define N 100,对于第一个栈就浪费了90个空间。
#define N 10
template<class T>
class Stack
{
private:T _a[N];size_t _top;
};
int main()
{Stack<int> st1;// 10Stack<int> st2;// 100return 0;
}
所以C++又增加了一个非类型模板参数,非类型模板参数与宏很类似但是比宏更灵活,本质还是由Stack实例化出的两个类:
template<class T, size_t N>
class Stack
{
private:T _a[N];size_t _top;
};
int main()
{Stack<int, 10> st1;// 10Stack<int, 100> st2;// 100return 0;
}

非类型模板参数也可以给缺省值:
template<class T, size_t N = 10>
class Stack
{
private:T _a[N];size_t _top;
};
int main()
{Stack<int> st1;// 10Stack<int, 100> st2;// 100return 0;
}
3、array
看看库里面使用非类型模板参数的容器:C++11新增的容器array(静态数组),与vector形成对照。

没有提供头插头删尾插尾删接口,因为空间是一定的,用下标随机访问就行。
严格来说,array对比的不是vector,因为vector是动态的,二者本质还是不一样的,array对比的是C语言中的静态数组。
array与C中的静态数组很像:存储的数据类型可以是自定义类型,也可以是内置类型的;sizeof出来的大小是一样的;只不过array中多了个迭代器,其实就是原生指针,C中静态数组可以用范围for,也是可以转换成原生指针。
int main()
{// C++中用类封装的静态数组arrayarray<int, 10> a1;array<int, 100> a2;array<string, 100> a3;// C中静态数组int aa1[10];int aa2[100];string aa3[100];cout << sizeof(a1) << endl;cout << sizeof(aa1) << endl;return 0;
}

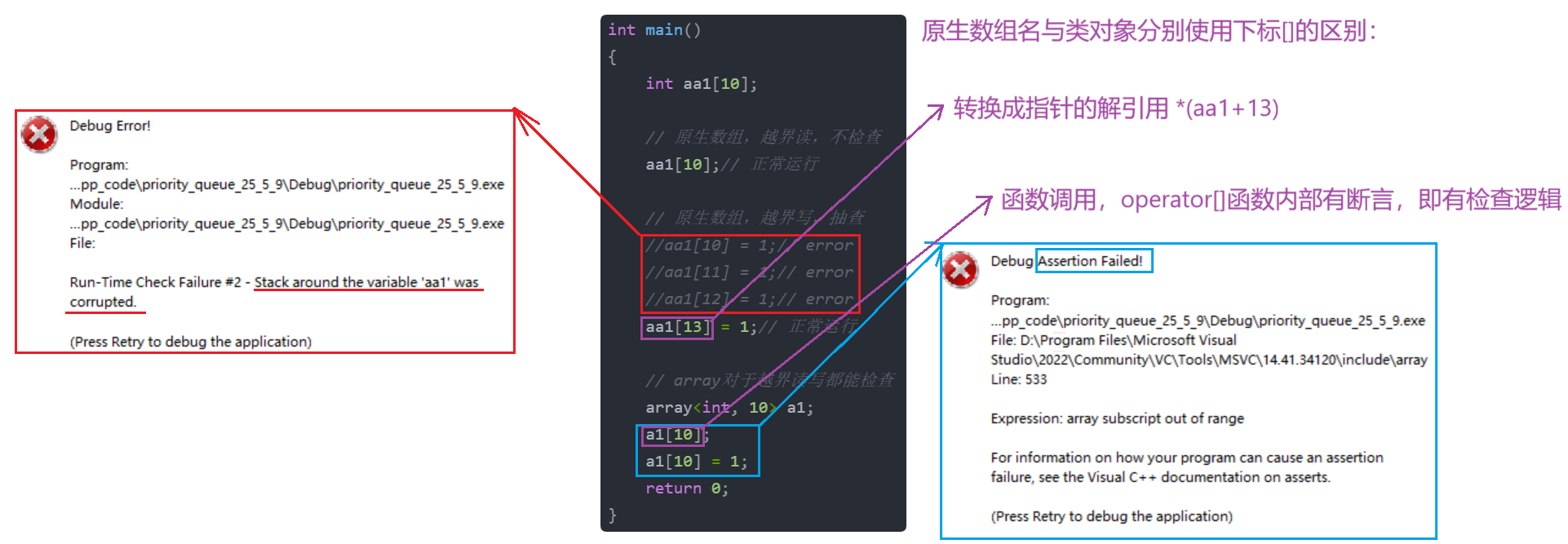
array与C中静态数组真正的区别只有一个:越界的检查方式不同。
- C中静态数组:
- 原生数组,越界读,不检查。
- 原生数组,越界写,抽查。一般在结束位置附近可以检查出来,但是再往后的位置越界就会检查不出来。
- array:
- array对于越界读写都能检查
那么array是怎么做到越界读写都能检查到的?自定义类型对象调用 operator[] ,函数里面有assert断言检查,所以报错报的是断言错误。
但是array用的很少,一般用的是vector。vector有初始化;array连初始化都没有,都是随机值。而且array实参N的值不能太大,栈空间不大,会栈溢出。若就想用静态数组,那么就可以用array替代C中静态数组。
4、注意
- 非类型模板参数一般要求只能是整型。浮点数、类对象以及字符串等其他类型是不允许作为非类型模板参数的。但是C++20以后可以支持其他类型作为非类型模板参数。
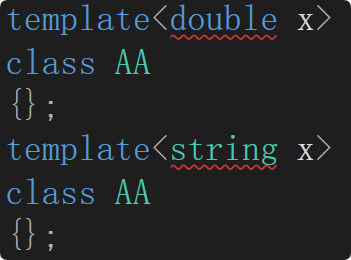
- 非类型的模板参数必须在编译期间就能确认结果。
二、模板的特化
1、概念
特化:特殊化处理。
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型可能会得到一些错误的结果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板。
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
int main()
{cout << Less(1, 2) << endl;// 可以比较,结果正确Date d1(2025, 5, 11);Date d2(2025, 5, 12);cout << Less(d1, d2) << endl;// 可以比较,结果正确Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl;// 可以比较,结果错误return 0;
}

可以看到,Less绝大多数情况下都可以正常比较,但是在特殊场景下就得到错误的结果。上述示例中,p1指向的d1显然小于p2指向的d2对象,但是Less内部并没有比较p1和p2指向的对象内容,而比较的是p1和p2指针的地址,这就无法达到预期而错误。
此时,就需要对模板进行特化。即:在原模板的基础上,对特殊类型进行特殊化的处理。模板特化分为函数模板特化与类模板特化。
2、函数模板特化
函数模板的特化步骤:
- 必须要先有一个基础的函数模板
- 关键字template后面接一对空的尖括号<>
- 函数名后跟一对尖括号,尖括号中指定需要特化的类型
- 函数形参表:必须要和函数模板的基础参数类型完全相同,如果不同编译器可能会报一些奇怪的错误。
(类模板的特化步骤与之类似,不过类模板特化和类模板里的函数参数列表没有必要完全相同)
函数模板本质是一种参数匹配,对函数模板进行特化本质也是一种参数匹配。
// 函数模板 -- 参数匹配
template<class T>
bool Less(T left, T right)
{return left < right;
}
// 对Less函数模板进行特化 -- 参数匹配
template<>
bool Less<Date*>(Date* left, Date* right)// T实例化成Date*
{return *left < *right;
}
int main()
{cout << Less(1, 2) << endl;Date d1(2025, 5, 11);Date d2(2025, 5, 12);cout << Less(d1, d2) << endl;Date* p1 = &d1;Date* p2 = &d2;cout << Less(p1, p2) << endl;// 调用特化之后的版本,而不走模板生成了return 0;
}
注意:一般情况下如果函数模板遇到不能处理或者处理有误的类型,为了实现简单通常都是将该函数直接给出。普通函数可以与函数模板同时存在,有现成吃现成,就会直接调用现有的函数,所以函数模板不建议特化,直接写普通函数即可。
bool Less(Date* left, Date* right)
{return *left < *right;
}
为什么不建议函数模板特化呢?函数模板的坑:
传值传参,若T是有深拷贝的自定义类型,代价太大了,所以会加引用。加了引用一般就会加const,这样普通对象、const对象都可以作为参数传递过来。对上述函数模板改造如下:
但是报错了,会不会是参数列表没有对上?但是加上了引用也还是报错了。
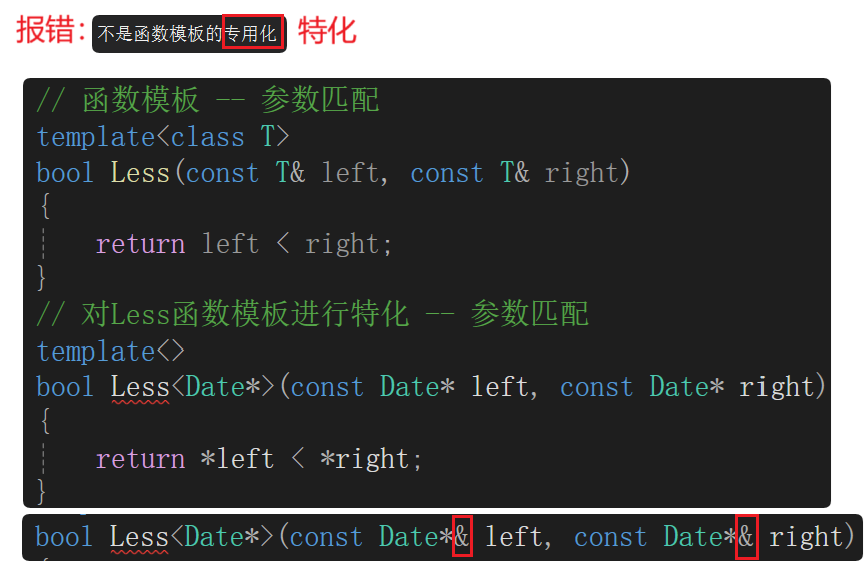
问题出现在const上,"不是函数模板的专用化"的原因是const修饰的匹配不上。所以特化的const的正确位置如右图。

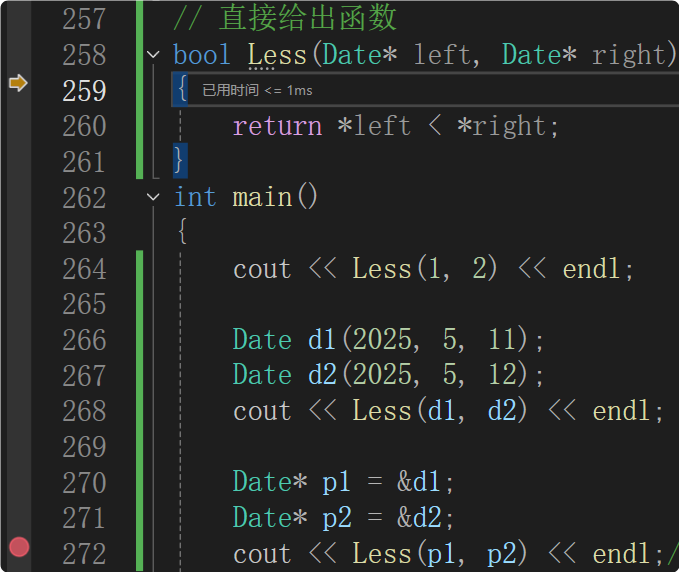
所以函数模板特化是很容易出现问题的,直接写成普通函数即可。
借助调试理解普通函数与函数模板特化同时存在时,会优先匹配普通函数。
3、类模板特化
(1)、全特化:全部模板参数都特化成具体的类型
函数模板可以特化,也可以写出普通函数。而对于类模板特化,没有普通类的概念,必须走类模板特化。因为函数与函数模板可以参数匹配,而类模板必须显示实例化。
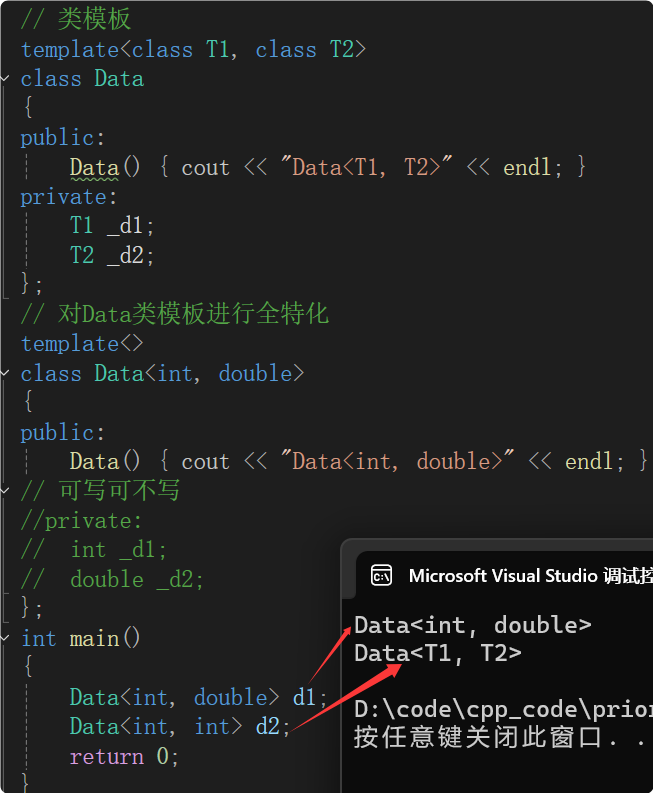
Data<int, double> d1;实例化出的类的数据类型T1是int、T2是double,就会优先匹配上面类模板特化的版本。
(2)、偏/半特化:部分模板参数特化成具体的类型,还可以是对参数的进一步限制
部分模板参数特化成具体的类型:
// 将第二个参数特化为char
template<class T1>
class Data<T1, char>
{
public:Data() { cout << "Data<T1, char>" << endl; }
};
对模板参数的进一步限制:
// 特化 -- 偏特化,实例化出的模板参数只要都是指针就会走这个版本
// 两个参数偏特化为指针类型
template<class T1, class T2>
class Data<T1*, T2*>
{
public:Data() { cout << "Data<T1*, T2*>" << endl; }
private:T1 _d1;T2 _d2;
};
// 特化 -- 偏特化,实例化出的模板参数只要都是引用就会走这个版本
// 两个参数偏特化为引用类型
template<class T1, class T2>
class Data<T1&, T2&>
{
public:Data() { cout << "Data<T1&, T2&>" << endl; }
private:T1 _d1;T2 _d2;
};
// 特化 -- 偏特化,还能特化成指针和引用混在一起的版本
// 实例化出的模板参数只要前一个是指针、后一个是引用就会走这个版本
template<class T1, class T2>
class Data<T1*, T2&>
{
public:Data() { cout << "Data<T1*, T2&>" << endl; }
private:T1 _d1;T2 _d2;
};
上面所有的类模板特化与类模板是同时存在的。

(3)、priority_queue中使用类模板特化
例如上一讲中的内容,是需要显示给出模板参数的:
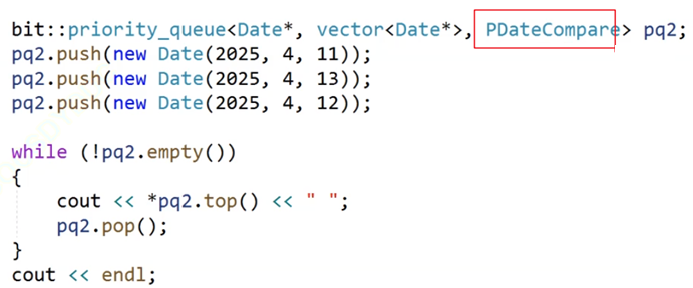
这里给的模板参数解决了日期类指针的问题,但是要是有int*等其他类型的指针呢?都去写仿函数就太多了,内容繁琐,而特化就能解决。
int main()
{zsy::priority_queue<Date> pq1;pq1.push({ 2025, 5, 10 });pq1.push({ 2025, 5, 19 });pq1.push({ 2025, 5, 23 });while (!pq1.empty()){cout << pq1.top() << " ";pq1.pop();}cout << endl;zsy::priority_queue<Date*> pq2;pq2.push(new Date(2025, 5, 10));pq2.push(new Date(2025, 5, 19));pq2.push(new Date(2025, 5, 23));while (!pq2.empty()){cout << *pq2.top() << " ";pq2.pop();}cout << endl;zsy::priority_queue<int*> pq3;pq3.push(new int(1));pq3.push(new int(2));pq3.push(new int(3));while (!pq3.empty()){cout << *pq3.top() << " ";pq3.pop();}cout << endl;return 0;
}
模拟实现的less仿函数:
template<class T>
class less
{
public:bool operator()(const T& x, const T& y){return x < y;}
};
这样写会报错,因为当T是指针时,const修饰的不是指针,而是指向的内容,前面讲解过了解决办法。
// 特化
template<class T>
class less<T*>
{
public:bool operator()(const T& x, const T& y){return *x < *y;}
};
这里还有一个解决办法:
// 特化
template<class T>// 这里的T保留
class less<T*>// 意思是T是指针T*时,就按照指向的内容去比较
{
public:bool operator()(const T* const & x, const T* const & y){return *x < *y;}
};
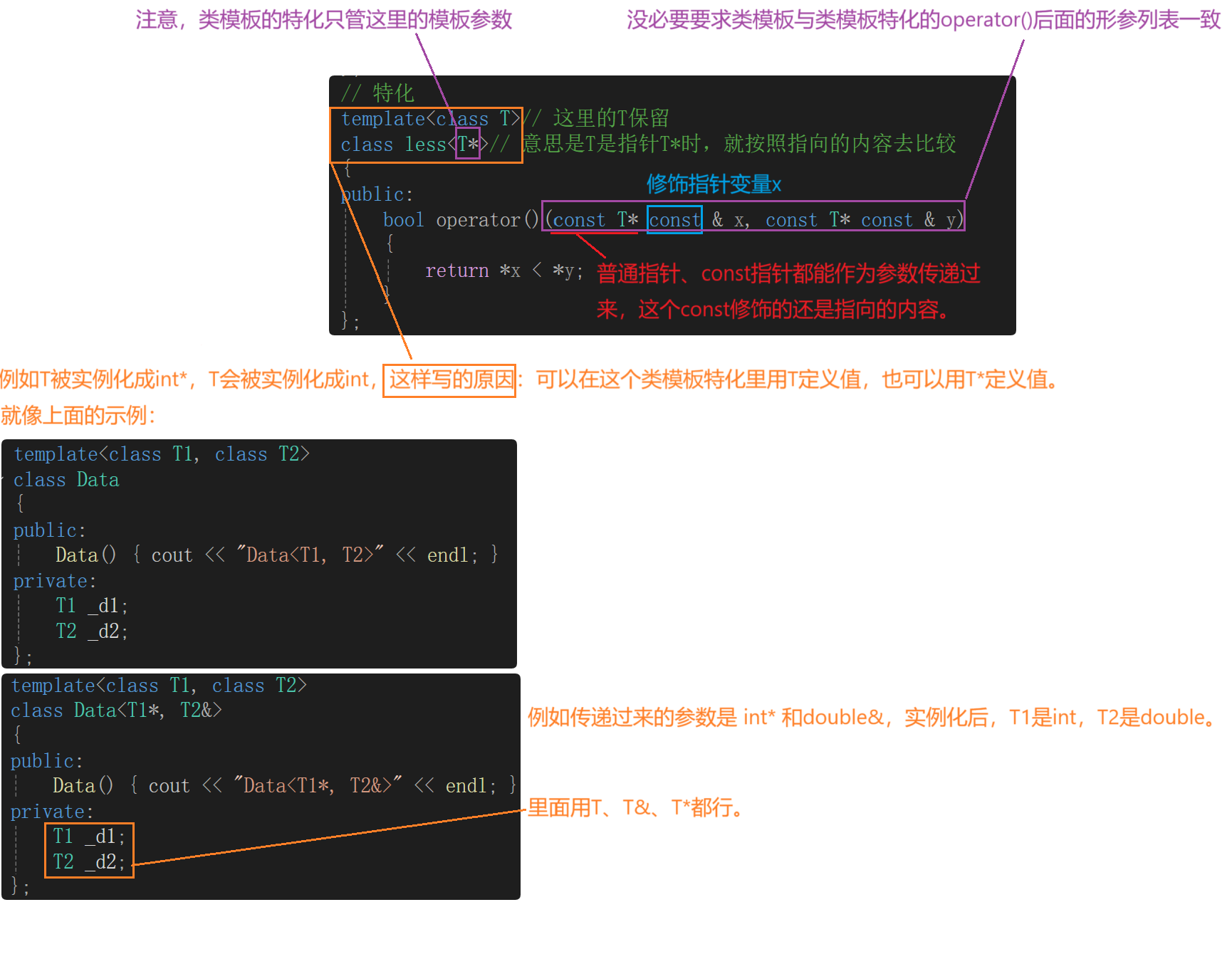
所以上一讲中对于priority_queue的模拟实现的仿函数改进如下:
template<class T>
class less
{
public:bool operator()(const T& x, const T& y){return x < y;}
};
// 特化
template<class T>
class less<T*>
{
public:bool operator()(const T* const & x, const T* const & y){return *x < *y;}
};
template<class T>
class greater
{
public:bool operator()(const T& x, const T& y){return x > y;}
};
// 特化
template<class T>
class greater<class T*>
{
public:bool operator()(const T* const& x, const T* const& y){return *x > *y;}
};
三、typename的特性
定义模板参数用关键字class/typename都行。最常用class,例如库里面的模板声明中大多都是用class定义模板参数的:

但是有一个场景下必须用typename定义:模板参数里面取内嵌类型时前面必须加typename,无论是用这个内嵌类型定义/声明对象。
示例1,想打印一些容器。vector、list提供了迭代器但是没有提供cout打印,我们现在想写一个通用的函数去对它们进行打印,比如写一个通用的打印容器的Print函数模板,但是会报编译错误:
#include <iostream>
#include <list>
#include <vector>
using namespace std;
template<class Container>
void Print(const Container& con)
{Container::const_iterator it = con.begin();while (it != con.end()){cout << *it << " ";++it;}cout << endl;
}
int main()
{vector<int> v = { 1, 2, 3, 4, 5 };list<int> lt = { 10, 20, 30 };Print(v);Print(lt);return 0;
}

问题所在:

前面加typename才会通过:

原因:从上往下编译,编译到Container::const_iterator it = con.begin();时,因为Container是模板参数,在未实例化时,编译器不知道Container到底是什么东西,根据域作用限定符,猜测Container可能是命名空间/类,因为是从上往下编译的,知道class后面是类型参数名,所以知道Container是个类型,故而编译器确定Container是个类。但是编译器不知道 :: 取的const_iterator是类型还是静态成员变量,既然不确定是什么,那么const_iterator就是不合法的。若const_iterator是个类型,编译就能通过,也不敢去Container里面找,因为不确定Container实例化是什么。而前面加个typename就是程序员先告诉编译器typename后面的Container::const_iterator肯定是个类型,让编译先通过,等到Container实例化时编译器再去确认Container::const_iterator具体的类型。
示例2:
虽然知道容器是vector,但是vector< T >还是没有实例化的。所以只要记住模板参数里面取内嵌类型前加typename即可。
typename vector<T>::const_iterator it = con.begin();
#include <iostream>
#include <list>
#include <vector>
using namespace std;
template<class Container>
void Print(const Container& con)
{typename Container::const_iterator it = con.begin();while (it != con.end()){cout << *it << " ";++it;}cout << endl;
}
template<class T>
void Print(const vector<T>& con)
{typename vector<T>::const_iterator it = con.begin();while (it != con.end()){cout << *it << " ";++it;}cout << endl;
}
int main()
{vector<int> v = { 1, 2, 3, 4, 5 };list<int> lt = { 10, 20, 30 };Print(v);Print(lt);return 0;
}
库里用到typename的容器:

四、模板的分离编译
分离编译:一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
模板的定义和声明可以分离在同一个文件中,但是不能分离在两个文件中,会有链接错误。
我们从简单的声明和定义的分离再逐渐过渡到为什么模板不支持声明和定义分离到两个文件进行讲解。
不支持分离在.h和.cpp里。
- 简单的声明和定义的分离:
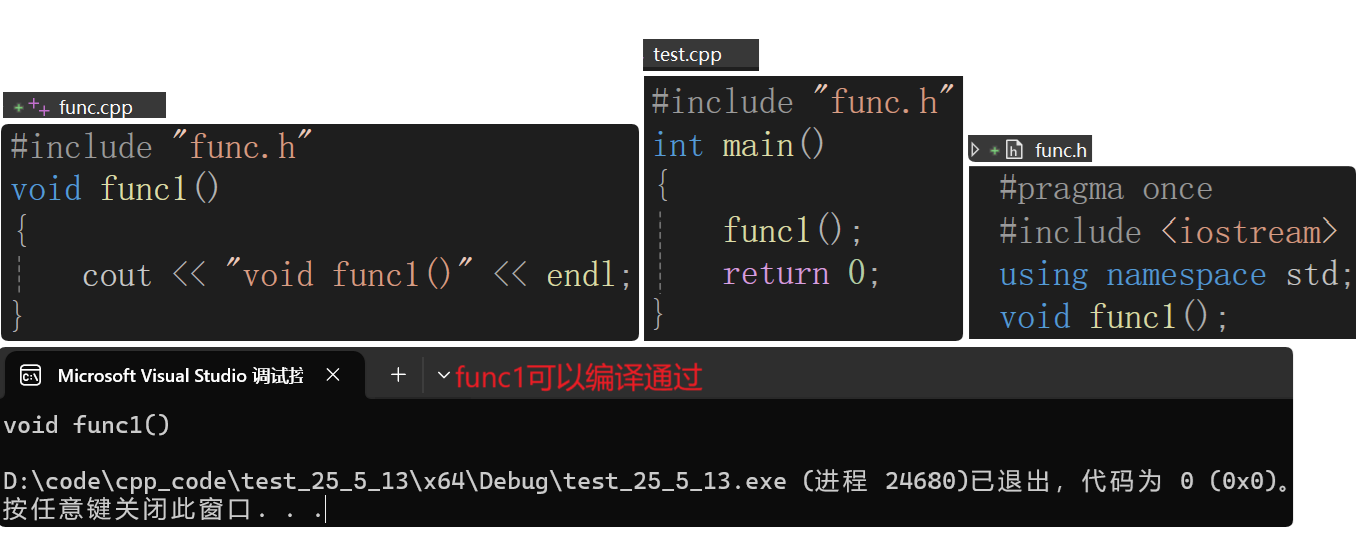
以下编译链接的过程按照Linux来讲:

条件编译:#ifdef、#ifndef、#endif等。写了一个需要跨平台的代码,例如分别在Windows、Linux调用,那么这个代码中就有条件编译。由于Windows、Linux接口不同,需要借助条件编译跨平台。例如:
在预处理阶段,如果满足if后面的宏,就会把这段代码放出来,否则就不放:
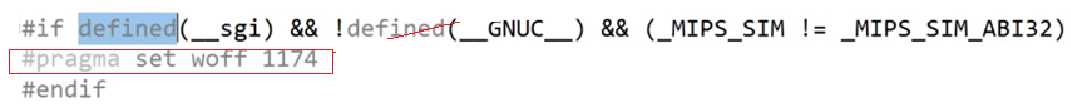
预处理期间,满足后面的条件,代码留下,否则就相当于把这段代码删去:
预处理阶段:.h在func.cpp和test.cpp下分别展开,展开头文件,相当于在新的文件中把.h文件拷贝到.cpp中,这一过程不在源文件中处理。所以编译时就没有.h了:

编译后会生成汇编代码,但是CPU看不懂汇编代码,"汇编代码"是一种"符号指令"级别的语言,是人们能看懂的符号,例如call、jump、add…,但是这些符号机器(CPU)看不懂,CPU(机器)只认识二进制语言0、1。所以我们还需要对符号指令进行翻译(翻译的例子:move指令假如叫111、add指令叫112,CPU看到112就知道是add)。所以编译后生成的.s文件需要进行汇编(与"汇编代码"区分),汇编是编译链接中的一个步骤,是将汇编代码转换成二进制机器码,CPU认识二进制机器码,这一步骤生成.o文件。
发现除了在"预处理"阶段会有.h的展开,func.h和func.cpp一起生成func.i、test.cpp和func.h一起生成test.i。其他步骤中.cpp与.cpp之间是各自生成各自的。"链接"是生成可执行程序,不是仅仅把它们合并在一起,而是把它们"链接"在一起。链接后,Linux下会生成a.out(具体会在学习到Linux时讲解),Windows下会生成xxx.exe,a.out和xxx.exe就是可执行程序了。
链接错误通常就是没有定义
这里报链接错误的原因是只有函数声明,没有函数定义。那么为什么会有这样的问题呢?

.h在预处理阶段会在func.cpp和test.cpp下分别展开,展开了之后func.i和test.i各有一份声明:

func.i没有问题,有func1函数的定义和声明;但是test.i会有问题,"编译"阶段检查语法,调用函数时,要找到它的出处,要有函数的定义,或者至少有函数的声明。调用函数func1()时,有它的函数声明,所以语法没有问题。
之后要在test.s中生成汇编代码,函数调用生成的汇编代码是"call一个地址",形象一点就是"call func1(?)"。函数的地址类似数组的地址,数组的地址就是第一个数据的地址,函数的定义被编译后是一串指令(好多句指令),每一句指令都会对应一个地址,第一句指令就是函数的地址。所以call这个函数的地址就是,先到一个jump指令,再跳转过去执行函数,再函数建立栈帧…
之前除预处理阶段各个.cpp之间不会交互,只有在链接阶段交互。
若.h里有这个函数的定义,预处理.cpp文件包了定义,有了定义就有这个函数的地址,函数定义被编译成一段指令,取第一句指令填写到"call func1(?)"中的?上,指令完整,即有了定义那么函数地址在编译阶段就能确定。但是示例中的情况是没有函数定义,只有函数声明,首先语法没有问题"编译"直接通过了,由于只有函数声明,所以不可能有函数地址,那么(定义)地址在哪里呢?在其他文件。这时会在"链接"阶段确定地址:利用func1函数名去其他文件找,为了更快速找到,每个.o文件都会有对应的一个符号表,每个符号表会把对应.o文件中的函数及其地址填进来,这样就不用在文件里找了,直接拿func1函数名去符号表找func1地址0x00112233,填在call func1(?)里call func1(0x00112233),这句指令才算完整。所以"链接"阶段不止把多个.o链接到一起,还有本段落的过程。然后就生成了可执行程序。
所以上面的链接错误的原因:拿func1函数名找不到函数的地址,没有定义所以没有函数的地址,所以链接错误通常就是没有定义。
顺便提一句编译好的动态库,平时编译链接程序就直接生成的是可执行程序,Windows下可以设置编译链接后生成的是动态库。比如一个多人写的项目,有多个动态库,只走链接的部分,可以加快编译的速度。(Linux讲解)
- 为什么模板不能声明和定义分离在.h和.cpp?
若声明和定义不分离,程序没问题;若声明和定义分离在.h文件是没问题的,.cpp包了.h既有声明,又有定义;
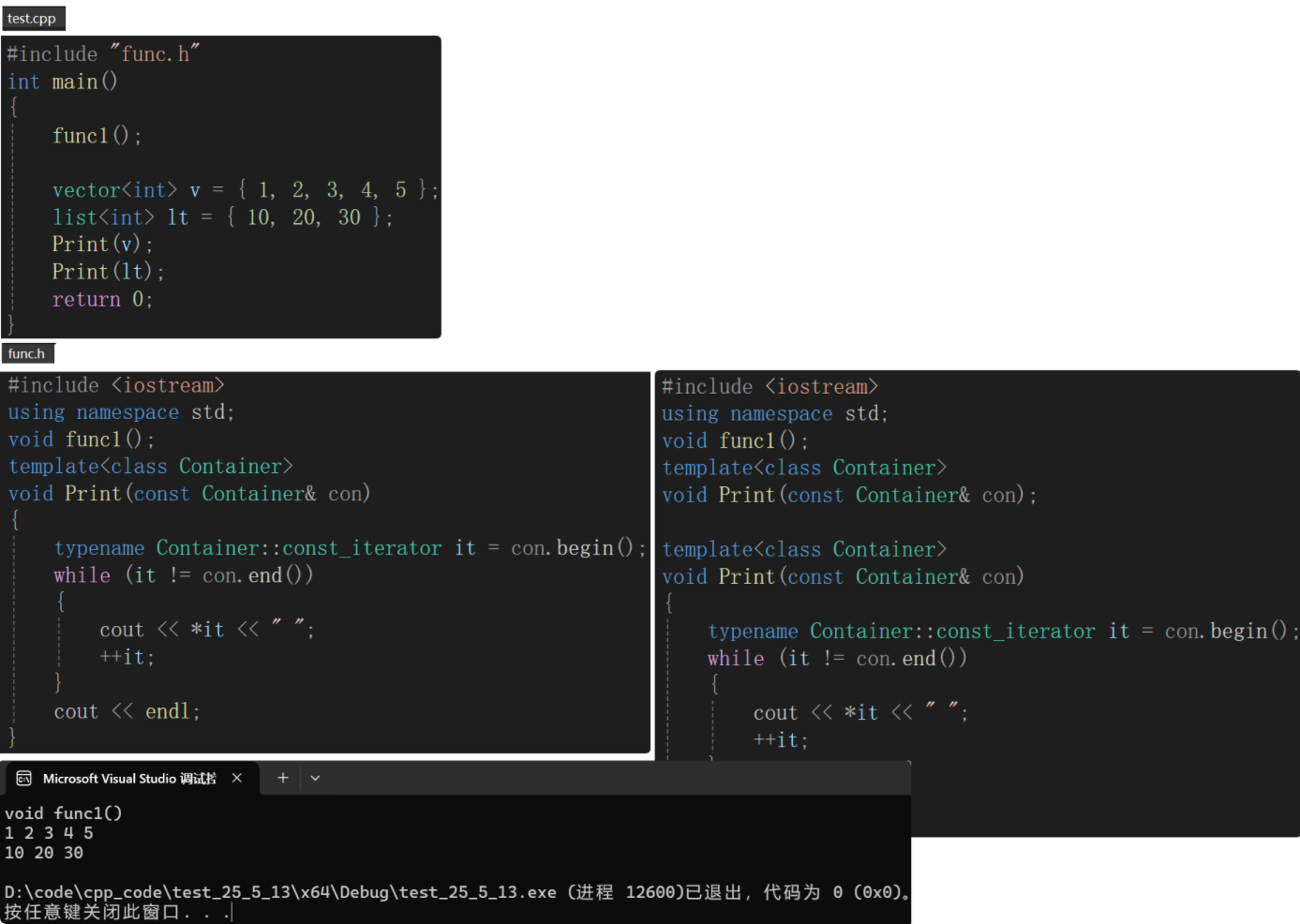
若声明和定义分离在两个文件,会出现链接错误,即找不到定义。func1链接错误是因为没有定义,但是为什么定义了Print模板还报链接错误?—— Contianer没有实例化。模板不能直接调用,是需要实例化模板参数Container的。
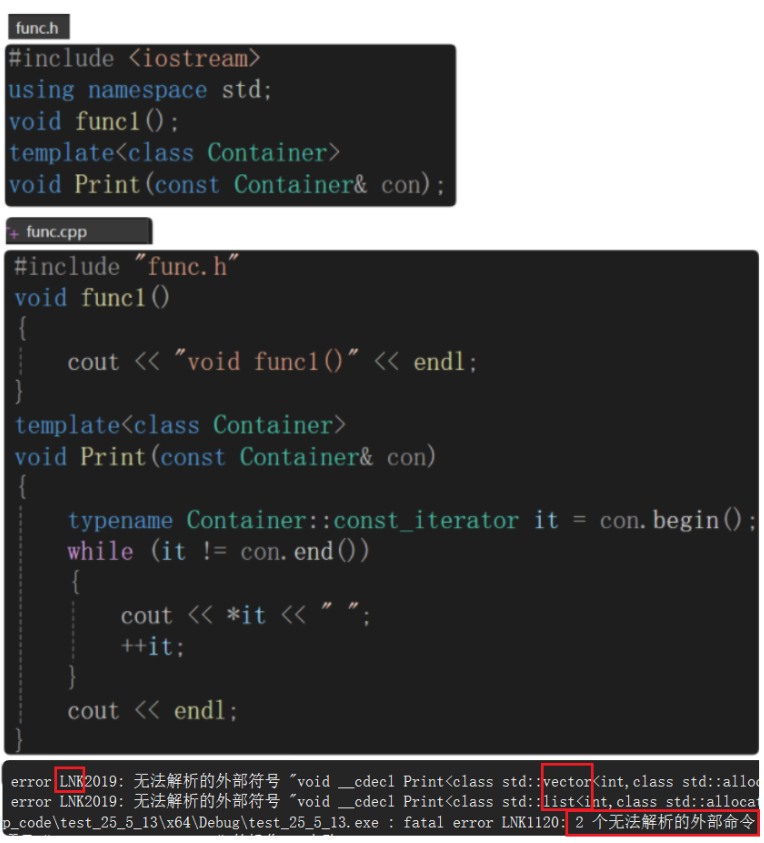
调用的地方Print()语法没有问题,出处是Print的声明,编译通过。
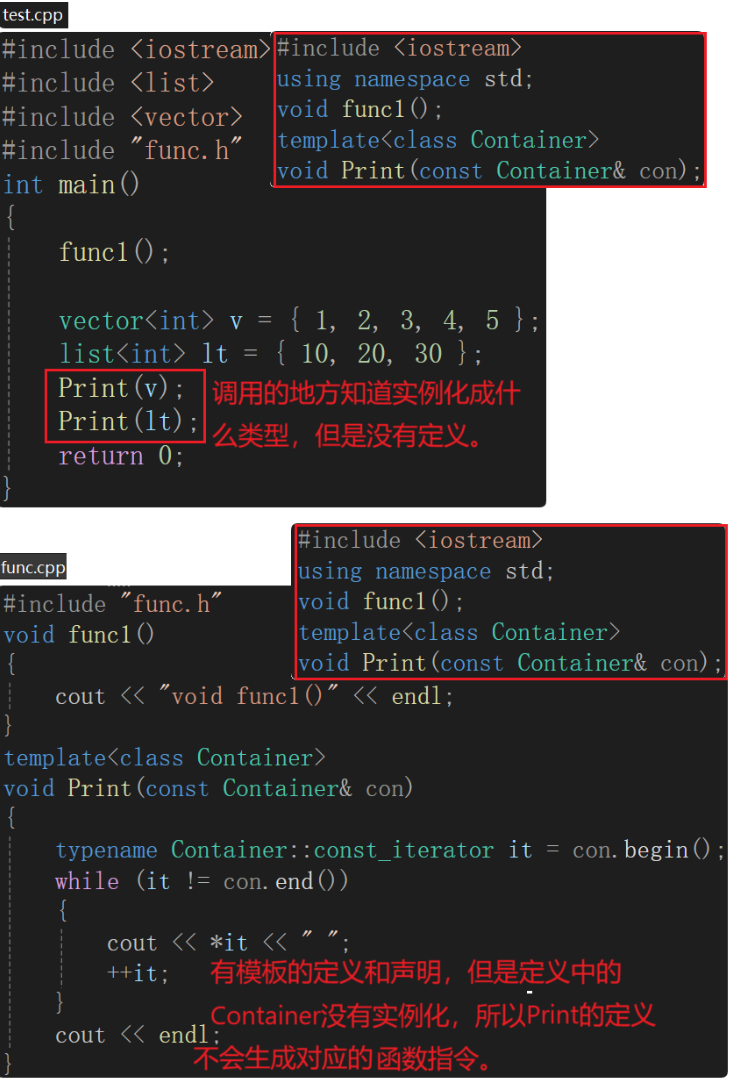
由于链接之前不会交互不会有问题,而在链接阶段会交互,用Print函数名去找定义会找不到,因为Print函数的定义没有实例化,在链接阶段出现的错误,即链接错误。
解决方案:
- 方法一:显示实例化
上面出现链接错误的原因就是Print函数的定义中的模板参数Contianer没有实例化,那就告诉编译器模板参数Container实例化为vector< int >
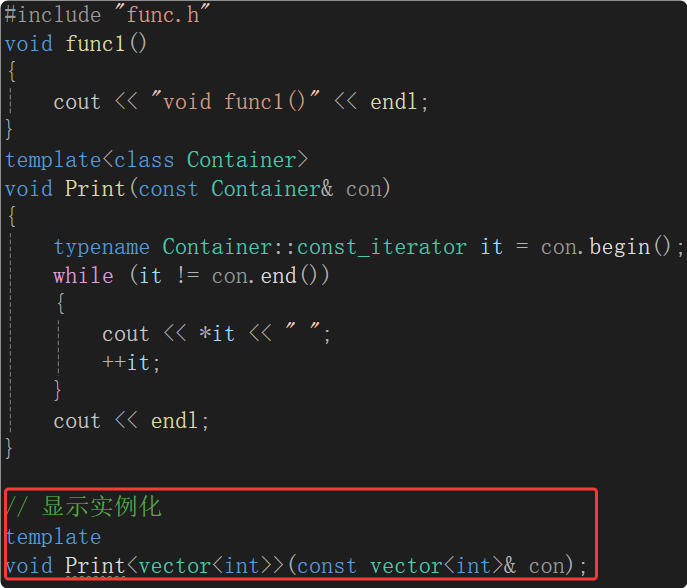
只会报一个链接错误了:

说明函数调用 Print(v); 找到对应的定义了,能链接上。
显示实例化,实例化生成一份Container为vector< int >的Print,知道了Print的实例化定义,编译生成它的地址,链接时在test.o的符号表里找Print<vector< int >>地址,call 一个地址。所以模板的定义和声明可以分离到两个文件中,不过实际上不会这么做的,太麻烦了,还有其他的类型就还需要显示实例化。
因此,"显示实例化"这种方式可行但不可取。
- 方法二,正确解决办法:模板直接在.h里定义,或者定义和声明在.h/.hpp里,不要分离到.cpp里。
为什么这样可以解决问题?
首先明确什么情况下需要链接?.h只有声明,哪个.cpp包含了这个.h在预处理后也只包了声明,编译阶段语法没有问题,但是(没有实例化)就没办法生成对应的指令,这时需要链接。
若.h就有模板定义,哪个.cpp包含了这个.h就会在预处理后也有定义,那么在调用的地方就知道实例化成什么,实例化后模板定义经过编译直接生成指令,这样编译阶段就有了地址,这时就不用链接确认地址了。所以没有链接错误,因为根本不用链接、不用到符号表里找。
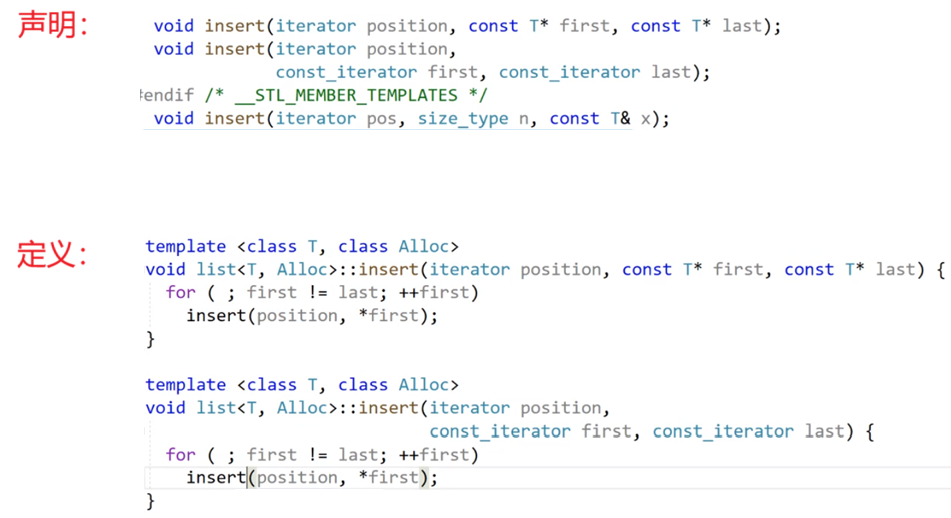
看一个list的源代码。模板没有.cpp,list是个模板,模板只会声明和定义都在.h里:

短小函数直接定义在类里,成为内联:

长一点的函数,在当前文件做了声明和定义的分离:
普通的函数和类都需要写.h、.cpp声明和定义的分离;模板就只定义在.h,后缀是.h,还有一些模板后缀是.hpp,就是.h和.cpp的合体,把声明和定义放在了一起,例如,boost库里好多模板就是这样的:
弄清楚:
1、模板的声明和定义分离在.h、.cpp为什么会报错?
2、解决方案?有两种:(1)、显示实例化 (2)、模板直接定义在.h
五、模板的优缺点
【优点】
- 模板复用了代码,节省资源,更快的迭代开发,C++的标准模板库(STL)因此而产生。
- 增强了代码的灵活性。
【缺陷】
- 模板会导致代码膨胀问题,也会导致编译时间变长。
- 出现一处模板编译错误时,可能就会导致一堆错误。错误信息非常凌乱,不易定位错误。
代码膨胀避免不了,比如写了一个vector模板有100行代码,实例化成多个不同类型时,就会导致有更多代码。
相关文章:

第九讲 | 模板进阶
模板进阶 一、非类型模板参数1、模板参数的分类2、应用场景3、array4、注意 二、模板的特化1、概念2、函数模板特化3、类模板特化(1)、全特化:全部模板参数都特化成具体的类型(2)、偏/半特化:部分模板参数特…...

联合建模组织学和分子标记用于癌症分类|文献速递-深度学习医疗AI最新文献
Title 题目 Joint modeling histology and molecular markers for cancer classification 联合建模组织学和分子标记用于癌症分类 01 文献速递介绍 癌症是对人类致命的恶性肿瘤,早期准确诊断对癌症治疗至关重要。目前,病理诊断仍是癌症诊断的金标准…...

会计要素+借贷分录+会计科目+账户,几个银行会计的重要概念
1.借贷分录还是借贷分路 正确表述是“借贷分录”。 “分录”即会计分录,它是指预先确定每笔经济业务所涉及的账户名称,以及计入账户的方向和金额的一种记录,简称分录。 在借贷记账法下,会计分录通过“借”和“贷”来表示记账方向…...

【C++】set和multiset的常用接口详解
前⾯我们已经接触过STL中的部分容器如:string、vector、list、deque、array、forward_list等,本篇文章将介绍一下map和multiset的使用。 1. 序列式容器和关联式容器 在介绍set之前我们先简单介绍一下什么是序列式容器和关联式容器。 前⾯我们已经接触过S…...

PostgreSQL 联合索引生效条件
最近面试的时候,总会遇到一个问题 在 PostgreSQL 中,联合索引在什么条件下会生效? 特此记录~ 前置信息 数据库版本 PostgreSQL 14.13, compiled by Visual C build 1941, 64-bit 建表语句 CREATE TABLE people (id SERIAL PRIMARY KEY,c…...

聊聊redisson的lockWatchdogTimeout
序 本文主要研究一下redisson的lockWatchdogTimeout lockWatchdogTimeout redisson/src/main/java/org/redisson/config/Config.java private long lockWatchdogTimeout 30 * 1000;/*** This parameter is only used if lock has been acquired without leaseTimeout param…...
-树形查找:红黑树)
数据结构第七章(三)-树形查找:红黑树
树形查找(二) 红黑树一、红黑树1.定义2.黑高3.性质 二、插入1.插入步骤2.举例 总结 红黑树 红黑树来喽~ 我们在上一篇说了二叉排序树(BST)和平衡二叉树(AVL),那么既然都有这两个了,…...

C++篇——多态
目录 引言 1,什么是多态 2. 多态的定义及实现 2_1,多态的构成条件 2_2,虚函数 2_3,虚函数的重写 2_4,虚函数重写的两个例外 2_4_1,协变(基类与派生类虚函数返回值类型不同) 2_4_2. 析构函数的重写(基类…...

AI实时对话的通信基础,WebRTC技术综合指南
在通过您的网络浏览器进行音频和视频通话、屏幕共享或实时数据传输时,您可能并不常思考其背后的技术。推动这些功能的核心力量之一就是WebRTC。2011年由谷歌发布的这个开源项目,如今已发展成为一个高度全面且不断扩展的生态系统。尤其是在AI技术大幅突破…...

【寻找Linux的奥秘】第五章:认识进程
请君浏览 前言1. 冯诺依曼体系结构数据流动 2. 操作系统(Operating System)2.1 概念2.2 设计OS的目的2.3 如何理解“管理”2.4 系统调用和库函数概念 3. 进程3.1 基本概念3.1.1 查看进程3.1.2 创建进程 3.2 进程状态3.2.1 简单介绍3.2.2 运行&&阻…...

uniapp微信小程序-长按按钮百度语音识别回显文字
流程图: 话不多说,上代码: <template><view class"content"><view class"speech-chat" longpress"startSpeech" touchend"endSpeech"><view class"animate-block" …...
.net开发的软件附带大型XML文件可以删除吗?AlipaySDKNet.OpenAPI.xml)
支付宝创建商家订单收款码(统一收单线下交易预创建).net开发的软件附带大型XML文件可以删除吗?AlipaySDKNet.OpenAPI.xml
支付宝创建商家订单收款码(统一收单线下交易预创建)一个程序55MB,XML就带了35MB AlipaySDKNet.OpenAPI.xml,BouncyCastle.Crypto.xml 支付宝店铺收款码创建的程序,这些文件可以不用吗 在支付宝店铺收款码创建的程序中…...

Profinet转Ethernet/IP网关模块通信协议适配配置
案例背景 在某自动化生产车间中,现有控制系统采用了西门子 S7 - 1500 PLC 作为主要控制器,负责生产流程的核心控制。同时,由于部分设备的历史原因,存在使用 AB 的 PLC 进行特定环节控制的情况。为了实现整个生产系统的信息交互与…...

4.6/Q1,GBD数据库最新文章解读
文章题目:Global burden, subtype, risk factors and etiological analysis of enteric infections from 1990-2021: population based study DOI:10.3389/fcimb.2025.1527765 中文标题:1990-2021 年肠道感染的全球负担、亚型、危险因素和病因…...

数字孪生技术:开启未来的“镜像”技术
想象一下,你拥有一个与现实世界一模一样的 “数字分身”,它不仅长得像你,行为举止、思维方式也和你毫无二致,甚至能提前预知你的下一步行动。这听起来像是科幻电影里的情节,但数字孪生技术却让它在现实中成为了可能。数…...
)
Java 序列化(Serialization)
一、理论说明 1. 序列化的定义 Java 序列化是指将对象转换为字节流的过程,以便将其存储到文件、数据库或通过网络传输。反序列化则是将字节流重新转换为对象的过程。通过实现java.io.Serializable接口,类可以被标记为可序列化的,该接口是一…...

Python解析Excel入库如何做到行的拆分
我们读取解析Excel入库经常会遇到这种场景,那就是行的拆分,如图: 比如我们入库,要以name为主键,可是表格name的值全是以逗号分割的多个,这怎么办呢?这就必须拆成多行了啊。 代码如下ÿ…...

信创国产化监控 | 达梦数据库监控全解析
达梦数据库(DM Database)是国产数据库的代表产品之一,在政府、金融、电信、能源等多个关键行业应用广泛,它具有高兼容性、高安全性、高可用性、高性能、自主可控等特点。随着国产化替代进程加速,达梦数据库在关键信息基…...

Parsec解决PnP连接失败的问题
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、准备环境二、DMZ三、端口映射1.Parsec设置固定端口2.路由器设置端口转发3.重启被控端Parsec四、多少一句1.有光猫管理员账号2.没有光猫管理员账号总结 前言…...
LLM数据基础)
LLM笔记(二)LLM数据基础
核心目标: 构建 LLM 的数据基础,将原始文本转化为模型可处理的、包含丰富语义和结构信息的数值形式。 一、 环境与库准备 (Environment & Libraries): 必要库确认: 在开始之前,确保 torch (PyTorch深度学习框架) 和 tiktoken (OpenAI的高效BPE分词…...
按顺序依次打印 A、B、C)
让三个线程(t1、t2、t3)按顺序依次打印 A、B、C
public class ThreadWait {private static final Object lock = new Object();private static boolean t1Output=true;private static boolean t2Output=false;private static boolean t3Output=false;public static void main(String[] args) {//线程1new Thread(new Runnable…...

2、ubantu系统配置OpenSSH | 使用vscode或pycharm远程连接
1、OpenSSH介绍 OpenSSH(Open Secure Shell)是一套基于SSH协议的开源工具,用于在计算机网络中提供安全的加密通信。它被广泛用于远程系统管理、文件传输和网络服务的安全隧道搭建,是保护网络通信免受窃听和攻击的重要工具。 1.1…...
)
idea启动报错:java: 警告: 源发行版 11 需要目标发行版 11(亲测解决)
引起原因 idea的jdk没有替换干净 1.配置project file–Project Structrue–Project 2.配置Modules-Sources file–Project Structrue–Modules-Sources 改为jdk11 3.配置Modules-Dependencies file–Project Structrue–Modules-Dependencies...

Pycharm IDEA加载大文件时报错:The file size exceeds configured limit
解决方案:配置一下idea.properties文件 文件里面写入代码: idea.max.intellisense.filesize50000重启IDEA即可;...

视频分辨率增强与自动补帧
一、视频分辨率增强 1.传统分辨率增强方法 传统的视频分辨率增强方法主要基于插值技术。这些方法通过对低分辨率视频帧中已知像素点的分布规律和相邻像素之间的相关性进行分析,在两者之间插入新的像素点以达到增加视频分辨率的目的。例如,最近邻插值算…...

深度学习让鱼与熊掌兼得
通常,一个大的复杂的模型的loss会低,但是拟合方面不够,小的模型在拟合方面更好,但是loss高,我们可以通过深度学习来得到一个有着低loss的小模型 我们之前学过,peacewise linear可以用常数加上一堆这个阶梯型函数得到,然后因为peacewise linear可以逼近任何function,所以理论上…...

面试 Linux 运维相关问题
标题Q1Shell脚本是什么、它是必需的吗? Shell脚本是一种用于自动化执行命令行任务的脚本程序,通常运行在Unix/Linux系统的Shell环境中(如Bash)。它通过将多个命令、逻辑控制(如条件判断、循环)和系统功能整合到一个文…...

阿里巴巴 1688 数据接口开发指南:构建自动化商品详情采集系统
在电商行业数据驱动决策的趋势下,高效获取商品详情数据成为企业洞察市场、优化运营的关键。通过阿里巴巴 1688 数据接口构建自动化商品详情采集系统,能够快速、精准地采集海量商品信息。本文将从开发准备、接口分析、代码实现等方面,详细介绍…...

python的宫崎骏动漫电影网站管理系统
目录 技术栈介绍具体实现截图系统设计研究方法:设计步骤设计流程核心代码部分展示研究方法详细视频演示试验方案论文大纲源码获取/详细视频演示 技术栈介绍 Django-SpringBoot-php-Node.js-flask 本课题的研究方法和研究步骤基本合理,难度适中…...

答题pk小程序道具卡的获取与应用
道具卡是答题PK小程序中必不可少的一项增加趣味性的辅助应用,那么道具卡是如何获取与应用的呢,接下来我们来揭晓答案: 一、道具卡的获取: 签到获取:在每日签到中签到不仅可获得当日的签到奖励积分,同时连…...

从零开始创建一个 Next.js 项目并实现一个 TodoList 示例
Next.js 是一个基于 React 的服务端渲染框架,它提供了很多开箱即用的功能,如自动路由、API 路由、静态生成、增量静态再生等。本文将带你一步步创建一个 Next.js 项目,并实现一个简单的 TodoList 功能。 效果地址 🧱 安装 Next.j…...

全面掌握JSR303校验:从入门到实战
一、JSR303校验简介 JSR303是Java EE 6中的一项规范,全称为"Bean Validation 1.0",它定义了一套基于注解的JavaBean校验机制。通过简单的注解,我们可以优雅地完成参数校验工作,避免在业务代码中编写大量的校验逻辑。 …...
)
「Java EE开发指南」如何使用MyEclipse的可视化JSF编辑器设计JSP?(二)
Visual JSF Designer(可视化JSF设计器)的目标是使创建JSF应用程序的特定于组件工作更容易可视化,在本教程中,您将使用可视化设计器设计JSF登录页面。您将学习如何: 创建一个JSF项目创建一个新的JSF页面设计JSF页面 该…...

Python 翻译词典小程序
一、概述 本工具是基于Python开发的智能翻译系统,采用有道词典进行翻译,并具有本地词典缓存以及单词本功能。 版本号:v1.0 (2025-05-15) 二、核心功能说明 1. 基础翻译功能 即时翻译:输入英文单词自动获取中文释义 词性识别&…...

kafka调优
以下是 Kafka 性能调优的核心策略与参数配置建议,综合生产环境和硬件层面的优化方案,覆盖生产者、消费者、Broker 三个关键组件: 一、生产者调优 批量发送优化 • batch.size:增大批量消息大小(默认 16KB,建…...

【hadoop】sqoop案例 hive->mysql
将temperature.log中的气象数据导入到Hive的temperature表中, 根据气象站id分组计算每个气象站30年来的*最高*气温, 然后将统计结果导出到MySQL当中。 思路: 1.在hive中创建表 2.数据导入到表中 3.计算后的结果写入另外的表 4.用sqoop导出…...

Git/GitLab日常使用的命令指南来了!
在 GitLab 中拉取并合并代码的常见流程是通过 Git 命令来完成的。以下是一个标准的 Git 工作流,适用于从远程仓库(如 GitLab)拉取代码、切换分支、合并更新等操作。 🌐 一、基础命令:拉取最新代码 # 拉取远程仓库的所…...

遗传算法求解旅行商问题分析
目录 一、问题分析 二、实现步骤 1)初始化种群 2)计算适应度 3)选择操作 4)交叉操作 5)变异操作 三、求解结果 四、总结 本文通过一个经典的旅行商问题,详细阐述在实际问题中如何运用遗传算法来进…...

【Hadoop】伪分布式安装
【Hadoop】伪分布式安装 什么是 Hadoop 伪分布式安装? Hadoop 伪分布式安装(Pseudo-Distributed Mode) 是一种在单台机器上模拟分布式集群环境的部署方式。它是介于 本地模式(Local Mode) 和 完全分布式模式…...

微服务概述
什么是微服务 微服务是一个架构方案,属于分布式架构的一种。 微服务提倡将模块以独立服务的方式独立管理,整个项目依靠多个小型的服务(单独进程)同时运作来支撑,单个服务只关注自己的业务实现并且有专业的团队进行开发。服务之间使用轻量的协议进行消息传送,并且对于单个…...

【网工】华为配置基础篇①
目录 ■华为设备登录配置 ■VLAN与VLANIF地址配置 ■DHCP配置命令 ■ACL访问控制列表配置 ■NAT地址转换配置 ■华为设备登录配置 <AR> system-view //进入系统模式 [AR]sysname Huawei //设备命名为Huawei [Huawei] telnet server enable //开启设备telnet功…...

React19源码系列之 Diff算法
在之前文章中root.render执行的过程,beginWork函数是渲染过程的核心,其针对不同类型的fiber进行不同的更新处理,在FunctionComponent(函数组件)中,会针对新旧fiber进行对比处理生成新fiber。因此此次就详细…...

华为2024年报:鸿蒙生态正在取得历史性突破
华为于2025年03月31日发布2024年年度报告。报告显示,华为经营结果符合预期,实现全球销售收入 8,621 亿元人民币,净利润 626 亿元人民币。2024 年研发投入达到 1,797 亿元人民币,约占全年收入的 20.8%,近十年累计投入的…...

如何在Firefox火狐浏览器里-安装梦精灵AI提示词管理工具
第一步:进入《梦精灵跨平台AI提示词管理工具》官网 梦精灵 跨平台AI提示词管理助手 - 官网梦精灵是一款专为AI用户打造的跨平台提示词管理插件,支持一键收藏、快速复制、智能分类等功能,适用于即梦、豆包、Kimi、DeepSeek等多个AI平台&…...

【鸿蒙开发】性能优化
语言层面的优化 使用明确的数据类型,避免使用模糊的数据类型,例如ESObject。 使用AOT模式 AOT就是提前编译,将字节码提前编译成机器码,这样可以充分优化,从而加快执行速度。 未启用AOT时,一边运行一边进…...

Makefile与CMake
一、Makefile 核心内容 1. Makefile 基础结构与工作原理 三要素: 目标(Target):要生成的文件或执行的操作(如可执行文件、清理操作)。依赖(Dependency):生成目标所需的…...

P8803 [蓝桥杯 2022 国 B] 费用报销
P8803 [蓝桥杯 2022 国 B] 费用报销 - 洛谷 题目描述 小明在出差结束后返回了公司所在的城市,在填写差旅报销申请时,粗心的小明发现自己弄丢了出差过程中的票据。 为了弥补小明的损失,公司同意小明用别的票据进行报销,但是公司财…...

11 web 自动化之 DDT 数据驱动详解
文章目录 一、DDT 数据驱动介绍二、实战 一、DDT 数据驱动介绍 数据驱动: 现在主流的设计模式之一(以数据驱动测试) 结合 unittest 框架如何实现数据驱动? ddt 模块实现 数据驱动的意义: 通过不同的数据对同一脚本实现…...

15:00开始面试,15:06就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到4月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...

深入理解浏览器渲染引擎:底层机制与性能优化实战
现代浏览器背后是一个庞大而复杂的系统工程,渲染引擎作为核心模块之一,承担着从解析 HTML/CSS 到最终绘制页面的关键职责。本文将从底层机制出发,系统梳理渲染引擎(如 Blink)工作原理、V8 与渲染流程的协作方式&#x…...