课程11. 计算机视觉、自编码器和生成对抗网络 (GAN)
计算机视觉、自编码器和生成对抗网络(GAN)
- 自动编码器
- Vanilla自动编码器
- 使用 AE 生成新对象. 变分 AE (VAE)
- AE 条件
- GAN
- 理论
- 示例
- 下载并准备数据
- GAN模型
- 额外知识
课程计划:
- 自动编码器:
- 自动编码器结构;
- 使用自动编码器生成图像;
- 条件自动编码器;
- 生成对抗网络:
- 生成对抗网络结构;
- 练习:构建和训练生成对抗网络;
自动编码器
Autoencoders
Vanilla自动编码器
自动编码器是一种神经网络,它学习重建输入信息。换句话说,它试图产生与输入完全相同的输出:
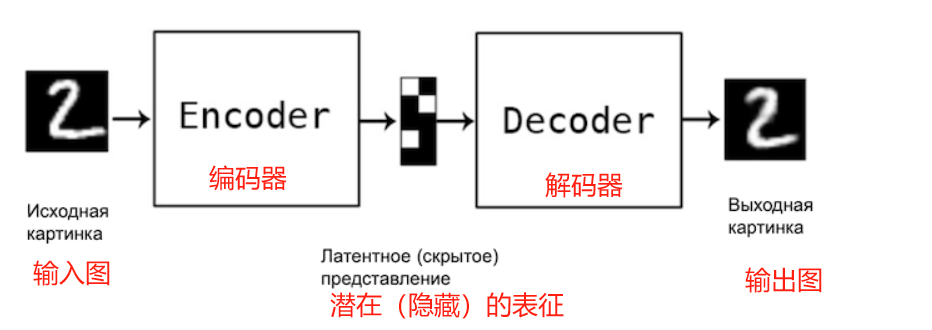
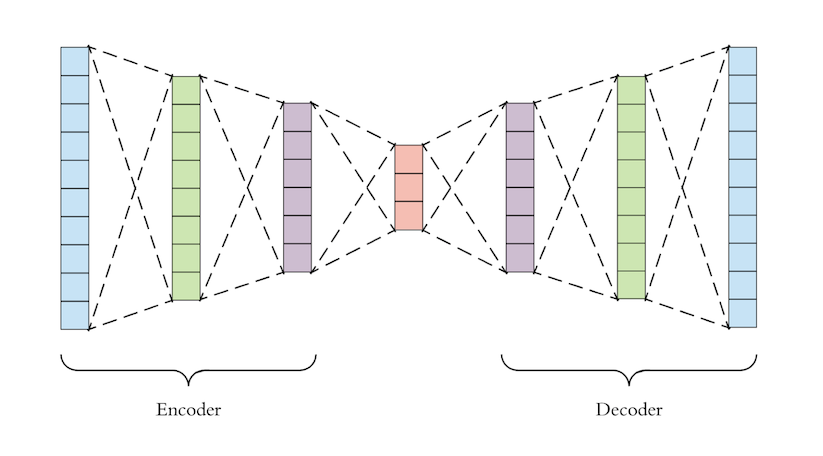
自动编码器通常设计为向中间逐渐变细,即中间层的神经元数量远小于网络前层的神经元数量。这样我们就得到了我们熟悉的编码器-解码器结构。
如果自动编码器中间层的神经元数量与输入层相同,那么在没有额外限制的情况下,自动编码器就毫无意义。它会学习id(身份)函数。
自动编码器的用途:
- 数据压缩和存储,特别是图像/视频压缩;
- 根据潜在表征对对象进行聚类;
- 查找相似对象(例如图像);
- 生成新对象(例如图像)。
- 查找数据中的异常;
- ……(可能还有更多 😃)。
自动编码器 (AE) 采用自监督学习模式进行训练。这意味着它无需数据标记即可进行训练。
例如,如果我们想在人脸图像数据集上训练 AE,那么在每次训练迭代中,我们会执行以下操作:
- 为 AE 输入一张图片;
- 将重建图像作为 AE 的输出;
- 计算重建图像与输入图像之间的 MSE/BCE 质量指标;
- 使用反向传播算法训练 AE。
与分类/检测/分割任务不同,AE 无需数据标记。
使用 AE 生成新对象. 变分 AE (VAE)
让我们更详细地讨论如何使用自编码器生成新物体。为了简单起见,我们假设处理的是人脸图像(其他类型的物体也一样)。
使用 AE 生成新图像:
- 在我们的人脸数据集上训练 AE;
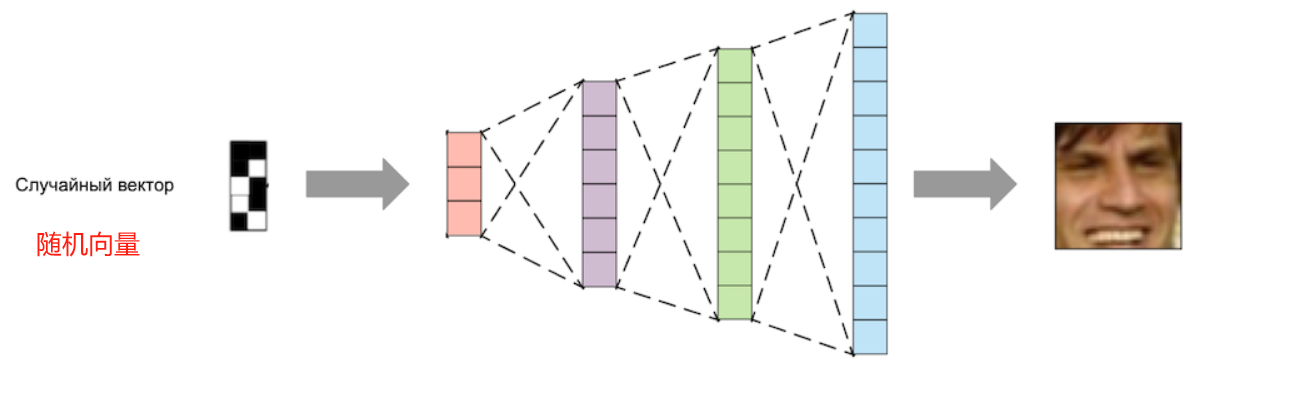
- 去掉编码器部分,只留下解码器部分;
- 将所需大小的随机数字向量输入到解码器部分的输入中,在输出端,我们将得到一张从未见过的人脸新图像。
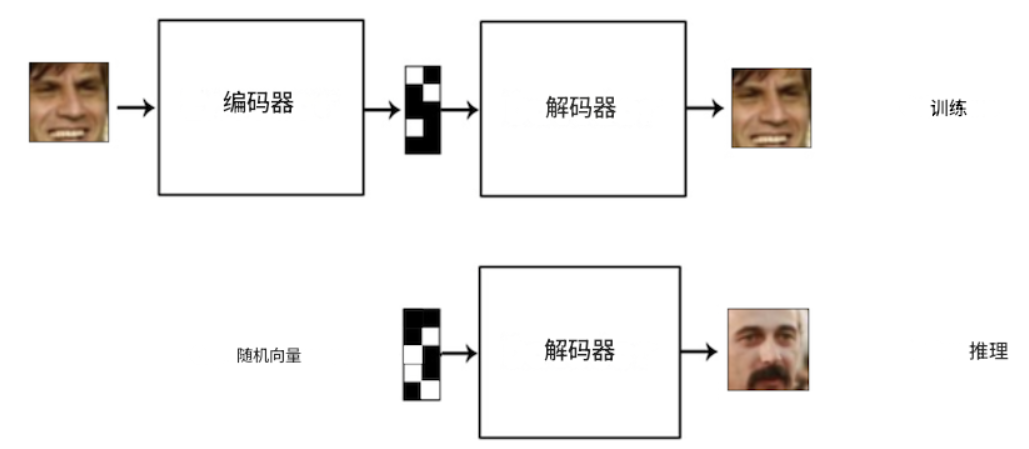
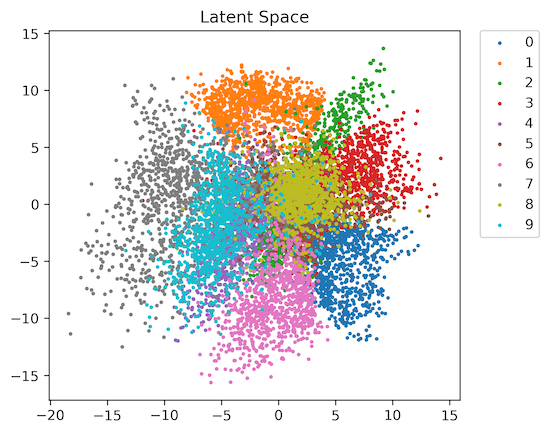
然而,常规(“原始”)AE 无法实现这样的效果。问题在于,它的潜在空间非常稀疏:并非空间中的每个点都对应一张真实的图片。
潜在空间看起来大致如下:

为了使自动编码器(AE)的潜在空间向量能够真正生成新的对象,我们需要强制自动编码器学习一个更连贯、更紧凑的潜在空间。
一种方法是指定潜在空间向量应该对应的分布。也就是说,对向量在潜在空间中的间距添加一个约束。
这种自动编码器被称为变分自动编码器(VAE)。它的潜在空间大致如下:
AE 条件
我们已经意识到 VAE 可以用来生成新对象。让我们来讨论一下如何生成不仅仅是任何新对象,而是具有给定属性的对象。
其思路是这样的:在训练过程中,解码器输入会输入一个编码属性以及潜在向量。例如,假设我们想要学习如何生成特定种族的人脸。假设我们只有 4 种种族类型。我们使用独热编码对它们进行编码:每种种族类型对应一个长度为 4 的向量,由 0 和 1 组成。解码器输入会输入一个潜在向量,该向量与该种族的独热向量连接在一起。
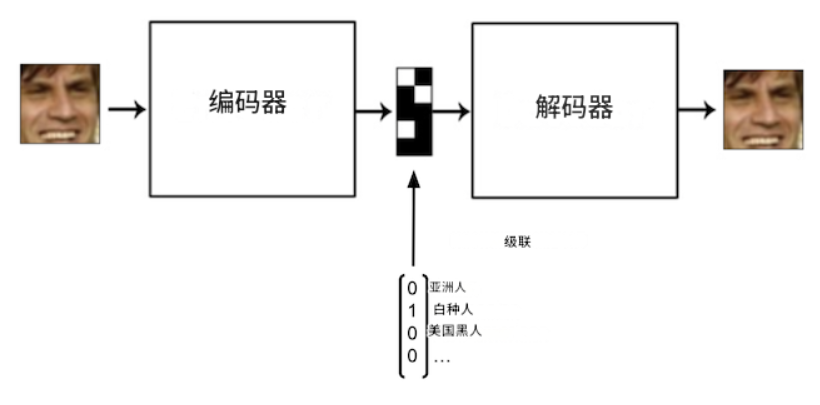
不仅可以将条件向量馈送到第一个解码器层的输入,还可以将其馈送到其所有层的输入。还可以将条件向量馈送到编码器层的输入。
问题:原始自动编码器用于什么任务的训练?
GAN
理论
GAN —— Generative adversarial Network —— 生成对抗网络。该架构于 2014 年发明,专门用于生成新图像(当然,GAN 不仅可以用来生成图像,还可以生成其他对象)。
让我们思考一下:如何训练神经网络生成新物体?
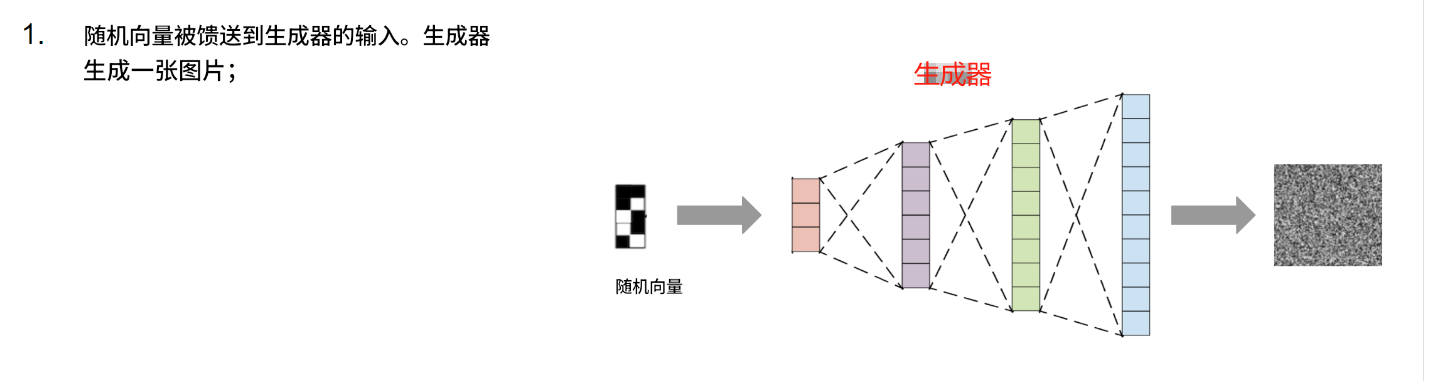
最简单的想法:创建一个神经网络,输入一个特定大小的随机向量,并输出一张生成的图像:
这个想法的问题在于如何训练这样的网络。如果你在训练过程中将随机向量输入到输入中,并将网络输出与训练数据集中的图片进行比较,这样的网络将学会只生成训练数据集中的图片。这几乎没什么用 =)
我希望在训练数据集有限的情况下,教会神经网络生成不同的人脸,即使是神经网络在训练过程中没有识别的人脸(即不在训练数据中的人脸)。
如何做到这一点?其中一个想法是 GAN——生成对抗网络。
它的工作原理如下:
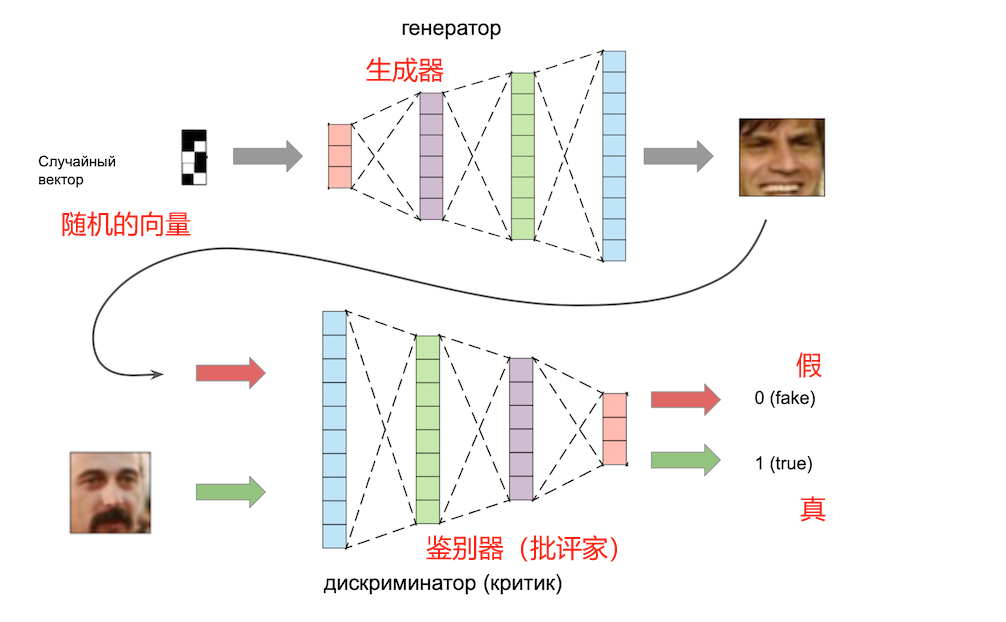
该模型由两个独立的神经网络组成:一个生成器和一个鉴别器。生成器以随机向量作为输入,输出一张图像。鉴别器以图像作为输入,输出一个答案:这张图片是真的还是假的(由生成器生成)。
生成器和鉴别器一起训练。鉴别器帮助生成器学习生成各种图像,而不仅仅是训练数据集中的图像。
 .
.
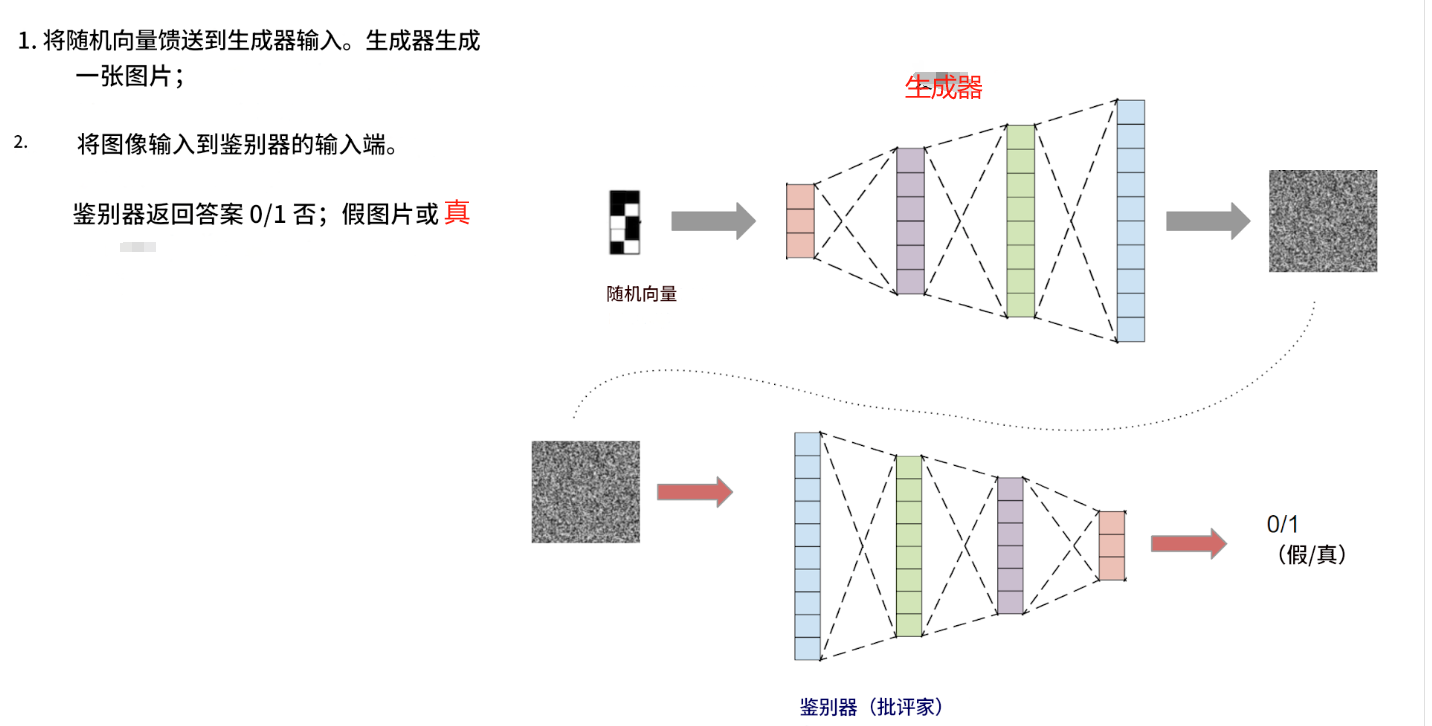
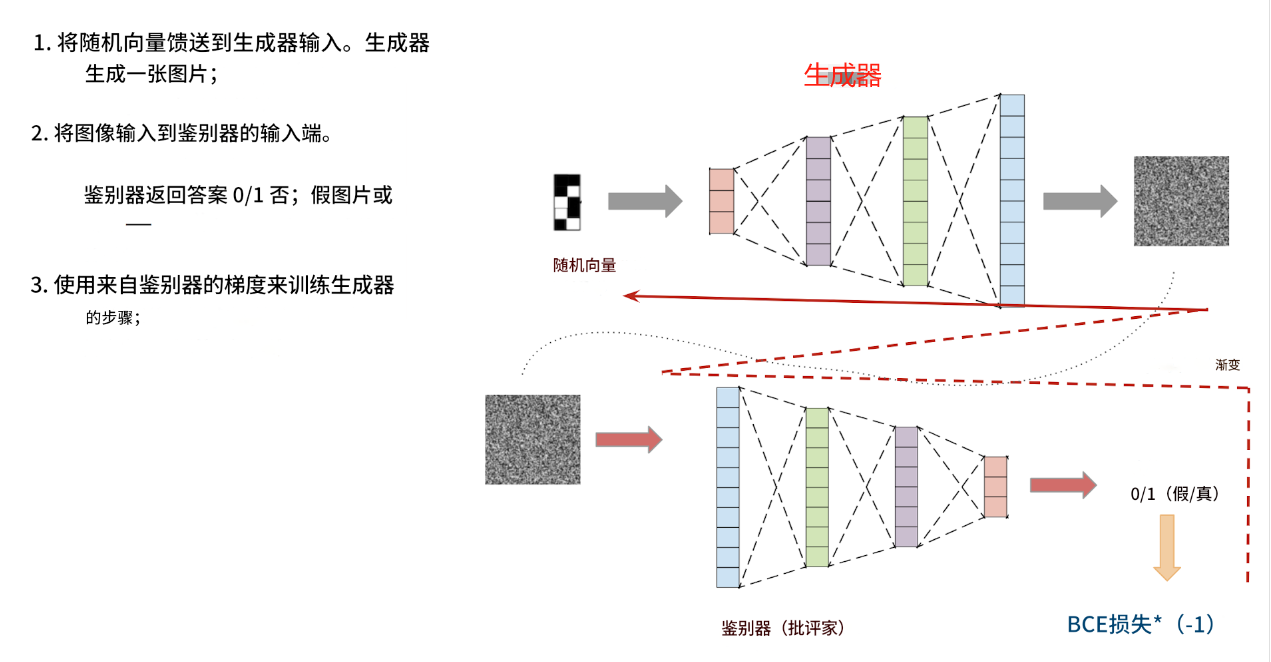
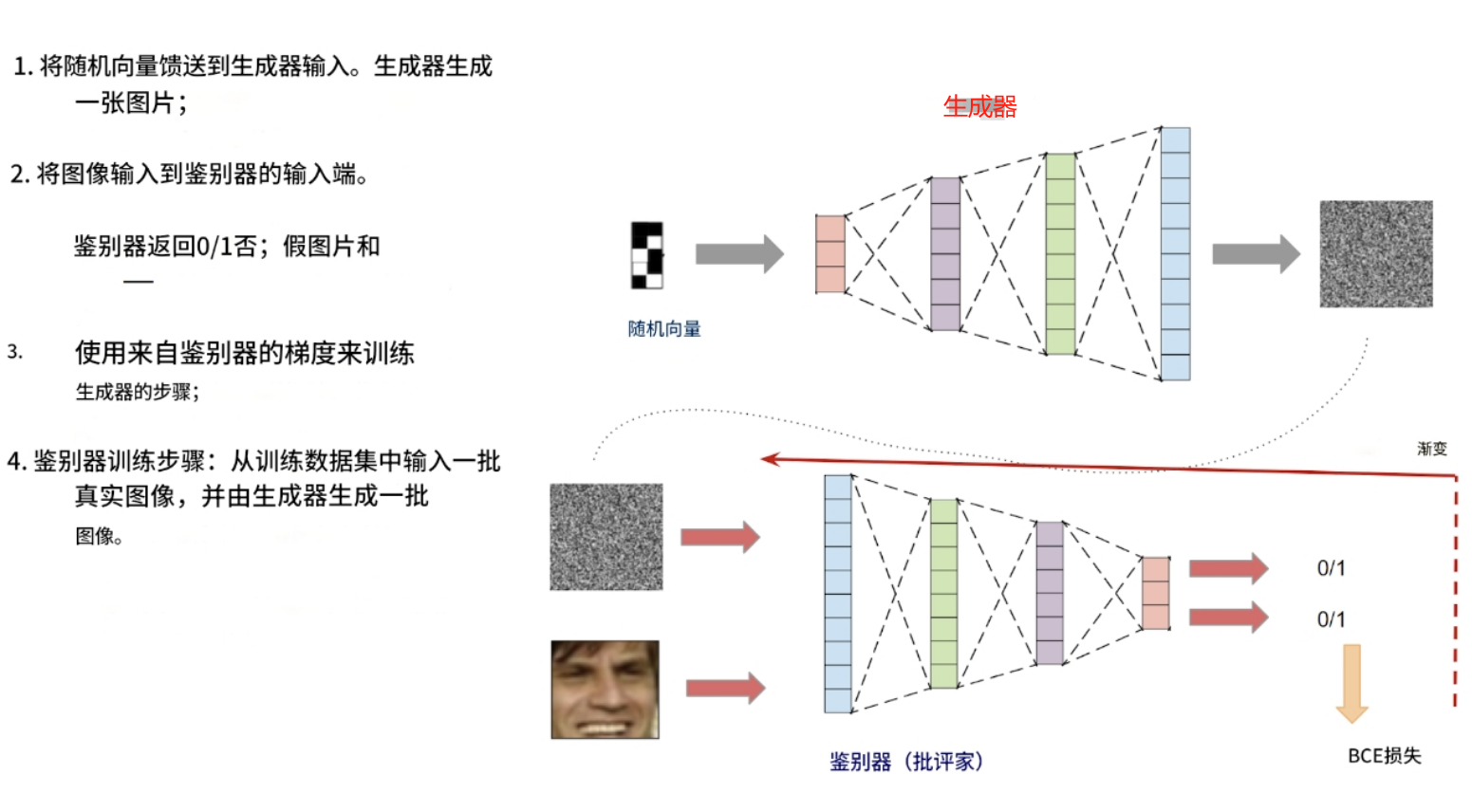
这一切的关键在于:鉴别器能够快速学会区分生成器生成的图片和真实图片(来自训练数据集)。之后,在生成器训练阶段,生成器会学习自适应,生成鉴别器无法再区分的图片。之后,鉴别器会学习区分生成器生成的新图片和真实图片。之后,生成器会再次学习生成更好的图片。如此反复。
这是生成器和鉴别器之间的对抗。
GAN 有一些缺点:
- GAN 训练起来相当困难。你需要选择合适的生成器和鉴别器架构:这样鉴别器就不会比生成器“聪明”太多(学会对图片进行分类的速度不会比生成器学会生成图片的速度快太多)。反之亦然:鉴别器也不应该比生成器“笨”太多,否则生成器将无法接收到良好的训练信号。
- 在 GAN 生成器中使用 BatchNorm 时应格外谨慎。BatchNorm 会均衡批次中所有元素的分布,因此同一批次中生成的所有图像可以具有相似的特征。
使用 BatchNorm 生成示例:

- GAN 通常存在一种崩溃模式:生成器开始针对任何随机输入向量生成大致相同的图像。有许多技术可以减少这种影响,并使生成器的生成更加多样化。崩溃模式的示例如下:

示例
让我们教 GAN 生成人脸。我们将使用 LFW 数据集
我们导入必要的库:
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
from IPython.display import clear_outputimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
输出:
device(type=‘cuda’)
下文将介绍如何下载和准备数据。所有代码与上面 AE 练习中的代码类似。如果您之前未下载过此笔记本中的数据,则需要取消注释并运行本节中的单元格。
下载并准备数据
!pip install deeplake==3.0
import deeplake
ds = deeplake.load('hub://activeloop/lfw')
dataloader = ds.pytorch(num_workers = 1, batch_size=1, shuffle = False)
import tqdm
from tqdm.auto import tqdm as tqdm
import PIL
faces = []
for b in tqdm(dataloader):faces.append(PIL.Image.fromarray(b['images'][0].detach().numpy()))
输出:

class Faces(Dataset):def __init__(self, faces):self.data = facesself.transform = transforms.Compose([transforms.CenterCrop((90, 90)),transforms.Resize((64, 64)),transforms.ToTensor(),# transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])def __getitem__(self, index):x = self.data[index]return self.transform(x).float()def __len__(self):return len(self.data)
def plot_gallery(images, n_row=3, n_col=6, from_torch=False):"""Helper function to plot a gallery of portraits"""if from_torch:images = [x.data.numpy().transpose(1, 2, 0) for x in images]plt.figure(figsize=(1.5 * n_col, 1.7 * n_row))plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)for i in range(n_row * n_col):plt.subplot(n_row, n_col, i + 1)plt.imshow(images[i])plt.xticks(())plt.yticks(())plt.show()
dataset = Faces(faces)# dataset[0] 是对 __getitem__(0) 方法的调用
img = dataset[0]print(img.shape)# 绘制图像及其分割蒙版
plot_gallery(dataset, from_torch=True)
输出:

train_size = int(len(dataset) * 0.8)
val_size = len(dataset) - train_sizeg_cpu = torch.Generator().manual_seed(8888)
train_data, val_data = torch.utils.data.random_split(dataset, [train_size, val_size], generator=g_cpu)train_loader = torch.utils.data.DataLoader(train_data, batch_size=16, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_data, batch_size=16, shuffle=False)
GAN模型
让我们分别声明鉴别器和生成器模型。
鉴别器模型是一个用于图像二分类的常规卷积网络:
class Discriminator(nn.Module):def __init__(self):super().__init__()# in: 3 x 64 x 64self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(64)# out: 64 x 32 x 32self.conv2 = nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(128)# out: 128 x 16 x 16self.conv3 = nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(256)# out: 256 x 8 x 8self.conv4 = nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1, bias=False)self.bn4 = nn.BatchNorm2d(512)# out: 512 x 4 x 4self.conv5 = nn.Conv2d(512, 1, kernel_size=4, stride=1, padding=0, bias=False)# out: 1 x 1 x 1self.flatten = nn.Flatten()self.sigmoid = nn.Sigmoid()def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = F.relu(self.bn2(self.conv2(x)))x = F.relu(self.bn3(self.conv3(x)))x = F.relu(self.bn4(self.conv4(x)))x = self.conv5(x)x = self.flatten(x)x = self.sigmoid(x)return x
生成器模型也是一个卷积神经网络,其输出必须与数据集中的图像具有相同的维度:
class Generator(nn.Module):def __init__(self, latent_size):super().__init__()# in: latent_size x 1 x 1self.convT1 = nn.ConvTranspose2d(latent_size, 512, kernel_size=4, stride=1, padding=0, bias=False)self.bn1 = nn.BatchNorm2d(512)# out: 512 x 4 x 4self.convT2 = nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(256)# out: 256 x 8 x 8self.convT3 = nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(128)# out: 128 x 16 x 16self.convT4 = nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, bias=False)self.bn4 = nn.BatchNorm2d(64)# out: 64 x 32 x 32self.convT5 = nn.ConvTranspose2d(64, 3, kernel_size=4, stride=2, padding=1, bias=False)self.tanh = nn.Tanh()# out: 3 x 64 x 64def forward(self, x):x = F.relu(self.bn1(self.convT1(x)))x = F.relu(self.bn2(self.convT2(x)))x = F.relu(self.bn3(self.convT3(x)))x = F.relu(self.bn4(self.convT4(x)))x = self.convT5(x)x = self.tanh(x)return x
我们将输入生成器以生成图像的随机向量的大小设置为 128:
latent_size = 128
让我们引入一个固定的噪声向量,以便在网络训练过程中我们可以跟踪生成器输出在这个固定向量上的变化:
fixed_latent = torch.randn(64, latent_size, 1, 1, device=device)
现在让我们开始训练 GAN. 训练算法如下:
-
训练鉴别器:
- 拍摄真实图像并赋予其标签 1
- 使用生成器生成图像并赋予其标签 0
- 将分类器训练成两类
-
训练生成器:
- 使用生成器生成图像并赋予其标签 0
- 使用鉴别器预测图像是否真实
from IPython.display import clear_output
from torchvision.utils import make_grid# 用于对图像进行反规范化的函数
stats = (0.5, 0.5, 0.5), (0.5, 0.5, 0.5)
def denorm(img_tensors):return img_tensors * stats[1][0] + stats[0][0]# 用于绘制图像生成器生成结果的函数
# 在我们的固定噪声向量上
def show_samples(latent_tensors):fake_images = generator(latent_tensors)fig, ax = plt.subplots(figsize=(8, 8))ax.set_xticks([]); ax.set_yticks([])ax.imshow(make_grid(denorm(fake_images[:64].cpu().detach()), nrow=8).permute(1, 2, 0))plt.show()# GAN的直接学习函数
def train(models, opts, loss_fns, epochs, train_loader, val_loader, batch_size=64):# Losses & scoreslosses_g = []losses_d = []real_scores = []fake_scores = []for epoch in range(epochs):# 打印当前epochprint('* Epoch %d/%d' % (epoch+1, epochs))# 使用来自 train_loader 的图像来训练网络models["discriminator"].train()models["generator"].train()# 用于存储损失值和准确率指标的数组# 网络训练期间的鉴别器loss_d_per_epoch = []loss_g_per_epoch = []real_score_per_epoch = []fake_score_per_epoch = []for i, X_batch in enumerate(train_loader):X_batch = X_batch.to(device)# 1. 鉴别器训练步骤。# 清除鉴别器梯度opts["discriminator"].zero_grad()# 1.1 真实图片出现亏损# 我们将批次 X_batch 中的真实图像输入到鉴别器的输入中real_preds = models["discriminator"](X_batch)# 鉴别器对这些图像的正确响应应该是一个由 1 组成的向量real_targets = torch.ones(X_batch.size(0), 1, device=device)# 我们在一批真实图像上计算鉴别器损失值real_loss = loss_fns["discriminator"](real_preds, real_targets)cur_real_score = torch.mean(real_preds).item()# 1.2 因假图片而蒙受损失# 让我们生成虚假图像。为此,我们生成一个大小为 (batch_size, latent_size, 1, 1) 的随机噪声向量,并将其输入到生成器中。latent = torch.randn(batch_size, latent_size, 1, 1, device=device)# 我们得到一批随机向量的生成器输出fake_images = models["generator"](latent)# 我们将来自批次 X_batch 的假图像输入到鉴别器的输入中fake_preds = models["discriminator"](fake_images)# 鉴别器对这些图像的正确响应应该是一个零向量fake_targets = torch.zeros(fake_images.size(0), 1, device=device)# 计算一批假图像上的鉴别器损失值fake_loss = loss_fns["discriminator"](fake_preds, fake_targets)cur_fake_score = torch.mean(fake_preds).item()real_score_per_epoch.append(cur_real_score)fake_score_per_epoch.append(cur_fake_score)# 1.3 更新鉴别器权重:执行梯度下降步骤loss_d = real_loss + fake_lossloss_d.backward()opts["discriminator"].step()loss_d_per_epoch.append(loss_d.item())# 2. 生成器训练步骤# 清理生成器梯度opts["generator"].zero_grad()# 让我们生成虚假图像。为此,我们生成一个大小为 (batch_size, latent_size, 1, 1) 的随机噪声向量,并将其输入到生成器中。latent = torch.randn(batch_size, latent_size, 1, 1, device=device)# 我们得到一批随机向量的生成器输出fake_images = models["generator"](latent)# 我们将来自批次 X_batch 的假图像输入到鉴别器的输入中preds = models["discriminator"](fake_images)# 我们将这些图片的“正确”答案向量设置为 1 的向量targets = torch.ones(batch_size, 1, device=device)# 计算预测和目标之间的损失loss_g = loss_fns["generator"](preds, targets)# 更新生成器权重loss_g.backward()opts["generator"].step()loss_g_per_epoch.append(loss_g.item())# 每 100 次训练迭代,我们将输出指标的当前值# 并绘制图像生成器生成的结果# 来自固定的随机向量if i%100 == 0:# Record losses & scoreslosses_g.append(np.mean(loss_g_per_epoch))losses_d.append(np.mean(loss_d_per_epoch))real_scores.append(np.mean(real_score_per_epoch))fake_scores.append(np.mean(fake_score_per_epoch))# Log losses & scores (last batch)print("Epoch [{}/{}], loss_g: {:.4f}, loss_d: {:.4f}, real_score: {:.4f}, fake_score: {:.4f}".format(epoch+1, epochs,losses_g[-1], losses_d[-1], real_scores[-1], fake_scores[-1]))# Show generated imagesclear_output(wait=True)show_samples(fixed_latent)return losses_g, losses_d, real_scores, fake_scores
最后,我们将声明模型、优化器、损失并训练模型:
generator = Generator(latent_size).to(device)
discriminator = Discriminator().to(device)models = {'generator': generator,'discriminator': discriminator
}criterions = {"discriminator": nn.BCELoss(),"generator": nn.BCELoss()
}lr = 0.0002
optimizers = {"discriminator": torch.optim.Adam(models["discriminator"].parameters(),lr=lr, betas=(0.5, 0.999)),"generator": torch.optim.Adam(models["generator"].parameters(),lr=lr, betas=(0.5, 0.999))}losses_g, losses_d, real_scores, fake_scores = train(models, optimizers, criterions, 10, train_loader, val_loader)
输出:

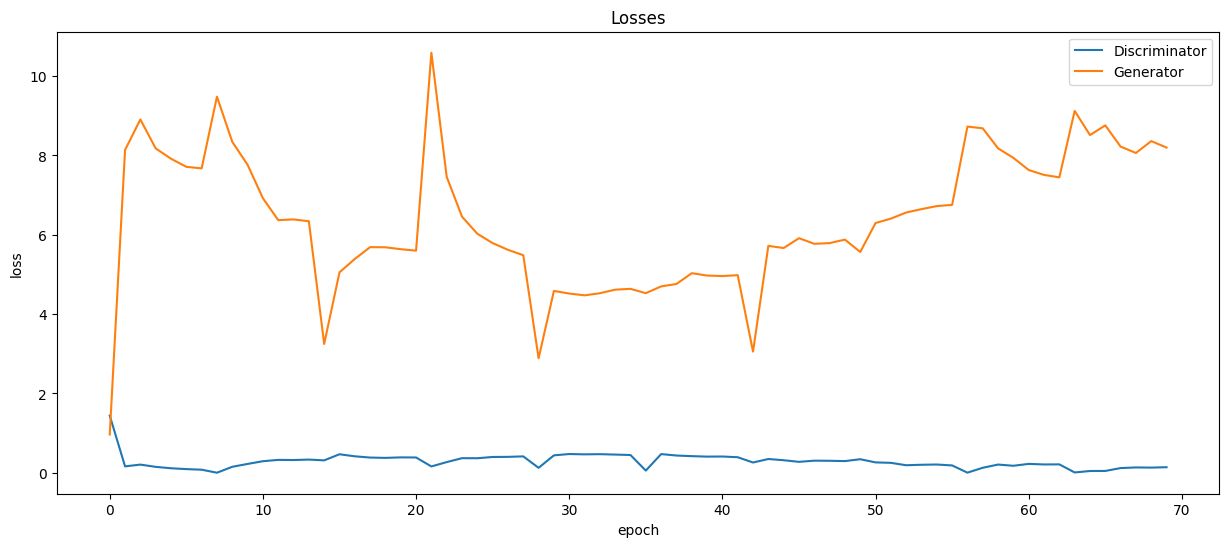
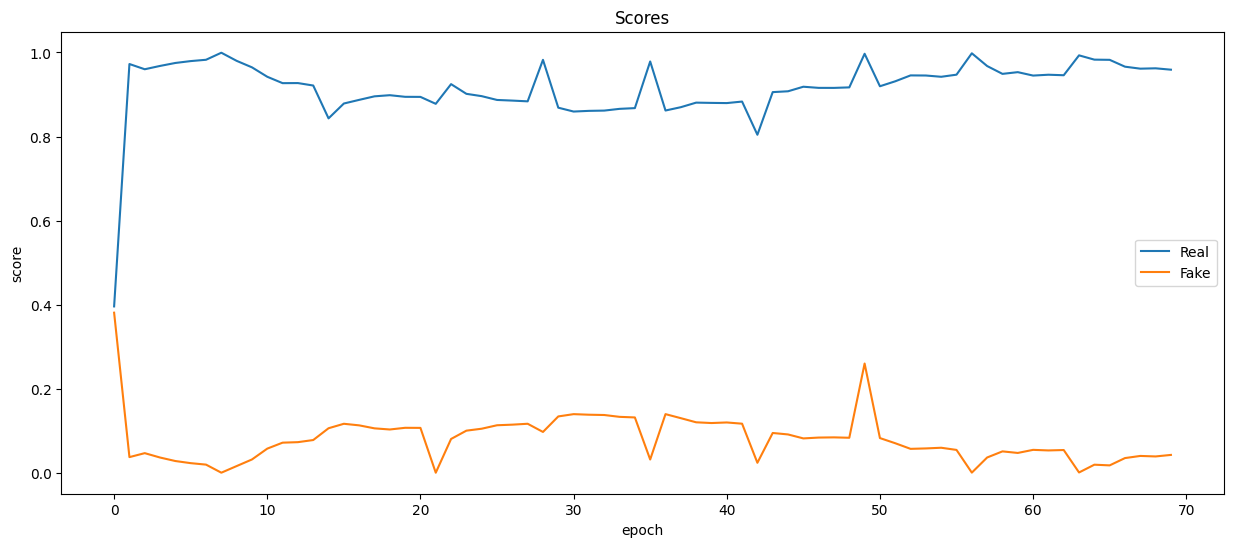
让我们直观地看到网络训练期间生成器的损失和准确度指标的变化图:
plt.figure(figsize=(15, 6))
plt.plot(losses_d, '-')
plt.plot(losses_g, '-')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['Discriminator', 'Generator'])
plt.title('Losses');
输出:
plt.figure(figsize=(15, 6))plt.plot(real_scores, '-')
plt.plot(fake_scores, '-')
plt.xlabel('epoch')
plt.ylabel('score')
plt.legend(['Real', 'Fake'])
plt.title('Scores');
输出:
额外知识
-
深度学习学校的一系列关于自动编码器的课程:
-
讲座:生成模型和自动编码器;
-
研讨会:自动编码器;
-
研讨会:VAE;
-
深度学习学校的一系列关于生成对抗网络的课程:
-
讲座:生成模型。生成对抗网络;
-
研讨会:GAN
-
已完成关于不同类型自编码器(Vanilla AE、VAE、条件 VAE)的笔记 及相关解释
-
关于 VAE 的英文文章,其中包含对相关工作思路和数学公式的详细解释
相关文章:
)
课程11. 计算机视觉、自编码器和生成对抗网络 (GAN)
计算机视觉、自编码器和生成对抗网络(GAN) 自动编码器Vanilla自动编码器使用 AE 生成新对象. 变分 AE (VAE)AE 条件 GAN理论示例下载并准备数据GAN模型 额外知识 课程计划: 自动编码器: 自动编码器结构;使用自动编码器…...

机器学习第十二讲:特征选择 → 选最重要的考试科目做录取判断
机器学习第十二讲:特征选择 → 选最重要的考试科目做录取判断 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手把手指南 一、学…...
)
Typescript学习教程,从入门到精通, TypeScript编程基础语法知识点及案例代码(3)
TypeScript编程基础语法知识点及案例代码 本文将详细介绍TypeScript编程的基础知识,包括注释、标识符、关键字、基础类型、变量、常量以及操作符。 1. 注释 语法知识点 TypeScript 支持三种类型的注释: 单行注释:使用 // 开始࿰…...

云原生数据库排障新挑战:AI驱动与分布式架构深度解析
云原生数据库排障新挑战:AI驱动与分布式架构深度解析 一、问题描述与快速解决方案 1. 2025年数据库故障新特征 随着云原生与AI技术的深度耦合,数据库故障呈现三大新特征: AI模型推理性能瓶颈:向量化查询响应时间突增࿰…...

用MCP往ppt文件里插入系统架构图
文章目录 一、技术架构解析1. Markdown解析模块(markdown_to_hierarchy)2. 动态布局引擎(give_hierarchy_positions)3. PPTX生成模块(generate_pptx)二、核心技术亮点1. 自适应布局算法2. MCP服务集成三、工程实践建议1. 性能优化方向2. 样式扩展方案3. 部署实践四、应用…...

ABC301——ABCD
A 统计比赛胜场 #include<bits/stdc.h> using namespace std;#define x first #define y secondtypedef long long LL; typedef pair<int, int> PII;const int N 2e5 10;int t, n, m, a[N]; string s;void solve() {cin >> n;int c1 0, c2 0;cin >…...

Rust 数据结构:Vector
Rust 数据结构:Vector Rust 数据结构:Vector创建数组更新数组插入元素删除元素 获取数组中的元素迭代数组中的值使用枚举存储多个类型删除一个数组会删除它的元素 Rust 数据结构:Vector vector 来自标准库,在内存中连续存储相同类…...

GpuGeek:为创新者提供灵活、快速、高效的云计算服务!
目录 一、前言 二、GpuGeek平台的显著优势 2.1 显卡资源充足:强大计算能力的基础 (1)多种GPU配置选择 (2)弹性扩展与资源管理 2.2 节点丰富:满足多种计算需求 (1)各种节点配置…...

国产化Word处理控件Spire.Doc教程:通过C# 删除 Word 文档中的超链接
Word 文档中的超链接是可点击的链接,允许读者导航到一个网站或另一个文档。虽然超链接可以提供有价值的补充信息,但有时也会分散注意力或造成不必要的困扰,因此可能会需要删除这些超链接。本文将介绍如何使用 Spire.Doc for .NET 通过 C# 删除…...

MySQL 开发的智能助手:通义灵码在 IntelliJ IDEA 中的应用
一、引言 MySQL 作为一款高度支持 SQL 标准的数据库,在众多应用程序中得到了广泛应用。 尽管大多数程序员具备一定的 SQL 编写能力,但在面对复杂的 SQL 语句或优化需求时,往往需要专业数据库开发工程师的协助。 通义灵码的出现为这一问题提…...

golang -- 认识channel底层结构
channel channel是golang中用来实现多个goroutine通信的管道(goroutine之间的通信机制),底层是一个叫做hchan的结构体,定义在runtime包中 type hchan struct {qcount uint // 循环数组中的元素个数(通道…...

使用PEFT库将原始模型与LoRA权重合并
使用PEFT库将原始模型与LoRA权重合并 步骤如下: 基础模型加载:需保持与LoRA训练时相同的模型配置merge_and_unload():该方法会执行权重合并并移除LoRA层保存格式:合并后的模型保存为标准HuggingFace格式,可直接用于推…...

基于微信小程序的在线聊天功能实现:WebSocket通信实战
基于微信小程序的在线聊天功能实现:WebSocket通信实战 摘要 本文将详细介绍如何使用微信小程序结合WebSocket协议开发一个实时在线聊天功能。通过完整的代码示例和分步解析,涵盖界面布局、WebSocket连接管理、消息交互逻辑及服务端实现,适合…...

SaaS基于云计算、大数据的Java云HIS平台信息化系统源码
利用云计算、大数据等现代信息技术研发的医疗信息管理系统(HIS)实现了医院信息化从局域网向互联网转型,重新定义医疗卫生信息化建设的理念、构架、功能和运维体系。平台构建了以患者为中心的云架构、云服务、云运维的信息体系,实现…...

【Linux】动静态库的使用
📝前言: 这篇文章我们来讲讲Linux——动静态库的使用 🎬个人简介:努力学习ing 📋个人专栏:Linux 🎀CSDN主页 愚润求学 🌄其他专栏:C学习笔记,C语言入门基础&…...

10.2 LangChain v0.3全面解析:模块化架构+多代理系统如何实现效率飙升500%
LangChain 框架概述 关键词:LangChain 技术栈, 模块化架构, LCEL 表达式语言, LangGraph 多代理系统, LangServe 服务化部署 1. 框架定位与技术演进 LangChain 是当前大模型应用开发的事实标准框架,通过模块化设计实现 AI 工作流编排、工具链集成 和 复杂业务逻辑封装。其演…...

开源免费iOS或macOS安装虚拟机运行window/Linux系统
官网地址:UTM 开源地址:https://github.com/utmapp/UTM 基于 QEMU(一个开源的硬件虚拟化工具),UTM 可以在 macOS(包括 Apple Silicon M1/M2 和 Intel x86)上运行 Windows、Linux、macOS&…...

《C++ vector详解》
目录 1.结构 2.构造函数 无参构造 指定参数构造 迭代器构造 初始化列表构造 3.拷贝构造 4.析构函数 5.遍历 重载【】 5.插入 扩容 尾插 指定位置插入 6.删除 尾删 指定位置删除 1.结构 vector是一个类似于数组一样的容器,里面可以放各种各样的元素…...
【现代深度学习技术】注意力机制07:Transformer
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

浅析 Spring 启动过程:从源码到核心方法
浅析 Spring 启动过程:从源码到核心方法 一、Spring 注解方式启动类 Demo二、Spring 启动过程源码解析AnnotationConfigApplicationContext构造函数refresh()方法详解 三、refresh()的核心方法/步骤obtainFreshBeanFactory() - 获取Bean工厂prepareBeanFactory(be…...

5G + 区块链:技术巨浪下的新型数字生态!
5G + 区块链:技术巨浪下的新型数字生态! 1. 为什么 5G 和区块链的结合如此重要? 区块链和 5G 这两大技术近几年风头正劲,一个在去中心化数据管理上展现潜力,一个在高吞吐低延迟通信方面带来颠覆。这两者结合,意味着: 更快的数据传输,让区块链交易速度提升,摆脱“低 …...

时序数据库IoTDB分布式架构解析与运维指南
一、IoTDB分布式架构概述 分布式系统由一组独立的计算机组成,通过网络通信,对外表现为一个统一的整体。IoTDB的原生分布式架构将服务分为两个核心部分: ConfigNode(CN):管理节点,负责管理…...

CertiK荣获以太坊基金会两项资助,领跑zkEVM形式化验证
近日,以太坊基金会公布了2025年第一季度研究资助名单,全球最大的Web3.0安全公司CertiK荣获两项研究资助,源于zkEVM形式化验证竞赛。这不仅是以太坊扩展性战略的里程碑式事件,也进一步彰显了CertiK在零知识证明(ZKP&…...

c++和c的不同
c:面向对象(封装,继承,多态),STL,模板 一、基础定义与背景 C语言 诞生年代:20世纪70年代,Dennis Ritchie在贝尔实验室开发。主要特点: 过程式、结构化编程面向系统底层…...

光流 | Matlab工具中的光流算法
在MATLAB中,光流算法用于估计图像序列中物体的运动。以下是详细解释及实现步骤: 1. 光流算法基础 光流基于两个核心假设: 亮度恒定:同一物体在连续帧中的像素亮度不变。微小运动:相邻帧之间的时间间隔短,物体运动幅度小。常见算法: Lucas-Kanade (局部方法):假设局部窗…...

@Controller 与 @RestController-笔记
1.Controller与RestController对比 Spring MVC 中 Controller 与 RestController 的功能对比: Controller是Spring MVC中用于标识一个类作为控制器的标准注解。它允许处理HTTP请求,并返回视图名称,通常和视图解析器一起使用来渲染页面。而R…...

LeetCode 热题 100 105. 从前序与中序遍历序列构造二叉树
LeetCode 热题 100 | 105. 从前序与中序遍历序列构造二叉树 大家好,今天我们来解决一道经典的二叉树问题——从前序与中序遍历序列构造二叉树。这道题在 LeetCode 上被标记为中等难度,要求根据给定的前序遍历和中序遍历序列,构造并返回二叉树…...

IP地址查询助力业务增长
IP地址查询的技术基石 IP地址分为IPv4和IPv6,目前IPv4仍广泛应用,它由四个0-255的十进制数组成,如192.168.1.1。而IPv6为应对IPv4地址枯竭问题而生,采用128位地址长度,极大扩充了地址空间。IP地址查询主要依赖庞大的I…...

Nginx核心功能及同类产品对比
Nginx 作为一款高性能的 Web 服务器和反向代理工具,凭借其独特的架构设计和丰富的功能,成为互联网基础设施中不可或缺的组件。以下是其核心功能及与同类产品(如 HAProxy、LVS)的对比优势: 一、Nginx 核心功能 高性能架…...

抽奖系统-奖品-活动
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言获取奖品列表前端页面活动创建需求分析活动创建后端实现1-控制层实现及校验活动活动创建后端实现2-保存信息活动插入活动奖品插入 整合活动信息存入redis测试活…...

【Java】 volatile 和 synchronized 的比较及使用场景
在 Java 的并发编程中,volatile 和 synchronized 是两个常用的关键字,它们分别用于保证多线程环境中的 可见性 和 原子性,但它们的工作原理和适用场景却有所不同。今天,我们将深入探讨这两个关键字的异同,帮助大家理解…...

javaScript简单版
简介 JavaScript(简称:JS)是一门跨平台、面向对象的脚本语言,是用来控制网页行为,实现页面的交互效果。 JavaScript和Java是完全不同的语言,不论是概念还是设计。但是基础语法类似。 组成: ECMAScript:规定了JS基础语法核心知…...
)
三种常见接口测试工具(Apipost、Apifox、Postman)
三种常见接口测试工具(Apipost、Apifox、Postman)的用法及优缺点对比总结: 🔧 一、Apipost ✅ 基本用法 支持 RESTful API、GraphQL、WebSocket 等接口调试自动生成接口文档支持环境变量、接口分组、接口测试用例编写可进行前置…...

蓝桥杯13届国B 完全日期
题目描述。 如果一个日期中年月日的各位数字之和是完全平方数,则称为一个完全日期。 例如:2021 年 6 月 5 日的各位数字之和为 20216516,而 16 是一个完全平方数,它是 4 的平方。所以 2021 年 6 月 5 日是一个完全日期。 例如&…...

kafka connect 大概了解
kafka connect Introduction Kafka Connect is the component of Kafka that provides data integration between databases, key-value stores, search indexes, file systems, and Kafka brokers. kafka connect 是一个框架,用来帮助集成其他系统的数据到kafka…...
gdb调试、单向链表练习、顺序表与链表对比)
嵌入式培训之数据结构学习(三)gdb调试、单向链表练习、顺序表与链表对比
目录 一、gdb调试 (一)一般调试步骤与命令 (二)找段错误(无下断点的地方) (三)调试命令 二、单向链表练习 1、查找链表的中间结点(用快慢指针) 2、找出…...

MySQL——九、锁
分类 全局锁表级锁行级锁 全局锁 做全库的逻辑备份 flush tables with read lock; unlock tables;在InnoDB引擎中,我们可以在备份时加上参数–single-transaction参数来完成不加锁的一致性数据备份 mysqldump --single-transaction -uroot -p123456 itcast>…...
:创业移情阶段的核心要点与实践方法)
精益数据分析(57/126):创业移情阶段的核心要点与实践方法
精益数据分析(57/126):创业移情阶段的核心要点与实践方法 在创业的浩瀚征程中,每一个阶段都承载着独特的使命与挑战。今天,我们继续秉持共同进步的理念,深入研读《精益数据分析》,聚焦创业的首…...

服务器被打了怎么应对
云服务器遭受攻击该如何应对? 在互联网时代,不少使用云服务器的网络工作者常常会面临网络攻击的威胁。若云服务器未配置完善的防火墙,极易引发服务器宕机,甚至被封禁隔离(俗称“陷入黑洞”),进…...
:C#联合Halcon回形针以及方向)
Halcon案例(二):C#联合Halcon回形针以及方向
本案例分3部分 识别效果,分别显示识别前后识别后;代码展示,分别是Halcon源码和Halcon转为C#的代码代码解释(解释在源码中); 原图如下 识别后图像: 其中计算回形针与X轴之间的夹角 Halcon代码: * clip.hdev: Orientation of clips *识别图像中的回形针,并且计算回形针与X轴之间…...
)
Spyglass:跨时钟域同步(同步单元)
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 简介 同步单元方案可以用于控制/数据信号跨时钟域同步,该方案使用约束或参数将目标时钟域中单元指定为同步单元,如图1所示。 图1 同步单元方案…...

JAVA异常体系
在 Java 里,异常体系是其错误处理机制的核心内容,它能够帮助开发者有效应对程序运行时出现的各种意外状况。 异常体系的基本架构 它主要包含两个重要分支: Error(错误):这类异常是程序自身无法处理的严重…...
)
Milvus 视角看主流嵌入式模型(Embeddings)
嵌入是一种机器学习概念,用于将数据映射到高维空间,其中语义相似的数据被紧密排列在一起。嵌入模型通常是 BERT 或其他 Transformer 系列的深度神经网络,它能够有效地用一系列数字(称为向量)来表示文本、图像和其他数据…...
协议:从大模型流式输出到实时通信场景)
全面解析 Server-Sent Events(SSE)协议:从大模型流式输出到实时通信场景
全面解析 Server-Sent Events(SSE)协议:从大模型流式输出到实时通信场景 一、SSE 协议概述 Server-Sent Events(SSE) 是 HTML5 标准中定义的一种基于 HTTP 的服务器向客户端单向推送实时数据的协议。其核心特性包括&a…...

数据库系统概论|第七章:数据库设计—课程笔记
前言 本章讨论数据库设计的技术和方法,主要讨论基于关系数据库管理系统的关系数据库设计问题,而关于数据库的设计过程中,关于数据模型、关系模型等基本概念在前文中已经有详尽介绍,此处便不再赘述,本文主要围绕概念结…...
)
Java项目拷打(外卖+点评)
一、点评星球(黑马点评) 1、项目概述 1.1、项目简介 本项目是基于Spring Boot与Redis深度整合的前后端分离的点评平台。系统以Redis为核心技术支撑,重点解决高并发场景下的缓存穿透、击穿、雪崩等问题,涵盖商户展示、优惠券秒杀…...

MCP:开启AI的“万物互联”时代
MCP:开启AI的“万物互联”时代 ——从协议标准到生态革命的技术跃迁 引言:AI的“最后一公里”困境 在2025年的AI技术浪潮中,大模型已从参数竞赛转向应用落地之争。尽管模型能生成流畅的对话、创作诗歌甚至编写代码,但用户逐渐发现…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】附录-D. 扩展插件列表(PostGIS/PostgREST等)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 附录D. PostgreSQL扩展插件速查表一、插件分类速查表二、核心插件详解三、安装与配置指南四、应用场景模板五、版本兼容性说明六、维护与优化建议七、官方资源与工具八、附录…...

Spring Boot拦截器详解:原理、实现与应用场景
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、拦截器概述 拦截器(Interceptor)是Spring MVC框架中用于对请求进行预处理和后处理的组件,主要作用于Controller层。相…...

万字解析:Java字符串
目录 一、 String类 1. String类的初始化 1.1 常用的三种构造String类的方式 1.2 String类如何存储字符串? 2. String类的常用功能方法 2.0 字符串长度的获取 2.1 String对象的比较 2.2 字符/字符串的查找 2.3 字符串的转化 2.4 字符 / 字符串的替换 2.5…...