【现代深度学习技术】注意力机制07:Transformer

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
- 一、模型
- 二、基于位置的前馈网络
- 三、残差连接和层规范化
- 四、编码器
- 五、解码器
- 六、训练
- 小结
自注意力和位置编码中比较了卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)。值得注意的是,自注意力同时具有并行计算和最短的最大路径长度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的。对比之前仍然依赖循环神经网络实现输入表示的自注意力模型,Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层。尽管Transformer最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语言、视觉、语音和强化学习领域。
一、模型
Transformer作为编码器-解码器架构的一个实例,其整体架构图在图1中展示。正如所见到的,Transformer是由编码器和解码器组成的。与基于Bahdanau注意力实现的序列到序列的学习相比,Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(embedding)表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中。

图1中概述了Transformer的架构。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为 s u b l a y e r \mathrm{sublayer} sublayer)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受残差网络的启发,每个子层都采用了残差连接(residual connection)。在Transformer中,对于序列中任何位置的任何输入 x ∈ R d \mathbf{x} \in \mathbb{R}^d x∈Rd,都要求满足 s u b l a y e r ( x ) ∈ R d \mathrm{sublayer}(\mathbf{x}) \in \mathbb{R}^d sublayer(x)∈Rd,以便残差连接满足 x + s u b l a y e r ( x ) ∈ R d \mathbf{x} + \mathrm{sublayer}(\mathbf{x}) \in \mathbb{R}^d x+sublayer(x)∈Rd。在残差连接的加法计算之后,紧接着应用层规范化(layer normalization)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个 d d d维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
在此之前已经描述并实现了基于缩放点积多头注意力和位置编码。接下来将实现Transformer模型的剩余部分。
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
二、基于位置的前馈网络
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的(positionwise)的原因。在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
#@save
class PositionWiseFFN(nn.Module):"""基于位置的前馈网络"""def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs, **kwargs):super(PositionWiseFFN, self).__init__(**kwargs)self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward(self, X):return self.dense2(self.relu(self.dense1(X)))
下面的例子显示,改变张量的最里层维度的尺寸,会改变成基于位置的前馈网络的输出尺寸。因为用同一个多层感知机对所有位置上的输入进行变换,所以当所有这些位置的输入相同时,它们的输出也是相同的。
ffn = PositionWiseFFN(4, 4, 8)
ffn.eval()
ffn(torch.ones((2, 3, 4)))[0]
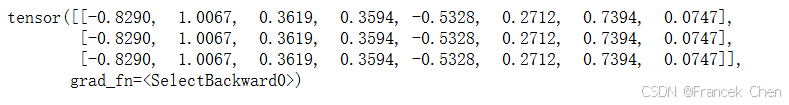
三、残差连接和层规范化
现在让我们关注图1中的加法和规范化(add&norm)组件。正如在本节开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
批量规范化中解释了在一个小批量的样本内基于批量规范化对数据进行重新中心化和重新缩放的调整。层规范化和批量规范化的目标相同,但层规范化是基于特征维度进行规范化。尽管批量规范化在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)批量规范化通常不如层规范化的效果好。
以下代码对比不同维度的层规范化和批量规范化的效果。
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
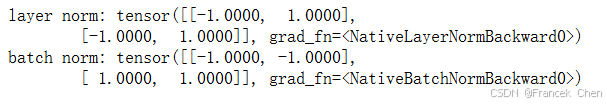
现在可以使用残差连接和层规范化来实现AddNorm类。暂退法也被作为正则化方法使用。
#@save
class AddNorm(nn.Module):"""残差连接后进行层规范化"""def __init__(self, normalized_shape, dropout, **kwargs):super(AddNorm, self).__init__(**kwargs)self.dropout = nn.Dropout(dropout)self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):return self.ln(self.dropout(Y) + X)
残差连接要求两个输入的形状相同,以便加法操作后输出张量的形状相同。
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape
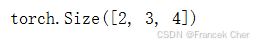
四、编码器
有了组成Transformer编码器的基础组件,现在可以先实现编码器中的一个层。下面的EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
#@save
class EncoderBlock(nn.Module):"""Transformer编码器块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):super(EncoderBlock, self).__init__(**kwargs)self.attention = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout, use_bias)self.addnorm1 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))return self.addnorm2(Y, self.ffn(Y))
正如从代码中所看到的,Transformer编码器中的任何层都不会改变其输入的形状。
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
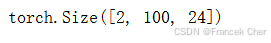
下面实现的Transformer编码器的代码中,堆叠了num_layers个EncoderBlock类的实例。由于这里使用的是值范围在 − 1 -1 −1和 1 1 1之间的固定位置编码,因此通过学习得到的输入的嵌入表示的值需要先乘以嵌入维度的平方根进行重新缩放,然后再与位置编码相加。
#@save
class TransformerEncoder(d2l.Encoder):"""Transformer编码器"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super(TransformerEncoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, use_bias))def forward(self, X, valid_lens, *args):# 因为位置编码值在-1和1之间,# 因此嵌入值乘以嵌入维度的平方根进行缩放,# 然后再与位置编码相加。X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self.attention_weights = [None] * len(self.blks)for i, blk in enumerate(self.blks):X = blk(X, valid_lens)self.attention_weights[i] = blk.attention.attention.attention_weightsreturn X
下面我们指定了超参数来创建一个两层的Transformer编码器。Transformer编码器输出的形状是(批量大小,时间步数目,num_hiddens)。
encoder = TransformerEncoder(200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
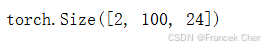
五、解码器
如图1所示,Transformer解码器也是由多个相同的层组成。在DecoderBlock类中实现的每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。
正如在本节前面所述,在掩蔽多头解码器自注意力层(第一个子层)中,查询、键和值都来自上一个解码器层的输出。关于序列到序列模型(sequence-to-sequence model),在训练阶段,其输出序列的所有位置(时间步)的词元都是已知的;然而,在预测阶段,其输出序列的词元是逐个生成的。因此,在任何解码器时间步中,只有生成的词元才能用于解码器的自注意力计算中。为了在解码器中保留自回归的属性,其掩蔽自注意力设定了参数dec_valid_lens,以便任何查询都只会与解码器中所有已经生成词元的位置(即直到该查询位置为止)进行注意力计算。
class DecoderBlock(nn.Module):"""解码器中第i个块"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super(DecoderBlock, self).__init__(**kwargs)self.i = iself.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm1 = AddNorm(norm_shape, dropout)self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size, num_hiddens, num_heads, dropout)self.addnorm2 = AddNorm(norm_shape, dropout)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm3 = AddNorm(norm_shape, dropout)def forward(self, X, state):enc_outputs, enc_valid_lens = state[0], state[1]# 训练阶段,输出序列的所有词元都在同一时间处理,# 因此state[2][self.i]初始化为None。# 预测阶段,输出序列是通过词元一个接着一个解码的,# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示if state[2][self.i] is None:key_values = Xelse:key_values = torch.cat((state[2][self.i], X), axis=1)state[2][self.i] = key_valuesif self.training:batch_size, num_steps, _ = X.shape# dec_valid_lens的开头:(batch_size,num_steps),# 其中每一行是[1,2,...,num_steps]dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)else:dec_valid_lens = None# 自注意力X2 = self.attention1(X, key_values, key_values, dec_valid_lens)Y = self.addnorm1(X, X2)# 编码器-解码器注意力。# enc_outputs的开头:(batch_size,num_steps,num_hiddens)Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)Z = self.addnorm2(Y, Y2)return self.addnorm3(Z, self.ffn(Z)), state
为了便于在“编码器-解码器”注意力中进行缩放点积计算和残差连接中进行加法计算,编码器和解码器的特征维度都是num_hiddens。
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape
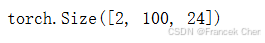
现在我们构建了由num_layers个DecoderBlock实例组成的完整的Transformer解码器。最后,通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。解码器的自注意力权重和编码器解码器注意力权重都被存储下来,方便日后可视化的需要。
class TransformerDecoder(d2l.AttentionDecoder):def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, **kwargs):super(TransformerDecoder, self).__init__(**kwargs)self.num_hiddens = num_hiddensself.num_layers = num_layersself.embedding = nn.Embedding(vocab_size, num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module("block"+str(i),DecoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, i))self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):return [enc_outputs, enc_valid_lens, [None] * self.num_layers]def forward(self, X, state):X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))self._attention_weights = [[None] * len(self.blks) for _ in range (2)]for i, blk in enumerate(self.blks):X, state = blk(X, state)# 解码器自注意力权重self._attention_weights[0][i] = blk.attention1.attention.attention_weights# “编码器-解码器”自注意力权重self._attention_weights[1][i] = blk.attention2.attention.attention_weightsreturn self.dense(X), state@propertydef attention_weights(self):return self._attention_weights
六、训练
依照Transformer架构来实例化编码器-解码器模型。在这里,指定Transformer的编码器和解码器都是2层,都使用4头注意力。与序列到序列学习(seq2seq)类似,为了进行序列到序列的学习,下面在“英语-法语”机器翻译数据集上训练Transformer模型。
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
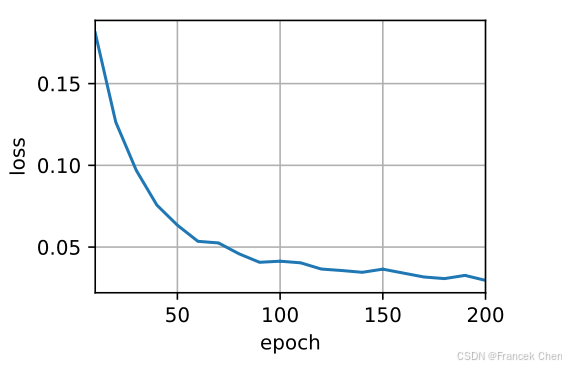
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)

训练结束后,使用Transformer模型将一些英语句子翻译成法语,并且计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):translation, dec_attention_weight_seq = d2l.predict_seq2seq(net, eng, src_vocab, tgt_vocab, num_steps, device, True)print(f'{eng} => {translation}, ', f'bleu {d2l.bleu(translation, fra, k=2):.3f}')

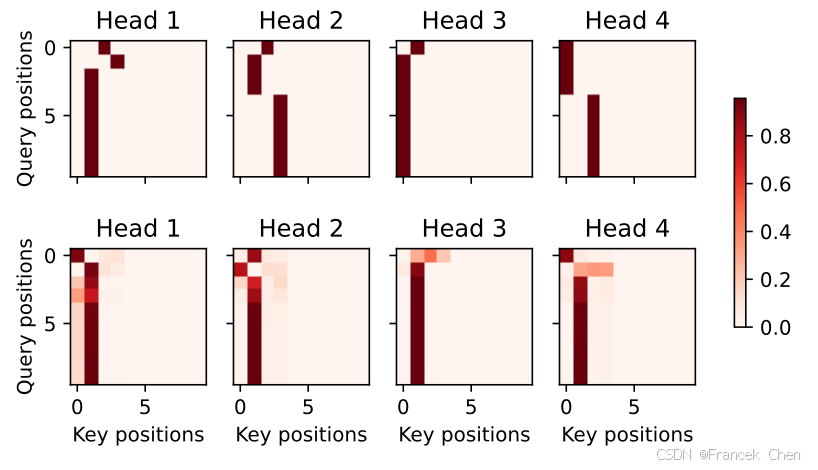
当进行最后一个英语到法语的句子翻译工作时,让我们可视化Transformer的注意力权重。编码器自注意力权重的形状为(编码器层数,注意力头数,num_steps或查询的数目,num_steps或“键-值”对的数目)。
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads, -1, num_steps))
enc_attention_weights.shape
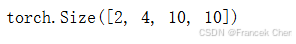
在编码器的自注意力中,查询和键都来自相同的输入序列。因为填充词元是不携带信息的,因此通过指定输入序列的有效长度可以避免查询与使用填充词元的位置计算注意力。接下来,将逐行呈现两层多头注意力的权重。每个注意力头都根据查询、键和值的不同的表示子空间来表示不同的注意力。
d2l.show_heatmaps(enc_attention_weights.cpu(), xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5))
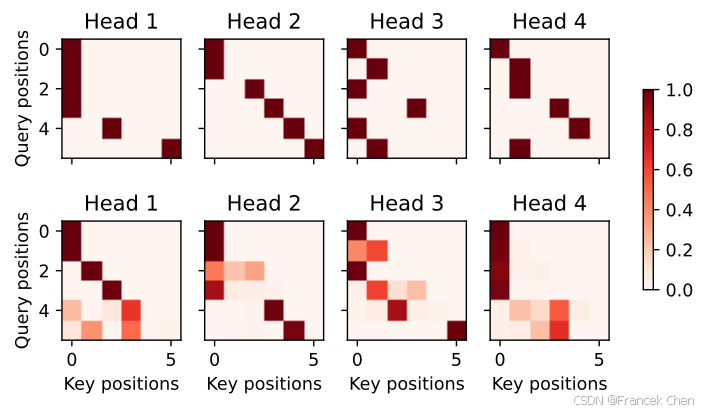
为了可视化解码器的自注意力权重和“编码器-解码器”的注意力权重,我们需要完成更多的数据操作工作。例如用零填充被掩蔽住的注意力权重。值得注意的是,解码器的自注意力权重和“编码器-解码器”的注意力权重都有相同的查询:即以序列开始词元(beginning-of-sequence,BOS)打头,再与后续输出的词元共同组成序列。
dec_attention_weights_2d = [head[0].tolist()for step in dec_attention_weight_seqfor attn in step for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape

由于解码器自注意力的自回归属性,查询不会对当前位置之后的“键-值”对进行注意力计算。
# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],xlabel='Key positions', ylabel='Query positions',titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))
与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。
d2l.show_heatmaps(dec_inter_attention_weights, xlabel='Key positions',ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],figsize=(7, 3.5))
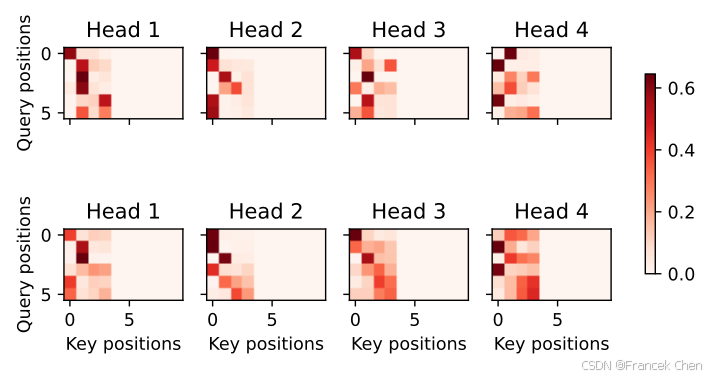
尽管Transformer架构是为了序列到序列的学习而提出的,但正如后面将提及的那样,Transformer编码器或Transformer解码器通常被单独用于不同的深度学习任务中。
小结
- Transformer是编码器-解码器架构的一个实践,尽管在实际情况中编码器或解码器可以单独使用。
- 在Transformer中,多头自注意力用于表示输入序列和输出序列,不过解码器必须通过掩蔽机制来保留自回归属性。
- Transformer中的残差连接和层规范化是训练非常深度模型的重要工具。
- Transformer模型中基于位置的前馈网络使用同一个多层感知机,作用是对所有序列位置的表示进行转换。
相关文章:
【现代深度学习技术】注意力机制07:Transformer
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

浅析 Spring 启动过程:从源码到核心方法
浅析 Spring 启动过程:从源码到核心方法 一、Spring 注解方式启动类 Demo二、Spring 启动过程源码解析AnnotationConfigApplicationContext构造函数refresh()方法详解 三、refresh()的核心方法/步骤obtainFreshBeanFactory() - 获取Bean工厂prepareBeanFactory(be…...

5G + 区块链:技术巨浪下的新型数字生态!
5G + 区块链:技术巨浪下的新型数字生态! 1. 为什么 5G 和区块链的结合如此重要? 区块链和 5G 这两大技术近几年风头正劲,一个在去中心化数据管理上展现潜力,一个在高吞吐低延迟通信方面带来颠覆。这两者结合,意味着: 更快的数据传输,让区块链交易速度提升,摆脱“低 …...

时序数据库IoTDB分布式架构解析与运维指南
一、IoTDB分布式架构概述 分布式系统由一组独立的计算机组成,通过网络通信,对外表现为一个统一的整体。IoTDB的原生分布式架构将服务分为两个核心部分: ConfigNode(CN):管理节点,负责管理…...

CertiK荣获以太坊基金会两项资助,领跑zkEVM形式化验证
近日,以太坊基金会公布了2025年第一季度研究资助名单,全球最大的Web3.0安全公司CertiK荣获两项研究资助,源于zkEVM形式化验证竞赛。这不仅是以太坊扩展性战略的里程碑式事件,也进一步彰显了CertiK在零知识证明(ZKP&…...

c++和c的不同
c:面向对象(封装,继承,多态),STL,模板 一、基础定义与背景 C语言 诞生年代:20世纪70年代,Dennis Ritchie在贝尔实验室开发。主要特点: 过程式、结构化编程面向系统底层…...

光流 | Matlab工具中的光流算法
在MATLAB中,光流算法用于估计图像序列中物体的运动。以下是详细解释及实现步骤: 1. 光流算法基础 光流基于两个核心假设: 亮度恒定:同一物体在连续帧中的像素亮度不变。微小运动:相邻帧之间的时间间隔短,物体运动幅度小。常见算法: Lucas-Kanade (局部方法):假设局部窗…...

@Controller 与 @RestController-笔记
1.Controller与RestController对比 Spring MVC 中 Controller 与 RestController 的功能对比: Controller是Spring MVC中用于标识一个类作为控制器的标准注解。它允许处理HTTP请求,并返回视图名称,通常和视图解析器一起使用来渲染页面。而R…...

LeetCode 热题 100 105. 从前序与中序遍历序列构造二叉树
LeetCode 热题 100 | 105. 从前序与中序遍历序列构造二叉树 大家好,今天我们来解决一道经典的二叉树问题——从前序与中序遍历序列构造二叉树。这道题在 LeetCode 上被标记为中等难度,要求根据给定的前序遍历和中序遍历序列,构造并返回二叉树…...

IP地址查询助力业务增长
IP地址查询的技术基石 IP地址分为IPv4和IPv6,目前IPv4仍广泛应用,它由四个0-255的十进制数组成,如192.168.1.1。而IPv6为应对IPv4地址枯竭问题而生,采用128位地址长度,极大扩充了地址空间。IP地址查询主要依赖庞大的I…...

Nginx核心功能及同类产品对比
Nginx 作为一款高性能的 Web 服务器和反向代理工具,凭借其独特的架构设计和丰富的功能,成为互联网基础设施中不可或缺的组件。以下是其核心功能及与同类产品(如 HAProxy、LVS)的对比优势: 一、Nginx 核心功能 高性能架…...

抽奖系统-奖品-活动
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言获取奖品列表前端页面活动创建需求分析活动创建后端实现1-控制层实现及校验活动活动创建后端实现2-保存信息活动插入活动奖品插入 整合活动信息存入redis测试活…...

【Java】 volatile 和 synchronized 的比较及使用场景
在 Java 的并发编程中,volatile 和 synchronized 是两个常用的关键字,它们分别用于保证多线程环境中的 可见性 和 原子性,但它们的工作原理和适用场景却有所不同。今天,我们将深入探讨这两个关键字的异同,帮助大家理解…...

javaScript简单版
简介 JavaScript(简称:JS)是一门跨平台、面向对象的脚本语言,是用来控制网页行为,实现页面的交互效果。 JavaScript和Java是完全不同的语言,不论是概念还是设计。但是基础语法类似。 组成: ECMAScript:规定了JS基础语法核心知…...
)
三种常见接口测试工具(Apipost、Apifox、Postman)
三种常见接口测试工具(Apipost、Apifox、Postman)的用法及优缺点对比总结: 🔧 一、Apipost ✅ 基本用法 支持 RESTful API、GraphQL、WebSocket 等接口调试自动生成接口文档支持环境变量、接口分组、接口测试用例编写可进行前置…...

蓝桥杯13届国B 完全日期
题目描述。 如果一个日期中年月日的各位数字之和是完全平方数,则称为一个完全日期。 例如:2021 年 6 月 5 日的各位数字之和为 20216516,而 16 是一个完全平方数,它是 4 的平方。所以 2021 年 6 月 5 日是一个完全日期。 例如&…...

kafka connect 大概了解
kafka connect Introduction Kafka Connect is the component of Kafka that provides data integration between databases, key-value stores, search indexes, file systems, and Kafka brokers. kafka connect 是一个框架,用来帮助集成其他系统的数据到kafka…...
gdb调试、单向链表练习、顺序表与链表对比)
嵌入式培训之数据结构学习(三)gdb调试、单向链表练习、顺序表与链表对比
目录 一、gdb调试 (一)一般调试步骤与命令 (二)找段错误(无下断点的地方) (三)调试命令 二、单向链表练习 1、查找链表的中间结点(用快慢指针) 2、找出…...

MySQL——九、锁
分类 全局锁表级锁行级锁 全局锁 做全库的逻辑备份 flush tables with read lock; unlock tables;在InnoDB引擎中,我们可以在备份时加上参数–single-transaction参数来完成不加锁的一致性数据备份 mysqldump --single-transaction -uroot -p123456 itcast>…...
:创业移情阶段的核心要点与实践方法)
精益数据分析(57/126):创业移情阶段的核心要点与实践方法
精益数据分析(57/126):创业移情阶段的核心要点与实践方法 在创业的浩瀚征程中,每一个阶段都承载着独特的使命与挑战。今天,我们继续秉持共同进步的理念,深入研读《精益数据分析》,聚焦创业的首…...

服务器被打了怎么应对
云服务器遭受攻击该如何应对? 在互联网时代,不少使用云服务器的网络工作者常常会面临网络攻击的威胁。若云服务器未配置完善的防火墙,极易引发服务器宕机,甚至被封禁隔离(俗称“陷入黑洞”),进…...
:C#联合Halcon回形针以及方向)
Halcon案例(二):C#联合Halcon回形针以及方向
本案例分3部分 识别效果,分别显示识别前后识别后;代码展示,分别是Halcon源码和Halcon转为C#的代码代码解释(解释在源码中); 原图如下 识别后图像: 其中计算回形针与X轴之间的夹角 Halcon代码: * clip.hdev: Orientation of clips *识别图像中的回形针,并且计算回形针与X轴之间…...
)
Spyglass:跨时钟域同步(同步单元)
相关阅读 Spyglasshttps://blog.csdn.net/weixin_45791458/category_12828934.html?spm1001.2014.3001.5482 简介 同步单元方案可以用于控制/数据信号跨时钟域同步,该方案使用约束或参数将目标时钟域中单元指定为同步单元,如图1所示。 图1 同步单元方案…...

JAVA异常体系
在 Java 里,异常体系是其错误处理机制的核心内容,它能够帮助开发者有效应对程序运行时出现的各种意外状况。 异常体系的基本架构 它主要包含两个重要分支: Error(错误):这类异常是程序自身无法处理的严重…...
)
Milvus 视角看主流嵌入式模型(Embeddings)
嵌入是一种机器学习概念,用于将数据映射到高维空间,其中语义相似的数据被紧密排列在一起。嵌入模型通常是 BERT 或其他 Transformer 系列的深度神经网络,它能够有效地用一系列数字(称为向量)来表示文本、图像和其他数据…...
协议:从大模型流式输出到实时通信场景)
全面解析 Server-Sent Events(SSE)协议:从大模型流式输出到实时通信场景
全面解析 Server-Sent Events(SSE)协议:从大模型流式输出到实时通信场景 一、SSE 协议概述 Server-Sent Events(SSE) 是 HTML5 标准中定义的一种基于 HTTP 的服务器向客户端单向推送实时数据的协议。其核心特性包括&a…...

数据库系统概论|第七章:数据库设计—课程笔记
前言 本章讨论数据库设计的技术和方法,主要讨论基于关系数据库管理系统的关系数据库设计问题,而关于数据库的设计过程中,关于数据模型、关系模型等基本概念在前文中已经有详尽介绍,此处便不再赘述,本文主要围绕概念结…...
)
Java项目拷打(外卖+点评)
一、点评星球(黑马点评) 1、项目概述 1.1、项目简介 本项目是基于Spring Boot与Redis深度整合的前后端分离的点评平台。系统以Redis为核心技术支撑,重点解决高并发场景下的缓存穿透、击穿、雪崩等问题,涵盖商户展示、优惠券秒杀…...

MCP:开启AI的“万物互联”时代
MCP:开启AI的“万物互联”时代 ——从协议标准到生态革命的技术跃迁 引言:AI的“最后一公里”困境 在2025年的AI技术浪潮中,大模型已从参数竞赛转向应用落地之争。尽管模型能生成流畅的对话、创作诗歌甚至编写代码,但用户逐渐发现…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】附录-D. 扩展插件列表(PostGIS/PostgREST等)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 附录D. PostgreSQL扩展插件速查表一、插件分类速查表二、核心插件详解三、安装与配置指南四、应用场景模板五、版本兼容性说明六、维护与优化建议七、官方资源与工具八、附录…...

Spring Boot拦截器详解:原理、实现与应用场景
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、拦截器概述 拦截器(Interceptor)是Spring MVC框架中用于对请求进行预处理和后处理的组件,主要作用于Controller层。相…...

万字解析:Java字符串
目录 一、 String类 1. String类的初始化 1.1 常用的三种构造String类的方式 1.2 String类如何存储字符串? 2. String类的常用功能方法 2.0 字符串长度的获取 2.1 String对象的比较 2.2 字符/字符串的查找 2.3 字符串的转化 2.4 字符 / 字符串的替换 2.5…...

0514得物、0509滴滴面试总结复盘
目前最欠缺的还是,编码不是很熟,很多都遇到过但是就是写不出来,或者靠背先写一点,然后去加,加的过程没考虑逻辑是不是对的,用滴滴面试官的一句话,就是多刷多练多编码! 第二块就是项目…...
对称二叉树)
记录算法笔记(20025.5.14)对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true 示例 2: 输入:root [1,2,2,null,3,null,3] 输出:false 提示: 树中节点数目…...

AI大模型从0到1记录学习 linux day23
第 1 章 MySQL概述 1.1 基本概念 1.1.1 数据库是什么? 数据库(DB:Database):存储数据的地方。 1.1.2 为什么要用数据库? 应用程序产生的数据是在内存中的,如果程序退出或者是断电了,…...

用git下载vcpkg时出现Connection was reset时的处理
用git安装vcpkg时出现Connect was rest(如上图)。多谢这位网友的博文解决了问题: 通过:http.sslVerify false全局来设置,执行以下命令: git config --global http.sslVerify "false" 原文链接:…...

【数据库复习】SQL语言
一、SQL通用语法与分类 (一)SQL通用语法 SQL语句的格式通常较为规范,以关键字开头,如CREATE、SELECT、INSERT等,后跟具体的表名、字段名和条件等。在MySQL中,还可以使用help命令获取帮助信息,…...

二叉树——层序遍历
目录 实现层序遍历 判断是否为完全二叉树 实现层序遍历 除了先序遍历,中序遍历,后序遍历外,还可以对二叉树进行层序遍历。设二叉树的结点所在层数为1,层序遍历就是从所在二叉树的根结点出发,首先访问第一层的树根结点…...

Seata源码—2.seata-samples项目介绍
大纲 1.seata-samples的配置文件和启动类 2.seata-samples业务服务启动时的核心工作 3.seata-samples库存服务的连接池配置 4.Seata对数据库连接池代理配置的分析 5.Dubbo RPC通信过程中传递全局事务XID 6.Seata跟Dubbo整合的Filter(基于SPI机制) 7.seata-samples的AT事…...

企业数字化转型背景下的企业知识管理挑战与经验杂谈
一、引言 在数字化转型的浪潮下,企业知识管理正面临前所未有的挑战。随着数据量的急剧增长,企业内部积累的信息呈现出碎片化、分散化的趋势,传统的知识管理体系已难以有效应对这一变革。首先,信息碎片化问题日益严重,…...

第二章:磁盘管理与文件管理
一、磁盘管理 1.windows和Linux磁盘管理的区别 windows资源管理方式 系统一般安装在C盘 C盘下的"Windows"目录是操作系统的核心 C盘下的"Program Files"目录下安装软件 C盘下的"用户"目录是所有的用户,包括超级管理员也在其中 …...

Java版OA管理系统源码 手机版OA系统源码
Java版OA管理系统源码 手机版OA系统源码 一:OA系统的主要优势 1. 提升效率 减少纸质流程和重复性工作,自动化处理常规事务,缩短响应时间。 2. 降低成本 节省纸张、打印、通讯及人力成本,优化资源分配。 3. 规范管理 固化企…...

springboot踩坑记录
之前运行好端端的项目,今天下午打开只是添加了一个文件之后 再运行都报Failed to configure a DataSource: url attribute is not specified and no embedded datasource could be configured.Reason: Failed to determine a suitable driver class Action: Conside…...

SpringAI
机器学习: 定义:人工智能的子领域,通过数据驱动的方法让计算机学习规律,进行预测或决策。 核心方法: 监督学习(如线性回归、SVM)。 无监督学习(如聚类、降维)。 强化学…...

acwing 1488. 最短距离 超级源点 最短路 堆优化Dijkstra
经验总结 邻接表 节点1连接到节点2,权重为3。 节点1连接到节点3,权重为5。 节点2连接到节点4,权重为2。 g[1] {{2, 3}, {3, 5}} g[2] {{1, 3}, {4, 2}} g[3] {{1, 5}} g[4] {{2, 2}} vector<vector<PII>> g;题目背景 有 N…...
)
2002-2024年地级市新质生产力词频统计数据(46个关键词词频)
2002-2024年地级市新质生产力词频统计数据(46个关键词词频) 1、时间:2002-2024年 2、来源:ZF工作报告 3、指标:行政区划代码、年份、地区、所属省份、文本总长度、仅中英文-文本总长度、文本总词频-全模式、文本总词…...

院校机试刷题第二天:1479 01字符串、1701非素数个数
一、1479 01字符串 1.题目描述 2.解题思路 方法一:暴力法 模拟过程,列出几个数据来a[1]1, a[2]2, a[3]3, a[4]5以此类推,这就是斐波那契数列,每一项都等于前两项之和,确定好a[1], a[2]即可。 方法二:动…...

2011-2019年各省总抚养比数据
2011-2019年各省总抚养比数据 1、时间:2011-2019年 2、来源:国家统计局 3、指标:行政区划代码、地区、年份、总抚养比(人口抽样调查)(%) 4、范围:31省 5、指标解释:总抚养比也称总负担系数。指人口总体中非劳动年…...
)
3337|3335. 字符串转换后的长度 I(||)
1.字符串转换后的长度 I 1.1题目 3335. 字符串转换后的长度 I - 力扣(LeetCode) 1.2解析 递推法解析 思路框架 我们可以通过定义状态变量来追踪每次转换后各字符的数量变化。具体地,定义状态函数 f(i,c) 表示经过 i 次转换后࿰…...

【电路笔记 通信】8B/10B编码 高速数据传输的串行数据编码技术 论文第三部分 The 8B/10B coding map
0810逻辑总览 The 8B/10B coding map 图 1 展示了一个通信适配器接口,它由八条数据线 A、B、C、D、E、F、G、H(注意:使用大写字母表示)、一条控制线 K,以及一条以字节速率运行的时钟线 BYTECLK 组成。控制线 K 用于指…...