通过迁移学习改进深度学习模型
在 ArcGIS Living Atlas of the World (Browse | ArcGIS Living Atlas of the World)中,可以下载能够分类或检测影像中要素的预训练深度学习模型。 深度学习模型在与用于训练模型的原始影像十分相似的影像上运行效果最好。 如果您所拥有的影像不同于原始影像,则可以通过向其提供感兴趣区域内的要素和影像的示例来改善模型的性能。 此过程称为迁移学习。
要求
- ArcGIS Pro
- ArcGIS Image Analyst
- ArcGIS Pro 的深度学习库(GitHub - Esri/deep-learning-frameworks: Installation support for Deep Learning Frameworks for the ArcGIS System)
- 推荐:至少具有 8GB 专用内存的 NVIDIA GPU
1 准备深度学习分析
在本教程的第一部分,您将设置 ArcGIS Pro 工程,选择一个深度学习预训练模型,准备影像使其与模型更匹配并了解迁移学习的需求。
1.1 设置工程
首先,您将下载一个包含本教程所有数据的工程,并在 ArcGIS Pro 中将其打开。 然后,您要将影像添加到工程文件夹。
- 下载 Seattle_Building_Detection.zip 文件并在计算机上找到下载的文件。
百度网盘 请输入提取码百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间![]() https://pan.baidu.com/s/1orLZJ5_IwIeD4cbIx1LQ4g?pwd=1tzh
https://pan.baidu.com/s/1orLZJ5_IwIeD4cbIx1LQ4g?pwd=1tzh
2. 打开提取的 Seattle_Building_Detection 文件夹,然后双击 Seattle_Building_Detection.aprx 以在 ArcGIS Pro 中打开工程。
工程随即打开。
地图仅包含默认地形底图。 在此工作流中,您将使用航空影像检测建筑物。 现在,您要将该影像添加到地图。
3. 单击功能区上的视图选项卡。 在窗口组中,单击目录窗格。
随即显示目录窗格。
4. 在目录窗格中,依次展开文件夹、Seattle_Building_Detection 和 Imagery_data。
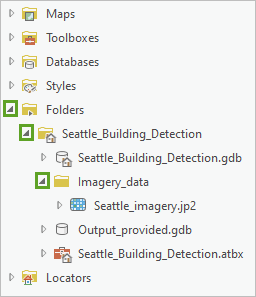
5. 右键单击 Seattle_imagery.jp2,然后选择添加到当前地图。
6. 如果系统提示您计算统计数据,请单击是。对影像执行某些任务需要统计数据,例如使用拉伸渲染图像。 影像将显示在地图上。 该影像表示西雅图区域。
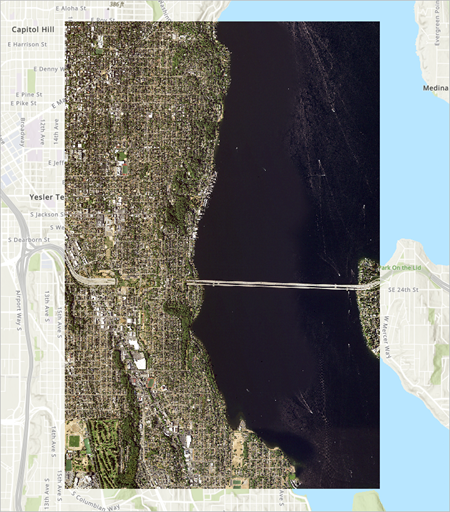
注:此航空影像来自美国国家农业影像计划 (NAIP) 网站。 覆盖整个美国区域的 NAIP 影像可通过 USGS Earth Explorer 网站下载。
7. 进行放大和平移以检查影像。 可以观察到影像中有许多建筑物。
1.2 选择一个预训练模型并进行检查
您希望使用深度学习提取航空影像中的建筑物。 如果您还没有可用的深度学习模型,则需要先从头开始训练一个模型,为其提供大量示例以向模型展示什么是建筑物。 高性能模型可能需要接触成千上万个示例。 作为替代方法,您可以使用已训练的模型。 您将检索一个这样的模型,并了解其规范。
注:在 ArcGIS Pro 中使用深度学习工具需要在计算机上安装正确的深度学习库。 如果您未安装这些文件,请保存工程,关闭 ArcGIS Pro,然后按照在ArcGIS Pro中为深度学习做好准备中提供的步骤说明操作。 在这些说明中,您还可以了解如何检查您的计算机硬件和软件能否运行深度学习工作流,以及获取其他有用的提示。 完成后,您可以重新打开工程并继续本教程。
- 转至 ArcGIS Living Atlas of the World 网站。(Browse | ArcGIS Living Atlas of the World)
- 在搜索框中,输入 Pretrained model,然后按 Enter 键。

3. 浏览结果列表以查看可用的 70 多个预训练模型。
4. 在搜索框中,输入 Building Footprint Extraction ,然后按 Enter 键。

结果列表包含用于世界上不同区域的预训练深度学习模型。 由于您的感兴趣区域位于美国,所以您将选择针对该区域训练的模型。
5. 在结果列表中,单击 Building Footprint Extraction – USA。

模型的描述页面随即显示。 其中包含大量有关模型的重要信息。 最需要了解的是模型预期的输入类型。 如果您的输入数据与模型训练数据的类型不够相似,则模型会表现不佳。
6. 花费一些时间来阅读该页面的内容。 尤其需要查看以下示例图片中显示的部分:

您了解了模型的一些基本资料:
-
- 输入 - 模型预期使用 8 位 3 波段高分辨率 (10-40 cm) 影像作为输入。 要了解您的数据是否符合这些规范,您需要进一步调查数据。 您将在本教程中进一步执行此操作。
- 输出 - 模型将生成一个包含建筑物覆盖区的要素类。 获取建筑物覆盖区面作为输出正是您需要的。
- 适用地理位置 - 此模型应适用于美国。 这一点很完美,因为您的感兴趣区域位于美国。
- 模型架构 - 该模型使用 MaskRCNN 模型架构。 您应记录此信息,因为在工作流的后续部分会需要它。
该模型似乎非常适合您的工程,因此您将下载模型。
7. 在概述下,单击下载。
片刻之后,下载将完成。
8. 在计算机上找到已下载的文件 usa_building_footprints.dlpk。
9. 在 Seattle_Building_Detection 文件夹中创建一个名为 Pretrained_model 的文件夹。
10. 将 usa_building_footprints.dlpk 模型文件从下载位置移动到 Pretrained_model 文件夹。
1.3 检查影像属性
现在,您将进行研究以了解您的数据与理想的 8 位 3 波段高分辨率 (10-40 cm) 影像输入的匹配程度。
- 在 ArcGIS Pro 中,返回到 Seattle_Building_Detection 工程。
- 在内容窗格中,右键单击 Seattle_imagery.jp2,然后选择属性。
3. 在图层属性窗口中,单击源并展开栅格信息。
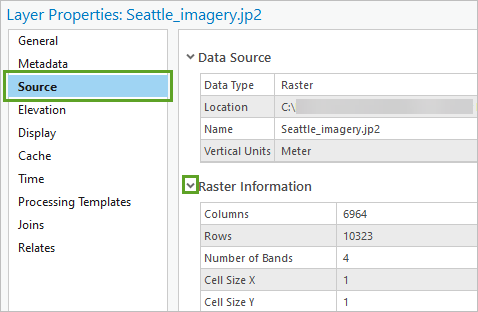
4. 查找波段数字段。
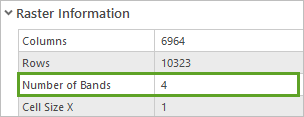
其值为 4。 NAIP 项目采集由红、绿、蓝和近红外四个光谱波段组成的多光谱影像。 近红外波段通常用于可视化植被健康。 而模型预期为三个波段(红、绿和蓝)。 您需要修复此差异。
5. 查找像元大小 X 和像元大小 Y 字段。
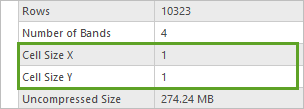
两个字段的值均为 1。 这意味着影像中的每个像元(或像素)的测量值为 1 米乘 1 米。 此 NAIP 影像确实采用 1 米的分辨率捕获。 该分辨率低于模型建议的 10-40 cm 分辨率。 您还需要修复此问题。
6. 查找像素深度字段。
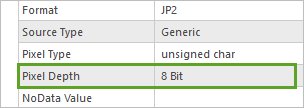
其值为 8 位,即与模型要求的 8 位相匹配。
7. 单击确定关闭图层属性窗口。您将学习另一种可视化波段数的方式。
8. 在内容窗格中,右键单击 Seattle_imagery.jp2,然后选择符号系统。
9. 在符号系统窗格中,对于红色,单击 Band_1 以展开下拉列表。
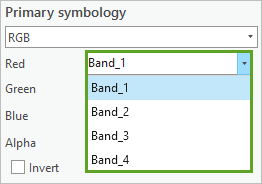
其中列出了四个波段。 当查看多光谱影像时,在给定时间只能显示三个波段,通过红色、绿色和蓝色通道将所选的三个波段组合成 RGB 合成。 但是,您可以看到影像中显示四个波段,且它们可以用于不同的分析目的。
10. 关闭符号系统窗格。

您发现您的影像与预训练模型的预期之间有两个条件不匹配:波段数和分辨率。 在此工作流的后续部分,您将了解如何修复这两个问题。
1.4 选择相关的影像波段
现在,您将修复波段不匹配问题。 您的影像具有四个光谱波段:
- 波段 1 - 红
- 波段 2 - 绿
- 波段 3 - 蓝
- 波段 4 - 近红外
而模型预期采用三波段输入(红、绿、蓝)。 要修复该问题,您需要生成一个仅包含 NAIP 影像的前三个波段的新图层,以便更符合模型的预期。 此步骤十分重要,如果跳过此步骤,模型可能表现不佳。
注:了解您的影像的准确波段顺序至关重要。 例如,一些其他类型影像的波段顺序可能有所不同:波段 1 - 蓝、波段 2 - 绿、波段 3 - 红。 您可以在影像的属性或文档中查找该信息。
您将使用栅格函数生成新的三波段图层。
- 在功能区影像选项卡的分析组中,单击栅格函数按钮。
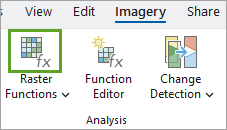
2. 在栅格函数窗格的搜索框中,输入提取波段。 在数据管理下,单击提取波段。
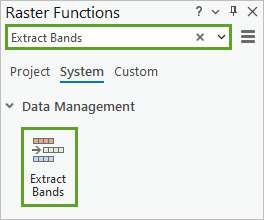
3. 设置以下提取波段参数值:
-
- 对于栅格,选择 Seattle_imagery.jp2。
- 对于组合,验证值是否为 1 2 3,参照波段 1(红)、波段 2(绿)和波段 3(蓝)。
- 对于缺失波段操作,选择失败。
缺失波段操作指定列出的其中一个波段不可用时将执行的操作。 失败表示栅格函数将终止且运行失败。 您选择此选项的原因是,要成功完成本教程,三个波段都必须存在。
4. 单击新建图层。名为 Extract Bands_Seattle_imagery.jp2 的新图层将显示在内容窗格中。 通过栅格函数创建的图层将动态计算,不会保存在磁盘上。 在当前情况下,您希望将生成的图层作为 TIFF 文件保留在计算机上。 您将使用导出栅格来执行此操作。
5. 右键单击 Extract Bands_Seattle_imagery.jp2,然后选择数据,导出栅格。
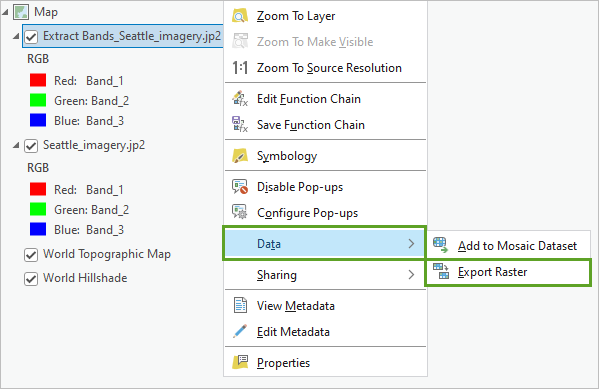
6. 在输出栅格窗格中,对于输出栅格数据集,单击浏览按钮。
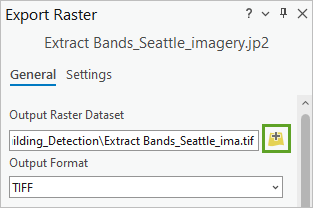
7. 在输出位置窗口中,浏览至 文件夹 > Seattle Building Detection > Imagery Data,对于名称,输入 Seattle_RGB.tif,然后单击保存。
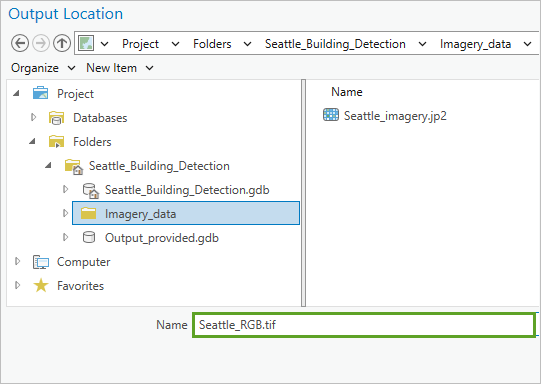
8. 在输出位置窗口中,接受所有其他默认值,然后单击导出。
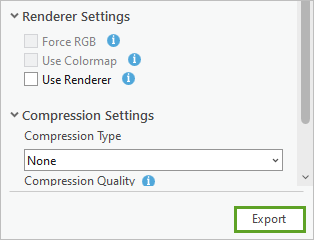
注:如果影像是 16 位的,导出栅格步骤可将其转换为模型所需的 8 位深度影像。 对于像素类型,选择 8 位无符号,然后选中缩放像素值框。 缩放像素值可确保值真正转换为 8 位(而不是丢弃高值)。 对于 NoData 值,输入原始图像的 NoData 值,例如 0。
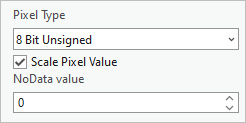
要找到 NoData 值,在内容窗格中,右键单击原始图像,选择属性,然后浏览到源 > 栅格信息 > NoData 值。
新的 Seattle_RGB.tif 图层将显示在内容窗格中。
9. 关闭导出栅格窗格。现在,您将验证波段数。
10. 在内容窗格中,右键单击 Seattle_RGB.tif,然后选择属性。
11. 在图层属性窗口中,单击源并展开栅格信息。
12. 查找波段数字段。
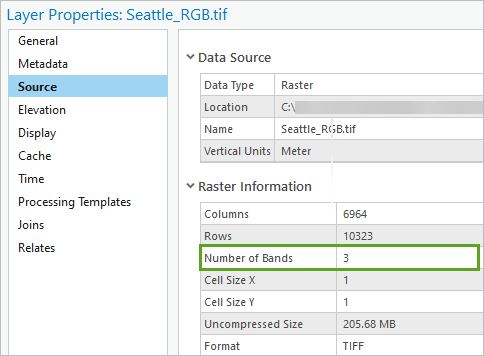
字段值为 3,确定图层现在包含三个波段,符合预训练模型的预期。
13. 关闭图层属性窗口。现在,您将移除在工作流的其余部分不再需要的影像图层。
14. 在内容窗格中,右键单击 Extract Bands_Seattle_imagery.jp2,然后选择移除。
15. 同样,移除 Seattle_imagery.jp2。您将保存工程。
16. 在快速访问工具栏上单击保存按钮。
![]()
现在,您已拥有三波段影像图层,这符合预训练模型的预期。
1.5 了解迁移学习的需求
现在,您必须修复分辨率不匹配问题,模型预期使用较高的分辨率 (10-40 cm),而 NAIP 影像采用较低的 1 米分辨率捕获。 如果将 Building Footprint Extraction – USA 预训练模型直接应用于 Seattle_RGB.tif 图层,您会得到质量较差的结果,如以下示例图像所示:
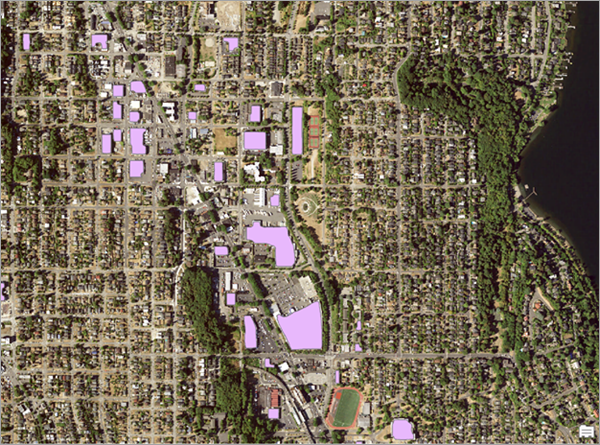
在该图像中,检测到的建筑物显示为粉色。 由于分辨率不匹配,该模型可以检测到较大的建筑物,但很难识别任何较小的建筑物。
注:有关直接并成功使用预训练模型的工作流的示例,请参阅使用深度学习预训练模型检测物体教程。
使用深度学习预训练模型检测物体-CSDN博客![]() https://blog.csdn.net/Xxy9426/article/details/147956628?spm=1001.2014.3001.5502 使用迁移学习是一种可修复此问题的方法。 迁移学习是机器学习中的一种技术,从任务中学到的知识将被重用以提高相关任务的性能。 在本例中,原来的任务是在 10-40 cm 分辨率的影像中检测建筑物,新任务是在 1 米分辨率的影像中检测建筑物。
https://blog.csdn.net/Xxy9426/article/details/147956628?spm=1001.2014.3001.5502 使用迁移学习是一种可修复此问题的方法。 迁移学习是机器学习中的一种技术,从任务中学到的知识将被重用以提高相关任务的性能。 在本例中,原来的任务是在 10-40 cm 分辨率的影像中检测建筑物,新任务是在 1 米分辨率的影像中检测建筑物。
注:迁移学习也可用于影像分辨率不匹配以外的其他原因。 例如,从已训练的用于检测特定国家建筑物的模型入手,您可以使用迁移学习使模型学习检测其他国家的建筑物。
迁移学习的一个主要优点是,与从头开始训练模型相比,它所需要的训练数据量较小,所需的训练时间较短。
注:如果您的影像和预期输入之间的差异过大,则迁移学习的效果也会受限。 例如,如果您拥有 30 米分辨率的卫星影像,在其中几乎看不到较小的建筑物,那么通过微调模型使其在该影像上得到较好的效果是不现实的。 新任务与原始任务的差异越大,迁移学习的效果越不明显。
警告:迁移学习并不适用于所有深度学习预训练模型。 例如,依赖 SAM 和 DeepForest 的模型不支持迁移学习。 您可以在 ArcGIS Living Atlas 网站上查看预训练模型的描述,以确定该模型是否依赖 SAM 或 DeepForest。
在本教程的其余部分中,您将学习如何执行迁移学习以微调预训练模型,从而提高其针对您的数据的性能。
2 准备用于迁移学习的训练样本
要执行迁移学习,首先需要生成训练示例,以向模型展示数据中建筑物的外观。 如果您从头开始训练模型,可能需要成千上万个建筑物样本。 幸好,借助迁移学习,您仅需要几百个样本。 在教程的这一部分中,您将学习如何生成训练样本。 首先,您将创建一个用于存储样本的空要素类。 然后,您将绘制表示建筑物的面并将其添加到要素类。 最后,您需将要素类和影像导出至用于迁移学习的训练片。
2.1 创建要素类
首先,您将创建要素类。
- 在功能区视图选项卡的窗口组中,单击地理处理。
将出现地理处理窗格。
2. 在地理处理窗格的搜索框内,输入创建要素类。 在结果列表中,单击创建要素类工具以将其打开。
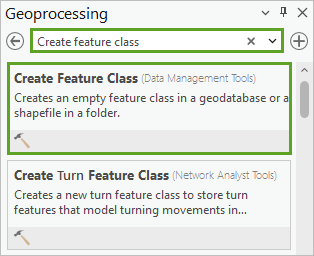
3. 设置以下参数值:
-
- 对于要素类名称,输入 Training_examples。
- 对于几何类型,验证是否已选择面。
- 对于坐标系,选择 Seattle_RGB.tif。
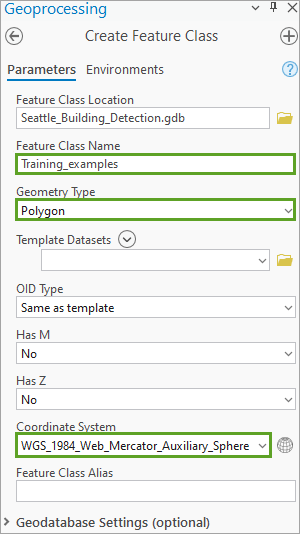
4. 接受所有其他默认值,然后单击运行。在内容窗格中,将显示新的 Training_examples 要素类。 当前仪表盘为空。
2.2 绘制训练示例
现在,您将描绘建筑物覆盖区,这些覆盖区将在 Training_examples 图层保存为面要素。
- 在功能区编辑选项卡的要素组中,单击创建。
创建要素窗格随即显示。
2. 在创建要素窗格中,单击 Training_examples,然后单击面按钮。
构造工具栏随即显示在地图上。 默认情况下,设置为线模式,该模式用于绘制直线。
![]()
3. 在构造工具栏上,单击直角线按钮。

4. 直角线模式将所有直线约束为直线,将所有角度约束为直角。 这在绘制建筑物覆盖区时很有帮助,因为大多数建筑物均为 90 度直角。 在绘制期间,您可以根据需要在此模式和线模式之间切换。
5. 在功能区上,单击地图选项卡,在导航组中单击书签,然后选择 Labeling extent。
您将在此区域中开始绘制用于描绘建筑物的面。 此过程也称为标注,因为您在告知模型感兴趣对象在影像中的位置。
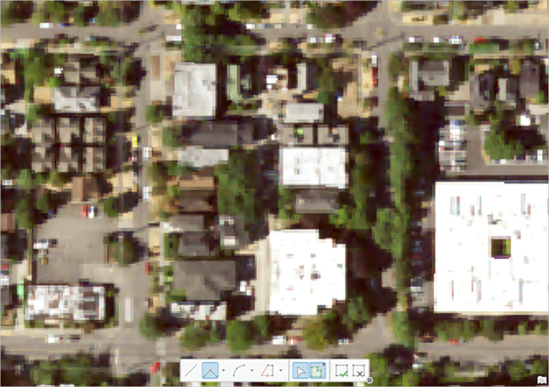
注:决定要在影像中的哪个位置创建训练示例时,请选择一个具有该地理位置典型建筑物的区域。
6. 在地图上,选择一个特定建筑物,然后单击其中一个角(或折点)。
7. 顺时针单击它的每个角。
8. 在最后一个角的位置双击以完成面。

注:要素类的颜色(此处为浅绿色)是随机指定的,在您的工程中,颜色可能有所不同。
9. 按照同样的方式,在同一区域再创建两个或三个面。
提示:如果您不喜欢创建的面,可以将其删除。 在功能区编辑选项卡的选择组中,单击选择。 在地图上,单击面。 在编辑选项卡的要素组中,单击删除。
您要将面要素保存到要素类。
10. 在构造工具栏上,单击完成按钮。

11. 在功能区编辑选项卡的管理编辑内容组中,单击保存。
12. 关闭创建要素窗格。在真实项目中,您可能需要再描绘 200 或 300 个建筑物。 但是,为了使本教程尽可能简洁,您将使用我们为您准备的一组训练示例(约 200 个)。
13. 在地理处理窗格的底部,单击目录以返回至改窗格。

14. 在目录窗格中,展开数据库和 Output_provided.gdb。
15. 右键单击 Training_examples_larger_set,然后选择添加至当前地图。
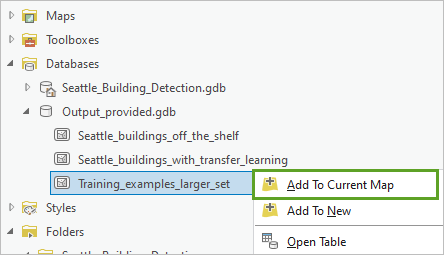
该训练样本集随即显示。
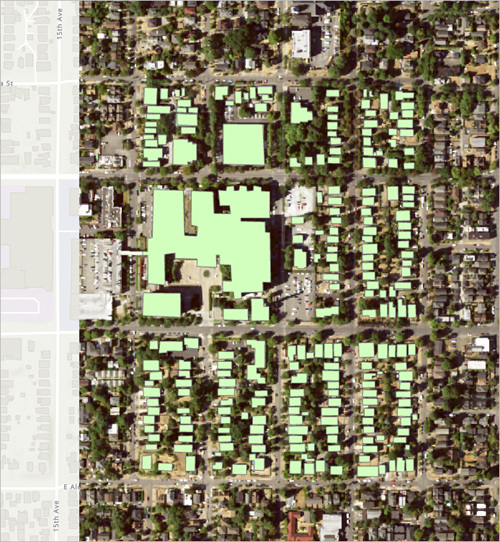
可以观察到已选择一个矩形范围,并且已为该范围内的每个建筑物创建面。 您将移除 Training_examples 图层,因为不再需要该图层。
16. 在内容窗格中,右键单击 Training_examples 图层,然后选择移除。
17. 按 Ctrl+S 以保存工程。现在,您拥有一个包含超过 200 个训练样本的图层。
2.3 添加类字段
现在,您已描绘建筑物覆盖区面,您必须将其全部指定为属于一个特定的类。 在某些工作流中,标注的对象可能属于不同的类(或类别),例如建筑物覆盖区、树木或车辆。 在本教程中,仅有一个类:建筑物覆盖区。 您将向 Training_examples_larger_set 图层添加一个 Class 字段并填充字段。
- 在内容窗格中,右键单击 Training_examples_larger_set 图层并选择属性表。
图层的属性表随即出现,其中显示各个面的相关信息。
2. 在 Training_examples_larger_set 属性表中,单击添加。
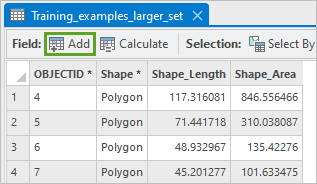
3. 在字段:Training_examples_larger_set 选项卡上,在表的最后一行输入以下信息。
-
- 对于字段名称,输入 Class。
- 对于数据类型,单击长整型,然后将其更改为短整型。
- 短整型数据类型存储整数值。
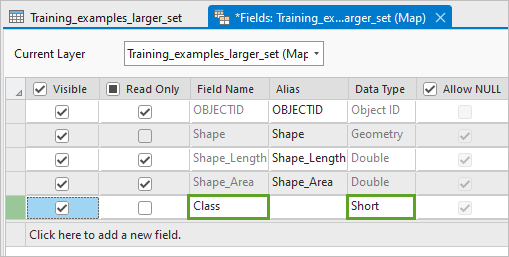
4. 在功能区字段选项卡的管理编辑内容组中,单击保存。
5. 关闭字段:Training_examples_larger_set 窗口。Class 字段已创建完成,您将使用数值填充此字段。 您随机决定使用数值 1 表示建筑物覆盖区类。
6. 在 Training_examples_larger_set 属性表中,单击计算。
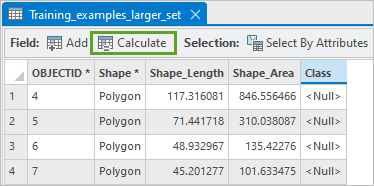
7. 在计算字段窗口中,设置以下参数值:
-
- 对于字段名称,选择 Class。
- 对于 Class =,输入 1。
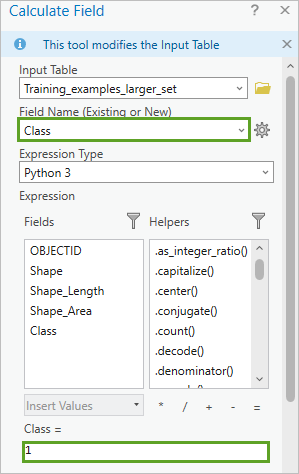
8. 接受所有其他默认值,然后单击确定。
9. 在 Class 列,验证值 1 是否已分配至每个面要素。
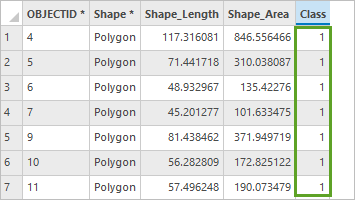
通过 Class 字段,模型将了解所有训练样本均为同一种对象:由 1 表示的建筑物覆盖区。
10. 关闭 Training_examples_larger_set 属性表。
2.4 了解有关训练片和裁剪影像的详细信息
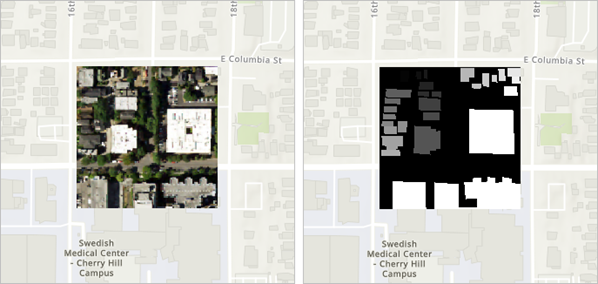
深度学习模型不能在一次运行中针对大型区域执行训练,它只能处理较小的裁切影像,即影像片。 影像片由影像切片和相应的标签切片组成,标签切片显示对象(在本例中为建筑物)的位置。 这些影像片将在迁移学习训练过程中传入模型。

图中显示了训练片,及其影像切片(左)和相应的标注切片(右)。
您将使用 Seattle_RGB.tif 影像和 Training_examples 图层来生成训练片。 有一点十分重要,即避免生成包含未标注建筑物的影像片。 这种影像片的存在等同于向模型展示建筑物,同时声明它们不是建筑物。 这会使模型困惑,进而降低其性能。 为防止此情况,您将创建一个影像片,该影像片限于训练样本所在的范围。

示例显示一个影像片,其中的一些建筑物未被标注。 必须避免使用此类影像片。
- 在目录窗格的底部,单击地理处理。
2. 在地理处理窗格中,单击后退按钮。
3. 搜索并打开裁剪栅格工具。
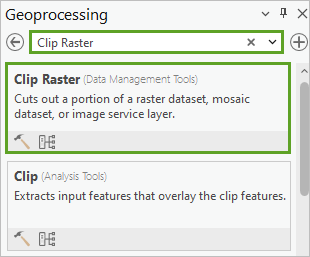
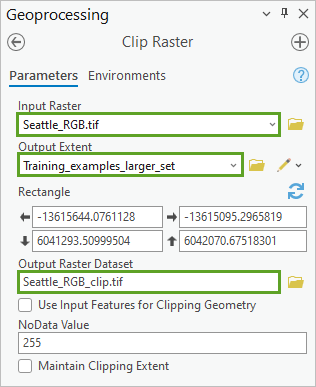
4. 设置以下裁剪栅格参数值:
-
- 对于输入栅格,选择 Seattle_RGB.tif。
- 对于输出范围,选择 Training_examples_larger_set。
- 对于输出栅格数据集,单击浏览按钮。 在输出栅格数据集窗口中,浏览至文件夹 >Seattle_Building_Detection > Imagery_data,对于名称,输入 Seattle_RGB_clip.tif,然后单击保存。
5. 单击运行。在内容窗格中,将显示 Seattle_RGB_clip.tif 图层。
6. 在内容窗格中,单击 Seattle_RGB.tif 旁边的框以关闭该图层。
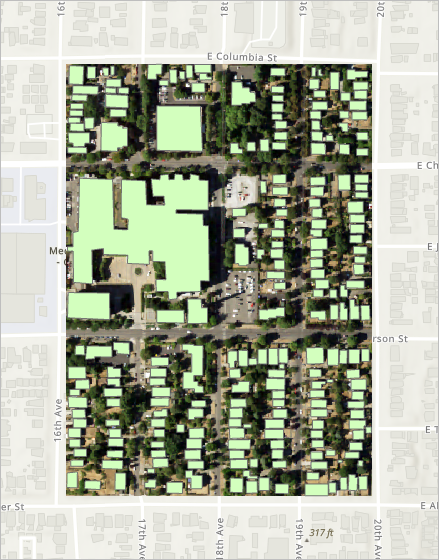
在地图上,您现在仅会看到裁剪的图层和训练样本。 影像中显示的所有建筑物都有对应的建筑物面。
2.5 生成训练片
现在,您将生成训练片。 首先,您将创建一个文件夹,以存储与迁移学习过程相关的数据元素。
- 单击目录选项卡以切换窗格。
- 如有必要,展开文件夹,然后展开 Seattle_Building_Detection。
- 右键单击 Seattle_Building_Detection,指向新建,然后选择文件夹。
4. 对于新文件夹名称,输入 Transfer_learning_data 然后按 Enter 键。
5. 单击地理处理选项卡以切换窗格。
6. 在地理处理窗格中,单击后退按钮。
7. 搜索并打开导出训练数据进行深度学习工具。
8. 为导出训练数据进行深度学习工具设置以下参数值:
-
- 对于输入栅格,选择 Seattle_RGB_clip.tif。
- 对于输出文件夹,单击浏览按钮。 在输出文件夹窗口中,浏览至文件夹 > Seattle_Building_Detection > Transfer_learning_data。 对于名称,输入 Training_chips,然后单击确定。
- 对于输入要素类,选择 Training_examples_larger_set。
从裁剪影像生成的影像片和训练数据将存储在名为 Training_chips 的文件夹中。
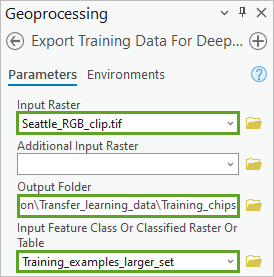
9. 对于类值字段,选择 Class。根据您之前的定义,Class 字段指定了哪些对象属于哪些标注(在本例中,所有对象均属于类 1,表示建筑物覆盖区)。
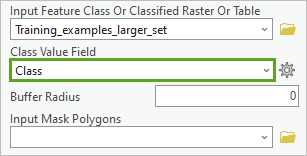
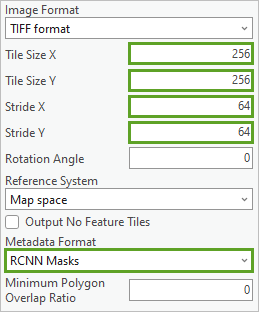
10. 对于切片大小 X 和切片大小 Y,验证值是否为 256。这些参数用于确定影像片在 X 和 Y 方向的大小(以像素为单位)。 在本例中,默认值 256 是不错的选择。
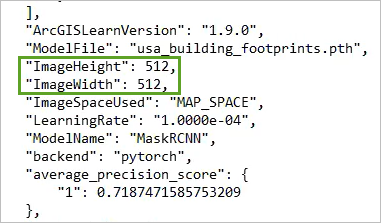
注:您希望使您的训练片与用于训练原始模型的影像片尽可能地相似。 原始模型使用 512 x 512 的影像片训练,这些影像片使用 10-40 cm 分辨率的数据生成。 您的 NAIP 影像的分辨率为 1 米。 该分辨率下 256 x 256 像素的影像片覆盖的面积大致等同于 40cm 分辨率下 512 x 512 的影像片覆盖的面积。 因此,选择 256 x 256 的影像片大小很合适。要了解预训练模型中最初使用的影像片大小,其中一种方法是查看 dlpk 包。 在 Microsoft File Explorer 中,在单独的文件夹中创建一个 usa_building_footprints.dlpk 文件的副本,然后将其扩展名从 .dlpk 更改为 .zip。 右键单击 .zip 文件并提取文件。 在提取的文件中,找到 usa_building_footprints.emd 并将其扩展名改为 .txt。 在文本编辑器中打开 usa_building_footprints.txt,然后查找行 "ImageHeight" 和 "ImageWidth"。
11. 对于步幅 X 和步幅 Y,输入 64。此参数控制创建下一个影像片时在 X 和 Y 方向上移动的距离(以像素为单位)。 此值取决于您拥有的训练数据量。 可以将此值设置得更小,从而尽可能多地生成影像片。 您可以使用此值进行试验,但在本教程中,已发现值 64 的运行效果较好。
12. 对于元数据格式,选择 RCNN 掩膜。不同的深度学习模型类型需要影像片采用不同的元数据格式。 在工作流前面的部分,您注意到预训练模型基于 MaskRCNN 架构。 在此,您必须选择该模型对应的值。
提示:要了解有关任意工具参数的详细信息,请指向该参数然后单击其旁边的信息按钮。

13. 接受所有默认值,然后单击运行。片刻之后,该过程将完成。
2.6 检查训练片
您将检查其中一些生成的影像片。
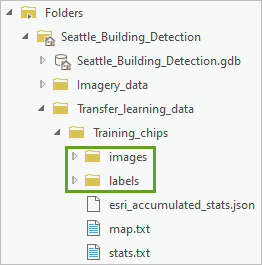
- 在目录窗格中,依次展开文件夹、Seattle_Building_Detection、Transfer_learning_data 和 Training_chips。
- 影像切片位于 images 文件夹中,而标注切片位于 labels 文件夹中。
3. 展开 images 文件夹,右键单击第一个影像 000000000000.tif,然后选择添加到当前地图。 如果系统提示您计算统计数据,单击否。
4. 在内容窗格中,关闭 Training_examples_larger_set 和 Seattle_RGB_clip.tif 以便更好地查看切片。
5. 在目录窗格中,折叠 images 文件夹,展开 labels 和 1 文件夹,然后向地图添加第一个标注切片 000000000000.tif。 如果系统提示您计算统计数据,单击否。
注:影像和标注对可以通过其一致的名称来识别。
6. 在内容窗格中,单击以打开和关闭标注切片,从而显示其下方的影像切片。
7. 单击其中一些标注切片像素,以在信息弹出窗口中查看其值。
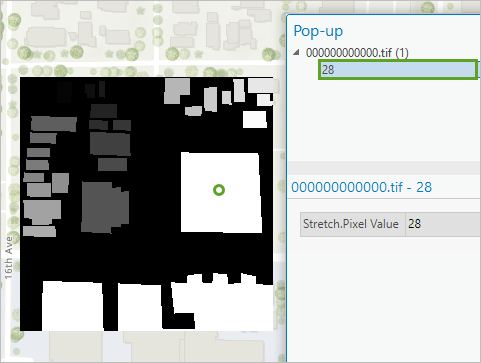
注:在标注切片上,不表示建筑物的像素的值为 0。 所有表示建筑物的像素的值均大于 0。 特殊值来自原始建筑物面的对象 ID,例如之前的示例图上的 28。
8. 可以选择性地向地图添加更多影像和标注切片对,并进行检查。
9. 完成后,从内容窗格中移除所有切片,然后再次打开 Training_examples_larger_set 和 Seattle_RGB.tif 图层。
10. 在目录窗格中,折叠 Training_chips 文件夹。
11. 按 Ctrl+S 以保存您的工程。
您已生成训练片,现在即可开始迁移学习过程。
3 执行迁移学习并提取建筑物
现在,您将执行迁移学习。 您将使用生成的影像片进一步训练 usa_building_footprints.dlpk 预训练模型。 然后,会将微调模型用于西雅图的影像并观察到现在的模型性能已显著提高。
3.1 微调模型
首先,您将使用训练深度学习模型工具对模型进行微调。
- 切换到地理处理窗格,然后单击返回按钮。
- 在地理处理窗格中,搜索并打开训练深度学习模型工具。
3. 为训练深度学习模型工具设置以下参数值:
-
- 对于输入训练数据,单击浏览按钮。 浏览至文件夹 > Seattle_Building_Detection > Transfer_learning_data。 选择 Training_chips,然后单击确定。
- 对于输出模型,单击浏览按钮。 浏览至文件夹 > Seattle_Building_Detection > Imagery_data > Transfer_learning_data。 输入 Seattle_1m_Building_Footprints_model,然后单击确定。
- 对于预训练模型,单击浏览按钮。 浏览至用于保存 usa_building_footprints.dlpk 预训练模型的文件夹,选择该文件夹,然后单击确定。
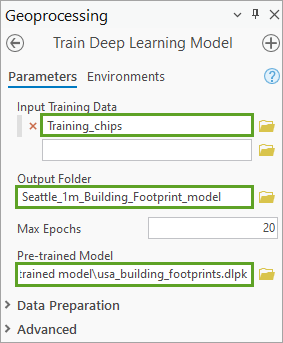
Seattle_1m_Building_Footprints_model 将是通过迁移学习过程生成的新微调模型的名称。
提示:如果将每个模型及其对应的训练片保存在同一文件夹中,则更容易记住在哪些数据上训练了哪些模型。
4. 展开高级部分并验证是否已选中冻结模型复选框。
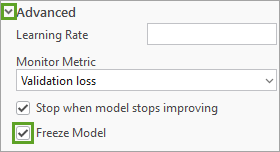
冻结模型选项可确保只有模型的最终图层会受到新训练数据的影响,而其核心图层保持不变。 在许多迁移学习案例中都需要选择此设置,因为它可以避免模型遗忘其核心知识的风险。
注:如果您在输入训练数据旁边看到错误指示符,则表示您安装的深度学习库不是正确的版本。 按 Ctrl+S 以保存您的工程,关闭 ArcGIS Pro 并按照说明安装适用于 ArcGIS 的深度学习框架。 如果您之前安装过深度学习库,请按照从先前版本进行升级下列出的说明操作。 安装完成后,您可以重新打开 ArcGIS Pro 工程,然后继续本教程。
5. 展开模型参数部分,并验证批量大小是否设置为 4。

提示:要了解有关任意工具参数的详细信息,请单击参数旁边的信息按钮。
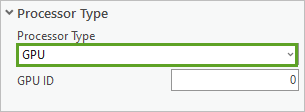
6. 在地理处理窗格中,单击环境选项卡。 对于处理器类型,选择 GPU。
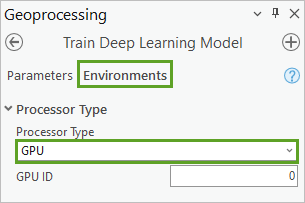
注:本教程假定您的计算机具有 GPU 功能。 如果计算机没有 GPU,您仍可使用 CPU 执行该过程,但用于处理数据的时间可能更长。 如果情况为后者,请选择 CPU 选项。
7. 接受所有默认值,然后单击运行。该过程的运行可能花费 10 分钟或更长时间。
提示:如果出现内存不足错误,可能是因为计算机没有足够的内存来一次性处理四个切片。 尝试将批量大小值从 4 减小至 2 或 1。 减小此值不会影响模型的质量,仅会影响模型训练过程的效率。
现在,您有一个增强的模型 Seattle_1m_Building_Footprints,该模型已经过微调以提高处理您的数据时的性能。
3.1 运行推断
完成迁移学习后,您将使用经过微调的模型在 Seattle_RGB.tif 影像图层上运行推断,从而检测其中包含的建筑物。
- 在地理处理窗格中,单击后退按钮。
- 搜索并打开使用深度学习检测对象工具。
3. 为使用深度学习检测对象工具设置以下参数值:
-
- 对于输入栅格,选择 Seattle_RGB.tif。
- 对于输出检测对象,输入 Seattle_buildings。
- 对于模型定义,单击浏览按钮。 浏览至 Seattle_Building_Detection 文件夹,展开 Transfer_learning_data 和 Seattle_1m_Building_Footprints_model,选择 Seattle_1m_Building_Footprints_model.dlpk,然后单击确定。
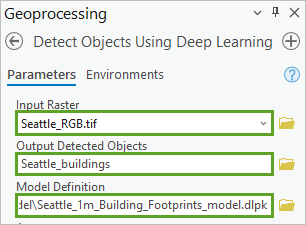
模型定义加载时,模型的参数会自动填充。
4. 对于 padding,验证值是否为 64。填充指定每个图像芯片中的边框区域,该区域将在检测期间被忽略。 如果建筑物的碎片出现在图像芯片的边缘,则填充将确保它不会被考虑进行检测。 值为 64 表示图像芯片每一侧的填充宽度为 64 像素。
注:模型将调整步幅以匹配填充的值。 随着模型向邻近区域移动,在前一个图像芯片边缘以碎片形式出现的建筑物很快就会完整地出现在下一个图像芯片的中心,并在那里被成功检测到。 在使用 ArcGIS Pro 提示和技巧进行深度学习:第 2 部分文章的了解推断参数部分中了解有关填充(和其他推断参数)的详细信息。
5. 对于 batch_size,使用在训练过程中所用的值(4 或更小值)。这将确保工具运行所用的内存不超过计算机上的可用内存量。
6. 对于 threshold,验证值是否为 0.9。这是介于 0 和 1 之间的边界值。 它表示在将对象声明为建筑物之前,模型必须达到的自信程度。 值 0.9 表示模型的置信度应为 90%。
7. 对于 tile_size,验证值是否为 256。这表示模型将用于运行推断的影像片的大小。 此值应与用于训练模型的影像片的大小相同。
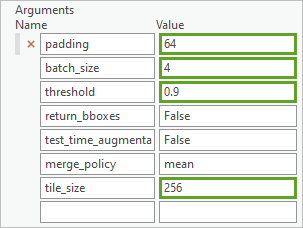
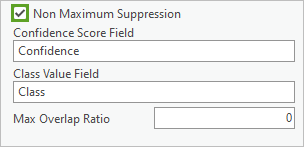
8. 对于非极大值抑制,选中该复选框。当存在重复的重叠建筑物覆盖区时,非极大值抑制选项可确保仅保留具有最高置信度的建筑物面要素,而其他要素会被删除。
9. 在地理处理窗格中,单击环境选项卡。
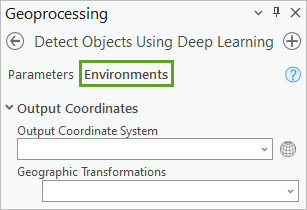
10. 对于处理器类型,选择 GPU。
此时,您可以按原样运行工具:工具将检测整个 Seattle_RGB.tif 影像中的建筑物,此过程可能花费 10 分钟到 1 小时的时间,具体取决于计算机的规格。 为使本教程尽可能简洁,您将仅检测输入影像的一小部分中的建筑物。
11. 在功能区地图选项卡的导航组中,单击书签,然后选择 Inference extent。
地图会放大到西雅图的一个较小的区域。
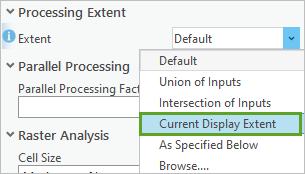
12. 在地理处理窗格环境选项卡中的处理范围下,对于范围,选择当前显示范围。
13. 单击运行。处理将在几分钟后完成,Seattle_buildings 输出图层将显示在内容窗格中和地图上。 此时,您可以看到几乎所有建筑物均被检测出来。
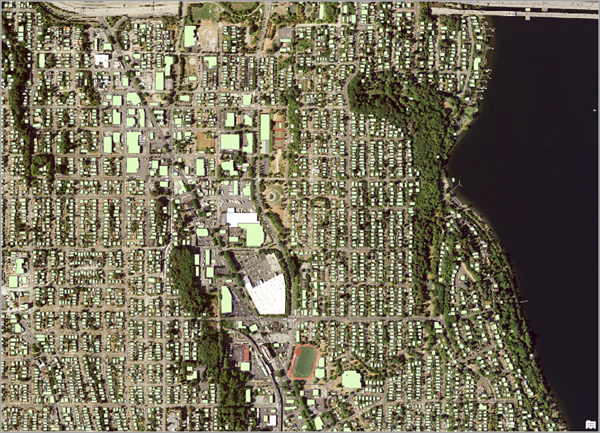
使用通过迁移学习微调的预训练模型,您已成功检测了西雅图某个区域内的建筑物。
3.3 比较结果
现在,您将对两个建筑物覆盖区图层进行比较,这两个图层分别通过运行现有预训练模型和使用迁移学习进行微调的模型获得。 在两种情况下,它们显示了整个影像范围的结果。 虽然您可以使用在先前内容中所学的方法自行生成这两个图层,但为了节省时间,您将使用教程为您准备的图层。 首先,您将打开一个包含这些图层的地图。
- 在目录窗格中,展开地图。 右键单击 Full extent results,然后选择打开。
随即显示该地图。 其中包含两个面要素类:
-
- Seattle_buildings_off_the_shelf
- Seattle_buildings_with_transfer_learning
您将使用卷帘工具比较两个图层。
2. 在内容窗格中,单击 Seattle_buildings_off_the_shelf 以将其选中。
3. 在功能区要素图层选项卡的比较组中,单击卷帘。
4. 在地图上,使用滑动控点重复地从上到下或从一侧向另一侧拖动,从而移开上方图层以显示下方图层。
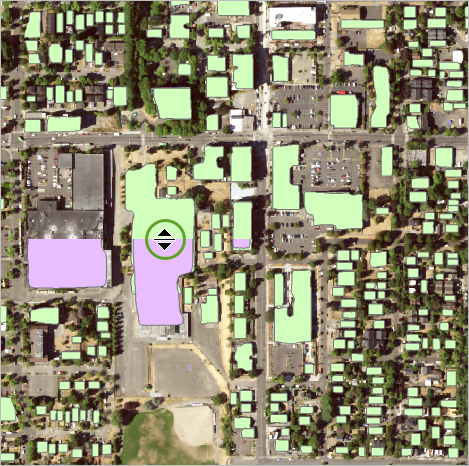
5. 进行缩放和平移以检查不同的区域,通过视觉评估结果质量的差异。
提示:在卷帘模式下,您可以使用鼠标滚轮放大和缩小视图,也可以按住键盘上的 C 键并使用鼠标拖动以进行平移。
与现有模型相比,微调模型在识别影像中较小建筑物的覆盖区时效果更好。 现在,您将使用卷帘工具对迁移学习图层中的结果和您在影像中可以观察到建筑物进行比较。
6. 在内容窗格中,关闭 Seattle_buildings_off_the_shelf 图层,然后选择Seattle_buildings_with_transfer_learning 图层。
7. 使用卷帘工具比较这两个图层。
您可能注意到,微调模型生成的图层仍不够完美,在各处均有一些缺失的建筑物。 通过迁移学习对模型进行微调往往是一个迭代过程。 您可以通过采集更多的训练示例并执行另一轮迁移学习训练来继续改善模型性能。 以下是简要概述的步骤:
-
- 首先,观察模型遗漏的建筑物类型。
- 针对此类建筑物采集新的示例面,然后生成新的训练片并将其保存到新的文件夹中。 您应该遵循在之前的操作中采用的指导原则,裁剪影像以确保影像片中不包括未标注的建筑物。
- 从现有预训练模型入手运行一个新的训练会话,为其提供到目前为止创建的所有影像片(即在输入训练数据参数中,您将列出所有影像片文件夹)。 这是确保模型平等对待所有训练片的最佳做法。
8. 在浏览完影像后,在功能区的地图选项卡中的导航组中,单击浏览按钮以退出卷帘模式。
10. 按 Ctrl+S 以保存您的工程。
在本教程中,您在 ArcGIS Pro 中使用了深度学习来提取航空影像中的建筑物覆盖区。 您从 ArcGIS Living Atlas 选择了一个预训练模型,了解了使输入数据与模型预期匹配的重要性。 您使用预期的波段数生成了新的影像图层。 然后,您应用了迁移学习以修复分辨率不匹配情况,然后微调了模型对影像的处理性能:您提供了少量新的训练样本,并进一步训练了模型。 然后,您对一个西雅图的社区应用了微调模型并获得了经过改善的结果。
相关文章:

通过迁移学习改进深度学习模型
在 ArcGIS Living Atlas of the World (Browse | ArcGIS Living Atlas of the World)中,可以下载能够分类或检测影像中要素的预训练深度学习模型。 深度学习模型在与用于训练模型的原始影像十分相似的影像上运行效果最好。 如果您所拥有的影像…...

SpringAI更新:废弃tools方法、正式支持DeepSeek!
AI 技术发展很快,同样 AI 配套的相关技术发展也很快。这不今天刚打开 Spring AI 的官网就发现它又又又又更新了,而这次更新距离上次更新 M7 版本才不过半个月的时间,那这次 Spring AI 给我们带来了哪些惊喜呢?一起来看。 重点升级…...
)
输入一个正整数,将其各位数字倒序输出(如输入123,输出321)
之前的解法: 这种方法仅支持三位数。 学了while之后,可以利用循环解决。 这种方法动态构建逆序数,支持任意长度的正整数。...

react+html2canvas+jspdf将页面导出pdf
主要使用html2canvasjspdf 1.将前端页面导出为pdf 2.处理导出后图表的截断问题 export default function AIReport() {const handleExport async () > {try {// 需要导出的内容idconst element document.querySelector(#AI-REPORT-CONTAINER);if (!element) {message.err…...

Spring Boot 自动装配技术方案书
Spring Boot 自动装配技术方案书(增强版) 一、Spring Boot 自动装配体系全景解析 1.1 核心设计理念 “约定优于配置”:通过合理的默认配置减少开发工作量“即插即用”:通过标准化扩展机制实现组件自动集成“分层解耦”:业务代码与基础设施分离,通过SPI机制实现扩展二、组…...

面试--HTML
1.src和href的区别 总结来说: <font style"color:rgb(238, 39, 70);background-color:rgb(249, 241, 219);">src</font>用于替换当前元素,指向的资源会嵌入到文档中,例如脚本、图像、框架等。<font style"co…...
python开发经验)
(3)python开发经验
文章目录 1 sender返回对象找不到函数2 获取绝对路径3 指定翻译字符 更多精彩内容👉内容导航 👈👉Qt开发 👈👉python开发 👈 1 sender返回对象找不到函数 在PySide6中多个信号绑定一个槽函数,使…...

机密虚拟机的威胁模型
本文将介绍近年兴起的机密虚拟机(Confidential Virtual Machine)技术所旨在抵御的威胁模型,主要关注内存机密性(confidentiality)和内存完整性(integrity)两个方面。在解释该威胁可能造成的问题…...
基本概念)
LLM笔记(一)基本概念
LLMs from scratch Developing an LLM: Building, Training, Finetuning LLM 的基本概念与定义: LLM是深度神经网络模型,能够理解、生成和解释类似人类的语言。“大型”指的是模型参数数量巨大以及训练数据集的规模庞大。LLM通常基于Transformer架构,并通…...
Day9)
嵌入式(c语言篇)Day9
嵌入式Day9 C语言字符串标准库函数笔记 一、概述 C语言提供了一系列字符串标准库函数用于处理字符串,使用这些函数需要包含头文件 <string.h>。主要函数包括求字符串长度、字符串复制、字符串拼接和字符串比较等。我们不仅要理解这些函数的行为,…...

006-nlohmann/json 结构转换-C++开源库108杰
绝大多数情况下,程序和外部交换的数据,都是结构化的数据。 1. 手工实现——必须掌握的基本功 在的业务类型的同一名字空间下,实现 from_json 和 to_json 两个自由函数(必要时,也可定义为类型的友元函数)&a…...

b站视频如何下载到电脑——Best Video下载器
你是不是也经常在B站刷到超赞的视频,想保存到电脑慢慢看,却发现下载不了?别急,今天教你一个超简单的方法,轻松下载B站视频到电脑,高清画质,随时随地想看就看! 为什么需要下载B站视频…...

【行为型之模板方法模式】游戏开发实战——Unity标准化流程与可扩展架构的核心实现
文章目录 🧩 模板方法模式(Template Method Pattern)深度解析一、模式本质与核心价值二、经典UML结构三、Unity实战代码(关卡流程系统)1. 定义抽象模板类2. 实现具体子类3. 客户端使用 四、模式进阶技巧1. 钩子方法&am…...

每日算法-250514
每日算法学习记录 (2024-05-14) 今天记录三道 LeetCode 算法题的解题思路和代码。 1. 两数之和 题目截图: 解题思路 这道题要求我们从一个整数数组中找出两个数,使它们的和等于一个给定的目标值 target,并返回这两个数的下标。 核心思路是使用 哈希…...

信息安全入门基础知识
信息安全是保护信息系统和数据免受未经授权的访问、使用、披露、中断、修改或破坏的实践。对于个人和组织来说,了解信息安全的基础知识至关重要。 1. CIA三元组 信息安全的三个主要目标,也称为CIA三元组: 机密性(Confidentiality): 确保信息不被未经授权的人访问或披露完整性…...

力扣-98.验证二叉搜索树
题目描述 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 class Solutio…...

Java 框架配置自动化:告别冗长的 XML 与 YAML 文件
在 Java 开发领域,框架的使用极大地提升了开发效率和系统的稳定性。然而,传统框架配置中冗长的 XML 与 YAML 文件,却成为开发者的一大困扰。这些配置文件不仅书写繁琐,容易出现语法错误,而且在项目规模扩大时ÿ…...

大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案
大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案 大疆无人机是低空行业无人机最具性价比的产品,尤其是大疆机场3的推出,以及持续自身产品升级迭代,包括司空2、大疆智图以及大疆智运等专业软件和…...

【机器人】复现 SG-Nav 具身导航 | 零样本对象导航的 在线3D场景图提示
SG-Nav提出了一种新的零样本物体导航框架,用三维场景图来表示观察到的场景。 并设计了一个分层的思路链提示,帮助LLM通过遍历节点和边,根据场景上下文推理目标位置。 本文分享SG-Nav复现和模型推理的过程~ 下面是一个查找椅子示…...

详细说说Spring的IOC机制
Spring 的 IOC(控制反转)是框架的核心机制,用于管理对象的创建和依赖注入,通过将控制权从应用程序代码转移到容器,实现组件间的解耦。以下是详细解析: 1. IOC 核心概念 控制反转(Inversion of C…...

Android Activity之间跳转的原理
一、Activity跳转核心流程 Android Activity跳转的底层实现涉及 系统服务交互、进程间通信(IPC) 和 生命周期管理,主要流程如下: startActivity() 触发请求 应用调用 startActivity() 时,通过 Inst…...

第二个五年计划!
下一阶段!5年后!33岁!体重维持在125斤内!腰围74! 健康目标: 体检指标正常,结节保持较小甚至变小! 工作目标: 每年至少在一次考评里拿A(最高S,A我理…...

交易所功能设计的核心架构与创新实践
交易所功能设计的核心架构与创新实践 ——从用户体验到安全合规的全维度解析 一、核心功能模块:构建交易生态的四大支柱 1. 用户账户管理 多因子身份验证:集成邮箱/手机注册、谷歌验证器(2FA)、活体检测(误识率<0…...

Windows10安装WSA
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、WSAOnWin10二、安装1.第一种方法2.第二种方法 总结 前言 有时候工作需要用到WSA,然而我们的电脑是Windows10的不能直接安装。接下来我就教你们…...
)
标签部件(lv_label)
一、如何创建标签部件以及设置文本? 知识点1:如何创建标签部件 lv_obj_t *label lv_label_create(parent); 知识点2:设置文本的3种方式 ①直接设置文本,存储文本的内存动态分配:lv_label_set_text(label,"he…...

Spring中的循环引用
循环依赖发生在两个或两个以上的bean互相持有对方,形成闭环。Spring框架允许循环依赖存在,并通过三级缓存解决大部分循环依赖问题: 一级缓存:单例池,缓存已完成初始化的bean对象。 二级缓存:缓存尚未完成生…...

技术选型不当,如何避免影响项目进展
建立选型评估机制、综合考虑业务与技术匹配度、引入技术决策审查流程、做好选型后的风险预案与替代方案准备 是避免因技术选型不当影响项目进展的关键措施。尤其要重视建立选型评估机制,通过全流程、数据化、多维度的评估体系,确保所选技术能在性能、可维…...

图表制作-基础饼图
首先登录自己的账号,没有账号的可以注册一个。 登录之后,在左侧菜单栏找到图表制作-统计图。 点击新建统计图,点击饼图-基础饼图。 初始会有一些演示数据,可以根据自己的需要进行修改。 如果嫌手动修改太麻烦,可以导入…...
)
Java 大视界 -- 基于 Java 的大数据分布式存储在工业互联网海量设备数据长期存储中的应用优化(248)
往期文章推荐: 《大数据新视界》和《 Java 大视界》专栏: Java 大视界 – Java 大数据在智能教育自适应学习路径动态调整中的应用与实践(247)(最新)Java 大视界 – Java 大数据在智能安防生物特征识别系统中的多模态…...
)
如何恢复被勒索软件加密的服务器文件(解密与备份策略)
针对勒索软件加密文件的恢复和解密策略,结合当前数据安全最佳实践,整理应对指南如下: 一、文件解密与修复方法 立即隔离设备 断开网络连接并禁用共享功能,防止病毒横向传播 通过文件后缀异常(如.locked、.wxx&…...

Java知识框架
一、Java 基础语法 1. 基础语法 数据类型 基本类型:int, double, boolean, char 等 引用类型:String, 数组, 对象 变量与常量 final 关键字 作用域(局部变量、成员变量) 运算符 算术、逻辑、位运算 三元运算符 ? : 控制…...

腾讯云-人脸核身+人脸识别教程
一。产品概述 慧眼人脸核身特惠活动 腾讯云慧眼人脸核身是一组对用户身份信息真实性进行验证审核的服务套件,提供人脸核身、身份信息核验、银行卡要素核验和运营商类要素核验等各类实名信息认证能力,以解决行业内大量对用户身份信息真实性核实的需求&a…...

102. 二叉树的层序遍历递归法:深度优先搜索的巧妙应用
二叉树的层序遍历是一种经典的遍历方式,它要求按层级逐层访问二叉树的节点。通常我们会使用队列来实现层序遍历,但递归法也是一种可行且有趣的思路。本文将深入探讨递归法解决二叉树层序遍历的核心难点,并结合代码和模拟过程进行详细讲解。 …...

电脑内存智能监控清理,优化性能的实用软件
软件介绍 Memory cleaner是一款内存清理软件。功能很强,效果很不错。 Memory cleaner会在内存用量超出80%时,自动执行“裁剪进程工作集”“清理系统缓存”以及“用全部可能的方法清理内存”等操作,以此来优化电脑性能。 同时,我…...

Chrome浏览器实验性API computePressure的隐私保护机制如何绕过?
一、computePressure API 设计原理与隐私保护机制 1.1 API 设计目标 computePressure是W3C提出的系统状态监控API,旨在: • 提供系统资源状态的抽象指标(非精确值) • 防止通过高精度时序攻击获取用户指纹 • 平衡开发者需求与用户隐私保护 1.2 隐私保护实现方式 // 典…...

开放传神创始人论道AI未来|“广发证券—国信中数人工智能赛道专家交流论坛“落幕
4月25日,“广发证券—国信中数人工智能赛道专家交流论坛”在广发证券大厦成功举办。本次论坛由广发证券股份有限公司与北京国信中数投资管理有限公司联合主办,汇聚了人工智能领域的50多位企业、行业专家、专业投资机构的精英代表,旨在搭建产学…...
)
MySQL八股(自用)
MySQL 定位慢查询 1.聚合查询 2.多表查询 3.表数据量过大查询 4.深度分页查询 MySQL自带慢日志 开启慢查询日志,配置文件(/etc/my.cnf) 开启慢日志,设置慢日志的时间 用EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信…...

2025年6月一区SCI-不实野燕麦优化算法Animated Oat Optimization-附Matlab免费代码
引言 近年来,在合理框架内求解优化问题的元启发式算法的发展引起了全球科学界的极大关注。本期介绍一种新的元启发式算法——不实野燕麦优化算法Animated Oat Optimization algorithm,AOO。该算法模拟了不实野燕麦的3种独特行为,于2025年6月…...

如何开发一款 Chrome 浏览器插件
Chrome是由谷歌开发的网页浏览器,基于开源软件(包括WebKit和Mozilla)开发,任何人都可以根据自己需要使用、修改或增强它的功能。Chrome凭借着其优秀的性能、出色的兼容性以及丰富的扩展程序,赢得了广大用户的信任。市场…...

UniApp 微信小程序绑定动态样式 :style 避坑指南
在使用 UniApp 开发跨端应用时,绑定动态样式 :style 是非常常见的操作。然而,很多开发者在编译为 微信小程序 时会遇到一个奇怪的问题: 原本在 H5 中可以正常渲染的样式,在微信小程序中却不生效! 让我们通过一个示例来…...

基于OpenCV中的图像拼接方法详解
文章目录 引言一、图像拼接的基本流程二、代码实现详解1. 准备工作2. 特征检测与描述detectAndDescribe 函数详解(1)函数功能(2)代码解析(3)为什么需要这个函数?(4)输出数…...

【BUG】滴答定时器的时间片轮询与延时冲突
SysTick定时器实现延时与时间戳的深度分析与问题解决指南 1. SysTick基础原理 1.1 SysTick的功能与核心配置 SysTick是ARM Cortex-M内核的系统定时器,常用于以下场景: 时间戳:通过周期性中断记录系统运行时间(如tick_ms计数器&…...

基于EFISH-SCB-RK3576/SAIL-RK3576的智能快递分拣机技术方案
(国产化替代J1900的物流自动化解决方案) 一、硬件架构设计 高速视觉识别系统 多目立体成像: 双MIPI-CSI接入16K线阵相机(扫描速度5m/s),支持0.1mm级条形码破损识别NPU加速YOLOv7算法࿰…...
题解)
The 2022 ICPC Asia Xian Regional Contest(E,L)题解
E Find Maximum 题意: 首先,通过观察与打表,可以发现: 规律: 对于非负整数 x,函数 f(x) 的值等于: 将 xx 写成三进制后,各个位数的数字之和 该三进制数的位数。 例如,…...

Jmeter 安装包与界面汉化
Jmeter 安装包: 通过网盘分享的文件:CSDN-apache-jmeter-5.5 链接: https://pan.baidu.com/s/17gK98NxS19oKmkdRhGepBA?pwd1234 提取码: 1234 Jmeter界面汉化:...
《Python星球日记》 第70天:Seq2Seq 与Transformer Decoder
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、Seq2Seq模型基础1. 什么是Seq2Seq模型?2. Encoder-Decoder架构详解1️⃣编码器(Encoder)2️⃣解码器(Decoder)3. 传统Seq2Seq模型的局限性…...
)
【Linux】基础指令(Ⅱ)
目录 1. mv指令 2. cat指令 3.echo指令 补:输出重定向 4. more指令 5. less指令 6. head指令和tail指令 7.date指令 时间戳: 8. cal指令 9. alias指令 10.grep指令 1. mv指令 语法:mv [选项]... 源文件/目录 目标文件/目录 …...

【Python3教程】Python3基础篇之输入与输出
博主介绍:✌全网粉丝23W+,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物联网、机器学习等设计与开发。 感兴趣的可…...

mysql的一个缺点
最近再移植一个从oracle转mysql的项目,喜提一个报错: You cant specify target table A016 for update in FROM clause 对应的程序代码: public void setCurrent(String setId, String pk, String userId) throws SysException {String[]…...

【C/C++】高阶用法_笔记
1. 模板元编程(TMP)与编译时计算 (1) 类型萃取与 SFINAE 类型萃取(Type Traits):利用模板特化在编译时推断类型属性。 template<typename T> struct is_pointer { static constexpr bool value false; };templ…...