LLM笔记(一)基本概念
LLMs from scratch
Developing an LLM: Building, Training, Finetuning
-
LLM 的基本概念与定义:
- LLM是深度神经网络模型,能够理解、生成和解释类似人类的语言。
- “大型”指的是模型参数数量巨大以及训练数据集的规模庞大。
- LLM通常基于Transformer架构,并通过在海量文本数据上进行下一词预测的任务进行训练。
- LLM是生成式人工智能 (Generative AI / GenAI) 的一种形式,处于人工智能 (AI) > 机器学习 (Machine Learning) > 深度学习 (Deep Learning) > LLM 的层级关系中。
-
LLM 的核心能力与学习范式 :
- 文本补全为核心,展现通用性: GPT模型虽然主要设计用于执行文本补全任务,但其能力展现出了非凡的通用性。
- 零样本与少样本学习: 这些模型擅长执行零样本学习 (zero-shot learning)(在没有任何先验特定示例的情况下,对完全陌生的任务进行泛化的能力)和少样本学习 (few-shot learning)(从用户提供的极少示例中进行学习)。
- 涌现行为 (Emergent Behavior): 模型执行其未经过专门训练的任务的能力被称为涌现行为。这种能力并非在训练过程中被明确教授,而是模型在各种不同情境下接触大量多语言数据后自然产生的结果。GPT模型能够“学习”语言之间的翻译模式并执行翻译任务,尽管它们并未针对翻译进行专门训练,这一事实彰显了这些大规模生成式语言模型的优势与能力。我们无需为每种任务使用不同的模型,就能执行各种各样的任务。
-
LLM 的应用:
- 应用广泛,包括机器翻译、文本生成(小说、代码)、情感分析、文本摘要、聊天机器人(如ChatGPT, Gemini)、知识检索等。
- 核心能力在于解析和生成文本。
-
构建、训练和应用LLM的阶段 (Phases of Building, Training, and Applying LLMs):
-
LLM的开发和应用通常遵循一个多阶段的过程,从基础构建到专业化应用。
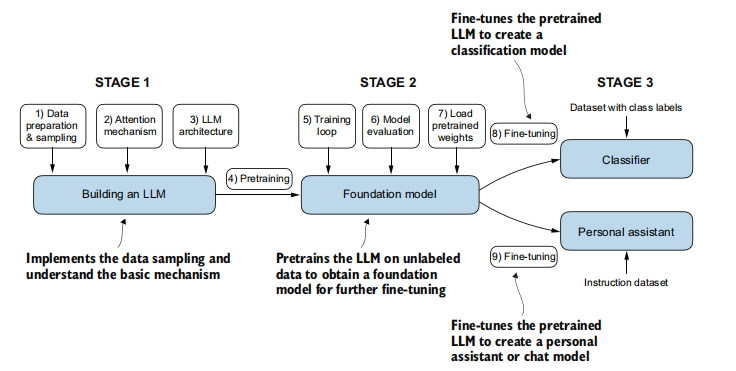
-
第一阶段:构建LLM与预训练 (Phase 1: Building the LLM and Pretraining)
- 这个阶段专注于实现数据采样技术并理解LLM开发的基本机制,最终目标是形成一个基础模型 (foundation model)。
- 数据准备与采样 (Data Preparation and Sampling): (详见第7点) 为预训练准备大规模、多样化的文本数据集。
- LLM架构设计 (LLM Architecture Design): (详见第1, 5, 8点) 选择或设计合适的模型架构,通常基于Transformer。
- 理解核心机制 (Understanding Core Mechanisms):
- 注意力机制 (Attention Mechanism): (详见第5点) 理解并实现如自注意力这样的核心组件。
- 预训练 (Pretraining): 在大规模、多样化的未标记文本数据上训练模型,使其获得对语言的广泛理解。预训练通常非常昂贵,需要大量的计算资源(如GPU/TPU)。
- 训练循环 (Training Loop): 实现并优化模型训练的迭代过程。
-
第二阶段:基础模型的评估与微调 (Phase 2: Foundation Model Evaluation and Fine-tuning)
- 这个阶段涉及在无标签数据上预训练LLM后,对形成的基础模型进行评估,并根据特定需求进行进一步的调整和优化。
- 加载预训练权重 (Loading Pretrained Weights): 可以加载已有的预训练模型权重作为起点,以节省资源和时间。
- 模型评估 (Model Evaluation): 对预训练的基础模型在标准基准测试集或特定任务上进行性能评估,以了解其通用能力和潜在瓶颈。
- 微调 (Fine-tuning): 在一个更小、针对特定任务或领域的已标记数据集上进一步训练预训练好的模型。
-
第三阶段:专业应用 (Phase 3: Specialized Applications)
- 基础模型可以通过不同方向的微调进行特化,以适应具体的应用场景:
- 分类微调 (Classification Fine-tuning): 使用包含类别标签的数据集进行微调,创建专门的分类器(例如,垃圾邮件分类、情感分析)。
- 指令微调 (Instruction Fine-tuning): 使用包含指令和对应输出的数据集进行微调,创建能够理解并执行用户指令的个人助手或聊天模型(例如,进行问答、按要求翻译、生成特定风格的文本)。
- 基础模型可以通过不同方向的微调进行特化,以适应具体的应用场景:
-
构建自定义LLM的优势:
- 针对特定领域或专有数据可能表现更好。
- 更好地控制数据隐私和安全。
- 可根据需求进行本地部署,降低对外部服务的依赖。
- 能够更灵活地调整模型架构和训练过程以满足特定需求。
-
-
Transformer 架构简介与LLM的关系 :
- 现代LLM大多依赖于2017年提出的Transformer架构。因此,“Transformer”和“大语言模型”这两个术语在文献中常被互换使用。
- 重要区分 :
- 并非所有Transformer都是大语言模型,因为Transformer也可用于计算机视觉等其他领域。
- 同样,并非所有大语言模型都基于Transformer,因为也有基于循环 (recurrent) 和卷积 (convolutional) 架构的大语言模型。这些替代方法背后的主要动机是提高大语言模型的计算效率。这些替代的大语言模型架构能否与基于Transformer的大语言模型的能力相媲美,以及它们是否会在实际中被采用,仍有待观察。
- 为简单起见,本书中使用的“大语言模型”一词特指类似于GPT的基于Transformer的大语言模型。(感兴趣的读者可在附录B中找到描述这些架构的文献参考。)
- 原始Transformer架构包含编码器 (Encoder)(处理输入文本)和解码器 (Decoder)(生成输出文本)两个子模块。
- 核心是自注意力机制 (Self-attention mechanism),允许模型在处理序列时权衡不同部分的重要性,有效捕捉长距离依赖关系。
- BERT等模型主要利用编码器部分,适用于文本分类、命名实体识别等理解型任务。
- GPT等模型主要利用解码器部分,擅长文本生成、对话等生成型任务。
-
嵌入 (Embeddings) 的概念与重要性:
- 本质: 从本质上讲,嵌入是一种从离散对象(如单词、图像甚至整个文档)到连续向量空间中的点的映射。这些向量表示旨在捕捉对象的语义关系。
- 目的: 嵌入的主要目的是将非数字数据(如文本)转换为神经网络可以有效处理和学习的数值格式。
- 类型与应用: 虽然词嵌入是最常见的文本嵌入形式,但也存在用于句子、段落或整个文档的嵌入。句子或段落嵌入是检索增强生成 (Retrieval Augmented Generation, RAG) 的常用选择。检索增强生成将生成(如生成文本)与检索(如搜索外部知识库)相结合,以便在生成文本时提取相关信息,这是一种超出本书范围的技术。由于本书的目标是训练类似GPT的大语言模型,这些模型学习一次生成一个单词,因此将专注于词嵌入。
- 维度: 词嵌入可以有不同的维度,从几十维到数千维不等。更高的维度可能会捕捉到更细微的语义关系和上下文信息,但代价是计算复杂度的增加和所需训练数据的增多。
-
大型数据集的应用与数据准备:
- LLM的强大能力得益于其在包含数十亿甚至数万亿词语的庞大数据集(如CommonCrawl, WebText2, Books, Wikipedia等公开数据集,以及可能的专有数据集)上的训练。
- 数据准备是预训练阶段的关键步骤,包括:
- 数据收集: 从多种来源获取海量文本数据。
- 数据清洗: 去除噪声、重复内容、格式转换等。
- 数据过滤: 筛选高质量、相关的文本。
- 分词 (Tokenization): 将文本切分成模型可以处理的单元(如单词、子词)。
- 数据采样 (Data Sampling): 从大规模数据集中选择合适的子集进行训练,或者在混合不同来源数据时调整其比例,以确保数据的多样性和代表性。
- 这些数据使得模型能够学习语言的句法规则、语义含义、上下文关联,甚至一定程度的常识和世界知识。
-
GPT 架构的特点:
- GPT (Generative Pre-trained Transformer) 模型通常是仅解码器 (decoder-only) 的Transformer架构,这使得其结构相比于包含编码器和解码器的完整Transformer更为简洁,特别适合生成任务。
- 它们是自回归模型 (autoregressive model),即逐个词元 (token) 地生成文本。在生成每个新词元时,模型会将先前所有已生成的词元作为上下文输入,来预测下一个最可能的词元。
相关文章:
基本概念)
LLM笔记(一)基本概念
LLMs from scratch Developing an LLM: Building, Training, Finetuning LLM 的基本概念与定义: LLM是深度神经网络模型,能够理解、生成和解释类似人类的语言。“大型”指的是模型参数数量巨大以及训练数据集的规模庞大。LLM通常基于Transformer架构,并通…...
Day9)
嵌入式(c语言篇)Day9
嵌入式Day9 C语言字符串标准库函数笔记 一、概述 C语言提供了一系列字符串标准库函数用于处理字符串,使用这些函数需要包含头文件 <string.h>。主要函数包括求字符串长度、字符串复制、字符串拼接和字符串比较等。我们不仅要理解这些函数的行为,…...

006-nlohmann/json 结构转换-C++开源库108杰
绝大多数情况下,程序和外部交换的数据,都是结构化的数据。 1. 手工实现——必须掌握的基本功 在的业务类型的同一名字空间下,实现 from_json 和 to_json 两个自由函数(必要时,也可定义为类型的友元函数)&a…...

b站视频如何下载到电脑——Best Video下载器
你是不是也经常在B站刷到超赞的视频,想保存到电脑慢慢看,却发现下载不了?别急,今天教你一个超简单的方法,轻松下载B站视频到电脑,高清画质,随时随地想看就看! 为什么需要下载B站视频…...

【行为型之模板方法模式】游戏开发实战——Unity标准化流程与可扩展架构的核心实现
文章目录 🧩 模板方法模式(Template Method Pattern)深度解析一、模式本质与核心价值二、经典UML结构三、Unity实战代码(关卡流程系统)1. 定义抽象模板类2. 实现具体子类3. 客户端使用 四、模式进阶技巧1. 钩子方法&am…...

每日算法-250514
每日算法学习记录 (2024-05-14) 今天记录三道 LeetCode 算法题的解题思路和代码。 1. 两数之和 题目截图: 解题思路 这道题要求我们从一个整数数组中找出两个数,使它们的和等于一个给定的目标值 target,并返回这两个数的下标。 核心思路是使用 哈希…...

信息安全入门基础知识
信息安全是保护信息系统和数据免受未经授权的访问、使用、披露、中断、修改或破坏的实践。对于个人和组织来说,了解信息安全的基础知识至关重要。 1. CIA三元组 信息安全的三个主要目标,也称为CIA三元组: 机密性(Confidentiality): 确保信息不被未经授权的人访问或披露完整性…...

力扣-98.验证二叉搜索树
题目描述 给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。 有效 二叉搜索树定义如下: 节点的左子树只包含 小于 当前节点的数。节点的右子树只包含 大于 当前节点的数。所有左子树和右子树自身必须也是二叉搜索树。 class Solutio…...

Java 框架配置自动化:告别冗长的 XML 与 YAML 文件
在 Java 开发领域,框架的使用极大地提升了开发效率和系统的稳定性。然而,传统框架配置中冗长的 XML 与 YAML 文件,却成为开发者的一大困扰。这些配置文件不仅书写繁琐,容易出现语法错误,而且在项目规模扩大时ÿ…...

大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案
大疆无人机自主飞行解决方案局限性及增强解决方案-AIBOX:特色行业无人机巡检解决方案 大疆无人机是低空行业无人机最具性价比的产品,尤其是大疆机场3的推出,以及持续自身产品升级迭代,包括司空2、大疆智图以及大疆智运等专业软件和…...

【机器人】复现 SG-Nav 具身导航 | 零样本对象导航的 在线3D场景图提示
SG-Nav提出了一种新的零样本物体导航框架,用三维场景图来表示观察到的场景。 并设计了一个分层的思路链提示,帮助LLM通过遍历节点和边,根据场景上下文推理目标位置。 本文分享SG-Nav复现和模型推理的过程~ 下面是一个查找椅子示…...

详细说说Spring的IOC机制
Spring 的 IOC(控制反转)是框架的核心机制,用于管理对象的创建和依赖注入,通过将控制权从应用程序代码转移到容器,实现组件间的解耦。以下是详细解析: 1. IOC 核心概念 控制反转(Inversion of C…...

Android Activity之间跳转的原理
一、Activity跳转核心流程 Android Activity跳转的底层实现涉及 系统服务交互、进程间通信(IPC) 和 生命周期管理,主要流程如下: startActivity() 触发请求 应用调用 startActivity() 时,通过 Inst…...

第二个五年计划!
下一阶段!5年后!33岁!体重维持在125斤内!腰围74! 健康目标: 体检指标正常,结节保持较小甚至变小! 工作目标: 每年至少在一次考评里拿A(最高S,A我理…...

交易所功能设计的核心架构与创新实践
交易所功能设计的核心架构与创新实践 ——从用户体验到安全合规的全维度解析 一、核心功能模块:构建交易生态的四大支柱 1. 用户账户管理 多因子身份验证:集成邮箱/手机注册、谷歌验证器(2FA)、活体检测(误识率<0…...

Windows10安装WSA
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、WSAOnWin10二、安装1.第一种方法2.第二种方法 总结 前言 有时候工作需要用到WSA,然而我们的电脑是Windows10的不能直接安装。接下来我就教你们…...
)
标签部件(lv_label)
一、如何创建标签部件以及设置文本? 知识点1:如何创建标签部件 lv_obj_t *label lv_label_create(parent); 知识点2:设置文本的3种方式 ①直接设置文本,存储文本的内存动态分配:lv_label_set_text(label,"he…...

Spring中的循环引用
循环依赖发生在两个或两个以上的bean互相持有对方,形成闭环。Spring框架允许循环依赖存在,并通过三级缓存解决大部分循环依赖问题: 一级缓存:单例池,缓存已完成初始化的bean对象。 二级缓存:缓存尚未完成生…...

技术选型不当,如何避免影响项目进展
建立选型评估机制、综合考虑业务与技术匹配度、引入技术决策审查流程、做好选型后的风险预案与替代方案准备 是避免因技术选型不当影响项目进展的关键措施。尤其要重视建立选型评估机制,通过全流程、数据化、多维度的评估体系,确保所选技术能在性能、可维…...

图表制作-基础饼图
首先登录自己的账号,没有账号的可以注册一个。 登录之后,在左侧菜单栏找到图表制作-统计图。 点击新建统计图,点击饼图-基础饼图。 初始会有一些演示数据,可以根据自己的需要进行修改。 如果嫌手动修改太麻烦,可以导入…...
)
Java 大视界 -- 基于 Java 的大数据分布式存储在工业互联网海量设备数据长期存储中的应用优化(248)
往期文章推荐: 《大数据新视界》和《 Java 大视界》专栏: Java 大视界 – Java 大数据在智能教育自适应学习路径动态调整中的应用与实践(247)(最新)Java 大视界 – Java 大数据在智能安防生物特征识别系统中的多模态…...
)
如何恢复被勒索软件加密的服务器文件(解密与备份策略)
针对勒索软件加密文件的恢复和解密策略,结合当前数据安全最佳实践,整理应对指南如下: 一、文件解密与修复方法 立即隔离设备 断开网络连接并禁用共享功能,防止病毒横向传播 通过文件后缀异常(如.locked、.wxx&…...

Java知识框架
一、Java 基础语法 1. 基础语法 数据类型 基本类型:int, double, boolean, char 等 引用类型:String, 数组, 对象 变量与常量 final 关键字 作用域(局部变量、成员变量) 运算符 算术、逻辑、位运算 三元运算符 ? : 控制…...

腾讯云-人脸核身+人脸识别教程
一。产品概述 慧眼人脸核身特惠活动 腾讯云慧眼人脸核身是一组对用户身份信息真实性进行验证审核的服务套件,提供人脸核身、身份信息核验、银行卡要素核验和运营商类要素核验等各类实名信息认证能力,以解决行业内大量对用户身份信息真实性核实的需求&a…...

102. 二叉树的层序遍历递归法:深度优先搜索的巧妙应用
二叉树的层序遍历是一种经典的遍历方式,它要求按层级逐层访问二叉树的节点。通常我们会使用队列来实现层序遍历,但递归法也是一种可行且有趣的思路。本文将深入探讨递归法解决二叉树层序遍历的核心难点,并结合代码和模拟过程进行详细讲解。 …...

电脑内存智能监控清理,优化性能的实用软件
软件介绍 Memory cleaner是一款内存清理软件。功能很强,效果很不错。 Memory cleaner会在内存用量超出80%时,自动执行“裁剪进程工作集”“清理系统缓存”以及“用全部可能的方法清理内存”等操作,以此来优化电脑性能。 同时,我…...

Chrome浏览器实验性API computePressure的隐私保护机制如何绕过?
一、computePressure API 设计原理与隐私保护机制 1.1 API 设计目标 computePressure是W3C提出的系统状态监控API,旨在: • 提供系统资源状态的抽象指标(非精确值) • 防止通过高精度时序攻击获取用户指纹 • 平衡开发者需求与用户隐私保护 1.2 隐私保护实现方式 // 典…...

开放传神创始人论道AI未来|“广发证券—国信中数人工智能赛道专家交流论坛“落幕
4月25日,“广发证券—国信中数人工智能赛道专家交流论坛”在广发证券大厦成功举办。本次论坛由广发证券股份有限公司与北京国信中数投资管理有限公司联合主办,汇聚了人工智能领域的50多位企业、行业专家、专业投资机构的精英代表,旨在搭建产学…...
)
MySQL八股(自用)
MySQL 定位慢查询 1.聚合查询 2.多表查询 3.表数据量过大查询 4.深度分页查询 MySQL自带慢日志 开启慢查询日志,配置文件(/etc/my.cnf) 开启慢日志,设置慢日志的时间 用EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信…...

2025年6月一区SCI-不实野燕麦优化算法Animated Oat Optimization-附Matlab免费代码
引言 近年来,在合理框架内求解优化问题的元启发式算法的发展引起了全球科学界的极大关注。本期介绍一种新的元启发式算法——不实野燕麦优化算法Animated Oat Optimization algorithm,AOO。该算法模拟了不实野燕麦的3种独特行为,于2025年6月…...

如何开发一款 Chrome 浏览器插件
Chrome是由谷歌开发的网页浏览器,基于开源软件(包括WebKit和Mozilla)开发,任何人都可以根据自己需要使用、修改或增强它的功能。Chrome凭借着其优秀的性能、出色的兼容性以及丰富的扩展程序,赢得了广大用户的信任。市场…...

UniApp 微信小程序绑定动态样式 :style 避坑指南
在使用 UniApp 开发跨端应用时,绑定动态样式 :style 是非常常见的操作。然而,很多开发者在编译为 微信小程序 时会遇到一个奇怪的问题: 原本在 H5 中可以正常渲染的样式,在微信小程序中却不生效! 让我们通过一个示例来…...

基于OpenCV中的图像拼接方法详解
文章目录 引言一、图像拼接的基本流程二、代码实现详解1. 准备工作2. 特征检测与描述detectAndDescribe 函数详解(1)函数功能(2)代码解析(3)为什么需要这个函数?(4)输出数…...

【BUG】滴答定时器的时间片轮询与延时冲突
SysTick定时器实现延时与时间戳的深度分析与问题解决指南 1. SysTick基础原理 1.1 SysTick的功能与核心配置 SysTick是ARM Cortex-M内核的系统定时器,常用于以下场景: 时间戳:通过周期性中断记录系统运行时间(如tick_ms计数器&…...

基于EFISH-SCB-RK3576/SAIL-RK3576的智能快递分拣机技术方案
(国产化替代J1900的物流自动化解决方案) 一、硬件架构设计 高速视觉识别系统 多目立体成像: 双MIPI-CSI接入16K线阵相机(扫描速度5m/s),支持0.1mm级条形码破损识别NPU加速YOLOv7算法࿰…...
题解)
The 2022 ICPC Asia Xian Regional Contest(E,L)题解
E Find Maximum 题意: 首先,通过观察与打表,可以发现: 规律: 对于非负整数 x,函数 f(x) 的值等于: 将 xx 写成三进制后,各个位数的数字之和 该三进制数的位数。 例如,…...

Jmeter 安装包与界面汉化
Jmeter 安装包: 通过网盘分享的文件:CSDN-apache-jmeter-5.5 链接: https://pan.baidu.com/s/17gK98NxS19oKmkdRhGepBA?pwd1234 提取码: 1234 Jmeter界面汉化:...
《Python星球日记》 第70天:Seq2Seq 与Transformer Decoder
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、Seq2Seq模型基础1. 什么是Seq2Seq模型?2. Encoder-Decoder架构详解1️⃣编码器(Encoder)2️⃣解码器(Decoder)3. 传统Seq2Seq模型的局限性…...
)
【Linux】基础指令(Ⅱ)
目录 1. mv指令 2. cat指令 3.echo指令 补:输出重定向 4. more指令 5. less指令 6. head指令和tail指令 7.date指令 时间戳: 8. cal指令 9. alias指令 10.grep指令 1. mv指令 语法:mv [选项]... 源文件/目录 目标文件/目录 …...

【Python3教程】Python3基础篇之输入与输出
博主介绍:✌全网粉丝23W+,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物联网、机器学习等设计与开发。 感兴趣的可…...

mysql的一个缺点
最近再移植一个从oracle转mysql的项目,喜提一个报错: You cant specify target table A016 for update in FROM clause 对应的程序代码: public void setCurrent(String setId, String pk, String userId) throws SysException {String[]…...

【C/C++】高阶用法_笔记
1. 模板元编程(TMP)与编译时计算 (1) 类型萃取与 SFINAE 类型萃取(Type Traits):利用模板特化在编译时推断类型属性。 template<typename T> struct is_pointer { static constexpr bool value false; };templ…...

AMS3xxi激光测距仪安装调试维护详解
一、应用原理介绍 如下图,AMS3xxi激光测距发出的激光通过特定反光板返回后,利用“时间飞行法”原理进行距离 测量。测量中若遮挡光束传播会导致测距失败,产品报警。 二、固定和调节位置说明 在安装板上,使用 4 个 M5 螺钉锁 AMS…...

建筑IT数字化突围:建筑设计企业的生存法则重塑
困局:铅笔与键盘的撕裂之痛 晨光中的设计院里,总工老张的办公桌上堆叠着三摞图纸:左边是刚收尾的住宅施工图,中间夹着结构专业提资的变更单,右边是甲方连夜发来的方案调整意见。这是他从业28年来的日常,也…...

VTK|类似CloudCompare的比例尺实现2-vtk实现
文章目录 实现类头文件实现类源文件调用逻辑关键问题缩放限制问题投影模式项目git链接实现类头文件 以下是对你提供的 ScaleBarController.h 头文件添加详细注释后的版本,帮助你更清晰地理解每个成员和方法的用途,尤其是在 VTK 中的作用: #ifndef SCALEBARCONTROLLER_H #de…...

Java高频面试之并发编程-17
volatile 和 synchronized 的区别 在 Java 并发编程中,volatile 和 synchronized 是两种常用的同步机制,但它们的适用场景和底层原理有显著差异。以下是两者的详细对比: 1. 核心功能对比 特性volatilesynchronized原子性不保证复合操作的原…...

最优化方法Python计算:有约束优化应用——近似线性可分问题支持向量机
二分问题的数据集 { ( x i , y i ) } \{(\boldsymbol{x}_i,y_i)\} {(xi,yi)}, i 1 , 2 , ⋯ , m i1,2,\cdots,m i1,2,⋯,m中,特征数据 { x i } \{\boldsymbol{x}_i\} {xi}未必能被一块超平面按其标签值 y i ∈ { − 1 , 1 } y_i\in\{-1,1\} yi∈…...

Excel中批量对多个结构相同的工作表执行操作,可以使用VBA宏来实现
【系列专栏】:博主结合工作实践输出的,解决实际问题的专栏,朋友们看过来! 《项目案例分享》 《极客DIY开源分享》 《嵌入式通用开发实战》 《C语言开发基础总结》 《从0到1学习嵌入式Linux开发》 《QT开发实战》 《Android开发实…...

Spring的Validation,这是一套基于注解的权限校验框架
为了保证数据的正确性、完整性,作为一名后端开发工程师,不能仅仅依靠前端来校验数据,还需要对接口请求的参数进行后端的校验。 controller 全局异常处理器 在项目中添加一个全局异常处理器,处理校验异常 RestControllerAdvice p…...

鸿蒙OSUniApp 开发的下拉刷新与上拉加载列表#三方框架 #Uniapp
使用 UniApp 开发的下拉刷新与上拉加载列表 前言 最近在做一个小程序项目时,发现列表的加载体验对用户至关重要。简单的一次性加载全部数据不仅会导致首屏加载缓慢,还可能造成内存占用过大。而分页加载虽然解决了这个问题,但如果没有良好的…...