密西根大学新作——LightEMMA:自动驾驶中轻量级端到端多模态模型
导读
目前将自动驾驶与视觉语言模型(VLMs)结合的研究越来越火热,VLMs已经证明了其对自动驾驶的重要作用。本文引入了一种用于自动驾驶的轻量级端到端多模态模型LightEMMA,它能够集成和评估当前的商业和开源模型,以研究VLMs在驾驶任务中的作用和局限性,从而推进VLMs在自动驾驶中的进一步发展。
©️【深蓝AI】编译
本文由paper一作——Zhijie Qiao授权【深蓝AI】编译发布!
论文题目:LightEMMA: Lightweight End-to-End Multimodal Model for Autonomous Driving
论文作者:Zhijie Qiao, Haowei Li, Zhong Cao, Henry X. Liu
论文地址:https://arxiv.org/pdf/2505.00284
代码地址:https://github.com/michigan-traffic-lab/LightEMMA
1.摘要
视觉语言模型(VLMs)已经证明了其对于端到端自动驾驶的巨大潜力。然而,充分利用VLMs安全且可靠的车辆控制能力仍然是一项开放的研究挑战。为了系统性地研究VLMs在驾驶任务中的作用和局限性,本文引入了LightEMMA,这是一种用于自动驾驶的轻量级端到端多模态模型。LightEMMA提供了一种统一的、基于VLM的自动驾驶框架,可以轻松集成和评估不断发展的最先进商业和开源模型。本文使用各种VLMs来构建12个自动驾驶智能体,并且评估其在nuScenes预测任务上的性能,综合地评估了推理时间、计算成本和预测准确性等指标。实验示例表明,尽管VLMs具有强大的场景解释能力,但是其在自动驾驶任务中的实际表现仍然不容乐观,突出了进一步改进的必要性。
2.介绍
近年来,自动驾驶汽车(AV)取得了巨大的进步,其提高了安全性、舒适性和可靠性。传统方法依赖于模块化设计、基于规则的系统和预定义的启发式方法。尽管这种结构化方法确保了可解释且可预测的行为,但是它限制了解释复杂场景和做出灵活、类人决策的能力。
最近的一种方法是基于学习的端到端自动驾驶方法,它将原始传感器输入以及高精地图和环境上下文直接映射到驾驶轨迹。与模块化流程不同,端到端模型旨在从数据中学习统一的表示,从而实现更全面、更高效的驾驶决策。然而,它们通常是可解释性有限的黑盒,在关键场景中会引发安全问题,并且它们需要大量、多样化的数据,使其容易受到数据不平衡和稀有性问题的影响。
一种有望解决这些挑战的新兴方法是视觉语言模型(VLMs)的发展。VLMs在包含文本、图像和视频的数据集上进行训练,它展现出强大的推理能力。最近的研究着重于基于VLMs的端到端自动驾驶系统。然而,现有的研究主要突出了VLMs在驾驶环境中的场景理解能力,而没有充分评估其优势和局限性。此外,许多应用涉及商用车部署,而没有可获取的源代码或者详细的实现,这限制了它们在更广泛的研究和协作中的可用性。
受到EMMA和开源实现工作OpenEMMA中最新进展的启发,本文引入了LightEMMA,这是一种轻量级的端到端多模态框架,用于自动驾驶。LightEMMA采用零样本方法,并且充分利用现有VLMs的能力。本文的主要贡献如下:
1)本文为端到端自动驾驶规划任务提供了一个开源的基线流程,旨在与最新的VLMs无缝集成,从而实现快速原型开发,同时最大限度地减少计算开销和传输开销;
2)本文使用nuScenes预测任务的150个测试场景对12个最先进的商业和开源VLMs进行全面评估。本文分析强调了当前基于VLM的驾驶策略的实际优势和局限性,并且详细讨论了其能力和未来改进的潜在方向。
3.方法
LightEMMA架构的概览如图1所示。下面概述了其简要的工作流程,并且在后续章节中提供详细说明。
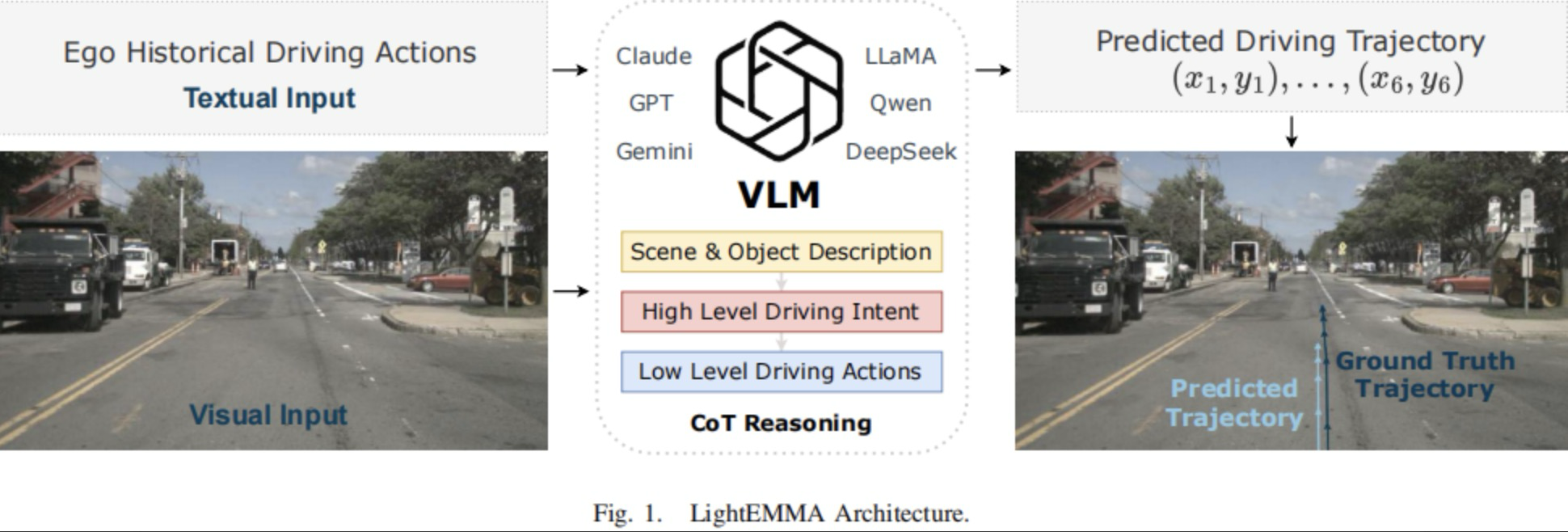
图1|LightEMMA架构
对于每个推理周期,当前的前视相机图像和历史车辆驾驶数据被输入到VLM中。为了提高可解释性并且促进结构化推理,本文采用了一种思维链(CoT)提示策略,其最后阶段显式地输出一系列预测的控制行为。这些行为被数值积分以生成预测的轨迹,随后将其与真值进行比较。所有的VLMs均采用一致的提示和评估过程进行统一评估,无需针对特定模型进行调整。
3.1 VLM选择
本文从开源和商业模型中选择最先进的VLMs,涵盖6种模型类型,总共12种模型。对于每种模型类型,本文评估两个变体:基础版本和高级版本。所有使用的模型都是支持文本和图像输入的最新开源版本。该设置允许在不同模型之间以及同一模型类内的变体之间进行全面的性能比较。所选择的模型为:GPT-4o、GPT-4.1、Gemini-2.0-Flash、Gemini-2.5-Pro、Claude-3.5-Sonnet、Claude-3.7-Sonnet、DeepSeek-VL2-16B、DeepSeek-VL2-28B、LLaMA-3.2-11B-Vision-Instruct、LLaMA-3.2-90B-Vision-Instruct、Qwen2.5-VL-7B-Instruct和Qwen2.5-VL-72B-Instruct。
对于商业模型,本文通过付费API访问它们。该方法通过消除管理本地硬件、软件更新和可扩展性的需求来简化部署,因为这些任务是由供应商直接处理的。
对于开源模型,本文从HuggingFace下载,并且使用H100 GPU在本地部署。大多数模型仅需要一个H100 GPU,尽管更大的模型可能需要更多GPU。本文在表格1中给出了所需的最少GPU数量。为了促进多GPU部署,本文利用PyTorch的自动设备映射来实现高效的GPU利用率。
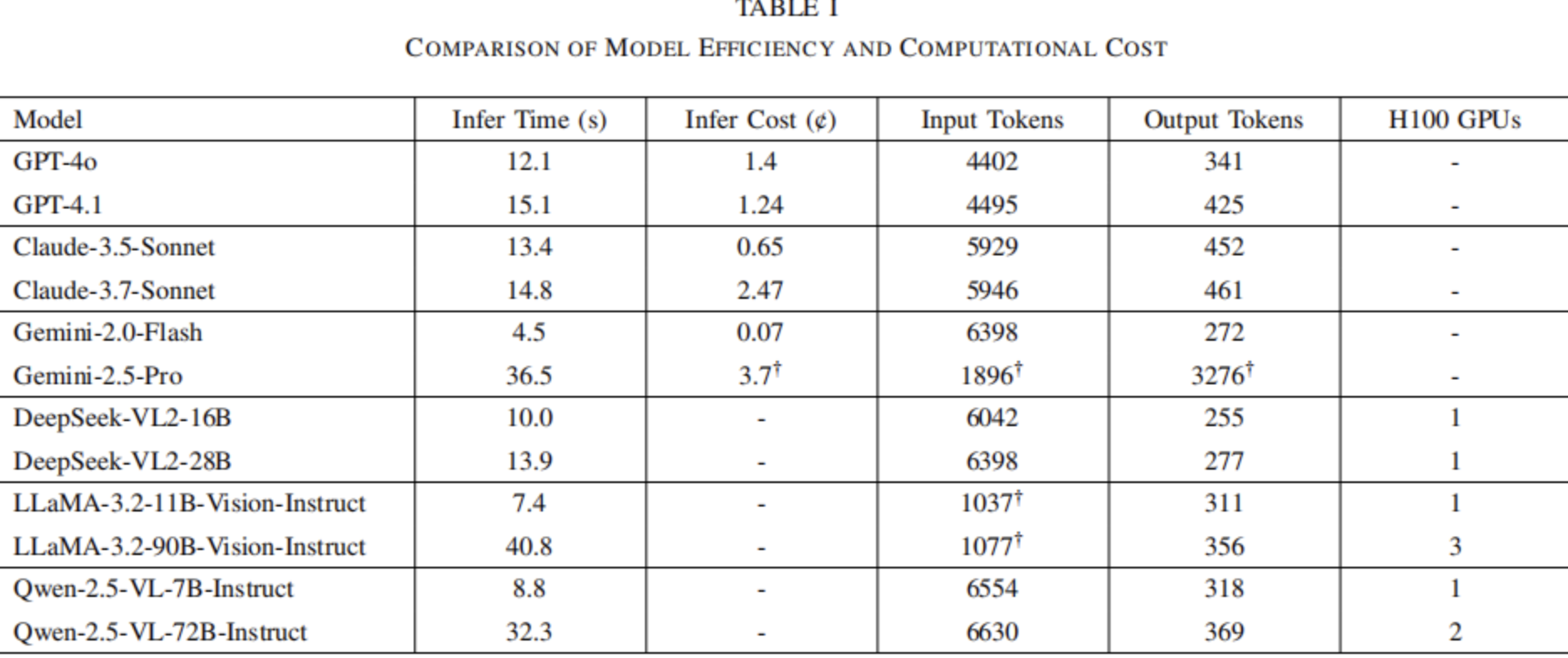
表格1|模型效率和计算成本的比较
3.2 相机输入
当将前视相机图像输入VLM时,本文不使用任何视觉编码器(例如CLIP),也不应用预处理技术来修改图像。本文研究结果表明,VLM能够有效地描述场景,并且直接从原始视觉输入中准确识别目标,这证明了其在处理视觉数据方面的鲁棒性。
根据该设计方法,本文还选择仅使用当前驾驶场景图像作为输入,而不是像先前研究那样连接多个过去的图像帧。初步实验表明,加入额外的帧不会获得明显的性能提升。相反,该模型倾向于在多个图像帧中冗余地提取相同的特征,而没有捕获有意义的时空动态。此外,加入更多的图像帧会导致处理时间和计算成本大致呈线性增加,而没有明显的性能优势。
VideoBERT和Video-MAE等模型通过专门的时间编码来支持视频输入,而不是简单地将视频作为图像帧序列。此类模型固有地采用不同的架构,并且可能捕获更丰富的时间信息。然而,探索这些专门面向视频的模型超出了本文目前的研究范围。
3.3 驾驶历史输入
本项工作使用速度和曲率来表示车辆行为,这是一种可解释的格式,其中速度捕获纵向运动,曲率描述横向运动。本文采用这种表示来代替显式的轨迹点,因为VLMs往往难以有效地推理涉及隐式物理约束的坐标。
3.4 VLM提示
本文采用简单的CoT方法来引导VLM的场景理解和行为生成,其中每个阶段的输出都与额外的提示一起集成到后续阶段:
1)场景描述:VLM接收一帧图像作为输入,并且提示其解释整个场景,包括车道标记、交通信号灯、车辆、行人活动和其他相关目标;
2)高级驾驶意图:生成的场景描述与自车的历史驾驶行为相结合,使VLM能够在当前场景上下文中解释过去的行为,并且预测下一高级驾驶行为;
3)低级驾驶命令:场景描述和生成的高级命令用于提示VLM,以指定格式输出低级驾驶行为的结构化列表,例如[(v1,c1),(v2,c2),(v3,c3),(v4,c4),(v5,c5),(v6,c6)],而无需额外的文本或者解释。
3.5 工作流程示例
本节使用图1所示的图像,演示了工作流程示例和来自CoT过程的结果。响应和轨迹由Claude-3.7-Sonnet生成。
场景描述:图像展示了一个城市街道场景,该场景中正在进行道路建设或者维护工作;一名警察站在道路中间指挥交通;可以看到几辆施工车辆,包括一辆黑色卡车和其它工作车辆停在道路左侧;在有警察在场和车道限制的情况下,这个施工区域的交通似乎得到了控制。
高级意图:给定当前正在施工和一名警察在道路中间指挥交通的场景,自车应该大幅度减速,为可能的停车做准备,在接下来的3秒内将速度降至3-4m/s左右。车辆应继续沿着车道行驶,同时准备在警察的指挥下完全停车。
低级命令:[(6.0,-0.001),(5.0,-0.001),(4.0,0.0),(3.5,0.0)]。
4.实验
本文使用所提出的方法和模型,评估了在nuScenes预测任务中的性能,该任务包含150个测试场景的总共3908帧。评估着重于两个方面:模型的计算效率及其轨迹预测的准确性。
4.1 推理时间
表格1汇总了推理时间,显示了每个图像帧的平均处理时间。Gemini-2.0-Flash以每帧4.5秒的速度实现了最快推理,而LLaMA-3.2-90b的推理速度最慢,每帧为40.8秒。Qwen-2.5-72B和Gemini-2.5-Pro也表现出相对较慢的性能,每帧需要30秒以上。其余模型通常以每帧10秒的速度运行,基础版本通常比高级版本运行更快。
值得注意的是,即使是最快的模型Gemini-2.0-Flash,其处理时间也明显低于实时更新的频率。为了真正有效地进行实际部署,这些模型需要以一到两个数量级更快的速度运行。此外,基于API的商业模型依赖于稳定的网络连接,这在行驶车辆上可能是不可靠的。相反,本地部署面临着计算能力有限和能耗的限制,这进一步限制了它们的实用性。
4.2 输入和输出Tokens
本文使用每个模型提供的官方指令来计算每帧输入和输出tokens的平均数量。如表格1所示,输入tokens的数量明显高于输出tokens,通常约为6000个输入tokens,而输出tokens约为300个。这符合预期,因为输入包括图像数据,而输出仅是文本。
然而,也存在一些例外。LLaMA模型给出每帧只有大约1000个输入tokens。经过进一步研究,发现官方的LLaMA token计数方法不包括图像tokens,只计算文本。
此外,Gemini-2.5-Pro的token计数在输入和输出token计算中明显包含错误,因为它们与可比较模型的结果之间存在显著偏差。值得注意的是,使用相同的token计数方式计算的Gemini-2.0-Flash生成了一致且合理的结果,这表明Gemini-2.5-Pro存在需要解决的问题。
4.3价格
本节仅适用于商业APIs。为了确保准确的衡量,根据输入和输出token的使用,将计费历史与官方定价表进行交叉引用。为清楚起见,表格1中显示的所有结果均以美分/帧为单位。
Gemini-2.0-Flash是最便宜的,价格仅为0.07,因此其价格可以忽略不计。GPT-4o和GPT-4.1的价格接近,约为1.3。Claude-3.7-Sonnet比Claude-3.5-Sonnet价格贵得多,尤其比GPT模型也贵很多。由于Gemini-2.5-Pro 的token计算不准确,因此很难做出准确估计。
4.4响应错误
在最终的模型输出阶段,本文观察到各种响应格式错误。尽管提示VLM严格返回格式为[(v1,c1),(v2,c2),(v3,c3),(v4,c4),(v5,c5),(v6,c6)]的输出,而没有额外的文本,但是偶尔会遇到偏差,例如缺少括号或者逗号、额外的解释或者标点符号以及不正确的列表长度。
如表格2所示,Qwen-2.5-72B的错误率最高,其错误率为62.9%,而其基础版本Qwen-2-5-7B没有产生错误。GPT-4.1的错误率为28.9%,而GPT-4o的错误率较低,为7.8%。其余模型均运行可靠,它们的错误率为零或者低于1%。
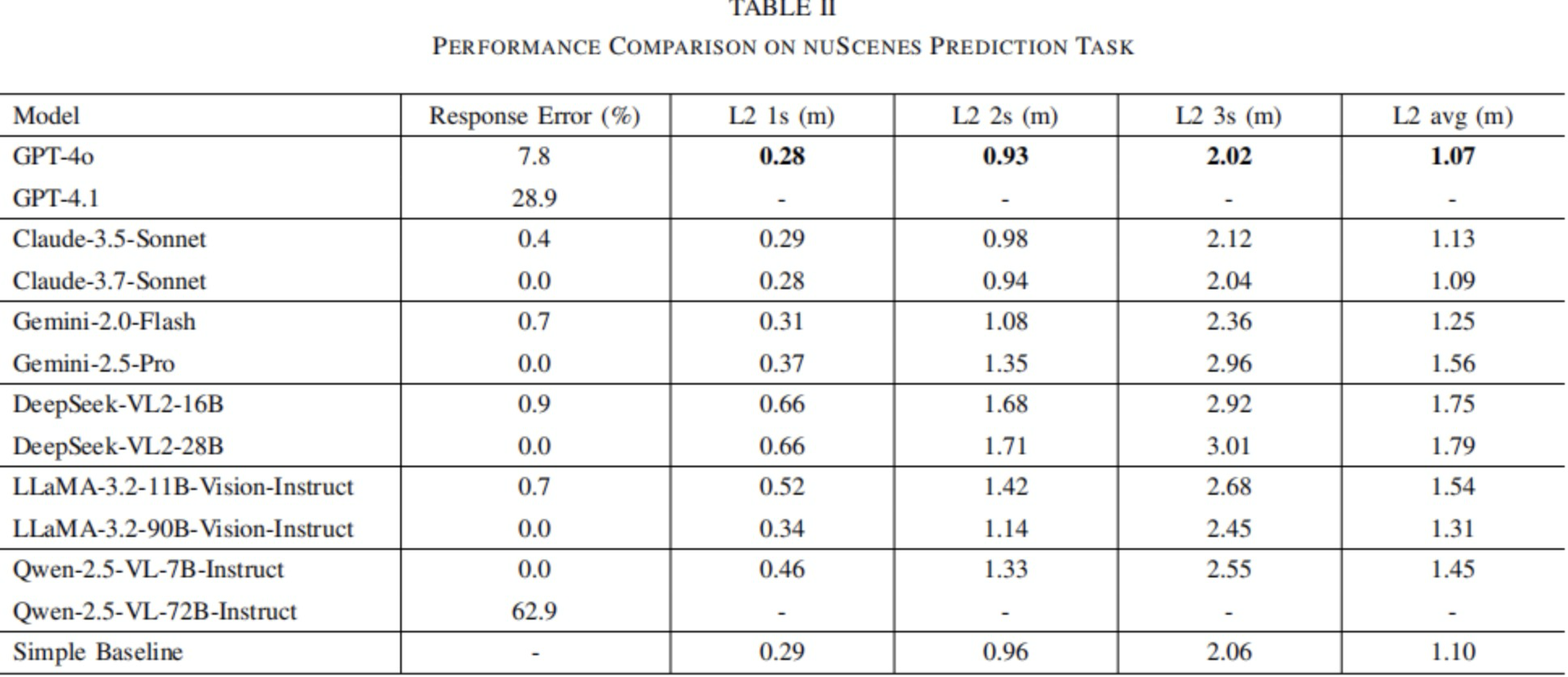
表格2|在nuScenes预测任务中的性能比较
本文认为,在所有模型的提示和工作流程相同的情况下,这些随机失效反映了固有的模型局限性,而不是框架中存在系统缺陷。虽然许多格式错误可以通过后处理、额外的提示或者其它增强技术来减少,但是本文的目标是评估而不是优化单个模型的性能。因此,本文保持一致的实验设计,并且在不进行修改的情况下给出观测到的错误率。
4.5预测准确性
预测准确性遵循nuScenes预测任务中采用的标准评估方法,以1s、2s和3s的间隔给出L2损失及其平均值。由于存在响应错误,每个模型都会对原始帧的不同子集进行预测。为了确保公平比较,如果任何一个模型无法为某帧生成有效的预测,就将该帧排除在所有模型的评估之外。由于Qwen-2.5-72B和GPT-4.1表现出特别高的失败率,本文将这两个模型完全排除在分析之外,以保留足够大的帧集合。
表格2汇总了L2损失结果。为了简化并且便于比较,本文的分析主要着重于平均L2损失(单位为米);总体而言,GPT-4o实现了最佳的性能,其L2损失为1.07米,紧随其后的是Claude-3.5-Sonnet和Claude-3.7-Sonnet,其结果略逊一筹。Gemini模型的表现相对较差;值得注意的是,Gemini-2.5-Pro的性能明显不如Gemini-2.0-Flash。总体而言,开源模型的表现不如商业模型,其中两个DeepSeek模型的性能最差。
4.6 L2损失基线
尽管L2损失提供了一种评估模型预测性能的简单方法,但是它可能无法完全捕获驾驶场景的复杂性。为了缓解这个问题,本文引入了一个简单而有效的基线:保持最新的AV行为在接下来的三秒内不变。然后,通过计算相对于真值的L2损失来评估这些恒定行为生成的轨迹。
本文的结果表明,该基线实现了1.10米的平均L2损失,与GPT-4o(1.07米)和Claude 3.7-Sonnet(1.09米)的最佳VLM结果非常接近,并且明显优于许多其它模型。这一比较突出了零样本VLM方法在轨迹规划任务中的当前局限性,这表明现有模型可能难以充分应对驾驶特定的复杂性。因此,这强调了需要有针对性的进行增强,例如专门为驾驶上下文来设计VLM架构或者使用领域特定的驾驶数据集对模型进行微调。
5.案例
本节讨论了图2所示的六个具有代表性的场景。由于可用帧的数量较多,因此从中精心挑选了一些示例来说明典型行为。每幅图都将VLMs预测的轨迹与真值轨迹进行比较。
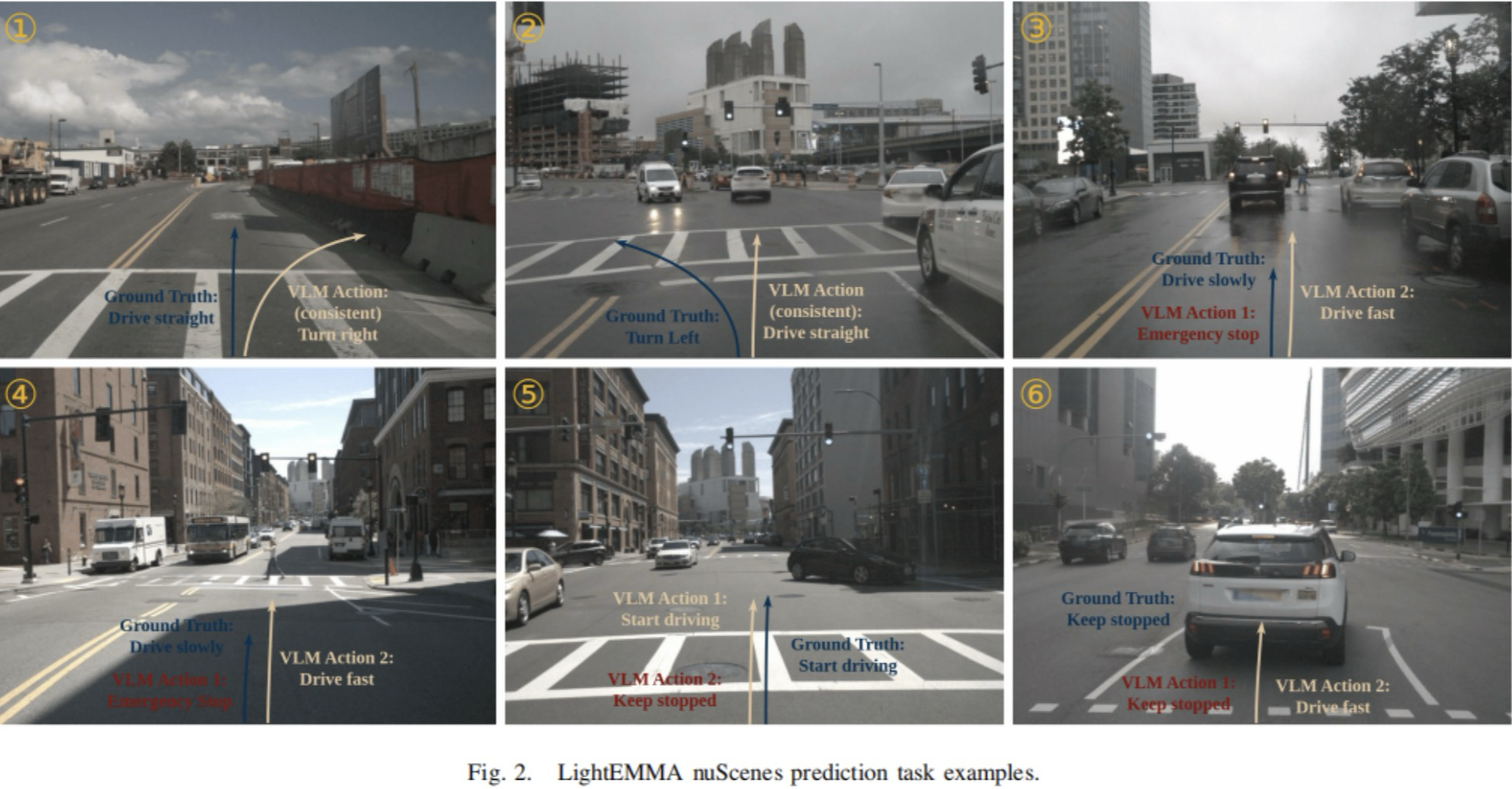
图2|LightEMMA nuScenes预测任务示例
5.1案例1:历史行为的轨迹偏差
图2.1展示了一个场景,其中真值轨迹为直线行驶,但是预测的轨迹为右转,它未能识别出右侧的障碍物。发生这种情况是因为自动驾驶汽车刚刚在该帧之前的交叉路口完成右转。因此,历史行为反映了右转的倾向。然而,VLMs很难仅根据当前的前视图像识别更新的道路状况。
5.2案例2:视觉线索的上下文不足
图2.2展示了另一种所有模型都一直失败的情况。在这种案例中,真值轨迹为左转,但是所有模型都错误地预测为继续直行。尽管这种场景本身就具有挑战性(人行道上没有显式的左转标志或者专用的交通信号灯),但是仍然存在隐式的指示。例如,自动驾驶汽车占据最左侧的车道,而右侧相邻车道上的车辆则继续直行。为了可靠地克服这个问题,模型可以结合额外的上下文信息,例如显式的导航指示来清楚地指明交叉路口处左转。
5.3案例3&4:对停车信号的不同响应
图2.3显示了一个突出VLM响应差异显著的场景。在这种案例中,自动驾驶汽车在红色交通信号灯控制的交叉路口处逐渐接近前方停止的车辆。真值轨迹显示,自动驾驶汽车平稳地逐渐减速,直到完全停在前方车辆后面。然而,VLM预测结果分为两类(紧急停车和快速通行),其中没有一类结果符合真值行为。
图2.4中观测到类似的情况。在该场景中,自动驾驶汽车接近有红色交通信号灯的交叉路口,行人正在穿越人行道。VLM预测要么预测突然紧急刹停(尽管前方有足够的距离),要么完全忽略行人和交通信号灯,预测自动驾驶汽车将保持速度通过路口。
5.4案例5:对启动信号的不同响应
图2.5描绘了一个场景,其中自动驾驶汽车最初是静止的,在交通信号灯控制的交叉路口等待。当交通信号灯从红色变为绿色时,真值行为为自动驾驶汽车迅速启动加速并且平稳地通过交叉路口。具有较低L2损失的模型复现了这种行为,准确地将绿色信号灯识别为继续前进的指示,从而预测出适当的加速轨迹。相反,具有较高L2损失的模型保持车辆静止,未能建立绿色信号灯与相应加速行为之间的重要联系。
5.5案例6:冲突的视觉线索和模型响应
最后一个示例如图2.6所示,其展示了一个有趣的场景,其中即使是具有较低L2损失的模型也表现出不同的行为。与图2.5中的情况类似,交通信号灯刚刚从红色转变为绿色。一组模型观察到绿灯并且预测立即加速,而忽略了前方车辆。相反,另一组模型准确地识别出冲突的线索(尽管有绿色信号,但是前方存在车辆),因此自动驾驶汽车必须保持静止。
此外,VLM的这种不同响应揭示了其在应用于自动驾驶任务时决策过程中固有的不稳定性。这种不一致性可能直接导致危险情况的发生,例如意外加速或者碰撞风险,这突出了建立鲁棒安全机制或者防护的必要性。
6.总结
本项工作引入了LightEMMA,这是一种轻量级的端到端自动驾驶框架,专门为与最先进的视觉语言模型集成而设计。本文使用了思维链提示策略,表明VLMs有时能够准确地解释复杂的驾驶场景并且生成智能的响应。值得注意的是,LightEMMA主要用作可访问的基线,而不是优化特定VLMs的性能。
nuScenes预测任务的系统性评估考虑了计算效率、硬件要求和API成本等多个维度。使用L2损失作为指标的定量分析强调了当前VLM预测的局限性,并且突出了仅依赖这一指标的不足。定性分析进一步确定了常见的缺点,包括过度依赖历史轨迹数据、有限的空间感知和被动的决策。因此,未来研究应该着重于开发驾驶特定的模型或者利用领域特定的数据集来微调现有的VLMs。
相关文章:

密西根大学新作——LightEMMA:自动驾驶中轻量级端到端多模态模型
导读 目前将自动驾驶与视觉语言模型(VLMs)结合的研究越来越火热,VLMs已经证明了其对自动驾驶的重要作用。本文引入了一种用于自动驾驶的轻量级端到端多模态模型LightEMMA,它能够集成和评估当前的商业和开源模型,以研究…...

MobiPDF:安卓设备上的专业PDF阅读与编辑工具
MobiPDF是一款专为安卓设备设计的PDF阅读和编辑工具,提供了丰富的功能,帮助用户在移动设备上轻松打开、阅读、批注和编辑PDF文件。无论是学生、专业人士还是普通用户,MobiPDF都能满足他们在移动设备上处理PDF文件的需求,提升工作效…...

印度尼西亚数据源对接技术指南
一、数据源全景概述 印度尼西亚作为东南亚最大经济体,其数据生态覆盖金融、产业、人口等多个维度。StockTV提供全链路印尼数据解决方案,涵盖以下核心领域: 数据类型覆盖范围更新频率典型应用场景金融市场数据IDX交易所股票/债券/衍生品实时…...

Apache Pulsar 消息、流、存储的融合
Apache Pulsar 消息、流、存储的融合 消息队列在大层面有两种不同类型的应用,一种是在线系统的message queue,一种是流计算,data pipeline的streaming高throughout,一致性较低,延迟较差的过程。 存算分离 扩容和缩容快…...

从零实现一个高并发内存池 - 2
上一篇https://blog.csdn.net/Small_entreprene/article/details/147904650?fromshareblogdetail&sharetypeblogdetail&sharerId147904650&sharereferPC&sharesourceSmall_entreprene&sharefromfrom_link 高并发内存池 - thread cache 一、基本结构与原…...

promise
handleFileChange(event) {var that this;// 处理文件上传并传递回调函数this.$commonJS.handleFileUpload(event, function (tables) {console.log(tables at line 786:, tables);// 使用 Promise.all 等待所有表格解析完成Promise.all(tables.map((table) > {return new …...
)
Django + Celery 打造企业级大模型异步任务管理平台 —— 从需求到完整实践(含全模板源码)
如需完整工程文件(含所有模板),可回复获取详细模板代码。 面向人群:自动化测试工程师、企业中后台开发人员、希望提升效率的 AI 业务从业者 核心收获:掌握 Django 三表关系设计、Celery 异步任务实践、基础 Web 交互与前后端分离思路,源码可直接落地,方便二次扩展 一、系…...

从零开始完成“大模型在牙科诊所青少年拉新系统中RAG与ReACT功能实现”的路线图
项目核心目标: 构建一个智能系统,利用大型语言模型(LLM)、检索增强生成(RAG)和推理与行动(ReACT)技术,通过七个专门的知识向量库,为牙科诊所精准吸引青少年客…...

c# 倒序方法
在C#中,有几种方法可以对List进行倒序排列: 1. 使用List的Reverse()方法(原地反转) List<int> numbers new List<int> { 1, 2, 3, 4, 5 };numbers.Reverse(); // 直接修改原列表// 结果:5, 4, 3, 2, 1 …...

【!!!!终极 Java 中间件实战课:从 0 到 1 构建亿级流量电商系统全链路解决方案!!!!保姆级教程---超细】
终极 Java 中间件实战课:电商系统架构实战教程 电商系统架构实战教程1. 系统架构设计1.1 系统模块划分1.2 技术选型 2. 环境搭建2.1 开发环境准备2.2 基础设施部署 3. 用户服务开发3.1 创建Maven项目3.2 创建用户服务模块3.3 配置文件3.4 实体类与数据库设计3.5 DAO…...

HarmonyOs开发之———使用HTTP访问网络资源
谢谢关注!! 前言:上一篇文章主要介绍HarmonyOs开发之———Video组件的使用:HarmonyOs开发之———Video组件的使用_华为 video标签查看-CSDN博客 HarmonyOS 网络开发入门:使用 HTTP 访问网络资源 HarmonyOS 作为新一代智能终端…...

Java Queue 接口实现
Date: 2025.05.14 20:46:38 author: lijianzhan Java中的Queue接口是位于java.util包中,它是一个用于表示队列的接口。队列是一种先进先出(First-In-First-Out, 简称为FIFO)的数据结构,其中元素被添加到队列的尾部,并从…...

【IDEA】注释配置
1. IDEA注释调整,去掉默认在第一列显示 修改为如下: 2. IDEA中修改代码中的注释颜色...

day25 python异常处理
目录 Python 的异常处理机制 核心概念 常见的异常处理结构 try-except try-except-else 常见异常类型 SyntaxError(语法错误) NameError(名称错误) TypeError(类型错误) ValueError(值…...

【测试】BUG
目录 1、描述BUG的要素: 2、BUG的级别 3、BUG的状态的流转 4、与开发产⽣争执怎么办(⾼频考题) 什么是BUG??? 程序与规格说明之间的不匹配才是错误 1、描述BUG的要素: 问题出现的版本、问…...

Java面向对象三大特性深度解析
Java面向对象三大特性封装继承多态深度解析 前言一、封装:数据隐藏与访问控制的艺术1.1 封装的本质与作用1.2 封装的实现方式1.2.1 属性私有化与方法公开化1.2.2 封装的访问修饰符 二、继承:代码复用与类型扩展的核心机制2.1 继承的定义与语法2.2 继承的…...
)
C 语言学习笔记(8)
内容提要 数组 数组的概念一维数组 数组 数组的概念 什么是数组 数组是相同类型,有序数据的集和 数组的特征 数组中的数据被称之为数组的元素(所谓的元素,其实就是数组的每一个匿名的变量空间),是同构。数组中的…...

Screen Mirroring App:轻松实现手机与电视的无缝投屏
Screen Mirroring App 是一款由2kit consulting发行的电视投屏软件,专为用户提供便捷的投屏解决方案。它支持将手机和平板屏幕上的内容实时投射到大电视上,无论是观看影视作品、玩游戏、浏览照片还是阅读电子书,都能提供清晰、稳定的画质和流…...

html js 原生实现web组件、web公共组件、template模版插槽
在现代浏览器中,通过 class 继承 HTMLElement 可以轻松创建原生 Web Components(自定义元素),并能享受与普通 HTML 元素同等的语义和性能优势。下面将从核心概念、生命周期方法、Shadow DOM、表单关联、自定义属性、以及与 Vue 3 …...

【爬虫】DrissionPage-2
之前的三个对象是4.0版本,看到的是网上大佬们网上的文章,因为看到官网更新了4.1,我觉得有必要了解一下:文档地址:💥 4.1 功能介绍 | DrissionPage官网 点击链接看官网就行,下面一样的。 4.1 的…...

鸿蒙OSUniApp 制作个人信息编辑界面与头像上传功能#三方框架 #Uniapp
UniApp 制作个人信息编辑界面与头像上传功能 前言 最近在做一个社交类小程序时,遇到了需要实现用户资料编辑和头像上传的需求。这个功能看似简单,但要做好用户体验和兼容多端,还是有不少细节需要处理。经过一番摸索,总结出了一套…...

系统漏洞扫描服务:维护网络安全的关键与服务原理?
系统漏洞扫描服务是维护网络安全的关键措施,能够迅速发现系统中的潜在风险,有效预防可能的风险和损失。面对网络攻击手段的日益复杂化,这一服务的重要性日益显著。 服务原理 系统漏洞扫描服务犹如一名恪尽职守的安全守护者。它运用各类扫描…...
: 在界面开发中, 如何利用C++高级特性“折叠表达式“?.)
[原创](现代C++ Builder 12指南): 在界面开发中, 如何利用C++高级特性“折叠表达式“?.
[序言] 在现代C++编程中, 现代C++引入的折叠表达式(Fold Expressions)是一项极具价值的特性, 它为模板编程带来了更高的灵活性和简洁性. 折叠表达式允许在参数包上执行简洁的折叠操作, 从而减少冗余代码, 提升代码的可读性与维护性. 在界面开发领域, 特别是使用C++ Builder 12进…...

KUKA机器人中断编程3—暂停功能的编程
在KUKA机器人的使用过程中,对于调试一个项目,当遇到特殊情况时需要暂停机器人,等异常情况处理完成后再继续机器人的程序运行。wait for指令是等待一个输入信号指令,没有输入信号,机器人一直等待。在一定程度上程序也不…...

【LeetCode 热题 100】反转链表 / 回文链表 / 有序链表转换二叉搜索树 / LRU 缓存
⭐️个人主页:小羊 ⭐️所属专栏:LeetCode 热题 100 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 相交链表反转链表回文链表环形链表环形链表 II合并两个有序链表两数相加删除链表的倒数第 N 个结点两两交换链表中的…...

Seata源码—1.Seata分布式事务的模式简介
大纲 1.Seata分布式事务框架简介 2.Seata AT模式实现分布式事务的机制 3.Seata AT模式下的写隔离机制 4.Seata AT模式下的读隔离机制 5.官网示例说明Seata AT模式的工作机制 6.Seata TCC模式的介绍以及与AT模式区别 7.Seata Saga模式的介绍 8.单服务多个库的分布式事务…...

牛客——签到题
分析 我拿到题就去看了示例,可以发现,并非是让难度最小,或者难度系数出现次数最多的成为签到题的难度。那我就有点懵了。。。。。。 但仔细观察题目本身的特定条件和目标,即在满足选择 m 道题的前提下,尽可能多地选择…...

【idea】调试篇 idea调试技巧合集
前言:之前博主写过一篇idea技巧合集的文章,由于技巧过于多了,文章很庞大,所以特地将调试相关的技巧单独成章, 调试和我们日常开发是息息相关的,用好调试可以事半功倍 文章目录 1. idea调试异步线程2. idea调试stream流…...
:部署Metrics Server实现kubectl top和HPA支持)
k8s监控方案实践补充(一):部署Metrics Server实现kubectl top和HPA支持
k8s监控方案实践补充(一):部署Metrics Server实现kubectl top和HPA支持 文章目录 k8s监控方案实践补充(一):部署Metrics Server实现kubectl top和HPA支持一、Metrics Server简介二、Metrics Server实战部署…...

直流电机风速仪
在处理直流电机风速仪的 ADC 读取问题时,下面为你详细介绍实现方法。 硬件连接 风速仪的输出通常是模拟信号,所以需要把它连接到微控制器的 ADC 输入引脚。比如,在 Arduino 上可以连接到 A0 - A5 这类模拟输入引脚。 ADC 读取原理 风速仪…...

dify 连接不上ollama An error occurred during credentials validation:
三大报错 An error occurred during credentials validation: HTTPConnectionPool(hosthost.docker.internal, port11434): Max retries exceeded with url: /api/chat (Caused by NameResolutionError("<urllib3.connection.HTTPConnection object at 0x7f26fc3c00b0&…...

19、云端工业物联网生态组件 - 工厂能效与预测维护 - /数据与物联网组件/cloud-iiot-factory-analysis
76个工业组件库示例汇总 云端工业物联网生态组件 - 工厂能效与预测维护 (模拟) 概述 这是一个交互式的 Web 组件,旨在模拟一个云端工业物联网 (IIoT) 平台的核心界面,专注于工厂层面的能效分析和基于传感器数据的预测性维护概念。用户可以监控模拟的设…...

python打卡day25
python的异常处理机制 知识点回顾: 异常处理机制debug过程中的各类报错try-except机制try-except-else-finally机制 在即将进入深度学习专题学习前,我们最后差缺补漏,把一些常见且重要的知识点给他们补上,加深对代码和流程的理解。…...

Jmeter变量传递介绍
文章目录 一、Jmeter变量类型及作用域二、变量传递方式1. 用户定义变量(User Defined Variables)2. CSV 数据文件(CSV Data Set Config)3.正则表达式提取器4.后置处理器(Post Processor)4.1BeanShell/JSR223 后置处理器…...

机器学习 Day16 聚类算法 ,数据降维
聚类算法 1.简介 1.1 聚类概念 无监督学习:聚类是一种无监督学习算法,不需要预先标记的训练数据 相似性分组:根据样本之间的相似性自动将样本归到不同类别 相似度度量:常用欧式距离作为相似度计算方法 1.2 聚类vs分类 聚类&…...

白日梦:一个方便快捷的将故事制作成视频的工具
我有故事,但我想把它制作成视频,有没有什么好用的工具可以使用呢?如果你也被类似的问题困扰,那么今天分享的这个工具将会解决这个问题。从需求来看,我们希望的是纯文本的故事输入,完整的故事视频输出&#…...

ultralytics中tasks.py---parse_model函数解析
一、根据scale获取对应的深度、宽度和最大通道数 具体例如yaml文件内容如下: depth=0.33,那么重复的模块例如C2f原本重复次数是3,6,6,3,那么T对应的模型重复次数就是三分之一即1,1,2,1次。这个在后面定义的: width=0.25,max_channels=1024 原本c2=64,但经过make_div…...
)
Codeforces Round 1003 (Div. 4)
A. Skibidus and Amog’u 题目大意 给你一个字符串,把末尾的us换成i 解题思路 删掉最后两个加上“i”即可 代码实现 #include <bits/stdc.h>using i64 long long;int main() {std::ios::sync_with_stdio(false);std::cin.tie(0);std::cout.tie(0);int …...

基于RFSOC ZU28DR+DSP 6U VPX处理板
板卡概述 基于RFSOC ZU28DRDSP 6U VPX处理板,是一款基于6U VPX总线架构的高速信号处理平台,数模混合信号处理卡,采用 Xilinx ZYNQ UltraScale RFSoC ZU28DR和TI DSP TMS320C6678组合设计,两者之间通过4x 5G SRIO互联。本板卡可实…...

C# 通过脚本实现接口
以前C#脚本用的委托注入模式,今天在AI提示下,尝试用脚本直接实现接口,然后C#可以动态或指定新类型创建接口实现对象。从代码角度看,稍显复杂,但脚本方面显得更简洁和有条理。 引用包需要Microsoft.CodeAnalysis、Micro…...

代码随想录算法训练营Day58
力扣695.岛屿的最大面积【medium】 力扣827.最大人工岛【hard】 一、力扣695.岛屿的最大面积【medium】 题目链接:力扣695.岛屿的最大面积 视频链接:代码随想录 1、思路 和岛屿数量那道题很像,只是递归这边要多一个怎么计算面积,…...

若依框架页面
1.页面地址 若依管理系统 2.账号和密码 管理员 账号admin 密码admin123 运维 账号yuwei 密码123456 自己搭建的地址方便大家学习,不要攻击哦,谢谢啊...

redis 缓存穿透,缓存击穿,缓存雪崩
一:什么是缓存 (1)计算机:cpu、内存、磁盘,cpu任何需要的数据都要从内容中读入数据放入cpu,从cup内部添加一个缓存 (2)web开发的每个阶段都可以添加缓存 (3)缓存优缺点&a…...

ORACLE查看归档是否打开
一、使用V$DATABASE视图 SELECT log_mode FROM v$database; 结果说明: ARCHIVELOG - 数据库处于归档模式 NOARCHIVELOG - 数据库处于非归档模式 二、 使用v$instance视图 SELECT archiver FROM v$instance; 结果说明: STARTED - 归档进程已启动(归档模…...

Python环境管理工具深度指南:pip、Poetry、uv、Conda
Python环境管理工具深度指南:pip、Poetry、uv、Conda Python开发中,环境管理和依赖管理是不可避开的重要话题。合理地管理项目的Python环境(尤其是虚拟环境)有助于隔离不同项目的依赖,避免版本冲突,并确保…...
)
高等数学第七章---微分方程(§7.4-§7.5可降阶的高阶微分方程、二阶线性微分方程)
7.4 可降阶的高阶微分方程 某些类型的高阶微分方程可以通过适当的变量代换,将其阶数降低,从而化为阶数较低的方程进行求解。 一、 y ( n ) f ( x ) y^{(n)}f(x) y(n)f(x) 型方程 特征:方程的左端是 y y y 的 n n n 阶导数,右…...

Jmeter对服务端进行压测快速上手
安装 下载 安装jmeter的之前必须先装有JDK 官网下载地址:https://archive.apache.org/dist/jmeter/binaries/ jmeter3.0的对应jdk1.7,jmeter4.0对应jdk1.8以上,否者启用jmeter也会报错 配置 配置环境变量 在系统变量PATH上加上: %JMET…...

【嵌入模型与向量数据库】
目录 一、什么是向量? 二、为什么需要向量数据库? 三、向量数据库的特点 四、常见的向量数据库产品 FAISS 支持的索引类型 vs 相似度 五、常见向量相似度方法对比 六、应该用哪种 七、向量数据库的核心逻辑 🔍 示例任务:…...

鸿蒙OSUniApp 开发实时聊天页面的最佳实践与实现#三方框架 #Uniapp
使用 UniApp 开发实时聊天页面的最佳实践与实现 在移动应用开发领域,实时聊天功能已经成为许多应用不可或缺的组成部分。本文将深入探讨如何使用 UniApp 框架开发一个功能完善的实时聊天页面,从布局设计到核心逻辑实现,带领大家一步步打造专…...

React构建组件
React构建组件 React 组件构建方式详解 React 组件的构建方式随着版本迭代不断演进,目前主要有 函数组件 和 类组件 两种核心模式,并衍生出多种高级组件设计模式。以下是完整的构建方式指南: 文章目录 React构建组件React 组件构建方式详解…...