半成品的开源双系统VLA模型,OpenHelix-发表于2025.5.6
半成品的开源双系统VLA模型,OpenHelix
https://openhelix-robot.github.io/
0. 摘要
随着OpenVLA的开源,VLA如何部署到真实的机器人上获得了越来越多的关注,各界人士也都开始尝试解决OpenVLA的效率问题,双系统方案是其中一个非常热门的方案,但是双系统的方案有很多,比如Helix,理想汽车MindVLA等,但是缺乏相关开源工作,难以继续研究。
这篇文章将总结和对比现有的双系统的结构,并系统地对它们的核心设计元素进行评估。
“为了搞清楚怎么设计更聪明的AI大脑,这篇文章会先看看别人是怎么做的,然后自己做实验测一测哪些设计最靠谱。”
最终,这篇论文将会提出一种低成本开源的模型,它们还会继续更新新的实验结论,并在Huggingface中提供开源模型。
1. 前世今生
1.1 VLA的定义
传统的策略学习主要侧重于使用轻量级模型从头(scratch)训练新的行为。这些模型对环境扰动(光照,背景杂乱)高度敏感,且泛化能力有限。
随着大型语言模型(LLMs)和视觉–语言模型(MLLMs)的出现,这一领域正在发生重大变革。
MLLMs 和 VLM 是一个东西吗?
VLM(视觉-语言模型):专注于视觉与语言的双模态交互
MLLMs(多模态大语言模型):扩展至多模态(视觉、语言、文本等),强调通用性
在这种背景下,RT-2 提出了开创性的“视觉–语言–动作模型”(VLAs)概念,它将最先进的视觉–语言模型在机器人轨迹数据和互联网规模的视觉–语言任务上进行联合微调。
VLA 在对新物体和语义多样的指令上展现出显著的泛化改进,同时表现出一系列的涌现(泛化)能力。
此外,VLA 作为强大的基础模型,有望彻底改变机器人技能获取的方法论,因为它们可以被直接微调,以适配特定领域的机器人应用。
无论是仓储拣货、户外巡检还是精准草莓采摘,都能在少量示例下快速微调。怎么微调?
继 RT-2 之后,出现了 OpenVLA、Helix 等开源与商用项目,社区与工业界都在积极探索。
1.2 VLA的限制
由于存在以下限制,将 VLA 直接应用于特定领域或真实场景仍具有挑战性。
- VLA 模型体量庞大、计算复杂,导致难以实现高效的实时运行。
- VLA 的预训练及端到端微调都极其耗费算力;而且在将通用模型应用到具体机器人场景时,常因领域差异导致“灾难性遗忘”,使模型丢失已有的多模态理解能力。
如何在实际应用中,既利用现有VLA模型的出色多模态理解、推理和生成能力,又保证足够快的推理速度以输出连贯动作,仍是亟待解决的问题。
1.3 双系统VLA的定义
因此,人们引入了“双系统 VLA”。Dual-System VLA 是在单一 VLA 难以同时兼顾速度与推理深度时提出的一种混合架构。
双过程理论将人类认知视为由两个截然不同的系统协同运行:
经典的双过程模型(见 Kahneman 等)认为,人脑在不同场景下会启用“快思考”与“慢思考”两种模式
System 1 快速、自动、直觉且无意识。它无需耗费太多精力,主要依赖启发式规则来做出判断和决定。特点是响应速度快、计算开销低,在简单场景下表现良好,但对环境或指令的微小变化敏感,与传统的轻量级策略网络相似——它们运算迅速,但通常只适用于特定任务。
System 2 缓慢、深思熟虑、费力且有意识。它负责推理、逻辑和对证据的仔细评估,当需要解决复杂问题或进行深度决策时会启动。它的显著优势在于能够处理复杂、多模态信息,为机器人带来更强的任务迁移和未知场景适应能力,但是消耗大量资源,在机器人领域对应MLLM。
虽然两系统并行工作,但它们更新信息的频率不同。较慢的 System 2 组件以低频率更新,负责基于高层抽象表示做出深度决策;而更快的 System 1 式组件则以高频率更新,快速生成机器人实时控制所需的底层动作。需要注意的是,慢系统的决策会存在时间延迟。该架构通过:
- 让 System 1 保持高频、低延迟的动作输出
- 同时让 System 2 定期提供复杂推理和任务规划
实现了实时性与深度推理能力的兼顾。
1.4 现有的双系统VLA
下面介绍最新的双系统 VLA 方法,其各自特色在下表中进行了对比分析。需要注意的是,要实现同步推理,System 1 必须接入实时感知输入(例如 RGB 图像)。因此,像 π0 、GR00TN1 等方法因不具备这一关键特征,无法归入双系统框架。
“快系统”不仅要快,还要能实时接收来自相机或其他传感器的数据,否则就不能算真正的双系统设计。为什么一定要接收呢?作用有多大呢?
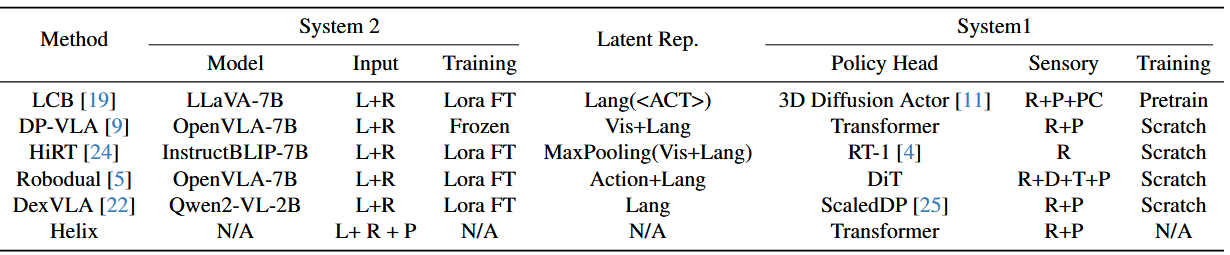
Method:不同的双系统VLA方法名称(如LCB、DP-VLA等)。
System 2(高层推理系统):
- Model:使用的视觉-语言模型(如LLaVA-7B、OpenVLA-7B)。
- Input:输入模态(如L+R表示语言+RGB图像)。
- Training:训练方式(如Lora FT表示用LoRA微调)。
- Latent Rep:中间表征的形式(如Lang()表示语言动作编码)。Latent Rep将S2生成的语义压缩为结构化、机器可解析的中间编码。
System 1(低层控制系统):
- Policy Head:动作生成策略(如3D Diffusion Actor、Transformer)。
- Sensory:感知输入模态(如R+P表示RGB+本体感知)。
- Training:训练方式(如Pretrain表示使用预训练策略头)。
LCB:
LCB 将 LLaVA 作为 System 2。给定一段高层任务描述(L)和 RGB 图像(R),LLaVA 会输出一段文字化动作描述及一个动作 token。该 token 来自模型最末层,用作高层潜在目标。System 1 则是预训练的 3D Diffusion Actor,它接收 RGB 图像、点云(Point Cloud-PC)和 token 来生成具体动作。System 2 用 LoRA 微调,而 System 1 则按常规方式微调。
Lang(act) 语言模型生成的动作标记(如GRASP),显式结构化,易解析但需预设词汇。
DP-VLA:
DP-VLA 将双过程理论引入到架构设计中,提供了更具普适性的方案:System 2 不必局限于 MLLM,也可以是以机器人轨迹数据预训练的 VLA。实验中,DP-VLA 选用 OpenVLA 作为 System 2,其编码器从语言指令与 RGB 观测中提取潜在特征,用以指导 System 1。System 1 则基于 Transformer,将 RGB 图像与本体感知(P)输入编码为动作。System 2 保持冻结,仅对 System 1 从零训练(Scratch)。
Vis+Lang 视觉+语言特征的简单拼接,隐式融合,灵活性高但可解释性弱。
HiRT:
HiRT 将 InstructBLIP 作为 System 2,利用其最后一层对语言指令和 RGB 图像的编码输出,通过 MAP 池化生成 MLLM 潜在特征来指导 System 1。System 1 则采用 EfficientNet-B3主干(RT-1也用的它) 加 MAP block,将 RGB 输入编码为动作。System 2 用 LoRA 微调,System 1 从零训练。
MaxPooling(Vis+Lang) 可视为一种轻量化特征聚合方式,兼顾表现与效率
EfficientNet-B3 在保持模型小型化的同时有较好性能,适合实时控制
RoboDual:
RoboDual 也使用 OpenVLA 作为 System 2,从语言指令与 RGB 观测中提取两类潜在特征:任务潜 latent(task latent)和最终动作潜 latent。System 1 则通过 ViT-based encoder 对 RGB、深度、触觉与本体感知信号进行编码,并用 Perceiver Resampler 提炼关键特征;随后由 DiT 模型结合提炼后特征、任务潜 latent 及带噪动作输入生成最终动作。System 2 以 LoRA 微调,System 1 从零训练。
1.5 双系统的关键设计
关键就在于如何设计这两套系统的架构,以及如何把慢系统的信息传递给快系统,既不丢失 System 2 的深度能力,又能高效地指导 System 1 执行动作。要造出又快又聪明的机器人,必须拿捏好这份“快-慢平衡”。
1.5.1 多模态大模型的选择(MLLM)
针对不同 VLA 应用场景,对多模态大模型(MLLM)的要求也不一样。在 MLLM 日新月异的今天,我们要搞清:到底哪种模型“足够轻”又“能干活”,这是个急需回答的问题。
此外,MLLM 是否要在机器人数据上再预训练,仍是悬而未决。多给它喂机器人工作过程数据,让它接触更多的指令,不仅能缩小领域差异,还能让它对指令理解更稳、更准——Robodual的实验就印证了这一点。
MLLM不一定是针对机器人进行训练的,可能是基于互联网上大量数据训练出来的,针对机器人的专业性可能一般
1.5.2 快系统小模型的选择
对于 System 1 这类“小模型”,大家意见比较统一:DiT 结构和 Flow Matching 都能干活。但随着 CARP 、Dense Policy 等新模型登场,快系统也许会有新花样。另一个有趣的问题是——像 Robodual 那样,快系统到底需不需要更多感觉模态?哪些模态才是它真正的“必需品”?
DiT(Diffusion Transformer)和Flow Matching:两大流行小模型框架。
RGB?深度?触觉?本体感知?各个研究流派说法不同,草莓采摘中这个力度触觉值得深入探索。
1.5.3 潜在特征表示的选取
潜在 token(latent features)的选取,是双系统设计里最复杂也最急需攻克的一环。
- DP‑VLA :直接拿 MLLM 最后一层的 hidden embedding;
- GR00T‑N1:用中间层特征,图像信息更丰富且推理更快;
- Roboflamnigo、HiRT :对语言和视觉的最后一层输出做 max‑pool,再拿来指导;
- LCB:创新性地引入 ACT token,把上下游“拧”在一起;
- Robodua:在此基础上加了多个 ACT token,同时也用最后一层语言特征。
总之,潜在特征的最佳选型仍是未来双系统研究的热点。
1.5.4 MLLM 训练策略
关于如何训练多模态大模型(MLLM),核心在于:既要在下游场景中无损地保持其泛化能力,又要保证与下游 System 1 的集成顺畅。目前常见做法有**“冻结”预训练权重不更新和“全量微调”**两种,但挖掘更高效、更低资源消耗的微调技术依然大有可为。
1.5.5 策略头训练方法
在训练 System 1(Policy)时,首要考虑是如何节省训练成本:若能基于已有的预训练策略再针对特定应用做微调,将大幅缩短训练时间;但若完全从零开始训练,需要评估新的优化目标是否会导致收敛变慢或不稳定。
1.5.6 双系统集成策略
关键在于如何把 System 2 提供的潜在信息“条件化”地灌输给 System 1。
LCB 中用 CLIP 损失让上游 latent 与原始文本 embedding 保持一致,但这样会把下游限制在已有训练集范围。引入新 embedding 后,上下游特征维度不一致,往往要插一个“投射器”(projector),如何训练这个投射器非常考验功力——特别是当下游是预训练模型时,投射器需要先对齐而不更新 MLLM,否则两者一起动会导致训练崩溃。最佳实践往往是先“冻结”大模型,仅调整投射器,再对接下游;若一同更新容易导致梯度互相干扰。
1.5.7 双系统异步策略
LCB、HiRT 和 Robodual 各有设计,LCB 最简单——训练时同步、推理时异步,让慢系统隔若干帧才出结果。或者完全异步管线:上游和下游独立运行,根据缓冲区或事件触发更新;实现更灵活但更难调试。异步是否真的提升了实时性与性能平衡,还是简单地掩盖了上游特征质量不足的问题,这个还有待商榷。
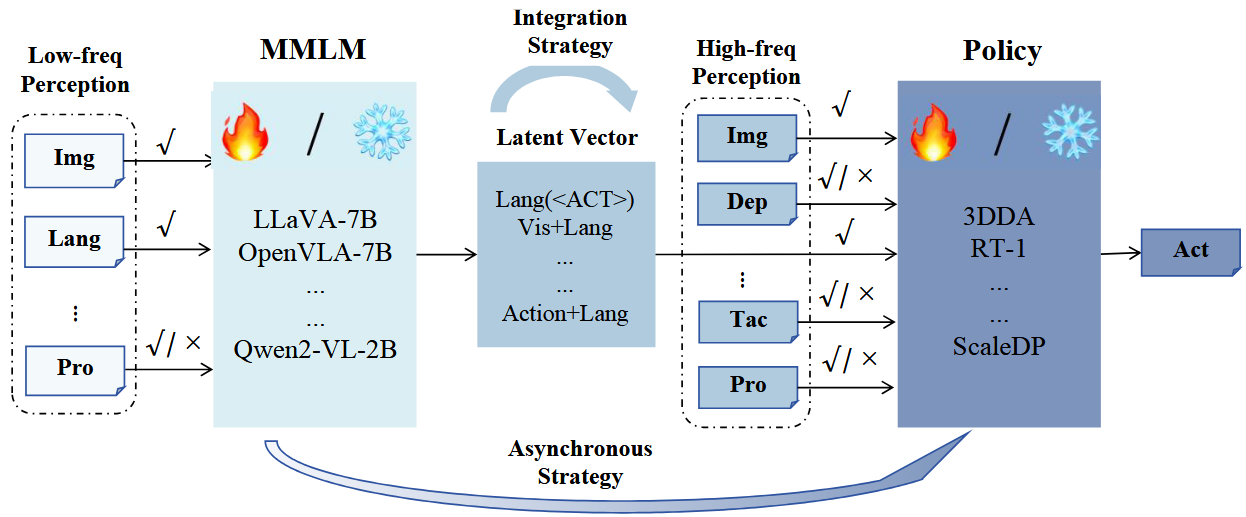
2. 实验评估
根据前面的综述,目前的双系统模型在多个方面表现出显著差异,包括选用的视觉-语言基础模型(MLLM)、下游策略网络的架构,以及潜在特征(latent features)的选取机制 。
多维度的差异导致很难直接比较各方法的优劣。这些差异凸显出开展一次系统且公平的对比实验的迫切必要,以评估不同设计思路背后的合理性,并为后续模型的开发奠定参考框架。
在本研究中,对条件 1(MLLM)、2(策略头)、3(Latent rep) 和 7(异步策略) 进行了标准化处理以保证一致性,并将评估重点放在条件 4(MLLM训练策略)、5(策略头训练) 和 6(双系统集成) 上。
这三项条件涵盖的技术手段具有广泛适用性,并在很大程度上不依赖于在条件 1、2、3、7 中的具体选型,有助于提炼出可迁移、与平台无关的关键经验。
即便我使用任意家的模型,训练策略和双系统集成策略是不变的。(暂时)后续还会继续评估剩余条件,所有更新和进展都在:https://github.com/OpenHelix-robot/OpenHelix/
目前应该只有部分代码、数据等,还没有模型。
2025-4 Initial release of OpenHelix codebase!
2.1 实验设置
模型选择
为与 LCB 保持一致,本文全程采用 LLaVA 1.0 作为视觉-语言大模型(MLLM);为消除不同策略网络架构带来的差异,所有实验统一使用 3DDA 作为下游策略;上游潜在特征的集成方式,完全参考 LCB 中的方法;在涉及异步设置的实验中,也与 LCB 一致,采用“训练同步、测试异步”的方式。
OpenVLA中选择使用 Prismatic-7B VLM,效果似乎更好
数据集处理
与 LCB 在 ACT之前构造对话式回复不同,我们直接将 ACT> token 拼接在指令后面。之所以这么做,是因为暂未实现对话式回复的生成;但经实验,省略该步骤的情况下模型表现仍然令人满意。
后续工作中,我们会补充对话式数据的处理流程。
仿真环境
为了对比那些闭源却有公开结果的方法,实验选用了它们的同款环境。与 LCB 和 RoboDual 保持一致,本工作将 CALVIN 环境作为主要的模拟对比平台。
后续还将补充真实世界环境下的验证实验。
标准评测
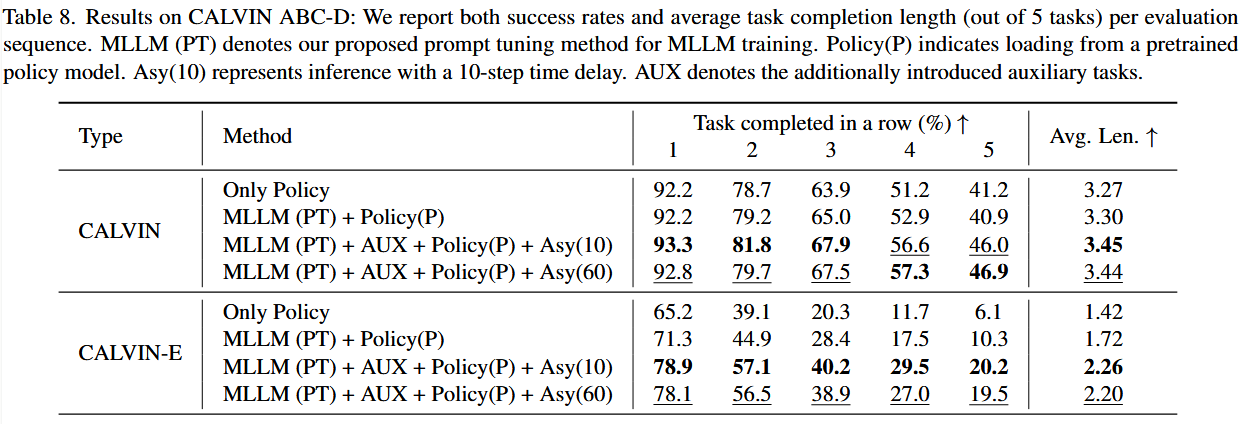
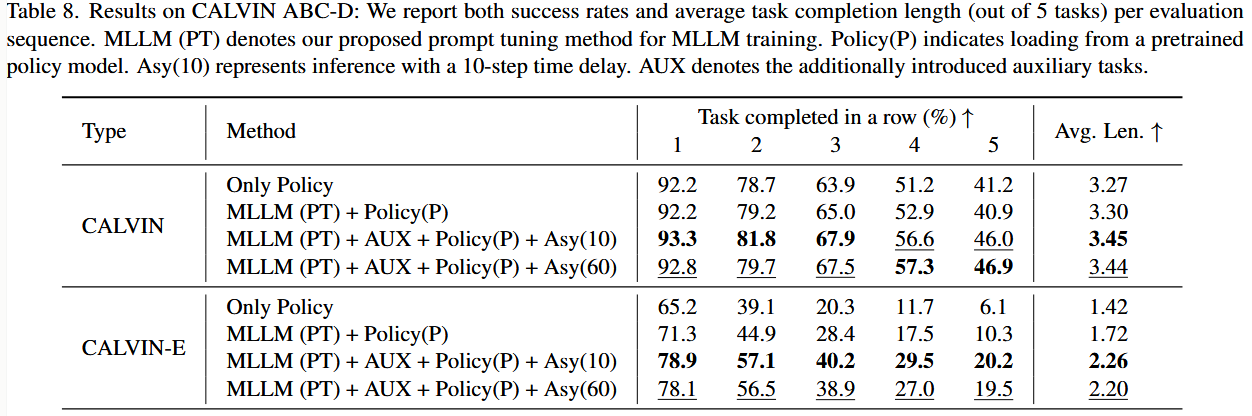
与已有工作一致,主要在 ABC-D 任务场景下进行效果验证。为加快消融实验的测试速度,先取标准 1,000 次评测中的前 100 次进行快速验证。在最终的完整评测(表 8)中,再跑满全部 1,000 次,以呈现更全面的结果。
强化评测
如图 2 所示,标准评测中的场景物体静止且指令规范。但双系统的真正价值在于:用大模型的语言泛化能力配合小模型的高频动作输出,来应对更动态的环境。
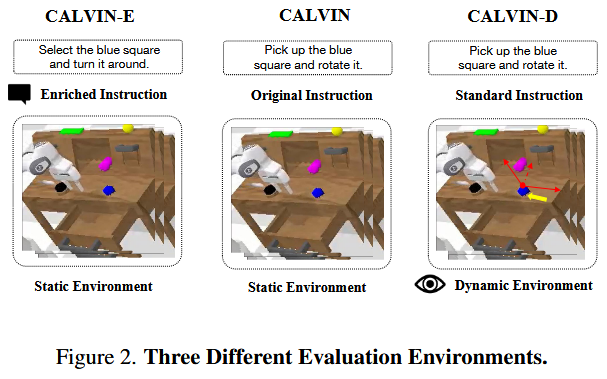
因此,本工作额外设计了两种“强化评测”场景:
- CALVIN-E:考察语言指令泛化,用更丰富多样的指令文本进行测试。(减少模型对标准化文本的依赖)
- CALVIN-D:考察动态场景下的鲁棒性,在抓取任务中让物体以四种不同方式运动,并评估模型应对动态变化的能力。
2.2 为什么不用单系统
实际上,“双系统”这一概念的界定一直并不十分清晰,但当我们设计了 CALVIN-D 动态环境实验后,发现以往的单系统方法(如 Roboflamnigo-RF )在此测试下一概无法完成任务,因此之后的实验中未再对单系统模型进行测试。
如果草莓被风吹动了,或者在摘某个草莓的时候其他草莓也动了,这对单系统VLA是不是一种毁灭打击?no
说明单系统难以兼顾实时感知与深度推理的双重需求。
实验证明:
我们将经标准 ABC 数据集训练的模型在 CALVIN-D 环境中进行 100 次测试。“Static”代表对象静止不动的场景,“Left”、 “Forward”、“Diagonal”和“Circle”分别对应四种对象移动模式。具体结果详见表 2。
Static:基准对照组,用以检验模型在普通静态条件下的性能。
Left / Forward / Diagonal / Circle:分别模拟物体沿左侧、前方、对角线或环形轨迹运动,全面测试模型对不同运动模式的适应性。
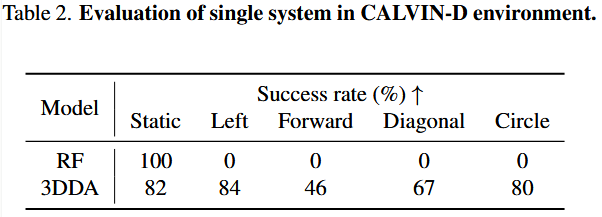
发现 RF 方法在 CALVIN-D 上的表现非常令人意外:在所有动态测试中均未能完成任务,成功率为零。其主要原因在于,RF 在测试时需处理前 6 帧图像来获取 LSTM 推理所需的潜在表示;而当环境中物体移动时,这些潜在表示在测试阶段会剧烈变化,与训练阶段的稳定性大相径庭,导致性能骤降。
它们同为目前在CALVIN系列抓取基准上表现领先的两种、但范式迥异的代表性方法,通过对比可以揭示:
1)视觉-语言大模型+历史帧LSTM(RF)在动态场景下的脆弱点;
2) 基于三维场景表示的扩散策略(3DDA)的鲁棒性优势;
3) 不同方法在静态vs 动态、简单 vs 复杂任务上的适用范围和局限。
不过,我们也观察到,RF 结合 MLLM 后,在简单静态任务上表现极佳,远强于更小的 3DDA 模型,这进一步凸显了以 MLLM 作“智能大脑”的重要性。
这一结论尚不十分严谨,因为尚未对 π0 、GR00TN1 等单系统方法在 CALVIN-D上进行测试。
后续工作中,我们会补充这些实验,以进一步验证单系统在动态环境中的局限性。
2.3 双系统的训练策略
对于双系统模型,主要的训练策略包含三个部分:
- 怎样训练低层策略(让机器人多次练习捡起不同形状的物体,不断试错来学会“怎么抓最稳”)
- 怎样训练高层大模型(告诉AI“现在你要做一个三明治”,它需要学会先找面包、再放火腿和奶酪,这种“任务分解”)
- 怎样把它们两个联系起来(高级MLLM决定“要抓起红球”,然后低级策略来执行“走过去、伸手、抓起”)
接下来的实验也包含这3个部分:
2.3.1 低层执行策略
初步设定: 对于 LCB 方法,其下游的低级策略使用了预训练的 3DDA;而 HiRT 则采用 RT-1 架构,并且从头开始训练;Robodual 则使用其自行设计的下游策略。
抛开各自配置的差别,策略训练主要有两种范式:一是“从头训练”,二是“在预训练模型上微调。
为了进行公平对比,大模型部分统一采用 LCB 的结构:以 LLaVA1.0 作为主干网络,通过一个特殊的 ACT token 来承载动作指令,并全部使用 CLIP Loss 来对齐ACT token 与下游指令。
CLIP Loss:一种让视觉与语言对齐的损失函数,用来确保 ACT token 真正学会对应不同指令。
唯一的区别就在于:下游策略要么用预训练好的 3DDA,要么完全从零开始训练。
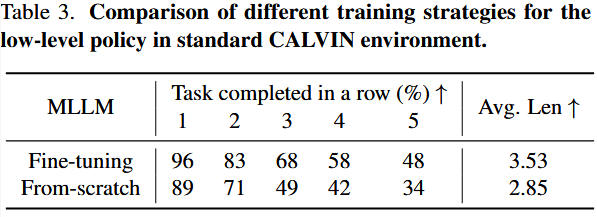
“Avg. Len”其实并不是指时间,而是指平均能连续完成多少个任务,越高代表总的实验/评估时间反而更短
使用预训练策略不仅能提升最终性能,还能缩短整体训练时间。因此,后续的所有实验都以在预训练策略模型上微调为基础。
2.3.2 MLLM训练策略
对于 LCB、HiRT 和 Robodual 三种方法,它们的上游大模型都是通过“微调”(fine-tuning)来训练的。虽然 GR00TN1 并不属于双系统框架,但它采用“冻结”(frozen)大模型参数的方式也取得了很好的效果。因此,本节实验同时考察了这两种训练范式。
到底是微调效果更好,还是冻结更省心又能拿高分?
为了公平对比,上游大模型依旧采用 LCB 中的那套结构:以 LLaVA1.0 为主干,通过一个特殊的 token 负责输出动作指令,并用 CLIP Loss 对齐该 token 与下游指令。
下游的低级策略一律采用微调方式训练。在把 MLLM 和策略模型连接起来时,还将“是否使用 CLIP Loss”作为一个可调变量。
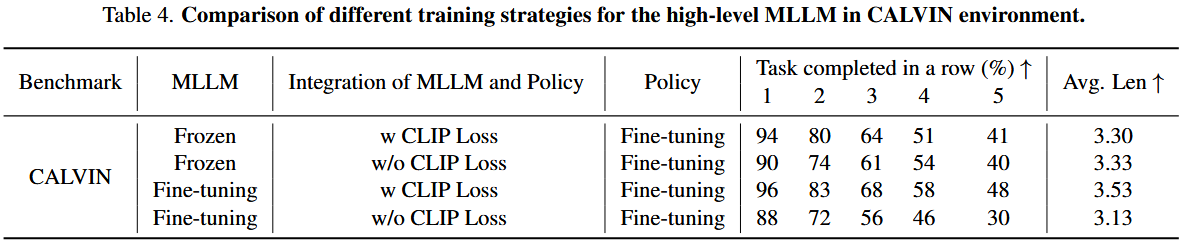
当大模型参数被“冻结”时,是否加 CLIP Loss 对性能影响很小——因为 CLIP Loss 本质上只是用来微调 model 输出以适配下游小模型,模型本身没变,输出结果差异不大,所以影响很小。
一旦大模型要“微调”,CLIP Loss 就非常关键:没有它,会很容易破坏下游模型已经学好的注意力机制,反而让性能下降。
虽然加了 CLIP Loss 后整体性能可以跑通,但它本质上还是会削弱大模型的泛化能力。要么冻结,保留泛化;要么微调,却牺牲泛化。能不能两全其美?
这种泛化对草莓采摘是很重要的,所以还是尽可能保留。
如图 3 所示,仅修改了 MLLM 的训练方式,改用“提示调优”(prompt tuning)。具体做法是在大模型词表里新增一个 ACT token,仅训练该 token 对应的 lm-head 参数,其他所有参数都保持冻结。这样,相当于只教模型认识一个与下游任务相关的新词,不动“旧知识”,因此理论上能既保住泛化能力,又让两套系统衔接更紧密。
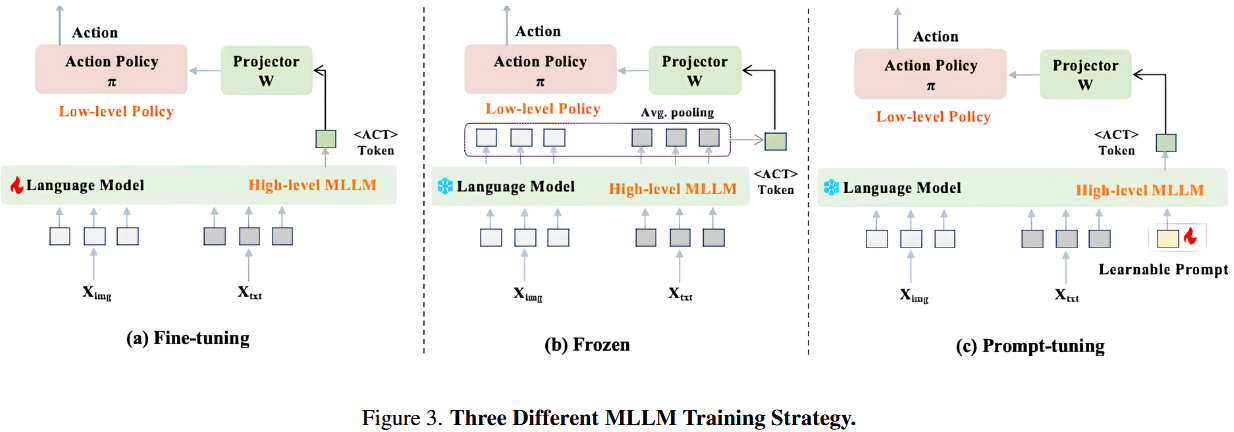
模型原来的语言理解、视觉推理通通不碰,只教它一个新词“ACT”应该在哪儿出现、代表什么动作信号。
接着,我们通过表 5 中的实验来验证上述假设。
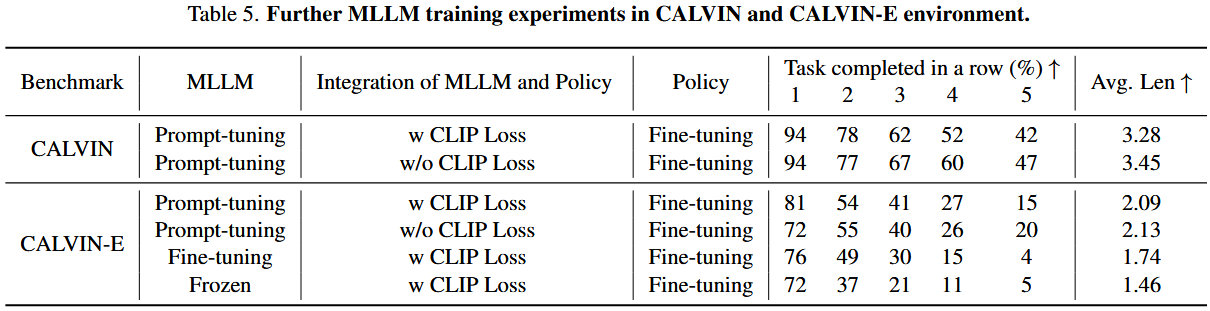
表 5 会对比“微调”、“冻结”、“提示调优”三种范式在标准测试和泛化测试上的表现差异。
采用提示调优时,在标准的 Calvin 测试环境里,其性能跟微调和冻结方法差不多;但在专门检验“语言泛化”能力的实验中,差距就大了。
在都用了 CLIP Loss 的条件下,提示调优的泛化效果远超微调和冻结;甚至不加 CLIP Loss 时,泛化能力还有些小幅提升。
它们这测试的是对语言的泛化,有没对视觉方面的泛化进行的实验?草莓植株各异主要还是针对图像方面吧?还是说这种对指令泛化能力的保留其实侧面证明了对图像的泛化能力?
结论:
- 微调:可塑性强,但易破坏泛化;
- 冻结:泛化保留,但连接松散;
- 提示调优:两者兼顾,小成本、大收获。
对那些需要高泛化和低算力消耗的双系统场景,首选提示调优
2.3.3 双系统联合策略
初步设定: 基于前面的小节实验,我们得出结论:使用预训练的低级策略,并对多模态大语言模型(MLLM)采用提示调优,是效果最好的组合。
但这一步还要解决一个关键问题——如何将“上游”大模型和“下游”策略模型衔接,因为两者在语义和特征空间上可能差距很大。因此,我们在这里主要做消融分析。
“大模型想告诉小模型做什么”这一步不是自动就通的,需要专门的接口
拆开对比不同接入方式,看看哪些环节最重要
为了连接上游大模型和下游策略,需要一个 MLP(多层感知机)投影器。我们比较了两种做法:
- 直接联合训练:同时解冻上下游模型和投影器,三者一齐训练;
- 分阶段训练:先冻结上游大模型,只训练投影器和下游策略,待它们预对齐后,再解冻大模型,进行联合训练。
这两种方法的核心区别就在于“是否先单独训练投影器”。具体对比结果见表 6。
MLP投影器:桥梁模块,把大模型输出映射到小模型输入所需的形式;
直接训练:一步到位,但可能因为初始化不佳导致对齐困难;
分阶段训练:先让投影器和下游“小脑”磨合,再引入“大脑”,能更平滑地衔接。
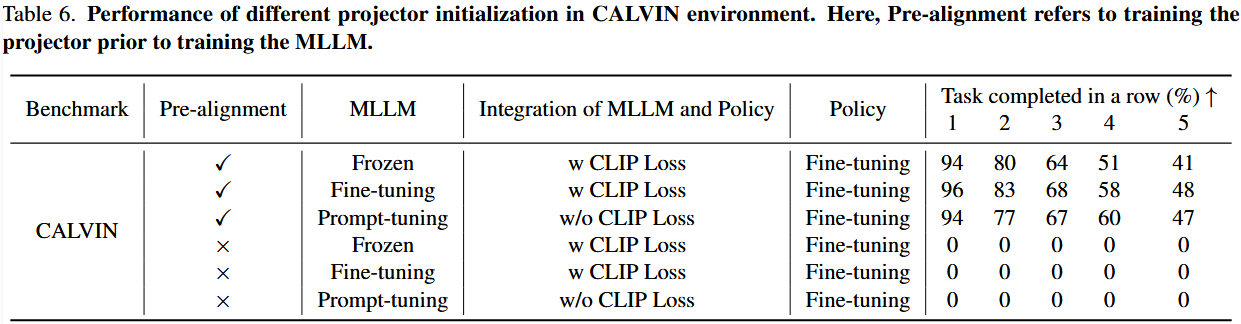
如果不先对投影器做预对齐(pre-alignment),无论是基于冻结、微调,还是提示调优的集成方式,直接连接上下游模型都会失败——性能极差。投影器如果一开始就要同时面对“大脑”和“小脑”的输出输入,很难学到正确映射,先让投影器学会桥接两者的映射关系非常关键。
阶段一:冻结大模型,只训练投影器 + 预训练策略,让它们先在特征空间里磨合;
阶段二:解冻大模型,三者联合微调,完成最终协同。
两个人语种不同,中间人翻译,得先让他学会一种,再学另一种,才能对齐颗粒度。
2.4 双系统的测试策略
初步设定: 双系统模型的核心在于,上层(MLLM)和下层(低级策略)需要“异步”协同。
- 在 LCB 中,作者并未在训练中引入异步,而是先同步训练,后异步推理;
- 在 HiRT 中,他们在训练时通过额外的缓冲区来实现异步;
- 在Robodual 中,则是用下层实时替换上层产生的粗动作,达到异步效果。
本节主要验证 LCB 的“训练同步 + 推理异步”这种方案,后面会补充对 HiRT 和 Robodual 式异步的测试。
实验设置: 在 CALVIN-D 环境里,我们让动作策略在每次 MLLM 推理之间,先后执行 1 到 60 个步长不等的动作。这里的“步长”指的是低级策略在一次大模型推理期间,连续调用多少次动作;3DDA 允许的最大步数是 60。
例如,当步长=10 时,大模型决定一次动作指令后,下层就连续跑 10 步,再等下一个指令;
这样可以模拟“MLLM慢、大动作;执行快、小动作”的异步互动。
如下图 4 所示,无论低级策略在两次大模型推理间执行多少步,整体成功率和效率变化都非常接近。即使在场景动态变化的情况下,实验结果依然如此。
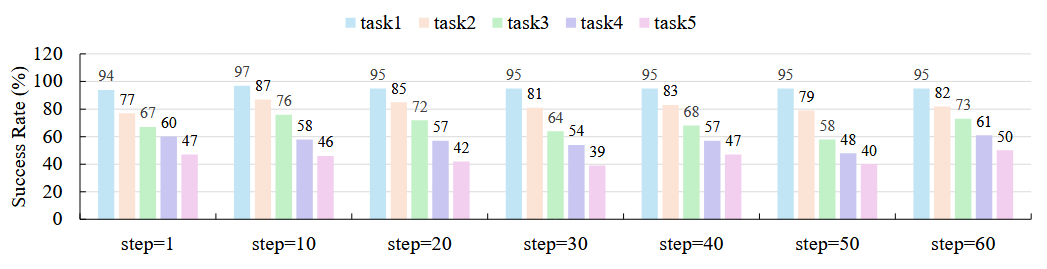
换句话说,让低级策略跑得快一点或慢一点,对最终效果几乎没影响。
直觉假设: 这个“步长无关性能”的现象表明,当前 MLLM 对环境动态并不敏感,令人费解。因此,我们要弄清楚,上层 latent 向量到底在传递什么信息给下游。
深入设计: 我们抽取了 MLLM 输出的动作 token 的隐向量(latent embedding),并将它们映射到语义空间里,通过计算与不同词的相似度,来判断这些 token 实际上传递了什么语义。实验场景是一个蓝色方块不断向左移动,结果见图 5。
隐向量映射相当于把“隐藏状态”转成“词向量”,再看它跟“left”“right”“up”等词有多近;
这样可以定量地知道,模型是“看环境”还是“背文本”。
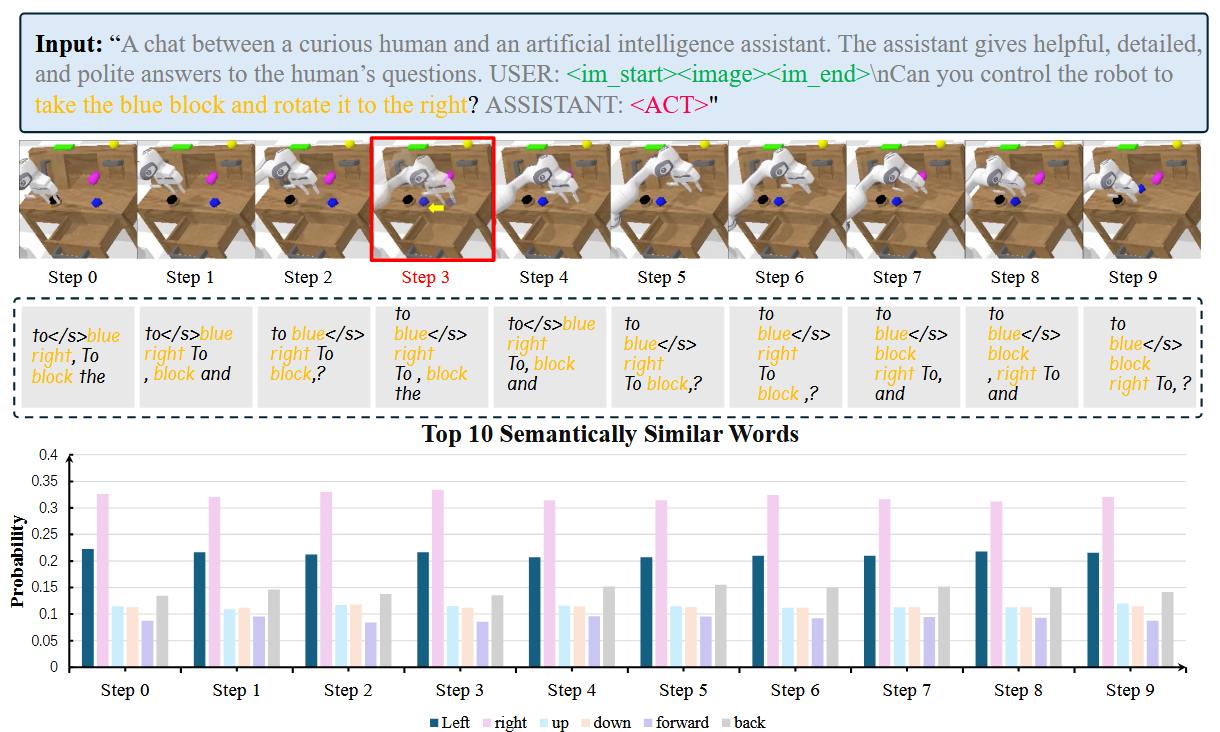
第一行是输入MLLM的信息:
“A chat between a curious human and an artificial intelligence assistant. …
USER: <im_start><image><im_end>
Can you control the robot to take the blue block and rotate it to the right?
ASSISTANT: <ACT>”
MLLM 收到的是真实环境图像(image)加上一条“取蓝色方块并向右旋转”的指令,最后期待它输出特殊接口 token ACT。
第二行表示:
环境在 Step 3 时,演示了对“蓝色方块”做了手动左移(红框标注)。这相当于在机器人执行过程中给场景加了个小“恶作剧”,考察 MLLM 对物体位置突变的鲁棒性。
第三行:
在每个时间步(Step 0…9),我们把 MLLM “准备输出 ACT” 时对应的隐藏向量,拿去在整个词表里找 语义最相近的 10 个词。
第四行:
选取了六个关键“方向词” {left, right, up, down, forward, back},展示它们在每个 Step 的归一化概率(总和为1,展示对各个方向的偏好)。
深入分析:
(1)空间词相似度: 无论机械臂向左还是向右移动,“right”(向右)的相似度概率始终高于“left”,且各空间介词随时间变化极小。这说明动作 token 学到的是一种“恒定语义特征”,与环境变化无关。“right”概率更高,可能因为它在语言里也有“正确”的含义,信息量更丰富。
(2)Top10 相似词: 在各时间步中,与 token 向量最相似的十个词,主要是“目标对象名”“空间关系词”和“动作语义”,夹杂少量噪声。也就是说,这些向量更多承载了“文本指令”的内容,对视觉变化几乎没反应。换言之,现有训练并未让 MLLM 真正做视觉推理,而只是把指令“复述”给下游策略。
低级策略几乎收不到新环境信息,只能按指令一成不变地执行。
2.5 双系统的MLLM是否有足够效率?
初步设定: 根据前面分析,通过隐向量传递的信息对下游策略还不够用,环境感知严重不足,难以高效完成任务。所以本节目标是在现有框架下,探索更充分利用上游 MLLM 输出的方法。
实验设置: 延续前面最佳方案:下游策略微调 + 分阶段投影器训练,上游大模型采用提示调优。但在如何使用 MLLM 上设计了三种变体:
- 标准 MLLM:保持多模态能力不变;
- 纯 LLM:剥离视觉输入,只当文字语言模型用;
- MLLM + 辅助损失:在隐向量之外接一个额外的 head,为其设计位置或旋转的预测任务。
目的是分离出“多模态”和“纯语言”能力的差别,并测试“强迫学习视觉信息”能否提升。

- 纯 LLM:表现远逊于标准 MLLM,表明去掉视觉输入后,模型无法胜任环境感知与动作决策;
- MLLM + 辅助损失:任务成功率显著提升。原因在于,附加的辅助预测任务(如位置、旋转)迫使模型从隐向量里编码更多与视觉相关的特征,从而让下游策略获得更丰富的环境信息,而不是仅仅依赖指令语义。
3. 一个简单但高效的双系统VLA
根据前面的分析,我们采用提示调优的方式来调整大模型的输出,而不是直接对多模态大语言模型(MLLM)自身进行微调。
此外,我们还引入了一个辅助任务,以充分利用 MLLM 的视觉推理能力。
这和直接使用VLM不同,VLM天然以文本为输出格式,而机器人需要的是连续的末端执行器轨迹或离散动作序列,二者之间需设计额外的“解码器/翻译器”模块。
在同一个大模型内部同时学习视觉理解、语言对齐和高频动作预测,容易因多任务冲突导致对任何单一子任务的性能折中,且难以独立优化和安全验证。
3.1 结构
网络结构:我们的系统由两个主要部分组成:一个预训练的多模态大语言模型 MLLM(记作 f ϕ f_ϕ fϕ,参数为 ϕ)和一个预训练的执行策略网络 π θ π_θ πθ(参数为 θ)。
MLLM 包含一个纯文本的大语言模型和一个视觉编码器,视觉编码器将图像映射到语言模型的嵌入空间,从而让模型同时理解文字和图像信息。
预训练执行策略网络包括一个视觉编码器和基于 Transformer 的扩散(diffusion)模型。通过多层交叉注意力(cross-attention),扩散模型融合了大量条件信息,比如三维场景表示、机器人本体感觉(关节角度、力觉等)以及来自高层模型的指令 token(如 ACT)。
扩散模型:一种生成式网络,可逐步“净化”噪声轨迹,预测机器人动作;
交叉注意力:让策略同时关注环境图像、本体状态和来自 MLLM 的指令。
选择 LLaVA 作为上游的多模态大语言模型,3DDA 作为下游的预训练扩散策略。
值得注意的是,我们用一个线性层替换了 3DDA 原有的文本编码器,以对齐:大模型输出的隐向量维度 ↔ 下游策略输入维度。线性层相当于一个“升/降维模块”,把 MLLM 的输出向量转换成策略网络能直接接收的格式。
输入输出:整个系统按示范轨迹的格式运行,整条数据结构: { l l l, (o₁, a₁), (o₂, a₂), …},其中:
- l l l= {wᵢ ∈ ℝᵈ}ᵢ₌₁ᴺ 表示一条长度为 N、每个 token 维度为 d 的任务指令;
- o t o_t ot 和 a t a_t at 分别表示第 t 步的视觉观察和对应的机器人动作。
任务指令:先将自然语言指令(如“pick up the blue block and rotate
right”)分词后,通过词嵌入或编码器映射成一系列 d 维实数向量,构成长度为 N 的序列。
模型的目标就是学习映射:
( l , o t ) → a t (l,o_t)→a_t (l,ot)→at
从而在新环境、新指令下生成正确动作。
通过这种格式,系统能够同时利用语言、视觉和动作数据进行联合建模,实现多模态条件下的一条示范到一条执行的端到端学习。
输入观察 o t o_t ot 包含两张来自不同视角的 RGB-D(彩色+深度)图像。输出动作 aₜ 定义末端执行器的姿态,分解为:三维位置 a t l a^l_t atl ∈ ℝ³、旋转参数 a t r a^r_t atr ∈ ℝ⁶,以及夹爪开闭状态 a t g a^g_t atg ∈ {0,1}。
上游模型 f ϕ f_ϕ fϕ接收任务指令 l l l和第三视角RGB 图像 o t , o_t^, ot,(比如俯视或侧视),输出隐向量 z t z_t zt 供下游策略使用。
下游预训练策略的输入包括:
- 当前的“噪声轨迹” τⁱₜ 和扩散步骤 i;
- 环境观测 oₜ、上游输出 zₜ,以及本体感觉 cₜ(关节状态等)。
它预测从时刻 t 到 t+T 这段的动作轨迹 和夹爪开闭状态 。
3.2 训练
提示调优
为了避免破坏多模态大语言模型(MLLM)已有的泛化能力,我们在原始指令 l 末尾新增一个可学习的特殊标记 ACT(维度为 ℝᵈ)。新的指令记作 l l l′ = { l l l, ACT}。
在训练过程中,MLLM 的所有参数都保持冻结状态,只对 ACT 这个 token 的向量表示进行更新。
多模态推理学习
之前的方法只用文本监督来对齐 MLLM 输出与 CLIP 文本编码,导致视觉推理能力被削弱。
因此,我们设计了一个辅助任务,无需额外数据,只需把通过 ACT token 得到的隐向量 z t z_t zt(由 MLLM 处理指令 l l l′ 和第三视角图像 o t o_t ot’ 得到)送入几个线性层,去预测:
1.末端执行器的开合动作 (用二元交叉熵 BCE 监督)
2.末端执行器在未来 T 步的三维位置 (用 L1 损失监督)
3.三维旋转参数 (同样用 L1 损失监督)
最终的总损失为三项之和,其中 ω1 和 ω2 用于平衡位置与旋转误差的权重。
辅助任务的价值:让 MLLM 的隐向量不仅仅“复述文本”,而且“读懂画面”以完成位置和旋转预测
| 任务 | 损失类型 | 目的 |
|---|---|---|
| 开合动作 a t : t + T g a_{t:t+T_g} at:t+Tg | 二元交叉熵 | 训练模型区分“抓取/松开”等离散指令,提高接口token的语义准确性 |
| 未来位置 a t : t + T l a_{t:t+T_l} at:t+Tl | L1 损失 | 惩罚位置预测误差,让隐向量编码精确的空间坐标信息 |
| 未来旋转 a t : t + T r a_{t:t+T_r} at:t+Tr | L1 损失 | 约束旋转参数预测,提高模型对朝向变化的敏感度 |
扩散学习
沿用了此前的扩散策略方法,以“动作去噪”(action denoising)为训练目标来优化模型。
扩散模型先将真实轨迹加噪,再学会“去噪”恢复正确动作,是一种生成式学习范式
在训练时,我们随机选取一个时刻 t 和扩散步骤 i,将噪声 ε = (εˡ, εʳ) 加到该时刻的真实轨迹 τₜ⁰ 上。
εˡ 加在位置序列上,εʳ 加在旋转序列上,二者分别对应下面的噪声恢复目标。
损失函数定义为:
夹爪开合预测损失:二元交叉熵BCE
位置噪声恢复损失:带权 L1
旋转噪声恢复损失:带权 L1
第一项让模型学会正确开关夹爪;
第二、三项分别监督模型从噪声位置与旋转中还原出真实的噪声分量,从而实现轨迹“去噪”
两阶段训练
我们采用两阶段的训练方法来优化所提的双系统架构。
第一阶段(预对齐):为使 MLLM 输出的隐向量与预训练执行策略的特征空间初步对齐,我们将大模型和低级策略网络的参数全部冻结,仅训练提示层(prompt)和投影层(projection)。
学会把高层输出映射到底层可用的格式
第二阶段:继续保持大模型冻结,解冻低级策略,同时与提示层和投影层一起进行联合微调。
阶段二则“拆除支架”,让预训练策略在已对齐的基础上进一步优化执行能力。
两个阶段的损失函数完全相同,唯一差别在于第二阶段允许低级策略更新。
总损失由两部分组成,可表示为 L L Ltotal= L L Llm+ L L Lpolicy
L L Llm对应前文的多模态推理辅助损失,让 MLLM 学会输出富含视觉和文本信息的嵌入;
L L Lpolicy是扩散策略的去噪与夹爪预测损失,保证下游动作的准确生成。
实现细节:
1. 模型选择:上游采用 LLaVA-7B,多模态大语言模型;下游采用 3D Diffuser Actor 扩散策略网络。
2. 预训练参数:使用 3D Diffuser Actor 在 65,000 次迭代时保存的检查点。
3. 训练迭代:第一阶段(投影与提示预对齐)训练 2,000 次迭代;第二阶段(联合微调)继续至总计 100,000 次迭代。
4. 投影层:线性层,用于将 MLLM 的输出维度从 4096 降到 512,以匹配下游策略的输入。
5. Prompt 设置:手动向 LLaVA 的分词器中添加 token,并冻结 MLLM 其余所有参数,仅微调此 token 对应的嵌入向量。
6. 其它训练细节与 3D Diffuser Actor 原论文设置保持一致
3.3 结论
基于表 8 的实验结果,我们得到与前面实证研究一致的三个结论:
- 将模型的上层(MLLM)与下层(策略网络)有效集成,其关键作用在于提升模型在语言泛化场景中的表现。
- 添加额外的辅助任务对提升标准任务指标和泛化性能都非常有帮助,主要原因在于它们增强了模型的动作执行能力。
- 异步推理对该通用任务模型的推理性能影响甚微;即便模型在两次大模型调用之间只执行一次最大步长的异步动作(Asy(60)),最终性能也基本保持不变。
换句话说,大模型不必每一步都参与推理,偶尔“放权”给底层策略,让它连续走 60 步,最后整体表现基本不变。
允许下层策略连续执行多达60步后才重新调用大模型,虽减少大模型调用次数,但也会导致较大的轨迹“漂移”
但是结果显示影响很小,所以极限情况下可以Asy(60)
4. 讨论与局限
它们离做出类似Helix的开源复现还有很长的路要走,只能在模拟器里运行,还不能“上机器人”,这篇技术报告只是它们研究的初版,其中有很多未完成内容,包括实验,模型等等。
它们将会持续更新它们提出的目标,对一些目前还没验证清楚的说法保持开放态度(也就是承认不确定性)。
半成品吧,具有一定指导意义,可以在后续保持关注。
相关文章:

半成品的开源双系统VLA模型,OpenHelix-发表于2025.5.6
半成品的开源双系统VLA模型,OpenHelix https://openhelix-robot.github.io/ 0. 摘要 随着OpenVLA的开源,VLA如何部署到真实的机器人上获得了越来越多的关注,各界人士也都开始尝试解决OpenVLA的效率问题,双系统方案是其中一个非…...

fiftyone-dataset使用基础
1.创建dataset 将dataset写入数据库时,对于已有的dataset name会报错: 解决方法:指定覆盖写 添加参数overwriteTrue, 默认为False # 在写入数据集时,指定overwriteTrue,表示当dataset_name在数据库中已存在时&#…...
Java Object类、Final、注解、设计模式、抽象类、接口、内部类)
(1-4)Java Object类、Final、注解、设计模式、抽象类、接口、内部类
目录 1. Object类 1.1 equals 1.2 toString() 2.final关键字 3.注解 4. 设计模式 4.1 单例模式 4.1.1 饿汉式 4.1.3 饿汉式 VS 懒汉式 5. 抽象类&抽象方法 6. 接口 1. Object类 1.1 equals 重写Object 的equals方法,两种实现方式…...

强力巨彩谷亚推出专业智慧显示屏,满足多元场景需求
LED显示屏作为信息传播与视觉展示的关键载体,其性能和品质的提升备受关注。为响应市场对高品质显示的迫切需求,强力巨彩旗下专业智慧显示高端品牌谷亚G-ART,携多款行业领先水平的LED显示屏产品亮相,为用户带来专业、高效且节能的显…...

基于Spring AI与Hugging Face TGI构建高效聊天应用:从配置到实践全解析
基于Spring AI与Hugging Face TGI构建高效聊天应用:从配置到实践全解析 前言 在人工智能技术蓬勃发展的当下,大语言模型(LLM)的应用场景日益丰富。如何快速将 Hugging Face 生态中的强大模型部署为可通过 API 访问的服务&#x…...

MySQL视图:虚拟表的强大功能与应用实践
在数据库管理系统中,视图(View)是一种极其重要却常被忽视的功能。作为MySQL数据库的核心特性之一,视图为开发者和数据库管理员提供了数据抽象、安全控制和查询简化的强大工具。本文将全面探讨MySQL视图的概念、工作原理、创建与管理方法,以及…...
)
matlab插值方法(简短)
在MATLAB中,可以使用interp1函数快速实现插值。以下代码展示了如何使用spline插值方法对给定数据进行插值: x1 [23,56]; y1 [23,56]; X 23:1:56*4; Y interp1(x1,y1,X,spline);% linear、 spline其中,x1和y1是已知数据点,X是…...

【拥抱AI】Deer-Flow字节跳动开源的多智能体深度研究框架
最近发现一款可以对标甚至可能超越GPT-Researcher的AI深度研究应用,Deer-Flow(Deep Exploration and Efficient Research Flow)作为字节跳动近期开源的重量级项目,正以其模块化、灵活性和人机协同能力引发广泛关注。该项目基于 La…...

基于开源AI大模型与S2B2C生态的个人品牌优势挖掘与标签重构研究
摘要:在数字文明时代,个人品牌塑造已从传统经验驱动转向数据智能驱动。本文以开源AI大模型、AI智能名片与S2B2C商城小程序源码为技术载体,提出"社会评价-数据验证-标签重构"的三维分析框架。通过实证研究发现,结合第三方…...

2025年PMP 学习十二 第9章 项目资源管理
2025年PMP 学习十二 第9章 项目资源管理 序号过程过程组1规划资源管理规划2估算活动资源规划3获取资源执行4建设团队执行5管理团队执行6控制资源监控 项目资源管理,包括实物资源和团队资源。 文章目录 2025年PMP 学习十二 第9章 项目资源管理项目团队和 项目管理团…...

AI生成功能测试文档|测试文档
AI生成功能测试文档:链接直达 计算机功能测试文档撰写教程 链接直达:生成功能测试文档工具 一、文档概述 (一)文档目的 明确计算机功能测试的流程、方法和标准,确保测试的有效性和可靠性,为软件的质量评…...
:logging模块)
Python 常用模块(八):logging模块
目录 一、引言:日志模块在项目开发中的重要性二、从 Django 日志配置看 Logging 模块的核心组成三、logging模块核心组件详解3.1 记录器Logger3.2 级别Level3.3 根记录器使用3.4 处理器Handler3.5 格式化器Formatter3.6 日志流3.7 日志示例 四、日志模块总结 一、引…...

入门OpenTelemetry——可观测性与链路追踪介绍
可观测性 什么是可观测性 可观察性(Observability)是从外部输出知识中推断所获得,可理解为衡量一个系统内部状态的方法。可观测性是一种能力,它能帮助你回答系统内部发生了什么——无需事先定义每种可能的故障或状态。系统的可观…...

c#队列及其操作
可以用数组、链表实现队列,大致与栈相似,简要介绍下队列实现吧。值得注意的是循环队列判空判满操作,在用链表实现时需要额外思考下出入队列条件。 设计头文件 #ifndef ARRAY_QUEUE_H #define ARRAY_QUEUE_H#include <stdbool.h> #incl…...
)
【Linux C/C++开发】轻量级关系型数据库SQLite开发(包含性能测试代码)
前言 之前的文件分享过基于内存的STL缓存、环形缓冲区,以及基于文件的队列缓存mqueue、hash存储、向量库annoy存储,这两种属于比较原始且高效的方式。 那么,有没有高级且高效的方式呢。有的,从数据角度上看,࿰…...
 】)
77. 组合【 力扣(LeetCode) 】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路四、参考代码 零、原题链接 77. 组合 一、题目描述 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。 二、测试用例 示例 1: 输入&…...
)
GpuGeek全栈AI开发实战:从零构建企业级大模型生产管线(附完整案例)
目录 背景一、算力困境:AI开发者的「三重诅咒」1.1 硬件成本黑洞1.2 资源调度失衡1.3 环境部署陷阱 二、三大核心技术突破GpuGeek的破局方案2.1 分时切片调度引擎(Time-Slicing Scheduler)2.2 异构计算融合架构2.3 AI资产自动化…...
(技巧)(计数;双指针))
LeetCode 热题 100_颜色分类(98_75_中等_C++)(技巧)(计数;双指针)
LeetCode 热题 100_颜色分类(98_75_中等_C) 题目描述:输入输出样例:题解:解题思路:思路一(计数):思路二(双指针): 代码实现代码实现&a…...

【前端】:单 HTML 去除 Word 批注
在现代办公中,.docx 文件常用于文档编辑,但其中的批注(注释)有时需要在分享或归档前被去除。本文将从原理出发,深入剖析如何在纯前端环境下实现对 .docx 文件注释的移除,并提供完整的实现源码。最后&#x…...

TTS-Web-Vue系列:Vue3实现内嵌iframe文档显示功能
🖼️ 本文是TTS-Web-Vue系列的新篇章,重点介绍如何在Vue3项目中优雅地实现内嵌iframe功能,用于加载外部文档内容。通过Vue3的响应式系统和组件化设计,我们实现了一个功能完善、用户体验友好的文档嵌入方案,包括加载状态…...

AWS CloudTrail日志跟踪启用
问题 启用日志管理。 步骤 审计界面,如下图: 点击创建跟踪,AWS云就会记录AWS账号在云中的操作。...

PHP 编程:现代 Web 开发的基石与演进
引言 PHP(Hypertext Preprocessor)自1995年诞生以来,已成为全球最流行的服务器端脚本语言之一。尽管近年来Node.js、Python等语言在特定领域崭露头角,但PHP仍占据着超过78%的网站市场份额(W3Techs数据)。本…...

NAT/代理服务器/内网穿透
目录 一 NAT技术 二 内网穿透/内网打洞 三 代理服务器 一 NAT技术 跨网络传输的时候,私网不能直接访问公网,就引入了NAT能讲私网转换为公网进行访问,主要解决IPv4(2^32)地址不足的问题。 1. NAT原理 当某个内网想访问公网,就必…...

[已解决] VS Code / Cursor / Trae 的 PowerShell 终端 conda activate 进不去环境的常见问题
背景 PS C:\Users\Lenovo\WPSDrive\669715199_3\WPS云盘\课程\研一\ROAS5700 Robot Motion Planning and Control\Final\LaTex报告\final-v1> conda activate mpPS C:\Users\Lenovo\WPSDrive\669715199_3\WPS云盘\课程\研一\ROAS5700 Robot Motion Planning and Control\Fin…...

Kuka AI音乐AI音乐开发「人声伴奏分离」 —— 「Kuka Api系列|中文咬字清晰|AI音乐API」第6篇
导读 今天我们来了解一下 Kuka API 的人声与伴奏分离功能。 所谓“人声伴奏分离”,顾名思义,就是将一段完整的音频拆分为两个独立的轨道:一个是人声部分,另一个是伴奏(乐器)部分。 这个功能在音乐创作和…...

深度伪造对知识产权保护的新挑战与应对之策
首席数据官高鹏律师团队 在科技的飞速发展带来了诸多便利的同时,也引发了一系列复杂的法律问题,其中深度伪造技术对知识产权保护的冲击尤为显著,亟待引起广泛关注与深入探讨。 深度伪造,简单来说,是借助先进的人工智…...

【嵌入式开发-软件定时器】
嵌入式开发-软件定时器 ■ 1.■ 2.■ 3.■ 4. ■ 1. ■ 2. ■ 3. ■ 4....

3天重庆和成都旅游规划
重庆和成都都是大城市,各自都有丰富的旅游资源。如果要在三天内两头都游览,可能需要合理安排时间,确保既能体验到重庆的特色,又能在成都游览主要景点。然而,考虑到交通时间,如果从重庆到成都需要一定的时间…...

JAVA中的文件操作
文章目录 一、文件认识(一)文件的分类(二)目录结构 二、文件操作(一)File类1.属性2.构造方法3.方法 (二)File类的具体使用1.文件路径的查看2.文件的基本操作(1࿰…...

深度解析网闸策略:构建坚固的网络安全防线
深度解析网闸策略:构建坚固的网络安全防线 在数字化浪潮中,网络安全已成为企业、机构乃至国家稳定发展的关键要素。随着网络攻击手段日益复杂多样,传统的网络安全防护措施难以满足日益增长的安全需求。网闸作为一种先进的网络安全设备&#x…...

【Rust trait特质】如何在Rust中使用trait特质,全面解析与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

滑动窗口算法笔记
力扣209 题目分析:想象一个窗口遍历着这个数组,不断扩大右边界,让r。往窗口中添加数字: 此时我们找到了这个窗口,它的和满足了大于等于target的条件,题目让我求最短的,那么我们就尝试来缩短它&…...

Problem A: 歌手打分
1.题目描述 在歌唱比赛中,共有10位评委进行打分,在计算歌手得分时,去掉一个最高分,去掉一个最低分,然后剩余的8位评委的分数进行平均,就是该选手的最终得分。输入每个评委的评分,求某选手的得分…...

容器安全-核心概述
文章摘要 本文探讨了容器安全的四个核心类别,包括环境基础设施安全、镜像安全、运行时安全和生态安全。尽管 EDR 能提供主机安全层面的部分防护,但无法覆盖容器的镜像安全和生态安全。容器的镜像安全和生态安全问题,如镜像漏洞、恶意镜像、容…...

Golang实践录:在go中使用curl实现https请求
之前曾经在一个 golang 工程调用 libcur 实现 https的请求,当前自测是通过的。后来迁移到另一个小系统出现段错误,于是对该模块代码改造,并再次自测。 问题提出 大约2年前,在某golang项目使用libcurl进行https请求(参…...

nvrtc环境依赖
一 下载 1.1 添加nvidia的源(不同于pypi) pip install nvidia-pyindex 1.2 pip dowload 执行 pip download nvidia-cuda-runtime nvidia-cuda-python 会发现文件夹多了以下几个文件 而需要安装的则只有红框的三个文件, 二 安装 对红框的…...

【计算机视觉】OpenCV实战项目:GraspPicture 项目深度解析:基于图像分割的抓取点检测系统
GraspPicture 项目深度解析:基于图像分割的抓取点检测系统 一、项目概述项目特点 二、项目运行方式与执行步骤(一)环境准备(二)项目结构(三)执行步骤 三、重要逻辑代码解析(一&#…...

Redis持久化存储
我们知道Redis是将数据放在内存中的,那怎么做到持久化存储呢?很简单,就是内存存一份,硬盘也存一份.那么两个地方都存会不会影响效率?答案是影响是不大的,要看具体的策略.同时也要注意内存的数据和硬盘中的数据可能会有一点不同.这也是取决于策略的不同. Redis持久化存储的两个…...

网络检测工具InternetTest v8.9.1.2504 单文件版,支持一键查询IP/DNS、WIFI密码信息
—————【下 载 地 址】——————— 【本章下载一】:https://drive.uc.cn/s/295e068b79314 【本章下载二】:https://pan.xunlei.com/s/VOQDXguH0DYPxrql5y2zlkhTA1?pwdg2nx# 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

elpis-core: 基于 Koa 实现 web 服务引擎架构设计解析
前言 内容来源于抖音【哲玄前端】大佬的《大前端全栈实践》课程,此课程是从零开始做一个企业级的全栈应用框架。此框架是基于koa.js构建的服务引擎,对BFF层的框架封装,让我感受颇深。 整体elpis项目架构设计 elpis-core设计思路 可以看到elpi…...

计算机网络-MPLS LDP基础实验配置
前面我们学习了LDP的会话建立、标签发布与交换、LDP的工作原理,今天通过一个基础实验来加深记忆。 一、LDP基础实验 实验拓扑: 1、IGP使用OSPF进行通告,使用Lookback接口作为LSR ID,LDP ID自动生成。 2、实验目的:使…...

搜索二维矩阵 II
存储m和n,用i表示行,j表示列,i从最后一行开始遍历,j从0开始遍历,当前值比目标值小j,反之i-- class Solution { public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int…...

C++中如何实现一个单例模式?
单利模式是指对象在整个程序中只有一个实例,提供一个访问方法供全局访问。实现单例模式有如下要求: 1.私有化构造函数:将构造函数定义为私有,以防外部通过构造函数创建其它实例。 2.静态实例:在内部提供一个静态实例…...

进程与线程
进程与线程:计算机世界的"公司与员工" 进程与线程的本质区别 进程(Process)是计算机中独立运行的程序实例,拥有自己的内存空间和系统资源;而线程(Thread)是进程内的执行单元,共享所属进程的资源,但拥有独立的执行路径。 🏢 生活类比:想象一个大型企业的运…...

JDK 命令行工具大全与学习方法总结 —— 从帮助文档到高效实践
JDK 命令行工具大全与学习方法总结 —— 从帮助文档到高效实践 Java开发与运维过程中,JDK自带的命令行工具是定位问题、性能调优、编译调试的基石。本文全面梳理JDK常用命令工具、帮助文档的获取方式,并总结类似Linux命令行的学习方法,助你系…...

行业趋势与技术创新:驾驭工业元宇宙与绿色智能制造
引言 制造业发展的新格局:创新势在必行 当今制造业正经历深刻变革,面临着供应链波动、个性化需求增长、可持续发展压力以及技能人才短缺等多重挑战。在这样的背景下,技术创新不再是可有可无的选项,而是企业保持竞争力、实现可持…...
 | 198.打家劫舍、213.打家劫舍II、337.打家劫舍III)
代码随想录算法训练营第三十九天(打家劫舍专题) | 198.打家劫舍、213.打家劫舍II、337.打家劫舍III
一、198.打家劫舍 题目链接:198. 打家劫舍 - 力扣(LeetCode) 文章讲解:代码随想录 视频讲解:动态规划,偷不偷这个房间呢?| LeetCode:198.打家劫舍_哔哩哔哩_bilibili 1. 思路 大家如…...

Linux514 rsync 解决方案环境配置
节点ab都改为NAT模式 网关和VMnet8网卡不一致 ping 不通外网 ping不通外网 是这里的问题吗 怎么突然就ping通了 没改啥啊 上面改了dhcp范围后 ping还是ping不通 为啥现在又ping通了 设置节点b 推测应该是dhcp范围问题 今日源码 节点b MX...

STM32F103_LL库+寄存器学习笔记23 - PWM波形输出及软件方式调整周期与占空比
导言 脉宽调制(PWM)是 STM32 定时器最常用的输出模式之一,广泛应用于电机驱动、LED 调光、伺服控制和功率管理等场景。本篇文章将以 TIM5 为例,从寄存器层面深入剖析 PWM 输出的原理与实现步骤。通过本篇博客,你不仅能…...

Canvas知识框架
一、Canvas基础 核心概念 Canvas是位图绘图区域,通过JavaScript(或Python等)动态绘制图形。 坐标系:左上角为原点 (0, 0),x向右递增,y向下递增。 绘图流程: const canvas document.getElemen…...