Python 常用模块(八):logging模块
目录
- 一、引言:日志模块在项目开发中的重要性
- 二、从 Django 日志配置看 Logging 模块的核心组成
- 三、logging模块核心组件详解
- 3.1 记录器Logger
- 3.2 级别Level
- 3.3 根记录器使用
- 3.4 处理器Handler
- 3.5 格式化器Formatter
- 3.6 日志流
- 3.7 日志示例
- 四、日志模块总结
一、引言:日志模块在项目开发中的重要性
在日常的 Python 项目开发中,日志系统往往是一个容易被初学者忽视,却对中大型项目至关重要的基础设施。很多初学者在调试程序时习惯使用 print() 语句输出变量和程序执行状态,但这种方式有明显的局限性:
- 信息不可控: print 输出会混杂在一起,无法区分严重程度;
- 维护成本高: 上线前还需要手动删除或注释掉调试语句;
- 缺乏上下文: 无法记录时间、代码位置、线程等信息;
- 不适用于线上环境: 一旦部署,无法查看标准输出,定位问题困难。
而 Python 标准库提供的 logging 模块,正是为了解决这些问题而设计的。在实际项目中,日志的作用包括但不限于:
- 调试和排查问题
- 当用户反馈出现 bug 时,通过日志文件可以还原出错时的系统状态和调用链;
- 比如:接口返回 500,日志能显示是数据库连接失败还是第三方服务超时。
- 监控系统运行状态
- 结合日志采集系统(如 ELK、Fluentd、Sentry 等)可以实时监控错误、异常和性能瓶颈;
- 比如:一个接口响应超过 1 秒,可以通过日志告警定位慢查询。
- 记录用户行为与业务日志
- 日志不仅是系统的
"体温计",也可以作为业务分析的数据源; - 比如:记录用户注册、登录、下单、支付等关键操作,帮助后续做运营分析。
- 日志不仅是系统的
- 满足合规与审计要求
- 某些金融、政务类项目要求保留操作日志,确保可追溯性和安全合规;
- 比如:记录某个管理员什么时候对用户数据进行了修改。
- 多模块协作与团队开发
- 在多人协作项目中,统一的日志规范和日志格式有助于快速定位代码问题,提升协作效率;
- 通过 logger 名称还能追踪是哪一个模块或组件产生日志,便于归类分析。
正因为日志在调试、监控、安全、分析等方面都扮演着重要角色,一个成熟的项目往往都离不开一套合理的日志体系。接下来,我们就一起系统掌握 Python 的标准日志模块 —— logging 的使用方法与实战技巧。
二、从 Django 日志配置看 Logging 模块的核心组成
如果你接触过 Django 项目中的日志配置,你可能见过类似这样的设置(位于 settings.py 中):
LOGGING = {"version": 1,"disable_existing_loggers": False,"formatters": {"verbose": {"format": "{levelname} {asctime} {module} {process:d} {thread:d} {message}","style": "{",},"simple": {"format": "{levelname} {message}","style": "{",},},"filters": {"special": {"()": "project.logging.SpecialFilter","foo": "bar",},"require_debug_true": {"()": "django.utils.log.RequireDebugTrue",},},"handlers": {"console": {"level": "INFO","filters": ["require_debug_true"],"class": "logging.StreamHandler","formatter": "simple",},"mail_admins": {"level": "ERROR","class": "django.utils.log.AdminEmailHandler","filters": ["special"],},},"loggers": {"django": {"handlers": ["console"],"propagate": True,},"django.request": {"handlers": ["mail_admins"],"level": "ERROR","propagate": False,},"myproject.custom": {"handlers": ["console", "mail_admins"],"level": "INFO","filters": ["special"],},},
}
参考链接:https://docs.djangoproject.com/zh-hans/5.0/topics/logging/#logging-explanation
这一配置可能让人望而生畏,但它其实正好体现了 Python logging 模块的 核心组成结构。学习 logging 模块时,我们其实只需要掌握下面几个关键概念,就能完全理解这段配置的意义。
日志系统的四大核心组件
- Logger(日志记录器)
- 每个 logger 负责产生日志消息。
- 你可以为每个模块或子系统创建不同的 logger(如:django, myapp.api)。
- 常用方法如:logger.info(),logger.error() 等。
- Handler(日志处理器),日志的实际处理者。有众多处理器子类
- 日志记录器本身不负责输出日志,而是将日志交给一个或多个 Handler 来处理。
- 例如:StreamHandler 控制台输出,FileHandler 写入文件,SMTPHandler 发送邮件等。
- 一个 logger 可以绑定多个 handler,实现
"一个日志,多个出口"。
- Formatter(格式化器,日志输出格式控制)
- 定义日志消息的输出格式,如是否包含时间、级别、模块名等。
- 不同的 handler 可以使用不同的格式器。
- Filter(过滤器,可选)
- 用于更精细地控制哪些日志记录可以通过,通常不作为初学重点。
- 示例用途:只记录某个模块或某种业务类型的日志。
为什么要掌握这些组件?
- 在 Django 项目中,LOGGING 配置就是对这四大组件的组合使用;
- 如果你自己写 Python 脚本或服务,也完全可以手动用代码构建出同样的日志体系;
- 理解这四个组件的关系,是灵活使用 logging 模块的关键。
接下来分别对各个组件进行详细讲解。
三、logging模块核心组件详解
3.1 记录器Logger
日志记录器都是 Logger 类的实例,可以通过它实例化得到。但是 logging 模块也提供了工厂方法。 Logger 实例的构建,使用 Logger 类也行,但推荐 getLogger 方法。
# 我目前使用的是python3.12版本,源码中约2015行,为Logger类注入一个manager类属性
Logger.manager = Manager(Logger.root)# 用工厂方法返回一个Logger实例
def getLogger(name=None):"""Return a logger with the specified name, creating it if necessary.If no name is specified, return the root logger."""if not name or isinstance(name, str) and name == root.name:return rootreturn Logger.manager.getLogger(name)
根记录器: logging 模块为了使用简单,提供了一些快捷方法,这些方法本质上都用到了记录器实例,即根记录器实例。
# 源码约1861行
class RootLogger(Logger):"""A root logger is not that different to any other logger, except thatit must have a logging level and there is only one instance of it inthe hierarchy."""def __init__(self, level):"""Initialize the logger with the name "root"."""Logger.__init__(self, "root", level)def __reduce__(self):return getLogger, ()# 根记录器默认是警告
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
可以跟进一下 WARNING:
# 看到日志的级别总共5种
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING # WARN不常用了,被WARNING所替代
INFO = 20
DEBUG = 10
NOTSET = 0_levelToName = {CRITICAL: 'CRITICAL',ERROR: 'ERROR',WARNING: 'WARNING',INFO: 'INFO',DEBUG: 'DEBUG',NOTSET: 'NOTSET',
}
_nameToLevel = {'CRITICAL': CRITICAL,'FATAL': FATAL,'ERROR': ERROR,'WARN': WARNING,'WARNING': WARNING,'INFO': INFO,'DEBUG': DEBUG,'NOTSET': NOTSET,
}
也就是说,logging 模块一旦加载,就立即创建了一个 root 对象,它是 Logger 子类 RootLogger 的实例,日志记录必须使用 Logger 实例。
实例和名称: 每一个 Logger 实例都有自己的名称,使用 getLogger 获取记录器实例时,必须指定名称。在管理器内部维护一个名称和 Logger 实例的字典,根记录器的名称就是 "root",未指定名称,getLogger 返回根记录器对象。示例代码:
# -*- coding: utf-8 -*-
# @Time : 2025-05-14 10:53
# @Author : AmoXiang
# @File : logging_demo.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import logging# 不同的方式取根记录器
root = logging.root
'''
<class 'logging.RootLogger'> <RootLogger root (WARNING)>
<RootLogger root (WARNING)>
True
True
'''
print(type(root), root)
print(logging.getLogger(None))
print(logging.getLogger(None) is root)
print(logging.Logger.root is root)# 通过Logger类实例化
l1 = logging.Logger('m1')
l2 = logging.Logger('m1')
'''
1611588981568 1611567646000 False
'''
print(id(l1), id(l2), l1 is l2)# 通过工厂方法获取记录器实例
m1 = logging.getLogger('m1')
print(type(m1), m1)
m2 = logging.getLogger('m2')
print(type(m2), m2)
m3 = logging.getLogger('m1')
'''
<class 'logging.Logger'> <Logger m1 (WARNING)>
<class 'logging.Logger'> <Logger m2 (WARNING)>
<class 'logging.Logger'> <Logger m1 (WARNING)>
1611561051312 1611588981616 1611561051312 True
m1 m2 m1
'''
print(type(m3), m3)
print(id(m1), id(m2), id(m3), m1 is m3)
print(m1.name, m2.name, m3.name)
层次结构: 记录器的名称另一个作用就是表示 Logger 实例的层次关系。Logger 是有层次结构的,使用 . 点号分割,如 'a'、'a.b' 或 'a.b.c.d',a 是 a.b 的 父 parent,a.b 是 a 的子 child。对于 foo 来说,名字为 foo.bar、foo.bar.baz、foo.bam 都是 foo 的后代。
import logging# 父子 层次关系
# 根logger
root = logging.getLogger()
'''
1 root <class 'logging.RootLogger'> None
2 a <class 'logging.Logger'> root True
3 a.b <class 'logging.Logger'> a True
'''
print(1, root.name, type(root), root.parent) # 根logger没有父
parent = logging.getLogger('a')
print(2, parent.name, type(parent), parent.parent.name, parent.parent is root)
child = logging.getLogger('a.b')
print(3, child.name, type(child), child.parent.name, child.parent is parent)
3.2 级别Level
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
级别可以是一个整数。0表示未设置,有特殊意义。级别可以用来表示日志消息级别、记录器级别、处理器级别。
消息级别: 每一条日志消息被封装成一个 LogRecord 实例,该实例包含消息本身、消息级别、记录器的 name 等信息。消息级别只能说明消息的重要等级,但不一定能输出。
记录器级别: 日志输出必须依靠记录器,记录器设定自己的级别,它决定着消息是否能够通过该日志记录器输出。如果日志记录器未设置自己的级别,默认级别值为0。
记录器有效级别: 如果日志记录器未设置自己的级别,默认级别值为0,等效级别就继承自己的父记录器的非0级别,如果设置了自己的级别且不为0,那么等效级别就是自己设置的级别。如果所有记录器都没有设置级别,最终根记录器一定有级别,且默认设置为 WARNING。 只有日志级别高于产生日志的记录器有效级别才有资格输出,涉及源码如下:
def getEffectiveLevel(self):"""Get the effective level for this logger.Loop through this logger and its parents in the logger hierarchy,looking for a non-zero logging level. Return the first one found."""logger = selfwhile logger:if logger.level:return logger.levellogger = logger.parentreturn NOTSET
处理器级别: 每一个 Logger 实例其中真正处理日志的是处理器 Handler,每一个处理器也有级别。它控制日志消息是否能通过该处理器 Handler 输出。
3.3 根记录器使用
产生日志: logging 模块提供了 debug、info、warning、error、critical 等快捷方法,可以快速产生相应级别消息。本质上这些方法使用的都是根记录器对象。举个例子:
import logginglogging.warning('test~')
运行结果如下图所示:
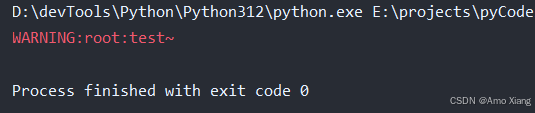
跟进 warning 方法,如下:
def warning(msg, *args, **kwargs):"""Log a message with severity 'WARNING' on the root logger. If the logger hasno handlers, call basicConfig() to add a console handler with a pre-definedformat."""# 1.可以看到操作的是根记录器 即都是使用的root# 2.由于我们没有给根记录器设置handler,先会走这里,root.handlers类型是一个列表,handlers该属性继承自Logger类# self.handlers = []if len(root.handlers) == 0:basicConfig()root.warning(msg, *args, **kwargs)class Logger(Filterer):def __init__(self, name, level=NOTSET):"""Initialize the logger with a name and an optional level."""Filterer.__init__(self)self.name = nameself.level = _checkLevel(level)self.parent = Noneself.propagate = Trueself.handlers = []self.disabled = Falseself._cache = {}class RootLogger(Logger):def __init__(self, level):"""Initialize the logger with the name "root"."""Logger.__init__(self, "root", level)def __reduce__(self):return getLogger, ()
接着我们跟进一下 basicConfig() 方法,看它又在干啥(看源码的时候,我们不一定要求每行都看懂,能知道大致逻辑即可),源码如下所示:
def basicConfig(**kwargs):"""Do basic configuration for the logging system.This function does nothing if the root logger already has handlersconfigured, unless the keyword argument *force* is set to ``True``.It is a convenience method intended for use by simple scriptsto do one-shot configuration of the logging package.The default behaviour is to create a StreamHandler which writes tosys.stderr, set a formatter using the BASIC_FORMAT format string, andadd the handler to the root logger.A number of optional keyword arguments may be specified, which can alterthe default behaviour.filename Specifies that a FileHandler be created, using the specifiedfilename, rather than a StreamHandler.filemode Specifies the mode to open the file, if filename is specified(if filemode is unspecified, it defaults to 'a').format Use the specified format string for the handler.datefmt Use the specified date/time format.style If a format string is specified, use this to specify thetype of format string (possible values '%', '{', '$', for%-formatting, :meth:`str.format` and :class:`string.Template`- defaults to '%').level Set the root logger level to the specified level.stream Use the specified stream to initialize the StreamHandler. Notethat this argument is incompatible with 'filename' - if bothare present, 'stream' is ignored.handlers If specified, this should be an iterable of already createdhandlers, which will be added to the root logger. Any handlerin the list which does not have a formatter assigned will beassigned the formatter created in this function.force If this keyword is specified as true, any existing handlersattached to the root logger are removed and closed, beforecarrying out the configuration as specified by the otherarguments.encoding If specified together with a filename, this encoding is passed tothe created FileHandler, causing it to be used when the file isopened.errors If specified together with a filename, this value is passed to thecreated FileHandler, causing it to be used when the file isopened in text mode. If not specified, the default value is`backslashreplace`.Note that you could specify a stream created using open(filename, mode)rather than passing the filename and mode in. However, it should beremembered that StreamHandler does not close its stream (since it may beusing sys.stdout or sys.stderr), whereas FileHandler closes its streamwhen the handler is closed... versionchanged:: 3.2Added the ``style`` parameter... versionchanged:: 3.3Added the ``handlers`` parameter. A ``ValueError`` is now thrown forincompatible arguments (e.g. ``handlers`` specified together with``filename``/``filemode``, or ``filename``/``filemode`` specifiedtogether with ``stream``, or ``handlers`` specified together with``stream``... versionchanged:: 3.8Added the ``force`` parameter... versionchanged:: 3.9Added the ``encoding`` and ``errors`` parameters."""# Add thread safety in case someone mistakenly calls# basicConfig() from multiple threads_acquireLock()try:# 这里我们没有传递参数,所以 kwargs 一定是 {}# pop()方法--删除字典中指定键对应的键值对并返回被删除的值# key不存在,返回设置的default值force = kwargs.pop('force', False) # Falseencoding = kwargs.pop('encoding', None) # Noneerrors = kwargs.pop('errors', 'backslashreplace') # backslashreplace# force为False不会进入该判断语句中执行其对应逻辑if force:for h in root.handlers[:]:root.removeHandler(h)h.close()# 条件成立,走这里面的逻辑处理if len(root.handlers) == 0:handlers = kwargs.pop("handlers", None)# 排他if handlers is None:if "stream" in kwargs and "filename" in kwargs:raise ValueError("'stream' and 'filename' should not be ""specified together")else:if "stream" in kwargs or "filename" in kwargs:raise ValueError("'stream' or 'filename' should not be ""specified together with 'handlers'")# 走到这里 if handlers is None:# Nonefilename = kwargs.pop("filename", None)# 'a'mode = kwargs.pop("filemode", 'a')# 由于filename为None,所以会走else逻辑if filename:if 'b' in mode:errors = Noneelse:encoding = io.text_encoding(encoding)h = FileHandler(filename, mode,encoding=encoding, errors=errors)else:stream = kwargs.pop("stream", None)# 得到一个StreamHandler实例# self.stream = stream# 身上挂了一个属性: stream = sys.stderr stderr属性——标准错误对象h = StreamHandler(stream)# 将得到的StreamHandler实例放入列表中,并赋值给handlershandlers = [h]dfs = kwargs.pop("datefmt", None) # Nonestyle = kwargs.pop("style", '%') # '%'# _STYLES是一个字典,你可以ctrl进去看,%是keyif style not in _STYLES:raise ValueError('Style must be one of: %s' % ','.join(_STYLES.keys()))# '%': (PercentStyle, BASIC_FORMAT),# 取值 _STYLES['%'] ⇒ (PercentStyle, BASIC_FORMAT)[1] ⇒ BASIC_FORMAT# BASIC_FORMAT = "%(levelname)s:%(name)s:%(message)s" # 从之前的输出结果来看,与BASIC_FORMAT设置的一模一样# levelname: WARNING,name: root,message: test~# WARNING:root:test~fs = kwargs.pop("format", _STYLES[style][1])# 格式化器Formatter,得到实例fmt = Formatter(fs, dfs, style)for h in handlers:if h.formatter is None:# 为handler设置输出格式h.setFormatter(fmt)# 将handler添加到日志处理器中,干活root.addHandler(h)# Nonelevel = kwargs.pop("level", None)if level is not None:root.setLevel(level)if kwargs:keys = ', '.join(kwargs.keys())raise ValueError('Unrecognised argument(s): %s' % keys)finally:_releaseLock()
至此 basicConfig() 方法整个逻辑执行完毕,接下来走:
root.warning(msg, *args, **kwargs)def warning(self, msg, *args, **kwargs):"""Log 'msg % args' with severity 'WARNING'.To pass exception information, use the keyword argument exc_info witha true value, e.g.logger.warning("Houston, we have a %s", "bit of a problem", exc_info=True)"""if self.isEnabledFor(WARNING):# 这里的源码有兴趣自己去看吧,太多了self._log(WARNING, msg, args, **kwargs)def isEnabledFor(self, level):"""Is this logger enabled for level 'level'?"""if self.disabled:return Falsetry:return self._cache[level]except KeyError:_acquireLock()try:if self.manager.disable >= level:is_enabled = self._cache[level] = Falseelse:is_enabled = self._cache[level] = (# 核心逻辑,判断消息级别是否大于等于记录器Logger的有效级别 # warning ⇒ 30 self.getEffectiveLevel() ⇒ 30 故返回True# 即self.isEnabledFor(WARNING): 为True,则会继续向下执行逻辑 # self._log(WARNING, msg, args, **kwargs) 所以最后能在控制台输出level >= self.getEffectiveLevel())finally:_releaseLock()return is_enabled
以上大致分析了 logging.warning() 函数的一个执行逻辑,其他函数类似一个道理,讲解到这里,你也应该知道,在我们没有进行任何配置的情况下, logging.info() 函数为啥不能在控制台输出 msg 了,本质是达不到有效级别。
在分析源码的过程中,我们看到了 BASIC_FORMAT = "%(levelname)s:%(name)s:%(message)s",这里罗列一下我们常会使用到的格式字符串:
| 占位符 | 含义描述 |
|---|---|
%(asctime)s | 日志记录时间,默认格式为 YYYY-MM-DD HH:MM:SS,mmm(毫秒) |
%(created)f | 日志事件的时间戳(UNIX 时间戳,float 类型) |
%(relativeCreated)d | 自 logging 模块加载以来的毫秒数(相对时间) |
%(msecs)d | 日志时间中的毫秒部分 |
%(levelname)s | 日志级别名称,如 DEBUG, INFO |
%(levelno)s | 日志级别的数值,如 10, 20 |
%(name)s | Logger 的名称 |
%(message)s | 日志消息内容,由 logger.debug()/info()/error() 等方法传入的内容。当调用Formatter.format()时设置 |
%(pathname)s | 当前执行代码的完整路径 |
%(filename)s | 当前执行代码的文件名 |
%(module)s | 模块名(即去掉扩展名后的 filename) |
%(funcName)s | 调用日志函数的函数名 |
%(lineno)d | 调用日志函数的源代码行号 |
%(thread)d | 当前线程的 ID |
%(threadName)s | 当前线程名称 |
%(process)d | 当前进程的 ID |
%(processName)s | 当前进程名称 |
%(stack_info)s | 堆栈信息(如果提供了 stack_info=True) |
示例 format 格式模板:
# 1.简洁风格:
"%(asctime)s - %(levelname)s - %(message)s"
# 2.包含模块和行号,适合调试用:
"%(asctime)s [%(levelname)s] %(filename)s:%(lineno)d - %(message)s"
# 3.适合生产环境的详细日志格式:
"%(asctime)s | %(levelname)s | %(name)s | %(process)d | %(threadName)s | %(message)s"
# 4.和 Django 默认格式类似:
"%(levelname)s %(asctime)s %(module)s %(process)d %(thread)d %(message)s"
基本配置: 从源码中我们可以看到 logging 模块提供 basicConfig() 函数,本质上是对根记录器做最基本配置。示例:
# -*- coding: utf-8 -*-
# @Time : 2025-05-14 10:53
# @Author : AmoXiang
# @File : logging_demo.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import loggingformatter = "%(asctime)s [%(levelname)s] %(filename)s:%(lineno)d - %(message)s"# 根logger
logging.basicConfig(level=logging.INFO, format=formatter) # 设置输出消息的格式
# 注意basicConfig只能调用一次
logging.basicConfig(level=logging.INFO) # 设置级别,默认WARNING
logging.basicConfig(filename="/tmp/test.log", filemode='w', encoding='utf-8') # 输出到文件
logging.info('info msg~') # info函数第一个参数就是格式字符串中的%(message)s
logging.debug('debug msg~') # 日志消息级别不够# 控制台输出结果为:
# 2025-05-14 14:01:39,587 [INFO] logging_demo.py:17 - info msg~
basicConfig() 函数执行完后,就会为 root 提供一个处理器,那么 basicConfig() 函数就不会再被调用了。
3.4 处理器Handler
日志记录器需要处理器来处理消息,处理器决定着日志消息输出的设备。Handler 控制日志信息的输出目的地,可以是控制台、文件。
可以单独设置level
可以单独设置格式
可以设置过滤器
Handler 类层次:
- Handler
- StreamHandler # 不指定使用 sys.stderr
- FileHandler # 文件
- _StderrHandler # 标准输出NullHandler # 什么都不做
- StreamHandler # 不指定使用 sys.stderr
日志输出其实是 Handler 做的,也就是真正干活的是 Handler。basicConfig() 函数执行后,默认会生成一个 StreamHandler 实例,如果设置了 filename,则只会生成一个 FileHandler 实例。每一个记录器实例可以设置多个 Handler 实例。
# 定义处理器
handler = logging.FileHandler('o:/test.log', 'w', 'utf-8')
handler.setLevel(logging.WARNING) # 设置处理器级别
3.5 格式化器Formatter
每一个记录器可以按照一定格式输出日志,实际上是按照记录器上的处理器上的设置的格式化器的格式字符串输出日志信息。如果处理器上没有设置格式化器,会调用缺省 _defaultFormatter,而缺省的格式符为:
class PercentStyle(object):default_format = '%(message)s'# 定义格式化器
formatter = logging.Formatter('#%(asctime)s <%(message)s>#')
# 为处理器设置格式化器
handler.setFormatter(formatter)
3.6 日志流
下图是官方日志流转图:
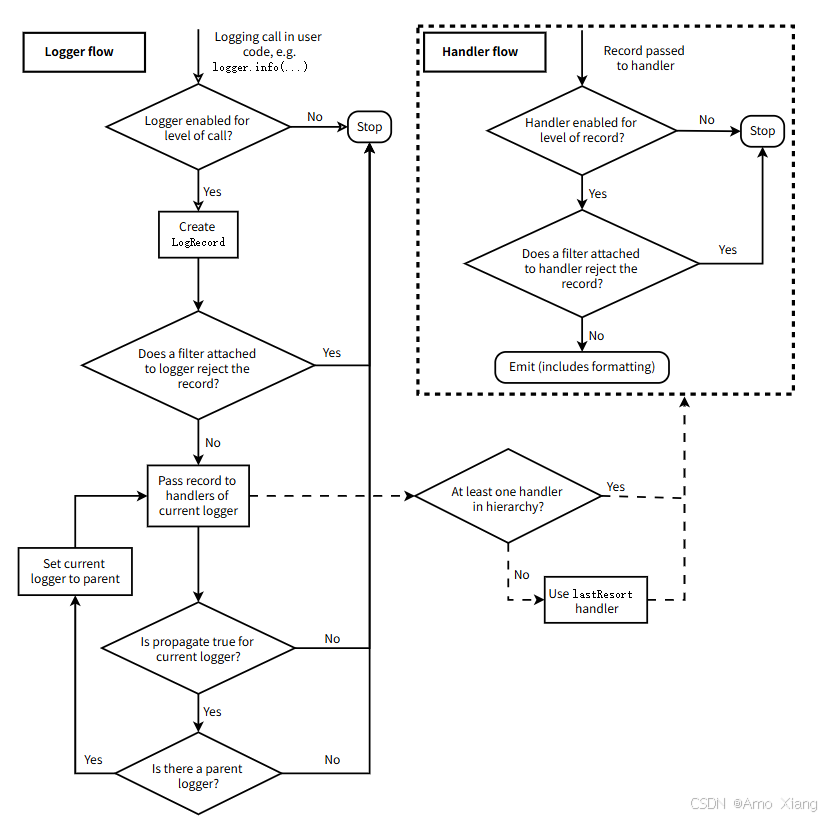
继承关系及信息传递:
- 每一个 Logger 实例的 level 如同入口,让水流进来,如果这个门槛太高,信息就进不来。例如
log3.warning('log3'),如果 log3 定义的级别高,就不会有信息通过 log3 - 如果 level 没有设置,就用父 logger 的,如果父 logger 的 level 没有设置,继续找父的父的,最终可以找到 root 上,如果 root 设置了就用它的,如果 root 没有设置,root 的默认值是 WARNING
- 消息传递流程
- 如果消息在某一个 logger 对象上产生,这个 logger 就是当前 logger,首先消息 level 要和当前 logger 的 EffectiveLevel 比较,如果低于当前 logger 的 EffectiveLevel,则流程结束;否则生成 log 记录
- 日志记录会交给当前 logger 的所有 handler 处理,记录还要和每一个 handler 的级别分别比较,低的不处理,否则按照 handler 输出日志记录
- 当前 logger 的所有 handler 处理完后,就要看自己的 propagate 属性,如果是 True 表示向父 logger 传递这个日志记录,否则到此流程结束
- 如果日志记录传递到了父 logger,不需要和父 logger 的 level 比较,而是直接交给父的所有 handler,父 logger 成为当前 logger。重复2、3步骤,直到当前 logger 的父 logger 是 None 退出,也就是说当前 logger 最后一般是 root logger(是否能到 root logger 要看中间的 logger 是否允许 propagate)
- logger 实例初始的 propagate 属性为 True,即允许向父 logger 传递消息
- logging.basicConfig() 函数,如果 root 没有 handler,就默认创建一个 StreamHandler,如果设置了 filename,就创建一个 FileHandler。如果设置了 format 参数,就会用它生成一个 Formatter 对象,否则会生成缺省 Formatter,并把这个 formatter 加入到刚才创建的 handler 上,然后把这些 handler 加入到 root.handlers 列表上。level 是设置给 root logger 的。如果 root.handlers 列表不为空,logging.basicConfig 的调用什么都不做。
3.7 日志示例
import logging# 根logger # 设置输出消息的格式
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(name)s %(threadName)s [%(message)s]")
print(logging.root.handlers)
mylogger = logging.getLogger(__name__) # level为0
mylogger.info('my info ~~~') # 实际上是传播给了root输出的
print('=' * 30)
# 定义处理器
handler = logging.FileHandler('./test.log', 'w', 'utf-8')
handler.setLevel(logging.WARNING) # 设置处理器级别
# 定义格式化器
formatter = logging.Formatter('#%(asctime)s <%(message)s>#')
# 为处理器设置格式化器
handler.setFormatter(formatter)
# 为日志记录器增加处理器
mylogger.addHandler(handler)
mylogger.propagate = False # 阻断向父logger的传播
mylogger.info('my info2 ~~~~')
mylogger.warning('my warning info ---')
mylogger.propagate = True
mylogger.warning('my warning info2 +++')
结合日志轮转 使用 RotatingFileHandler 或 TimedRotatingFileHandler,避免日志文件无限增长。示例:
import logging
from logging.handlers import TimedRotatingFileHandler
import time# 根logger # 设置输出消息的格式
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(name)s %(threadName)s [%(message)s]")
print(logging.root.handlers)
mylogger = logging.getLogger(__name__) # level为0
# 定义处理器
handler = TimedRotatingFileHandler('./test.log', 's', 30)
handler.setLevel(logging.INFO) # 设置处理器级别
# 定义格式化器
formatter = logging.Formatter('#%(asctime)s <%(message)s>#') # 为处理器设置格式化器
handler.setFormatter(formatter)
# 为日志记录器增加处理器
mylogger.addHandler(handler)
# mylogger.propagate = True # 默认传播到父
for i in range(20):time.sleep(3)mylogger.info('my message {:03} +++'.format(i))
'''
#2025-05-14 14:29:09,325 <my message 000 +++>#
#2025-05-14 14:29:12,325 <my message 001 +++>#
#2025-05-14 14:29:15,326 <my message 002 +++>#
#2025-05-14 14:29:18,327 <my message 003 +++>#
#2025-05-14 14:29:21,327 <my message 004 +++>#
#2025-05-14 14:29:24,328 <my message 005 +++>#
#2025-05-14 14:29:27,329 <my message 006 +++>#
#2025-05-14 14:29:30,329 <my message 007 +++>#
'''
四、日志模块总结
在深入学习并阅读了 logging 模块的源码之后,我们会发现:整个日志系统的设计其实非常清晰 —— 模块化的组件组合(Logger、Handler、Formatter)加上可配置化的等级和输出方式,逻辑非常清楚,上手也并不复杂。但在真实项目中,日志系统真正的挑战不在于 "如何使用 logging",而在于 "日志应该写在哪里,写多少,写什么"。
这部分并没有标准答案,它是依赖于经验、项目规模、团队协作模式和后期分析工具的。以下是一些实际工作中常见的思考与经验总结:
| 场景 | 应该写日志的位置 |
|---|---|
| 关键业务流程 | 例如:用户下单、支付、扣库存、发货等,建议打 INFO 日志记录业务链路状态 |
| 异常捕获 | 在 try...except 中用 logger.exception() 记录异常栈 |
| 性能瓶颈点 | 比如:数据库慢查询、接口超时、调用外部 API 的耗时,建议使用 WARNING 或 INFO 并记录耗时数据 |
| 调试分支 | 某些重要但不常触发的代码分支,用 DEBUG 打印关键变量值 |
| 用户输入与验证失败 | 用户输入数据异常、验证失败、权限拒绝等,可用 WARNING 等级记录 |
| 第三方服务调用失败 | 例如:请求微信支付、发短信失败等,要及时打日志,方便运维排查 |
如何写出 "对未来有用" 的日志?
- 上下文清晰:日志中要包含发生了什么,在哪儿发生的,哪些参数,结果如何;
- 结构化内容:即便不使用 JSON,日志内容也要方便后续正则匹配、搜索;
- 避免日志泛滥:不要什么都打印,会掩盖重点(特别是在循环、频繁调用中);
- 区分等级与模块:合理使用
DEBUG/INFO/WARNING/ERROR/CRITICAL,并为每个模块设置不同 logger,有助于日志隔离; - 提前考虑分析方式:日志最终可能用于搜索、告警、监控、审计,所以写日志时可以站在
"未来使用者"的角度思考。
日志模块在爬虫项目中的典型用途:
-
记录请求与响应状态。 在爬虫中,请求网页的每一个步骤都可能出现问题。我们通常会记录如下内容:请求的 URL、响应状态码(200、403、404 等)、是否触发反爬机制(验证码、跳转)、页面解析是否成功
logger.info(f"正在请求页面: {url}") response = requests.get(url, headers=headers) if response.status_code != 200:logger.warning(f"请求失败,状态码: {response.status_code},URL: {url}") -
捕捉异常与失败信息。 爬虫运行过程中常见如连接超时、JSON 解析失败、数据字段缺失、页面结构变化等问题。
try:data = response.json() except Exception as e:logger.exception(f"解析 JSON 失败,url={url}") -
记录数据抓取情况。 你可以用日志记录:
-
每个页面成功抓取的数据量;
-
每条数据是否完整;
-
抓取成功/失败总计(可用于后期统计);
logger.info(f"成功抓取 {len(items)} 条数据 from {url}")
-
-
调试与优化爬虫逻辑。 通过调试级别的日志输出字段、分页参数、选择器内容、cookie 状态等,有助于在开发阶段排查问题。上线前可以关闭 DEBUG 级别日志,避免输出过多无关信息。
logger.debug(f"当前请求参数: page={page}, keyword={keyword}") -
应对反爬机制。 一些反爬机制会导致某些请求被封锁或重定向,你可以通过日志及时发现:UA 被识别、IP 被封、验证码页面、页面结构突变
if "请输入验证码" in response.text:logger.warning(f"触发验证码,已停止爬取: {url}") -
分模块记录日志。 对于较大的爬虫系统(如 Scrapy、分布式爬虫),可以对不同模块(抓取、解析、存储、调度等)使用不同的 logger 进行分类管理。这样你可以只查看某一类日志,如只分析解析失败的日志。
fetch_logger = logging.getLogger("fetcher") parse_logger = logging.getLogger("parser") save_logger = logging.getLogger("saver")
推荐一个第三方好用的日志库:https://github.com/Delgan/loguru 优点:
- 开箱即用,几乎无需配置
- 自动格式化、美化输出(支持颜色)
- 内置异常捕捉
- 支持日志文件自动轮转、压缩、保留策略
- 支持 enqueue=True 异步写入
简单示例:
from loguru import loggerlogger.add("logfile.log", rotation="10 MB", retention="7 days", compression="zip")logger.info("抓取成功:{}", "http://example.com")
logger.warning("触发验证码:{}", "http://example.com/captcha")
logger.exception("解析异常")
运行结果如下所示:

适用场景: 适合中小型项目、快速开发、爬虫项目、自动化脚本等,极度推荐用于替代 logging 的简洁封装。
总结一句话:logging 模块的语法可以一天掌握,但写出对将来有价值的日志,需要很多天,很多项目,很多线上问题的积累。
相关文章:
:logging模块)
Python 常用模块(八):logging模块
目录 一、引言:日志模块在项目开发中的重要性二、从 Django 日志配置看 Logging 模块的核心组成三、logging模块核心组件详解3.1 记录器Logger3.2 级别Level3.3 根记录器使用3.4 处理器Handler3.5 格式化器Formatter3.6 日志流3.7 日志示例 四、日志模块总结 一、引…...

入门OpenTelemetry——可观测性与链路追踪介绍
可观测性 什么是可观测性 可观察性(Observability)是从外部输出知识中推断所获得,可理解为衡量一个系统内部状态的方法。可观测性是一种能力,它能帮助你回答系统内部发生了什么——无需事先定义每种可能的故障或状态。系统的可观…...

c#队列及其操作
可以用数组、链表实现队列,大致与栈相似,简要介绍下队列实现吧。值得注意的是循环队列判空判满操作,在用链表实现时需要额外思考下出入队列条件。 设计头文件 #ifndef ARRAY_QUEUE_H #define ARRAY_QUEUE_H#include <stdbool.h> #incl…...
)
【Linux C/C++开发】轻量级关系型数据库SQLite开发(包含性能测试代码)
前言 之前的文件分享过基于内存的STL缓存、环形缓冲区,以及基于文件的队列缓存mqueue、hash存储、向量库annoy存储,这两种属于比较原始且高效的方式。 那么,有没有高级且高效的方式呢。有的,从数据角度上看,࿰…...
 】)
77. 组合【 力扣(LeetCode) 】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路四、参考代码 零、原题链接 77. 组合 一、题目描述 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。 二、测试用例 示例 1: 输入&…...
)
GpuGeek全栈AI开发实战:从零构建企业级大模型生产管线(附完整案例)
目录 背景一、算力困境:AI开发者的「三重诅咒」1.1 硬件成本黑洞1.2 资源调度失衡1.3 环境部署陷阱 二、三大核心技术突破GpuGeek的破局方案2.1 分时切片调度引擎(Time-Slicing Scheduler)2.2 异构计算融合架构2.3 AI资产自动化…...
(技巧)(计数;双指针))
LeetCode 热题 100_颜色分类(98_75_中等_C++)(技巧)(计数;双指针)
LeetCode 热题 100_颜色分类(98_75_中等_C) 题目描述:输入输出样例:题解:解题思路:思路一(计数):思路二(双指针): 代码实现代码实现&a…...

【前端】:单 HTML 去除 Word 批注
在现代办公中,.docx 文件常用于文档编辑,但其中的批注(注释)有时需要在分享或归档前被去除。本文将从原理出发,深入剖析如何在纯前端环境下实现对 .docx 文件注释的移除,并提供完整的实现源码。最后&#x…...

TTS-Web-Vue系列:Vue3实现内嵌iframe文档显示功能
🖼️ 本文是TTS-Web-Vue系列的新篇章,重点介绍如何在Vue3项目中优雅地实现内嵌iframe功能,用于加载外部文档内容。通过Vue3的响应式系统和组件化设计,我们实现了一个功能完善、用户体验友好的文档嵌入方案,包括加载状态…...

AWS CloudTrail日志跟踪启用
问题 启用日志管理。 步骤 审计界面,如下图: 点击创建跟踪,AWS云就会记录AWS账号在云中的操作。...

PHP 编程:现代 Web 开发的基石与演进
引言 PHP(Hypertext Preprocessor)自1995年诞生以来,已成为全球最流行的服务器端脚本语言之一。尽管近年来Node.js、Python等语言在特定领域崭露头角,但PHP仍占据着超过78%的网站市场份额(W3Techs数据)。本…...

NAT/代理服务器/内网穿透
目录 一 NAT技术 二 内网穿透/内网打洞 三 代理服务器 一 NAT技术 跨网络传输的时候,私网不能直接访问公网,就引入了NAT能讲私网转换为公网进行访问,主要解决IPv4(2^32)地址不足的问题。 1. NAT原理 当某个内网想访问公网,就必…...

[已解决] VS Code / Cursor / Trae 的 PowerShell 终端 conda activate 进不去环境的常见问题
背景 PS C:\Users\Lenovo\WPSDrive\669715199_3\WPS云盘\课程\研一\ROAS5700 Robot Motion Planning and Control\Final\LaTex报告\final-v1> conda activate mpPS C:\Users\Lenovo\WPSDrive\669715199_3\WPS云盘\课程\研一\ROAS5700 Robot Motion Planning and Control\Fin…...

Kuka AI音乐AI音乐开发「人声伴奏分离」 —— 「Kuka Api系列|中文咬字清晰|AI音乐API」第6篇
导读 今天我们来了解一下 Kuka API 的人声与伴奏分离功能。 所谓“人声伴奏分离”,顾名思义,就是将一段完整的音频拆分为两个独立的轨道:一个是人声部分,另一个是伴奏(乐器)部分。 这个功能在音乐创作和…...

深度伪造对知识产权保护的新挑战与应对之策
首席数据官高鹏律师团队 在科技的飞速发展带来了诸多便利的同时,也引发了一系列复杂的法律问题,其中深度伪造技术对知识产权保护的冲击尤为显著,亟待引起广泛关注与深入探讨。 深度伪造,简单来说,是借助先进的人工智…...

【嵌入式开发-软件定时器】
嵌入式开发-软件定时器 ■ 1.■ 2.■ 3.■ 4. ■ 1. ■ 2. ■ 3. ■ 4....

3天重庆和成都旅游规划
重庆和成都都是大城市,各自都有丰富的旅游资源。如果要在三天内两头都游览,可能需要合理安排时间,确保既能体验到重庆的特色,又能在成都游览主要景点。然而,考虑到交通时间,如果从重庆到成都需要一定的时间…...

JAVA中的文件操作
文章目录 一、文件认识(一)文件的分类(二)目录结构 二、文件操作(一)File类1.属性2.构造方法3.方法 (二)File类的具体使用1.文件路径的查看2.文件的基本操作(1࿰…...

深度解析网闸策略:构建坚固的网络安全防线
深度解析网闸策略:构建坚固的网络安全防线 在数字化浪潮中,网络安全已成为企业、机构乃至国家稳定发展的关键要素。随着网络攻击手段日益复杂多样,传统的网络安全防护措施难以满足日益增长的安全需求。网闸作为一种先进的网络安全设备&#x…...

【Rust trait特质】如何在Rust中使用trait特质,全面解析与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

滑动窗口算法笔记
力扣209 题目分析:想象一个窗口遍历着这个数组,不断扩大右边界,让r。往窗口中添加数字: 此时我们找到了这个窗口,它的和满足了大于等于target的条件,题目让我求最短的,那么我们就尝试来缩短它&…...

Problem A: 歌手打分
1.题目描述 在歌唱比赛中,共有10位评委进行打分,在计算歌手得分时,去掉一个最高分,去掉一个最低分,然后剩余的8位评委的分数进行平均,就是该选手的最终得分。输入每个评委的评分,求某选手的得分…...

容器安全-核心概述
文章摘要 本文探讨了容器安全的四个核心类别,包括环境基础设施安全、镜像安全、运行时安全和生态安全。尽管 EDR 能提供主机安全层面的部分防护,但无法覆盖容器的镜像安全和生态安全。容器的镜像安全和生态安全问题,如镜像漏洞、恶意镜像、容…...

Golang实践录:在go中使用curl实现https请求
之前曾经在一个 golang 工程调用 libcur 实现 https的请求,当前自测是通过的。后来迁移到另一个小系统出现段错误,于是对该模块代码改造,并再次自测。 问题提出 大约2年前,在某golang项目使用libcurl进行https请求(参…...

nvrtc环境依赖
一 下载 1.1 添加nvidia的源(不同于pypi) pip install nvidia-pyindex 1.2 pip dowload 执行 pip download nvidia-cuda-runtime nvidia-cuda-python 会发现文件夹多了以下几个文件 而需要安装的则只有红框的三个文件, 二 安装 对红框的…...

【计算机视觉】OpenCV实战项目:GraspPicture 项目深度解析:基于图像分割的抓取点检测系统
GraspPicture 项目深度解析:基于图像分割的抓取点检测系统 一、项目概述项目特点 二、项目运行方式与执行步骤(一)环境准备(二)项目结构(三)执行步骤 三、重要逻辑代码解析(一&#…...

Redis持久化存储
我们知道Redis是将数据放在内存中的,那怎么做到持久化存储呢?很简单,就是内存存一份,硬盘也存一份.那么两个地方都存会不会影响效率?答案是影响是不大的,要看具体的策略.同时也要注意内存的数据和硬盘中的数据可能会有一点不同.这也是取决于策略的不同. Redis持久化存储的两个…...

网络检测工具InternetTest v8.9.1.2504 单文件版,支持一键查询IP/DNS、WIFI密码信息
—————【下 载 地 址】——————— 【本章下载一】:https://drive.uc.cn/s/295e068b79314 【本章下载二】:https://pan.xunlei.com/s/VOQDXguH0DYPxrql5y2zlkhTA1?pwdg2nx# 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

elpis-core: 基于 Koa 实现 web 服务引擎架构设计解析
前言 内容来源于抖音【哲玄前端】大佬的《大前端全栈实践》课程,此课程是从零开始做一个企业级的全栈应用框架。此框架是基于koa.js构建的服务引擎,对BFF层的框架封装,让我感受颇深。 整体elpis项目架构设计 elpis-core设计思路 可以看到elpi…...

计算机网络-MPLS LDP基础实验配置
前面我们学习了LDP的会话建立、标签发布与交换、LDP的工作原理,今天通过一个基础实验来加深记忆。 一、LDP基础实验 实验拓扑: 1、IGP使用OSPF进行通告,使用Lookback接口作为LSR ID,LDP ID自动生成。 2、实验目的:使…...

搜索二维矩阵 II
存储m和n,用i表示行,j表示列,i从最后一行开始遍历,j从0开始遍历,当前值比目标值小j,反之i-- class Solution { public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int…...

C++中如何实现一个单例模式?
单利模式是指对象在整个程序中只有一个实例,提供一个访问方法供全局访问。实现单例模式有如下要求: 1.私有化构造函数:将构造函数定义为私有,以防外部通过构造函数创建其它实例。 2.静态实例:在内部提供一个静态实例…...

进程与线程
进程与线程:计算机世界的"公司与员工" 进程与线程的本质区别 进程(Process)是计算机中独立运行的程序实例,拥有自己的内存空间和系统资源;而线程(Thread)是进程内的执行单元,共享所属进程的资源,但拥有独立的执行路径。 🏢 生活类比:想象一个大型企业的运…...

JDK 命令行工具大全与学习方法总结 —— 从帮助文档到高效实践
JDK 命令行工具大全与学习方法总结 —— 从帮助文档到高效实践 Java开发与运维过程中,JDK自带的命令行工具是定位问题、性能调优、编译调试的基石。本文全面梳理JDK常用命令工具、帮助文档的获取方式,并总结类似Linux命令行的学习方法,助你系…...

行业趋势与技术创新:驾驭工业元宇宙与绿色智能制造
引言 制造业发展的新格局:创新势在必行 当今制造业正经历深刻变革,面临着供应链波动、个性化需求增长、可持续发展压力以及技能人才短缺等多重挑战。在这样的背景下,技术创新不再是可有可无的选项,而是企业保持竞争力、实现可持…...
 | 198.打家劫舍、213.打家劫舍II、337.打家劫舍III)
代码随想录算法训练营第三十九天(打家劫舍专题) | 198.打家劫舍、213.打家劫舍II、337.打家劫舍III
一、198.打家劫舍 题目链接:198. 打家劫舍 - 力扣(LeetCode) 文章讲解:代码随想录 视频讲解:动态规划,偷不偷这个房间呢?| LeetCode:198.打家劫舍_哔哩哔哩_bilibili 1. 思路 大家如…...

Linux514 rsync 解决方案环境配置
节点ab都改为NAT模式 网关和VMnet8网卡不一致 ping 不通外网 ping不通外网 是这里的问题吗 怎么突然就ping通了 没改啥啊 上面改了dhcp范围后 ping还是ping不通 为啥现在又ping通了 设置节点b 推测应该是dhcp范围问题 今日源码 节点b MX...

STM32F103_LL库+寄存器学习笔记23 - PWM波形输出及软件方式调整周期与占空比
导言 脉宽调制(PWM)是 STM32 定时器最常用的输出模式之一,广泛应用于电机驱动、LED 调光、伺服控制和功率管理等场景。本篇文章将以 TIM5 为例,从寄存器层面深入剖析 PWM 输出的原理与实现步骤。通过本篇博客,你不仅能…...

Canvas知识框架
一、Canvas基础 核心概念 Canvas是位图绘图区域,通过JavaScript(或Python等)动态绘制图形。 坐标系:左上角为原点 (0, 0),x向右递增,y向下递增。 绘图流程: const canvas document.getElemen…...

【SSL证书系列】客户端如何验证https网站服务器发的证书是否由受信任的根证书签发机构签发
客户端验证HTTPS网站证书是否由受信任的根证书颁发机构(CA)签发,是一个多步骤的过程,涉及证书链验证、信任锚(Trust Anchor)检查、域名匹配和吊销状态验证等。以下是详细的验证流程: 1. 证书链的…...

spark小任务
import org.apache.spark.{Partitioner, SparkConf, SparkContext}object PartitionCustom {// 分区器决定哪一个元素进入某一个分区// 目标: 把10个分区器,偶数分在第一个分区,奇数分在第二个分区// 自定义分区器// 1. 创建一个类继承Partitioner// 2. …...

git push 报错:send-pack: unexpected disconnect while reading sideband packet
背景 新建了一个仓库,第一次push 代码文件,文件中有一个依赖的jar,有80MB,结果push的时候报错。 错误信息 error: RPC failed; HTTP 500 curl 22 The requested URL returned error: 500 send-pack: unexpected disconnect whi…...

读入csv文件写入MySQL
### 使用 Spark RDD 读取 CSV 文件并写入 MySQL 的实现方法 #### 1. 环境准备 在使用 Spark 读取 CSV 文件并写入 MySQL 数据库之前,需要确保以下环境已配置完成: - 添加 Maven 依赖项以支持 JDBC 连接。 - 配置 MySQL 数据库连接参数,包括 …...

5.18-AI分析师
强化练习1 神经网络训练案例(SG) #划分数据集 #以下5行需要背 folder datasets.ImageFolder(rootC:/水果种类智能训练/水果图片, transformtrans_compose) n len(folder) n1 int(n*0.8) n2 n-n1 train, test random_split(folder, [n1, n2]) #训…...

腾讯云运营开发 golang一面
redis为什么单线程会快 每秒10w吞吐量 io多路复用 一个文件描述符整体拷贝;调用epoll_ctl 单个传递 内核遍历文件描述符判断是否有事件发送;回调函数列表维护 修改有事件发送的socket为可读或可写,返回整个文件描述符;返回链…...

spark数据压缩
### Spark 数据压缩方法及其实现 在大数据处理框架中,数据压缩是一个重要的环节,它不仅能够减少磁盘占用空间,还能降低网络传输成本。然而,在分布式计算环境中(如 Spark),选择合适的压缩编解码…...

synchronized关键字详解
synchronized关键字详解 1. 基本概念与使用方式 作用:确保多个线程在访问共享资源时的互斥性,防止数据不一致。使用方式: 修饰实例方法:锁对象为当前实例(this)。public synchronized void instanceMethod() {// 同步代码 }修饰静态方法:锁对象为类的Class对象。public…...

React useState 的同步/异步行为及设计原理解析
一、useState 的同步/异步行为 异步更新(默认行为) • 场景:在 React 合成事件(如 onClick)或生命周期钩子(如 useEffect)中调用 useState 的更新函数时,React 会将这些更新放入队列…...

《社交应用动态表情:RN与Flutter实战解码》
React Native依托于JavaScript和React,为动态表情的实现开辟了一条独特的道路。其核心优势在于对原生模块的便捷调用,这为动态表情的展示和交互提供了强大支持。在社交应用中,当用户点击发送动态表情时,React Native能够迅速调用相…...

【Oracle专栏】清理告警日志、监听日志
Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 今天在导入数据库时,发现之前可以导入,今天导入时居然报空间不足,于是检查是哪里占用空间比较大。检查回收站、归档日志,发现没有。然后检查告警日志、监听日志,发现果然占用空间比较大,于是进行…...