【Linux C/C++开发】轻量级关系型数据库SQLite开发(包含性能测试代码)
前言
之前的文件分享过基于内存的STL缓存、环形缓冲区,以及基于文件的队列缓存mqueue、hash存储、向量库annoy存储,这两种属于比较原始且高效的方式。
那么,有没有高级且高效的方式呢。有的,从数据角度上看,(封装好底层的)SQL语法开发就是一种成熟、高效的方式。
本文主要讲解的是不需要搭建服务器的数据库类型(支持SQL语法)的轻量级缓存数据库SQLite。
SQLite特性
- 单文件存储:整个数据库(表、索引、视图等)存储在一个文件中,便于移植和备份;
- 无服务器架构:无需独立服务进程,通过函数调用操作数据;
- 资源占用低:库文件仅约 1MB,内存消耗少,适合资源受限环境;
- 高性能:读写操作直接访问磁盘文件,省去网络开销,响应速度快;
- 跨平台兼容:支持所有主流操作系统(Windows、Linux、macOS、Android、iOS等),文件格式统一,跨平台迁移无需转换;
局限性
- 并发写入:同一时间仅支持单线程写入,高并发写场景性能受限;
- 无用户管理:缺乏内置的用户权限系统,依赖文件系统权限;
- 数据规模:单库文件理论上支持 TB 级数据,但更适合中小规模应用;
使用场景
从以上特性及局限性可以看出sqlite是适合本地调用的GB级别数据库,可以很好的支持资源受限的移动应用、嵌入式设备,以及访问量较低的中小型网站、缓存数据量较低的应用场景()。
特别适合这种场景:比如计划安装redis、mysql来搭建SQL服务时,经过评估每日数据量,一个表都达不到100万条数据的情况下,可以直接选用SQLite提供数据库存储。
这里要额外的说明,SQLite本身不支持网络访问,如果是C/S架构,可以在服务器端搭建的网络服务中间件(比如通过前端、python、C/C++ socket方式提供网络服务)。
详细讲解
本文的源码是在国产桌面操作系统(统信UOS和麒麟kylin系统)下进行编译开发的,默认安装有sqlite3,如果没有安装,可以用以下命令安装:
sudo apt install sqlite3 libsqlite3-dev命令行操作
安装完成之后,可以在命令行查看库文件:
sqlite3库开发
本文分享的源码中,在SQLiteDB类中封装了打开数据库、创建表、插入表、批量插入表、更新表、查询表的功能,其中批量插入表提供批量插入模板(支持传结构体),文件结构如下:
mysqlite.h
#ifndef MY_SQLITE_H
#define MY_SQLITE_H
#include <sqlite3.h>
#include <iostream>
#include <list>
#include <vector>
#include <map>
#include <string>
#include <set>// 查询结果的数据结构
typedef struct QueryResult {void* data; //指向C++的QueryResult对象
} QueryResult;class SQLiteDB {
public:// 构造函数/析构函数explicit SQLiteDB(const std::string& dbname);~SQLiteDB();// 基础操作int createTable(const char* sql);// 创建表int insertTable(const char* sql);// 插入数据int updateTable(const char* sql);// 更新数据int queryTable(const char* sql , QueryResult* result);// 查询数据void closedb();// 关闭数据库//批量插入模板template<typename Container, typename BindFunc>int batchInsertTemplate(const char* insert_sql,const Container& container,BindFunc binder){// 使用预编译语句优化插入性能sqlite3_stmt* stmt = nullptr;// 准备预编译语句if (sqlite3_prepare_v2(sql_db, insert_sql, -1, &stmt, nullptr) != SQLITE_OK) {std::cerr << "准备预编译语句失败: " << sqlite3_errmsg(sql_db) << std::endl;return -1;}setcache();beginTransaction(); // 开启事务int success_count = 0;int batch_size = 1000; // 每批插入量try {int counter = 0;for (const auto& item : container) {// 绑定参数binder(stmt, item);// 执行插入int rc = sqlite3_step(stmt);if (rc != SQLITE_DONE) {//std::cerr << "插入数据失败[" << counter << "]: "// << sqlite3_errmsg(db) << " Phone: " << user.phone << std::endl;// 继续尝试下一条而非直接返回} else {success_count++;}sqlite3_reset(stmt);counter++;// 分批提交if (counter % batch_size == 0) {commitTransaction();// 提交记录beginTransaction(); // 开启新事务}}// 提交剩余记录commitTransaction();// 提交最后一批可能不足1000条的记录} catch (...) {rollbackTransaction();sqlite3_finalize(stmt);// 释放预编译语句throw; // 重新抛出异常}// 释放预编译语句sqlite3_finalize(stmt);return success_count;}//读取结果QueryResult* createQueryResult();void freeQueryResult(QueryResult* result);//释放QueryResult内存const std::list<std::string>& getColumnNames(const QueryResult* result);const std::vector<std::map<int, std::string>>& getRows(const QueryResult* result);bool m_status;
private:bool opendb(const char* dbname);int execsql(const char* sql);// 实现事务函数int beginTransaction();int commitTransaction();int rollbackTransaction();int setcache();sqlite3* sql_db;
};#endif // MY_SQLITE_H
mysqlite.cpp
#include "mysqlite.h"struct InternalQueryResult {std::list<std::string> columnNames;std::vector<std::map<int, std::string>> rows;
};SQLiteDB::SQLiteDB(const std::string& dbname){opendb(dbname.c_str());
}SQLiteDB::~SQLiteDB(){}bool SQLiteDB::opendb(const char* dbname) {m_status=true;int rc = sqlite3_open(dbname, &sql_db);if (rc != SQLITE_OK) {//std::cerr << "无法打开数据库: " << sqlite3_errmsg(db) << std::endl;sqlite3_close(sql_db); // 打开失败时关闭数据库m_status = false;//return m_status;}return m_status;
}int SQLiteDB::execsql(const char* sql) {char* errMsg = nullptr;int rc = sqlite3_exec(sql_db, sql, nullptr, nullptr, &errMsg);if (rc != SQLITE_OK) {sqlite3_free(errMsg);//std::cerr << "执行失败: " << errMsg << std::endl;return -1;}return 0;
}int SQLiteDB::createTable(const char* sql) {int ret=execsql(sql);if(ret==-1) std::cerr << "创建表失败: " << std::endl;else std::cout << "创建表成功" << std::endl;return ret;
}int SQLiteDB::insertTable( const char* sql) {int ret=execsql(sql);//if(ret==-1) std::cerr << "插入数据失败: " << std::endl;//else std::cout << "插入数据成功" << std::endl;return ret;
}int SQLiteDB::updateTable( const char* sql) {int ret=execsql(sql);//if(ret==-1) std::cerr << "更新数据失败: " << std::endl;//else std::cout << "更新数据成功" << std::endl;return ret;
}// 回调函数:将数据存储到QueryResult中
static int callback(void* data, int argc, char** argv, char** colName) {InternalQueryResult* retdata = static_cast<InternalQueryResult*>(data);// 保存列名(只在第一次回调时保存)if (retdata->columnNames.empty()) {for (int i = 0; i < argc; i++) {retdata->columnNames.push_back(colName[i]);}}// 保存当前行数据std::map<int, std::string> row;for (int i = 0; i < argc; i++) {row[i] = argv[i] ? argv[i] : "NULL"; // 键=列索引,值=数据}retdata->rows.push_back(row);return 0;
}// 创建QueryResult对象
QueryResult* SQLiteDB::createQueryResult() {auto* result = new QueryResult;result->data = new InternalQueryResult;return result;
}// 释放QueryResult内存
void SQLiteDB::freeQueryResult(QueryResult* result) {if (result) {delete static_cast<InternalQueryResult*>(result->data);delete result;}
}// 获取列名列表
const std::list<std::string>& SQLiteDB::getColumnNames(const QueryResult* result) {return static_cast<InternalQueryResult*>(result->data)->columnNames;
}// 获取行数据
const std::vector<std::map<int, std::string>>& SQLiteDB::getRows(const QueryResult* result) {return static_cast<InternalQueryResult*>(result->data)->rows;
}int SQLiteDB::queryTable(const char* sql , QueryResult* result) {char* errMsg = nullptr;auto* internalResult = static_cast<InternalQueryResult*>(result->data);int rc = sqlite3_exec(sql_db, sql, callback, internalResult, &errMsg);if (rc != SQLITE_OK) {std::cerr << "查询失败: " << errMsg << std::endl;sqlite3_free(errMsg);return -1;}return 0;
}void SQLiteDB::closedb() {sqlite3_close(sql_db);
}// 实现事务模式
int SQLiteDB::beginTransaction() {return sqlite3_exec(sql_db, "BEGIN IMMEDIATE TRANSACTION;", nullptr, nullptr, nullptr);
}int SQLiteDB::setcache() {return sqlite3_exec(sql_db, "PRAGMA cache_size=10000;", nullptr, nullptr, nullptr);
}
//
int SQLiteDB::commitTransaction() {return sqlite3_exec(sql_db, "COMMIT;", nullptr, nullptr, nullptr);
}int SQLiteDB::rollbackTransaction() {return sqlite3_exec(sql_db, "ROLLBACK;", nullptr, nullptr, nullptr);
}
引用类的主程序main.cpp
#include "mysqlite.h"
#include <string>
#include <iostream>
#include <chrono>
#include <random>
#include <set>
// 用户结构体定义
typedef struct user_st {std::string phone;std::string name;std::string sex;// 用于set排序的比较函数bool operator<(const user_st& other) const {return phone < other.phone;}
} user_st;// 准备绑定函数
auto stBinder = [](sqlite3_stmt* stmt, const user_st& p) {return sqlite3_bind_text(stmt, 1, p.phone.c_str(), -1, SQLITE_TRANSIENT) == SQLITE_OK &&sqlite3_bind_text(stmt, 2, p.name.c_str(), -1, SQLITE_TRANSIENT) == SQLITE_OK &&sqlite3_bind_text(stmt, 3, p.sex.c_str(), -1, SQLITE_TRANSIENT) == SQLITE_OK;
};// 生成随机手机号 (135xxxxxxxx)
std::string generatePhone() {std::random_device rd;std::mt19937 gen(rd());std::uniform_int_distribution<> dis(0, 99999999);char buf[12];snprintf(buf, sizeof(buf), "135%08d", dis(gen));return buf;
}int main() {// 打开数据库SQLiteDB litedb("massive_data.db");if (!litedb.m_status) {std::cerr << "无法打开数据库" << std::endl;return -1;}if(0)//创建表并批量插入测试{// 创建表(如果不存在)const char* createTableSQL ="CREATE TABLE IF NOT EXISTS users (""phone TEXT PRIMARY KEY NOT NULL,""name TEXT,""sex TEXT CHECK(sex IN ('M', 'F'))"");";if (litedb.createTable(createTableSQL) != 0) {std::cerr << "创建表失败" << std::endl;litedb.closedb();return -1;}std::set<user_st> user_set;for (int i = 0; i < 1000000; ++i) {user_st usermsg;usermsg.phone = generatePhone();usermsg.name = "User_" + std::to_string(i);usermsg.sex = (i % 2) ? "M" : "F";user_set.insert(usermsg);}//插入100万条数据(批量事务优化)std::cout << "开始插入100万条数据..." << std::endl;auto startInsert = std::chrono::high_resolution_clock::now();const char* insert_sql = "INSERT OR IGNORE INTO users (phone, name, sex) VALUES (?, ?, ?);";litedb.batchInsertTemplate(insert_sql,user_set,stBinder);auto endInsert = std::chrono::high_resolution_clock::now();std::chrono::duration<double> insertTime = endInsert - startInsert;std::cout << "插入完成,耗时: " << insertTime.count() << "秒" << std::endl;}{//查询数据std::cout << "测试100万条数据查询速度..." << std::endl;auto startquery = std::chrono::high_resolution_clock::now();QueryResult* result = litedb.createQueryResult();const char* sqlstr = "SELECT * FROM users WHERE phone='13555927718';";std::vector<std::string> colname;if (litedb.queryTable(sqlstr,result) == 0) {// 打印列名std::cout << "列名: ";for (const auto& col : litedb.getColumnNames(result)) {std::cout << col << " ";colname.push_back(col);}std::cout << std::endl;// 打印所有行数据int rowNum = 0;for (const auto& row : litedb.getRows(result)) {std::cout << "行 " << rowNum++ << ": ";for (const auto& pair : row) {//std::cout << pair.first << "=" << pair.second << " ";std::cout << colname[pair.first] << "=" << pair.second << " ";}std::cout << std::endl;}}litedb.freeQueryResult(result);auto endquery = std::chrono::high_resolution_clock::now();std::chrono::duration<double> duration = endquery - startquery;std::cout << "查询完成,耗时: " << duration.count() << "秒" << std::endl;}litedb.closedb();return 0;
}
Makefile文件
CC = g++
CFLAGS =
DEBUGFLAG = -g -Wall
SRCS = $(wildcard *.cpp)
LIBDIRS = -L./
LIBS = -lsqlite3
INCLUDE = -I.
TARGET = sqlitetest
OBJS = $(SRCS:.cpp=.o)all: $(TARGET)# 生成可执行文件
$(TARGET): $(OBJS)$(CC) $(LIBS) $^ -o $@# 通用规则:编译 .cpp 文件为 .o 文件
%.o: %.cpp$(CC) $(LIBS) -c $< -o $@clean:rm -f $(OBJS) $(TARGET).PHONY: all clean
测试效果图:

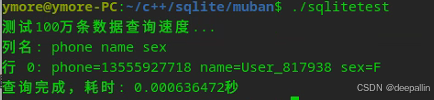
通过以上的批量插入和查询性能测试,我的国产信创终端设备,插入100万条速度15秒,查询速度是0.6毫秒,满足我的QT应用及后台应用开发需求(1条处理不超过1000条数据)。
sqlite默认是使用 B+ Tree作为其主要的索引结构(与MySQL一样)能够进行高效的范围查询。另外
其他分享:之前分享的hash存储查询方式,是在同一台国产设备上运行的,100万条记录查询1条记录速度是1微妙,比sqlite要强很多,适合TB级数据处理。hash存储查询![]() https://blog.csdn.net/liangyuna8787/article/details/147492363?spm=1001.2014.3001.5501
https://blog.csdn.net/liangyuna8787/article/details/147492363?spm=1001.2014.3001.5501
篇尾
sqlite的轻量级数据库特性,不仅易于部署,并且容易移植,且维护成本低,适合对数据库依赖性低的项目,C/C++项目本身就对数据库依赖低,所以本文专门分享从性能测试角度来选型sqlite。
相关文章:
)
【Linux C/C++开发】轻量级关系型数据库SQLite开发(包含性能测试代码)
前言 之前的文件分享过基于内存的STL缓存、环形缓冲区,以及基于文件的队列缓存mqueue、hash存储、向量库annoy存储,这两种属于比较原始且高效的方式。 那么,有没有高级且高效的方式呢。有的,从数据角度上看,࿰…...
 】)
77. 组合【 力扣(LeetCode) 】
文章目录 零、原题链接一、题目描述二、测试用例三、解题思路四、参考代码 零、原题链接 77. 组合 一、题目描述 给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。 你可以按 任何顺序 返回答案。 二、测试用例 示例 1: 输入&…...
)
GpuGeek全栈AI开发实战:从零构建企业级大模型生产管线(附完整案例)
目录 背景一、算力困境:AI开发者的「三重诅咒」1.1 硬件成本黑洞1.2 资源调度失衡1.3 环境部署陷阱 二、三大核心技术突破GpuGeek的破局方案2.1 分时切片调度引擎(Time-Slicing Scheduler)2.2 异构计算融合架构2.3 AI资产自动化…...
(技巧)(计数;双指针))
LeetCode 热题 100_颜色分类(98_75_中等_C++)(技巧)(计数;双指针)
LeetCode 热题 100_颜色分类(98_75_中等_C) 题目描述:输入输出样例:题解:解题思路:思路一(计数):思路二(双指针): 代码实现代码实现&a…...

【前端】:单 HTML 去除 Word 批注
在现代办公中,.docx 文件常用于文档编辑,但其中的批注(注释)有时需要在分享或归档前被去除。本文将从原理出发,深入剖析如何在纯前端环境下实现对 .docx 文件注释的移除,并提供完整的实现源码。最后&#x…...

TTS-Web-Vue系列:Vue3实现内嵌iframe文档显示功能
🖼️ 本文是TTS-Web-Vue系列的新篇章,重点介绍如何在Vue3项目中优雅地实现内嵌iframe功能,用于加载外部文档内容。通过Vue3的响应式系统和组件化设计,我们实现了一个功能完善、用户体验友好的文档嵌入方案,包括加载状态…...

AWS CloudTrail日志跟踪启用
问题 启用日志管理。 步骤 审计界面,如下图: 点击创建跟踪,AWS云就会记录AWS账号在云中的操作。...

PHP 编程:现代 Web 开发的基石与演进
引言 PHP(Hypertext Preprocessor)自1995年诞生以来,已成为全球最流行的服务器端脚本语言之一。尽管近年来Node.js、Python等语言在特定领域崭露头角,但PHP仍占据着超过78%的网站市场份额(W3Techs数据)。本…...

NAT/代理服务器/内网穿透
目录 一 NAT技术 二 内网穿透/内网打洞 三 代理服务器 一 NAT技术 跨网络传输的时候,私网不能直接访问公网,就引入了NAT能讲私网转换为公网进行访问,主要解决IPv4(2^32)地址不足的问题。 1. NAT原理 当某个内网想访问公网,就必…...

[已解决] VS Code / Cursor / Trae 的 PowerShell 终端 conda activate 进不去环境的常见问题
背景 PS C:\Users\Lenovo\WPSDrive\669715199_3\WPS云盘\课程\研一\ROAS5700 Robot Motion Planning and Control\Final\LaTex报告\final-v1> conda activate mpPS C:\Users\Lenovo\WPSDrive\669715199_3\WPS云盘\课程\研一\ROAS5700 Robot Motion Planning and Control\Fin…...

Kuka AI音乐AI音乐开发「人声伴奏分离」 —— 「Kuka Api系列|中文咬字清晰|AI音乐API」第6篇
导读 今天我们来了解一下 Kuka API 的人声与伴奏分离功能。 所谓“人声伴奏分离”,顾名思义,就是将一段完整的音频拆分为两个独立的轨道:一个是人声部分,另一个是伴奏(乐器)部分。 这个功能在音乐创作和…...

深度伪造对知识产权保护的新挑战与应对之策
首席数据官高鹏律师团队 在科技的飞速发展带来了诸多便利的同时,也引发了一系列复杂的法律问题,其中深度伪造技术对知识产权保护的冲击尤为显著,亟待引起广泛关注与深入探讨。 深度伪造,简单来说,是借助先进的人工智…...

【嵌入式开发-软件定时器】
嵌入式开发-软件定时器 ■ 1.■ 2.■ 3.■ 4. ■ 1. ■ 2. ■ 3. ■ 4....

3天重庆和成都旅游规划
重庆和成都都是大城市,各自都有丰富的旅游资源。如果要在三天内两头都游览,可能需要合理安排时间,确保既能体验到重庆的特色,又能在成都游览主要景点。然而,考虑到交通时间,如果从重庆到成都需要一定的时间…...

JAVA中的文件操作
文章目录 一、文件认识(一)文件的分类(二)目录结构 二、文件操作(一)File类1.属性2.构造方法3.方法 (二)File类的具体使用1.文件路径的查看2.文件的基本操作(1࿰…...

深度解析网闸策略:构建坚固的网络安全防线
深度解析网闸策略:构建坚固的网络安全防线 在数字化浪潮中,网络安全已成为企业、机构乃至国家稳定发展的关键要素。随着网络攻击手段日益复杂多样,传统的网络安全防护措施难以满足日益增长的安全需求。网闸作为一种先进的网络安全设备&#x…...

【Rust trait特质】如何在Rust中使用trait特质,全面解析与应用实战
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

滑动窗口算法笔记
力扣209 题目分析:想象一个窗口遍历着这个数组,不断扩大右边界,让r。往窗口中添加数字: 此时我们找到了这个窗口,它的和满足了大于等于target的条件,题目让我求最短的,那么我们就尝试来缩短它&…...

Problem A: 歌手打分
1.题目描述 在歌唱比赛中,共有10位评委进行打分,在计算歌手得分时,去掉一个最高分,去掉一个最低分,然后剩余的8位评委的分数进行平均,就是该选手的最终得分。输入每个评委的评分,求某选手的得分…...

容器安全-核心概述
文章摘要 本文探讨了容器安全的四个核心类别,包括环境基础设施安全、镜像安全、运行时安全和生态安全。尽管 EDR 能提供主机安全层面的部分防护,但无法覆盖容器的镜像安全和生态安全。容器的镜像安全和生态安全问题,如镜像漏洞、恶意镜像、容…...

Golang实践录:在go中使用curl实现https请求
之前曾经在一个 golang 工程调用 libcur 实现 https的请求,当前自测是通过的。后来迁移到另一个小系统出现段错误,于是对该模块代码改造,并再次自测。 问题提出 大约2年前,在某golang项目使用libcurl进行https请求(参…...

nvrtc环境依赖
一 下载 1.1 添加nvidia的源(不同于pypi) pip install nvidia-pyindex 1.2 pip dowload 执行 pip download nvidia-cuda-runtime nvidia-cuda-python 会发现文件夹多了以下几个文件 而需要安装的则只有红框的三个文件, 二 安装 对红框的…...

【计算机视觉】OpenCV实战项目:GraspPicture 项目深度解析:基于图像分割的抓取点检测系统
GraspPicture 项目深度解析:基于图像分割的抓取点检测系统 一、项目概述项目特点 二、项目运行方式与执行步骤(一)环境准备(二)项目结构(三)执行步骤 三、重要逻辑代码解析(一&#…...

Redis持久化存储
我们知道Redis是将数据放在内存中的,那怎么做到持久化存储呢?很简单,就是内存存一份,硬盘也存一份.那么两个地方都存会不会影响效率?答案是影响是不大的,要看具体的策略.同时也要注意内存的数据和硬盘中的数据可能会有一点不同.这也是取决于策略的不同. Redis持久化存储的两个…...

网络检测工具InternetTest v8.9.1.2504 单文件版,支持一键查询IP/DNS、WIFI密码信息
—————【下 载 地 址】——————— 【本章下载一】:https://drive.uc.cn/s/295e068b79314 【本章下载二】:https://pan.xunlei.com/s/VOQDXguH0DYPxrql5y2zlkhTA1?pwdg2nx# 【百款黑科技】:https://ucnygalh6wle.feishu.cn/wiki/…...

elpis-core: 基于 Koa 实现 web 服务引擎架构设计解析
前言 内容来源于抖音【哲玄前端】大佬的《大前端全栈实践》课程,此课程是从零开始做一个企业级的全栈应用框架。此框架是基于koa.js构建的服务引擎,对BFF层的框架封装,让我感受颇深。 整体elpis项目架构设计 elpis-core设计思路 可以看到elpi…...

计算机网络-MPLS LDP基础实验配置
前面我们学习了LDP的会话建立、标签发布与交换、LDP的工作原理,今天通过一个基础实验来加深记忆。 一、LDP基础实验 实验拓扑: 1、IGP使用OSPF进行通告,使用Lookback接口作为LSR ID,LDP ID自动生成。 2、实验目的:使…...

搜索二维矩阵 II
存储m和n,用i表示行,j表示列,i从最后一行开始遍历,j从0开始遍历,当前值比目标值小j,反之i-- class Solution { public:bool searchMatrix(vector<vector<int>>& matrix, int target) {int…...

C++中如何实现一个单例模式?
单利模式是指对象在整个程序中只有一个实例,提供一个访问方法供全局访问。实现单例模式有如下要求: 1.私有化构造函数:将构造函数定义为私有,以防外部通过构造函数创建其它实例。 2.静态实例:在内部提供一个静态实例…...

进程与线程
进程与线程:计算机世界的"公司与员工" 进程与线程的本质区别 进程(Process)是计算机中独立运行的程序实例,拥有自己的内存空间和系统资源;而线程(Thread)是进程内的执行单元,共享所属进程的资源,但拥有独立的执行路径。 🏢 生活类比:想象一个大型企业的运…...

JDK 命令行工具大全与学习方法总结 —— 从帮助文档到高效实践
JDK 命令行工具大全与学习方法总结 —— 从帮助文档到高效实践 Java开发与运维过程中,JDK自带的命令行工具是定位问题、性能调优、编译调试的基石。本文全面梳理JDK常用命令工具、帮助文档的获取方式,并总结类似Linux命令行的学习方法,助你系…...

行业趋势与技术创新:驾驭工业元宇宙与绿色智能制造
引言 制造业发展的新格局:创新势在必行 当今制造业正经历深刻变革,面临着供应链波动、个性化需求增长、可持续发展压力以及技能人才短缺等多重挑战。在这样的背景下,技术创新不再是可有可无的选项,而是企业保持竞争力、实现可持…...
 | 198.打家劫舍、213.打家劫舍II、337.打家劫舍III)
代码随想录算法训练营第三十九天(打家劫舍专题) | 198.打家劫舍、213.打家劫舍II、337.打家劫舍III
一、198.打家劫舍 题目链接:198. 打家劫舍 - 力扣(LeetCode) 文章讲解:代码随想录 视频讲解:动态规划,偷不偷这个房间呢?| LeetCode:198.打家劫舍_哔哩哔哩_bilibili 1. 思路 大家如…...

Linux514 rsync 解决方案环境配置
节点ab都改为NAT模式 网关和VMnet8网卡不一致 ping 不通外网 ping不通外网 是这里的问题吗 怎么突然就ping通了 没改啥啊 上面改了dhcp范围后 ping还是ping不通 为啥现在又ping通了 设置节点b 推测应该是dhcp范围问题 今日源码 节点b MX...

STM32F103_LL库+寄存器学习笔记23 - PWM波形输出及软件方式调整周期与占空比
导言 脉宽调制(PWM)是 STM32 定时器最常用的输出模式之一,广泛应用于电机驱动、LED 调光、伺服控制和功率管理等场景。本篇文章将以 TIM5 为例,从寄存器层面深入剖析 PWM 输出的原理与实现步骤。通过本篇博客,你不仅能…...

Canvas知识框架
一、Canvas基础 核心概念 Canvas是位图绘图区域,通过JavaScript(或Python等)动态绘制图形。 坐标系:左上角为原点 (0, 0),x向右递增,y向下递增。 绘图流程: const canvas document.getElemen…...

【SSL证书系列】客户端如何验证https网站服务器发的证书是否由受信任的根证书签发机构签发
客户端验证HTTPS网站证书是否由受信任的根证书颁发机构(CA)签发,是一个多步骤的过程,涉及证书链验证、信任锚(Trust Anchor)检查、域名匹配和吊销状态验证等。以下是详细的验证流程: 1. 证书链的…...

spark小任务
import org.apache.spark.{Partitioner, SparkConf, SparkContext}object PartitionCustom {// 分区器决定哪一个元素进入某一个分区// 目标: 把10个分区器,偶数分在第一个分区,奇数分在第二个分区// 自定义分区器// 1. 创建一个类继承Partitioner// 2. …...

git push 报错:send-pack: unexpected disconnect while reading sideband packet
背景 新建了一个仓库,第一次push 代码文件,文件中有一个依赖的jar,有80MB,结果push的时候报错。 错误信息 error: RPC failed; HTTP 500 curl 22 The requested URL returned error: 500 send-pack: unexpected disconnect whi…...

读入csv文件写入MySQL
### 使用 Spark RDD 读取 CSV 文件并写入 MySQL 的实现方法 #### 1. 环境准备 在使用 Spark 读取 CSV 文件并写入 MySQL 数据库之前,需要确保以下环境已配置完成: - 添加 Maven 依赖项以支持 JDBC 连接。 - 配置 MySQL 数据库连接参数,包括 …...

5.18-AI分析师
强化练习1 神经网络训练案例(SG) #划分数据集 #以下5行需要背 folder datasets.ImageFolder(rootC:/水果种类智能训练/水果图片, transformtrans_compose) n len(folder) n1 int(n*0.8) n2 n-n1 train, test random_split(folder, [n1, n2]) #训…...

腾讯云运营开发 golang一面
redis为什么单线程会快 每秒10w吞吐量 io多路复用 一个文件描述符整体拷贝;调用epoll_ctl 单个传递 内核遍历文件描述符判断是否有事件发送;回调函数列表维护 修改有事件发送的socket为可读或可写,返回整个文件描述符;返回链…...

spark数据压缩
### Spark 数据压缩方法及其实现 在大数据处理框架中,数据压缩是一个重要的环节,它不仅能够减少磁盘占用空间,还能降低网络传输成本。然而,在分布式计算环境中(如 Spark),选择合适的压缩编解码…...

synchronized关键字详解
synchronized关键字详解 1. 基本概念与使用方式 作用:确保多个线程在访问共享资源时的互斥性,防止数据不一致。使用方式: 修饰实例方法:锁对象为当前实例(this)。public synchronized void instanceMethod() {// 同步代码 }修饰静态方法:锁对象为类的Class对象。public…...

React useState 的同步/异步行为及设计原理解析
一、useState 的同步/异步行为 异步更新(默认行为) • 场景:在 React 合成事件(如 onClick)或生命周期钩子(如 useEffect)中调用 useState 的更新函数时,React 会将这些更新放入队列…...

《社交应用动态表情:RN与Flutter实战解码》
React Native依托于JavaScript和React,为动态表情的实现开辟了一条独特的道路。其核心优势在于对原生模块的便捷调用,这为动态表情的展示和交互提供了强大支持。在社交应用中,当用户点击发送动态表情时,React Native能够迅速调用相…...

【Oracle专栏】清理告警日志、监听日志
Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 今天在导入数据库时,发现之前可以导入,今天导入时居然报空间不足,于是检查是哪里占用空间比较大。检查回收站、归档日志,发现没有。然后检查告警日志、监听日志,发现果然占用空间比较大,于是进行…...

Ubuntu24.04编译ORB_SLAM的一系列报错解决
Ubuntu24.04编译ORB_SLAM的一系列报错解决 decay_t报错 报错信息:error: ‘decay_t’ is not a member of ‘std’;did you mean ‘decay’ 将CMakeLists.txt中第17行的c标准修改为c14即可: 修改前: CHECK_CXX_COMPILER_FLAG…...

Python × CARLA:如何在自动驾驶仿真世界里打造智能驾驶系统?
Python CARLA:如何在自动驾驶仿真世界里打造智能驾驶系统? 在人工智能与自动驾驶的浪潮中,真实世界的测试成本高昂,而自动驾驶仿真已成为开发者训练和测试 AI 驾驶算法的关键技术手段。其中,CARLA(Car Learning to Act)作为开源自动驾驶仿真平台,凭借其真实感强、高度…...

如何迁移 WSL 卸载 Ubuntu WSL
迁移 WSL 到其他盘区 假设您已经安装了 WSL 上的 Ubuntu 22.04 LTS,并且想要将其从 C 盘迁移到 D 盘。 查看 WSL 状态: 打开 PowerShell 或 CMD,运行以下命令查看当前安装的 WSL 发行版: wsl -l -v假设输出显示 Ubuntu-22.04 正在…...