自然语言处理入门级项目——文本分类
文章目录
- 前言
- 1.数据预处理
- 1.1数据集介绍
- 1.2数据集抽取
- 1.3划分数据集
- 1.4数据清洗
- 1.5数据保存
- 2.样本的向量化表征
- 2.1词汇表
- 2.2向量化
- 2.3自定义数据集
- 2.4备注
- 结语
前言
本篇博客主要介绍自然语言处理领域中一个项目案例——文本分类,具体而言就是判断评价属于积极还是消极的模型,选用的模型属于最简单的单层感知机模型。
1.数据预处理
1.1数据集介绍
本项目数据集来源:2015年,Yelp 举办了一场竞赛,要求参与者根据点评预测一家餐厅的评级。该数据集分为 56 万个训练样本和3.8万个测试样本。共计两个类别,分别代表该评价属于积极还是消极。这里以训练集为例,进行介绍展示:
import pandas as pdtrain_reviews=pd.read_csv('data/yelp/raw_train.csv',header=None,names=['rating','review'])
train_reviews,train_reviews.rating.value_counts()
运行结果:
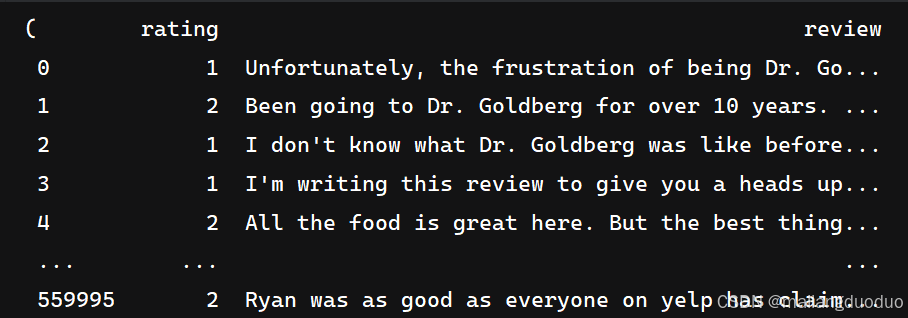
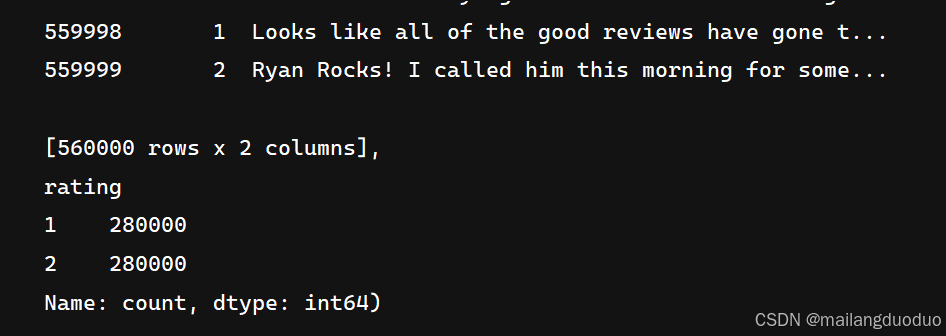
共计两个类别,同时类别数量相等,因此不需要进行类平衡操作。因为当前数据集过大,因此这里对数据集进行抽取。
1.2数据集抽取
首先,将两个类别的数据分别使用两个列表进行保存。代码如下:
import collectionsby_rating = collections.defaultdict(list)
for _, row in train_reviews.iterrows():by_rating[row.rating].append(row.to_dict())运行查看:
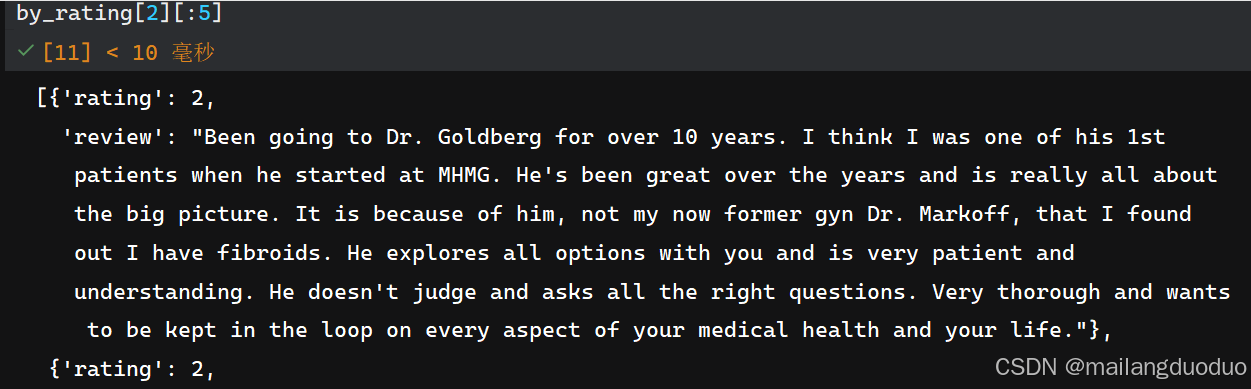
共计两个类别,分别存储在by_rating[1]和by_rating[2]对于的列表中。
接着选择合适的比例将数据从相应的类别中抽取出来,这里选择的比例为0.01,具体代码如下:
review_subset = []
for _, item_list in sorted(by_rating.items()):n_total = len(item_list)n_subset = int(0.01 * n_total)review_subset.extend(item_list[:n_subset])
为了可视化方便,这里将抽取后的子集转化为DataFrame数据格式,具体代码如下:
review_subset = pd.DataFrame(review_subset)
review_subset.head(),review_subset.shape
运行结果:
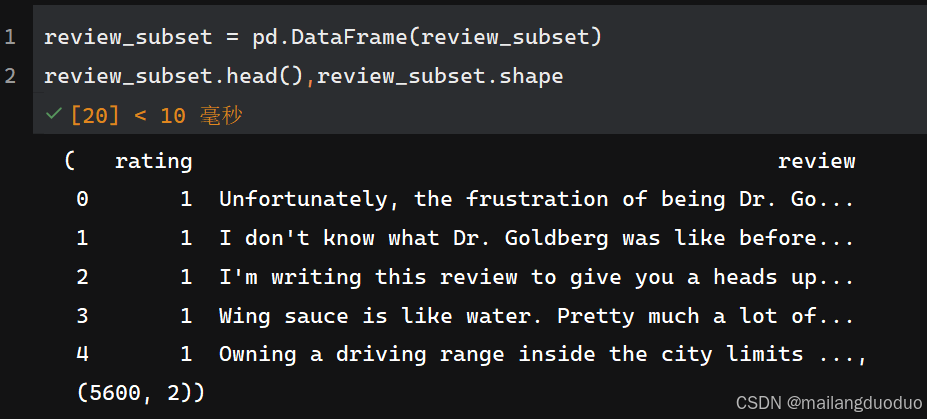
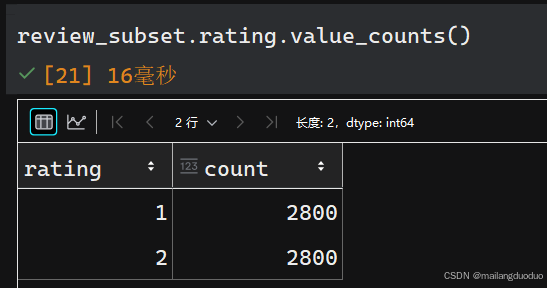
共计两个类别,每个类别均有2800条数据。
1.3划分数据集
首先,将两个类别的数据分别使用两个列表进行保存。代码如下:
by_rating = collections.defaultdict(list)
for _, row in review_subset.iterrows():by_rating[row.rating].append(row.to_dict())因为该过程包括了打乱顺序,为了保证结果的可重复性,因此设置了随机种子。这里划分的训练集:验证集:测试集=0.70:0.15:0.15,同时为了区分数据,增加了一个属性split,该属性共有三种取值,分别代表训练集、验证集、测试集。
import numpy as npfinal_list = []
np.random.seed(1000)for _, item_list in sorted(by_rating.items()):np.random.shuffle(item_list)n_total = len(item_list)n_train = int(0.7 * n_total)n_val = int(0.15 * n_total)n_test = int(0.15 * n_total)for item in item_list[:n_train]:item['split'] = 'train'for item in item_list[n_train:n_train+n_val]:item['split'] = 'val'for item in item_list[n_train+n_val:n_train+n_val+n_test]:item['split'] = 'test'final_list.extend(item_list)
同理为了可视化方便,将其转化为DataFrame类型,代码如下:
final_reviews = pd.DataFrame(final_list)
final_reviews.head()
运行结果:
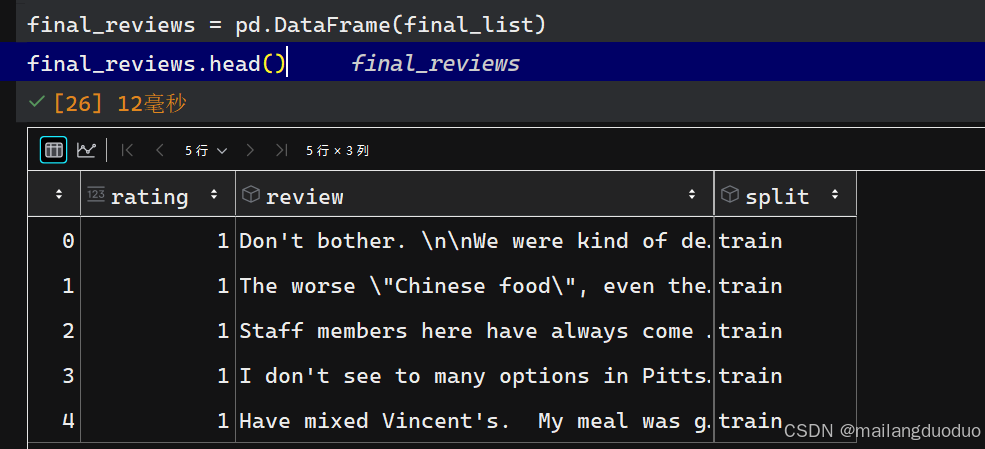
从上述结果可以看到,每条数据中还是有很多无意义的字符,如\,因此希望将其过滤掉,这就需要对数据进行清洗。
1.4数据清洗
这里为了将无意义的字符去除掉,自然就会想到正则表达式,用于匹配指定格式的字符串。具体操作代码如下:
import redef preprocess_text(text):text = text.lower()text = re.sub(r"([.,!?])", r" \1 ", text)text = re.sub(r"[^a-zA-Z.,!?]+", r" ", text)return textfinal_reviews.review = final_reviews.review.apply(preprocess_text)
这里对上述代码进行解释:
\1:指的是被匹配的字符,该段代码的功能是将匹配到的标点符号前后均加一个空格。- 第二个正则表达式:将除表示的字母及标点符号,其他符号均使用空格替代。
运行结果:
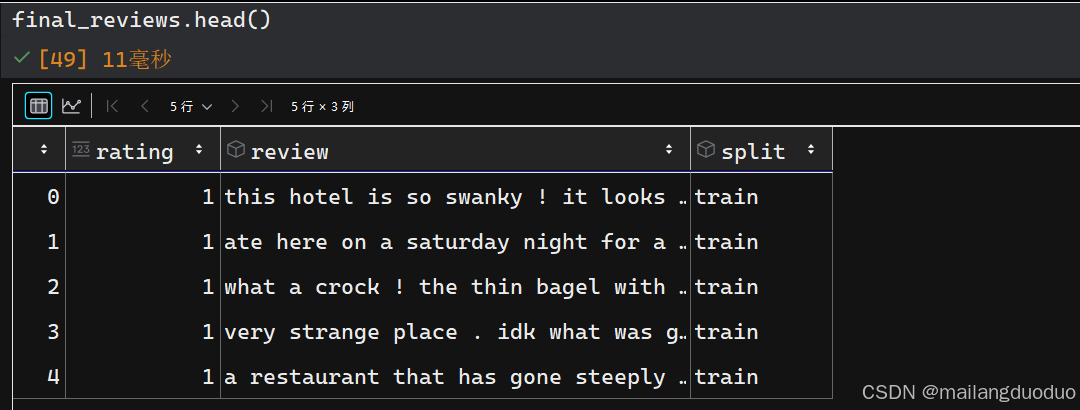
这里为了更好的展示数据,将rating属性做了更改,替换为negative和positive,
代码如下:
final_reviews['rating'] = final_reviews.rating.apply({1: 'negative', 2: 'positive'}.get)
final_reviews.head()
运行结果:
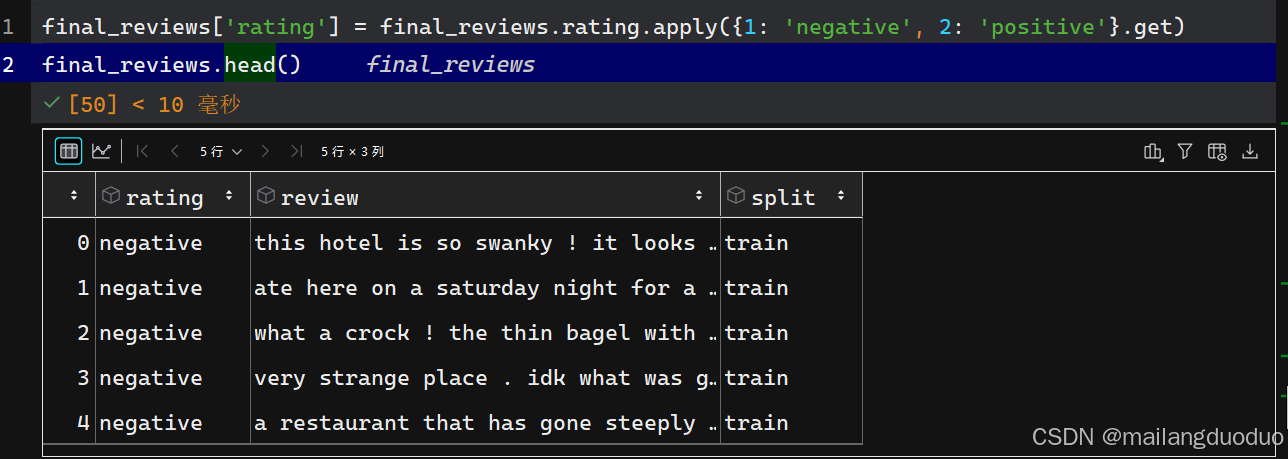
1.5数据保存
至此数据预处理基本完成,这里将处理好的数据进行保存。
final_reviews.to_csv('data/yelp/reviews_with_splits_lite_new.csv', index=False)
在输入模型前,总不能是一个句子吧,因此需要将每个样本中的review表示为向量化。
2.样本的向量化表征
2.1词汇表
这里定义了一个 Vocabulary 类,用于处理文本并提取词汇表,以实现单词和索引之间的映射。具体代码如下:
class Vocabulary(object):"""处理文本并提取词汇表,以实现单词和索引之间的映射"""def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):"""参数:token_to_idx (dict): 一个已有的单词到索引的映射字典add_unk (bool): 指示是否添加未知词(UNK)标记unk_token (str): 要添加到词汇表中的未知词标记"""if token_to_idx is None:token_to_idx = {}self._token_to_idx = token_to_idxself._idx_to_token = {idx: token for token, idx in self._token_to_idx.items()}self._add_unk = add_unkself._unk_token = unk_tokenself.unk_index = -1if add_unk:self.unk_index = self.add_token(unk_token) def to_serializable(self):"""返回一个可序列化的字典"""return {'token_to_idx': self._token_to_idx, 'add_unk': self._add_unk, 'unk_token': self._unk_token}@classmethoddef from_serializable(cls, contents):"""从一个序列化的字典实例化 Vocabulary 类"""return cls(**contents)def add_token(self, token):"""根据传入的单词更新映射字典。参数:token (str): 要添加到词汇表中的单词返回:index (int): 该单词对应的整数索引"""if token in self._token_to_idx:index = self._token_to_idx[token]else:index = len(self._token_to_idx)self._token_to_idx[token] = indexself._idx_to_token[index] = tokenreturn indexdef add_many(self, tokens):"""向词汇表中添加一组单词参数:tokens (list): 一个字符串单词列表返回:indices (list): 一个与这些单词对应的索引列表"""return [self.add_token(token) for token in tokens]def lookup_token(self, token):"""查找与单词关联的索引,若单词不存在则返回未知词索引。参数:token (str): 要查找的单词返回:index (int): 该单词对应的索引注意:`unk_index` 需要 >=0(即已添加到词汇表中)才能启用未知词功能"""if self.unk_index >= 0:return self._token_to_idx.get(token, self.unk_index)else:return self._token_to_idx[token]def lookup_index(self, index):"""返回与索引关联的单词参数: index (int): 要查找的索引返回:token (str): 该索引对应的单词异常:KeyError: 若索引不在词汇表中"""if index not in self._idx_to_token:raise KeyError("索引 (%d) 不在词汇表中" % index)return self._idx_to_token[index]def __str__(self):"""返回表示词汇表大小的字符串"""return "<Vocabulary(size=%d)>" % len(self)def __len__(self):"""返回词汇表中单词的数量"""return len(self._token_to_idx)
这里对该类中方法体做以下解释:
__init__构造方法:若token_to_idx为 None,则初始化为空字典。_idx_to_token是索引到单词的映射字典,通过_token_to_idx反转得到。若add_unk为 True,则调用add_token 方法添加未知词标记,并记录其索引。to_serializable 方法:返回一个字典,包含_token_to_idx、_add_unk和_unk_token,可用于序列化存储。from_serializable: 是类方法,接收一个序列化的字典,通过解包字典参数创建 Vocabulary 类的实例。add_token 方法:用于向词汇表中添加单个单词。若单词已存在,返回其索引;否则,分配一个新索引并更新两个映射字典。add_many 方法:用于批量添加单词列表,返回每个单词对应的索引列表。lookup_token 方法:根据单词查找对应的索引。若单词不存在且unk_index大于等于 0,则返回 unk_index;否则,返回单词的索引。lookup_index 方法:根据索引查找对应的单词。若索引不存在,抛出 KeyError 异常。__str__ 方法返回一个字符串,显示词汇表的大小。__len__ 方法:返回词汇表中单词的数量。
2.2向量化
此处定义了 ReviewVectorizer 类,其作用是协调词汇表(Vocabulary)并将其投入使用,主要负责把文本评论转换为可用于模型训练的向量表示。具体代码如下:
class ReviewVectorizer(object):""" 协调词汇表并将其投入使用的向量化器 """def __init__(self, review_vocab, rating_vocab):"""参数:review_vocab (Vocabulary): 将单词映射为整数的词汇表rating_vocab (Vocabulary): 将类别标签映射为整数的词汇表"""self.review_vocab = review_vocabself.rating_vocab = rating_vocabdef vectorize(self, review):"""为评论创建一个压缩的独热编码向量参数:review (str): 评论文本返回:one_hot (np.ndarray): 压缩后的独热编码向量"""# 初始化一个长度为词汇表大小的全零向量one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)# 遍历评论中的每个单词for token in review.split(" "):# 若单词不是标点符号if token not in string.punctuation:# 将向量中对应单词索引的位置置为 1one_hot[self.review_vocab.lookup_token(token)] = 1return one_hot@classmethoddef from_dataframe(cls, review_df, cutoff=25):"""从数据集的 DataFrame 实例化向量化器参数:review_df (pandas.DataFrame): 评论数据集cutoff (int): 基于词频过滤的阈值参数返回:ReviewVectorizer 类的一个实例"""# 创建评论词汇表,添加未知词标记review_vocab = Vocabulary(add_unk=True)# 创建评分词汇表,不添加未知词标记rating_vocab = Vocabulary(add_unk=False)# 添加评分标签到评分词汇表for rating in sorted(set(review_df.rating)):rating_vocab.add_token(rating)# 统计词频,若词频超过阈值则添加到评论词汇表word_counts = Counter()for review in review_df.review:for word in review.split(" "):if word not in string.punctuation:word_counts[word] += 1for word, count in word_counts.items():if count > cutoff:review_vocab.add_token(word)return cls(review_vocab, rating_vocab)@classmethoddef from_serializable(cls, contents):"""从可序列化的字典实例化 ReviewVectorizer参数:contents (dict): 可序列化的字典返回:ReviewVectorizer 类的一个实例"""# 从可序列化字典中恢复评论词汇表review_vocab = Vocabulary.from_serializable(contents['review_vocab'])# 从可序列化字典中恢复评分词汇表rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)def to_serializable(self):"""创建用于缓存的可序列化字典返回:contents (dict): 可序列化的字典"""return {'review_vocab': self.review_vocab.to_serializable(),'rating_vocab': self.rating_vocab.to_serializable()}
这里对该类中方法体做以下解释:
__init__方法:类的构造方法,接收两个 Vocabulary 类的实例:
review_vocab:将评论中的单词映射为整数。
rating_vocab:将评论的评分标签映射为整数。vectorize 方法:将输入的评论文本转换为压缩的独热编码向量。具体操作为:
首先创建一个长度为词汇表大小的全零向量 one_hot。
遍历评论中的每个单词,若该单词不是标点符号,则将向量中对应单词索引的位置置为 1。
最后返回处理好的独热编码向量。from_dataframe类方法:用于从包含评论数据的 DataFrame 中实例化ReviewVectorizer。具体操作为:
创建两个Vocabulary实例,review_vocab添加未知词标记,rating_vocab不添加。
遍历数据框中的评分列,将所有唯一评分添加到 rating_vocab 中。
统计评论中每个非标点单词的出现频率,将出现次数超过 cutoff 的单词添加到 review_vocab 中。
最后返回 ReviewVectorizer 类的实例。from_serializable 方法:从一个可序列化的字典中实例化ReviewVectorizer。
从字典中提取review_vocab和rating_vocab对应的序列化数据,分别创建 Vocabulary 实例。
最后返回 ReviewVectorizer 类的实例。to_serializable 方法:创建一个可序列化的字典,用于缓存 ReviewVectorizer 的状态。调用 review_vocab 和 rating_vocab 的 to_serializable 方法,将结果存储在字典中并返回。
2.3自定义数据集
该数据集继承Dataset,具体代码如下:
class ReviewDataset(Dataset):def __init__(self, review_df, vectorizer):"""参数:review_df (pandas.DataFrame): 数据集vectorizer (ReviewVectorizer): 从数据集中实例化的向量化器"""self.review_df = review_dfself._vectorizer = vectorizer# 从数据集中筛选出训练集数据self.train_df = self.review_df[self.review_df.split=='train']# 训练集数据的数量self.train_size = len(self.train_df)# 从数据集中筛选出验证集数据self.val_df = self.review_df[self.review_df.split=='val']# 验证集数据的数量self.validation_size = len(self.val_df)# 从数据集中筛选出测试集数据self.test_df = self.review_df[self.review_df.split=='test']# 测试集数据的数量self.test_size = len(self.test_df)# 用于根据数据集划分名称查找对应数据和数据数量的字典self._lookup_dict = {'train': (self.train_df, self.train_size),'val': (self.val_df, self.validation_size),'test': (self.test_df, self.test_size)}# 默认设置当前使用的数据集为训练集self.set_split('train')@classmethoddef load_dataset_and_make_vectorizer(cls, review_csv):"""从文件加载数据集并从头创建一个新的向量化器参数:review_csv (str): 数据集文件的路径返回:ReviewDataset 类的一个实例"""review_df = pd.read_csv(review_csv)# 从数据集中筛选出训练集数据train_review_df = review_df[review_df.split=='train']return cls(review_df, ReviewVectorizer.from_dataframe(train_review_df))@classmethoddef load_dataset_and_load_vectorizer(cls, review_csv, vectorizer_filepath):"""加载数据集和对应的向量化器。用于向量化器已被缓存以便重复使用的情况参数:review_csv (str): 数据集文件的路径vectorizer_filepath (str): 保存的向量化器文件的路径返回:ReviewDataset 类的一个实例"""review_df = pd.read_csv(review_csv)vectorizer = cls.load_vectorizer_only(vectorizer_filepath)return cls(review_df, vectorizer)@staticmethoddef load_vectorizer_only(vectorizer_filepath):"""一个静态方法,用于从文件加载向量化器参数:vectorizer_filepath (str): 序列化的向量化器文件的路径返回:ReviewVectorizer 类的一个实例"""with open(vectorizer_filepath) as fp:return ReviewVectorizer.from_serializable(json.load(fp))def save_vectorizer(self, vectorizer_filepath):"""使用 JSON 将向量化器保存到磁盘参数:vectorizer_filepath (str): 保存向量化器的文件路径"""with open(vectorizer_filepath, "w") as fp:json.dump(self._vectorizer.to_serializable(), fp)def get_vectorizer(self):"""返回向量化器"""return self._vectorizerdef set_split(self, split="train"):"""根据数据框中的一列选择数据集中的划分参数:split (str): "train", "val", 或 "test" 之一"""self._target_split = splitself._target_df, self._target_size = self._lookup_dict[split]def __len__(self):"""返回当前所选数据集划分的数据数量"""return self._target_sizedef __getitem__(self, index):"""PyTorch 数据集的主要入口方法参数:index (int): 数据点的索引返回:一个字典,包含数据点的特征 (x_data) 和标签 (y_target)"""row = self._target_df.iloc[index]# 将评论文本转换为向量review_vector = \self._vectorizer.vectorize(row.review)# 获取评分对应的索引rating_index = \self._vectorizer.rating_vocab.lookup_token(row.rating)return {'x_data': review_vector,'y_target': rating_index}def get_num_batches(self, batch_size):"""根据给定的批次大小,返回数据集中的批次数量参数:batch_size (int): 批次大小返回:数据集中的批次数量"""return len(self) // batch_sizedef generate_batches(dataset, batch_size, shuffle=True,drop_last=True, device="cpu"):"""一个生成器函数,封装了 PyTorch 的 DataLoader。它将确保每个张量都位于正确的设备上。"""dataloader = DataLoader(dataset=dataset, batch_size=batch_size,shuffle=shuffle, drop_last=drop_last)for data_dict in dataloader:out_data_dict = {}for name, tensor in data_dict.items():out_data_dict[name] = data_dict[name].to(device)yield out_data_dict这里不对代码进行解释了,关键部分已添加注释。
2.4备注
上述代码可能过长,导致难以理解,其实就是一个向量化表征的思想。上述采用的思想就是基于词频统计的,将整个训练集上的每条评论数据使用split(" ")分开形成若干个token,统计这些token出现的次数,将频次大于cutoff=25的token加入到词汇表中,并分配一个编码,其实就是索引。样本中的每条评论数据应该怎么表征呢,其实就是一个基于上述创建的词汇表的独热编码,因此是一个向量。
至此样本的向量化表征到此结束。接着就到定义模型,进行训练了。
结语
为了避免博客内容过长,这里就先到此结束,后续将接着上述内容进行阐述!同时本项目也是博主接触的第一个NLP领域的项目,如有不足,请批评指正!!!
备注:本案例代码参考本校《自然语言处理》课程实验中老师提供的参考代码
相关文章:

自然语言处理入门级项目——文本分类
文章目录 前言1.数据预处理1.1数据集介绍1.2数据集抽取1.3划分数据集1.4数据清洗1.5数据保存 2.样本的向量化表征2.1词汇表2.2向量化2.3自定义数据集2.4备注 结语 前言 本篇博客主要介绍自然语言处理领域中一个项目案例——文本分类,具体而言就是判断评价属于积极还…...

UOS专业版上通过源码安装 Python 3.13 并保留系统默认版本
在 UOS 专业版上通过源码安装 Python 3.13 并保留系统默认版本,可按照以下步骤操作: 1. 安装依赖 首先安装编译 Python 所需的依赖库: sudo apt update sudo apt install -y build-essential zlib1g-dev libncurses5-dev \ libgdbm-dev li…...

【论文笔记】ViT-CoMer
【题目】:ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions 【引用格式】:Xia C, Wang X, Lv F, et al. Vit-comer: Vision transformer with convolutional multi-scale feature interaction…...

kaggle薅羊毛
参考:https://pytorch-tutorial.readthedocs.io/en/latest/tutorial/chapter05_application/5_1_kaggle/#512-kaggle https://github.com/girls-in-ai/Girls-In-AI/blob/master/machine_learning_diary/data_analysis/kaggle_intro.md 1,code training…...

Python 之 Flask 入门学习
安装 Flask 在开始使用 Flask 之前,需要先安装它。可以通过 pip 命令来安装 Flask: pip install Flask创建第一个 Flask 应用 创建一个简单的 Flask 应用,只需要几行代码。以下是一个最基本的 Flask 应用示例: from flask imp…...
+代码讲解视频)
SpringBoot Vue MySQL酒店民宿预订系统源码(支付宝沙箱支付)+代码讲解视频
💗博主介绍💗:✌在职Java研发工程师、专注于程序设计、源码分享、技术交流、专注于Java技术领域和毕业设计✌ 温馨提示:文末有 CSDN 平台官方提供的老师 Wechat / QQ 名片 :) Java精品实战案例《700套》 2025最新毕业设计选题推荐…...

Oracle日期计算跟Mysql计算日期差距问题-导致两边计算不一致
Oracle数据库对日期做加法时,得到的时间是某天的12:00:00 例: Oracle计算 select (TO_DATE(2025-04-14, YYYY-MM-DD)1.5*365) from dual; 结果:2026/10/13 12:00:00Mysql计算 select DATE_ADD( str_to_date( 2025-04-14, %Y-%m-%d ), INTER…...
)
多线程(三)
上一期关于线程的执行,咱们说到线程是 “ 随机调度,抢占式执行 ”。所以我们对于线程之间执行的先后顺序是难以预知的。 例如咱们打篮球的时候,球场上的每一位运动员都是一个独立的 “ 执行流 ”,也可以认为是一个线程࿰…...
开篇、服务划分)
微服务商城(1)开篇、服务划分
参考:https://mp.weixin.qq.com/s?__bizMzg2ODU1MTI0OA&mid2247485597&idx1&sn7e85894b7847cc50df51d66092792453&scene21#wechat_redirect 为什么选择go-zero go-zero 为我们提供了许多高并发场景下的实用工具,比如为了降低接口耗时…...

刘强东 “猪猪侠” 营销:重构创始人IP的符号革命|创客匠人热点评述
当刘强东身着印有外卖箱猪猪侠的 T 恤漫步东京涩谷街头时,这场看似荒诞的行为艺术实则揭开了互联网商业竞争的新篇章。这位曾经以严肃企业家形象示人的京东创始人,正通过二次元 IP 的深度绑定,完成从商业领袖到文化符号的华丽转身。 一、IP …...

MQ消息队列的深入研究
目录 1、Apache Kafka 1.1、 kafka架构设 1.2、最大特点 1.3、功能介绍 1.4、Broker数据共享 1.5、数据一致性 2、RabbitMQ 2.1、架构图 2.2、最大特点 2.3、工作原理 2.4、功能介绍 3、RocketMQ 3.1、 架构设计 3.2、工作原理 3.3、最大特点 3.4、功能介绍 3…...
)
填涂颜色(bfs)
归纳编程学习的感悟, 记录奋斗路上的点滴, 希望能帮到一样刻苦的你! 如有不足欢迎指正! 共同学习交流! 🌎欢迎各位→点赞 👍+ 收藏⭐ + 留言📝 含泪播种的人一定能含笑收获! 题目描述 由数字 0 0 0 组成的方阵中,有一任意形状的由数字 1 1 1 构成的闭合圈。现…...

FFplay 音视频同步机制解析:以音频为基准的时间校准与动态帧调整策略
1.⾳视频同步基础 1.2 简介 看视频时,要是声音和画面不同步,体验会大打折扣。之所以会出现这种情况,和音视频数据的处理过程密切相关。音频和视频的输出不在同一个线程,就像两个工人在不同车间工作,而且不一定会同时…...

【Linux笔记】——进程信号的捕捉——从中断聊聊OS是怎么“活起来”的
🔥个人主页🔥:孤寂大仙V 🌈收录专栏🌈:Linux 🌹往期回顾🌹:【Linux笔记】——进程信号的保存 🔖流水不争,争的是滔滔不息 一、信号捕捉的流程二、…...

VCS X-PROP建模以及在方针中的应用
VCS X-PROP建模以及在方针中的应用 摘要:VCS X-Prop(X-Propagation)是 Synopsys VCS 仿真工具中的一种高级功能,用于增强 X 态(未知态)和 Z 态(高阻态)在 RTL 仿真中的建模和传播能力…...

OpenSHMEM 介绍和使用指南
OpenSHMEM 介绍和使用指南 什么是 OpenSHMEM? OpenSHMEM 是一个用于并行计算的标准化 API,它提供了一种分区全局地址空间 (PGAS) 编程模型。OpenSHMEM 最初由 Cray 公司开发,后来成为一个开源项目,旨在为高性能计算提供高效的通…...

Electron入门指南:用前端技术打造桌面应用
🌟 目录速览 什么是Electron?为什么要用Electron?核心概念三分钟掌握快速创建第一个应用典型应用场景开发注意事项常见问题解答 一、什么是Electron?🤔 Electron就像魔法转换器,它能将你熟悉的࿱…...

机器学习第十讲:异常值检测 → 发现身高填3米的不合理数据
机器学习第十讲:异常值检测 → 发现身高填3米的不合理数据 资料取自《零基础学机器学习》。 查看总目录:学习大纲 关于DeepSeek本地部署指南可以看下我之前写的文章:DeepSeek R1本地与线上满血版部署:超详细手把手指南 一、幼儿…...

【Redis】缓存穿透、缓存雪崩、缓存击穿
1.缓存穿透 是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,导致请求直接穿透缓存到达数据库,给数据库带来压力的情况。 常见的解决方案有两种: 缓存空对象:实现简单,维护方便&am…...

科学养生指南:打造健康生活
在快节奏的现代生活中,健康养生成为人们关注的焦点。科学养生无需复杂理论,掌握以下几个关键要素,就能为身体构筑坚实的健康防线。 合理饮食是健康的基础。世界卫生组织建议,每天应摄入至少 5 份蔬菜和水果,保证维生…...

解锁健康生活:现代养生实用方案
早上被闹钟惊醒后匆忙灌下咖啡,中午用外卖应付一餐,深夜刷着手机迟迟不肯入睡 —— 这样的生活模式,正在不知不觉侵蚀我们的健康。科学养生并非遥不可及的目标,只需从生活细节入手,就能逐步改善身体状态。 饮食管理…...
)
深入解析JVM字节码解释器执行流程(OpenJDK 17源码实现)
一、核心流程概述 JVM解释器的核心任务是将Java字节码逐条翻译为本地机器指令并执行。其执行流程可分为以下关键阶段: 方法调用入口构建:生成栈帧、处理参数、同步锁等。 字节码分派(Dispatch):根据字节码跳转到对应…...

【HCIA】BFD
前言 前面我们介绍了浮动路由以及出口路由器的默认路由配置,可如此配置会存在隐患,就是出口路由器直连的网络设备并不是运营商的路由器,而是交换机。此时我们就需要感知路由器的存活状态,这就需要用到 BFD(Bidirectio…...

vue使用路由技术实现登录成功后跳转到首页
文章目录 一、概述二、使用步骤安装vue-router在src/router/index.js中创建路由器,并导出在vue应用实例中使用router声明router-view标签,展示组件内容 三、配置登录成功后跳转首页四、参考资料 一、概述 路由,决定从起点到终点的路径的进程…...

用户模块 - IP归属地框架吞吐测试
一、引言 在很多用户系统中,我们常常需要知道一个IP地址来自哪里,比如判断一个用户是否来自国内、识别异常登录等。而实现这个功能,通常会使用一个“IP归属地解析框架”,它可以根据IP地址返回国家、省份、城市等信息。 不过&#…...

生活实用小工具-手机号归属地查询
一、接口定义 手机号码归属地接口(又称手机号查询API)是一种通过输入手机号码,快速返回其归属地信息(如省份、城市、运营商、区号等)的应用程序接口。其数据基础来源于运营商(移动、联通、电信)…...

鸿蒙-5.1.0-release源码下载
源码获取 前提条件 注册码云gitee帐号。注册码云SSH公钥,请参考码云帮助中心。安装git客户端和git-lfs并配置用户信息。 git config --global user.name "yourname" # 这得和gitee的账号对的上 git config --global user.email "your-email-ad…...

2020年下半年试题三:论云原生架构及其应用
论文库链接:系统架构设计师论文 论文题目 近年来,随着数字化转型不断深入,科技创新与业务发展不断融合,各行各业正在从大工业时代的固化范式进化成面向创新型组织与灵活型业务的崭新模式。在这一背景下,以容器盒微服务…...

Flutter到HarmonyOS Next 的跨越:memory_info库的鸿蒙适配之旅
Flutter到鸿蒙的跨越:memory_info库的鸿蒙适配之旅 本项目作者:kirk/坚果 您可以使用这个Flutter插件来更改应用程序图标上的角标 作者仓库:https://github.com/MrOlolo/memory_info/tree/master/memory_info 在数字化浪潮的推动下&#…...

昆士兰科技大学无人机自主导航探索新框架!UAVNav:GNSS拒止与视觉受限环境中的无人机导航与目标检测
作者: Sebastien Boiteau, Fernando Vanegas, Felipe Gonzalez 单位:昆士兰科技大学电气工程与机器人学院,昆士兰科技大学机器人中心 论文标题:Framework for Autonomous UAV Navigation and Target Detection in Global-Naviga…...

uniapp设置 overflow:auto;右边不显示滚动条的问题
设置了overflow:auto;或者其它overflow的属性不显示滚动条是因为在uniapp中默认隐藏了滚动条 解决方法: //强制显示滚动条 ::-webkit-scrollbar {width: 8px !important;background: #ccc !important;display: block !important;}//设置滚动条颜色.cu-…...

基于SIP协议的VOIP话机认证注册流程分析与抓包验证
话机的认证注册报文怎么看? 在SIP协议中,当VOIP话机首次启动的时候,他会向SIP服务器发送一个Register请求来注册自己的信息地址,,告诉服务器 话机当前在线话机的IP地址和端口是什么话机希望接收通话的联系方式 认证注…...

JS,ES,TS三者什么区别
Java Script(JS)、ECMAScript(ES)、TypeScript(TS) 的核心区别与关联的详细解析,结合技术背景、设计目标及应用场景展开说明: 一、核心定义与关系 JavaScript(JS) 定义:一种动态类型、基于原型的脚本语言,由 Netscape 公司于 1995 年首次开发,用于网页交互功能。角…...
)
深度理解指针(2)
🎁个人主页:工藤新一 🔍系列专栏:C面向对象(类和对象篇) 🌟心中的天空之城,终会照亮我前方的路 🎉欢迎大家点赞👍评论📝收藏⭐文章 深入理解指…...

笔记本/台式机加装PCIe 5.0固态硬盘兼容性与安装方法详解 —— 金士顿Kingston FURY Renegade G5装机指南
在2025年,存储设备市场迎来了革命性的升级浪潮。作为最高性能PCIe 5.0固态硬盘的代表,Kingston FURY Renegade G5 PCIe 5.0 NVMe M.2 固态硬盘不仅刷新了读写速度新高,更以优异的能耗和温控表现成为高端PC、游戏本和工作站升级的“定心丸”。…...

使用libUSB-win32的简单读写例程参考
USB上位机程序的编写,函数的调用过程. 调用 void usb_init(void); 进行初始化 调用usb_find_busses、usb_find_devices和usb_get_busses这三个函数,获得已找到的USB总线序列;然后通过链表遍历所有的USB设备,根据已知的要打开USB设…...

Tailwind CSS 实战教程:从入门到精通
Tailwind CSS 实战教程:从入门到精通 前言 在Web开发的世界里,CSS框架层出不穷。从早期的Bootstrap到现在的Tailwind CSS,前端开发者们总是在寻找更高效、更灵活的样式解决方案。今天,我们就来深入探讨这个被称为"实用优先…...

【IC】如何获取良好的翻转数据来改进dynamic IR drop分析?
动态电压降分析是一个复杂的过程。为了成功执行适当的分析,需要组合多个输入文件和不同的配置设置。 切换场景是任何动态压降分析的关键。设计中的所有门电路和实例不会同时处于活动状态。此外,对于更复杂的单元,可能的切换模式会非常多。这…...

WebGL知识框架
一、WebGL 基础概念 1. WebGL 简介 是什么? 基于 OpenGL ES 的浏览器 3D 图形 API,直接操作 GPU 渲染。 核心特点 底层、高性能、需手动控制渲染管线。 依赖 JavaScript 和 GLSL(着色器语言)。 与 Three.js 的关系 Three.js…...

集成 ONLYOFFICE 与 AI 插件,为您的服务带来智能文档编辑器
在数字化办公浪潮中,文档处理效率对企业发展具有关键意义。但许多办公平台仅支持基础流程,查阅、批注和修改需借助外部工具,增加了操作复杂性和沟通成本。本文将为开发者介绍如何集成 ONLYOFFICE 文档并利用其中的 AI 插件,智能处…...

Simulink模型回调
Simulink 模型回调函数是一种特殊的 MATLAB 函数,可在模型生命周期的特定阶段自动执行。它们允许用户自定义模型行为、执行初始化任务、验证参数或记录数据。以下是各回调函数的详细说明: 1. PreLoadFcn 触发时机:Simulink 模型加载到内存之…...

网络协议分析 实验五 UDP-IPv6-DNS
文章目录 实验5.1 UDP(User Datagram Protocol)练习二 UDP单播通信练习三 利用仿真编辑器编辑UDP数据包,利用工具接收练习四 UDP受限广播通信练习六 利用仿真编辑器编辑IPV6的UDP数据包并发送实验5.2 DNS(Domain Name System)练习二 仿真编辑DNS查询报文(…...

共享代理IP vs 动态IP:企业级业务场景的选型深度解析
在数字化转型加速的今天,IP地址管理已成为企业网络架构中的核心命题。无论是跨境电商的多账号运营、大数据采集的精准度保障,还是网络安全的纵深防御,IP解决方案的选择直接关系到业务效能与合规风险。本文将从技术底层逻辑出发,结…...

鸿蒙OSUniApp制作一个小巧的图片浏览器#三方框架 #Uniapp
利用UniApp制作一个小巧的图片浏览器 最近接了个需求,要求做一个轻量级的图片浏览工具,考虑到多端适配的问题,果断选择了UniApp作为开发框架。本文记录了我从0到1的开发过程,希望能给有类似需求的小伙伴一些参考。 前言 移动互联…...
)
Java并发编程面试题:并发工具类(10题)
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

【Oracle专栏】扩容导致数据文件 dbf 丢失,实操
Oracle相关文档,希望互相学习,共同进步 风123456789~-CSDN博客 1.背景 同事检查扩容情况,发现客户扩容后数据盘后,盘中原有文件丢失,再检查发现数据库没有启动。通过检查发现数据盘中丢失的是oracle的 dbf 表空间文件。数据库无法启动。 检查情况:1)没有rman备份 …...

【Linux】Linux 的管道与重定向的理解
目录 一、了解Linux目录配置标准FHS 二、Linux数据重定向的理解与操作 2.1基本背景 2.2重定向的理解 2.3Linux管道命令的理解与操作 三、Linux 环境变量与PATH 3.1环境变量PATH 一、了解Linux目录配置标准FHS FHS本质:是一套规定Linux目录结构,软…...

【交互 / 差分约束】
题目 代码 #include <bits/stdc.h> using namespace std; using ll long long;const int N 10510; const int M 200 * 500 10; int h[N], ne[M], e[M], w[M], idx; ll d[N]; int n, m; bool st[N]; int cnt[N];void add(int a, int b, int c) {w[idx] c, e[idx] b…...

1. Go 语言环境安装
👑 博主简介:高级开发工程师 👣 出没地点:北京 💊 人生目标:自由 ——————————————————————————————————————————— 版权声明:本文为原创文章…...

灰度图像和RGB图像在数据大小和编码处理方式差别
技术背景 好多开发者对灰度图像和RGB图像有些认知差异,今天我们大概介绍下二者差别。灰度图像(Grayscale Image)和RGB图像在编码处理时,数据大小和处理方式的差别主要体现在以下几个方面: 1. 通道数差异 图像类型通道…...