用PyTorch在超大规模下训练深度学习模型:并行策略全解析
我猜咱们每个人肯定都累坏了,天天追着 LLM 研究社区跑,感觉每天都冒出个新的最牛模型,把之前的基准都给打破了呢。要是你好奇为啥创新速度能这么快,那主要就是研究人员能够在超大规模下训练和验证模型啦,这全靠并行计算的功劳呀。
要是你还没听说过呢,5D 并行这个术语最早是 Meta AI 的论文 — The Llama 3 Herd of Models 里火起来的哦。传统上,它指的是结合数据、张量、上下文、流水线和专家并行这些技术呢。不过最近呀,又冒出了个新的玩意儿 — ZeRO (Zero Redundancy Optimizer),这可是个大杀器,通过减少分布式计算中的冗余来优化内存呢。每种技术都针对训练挑战的不同方面,它们组合起来就能搞定那些有几十亿甚至几万亿参数的模型啦。
我之前已经讲过一些比较底层的技巧啦,这些技巧能让你用 PyTorch 训练和部署模型的速度更快哦。虽然这些小贴士和小技巧能在训练时给你加分,但它们也就是加分项而已呀。要是你没有从根本上搞懂它们该在啥时候、啥地方用,那很可能就会用错地方啦。
这篇文章的重点呢,就是要给大家讲清楚模型操作的高层组织结构,还会用 PyTorch 来举些例子哦。这些并行计算的基本原则,就是现在能让模型在超大规模下(想想看,日活跃用户有几千万呢)更快迭代和部署的关键因素哦。
1. 数据并行
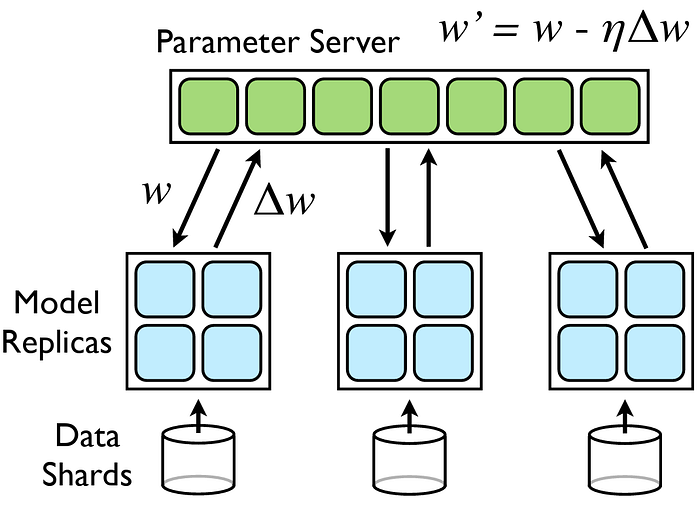
数据并行 [图片来源]
数据并行是最简单也是最常用的并行技术啦。它就是创建多个相同的模型副本,然后让每个副本在数据的不同子集上进行训练呢。在本地计算完梯度后,就会通过全归约操作(all-reduce operation)把梯度聚合起来,用来更新所有模型副本的参数呢。
当模型本身能装进单个 GPU 的内存里,但数据集太大没法按顺序处理的时候,这种方法特别管用哦。
PyTorch 通过 torch.nn.DataParallel 和 torch.nn.parallel.DistributedDataParallel(DDP) 模块,为数据并行提供了现成的支持呢。这其中呀,DDP 更受大家青睐,因为它在多节点设置下有更好的可扩展性和效率呢。NVIDIA 的 NeMo 框架就很好地展示了它是怎么工作的哦 —

数据并行示意图 [图片来源]
一个实现示例可能长这样:
import torch
import torch.nn as nn
import torch.optim as optim# 定义你的模型
model = nn.Linear(10, 1)# 用 DataParallel 包裹模型
model = nn.DataParallel(model)# 把模型移到 GPU
model = model.cuda()# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 假数据
inputs = torch.randn(64, 10).cuda()
targets = torch.randn(64, 1).cuda()# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets)# 反向传播和优化
loss.backward()
optimizer.step()
重点收获
- 小模型 / 大数据集 — 只有当模型能装进单个 GPU 的内存,但数据集太大时,这种方法才有效哦。
- 模型复制 — 每个 GPU 都会保存一份相同的模型参数副本呢。
- 小批量分割 — 输入数据会在 GPU 之间分配,确保每个设备处理一个独立的小批量数据哦。
- 梯度同步 — 在前向和反向传播之后,梯度会在 GPU 之间同步,以保持一致性呢。
优点和注意事项
- 简单高效 — 实现起来很简单,能很轻松地和现有的代码库集成,而且在处理大数据集时扩展性特别好哦。
- 通信开销 — 在梯度同步时的通信开销可能会成为大规模系统的一个瓶颈呢。
2. 张量并行
张量并行 [图片来源]
数据并行关注的是分割数据,而 张量并行(或者叫 模型并行)则是把模型本身分散到多个设备上呢。这种方法会把大型权重矩阵和中间张量分割开来,让每个设备只负责一部分计算呢。和数据并行不同(数据并行会在每个 GPU 上复制整个模型),张量并行会把模型的层或者张量分散到不同的设备上呢。每个设备负责计算模型前向和反向传播的一部分哦。
当模型太大,没办法装进单个 GPU 的内存时,这种方法就特别有用啦,尤其是对于那些基于 Transformer 的超大模型呢。
虽然 PyTorch 没有直接提供现成的张量并行支持,但用 PyTorch 灵活的张量操作和分布式通信原语,很容易就能实现自定义的张量并行呢。不过呢,要是想要更强大的解决方案,像 DeepSpeed 和 Megatron-LM 这样的框架就能扩展 PyTorch 来实现这个功能哦。一个简单的张量并行实现示例如下:
import torch
import torch.distributed as distdef tensor_parallel_matmul(a, b, devices):# a 按行分割,b 在设备间共享a_shard = a.chunk(len(devices), dim=0)results = []for i, dev in enumerate(devices):a_device = a_shard[i].to(dev)b_device = b.to(dev)results.append(torch.matmul(a_device, b_device))# 把各个设备的结果拼接起来return torch.cat(results, dim=0)# 示例用法:
a = torch.randn(1000, 512) # 假设这个张量太大,一个 GPU 装不下
b = torch.randn(512, 256)
devices = ['cuda:0', 'cuda:1']result = tensor_parallel_matmul(a, b, devices)
重点收获
- 大模型 — 当模型太大,装不下单个 GPU 的内存时,这种方法特别有效哦。
- 分割权重 — 不是在每个设备上复制整个模型,张量并行会把模型的参数切片呢。
- 集体计算 — 前向和反向传播是在 GPU 之间集体完成的,需要精心协调,以确保张量的所有部分都被正确计算呢。
- 自定义操作 — 往往要用到专门的 CUDA 内核或者第三方库,才能高效地实现张量并行哦。
优点和注意事项
- 内存效率 — 通过分割大型张量,你就能训练那些超出单个设备内存的模型啦。它还能显著减少矩阵操作的延迟呢。
- 复杂性 — 设备之间的协调增加了额外的复杂性哦。当扩展到超过两个 GPU 时,开发者必须仔细管理同步呢。由于手动分割可能导致的负载不平衡,以及为了避免 GPU 空闲太久而需要进行的设备间通信,是这些实现中常见的问题呢。
- 框架增强 — 像 Megatron-LM 这样的工具已经为张量并行树立了标杆,而且很多这样的框架都能和 PyTorch 无缝集成呢。不过,集成并不总是那么顺利哦。
3. 上下文并行
上下文并行采用了一种不同的方法,它针对的是输入数据的上下文维度,尤其在基于序列的模型(比如 Transformer)中特别厉害呢。主要思想就是把长序列或者上下文信息分割开来,让不同的部分同时进行处理呢。这样能让模型在不超出内存或者计算能力的情况下,处理更长的上下文哦。当需要一起训练多个任务时,比如在多任务 NLP 模型中,这种方法就特别有用啦。
和张量并行类似,PyTorch 本身并没有原生支持上下文并行呢。不过,通过巧妙地重构数据,我们就能有效地管理长序列啦。想象一下,有一个 Transformer 模型需要处理长文本 —— 可以把序列分解成更小的片段,然后并行处理,最后再合并起来呢。
下面就是一个自定义 Transformer 块中上下文如何分割的示例哦。在这个示例中,这个块可能会并行处理长序列的不同片段,然后把输出合并起来进行最后的处理呢。
import torch
import torch.nn as nnclass ContextParallelTransformer(nn.Module):def __init__(self, d_model, nhead, context_size):super(ContextParallelTransformer, self).__init__()self.context_size = context_sizeself.transformer_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead)def forward(self, x):# x 的形状:[batch, seq_len, d_model]batch, seq_len, d_model = x.size()assert seq_len % self.context_size == 0, \"序列长度必须能被 context_size 整除"# 把序列维度分割成片段segments = x.view(batch, seq_len // self.context_size,self.context_size, d_model)# 使用循环或者并行映射并行处理每个片段processed_segments = []for i in range(segments.size(1)):segment = segments[:, i, :, :]processed_segment = self.transformer_layer(segment.transpose(0, 1))processed_segments.append(processed_segment.transpose(0, 1))# 把处理过的片段拼接回完整的序列return torch.cat(processed_segments, dim=1)# 示例用法:
model = ContextParallelTransformer(d_model=512, nhead=8, context_size=16)
# [batch, sequence_length, embedding_dim]
input_seq = torch.randn(32, 128, 512)
output = model(input_seq)
重点收获
- 序列分割 — 把序列或者上下文维度分割开来,就能在不同的数据片段上并行计算啦。
- 长序列的可扩展性 — 这对于处理特别长的序列的模型特别有用,要是把整个上下文一次性处理,那既不可能,也不高效哦。
- 注意力机制 — 在 Transformer 中,把注意力计算分割到不同的片段上,能让每个 GPU 处理序列的一部分以及它相关的自注意力计算呢。
优点和注意事项
- 高效的长序列处理 — 把长上下文分割成并行的片段,模型就能在不过度占用内存资源的情况下处理超长的序列啦。
- 序列依赖性 — 必须特别注意跨越上下文片段边界的依赖关系哦。可能需要采用重叠片段或者额外的聚合步骤等技术呢。
- 新兴领域 — 随着研究的不断深入,我们期待会有更多专门促进 PyTorch 中上下文并行的标准工具和库出现呢。
4. 流水线并行

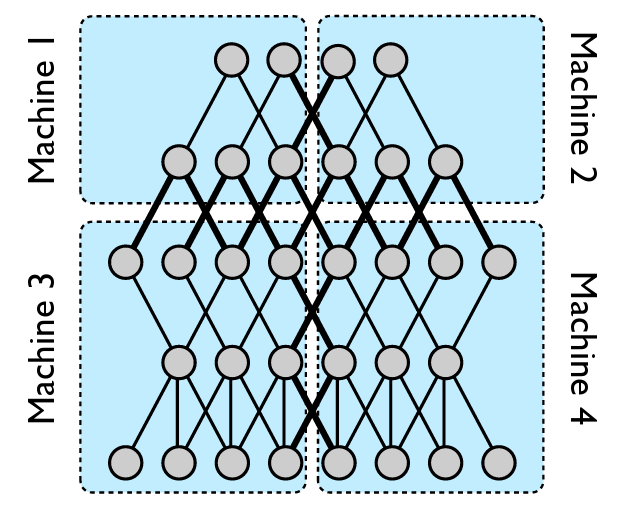
流水线并行示意图 [图片来源]
流水线并行引入了把神经网络分割成一系列阶段的概念,每个阶段都在不同的 GPU 上进行处理呢。当数据流经网络时,中间结果会从一个阶段传递到下一个阶段,就像流水线一样呢。这种错开的执行方式能让计算和通信重叠起来,从而提高整体的吞吐量呢。
幸运的是,PyTorch 有一个现成的 API 支持这个功能,叫做 Pipe,用它就能非常轻松地创建分段的模型呢。这个 API 会自动把一个顺序模型分割成微批次,这些微批次会在指定的 GPU 上流动呢。
一个简单的使用示例如下:
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe# 定义模型的两个顺序片段
segment1 = nn.Sequential(nn.Linear(1024, 2048),nn.ReLU(),nn.Linear(2048, 2048)
)segment2 = nn.Sequential(nn.Linear(2048, 2048),nn.ReLU(),nn.Linear(2048, 1024)
)# 使用 Pipe 把片段组合起来
# 如果提供了设备分配,Pipe 会自动处理模块在设备上的放置
# 这里是自动分配的
model = nn.Sequential(segment1, segment2)
model = Pipe(model, chunks=4)# 现在,当你把数据传递给模型时,微批次就会以流水线的方式进行处理啦。
inputs = torch.randn(16, 1024)
outputs = model(inputs)import torch
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe# 定义模型片段
segment1 = nn.Sequential(nn.Linear(1024, 2048),nn.ReLU(),nn.Linear(2048, 2048)
)
segment2 = nn.Sequential(nn.Linear(2048, 2048),nn.ReLU(),nn.Linear(2048, 1024)
)# 使用 Pipe 把片段组合成一个模型
model = nn.Sequential(segment1, segment2)
# 把模型分割成微批次,这些微批次会在 'cuda:0' 和 'cuda:1' 设备上流动
model = Pipe(model, devices=['cuda:0', 'cuda:1'], chunks=4)# 模拟输入批次
inputs = torch.randn(16, 1024).to('cuda:0')
outputs = model(inputs)
重点收获
- 分阶段计算 — 把模型分割成一系列阶段(或者叫“流水线”)。每个阶段都分配给不同的 GPU 哦。
- 微批次 — 不是把一个大批次一次性传给一个阶段,而是把批次分割成微批次,这些微批次会持续不断地流经流水线呢。
- 提高吞吐量 — 通过确保所有设备都在同时工作(即使是在处理不同的微批次),流水线并行可以显著提高吞吐量哦。
优点和注意事项
- 资源利用 — 流水线并行可以通过重叠不同阶段的计算,提高 GPU 的利用率哦。
- 延迟与吞吐量的权衡 — 虽然吞吐量提高了,但可能会因为引入的流水线延迟,稍微影响一下延迟呢。
- 复杂的调度 — 有效的微批次调度和负载平衡对于在各个阶段实现最佳性能至关重要哦。
5. 专家并行
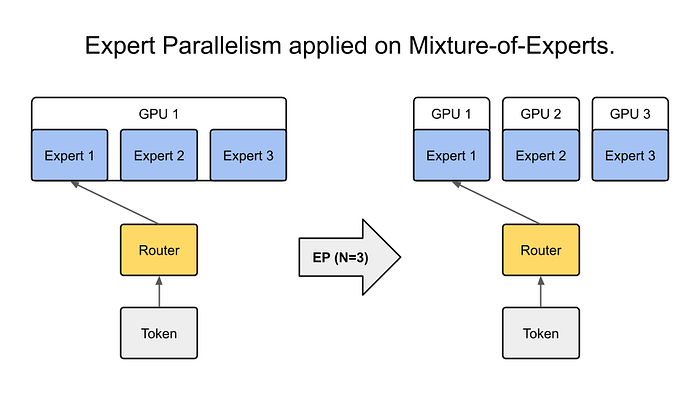
专家并行 [图片来源]
专家并行是一种受 混合专家模型(MoE) 启发的技术,旨在在保持计算成本可控的同时,扩展模型的容量呢。在这个范式中,模型由多个专门的“专家”组成 —— 这些子网络通过一个门控机制,为每个输入选择性地激活呢。对于每个样本,只有部分专家会参与处理,这样就能在不大幅增加计算开销的情况下,拥有巨大的模型容量啦。
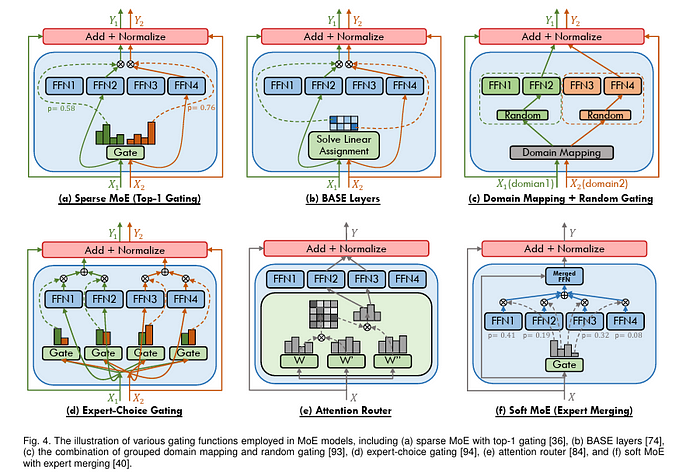
混合专家模型使用的门控函数 [图片来源]
同样呢,PyTorch 并没有直接提供现成的专家并行解决方案哦,不过它模块化的设计使得创建自定义实现成为可能呢。这种策略通常涉及定义一组专家层,以及一个决定激活哪些专家的门控器呢。
在生产环境中,专家并行通常会和其他并行策略结合起来使用哦。比如,你可以同时使用数据并行和专家并行,既能处理大型数据集,又能处理大量的模型参数 —— 同时,还能通过门控机制,把计算有选择性地路由到合适的专家那里呢。下面就是一个简化版的实现示例:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass Expert(nn.Module):def __init__(self, input_dim, output_dim):super(Expert, self).__init__()self.fc = nn.Linear(input_dim, output_dim)def forward(self, x):return F.relu(self.fc(x))class MoE(nn.Module):def __init__(self, input_dim, output_dim, num_experts, k=2):super(MoE, self).__init__()self.num_experts = num_expertsself.k = k # 每个样本使用的专家数量self.experts = nn.ModuleList([Expert(input_dim, output_dim)for _ in range(num_experts)])self.gate = nn.Linear(input_dim, num_experts)def forward(self, x):# x 的形状:[batch, input_dim]gate_scores = self.gate(x) # [batch, num_experts]# 为每个输入选择 top-k 个专家topk = torch.topk(gate_scores, self.k, dim=1)[1]outputs = []for i in range(x.size(0)):expert_output = 0for idx in topk[i]:expert_output += self.experts[idx](x[i])outputs.append(expert_output / self.k)return torch.stack(outputs)# 示例用法:
batch_size = 32
input_dim = 512
output_dim = 512
num_experts = 4
model = MoE(input_dim, output_dim, num_experts)
x = torch.randn(batch_size, input_dim)
output = model(x)
重点收获
- 混合专家 — 对于每个训练样本,只使用部分专家,这样就能在不大幅增加每个样本计算量的情况下,保持巨大的模型容量哦。
- 动态路由 — 门控函数会动态决定哪些专家应该处理每个输入标记或者数据片段呢。
- 专家级别的并行 — 专家可以在多个设备上分布开来,这样就能并行计算,进一步减少瓶颈啦。
优点和注意事项
- 可扩展的模型容量 — 专家并行让你能够构建出容量巨大的模型,而不会因为每个输入都增加计算量哦。
- 高效的计算 — 通过只为每个输入处理选定的专家子集,就能实现高效的计算啦。
- 路由复杂性 — 门控机制非常关键哦。要是设计得不好,可能会导致负载不平衡和训练不稳定呢。
- 研究前沿 — 专家并行仍然是一个活跃的研究领域,目前正在进行的研究旨在改进门控方法以及专家之间的同步呢。
6. ZeRO:零冗余优化器
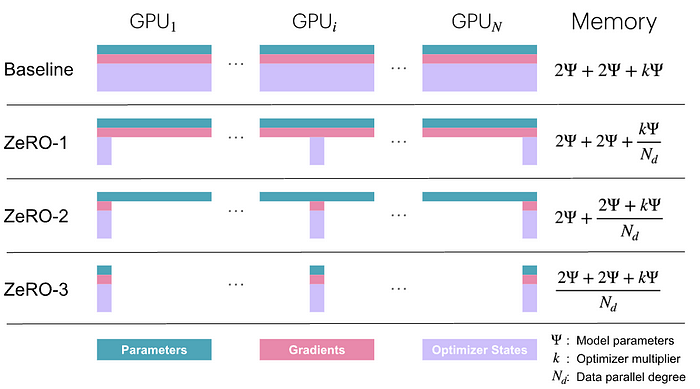
分区策略和 GPU 性能 [图片来源]
ZeRO,也就是 零冗余优化器,在大规模训练的内存优化方面可是个突破性的成果哦。作为 DeepSpeed 库的一部分,ZeRO 通过分区优化器状态、梯度和模型参数,解决了分布式训练中的内存限制问题呢。说白了,ZeRO 就是消除了每个 GPU 都保存一份所有东西的冗余,从而节省了大量的内存呢。
它的运作方式是把优化器状态和梯度的存储分散到所有参与的设备上,而不是复制它们呢。这种策略不仅能减少内存使用量,还能让那些原本会超出单个 GPU 内存容量的模型也能进行训练呢。ZeRO 通常会分三个阶段来实现,每个阶段都针对不同的内存冗余问题:
ZeRO-1:优化器状态分区
- 把优化器状态(比如动量缓冲区)分区到各个 GPU 上呢
- 每个 GPU 只保存其参数部分的优化器状态哦
- 模型参数和梯度仍然在所有 GPU 上复制呢
ZeRO-2:梯度分区
- 包含了 ZeRO-1 的所有内容呢
- 另外还会把梯度分区到各个 GPU 上哦
- 每个 GPU 只计算并保存其参数部分的梯度呢
- 模型参数仍然在所有 GPU 上复制呢
ZeRO-3:参数分区
- 包含了 ZeRO-1 和 ZeRO-2 的所有内容呢
- 另外还会把模型参数分区到各个 GPU 上哦
- 每个 GPU 只保存模型参数的一部分呢
- 在前向和反向传播过程中需要收集参数呢
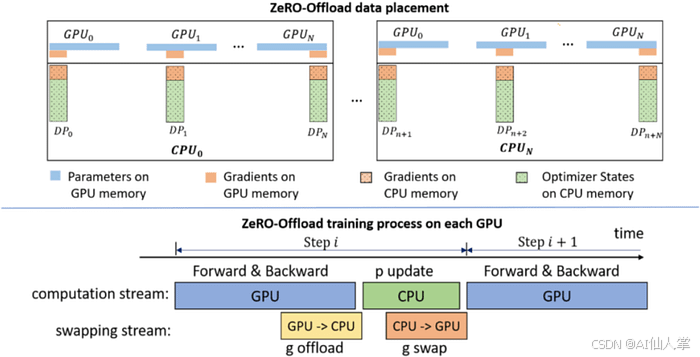
ZeRO Offload 的架构 [图片来源]
ZeRO 提供了最大的灵活性,因为它结合了数据和模型并行的好处,如上图所示呢。
虽然 ZeRO 是 DeepSpeed 的一个特性,但它和 PyTorch 的集成使得它成为了训练优化工具箱中的一个重要工具,有助于高效地管理内存,并让以前无法训练的模型大小在现代硬件上成为可能呢。下面是一个示例实现:
import torch
import torch.nn as nn
import deepspeedclass LargeModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(LargeModel, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_dim, output_dim)def forward(self, x):x = self.relu(self.fc1(x))return self.fc2(x)model = LargeModel(1024, 4096, 10)# DeepSpeed 配置,带有 ZeRO 优化器设置
ds_config = {"train_batch_size": 32,"optimizer": {"type": "Adam","params": {"lr": 0.001}},"zero_optimization": {"stage": 2, # 第 2 阶段:梯度分区"allgather_partitions": True,"reduce_scatter": True,"allgather_bucket_size": 2e8,"overlap_comm": True}
}# 用 ZeRO 初始化 DeepSpeed 和模型
model_engine, optimizer, _, _ = deepspeed.initialize(model=model,config=ds_config)
inputs = torch.randn(32, 1024).to(model_engine.local_rank)
outputs = model_engine(inputs)
loss = outputs.mean() # 简化的损失计算
model_engine.backward(loss)
model_engine.step()
重点收获
- 阶段选择 — ZeRO 通常分多个阶段实现,每个阶段在内存节省和通信开销之间提供了不同的平衡呢。根据模型大小、网络能力以及可以接受的通信开销水平,选择合适的阶段至关重要哦。
- 与其他技术的集成 — 它可以无缝地融入一个可能还包括上述并行策略的生态系统中呢。
优点和注意事项
- 通信开销 — 这种策略的一个固有挑战是,减少内存冗余通常会增加 GPU 之间的数据交换量哦。因此,高效利用高速互连(比如 NVLink 或 InfiniBand)就变得更加关键啦,因为这个原因。
- 配置复杂性 — ZeRO 比传统优化器引入了更多的配置参数呢。这些设置需要仔细地进行实验和分析,以匹配硬件的优势,确保优化器能够高效运行呢。设置内容包括但不限于 — 适当的梯度聚合桶大小,以及各种状态(优化器状态、梯度、参数)的分区策略。
- 强大的监控 — 在启用 ZeRO 的训练中调试问题可能会非常困难哦。因此,提供对 GPU 内存使用情况、网络延迟以及整体吞吐量等信息的监控工具就变得至关重要啦,因为这个原因。
把它们全部结合起来
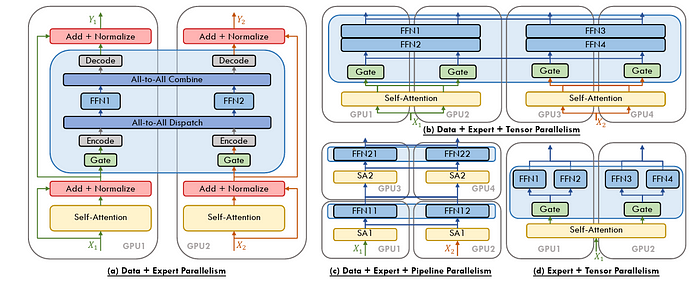
并行的各种混合方法 [图片来源]
在超大规模下训练深度学习模型,很多时候都需要采用混合方法 —— 通常会结合上述提到的这些技术呢。比如,一个最先进的 LLM 可能会使用数据并行来在节点之间分配批次,张量并行来分割巨大的权重矩阵,上下文并行来处理长序列,流水线并行来连接顺序模型阶段,专家并行来动态分配计算资源,最后再用 ZeRO 来优化内存使用呢。这种协同作用确保了即使是参数数量天文数字级别的模型,也仍然能够进行训练,并且保持高效的哦。
搞清楚在什么时候、在什么地方以及如何使用这些技术,对于突破可能的极限至关重要呢。再加上 PyTorch 的模块化和即插即用的库,构建能够突破传统硬件限制的健壮、可扩展的训练管道,已经变得越来越容易被更多人掌握了呢。
相关文章:

用PyTorch在超大规模下训练深度学习模型:并行策略全解析
我猜咱们每个人肯定都累坏了,天天追着 LLM 研究社区跑,感觉每天都冒出个新的最牛模型,把之前的基准都给打破了呢。要是你好奇为啥创新速度能这么快,那主要就是研究人员能够在超大规模下训练和验证模型啦,这全靠并行计算…...

linux-进程信号捕捉
1. 信号捕捉流程 操作系统会在合适的时候处理信号,那这个合适的时候是什么时候呢?进程从内核态返回到用户态的时候。 假如用户程序注册了 SIGQUIT 信号的处理函数 sighandler。当程序正在执行 main 函数时,如果发生中断、异常或系统调用&…...
shellcode加密)
【免杀】C2免杀技术(三)shellcode加密
前言 shellcode加密是shellcode混淆的一种手段。shellcode混淆手段有多种:加密(编码)、偏移量混淆、UUID混淆、IPv4混淆、MAC混淆等。 随着杀毒软件的不断进化,其检测方式早已超越传统的静态特征分析。现代杀软往往会在受控的虚…...

人工智能驱动的临床路径体系化解决方案与实施路径
引言 临床路径管理作为现代医疗质量管理的重要工具,其核心在于通过标准化诊疗流程来提升医疗服务的规范性、一致性和效率。然而,传统临床路径管理面临路径设计僵化、执行依从性低、变异管理滞后等诸多挑战,亟需借助人工智能技术实现转型升级。本研究旨在探讨如何通过构建系…...

旋变信号数据转换卡 旋变解码模块 汽车永磁同步电机维修工具
旋变信号数据转换卡,是一款专门针对与永磁同步电机的旋变编码器和 BRX 型旋转变压器编码器进行旋变信号解码转换串行总线协议的专用转换卡。此款转换卡结合了专用的旋变信号解码芯片解码逻辑处理,解码信号分辨率高、线性度高、响应速度快。板卡采用工业级…...

RPM 包制作备查 SRPM 包编译
🌈 个人主页:Zfox_ 目录 🔥 前言 一:🔥 准备 二:🔥 制作 rpm 1.设置目录结构(制作车间)2. 源码放置到规划好的目录当中3. 创建一个spec文件,指挥如何使用这些…...

[学习] RTKLib详解:rtcm2.c、rtcm3.c、rtcm3e与rtcmn.c
RTKLib详解:rtcm2.c、rtcm3.c、rtcm3e与rtcmn.c 本文是 RTKLlib详解 系列文章的一篇,目前该系列文章还在持续总结写作中,以发表的如下,有兴趣的可以翻阅。 [学习] RTKlib详解:功能、工具与源码结构解析 [学习]RTKLib详…...
:智能皮电手环(GSR智能手环)性能与存储的深度评测)
MCU ESP32-S3+SD NAND(贴片式T卡):智能皮电手环(GSR智能手环)性能与存储的深度评测
在智能皮电手环与数据存储领域,主控MCU ESP32-S3FH4R2 与 存储SD NAND MKDV2GIL-AST 的搭档堪称行业新典范。二者深度融合低功耗、高速读写、SMART 卓越稳定性等核心优势,以高容量、低成本的突出特性,为大规模生产场景带来理想的数据存储方案…...

股指期货套期保值怎么操作?
股指期货套期保值就是企业或投资者通过持有与其现货市场头寸相反的期货合约,来对冲价格风险的一种方式。换句话说,就是你在股票市场上买了股票(现货),担心股价下跌会亏钱,于是就在期货市场上卖出相应的股指…...

Pytorch的Dataloader使用详解
PyTorch 的 DataLoader 是数据加载的核心组件,它能高效地批量加载数据并进行预处理。 Pytorch DataLoader基础概念 DataLoader基础概念 DataLoader是PyTorch基础概念 DataLoader是PyTorch中用于加载数据的工具,它可以:批量加载数据…...
)
Ros2 - Moveit2 - DeepGrasp(深度抓握)
本教程演示了如何在 MoveIt 任务构造器中使用抓握姿势检测 (GPD)和 Dex-Net 。 GPD(左)和 Dex-Net(右)用于生成拾取圆柱体的抓取姿势。 https://moveit.picknik.ai/main/_images/mtc_gpd_panda.gif 入门 如果您还没有这样做&am…...

【DRAM存储器五十一】LPDDR5介绍--CK、WCK、RDQS单端模式、Thermal Offset、Temperature Sensor
👉个人主页:highman110 👉作者简介:一名硬件工程师,持续学习,不断记录,保持思考,输出干货内容 参考资料:《某LPDDR5数据手册》 、《JESD209-5C》 目录 CK、WCK、RDQS单端模式 Thermal Offset Temperature Sensor...
】Eureka 客户端服务注册(含源代码)(四))
【springcloud学习(dalston.sr1)】Eureka 客户端服务注册(含源代码)(四)
d该系列项目整体介绍及源代码请参照前面写的一篇文章【springcloud学习(dalston.sr1)】项目整体介绍(含源代码)(一) 这篇文章主要介绍Eureka客户端服务注册到eureka的server端。 上篇文章【springcloud学习(dalston.sr1)】Eurek…...

数据结构 栈和队列
文章目录 📕1.栈(Stack)✏️1.1 栈的基本操作✏️1.2 栈的模拟实现🔖1.2.1 构造方法🔖1.2.2 扩容方法🔖1.2.3 判断栈是否为空或是否满🔖1.2.4 存储元素🔖1.2.5 删除元素🔖1.2. 6 获取栈顶元素 ✏…...

[数据结构]5. 栈-Stack
栈-Stack 1. 介绍2. 栈的实现2.1 基于链表的实现2.2 基于数组的实现 3. 栈操作CreateInitilizateDestoryPushPopTopEmptySize 1. 介绍 栈(stack) 是一种遵循先入后出逻辑的线性数据结构。顶部称为“栈顶”,底部称为“栈底”。把元素添加到栈…...
)
Git的安装和配置(idea中配置Git)
一、Git的下载和安装 前提条件:IntelliJ IDEA 版本是2023.3 ,那么配置 Git 时推荐使用 Git 2.40.x 或更高版本 下载地址:CNPM Binaries Mirror 操作:打开链接 → 滚动到页面底部 → 选择2.40.x或更高版本的 .exe 文件…...

QT-1.信号与槽
一、信号与槽机制概述 四、信号与槽的连接 六、自定义信号与槽 思考 定义与作用 :信号与槽是Qt中的核心通信机制,用于实现对象间的数据交互和事件处理。当特定事件发生时,对象会发出信号,而与之相连的槽函数会被自动调用。 特点 …...

常用的应用层网络协议对比
概述 协议通信模式加密支持传输层主要特点典型应用场景WSS全双工是(TLS/SSL)TCP安全的实时双向通信实时聊天、在线游戏WebSocket (WS)全双工否TCP持久连接、低延迟协同编辑、实时通知HTTPS请求-响应是(TLS/SSL)TCP安全性强、兼容…...

数据结构与算法:状压dp
前言 状压dp在整个动态规划专题里特别重要,用位信息表示元素的思想更是重中之重。 一、状态压缩 1.内容 对于一些带路径的递归,通常来讲没法改记忆化搜索和严格位置依赖的动态规划。但如果这个路径的数据量在一定范围内,就可以考虑使用一个整数status的位信息0和1来存路…...

Spring Cloud Gateway 聚合 Swagger 文档:一站式API管理解决方案
前言 在微服务架构中,随着服务数量的增加,API文档管理变得越来越复杂。每个微服务都有自己的Swagger文档,开发人员需要记住每个服务的文档地址,这无疑增加了开发难度。本文将介绍如何使用Spring Cloud Gateway聚合所有微服务的Sw…...

Android 适配之——targetSdkVersion 30升级到31-34需要注意些什么?
在Android 16即将到来的之际。也就是targetSdkVersion即将出现36,而30已然会成为历史。那么我的项目已经停留在30很久了。是时候要适配一下适用市场的主流机型了。正常来查找资料的,无非就是已经升级和准备升级targetSdkVersion开发版本。所以你是哪一种…...

网络运维过程中的常用命令
一、通用网络命令 ping 作用:测试与目标 IP 或域名的连通性。 示例: ping www.baidu.com # 持续发送ICMP包 ping -c 4 8.8.8.8 # 发送4个包后停止 traceroute/tracert 功能:追踪数据包经过的路由节点。 示例: traceroute…...
)
[Java实战]Spring Boot 3整合JWT实现无状态身份认证(二十四)
[Java实战]Spring Boot 3整合JWT实现无状态身份认证(二十四) 一、JWT简介与核心概念 1. JWT是什么? JSON Web Token (JWT) 是一种开放标准(RFC 7519),用于在各方之间安全地传输信息。JWT由三部分组成&am…...

【Java-EE进阶】SpringBoot针对某个IP限流问题
目录 简介 1. 使用Guava的RateLimiter实现限流 添加Guava依赖 实现RateLimiter限流逻辑 限流管理类 控制器中应用限流逻辑 2. 使用计数器实现限流 限流管理类 控制器中应用限流逻辑 简介 针对某个IP进行限流以防止恶意点击是一种常见的反爬虫和防止DoS的措施。限流策…...

软考冲刺——案例分析题 MUX VLAN
上一篇文章介绍了VLAN高级应用的Super VLAN,本次介绍MUX VLAN内容,MUX VLAN在2024.11月考察过选择题,案例题中有可能出现。 考点一:MUX VLAN原理及实现方式;通过简答题出现。 考点二:配置命令填空。 一&…...

Git 用户名与邮箱配置全解析:精准配置——基于场景的参数选择
目录 一、配置查看:理解多层级配置体系二、精准配置:基于场景的参数选择1. 仓库级配置(推荐)2. 用户级配置3. 系统级配置 三、历史提交信息修改1. 修改最近一次提交2. 修改多个历史提交(危险操作) 五、配置…...
,UART)
OpenHarmony平台驱动开发(十七),UART
OpenHarmony平台驱动开发(十七) UART 概述 功能简介 UART指异步收发传输器(Universal Asynchronous Receiver/Transmitter),是通用串行数据总线,用于异步通信。该总线双向通信,可以实现全双工…...
系列之一)
仿生眼机器人(人脸跟踪版)系列之一
文章不介绍具体参数,有需求可去网上搜索。 特别声明:不论年龄,不看学历。既然你对这个领域的东西感兴趣,就应该不断培养自己提出问题、思考问题、探索答案的能力。 提出问题:提出问题时,应说明是哪款产品&a…...

Redis的Pipeline和Lua脚本适用场景是什么?使用时需要注意什么?
Redis Pipeline 和 Lua 脚本详解 一、Pipeline(管道) 定义 一种批量执行命令的机制,客户端将多个命令一次性发送给服务器,减少网络往返时间(RTT) 适用场景 ✅ 批量数据操作(如万级 key 的写入…...

【Pycharm】pycharm修改注释文字的颜色
一、默认颜色-灰色 这个默认的灰色视觉效果太弱,不便于学习时使用 二、修改颜色 打开Settings 也可以从右上角设置那里打开 还可以快捷键Ctrl+Alt+S打开 找到这个页面把这个√取消掉 然后就能自定义颜色啦...

webgl2着色语言
一、数据类型 标量:布尔型、整型、浮点型 向量:基本类型:bool、int、float 数量 : 2,3,4 矩阵: 移位、旋转、缩放等变换 采样器: 执行纹理采样的相关操作 结构体: 为开…...

Nginx+Lua 实战避坑:从模块加载失败到版本冲突的深度剖析
Nginx 集成 Lua (通常通过 ngx_http_lua_module 或 OpenResty) 为我们提供了在 Web 服务器层面实现动态逻辑的强大能力。然而,在享受其高性能和灵活性的同时,配置和使用过程中也常常会遇到各种令人头疼的问题。本文将结合实际案例,深入分析在 Nginx+Lua 环境中常见的技术问题…...

什么是alpaca 或 sharegpt 格式的数据集?
环境: LLaMA-Factory 问题描述: alpaca 或 sharegpt 格式的数据集? 解决方案: “Alpaca”和“ShareGPT”格式的数据集,是近年来在开源大语言模型微调和对话数据构建领域比较流行的两种格式。它们主要用于训练和微调…...

C++效率掌握之STL库:map set底层剖析及迭代器万字详解
文章目录 1.map、set的基本结构2.map、set模拟实现2.1 初步定义2.2 仿函数实现2.3 Find功能实现2.4 迭代器初步功能实现2.4.1 运算符重载2.4.2 --运算符重载2.4.3 *运算符重载2.4.4 ->运算符重载2.4.5 !运算符重载2.4.6 begin()2.4.7 end() 2.5 迭代器进阶功能实现2.5.1 set…...

使用 Docker Desktop 安装 Neo4j 知识图谱
一、简介 Neo4j是一个高性能的,基于java开发的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中;它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎。 Neo4j分为企业版和社区版,企业版可以创…...

从构想到交付:专业级软开发流程详解
目录 一、软件开发生命周期(SDLC)标准化流程 1. 需求工程阶段(Requirement Engineering) 2. 系统设计阶段(System Design) 3. 开发阶段(Implementation) 4. 测试阶段&a…...

时源芯微| KY键盘接口静电浪涌防护方案
KY键盘接口静电浪涌防护方案通过集成ESD保护元件、电阻和连接键,形成了一道有效的防护屏障。当键盘接口受到静电放电或其他浪涌冲击时,该方案能够迅速将过电压和过电流引导至地,从而保护后续电路免受损害。 ESD保护元件是方案中的核心部分&a…...

数据库故障排查指南:从理论到实践的深度解析
数据库作为现代信息系统的核心组件,承载着数据存储、查询和事务处理等关键任务。然而,数据库系统在运行过程中可能遭遇各种故障,从硬件故障到软件配置问题,从性能瓶颈到安全漏洞,这些问题都可能影响业务的连续性和数据…...
)
电脑开机提示按f1原因分析及解决方法(6种解决方法)
经常有网友问到一个问题,我电脑开机后提示按f1怎么解决?不管理是台式电脑,还是笔记本,都有可能会遇到开机需要按F1,才能进入系统的问题,引起这个问题的原因比较多,今天小编在这里给大家列举了比较常见的几种电脑开机提示按f1的解决方法。 电脑开机提示按f1原因分析及解决…...

常用的Java工具库
1. Collections 首先是 java.util 包下的 Collections 类。这个类主要用于操作集合,我个人非常喜欢使用它。以下是一些常用功能: 1.1 排序 在工作中,经常需要对集合进行排序。让我们看看如何使用 Collections 工具实现升序和降序排列&…...
在企业报表中的报表数据中心里计算某张报表时,一直计算不出数据的解决办法。)
NC65开发环境(eclipse启动)在企业报表中的报表数据中心里计算某张报表时,一直计算不出数据的解决办法。
NC65开发环境(eclipse启动)在企业报表中的报表数据中心里计算某张报表时,一直计算不出数据的解决办法。 如下图,在报表数据中心,针对现金内部往来明细表计算5月的数据,然后报表下面一张显示计算,…...

React 第三十九节 React Router 中的 unstable_usePrompt Hook的详细用法及案例
React Router 中的 unstable_usePrompt 是一个用于在用户尝试离开当前页面时触发确认提示的自定义钩子,常用于防止用户误操作导致数据丢失(例如未保存的表单)。 一、unstable_usePrompt用途 防止意外离开页面:当用户在当前页面有…...
《P4391 [BalticOI 2009] Radio Transmission 无线传输 题解》
题目描述 给你一个字符串 s1,它是由某个字符串 s2 不断自我连接形成的(保证至少重复 2 次)。但是字符串 s2 是不确定的,现在只想知道它的最短长度是多少。 输入格式 第一行一个整数 L,表示给出字符串的长度。…...
)
使用ECS搭建云上博客wordpress(ALMP)
一、需求分析与技术选型 1. 架构组成及含义 本文使用ECS云服务器,采用ALMP架构搭建wordpress。组件具体的含义如下表: 组件作用WordPress中的功能体现Linux操作系统基础,提供稳定运行环境支持PHP运行和服务器管理ApacheWeb服务器ÿ…...

Scratch游戏 | 企鹅大乱斗
有没有过无聊到抓狂的时刻?试试这款 企鹅大乱斗 吧!超简单的玩法,让你瞬间告别无聊! 🎮 玩法超简单 等待屏幕出现 ”Go!” 疯狂点击,疯狂拍打企鹅! 💥 游戏特色 解压神器&#x…...

深入理解SpringBoot中的SpringCache缓存技术
深入理解SpringBoot中的SpringCache缓存技术 引言 在现代应用开发中,缓存技术是提升系统性能的重要手段之一。SpringBoot提供了SpringCache作为缓存抽象层,简化了缓存的使用和管理。本文将深入探讨SpringCache的核心技术点及其在实际业务中的应用场景。…...

URP相机如何将场景渲染定帧模糊绘制
1)URP相机如何将场景渲染定帧模糊绘制 2)为什么Virtual Machine会随着游戏时间变大 3)出海项目,打包时需要勾选ARMv7吗 4)Unity是手动还是自动调用GC.Collect 这是第431篇UWA技术知识分享的推送,精选了UWA社…...

嵌入式中深入理解C语言中的指针:类型、区别及应用
在嵌入式开发中,C语言是一种基础且极为重要的编程语言,其中指针作为一个非常强大且灵活的工具,广泛应用于内存管理、动态数据结构的实现以及函数参数的传递等方面。然而,尽管指针的使用极为常见,很多开发者在掌握其基本使用后,往往对指针的深入理解还不够。本文将深入分析…...

.NET程序启动就报错,如何截获初期化时的问题json
一:背景 1. 讲故事 前几天训练营里的一位朋友在复习课件的时候,程序一跑就报错,截图如下: 从给出的错误信息看大概是因为json格式无效导致的,在早期的训练营里曾经也有一例这样的报错,最后定位下来是公司…...
)
WeakAuras Lua Script ICC (BarneyICC)
WeakAuras Lua Script ICC (BarneyICC) https://wago.io/BarneyICC/69 全量英文字符串: !WA:2!S33c4TXX5bQv0kobjnnMowYw2YAnDKmPnjnb4ljzl7sqcscl(YaG6HvCbxaSG7AcU76Dxis6uLlHNBIAtBtRCVM00Rnj8Y1M426ZH9XDxstsRDR)UMVCTt0DTzVhTjNASIDAU…...