大模型微调实战:基于GpuGeek平台的低成本高效训练方案
文章目录
- 引言
- 一、GpuGeek平台使用入门
- 1. 注册与账号设置
- 2. 控制台功能概览
- 3. 快速创建GPU实例
- 3. 预置镜像与自定义环境
- 二、GpuGeek平台核心优势解析
- 1. 显卡资源充足:多卡并行加速训练
- 2. 镜像超多:开箱即用的开发环境
- 3. 计费灵活:按需付费降低成本
- 三、全流程实战:从数据预处理到模型评估
- 1. 环境配置与实例创建
- 2. 数据预处理与格式转换
- 3. 模型加载与分布式训练配置
- 4. 训练监控与性能对比
- 四、关键优化技巧与平台特性融合
- 1. 显存墙突破:梯度检查点与混合精度
- 2. 成本控制:弹性调度与Spot实例
- 五、模型评估与部署
- 1. 评估指标与可视化
- 2. 服务化部署
- 六、结语
引言
大模型微调(Fine-tuning)已成为垂直领域AI应用落地的核心技术,但在实际工程中,开发者常面临显存不足、环境配置复杂、算力成本高昂等问题。
本文以开源大模型Llama-2-13B和ChatGLM3-6B为例,结合GpuGeek平台的优势,系统性讲解从数据预处理到分布式训练的全流程实战方案,并对比本地训练与云平台的效率差异。通过代码示例与优化技巧,展现如何利用云平台特性实现训练时间缩短50%、显存占用降低60%的高效训练。
一、GpuGeek平台使用入门
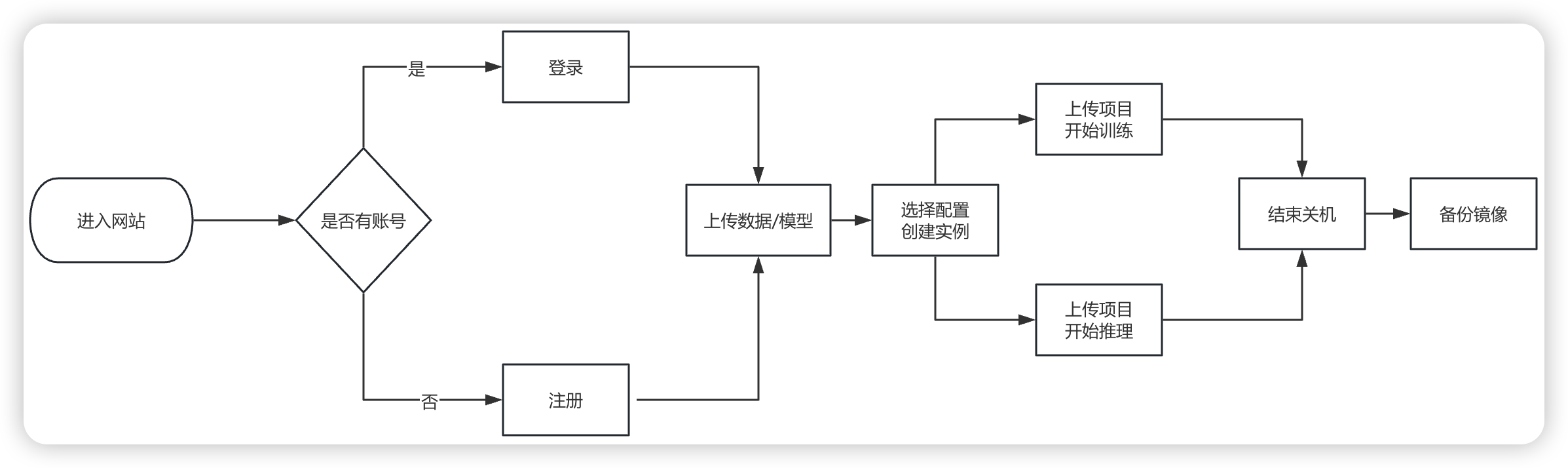
1. 注册与账号设置
首先,用户需要访问 GPUGEEK 平台的👉官方网站,在首页,右上角找到注册入口。输入手机号注册,用户输入有效的手机号码,点击获取验证码,将收到的验证码填入相应位置,设置好密码后,点击注册按钮,即可完成注册流程。
注册成功后,用户需要对账号进行一些基本设置。登录账号后,进入个人中心页面,在这里可以完善个人信息,如头像、昵称、所在行业等相关信息。注册成功后,系统会送通用券和模型调用券各十元,够咱们疯狂试错了!
2. 控制台功能概览
GpuGeek平台提供简洁的Web控制台,支持实例管理、镜像选择、资源监控等功能。以下是核心模块解析:
- 实例列表:查看当前运行的GPU实例状态(运行中/已停止/计费中等)。
- 镜像市场:预置超过200个深度学习框架镜像(PyTorch、TensorFlow、JAX等),支持一键加载。
- 监控面板:实时显示GPU利用率、网络流量、存储读写速率等指标。
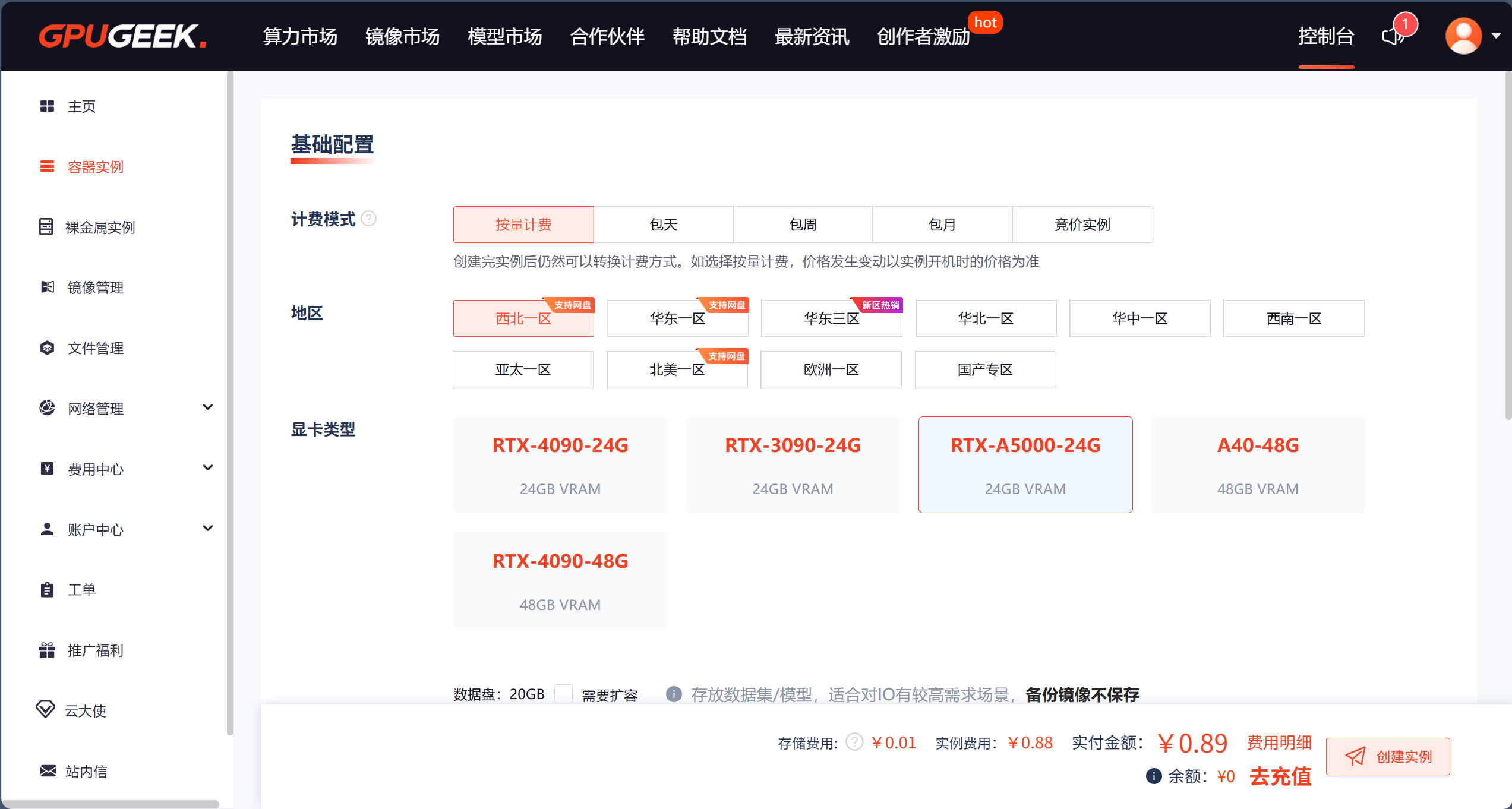
3. 快速创建GPU实例
步骤1:选择实例规格与镜像
- 进入控制台,点击“创建实例”。
- 根据需求选择GPU型号(如A100/A10/T4)和数量(单卡或多卡)。
- 从镜像市场选择预装框架(推荐“PyTorch 2.0 + DeepSpeed”)。
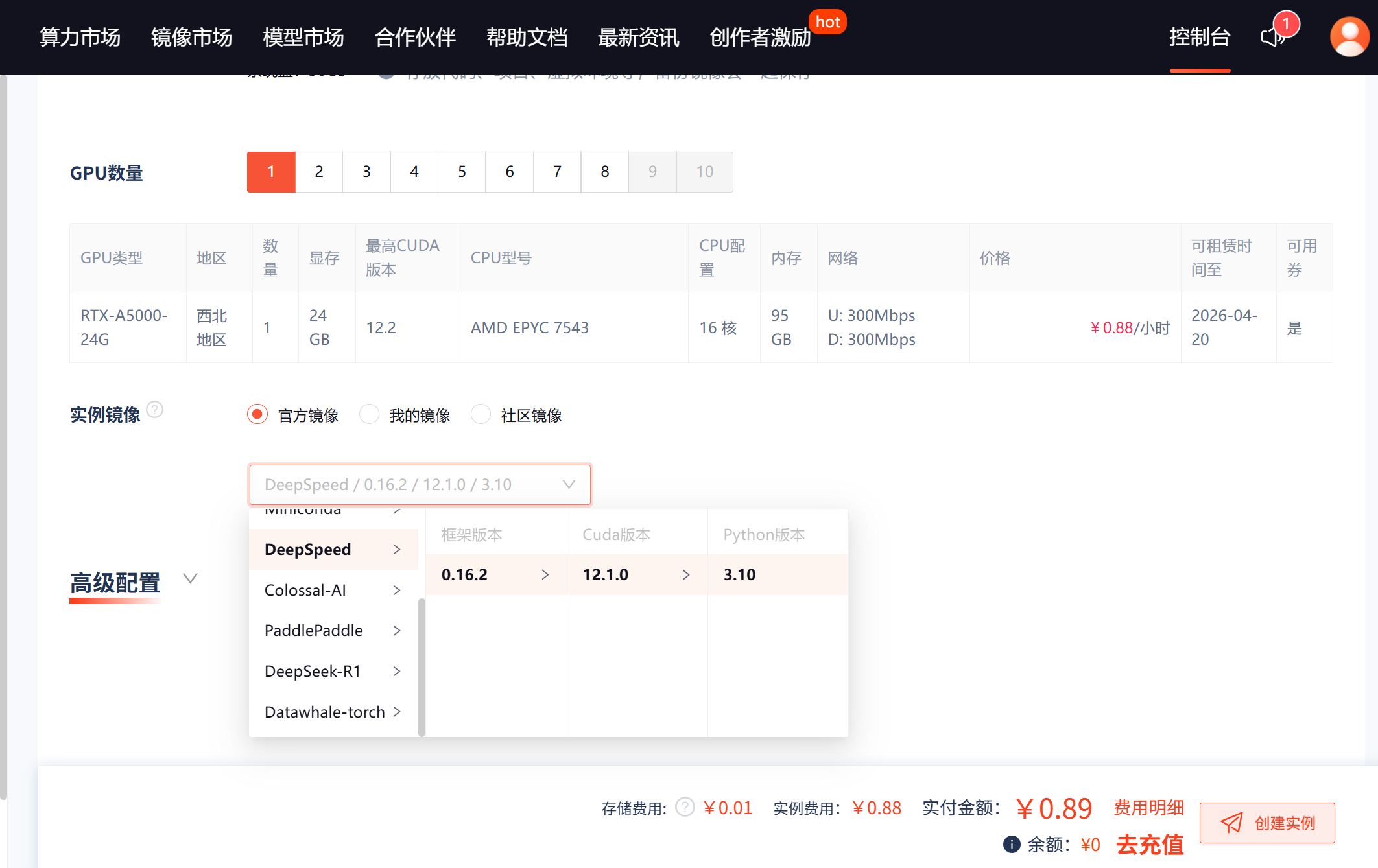
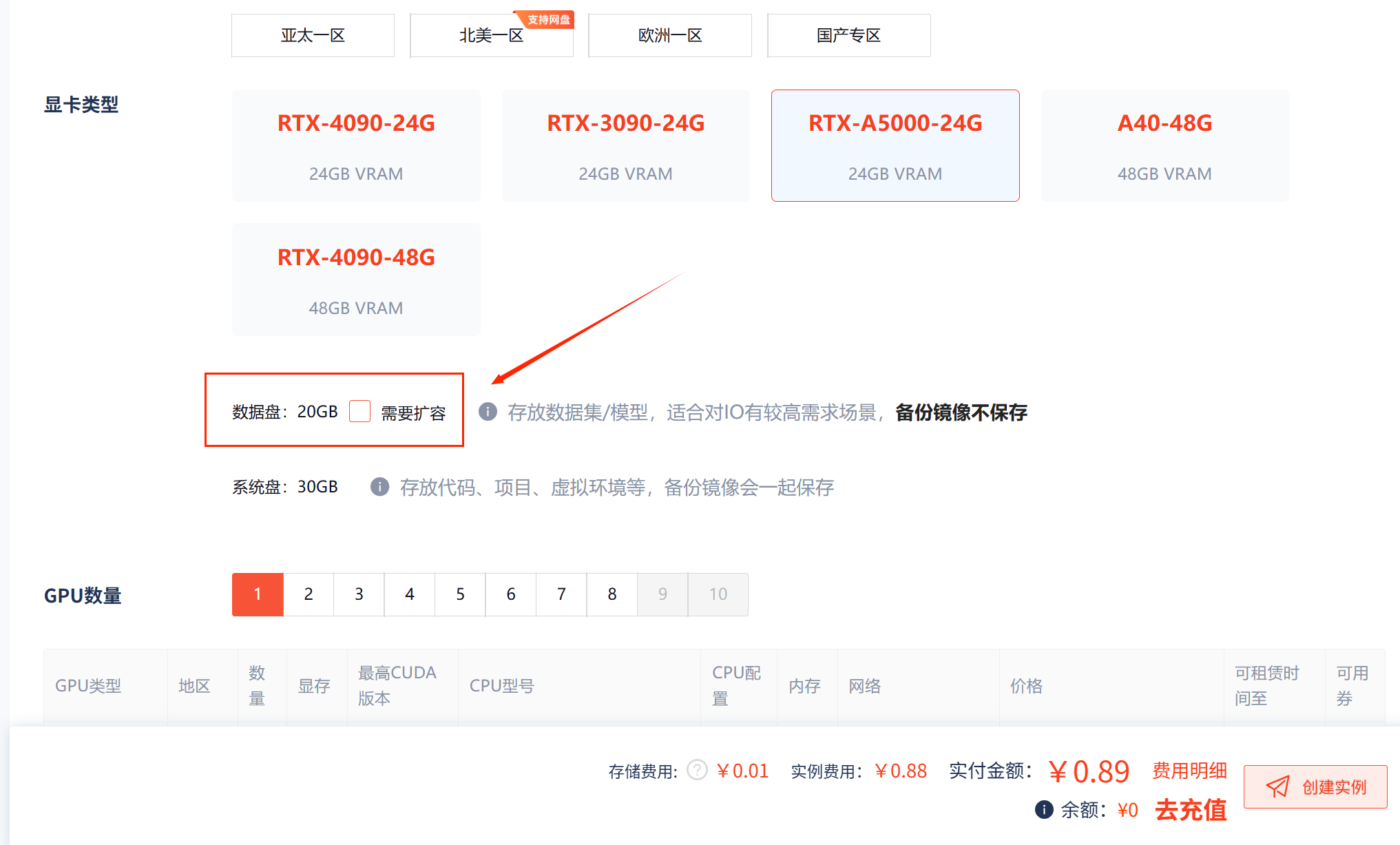
步骤2:配置存储与网络
- 存储扩容:默认系统盘30GB,建议添加数据盘用于存放模型和数据集。
- 学术加速:勾选“启用Github/Hugging Face加速”,下载速度提升3-5倍。
步骤3:启动实例并连接
- 支持SSH密钥或密码登录。
- 实例启动后,自动分配公网IP和端口。
# SSH连接示例(替换实际IP和端口)
ssh -p 32222 root@123.45.67.89
3. 预置镜像与自定义环境
GpuGeek提供两类镜像:
- 官方镜像:包含主流框架和工具链(CUDA、cuDNN、NCCL等),开箱即用。
- 社区镜像:用户共享的定制化镜像(如Stable Diffusion WebUI、LangChain开发环境)。
通过CLI加载自定义镜像
from gpugeek import ImageClient# 上传本地Docker镜像至平台仓库
image_client = ImageClient(api_key="YOUR_API_KEY")
image_id = image_client.upload_image("my_custom_image.tar")
print(f"镜像ID:{image_id}")# 使用自定义镜像创建实例
instance = client.create_instance(instance_type="A100x1",image_id=image_id,storage_size=200
)
二、GpuGeek平台核心优势解析
1. 显卡资源充足:多卡并行加速训练
- 多机多卡支持:支持A100/A10等高性能GPU实例,单节点最高可扩展至8卡,通过3D并行(数据并行+模型并行+流水线并行)突破千亿级模型显存限制。
- 弹性资源调度:按需选择实例规格(如单卡T4用于小规模微调,多卡A100集群用于全参数训练),避免资源闲置。
2. 镜像超多:开箱即用的开发环境
- 预置框架镜像:一键加载PyTorch 2.0+DeepSpeed、Hugging Face Transformers等镜像,内置NCCL通信库与CUDA驱动,省去环境配置时间。
- 自定义镜像托管:支持上传个人Docker镜像,实现实验环境快速迁移。
3. 计费灵活:按需付费降低成本
- 按秒计费:训练任务完成后立即释放实例,单次实验成本可低至0.5元(T4实例)。
- 竞价实例(Spot Instance):以市场价1/3的成本抢占空闲算力,适合容错性高的长时任务。
# 创建竞价实例(价格波动时自动终止)
spot_instance = client.create_spot_instance(bid_price=0.5, # 出价为按需价格的50%instance_type="A100x4",max_wait_time=3600 # 最长等待1小时
)
三、全流程实战:从数据预处理到模型评估
1. 环境配置与实例创建
步骤1:通过GpuGeek API快速创建GPU实例
import gpugeek# 初始化客户端
client = gpugeek.Client(api_key="YOUR_API_KEY")# 创建含2块A100的实例(预装PyTorch+DeepSpeed镜像)
instance = client.create_instance(instance_type="A100x2",image_id="pt2.0-deepspeed",storage_size=100 # 数据盘扩容100GB
)
print(f"实例已创建,SSH连接信息:{instance.ip}:{instance.port}")
步骤2:配置学术加速与依赖安装
# 启用Hugging Face镜像加速
export HF_ENDPOINT=https://hf-mirror.com# 安装微调工具链
pip install transformers==4.40.0 peft==0.11.0 accelerate==0.29.0
2. 数据预处理与格式转换
示例:构建金融领域指令微调数据集
from datasets import load_dataset# 加载原始数据(JSON格式)
dataset = load_dataset("json", data_files="finance_instructions.json")# 转换为Alpaca格式(instruction-input-output)
def format_alpaca(sample):return {"instruction": sample["query"],"input": sample["context"],"output": sample["response"]}dataset = dataset.map(format_alpaca)
dataset.save_to_disk("formatted_finance_data")
3. 模型加载与分布式训练配置
技术选型:QLoRA + DeepSpeed Zero-3
- QLoRA:4-bit量化加载基座模型,仅训练低秩适配器,显存占用降低75%。
- DeepSpeed Zero-3:优化器状态分片存储,支持千亿级参数分布式训练。
启动多卡训练
from transformers import TrainingArguments, Trainer
from peft import LoraConfig, get_peft_model# 加载Llama-2-13B(4-bit量化)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-chat-hf",load_in_4bit=True,device_map="auto"
)# 配置LoRA
peft_config = LoraConfig(r=64, lora_alpha=16, target_modules=["q_proj", "v_proj"],lora_dropout=0.05, task_type="CAUSAL_LM"
)
model = get_peft_model(model, peft_config)# 分布式训练参数
training_args = TrainingArguments(output_dir="./results",per_device_train_batch_size=4,gradient_accumulation_steps=8,num_train_epochs=3,learning_rate=2e-5,fp16=True,deepspeed="configs/deepspeed_zero3.json", # Zero-3优化配置report_to="wandb"
)# 启动训练
trainer = Trainer(model=model, args=training_args,train_dataset=dataset["train"],
)
trainer.train()
4. 训练监控与性能对比
GpuGeek平台监控面板
- 实时指标:GPU利用率、显存占用、网络吞吐量。
- 成本统计:任务累计消耗的GPU小时数与费用。
效率对比(Llama-2-13B微调)
| 环境 | 显存占用 | 训练时间 | 单周期成本 |
|---|---|---|---|
| 本地(RTX 3090单卡) | OOM | - | - |
| GpuGeek(A100x2 + DeepSpeed) | 24GB/卡 | 8小时 | ¥320 |
四、关键优化技巧与平台特性融合
1. 显存墙突破:梯度检查点与混合精度
- 梯度检查点(Gradient Checkpointing):牺牲10%计算时间换取显存降低50%,通过
model.gradient_checkpointing_enable()启用。 - BF16混合精度:A100支持BF16计算,相比FP16精度更高且不易溢出。
2. 成本控制:弹性调度与Spot实例
# 创建竞价实例(价格波动时自动终止)
spot_instance = client.create_spot_instance(bid_price=0.5, # 出价为按需价格的50%instance_type="A100x4",max_wait_time=3600 # 最长等待1小时
)
五、模型评估与部署
1. 评估指标与可视化
# 计算困惑度(Perplexity)
eval_results = trainer.evaluate()
print(f"验证集困惑度:{eval_results['perplexity']:.2f}")# 结果可视化(Weights & Biases集成)
wandb.log({"accuracy": eval_results["accuracy"]})
2. 服务化部署
# 导出为ONNX格式(加速推理)
python -m transformers.onnx --model=./checkpoints --feature=causal-lm onnx/
六、结语
通过GpuGeek平台,开发者可快速实现从单卡实验到多机分布式训练的平滑过渡。
结合QLoRA量化、DeepSpeed Zero-3与弹性计费,微调千亿级模型的综合成本降低60%以上。未来,随着平台集成更多自动化调优工具(如超参搜索、自适应资源分配),大模型落地的技术门槛将进一步降低。
相关文章:

大模型微调实战:基于GpuGeek平台的低成本高效训练方案
文章目录 引言一、GpuGeek平台使用入门1. 注册与账号设置2. 控制台功能概览3. 快速创建GPU实例3. 预置镜像与自定义环境 二、GpuGeek平台核心优势解析1. 显卡资源充足:多卡并行加速训练2. 镜像超多:开箱即用的开发环境3. 计费灵活:按需付费降…...
)
黑马k8s(六)
1.Deployment(Pod控制器) Selector runnginx 标签选择:会找pod打的标签 执行删除之后,pod也会删除,Terminating正在删除 如果想要访问其中的一个pod借助:IP地址端口号访问 假设在某一个瞬间,…...

WEB安全--Java安全--CC1利用链
一、梳理基本逻辑 WEB后端JVM通过readObject()的反序列化方式接收用户输入的数据 用户编写恶意代码并将其序列化为原始数据流 WEB后端JVM接收到序列化后恶意的原始数据并进行反序列化 当调用: ObjectInputStream.readObject() JVM 内部逻辑: → 反…...
)
16S18S_OTU分析(3)
OTU的定义 OTU:操作分类单元是在系统发生学研究或群体遗传学研究中,为了便于进行分析,人为给某一个分类单元(如品系、种、属、分组等)设置的同一标志。目的:OTU用于将相似的序列归为一类,以便于…...
Day20)
嵌入式开发学习日志(数据结构--单链表)Day20
一、gdb调试 (一)一般调试步骤与命令 1、gcc -g (调试版本,内含调试信息与源码;eg:gcc -g main.c linklist.c) 2、gdb a.out(调试可执行文件,eg:gdb …...
 failed in /etc/nginx/nginx.conf:2)
nginx报错-[emerg] getpwnam(“nginx“) failed in /etc/nginx/nginx.conf:2
报错 - nginx: [emerg] getpwnam(“nginx”) failed in /etc/nginx/nginx.conf:2 问题描述: nginx: [emerg] getpwnam(“nginx”) failed in /etc/nginx/nginx.conf:2 问题原因: 是因为配制文件中使用的启动账户在系统中并没有找到 解决方法&#x…...

Linux系统编程——fork函数的使用方法
在 Linux 系统编程 中,fork() 函数是创建新进程的关键系统调用。fork() 在当前进程(父进程)中创建一个几乎完全相同的子进程。子进程和父进程从调用 fork() 的位置继续执行,但它们是两个独立的进程,每个进程都有自己的…...
)
Linux进程信号处理(26)
文章目录 前言一、信号的处理时机处理情况“合适”的时机 二、用户态与内核态概念重谈进程地址空间信号的处理过程 三、信号的捕捉内核如何实现信号的捕捉?sigaction 四、信号部分小结五、可重入函数六、volatile七、SIGCHLD 信号总结 前言 这篇就是我们关于信号的最…...
)
黑马Java跟学.最新AI+若依框架项目开发(一)
黑马Java跟学.最新AI若依框架项目开发.一 前瞻为什么学习若依?AI局限性若依是什么?创新项目开发新方案课程安排前置知识 一、若依搭建若依版本官方非官方 RuoYi-Vue运行后端项目初始化项目Git下载Maven构建 MySQL相关导入sql配置信息 Redis相关启动配置信息 项目运…...

【自学30天掌握AI开发】第1天 - 人工智能与大语言模型基础
自学30天掌握AI开发 - 第1天 📆 日期和主题 日期:第1天 主题:人工智能与大语言模型基础 🎯 学习目标 了解人工智能的发展历史和基本概念掌握大语言模型的基本原理和工作机制区分不同类型的AI模型及其特点理解AI在当前社会中的…...
Java String类全面解析)
(十六)Java String类全面解析
一、String类概述 1.1 String的本质 在Java中,String类可能是使用最频繁的类之一,但它也是最容易被误解的类之一。从本质上讲,String代表的是一个不可变的Unicode字符序列。这种不可变性(immutability)是String类设计的核心特性。 java S…...

Android架构之自定义native进程
在Android五层架构中,native层基本上全是c的世界,这些c进程基本上靠android世界的第一个进程init进程创建,init通过rc配置文件,创建了众多的c子进程,也是这众多的c进程,构建了整个android世界的native层。 …...

#跟着若城学鸿蒙# HarmonyOS NEXT学习之AlphabetIndexer组件详解
一、组件介绍 AlphabetIndexer(字母索引条)是HarmonyOS NEXT中一个非常实用的UI组件,它主要用于在列表视图中提供快速的字母导航功能。当应用中有大量按字母顺序排列的数据(如联系人列表、城市列表等)时,A…...

React百日学习计划——Deepseek版
阶段一:基础巩固(1-20天) 目标:掌握HTML/CSS/JavaScript核心语法和开发环境搭建。 每日学习内容: HTML/CSS(1-10天) 标签语义化、盒模型、Flex布局、Grid布局、响应式设计(媒体查询…...

Room持久化库:从零到一的全面解析与实战
简介 在Android开发中,Room作为官方推荐的数据库持久化库,提供了对SQLite的抽象层,使得数据库操作更加安全、高效且易于维护。 Room通过注解处理器和编译时验证,显著降低了数据库操作的复杂度,同时支持响应式编程模式,使开发者能够轻松实现数据变化的实时监听。对于企业…...
)
Linux云计算训练营笔记day07(MySQL数据库)
数据库 DataBase 保存数据的仓库 数据库管理系统 DBMS 这是一个可以独立运行,用于维护磁盘上的数据的一套软件 特点: 维护性高,灵活度高,效率高,可扩展性强 常见的DBMS Mysql Mariadb Oracle DB2 SQLServer MySQL是一个关系型…...

C语言之旅5---分支与循环【2】
💫只有认知的突破💫才来带来真正的成长💫编程技术的学习💫没有捷径💫一起加油💫 🍁感谢各位的观看🍁欢迎大家留言🍁咱们一起加油🍁努力成为更好的自己&#x…...

K230 ISP:一种新的白平衡标定方法
第一次遇见需要利用光谱响应曲线进行白平衡标定的方法。很好奇是如何利用光谱响应曲线进行白平衡标定的。 参考资料参考:K230 ISP图像调优指南 K230 介绍 嘉楠科技 Kendryte 系列 AIoT 芯片中的最新一代 AIoT SoC K230 芯片采用全新的多核异构单元加速计算架构&a…...

【Web应用】Vue 项目前端项目文件夹和文件介绍
文章目录 ⭐前言⭐一、文件夹介绍🌟1、.idea🌟2、bin🌟3、build🌟4、node_modules🌟5、public🌟6、src ⭐二、文件介绍🌟1、.editorconfig🌟2、.env.development、.env.production、…...

Leetcode 3544. Subtree Inversion Sum
Leetcode 3544. Subtree Inversion Sum 1. 解题思路2. 代码实现 题目链接:3544. Subtree Inversion Sum 1. 解题思路 这一题我的思路上就是一个动态规划的思路,因为原则上我们只需要遍历一下所有的状态即可,但是这样显然时间复杂度过高&am…...

分别在windows和linux上使用curl,有啥区别?
作为开发者常用的网络工具,curl 在 Windows 和 Linux 上的使用看似相似,但实际存在不少细节差异。以下从 命令语法、环境特性、功能支持 和 开发体验 四个角度展开对比,帮助读者避免跨平台开发时的常见“坑”。 一、命令语法差异:…...
)
微服务八股(自用)
微服务 SpringCloud 注册中心:Eureka 负载均衡:Ribbon 远程调用:Feign 服务熔断:Hystrix 网关:Gateway/Zuul Alibaba 配置中心:Nacos 负载均衡:Ribbon 服务调用:Feign 服务…...

TCP首部格式及三次握手四次挥手
TCP协议详解:首部格式与连接管理 一、TCP首部格式 TCP首部最小20字节,最大60字节,包含以下字段: | 源端口号(16bit) | 目的端口号(16bit) | | 序列号(32bit) | | 确认号(32bit) | | 数据偏移(4bit)| 保留(6bit) |U|A|P|R|S|…...

Python查询ES错误ApiError(406, ‘Content-Type ...is not supported
现象 使用python查询es数据时出现下面错误 Traceback (most recent call last):File "getUsers.py", line 26, in <module>response es.search(index"lizz_users", bodyquery)File "/usr/local/lib/python3.6/site-packages/elasticsearch/_…...

下周,Coinbase将被纳入标普500指数
Coinbase加入标普500指数紧随比特币突破10万美元大关之后。加密资产正在日益成为美国金融体系的一部分。大型机构已获得监管批准创建现货比特币交易所交易基金,进一步推动了加密货币的主流化进程。 加密货币行业迎来里程碑时刻,Coinbase即将加入标普500…...

物理:由基本粒子组成的个体能否提炼和重组?
个体差异源于基本粒子组合的复杂性与随机性,这一假设若成立,确实可能为生物医学带来革命性突破——但需要突破技术、理论与系统层级的多重壁垒。以下从科学逻辑与技术路径展开分析: 一、随机组合中的共性与稳定结构 1. 自然界的自组织规律 涌现性(Emergence):尽管粒子组…...

Python Day 24 学习
讲义Day16内容的精进 NumPy数组 Q. 什么是NumPy数组? NumPy数组是Python中由NumPy库提供的一种多维数组对象,它称为N-dimensional array,简称ndarray。它是用于数值计算的核心数据结构,能够高效地存储和操作大量的同类型数据。 Q. NumPy数…...

ppy/osu构建
下载 .NET (Linux、macOS 和 Windows) | .NET dotnet还行 构建:f5 运行:dotnet run --project osu.Desktop -c Debug...
—— CSS详解与使用)
前端学习(2)—— CSS详解与使用
目录 一,CSS基础 1.1 语法规范 1.2 引入方式 1.3 选择器 1.3.1 基础选择器 1.3.2 复合选择器 1.3.3 选择器小结 二,CSS使用 2.1 字体设置 2.2 文本属性 2.3 背景属性 2.2 圆角矩形 三,关于浏览器 3.1 Chrome 调试工具 -- 查看 …...

邀请函|PostgreSQL培训认证报名正式开启
掌握PostgreSQL 轻松驾驭主流国产数据库 PostgreSQL培训认证 6月开课 报名火热进行中~ 美创中国PostgreSQL培训认证合作机构 中国PostgreSQL培训认证由中国开源软件联盟PostgreSQL分会联合中国电子工业标准化技术协会共同打造,是国内权威的PG技术等级…...

力扣HOT100之二叉树:543. 二叉树的直径
这道题本来想到可以用递归做,但是还是没想明白,最后还是去看灵神题解了,感觉这道题最大的收获就是巩固了我对lambda表达式的掌握。 按照灵神的思路,直径可以理解为从一个叶子出发向上,在某个节点处拐弯,然后…...

深入理解 NumPy:Python 科学计算的基石
在数据科学、人工智能和科学计算的世界里,NumPy 是一块绕不过去的基石。它是 Python 语言中用于高性能科学计算的基础包,几乎所有的数据分析与机器学习框架(如 Pandas、TensorFlow、Scikit-learn)都离不开它的支持。 一、什么是 …...

基于STM32、HAL库的ADAU1701JSTZ-RL音频接口芯片驱动程序设计
一、简介: ADAU1701JSTZ-RL 是一款高性能音频编解码器 (Codec),专为便携式和低功耗应用设计。它集成了 ADC、DAC、麦克风前置放大器、耳机放大器和数字信号处理功能,支持 I2S/PCM 音频接口和 I2C 控制接口,非常适合与 STM32 微控制器配合使用。 二、硬件接口: 典型的 ST…...

SpringBoot--springboot简述及快速入门
spring Boot是spring提供的一个子项目,用于快速构建spring应用程序 传统方式: 在众多子项目中,spring framework项目为核心子项目,提供了核心的功能,其他的子项目都需要依赖于spring framework,在我们实际…...

智慧校园场景下iVX 研发基座应用实践与行业适配研究
一、智慧校园多系统协同实践 在智慧校园建设中,iVX 研发基座通过模块化协作开发模式实现跨系统集成与数据治理。以校园门户与子系统整合为例,基座通过统一身份认证体系实现单点登录(SSO),用户中心基于 ABAC 模型动态控…...
)
故障诊断模型评估——混淆矩阵,如何使样本量一致(上)
往期精彩内容: Python-凯斯西储大学(CWRU)轴承数据解读与分类处理 基于FFT CNN - BiGRU-Attention 时域、频域特征注意力融合的轴承故障识别模型-CSDN博客 基于FFT CNN - Transformer 时域、频域特征融合的轴承故障识别模型-CSDN博客 P…...

Redis Cluster 集群搭建和集成使用的详细步骤示例
以下是Redis集群搭建和集成使用的详细步骤示例: 搭建Redis集群 环境准备 下载Redis:从Redis官方网站下载最新稳定版本的Redis源代码,解压到指定目录,如/opt/redis。安装依赖:确保系统安装了必要的依赖,如…...

【技巧】使用UV创建python项目的开发环境
回到目录 【技巧】使用UV创建python项目的开发环境 0. 为什么用UV 下载速度快、虚拟环境、多版本python支持、清晰的依赖关系 1. 安装基础软件 1.1. 安装python 下载地址:https://www.python.org/downloads/windows/ 1.2. 安装UV > pip install uv -i ht…...

竞业禁止协议中AI技能限制的深度剖析
首席数据官高鹏律师团队 在当今科技飞速发展的时代,人工智能(AI)领域成为了商业竞争的关键战场。随着AI技术在各行业的广泛渗透,竞业禁止协议中涉及AI技能的限制条款愈发受到关注,其背后蕴含着复杂而关键的法律与商业…...

Mirror的多人连接管理及房间系统
以下是一个基于Mirror的多人连接管理及房间系统的服务端实现方案,包含部署说明: 一、服务端架构设计 网络管理扩展 using Mirror; using UnityEngine;public class RoomNetworkManager : NetworkManager {// 房间字典(房间ID -> 房间对象…...

基于Session实现短信登录全流程详解
前言 在当今的Web应用中,短信验证码登录已成为最常用的身份验证方式之一。本文将详细介绍基于Session实现短信登录的全套流程,包括技术选型、流程设计、具体实现以及安全防护措施。通过本文,您将掌握从发送验证码到完成登录的完整实现方案。…...

关于 javax.validation.constraints的详细说明
以下是关于 javax.validation.constraints(现为 Jakarta Bean Validation)的详细说明,涵盖核心注解、使用场景、代码示例及最佳实践: 一、javax.validation.constraints 是什么? 作用:提供一组标准注…...

linux系统如何将采集的串口数据存储到txt
步骤: 确认串口设备:通常为/dev/ttyS0(COM1)或/dev/ttyUSB0(USB转串口)。设置波特率等参数:使用stty命令,例如: bash stty -F /dev/ttyUSB0 9600 cs8 -icanon -ixon 实时…...
==>一篇解决!(Java版))
(顺序表、单链表、双链表)==>一篇解决!(Java版)
文章目录 一、线性表二、顺序表三、单链表四、双链表 一、线性表 线性表是最基本、最简单、也是最常用的一种数据结构。一个线性表是n个具有相同特性的数据元素的有限序列。 线性表的特征:数据元素之间具有一种“一对一”的逻辑关系。 线性表的分类: 线…...

大模型常用位置编码方式
深度学习中常见的位置编码方式及其Python实现: 一、固定位置编码(Sinusoidal Positional Encoding) 原理 通过不同频率的正弦和余弦函数生成位置编码,使模型能够捕捉绝对位置和相对位置信息。公式为: 公式标准数学表达…...

【fastadmin开发实战】在前端页面中使用bootstraptable以及表格中实现文件上传
先看效果: 1、前端页面中引入了表格 2、表格中实现文件上传 3、增加截止时间页面 难点在哪呢? 1、这是前端页面,并不支持直接使用btn-dialog的类属性实现弹窗; 2、前端页面一般绑定了layout模板,如何实现某个页面不…...

IO、存储、硬盘、文件系统相关常识
目录 1. IO(输入输出)基础概念 1.1 IO的定义 1.2 流 1.3 IO流 2.存储 2.1 存储技术 2.2 存储介质的分类(机械硬盘、固态硬盘、光盘、磁带) 2.2.1 机械硬盘 2.2.2 固态硬盘 2.2.3 光盘 2.2.4 磁盘 2.3 存储管理 2.4 存…...

amd架构主机构建arm架构kkfileview
修改本机使用镜像仓库地址 vim /etc/docker/daemon.json { “experimental”: true, “registry-mirrors”: [ “https://docker.m.daocloud.io”, “https://docker.1panel.live”, “http://mirrors.ustc.edu.cn/”, “http://mirror.azure.cn/”, “https://docker.hpcloud.…...

日志链路ID配置,traceId多线程不打印什么鬼?
logback.xml 关键配置 [traceId:%X{traceId}] <!-- 彩色日志格式模板 --><property name"log.pattern.color"value"%green(%d{yyyy-MM-dd HH:mm:ss.SSS}) [%thread] %highlight(%-5level){FATALred, ERRORred, WARNyellow, INFOgreen, DEBUGcyan, TRA…...

InfluxDB-数据看板实现流程:从数据采集到可视化展示
数据看板的实现涉及到多个步骤和技术组件,以下是基于提供的知识库内容,详细解释数据看板(特别是30日活跃用户数趋势)的实现过程: 1. 数据来源 所有用户行为数据通过网关进行数据埋点,并通过消息队列&…...