【大模型LLM学习】MiniCPM的注意力机制学习
【大模型LLM学习】MiniCPM的注意力机制学习
- 前言
- 1 Preliminary
- 1.1 MHA
- 1.2 KV-cache
- 2 GQA
- GQA的MiniCPM实现
- 3 MLA
- MLA的MiniCPM-3-4b的实现
- TODO
前言
之前MiniCPM3-4B是最早达到gpt-3.5能力的端侧小模型,其注意力机制使用了MLA。本来想借着MiniCPM从MHA过到MLA的,但是最后发现MiniCPM3是attention结构使用的MLA,但是因为和其它框架等兼容性问题,kv-cache存储方式和MHA一样,有一些尴尬,在这记录一下学习过程。
- OpenBMB的官方文档——MiniCPM的三代注意力机制
- 苏神的空间关于从MHA到MLA的详细介绍——从MHA、MQA、GQA到MLA
- MiniCPM的1代模型代码地址——MiniCPM-2b-sft
- MiniCPM的2代模型代码地址——MiniCPM-1b-sft
- MiniCPM的3代模型代码地址——MiniCPM3-4b
- The illustrated系列(图画的都非常好)——The illustrated transformers
1 Preliminary
1.1 MHA
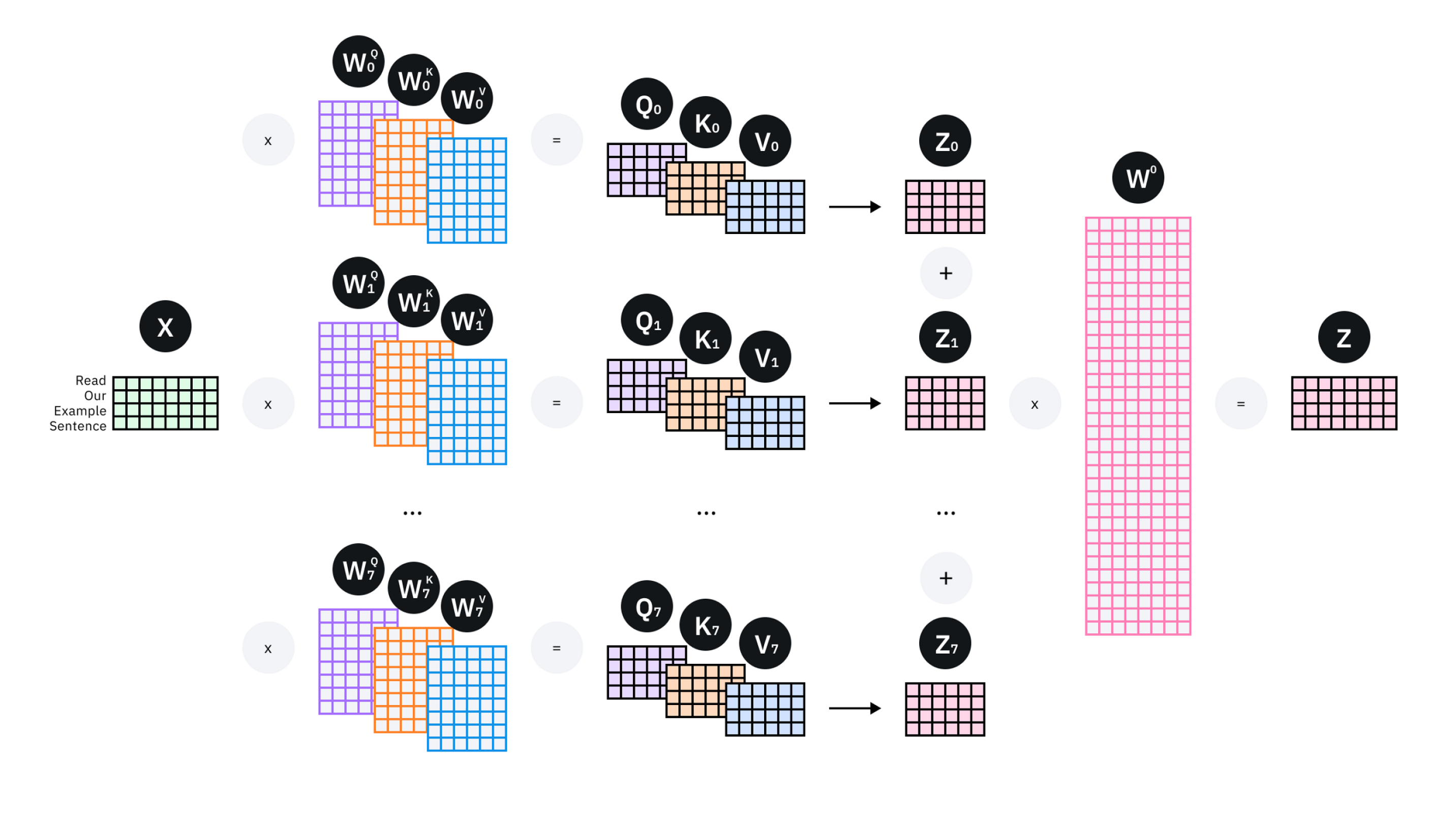
MHA是multi-head attention,前面在qwen1-LLM里面看到过,计算attention的时候把qkv矩阵从hiddensize的大小变成了num_heads个head_dim大小的小矩阵。
def _split_heads(self, tensor, num_heads, attn_head_size):new_shape = tensor.size()[:-1] + (num_heads, attn_head_size) # 前面维度不变,最后一维拆开tensor = tensor.view(new_shape)return tensorquery, key, value = mixed_x_layer.split(self.split_size, dim=2) # 分开qkv,每个的维度为(batch_size, seq_len, hidden_size)query = self._split_heads(query, self.num_heads, self.head_dim) # new_shape = tensor.size()[:-1] + (num_heads, attn_head_size),前面维度不变,最后一维hidden_size拆开
key = self._split_heads(key, self.num_heads, self.head_dim)
value = self._split_heads(value, self.num_heads, self.head_dim)
图示来看是这样的
1.2 KV-cache
为了节省计算开销和推理时KV-cache的显存开销,有篇huggingface上的介绍KV-cache非常好的blog——KV-cache介绍。
在训练的时候不存在KV-cache的概念,因为在训练时,一条样本输入模型后,直接输出了对应长度的结果,不需要解码。例如是文本生成任务,对于一条样本,如果输入是X=[x1,x2,xm],输出是Y=[y1,…,yn],实际上模型的输入是类似X+Y的形式(加上一些special token例如bos和eos),输出结果y_pred是基于attention mask这个下三角矩阵可以一次性输出的,每个token只看得到它之前的token的k和v:
- 输入数据X,长度为T:[x1,x2,xm,y1,…,yn-1]
- 预测目标Y,长度为T:(右shift一位)[x2,xm,y1,…,yn]
通常,模型的NTP loss(Next Token Prediciton)使用下面的方法计算
if labels is not None:labels = labels.to(lm_logits.device)shift_logits = lm_logits[..., :-1, :].contiguous() # 训练的时候是可以一次性推理出结果的,因为有答案,相当于只基于之前的词的ground truth预测了下一个词(mask机制)shift_labels = labels[..., 1:].contiguous()loss_fct = CrossEntropyLoss()loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
但是在推理时,没有完整的答案,不能一次得到结果,需要每次推理一个token,看看是不是结束标志<eos>,不是的话继续解码。在解码第t个token时,能看到 k ≤ t k_{\leq t} k≤t和 v ≤ t v_{\leq t} v≤t,使用 q t q_t qt和 K [ : t ] K_{[:t]} K[:t]、 V [ : t ] V_{[:t]} V[:t]相乘。
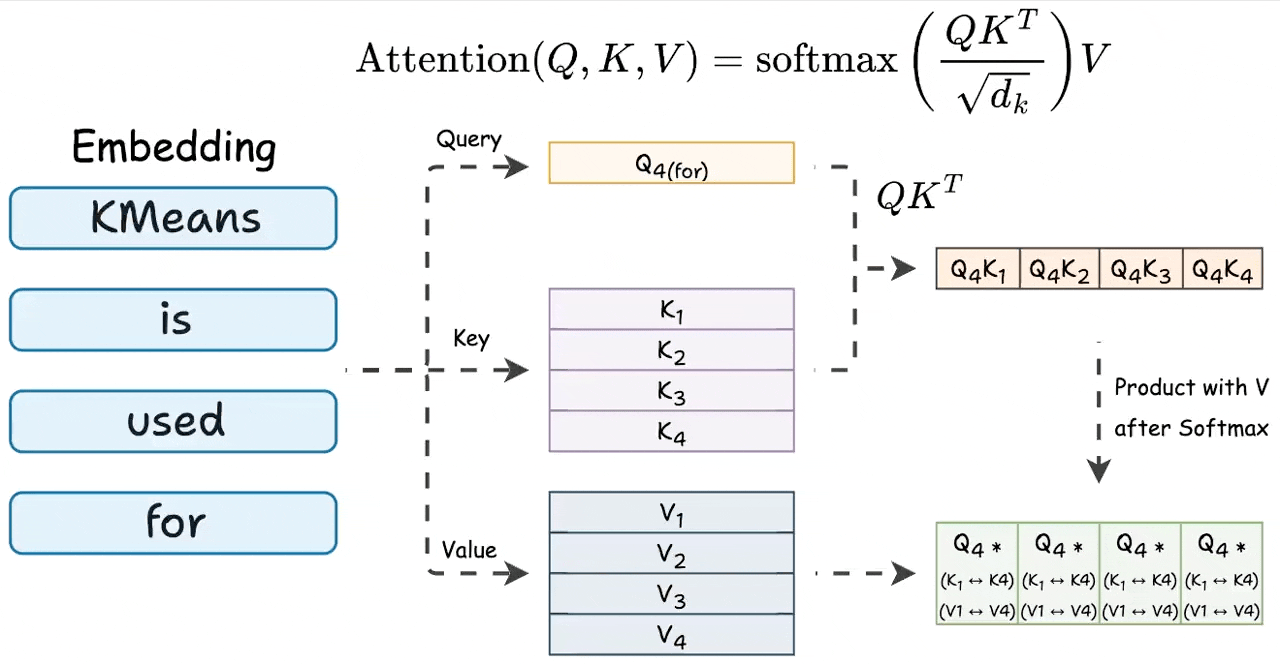
可以发现,在这个过程中,所有的之前的时间步的 k ≤ t k_{\leq t} k≤t和 v ≤ t v_{\leq t} v≤t是不会改变的,每次解码后,只会有 k k k和 v v v的增量拼接在原始的 k k k和 v v v后面。如果每次都需要计算 x W k x W_k xWk和 x W v x W_v xWv是很耗费计算资源和时间的。为了加速推理速度,KV-cache做的事情是,把这些 k k k和 v v v存起来,如果没有解码结束,下次把存起来的 k k k和 v v v读出来就行,节省计算时间,用空间换时间。
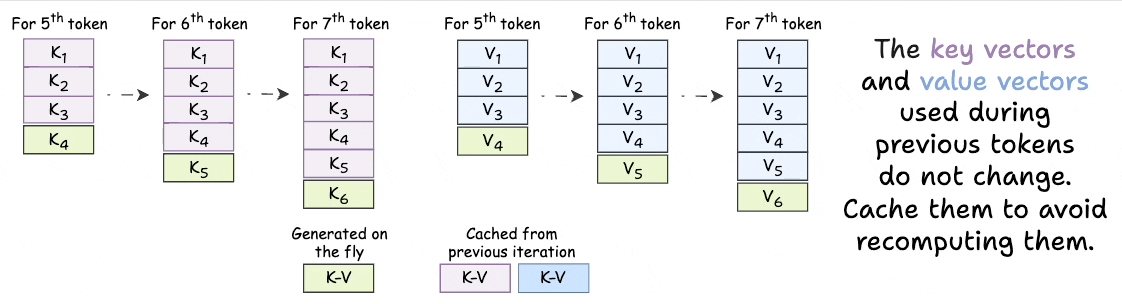
但是空间是有限的,尤其长文本推理的情况下,使用MQA、GQA和MLA等attention机制的模型通过改变attention计算方法、KV-cache的存储内容来节省空间。
2 GQA
从MiniCPM-2b-sft里面就使用了GQA (Grouped Query Attention),MHA里面有 N N N个注意力头,在GQA里面也有 N N N个注意力头,只不过GQA把 N N N个注意力头分成了 g g g个组,在每个组内的所有head,参数是一样的, g g g个组,只有 g g g个不一样的k和v。最极端的情况是MQA (Multi-Query Attention)的形式,只有一组KV,所有 N N N个注意力头参数一样。
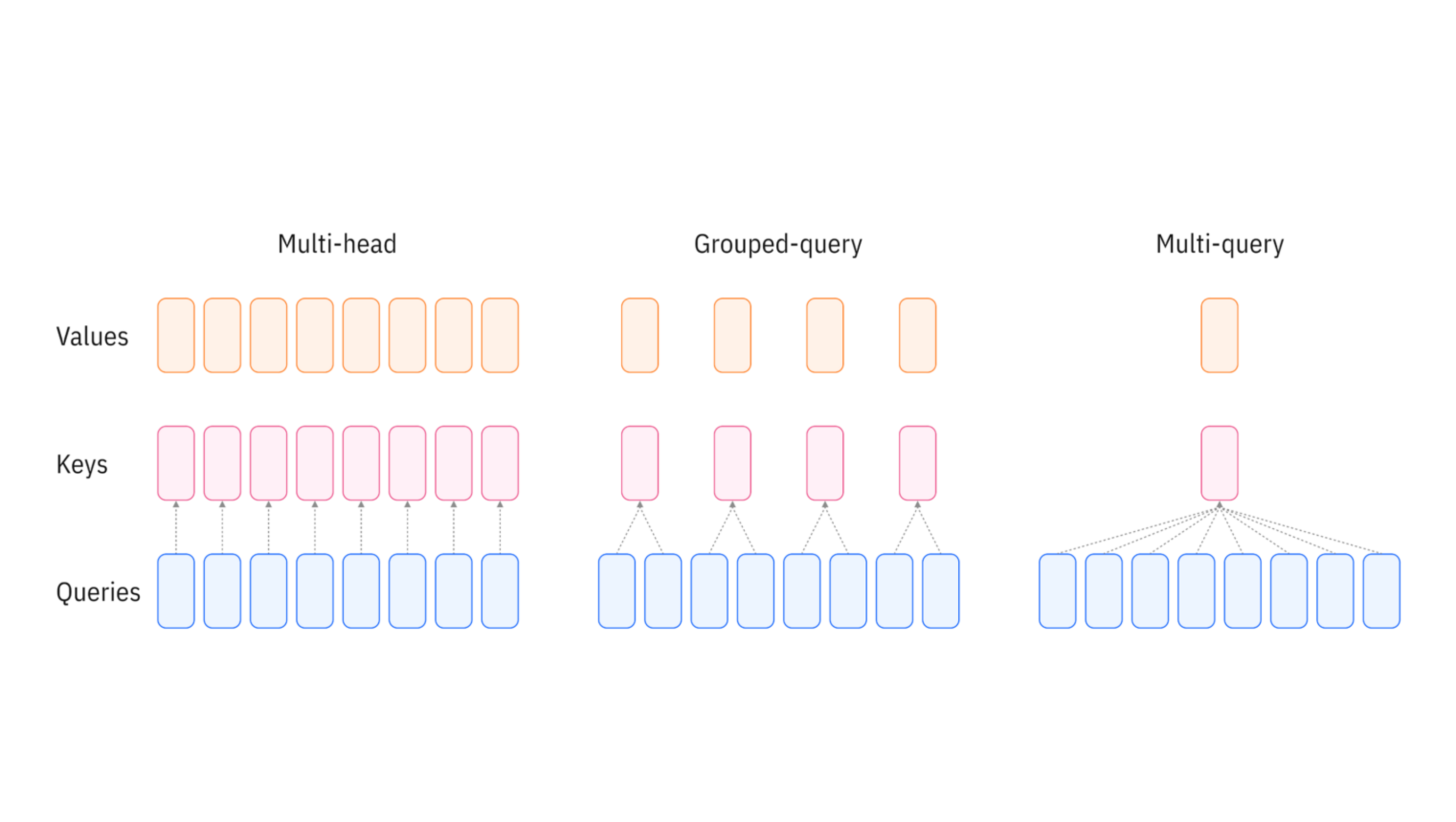
相比于MHA,GQA节省了KV的存储,只需要之前的 N / g N/g N/g的存储空间来存储KV。但是由于每个group里面参数是一样的,最后模型的效果肯定有一点下降。
GQA的MiniCPM实现
- 可以看到使用repeat_kv把k和v进行了复制,但是是在repeat之前对kv-cache进行了更新和存储,因此节省了kv-cache的存储
- 相比于MHA,除了要保存的keys和values变小了(组内共享),GQA的 W k W_k Wk和 W v W_v Wv也变小了,节省了计算开销
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:batch, num_key_value_heads, slen, head_dim = hidden_states.shapeif n_rep == 1:return hidden_stateshidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim) # 复制return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)class MiniCPMAttention(nn.Module):def __init__(self, config: MiniCPMConfig, layer_idx: Optional[int] = None):self.hidden_size = config.hidden_sizeself.num_heads = config.num_attention_heads # 24self.head_dim = self.hidden_size // self.num_headsself.num_key_value_heads = config.num_key_value_heads # 8self.num_key_value_groups = self.num_heads // self.num_key_value_heads # 3self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)def forward()bsz, q_len, _ = hidden_states.size()query_states = self.q_proj(hidden_states)key_states = self.k_proj(hidden_states)value_states = self.v_proj(hidden_states)query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2) # [bsz, num_heads, q_len, head_dim]## KV只有num_key_value_heads个,而不是num_heads个key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2) # [bsz, num_key_value_heads, kv_len, head_dim]value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)kv_seq_len = key_states.shape[-2]if past_key_value is not None: # 推理时有KV的情况下kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)cos, sin = self.rotary_emb(value_states.to(torch.float32), seq_len=kv_seq_len)query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)# 是在repeat之前存储if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)key_states = repeat_kv(key_states, self.num_key_value_groups) # [bsz, num_heads, kv_len, head_dim],复制key,同一个组共享value_states = repeat_kv(value_states, self.num_key_value_groups)attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
- p.s. 除了MiniCPM系列,qwen2和qwen3使用的也是GQA,而不是MLA。
3 MLA
因为在GQA里面,每个组内的注意力头参数共享,降低了模型的表达能力。MLA (Multi-head Latent Attention)在GQA的基础上,减少KV-cache的同时,让每个注意力头的参数还不一样。MLA的操作略微有一些复杂,在看了很多博客之后发现还是先看代码更容易理解。
MLA的核心是,对矩阵进行低秩分解,存low rank的矩阵(有点类似lora),分解后的两个矩阵是比原来的大矩阵小的,计算成本比之前低,存储成本也会低如果存低秩矩阵(当然并没有直接存这两个小矩阵)。推理的时候再做一次矩阵乘法把KV恢复(这个乘法矩阵会比原始的 W k W_k Wk和 W v W_v Wv小,计算成本低)。
MLA的MiniCPM-3-4b的实现
- 相比于MHA和GQA,在dim上多了"lora_rank"、"nope_dim"和"rope_dim"这几项,其中"lora_rank"和低秩矩阵有关,"nope"的是没有rope信息的分量,"rope"的是含有rope信息的分量
- 在矩阵运算上, W q W_q Wq对应 q q q相关的有a\b两个proj矩阵, W k W_k Wk和 W v W_v Wv对应另外两个a/b的proj矩阵。
class MiniCPMAttention(nn.Module):def __init__():self.hidden_size = config.hidden_size # 2560self.num_heads = config.num_attention_heads # 40self.max_position_embeddings = config.max_position_embeddings # 32768self.q_lora_rank = config.q_lora_rank # 768self.qk_rope_head_dim = config.qk_rope_head_dim # 32self.kv_lora_rank = config.kv_lora_rank # 256self.v_head_dim = config.hidden_size // config.num_attention_heads # 2560 // 40 = 64self.qk_nope_head_dim = config.qk_nope_head_dim # 64self.q_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim # 64+32=96self.q_a_proj = nn.Linear(self.hidden_size, config.q_lora_rank, bias=config.attention_bias) # hiddensize -> q_lora_rank 2560->768self.q_a_layernorm = MiniCPMRMSNorm(config.q_lora_rank)self.q_b_proj = nn.Linear(config.q_lora_rank, self.num_heads * self.q_head_dim, bias=False) # q_lora_rank -> num_heads * q_head_dim = 768 -> 40*(64+32)self.kv_a_proj_with_mqa = nn.Linear(self.hidden_size,config.kv_lora_rank + config.qk_rope_head_dim,bias=config.attention_bias,) # kv_lora_rank = 256, qk_rope_head_dim = 32 2560 -> 256 + 32self.kv_a_layernorm = MiniCPMRMSNorm(config.kv_lora_rank)self.kv_b_proj = nn.Linear(config.kv_lora_rank,self.num_heads* (self.q_head_dim - self.qk_rope_head_dim + self.v_head_dim),bias=False,) # kv_lora_rank -> num_heads * (q_head_dim - qk_rope_head_dim + v_head_dim) = 40*(96-32+64) = 40 * 128 = 5120self.o_proj = nn.Linear(self.num_heads * self.v_head_dim,self.hidden_size,bias=config.attention_bias,) # num_heads * v_head_dim -> hiddensize 40*64 -> 2560
- 在MLA的实现上,对于 q q q的计算,使用2个低秩小矩阵的乘法,节约计算成本【假设原始是 x ⋅ W q x \cdot W_q x⋅Wq, x x x大小是 ( 1 , d ) (1,d) (1,d), W q W_q Wq大小是 ( d , D ) (d,D) (d,D),计算复杂度是 O ( d ⋅ D ) O(d⋅D) O(d⋅D);令 U V = W q UV=W_q UV=Wq,其中 U U U的大小为 ( d , r ) (d,r) (d,r), V V V的大小是 ( r , D ) (r,D) (r,D), x U V xUV xUV的计算复杂度是 O ( d ⋅ r + r ⋅ D ) O(d\cdot r+r \cdot D) O(d⋅r+r⋅D), r r r是低秩的情况下】
- 同时,因为MLA里面要存储低秩的K,和ROPE的实现有一些冲突,直接实现起来要么需要存原始的K,要么推理时需要大的计算量,所以实现上,单独把ROPE的信息作为一个分量来进行单独的存储和计算,和K对应的q里面会有一份不带有ROPE信息的q_nope,以及后续会加上rope信息的q_pe,所以会看到这里面q做了split。
def forward(self,hidden_states: torch.Tensor,attention_mask: Optional[torch.Tensor] = None,position_ids: Optional[torch.LongTensor] = None,past_key_value: Optional[Cache] = None,output_attentions: bool = False,use_cache: bool = False,**kwargs,) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:bsz, q_len, _ = hidden_states.size() # hidden_size=2560# q使用2个小矩阵乘法,而不是直接和大矩阵相乘,节约计算成本q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states))) # hiddensize -> q_lora_rank -> num_heads * q_head_dim = 40*(64+32)q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1) # q的大小为40*96;qk_nope_head_dim=64, qk_rope_head_dim=32;q沿着最后一个维度拆分成两部分,所以q_nope=40*64,q_pe=40*32- 接着的部分,首先计算出一个compressed_kv,注意它的维度上没有num_heads这个维度,看上去是对于所有head都是共用的一个向量
- compressed_kv会分出来不使用rope的部分,以及使用rope的部分k_pe
- 接着最核心的是,把compressed_kv通过投影矩阵kv_b_proj映射后,又有num_heads的维度了,后面split拆分后可以看到,每个注意力头是有自己的K和V的,和MHA一样的效果
compressed_kv = self.kv_a_proj_with_mqa(hidden_states) # (bsz,q_len,2560)->(bsz,q_len,256+32)compressed_kv, k_pe = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1) # kv_lora_rank=256, qk_rope_head_dim=32,split后,compressed_kv=256,k_pe=32;拆分出来要使用rope和不使用rope的分量k_pe = k_pe.view(bsz, q_len, 1, self.qk_rope_head_dim).transpose(1, 2) # (bsz, 1, q_len, 32)kv = (self.kv_b_proj(self.kv_a_layernorm(compressed_kv)) # 256-> 40*128 -> 5120.view(bsz, q_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim) # 40*(64+64) = 40*128.transpose(1, 2) # (num_heads, bsz, q_len, (self.qk_nope_head_dim + self.v_head_dim)) = (40,bsz, q_len, 128))k_nope, value_states = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1) # k_nope=40*bsz*q_len*64,value_states=40*bsz*q_len*64
- 加入ROPE信息, q q q里面的是q_pe分量, k k k里面的是k_pe分量
- 【bug】尴尬的地方来了,目前官方的实现里面可能是为了兼容的原因,KV-cache存的是恢复后的K和V,不是存的compressed_kv
kv_seq_len = value_states.shape[-2]if past_key_value is not None:kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) # 初始化的时候,这个函数里面的dim是32;这里只是用value_states的dtypeq_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids) # q_pe的维度为32,k_pe的维度为32query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim) # num_heads=40, q_head_dim=96query_states[:, :, :, : self.qk_nope_head_dim] = q_nope # q的前64维是没有rope信息query_states[:, :, :, self.qk_nope_head_dim :] = q_pe # q的后32维是有rope信息key_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim) # num_heads=40, q_head_dim=96key_states[:, :, :, : self.qk_nope_head_dim] = k_nope # k的前64维是没有rope信息key_states[:, :, :, self.qk_nope_head_dim :] = k_pe # k的后32维是有rope信息if past_key_value is not None:cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE modelskey_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs) # past_key_value是一个Cache对象,update函数会把past_key_value的key和value更新为当前的key和valueattn_weights = (torch.matmul(query_states, key_states.transpose(2, 3)) * self.softmax_scale) # (bsz, num_heads, q_len, q_head_dim) @ (bsz, num_heads, q_head_dim, kv_seq_len) -> (bsz, num_heads, q_len, kv_seq_len)
- 所以minicpm3在结构上是MLA,但是推理阶段目前没有做减少存储/加速的处理
DeepSeek V3里面的MLA,可以看到在存KV的时候存的是压缩之后的
compressed_kv = self.kv_a_proj_with_mqa(hidden_states)k_pass, k_rot = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)k_pass = self.kv_b_proj(self.kv_a_layernorm(k_pass)).view(key_shape).transpose(1, 2)k_pass, value_states = torch.split(k_pass, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)k_rot = k_rot.view(batch_size, 1, seq_length, self.qk_rope_head_dim)cos, sin = position_embeddingsif self.config.rope_interleave: # support using interleaved weights for efficiencyq_rot, k_rot = apply_rotary_pos_emb_interleave(q_rot, k_rot, cos, sin)else:q_rot, k_rot = apply_rotary_pos_emb(q_rot, k_rot, cos, sin)k_rot = k_rot.expand(*k_pass.shape[:-1], -1)query_states = torch.cat((q_pass, q_rot), dim=-1)key_states = torch.cat((k_pass, k_rot), dim=-1)if past_key_value is not None:# sin and cos are specific to RoPE models; cache_position needed for the static cachecache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
TODO
- 完整的MLA机制学习,可能涉及attention和flashattention的底层实现原理
相关文章:

【大模型LLM学习】MiniCPM的注意力机制学习
【大模型LLM学习】MiniCPM的注意力机制学习 前言1 Preliminary1.1 MHA1.2 KV-cache 2 GQAGQA的MiniCPM实现 3 MLAMLA的MiniCPM-3-4b的实现 TODO 前言 之前MiniCPM3-4B是最早达到gpt-3.5能力的端侧小模型,其注意力机制使用了MLA。本来想借着MiniCPM从MHA过到MLA的&am…...

stm32之PWR、WDG
目录 1.PWR1.1 简介1.2 电源框图1.3 上电复位和掉电复位1.4 可编程电压监测器1.5 低功耗模式1.5.1 模式选择1.5.2 睡眠模式1.5.3 停止模式1.5.4 待机模式 1.6 实验1.6.1 修改主频1.6.2 睡眠模式串口发送接收1.6.3 停止模式对射式红外传感器计次1.6.4 待机模式实时时钟 2.看门狗…...

分布式任务调度XXL-Job
XXL-Job 是一款轻量级、分布式的任务调度平台,其核心设计解决了传统任务调度(如Quartz)在分布式场景下的任务分片、高可用、可视化管控等痛点。以下从原理、核心架构、应用场景、代码示例及关联中间件展开详解 一、主流任务…...

内存泄漏与OOM崩溃根治方案:JVM与原生内存池差异化排查手册
内存泄漏与OOM崩溃根治方案:JVM与原生内存池差异化排查手册 一、问题描述与快速解决方案 1. 核心问题分类 内存泄漏(Memory Leak) 现象:应用运行时间越长,内存占用持续攀升,GC回收效率下降,最…...

火山引擎发展初始
火山引擎是字节跳动旗下的云计算服务品牌,其云服务业务的启动和正式商业化时间线如下: 1. **初期探索(2020年之前)** 字节跳动在早期为支持自身业务(如抖音、今日头条等)构建了强大的基础设施和技术中…...

使用光标测量,使用 TDR 测量 pH 和 fF
时域反射计 (TDR) 是一种通常用于测量印刷电路板 (PCB) 测试试样和电缆阻抗的仪器。TDR 对于测量过孔和元件焊盘的电感和电容、探针尖端电容和电感,甚至寄生电感收发器耦合电容器也非常有用。这也是验证仿真或提取您自…...

mybatisplus 集成逻辑删除
一开始,没去查资料,后面要被AI气死了,先看它的的话 一开始,看ai的描述,我还以为,不需要改数据库,mybatis-puls自动拦截集成就可以实现逻辑删除,c,最后还是要给数据库加一…...

ABAP+旧数据接管的会计年度未确定
导资产主数据时,报错旧数据接管的会计年度未确定 是因为程序里面使用了下列函数AISCO_CALCULATE_FIRST_DAY,输入公司代码,获取会计年度,这个数据是在后台表T093C表中取数的,通过SE16N可以看到后台表数据没有数…...

KT148A语音芯片发码很难播放_将4脚对地一下再发正常,什么原因?
问题描述如下:您好,遇到一点问题请帮忙支持一下: KT148A 这颗芯片, 我们上电后发码很难触发播放, 但用镊子将4pin PB0对地短接触发一下,再发码就很正常,这是什么原因? 根据现象来看…...

【大模型】DeepResearcher:通用智能体通过强化学习探索优化
DeepResearcher:通过强化学习在真实环境中扩展深度研究 一、引言二、技术原理(一)强化学习与深度研究代理(二)认知行为的出现(三)模型架构 三、实战运行方式(一)环境搭建…...

SpringBoot 3.X 开发自己的 Spring Boot Starter 和 SpringBoot 2.x 的区别
SpringBoot 2.x 在模块中创建 src/main/resources/META-INF/spring.factories 文件 文件内容如下: org.springframework.boot.autoconfigure.EnableAutoConfiguration\com.xxx.xxx.yourfilejava1,\com.xxx.xxx.yourfilejava2 SpringBoot 3.x 在模块中创建 src/m…...

NY164NY165美光固态闪存NY166NY172
美光NY系列固态闪存深度解析:技术、体验与行业洞察 一、技术架构与核心特性解析 美光NY系列(NY164/NY165/NY166/NY172)作为面向企业级市场的固态闪存产品,其技术设计聚焦高可靠性与性能优化。从架构上看,该系列可能采…...

Spring Boot中HTTP连接池的配置与优化实践
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、HTTP连接池的核心价值 在微服务架构和分布式系统场景中,HTTP客户端频繁创建/断开连接会产生显著的性能损耗。通过连接池技术可以实现&#x…...

【docker】--镜像管理
文章目录 拉取镜像启动镜像为容器连接容器法一法二 保存镜像加载镜像镜像打标签移除镜像 拉取镜像 docker pull mysql:8.0.42启动镜像为容器 docker run -dp 8080:8080 --name container_mysql8.0.42 -e MYSQL_ROOT_PASSWORD123123123 mysql:8.0.42 连接容器 法一 docker e…...
 头歌-存储系统设计实验(汉字库存储芯片扩展实验、MIPS寄存器文件设计))
Logisim实验--华科计算机组成原理(保姆级教程) 头歌-存储系统设计实验(汉字库存储芯片扩展实验、MIPS寄存器文件设计)
汉字库存储芯片扩展实验 电路一: 电路二:电路和译码器设置。 两个电路的分线器设计: 只要把电路正确连接就能提交了,但要看到正确的实验结果就想要进行如下操作: 打开参考电路,我要做的就是将每个存储器内…...

Hapi.js知识框架
一、Hapi.js 基础 1. 核心概念 企业级Node.js框架:由Walmart团队创建,现由社区维护 配置驱动:强调声明式配置而非中间件 插件架构:高度模块化设计 安全优先:内置安全最佳实践 丰富的生态系统:官方维护…...

Baklib知识中台架构与智能引擎实践
知识中台架构设计实践 在数字化转型进程中,Baklib基于企业级知识管理需求,构建了模块化分层架构的知识中台体系。该架构采用数据湖仓融合技术,通过统一元数据管理打通业务系统间的信息壁垒,形成覆盖数据采集、清洗、标注的全链路…...

传输层协议UDP
传输层 负责数据能够从发送端传输接收端 . 再谈端口号 端口号 (Port) 标识了一个主机上进行通信的不同的应用程序 ; 在 TCP/IP 协议中 , 用 " 源 IP", " 源端口号 ", " 目的 IP", " 目的端口号 ", " 协议号 " 这样一…...

在Java中实现Parcelable接口和Serializable接口有什么区别?
在 Java 中,Parcelable 和 Serializable 接口都用于对象的序列化和反序列化,但它们的实现方式、性能和使用场景有很大区别。以下是它们的核心对比: 1. 实现方式 Serializable 是 Java 原生接口,只需声明 implements Serializable…...

MinIO WebUI 页面使用
上传文件到桶,选择Share 如果桶是pulic权限,则可以有以下两种方式访问到该对象文件: http://ip:9001/api/v1/download-shared-object/aHR0cDovLzEyNy4wLjAuMTo5MDAwL3dhcmVob3VzZS9wYWltb24vRmxpbmstTG9nby5wbmc_WC1BbXotQWxnb3JpdGhtPUFXU…...

Python | Dashboard制作
运行环境:jupyter notebook (python 3.12.7) Pyecharts 1.安装pyecharts !pip install pyecharts 验证安装是否成功: from pyecharts import __version__ print("Pyecharts版本:", __version__) # 应显示1.x以上版本 2.运行基础版代码&am…...

视频编辑软件无限音频、视频、图文轨
威力导演APP的特色功能包括无限音频、视频、图文轨,以及上百种二/三维特技转场、音/视频滤镜和多种音视频混编输出。此外,它还支持实时高清HDV格式、模拟信号输出,并具有DV25、DVACM、DV、HDV输入和输出等功能。在视频编辑领域,威…...

HttpSession 的运行原理
HttpSession 的运行原理(基于 Java Web) HttpSession 是 Java Web 开发中用于在服务器端存储用户会话数据的机制,它的核心作用是跟踪用户状态(如登录信息、购物车数据等)。 1. HttpSession 的基本概念 会话࿰…...
)
Axure应用交互设计:表格跟随菜单移动效果(超长表单)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!本文如有帮助请订阅 Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:表格跟随菜单移动 主要内容:表格交互设计、动态面板嵌套、拖动时事件、移动动作 应用场景…...

Flannel vxlan模式的优缺点
VXLAN 模式的特点、优缺点 优点 高性能:VXLAN 利用内核态处理封装/解封装,性能优于用户态方案(如 UDP),适合大规模集群。网络隔离:通过 VNI(VXLAN Network Identifier,24 位&#…...

中电金信参编的国家标准《信息技术 中间件 消息中间件技术要求》正式发布
近日,国家市场监督管理总局、国家标准化管理委员会发布中华人民共和国国家标准公告(2025年第10号),GB/T 28168—2025《信息技术 中间件 消息中间件技术要求》国家标准正式发布,并将于2025年11月1日正式实施。中电金信作…...
字段)
AcroForm 格式化文本(域)字段
概述 Acrobat提供了两个事件(脚本位置)来处理文本字段格式化:Keystroke(更改)事件和 Format事件。这两个事件可以共同控制输入到字段中的数据的格式以及文本字段中显示数据的外观。本文中涉及的所有脚本以及更多示例都包含在FormattingExamples.pdf文件中。 Keystroke事…...

机器学习——聚类算法练习题
一、 随机创建不同二维数据集作为训练集 ,并结合k-means算法将其聚类 ,你可以尝试分别聚类不同数量的簇 ,并观察聚类 效果: 聚类参数n_cluster传值不同 ,得到的聚类结果不同 代码展示: from sklearn.da…...

U-BOOT
使用正点原子已经移植好的U-BOOT编译完成后拷贝到SD卡中烧写到板子上中,将开发板设为SD卡启动模式,上电启动开发板;打开 MobaXterm 终端模拟软件,设置好串口参数连接开发板 USB 调试串口,最后按核心板上的 PS_RST 复位…...

JVM之虚拟机运行
虚拟机运行快速复习 try-catch:catch-异常表栈展开,finally-代码复制异常表兜底 类的生命周期:加载,连接(验证,准备,解析),初始化,使用,卸载 类…...
)
玩转ChatGPT:DeepSeek实战(统一所在地格式)
一、写在前面 前段时间去交流,又被问到一个实际问题: 在组织全区活动时,我们设计了一份签到表,其中包含“所在单位地区”一列,目的是希望按地级市(如南宁市、柳州市等)对参与者进行分组&#…...

蓝桥杯题库经典题型
1、数列排序(数组 排序) 问题描述 给定一个长度为n的数列,将这个数列按从小到大的顺序排列。1<n<200 输入格式 第一行为一个整数n。 第二行包含n个整数,为待排序的数,每个整数的绝对值小于10000。 输出格式 输出…...

极限学习机进行电厂相关数据预测
使用极限学习机(Extreme Learning Machine, ELM)进行电厂相关数据预测的详细步骤和MATLAB代码示例。假设任务是预测电厂发电量或设备状态(如温度、压力),代码包含数据预处理、ELM模型构建、训练与预测全过程。 1. 数据…...

【Axure视频教程】中继器表格间批量控制和传值
今天教大家在Axure中制作中继器表格间批量控制和传值的原型模板,效果包括: 选中和取消选中——点击表格中的多选按钮可以选中或取消选中该行内容; 全选和全部取消选中——点击表头左上角的多选按钮可以选中或取消选中表格的所有内容…...

Axure高级交互设计:文本框循环赋值实现新增、修改和查看
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢!本文如有帮助请订阅本专栏! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:文本框循环赋值 主要内容:使用设置文本动作实现文本框、文字标签的读取与赋值 应…...

Springboot之类路径扫描
SpringBoot框架中默认提供的扫描类为:ClassPathBeanDefinitionScanner。 webFlux框架中借助RepositoryComponentProvider扫描符合条件的Repository。 public class ClassPathScanningCandidateComponentProvider{private final List<TypeFilter> includeFilt…...
是 OpenCV 的 CUDA 模块中用于在 GPU 上对图像或矩阵进行转置操作函数cv::cuda::transpose
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::transpose 是 OpenCV 的 CUDA 模块中的一个函数,用于在 GPU 上对图像或矩阵进行转置操作(Transpose࿰…...

2025B卷 - 华为OD机试七日集训第1期 - 按算法分类,由易到难,循序渐进,玩转OD
目录 推荐刷题方法: 一、适合人群二、本期训练时间三、如何参加四、七日集训第1期五、精心挑选21道高频100分经典题目,作为入门。第1天、逻辑分析第2天、逻辑分析第3天、逻辑分析第4天第5天第6天第7天 六、集训总结国内直接使用最新o3、o4-mini-high、GP…...

从数据中台到数据飞轮:数字化转型的演进之路
从数据中台到数据飞轮:数字化转型的演进之路 数据中台 数据中台是企业为整合内部和外部数据资源而构建的中介层,实现数据的统一管理、共享和高效利用,目标是打破信息孤岛,提高数据使用效率,支持业务决策和创新 实施成本…...

【Linux网络】HTTPS
HTTPS协议原理 定义 HTTPS 也是一个应用层协议.是在HTTP协议的基础上引入了一个加密层. HTTP 协议内容都是按照文本的方式明文传输的.这就导致在传输过程中会出现一些被篡改的情况。 加密 加密就是把明文(要传输的信息)进行一系列变换,生成密文. 解密就是把密文再进行一系…...

UE5中制作动态数字Decal
在进行城市道路编辑时,经常需要绘制人行道、交通标志、停车线等路面元素。如果能够使用具有动态修改功能的 Decal(贴花),将大大提升编辑效率和灵活性。接下来讲解如何制作。 1.首先准备一张包含所需元素的Texture,这里…...

销量预测评估指标
销量预测评估指标 一、背景 在零售、供应链等场景中,销量预测的准确性直接影响库存管理、成本控制和客户满意度: 预测偏低:可能导致缺货(损失销售额和客户信任)。预测偏高:导致库存积压(增加…...
报错Gradle build failed解决方法)
Unity3d 打包安卓平台(Android apk)报错Gradle build failed解决方法
问题 Unity3d 版本为2022.3.*版本,而且工程内部没有包含比较特殊的插件,安卓模块(module)也是随编辑一起安装,JDK、Android SDK Tools、Android NDK和Gradle都是默认安装。打包设置Project Settings也是默认设置,打包的工程不包含…...

STM32 启动文件分析
一、启动文件的核心作用 STM32启动文件(如startup_stm32f10x_hd.s)是芯片上电后执行的第一段代码,用汇编语言编写,主要完成以下关键任务: 初始化堆栈指针(SP) 设置主堆栈指针(…...

OSCP备战-Kioptrix4详细教程
目录 配置靶机 目标IP探测 编辑端口扫描 139/445端口 Samba 80端口获取shell 绕过lshell 方法一 编辑 方法二 编辑提权 内核漏洞 mysql udf提权 配置靶机 使用vm新建虚拟机,选择vmdk文件打开。 目标IP探测 arp-scan -l 得出目标IP:19…...

清华大学开源软件镜像站地址
清华大学开源软件镜像站: https://mirrors.tuna.tsinghua.edu.cn/...

java基础-package关键字、MVC、import关键字
1.package关键字: (1)为了更好管理类,提供包的概念 (2)声明类或接口所属的包,声明在源文件首行 (3)包,属于标识符,用小写字母表示 ࿰…...
动态计算swiper高度封装自定义hook)
uniapp(vue3)动态计算swiper高度封装自定义hook
// useCalculateSwiperHeight.ts import { ref, onMounted } from vue;export function useCalculateSwiperHeight(headerSelector: string .header-search, tabsWrapperSelector: string .u-tabs .u-tabs__wrapper) {const swiperHeight ref<number>(0);// 封装uni.g…...

Java SpringMVC 和 MyBatis 整合项目的事务管理配置详解
目录 一、事务管理的基本概念二、在 SpringMVC 和 MyBatis 整合项目中配置事务管理1. 配置数据源2. 配置事务管理器3. 使用事务注解4. 配置 MyBatis 的事务支持5. 测试事务管理三、总结在企业级应用开发中,事务管理是确保数据一致性和完整性的重要机制。特别是在整合了 Spring…...

C++的历史与发展
目录 一、C 的诞生与早期发展 (一)C 语言的兴起与局限 (二)C 的雏形:C with Classes (三)C 命名与早期特性丰富 二、C 的主要发展历程 (一)1985 年:经典…...