5月13日day24日打卡
元组和OS模块
知识点回顾:
- 元组
- 可迭代对象
- os模块
作业:对自己电脑的不同文件夹利用今天学到的知识操作下,理解下os路径。
元组
元组的特点:
- 有序,可以重复,这一点和列表一样
- 元组中的元素不能修改,这一点非常重要,深度学习场景中很多参数、形状定义好了确保后续不能被修改。
很多流行的ML/DL库(如TensorFlow,PyTorch,NumPy)在其API中都广泛使用了元组来表示形状、配置等。
可以看到,元组最重要的功能是在列表之上,增加了不可修改这个需求
元组的创建
my_tuple1 = (1, 2, 3)
my_tuple2 = ('a', 'b', 'c')
my_tuple3 = (1, 'hello', 3.14, [4, 5]) # 可以包含不同类型的元素
print(my_tuple1)
print(my_tuple2)
print(my_tuple3) 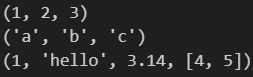
# 可以省略括号
my_tuple4 = 10, 20, 'thirty' # 逗号是关键
print(my_tuple4)
print(type(my_tuple4)) # 看看它的类型 ![]()
# 创建空元组
empty_tuple = ()
# 或者使用 tuple() 函数
empty_tuple2 = tuple()
print(empty_tuple)
print(empty_tuple2) ![]()
元组的常见用法
# 元组的索引
my_tuple = ('P', 'y', 't', 'h', 'o', 'n')
print(my_tuple[0]) # 第一个元素
print(my_tuple[2]) # 第三个元素
print(my_tuple[-1]) # 最后一个元素![]()
# 元组的切片
my_tuple = (0, 1, 2, 3, 4, 5)
print(my_tuple[1:4]) # 从索引 1 到 3 (不包括 4)
print(my_tuple[:3]) # 从开头到索引 2
print(my_tuple[3:]) # 从索引 3 到结尾
print(my_tuple[::2]) # 每隔一个元素取一个 
# 元组的长度获取
my_tuple = (1, 2, 3)
print(len(my_tuple)) ![]()
管道工程中pipeline类接收的是一个包含多个小元组的列表作为输入。
可以这样理解这个结构:
- 列表[]:定义了步骤执行的先后顺序。Pipeline会按照列表中的顺序依次处理数据。之所以用列表,是未来可以对这个列表进行修改。
- 元组():用于将每个步骤的名称和处理对象捆绑在一起。名称用于在后续访问或设置参数时引用该步骤,而对象则是实际执行数据转换或模型训练的工具。固定了操作名+操作
不用字典因为字典是无序的。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score# 1. 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 构建管道
# 管道按顺序执行以下步骤:
# - StandardScaler(): 标准化数据(移除均值并缩放到单位方差)
# - LogisticRegression(): 逻辑回归分类器
pipeline = Pipeline([('scaler', StandardScaler()),('logreg', LogisticRegression())#在 scikit-learn 的 Pipeline(管道)中,每个元组代表一个处理步骤,格式为 ('步骤名称', 处理器对象)。
])# 4. 训练模型
pipeline.fit(X_train, y_train)# 5. 预测
y_pred = pipeline.predict(X_test)# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型在测试集上的准确率: {accuracy:.2f}")![]()
可迭代对象
可迭代对象(Iterable)是Python中一个非常核心的概念。简单来说,一个可迭代对象就是指那些能够一次返回其成员(元素)的对象,让你可以在一个循环(比如for循环)中遍历它们。
Python中有很多内置的可迭代对象,目前我们见过的类型包括:
- 序列类型(Sequence Types):
- list(列表)
- tuple(元组)
- str(字符串)
- range(范围)
- 集合类型(Set Types):
- oset(集合)
- 字典类型(Mapping Types):
- dict(字典)-迭代时返回键(keys)
- 文件对象(File objects)
- 生成器(Generators)
- 迭代器(Iterators)本身
# 列表 (list)
print("迭代列表:")
my_list = [1, 2, 3, 4, 5]
for item in my_list:print(item)
# 元组 (tuple)
print("迭代元组:")
my_tuple = ('a', 'b', 'c')
for item in my_tuple:print(item) 
# 字符串 (str)
print("迭代字符串:")
my_string = "hello"
for char in my_string:print(char) 
# range (范围)
print("迭代 range:")
for number in range(5): # 生成 0, 1, 2, 3, 4print(number) 
# 集合类型 (Set Types)# 集合 (set) - 注意集合是无序的,所以每次迭代的顺序可能不同
print("迭代集合:")
my_set = {3, 1, 4, 1, 5, 9}
for item in my_set:print(item) 
# 字典 (dict) - 默认迭代时返回键 (keys)
print("迭代字典 (默认迭代键):")
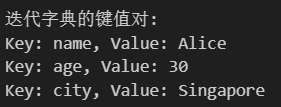
my_dict = {'name': 'Alice', 'age': 30, 'city': 'Singapore'}
for key in my_dict:print(key)#my_dict 是一个字典,包含键值对:'name' → 'Alice', 'age' → 30, 'city' → 'Singapore'
#当执行 for key in my_dict 时,key 变量会依次被赋值为字典的键('name', 'age', 'city')
#因此 print(key) 会输出这些键,而不是对应的值
#如果需要输出值('Alice', 30, 'Singapore'),可以显式调用字典的 values() 方法:
#for value in my_dict.values():#print(value)
#如果需要同时输出键和值,可以用 items() 方法:
#for key, value in my_dict.items():#print(f"键: {key}, 值: {value}")
# 迭代字典的值 (values)
print("迭代字典的值:")
for value in my_dict.values():print(value) 
# 迭代字典的键值对 (items)
print("迭代字典的键值对:")
for key, value in my_dict.items(): # items方法很好用print(f"Key: {key}, Value: {value}")
OS模块
随着深度学习项目变得越来越大、数据量越来越多、代码结构越来越复杂,你会越来越频繁地用到Os模块来管理文件、目录、路径,以及进行一些基本的操作系统交互。虽然深度学习的核心在于模型构建和训练,但数据和模型的有效管理是项目成功的关键环节,而Os模块为此提供了重要的工具。
在简单的入门级项目中,你可能只需要使用pd.read csv0加载数据,而不需要直接操作文件路径。但是,当你开始处理图像数据集、自定义数据加载流程、保存和加载复杂的模型结构时,Os模块就会变得非常有用。
好的代码组织和有效的文件管理是大型深度学习项目的基石。Os模块是实现这些目标的重要组成
部分。
import os
# os是系统内置模块,无需安装获取当前工作目录
os.getcwd() # get current working directory 获取当前工作目录的绝对路径 ![]()
获取当前工作目录下的文件列表
os.listdir() # list directory 获取当前工作目录下的文件列表 ![]()
# 我们使用 r'' 原始字符串,这样就不需要写双反斜杠 \\,因为\会涉及到转义问题
path_a = r'C:\Users\YourUsername\Documents' # r''这个写法是写给python解释器看,他只会读取引号内的内容,不用在意r的存在会不会影响拼接
path_b = 'MyProjectData'
file = 'results.csv'# 使用 os.path.join 将它们安全地拼接起来,os.path.join 会自动使用 Windows 的反斜杠 '\' 作为分隔符
file_path = os.path.join(path_a , path_b, file)file_path ![]()
环境变量方法
# os.environ 表现得像一个字典,包含所有的环境变量
os.environ 
# 使用 .items() 方法可以方便地同时获取变量名(键)和变量值,之前已经提过字典的items()方法,可以取出来键和值
# os.environ是可迭代对象for variable_name, value in os.environ.items():# 直接打印出变量名和对应的值print(f"{variable_name}={value}")# 你也可以选择性地打印总数
print(f"\n--- 总共检测到 {len(os.environ)} 个环境变量 ---")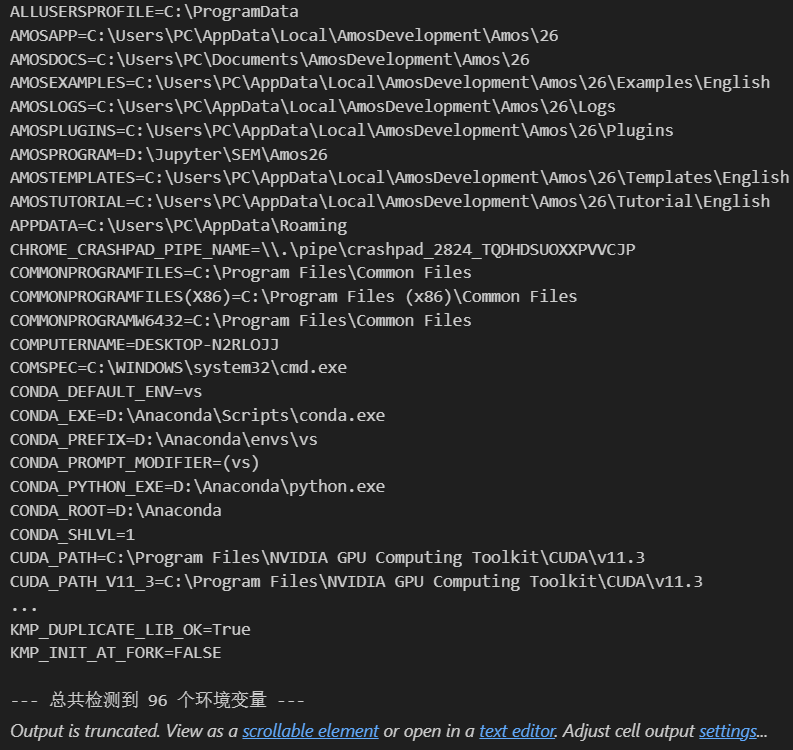
目录树
os.walk0是Python os模块中一个非常有用的函数,它用于遍历(或称"行走")一个目录树。
核心功能:
os.walk(top,topdown=True,οnerrοr=-None,followlinks-=False)会为一个目录树生成文件名。对于树中的每个目录(包括top目录本身),它会yield(产生)一个包含三个元素的元组(tuple):
(dirpath,dirnames,filenames)
1.dirpath:一个字符串,表示当前正在访问的目录的路径。
2.dirnames:一个列表(Iist),包含了dirpath目录下所有子目录的名称(不包括.和..)。
3.filenames:一个列表(Iist),包含了dirpath目录下所有非目录文件的名称。
示例目录结构(Markdown形式):
假设你的start_directory(当前工作目录.)是my_project,其结构如下:
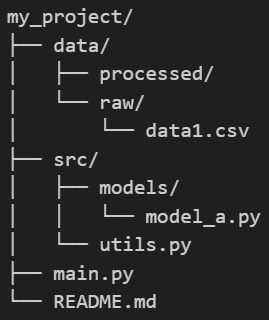
os.walk的遍历顺序及输出(模拟):
(注意:dirnames和fiLenames的顺序可能因操作系统或文件系统而略有不同,但遍历的深度优先逻辑是一致的)
开始遍历目录:my_project
当前访问目录(dirpath):my_project
子目录列表(dirnames):['data','src'] #列出第一层子目录
文件列表(filenames):['main.py','README.md']
当前访问目录(dirpath):my_project/data #深入到data
子目录列表(dirnames):["processed','raw'] #列出data下的子目录
文件列表(filenames):[]
当前访问目录(dirpath):my_project,/data/processed #深入到processed
子目录列表(dirnames):[]
文件列表(filenames):[]
当前访问目录(dirpath):my_project/data/raw #回溯到data,然后深入到raw
子目录列表(dirnames):[]
文件列表(filenames):['data1.csv']
当前访问目录(dirpath):my_project/src #回湖到my_project,然后深入到src
子目录列表(dirnames):['models']
文件列表(filenames):['utils.py']
当前访问目录(dirpath):my_project/src/models #深入到models
子目录列表(dirnames):[]
文件列表(filenames):['model_a.py']
#遍历结束
总结:
os.walk会首先访问起始目录(my_project),然后它会选择第一个子目录(data)并深入进去,访问data目录本身,然后继续深入它的子目录(processed——>raw)。只有当data分支下的所有内容都被访问完毕后,它才会回到my project这一层,去访问下一个子目录(src),并对src分支重复深度优先的探索。
它不是按层级(先访问所有第一层,再访问所有第二层)进行的,而是按分支深度进行的。这种
策略被称之为深度优先
import osstart_directory = os.getcwd() # 假设这个目录在当前工作目录下print(f"--- 开始遍历目录: {start_directory} ---")for dirpath, dirnames, filenames in os.walk(start_directory):print(f" 当前访问目录 (dirpath): {dirpath}")print(f" 子目录列表 (dirnames): {dirnames}")print(f" 文件列表 (filenames): {filenames}")# # 你可以在这里对文件进行操作,比如打印完整路径# print(" 文件完整路径:")# for filename in filenames:# full_path = os.path.join(dirpath, filename)# print(f" - {full_path}")
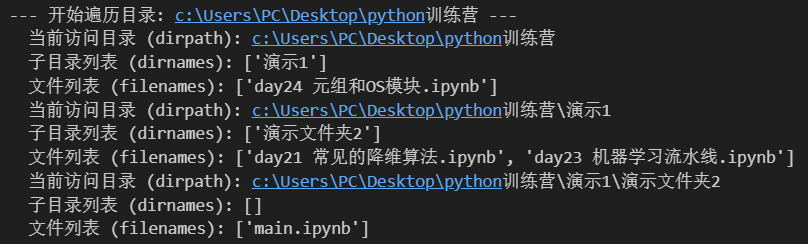
介绍这个方法,是因为在你面临云服务器时候,往往只能通过命令行和代码块中函数来查看,无法像电脑一样在界面中查看,所以,这个方法可以让你直接在代码块中查看。
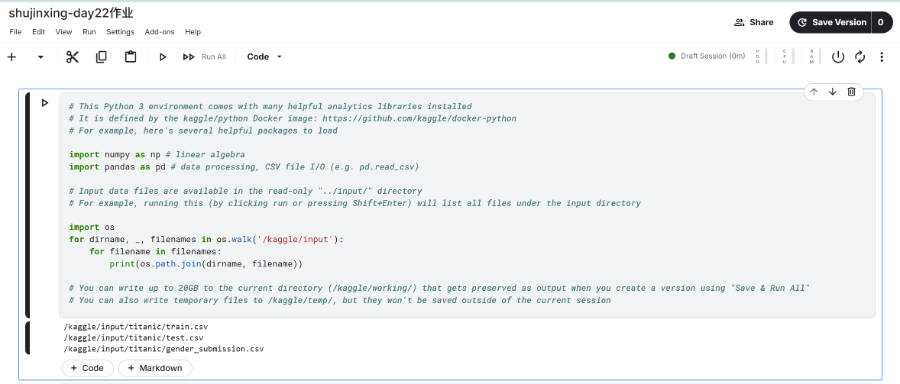 上图为kaggle平台代码提交的代码理解下这个函数的遍历以后如果这个训练营说到大模型相关,我们还会经常和0s模块打交道。
上图为kaggle平台代码提交的代码理解下这个函数的遍历以后如果这个训练营说到大模型相关,我们还会经常和0s模块打交道。
作业:
import osstart_directory = os.getcwd() # 假设这个目录在当前工作目录下print(f"--- 开始遍历目录: {start_directory} ---")for dirpath, dirnames, filenames in os.walk(start_directory):print(f" 当前访问目录 (dirpath): {dirpath}")print(f" 子目录列表 (dirnames): {dirnames}")print(f" 文件列表 (filenames): {filenames}")# # 你可以在这里对文件进行操作,比如打印完整路径# print(" 文件完整路径:")# for filename in filenames:# full_path = os.path.join(dirpath, filename)# print(f" - {full_path}")

import os# 原代码:设置遍历起点(可修改为你需要的目录,如绝对路径)
start_directory = "D:/桌面/研究项目/打卡文件"
print(f"--- 开始遍历目录: {start_directory} ---")# 新增:定义要查找的目标文件名
target_file = "day5.py"for dirpath, dirnames, filenames in os.walk(start_directory):print(f" 当前访问目录 (dirpath): {dirpath}")print(f" 子目录列表 (dirnames): {dirnames}")print(f" 文件列表 (filenames): {filenames}")# 新增:检查当前目录下是否有目标文件if target_file in filenames:full_path = os.path.join(dirpath, target_file) # 拼接完整路径print(f" ✅ 找到文件 '{target_file}',完整路径: {full_path}")# ...(原注释中的其他操作保留,如打印完整路径的代码)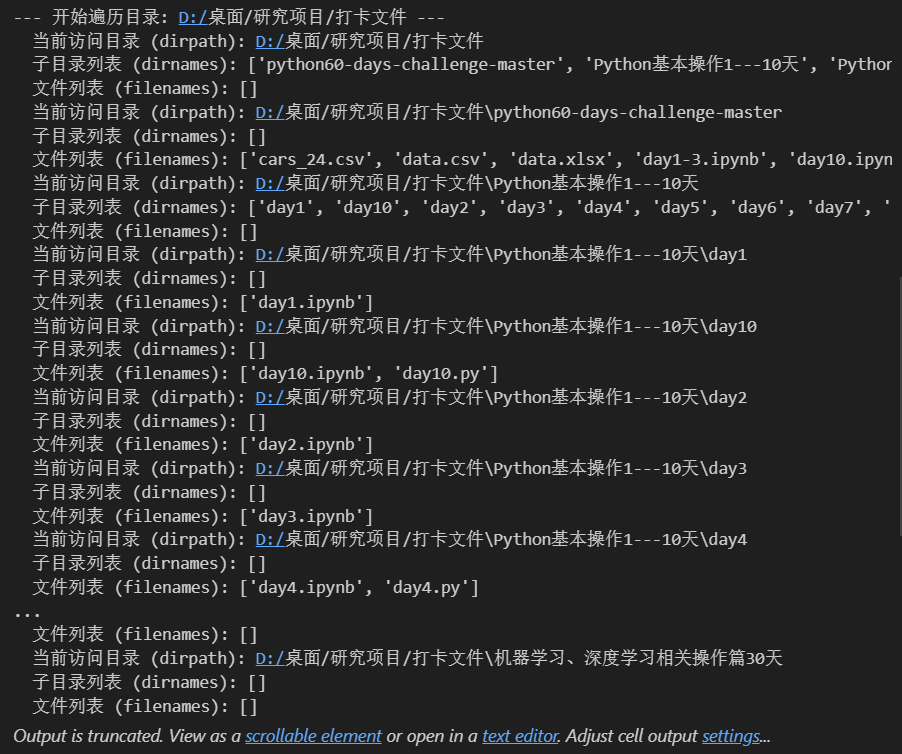
@浙大疏锦行
相关文章:

5月13日day24日打卡
元组和OS模块 知识点回顾: 元组可迭代对象os模块 作业:对自己电脑的不同文件夹利用今天学到的知识操作下,理解下os路径。 元组 元组的特点: 有序,可以重复,这一点和列表一样元组中的元素不能修改…...

[51单片机]---DS18B20 温度检测
1,DS18B20 2,DS18B20时序 void ds18b20_reset() {//ds18b20复位信号 拉低总线750us后释放总线DS18B20_PORT 0; delay_10us(75); DS18B20_PORT 1; delay_10us(2);}//为啥需要检测模块?当我们发生了复位,根据时序图,d…...

Win11 + Visual Studio 2022 + FLTK 1.4.3 + Gmsh 4.13.1 源码编译指南
一、编译环境准备 本文档详细记录了在 Windows 11 系统下,使用 Visual Studio 2022(版本 17)编译 FLTK 1.4.3 和 Gmsh 4.13.1 的完整过程。目标是帮助开发者顺利完成库的编译,并实现基本的功能测试。 二、编译 FLTK 1.4.3 2.1 …...

AUTOSAR图解==>AUTOSAR_TPS_ECUResourceTemplate
AUTOSAR ECU资源模板详解 基于AUTOSAR R4.4.0标准规范 目录 1. 简介 1.1 ECU资源模板的范围1.2 ECU资源模板概述 2. 一般硬件描述 2.1 硬件描述实体2.2 硬件类型2.3 硬件元素2.4 硬件引脚和引脚组2.5 硬件连接2.6 硬件类别定义 3. 硬件类型特定描述 3.1 硬件元素类别3.2 硬件引…...

如何在设计阶段考虑 Python 服务的可伸缩性,避免后期的重构
在如今的软件开发世界里,变化是唯一不变的主题。用户量可能一夜之间从几十人暴增到几十万,业务需求可能在半年内翻天覆地,技术栈也可能因为新工具的出现而需要调整。而作为开发者,尤其是用 Python 打造服务的开发者,我们常常会面临一个绕不过去的问题:如何让我们的服务在…...

ExoPlayer 如何实现音画同步
在解释这个问题之前,先讲一下 ExoPlayer 中音频播放的三种输出模式。 第一种是PCM模式(普通播放模式)。这是最基本的播放模式,音频以PCM(脉冲编码调制)数据形式处理,可以通过音频处理器进行各种…...

C++中void*知识详解和注意事项
一、void* 是什么? 在 C/C 中,void* 表示一个通用指针类型(generic pointer),可以指向任意类型的对象,但 不能直接解引用或进行算术运算,必须先进行类型转换。 void* ptr; // 可以指向任意类型…...

ssl 中 key 和pem 和crt是什么关系
.pem 文件(通用容器格式) 作用:PEM(Privacy-Enhanced Mail)是一种文本格式,可以存储 证书、私钥、中间证书 等。 特点: 以 -----BEGIN XXX----- 和 -----END XXX----- 包裹内容(如…...

CSS可以继承的样式汇总
CSS可以继承的样式汇总 在CSS中,以下是一些常见的可继承样式属性: 字体属性:包括 font-family (字体系列)、 font-size (字体大小)、 font-weight (字体粗细)、 font-sty…...

菜狗的脚步学习
文章目录 一、pdf到h文件转换并恢复二、三、 一、pdf到h文件转换并恢复 编写一个bat,将当前文件的.pdf文件后缀改为.h文件,然后将当前文件下的.h文件全部打开,再依次关闭,待所有.h文件都关闭后,再将.h文件改为.pdf后缀…...

latex公式格式
几个公式只标一个序号 \begin{equation}\begin{aligned}yX\\y2x\\y3x,\end{aligned} \end{equation}要想公式的等号对齐则用下面的格式 若想实现三个公式等号对齐且只编一个号,用 equation 包裹 aligned 环境即可 \begin{equation}\begin{aligned}y&X\\y&…...

在Babylon.js中实现完美截图:包含Canvas和HTML覆盖层
在现代Web 3D应用开发中,Babylon.js作为强大的3D引擎被广泛应用。一个常见的需求是实现场景截图功能,特别是当场景中包含HTML覆盖层(如UI控件、菜单等)时。本文将深入探讨如何在Babylon.js中实现完整的截图方案。 问题背景 这里我是希望实现一个渐隐的…...

LeetCode 648 单词替换题解
LeetCode 648 单词替换题解 题目描述 题目链接 在英语中,我们有一个叫做「词根」的概念,可以缩短其他单词的长度。给定一个词典和一句话,将句子中的所有单词用其最短匹配词根替换。 解题思路 哈希表 前缀匹配法 预处理词典:…...

从虚拟现实到混合现实:沉浸式体验的未来之路
摘要 近年来,虚拟现实(VR)和增强现实(AR)技术的快速发展,为沉浸式体验带来了前所未有的变革。随着技术的不断进步,混合现实(MR)作为VR和AR的融合形态,正在成为…...

基于深度学习的水果识别系统设计
一、选择YOLOv5s模型 YOLOv5:YOLOv5 是一个轻量级的目标检测模型,它在 YOLOv4 的基础上进行了进一步优化,使其在保持较高检测精度的同时,具有更快的推理速度。YOLOv5 的网络结构更加灵活,可以根据不同的需求选择不同大…...

黑马Java基础笔记-10
权限修饰符 修饰符同一个类中同一个包中其他类不同包的子类不同包无关类private√空着不写 (default)√√protected√√√public√√√√ 代码块 局部代码块(了解) public class Test {public static void main(String[] args) {{int a 10;System.out.println(a);}//运行到…...

职坐标AIoT开发技能精讲培训
在人工智能与物联网(AIoT)技术高速迭代的今天,掌握边缘计算、智能设备开发与实时数据处理三大核心模块,已成为开发者突破行业壁垒的关键。职坐标AIoT开发技能精讲培训以技术融合与场景落地为双引擎,从底层硬件协议到上…...

Kafka 4.0版本的推出:数据处理新纪元的破晓之光
之前做大数据相关项目,在项目中都使用过kafka。在数字化时代,数据如洪流般涌来,如何高效处理这些数据成为关键。Kafka 就像是一条 “智能数据管道”,在数据的世界里扮演着至关重要的角色。如果你第一次接触它,不妨把它…...

从0到1上手Kafka:开启分布式消息处理之旅
目录 一、Kafka 是什么 二、Kafka 的基础概念 2.1 核心术语解读 2.2 工作模式剖析 三、Kafka 的应用场景 四、Kafka 与其他消息队列的比较 五、Kafka 的安装与配置 5.1 环境准备 5.2 安装步骤 5.3 常见问题及解决 六、Kafka 的基本操作 6.1 命令行工具使用 6.1.1 …...

以价值为导向的精准数据治理实践,赋能业务决策
在数字化浪潮席卷全球的今天,数据已成为企业最宝贵的资产之一。然而,如何将海量数据转化为驱动业务增长的强大动力,是摆在每个企业面前的难题。某大型国企公司,作为集团金融板块的重要组成部分,在数字化转型过程中&…...

文件相关操作
文本文件 程序运行时产生的数据都属于临时数据,程序一旦运行结束都会被释放 通过文件可以将数据持久化 C的文件操作需要包含头文件 文件分类 文本文件:文件以文本的ASCII码形式存储在计算机中 二进制文件:文件以文本的二进制形式存储在计算…...

在Window上面添加交叉编译链 MinGW+NDK
需要工具 1,minGW Releases niXman/mingw-builds-binaries GitHub 2,ndk包 NDK 下载 | Android NDK | Android Developers 3,python(现在的交叉编译链工具不是.sh,而是.py) python可以根据自己…...

2.4GHz无线通信芯片选型指南:集成SOC与低功耗方案解析
今天给大家分享几款2.4GHz无线通信芯片方案: 一、集成SOC芯片方案 XL2407P(芯岭技术) 集成射频收发机和微控制器(如九齐NY8A054E) 支持一对多组网和自动重传 发射功率8dBm,接收灵敏度-96.5dBm(…...

MySQL的Docker版本,部署在ubantu系统
前言 MySQL的Docker版本,部署在ubantu系统,出现问题: 1.执行一个SQL,只有错误编码,没有错误提示信息,主要影响排查SQL运行问题; 2.这个问题,并不影响实际的MySQL运行,如…...

upload-labs通关笔记-第4关 文件上传之.htacess绕过
目录 一、.htacess 二、代码审计 三、php ts版本安装 1、下载ts版本php 2、放入到phpstudy指定文件夹中 3、修改php配置文件 4、修改php.ini文件 5、修改httpd.conf文件 (1)定位文件 (2)修改文件 6、重启小皮 7、切换…...

ThingsBoard使用Cassandra部署时性能优化
1、概述 当遇到ThingsBoard设备数量特别多的时候,并且传输数据遥测点量特别大的时候,我们需要调整一下参数来进行优化,使其性能达到最佳的进行快速写入。 注意:以下这些参数再系统部署的时候就需要规划好配置,不能安装好了再二次来进行配置。 2、Cassandra配置参数优化 …...
超市管理系统(测试版)(指针)(数据结构)(二进制文件读写))
(C语言)超市管理系统(测试版)(指针)(数据结构)(二进制文件读写)
目录 前言: 源代码: product.h product.c fileio.h fileio.c main.c 代码解析: fileio模块(文件(二进制)) 写文件(保存) 函数功能 代码逐行解析 关键知识点 读文…...

解锁城市排水系统设计与二次开发的钥匙-SWMM复杂城市排水系统模型及排水防涝、海绵城市设计等工程实践应用
在城市化进程日益加速的今天,城市排水系统的设计与优化成为了保障城市安全、提升居民生活质量的关键环节。为了应对复杂多变的城市水文环境,掌握先进的排水系统模拟技术显得尤为重要。美国环保局的雨水管理模型(SWMM)作为当前最为…...

LS-NET-012-TCP的交互过程详解
LS-NET-012-TCP的交互过程详解 附加:TCP如何保障数据传输 TCP的交互过程详解 一、TCP协议核心交互流程 TCP协议通过三次握手建立连接、数据传输、四次挥手终止连接三大阶段实现可靠传输。整个过程通过序列号、确认应答、窗口控制等机制保障传输可靠性。 1.1 三次…...

【Qt开发】信号与槽
目录 1,信号与槽的介绍 2,信号与槽的运用 3,自定义信号 1,信号与槽的介绍 在Qt框架中,信号与槽机制是一种用于对象间通信的强大工具。它是在Qt中实现事件处理和回调函数的主要方法。 信号:窗口中&#x…...
)
Java【10_1】用户注册登录(面向过程与面向对象)
测试题 1、基于文本界面实现登录注册的需求(要求可以满足多个用户的注册和登录) 通过工具去完成 公共类: public class User { private int id;//用户编号 private int username;//用户名 private int password;//密码 private String name;//真…...

IntelliJ IDEA给Controller、Service、Mapper不同文件设置不同的文件头注释模板、Velocity模板引擎
通过在 IntelliJ IDEA 中的 “Includes” 部分添加多个文件头模板,并在 “Files” 模板中利用这些包含来实现不同类型文件的注释。以下是为 Controller、Service、Mapper 文件设置不同文件头的完整示例: 1. 设置 Includes 文件头模板 File > Settin…...

python共享内存实际案例,传输opencv frame
主进程程序 send.py import cv2 import numpy as np from multiprocessing import shared_memory, resource_trackercap cv2.VideoCapture(0) if not cap.isOpened():print("无法打开 RTSP 流,请检查地址、网络连接或 GStreamer 配置。") else:# 创建共…...

JVM——方法内联之去虚化
引入 在Java虚拟机的即时编译体系中,方法内联是提升性能的核心手段,但面对虚方法调用(invokevirtual/invokeinterface)时,即时编译器无法直接内联,必须先进行去虚化(Devirtualizationÿ…...

1.6 关于static和final的修饰符
一.static static是静态修饰符,用于修饰类成员(变量,方法,代码块) 被修饰的类成员属于类,不必生成示例,即可直接调用属性或者方法。 关于代码块,被static修饰的代码块是静态代码块…...

Django 中时区的理解
背景 设置时区为北京时间 TIME_ZONE ‘Asia/Shanghai’ # 启用时区支持 USE_TZ True 这样设置的作用 前端 (实际上前端el-date-picker 显示的是当地时区的时间) Element组件转换后,我们是东八区,前端传给后端的时间为&…...

hadoop中创建MySQL新数据库数据表
在Hadoop环境中创建MySQL数据库和数据表,通常需要通过MySQL命令行工具来完成,而不是直接在Hadoop中操作。以下是具体步骤: 1. 登录MySQL 首先,需要登录到MySQL服务器。在命令行中输入以下命令: mysql -u root -p 输…...

ridecore流水线解读
文章目录 流水线stage分属前后端PCpipelineIFIDDPDP 与 SW 中间没有latchSWCOM 源码地址 流水线stage分属前后端 IF -> ID -> DP -> SW -> EX -> COM分类阶段说明前端IF指令获取阶段。PC 使用分支预测器,访问指令存储器。典型前端操作。前端ID解码并…...

基于C语言实现网络爬虫程序设计
如何用好C语言来做爬虫,想必接触过的大神都能说扥头头是道,但是对于新手小白来说,有这么几点需要注意的。根据设计程序结构,我们需要一个队列来管理待爬取的URL,一个集合或列表来记录已访问的URL。主循环从队列中取出U…...

github 上的 CI/CD 的尝试
效果 步骤 新建仓库设置仓库的 page 新建一个 vite 的项目,改一下 vite.config.js 中的 base 工作流 在项目的根目录下新建一个 .github/workflows/ci.yml 文件,然后编辑一下内容 name: Build & Deploy Vue 3 Appon:push:branches: [main]permi…...

飞书配置表数据同步到数据库中
这是我的从飞书取数据的代码 def get_employee_from_feishu():staff_setting settings.FEISHU_SETTING["sales_order"]["employee"]app_token staff_setting ["app_token"]table_id staff_setting ["table_id"]page_token Noneh…...

Nacos源码—9.Nacos升级gRPC分析八
大纲 10.gRPC客户端初始化分析 11.gRPC客户端的心跳机制(健康检查) 12.gRPC服务端如何处理客户端的建立连接请求 13.gRPC服务端如何映射各种请求与对应的Handler处理类 14.gRPC简单介绍 12.gRPC服务端如何处理客户端的建立连接请求 (1)gRPC服务端是如何启动的 (2)connec…...

开源免费无广告专注PDF编辑、修复和管理工具 办公学术 救星工具
各位PDF处理小能手们!我跟你们说啊,今天要给大家介绍一款超牛的国产开源PDF处理工具,叫PDFPatcher,也叫PDF补丁丁。它就像一个PDF文档的超级修理工,专门解决PDF编辑、修复和管理的各种难题。 这软件的核心功能和特点&a…...

C++设计模式——单例模式
单例模式 方法1:C11 线程不安全懒汉模式(不推荐) 懒汉式单例模式在第一次使用时才创建实例,但这种方式在多线程环境下可能会出现问题。 class Singleton { private:static Singleton* instance; // 静态指针,用于存储…...

装饰器在Python中的作用及在PyTorchMMDetection中的实战应用
装饰器在Python中的作用 1. 装饰器是什么?为什么它很重要? 装饰器(Decorator)是Python中的一种高级语法,用于在不修改原函数代码的情况下,动态增强函数的功能。它的核心思想是**"装饰"现有函数*…...

时间序列预测建模的完整流程以及数据分析【学习记录】
文章目录 1.时间序列建模的完整流程2. 模型选取的和数据集2.1.ARIMA模型2.2.数据集介绍 3.时间序列建模3.1.数据获取3.2.处理数据中的异常值3.2.1.Nan值3.2.2.异常值的检测和处理(Z-Score方法) 3.3.离散度3.4.Z-Score3.4.1.概述3.4.2.公式3.4.3.Z-Score与…...

【工作记录】Kong Gateway入门篇之简介
1. 什么是 Kong Gateway? Kong Gateway 是一个开源的、云原生的 API 网关,专为现代微服务架构设计。它基于 Nginx 和 Lua 构建,提供了高性能、可扩展的 API 管理解决方案。Kong Gateway 不仅能够处理 API 请求的路由和负载均衡,还…...

华为鸿蒙电脑能否作为开发机?开发非鸿蒙应用?
目录 一、鸿蒙电脑作为开发机的核心能力1. 硬件与系统架构2. 开发工具链支持 二、开发非鸿蒙应用的可行性分析1. 适配优势与局限性2. 生态限制 三、鸿蒙电脑的核心适用场景1. 推荐开发场景2. 目标用户群体3. 非推荐场景 四、未来生态演进与战略意义五、总结 一、鸿蒙电脑作为开…...

jackson-dataformat-xml引入使用后,响应体全是xml
解决方案: https://spring.io/blog/2013/05/11/content-negotiation-using-spring-mvc import org.springframework.context.annotation.Configuration; import org.springframework.http.MediaType; import org.springframework.web.servlet.config.annotation.Con…...

【deekseek】TCP Offload Engine
是的,TOE(TCP Offload Engine)通过专用硬件电路(如ASIC或FPGA)完整实现了TCP/IP协议栈,将原本由CPU软件处理的协议计算任务完全转移到网卡硬件中。其延迟极低的核心原因在于 硬件并行性、零拷贝架构 和 绕过…...