时间序列预测建模的完整流程以及数据分析【学习记录】
文章目录
- 1.时间序列建模的完整流程
- 2. 模型选取的和数据集
- 2.1.ARIMA模型
- 2.2.数据集介绍
- 3.时间序列建模
- 3.1.数据获取
- 3.2.处理数据中的异常值
- 3.2.1.Nan值
- 3.2.2.异常值的检测和处理(Z-Score方法)
- 3.3.离散度
- 3.4.Z-Score
- 3.4.1.概述
- 3.4.2.公式
- 3.4.3.Z-Score与标准差
- 3.4.4.Z-Score与数据标准化
- 3.4.5.欧几里得距离
- 4.数据分析
- 4.1.重置DateFrame类型数据索引
- 4.2.数据可视化
- 4.2.Python 库 – statsmodels
- 4.2.3.特性
- 4.2.4.基本功能
- 4.2.5.高级功能
- 4.2.6.实际应用
- 4.3.趋势性分析
- 4.4.季节性分析
- 4.5.周期性分析
- 4.6.整合图
- 4.7. ACF和PACF
- 4.8.平稳性检验
- 5.模型训练
- 6.Python库 – pdmarima
- 6.1.主要功能
- 6.2.基本用法
- 6.3.高级用法
- 7.ARIMA模型分析流程
1.时间序列建模的完整流程
-
数据收集:
首先收集时间序列数据。这些数据应该是按时间顺序排列的连续观察值(数据的时间不连续可以么,是不可以如果有这种不连续的情况,建议提高时间单位从而避免这个情况)。
-
数据预处理:
数据清洗:处理缺失值。
异常值数据转换:如对数转换,归一化等,以稳定数据的方差(此处应该是两部分包括异常值检测和异常值处理)。 -
数据分析:分析数据的特征,如季节性、趋势、周期性等,这一步是重要的你的模型的效果好坏可能百分之60来源于模型,另外的百分之40就来源于这一步。
-
模型选择:
可以选择的模型包括ARIMA(自回归积分滑动平均模型)、季节性ARIMA、指数平滑、Prophet模型、机器学习模型等。
还可以使用深度学习方法,如循环神经网络(RNN)、长短期记忆网络(LSTM)。
同时还有这两年比较流行的Transformer模型,此方法适合想要发论文的同学。 -
划分数据集:将数据集划分为测试集验证集训练集
-
模型训练:使用训练数据集来训练选定的模型。
-
模型评估:
在测试集上评估模型性能。
常用的评估指标包括均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)等。 -
参数调优:根据模型在测试集上的表现调整参数,以提高预测准确性。
2. 模型选取的和数据集
2.1.ARIMA模型
ARIMA模型对于参数的设定是十分敏感的,不同的参选择效果可能差异很大
2.2.数据集介绍
一个股票数据集,从2016-01-04开始到2018-12-28,每天采集一次数据,中间时期有缺失值
(PS:electricity数据集是平稳的)
3.时间序列建模
3.1.数据获取
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_16:37
@FileName:1获取数据.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd"""
pd.read_csv()读取.csv文件,并将其加载到一个Pandas DateFrame中
index_col=['date']:指定date列作为DateFrame的索引
parse_dates=['date']:将date列解析为日期时间格式,如果不指定这一参数,date列将被视为普通的字符串
"""
data = pd.read_csv(r"E:\07-code\time_series_study\data\traffic.csv", index_col=['date'], parse_dates=['date'])
print(data.index)
print(data)
3.2.处理数据中的异常值
3.2.1.Nan值
"""
@Author: zhang_zhiyi
@Date: 2024/7/3_17:26
@FileName:2处理数据中的Nan值.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np
import pandas as pddata_dict = {'Date': pd.date_range(start='2023-01-01', periods=10, freq='D'),'Volume': [100, np.nan, 200, 300, np.nan, 400, 500, np.nan, 600, 700]
}
data = pd.DataFrame(data_dict).set_index('Date')
"""Volume
Date
2023-01-01 100.0
2023-01-02 NaN
2023-01-03 200.0
2023-01-04 300.0
2023-01-05 NaN
2023-01-06 400.0
2023-01-07 500.0
2023-01-08 NaN
2023-01-09 600.0
2023-01-10 700.0
"""
print(data.to_string())"""
data['Volume']: 选择 data DataFrame 中的 Volume 列
.rolling(window=5, min_periods=1): 创建一个滑动窗口对象,该对象将在 Volume 列上滑动。window=5 指定窗口大小为 5(即计算每个位置的前 5 个值的平均值)min_periods=1 指定窗口中至少有 1 个非 NaN 值时才计算平均值
.mean(): 计算每个滑动窗口的平均值,返回一个与 Volume 列大小相同的 Series,对应位置的值为该位置滑动窗口内的平均值。
"""
moving_avg = data['Volume'].rolling(window=5, min_periods=1).mean()
"""
Date
2023-01-01 100.0
2023-01-02 100.0
2023-01-03 150.0
2023-01-04 200.0
2023-01-05 200.0
2023-01-06 300.0
2023-01-07 350.0
2023-01-08 400.0
2023-01-09 500.0
2023-01-10 550.0
"""
print(moving_avg)# Fill NA/NaN values using the specified method.
# dict/Series/DataFrame, This value cannot be a list.
data['Volume'] = data['Volume'].fillna(moving_avg)
"""Volume
Date
2023-01-01 100.0
2023-01-02 100.0
2023-01-03 200.0
2023-01-04 300.0
2023-01-05 200.0
2023-01-06 400.0
2023-01-07 500.0
2023-01-08 400.0
2023-01-09 600.0
2023-01-10 700.0
"""
print(data.to_string())print("---traffic数据集---")
re_data = pd.read_csv(r'E:\07-code\time_series_study\data\exchange_rate_test.csv', index_col=['date'], parse_dates=['date'])
print("原始数据:")
# print(tr_data)
moving_avg = re_data['OT'].rolling(window=5, min_periods=1).mean()
print("移动平均值:")
print(moving_avg)
re_data['OT'] = re_data['OT'].fillna(moving_avg)
print("去Nan值后的数据:")
# print(tr_data)
print("over")3.2.2.异常值的检测和处理(Z-Score方法)
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_8:58
@FileName:3检查和处理异常值.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
# 示例
# TODO:1.模拟数据
"""
pd.date_range 函数中的 freq 参数用于指定日期范围的频率。它决定了生成的日期索引之间的时间间隔。常用的频率选项包括日、月、年等。
"""
data = {'date': pd.date_range(start='2024-07-04', periods=10, freq='D'),'Volume': [100, 200, 300, 400, 500, 600, 700, 800, 900, 1000]
}
data = pd.DataFrame(data=data).set_index('date')
# 引入一些异常值
"""
loc():Access a group of rows and columns by label(s) or a boolean array.
data.loc[...]:这是 Pandas 的 loc 索引器,用于按标签选择数据。.loc[] is primarily label based, but may also be used with a boolean array.data.loc['2023-07-06', 'Volume']:选择 2023-07-06 这一天的 Volume 列。
"""
data.loc['2024-07-06', 'Volume'] = 5000
data.loc['2024-07-11', 'Volume'] = -2000
# 打印原始数据
print("原始数据:")
print(data.to_string())# TODO:2.计算激动平均值、Z-Score
# 计算移动平均值
data['moving_average'] = data['Volume'].rolling(window=5, min_periods=1).mean()
# 计算Z-Score
data['Z-Score'] = (data['Volume'] - data['Volume'].mean()) / data['Volume'].std()
"""
.abs()取绝对值
"""
# 输出data['Z-Score']的绝对值
print("data['Z-Score']的绝对值:")
print(data['Z-Score'].abs())# TODO:3.检查并处理异常值
# 将异常值替换为移动平均值
data.loc[data['Z-Score'].abs() > 1.5, 'Volume'] = data['moving_average']
# 打印处理后的数据
print("处理后的数据:")
print(data.to_string())# 真实数据示例
# TODO:1.获取数据
data = pd.read_csv(r"E:\07-code\time_series_study\data\exchange_rate_test.csv",index_col=['date'],parse_dates=['date']
)
# TODO:2.计算移动平均值和Z-Score
# 假设 data 是你的 DataFrame,column_name 是需要处理的列名
data['moving_avg'] = data['OT'].rolling(window=5, min_periods=1).mean()# 计算 Z-Score
data['z-score'] = (data['OT'] - data['OT'].mean()) / data['OT'].std()# TODO:3.检测并处理异常值
# 将异常值替换为移动平均值
data.loc[data['z-score'].abs() > 1.5, 'OT'] = data['moving_avg']
print()3.3.离散度
离散度的评价方法:
-
极差
最大值-最小值
-
离均差平方和
离均差是数据与均值之差,为了避免正负问题:绝对值、平方,为了避免符号问题最常用的就是平方
-
方差
由于离均差的平方和与样本个数有关,只能反映相同样本的离散度,而实际工作中做比较很难做到相同的样本,因此为了消除样本个数的影响,增加可比性,将离均差的平方和求平均值,这就是我们所说的方差成了评价离散度的较好指标。
-
标准差
由于方差是数据的平方,与检测值本身相差太大,人们难以直观的衡量,所以常用**方差开根号**换算回来这就是我们要说的标准差。
-
变异系数
3.4.Z-Score
3.4.1.概述
z-score 也叫 standard score, 用于评估样本点到总体均值的距离。z-score主要的应用是测量原始数据与数据总体均值相差多少个标准差。
z-score是比较测试结果与正常结果的一种方法。测试与调查的结果往往有不同的单位和意义,简单地从结果本身来看可能毫无意义。当我们知道小明数学考了90分(满分100),我们也许会认为这是一个好消息,但是如果我们拿小明的成绩与班上平均成绩相比较,我们也许会深感惋惜。z-score可以告诉我们小明数学成绩和总体数学平均成绩的比值。
3.4.2.公式
Z-Score 公式:单个样本的情况:
z = x − μ σ z=\frac{x-\mu}{\sigma} z=σx−μ
例如:小明的数学成绩是90,班级的数学平均成绩为95,标准差为2,此时对于此例中的z score为:
z = x − μ σ = 90 − 95 2 = − 2.5 z = \frac{x-\mu}{\sigma}=\frac{90-95}{2}=-2.5 z=σx−μ=290−95=−2.5
z score告诉我们这个分数距离平均分数相差几个标准差。此例中,小明的数学分数低于班级平均分数2.5个标准差。
当我们不知道数据总体的μ和σ ,我们可以使用样本均值和样本标准差 ,此时我们可以用下式精确地表示式:
z i = x i − x ‾ S z_i=\frac{x_i-\overline{x}}{S} zi=Sxi−x
Z-Score 公式:均值的标准误差:
如果我们有多个样本,并且想知道这些样本均值与总体均值距离多少个标准差,可以使用此公式:
z = x ‾ − μ σ ÷ n z=\frac{\overline{x}-\mu}{\sigma\div\sqrt{n}} z=σ÷nx−μ
例如:考过这张数学卷子的人的平均成绩为80,标准差为15。那么对于包括小明等40位同学所在的班级来说:
z = x ‾ − μ σ ÷ n = 95 − 80 15 ÷ 40 = 6.3 z=\frac{\overline{x}-\mu}{\sigma\div\sqrt{n}}=\frac{95-80}{15\div\sqrt{40}}=6.3 z=σ÷nx−μ=15÷4095−80=6.3
3.4.3.Z-Score与标准差
Z-Score表示抽样样本值与数据均值相差标准差的数目。举个例子:
- z-score = 1 意味着样本值超过均值 1 个标准差;
- z-score = 2 意味着样本值超过均值 2 个标准差;
- z-score = -1.8 意味着样本值低于均值 1.8 个标准差。
Z-Score告诉我们样本值在正态分布曲线中所处的位置。Z-Score = 0告诉我们该样本正好位于均值处,Z-Score = 3 则告诉我们样本值远高于均值。
3.4.4.Z-Score与数据标准化
Z-Score是一个经常被用于数据标准化的方法。在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的数量级和单位,如果直接利用原始数据,就会突出数值较高的指标在分析中的作用,相对弱化数值较低指标的作用。因此,为了保证结果的可靠性,需要对原始数据进行标准化。
通过Z-Score 公式进行标准化(或者规范化):
z = x − μ σ z=\frac{x-\mu}{\sigma} z=σx−μ
其中:
- z是规范化后的值(也称为z分数或者标准分数)
- x是原始数据
- μ是原始数据的均值
- σ是原始数据集的标准差
Z-Score标准化的目的:
Z-score规范化的原理基于统计学中的标准分数概念。它的主要目的是将原始数据转换成一个标准的尺度,以便进行比较和分析。
- **中心化:**Z-score规范化通过从每个原始数据点中减去数据集的均值(μ),将数据的中心移动到零点。这一步是为了消除数据的原始均值对分析结果的影响,使得新的数据集具有零均值。
- **缩放尺度:**除了中心化之外,Z-score规范化还通过将中心化后的每个数据点除以数据集的标准差(σ),将数据缩放到相同的尺度。这一步是为了消除数据的尺度(或单位)差异,使得不同特征或不同数据集之间的比较更加公平和有意义。
通过这两步操作,原始数据被转换为一个具有零均值和单位方差的新数据集。这个过程也叫做标准化,得到的数据被称为标准分数或Z分数。
Z-score规范化的主要优点包括:
- **尺度不变形:**规范化后的数据具有相同的尺度,这使得不同特征之间的比较更加公平。
- **中心化:**数据被中心化到均值为0,这有助于某些机器学习算法(如支持向量机和逻辑回归)的性能和稳定性。
- **保持数据分布:**Z-score规范化不会改变数据的分布形状。如果原始数据近似正态分布,那么规范化后的数据将具有均值为0和标准差为1,但仍然保持其原有的分布形状。
- **距离解释性:**在规范化后的空间中,欧几里得距离可以解释为标准差的倍数,这有助于理解数据点之间的相对距离。
在实际应用中,Z-score规范化广泛应用于机器学习和数据分析领域,特别是当算法对数据的尺度和分布敏感时。例如,支持向量机(SVM)和K-均值聚类等算法在处理具有相同尺度的数据时表现更好。
此外,Z-score规范化也有助于提高梯度下降等优化算法的收敛速度。
3.4.5.欧几里得距离
欧几里得距离(Euclidean distance)是在数学中常用于衡量两个点之间的距离的一种方法。它在几何学和机器学习等领域都有广泛的应用。欧几里得距离基于两点之间的直线距离,可以看作是在一个多维空间中测量两个点之间的直线距离。
4.数据分析
分析数据的特征,如季节性、趋势、周期性等(这一步是重要的,模型的效果好坏可能百分之60来源于模型,另外的百分之40就来源于数据分析)。
4.1.重置DateFrame类型数据索引
import pandas as pddata = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)
# 重置索引,创建一个新的整数索引
"""
pandas.DataFrame.reset_index:Reset the index, or a level of it.set the index of the DataFrame, and use the default one instead. If the DataFrame has a MultiIndex, this method can remove one or more levels.
参数:drop: bool, default FalseDo not try to insert index into dataframe columns. This resets the index to the default integer index."""
data = data.reset_index(drop=True)# 重置索引,创建一个新的整数索引
data = data.reset_index(drop=True)
4.2.数据可视化
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_10:55
@FileName:4数据分析-数据可视化.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
from matplotlib import pyplot as pltfrom statsmodels.tsa.seasonal import seasonal_decomposedata_name = 'zgpa_train'# 获取数据
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,创建一个新的整数索引
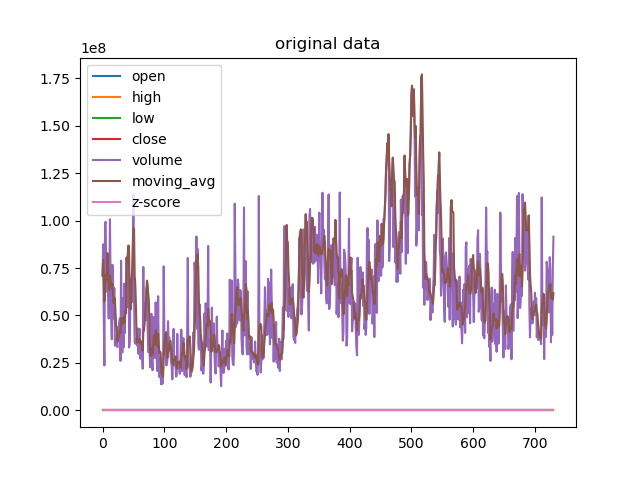
data = data.reset_index(drop=True)data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()data['volume'] = data['volume'].fillna(data['moving_avg'])data['z-score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()data.loc[data['z-score'].abs() > 1.5, 'volume'] = data['moving_avg']# 可视化原始数据
data.plot()
plt.title('original data')
"""
plt.tight_layout() 是 Matplotlib 库中的一个方法,用于自动调整子图参数,以便让子图、轴标签、标题和刻度标签更好地适应图形区域。其目的是解决默认情况下子图可能会重叠或布局不佳的问题。
"""
plt.tight_layout()
plt.savefig(fr'E:\07-code\time_series_study\data\{data_name}_visual.png')
plt.show()
4.2.Python 库 – statsmodels
Python statsmodels是一个强大的统计分析库,提供了丰富的统计模型和数据处理功能,可用于数据分析、预测建模等多个领域。本文将介绍statsmodels库的安装、特性、基本功能、高级功能、实际应用场景等方面。
安装statsmodels库非常简单,可以使用pip命令进行安装:
pip install statsmodels
4.2.3.特性
- 提供了多种统计模型:包括线性回归、时间序列分析、广义线性模型等多种统计模型。
- 数据探索和可视化:提供了丰富的数据探索和可视化工具,如散点图、箱线图、直方图等。
- 假设检验和统计推断:支持各种假设检验和统计推断,如t检验、方差分析等。
4.2.4.基本功能
-
线性回归分析
Python statsmodels库可以进行线性回归分析,通过最小二乘法拟合数据,得到回归系数和模型评估指标。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:44 @FileName:5数据分析-statsmodels库-线性回归分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import statsmodels.api as sm import numpy as np# 构造数据 x = np.array([1, 2, 3, 4, 5]) y = np.array([2, 3, 4, 5, 6])# 添加常数项 X = sm.add_constant(x)# 拟合线性回归模型 model = sm.OLS(y, X) results = model.fit()# 打印回归系数和模型评估指标 print(results.summary()) -
时间序列分析
Python statsmodels库支持时间序列分析,包括ADF检验、ARIMA模型等功能,可用于时间序列数据的预测和建模。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:53 @FileName:5数据分析-statsmodels库-时间序列分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import numpy as np import pandas as pd import statsmodels.api as sm# 构造时间序列数据 dates = pd.date_range('2020-01-01', periods=100) data = pd.DataFrame(np.random.randn(100, 2), index=dates, columns=['A', 'B'])# 进行时间序列分析 model = sm.tsa.ARIMA(data['A'], order=(1, 1, 1)) results = model.fit()# 打印模型预测结果 print(results.summary())
4.2.5.高级功能
-
多元线性回归分析
Python statsmodels库支持多元线性回归分析,可以处理多个自变量和响应变量的回归分析问题。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:55 @FileName:5数据分析-statsmodels-多元线性回归分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import statsmodels.api as sm import numpy as np# 构造数据 X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) y = np.array([2, 3, 4, 5])# 添加常数项 X = sm.add_constant(X)# 拟合多元线性回归模型 model = sm.OLS(y, X) results = model.fit()# 打印回归系数和模型评估指标 print(results.summary()) -
时间序列预测
Python statsmodels库可以进行时间序列预测,通过历史数据构建模型,并预测未来的数据趋势。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:56 @FileName:5数据分析-statusmodels-时间序列预测.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import numpy as np import pandas as pd import statsmodels.api as sm# 构造时间序列数据 dates = pd.date_range('2020-01-01', periods=100) data = pd.DataFrame(np.random.randn(100, 2), index=dates, columns=['A', 'B'])# 进行时间序列预测 model = sm.tsa.ARIMA(data['A'], order=(1, 1, 1)) results = model.fit()# 预测未来数据 forecast = results.forecast(steps=10) print(forecast)
4.2.6.实际应用
Python statsmodels库在实际应用中有着广泛的用途,特别是在数据分析、金融建模、经济学研究等领域,可以帮助分析师和研究人员进行数据探索、模型建立和预测分析。
-
数据探索和可视化
在数据分析过程中,经常需要对数据进行探索性分析和可视化,以便更好地理解数据的特征和关系。
""" @Author: zhang_zhiyi @Date: 2024/7/4_11:58 @FileName:5数据分析-statusmodels-数据探索和可视化.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import pandas as pd import statsmodels.api as sm import matplotlib.pyplot as plt# 导入数据 data = pd.read_csv(r'E:\07-code\time_series_study\data\electricity_test.csv')# 数据探索 print(data.head()) print(data.describe())# 绘制散点图 plt.scatter(data['date'], data['OT']) plt.xlabel('X') plt.ylabel('Y') plt.title('Scatter Plot') plt.show() -
时间序列分析
在金融领域和经济学研究中,时间序列分析是一项重要的工作,可以用来分析和预测时间序列数据的趋势和周期性。
""" @Author: zhang_zhiyi @Date: 2024/7/4_12:01 @FileName:5数据分析-statusmodels-时间序列分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import pandas as pd import statsmodels.api as sm# 导入时间序列数据 data = pd.read_csv(r'E:\07-code\time_series_study\data\electricity_test.csv', parse_dates=['date'], index_col='date')# 进行时间序列分析 model = sm.tsa.ARIMA(data['OT'], order=(1, 1, 1)) results = model.fit()# 打印模型预测结果 print(results.summary())# 预测未来数据 forecast = results.forecast(steps=10) print(forecast) -
回归分析
在经济学研究和社会科学领域,回归分析是常用的方法之一,可以用来研究变量之间的关系和影响因素。
""" @Author: zhang_zhiyi @Date: 2024/7/4_12:03 @FileName:5数据分析-statusmodels-回归分析.py @LastEditors: zhang_zhiyi @version: 1.0 @lastEditTime: @Description: """ import pandas as pd import statsmodels.api as sm# 导入数据 data = pd.read_csv('regression_data.csv')# 进行线性回归分析 X = data[['X1', 'X2']] y = data['Y'] X = sm.add_constant(X)model = sm.OLS(y, X) results = model.fit()# 打印回归系数和模型评估指标 print(results.summary())
4.3.趋势性分析
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_11:42
@FileName:6数据分析-趋势性分析.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
from matplotlib import pyplot as pltfrom statsmodels.tsa.seasonal import seasonal_decomposedata_name = 'zgpa_train'# 获取数据
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,创建一个新的整数索引
data = data.reset_index(drop=True)data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()data['volume'] = data['volume'].fillna(data['moving_avg'])data['z-score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()data.loc[data['z-score'].abs() > 1.5, 'volume'] = data['moving_avg']# 趋势分析
"""
model : {"additive", "multiplicative"}, optionalType of seasonal component. Abbreviations are accepted.
"""
# 或者model='additive'取决于数据
# decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
trend = decomposition.trend
trend.plot()
plt.title('trend')
plt.tight_layout()
plt.savefig(fr'E:\07-code\time_series_study\data\{data_name}_trend.png')
plt.show()
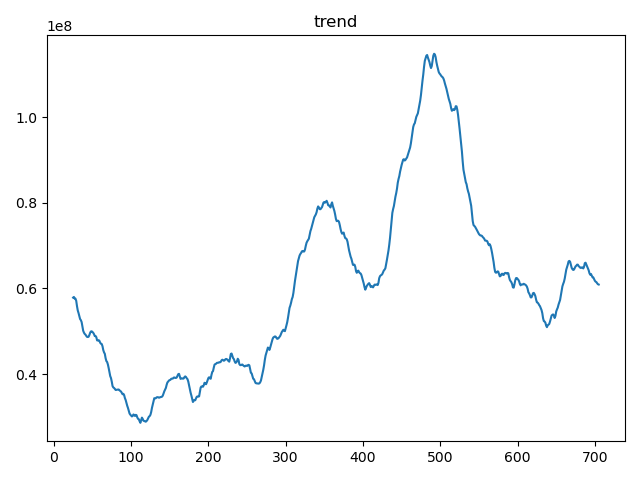
小结:
从这张趋势图上其中显示数据存在波动,有局部上升趋势,但整体相对稳定。我们看到数据点在某个水平线附近上下波动,这可能表示一个周期性的波动模式,而不是线性或单调的趋势。
4.4.季节性分析
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_14:15
@FileName:7数据分析-季节性分析.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import osimport pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose# TODO:1.获取数据
data_name = 'zgpa_train'
output_path = r'E:\07-code\time_series_study\data'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,创建一个新的整数索引
data = data.reset_index(drop=True)# TODO:2.处理异常值
# 获取移动平均值
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
# 处理Nan值
data['volume'] = data['volume'].fillna(data['moving_avg'])
# 根据Z-Score处理异常值
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# TODO:3.季节性分析
# 季节性分析
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
seasonal = decomposition.seasonal
seasonal.plot()
plt.title('season')
plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name) + '_season.png')
plt.show()
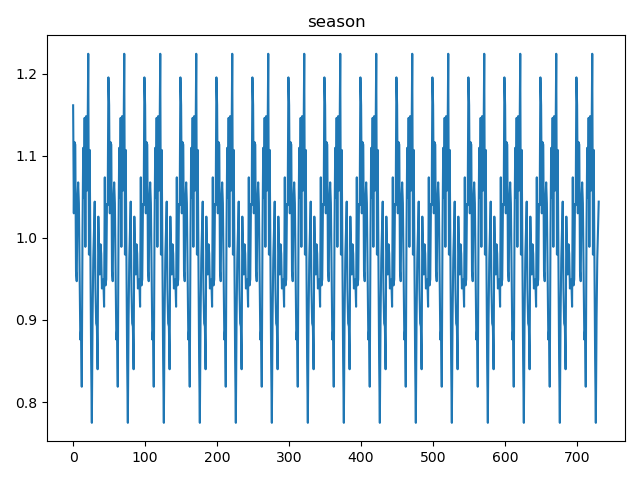
小结:
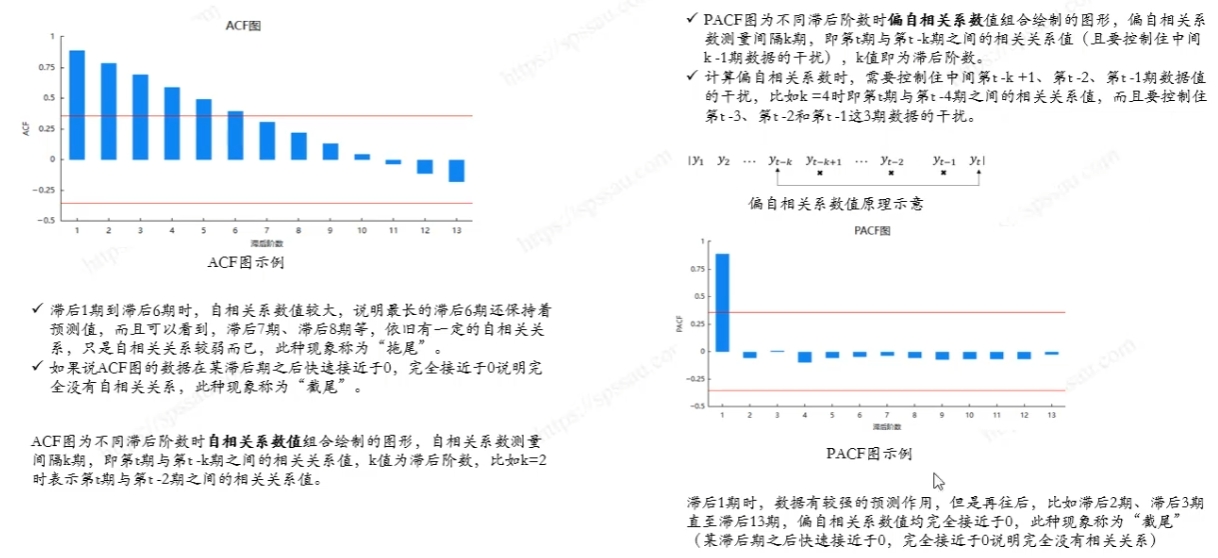
基于季节性分量图像,我们可以使用横坐标的数字来估计一个季节周期。通常,一个季节周期是指从一个峰值到下一个相同峰值的距离,或者从一个谷值到下一个相同谷值的距离。
通过观察季节性分量图像,我们可以估计:
- 从一个峰值到下一个峰值(或谷值到谷值)的距离看起来相对一致。
- 如果我们可以从图像上精确读取两个相邻峰值或谷值的横坐标值,就可以通过它们的差来估算周期长度。
通过图例可以看出季节周期大约为50个数据点**(这里设置的period=50,好像是有关系的?)**
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
4.5.周期性分析
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_15:18
@FileName:8数据分析-周期性分析.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import osimport pandas as pd
from matplotlib import pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose# TODO:1.获取数据
data_name = 'zgpa_train'
output_path = r'E:\07-code\time_series_study\data'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv',index_col=['date'],parse_dates=['date']
)# 重置索引,创建一个新的整数索引
data = data.reset_index(drop=True)# TODO:2.处理异常值
# 获取移动平均值
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
# 处理Nan值
data['volume'] = data['volume'].fillna(data['moving_avg'])
# 根据Z-Score处理异常值
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# 确保数据没有缺失值
# data['volume'] = data['volume'].fillna(method='ffill').fillna(method='bfill')# TODO:3.周期性分析
# 周期性分析(残差)
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50)
residual = decomposition.resid
residual.plot()
plt.title('Periodicity (residual)')
plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name + '_residual.png'))
plt.show()
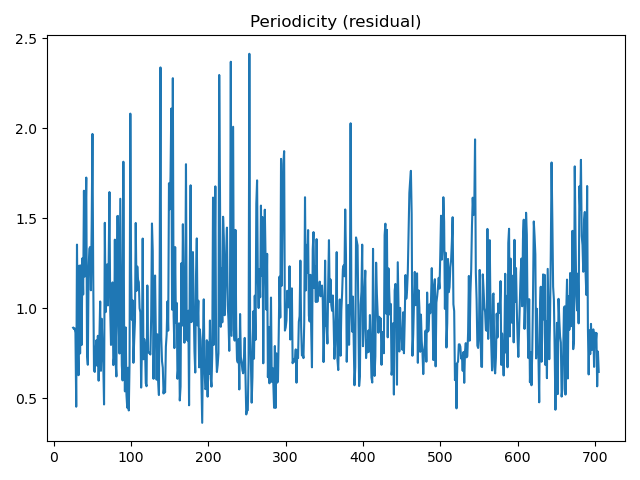
小结:
周期性残差的波动表明除了季节性之外,可能还存在其他非固定周期的影响因素,这些可能是因为其他因素引起的所以我们最好可以增加一些其它变量。
4.6.整合图
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_17:25
@FileName:9数据分析-整合图例.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import os
import pandas as pdfrom matplotlib import pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose# TODO:1.获取数据
output_path = r'E:\07-code\time_series_study\data'
data_name = 'zgpa_train'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv', index_col=['date'], parse_dates=['date'])
data = data.reset_index(drop=True)
# TODO:2.去除异常数据
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']
# TODO:3.数据分析
result = seasonal_decompose(data['volume'], model='multiplicative', period=50)result.plot()
plt.title(f"{data_name} Data Analysis Result")
plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name) + "_seasonal_decompose.png")
plt.show()

4.7. ACF和PACF
ACF和PACF的概念理解见7.ARIMA模型分析流程
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_17:50
@FileName:10ACF和PACF.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description: 自相关和偏自相关图
"""
import os
import pandas as pd
from matplotlib import pyplot as plt
import statsmodels.api as sm# TODO:1.获取数据
output_path = r'E:\07-code\time_series_study\data'
data_name = 'zgpa_train'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv', index_col=['date'], parse_dates=['date'])
data = data.reset_index(drop=True)# TODO:2.去除异常数据
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# TODO:3.自相关和偏自相关
# 自相关和偏自相关图
fig, ax = plt.subplots(2, 1, figsize=(12,8))
sm.graphics.tsa.plot_acf(data['volume'].dropna(), lags=40, ax=ax[0])
sm.graphics.tsa.plot_pacf(data['volume'].dropna(), lags=40, ax=ax[1])plt.tight_layout()
plt.savefig(os.path.join(output_path, data_name) + '_ACK_PACK')
plt.show()
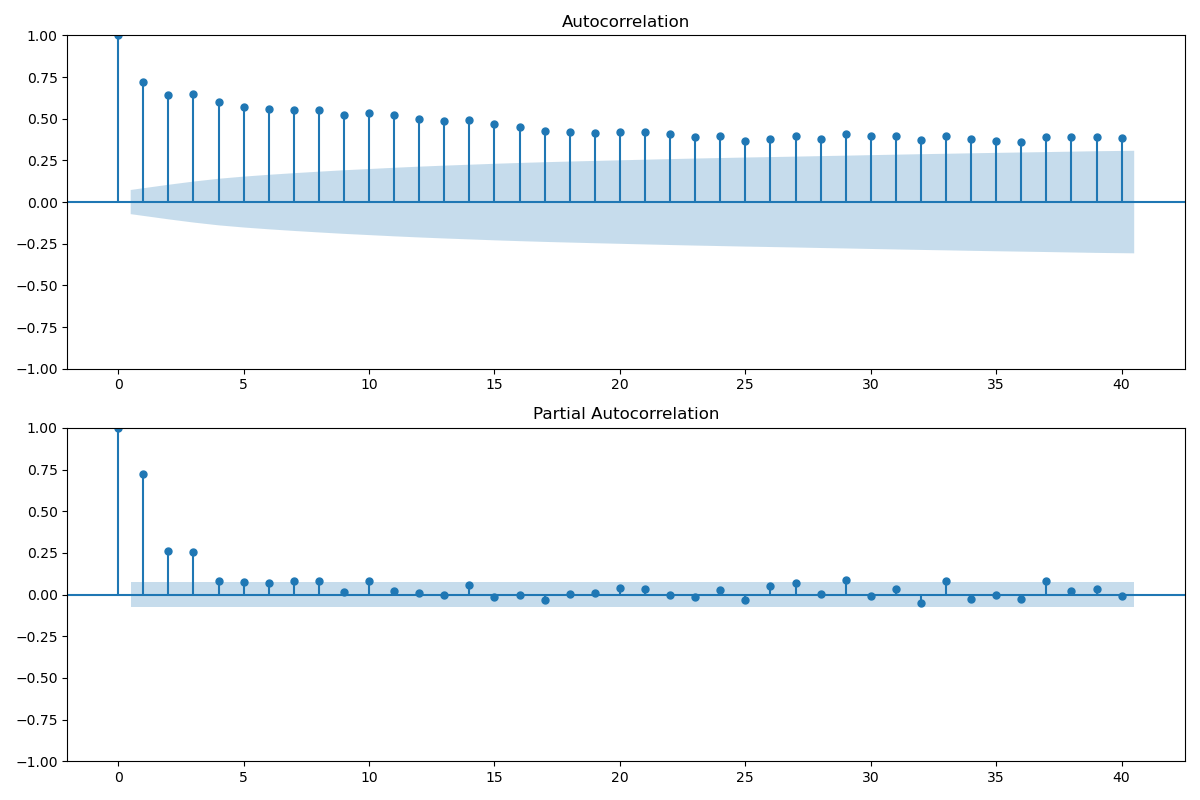
ACK:
PACK:
- PACF 图在第一个滞后处显示了一个显著的尖峰,之后迅速下降至不显著,这是典型的AR(1)过程的特征,意味着一个数据点主要受到它前一个数据点的影响。
- 在第一滞后之后,大多数滞后的PACF值都不显著(即在蓝色置信区间内),这表明一个阶的自回归模型可能足以捕捉时间序列的相关结构。
4.8.平稳性检验
Augmented Dickey-Fuller (ADF) 测试的结果提供了是否拒绝时间序列具有单位根的依据,即时间序列是否是非平稳的。ADF测试的两个关键输出是:
- ADF 统计量:这是一个负数,它越小,越有可能拒绝单位根的存在。
- p-值:如果p-值低于给定的显著性水平(通常为0.05或0.01),则拒绝单位根的假设,表明时间序列是平稳的。
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_17:59
@FileName:11平稳性检测.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import pandas as pd
from statsmodels.tsa.stattools import adfuller# TODO:1.获取数据
output_path = r'E:\07-code\time_series_study\data'
data_name = 'zgpa_train'
data = pd.read_csv(r'E:\07-code\time_series_study\data\zgpa_train.csv', index_col=['date'], parse_dates=['date'])
data = data.reset_index(drop=True)# TODO:2.去除异常数据
data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])
data['Z-Score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.loc[data['Z-Score'].abs() > 1.5, 'volume'] = data['moving_avg']# TODO:3.平稳性检测
# 平稳性检测
adf_test = adfuller(data['volume'])
print('ADF 统计量: ', adf_test[0])
print('p-值: ', adf_test[1])
小结:
如上图所示:
ADF统计量为:-3.1400413587267337
p-值为:0.023728394879258534
由于p-值介于0.01和0.05之间,说明我们不足以拒绝单位根的存在,所以数据可能是非平稳的,这意味着时间序列数据中可能存在随时间变化的趋势或者季节性成分,需要通过适当变换(如差分)去除
备注:
平稳的时序数据适合使用ARIMA或类似的自回归模型来进行建模和预测。
(PS:electricity数据集是平稳的,但是数据量有些大)
5.模型训练
以ARIMA模型为例
"""
@Author: zhang_zhiyi
@Date: 2024/7/4_18:12
@FileName:12模型训练.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description: 以ARIMA模型为例
"""
from math import sqrt
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from pmdarima import auto_arima
from sklearn.metrics import mean_squared_error
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import adfullerdata = pd.read_csv(r"E:\07-code\time_series_study\data\zgpa_train.csv", index_col=['date'], parse_dates=['date'])data = data.reset_index(drop=True)data['moving_avg'] = data['volume'].rolling(window=5, min_periods=1).mean()
data['volume'] = data['volume'].fillna(data['moving_avg'])# 计算 Z-Score
data['z_score'] = (data['volume'] - data['volume'].mean()) / data['volume'].std()
data.reset_index(drop=True, inplace=True)
# 将异常值替换为移动平均值
data.loc[data['z_score'].abs() > 1.5, 'volume'] = data['moving_avg']# 可视化原始数据
data.plot()
plt.title('original data')
plt.tight_layout()
plt.show()# 趋势分析
decomposition = seasonal_decompose(data['volume'], model='multiplicative', period=50) # 或者model='multiplicative'取决于数据
trend = decomposition.trend
trend.plot()
plt.title('trend')
plt.tight_layout()
plt.show()# 季节性分析
seasonal = decomposition.seasonal
seasonal.plot()
plt.title('season')
plt.tight_layout()
plt.show()# 周期性分析(残差)
residual = decomposition.resid
residual.plot()
plt.title('Periodicity (residual)')
plt.tight_layout()
plt.show()# 自相关和偏自相关图
fig, ax = plt.subplots(2, 1, figsize=(12, 8))
sm.graphics.tsa.plot_acf(data['volume'].dropna(), lags=40, ax=ax[0])
sm.graphics.tsa.plot_pacf(data['volume'].dropna(), lags=40, ax=ax[1])
plt.show()# 平稳性检测
adf_test = adfuller(data['volume'])
print('ADF 统计量: ', adf_test[0])
print('p-值: ', adf_test[1])# 划分数据集
train_ds = data['volume'][:int(0.9 * len(data))]
test_ds = data['volume'][-int(0.1 * len(data)):]# 将从上面分析过来的结果输入的auto_arima里面进行模型的拟合
model = auto_arima(train_ds, trace=True, error_action='ignore', suppress_warnings=True, seasonal=True, m=50,stationary=False, D=2)model.fit(train_ds)
forcast = model.predict(n_periods=len(test_ds))
# forcast = pd.DataFrame(forcast, index=test_ds.index, columns=['Prediction'])rms = sqrt(mean_squared_error(test_ds, forcast))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(15, 7))
# plt.figure('Forecast')
plt.title("forecast value as real")
plt.plot(range(len(train_ds)), train_ds, label='Train')
plt.plot(range(len(train_ds), len(train_ds) + len(test_ds)), test_ds.values, label='Test')
plt.plot(range(len(train_ds), len(train_ds) + len(test_ds)), forcast.values, label='Prediction')
plt.legend()
plt.tight_layout()
plt.show()
6.Python库 – pdmarima
pmdarima 是一个 Python 库,全名是 “Python AutoRegressive Integrated Moving Average (ARIMA)(自回归整合滑动平均)” 模型的封装库。它构建在 statsmodels 和 scikit-learn 的基础上,并提供了一种简单而强大的方式来选择和拟合时间序列模型。
6.1.主要功能
- 自动模型选择:pmdarima 可以自动选择合适的 ARIMA 模型,无需手动调整超参数。这减少了时间序列建模的繁琐性。
- 模型拟合:一旦选择了模型,pmdarima 可以对时间序列数据进行拟合,并提供有关拟合质量的信息。
- 季节性分解:pmdarima 允许对具有季节性成分的时间序列进行分解,以更好地理解数据。
- 交叉验证:您可以使用交叉验证来评估模型的性能,以确保模型对未来数据的泛化效果。
- 可视化工具:pmdarima 提供了可视化工具,帮助您直观地了解模型的性能和预测结果。
6.2.基本用法
"""
@Author: zhang_zhiyi
@Date: 2024/7/5_9:25
@FileName:13pmdarima库-基础用法.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np
from pmdarima import auto_arima
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体为SimHei
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# TODO:1.pmdarima的基本用法
# 生成一个时序数据
np.random.seed(0)
data = np.random.randn(100) # 100个数据点的时间序列# print("原始数据:")
# print(data)# 使用auto_arima选择ARIMA模型, pmdarima 自动选择了适合数据的 ARIMA 模型,并返回了拟合的模型对象。
model = auto_arima(data, seasonal=True, m=12) # 带季节性的 ARIMA 模型,季节周期为12# 预测未来12个时间点的值
"""
def predict(self,n_periods=10,X=None,return_conf_int=False,alpha=0.05,
)
Parameters:n_periods : int, optional (default=10) The number of periods in the future to forecast.X : array-like, shape=[n_obs, n_vars], optional (default=None) An optional 2-d array of exogenous variables. return_conf_int : bool, optional (default=False) Whether to get the confidence intervals of the forecasts.alpha : float, optional (default=0.05) The confidence intervals for the forecasts are (1 - alpha) %
Return:forecasts : array-like, shape=(n_periods,) The array of fore-casted values.conf_int : array-like, shape=(n_periods, 2), optional The confidence intervals for the forecasts. Only returned if return_conf_int is True.
"""
# forecast 变量包含了未来时间点的预测值,而 conf_int 变量包含了置信区间。
forecast, conf_int = model.predict(n_periods=12, return_conf_int=True)
print('conf_int:', conf_int)
print('conf_int[:, 0]:', conf_int[:, 0])
print('conf_int[:, 1]:', conf_int[:, 1])
# print("预测数据:")
# print(forcast)
# print(conf_int)# 可视化预测结果
plt.plot(data, label='观测数据')
plt.plot(range(len(data), len(data) + len(forecast)), forecast, label='预测值', color='red')
"""matplotlib.pyplot.fill_between Fill the area between two horizontal curves.
"""
plt.fill_between(range(len(data), len(data) + len(forecast)), conf_int[:, 0], conf_int[:, 1], color='pink', alpha=0.5, label='置信区间')
plt.legend()
plt.xlabel('时间步')
plt.ylabel('值')
plt.title('时间序列预测')
plt.tight_layout()
plt.show()
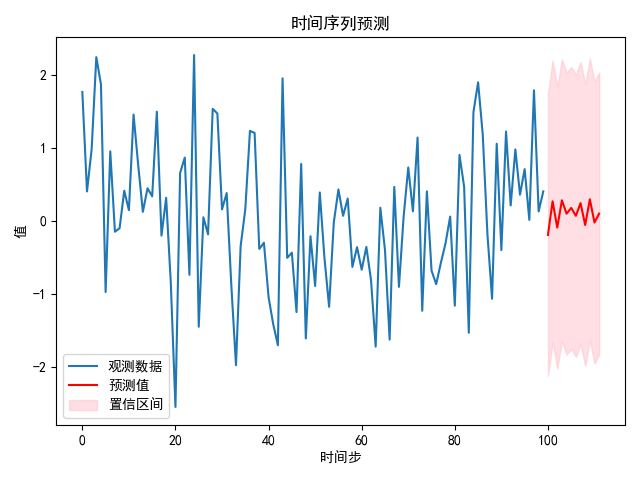 6.3.高级用法
6.3.高级用法
"""
@Author: zhang_zhiyi
@Date: 2024/7/5_10:23
@FileName:14pmdarima库-高级用法.py
@LastEditors: zhang_zhiyi
@version: 1.0
@lastEditTime:
@Description:
"""
import numpy as np
from pmdarima import ARIMA
from pmdarima.model_selection import cross_val_score# TODO:2.高级用法
# 生成一个时序数据
np.random.seed(0)
data = np.random.randn(100) # 100个数据点的时间序列# 虽然 pmdarima 提供了自动模型选择的功能,但也可以手动指定模型的超参数,以更精细地控制建模过程。
# 手动指定ARIMA模型
"""
Parameters:order : iterable or array-like, shape=(3,)The (p,d,q) order of the model for the number of AR parameters, differences, and MA parameters to use.order : iterable or array-like, shape=(3,)The (P,D,Q,s) order of the seasonal component of the model for the AR parameters, differences, MA parameters, and periodicity. seasonal_order : array-like, shape=(4,), optional (default=(0, 0, 0, 0))The (P,D,Q,s) order of the seasonal component of the model for the AR parameters, differences, MA parameters, and periodicity.
"""
model = ARIMA(order=(1, 1, 1), seasonal_order=(0, 1, 1, 12))
"""
fit(y, X=None, **fit_args)Fit an ARIMA to a vector, y, of observations with an optional matrix of X variables.
"""
model.fit(data)# 交叉验证是评估模型性能的重要方法。pmdarima 可以执行交叉验证来评估模型的泛化性能。
# 执行交叉验证
# scores = cross_val_score(model, data, cv=5) # 使用5折交叉验证
"""scoring : str or callable, optional (default=None)The scoring metric to use. If a callable, must adhere to the signature``metric(true, predicted)``. Valid string scoring metrics include:- 'smape'- 'mean_absolute_error'- 'mean_squared_error'
"""
scores = cross_val_score(model, data, scoring='smape')
"""
观察值太少:用于估计季节性ARMA模型的起始参数的观察值太少,除了方差以外的所有参数都将设置为零。
UserWarning: Too few observations to estimate starting parameters for seasonal ARMA.
All parameters except for variances will be set to zeros.warn('Too few observations to estimate starting parameters%s.'非可逆的起始季节性移动平均参数:使用零作为起始参数。
UserWarning: Non-invertible starting seasonal moving average Using zeros as starting parameters.warn('Non-invertible starting seasonal moving average'最大似然优化未收敛:最大似然优化未能收敛,可能是由于数据不足或模型参数不合适。
ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals warnings.warn("Maximum Likelihood optimization failed to "解决方案增加数据量:尝试使用更多的数据点进行模型训练。调整模型参数:检查并调整模型的参数,以提高拟合的稳定性。检查数据的季节性:确保数据具有足够明显的季节性特征,并且季节周期设置正确。
"""
print(scores)
# from pmdarima import seasonal_decompose
# 季节性分解
# result = seasonal_decompose(data, model='multiplicative', freq=12)
7.ARIMA模型分析流程
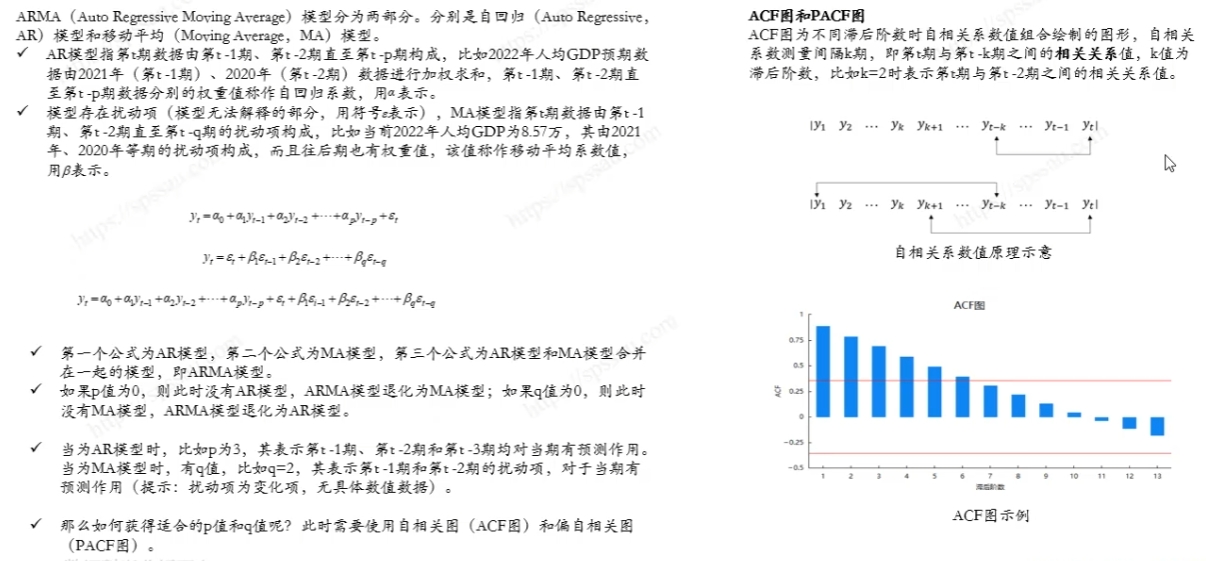
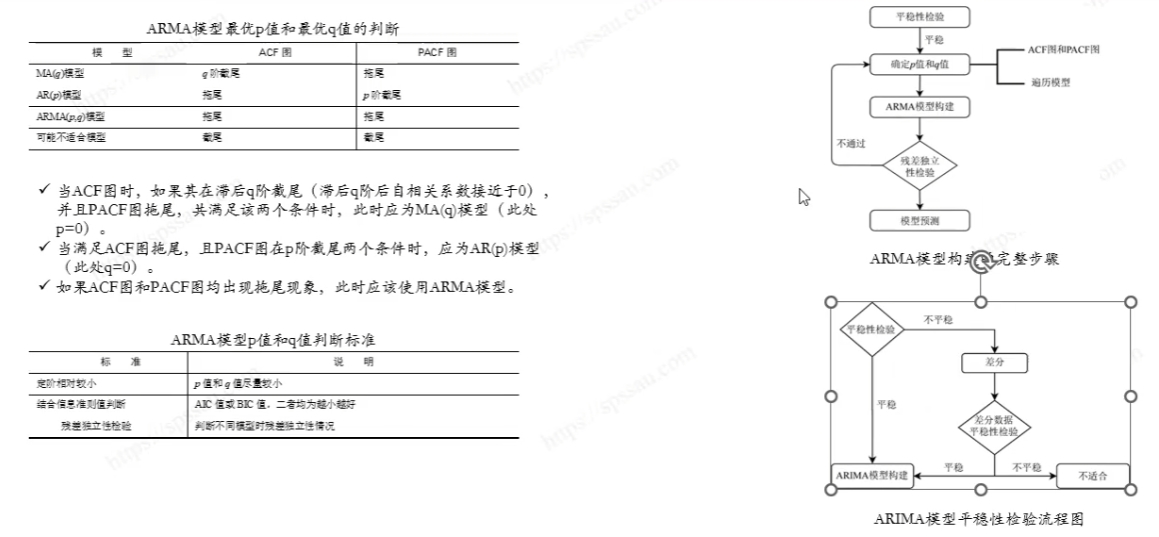
相关文章:

时间序列预测建模的完整流程以及数据分析【学习记录】
文章目录 1.时间序列建模的完整流程2. 模型选取的和数据集2.1.ARIMA模型2.2.数据集介绍 3.时间序列建模3.1.数据获取3.2.处理数据中的异常值3.2.1.Nan值3.2.2.异常值的检测和处理(Z-Score方法) 3.3.离散度3.4.Z-Score3.4.1.概述3.4.2.公式3.4.3.Z-Score与…...

【工作记录】Kong Gateway入门篇之简介
1. 什么是 Kong Gateway? Kong Gateway 是一个开源的、云原生的 API 网关,专为现代微服务架构设计。它基于 Nginx 和 Lua 构建,提供了高性能、可扩展的 API 管理解决方案。Kong Gateway 不仅能够处理 API 请求的路由和负载均衡,还…...

华为鸿蒙电脑能否作为开发机?开发非鸿蒙应用?
目录 一、鸿蒙电脑作为开发机的核心能力1. 硬件与系统架构2. 开发工具链支持 二、开发非鸿蒙应用的可行性分析1. 适配优势与局限性2. 生态限制 三、鸿蒙电脑的核心适用场景1. 推荐开发场景2. 目标用户群体3. 非推荐场景 四、未来生态演进与战略意义五、总结 一、鸿蒙电脑作为开…...

jackson-dataformat-xml引入使用后,响应体全是xml
解决方案: https://spring.io/blog/2013/05/11/content-negotiation-using-spring-mvc import org.springframework.context.annotation.Configuration; import org.springframework.http.MediaType; import org.springframework.web.servlet.config.annotation.Con…...

【deekseek】TCP Offload Engine
是的,TOE(TCP Offload Engine)通过专用硬件电路(如ASIC或FPGA)完整实现了TCP/IP协议栈,将原本由CPU软件处理的协议计算任务完全转移到网卡硬件中。其延迟极低的核心原因在于 硬件并行性、零拷贝架构 和 绕过…...

Flannel Host-gw模式的优缺点
Host-gw 模式的特点、优缺点 优点 高性能:无封装开销,数据包直接通过主机路由表转发,延迟和吞吐量接近原生网络。零额外开销:不使用隧道或封装,无额外字节,带宽利用率最高。配置简单:只需配置…...

SD-HOST Controller design-----SD CLK 设计
hclk的分频电路,得到的分频时钟作为sd卡时钟。 该模块最终输出两个时钟:一个为fifo_sd_clk,另一个为out_sd_clk_dft。当不分频时,fifo_sd_clk等于hclk;当分频时候,div_counter开始计数,记到相应分频的时候…...
)
zabbix最新版本7.2超级详细安装部署(一)
如果文章对你有用,请留下痕迹在配置过程中有问题请及时留言,本作者可以及时更新文章 目录 1、提前准备环境 2、zabbix7.2安装部署 3、安装并配置数据库 4、为Zabbix server配置数据库 5、为Zabbix前端配置PHP 6、启动Zabbix server和agent进程 7、关闭防…...
)
BFS算法篇——打开智慧之门,BFS算法在拓扑排序中的诗意探索(上)
文章目录 引言一、拓扑排序的背景二、BFS算法解决拓扑排序三、应用场景四、代码实现五、代码解释六、总结 引言 在这浩瀚如海的算法世界中,有一扇门,开启后通向了有序的领域。它便是拓扑排序,这个问题的解决方法犹如一场深刻的哲学思考&#…...
:探秘滑块的计算逻辑)
【Nova UI】十六、打造组件库之滚动条组件(中):探秘滑块的计算逻辑
序言 在上篇文章中,我们完成了滚动条组件开发的前期准备工作,包括理论推导、布局规划和基础设置。现在,我们将把这些准备转化为实际代码,开启滚动条组件的具体开发之旅🌟。我们会详细阐述如何实现各项功能,…...

题海拾贝:P1833 樱花
Hello大家好!很高兴我们又见面啦!给生活添点passion,开始今天的编程之路! 我的博客:<但凡. 我的专栏:《编程之路》、《数据结构与算法之美》、《题海拾贝》、《C修炼之路》 欢迎点赞,关注&am…...

集成钉钉消息推送功能
1. 概述 本文档详细描述了在若依框架基础上集成钉钉消息推送功能的开发步骤。该功能允许系统向指定钉钉用户发送文本和富文本消息通知。 2. 环境准备 2.1 钉钉开发者账号配置 登录钉钉开发者平台:https://open.dingtalk.com/创建/选择企业内部应用获取以下关键信…...

texlive 与 Texmaker 安装
一、安装 Texmaker 1、下载Texmaker 链接地址: Texmaker (free cross-platform latex editor) 点击 FREE DOWNLOAD ,点击 Texmaker_6.0.1_Win_x64.msi ,下载即可。 2、安装Texmaker 双击如下文件 若出现如下,点击更多信息 点击仍要运行 …...
:过滤搜索、范围搜索、分组搜索)
Milvus(21):过滤搜索、范围搜索、分组搜索
1 过滤搜索 ANN 搜索能找到与指定向量嵌入最相似的向量嵌入。但是,搜索结果不一定总是正确的。您可以在搜索请求中包含过滤条件,这样 Milvus 就会在进行 ANN 搜索前进行元数据过滤,将搜索范围从整个 Collections 缩小到只搜索符合指定过滤条件…...

AD PCB布局时常用的操作命令
1. 框选 往右下方框选:选中矩形接触到的对象(选中整体才会被选中) 往左上方框选:选中矩形接触到的对象(选中局部,也是选中整体) 线选:快捷键S,弹出界面: …...
【论文+源码+SQL脚本】)
[免费]微信小程序医院预约挂号管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序医院预约挂号管理系统(uni-appSpringBoot后端Vue管理端),分享下哈。 项目视频演示 【免费】微信小程序医院预约挂号管理系统(uni-appSpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩…...

分析Docker容器Jvm 堆栈GC信息
# 打印jvm启动参数 docker exec -ti <容器名> jcmd 1 VM.flags-XX:CICompilerCount3 -XX:InitialHeapSize1073741824 -XX:MaxHeapSize2147483648 -XX:MaxMetaspaceSize157286400 -XX:MaxNewSize715653120 -XX:MinHeapDeltaBytes524288 -XX:NewSize357564416 -XX:OldSize7…...

Java——集合基础
一、集合与数组的特点对比 1.集合类的特点:提供一种存储空间可变的存储模型,存储的数据容量可以发生改变 2.集合和数组的区别 共同点:都是存储数据的容器不同点:数组的容量是固定的,集合的容量是可变的 3.如果存储…...

spark MySQL数据库配置
Spark 连接 MySQL 数据库的配置 要让 Spark 与 MySQL 数据库实现连接,需要进行以下配置步骤。下面为你提供详细的操作指南和示例代码: 1. 添加 MySQL JDBC 驱动依赖 你得把 MySQL 的 JDBC 驱动添加到 Spark 的类路径中。可以通过以下两种方式来完成&a…...

http断点续传
🛑 默认的 http.server(Python 的 SimpleHTTPRequestHandler)在某些版本和实现中并不可靠地支持 HTTP Range 请求(即断点续传)。 尤其在 Python 3.7~3.10 之间的某些版本中,这种支持是不完整或不可预测的。…...

# YOLOv3:基于 PyTorch 的目标检测模型实现
YOLOv3:基于 PyTorch 的目标检测模型实现 引言 YOLOv3(You Only Look Once)是一种流行的单阶段目标检测算法,它能够直接在输入图像上预测边界框和类别概率。YOLOv3 的优势在于其高效性和准确性,使其在实时目标检测任…...

Mac修改hosts文件方法
Mac修改hosts文件方法 在 macOS 上修改 hosts 文件需要管理员权限 步骤 1:打开终端 通过 Spotlight 搜索(Command 空格)输入 Terminal,回车打开。或进入 应用程序 > 实用工具 > 终端。 步骤 2:备份 hosts 文件…...

构建你的第一个简单AI助手 - 入门实践
在当今AI迅速发展的时代,构建自己的AI助手不再是高不可攀的技术壁垒。即使对于刚接触AI开发的程序员,也可以利用现代大语言模型(LLM)API构建功能丰富的AI助手。本文将带您完成一个简单但实用的AI助手构建过程,帮助您在日常工作中提高效率。 …...

Qt在统信UOS及银河麒麟Kylin系统中进行软件开发的环境配置,打包发布和注意事项
前述 之前由于项目的产品需要,必须将原本Windows上的产品移植到信创环境,也就是现在的主流国产操作系统统信UOS及银河麒麟Kylin。 先大概讲下信创系统: 信创系统就像是中国自己打造的 “数字基建”,目的是让咱们国家的信息技术不…...

一个完整的项目示例:taro开发微信小程序
前一周完成了一个项目,体测成绩转换的工具,没做记录,。这次计划开发一个地图应用小程序,记录一下。方便给使用的人。 一、申请微信小程序,填写相应的信息,取得开发者ID。这个要给腾讯地图使用的。 二、申…...

二次封装 el-dialog 组件:打造更灵活的对话框解决方案
文章目录 引言为什么需要二次封装?封装思路代码实现1. 基础封装组件 (Dialog.vue)2. Vue中引入使用示例 封装后的优势进阶优化建议 总结 引言 在 Vue 项目中,Element UI 的 el-dialog 是一个非常实用的对话框组件。但在实际开发中,我们经常会…...

3.2 一点一世界
第一步:引入背景与动机 “一点一世界”这个概念来源于泰勒公式的思想,即通过一个点及其导数信息来近似描述整个函数的行为。这种方法在数学分析中非常有用,因为它允许我们将复杂的函数简化为多项式形式,从而更容易进行计算和理解…...

力扣第156场双周赛
1. 找到频率最高的元音和辅音 给你一个由小写英文字母(a 到 z)组成的字符串 s。你的任务是找出出现频率 最高 的元音(a、e、i、o、u 中的一个)和出现频率最高的辅音(除元音以外的所有字母),并返…...

学习日志05 java
1 java里面的类型转换怎么做?int转double为例 在 Java 里,把int转换为double有自动类型转换和强制类型转换两种方式。下面为你详细介绍: 自动类型转换(隐式转换) 由于double的取值范围比int大,Java 能够…...

4.7/Q1,GBD数据库最新文章解读
文章题目:Burden of non-COVID-19 lower respiratory infections in China (1990-2021): a global burden of disease study analysis DOI:10.1186/s12931-025-03197-7 中文标题:中国非 COVID-19 下呼吸道感染负担(1990-2021 年&a…...

do while
先进再查 import java.util.Scanner;public class Hello {public static void main(String[] args) {Scanner in new Scanner(System.in);int number in.nextInt();int count 0;do{number number / 10;count count 1;} while( number > 0 );System.out.println(count…...

MySQL 主从复制与读写分离
一、MySQL 主从复制 (0)概述 MySQL 主从复制是一种数据同步机制,允许数据从一个主数据库(Master)复制到一个或多个从数据库(Slave)。其主要用途包括: 数据冗余与灾备:通…...

CSS3 基础知识、原理及与CSS的区别
CSS3 基础知识、原理及与CSS的区别 CSS3 基础知识 CSS3 是 Cascading Style Sheets 的第3个版本,是CSS技术的升级版本,于1999年开始制订,2001年5月23日W3C完成了CSS3的工作草案。 CSS3 主要模块 选择器:更强大的元素选择方式盒…...

第十七章:Llama Factory 深度剖析:易用性背后的微调框架设计
章节引导:在模型定制的实践中,Llama Factory (github.com/hiyouga/LLaMA-Factory) 以其惊人的易用性和对多种开源大模型、多种参数高效微调方法(PEFT)的广泛支持,迅速成为开源社区的热门选择。你可能已经熟练掌握了如何…...

SpringSecurity当中的CSRF防范详解
CSRF防范 什么是CSER 以下是基于 CSRF 攻击过程的 顺序图 及详细解释,结合多个技术文档中的攻击流程: CSRF 攻击顺序图 #mermaid-svg-FqfMBQr8DsGRoY2C {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#m…...

CSRF防范歪招
不保存到Cookie里呗 如果每次请求都强制通过请求头携带Token,并且不将Token存储在Cookie中,这种设计可以有效防御CSRF攻击。以下是具体原因和关键实现要点: 1. 防御原理 CSRF攻击的本质是攻击者伪造用户的请求,利用浏览器自动携…...

MyBatis与MyBatis-Plus深度分析
MyBatis与MyBatis-Plus深度分析 一、MyBatis原理与基础 1. MyBatis核心原理 MyBatis是一个半自动ORM框架,主要原理包括: SQL与代码分离:通过XML或注解配置SQL语句动态SQL:提供if、choose、foreach等标签实现动态SQL结果集映射…...

STM32 变量加载到flash的过程中
在STM32中,BIN文件内需要加载到RAM的数据由链接脚本(Linker Script)和启动代码(Startup Code)共同决定,具体机制如下: 一、BIN文件内容结构 STM32的BIN文件包含三类数据: Co…...

TCP核心机制
1. TCP五大核心机制 1.1. 顺序问题(稳重不乱) 背景:网络传输中数据包可能因路径不同或网络波动导致乱序到达,需保证接收方能按正确顺序处理数据。 原理: 序列号(Sequence Number)࿱…...

6.3对象序列化
在 Java 中,ObjectInputStream 和 ObjectOutputStream 是用于实现对象序列化(Serialization)和反序列化(Deserialization)的核心类。通过这两个类,可以将对象转换为字节流进行存储或传输,并在需…...

Flutter小白入门指南
Flutter小白入门指南 🚀 轻松构建漂亮的跨平台应用 📑 目录 一、Flutter是什么? 为什么选择Flutter?Flutter工作原理 二、环境搭建与命令行 安装Flutter SDK常用Flutter命令创建第一个项目 三、Flutter基础语法 变量与类型函数条…...

Python -将MP4文件转为GIF图片
给大家提供一个工具代码,使用Python,将MP4格式的视频文件,转换为GIF图片 首先先安装必要的包: pip install imageio pip install imageio[ffmpeg] 工具代码: import imageio# 视频文件路径 video_path r""…...

51c嵌入式~电路~合集27
我自己的原文哦~ 一、7805应用电路 简介 如上图,7805 集成稳压电路。 7805是串联式三端稳压器,三个端口分别是电压输入端(IN),地线(GND),稳压输出(OUT)…...
)
数据结构—(链表,栈,队列,树)
本文章写的比较乱,属于是缝合怪,很多细节没处理,显得粗糙,日后完善,今天赶时间了。 1. 红黑树的修复篇章 2. 红黑树的代码理解(部分写道注释之中了) 3. 队列与栈的代码 4. 重要是理解物理逻辑&a…...
)
GitHub 趋势日报 (2025年05月12日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1harry0703/MoneyPrinterTurbo利用ai大模型,一键生成高清短视频使用…...

ebook2audiobook开源程序使用动态 AI 模型和语音克隆将电子书转换为带有章节和元数据的有声读物。支持 1,107+ 种语言
一、软件介绍 文末提供程序和源码下载 ebook2audiobook开源程序使用动态 AI 模型和语音克隆将电子书转换为带有章节和元数据的有声读物。支持 1,107 种语言。从电子书到带有章节和元数据的有声读物的 CPU/GPU 转换器,使用 XTTSv2、Bark、Vits、Fairseq、YourTTS …...
》阅读笔记:p39-p48)
《算法导论(第4版)》阅读笔记:p39-p48
《算法导论(第4版)》学习第 13 天,p39-p48 总结,总计 10 页。 一、技术总结 1. recurrence/recurrence equation 书里面 recurrence(递归式) 和 recurrence equation(递归方程) 指的是同一个东西。 二、英语总结(生词:2) 1. squint (1)…...

c语言第一个小游戏:贪吃蛇小游戏07
贪吃蛇吃饭喽 所谓贪吃蛇的食物,也就是创建一个和蛇身一样的结构体,只是这个结构体不是链表,也是将这个结构体设置hang和lie坐标,放进gamepic进行扫描,扫到了就也是做操作将 ## 打出来 #include <curses.h> #i…...
深度学习---神经网络原理与实现)
(七)深度学习---神经网络原理与实现
分类问题回归问题聚类问题各种复杂问题决策树√线性回归√K-means√神经网络√逻辑回归√岭回归密度聚类深度学习√集成学习√Lasso回归谱聚类条件随机场贝叶斯层次聚类隐马尔可夫模型支持向量机高斯混合聚类LDA主题模型 一.神经网络原理概述 二.神经网络的训练方法 三.基于Ker…...

VSCode中Node.js 使用教程
一、visual studio code下载与安装 二、修改vscode主题颜色 三、汉化 菜单view-->Command Palette...,输入Configure Display Language。 重启之后如下: 四、安装node.js Node.js 是一个基于Chrome V8引擎的JavaScript运行环境,使用了事件驱动、非阻…...