推理加速新范式:火山引擎高性能分布式 KVCache (EIC)核心技术解读

资料来源:火山引擎-开发者社区
分布式 KVCache 的兴起
背景
在大模型领域,随着模型参数规模的扩大和上下文长度增加,算力消耗显著增长。在 LLM 推理过程中,如何减少算力消耗并提升推理吞吐已经成为关键性优化方向。以多轮对话场景为例,随着对话轮数增加,历史 token 重算占比持续增长。实验数据表明(如图1),当每轮输入为 8k tokens 时,运行 6 轮后,历史 token 重复计算占比超过 80%,直接导致了 GPU 算力的冗余消耗。在此背景下,构建高效的历史 token 计算结果缓存机制,理论上可以实现对重复计算过程的智能规避,从而显著提升计算资源的利用效率。
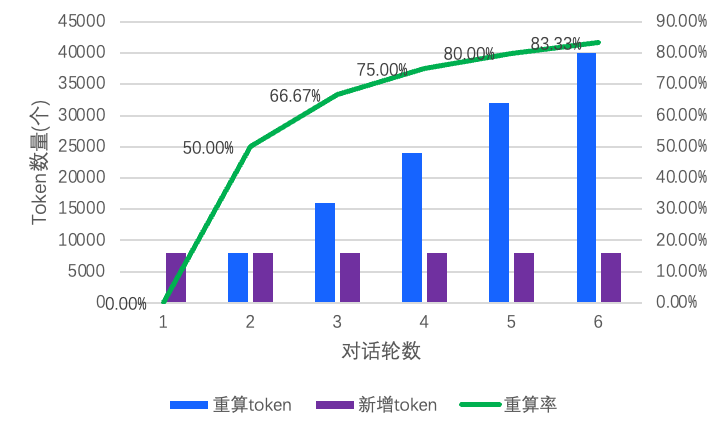
图1 对话轮数及重算率的变化
在应对上述技术挑战中,KVCache 技术应运而生。
作为现代推理框架的核心组件,KVCache 能显著优化系统性能。 以 vLLM 为例,其通过 Prefix Cache 和 PageAttention 技术,构建了基于本地 HBM 的 Local KVCache 方案。该方案中,缓存重用率(Cache 可被重复使用的比例)作为核心指标,通常认为与缓存容量呈正相关关系,即空间越大重用率越高,然而 Local KVCache 受限于本地存储空间,容易遇到瓶颈。
从实验数据看出(如图2),在 H20 硬件平台运行 LLaMA-70B 模型时,每处理 1K token 需要 1.6GB 空间,导致 Prefill 在 20 分钟内即突破内存阈值。这一内存墙问题会引发 KVCache 频繁驱逐旧数据,导致重用率下降,进而严重影响 KVCache 记忆长度,最终导致大量 token 重计算。为验证内存墙问题的影响,我们在 LLaMA-70B 模型的长文本场景测试中发现(如图 3),随着文档规模的增长,系统会快速触及单机内存上限,导致 token 吞吐量骤降 70%,迫使系统陷入算力重复消耗的恶性循环。
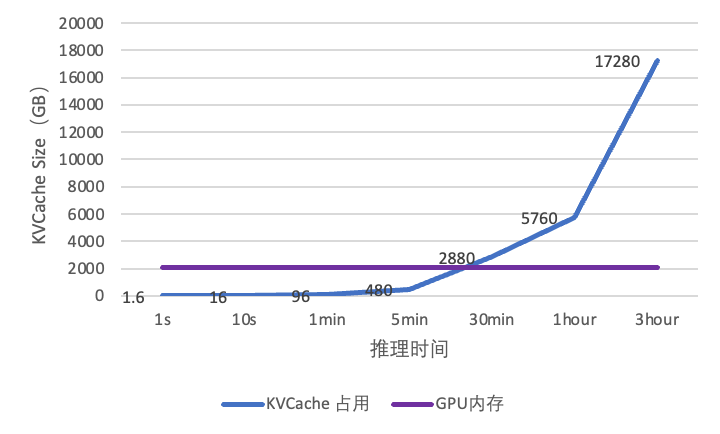
图2 KVCache 内存占用

图3 Token 吞吐和 KVCache 重用率
Local KVCache 另一个关键局限于在于无法多机共享,主要影响以下典型场景:
- 多轮对话调度:多级推理通常需要通过复杂的调度来提升缓存重用率,如多轮对话中,同一会话需要尽可能调度至固定 GPU 以复用缓存,容易引发调度热点与负载不均衡问题,实际场景中难以实现性能与资源利用率的平衡。
- PD 分离架构:系统将 Prefilling 和 Decoding 两阶段分离部署,需要通过高速网络直接传输 KVCache。这不仅要求 PD 节点间网络需要具备高吞吐能力以保证传输效率,还需避免传输过程中因调度问题触发缓存失败而引发重计算。同时,PD 分离中 Decoding 阶段 KVCache 也难以被之后的推理复用,导致 GPU 算力空耗。
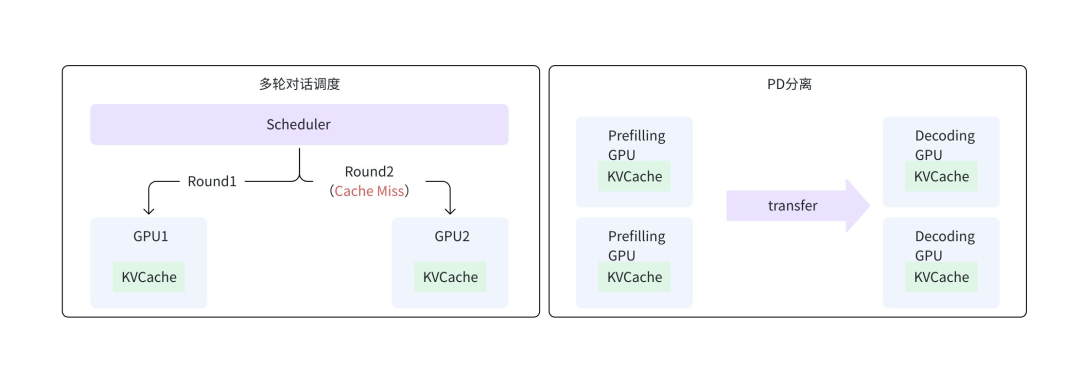
图4 KVCache 不能共享的场景
需求
基于上述分析,我们构建了一个弹性高性能的分布式 KVCache 服务,来优化 Local KVCache 方案的内存墙和不能共享的问题。区别于传统分布式服务,分布式 KVCache 要求更高,对存储的核心挑战与需求如下:
- 更大的容量:构建分布式服务的初衷是为了解决传统方案内存墙问题,需具备海量容量用以支撑大规模推理的高命中率需要。
- 更低的访问时延:HBM 到分布式缓存之间存在网络开销,开销太大会影响 GPU 执行效率,提升 HBM 及分布式 Cache 之间的交换效率至关重要。
- 更高的吞吐:KVCache 通过多机间共享提升重用率,这是分布式 KVCache 的优势,然而随之而来的,需要KVCache 服务提供更加极致的吞吐以支撑大规模推理服务部署。
火山引擎推理 KVCache 解决方案
弹性极速缓存 EIC
弹性极速缓存 EIC(Elastic Instant Cache)是火山引擎存储团队面向大语言模型推理场景推出的高性能分布式 KVCache 缓存服务。随着互联网技术的演进与流量规模的激增,缓存技术逐渐成为系统架构的核心组件,火山引擎存储团队基于自身业务内部加速需求自主研发了 EIC,历经 4 年技术沉淀,该系统已支撑了公司内部存储、推理、广告推荐等大规模业务场景。
EIC KVCache 支持将内存和 SSD 组成一个分布式服务,构建多层缓存体系,实现显存容量的灵活扩展与计算资源的高效解耦。还支持和 GPU 混合部署,将 GPU 剩余显存、内存和磁盘统一池化管理,在提升计算效率的同时显著扩展上下文长度,成为加速推理框架的核心链路。基于通用模型和推理引擎,无缝兼容主流大语言模型架构,达成单客户端百 GB 级 KVCache 吞吐与亚毫秒级响应,满足高并发、低延迟的生成式 AI 场景需求。
EIC 核心特性
缓存池化:多级缓存、数据流动
EIC 通过整合 GPU 集群闲置内存和磁盘,构建分布式缓存池,突破单机内存墙限制。分布式内存池化的核心目标是基于统一的多级存储资源池化管理(GPU 显存、CPU 内存、SSD及其他缓存系统),实现显存容量的灵活扩展与计算资源的高效解耦。
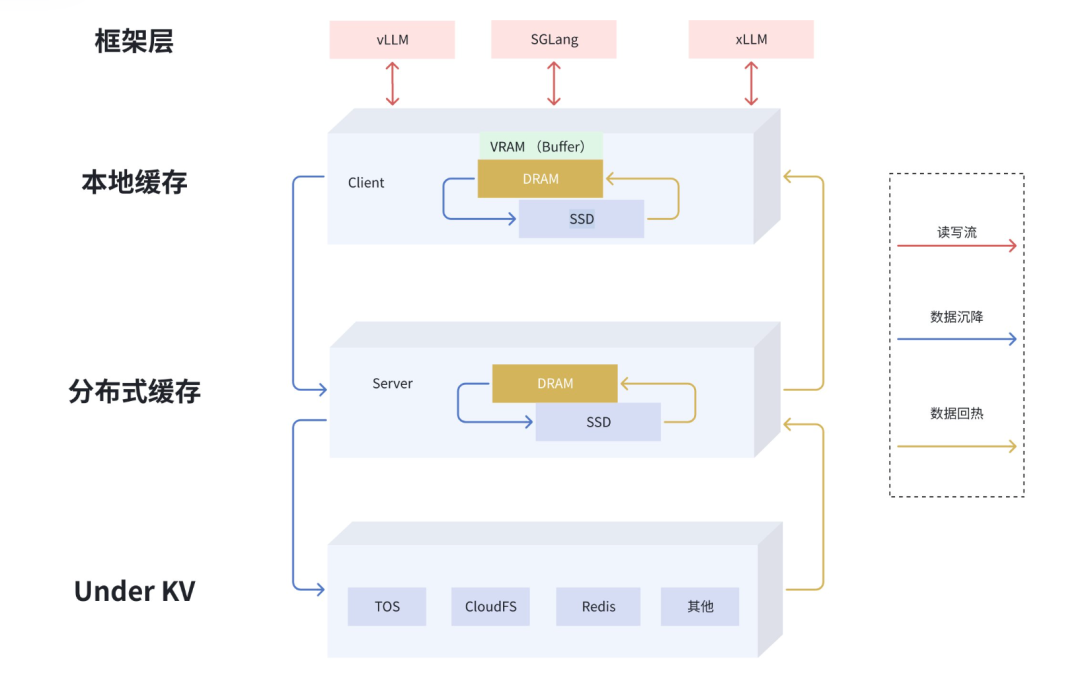
图5 多级透明缓存
推理缓存 KVCache Offload 至分布式缓存后,具备以下优势:
- 去中心架构:采用去中心化 DHT 架构,实现数据与元数据面解耦,支撑高性能读写,支持在线扩缩容和数据迁移。
- 超大容量:支持灵活 Scale-out,通过云原生平台快速纳管 GPU 节点空闲资源,构建 10PB 级存储池,缓存命中率提升 10 倍以上。
- 多级缓存:兼顾容量与性能,支持 GPU-本地缓存-分布式缓存(RAM+SSD) 等多层级缓存系统,基于不同存储介质特性,构建大容量缓存池,并且支持缓存在各层级间高效流动,实现性能的最大化。
- 数据流动:支持缓存在不同层级间的流动,可基于用户需求,将冷数据下沉到低速存储,将热数据上升到高速缓存,支持包括基于时间的 TTL 策略、基于空间的 LRU/ARC/FIFO 等策略。
- 内存持久化:支持进程故障和在线热升级,写入内存缓存不丢失,支持毫秒级快速恢复,同时内存引擎支持 Hugepage、Numa Aware、全链路零拷贝、JumboFrame 等新特性。
- 热点均衡:支持热点缓存识别,同时支持热点缓存进行副本自动扩展和生命周期管理,通过多副本负载均衡,避免少量热点缓存和节点成为系统瓶颈,确保了热点场景的服务稳定性。
低时延:GPU Direct RDMA
- GPU Direct:GPU Direct 是 NVIDIA 开发的一项技术,可实现 GPU 与其他设备(例如网络接口卡 GPU Direct RDMA和存储设备 GPU Direct Storage)之间绕过 CPU 的直接通信和数据传输。该技术允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介,能够显著减少传输时延提高传输带宽,尤其适用于高吞吐、低延迟的 AI 推理场景。
- 多协议兼容性:EIC 支持内核态TCP、用户态TCP、RDMA 及 GPU Direct RDMA 访问,适配各种硬件环境。
- 网络极致优化:在高带宽和推理 IO 突发场景下,通过深度优化投递模型、线程模型、网络传输等,大幅降低了网络传输(包括突发场景)长尾时延,从而提升推理体验。
GDR 可以实现全链路内存零拷贝,支持极低的访问时延。在不同 IO 大小的测试中,GDR 的表现良好(图 7),时延可以达到 TCP 或 RDMA 的十分之一。
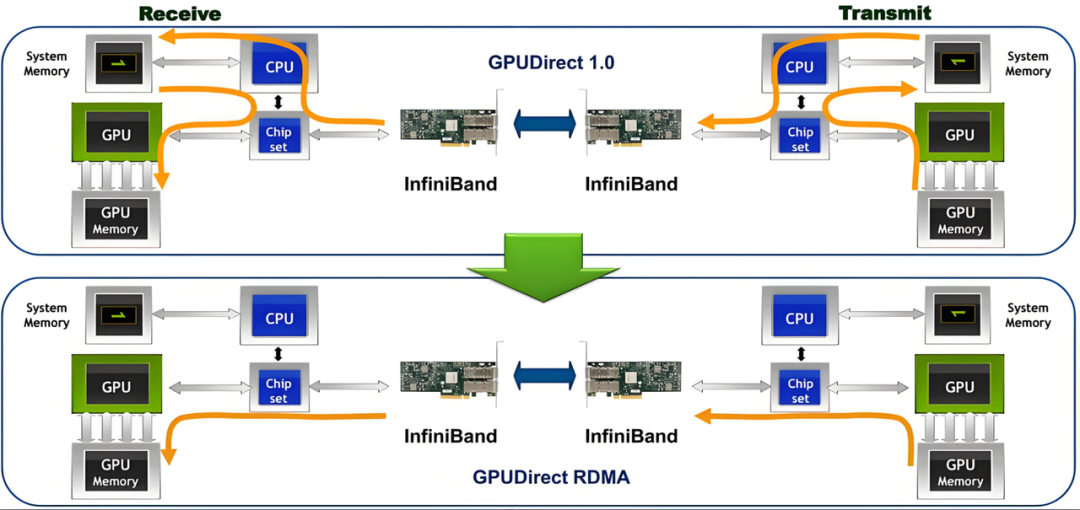
图6 GDR 工作示意图
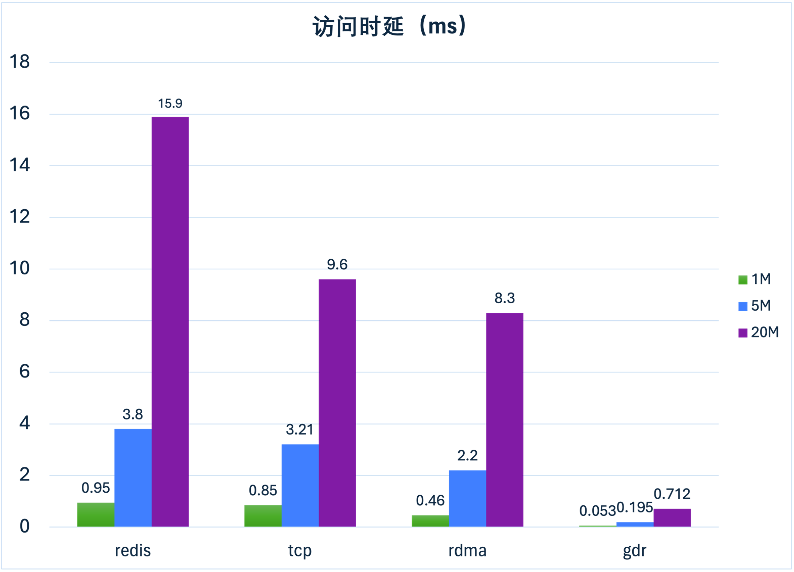
图7 GDR 性能对比
EIC 与 Local KVCache 在实际推理场景中的效果对比如下:
- 推理场景:使用两台 H20 部署 SGLang + Deepseek R1 做推理,设置 TTFT SLO 5 秒、8K Input 200 output 测试多轮对话。
- 实测数据对比:
- 吞吐提升:首轮无 KVCache 复用阶段,性能基本持平;次轮起 EIC 吞吐从 1.5K 增长至 5.5K,实现 3 倍以上性能提升(图 8)。
- 时延优化:首轮无 KVCache 复用阶段,性能基本持平;次轮起时延降至 1秒,降幅达 67%。
- 结论:得益于 EIC 低时延和大容量带来的缓存高复用,同等算力条件下,推理吞吐性能可提升 3 倍以上;若维持原有性能指标,算力需求可大幅缩减,实现性能与成本的双重优化。
图8 EIC KVCache 推理框架以存代算性能对比
高吞吐:多网卡、拓扑亲和、模型高速加载
模型分发场景中,推理冷启动对模型加载的速度要求较高,模型加载的速度决定了推理服务的弹性能力。随着模型的增长,传统存储服务的加载速度逐渐缓慢。EIC 通过分布式缓存,实现模型文件到推理框架的高速加载,显著提升推理服务弹性。我们对比了模型在 H20 机型上从 NVMe SSD (传统存储服务的性能基线) 和 从 EIC 的加载速度,测试数据显示(图9):
- DeepSeek-R1(642GB):模型文件 IO 加载时间从 NVMe SSD 的 546 秒降至 13 秒,效率提升 42 倍。
- DeepSeek-R1-Distill-Llama-70B (131GB):模型文件 IO 加载时间从 84 秒压缩至 5 秒,加载速度提升 16 倍,加速效果十分显著。
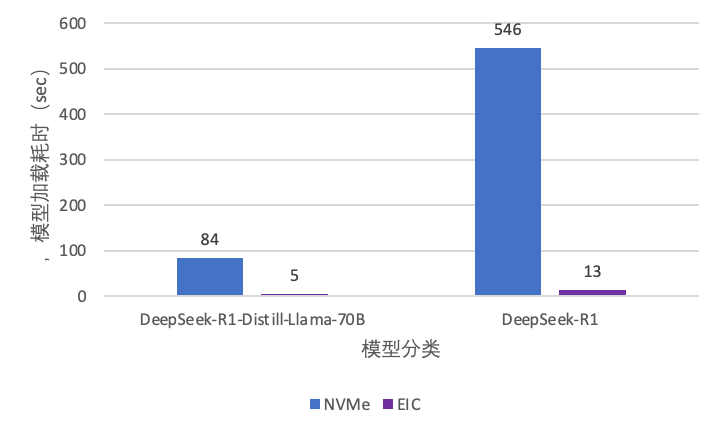
图9 EIC KVCache 推理框架模型加载性能对比
为应对大模型高并发场景的 KVCache 吞吐需求,EIC 通过多网卡并行传输和负载均衡技术,大幅提升了系统性能上限;同时为了解决不同 GPU 间访问网卡的时延差异,EIC 支持感知 GPU 和网卡拓扑结构,基于亲和性来选择最优网卡传输数据,达到时延和吞吐的极致优化(如图 10)。GPU 机型的 Root Complex 是 Socket 级别,可转化为 NUMA 级别亲和,比如 Mem0 利用 R0 网卡和 R1 网卡发送延迟更低,GPU0 利用 R0 网卡发送延迟更低,我们测试多种配置场景,依赖多网卡、拓扑亲和等特性,单机可以轻松突破 100GB/s 带宽(图 11)。
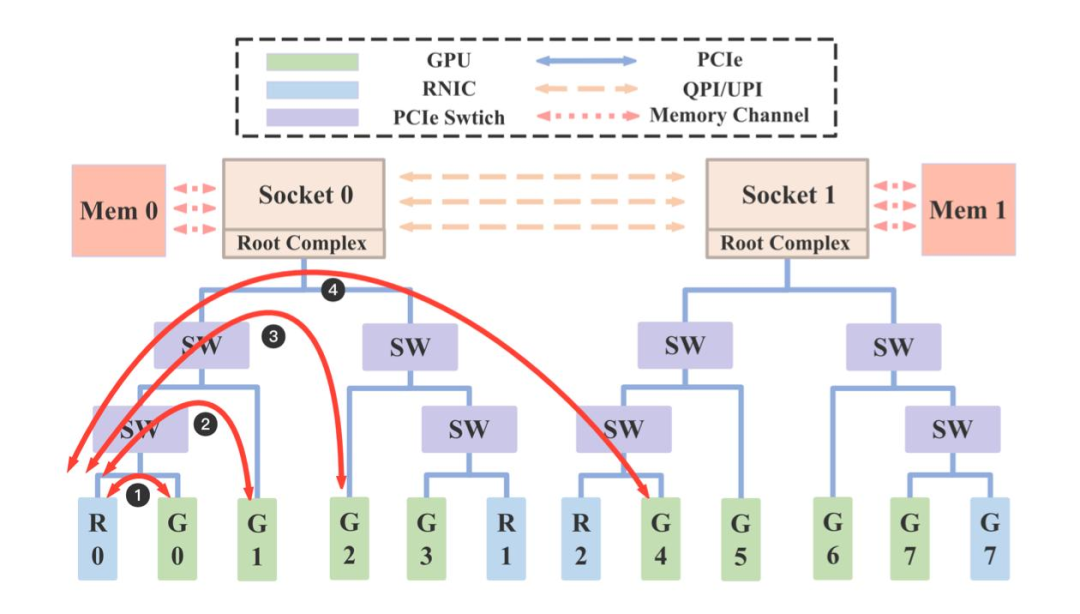
图10 GPU 网络亲和示意图
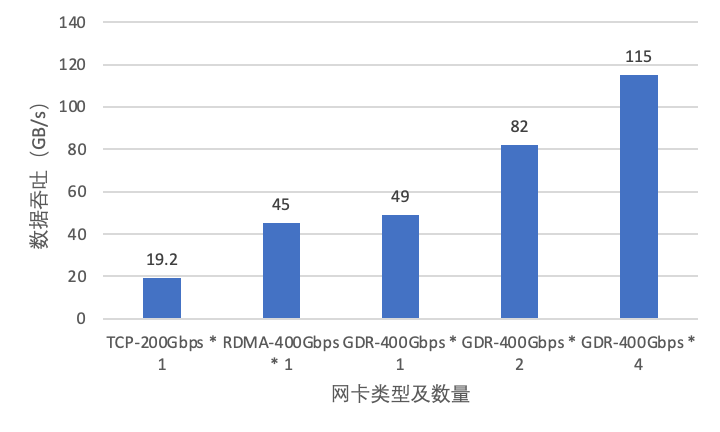
图11 EIC 读带宽性能测试
高易用:Namespace 切分
EIC 支持多 Namespace 能力,可以实现数据分类,围绕 Namespace 支持以下特性:
- 适配多种介质:支持为 Namespace 设置不同存储介质,如内存、SSD 或组合模式,满足不同场景对容量和性能的需求。
- 数据流动策略:当选择内存 + SSD 混合模式时,支持选择不同数据流动和驱逐策略,如TTL、LRU、LFU、ARC 等。
- 空间配额:支持为单个 Namespace 设置空间大小,避免跨 Namespace 空间抢占。
- QoS 策略:支持为单个 Namespace 设置不同的 IOPS 和带宽,避免跨 Namespace 吞吐抢占。
- 可观测性:基于 Namespace 监控吞吐/时延 /命中率/缓存数量/缓存容量等,方便用户细粒度观察系统。
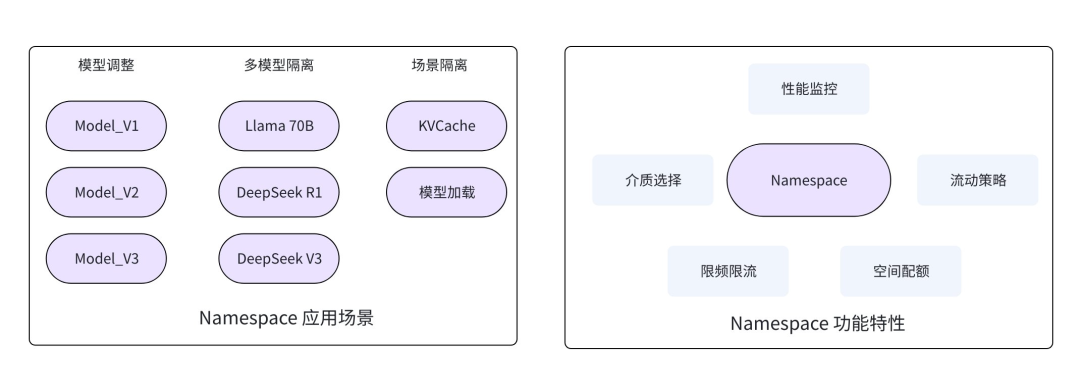
图12 Namespace 特性及应用场景
在 LLM 场景中,Namespace 能力有以下应用,满足实际场景需求:
- 模型隔离:基于模型类型隔离,简化代码接入流程,支持不同模型的精细化调优。
- 模型调整:通过模型版本号的方式设置 Namespace,实现新模型无缝切换部署,旧版本 KVCache 自动失效并快速释放缓存资源。
- 场景隔离:在大规模模型冷启动场景中,系统对吞吐带宽的需求极高,且与模型规模呈正相关关系。在此场景下,模型加载过程可能会抢占 KVCache 的带宽资源。此时可将两种数据通过 Namespace 隔离划分,并针对模型加载对应的 Namespace 配置限流策略和优先级队列,实现相对公平的 WFQ (加权公平排队, Weighted Fair Queuing),保障 KVCache 服务稳定性。
生态兼容:AI 云原生和开源生态集成
EIC 支持用户利用其 GPU 服务器的空闲内存和 SSD 资源,构建半托管或者全托管的高性能缓存池,目前, EIC 管控服务基于火山引擎托管,既能够依托火山引擎的 VKE 构建服务,也可基于开源的 K8S 构建服务。我们积极融入开源生态,已完成对 vLLM、SGLang 以及 Dynamo 等推理框架的适配,并将其集成至火山引擎 AI 相关重要业务中。
开源生态集成
我们基于 vLLM、SGLang 与 Dynamo 的开源实现,开发了 KV Transfer 缓存共享(Cache Reuse and Sharing)技术。该技术已成功在 PD 分离和模型并行架构下实现高效共享。与传统方案相比,在长文本场景中,推理吞吐提升 3 倍,首次 token 生成时间(TTFT)降低 67%。同时,我们优化了模型加载链路,支持模型通过多网卡从 EIC 进行高速直传,以 DeepSeek-R1(642GB)模型为例,其加载时间可缩减至 13 秒,显著提升模型部署效率。目前,我们已完成 EIC 集成的预制镜像制作,并计划将其贡献至开源社区,与社区开发者共同打造更高效、灵活的推理解决方案。
云原生开箱即用
在 EIC 集成方面,我们提供的预制镜像与白屏化集群管理平台深度协同,用户仅需在集群管理页面一键操作,即可将 VKE 和自建 K8S 推理集群集成 EIC 服务,并自动生成适配 SGLang、vLLM 和 Dynamo的 Helm Chart 包。借助该工具,推理框架的部署流程得到大幅简化,真正实现一键式快速启动。我们编制了详尽的最佳实践文档,围绕 VKE(容器服务)/Kubernetes Yaml 及 Helm 两种主流部署方式,完整展示从环境配置、参数优化到服务上线的全流程操作指南,帮助用户快速掌握高效部署方法,降低技术门槛,加速 EIC 与推理框架的深度融合应用。
展望
未来 EIC 将继续从以下维度持续演进,进一步提升产品能力和用户体验,敬请期待:
- 特性层面:深度结合大模型,支持推理算子下推、Sparse Attention,提供更易用的 AI 数据类型和接口,实现更加智能的数据流动,贴近开发者优化开箱即用等,提供更贴近 AI 云原生的使用方式和服务体验。
- 性能层面:随网络极限(200/400/800Gb)拓展 EIC 的单机极限上限,确保接近网络极限时始终保持高吞吐和低延迟稳定性;同时结合软件/网络多路径,优化推理长尾时延。
- 缓存层面:进一步优化内存 / SSD 等缓存使用效率,同时结合大模型 IO 特性进行智能化压缩,为用户节省成本;持续整合 VRAM、DRAM、SSD、UnderKV 等异构介质和服务器,形成统一大缓存池并实现高效利用和管理。
- 生态层面:快速跟进大模型技术演进,与社区合作深度合作,推进与 vLLM/SGLang/Dynamo 等框架在 PD 分离、推理调度、缓存多机共享等特性上的共同演进与深度融合。
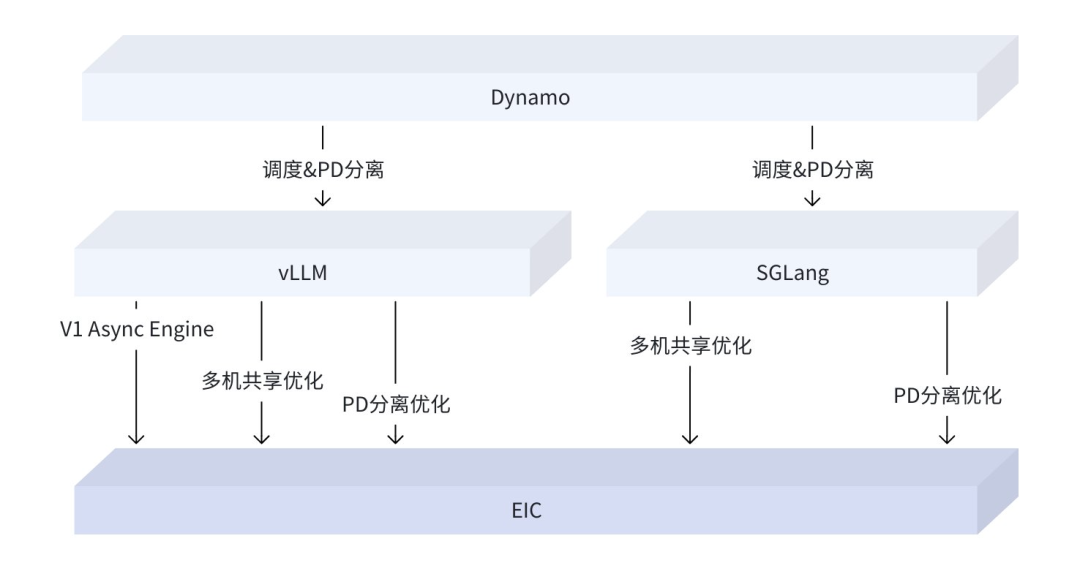
图13 推理框架与 EIC 生态演进
相关文章:
核心技术解读)
推理加速新范式:火山引擎高性能分布式 KVCache (EIC)核心技术解读
资料来源:火山引擎-开发者社区 分布式 KVCache 的兴起 背景 在大模型领域,随着模型参数规模的扩大和上下文长度增加,算力消耗显著增长。在 LLM 推理过程中,如何减少算力消耗并提升推理吞吐已经成为关键性优化方向。以多轮对话场…...

2025年5月12日第一轮
1.百词斩 2.阅读 3.翻译 4.单词 radical 激进的 Some people in the US have asserted that forgiving student loan debt is one way to stimulate the economy and give assistance to those in need. 1.数学 Hainan was the second island on the Taiwan,a province whi…...

Spark目前支持的部署模式。
一、本地模式(Local Mode) 特点: 在单台机器上运行,无需集群。主要用于开发、测试和调试。所有组件(Driver、Executor)在同一个 JVM 中运行。 启动命令: bash spark-submit --master local[*]…...

如何理解“数组也是对象“——Java中的数组
在Java中,数组确实是一种特殊的对象,这一点经常让初学者感到困惑。本文将深入探讨数组的对象本质,并通过代码示例展示数组作为对象的特性。 数组是对象的证据 1. 数组继承自Object类 所有Java数组都隐式继承自java.lang.Object类ÿ…...

第二章、物理层
目录 2.1、物理层的基本概念 2.2、数据通信的基础知识 2.2.1、数据通信系统的模型 2.2.2、有关信道的几个基本概念 调制的方法 常用的编码方式 基本的带通调制 2.2.3、信道的极限容量 信道能够通过的频率范围 2.3、物理层下面的传输媒介 2.3.1、导引型传输媒体 &…...

UART16550 IP core笔记二
XIN时钟 表示use external clk for baud rate选型,IP核会出现Xin时钟引脚 XIN输入被外部驱动,也就是外部时钟源,那么外部时钟必须要满足特定的要求,就是XIN 的range范围是xin<S_AXI_CLK/2,如果不满足这个条件,那么A…...

websocketpp 安装及使用
介绍 WebSocket 是从 HTML5 开始支持的一种网页端和服务端保持长连接的消息推送机制。 传统的 web 程序都是属于 "一问一答" 的形式,即客户端给服务器发送了一个 HTTP 请求,服务器给客户端返回一个 HTTP 响应。这种情况下服务器是属于被动…...

【大数据】MapReduce 编程--WordCount
API 是“Application Programming Interface”的缩写,即“应用程序编程接口” Hadoop 提供了一套 基于 Java 的 API,用于开发 MapReduce 程序、访问 HDFS、控制作业等 MapReduce 是一种 分布式并行计算模型,主要用于处理 大规模数据集。它将…...

北京市通州区经信局对新增通过国家级生成式人工智能及深度合成算法备案企业给予100w、20w一次性补贴
北京市通州区经济和信息化局 关于发布支持北京城市副中心数字经济高质量发展的实施指南(第一批)的通知 各有关单位: 为培育千亿级数字经济产业集群,促进数字经济和实体经济深度融合,助推北京城市副中心产业高质量发展&…...

机器学习驱动的智能化电池管理技术与应用
在人工智能与电池管理技术融合的背景下,电池科技的研究和应用正迅速发展,创新解决方案层出不穷。从电池性能的精确评估到复杂电池系统的智能监控,从数据驱动的故障诊断到电池寿命的预测优化,人工智能技术正以其强大的数据处理能力…...

GTC2025——英伟达布局推理领域加速
英伟达GTC2025大会于今年3月18日举行,会上NVIDIA CEO黄仁勋展示了其过去所取得的成就,以及未来的布局目标——通过纵向扩展(scale out)和横向扩展(scale up)解决终极的计算问题——推理。本文将回顾NVIDIA在…...

5.12 note
Leetcode 图 邻接矩阵的dfs遍历 class Solution { private: vector<vector<int>> paths; vector<int> path; void dfs(vector<vector<int>>& graph, int node) { // 到n - 1结点了保存 if (node graph.size() - 1)…...

Java Spring Boot项目目录规范示例
以下是一个典型的 Java Spring Boot 项目目录结构规范示例,结合了分层架构和模块化设计的最佳实践: text 复制 下载 src/ ├── main/ │ ├── java/ │ │ └── com/ │ │ └── example/ │ │ └── myapp/ │…...

记录裁员后的半年前端求职经历
普通的人生终起波澜 去年下半年应该算是我毕业以来发生人生变故最多的一段时间。 先是 7 月份的时候发作了一次急性痛风,一个人在厦门,坐在床上路都走不了,那时候真的好想旁边能有个人能扶我去医院,真的是感受到 10 级的孤独。尝…...

学习黑客BitLocker与TPM详解
BitLocker与TPM详解:数据加密的坚固堡垒 🔐🛡️ 学习目标:掌握BitLocker加密原理、TPM工作机制及其配置方法,提升数据安全防护水平 1. 数据保护的最后防线:BitLocker与TPM简介 💼 在当今世界&a…...

综合实验二之grub2密文加密
实验二、grub2密文加密 Grub2 密文加密的作用: 保护系统安全: 防止未经授权的用户在系统启动时进入 Grub2 菜单,通过修改启动参数来绕过系统的安全机制,进而访问或篡改系统文件和数据。例如,恶意用户可能试图通过修改启…...

【Java学习】Lambda表达式
目录 一、函数式匿名 1.环境确定 2.Lambda部分实现 二、函数式书写 Lambda表达式: 三、函数式接口 1.Consumer行为接口 1.1Lambda匿名实现(核心) 1.2创建使用全过程 1.2.1创建匿名子类实例 1.2.1.1环境确定 1.2.1.2匿名实现 1.2.2向上转型 1.2.3Lamb…...
:双边市场模式的挑战、策略与创业阶段关联)
精益数据分析(55/126):双边市场模式的挑战、策略与创业阶段关联
精益数据分析(55/126):双边市场模式的挑战、策略与创业阶段关联 在创业和数据分析的学习旅程中,我们持续探索不同商业模式的奥秘。今天,依旧怀揣着与大家共同进步的想法,深入研读《精益数据分析》…...

人工智能100问☞第21问:神经网络如何模拟人脑结构?
目录 一、通俗解释 二、专业解析 三、权威参考 神经网络通过分层连接的人工神经元模拟人脑结构,其中输入层接收信号(模拟树突接收信息),隐藏层通过权重调整(模拟突触可塑性)进行特征提取,输出层生成结果(类似轴突传递信号),并利用反向传播机制(类比生物神…...

Vue 3 实现转盘抽奖效果
🎡 使用 Vue 3 实现转盘抽奖效果 在移动端或营销活动中,转盘抽奖是一种非常常见的互动方式。本文基于 Vue 3 TypeScript 实现一个视觉炫酷、逻辑完整的转盘抽奖功能,并支持「指定奖品必中」的逻辑。 iShot_2025-05-12_11.31.27 ᾟ…...

Python 处理图像并生成 JSONL 元数据文件 - 灵活text版本
Python 处理图像并生成 JSONL 元数据文件 - 灵活text版本 flyfish import os import json import argparse from PIL import Image from xpinyin import Pinyinclass ImageConverter:def __init__(self, src_folder, dest_folder, target_size1024, output_format"JPEG&…...
—— ACT 在 Mobile ALOHA 训练与部署)
LeRobot 项目部署运行逻辑(七)—— ACT 在 Mobile ALOHA 训练与部署
全部流程为:硬件配置 -> 环境安装 -> 遥操作数据采集 -> 数据集可视化 -> 策略训练 -> 策略评估 在之前的笔记中已经完成了绝大部分,最后再记录一下最后的训练部署,算是最简单的部分了 目录 1 ACT 训练 2 ALOHA 部署 3 更…...

【NextPilot日志移植】ULog
📚 ULog 日志系统详解 关键词:结构化日志、飞行数据记录、自描述格式、嵌入式系统、PX4、NextPilot 🧠 一、ULog 是什么? ULog(Universal Log) 是 PX4/NextPilot 飞控系统中使用的结构化日志格式ÿ…...

扩展:React 项目执行 yarn eject 后的 scripts 目录结构详解
扩展:React 项目执行 yarn eject 后的 scripts 目录结构详解 什么是 yarn eject?scripts 目录结构与说明各脚本说明说明 什么是 yarn eject? yarn eject 是 Create React App(简称 CRA)提供的一条命令,用于…...

Android11.0 framework第三方无源码APP读写断电后数据丢失问题解决
1.前言 在11.0中rom定制化开发中,在某些产品开发中,在某些情况下在App用FileOutputStream读写完毕后,突然断电 会出现写完的数据丢失的问题,接下来就需要分析下关于使用FileOutputStream读写数据的相关流程,来实现相关 功能 2.framework第三方无源码APP读写断电后数据丢…...
)
多样本整合Banksy空间聚类分析(Visium HD, Xenium, CosMx)
在空间数据分析中,传统的单细胞聚类算法,例如Seurat和Scanpy中的lovain和leiden等聚类算法,通常在处理空间数据时忽略了空间信息。然而,由于细胞状态受其周围细胞的影响,将转录组数据与细胞的空间信息结合起来进行聚类…...

【2025最新】Vm虚拟机中直接使用Ubuntu 免安装过程直接使用教程与下载
Ubuntu 是一个基于 Debian 的自由开源 Linux 操作系统,面向桌面、服务器和云计算平台广泛应用。 由英国公司 Canonical Ltd. 维护和发布,Ubuntu 强调易用性、安全性和稳定性,适合个人用户、开发者以及企业部署使用。 Ubuntu 默认使用 GNOME …...

【Leetcode】系列之206反转链表
反转链表 题目描述解决思路过程示例代码示例结果展示 总结 题目描述 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 解决思路 next_node:临时存放当前指针指向下一个指针的变量;pre:存放空指针;curr࿱…...

图灵爬虫练习平台第十九题js逆向
题十九:法外狂徒 该题适合JS逆向学习的小伙伴练习,模拟国内某大型网站 数据加密设计,给大家练练手 还是先f12看看是什么加密,发现是 返回数据最后加密了 还是先堆栈分析一下,直接点进去 打上断点分析一下,…...
)
Ubuntu 22初始配置(root、ssh)
1.设置root密码 并启用root用户 sudo passwd root sudo passwd -u root 2.安装ssh apt install openssh-server systemctl enable --now ssh 3.支持root通过ssh登录 vim /etc/ssh/sshd_config 是sshd_config(服务端) 不是ssh_config(客户端) 最后增加一…...

css3响应式布局
css3响应式布局 响应式设计是现代网页开发的重要组成部分,它确保网页在不同的屏幕尺寸上都有良好的显示效果。 在CSS中,实现响应式布局是一种常用的技术,旨在使网页能够根据用户的设备和屏幕尺寸自动调整其布局和样式。这种技术对于确保网站…...

【DeepSeek问答记录】请结合实例,讲解一下pytorch的DataLoader的使用方法
PyTorch的DataLoader是数据加载的核心工具,可高效处理批量数据、并行加载和自动打乱。以下是一个结合实例的分步讲解: 1. 基础使用流程 import torch from torch.utils.data import Dataset, DataLoader# 自定义数据集类(必须实现__len__和…...
(A-D))
Codeforces Round 1024 (Div. 2)(A-D)
题面链接:Dashboard - Codeforces Round 1024 (Div. 2) - Codeforces A. Dinner Time 思路 一共n个数被分成n/p个区间,每个区间内的和是q,如果还有除构成区间外剩余的数那么就一定能构造,如果没有剩余就看所有区间的和是否等于…...

大语言模型强化学习双强:OpenRLHF与verl技术解析
引言 随着大语言模型(LLM)参数规模突破千亿级,如何高效完成基于人类反馈的强化学习(RLHF)训练成为行业焦点。OpenRLHF与verl作为开源社区两大标杆框架,分别以Ray分布式架构和HybridFlow混合控制器为核心&a…...

ARM Cortex-M3内核详解
目录 一、ARM Cortex-M3内核基本介绍 (一)基本介绍 (二)主要组成部分 (三)调试系统 二、ARM Cortex-M3内核的内核架构 三、ARM Cortex-M3内核的寄存器 四、ARM Cortex-M3内核的存储结构 五、ARM Co…...

关于高并发GIS数据处理的一点经验分享
1、背景介绍 笔者过去几年在参与某个大型央企的项目开发过程中,遇到了十分棘手的难题。其与我们平常接触的项目性质完全不同。在一般的项目中,客户一般只要求我们能够通过桌面软件对原始数据进行加工处理,将各类地理信息数据加工处理成地图/场景和工作空间,然后再将工作空…...

vue3+flask+sqlite前后端项目实战
基础环境安装 pycharm 下载地址: https://www.jetbrains.com/zh-cn/pycharm/download/?sectionwindows vscode 下载地址 https://code.visualstudio.com/docs/?dvwin64user python 下载地址 https://www.python.org/downloads/windows/ Node.js(含npm…...

支付宝API-SKD-GO版
前言 支付宝api的sdk没有提供go版,这里自己封装了一个go版的sdk,有需要的朋友可以自取使用 支付宝 AliPay SDK for Go, 集成简单,功能完善,持续更新,支持公钥证书和普通公钥进行签名和验签。 安装 go get github.c…...
>关于父子组件的样式传递问题(自定义组件样式穿透))
uniapp(微信小程序)>关于父子组件的样式传递问题(自定义组件样式穿透)
由于"微信小程序"存在【样式隔离机制】,且默认设置为isolated(启用样式隔离),因此这里给出以下两种解决方案: 注意: 这2种方案父子组件<style>标签不能添加"scoped" 1.CSS变量穿透(推荐: 此方案不受样…...

AI时代还需要目视解译吗?——目视解译详解
在遥感技术迅猛发展的今天,尽管计算机自动解译算法层出不穷,目视解译仍然保持着其基础性和权威性的地位。作为遥感信息提取的"黄金标准",目视解译凭借人类认知系统的独特优势,在多个专业领域持续发挥着不可替代的作用。…...

苹果电脑笔记本macos Mac安装mixly 米思齐软件详细指南
一、下载安装包 二、安装 1、解压下载的文件,然后将解压后文件夹中的中文名称部分删掉只保留英文名称,例如:mixly2.0-mac 2、将mixly2.0-mac文件夹移动到当前用户的Documents路径下,注意路径中不要有中文。 3、进入mixly2.0-mac文…...

slackware系统详解
Slackware 是最古老的活跃维护的 Linux 发行版之一,由 Patrick Volkerding 于 1993 年创建。它以简洁性、稳定性和遵循 Unix 哲学为核心理念,适合追求高度控制和手动配置的用户。以下是 Slackware 的详细介绍: 1. 核心特点 简洁性 (Simplici…...
)
力扣210(拓扑排序)
210. 课程表 II - 力扣(LeetCode) 这是一道拓扑排序的模板题。简单来说,给出一个有向图,把这个有向图转成线性的排序就叫拓扑排序。如果有向图中有环就没有办法进行拓扑排序了。因此,拓扑排序也是图论中判断有向无环图…...

Promise/A+ 规范中文解读
一、简介 Promise/A 是一个开放、健全且通用的JavaScript Promise标准,由开发者制定并供开发者参考。其核心目标是定义then方法的行为,确保不同Promise实现的互操作性。规范聚焦于异步操作的最终结果交互机制,而非Promise的创建、解决或拒绝…...

多媒体预研
主要包含h265 av1 等各种 多媒体的具体应用 svac_plugin ZLMediaKit/ext-codec at master cyf88/ZLMediaKit D:\java\xiachu\otherzlm\ZLMediaKit> sip-client GB28181-Service/SipClient at master Washington-DC/GB28181-Service yolo Jackson-Tan/wvp_pro_yolo: 小…...

动态网站 LNMP
一、名词解释: LNMP: L : 代表 Linux 操作系统,为网站提供了可靠的运行环境N : 代表 Nginx,它是一款轻量级的高性能 Web 服务器,能够快速处理大量并 发连接,有效提升网站的访问速度和性能 M : 代表…...

【Leetcode刷题随笔】349. 两个数组的交集
1. 题目描述 给定两个数组nums1和nums2,返回它们的交集。输出结果中的每个元素一定是唯一的。我们可以不考虑输出结果的顺序。 示例1: 输入:nums1 [1,2,2,1], nums2 [2,2] 输出:[2] 题目条件: 1 < nums1.length, nums2.length < 10…...

如何优雅的使用CMake中的FindPkgConfig模块
背景 如果你遇到下面的场景,那么FindPkgConfig模块可以用来解决我们引用上游库的问题。 上游库没有提供CMake的配置文件。CMake没有提供相应的查找模块,即Find<PackageName>.cmake的文件。上游库提供了pkg-config使用的.pc文件。 如果上面三个条…...

Docker Volumes
Docker Volumes 是 Docker 提供的一种机制,用于持久化存储容器数据。与容器的生命周期不同,Volumes 可以独立存在,即使容器被删除,数据仍然保留。以下是关于 Docker Volumes 的详细说明: 1. 为什么需要 Volumes&#…...
:[macOS 64bit App开发]: 如何获取当前用户主目录(即:~波浪符号目录)?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: 如何获取当前用户主目录(即:~波浪符号目录)?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...