【大数据】MapReduce 编程--WordCount
API 是“Application Programming Interface”的缩写,即“应用程序编程接口”
Hadoop 提供了一套 基于 Java 的 API,用于开发 MapReduce 程序、访问 HDFS、控制作业等
MapReduce 是一种 分布式并行计算模型,主要用于处理 大规模数据集。它将计算任务分为两个阶段:
阶段 功能 程序类名(通常) Map 阶段 对输入数据进行处理和拆分,生成键值对(key-value) Mapper 类 Reduce 阶段 汇总 Map 输出的 key-value 数据,对相同 key 的数据进行合并处理 Reducer 类
MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)
Mapper实现
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{//重写map这个方法//mapreduce框架每读一行数据就调用一次该方法protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value//key是这一行数据的起始偏移量,value是这一行的文本内容}
}WcMap 类继承了 Hadoop 提供的 Mapper 类,并且指定了四个泛型参数
Mapper 的泛型Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
-
KEYIN: 输入键的类型(Map函数输入)-- -
VALUEIN: 输入值的类型 -
KEYOUT: 输出键的类型(Map函数输出) -
VALUEOUT: 输出值的类型
| 参数 | 类型 | 含义 |
|---|---|---|
LongWritable | 输入键 | 一行文本的起始偏移量(比如第几字节开始) |
Text | 输入值 | 一整行文本内容 |
Text | 输出键 | 单词(比如:"Hello") |
LongWritable | 输出值 | 单词的计数(一般为 1) |
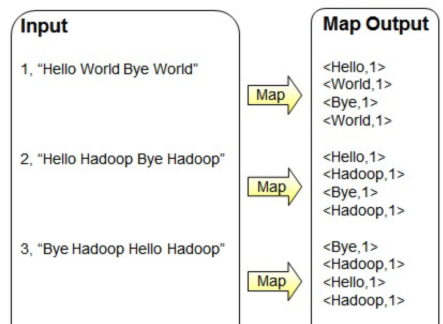
Map过程:并行读取文本,对读取的单词进行map操作,每个词都以
<key,value>形式生成。一个有三行文本的文件进行MapReduce操作。
读取第一行
Hello World Bye World,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>读取第二行
Hello Hadoop Bye Hadoop,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>读取第三行
Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
MapReduce 中的 Mapper 实现,用于实现“词频统计”(WordCount)功能
按行读取文本,把每个单词都变成 <word, 1> 输出,为后续的词频统计做准备
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**** * @author Administrator* 1:4个泛型中,前两个是指定mapper输入数据的类型,KEYIN是输入的key的类型,VALUEIN是输入的value的值* KEYOUT是输入的key的类型,VALUEOUT是输入的value的值 * 2:map和reduce的数据输入和输出都是以key-value的形式封装的。* 3:默认情况下,框架传递给我们的mapper的输入数据中,key是要处理的文本中一行的起始偏移量,这一行的内容作为value* 4:key-value数据是在网络中进行传递,节点和节点之间互相传递,在网络之间传输就需要序列化,但是jdk自己的序列化很冗余* 所以使用hadoop自己封装的数据类型,而不要使用jdk自己封装的数据类型;* Long--->LongWritable* String--->Text */
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{//重写map这个方法//mapreduce框架每读一行数据就调用一次该方法@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {//具体业务逻辑就写在这个方法体中,而且我们业务要处理的数据已经被框架传递进来,在方法的参数中key-value//key是这一行数据的起始偏移量,value是这一行的文本内容//1:String str = value.toString();//2:切分单词,空格隔开,返回切分开的单词String[] words = StringUtils.split(str," ");//3:遍历这个单词数组,输出为key-value的格式,将单词发送给reducefor(String word : words){//输出的key是Text类型的,value是LongWritable类型的context.write(new Text(word), new LongWritable(1));}}
}
继承 Hadoop Mapper 的类---------------- public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>
重写的 map 方法---MapReduce 框架自动调用,对文件的每一行都会调用一次
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
| 参数 | 作用 |
|---|---|
key | 当前行在文件中的偏移量(不重要) |
value | 当前这一行的文本内容(例如:"Hello Hadoop Bye") |
context | Hadoop 框架提供的对象,用于输出结果 |
把 Text 类型转换成普通字符串:String str = value.toString();
按空格切分字符串,获取单词数组:String[] words = StringUtils.split(str," ");例如:"Hello Hadoop Bye" => ["Hello", "Hadoop", "Bye"]-----Apache Commons 的 StringUtils.split 方法
遍历所有单词
for(String word : words){context.write(new Text(word), new LongWritable(1));
}
每拿到一个单词,就创建一对键值对 <单词, 1> 输出出去。这些结果会传给 Reduce 处理
Hadoop 的 MapReduce 任务运行在集群中,key-value 是在网络上传输的, 不能使用 Java 原生类型(如 String、long),必须使用 Hadoop 提供的可序列化数据类型
Java类型 Hadoop类型 String Textlong LongWritableint IntWritablefloat FloatWritable
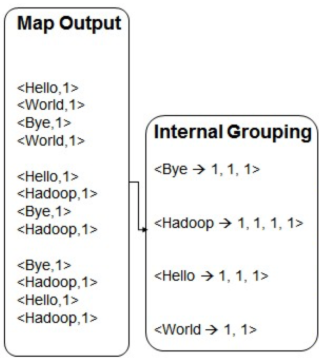
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>不是我们写的代码做的,而是 MapReduce 框架自动完成的工作,叫做 Shuffle + 分组过程(有时也叫分区、排序、合并)
MapReduce 的完整流程
Mapper 阶段
输入的 3 行:
Hello World Bye World
Hello Hadoop Bye Hadoop
Bye Hadoop Hello Hadoop
Mapper 输出
<Hello,1> <World,1> <Bye,1> <World,1>
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
Combiner 阶段(局部归约)
如果配置了 Combiner(它的逻辑通常和 Reducer 是一样的),那在每台 Map 机器本地就会先对相同的 key 做一次合并
<Hello,1> <Hello,1> <Hello,1>合成:<Hello,3>
Combiner 是可选的优化步骤,有助于减少网络传输数据量--:Combiner 需要配置,它不是自动就起作用的
Shuffle + Sort + Grouping(框架自动做)
这一步发生在 Mapper 和 Reducer 之间,称为 洗牌过程(Shuffle),是 MapReduce 的精髓。
| 步骤 | 解释 |
|---|---|
| Shuffle | 把相同 key 的数据发送给同一个 Reducer(网络传输) |
| Sort | 对 key 进行排序(Hadoop 默认会对 key 排序) |
| Group | 把相同 key 的多个 value 放在一个集合中 |
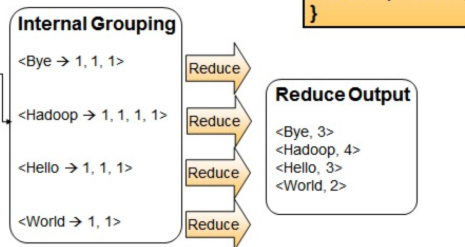
最终 Reducer 接收到的数据
<Hello, [1,1,1]>
<World, [1,1]>
<Bye, [1,1,1]>
<Hadoop, [1,1,1,1]>
假设你原始文本是:Hello World Hello
Map 阶段输出:<Hello,1> <World,1> <Hello,1>
Reduce 阶段输入(自动分组):key = Hello, values = [1, 1] key = World, values = [1]
Reduce 输出:<Hello,2> <World,1>
Reducer 实现
WcReduce 是 MapReduce 中的 Reducer 实现类
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{//继承Reducer之后重写reduce方法//第一个参数是key,第二个参数是集合。//框架在map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法protected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {}
}继承了 Hadoop 提供的 Reducer 类
| 泛型参数 | 类型 | 含义 |
|---|---|---|
KEYIN | Text | 单词 |
VALUEIN | LongWritable | 数字 |
KEYOUT | Text | Reduce 的输出 key(还是单词) |
VALUEOUT | LongWritable | Reduce 的输出 value(统计的总次数) |
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
reduce 方法就处理每一组(key 相同)Map 输出的结果
-
key: 单词,例如"Hello"、"Hadoop"。 -
values: 一个可遍历的对象,包含所有这个单词对应的值,例如<"Hello", [1, 1, 1]>。 -
context: 用来把结果写出去
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**** * @author Administrator* 1:reduce的四个参数,第一个key-value是map的输出作为reduce的输入,第二个key-value是输出单词和次数,所以* 是Text,LongWritable的格式;*/
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{//继承Reducer之后重写reduce方法//第一个参数是key,第二个参数是集合。//框架在map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,valus{}>,调用一次reduce方法//<hello,{1,1,1,1,1,1.....}>@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {//将values进行累加操作,进行计数long count = 0;//遍历value的list,进行累加求和for(LongWritable value : values){count += value.get();}//输出这一个单词的统计结果//输出放到hdfs的某一个目录上面,输入也是在hdfs的某一个目录context.write(key, new LongWritable(count));}
}累加单词出现次数
long count = 0;
for(LongWritable value : values){count += value.get();
}
LongWritable 是 Hadoop 提供的可序列化的 long 类型(因为 MapReduce 要在网络中传输数据,不能用普通的 Java 类型)
定义一个变量 count,用来统计每个单词出现的总次数
遍历传进来的所有 value 值(也就是 1)
context.write(key, new LongWritable(count));
执行MapReduce任务
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。
设置了使用TokenizerMapper完成Map过程中的处理和使用IntSumReducer完成Combine和Reduce过程中的处理
设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。
任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。
完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务。
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Scanner;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import java.net.URI;
/**** 1:用来描述一个特定的作业* 比如,该作业使用哪个类作为逻辑处理中的map,那个作为reduce* 2:还可以指定该作业要处理的数据所在的路径* 还可以指定改作业输出的结果放到哪个路径* @author Administrator**/
public class WcRunner{public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//创建配置文件Configuration conf = new Configuration();//获取一个作业Job job = Job.getInstance(conf);//设置整个job所用的那些类在哪个jar包job.setJarByClass(WcRunner.class);//本job使用的mapper和reducer的类job.setMapperClass(WcMap.class);job.setReducerClass(WcReduce.class);//指定reduce的输出数据key-value类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//指定mapper的输出数据key-value类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);Scanner sc = new Scanner(System.in);System.out.print("inputPath:");String inputPath = sc.next();System.out.print("outputPath:");String outputPath = sc.next();//指定要处理的输入数据存放路径FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000"+inputPath));//指定处理结果的输出数据存放路径FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000"+outputPath));//将job提交给集群运行 job.waitForCompletion(true);//输出结果try {FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());Path srcPath = new Path(outputPath+"/part-r-00000");FSDataInputStream is = fs.open(srcPath);System.out.println("Results:");while(true) {String line = is.readLine();if(line == null) {break;}System.out.println(line);}is.close();}catch(Exception e) {e.printStackTrace();}}
}从 HDFS 读取输出文件 part-r-00000,然后打印文件的每一行,直到文件内容读取完为止。其核心操作是通过 FileSystem 获取 HDFS 文件系统,然后使用 FSDataInputStream 读取文件的内容
----------
FileSystem.get() 方法获取 HDFS 文件系统的实例
URI: 这是 HDFS 文件系统的 URI,指定了 HDFS 的访问路径。"hdfs://master:9000" 表示 HDFS 在 master 主机的 9000 端口上运行
Configuration: 这是 Hadoop 的配置对象,包含了关于 Hadoop 系统的各种设置。new Configuration() 会创建一个默认的配置
outputPath 是用户在输入时提供的输出路径,这里使用 outputPath + "/part-r-00000" 来构建文件路径---part-r-00000 是默认的输出文件名
FSDataInputStream 对象是用来读取文件内容的
is.readLine() 方法逐行读取文件的内容。
-
如果
readLine()返回null,表示文件已经读完。 -
每读取一行,就将其打印出来。
相关文章:

【大数据】MapReduce 编程--WordCount
API 是“Application Programming Interface”的缩写,即“应用程序编程接口” Hadoop 提供了一套 基于 Java 的 API,用于开发 MapReduce 程序、访问 HDFS、控制作业等 MapReduce 是一种 分布式并行计算模型,主要用于处理 大规模数据集。它将…...

北京市通州区经信局对新增通过国家级生成式人工智能及深度合成算法备案企业给予100w、20w一次性补贴
北京市通州区经济和信息化局 关于发布支持北京城市副中心数字经济高质量发展的实施指南(第一批)的通知 各有关单位: 为培育千亿级数字经济产业集群,促进数字经济和实体经济深度融合,助推北京城市副中心产业高质量发展&…...

机器学习驱动的智能化电池管理技术与应用
在人工智能与电池管理技术融合的背景下,电池科技的研究和应用正迅速发展,创新解决方案层出不穷。从电池性能的精确评估到复杂电池系统的智能监控,从数据驱动的故障诊断到电池寿命的预测优化,人工智能技术正以其强大的数据处理能力…...

GTC2025——英伟达布局推理领域加速
英伟达GTC2025大会于今年3月18日举行,会上NVIDIA CEO黄仁勋展示了其过去所取得的成就,以及未来的布局目标——通过纵向扩展(scale out)和横向扩展(scale up)解决终极的计算问题——推理。本文将回顾NVIDIA在…...

5.12 note
Leetcode 图 邻接矩阵的dfs遍历 class Solution { private: vector<vector<int>> paths; vector<int> path; void dfs(vector<vector<int>>& graph, int node) { // 到n - 1结点了保存 if (node graph.size() - 1)…...

Java Spring Boot项目目录规范示例
以下是一个典型的 Java Spring Boot 项目目录结构规范示例,结合了分层架构和模块化设计的最佳实践: text 复制 下载 src/ ├── main/ │ ├── java/ │ │ └── com/ │ │ └── example/ │ │ └── myapp/ │…...

记录裁员后的半年前端求职经历
普通的人生终起波澜 去年下半年应该算是我毕业以来发生人生变故最多的一段时间。 先是 7 月份的时候发作了一次急性痛风,一个人在厦门,坐在床上路都走不了,那时候真的好想旁边能有个人能扶我去医院,真的是感受到 10 级的孤独。尝…...

学习黑客BitLocker与TPM详解
BitLocker与TPM详解:数据加密的坚固堡垒 🔐🛡️ 学习目标:掌握BitLocker加密原理、TPM工作机制及其配置方法,提升数据安全防护水平 1. 数据保护的最后防线:BitLocker与TPM简介 💼 在当今世界&a…...

综合实验二之grub2密文加密
实验二、grub2密文加密 Grub2 密文加密的作用: 保护系统安全: 防止未经授权的用户在系统启动时进入 Grub2 菜单,通过修改启动参数来绕过系统的安全机制,进而访问或篡改系统文件和数据。例如,恶意用户可能试图通过修改启…...

【Java学习】Lambda表达式
目录 一、函数式匿名 1.环境确定 2.Lambda部分实现 二、函数式书写 Lambda表达式: 三、函数式接口 1.Consumer行为接口 1.1Lambda匿名实现(核心) 1.2创建使用全过程 1.2.1创建匿名子类实例 1.2.1.1环境确定 1.2.1.2匿名实现 1.2.2向上转型 1.2.3Lamb…...
:双边市场模式的挑战、策略与创业阶段关联)
精益数据分析(55/126):双边市场模式的挑战、策略与创业阶段关联
精益数据分析(55/126):双边市场模式的挑战、策略与创业阶段关联 在创业和数据分析的学习旅程中,我们持续探索不同商业模式的奥秘。今天,依旧怀揣着与大家共同进步的想法,深入研读《精益数据分析》…...

人工智能100问☞第21问:神经网络如何模拟人脑结构?
目录 一、通俗解释 二、专业解析 三、权威参考 神经网络通过分层连接的人工神经元模拟人脑结构,其中输入层接收信号(模拟树突接收信息),隐藏层通过权重调整(模拟突触可塑性)进行特征提取,输出层生成结果(类似轴突传递信号),并利用反向传播机制(类比生物神…...

Vue 3 实现转盘抽奖效果
🎡 使用 Vue 3 实现转盘抽奖效果 在移动端或营销活动中,转盘抽奖是一种非常常见的互动方式。本文基于 Vue 3 TypeScript 实现一个视觉炫酷、逻辑完整的转盘抽奖功能,并支持「指定奖品必中」的逻辑。 iShot_2025-05-12_11.31.27 ᾟ…...

Python 处理图像并生成 JSONL 元数据文件 - 灵活text版本
Python 处理图像并生成 JSONL 元数据文件 - 灵活text版本 flyfish import os import json import argparse from PIL import Image from xpinyin import Pinyinclass ImageConverter:def __init__(self, src_folder, dest_folder, target_size1024, output_format"JPEG&…...
—— ACT 在 Mobile ALOHA 训练与部署)
LeRobot 项目部署运行逻辑(七)—— ACT 在 Mobile ALOHA 训练与部署
全部流程为:硬件配置 -> 环境安装 -> 遥操作数据采集 -> 数据集可视化 -> 策略训练 -> 策略评估 在之前的笔记中已经完成了绝大部分,最后再记录一下最后的训练部署,算是最简单的部分了 目录 1 ACT 训练 2 ALOHA 部署 3 更…...

【NextPilot日志移植】ULog
📚 ULog 日志系统详解 关键词:结构化日志、飞行数据记录、自描述格式、嵌入式系统、PX4、NextPilot 🧠 一、ULog 是什么? ULog(Universal Log) 是 PX4/NextPilot 飞控系统中使用的结构化日志格式ÿ…...

扩展:React 项目执行 yarn eject 后的 scripts 目录结构详解
扩展:React 项目执行 yarn eject 后的 scripts 目录结构详解 什么是 yarn eject?scripts 目录结构与说明各脚本说明说明 什么是 yarn eject? yarn eject 是 Create React App(简称 CRA)提供的一条命令,用于…...

Android11.0 framework第三方无源码APP读写断电后数据丢失问题解决
1.前言 在11.0中rom定制化开发中,在某些产品开发中,在某些情况下在App用FileOutputStream读写完毕后,突然断电 会出现写完的数据丢失的问题,接下来就需要分析下关于使用FileOutputStream读写数据的相关流程,来实现相关 功能 2.framework第三方无源码APP读写断电后数据丢…...
)
多样本整合Banksy空间聚类分析(Visium HD, Xenium, CosMx)
在空间数据分析中,传统的单细胞聚类算法,例如Seurat和Scanpy中的lovain和leiden等聚类算法,通常在处理空间数据时忽略了空间信息。然而,由于细胞状态受其周围细胞的影响,将转录组数据与细胞的空间信息结合起来进行聚类…...

【2025最新】Vm虚拟机中直接使用Ubuntu 免安装过程直接使用教程与下载
Ubuntu 是一个基于 Debian 的自由开源 Linux 操作系统,面向桌面、服务器和云计算平台广泛应用。 由英国公司 Canonical Ltd. 维护和发布,Ubuntu 强调易用性、安全性和稳定性,适合个人用户、开发者以及企业部署使用。 Ubuntu 默认使用 GNOME …...

【Leetcode】系列之206反转链表
反转链表 题目描述解决思路过程示例代码示例结果展示 总结 题目描述 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 解决思路 next_node:临时存放当前指针指向下一个指针的变量;pre:存放空指针;curr࿱…...

图灵爬虫练习平台第十九题js逆向
题十九:法外狂徒 该题适合JS逆向学习的小伙伴练习,模拟国内某大型网站 数据加密设计,给大家练练手 还是先f12看看是什么加密,发现是 返回数据最后加密了 还是先堆栈分析一下,直接点进去 打上断点分析一下,…...
)
Ubuntu 22初始配置(root、ssh)
1.设置root密码 并启用root用户 sudo passwd root sudo passwd -u root 2.安装ssh apt install openssh-server systemctl enable --now ssh 3.支持root通过ssh登录 vim /etc/ssh/sshd_config 是sshd_config(服务端) 不是ssh_config(客户端) 最后增加一…...

css3响应式布局
css3响应式布局 响应式设计是现代网页开发的重要组成部分,它确保网页在不同的屏幕尺寸上都有良好的显示效果。 在CSS中,实现响应式布局是一种常用的技术,旨在使网页能够根据用户的设备和屏幕尺寸自动调整其布局和样式。这种技术对于确保网站…...

【DeepSeek问答记录】请结合实例,讲解一下pytorch的DataLoader的使用方法
PyTorch的DataLoader是数据加载的核心工具,可高效处理批量数据、并行加载和自动打乱。以下是一个结合实例的分步讲解: 1. 基础使用流程 import torch from torch.utils.data import Dataset, DataLoader# 自定义数据集类(必须实现__len__和…...
(A-D))
Codeforces Round 1024 (Div. 2)(A-D)
题面链接:Dashboard - Codeforces Round 1024 (Div. 2) - Codeforces A. Dinner Time 思路 一共n个数被分成n/p个区间,每个区间内的和是q,如果还有除构成区间外剩余的数那么就一定能构造,如果没有剩余就看所有区间的和是否等于…...

大语言模型强化学习双强:OpenRLHF与verl技术解析
引言 随着大语言模型(LLM)参数规模突破千亿级,如何高效完成基于人类反馈的强化学习(RLHF)训练成为行业焦点。OpenRLHF与verl作为开源社区两大标杆框架,分别以Ray分布式架构和HybridFlow混合控制器为核心&a…...

ARM Cortex-M3内核详解
目录 一、ARM Cortex-M3内核基本介绍 (一)基本介绍 (二)主要组成部分 (三)调试系统 二、ARM Cortex-M3内核的内核架构 三、ARM Cortex-M3内核的寄存器 四、ARM Cortex-M3内核的存储结构 五、ARM Co…...

关于高并发GIS数据处理的一点经验分享
1、背景介绍 笔者过去几年在参与某个大型央企的项目开发过程中,遇到了十分棘手的难题。其与我们平常接触的项目性质完全不同。在一般的项目中,客户一般只要求我们能够通过桌面软件对原始数据进行加工处理,将各类地理信息数据加工处理成地图/场景和工作空间,然后再将工作空…...

vue3+flask+sqlite前后端项目实战
基础环境安装 pycharm 下载地址: https://www.jetbrains.com/zh-cn/pycharm/download/?sectionwindows vscode 下载地址 https://code.visualstudio.com/docs/?dvwin64user python 下载地址 https://www.python.org/downloads/windows/ Node.js(含npm…...

支付宝API-SKD-GO版
前言 支付宝api的sdk没有提供go版,这里自己封装了一个go版的sdk,有需要的朋友可以自取使用 支付宝 AliPay SDK for Go, 集成简单,功能完善,持续更新,支持公钥证书和普通公钥进行签名和验签。 安装 go get github.c…...
>关于父子组件的样式传递问题(自定义组件样式穿透))
uniapp(微信小程序)>关于父子组件的样式传递问题(自定义组件样式穿透)
由于"微信小程序"存在【样式隔离机制】,且默认设置为isolated(启用样式隔离),因此这里给出以下两种解决方案: 注意: 这2种方案父子组件<style>标签不能添加"scoped" 1.CSS变量穿透(推荐: 此方案不受样…...

AI时代还需要目视解译吗?——目视解译详解
在遥感技术迅猛发展的今天,尽管计算机自动解译算法层出不穷,目视解译仍然保持着其基础性和权威性的地位。作为遥感信息提取的"黄金标准",目视解译凭借人类认知系统的独特优势,在多个专业领域持续发挥着不可替代的作用。…...

苹果电脑笔记本macos Mac安装mixly 米思齐软件详细指南
一、下载安装包 二、安装 1、解压下载的文件,然后将解压后文件夹中的中文名称部分删掉只保留英文名称,例如:mixly2.0-mac 2、将mixly2.0-mac文件夹移动到当前用户的Documents路径下,注意路径中不要有中文。 3、进入mixly2.0-mac文…...

slackware系统详解
Slackware 是最古老的活跃维护的 Linux 发行版之一,由 Patrick Volkerding 于 1993 年创建。它以简洁性、稳定性和遵循 Unix 哲学为核心理念,适合追求高度控制和手动配置的用户。以下是 Slackware 的详细介绍: 1. 核心特点 简洁性 (Simplici…...
)
力扣210(拓扑排序)
210. 课程表 II - 力扣(LeetCode) 这是一道拓扑排序的模板题。简单来说,给出一个有向图,把这个有向图转成线性的排序就叫拓扑排序。如果有向图中有环就没有办法进行拓扑排序了。因此,拓扑排序也是图论中判断有向无环图…...

Promise/A+ 规范中文解读
一、简介 Promise/A 是一个开放、健全且通用的JavaScript Promise标准,由开发者制定并供开发者参考。其核心目标是定义then方法的行为,确保不同Promise实现的互操作性。规范聚焦于异步操作的最终结果交互机制,而非Promise的创建、解决或拒绝…...

多媒体预研
主要包含h265 av1 等各种 多媒体的具体应用 svac_plugin ZLMediaKit/ext-codec at master cyf88/ZLMediaKit D:\java\xiachu\otherzlm\ZLMediaKit> sip-client GB28181-Service/SipClient at master Washington-DC/GB28181-Service yolo Jackson-Tan/wvp_pro_yolo: 小…...

动态网站 LNMP
一、名词解释: LNMP: L : 代表 Linux 操作系统,为网站提供了可靠的运行环境N : 代表 Nginx,它是一款轻量级的高性能 Web 服务器,能够快速处理大量并 发连接,有效提升网站的访问速度和性能 M : 代表…...

【Leetcode刷题随笔】349. 两个数组的交集
1. 题目描述 给定两个数组nums1和nums2,返回它们的交集。输出结果中的每个元素一定是唯一的。我们可以不考虑输出结果的顺序。 示例1: 输入:nums1 [1,2,2,1], nums2 [2,2] 输出:[2] 题目条件: 1 < nums1.length, nums2.length < 10…...

如何优雅的使用CMake中的FindPkgConfig模块
背景 如果你遇到下面的场景,那么FindPkgConfig模块可以用来解决我们引用上游库的问题。 上游库没有提供CMake的配置文件。CMake没有提供相应的查找模块,即Find<PackageName>.cmake的文件。上游库提供了pkg-config使用的.pc文件。 如果上面三个条…...

Docker Volumes
Docker Volumes 是 Docker 提供的一种机制,用于持久化存储容器数据。与容器的生命周期不同,Volumes 可以独立存在,即使容器被删除,数据仍然保留。以下是关于 Docker Volumes 的详细说明: 1. 为什么需要 Volumes&#…...
:[macOS 64bit App开发]: 如何获取当前用户主目录(即:~波浪符号目录)?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: 如何获取当前用户主目录(即:~波浪符号目录)?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

day23 机器学习管道 Pipeline
在机器学习中,数据预处理、特征提取、模型训练和评估等步骤通常是按顺序执行的。为了更高效地管理和复用这些步骤,我们可以使用 Pipeline(管道)来构建一个完整的机器学习流水线。本文将详细介绍 Pipeline 的基础概念,并…...

The Graph:区块链数据索引的技术架构与创新实践
作为Web3生态的核心基础设施,The Graph通过去中心化索引协议重塑了链上数据访问的范式。其技术设计不仅解决了传统区块链数据查询的效率瓶颈,还通过经济模型与多链兼容性构建了一个开放的开发者生态。本文从技术角度解析其架构、机制及创新实践。 一、技…...

nginx配置sse流传输问题:直到所有内容返回后才往下传输
一、禁用缓冲(如实时流传输): location /stream {proxy_buffering off; } 二、开启分块传输 location /your-path {proxy_chunked_transfer_encoding on; # 显式启用分块传输(默认已启用) }...

使用Daemonset部署日志收集守护进程
1.DaemonSet简介: 在Kubernetes(简称k8s)中,DaemonSet是一种控制器,用于确保集群中的每个(或部分)节点运行一个指定的Pod副本。DaemonSet非常适合需要全局部署、节点级运行的服务,如…...

在Mac环境下搭建Docker环境的全攻略
在Mac环境下搭建Docker环境的全攻略 在现代软件开发中,Docker已经成为不可或缺的工具之一。它不仅简化了应用的部署和管理,还极大地提升了开发效率。然而,在某些公司环境中,桌面版的Docker可能会被禁用,这给开发工作带…...
 的使用)
Go 语言 slice(切片) 的使用
序言 在许多开发语言中,动态数组是必不可少的一个组成部分。在实际的开发中很少会使用到数组,因为对于数组的大小大多数情况下我们是不能事先就确定好的,所以他不够灵活。动态数组通过提供自动扩容的机制,极大地提升了开发效率。这…...

C++ string比较、string随机访问、string字符插入、string数据删除
string的字符串进行比较,代码见下。 #include<iostream>using namespace std;int main() {// 1 comparestring s1 "aab";string t11 "aab";int r11 s1.compare(t11);cout << "1: " << r11 << endl;strin…...