Python训练营打卡——DAY22(2025.5.11)
复习日
学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
泰坦尼克号——来自灾难的机器学习
数据来源:
kaggle泰坦里克号人员生还预测
挑战
泰坦尼克号沉没是历史上最臭名昭著的海难之一。
1912年4月15日,在被普遍认为“永不沉没”的皇家邮轮泰坦尼克号的处女航中,它与冰山相撞沉没。不幸的是,船上没有足够的救生艇供所有人使用,导致2224名乘客和船员中1502人遇难。
虽然生存需要一些运气的因素,但似乎有些群体比其他群体更有可能生存下来。
在这个挑战中,我们要求您使用乘客数据(即姓名、年龄、性别、社会经济阶层等)建立一个预测模型来回答这个问题:“什么样的人更有可能生存?”
Kaggle 竞赛如何运作
- 参加比赛
阅读挑战描述,接受比赛规则并获得比赛数据集的访问权限。 - 开始工作
下载数据,在本地或 Kaggle Notebooks(我们的无需设置、可定制的 Jupyter Notebooks 环境,带有免费 GPU)上构建模型并生成预测文件。 - 提交
您的预测并将其作为提交上传到 Kaggle 并获得准确度分数。 - 查看排行榜
查看您的模型在我们的排行榜上与其他 Kaggler 的排名。 - 提高您的分数
查看讨论论坛,查找来自其他竞争对手的大量教程和见解。
我将在本次比赛中使用哪些数据?
在本次比赛中,您将获得两个相似的数据集,其中包括乘客信息,如姓名、年龄、性别、社会经济阶层等。一个数据集的标题为train.csv,另一个数据集的标题为test.csv。
Train.csv将包含机上部分乘客(确切地说是 891 人)的详细信息,重要的是,将揭示他们是否幸存,也称为“地面真相”。
数据test.csv集包含类似的信息,但并未披露每位乘客的“基本事实”。你的任务就是预测这些结果。
使用您在数据中发现的模式train.csv,预测机上其他 418 名乘客(在 中找到test.csv)是否幸存。
查看“数据”选项卡,进一步探索数据集。一旦你认为自己创建了一个具有竞争力的模型,就可以将其提交到 Kaggle,看看你的模型在我们的排行榜上与其他 Kaggle 选手的排名。
如何向 Kaggle 提交你的预测
一旦您准备好提交并进入排行榜:
- 点击“提交预测”按钮
- 上传提交文件格式的 CSV 文件。您每天最多可以提交 10 份。
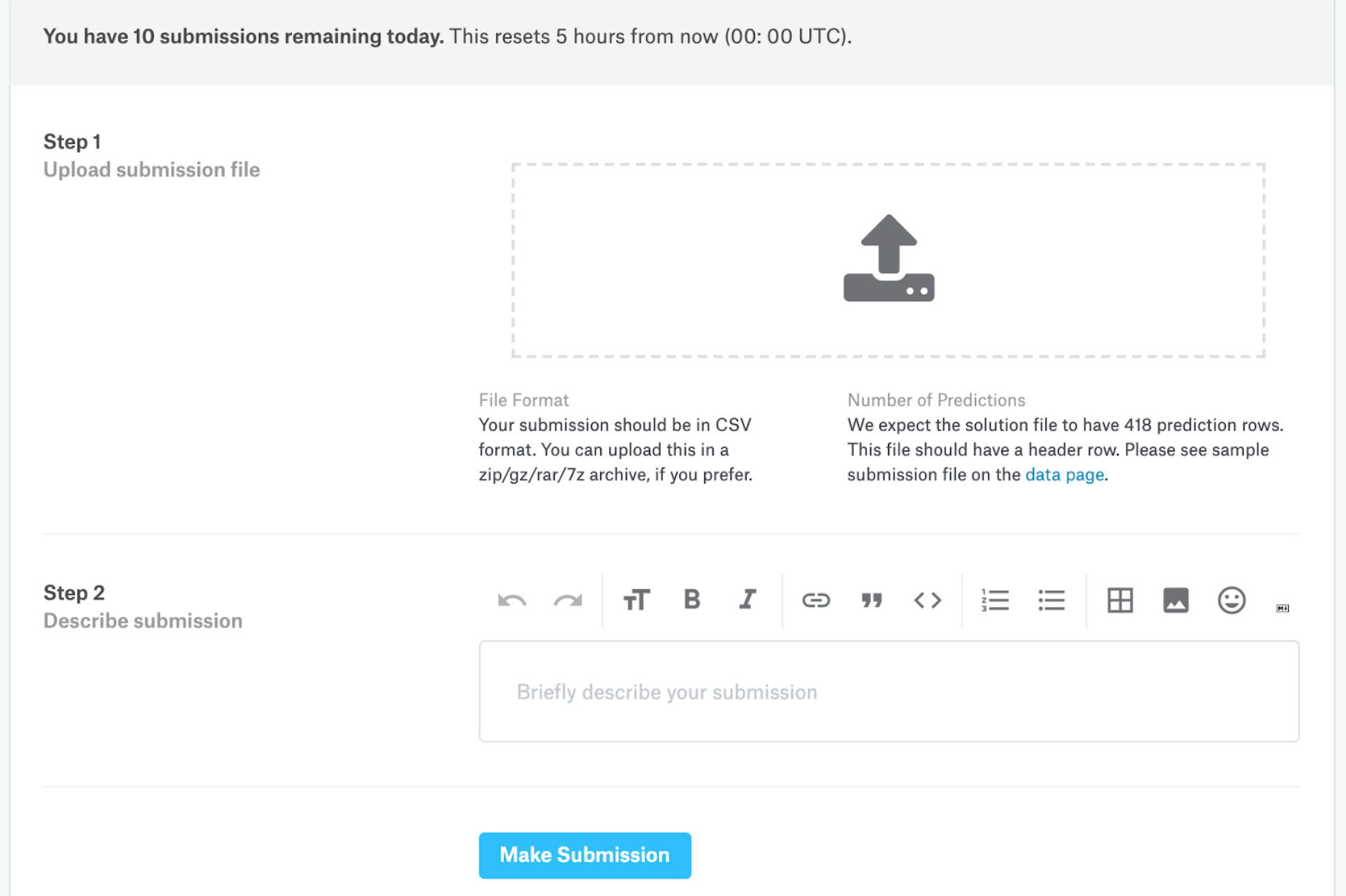
提交文件格式:
PassengerId您应该提交一个包含 418 个条目和一个标题行的 csv 文件。如果您提交的数据包含多余的列(超过和Survived)或行,则会显示错误。
该文件应该恰好有 2 列:
PassengerId(不分先后顺序)Survived(包含您的二进制预测:1 表示幸存,0 表示死亡)
1. 导入包
import warnings
warnings.filterwarnings("ignore") #忽略警告信息# 数据处理清洗包
import pandas as pd
import numpy as np
import random as rnd# 可视化包
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline# 机器学习算法相关包
from sklearn.linear_model import LogisticRegression, Perceptron, SGDClassifier
#逻辑回归、感知机、随机梯度下降法
from sklearn.svm import SVC, LinearSVC
#支持向量机、线性支持向量机
from sklearn.neighbors import KNeighborsClassifier
#最近邻
from sklearn.naive_bayes import GaussianNB
#朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier2. 加载数据集
train_df = pd.read_csv('./titanic/train.csv')
test_df = pd.read_csv('./titanic/test.csv')
combine = [train_df, test_df] # 合并数据
#这只是放到一个列表,以便后续合并,现在还没合并
#combined_df = pd.concat([train_df, test_df], axis=1, ignore_index=True)这才是合并
#combine.head()会报错,因为列表没有head方法3. 描述性统计分析
# 获取所有特征名
print(train_df.columns.values)# 预览数据
train_df.head()train_df.tail()print(train_df.isnull().sum())
# 返回每列(特征)中的缺失值数量
print('_'*40)
#打印一行分隔线,其中包含40个连续的下划线字符
test_df.isnull().sum()train_df.info()
print('_'*40)
test_df.info()
#714 non-null意为714个非空值
# RangeIndex: 891 entries, 0 to 890 表示891行数据
# Data columns (total 12 columns) 表示12列(11个特征 1个标签)round(train_df.describe(percentiles=[.5, .6, .7, .75, .8, .9, .99]),2)
#describe(percentiles=[.5, .6, .7, .75, .8, .9, .99])指定百分位描述
#round()保留2位小数
#describe()方法只描述数值型数据,12个特征中有5个object所以不表示train_df.describe(include=['O'])
# 获取非数值型(对象型)列的描述性统计信息的方法
# count:非缺失值的数量。
# unique:唯一值的数量,表示多少种数值
# top:出现次数最多的值。
# freq:出现次数最多的值的频数。4. 基于数据分析的假设
# 针对Pclass和Survived进行分类汇总
# pclass是票价等级
train_df[['Pclass','Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
# groupby是分类汇总函数,这个功能类似于数据透视表,选择分类列和汇总列
# sort_values(by='Survived', ascending=False)意思为根据survive这一列降序排序
# 另一种写法为pd.DataFrame(train_df.groupby('Pclass', as_index=False)['Survived'].mean()).sort_values(by='Survived', ascending=False)train_df[['Sex','Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)train_df[['SibSp','Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived',ascending=False)train_df[['Parch','Survived']].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived',ascending=False)5. 可视化数据分析
g = sns.FacetGrid(train_df, col='Survived') #FacetGrid(data, row, col, hue, height, aspect, palette, ...)
# col='Survived'指定了将数据分成两列,分别对应于Survived列的0和1g.map(plt.hist, 'Age', bins=20)
# plt.hist来绘制直方图,并传递了'Age'列作为数据,,bins=20指定了直方图的分箱数#grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.5, aspect=1.6)
grid = sns.FacetGrid(train_df, col='Pclass', hue='Survived')
grid.map(plt.hist, 'Age', alpha=0.5, bins=20)
grid.add_legend();grid = sns.FacetGrid(train_df, col='Embarked')
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend();grid = sns.FacetGrid(train_df, col='Embarked', hue='Survived', palette={0: 'b', 1: 'r'})
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()1
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]"After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shapetrain_df['Name'].head(10)# 使用正则表达式提取Title特征
for dataset in combine:dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand=False)
# 从姓名字符串中匹配一个或多个字母,并且以句点 (.) 结尾的部分,这通常是表示称号的部分
# 提取的称号被存储在一个新的 Title 列中
pd.crosstab(train_df['Title'], train_df['Sex']).sort_values(by='female', ascending=False) # pd.crosstab列联表
#这部分代码使用 pd.crosstab 来创建一个列联表,用于计算不同称号 和性别之间的关系
#crosstab 会统计每个组合的数量,并返回一个交叉表。combine
#还没有按列合并,还是2个数据表# 可以用更常见的名称替换许多标题或将它们归类为稀有
for dataset in combine:dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')dataset['Title'] = dataset['Title'].replace(['Mlle', 'Ms'], 'Miss')dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()train_df.head()# 将分类标题转换为序数
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:dataset['Title'] = dataset['Title'].map(title_mapping) # 将序列中的每一个元素,输入函数,最后将映射后的每个值返回合并,得到一个迭代器dataset['Title'] = dataset['Title'].fillna(0) train_df.head()# 现在可以从训练和测试数据集中删除Name特征以及训练集中的PassengerId 特征
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape# 转换分类特征Sex
for dataset in combine:dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int) #男性赋值为0,女性赋值为1,并转换为整型数据train_df.head()# 绘制Age, Pclass, Sex复合直方图
#grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid = sns.FacetGrid(train_df, col='Pclass', hue='Sex')
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()# 创建空数组
guess_ages = np.zeros((2,3))
guess_ages# 遍历 Sex (0 或 1) 和 Pclass (1, 2, 3) 来计算六种组合的 Age 猜测值
for dataset in combine:# 第一个for循环计算每一个分组的Age预测值for i in range(0, 2):for j in range(0, 3):guess_df = dataset[(dataset['Sex'] == i) & \(dataset['Pclass'] == j+1)]['Age'].dropna()# age_mean = guess_df.mean()# age_std = guess_df.std()# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)age_guess = guess_df.median()# 将随机年龄浮点数转换为最接近的 0.5 年龄(四舍五入)guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5# 第二个for循环对空值进行赋值 for i in range(0, 2):for j in range(0, 3):dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\'Age'] = guess_ages[i,j]dataset['Age'] = dataset['Age'].astype(int)
train_df.head()# 创建了一个新的列:年龄段AgeBand,并确定其与Survived的相关性
# 一般在建立分类模型时,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险
train_df['AgeBand'] = pd.cut(train_df['Age'], 5) # 将年龄分割为5段,等距分箱
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)# 将这些年龄区间替换为序数
for dataset in combine: dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3dataset.loc[ dataset['Age'] > 64, 'Age'] = 4
train_df.head()train_df = train_df.drop(['AgeBand'], axis=1) # 删除训练集中的AgeBand特征
combine = [train_df, test_df]
train_df.head()
test_dffor dataset in combine:dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)# 创建新特征IsAlone
for dataset in combine:dataset['IsAlone'] = 0dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]train_df.head(20)# 创建Age*Pclass特征以此用来结合Age和Pclass变量
for dataset in combine:dataset['Age*Pclass'] = dataset.Age * dataset.Pclasstrain_df.loc[:, ['Age*Pclass', 'Age', 'Pclass']].head(10)
train_df[['Age*Pclass', 'Survived']].groupby(['Age*Pclass'], as_index=False).mean()freq_port = train_df.Embarked.dropna().mode()[0]
# mode() 计算众数,这里只有一个值,加不加[0] 都一样,一般返回的众数是每一列的众数构成的series
for dataset in combine:dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)# 同样转换分类特征为序数
for dataset in combine:dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)train_df.head()# 测试集中Fare有一个缺失值,用中位数进行填补
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()plt.hist(train_df['Fare'])# 对票价进行连续数据离散化
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4) # 根据样本分位数进行分箱,等频分箱
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)for dataset in combine:dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3dataset['Fare'] = dataset['Fare'].astype(int)train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]train_df.head(10)test_df.head(10)相关文章:
)
Python训练营打卡——DAY22(2025.5.11)
复习日 学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 泰坦尼克号——来自灾难的机器学习 数据来源: kaggle泰坦里克号人员生还预测 挑战 泰坦尼克号沉没是历史上最臭名昭著的海难之一。 1912年4月15日,在被普…...

【计算机视觉】OpenCV实战项目 :Image_Cartooning_Web_App:基于深度学习的图像卡通化
Image_Cartooning_Web_App:基于深度学习的图像卡通化Web应用深度解析 1. 项目概述2. 技术原理与模型架构2.1 核心算法2.2 系统架构 3. 实战部署指南3.1 环境配置3.2 模型部署3.3 处理流程示例 4. 常见问题与解决方案4.1 模型加载失败4.2 显存溢出4.3 边缘伪影 5. 关…...

王道计算机网络知识点总结
计算机网络知识点总结 一、计算机网络体系结构 (一)计算机网络概述 计算机网络概念:互连的、自治的计算机系统的集合,目的是资源共享,组成包括多台自治计算机,规则是网络协议。 计算机网络的组成&#…...
)
Java学习笔记(对象)
一、对象本质 状态(State):通过成员变量(Field)描述 行为(Behavior):通过成员方法(Method)实现 class Person {String name;int age;void eat() {System.o…...
)
并发笔记-给数据上锁(二)
文章目录 核心挑战 (The CRUX)29.1 并发计数器 (Concurrent Counters)1. 简单非并发计数器 (Figure 29.1)2. 同步计数器(单锁版本 - Coarse-Grained Lock, Figure 29.2)3. 可伸缩计数:近似/懒惰计数器 (Approximate/Sloppy Counter, Figure 2…...

Three.js + React 实战系列 - 页脚区域 Footer 组件 ✨
对个人主页设计和实现感兴趣的朋友可以订阅我的专栏哦!!谢谢大家!!! 为个人主页画上完美句号:设计一个美观实用的页脚组件 在完成 Hero、About、Projects、Contact 等模块后,我们为整个页面添上…...

基于Flask、Bootstrap及深度学习的水库智能监测分析平台
基于Flask、Bootstrap及深度学习的水库智能监测分析平台 项目介绍 本项目是基于Flask框架构建的水库智能监测分析平台,集水库数据管理、实时监测预警、可视化分析和智能预测功能于一体。 预测水位的预警级别:蓝色预警没有超过正常水位且接近正常水位1米…...
)
JavaSE核心知识点02面向对象编程02-08(异常处理)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点02面向对象编程02-08&#…...

7系列 之 SelectIO 资源
背景 《ug471_7Series_SelectIO.pdf》介绍了Xilinx 7 系列 SelectIO 的输入/输出特性及逻辑资源的相关内容。 第 1 章《SelectIO Resources》介绍了输出驱动器和输入接收器的电气特性,并通过大量实例解析了各类标准接口的实现。 第 2 章《SelectIO Logic Resource…...

【目标检测系列】YOLOV1解读
目标检测系列文章 目录 目标检测系列文章📄 论文标题🧠 论文逻辑梳理1. 引言部分梳理 (动机与思想) 📝 三句话总结🔍 方法逻辑梳理🚀 关键创新点🔗 方法流程图关键疑问解答Q1: 关于 YOLOv1 中的 "conf…...

GIF图像技术介绍
以下是对GIF格式的详细介绍,涵盖其定义、发展历程、技术特性、应用场景及与其他格式的对比: 一、GIF的定义与起源 GIF(Graphics Interchange Format,图形交换格式)由美国CompuServe公司于1987年推出,旨在解决早期互联网带宽不足的问题。其开发者Steve Wilhite采用LZW无损…...

【TI MSPM0】CCS工程管理
一、关于WORKSPACE 1.导入工程路径 导入工程时,实际是将工程从原路径复制到了Workspace路径下(默认是在C盘user路径下) 2.工程保存备份 关于工程的保存,可以右击文件夹,点击Reveal打开文件夹 将对应的文件夹进行复…...

牛客周赛 Round 92-题解
牛客周赛 Round 92-题解 A-小红的签到题 code #include<iostream> #include<string> using namespace std; string s; int main() {int n;cin >> n;cout << "a_";for (int i 0; i < n - 2; i )cout << b;return 0; }B-小红的模…...

iVX 图形化编程平台:结合 AI 原生开发的革新与实践
一、技术架构:重构 AI 与编程的交互逻辑 1. 信息密度革命:从线性代码到图形化语义单元 传统文本编程存在显著的信息密度瓶颈。以 "按钮点击→条件判断→调用接口→弹窗反馈" 流程为例,Python 实现需定义函数、处理缩进并编写 30 …...

微服务架构中如何保证服务间通讯的安全
在微服务架构中,保证服务间通信的安全至关重要。服务间的通信通常是通过HTTP、gRPC、消息队列等方式实现的,而这些通信链路可能面临多种安全风险。为了应对这些风险,可以采取多种措施来保证通信安全。 常见的服务间通信风险 1.数据泄露:在服务间通信过程中,敏感数据可能会…...
深度解析:从理论到实践的全方位指南)
长短期记忆网络(LSTM)深度解析:从理论到实践的全方位指南
一、LSTM基础理论:超越传统RNN的记忆架构 1.1 RNN的长期依赖问题 传统循环神经网络(RNN)在处理长序列时面临的根本挑战是梯度消失/爆炸问题。当序列长度超过10-20个时间步时,RNN难以学习到早期时间步的信息。数学上,这源于反向传播过程中梯度的链式法则: 复制 下载 ∂…...

FramePack AI图片生成视频 v1.1 整合包
今天,我兴奋地要为大家介绍一款革命性的AI工具——FramePack,这是一个让人眼前一亮的图生视频整合包。想象一下,在2025年5月11日的今天,哪怕你的电脑显存仅有6G,你也可以轻松创造艺术! FramePack的神奇之处…...

在 C++中,指针数组与数组指针的区别
1. 指针数组:本质上是一个数组,数组中的每个元素都是一个指针。也就是说,这个数组存储的是多个指针变量,这些指针可以指向不同的对象(比如不同的变量、数组等) 。 2. 数组指针:本质上是一个指针,这个指针指向一个数组。即它指向的是数组的首地址,通过这个指针可以操作…...

Ubuntu 24服务器部署abp vnext应用程序的完整教程
一、服务器配置 1、安装Nginx 2、安装.NetCore SDK 或.NetCore 运行时 以上两步参考 《UbuntuNginxSupervisord部署.net core web应用程序_nginx部署netcore-CSDN博客》 二、abp vnext程序部署 1、程序发布 使用VS进行发布 2、程序上传 使用winSCP工具 3、openiddict…...

Ingrees 控制器与 Ingress 资源的区别
在 Kubernetes 中,单纯的 Ingress 资源定义文件(YAML)本身不会直接创建 Pod。Ingress 的作用是定义路由规则(如将外部流量路由到集群内的服务),而实际处理流量的 Pod 是由 Ingress 控制器(如 Ng…...

动态路由实现原理及前端控制与后端控制的核心差异
在 Web 开发领域,动态路由是构建灵活、高效应用的关键技术之一。它能够根据不同的条件和请求,动态地决定页面的跳转和数据的加载,极大提升用户体验。本文将深入剖析动态路由的实现原理,并详细探讨前端控制和后端控制两种模式的最大…...

stm32 WDG看门狗
目录 stm32 WDG看门狗一、WDG基础知识1)WDG(Watchdog)看门狗简介 二、IWDG独立看门狗1)IWDG键寄存器2)IWDG超时时间 三、WWDG窗口看门狗1)WWDG框图2)WWDG工作特性3)WWDG超时时间4&am…...
(SQL性能分析,索引使用))
MySQL索引详解(下)(SQL性能分析,索引使用)
索引是MySQL性能优化的核心,但如何精准分析查询瓶颈、合理设计索引,是开发者必须掌握的技能。本文结合实战案例,系统讲解SQL性能分析工具链与索引使用技巧,帮助读者构建高性能数据库系统。 一、SQL性能分析:从宏观到微…...

添加文字标签
上节我们学会了如何在地图中标记位置,那么可不可以为地图添加文字注释呢?答案是肯定的,我们依旧以广州塔为例. //添加文字标签和广告牌var label viewer.entities.add({position: Cesium.Cartesian3.fromDegrees(113.3191,23.109,100),label:{text:"广州塔",font:&…...

数据并行基础概念知识
架构分为PS与ring-allreduce;方法主要是zero系列zeroDP123、ZeroR 、Zero-offerload、Zero-Infinite、Zero 相关博客介绍的很清楚,在这里总结一下 图解系列很通透,通俗易懂1 更详细的介绍后面几种方式,提供动图链接2 提供混合精度…...
----用户和用户组管理、系统管理)
Linux系列(3)----用户和用户组管理、系统管理
声明: 本文参考 ❤️肝下25万字的《决战Linux到精通》笔记,你的Linux水平将从入门到入魔❤️【建议收藏】_linux笔记 小小明-CSDN博客 不理解的命令需要自己操作一遍 方可理解 不知道怎么租用服务器并链接的看这个文章 如何租用服务器并通过ssh连接…...

【沉浸式求职学习day36】【初识Maven】
沉浸式求职学习 Maven1. Maven项目架构管理工具2.下载安装Maven3.利用Tomcat和Maven进入一个网站 Maven 为什么要学习这个技术? 在Java Web开发中,需要使用大量的jar包,我们手动去导入,这种操作很麻烦,PASS!…...

Nipype 简单使用教程
Nipype 简单使用教程 基础教程**一、Nipype 核心概念与工作流构建****1. 基本组件****2. 工作流构建步骤** **二、常用接口命令速查表****1. FSL 接口****2. FreeSurfer 接口****3. ANTS 接口****4. 数据处理接口** **三、高级特性与最佳实践****1. 条件执行(基于输…...
)
DA14585墨水屏学习(2)
一、user_svc2_wr_ind_handler函数 void user_svc2_wr_ind_handler(ke_msg_id_t const msgid,struct custs1_val_write_ind const *param,ke_task_id_t const dest_id,ke_task_id_t const src_id) {// sprintf(buf2,"HEX %d :",param->length);arch_printf("…...

【LeetCode Hot100 | 每日刷题】排序数组
912. 排序数组 - 力扣(LeetCode) 题目: 给你一个整数数组 nums,请你将该数组升序排列。 你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。 示例 1&…...

leetcode热题100——day26
21. 合并两个有序链表 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 AC代码 # Definition for singly-linked list. # class ListNode(object): # def __init__(self, val0, nextNone): # self.val val # …...

Python httpx库终极指南
一、发展历程与技术定位 1.1 历史演进 起源:httpx 由 Encode 团队开发,于 2019 年首次发布,目标是提供一个现代化的 HTTP 客户端,支持同步和异步操作,并兼容 HTTP/1.1 和 HTTP/2。背景: requests 库虽然功…...
Redisson详解)
#Redis黑马点评#(五)Redisson详解
目录 一 基于Redis的分布式锁优化 二 Redisson 1 实现步骤 2 Redisson可重入锁机制 3 Redisson可重试机制 4 Redisson超时释放机制 5 RedissonMultiLock解决主从一致性 三 Redis优化秒杀 一 基于Redis的分布式锁优化 二 Redisson Redisson是一个在Redis的基础上实现的…...

redis存储结构
一、存储结构 存储转换: string int:字符串长度 ≤ 20 且能转成整数raw:字符串长度 > 44embstr:字符串长度 ≤ 44附加:CPU 缓存中基本单位为 cacheline 64 字节 list quicklist(双向链表)zi…...

wordpress自学笔记 第三节 独立站产品和类目的三种展示方式
wordpress自学笔记 摘自 超详细WordPress搭建独立站商城教程-第三节 独立站产品和类目的三种展示方式,2025 WordPress搭建独立站教程#WordPress建站教程https://www.bilibili.com/video/BV1rwcteuETZ?spm_id_from333.788.videopod.sections&vd_sourcea0af3b…...
)
Python 自动化脚本开发秘籍:从入门到实战进阶(6/10)
摘要:本文详细介绍了 Python 自动化脚本开发的全流程,从基础的环境搭建到复杂的实战场景应用,再到进阶的代码优化与性能提升。涵盖数据处理、文件操作、网络交互、Web 测试等核心内容,结合实战案例,助力读者从入门到进…...
)
封装和分用(网络原理)
UDP/TCP协议知识及相关机制 优质好文推荐👆👆 我们如果想要了解封装与分用,先需要了解TCP/IP五层协议~~ 该图的右边就是TCP/IP五层协议~~需要先理解一下各层是什么含义~ 应用层:直接为用户应用程序提供网络服务和通信协议。它定…...

MySQL数据库容灾设计案例与SQL实现
MySQL数据库容灾设计案例与SQL实现 一、主从复制容灾方案 1. 配置主从复制 -- 在主库执行(创建复制账号) CREATE USER repl_user% IDENTIFIED BY SecurePass123!; GRANT REPLICATION SLAVE ON *.* TO repl_user%;-- 查看主库状态(记录File…...

各类有关NBA数据统计数据集大合集
这些数据我已上传大家在CSDN上直接搜索就可以! 一、【2022-2023 NBA球员统计】数据集 关键词: 篮球 描述: 语境 该数据集每场比赛包含2022-2023常规赛NBA球员统计数据。 请注意,由团队更改产生了重复的球员名称。 * [2021-2022 NBA播放器统计]&#…...

【基于 LangChain 的异步天气查询5】多轮对话天气智能助手
目录 项目概述 1. 天气查询功能 2. 多轮对话与聊天 3. 语音输入与输出 4. 历史记录管理 5. 项目结构 6. 核心功能流程 7. 项目特色 🗂️ 项目目录结构 📄 chat_runnable.py 📄 main.py 📄 history_manager.py 📄 weather_runnable.py 📄 tools.py �…...

图片转ICO图标工具
图片转ICO图标 可批量操作 下载地址: 链接:https://pan.quark.cn/s/6312c565ec98 这个工具是一个批量图片转ICO图标的神器,有了它,以后再也不用为ICO格式的转换烦恼!而且这个软件特别小巧,完全不用安装。…...

istio in action之服务网格和istio组件
微服务和服务网格 微服务 微服务将大系统拆解成一个个独立的、小型的服务单元。每个服务可以独立部署、快速迭代,团队可以自主决策,大大降低了变更风险。当然,微服务不是万能药,它需要强大的自动化和DevOps实践作为支撑。而Isti…...

5 从众效应
引言 有一个成语叫做三人成虎,意思是说,有三个人谎报市上有老虎,听者就信以为真。这种人在社会群体中,容易不加分析地接受大多数人认同的观点或行为的心理倾向,被称为从众效应。 从众效应(Bandwagon Effec…...

超市销售管理系统 - 需求分析阶段报告
1. 系统概述 超市销售管理系统是为中小型超市设计的信息化管理解决方案,旨在通过信息化手段实现商品管理、销售处理、库存管理、会员管理等核心业务流程的数字化,提高超市运营效率和服务质量,同时为管理者提供决策支持数据。 2. 业务需求分…...

懒人美食帮SpringBoot订餐系统开发实现
概述 快速构建一个订餐系统,今天,我们将通过”懒人美食帮”这个基于SpringBoot的订餐系统项目,为大家详细解析从用户登录到多角色权限管理的完整实现方案。本教程特别适合想要学习企业级应用开发的初学者。 主要内容 1. 用户系统设计与实现…...

【计算机视觉】基于Python的相机标定项目Camera-Calibration深度解析
基于Python的相机标定项目Camera-Calibration深度解析 1. 项目概述技术核心 2. 技术原理与数学模型2.1 相机模型2.2 畸变模型 3. 实战指南:项目运行与标定流程3.1 环境配置3.2 数据准备3.3 执行步骤3.4 结果验证 4. 常见问题与解决方案4.1 角点检测失败4.2 标定结果…...

彩票假设学习笔记
彩票假设 文章目录 彩票假设一、基本概念1. 核心观点2. 关键要素 二、彩票假设的用途三、训练流程四、意义和局限性1. 意义2. 局限性 五、总结 一、基本概念 彩票假设(Lottery Ticket Hypothesis)是由 Jonathan Frankle 和 Michael Carbin 在 2019 年的…...
》阅读笔记:p18-p31)
《算法导论(第4版)》阅读笔记:p18-p31
《算法导论(第4版)》学习第 11 天,p18-p31 总结,总计 4 页。 一、技术总结 1. Fourier transform(傅里叶变换) In mathematics, the Fourier transform (FT) is an integral transform that takes a function as input then outputs another function…...

编程技能:字符串函数02,strcpy
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:字符串函数01,引言 回到目录 …...

UOJ 164【清华集训2015】V Solution
Description 给定序列 a ( a 1 , a 2 , ⋯ , a n ) a(a_1,a_2,\cdots,a_n) a(a1,a2,⋯,an),另有序列 h h h,初始时 h a ha ha. 有 m m m 个操作分五种: add ( l , r , v ) \operatorname{add}(l,r,v) add(l,r,v):…...