常见的排序算法(Java版)简单易懂好上手!!
排序
“排序”顾名思义就是把乱序的变成有序的,就像我们玩斗地主这种牌类游戏时,我们拿到牌都会将牌给排序一下,更好的在对局中方便思考和观察,我们排序算法也亦是如此。
文章目录
- 排序
- 一、冒泡排序
- 二、选择排序
- 三、插入排序
- 四、希尔排序
- 五、归并排序
- 六、快速排序
- 总结
一、冒泡排序
冒泡排序的过程就像是我们在烧水时,气泡大的会向上冒,气泡小的则在下面,就是冒泡的一个过程,数字大的就是大气泡,数字小的就是小气泡,例如:

过程:从第一个数开始和后面一个数进行比较,大了便交换,否则便下一个次比较,如上图所示,用4与5进行比较,4 < 5,则用5与6比较,5 < 6, 则用6与3比较,6 > 3,则交换位置,以此类推6到了最后一个位置则这一个过程则称为第一次冒泡,每一次冒泡就是将未排序的数组中最大数向上推的过程。
代码实例:
public class BubbleSort {
/*//将给定的数组排序public static void sort(Comparable[] arr) {//有几个数就需要比较几次,数比较大的就交换for (int i = 1; i < arr.length; i++) {//前一个数和后一个数比较for (int j = 0; j < arr.length - 1; j++) {if (compare(arr[j],arr[j + 1])) {swap(arr,j,j + 1);}}}}
*///将上面的代码进行改进 => 每次比较后最大的数都将位于数组的最后一位,// 所以每次排序都可以把原本最后一次比较省略掉public static void sort(Comparable[] arr) {for (int i = arr.length - 1; i > 0; i--) {for (int j = 0; j < i; j++) {if (compare(arr[j], arr[j + 1])) {swap(arr, j, j + 1);}}}}//比较元素大小public static boolean compare(Comparable a, Comparable b) {return a.compareTo(b) > 0;}//交换元素public static void swap(Comparable[] arr, int i, int j) {Comparable temp;temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}测试一下:

运行结果
冒泡排序的特性总结:
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
二、选择排序
选择排序的过程是:在待排序的数组中选择一个最小的元素放在起始位置,直到数组排序完,如下图所示:
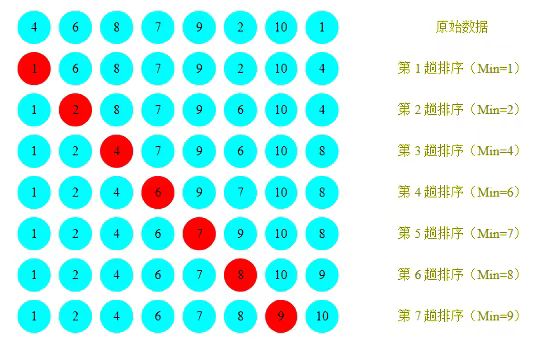
我们首先假定数组第一个数的下标是最小值的下标索引,然后一次向后比较,遇到较小的数便与其交换下标索引,每次比较完后最小值的下标索引便与待排数组的收尾进行交换,这样便会保证每次交换到的都是待排数组中最小的值,我们可以观察到我们需要进行n-1次排序。
代码实现:
public class SelectSort {public static void sort(Comparable[] arr) {//总共需要比较n - 1次for (int i = 0; i < arr.length - 1; i++) {//定义一个的下标索引,记录最小值的下标int minIndex = i;for (int j = i + 1; j < arr.length; j++) {if (compare(arr[minIndex], arr[j])) {minIndex = j;}}//每次比较完,都要交换i和minIndex下标的值swap(arr, i, minIndex);}}//比较元素大小public static boolean compare(Comparable a, Comparable b) {return a.compareTo(b) > 0;}//交换元素public static void swap(Comparable[] arr, int i, int j) {Comparable temp;temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}测试一下:
运行结果:
直接选择排序的特性总结:
1. 直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:不稳定
三、插入排序
插入排序的过程就像是,我们在打扑克牌或麻将一样,我们要将没有排序的牌进行排序就需要拿起一张牌,然后将其想前比对,比前面的牌小则交换,反之则不变那便是这张牌所属的位置,例如:
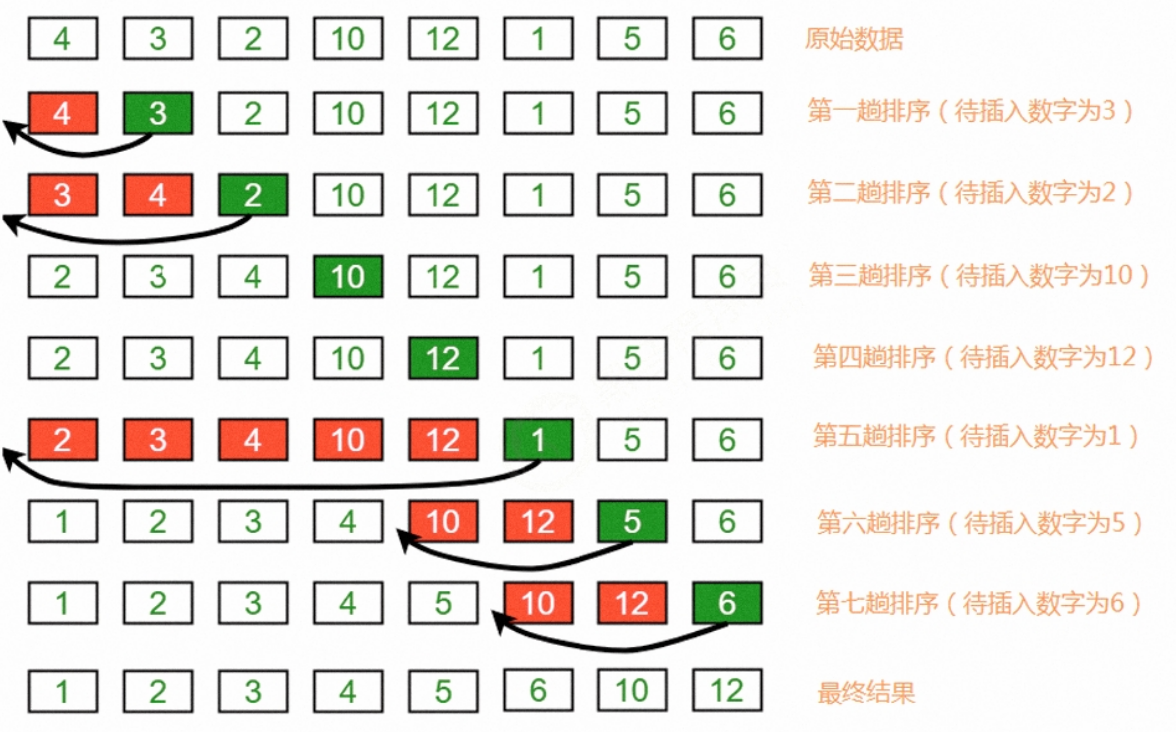
我们将第一位数看做已排好序的,然后后面的剩余的为待排序的,我们进行比较,在合适的位置进行插入,依次类推便得到排好序的结果。
代码实现:
public class InsertSort {public static void sort(Comparable[] arr) {//将数组的首个数字表示为已排序的,后面的未排序的,然后遍历已排序的数组,进行插入for (int i = 1; i < arr.length; i++) {//将数组下标j 和下标j - 1的值进行比较,如果下标j - 1的值大于下标j的值则交换数据,反之则为找到合适的位置,退出循环for (int j = i; j > 0; j--) {if (compare(arr[j - 1], arr[j])) {swap(arr, j -1, j);} else {break;}}}}//比较元素大小public static boolean compare(Comparable a, Comparable b) {return a.compareTo(b) > 0;}//交换元素public static void swap(Comparable[] arr, int i, int j) {Comparable temp;temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}
测试一下:

运行:
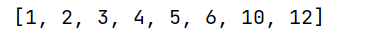
直接插入排序的特性总结:
- 元素集合越接近有序,直接插入排序算法的时间效率越高
- 时间复杂度:O(N^2)
- 空间复杂度:O(1),它是一种稳定的排序算法
- 稳定性:稳定
四、希尔排序
希尔排序的过程与插入排序的过程大同小异,又称“缩小增量排序”,是插入排序的升级版,变得更高效一点。具体就是我们先定义一个增量h,然后利用这个增量对数组进行分组,分组完以后进行插入排序,得到的便是接近有序的数组:然后缩小其增量,然后执行上述操作,使增量h缩小至1时,排序后便是有序数组。相对于增量h也有其相关的定义规则和缩小规则:
//确定增长量h的最大值
int h=1;
while(h<N/2){
h=h*2+1;
}
h的减小规则为:
h=h/2
我们给出例图更直观的感受一下:
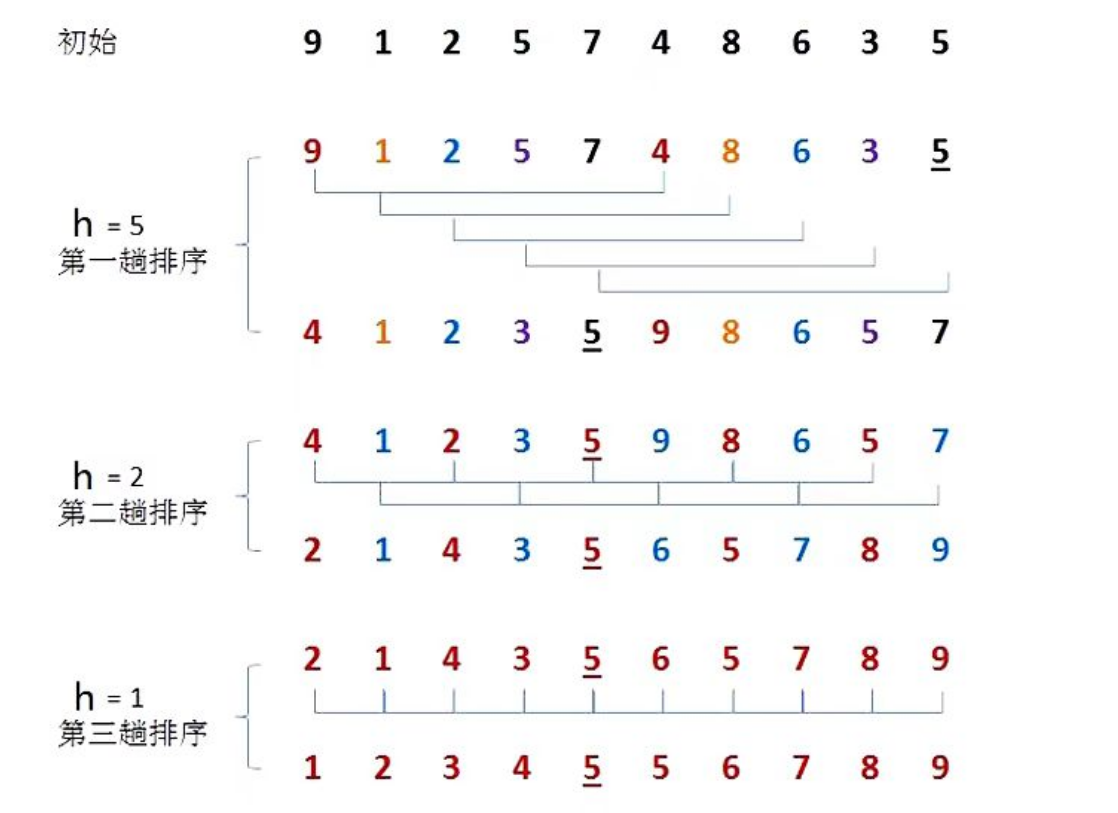
归纳一下排序原理:
1.选定一个增长量h,按照增长量h作为数据分组的依据,对数据进行分组;
2.对分好组的每一组数据完成插入排序;
3.减小增长量,最小减为1,重复第二步操作
代码实现:
public class ShellSort {public static void sort(Comparable[] arr) {//数组长度int N = arr.length;//确定增量h的值int h = 1;while (h < N) {h = h * 2 + 1;}//当h<1时,排序结束while (h >= 1){//1.找到待插入的元素for (int i = h; i < N; i++) {//arr[i]就是待插入的元素//然后将arr[i]插入到分好组的序列中arr[i - h],arr[i - 2h]...for (int j = i; j >= h; j-=h) {//将arr[j - h]与arr[j]进行比较,较大则交换,//反之则退出此次循环if (compare(arr[j - h], arr[j])) {swap(arr,j-h, j);} else {break;}}}//2.缩小增量hh /= 2;}}//比较元素大小public static boolean compare(Comparable a, Comparable b) {return a.compareTo(b) > 0;}//交换元素public static void swap(Comparable[] arr, int i, int j) {Comparable temp;temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}
测试一下:

运行:
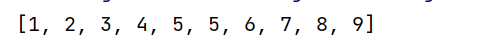
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定:


五、归并排序
归并排序的过程,是分治法的应用过程,将一组数据尽可能的拆分成两组相同的数据,并对每一组数据在拆分,直到数据的大小为1不可再拆时,我们就向上返回,进行排序,实际也是一种递归的过程,分治法顾名思义就是“分”=>分组,“治”=>共治,两个步骤组成,光光有文字叙述,我觉得会有点难以理解,我们上图看一下,体会这个过程:
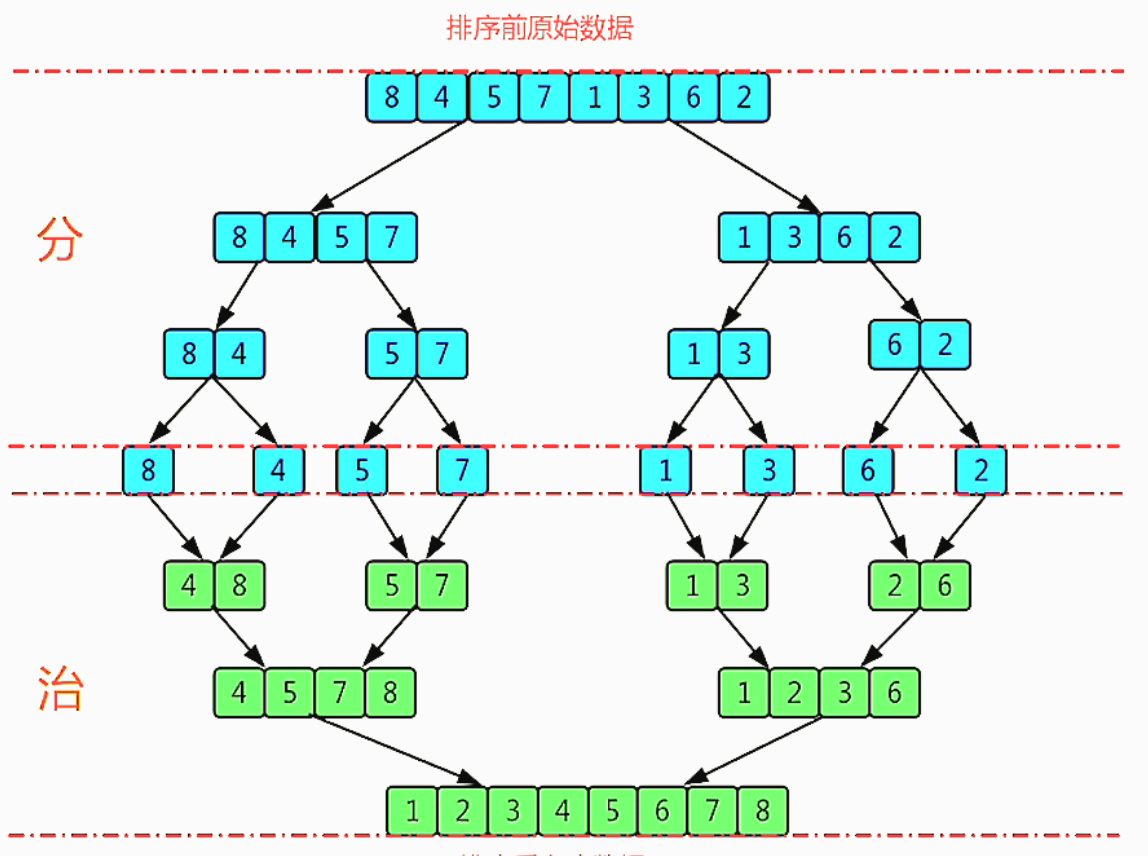
简单概述一下就是:
1.我们对数据进行分组
2.相邻的两组进行合并
在上图我们发现了,其每组的过程都是一样的,只是数据不同,那我们肯定要运用到递归来实现,我们接下来用代码实现在分析:
public class MergeSort {//定义一个辅助数组assistprivate static Comparable[] assist;//将数据进行分组排序public static void sort(Comparable[] arr) {assist = new Comparable[arr.length];//定义左右指针,表示需要进行分组的范围int left = 0;int right = arr.length - 1;//利用sort的重构方法进行分组排序sort(arr, left, right);}public static void sort(Comparable[] arr, int left, int right) {//安全性校验if (right <= left) return;//定义中间指针,进行拆分int mid = left + (right - left) / 2;//递归不断拆分sort(arr, left, mid);sort(arr, mid + 1, right);//进行合并merge(arr,left,mid,right);}//归并public static void merge(Comparable[] arr, int left, int mid, int right) {int index = left;//这个是指向assist数组开始填充的指针int p1 = left;//这个是指向第一组数据的第一个数int p2 = mid + 1;//指向第二组数据的第一个数//两组数据依次进行比较,较小的数填充到assist数组中,指针向后移,//循环结束条件就是有一组数据已经遍历完了,退出while (p1 <= mid && p2 <= right) {if (compare(arr[p1], arr[p2])) {//如果arr[p1] 大于 arr[p2],则填充arr[p2]assist[index++] = arr[p2++];}else {//反之则填充arr[p1]assist[index++] = arr[p1++];}}//跳出循环后,表示有一组数据已经遍历完了,那我们需要将剩下一组没有遍历完的数据直接顺序填充即可,因为同一组数据本身就是一排好序的//但是我们并不知道的是那组数据先结束,所以都需要进行判断while (p1 <= mid) {assist[index++] = arr[p1++];}while (p2 <= right) {assist[index++] = arr[p2++];}//我们只需将我们排好序的辅助数组assist复制到原数组即可for (int i = 0; i <= right; i++) {arr[i] = assist[i];}}//比较元素大小public static boolean compare(Comparable a, Comparable b) {return a.compareTo(b) > 0;}//交换元素public static void swap(Comparable[] arr, int i, int j) {Comparable temp;temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
}整个的代码量还是相对较多的,但具体都挺好理解的,我们自己画一画整个过程,明白了其具体流程,我们在敲代码的时候也是手到擒来哈哈哈,其中我们要注意的是一些边界条件,如果边界条件没有弄清楚,很容易就迷了,多多练习,理解每一次都会有不同的收获.
其中我们利用辅助数组对其填充,就是比较两组数据大小,然后填到一个空数组中的一个过程,如图:
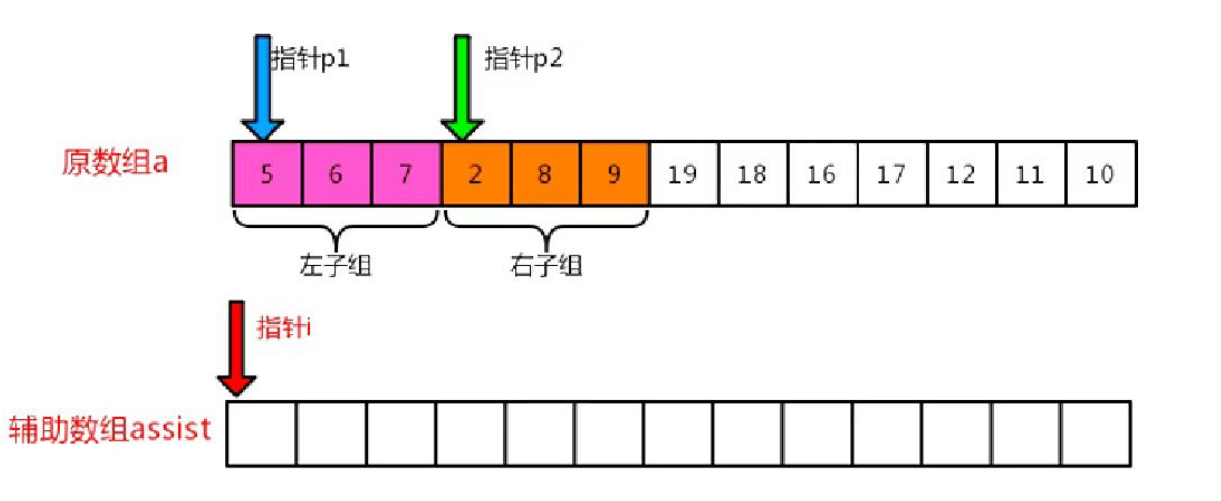
我们进行测试一下:

归并排序总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
六、快速排序
快速排序是对冒泡排序的一种改进。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
排序原理:
1.首先设定一个分界值,通过该分界值将数组分成左右两部分;
2.将大于或等于分界值的数据放到到数组右边,小于分界值的数据放到数组的左边.此时左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值;
3.然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
4.重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左侧和右侧两个部分的数据排完序后,整个数组的排序也就完成了。
具体的我们还是得通过图例才能更好的表现出来:

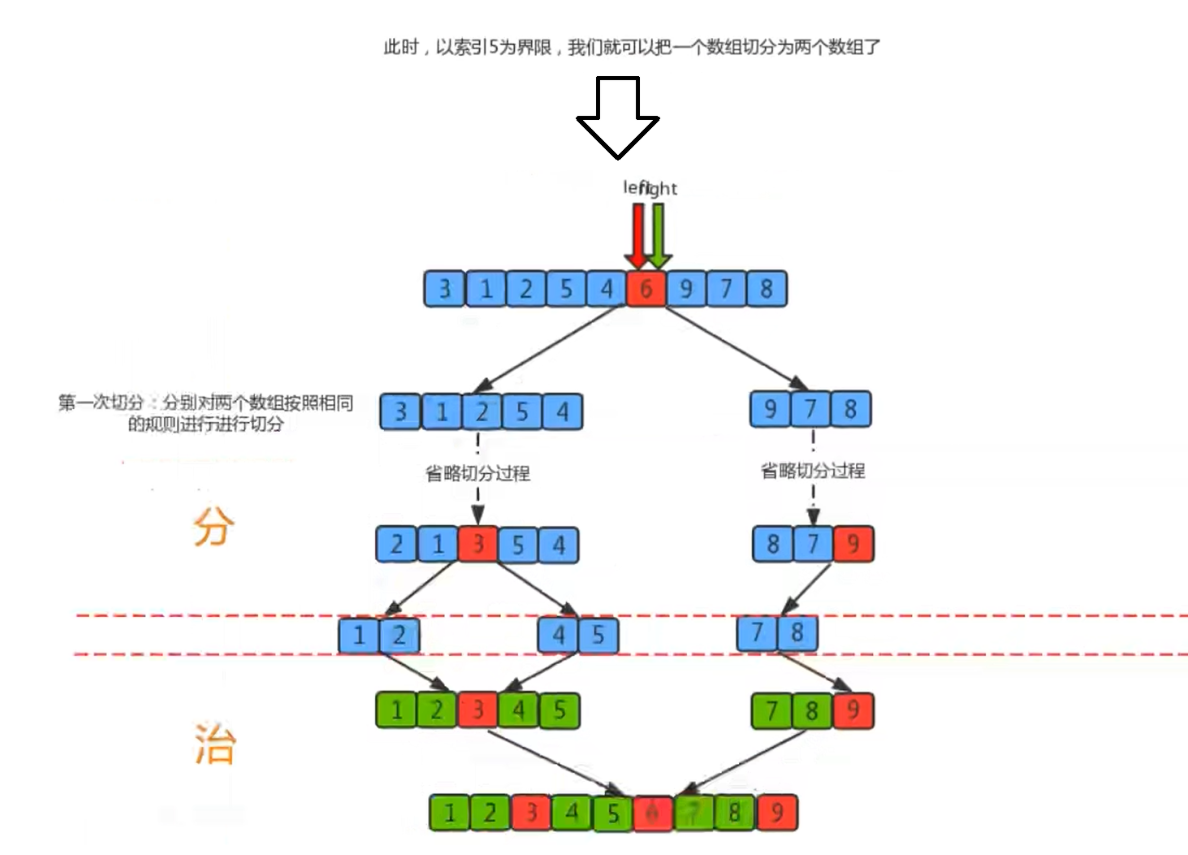
代码实现:
public class QuickSort {public static void sort(Comparable[] arr) {int p1 = 0;//首个元素的下标int p2 = arr.length - 1;//最后一个元素的下标//将数据的p1~p2元素进行排序sort(arr, p1, p2);}public static void sort(Comparable[] arr, int p1, int p2) {//安全性检查if (p2 <= p1) return;//对数据进行切分int partition = partition(arr, p1, p2);//partition的下标的值是基准值,我们将其左右两部分分开排序//将p1~partition - 1的元素进行排序sort(arr,p1,partition - 1);//将partition + 1~p2之间的元素进行排序sort(arr,partition + 1, p2);}public static int partition(Comparable[] arr, int p1, int p2) {//我们通常定义首个元素为基准值Comparable key = arr[p1];//定义左右指针,分别指向首元素和尾元素int left = p1;int right = p2 + 1;//进行切分//从右往左找比基准值小的数//从左往右找比基准值大的数while (true) {// 1.首先从右往左扫描while (compare(arr[--right], key)) {//如果扫描完发现都没有比基准值小的数,则退出循环if (right == p1) break;}// 2.从左往右扫描while (compare(key, arr[++left])) {//如果扫描完发现都没有比基准值大的数,则退出循环if (left == p2) break;}//当左指针和右指针相遇时,则表示扫描完毕,即可退出循环if (left >= right) {break;} else {//当左右指针还没有相遇时,找到相应的数了,交换位置swap(arr, left, right);}}//每趟循环完成,交换基准值和左右指针相遇位置的值即可swap(arr, p1, right);//左右指针相遇的地方就是切分的位置,所以这里返回left或者right都可以return right;}//比较元素大小public static boolean compare(Comparable a, Comparable b) {return a.compareTo(b) > 0;}//交换元素public static void swap(Comparable[] arr, int i, int j) {Comparable temp;temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}
测试一下:

快速排序总结:
-
快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
-
时间复杂度:O(N*logN)
-
空间复杂度:O(logN)
-
稳定性:不稳定
总结
这里总结了我们常见算法的一些原理,是自己学习过程中的一些总结,希望对大家也有所帮助.
相关文章:
简单易懂好上手!!)
常见的排序算法(Java版)简单易懂好上手!!
排序 “排序”顾名思义就是把乱序的变成有序的,就像我们玩斗地主这种牌类游戏时,我们拿到牌都会将牌给排序一下,更好的在对局中方便思考和观察,我们排序算法也亦是如此。 文章目录 排序一、冒泡排序二、选择排序三、插入排序四、…...

用统计零花钱的例子解释:Shuffle 是啥?
举个栗子 🌰:统计全班同学的零花钱总和 假设你是班长,全班有 4个小组,每个小组记录了自己的零花钱情况: 第1组:张三(5元)、李四(3元)、张三(2元) 第2组:王五(4元)、张三(1元)、李四(2元) …...

Kafka topic 中的 partition 数据倾斜问题
在 Kafka 中,如果一个 Topic 有多个 Partition,但这些 Partition 中的消息数量或流量分布不均衡,就会出现 数据倾斜(Data Skew) 的问题。 ✅ 什么是数据倾斜? 数据倾斜指的是: 某些 Partitio…...
之函数)
Python基础总结(十)之函数
Python函数 函数是Python中也是非常重要的,函数是带名字的代码块,用于完成具体的工作。要执行函数定义的特定任务,可调用该函数。 一、函数的定义 函数的定义要使用def关键字,def后面紧跟函数名,缩进的为函数的代码…...
 解除Gatekeeper限制)
macOS 15 (Sequoia) 解除Gatekeeper限制
macOS 15 (Sequoia) 解除Gatekeeper限制指南 问题描述 在macOS 15中执行sudo spctl --global-disable命令后,系统提示: Globally disabling the assessment system needs to be confirmed in System Settings 但隐私与安全性界面未显示"任何来源&…...

【Flask开发踩坑实录】pip 安装报错:“No matching distribution found” 的根本原因及解决方案!
关键词:pip 报错、镜像源问题、flask-socketio、Python开发环境、安装失败 作者:未名编程 | 更新时间:2025.05.11 📌 引言:一场莫名其妙的 pip 安装失败 最近在开发一个基于 Flask 的图像检索网站时&#…...

50.辐射抗扰RS和传导抗扰CS测试环境和干扰特征分析
辐射抗扰RS和传到抗扰CS测试环境和干扰特征分析 1. 辐射抗扰RS2. 传导抗扰CS 1. 辐射抗扰RS 辐射抗扰RS考察对外界电磁场干扰得抗扰能力,测试频段为80MHz~2000MHz,用1KHz得正弦波进行调幅,在电波暗室内进行。测试标准:IEC 61000-…...

零基础玩转sqlmap - 从入门到摸清数据库
sqlmap 包下载链接:https://pan.quark.cn/s/a6ab2586f77e 基本操作 最简单的用法:sqlmap -u "网址" - 直接测试这个网址有没有SQL注入漏洞 带参数的测试:如果网址后面有参数,比如 id1,sqlmap会自动检测 指…...

AI面经总结-试读
写在前面 该面经于2022年秋招上岸后耗时一个半月整理完毕,目前涵盖Python、基础理论、分类与聚类、降维、支持向量机SVM、贝叶斯|决策树、KNN、Boosting&Bagging、回归、代价函数与损失函数、激活函数、优化函数、正则优化、初始化与归一化、卷积、池化、传统图…...

python打卡day22@浙大疏锦行
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 一、数据预处理 import pandas as pd import numpy as np import matplo…...

网络安全设备配置与管理-实验5-p150虚拟防火墙配置
实验5-p150虚拟防火墙配置 做不出来可以把项目删掉再新建。 实验六多加几步配置静态路由表就行。 文章目录 实验5-p150虚拟防火墙配置1. 实验目的2. 实验任务3. 实验设备4. 实验拓扑图和设备接口5. 实验命令与步骤1. 连线与配置2. 实验验证 思考题 1. 实验目的 通过该实验掌握…...

数值运算的误差估计
数值运算的误差估计 设两个近似数 x 1 ∗ x_1^* x1∗与 x 2 ∗ x_2^* x2∗的误差限分别为 ε ( x 1 ∗ ) \varepsilon(x_{1}^{*}) ε(x1∗)和 ε ( x 2 ∗ ) \varepsilon(x_{2}^{*}) ε(x2∗) 误差限满足一下运算法则: 和差运算的误差限: 设 y …...

HCIP-BGP实验一
一:拓扑图 二:需求分析: 保证R1-R5的环回地址相互能够通讯。 分析; 1.IP的配置 2.R2-R4完成IGP配置,配置OSPF 3.完成BGP配置。 4.优化配置,包括下一跳的选择,IBGP对等体建邻的IP地址。 三…...

linux内核pinctrl/gpio子系统驱动笔记
目录 一、简单介绍二、主要源码文件和目录gpio子系统pinctrl子系统两个子系统之间的关系设备树例子 三、主要的数据结构gpio子系统pinctrl子系统 四、驱动初始化流程五、难点说明 一、简单介绍 GPIO子系统: Linux GPIO子系统是Linux内核中负责处理GPIO(通用输入输出…...

Qt—多线程基础
一、QThread 1.为什么使用多线程 在默认情况下,Qt使用的是单线程,当你启动一个 Qt 应用程序时,它会运行在一个单一的主线程(也被称为 GUI 线程)中。这个主线程负责处理所有的 GUI 事件和界面渲染。 但在一些其他情况下…...

HTML5表格语法格式详解
HTML5 表格的基本结构 HTML5 表格由 <table> 标签定义,表格中的每一行由 <tr> 标签定义,表头单元格由 <th> 标签定义,数据单元格由 <td> 标签定义。表格的基本结构如下: <table><tr><th…...

《Go小技巧易错点100例》第三十三篇
Validator自定义校验规则 Go语言中广泛使用的validator库支持通过结构体标签定义校验规则。当内置规则无法满足需求时,我们可以轻松扩展自定义校验逻辑。 示例场景:验证用户年龄是否成年(≥18岁) type User struct {Age in…...
——Chat Memory)
Spring AI(3)——Chat Memory
Chat Memory介绍 大型语言模型(LLM)是无状态的,这意味着它们不保留关于以前互动的信息。为了解决这个问题,Spring AI提供了Chat Memory(聊天记忆)功能。通过Chat Memory,用户可以实现在与LLM的…...
详解)
双向循环神经网络(Bi-RNN)详解
双向循环神经网络(Bidirectional Recurrent Neural Network, Bi-RNN)是一种能够同时利用序列数据过去和未来信息的循环神经网络架构,在许多序列建模任务中表现出色。 1. Bi-RNN基本概念 1.1 核心思想 Bi-RNN通过组合两个独立的RNN层来工作: 前向RNN&…...

【Bluedroid】HID DEVICE 连接的源码分析
本文分析Android Bluetooth协议栈中HID device设备连接流程的完整实现,从应用层接口到协议栈底层的交互细节。通过关键函数(如connect()、BTA_HdConnect()、HID_DevConnect()等)的代码解析,重点关注btif、bta、HID协议栈三层的协同机制,揭示BTA_HD_CONN_STATE_EVT事件传递…...
)
第二十一周:项目开发中遇到的相关问题(二)
本周接着介绍本次新闻项目中遇到的一些问题。首先谈谈Controller层中的请求路径问题(RequestMapping),RequestMapping注解是Spring框架中用于处理HTTP请求映射的核心注解,它可以将HTTP请求映射到具体的控制器方法上。 1.关于它的基本作用&…...

深度解析大模型学习率:优化策略与挑战
大模型超参数Learning Rate的深度学习 学习率(Learning Rate)是机器学习和深度学习中最核心的超参数之一,尤其在训练大规模语言模型(LLMs)时,其设置直接影响模型的收敛速度、训练稳定性及最终性能。以下从多维度详细解析学习率的定义、作用、挑战及优化策略。 一、学习率…...

云计算-容器云-KubeVirt 运维
KubeVirt 运维:创建 VM 使用提供的镜像在 kubevirt 命名空间下创建一台 VM,名称为 exam,指定 VM 的内存、CPU、网卡和磁盘等配置。 [rootk8s-master-node1 ~]# kubectl explain kubevirt.spec. --recursive |grep useuseEmulation <boo…...

C++内存管理详解
目录 1.C/C中的内存 2.C内存管理 2.1C语言内存管理 2.2new和delete 2.2.1概念及定义 2.2.2自定义类型内存管理 2.2.3 delete与delete[ ] 1.C/C中的内存 在C/C中编译器会对不同的代码进行内存分配,给代码的内存区主要分为栈区、堆区、数据段(静态区)、代码段(…...

二叉搜索树讲解
1. 二叉搜索树的概念 二叉搜索树又称二叉排序树,它或者是一颗空树,或者是具有以下性质的二叉树: 1. 若它的左子树不为空,则左子树上的所有结点的值都小于等于根节点的值。 2. 若它的右子树不为空,则右子树上的所有结…...

MySQL 索引设计宝典:原理、原则与实战案例深度解析
目录 前言第一章:索引设计的基础原则 (知其然,更要知其所以然)第二章:实战案例:电商订单系统的索引设计第三章:索引设计的实践流程总结结语 🌟我的其他文章也讲解的比较有趣😁,如果喜…...

如何租用服务器并通过ssh连接远程服务器终端
这里我使用的是智算云扉 没有打广告 但确实很便宜 还有二十小时免费额度 链接如下 注册之后 租用新实例 选择操作系统 选择显卡型号 点击租用 选择计费方式 选择镜像 如果跑深度学习的话 就选项目对应的torch版本 没有的话 就创建纯净的cuda 自己安装 点击创建实例 创建之后 …...

TikTok 账号运营干货:AI 驱动优化
TikTok 账号运营是一项需要全方位精心雕琢的工作。首先,账号资料的打造至关重要,务必保证完整且富有吸引力。头像要清晰醒目,能够直观传达账号的核心特色;昵称需简洁易记,方便用户快速识别与记忆;简介则要精…...

Redis 分布式锁
什么是分布式锁 在一个分布式的系统中, 也会涉及到多个节点访问同一个公共资源的情况. 此时就需要通过 锁 来做互斥控制, 避免出现类似于 "线程安全" 的问题 而 java 的 synchronized 或者 C 的 std::mutex, 这样的锁都是只能在当前进程中生效, 在分布式的这种多个进…...

Redis爆肝总结
一、基础 1.介绍 本质上是一个Key-Value类型的内存数据库,数据的加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。 速度快的根本原因 纯内存操作,性能非常出色,每秒可以处理超过10万次读写操作&a…...

Qt模块化架构设计教程 -- 轻松上手插件开发
概述 在软件开发领域,随着项目的增长和需求的变化,保持代码的可维护性和扩展性变得尤为重要。一个有效的解决方案是采用模块化架构,尤其是利用插件系统来增强应用的功能性和灵活性。Qt框架提供了一套强大的插件机制,可以帮助开发者轻松实现这种架构。 模块化与插件系统 模…...

[项目总结] 抽奖系统项目技术应用总结
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

【运维】基于Python打造分布式系统日志聚合与分析利器
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在分布式系统中,日志数据分散在多个节点,管理和分析变得复杂。本文详细介绍如何基于Python开发一个日志聚合与分析工具,结合Logstash和F…...
)
MySql(基础)
表名建议用 反引号 包裹(尤其是表名包含特殊字符或保留字时),但如果表名是普通字符串(如 user),可以省略。 注释(COMMENT 姓名) 数据库 1.查看数据库:show databases…...
)
怎样选择成长股 读书笔记(一)
文章目录 第一章 成长型投资的困惑一、市场不可预测性的本质困惑二、成长股的筛选悖论三、管理层评估的认知盲区四、长期持有与估值波动的博弈五、实践中的认知升级路径总结:破解困惑的行动框架 第二章 如何阅读应计制利润表一、应计制利润表的本质与核心原则1. 权责…...

系统思考:个人与团队成长
四年前,我交付的系统思考项目,今天学员的反馈依然深深触动了我。 我常常感叹,系统思考不仅仅是一场培训,更像是一场持续的“修炼”。在这条修炼之路上,最珍贵的,便是有志同道合的伙伴们一路同行࿰…...

并行发起http请求
1. 使用 axios Promise.all <template><input type"file" multiple change"handleFileUpload" /> </template><script> import axios from axios;export default {methods: {async handleFileUpload(event) {const files event…...

【数据结构入门训练DAY-31】组合的输出
本文介绍了如何使用深度优先搜索(DFS)算法解决数的组合问题。题目要求从1到n的自然数中选取r个数,输出所有可能的组合,并按字典顺序排列。文章详细描述了解题思路,包括建立数组存储数字、使用DFS递归处理候选数、以及如…...

leetcode0815. 公交路线-hard
1 题目: 公交路线 官方标定难度:难 给你一个数组 routes ,表示一系列公交线路,其中每个 routes[i] 表示一条公交线路,第 i 辆公交车将会在上面循环行驶。 例如,路线 routes[0] [1, 5, 7] 表示第 0 辆公…...

花朵识别系统Python+深度学习+卷积神经网络算法+TensorFlow+人工智能
一、介绍 花朵识别系统。本系统采用Python作为主要编程语言,基于TensorFlow搭建ResNet50卷积神经网络算法模型,并基于前期收集到的5种常见的花朵数据集(向日葵、玫瑰、蒲公英、郁金香、菊花)进行处理后进行模型训练,最…...
LLM Post-Training: A Deep Dive into Reasoning Large Language Models)
LLM 论文精读(四)LLM Post-Training: A Deep Dive into Reasoning Large Language Models
这是一篇2025年发表在arxiv中的LLM领域论文,是一篇非常全面的综述类论文,介绍了当前主流的强化学习方法在LLM上的应用,文章内容比较长,但建议LLM方面的从业人员反复认真阅读。 写在最前面 为了方便你的阅读,以下几点的…...

网址为 http://xxx:xxxx/的网页可能暂时无法连接,或者它已永久性地移动到了新网址
这是由于浏览器默认的非安全端口所导致的,所谓非安全端口,就是浏览器出于安全问题,会禁止一些网络浏览向外的端口。 避免使用6000,6666这样的端口 6000-7000有很多都不行,所以尽量避免使用这个区间 还有在云服务器中,…...

【C++】16.继承
C三大特性:封装,继承,多态 在前面的章节中,我们讲过了封装,也就是通过类和访问修饰符来进行封装。 接下来我们就来认识一下新的特性——继承 1. 继承的概念及定义 1.1 继承的概念 继承(inheritance)机制是面向对…...

LlamaIndex 第七篇 结构化数据提取
大型语言模型(LLMs)在数据理解方面表现出色,这也促成了它们最重要的应用场景之一:能够将常规的人类语言(我们称之为非结构化数据)转化为特定的、规范的、可被计算机程序处理的格式。我们将这一过程的输出称…...

PHP API安全设计四要素:构建坚不可摧的接口防护体系
引言:API安全的重要性 在当今前后端分离和微服务架构盛行的时代,API已成为系统间通信的核心枢纽。然而,不安全的API可能导致: 数据泄露:敏感信息被非法获取篡改风险:传输数据被中间人修改重放攻击&#x…...

英语16种时态
时态应用场合格式例子一般现在时表示经常、反复发生的动作,客观事实或普遍真理主语 动词原形(第三人称单数作主语时动词加 -s/-es)The sun rises in the east.一般过去时表示过去某个时间发生的动作或存在的状态主语 动词的过去式I visited…...

使用 goaccess 分析 nginx 访问日志
介绍 goaccess 是一个在本地解析日志的工具, 可以直接在命令行终端环境中使用 TUI 界面查看分析结果, 也可以导出为更加丰富的 HTML 页面. 官网: https://goaccess.io/ 下载安装 常见的 Linux 包管理器中都包含了 goaccess, 直接安装就行. 以 Ubuntu 为例: sudo apt instal…...

什么是中央税
中央税(又称国家税)是指由中央政府直接征收、管理和支配的税种,其收入全额纳入中央财政,用于保障国家层面的财政支出和宏观调控。中央税通常具有税基广泛、收入稳定、涉及国家主权或全局性经济调控的特点。 --- 中央税的核心特征…...
:个人助手应用)
AI Agent(10):个人助手应用
引言 本文聚焦AI Agent在个人助手领域的应用,探讨其如何在个人生产力提升、健康与生活管理、学习与教育辅助以及娱乐与社交互动四个方面,为用户创造价值并解决实际问题。 AI个人助手正从简单的指令执行者逐渐发展为具有自主性、适应性和个性化能力的智能伙伴。这一转变不仅…...

力扣70题解
记录 2025.5.8 题目: 思路: 1.初始化:p 和 q 初始化为 0,表示到达第 0 级和第 1 级前的方法数。r 初始化为 1,表示到达第 1 级台阶有 1 种方法。 2.循环迭代:从第 1 级到第 n 级台阶进行迭代: p 更新为前…...