AI面经总结-试读
写在前面
- 该面经于2022年秋招上岸后耗时一个半月整理完毕,目前涵盖Python、基础理论、分类与聚类、降维、支持向量机SVM、贝叶斯|决策树、KNN、Boosting&Bagging、回归、代价函数与损失函数、激活函数、优化函数、正则优化、初始化与归一化、卷积、池化、传统图像算法、模型评价指标、经典分类网络与发展、经典目标检测网络与发展、经典分割网络与发展、Transformer、特征工程、模型优化等方向,共387题(含参考答案)。
- 入行三年,如今也解锁了面试官身份(技术一面),将带着在自动驾驶、机器人领域中新的理解填充这份面经,计划不断更新更多方向,欢迎订阅
- 总目录详见人工智能算法面试大总结-总目录
以下为各章节挑选几个例子作为试读参考
Python
说说Python的作用域?
Python中的作用域分4种情况:
L:local,局部作用域,即函数中定义的变量;
E:enclosing,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域;
G:global,全局变量,就是模块级别定义的变量;
B:built-in,系统固定模块里面的变量,比如int, bytearray等。 搜索变量的优先级顺序依次是:作用域局部>外层作用域>当前模块中的全局>python内置作用域,也就是LEGB。
x=int(2.9) # int built-in
g_count = 0 # Global
def outer():o_count = 1 # Enclosingdef inner():i_count = 2 # Localprint(o_count)# print(i_count)找不到inner()
outer()#print(o_count)#找不到
说说Python垃圾回收机制?
Python的垃圾回收机制是以:引用计数器为主,标记清除和分代回收为辅。
方式1:引用计数:每个对象内部都维护了一个值,该值记录这此对象被引用的次数,如果次数为0,则Python垃圾回收机制会自动清除此对象。
方式2:标记-清除(Mark—Sweep):被分配对象的计数值与被释放对象的计数值之间的差异累计超过某个阈值,则Python的收集机制就启动A)标记阶段,遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达;
B)清除阶段,再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收。方式3:“分代回收”(Generational Collection)。当代码中主动执行 gc.collect() 命令时,Python解释器就会进行垃圾回收。
总体来说,在Python中,主要通过引用计数进行垃圾回收;通过 “标记-清除” 解决容器对象可能产生的循环引用问题;通过 “分代回收” 以空间换时间的方法提高垃圾回收效率
基础理论
说说归一化的目的?
1.为了数据处理的方便,归一化的确可以避免一些不必要的数值问题。
2.为了程序运行时收敛加快。
3.统一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
4.避免神经元饱和。即当神经元的激活在接近0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近0而“杀死”梯度。
5. 保证输出数据中数值小的不被吞食。
说说为什么深度神经网络较浅层网络难以训练?
1.梯度消失。指通过隐藏层从后向前看,梯度会变的越来越小,说明前面层的学习会显著慢于后面层的学习,所以训练会卡住,除非梯度变大。
2.梯度爆炸。由于梯度可更新过程中不断累积,变成非常大的梯度,导致网络权重值大幅更新,使得网络不稳定;在极端情况下,权重值甚至会溢出,变为Nan,再也无法更新。
3.权重矩阵的退化导致模型有效自由度减少。参数空间中学习的退化速度减慢,导致减少了模型的有效维数,网络的可用自由度对学习中梯度范数的贡献不均衡,随着相乘矩阵的数量(即网络深度)的增加,矩阵的乘积变得越来越退化。
分类与聚类
说说聚类算法有哪些衡量标准?
- 算法处理大数据集的能力,即算法复杂度。
- 处理数据噪声的能力。
- 处理任意形状,包括有间隙的嵌套的数据的能力。
- 算法是否需要预设条件。是否需要预先知道聚类个数,是否需要用户给出领域知识。
- 算法的数据输入属性。算法处理的结果与数据输入的顺序是否相关,即算法是否独立于数据输入顺序。
- 算法处理有属性很多的数据的能力,也就是对数据维数是否敏感,对数据的类型有无要求。
说说聚类与分类的区别?
聚类(Clustering)
- 简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此聚类通常并不需要使用训练数据进行学习,在机器学习中属于无监督学习。
分类(Classification)
- 对于一个分类器,通常需要你告诉它“这个东西被分为某某类”。一般情况下,一个分类器会从它得到的训练集中进行学习,从而具备对未知数据进行分类的能力,在机器学习中属于监督学习。
降维
说说降维有什么意义?
1.减少预测变量个数。
2.确保变量相互独立。
3.提供一个框架来解释结果。相关重要特征更能在数据中明确显示出来,尤其二维或三维更便于可视化展示。
4.数据在低维下更容易处理。
5.去除数据噪声。
6.降低算法运算开销。
说说PCA核心思想?
1.PCA是将高维的数据通过线性变换投影到低维空间。
2.投影。找出最能够代表原始数据的投影方法。被PCA降掉维度只能是那些噪声或是冗余的数据。
3.去冗余。去除可以被其他向量代表的线性相关向量,这部分信息量是多余的。
4.去噪声。去除较小特征值对应的特征向量,特征值的大小反映了变换后在特征向量方向上变换的幅度,幅度越大。说明这个方向上的元素差异也越大,要保留。
5.对角化矩阵。寻找极大线性无关组,保留较大的特征值,去除较小特征值,组成一个投影矩阵,对原始样本矩阵进行投影,得到降维后的新样本矩阵。
6.协方差矩阵。完成PCA的关键是协方差矩阵,能同时表现不同维度间的相关性以及各个维度上的方差。协方差矩阵度量的是维度与维度之间的关系,而非样本与样本之间。
7.对角化。因为对角化之后非对角上的元素都是0,达到去噪声的目的。对角化后的协方差矩阵,对角线上较小的新方差对应的就是那些该去掉的维度。所以我们只取那些含有较大能量(特征值)的维度,其余的就舍掉,即去冗余。
贝叶斯
说说先验概率与后验概率?
用“瓜熟蒂落”这个因果例子,从概率(probability)的角度说一下
先验概率:就是常识、经验所透露出的“因”的概率,即瓜熟的概率。
后验概率:就是在知道“果”之后,去推测“因”的概率,也就是说,如果已经知道瓜蒂脱落,那么瓜熟的概率是多少。
后验和先验的关系可以通过贝叶斯公式来求。也就是:P(瓜熟 | 已知蒂落)=P(瓜熟)×P(蒂落 | 瓜熟)/ P(蒂落)
说说朴素贝叶斯中有没有超参数可以调?
朴素贝叶斯是没有超参数可以调的,所以它不需要调参,朴素贝叶斯是根据训练集进行分类,分类出来的结果基本上就是确定的,拉普拉斯估计器不是朴素贝叶斯中的参数,不能通过拉普拉斯估计器来对朴素贝叶斯调参。
决策树
说说决策树有哪些要素?
一棵决策树的生成过程主要分为3个部分(三要素!):
1.特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策树算法。
2.决策树生成:根据选择的特征评估标准,从上至下递归生成子节点,直到数据集不可分则决策树停止生长。树结构来说,递归结构是最容易理解的方式。
3.剪枝:决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
说说决策树中剪枝的作用?
剪枝是决策树学习算法用来解决过拟合问题。
为尽可能正确分类训练样本,节点划分过程不断重复,有时造成决策树分支过多,以至于将训练样本集自身特点当作泛化特点导致过拟合。 因此可以采用剪枝处理来去掉一些分支来降低过拟合风险。
KNN
说说欧式距离与曼哈顿距离,KNN用什么?
欧式距离:平方差求和再开方
曼哈顿距离:坐标差的绝对值求和
KNN一般用欧式距离更多,原因:欧式距离适用于不同空间,表示不同空间点之间的距离;曼哈顿距离只计算水平或垂直距离,有维度限制。
说说KNN数据是否需要归一化?
KNN对数据量纲敏感,所以数据要先归一化。因为KNN使用的方差来反映“距离”,量纲对方差计算影响较大。
Boosting&Bagging
说说XGBoost缺失值处理方法?
论文中关于缺失值的处理将其与稀疏矩阵的处理看作一样。在寻找split point的时候,不会对该特征为missing的样本进行遍历统计,只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找split point的时间开销。
在逻辑实现上,为保证完备性,会分别将missing特征值的样本分配到左叶子结点和右叶子结点的两种情形,计算增益后选择增益大的方向进行分裂即可。可以为缺失值或者指定值指定分支的默认方向,能大大提升算法效率。如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子树。
说说随机森林是什么随机?
1.应用 Bootstrap法有放回地随机抽取 k个新的自助样本集(Boostrap),并由此构建k棵分类树(ID3、C4.5、CART)样本扰动。
2.先随机选择属性子集,个数为k,然后再从这个子集中选择一个最优属性用于划分。
回归
说说独立同分布?
指随机过程中,任何时刻的取值都为 随机变量 ,如果这些随机变量服从同一分布 ,并且互相独立,那么这些随机变量是独立同分布。
举例:独立:张三、李四一起来贷款,但是他们两个没关系。
同分布:他们两个都是来假定的这家银行。
高斯分布:银行可能会多给,也可能会少给,但是绝大多数情况下这个浮动不会太大,极小情况下浮动会比较大,符合正常情况。
说说回归与分类的区别?
1.两者的预测目标变量类型不同,回归问题是连续变量,分类问题离散变量。
2.回归问题是定量问题(预测),分类问题是定性问题(分类)。
3.回归目标是得到最优拟合;而分类目标是得到决策边界。
4.评价指标不同:回归的评价指标通常是MSE;分类评价指标通常是Accuracy、Precision、Recall。
代价函数与损失函数
说说代价函数为什么要非负?
因为目标函数存在下界,在优化过程当中,如果优化算法能够使目标函数不断减小,根据单调有界准则,这个优化算法就能证明是收敛有效的。 只要设计的目标函数有下界,基本上都可以,代价函数非负更为方便。
说说交叉熵损失函数(Cross-entropy)和 均方误差损失函数(MSE)的区别?
1. 概念不同
均方差损失函数是求 n n n 个样本的 n n n 个输出与期望输出的差的平方的平均值。
L ( Y , f ( x ) ) = 1 N ∑ n ( Y − f ( x ) ) 2 L(Y, f(x))=\frac{1}{N} \sum_{n}(Y-f(x))^{2} L(Y,f(x))=N1n∑(Y−f(x))2
交叉樀损失函数描述模型预测值和真实值的差距大小,越大代表越不相近。
C = − 1 N ∑ x [ y ln a + ( 1 − y ) ln ( 1 − a ) ] C=-\frac{1}{N} \sum_{x}[y \ln a+(1-y) \ln (1-a)] C=−N1x∑[ylna+(1−y)ln(1−a)]2. 参数更新速度不同
均方差损失函数受Sigmoid函数影响,导数更新缓慢。交叉樀损失函数参数更新只和误差有关,当误差大的时候,权重更新快;当误差小的时候,权重更新慢。
3. sigmoid作为激活函数的时候,如果采用均方误差损失函数,那么这是一个非凸优化问题,不宜求解。而采用交叉嫡损失函数依然是一 个凸优化问题,更容易优化求解。
4. 使用场景不同:MSE更适合回归问题,交叉熵损失函数更适合分类问题。
激活函数
说说激活函数为什么需要非线性函数?
1.假若网络中全是线性部件,那么线性的组合还是线性,与单独一个线性分类器无异。做不到用非线性来逼近任意函数。
2.使用非线性激活函数 ,使网络更加强大,可以学习复杂的事物,表示输入输出之间非线性的复杂的任意函数映射。使用非线性激活函数,能够从输入输出之间生成非线性映射。
Sigmoid求导推导一下?
Sigmoid公式为:
σ ( x ) = 1 1 + exp ( − z ) \sigma(x)=\frac{1}{1+\exp (-z)} σ(x)=1+exp(−z)1
求导推导:
σ ′ ( x ) = ( 1 1 + e − z ) ′ = 1 ( 1 + e − z ) 2 ⋅ ( e − z ) = 1 1 + e − z ⋅ e − z 1 + e − z = 1 1 + e − z ⋅ ( 1 − 1 1 + e − z ) = σ ( z ) ( 1 − σ ( z ) ) \begin{aligned} \sigma^{\prime}(x)&=\left(\frac{1}{1+e^{-z}}\right)^{\prime} \\ &=\frac{1}{\left(1+e^{-z}\right)^{2}} \cdot\left(e^{-z}\right) \\ &=\frac{1}{1+e^{-z}} \cdot \frac{e^{-z}}{1+e^{-z}} \\ &=\frac{1}{1+e^{-z}} \cdot\left(1-\frac{1}{1+e^{-z}}\right) \\ &=\sigma(z)(1-\sigma(z)) \end{aligned} σ′(x)=(1+e−z1)′=(1+e−z)21⋅(e−z)=1+e−z1⋅1+e−ze−z=1+e−z1⋅(1−1+e−z1)=σ(z)(1−σ(z))
优化函数
说说梯度下降法的作用?
1.梯度下降是迭代法的一种,可以用于求解最小二乘问题。
2.求解机器学习算法模型参数,即无约束优化问题时,主要有梯度下降法(Gradient Descent)和最小二乘法。
3.在求解损失函数最小值时,可通过梯度下降法来迭代求解,得到最小化的损失函数和模型参数值。
4.如果需要求解损失函数的最大值,可通过梯度上升法来迭代。梯度下降法和梯度上升法可相互转换。
说说SGD和Adam的对比?
SGD算法没有动量的概念,SGD和Adam相比,缺点是下降速度慢,对学习率要求严格。
Adam引入了一阶动量和二阶动量,下降速度比SGD快,Adam可以自适应学习率,所以初始学习率可以很大。
SGD相比Adam,更容易达到全局最优解。主要是后期Adam的学习率太低,影响了有效的收敛。
可以前期使用Adam,后期使用SGD进一步调优。
正则优化
说说L1(lasso)与L2(ridge)正则的区别?
1.L1是模型各参数绝对值之和;L2是模型各参数平方和的开方值。
2.L1会趋向于产生少量的特征,而其他的特征都是0;L2会选择更多的特征,这些特征都会接近于0。(注意啊,一个是产生0,一个趋向0)
说说Dropout改进?
经过交叉验证,隐含节点Dropout 率等于0.5的时候效果最好,原因是0.5的时候Dropout随机生成的网络结构最多。
Dropout也可被用作一种添加噪声的方法,直接对input进行操作。输入层设为更接近1的数。使得输入变化不会太大。
对参数w的训练进行球形限制 (max-normalization),对Dropout 的训练非常有用。
球形半径c是一个需要调整的参数,可使用验证集进行参数调优。
Dropout、max-normalization、large decaying learning rates and high momentum 组合起来效果更好,比如 max-norm regularization 就可以防止大的学习率导致的参数梯度爆炸。
使用预训练方法也可以帮助Dropout 训练参数,在使用Dropout 时,要将所有参数都除以1-p。
初始化与归一化
说说理想的参数初始化应该是什么?
最理想化的参数初始化:最理想化的参数初始化就是,经过多层网络后,信号不被过分放大或过分减弱。数学化的方法就是使每层网络的输入输出方差一致。然后还要尽量保证每层网络参数分布均值为0,如同归一化。归一化的好处是加快训练,另一个原因也是为了计算方便。
说说He初始化?
He初始化由何凯明提出,为了解决 “Xavier初始化“的缺点。对于非线性激活函数ReLU,“Xavier初始化"方法失效。He初始化基本思想是当使用ReLU作为激活函数时,Xavier的效果不好,原因在于,当ReLU的输入小于0时,输出为0 ,相当于该神经元不起作用, 影响输出的分布模式。
因此He初始化在Xavier的基础上,假设每层网络有一半的神经元被关闭,其分布的方差也会变小。经过验证发现当对初始化值缩小一半时效果最好,故He初始化可以认为是Xavier初始1 / 2的结果。
所以原本Xavier方差规范化的分母不再是 n i n \sqrt{n_{i n}} nin 而是 n i n 2 \sqrt{\frac{n_{i n}}{2}} 2nin ,这里是正态分布。如果是均匀分布,则参数的随机取值范围为 [ − 6 n i n , 6 n i n ] [\left.-\sqrt{\frac{6}{n_{i n}}}, \sqrt{\frac{6}{n_{i n}}}\right] [−nin6,nin6]
卷积
说说1x1卷积作用?
1.实现跨通道的交互和信息整合
2.进行卷积核通道数的降维和升维
3.对于单通道feature map 用单核卷积即为乘以一个参数,而一般情况都是多核卷积多通道,实现多个feature map的线性组合
4.可以实现与全连接层等价的效果。如用1x1xm的卷积核卷积n(如512)个特征图的每一个位置(像素点),其实对于每一个位置的1x1卷积本质上都是对该位置上n个通道组成的n维vector的全连接操作。
手推卷积实现原理?
void im2col_cpu(float* data_im,int channels, int height, int width,int ksize, int stride, int pad, float* data_col) {int c,h,w; //输入特征图转化得到的矩阵尺度 = (卷积组输入通道数*卷积核高*卷积核宽) * (卷积层输出单通道特征图高 * 卷积层输出单通道特征图宽)int height_col = (height + 2*pad - ksize) / stride + 1; // 高度方向计算几次卷积int width_col = (width + 2*pad - ksize) / stride + 1; // 宽度方向计算几次卷积int channels_col = channels * ksize * ksize; // 输入矩阵展开//卷积核大小和通道数for (c = 0; c < channels_col; ++c) { // 输出为:(输入通道*kh*kw)*卷积滑动的次数//多通道img2col的第一行int w_offset = c % ksize; // 卷积核的索引 // 卷积核的宽度方向indexint h_offset = (c / ksize) % ksize; // 多通道img2col // 卷积核的高度方向indexint c_im = c / ksize / ksize; // 图像上的第index个通道 // 卷积核的通道方向的indexfor (h = 0; h < height_col; ++h) { // 高度方向计算几次卷积 和卷积的计算方式,只是值相同,无任何相关意义for (w = 0; w < width_col; ++w) { // 宽度方向计算几次卷积int im_row = h_offset + h * stride; // 第几次卷积所需要的图像数据索引,行方向int im_col = w_offset + w * stride; // 列方向int col_index = (c * height_col + h) * width_col + w; // img2col之后,列项的索引data_col[col_index] = im2col_get_pixel(data_im, height, width, channels,im_row, im_col, c_im, pad);}}}
}
池化
说说池化层的作用?
1.invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度)。
2.保留主要的特征同时减少参数(降维,效果类似PCA)和计算量,防止过拟合,提高模型泛化能力。
3.减少计算量。做窗口滑动卷积的时候,卷积值代表整个窗口的特征。因为滑动的窗口间有大量重叠区域,卷积值有冗余,进行最大pooling或者平均pooling就是减少冗余。同时,pooling也丢掉了局部位置信息,所以局部有微小形变,但结果也是一样的。
总的来说即保留显著特征、降低特征维度,提升网络不变性,描述图像的高层抽象。
说说卷积层与池化层的区别?
| 卷积层 | 池化层 | |
|---|---|---|
| 结构 | 零填充时输出维度不变,而通道数改变 | 通常特征维度会降低,通道数不变 |
| 稳定性 | 输入特征发生细微改变时,输出结果会改变 | 感受野内的细微变化不影响输出结果 |
| 作用 | 感受野内提取局部关联特征 | 感受野内提取泛化特征,降低维度 |
| 参数量 | 与卷积核尺寸、卷积核个数相关 | 不引入额外参数 |
传统图像算法
说说Canny边缘检测算子?
Canny算子是一种先平滑再求导的边缘检测算子,其检测流程如下:
1.对图像用高斯滤波器进行平滑处理。高斯滤波用于对图像进行减噪,采用邻域加权平均的方法计算每一个像素点的值。
2.利用一阶差分计算边缘的方向与幅值。
首先在水平和垂直方向采用 Sobel kernel 计算得到水平方向和垂直方向梯度,然后计算每个像素的边缘梯度和梯度方向。卷积模板如下。
H 1 = ∣ − 1 − 1 1 1 ∣ H 2 = ∣ 1 − 1 1 − 1 ∣ φ 1 ( m , n ) = f ( m , n ) ∗ H 1 ( x , y ) φ 2 ( m , n ) = f ( m , n ) ∗ H 2 ( m , n ) φ ( m , n ) = φ 1 2 ( m , n ) + φ 2 2 ( m , n ) θ φ = tan − 1 φ 2 ( m , n ) φ 1 ( m , n ) \begin{aligned} &H_{1}=\left|\begin{array}{cc} -1 & -1 \\ 1 & 1 \end{array}\right| \quad H_{2}=\left|\begin{array}{ll} 1 & -1 \\ 1 & -1 \end{array}\right| \\ &\varphi_{1}(m, n)=f(m, n)^{*} H_{1}(x, y) \\ &\varphi_{2}(m, n)=f(m, n) * H_{2}(m, n) \\ &\varphi(m, n)=\sqrt{\varphi_{1}^{2}(m, n)+\varphi^{2}{ }^{2}(m, n)} \\ &\theta_{\varphi}=\tan ^{-1} \frac{\varphi_{2}(m, n)}{\varphi_{1}(m, n)} \end{aligned} H1= −11−11 H2= 11−1−1 φ1(m,n)=f(m,n)∗H1(x,y)φ2(m,n)=f(m,n)∗H2(m,n)φ(m,n)=φ12(m,n)+φ22(m,n)θφ=tan−1φ1(m,n)φ2(m,n)3.应用非极大抑制技术来消除边缘误检。
仅求出全局的梯度方向并不能确定边缘的位置。所以需要对一些梯度值不是最大的点进行抑制,突出真正边缘。
在2中,求出的梯度的方向可以是360°的,我们将这360°的区域划分为4个空间,如下图所示。
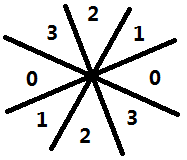
对应到图像中,一个像素点与其相邻的8个像素点,也可以划分为4个区域。
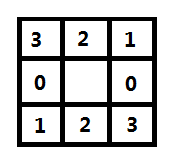
再判断沿着梯度方向的3个像素点(中心像素点与另外两个梯度方向区域内的像素点),若中心像素点的梯度值不比其他两个像素点的梯度值大,则将该像素点的灰度值置0。
4.应用双阈值的方法来决定可能的潜在边界。
任何边缘的强度梯度大于 maxVal 的确定为边缘;而小于 minVal 的确定为非边缘,并丢弃。位于max和min阈值间的边缘为待分类边缘,或非边缘,基于连续性进行判断。如果边缘像素连接着 “确定边缘” 像素,则认为该边缘属于真正边缘的一部分;否则,丢弃该边缘。
模型评价指标
说说分类模型评估有哪些常用方法?
| 指标 | 描述 |
|---|---|
| Accuracy | 准确率 |
| Precision | 精准度/查准率 |
| Recall | 召回率/查全率 |
| P-R曲线 | 查准率为纵轴,查全率为横轴,作图 |
| F1 | F1值 |
| Confusion Matrix | 混淆矩阵 |
| ROC | ROC曲线 |
| AUC | ROC曲线下的面积 |
说说如何计算AUC?
1.将坐标点按照横坐标FPR排序 。
2.计算第 i i i个坐标点和第 i + 1 i+1 i+1个坐标点的间距 d x dx dx 。
3.获取第 i i i或者 i + 1 i+1 i+1个坐标点的纵坐标y。
4.计算面积微元 d s = y d x ds=ydx ds=ydx。
5.对面积微元进行累加,得到AUC。
经典分类网络与发展
简要说说MobileNet系列?
1.MobileNet V1
谷歌在2017年提出,专注于移动端或者嵌入式设备中的轻量级CNN网络。
该论文最大的创新点是,提出了深度可分离卷积(depthwise separable convolution)。
使用RELU6作为激活函数,这个激活函数在float16/int8的嵌入式设备中效果很好,能较好地保持网络的鲁棒性。2.MobileNet V2
时隔一年,谷歌的又一力作。V2在V1的基础上,主要解决了V1在训练过程中非常容易特征退化的问题,引入了Inverted Residuals和Linear Bottlenecks。
所谓倒置残差块,如图所示,与残差块做对比。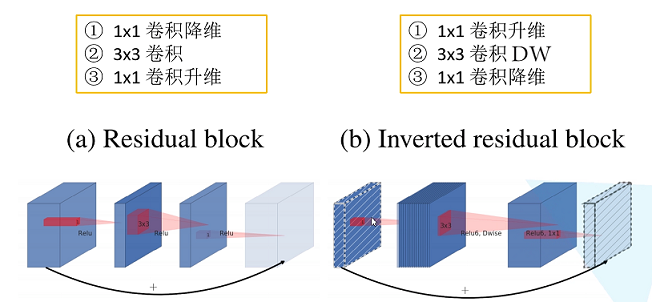
残差块是先降维再升维,两头胖,中间瘦。倒残差结构就是 两头瘦,中间胖;
Linear Bottlenecks:在V1中 depthwise 中有0卷积的原因就是 Relu 造成的,换成 Linear 解决了这个问题;3.MobileNet V3
v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,提出了h-switch作为激活函数,利用NAS(神经结构搜索)来搜索网络的配置和参数(NAS就是不需要人工调参,自动搜索,要先给出搜索空间和搜索方式)。
经典目标检测网络与发展
说说Single Shot MultiBox Detector(SSD)?
1.创新点
(1)基于Faster R-CNN的Anchor机制,提出了先验框(Prior box)
(2)从不同比例的特征图(多尺度特征)中产生不同比例的预测,并明确地按长宽比分离预测。SSD在多个特征图上设置不同缩放比例和不同宽高比的先验框以融合多尺度特征图进行检测,大尺度特征图可以检测小物体信息,小尺度特征图能捕捉大物体信息,从而提高检测的准确性和定位的准确性。
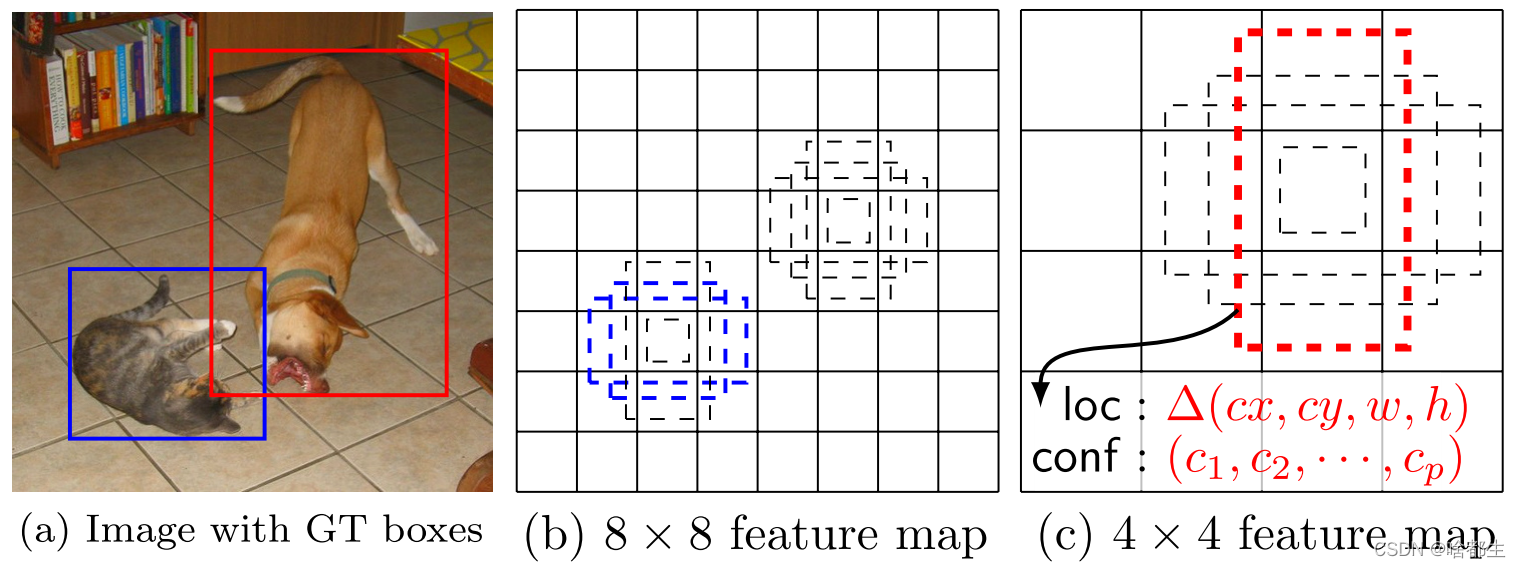
2.锚框不同于Faster R-CNN只在最后一个特征层取anchor, SSD在多个特征层上取default box,可以得到不同尺度的default box。在特征图的每个单元上取不同宽高比的default box,一般宽高比在{1,2,3,1/2,1/3}中选取,有时还会额外增加一个宽高比为1但具有特殊尺度的box。如下图所示,在8x8的feature map和4x4的feature map上的每个单元取4个不同的default box。
3.先验框匹配准则
(1)对图片中的每个ground truth, 在先验框中找到与其IOU最大的先验框,则该先验框对应的预测边界框与ground truth 匹配。
(2)对于(1)中每个剩下的没有与任何ground truth匹配到的先验框,找到与其IOU最大的ground truth,若其与该ground truth的IOU值大于某个阈值(一般设为0.5),则该先验框对应的预测边界框与该ground truth匹配。
按照这两个原则进行匹配,匹配到ground truth的先验框对应的预测边界框作为正样本,没有匹配到ground truth的先验框对应的预测边界框作为负样本。尽管一个ground truth可以与多个先验框匹配,但是ground truth的数量相对先验框还是很少,按照上面的原则进行匹配还是会造成负样本远多于正样本的情况。为了使正负样本尽量均衡(一般保证正负样本比例约为1:3),SSD采用hard negative mining, 即对负样本按照其预测背景类的置信度进行降序排列,选取置信度较小的top-k作为训练的负样本。
经典分割网络与发展
说说Mask R-CNN?
Mask R-CNN 架构相当简单,它是流行的 Faster R-CNN 架构的扩展,在其基础上进行必要的修改,以执行语义分割。如图,其中黑色部分为原来的Faster-RCNN,红色部分为在Faster网络上的修改。
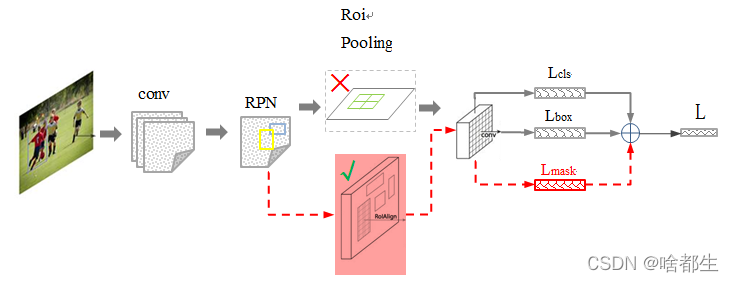
在Faster R-CNN 上添加辅助分支以执行语义分割。
对每个实例进行的 RoIPool 操作已经被修改为 RoIAlign ,它避免了特征提取的空间量化,因为在最高分辨率中保持空间特征不变对于语义分割很重要。
Mask R-CNN 与 Feature Pyramid Networks(类似于PSPNet,对特征使用了金字塔池化)相结合,在 MS COCO数据集上取得了最优结果。
Transformer
说说Transformer中的Encoder?
Transformer模型的Encoder是由多个相同结构的层堆叠而成的组件,用于将输入序列转化为一系列的隐藏表示。每个层由两个子层构成:多头自注意力机制和前馈神经网络。Encoder的最底层接收输入序列作为输入,然后每个层通过对前一层的隐藏表示进行转换,依次传递给下一层。最终,Encoder的输出是一个与输入序列长度相同的隐藏表示序列。
在自注意力机制中,Encoder将输入序列的每个位置的隐藏表示作为查询、键和值,通过计算注意力权重,对序列中的不同位置进行加权求和得到每个位置的输出。这使得Encoder能够获得全局的上下文信息,并且可以在处理不同位置时自动捕捉到序列中的长程依赖关系。
在前馈神经网络中,Encoder对每个位置的隐藏表示应用一个全连接层,并使用激活函数对其进行变换。这个层充当了局部模式的提取器,帮助模型更好地捕捉到输入序列中的局部关系。
通过多个堆叠的Encoder层,Transformer模型的Encoder可以通过迭代处理序列,逐渐提取更丰富的上下文信息,并生成更高层次的隐藏表示,用于后续的任务。
说说Transformer中的Decoder?
Decoder负责根据Encoder提供的编码信息和已生成的部分输出序列,预测下一个输出的单词或符号。
Decoder由多个编码层组成,每个编码层由两个子层组成:自注意力机制子层和前馈神经网络子层。自注意力机制子层可以帮助Decoder在生成每个单词时,关注与当前单词相关的输入序列的其他位置。前馈神经网络子层则用于对自注意力机制子层的输出进行进一步的处理和映射。
Decoder的输入包括Encoder提供的编码信息和已生成的输出序列,通过多个编码层的处理,逐步生成输出序列。在每个编码层内部,Decoder会逐步生成每个输出的单词或符号,并将其作为下一个编码层的输入。
通过使用自注意力机制和前馈神经网络等机制,Decoder能够在生成输出序列时,充分考虑输入序列的上下文信息和已生成的部分输出序列,从而提高翻译等任务的性能。
特征工程
说说深度学习中解决样本不均衡问题的方法?
在机器学习中适用的方法在深度学习中同样适用。比如说:扩大数据集、类别均衡采样、人工产生数据样本,添加少类别样本的来loss惩罚项等。
类别均衡采样
类别重组法只需要原始图像列表即可完成同样的均匀采样任务,步骤如下:
首先按类别顺序对原始样本排序,计算每个类别的样本数,记录样本最多类的样本数目。
之后,根据最多样本数对每类样本产生一个随机排列的列表, 然后用此列表中的随机数对各自类别的样本数取余,得到对应的索引值。
接着,根据索引从该类的图像中提取图像,生成该类的图像随机列表。之后将所有类的随机列表连在一起随机打乱次序,即可得到最终的图像列表。
最终列表中每类样本数目均等。根据此列表训练模型,在训练时列表遍历完毕,则重头再做一遍上述操作即可进行第二轮训练,如此往复。优点在于,只需要原始图像列表,且所有操作均在内存中在线完成,易于实现。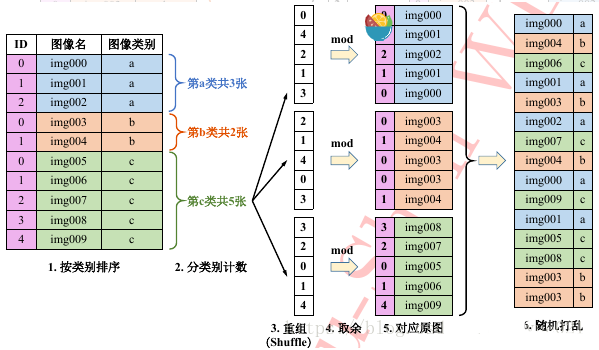
在线难例挖掘(OHEM)
算法的核心思想是根据输入样本的损失进行筛选,筛选出hard example,然后将筛选得到的这些样本应用在随机梯度下降中训练。在实际操作中是将原来的一个ROI Network扩充为两个ROI Network,这两个ROI Network共享参数。其中前面一个ROI Network只有前向操作,主要用于计算损失;后面一个ROI Network包括前向和后向操作,以hard example作为输入,计算损失并回传梯度。作者将该算法应用在Fast RCNN中。
算法优点:对于数据的类别不平衡问题不需要采用设置正负样本比例的方式来解决,这种在线选择方式针对性更强。通俗的讲OHEM就是加强loss大样本的训练。Focal Loss(前面已经讲过了这里不重复)
多尺度训练
Soft NMS
带权重的softmaxLoss样本量大的类别往往会主导训练过程,因为其累积loss会比较大。带权重的softmaxloss函数通过加权来决定主导训练的类别。具体为增加pos_mult(指定某类的权重乘子)和pos_cid(指定的某类的类别编号)两个参数来确定类别和当前类别的系数。(若pos_mult=0.5,就表示当然类别重要度减半)。
模型优化
说说模型压缩的作用与意义?
对于在线学习和增量学习等实时应用而言,如何减少含有大量层级及结点的大型神经网络所需要的内存和计算量显得极为重要。
模型的参数在一定程度上能够表达其复杂性,相关研究表明,并不是所有参数都在模型中发挥作用,部分参数作用有限、表达冗余,甚至会降低模型的性能。
高额的存储空间、计算资源消耗是使复杂模型难以有效应用在各硬件平台上的重要原因。
智能设备的流行提供了内存、CPU、能耗和宽带等资源,使得深度学习模型部署在智能移动设备上变得可行。
说说低秩近似?
神经网络的基本运算卷积,实则就是矩阵运算,低秩近似的技术是通过一系列小规模矩阵将权重矩阵重构出来,以此降低运算量和存储开销。目前有两种常用的方法:
一是Toeplitz矩阵直接重构权重矩阵
二是奇异值分解(SVD),将权重矩阵分解为若干个小矩阵。
事项 特点 优点 可以降低存储和计算消耗;
一般可以压缩2-3倍;精度几乎没有损失;缺点 模型越复杂,权重矩阵越大,利用低秩近似重构参数矩阵不能保证模型的性能 ;
超参数的数量随着网络层数的增加呈线性变化趋势,例如中间层的特征通道数等等。
随着模型复杂度的提升,搜索空间急剧增大。
相关文章:

AI面经总结-试读
写在前面 该面经于2022年秋招上岸后耗时一个半月整理完毕,目前涵盖Python、基础理论、分类与聚类、降维、支持向量机SVM、贝叶斯|决策树、KNN、Boosting&Bagging、回归、代价函数与损失函数、激活函数、优化函数、正则优化、初始化与归一化、卷积、池化、传统图…...

python打卡day22@浙大疏锦行
复习日 仔细回顾一下之前21天的内容,没跟上进度的同学补一下进度。 作业: 自行学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码 一、数据预处理 import pandas as pd import numpy as np import matplo…...

网络安全设备配置与管理-实验5-p150虚拟防火墙配置
实验5-p150虚拟防火墙配置 做不出来可以把项目删掉再新建。 实验六多加几步配置静态路由表就行。 文章目录 实验5-p150虚拟防火墙配置1. 实验目的2. 实验任务3. 实验设备4. 实验拓扑图和设备接口5. 实验命令与步骤1. 连线与配置2. 实验验证 思考题 1. 实验目的 通过该实验掌握…...

数值运算的误差估计
数值运算的误差估计 设两个近似数 x 1 ∗ x_1^* x1∗与 x 2 ∗ x_2^* x2∗的误差限分别为 ε ( x 1 ∗ ) \varepsilon(x_{1}^{*}) ε(x1∗)和 ε ( x 2 ∗ ) \varepsilon(x_{2}^{*}) ε(x2∗) 误差限满足一下运算法则: 和差运算的误差限: 设 y …...

HCIP-BGP实验一
一:拓扑图 二:需求分析: 保证R1-R5的环回地址相互能够通讯。 分析; 1.IP的配置 2.R2-R4完成IGP配置,配置OSPF 3.完成BGP配置。 4.优化配置,包括下一跳的选择,IBGP对等体建邻的IP地址。 三…...

linux内核pinctrl/gpio子系统驱动笔记
目录 一、简单介绍二、主要源码文件和目录gpio子系统pinctrl子系统两个子系统之间的关系设备树例子 三、主要的数据结构gpio子系统pinctrl子系统 四、驱动初始化流程五、难点说明 一、简单介绍 GPIO子系统: Linux GPIO子系统是Linux内核中负责处理GPIO(通用输入输出…...

Qt—多线程基础
一、QThread 1.为什么使用多线程 在默认情况下,Qt使用的是单线程,当你启动一个 Qt 应用程序时,它会运行在一个单一的主线程(也被称为 GUI 线程)中。这个主线程负责处理所有的 GUI 事件和界面渲染。 但在一些其他情况下…...

HTML5表格语法格式详解
HTML5 表格的基本结构 HTML5 表格由 <table> 标签定义,表格中的每一行由 <tr> 标签定义,表头单元格由 <th> 标签定义,数据单元格由 <td> 标签定义。表格的基本结构如下: <table><tr><th…...

《Go小技巧易错点100例》第三十三篇
Validator自定义校验规则 Go语言中广泛使用的validator库支持通过结构体标签定义校验规则。当内置规则无法满足需求时,我们可以轻松扩展自定义校验逻辑。 示例场景:验证用户年龄是否成年(≥18岁) type User struct {Age in…...
——Chat Memory)
Spring AI(3)——Chat Memory
Chat Memory介绍 大型语言模型(LLM)是无状态的,这意味着它们不保留关于以前互动的信息。为了解决这个问题,Spring AI提供了Chat Memory(聊天记忆)功能。通过Chat Memory,用户可以实现在与LLM的…...
详解)
双向循环神经网络(Bi-RNN)详解
双向循环神经网络(Bidirectional Recurrent Neural Network, Bi-RNN)是一种能够同时利用序列数据过去和未来信息的循环神经网络架构,在许多序列建模任务中表现出色。 1. Bi-RNN基本概念 1.1 核心思想 Bi-RNN通过组合两个独立的RNN层来工作: 前向RNN&…...

【Bluedroid】HID DEVICE 连接的源码分析
本文分析Android Bluetooth协议栈中HID device设备连接流程的完整实现,从应用层接口到协议栈底层的交互细节。通过关键函数(如connect()、BTA_HdConnect()、HID_DevConnect()等)的代码解析,重点关注btif、bta、HID协议栈三层的协同机制,揭示BTA_HD_CONN_STATE_EVT事件传递…...
)
第二十一周:项目开发中遇到的相关问题(二)
本周接着介绍本次新闻项目中遇到的一些问题。首先谈谈Controller层中的请求路径问题(RequestMapping),RequestMapping注解是Spring框架中用于处理HTTP请求映射的核心注解,它可以将HTTP请求映射到具体的控制器方法上。 1.关于它的基本作用&…...

深度解析大模型学习率:优化策略与挑战
大模型超参数Learning Rate的深度学习 学习率(Learning Rate)是机器学习和深度学习中最核心的超参数之一,尤其在训练大规模语言模型(LLMs)时,其设置直接影响模型的收敛速度、训练稳定性及最终性能。以下从多维度详细解析学习率的定义、作用、挑战及优化策略。 一、学习率…...

云计算-容器云-KubeVirt 运维
KubeVirt 运维:创建 VM 使用提供的镜像在 kubevirt 命名空间下创建一台 VM,名称为 exam,指定 VM 的内存、CPU、网卡和磁盘等配置。 [rootk8s-master-node1 ~]# kubectl explain kubevirt.spec. --recursive |grep useuseEmulation <boo…...

C++内存管理详解
目录 1.C/C中的内存 2.C内存管理 2.1C语言内存管理 2.2new和delete 2.2.1概念及定义 2.2.2自定义类型内存管理 2.2.3 delete与delete[ ] 1.C/C中的内存 在C/C中编译器会对不同的代码进行内存分配,给代码的内存区主要分为栈区、堆区、数据段(静态区)、代码段(…...

二叉搜索树讲解
1. 二叉搜索树的概念 二叉搜索树又称二叉排序树,它或者是一颗空树,或者是具有以下性质的二叉树: 1. 若它的左子树不为空,则左子树上的所有结点的值都小于等于根节点的值。 2. 若它的右子树不为空,则右子树上的所有结…...

MySQL 索引设计宝典:原理、原则与实战案例深度解析
目录 前言第一章:索引设计的基础原则 (知其然,更要知其所以然)第二章:实战案例:电商订单系统的索引设计第三章:索引设计的实践流程总结结语 🌟我的其他文章也讲解的比较有趣😁,如果喜…...

如何租用服务器并通过ssh连接远程服务器终端
这里我使用的是智算云扉 没有打广告 但确实很便宜 还有二十小时免费额度 链接如下 注册之后 租用新实例 选择操作系统 选择显卡型号 点击租用 选择计费方式 选择镜像 如果跑深度学习的话 就选项目对应的torch版本 没有的话 就创建纯净的cuda 自己安装 点击创建实例 创建之后 …...

TikTok 账号运营干货:AI 驱动优化
TikTok 账号运营是一项需要全方位精心雕琢的工作。首先,账号资料的打造至关重要,务必保证完整且富有吸引力。头像要清晰醒目,能够直观传达账号的核心特色;昵称需简洁易记,方便用户快速识别与记忆;简介则要精…...

Redis 分布式锁
什么是分布式锁 在一个分布式的系统中, 也会涉及到多个节点访问同一个公共资源的情况. 此时就需要通过 锁 来做互斥控制, 避免出现类似于 "线程安全" 的问题 而 java 的 synchronized 或者 C 的 std::mutex, 这样的锁都是只能在当前进程中生效, 在分布式的这种多个进…...

Redis爆肝总结
一、基础 1.介绍 本质上是一个Key-Value类型的内存数据库,数据的加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。 速度快的根本原因 纯内存操作,性能非常出色,每秒可以处理超过10万次读写操作&a…...

Qt模块化架构设计教程 -- 轻松上手插件开发
概述 在软件开发领域,随着项目的增长和需求的变化,保持代码的可维护性和扩展性变得尤为重要。一个有效的解决方案是采用模块化架构,尤其是利用插件系统来增强应用的功能性和灵活性。Qt框架提供了一套强大的插件机制,可以帮助开发者轻松实现这种架构。 模块化与插件系统 模…...

[项目总结] 抽奖系统项目技术应用总结
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

【运维】基于Python打造分布式系统日志聚合与分析利器
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在分布式系统中,日志数据分散在多个节点,管理和分析变得复杂。本文详细介绍如何基于Python开发一个日志聚合与分析工具,结合Logstash和F…...
)
MySql(基础)
表名建议用 反引号 包裹(尤其是表名包含特殊字符或保留字时),但如果表名是普通字符串(如 user),可以省略。 注释(COMMENT 姓名) 数据库 1.查看数据库:show databases…...
)
怎样选择成长股 读书笔记(一)
文章目录 第一章 成长型投资的困惑一、市场不可预测性的本质困惑二、成长股的筛选悖论三、管理层评估的认知盲区四、长期持有与估值波动的博弈五、实践中的认知升级路径总结:破解困惑的行动框架 第二章 如何阅读应计制利润表一、应计制利润表的本质与核心原则1. 权责…...

系统思考:个人与团队成长
四年前,我交付的系统思考项目,今天学员的反馈依然深深触动了我。 我常常感叹,系统思考不仅仅是一场培训,更像是一场持续的“修炼”。在这条修炼之路上,最珍贵的,便是有志同道合的伙伴们一路同行࿰…...

并行发起http请求
1. 使用 axios Promise.all <template><input type"file" multiple change"handleFileUpload" /> </template><script> import axios from axios;export default {methods: {async handleFileUpload(event) {const files event…...

【数据结构入门训练DAY-31】组合的输出
本文介绍了如何使用深度优先搜索(DFS)算法解决数的组合问题。题目要求从1到n的自然数中选取r个数,输出所有可能的组合,并按字典顺序排列。文章详细描述了解题思路,包括建立数组存储数字、使用DFS递归处理候选数、以及如…...

leetcode0815. 公交路线-hard
1 题目: 公交路线 官方标定难度:难 给你一个数组 routes ,表示一系列公交线路,其中每个 routes[i] 表示一条公交线路,第 i 辆公交车将会在上面循环行驶。 例如,路线 routes[0] [1, 5, 7] 表示第 0 辆公…...

花朵识别系统Python+深度学习+卷积神经网络算法+TensorFlow+人工智能
一、介绍 花朵识别系统。本系统采用Python作为主要编程语言,基于TensorFlow搭建ResNet50卷积神经网络算法模型,并基于前期收集到的5种常见的花朵数据集(向日葵、玫瑰、蒲公英、郁金香、菊花)进行处理后进行模型训练,最…...
LLM Post-Training: A Deep Dive into Reasoning Large Language Models)
LLM 论文精读(四)LLM Post-Training: A Deep Dive into Reasoning Large Language Models
这是一篇2025年发表在arxiv中的LLM领域论文,是一篇非常全面的综述类论文,介绍了当前主流的强化学习方法在LLM上的应用,文章内容比较长,但建议LLM方面的从业人员反复认真阅读。 写在最前面 为了方便你的阅读,以下几点的…...

网址为 http://xxx:xxxx/的网页可能暂时无法连接,或者它已永久性地移动到了新网址
这是由于浏览器默认的非安全端口所导致的,所谓非安全端口,就是浏览器出于安全问题,会禁止一些网络浏览向外的端口。 避免使用6000,6666这样的端口 6000-7000有很多都不行,所以尽量避免使用这个区间 还有在云服务器中,…...

【C++】16.继承
C三大特性:封装,继承,多态 在前面的章节中,我们讲过了封装,也就是通过类和访问修饰符来进行封装。 接下来我们就来认识一下新的特性——继承 1. 继承的概念及定义 1.1 继承的概念 继承(inheritance)机制是面向对…...

LlamaIndex 第七篇 结构化数据提取
大型语言模型(LLMs)在数据理解方面表现出色,这也促成了它们最重要的应用场景之一:能够将常规的人类语言(我们称之为非结构化数据)转化为特定的、规范的、可被计算机程序处理的格式。我们将这一过程的输出称…...

PHP API安全设计四要素:构建坚不可摧的接口防护体系
引言:API安全的重要性 在当今前后端分离和微服务架构盛行的时代,API已成为系统间通信的核心枢纽。然而,不安全的API可能导致: 数据泄露:敏感信息被非法获取篡改风险:传输数据被中间人修改重放攻击&#x…...

英语16种时态
时态应用场合格式例子一般现在时表示经常、反复发生的动作,客观事实或普遍真理主语 动词原形(第三人称单数作主语时动词加 -s/-es)The sun rises in the east.一般过去时表示过去某个时间发生的动作或存在的状态主语 动词的过去式I visited…...

使用 goaccess 分析 nginx 访问日志
介绍 goaccess 是一个在本地解析日志的工具, 可以直接在命令行终端环境中使用 TUI 界面查看分析结果, 也可以导出为更加丰富的 HTML 页面. 官网: https://goaccess.io/ 下载安装 常见的 Linux 包管理器中都包含了 goaccess, 直接安装就行. 以 Ubuntu 为例: sudo apt instal…...

什么是中央税
中央税(又称国家税)是指由中央政府直接征收、管理和支配的税种,其收入全额纳入中央财政,用于保障国家层面的财政支出和宏观调控。中央税通常具有税基广泛、收入稳定、涉及国家主权或全局性经济调控的特点。 --- 中央税的核心特征…...
:个人助手应用)
AI Agent(10):个人助手应用
引言 本文聚焦AI Agent在个人助手领域的应用,探讨其如何在个人生产力提升、健康与生活管理、学习与教育辅助以及娱乐与社交互动四个方面,为用户创造价值并解决实际问题。 AI个人助手正从简单的指令执行者逐渐发展为具有自主性、适应性和个性化能力的智能伙伴。这一转变不仅…...

力扣70题解
记录 2025.5.8 题目: 思路: 1.初始化:p 和 q 初始化为 0,表示到达第 0 级和第 1 级前的方法数。r 初始化为 1,表示到达第 1 级台阶有 1 种方法。 2.循环迭代:从第 1 级到第 n 级台阶进行迭代: p 更新为前…...
)
2025御网杯wp(web,misc,crypto)
文章目录 miscxor10图片里的秘密被折叠的显影图纸 Cryptoeasy_rsagift**1. 礼物数学解析****最终答案** 草甸方阵的密语easy-签到题baby_rsa webYWB_Web_xffYWB_Web_未授权访问easywebYWB_Web_命令执行过滤绕过反序列化 misc xor10 ai一把梭 根据题目中的字符串和提示&#…...

【深度学习】将本地工程上传到Colab运行的方法
1、将本地工程(压缩包)上传到一个新的colab窗口:如下图中的 2.zip,如果工程中有数据集,可以删除掉。 2、解压压缩包。 !unzip /content/2.zip -d /content/2 如果解压出了不必要的文件夹可以递归删除: #…...
)
多模态大语言模型arxiv论文略读(六十九)
Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models ➡️ 论文标题:Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models ➡️ 论文作者:Yue Zha…...

Lua再学习
因为实习的项目用到了Lua,所以再来深入学习一下 函数 函数的的多返回值 Lua中的函数可以实现多返回值,实现方法是再return后列出要返回的值的列表,返回值也可以通过变量接收到,变量不够也不会影响接收对应位置的返回值 Lua中传…...

Linux计划任务与进程
at 命令使用方法 at 命令可在指定时间执行任务,适用于一次性任务调度。以下是基本用法: 安装 atd 服务(如未安装) # Debian/Ubuntu sudo apt-get install at# CentOS/RHEL sudo yum install at启动服务 sudo systemctl start atd…...

JavaEE--文件操作和IO
目录 一、认识文件 二、 树型结构组织和目录 三、文件路径 1. 绝对路径 2. 相对路径 四、文件类型 五、文件操作 1. 构造方法 2. 方法 六、文件内容的读写——数据流 1. InputStream概述 2. FileInputStream概述 2.1 构造方法 2.2 示例 3. OutputStream概述 3.…...

k8s的节点是否能直接 curl Service 名称
在 Kubernetes 中,节点(Node)默认情况下不能直接通过 Service 的 DNS 名称(如 my-svc.default.svc.cluster.local)访问 Service。以下是详细分析和解决方案: 1. 默认情况下节点无法解析 Service 的 DNS 名…...
Mask-aware Pixel-Shuffle Down-Sampling (MPD) 下采样
来源 简介:这个代码实现了一个带有掩码感知的像素重排下采样模块,主要用于图像处理任务(如图像修复或分割)。 论文题目:HINT: High-quality INpainting Transformer with Mask-Aware Encoding and Enhanced Attentio…...