Redis爆肝总结
一、基础
1.介绍
本质上是一个Key-Value类型的内存数据库,数据的加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。
速度快的根本原因
纯内存操作,性能非常出色,每秒可以处理超过10万次读写操作,是性能最快的Key-Value DB;
- 将数据存储在内存中,提供快速的读写速度,相比于传统的磁盘数据库,内存访问速度快得多。
- 使用单线程事件驱动模型结合I/O多路复用,避免了多线程上下文切换和竞争条件,提高了并发处理效率。
- 提供多种高效的数据结构(如字符串、哈希、列表、集合等),这些结构经过优化,能够快速完成各种操作。
主要缺点:受内存的直接限制,不能用作海量数据的高性能读写,但适合较小数据量的高性能操作和运算上。
redis通过文件描述符来实现以下功能:
- 管理客户端连接
- 网络监听
- 持久化操作
- 管理I/O资源
这时候观测文件描述符变更带来的处理模式,有两种可以选择,主动循环和事件监听模型;
Poll【轮循】
poll 采用轮询的方式来检查文件描述符的就绪状态,当文件描述符数量较多时,需要遍历整个文件描述符集合,时间复杂度为 O(n),随着文件描述符数量的增加,性能会逐渐下降。【主动扫描响应机制】
EPoll【事件监听】
epoll 在内核中维护了一个就绪队列,当有文件描述符就绪时,内核会将其加入到就绪队列中。应用程序通过 epoll_wait 函数获取就绪的文件描述符,不需要遍历所有文件描述符,时间复杂度为 O(1);
在高并发场景下,文件描述符数量越多,EPoll提高性能越显著。【事件监听被动的响应机制】
2、数据类型
1. 字符串(String)
- 特点:键值对形式,值可以是字符串、整数或浮点数,能对数值类型进行原子性增减操作。
- 数据结构:简单动态字符串(SDS)【空间预分配、惰性释放】
- 使用场景:用于缓存数据、实现计数器、分布式锁等。
- 优点:操作简单,读写速度快,支持原子操作。
- 缺点:不适合存储复杂数据结构。
- 支持的命令:
SET、GET、INCR、DECR、MSET、MGET等。 - 最大长度:单个字符串值最大长度为 512MB。
命令
- 设置值:SET、SETNX、SETEX、PSETEX、MSET、SETBIT
- 获取值:GET、MGET、GETRANGE、GETSET、STRLEN、GETBIT
- 数值操作:INCR、DECR、INCRBY、DECRBY、INCRBYFLOAT
- 追加操作:APPEND
2. 列表(List)
- 特点:元素有序,可在两端进行插入和删除操作,能实现队列和栈。【也可以实现
MQ】 - 数据结构:
- 3.2版本之后:默认使用QuickList结构
- 3.2版本之前:默认情况下,【元素少且值小】时用压缩列表(ziplist);反之则用双向链表(linkedlist)
- 使用场景:可用于消息队列、存储最新消息列表等。
- 优点:支持双向操作,插入和删除效率高。
- 缺点:查找操作效率低,时间复杂度为 O (n)
- 支持的命令:
LPUSH、RPUSH、LPOP、RPOP、LRANGE等 - 最大长度:列表最多可包含 【2的32次方-1】个元素
命令
- 插入元素:LPUSH、RPUSH、LPUSHX、RPUSHX
- 移除元素:LPOP、RPOP、RPOPLPUSH、LREM
- 获取元素:LRANGE、LINDEX、LLEN
- 修剪列表:LTRIM
- 阻塞操作:BLPOP、BRPOP、BRPOPLPUSH
QuickList【快速链表】
QuickList 是【LinkedList】和【ZipList】的结合体,由多个 ziplist 和一个双向循环链表组成;
- 综合性能好:结合压缩列表和双向链表的优点,将多个压缩列表用双向链表连接起来。
既利用了压缩列表节省内存的特点,又利用了双向链表便于操作的特性。 - 可配置性强:通过调整每个压缩列表节点中元素的数量【默认节点压缩个数=2】,平衡内存和效率;
- 两端操作高效:支持在列表的两端进行快速的插入和删除操作,时间复杂度为 O(1)。
做范围查询效率不行,实现复杂,需要维护双向链表和压缩链表的结构;
ZipList【压缩链表】
ZipList是一种内存紧凑的数据结构,占用一块连续的内存空间,能有效提升内存使用率,适合小数据集合存储;
LinkedList【双向链表】
双向链表结构,逻辑有序,但是内存不连续;
- 插入和删除操作高效,只需要修改相邻的两个节点;
- 内存开销大,存的数据太多了【数据、相邻节点指针】
- 随机访问效率低,但扩展性好
3. 哈希(Hash-KV键值)
- 特点:存储键值对集合,适合存储对象。
- 数据结构:元素较少且值小时用压缩列表(ziplist);元素较多时用哈希表(hashtable)。
- 使用场景:常用于存储对象信息,如用户信息、商品信息。
- 优点:可将相关字段组织在一起,方便管理,操作效率高。
- 缺点:存储大量字段 - 值对时性能会受影响。
- 支持的命令:
HSET、HGET、HDEL、HKEYS、HVALS、HMSET、HMGET等。 - 最大长度:一个哈希表最多可包含 【2的32次方-1】个字段 - 值对。
命令
- 设置字段值:HSET、HSETNX、HMSET
- 获取字段值:HGET、HMGET、HGETALL、HKEYS、HVALS、HSCAN
- 删除字段:HDEL
- 字段操作:HINCRBY、HINCRBYFLOAT、HEXISTS、HLEN
zipList
ZipList是一种内存紧凑的数据结构,占用一块连续的内存空间,提升内存使用率
hashtable
Set结构,只不过value=null
4. 集合(Set)
- 特点:元素无序且唯一,支持交集、并集、差集等操作。
- 数据结构:元素为整数且数量少时用整数集合(intset);元素多或含非整数元素时用哈希表(hashtable)。
- 使用场景:用于去重、处理社交关系等。
- 优点:集合操作高效,能保证元素唯一性。
- 缺点:不支持有序操作。
- 支持的命令:
SADD、SMEMBERS、SREM、SINTER、SUNION等。 - 最大长度:一个集合最多可包含 【2的32次方-1】个元素。
命令
- 添加元素:SADD
- 移除元素:SREM、SPOP、SMOVE
- 获取元素:SMEMBERS、SISMEMBER、SCARD、SSCAN
- 集合操作:SINTER、SUNION、SDIFF、SINTERSTORE、SUNIONSTORE、SDIFFSTORE
- 随机获取:SRANDMEMBER
intset【整数数组】
Set使用它做数据结构需要满足下面两个条件:
- 元素个数不少于默认值512;
- set-max-intset-entries的值为512。
hashtable【哈希表】
Set结构,只不过value=null
5. 有序集合(ZSet)
排行榜,延时队列,都通过设置score来控制优先级
类似于集合(Set),但每个元素都关联了一个分数Score,用于进行有序排序;【支持单个和范围查询】
- 特点:每个元素关联一个分值,元素按分值有序排列,支持范围查找。
- 数据结构:由跳跃表(skiplist)和哈希表(hashtable)组成。
- 使用场景:适用于排行榜、热门列表等场景。
- 优点:能高效地根据分值进行范围查找和排序。
- 缺点:插入、删除和更新操作相对复杂。
- 支持的命令:
ZADD、ZRANGE、ZREVRANGE、ZREM等。 - 最大长度:一个有序集合最多可包含 232−1(4294967295)个元素。
命令
- 添加元素:ZADD
- 移除元素:ZREM、ZREMRANGEBYRANK、ZREMRANGEBYSCORE
- 获取元素:ZRANGE、ZREVRANGE、ZRANGEBYSCORE、ZREVRANGEBYSCORE、ZRANK、ZREVRANK、ZSCORE、ZSCAN
- 统计操作:ZCARD、ZCOUNT、ZLEXCOUNT
- 分数操作:ZINCRBY
SkipList【跳表】
对链表进行改造,在链表上建索引,即每两个结点提取一个结点到上一级,把抽出来的那一级叫作索引。

它可以保证【增、删、查】等操作时的时间复杂度为O(logN),且维持结构平衡的成本比较低,完全依靠随机
跳表占用的空间比较大(多级索引),空间换时间的思想。
特点:
- 由许多层结构组成。
- 每一层都是一个有序的链表。
- 最底层 (Level 1) 的链表包含所有元素。
- 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
- 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
数据查询【target】
- 从顶层链表的头部元素开始,然后遍历该链表的索引,直到找到元素 >= target节点
- 当前元素等于目标,那么就直接返回它
- 当前元素小于目标元素,垂直下降到下一层继续搜索
- 当前元素大于target节点或到达链表尾部
- 则移动到前一个节点的位置,再垂直下降到下一层
数据插入

若不停的向跳表中插入元素,就可能会造成两个索引点之间的结点过多的情况。
结点过多的话,建立跳表索引的优势也没有了,因为需要维护索引与原始链表的大小平衡,即节点增多了,索引也会增加,此时redis会通过一个随机函数来维护这个平衡的,当我们向跳表中插入数据的的时候,可以选择同时把这个数据插入到索引里,具体插入到哪一级的索引,这就需要随机函数,来决定了。
这个随机函数可以很有效的防止跳表退化带来的造成效率变低问题发生
数据删除
整个删除过程,可以简化理解为:先找到,断关联,删内存
-
自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
-
删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
3.特殊的数据类型
Bitmap 基于字符串String类型来存储数据,字符串中的每个字节由 8 个二进制位组成,每个位可以表示 0 或 1。【key:字符串(最大512mb),value:0或1】
通过对这些位的操作,可以实现一些特定的功能,如计数、状态标识等。
1.位图(bitmap)
**偏移量:**代表字符串的位置信息【必须是正整数】,比如字符串最大是512MB,那么这个地方可以表示对应位置的元素,上面的示例可以表示uid=100
值:只能是0和1
键key 偏移量 值
SETBIT user_status:20250429 100 1
**特征:**使用位数组来表示一系列布尔值,每个布尔值对应位数组中的一个位
**底层原理:**通过位运算来高效地存储和查询大量布尔值。每个位独立地设置为0或1,代表对应元素某种状态
**使用场景:**适合用于统计和分析大规模数据,例如用户的活跃情况、网站的访问情况、商品的销售情况等
命令
- 设置位:SETBIT
- 获取位:GETBIT
- 位统计:BITCOUNT
- 位操作:BITOP、BITPOS
Bitmap 占用的内存主要取决于存储的数据量,即二进制位的数量。
它的优点是在存储大量的二进制状态数据时,内存使用效率非常高,相比其他数据结构可以节省大量的内存空间。
例如,存储 1000 万个用户状态,只需约 1.25MB 的内存空间(1000 * 10000 / 8 / 1024 / 1024)
# 用户 uid1,uid2 在 2025-04-11 登录、未登录,一个bitmap可以存
SETBIT user_stataus:2025-04-11 uid1 1
SETBIT user_stataus:2025-04-11 uid2 0
SETBIT user_stataus:2025-04-11 uid这个key最多可以存4294967295个值
- Redis 的字符串最大长度为 【2的32次方-1】 个字节,也就是 4GB
- 由于每个字节有 8 位,这意味着理论上使用的偏移量范围是从 0 到 4294967295(40亿)
2.地理位置(Geo)
**特征:**使用有序集合(Sorted Set)来实现地理空间索引,有序集合中的每个成员都与一个经度和纬度相关联,成员按照分数(在地理空间中即距离)排序。
**底层原理:**利用 GeoHash 算法对地理位置进行编码,并将编码后的值作为有序集合的成员,距离作为分数。当执行地理空间相关的操作时(如查询附近地点),会根据GeoHash 值和给定半径范围来检索符合条件的成员。
**使用场景:**适合存储和查询具有地理位置信息的数据,如用户位置、附近的商家、地理围栏等。
命令
- 添加位置:GEOADD
- 获取位置:GEOPOS
- 计算距离:GEODIST
- 范围查询:GEORADIUS、GEORADIUSBYMEMBER
3.基数概率统计(HyperLogLog)
**特征:**一种用于基数统计的算法,只需要使用很少的内存就能估计集合中不同元素的数量。
**底层原理:**基于概率计数原理,通过对每个元素进行哈希,并记录哈希值的最高位非零位的位置,从而估计集合的大小。随着元素的增加,算法会逐渐收敛到真实基数的近似值。
**使用场景:**适合用于统计网站的 UV、独立 IP 数、用户访问量等场景。
5、缓存穿透、击穿、雪崩
| 问题 | 产生原因 | 解决方案 |
|---|---|---|
| 穿透 | 缓存和DB均不存在 | 1. 缓存空值:存空值&设短过期时间 2. 布隆过滤器 |
| 击穿 | 热点数据缓存过期,请求打到DB | 1.热点数据 永不过期 2. 加互斥锁:只有获取锁的线程查库才能更新缓存 |
| 雪崩 | 大量缓存集中过期 | 1. 分散过期时间:设置过期时间加随机偏移量 2. 多级缓存:用本地缓存和 Redis 构建多级缓存 |
6.监控缓存命中率
监控软件,监控redis热点接口或热点key的缓存命中率
二、生产模式
将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);
数据同步
- 主节点将数据更新操作记录在内存中的复制积压缓冲区,将其持久化到磁盘的 RDB 或 AOF 文件中。
- 从节点在启动时,会向主节点发送 SYNC 命令,请求进行全量数据同步。主节点收到请求后,执行 BGSAVE 命令生成 RDB 文件,并发送给从节点。从节点接收并加载 RDB 文件,将数据加载到内存中,完成全量同步。
命令传播
- 全量同步完成后,主从节点之间会进入增量同步阶段。主节点会将接收到的写命令通过网络连接发送给从节点,从节点接收并执行这些命令,从而保持与主节点的数据一致性。
- 主节点会为每个从节点维护一个复制偏移量,记录主节点向从节点发送的字节数。从节点也会维护自己的复制偏移量,记录已接收并执行的字节数。通过对比复制偏移量,主从节点可以检测数据是否一致。
心跳检测
- 主节点和从节点之间会定期发送心跳包,用于检测对方的存活状态和连接状态。
- 从节点会向主节点发送 REPLCONF ACK 命令,携带自己的复制偏移量,告知主节点自己的同步进度。主节点根据从节点的复制偏移量判断从节点是否落后,如果从节点落后太多,主节点可能会采取一些措施,如调整复制策略或通知管理员。
1.主从集群【一主多从-常用】
数据复制是单向的,只能主节点到从节点,有两种复制模式:rdb 、aof
1. AOF【增量实时】
append only file;日志的形式记录服务器所处理的每一个写、删除操作,查询不会记录
appendonly yes;
实时更新,但aof文件较大,性能开销大
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘【推荐】
appendfsync no #让操作系统决定何时进行同步
2.RDB/快照【默认快照】
它的持久化是在指定的时间间隔内将内存中的数据集快照写入磁盘
性能高,恢复速度快,但存在数据丢失风险,不适合频繁更新的场景
原理:
-
fork进程:通过创建子进程来进行RDB操作 -
cow进程(copy or write):子进程创建后,父子进程共享数据段
手动触发
- SAVE:阻塞主进程,直到快照生成完成
- BGSAVE:后台异步生成快照,不阻塞主进程
可以对快照进行备份,将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),以便重启服务器时使用;
自动触发
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发创建快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发创建快照。
3. 4.0版本混合持久化
历史快照使用rdb,增量实时持久化交给aof
混合持久化结合了RDB和AOF持久化的优点,开头为RDB的格式,使得Redis可以更快的启动,同时结合AOF的优点,有减低了大量数据丢失的风险。
aof-use-rdb-preamble yes
4. 持久化方式总结
Redis的持久化默认策略是RDB,因为默认AOF的方式是关闭的,需要我们手动开启和配置;
4.0版本之前,可以把两个持久化机制,都给开启
- RDB:适合需要高性能和快速恢复的场景,但存在数据丢失风险。
- AOF:适合需要高数据安全性的场景,但文件较大且恢复速度较慢。
- 结合使用:可以同时启用 RDB 和 AOF,兼顾性能和数据安全性。
建议配置:RDB和AOF两种都启用,启用AOF同步策略设置为everysec。如果是支持混合持久化的Redis版本,建议也开启混合持久化。(推荐)
2.Sentinel哨兵【一主多从】
刚刚提到了,主从模式,当主节点宕机之后,从节点是可以作为主节点顶上来,继续提供服务的。
但是有一个问题,主节点的IP已经变动了,此时应用服务还是拿着原主节点的地址去访问,这就很尴尬了;
因此需要一种机制帮助做故障恢复的自动化,就引出了哨兵模式中间层
客户端连接的是哨兵集群,由哨兵节点去操作、访问redis数据

哨兵节点
哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据,负责访问处理和集群监控;
一旦发现redis集群出现了问题,比如刚刚说的主节点挂了,从节点会顶上来。但是主节点地址变了,这时候应用服务无感知,也不用更改访问地址,因为哨兵才是和应用服务做交互的。
哨兵任务
- 每个
Sentinel每 1 秒一次的频率,向它已知的所有服务器以及其他Sentinel实例 发送PING【网络确认】 - 每个
Sentinel每 10 秒一次的频率,向它已知的所有服务器发送INFO。【主从关系确认】 - 每个
Sentinel每 2 秒通过主服务器的channel交换信息(Publish/Subscribe);【角色一致性确认】
故障转移
- 如果一个实例距离最后一次有效回复
PING命令的时间超过down-after-milliseconds所指定的值,那么这个实例会被Sentinel标记为主观下线。 - 如果一个主服务器标记为主观下线, 那正在监视这个主服务器的所有
Sentinel节点,要以每秒一次的频率确认该主服务器是否的确进入主观下线状态。 - 如果一个主服务器标记为主观下线,且有 足够数量 的
Sentinel(至少达到配置文件指定的数量【仲裁下线判断的哨兵数量】)在指定的时间范围内同意这一判断,那么该主服务器被标记为客观下线。 - 当一个 主服务器 被
Sentinel标记为 客观下线 时,Sentinel向下线主服务器 的所有从服务器 发送INFO命令的频率,会从10秒一次改为1秒一次。 Sentinel和其他Sentinel协商 主节点 状态,若主节点处于SDOWN状态,则投票自动选出新的主节点。将剩余的 从节点指向 新的主节点 进行数据复制。- 当没有足够数量的
Sentinel同意 主服务器 下线时, 主服务器 的 客观下线状态 就会被移除。当 主服务器 重新向Sentinel的PING命令返回 有效回复 时,主服务器 的 主观下线状态 就会被移除。
优点
- 哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
- 主从节点可以自动切换,系统更健壮,可用性更高。
Sentinel会不断的检查 主服务器 和 从服务器 是否正常运行。当被监控的某个Redis服务器出现问题,Sentinel通过API脚本向管理员或者其他的应用程序发送通知。
缺点
有点浪费机器,尤其是在当下这个成本需要控制的时代
Redis较难支持在线扩容,对于集群,容量达到上限时在线扩容会变得很复杂。【数据量问题】
3.Cluster分片集群【多主多从】
Cluster分片集群通过数据分片的方式来进行数据共享问题,同时提供数据复制和故障转移功能。【极少数场景才会启用】
主从和哨兵模式都没有解决一个问题:单个节点的存储能力和访问能力是有限的。
它把整个数据库的键空间划分为 16384 个哈希槽(编号从 0 到 16383)。
集群中的每个节点负责处理一部分哈希槽,通过这种方式将数据分散到各个节点上。
例如包含 3 个节点的集群,可能节点 A、B、C均分【0-16383 号哈希槽】,分别处理不同数据映射槽数据
数据分片规则
集群的键空间被分割为16384个slots(即hash槽),通过hash的方式将数据分到不同的分片上的。
HASH_SLOT = CRC16(key) & 16384 # CRC16是一种循环校验算法
集群架构

【3主3从】采用交叉复制架构类型,这样可以做到最多坏一台主机集群还是正常可以用的,如果每台主机的6381节点都是6380节点的备份,那么这台机器坏了,集群就不可用了,因此想要做到高可用,就采用交叉复制;

即使服务器1挂掉,也可以通过其他服务器进行数据同步和恢复;
主节点可以有多个从节点或者没有从节点
从节点只能有1个主节点
读写流程
-
读、写请求进
redis之后,根据哈希槽进行定位到相应的master节点 -
再由主节点处理写操作,读操作分发给
master下的slave节点; -
数据同步从
master到slave节点。
读写分离提高并发能力,增加高性能。
水平扩展
现在业务需要新增了一个master节点,四个节点共同占有16384个槽;
槽需要重新分配,数据也需要重新迁移,虽然服务不需要下线,但是资源的重新分配还是会带来压力;

故障转移
假如途中红色的节点故障了,此时master3上面的从节点会通过 选举 产生一个主节点。替换原来的故障节点。
实例之间通过ping/pong消息实现节点通信,消息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等。
因此故障发现也是通过消息传播机制实现的,主要环节包括:主观下线(PFAIL-Possibly Fail)和客观下线(Fail)
通过消息投票机制投票来下线主节点,替换原主节点
为什么必须是负责槽的主节点参与故障发现决策?
- 只有主节点负责维护集群槽等关键信息
- 只有主节点才负责写请求处理
优缺点
优点
- 通过利用多台计算机内存的和值,允许我们构造更大的数据库。
- 通过多核和多台计算机,允许我们扩展计算能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。
缺点
- 涉及多个
key的操作、事务不能使用。 - 使用分区时,数据处理较为复杂,比如需要处理多个
rdb/aof文件,并且从多个实例和主机备份持久化文件。 - 增加或删除容量也比较复杂。
redis集群大多数支持在运行时增加、删除节点的透明数据平衡的能力;
4、集群模式对比
- 主从模式主要为了数据冗余,和读性能的扩展;但无法做故障转移(即主节点崩溃,无法将从节点转移成主节点)
- 哨兵模式主要为了增加高可用,检测集群的健康状态,对故障机器下线投票,从节点在确定主节点故障时,可以晋升为主节点【故障转移+高可用】
- 分片模式解决了上面两个模式的单点故障问题,因为它们只有一个主节点,且数据采用分片形式对读写做负载均衡【故障转移+高可用+高并发】
| 模式 | 数据冗余 | 故障恢复 | 写入负载均衡 | 存储扩展性 |
|---|---|---|---|---|
| 主从模式【一主多从】 | ✔️ | 手动 | ❌ | ❌ |
| 哨兵模式【一主多从 + 多个哨兵】 | ✔️ | 自动 | ❌ | ❌ |
| Cluster模式【多主多从】 | ✔️ | 自动 | ✔️ | ✔️ |
三、Redission分布式锁
Redisson是Redis服务器上的分布式可伸缩Java数据结构【驻内存数据网格】;
底层使用netty框架,并提供了与java对象相对应的分布式对象、分布式集合、分布式锁和同步器、分布式服务等一系列的Redisson的分布式对象;
RLock是它的分布式锁,底层采用大量Lua脚本,能使用RLock就不使用jedis+lua;
1.简介
在以前的项目中,经常会使用Redis的setnx特性来实现分布式锁,但是有可能会带来死锁的问题,那么就可以使用Redisson来实现Redis的分布式锁。
它将整个分布式环境进行协调控制,将其当做和单体项目来处理锁相关的资源一样,来实现分布式锁,可以看到分布式环境统一调度下的Lock,本身RLock接口也是实现的java的Lock接口;
2.作用
设计分布式锁的时候,应该考虑分布式锁至少要满足的一些条件,同时考虑如何高效的设计分布式锁;
1、互斥
在分布式高并发的条件下,我们最需要保证,同一时刻只能有一个线程获得锁,这是最基本的一点。
2、防止死锁[重要]
高并发下,比如有个线程获得锁的同时,还没来得及释放锁,就因为系统故障或者其它原因使它无法执行释放锁的命令,导致其它线程无法获得锁,造成死锁。
分布式非常有必要设置锁的有效时间,确保系统出现故障后,在一定时间内能主动去释放锁,避免死锁。
3、锁性能
对于访问量大的共享资源,需要考虑减少锁等待的时间,避免导致大量线程阻塞。
-
锁粒度要小
-
锁范围要小
4、重入
我们知道ReentrantLock是可重入锁,特点就是:同一个线程可以重复拿到同一个资源的锁。重入锁非常有利于资源的高效利用。关于这点之后会做演示。
3.锁类型
1、可重入锁RLock
最常用的锁类型,与java的ReentrantLock类似,支持同一个线程重复获取。如果重入多次,也需要多次释放;
-
加锁原理:当一个线程尝试获取可重入锁时,Redisson 会向 Redis 发送一个 Lua 脚本,该脚本会先检查锁对应的键是否存在。
- 若不存在:设置该键并将其值设为 1,同时设置过期时间,代表锁已被获取;
- 若键已存在:且持有锁的线程就是当前线程,就将键的值加 1,实现可重入。
由于 Lua 脚本在 Redis 中是原子执行的,所以能保证操作的原子性。
-
解锁原理:解锁时执行 Lua 脚本,先检查锁的键是否存在且持有锁的线程是当前线程。若键的值大于 1,就将值减 1;若值为 1,就删除该键,代表释放
// 获取可重入锁
RLock lock = redisson.getLock("myLock");
// 加锁
lock.lock();
lock.unlock();
2、公平锁FairLock
保证多个线程获取锁的顺序是按照请求锁的先后顺序进行的,即先请求锁的线程会先获得锁,避免某些线程长时间等待。
- 加锁原理:公平锁在 Redis 中借助列表(List)和有序集合(Sorted Set)来实现。当线程请求锁时,会先将自己的标识放入列表尾部,然后尝试获取锁。同时,将请求锁的时间戳和线程标识存入有序集合。线程会不断检查自己是否在列表头部,若是且能成功获取锁,就代表获取成功。
- 解锁原理:解锁时,从列表头部移除当前线程的标识,并从有序集合中删除对应的记录,然后通知下一个等待的线程尝试获取锁。
RLock fairLock = redisson.getFairLock("myFairLock");
fairLock.lock();
fairLock.unlock();
3、联锁MultiLock
将多个锁作为一个整体进行管理,只有当所有的锁都被成功获取时,才能继续执行后续的业务逻辑。
- 加锁原理:联锁会尝试依次获取多个锁,只有当所有锁都获取成功时,才认为加锁成功。在获取每个锁时,会使用可重入锁的加锁逻辑。Redisson 会并行地向多个 Redis 节点发送加锁请求,以提高加锁效率。
- 解锁原理:解锁时,会依次释放所有的锁,释放每个锁时使用可重入锁的解锁逻辑。
RLock lock1 = redisson.getLock("lock1");
RLock lock2 = redisson.getLock("lock2");
RLock lock3 = redisson.getLock("lock3");
// 获取联锁
RMultiLock multiLock = redisson.getMultiLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.unlock();
4、红锁RedLock
在分布式环境下实现更可靠的锁机制。会尝试在多个独立的 Redis 节点上同时获取锁,只有当大多数节点上的锁都被成功获取时,才认为锁获取成功。
- 加锁原理:红锁算法会在多个独立的 Redis 节点上尝试获取锁。线程会依次向每个节点发送加锁请求,若在大多数节点(超过一半)上都成功获取到锁,且整个加锁过程的时间小于锁的有效时间,就认为加锁成功。
- 解锁原理:解锁时,会向所有参与红锁的节点发送解锁请求,确保在所有节点上都释放锁。
RLock lock1 = redisson1.getLock("lock1");
RLock lock2 = redisson2.getLock("lock2");
RLock lock3 = redisson3.getLock("lock3");
RRedLock redLock = new RRedLock(lock1, lock2, lock3);
redLock.lock();
redLock.unlock();
5、读写锁
将读操作和写操作的锁进行分离,多线程可同时进行读操作,但在写操作时会互斥,即写操作时不允许其他线程进行读或写操作,读操作时不允许进行写操作。
- 读锁加锁原理:当线程请求读锁时,Redisson 会向 Redis 发送 Lua 脚本,检查是否有写锁存在。若没有写锁,就将读锁计数器加 1,代表获取读锁成功;若有写锁,线程就会进入等待状态。
- 读锁解锁原理:解锁时,将读锁计数器减 1。若计数器变为 0,且有写线程在等待,就通知一个写线程尝试获取写锁。
- 写锁加锁原理:请求写锁时,检查是否有读锁或写锁存在。若没有,就获取写锁并将写锁标识设置为当前线程;若有,线程进入等待状态。
- 写锁解锁原理:解锁时,清除写锁标识,并通知所有等待的读线程和写线程尝试获取锁。
RReadWriteLock rwLock = redisson.getReadWriteLock("myReadWriteLock");
// 获取读锁
rwLock.readLock().lock();
rwLock.readLock().unlock();
// 获取写锁
rwLock.writeLock().lock();
rwLock.writeLock().unlock();
1、加锁机制
SETNX:SETNX key value,意为 “若键不存在则设置”。当指定键不存在时,设置键值对到 Redis,存在则不操作。
SETEX: SETEX key seconds value,用于设置键值对并同时设过期时间(秒)。无论键之前是否存在,都会设新键值对和过期时间。
两者都单独拿来做分布式锁,但都存在缺陷,前者无法保证value设置和超时设置一步完成,后者则违反了互斥性,失败时会修改他人持有锁的时间;
如何解决这个问题:
-
新版本Redis扩展了SET命令的参数,把NX/EX集成到了SET命令中,一条命令实现加锁和设置过期时间的原子操作
-
低版本的redis使用
jedis+lua脚本的方法,利用setNx的特性来获取锁,如果获取锁之后,再使用setEx来设置value和超时时间 -
直接使用RedissionLock
2、watch dog自动延期机制【续命】
RLock lock = redissonClient.getLock("order_lock");// 拿锁
try{lock.lock();// 不设置过期时间// 处理业务的时间1waiting......【看门狗监控,续命】// 处理业务的时间2waiting......【看门狗监控,续命】
}finally{lock.unlock();// 释放锁
}
当使用 Redisson 获取分布式锁时,如果没有显式地指定锁的过期时间,Redisson 会默认开启看门狗机制;
【看门狗】就出现了,它的作用就是 线程1 业务还没有执行完,时间就过了,线程1 还想持有锁的话,会自动启动一个watch dog后台线程【守护线程】,不断的延长锁key的过期时间。
注意:正常这个看门狗线程是不启动的,看门狗启动后对整体性能也会有一定影响,所以不建议开启看门狗。
3、底层为什么用lua脚本
- 原子性保证:在 Redis 中执行 Lua 脚本是原子性的操作。避免了多线程环境下可能出现的竞态条件。
- 减少网络开销:使用 Lua 脚本可以将多个 Redis 命令组合在一起,仅一次网络请求发送到 Redis 服务器执行。在处理复杂分布式锁逻辑时,减少网络开销。
- 代码复用和可维护性:屏蔽底层细节,将分布式锁的相关逻辑封装在 Lua 脚本中,便于代码的复用和维护。
- 与 Redis 的集成性好:Lua 是 Redis 内置的脚本语言,Redis 对 Lua 脚本提供了良好的支持。
4、可重入加锁机制
Redisson 可以实现可重入加锁机制的原因,我觉得跟两点有关:
Redis存储锁的数据类型是Hash类型Hash数据类型的key值包含了当前线程信息
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {this.internalLockLeaseTime = unit.toMillis(leaseTime);return this.commandExecutor.evalWriteAsync(this.getName(), LongCodec.INSTANCE, command, "if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);", Collections.singletonList(this.getName()), new Object[]{this.internalLockLeaseTime, this.getLockName(threadId)});}
4.看门狗
普通的 Redis 分布式锁的缺陷
在网上看到的redis分布式锁的工具方法,大都满足互斥、防止死锁的特性,有些工具方法会满足可重入特性。
Redisson提供了一个监控锁的看门狗(watch dog【实现续命锁】)
它为防止在业务逻辑执行过程中【正常执行】锁过期而导致其他线程获取到锁,Redisson 提供了看门狗机制:
- 当线程成功获取到锁后, 会启动一个定时任务,默认每隔 10 秒(可配置)检查锁是否还被当前线程持有。
- 如果锁还被持有,就会延长锁的过期时间,确保在业务逻辑执行期间锁不会过期。
如果加锁的业务执行过程异常,看门狗机制会退出,锁会正常按照过期时间释放
5.锁类型
公平锁和飞公平锁:是否有保证线程获取锁的公平性,直接进行锁抢占Or检查是否有其他线程竞争排队。
读写锁:读锁、写锁分别使用不同的变量来标记是否被占用
public interface RedissonClient {/*** 获取锁(默认的非公平锁)*/RLock getLock(String name);/*** 获取公平锁*/RLock getFairLock(String name);/*** 获取读写锁*/RReadWriteLock getReadWriteLock(String name);
}
6.缺点
主从模式下:
- 单点故障:如果该点故障或者崩溃,redisson锁也会异常【可依靠云平台做主从切换】
- 性能瓶颈:集群带来的,而非redisson本身
哨兵模式下:
- 数据复制延迟
- 脑裂问题
- 故障转移期间不可用
Cluster集群模式下:
- 集群扩展和维护复杂:集群本身带来的,也会影响redisson
- 网络影响
- 跨节点通讯开销
三、redis实战
1. 远程登录redis
cmd> redis-cli -h 127.0.0.1 -p 6379 -a 123456
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> scan 0
1) "0"
2) 1) "send_order_local"2) "send_order"
127.0.0.1:6379> type send_order
string
127.0.0.1:6379>
2.生产消费模式实现
1、List数据结构【点对点】
List数据结构【点对点】Redis 还提供了 BLPOP、BRPOP 这种阻塞式读取的命令(带 B-Bloking的都是阻塞式),客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。这种方式就节省了不必要的 CPU 开销。
- 【
LPUSH、BRPOP左进右阻塞出】+ 【while循环检测】 - 【
RPUSH、BLPOP右进左阻塞出】】+ 【while循环检测】
缺点:存在性能损耗,没有ack机制【备份队列】
2、使用发布、订阅模式【类MQ】
Redis 通过【PUBLISH 、 SUBSCRIBE】等命令实现了订阅与发布模式;
这个功能提供两种信息机制, 分别是【订阅/发布到频道】和【订阅/发布到模式】。
- 订阅者可以订阅一个或者多个频道(
channel) - 发布者可以向指定的频道(
channel)发送消息 - 所有订阅此频道的订阅者都会收到此消息
优点:灵活性高,实时性强
缺点:无法保证顺序、可能影响性能【主要还是当缓存用】、消息无法持久化,没有ack机制
3、使用Stream【redis5.0版本的消息链表】
Redis 发布订阅模式有个缺点如果出现网络断开、Redis 宕机等,消息就会被丢弃。没有 Ack 机制来保证数据的可靠性,假设一个消费者都没有,那消息就直接被丢弃了。
Redis 5.0版本新增了一个更强大的数据结构——Stream。它提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
它就像是个仅追加内容的消息链表,把所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容。
而且消息是持久化的。
3.布隆过滤器
一个空间效率的概率性模型,用于判断一个元素是否在集合中存在;【redis要使用的话需要单独下载package】
原理:对key进行3次hash算法获取k个值,在bitmap中将这k个值散列后设定为1,查的时候如果特定的这几个位置都为1,那么布隆过滤器判断该key存在;
-
不存储元素本身,仅存储哈希结果取模运算后的位标记【代表N个哈希函数bit值】
-
某个数据存在时,这个数据可能不存在;
-
某个数据不存在时,那么这个数据一定不存在;
布隆过滤器可以插入元素,但是不可以删除已有元素;
1.初始设置
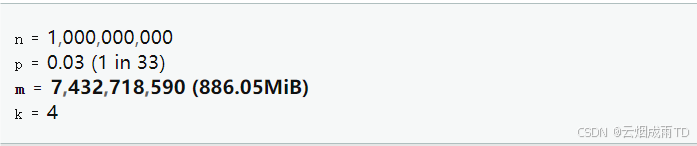
假设设置误判率 【p=3%】 ,预期元素个数设置【n=10 亿】【必传的两个预期参数】
布隆过滤器会自动计算=> 【k=4】个哈希函数,占用【m= 900MB】空间
2.实现方式
Guava、Redission都有对布隆过滤器做实现,设置预计插入的元素数量和误判率即可
// 创建 Redisson 客户端
RedissonClient redisson = Redisson.create(config);
// 获取布隆过滤器实例
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("接口名称1_布隆过滤器key1");
// 初始化布隆过滤器,设置预计插入的元素数量和期望的误判率
long expectedInsertions = 10000;// m
double falseProbability = 0.01; // 误判率设置为 1%,
bloomFilter.tryInit(expectedInsertions, falseProbability);
// 向布隆过滤器中添加元素
bloomFilter.add("element1");
// 检查元素是否存在
boolean exists = bloomFilter.contains("element1");
System.out.println("Element exists: " + exists);
3.实战下的选择
因为其原理的特殊性,导致它无法删除数据,意味着内存需要面临无限增长的问题,对于一个持续增长的业务系统,我个人并不想用它来解决缓存穿透的问题;
还有一种优秀的过滤器:布谷鸟过滤器,在误判率能接受>3%时,算是一个平替,空间优化40%,且支持删除
四、面试题
1.怎么理解Redis事务
事务中的所有命令都会序列化、按顺序地执行。事务执行的过程中,不会被其他客户端发送来的命令请求打断;
相关命令有:【MULTI、EXEC、DISCARD、WATCH】
2.过期和淘汰策略
1.过期策略
默认策略:定期删除和惰性删除
| 策略 | 工作原理 | 优点 | 缺点 |
|---|---|---|---|
当键到达过期时间时,定时器立即触发删除操作。 | 2. 减少过期键内存占用。 | 2. 不适合高并 | |
| 惰性删除 | 只在键被访问时检查其是否过期 如果发现键已过期,则在访问时删除它。 | 1. 系统性能影响小,无需维护定时器。 2. 按需删除,减少不必要开销。 | 过期键若一直未被访问,会持续占用内存,对内存敏感场景不适用。 |
| 定期删除 | 周期性地扫描部分设置了过期时间的键并删除已过期的键,默认频率为每秒 10 次 | 1. 可删除过期键,影响较小。 2. 适用于多数场景。 | 1. 扫描频率低或过期键多,导致内存膨胀。 2. 扫描会占用一定 CPU 资源。 |
2.淘汰策略
当内存达到最大限制时,有多种淘汰策略来删除数据
- noeviction:内存不足时,返回错误,不再接受写入操作。【默认】
- allkeys-lru:从所有键中使用最近最少使用(LRU)算法删除键。
- volatile-lru:从设置了过期时间的键中使用 LRU 算法删除键。
- allkeys-random:随机删除键。
- volatile-random:随机删除设置了过期时间的键。
- volatile-ttl:从设置了过期时间的键中删除即将过期的键。
3.Redis如何手动持久化和备份恢复?
持久化保存,输入Save或者BGSave【后台执行】命令;
redis 127.0.0.1:6379> SAVE
127.0.0.1:6379> BGSAVE
该命令将在 redis 安装目录中创建dump.rdb文件。
恢复备份
只需将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可。
获取 redis 目录可以使用Config命令获取保存的数据文件地址信息;
redis 127.0.0.1:6379> CONFIG GET dir
1) "dir"
2) "/usr/local/redis/bin"
4.Redis内存使用满了,会发生什么?
写命令会返回错误信息(但是读命令还可以正常返回)或者你可以将Redis当缓存来使用配置淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
5.【亮点】MySQL数据2000w,Redis只存20w,如何让Redis都是热点数据?
redis内存数据集大小上升到一定大小的时候,就会施行数据【allkeys-lru】淘汰策略。
6.如何统计活跃用户?
Set数据类型
用户登录一次,对Set进行一次sadd;
127.0.0.1:6379> sadd users_2019_06_17 user1
(integer) 1
127.0.0.1:6379> sadd users_2019_06_17 user2
(integer) 1
127.0.0.1:6379> sadd users_2019_06_17 user3
(integer) 1
统计的时候输入
127.0.0.1:6379> scard users_2019_06_17
(integer) 3
直接得到3条数据,即2019-06-17的活跃用户数为3;
但集合只适用于用户数比较少的场合,假如用户有100万,set存储100万个id号,一个id号占32个字节,总共就差不多32 M,一个月就960 M 差不多1 G
Bitmap数据类型
假如要做一个活跃用户的统计功能:
我们存放100万个id号需要100万个bit位,也就是【100万 / 8位 = 125 K】,直接用以id号和100万取余,余数作为bit的索引:
127.0.0.1:6379> setbit login_2019_06_17 10000 1
(integer) 0
127.0.0.1:6379> setbit login_2019_06_17 1024 1
(integer) 0
127.0.0.1:6379> setbit login_2019_06_17 238 1
(integer) 0
127.0.0.1:6379> setbit login_2019_06_17 3434 1
(integer) 0
其实也才125 K,一个月其实也就4 M;对比上述的Set做的数据,好几百倍的空间节省;
7. 缓存+数据库双写/双删存在什么问题?
指的是当数据更新时,既要更新数据库中的数据,又要更新 Redis 中的数据,并且要保证这两份数据的一致性。
Redis 双写产生一致性问题的原因主要是由于写入顺序、并发操作以及系统故障等因素影响,具体如下:
产生原因
-
先写数据库,后写缓存:写缓存这一步出现故障,例如网络或Redis 服务器故障等,导致数据库中数据是最新,而缓存数据是旧,不一致。
-
先写缓存,后写数据库:写数据库失败,缓存中的数据就会与数据库中数据不一致。其他请求可能会从缓存中读取到错误的最新数据,不一致。
-
并发操作影响:在高并发场景下,多个请求同时进行双写操作时,可能会出现数据覆盖的情况。假设请求 A 和请求 B 同时更新同一条数据,请求 A 先写数据库,然后写缓存;请求 B 后写数据库,但先于请求 A 写缓存,那么请求 A 写入缓存的数据就会被请求 B 覆盖,导致缓存中的数据与数据库不一致。
解决方案
- 延时双删【最终一致性】【顺序删除一次,再延迟删除一次,避免数据同步期间节点数据不一致的情况】
- 第一次删除:防止后续请求获取到DB中的旧数据
- 第二次删除:防止网络问题导致DB更新数据在传播扩散到其他节点之前,存入旧的缓存【mysql同步】
- 使用分布式读写锁包裹,并对正常、异常的情况捕获处理【有点重,但是稳定】
- canal监听数据变更:mysql数据变化之后通知 Redis 删除数据
8.使用keys查询会怎么样
Redis是单线程的。keys指令会导致线程阻塞一段时间,如果很多,线上服务会停顿,直到指令执行完毕服务才能恢复。
答:推荐使用scan指令,它采用渐进式迭代的方式来遍历键空间【少量多次的方式无阻塞获取】
9、如何安全的释放锁?直接DEL?【重要】
可能产生以下问题:【释放了别人的的锁】
- 客户端A持有锁,但处理时间超过了锁的过期时间;
- 锁自动释放,此时客户端B获取了锁;
- 客户端A完成操作,直接删除锁 —— 但这时删除的是客户端B的锁!
避免的策略:
- 业务上尽量不共用同一把锁【基础】
- 释放锁时判断当前锁的持有对象是否还是自己【重要】,如果不是自己,则不做锁的删除【redis加锁会有一个唯一值】
RLock lock = redisson.getLock("myLock");
try {boolean isLocked = lock.tryLock(100, 5, TimeUnit.SECONDS);// 尝试加锁,最多等待 100 秒,锁的持有时间为 10 秒if (isLocked) {// 执行业务逻辑System.out.println("获取到锁,执行业务逻辑...");} System.out.println("未能获取到锁");
} catch (InterruptedException e) {e.printStackTrace();
} finally {// 释放锁对持有者是否是自己的判断if (lock.isHeldByCurrentThread()) {lock.unlock();System.out.println("成功释放锁");}
}
10、业务执行时间不固定,如何避免锁的提前释放
这就是锁续期问题。比如电商扣库存,锁30秒过期,但业务卡了40秒,这时锁提前释放,其他线程进来重复扣减——直接超卖!
- 自动续锁机制【Redission的看门狗机制,不推荐,不可控】
- 合理预估超时时间【一般】
- 手动续期【可以加两个时间,来判断是否加锁acquire和currentTime的时间差是否大于超时时间】
// 手动延长锁的过期时间
if (lock.isHeldByCurrentThread()) {// 检查时间戳,假设允许最大持有时间为 30 秒long currentTime = System.currentTimeMillis();if (currentTime - acquireTime < 30000) {// 延长锁的过期时间为 20 秒lock.expire(20, TimeUnit.SECONDS);System.out.println("锁的过期时间已成功延长");// 继续执行业务逻辑Thread.sleep(15000);} else {System.out.println("锁已超出最大持有时间,不进行延长操作");}
}
11、一般你们是怎么使用redis的
正常使用,也可以考虑使用策略组合:【caffeine(本地)+redis】
-
性能提升
-
Caffeine 提供本地缓存高性能【不要设置过大,会占用jvm内存】
-
Redis 保证分布式数据一致性
-
-
减少网络开销
-
缓存分层加载和数据预加载【caffeine预加载一些固定缓存配置,后续的交给redis】
相关文章:

Redis爆肝总结
一、基础 1.介绍 本质上是一个Key-Value类型的内存数据库,数据的加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。 速度快的根本原因 纯内存操作,性能非常出色,每秒可以处理超过10万次读写操作&a…...

Qt模块化架构设计教程 -- 轻松上手插件开发
概述 在软件开发领域,随着项目的增长和需求的变化,保持代码的可维护性和扩展性变得尤为重要。一个有效的解决方案是采用模块化架构,尤其是利用插件系统来增强应用的功能性和灵活性。Qt框架提供了一套强大的插件机制,可以帮助开发者轻松实现这种架构。 模块化与插件系统 模…...

[项目总结] 抽奖系统项目技术应用总结
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...

【运维】基于Python打造分布式系统日志聚合与分析利器
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在分布式系统中,日志数据分散在多个节点,管理和分析变得复杂。本文详细介绍如何基于Python开发一个日志聚合与分析工具,结合Logstash和F…...
)
MySql(基础)
表名建议用 反引号 包裹(尤其是表名包含特殊字符或保留字时),但如果表名是普通字符串(如 user),可以省略。 注释(COMMENT 姓名) 数据库 1.查看数据库:show databases…...
)
怎样选择成长股 读书笔记(一)
文章目录 第一章 成长型投资的困惑一、市场不可预测性的本质困惑二、成长股的筛选悖论三、管理层评估的认知盲区四、长期持有与估值波动的博弈五、实践中的认知升级路径总结:破解困惑的行动框架 第二章 如何阅读应计制利润表一、应计制利润表的本质与核心原则1. 权责…...

系统思考:个人与团队成长
四年前,我交付的系统思考项目,今天学员的反馈依然深深触动了我。 我常常感叹,系统思考不仅仅是一场培训,更像是一场持续的“修炼”。在这条修炼之路上,最珍贵的,便是有志同道合的伙伴们一路同行࿰…...

并行发起http请求
1. 使用 axios Promise.all <template><input type"file" multiple change"handleFileUpload" /> </template><script> import axios from axios;export default {methods: {async handleFileUpload(event) {const files event…...

【数据结构入门训练DAY-31】组合的输出
本文介绍了如何使用深度优先搜索(DFS)算法解决数的组合问题。题目要求从1到n的自然数中选取r个数,输出所有可能的组合,并按字典顺序排列。文章详细描述了解题思路,包括建立数组存储数字、使用DFS递归处理候选数、以及如…...

leetcode0815. 公交路线-hard
1 题目: 公交路线 官方标定难度:难 给你一个数组 routes ,表示一系列公交线路,其中每个 routes[i] 表示一条公交线路,第 i 辆公交车将会在上面循环行驶。 例如,路线 routes[0] [1, 5, 7] 表示第 0 辆公…...

花朵识别系统Python+深度学习+卷积神经网络算法+TensorFlow+人工智能
一、介绍 花朵识别系统。本系统采用Python作为主要编程语言,基于TensorFlow搭建ResNet50卷积神经网络算法模型,并基于前期收集到的5种常见的花朵数据集(向日葵、玫瑰、蒲公英、郁金香、菊花)进行处理后进行模型训练,最…...
LLM Post-Training: A Deep Dive into Reasoning Large Language Models)
LLM 论文精读(四)LLM Post-Training: A Deep Dive into Reasoning Large Language Models
这是一篇2025年发表在arxiv中的LLM领域论文,是一篇非常全面的综述类论文,介绍了当前主流的强化学习方法在LLM上的应用,文章内容比较长,但建议LLM方面的从业人员反复认真阅读。 写在最前面 为了方便你的阅读,以下几点的…...

网址为 http://xxx:xxxx/的网页可能暂时无法连接,或者它已永久性地移动到了新网址
这是由于浏览器默认的非安全端口所导致的,所谓非安全端口,就是浏览器出于安全问题,会禁止一些网络浏览向外的端口。 避免使用6000,6666这样的端口 6000-7000有很多都不行,所以尽量避免使用这个区间 还有在云服务器中,…...

【C++】16.继承
C三大特性:封装,继承,多态 在前面的章节中,我们讲过了封装,也就是通过类和访问修饰符来进行封装。 接下来我们就来认识一下新的特性——继承 1. 继承的概念及定义 1.1 继承的概念 继承(inheritance)机制是面向对…...

LlamaIndex 第七篇 结构化数据提取
大型语言模型(LLMs)在数据理解方面表现出色,这也促成了它们最重要的应用场景之一:能够将常规的人类语言(我们称之为非结构化数据)转化为特定的、规范的、可被计算机程序处理的格式。我们将这一过程的输出称…...

PHP API安全设计四要素:构建坚不可摧的接口防护体系
引言:API安全的重要性 在当今前后端分离和微服务架构盛行的时代,API已成为系统间通信的核心枢纽。然而,不安全的API可能导致: 数据泄露:敏感信息被非法获取篡改风险:传输数据被中间人修改重放攻击&#x…...

英语16种时态
时态应用场合格式例子一般现在时表示经常、反复发生的动作,客观事实或普遍真理主语 动词原形(第三人称单数作主语时动词加 -s/-es)The sun rises in the east.一般过去时表示过去某个时间发生的动作或存在的状态主语 动词的过去式I visited…...

使用 goaccess 分析 nginx 访问日志
介绍 goaccess 是一个在本地解析日志的工具, 可以直接在命令行终端环境中使用 TUI 界面查看分析结果, 也可以导出为更加丰富的 HTML 页面. 官网: https://goaccess.io/ 下载安装 常见的 Linux 包管理器中都包含了 goaccess, 直接安装就行. 以 Ubuntu 为例: sudo apt instal…...

什么是中央税
中央税(又称国家税)是指由中央政府直接征收、管理和支配的税种,其收入全额纳入中央财政,用于保障国家层面的财政支出和宏观调控。中央税通常具有税基广泛、收入稳定、涉及国家主权或全局性经济调控的特点。 --- 中央税的核心特征…...
:个人助手应用)
AI Agent(10):个人助手应用
引言 本文聚焦AI Agent在个人助手领域的应用,探讨其如何在个人生产力提升、健康与生活管理、学习与教育辅助以及娱乐与社交互动四个方面,为用户创造价值并解决实际问题。 AI个人助手正从简单的指令执行者逐渐发展为具有自主性、适应性和个性化能力的智能伙伴。这一转变不仅…...

力扣70题解
记录 2025.5.8 题目: 思路: 1.初始化:p 和 q 初始化为 0,表示到达第 0 级和第 1 级前的方法数。r 初始化为 1,表示到达第 1 级台阶有 1 种方法。 2.循环迭代:从第 1 级到第 n 级台阶进行迭代: p 更新为前…...
)
2025御网杯wp(web,misc,crypto)
文章目录 miscxor10图片里的秘密被折叠的显影图纸 Cryptoeasy_rsagift**1. 礼物数学解析****最终答案** 草甸方阵的密语easy-签到题baby_rsa webYWB_Web_xffYWB_Web_未授权访问easywebYWB_Web_命令执行过滤绕过反序列化 misc xor10 ai一把梭 根据题目中的字符串和提示&#…...

【深度学习】将本地工程上传到Colab运行的方法
1、将本地工程(压缩包)上传到一个新的colab窗口:如下图中的 2.zip,如果工程中有数据集,可以删除掉。 2、解压压缩包。 !unzip /content/2.zip -d /content/2 如果解压出了不必要的文件夹可以递归删除: #…...
)
多模态大语言模型arxiv论文略读(六十九)
Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models ➡️ 论文标题:Prompt-Aware Adapter: Towards Learning Adaptive Visual Tokens for Multimodal Large Language Models ➡️ 论文作者:Yue Zha…...

Lua再学习
因为实习的项目用到了Lua,所以再来深入学习一下 函数 函数的的多返回值 Lua中的函数可以实现多返回值,实现方法是再return后列出要返回的值的列表,返回值也可以通过变量接收到,变量不够也不会影响接收对应位置的返回值 Lua中传…...

Linux计划任务与进程
at 命令使用方法 at 命令可在指定时间执行任务,适用于一次性任务调度。以下是基本用法: 安装 atd 服务(如未安装) # Debian/Ubuntu sudo apt-get install at# CentOS/RHEL sudo yum install at启动服务 sudo systemctl start atd…...

JavaEE--文件操作和IO
目录 一、认识文件 二、 树型结构组织和目录 三、文件路径 1. 绝对路径 2. 相对路径 四、文件类型 五、文件操作 1. 构造方法 2. 方法 六、文件内容的读写——数据流 1. InputStream概述 2. FileInputStream概述 2.1 构造方法 2.2 示例 3. OutputStream概述 3.…...

k8s的节点是否能直接 curl Service 名称
在 Kubernetes 中,节点(Node)默认情况下不能直接通过 Service 的 DNS 名称(如 my-svc.default.svc.cluster.local)访问 Service。以下是详细分析和解决方案: 1. 默认情况下节点无法解析 Service 的 DNS 名…...
Mask-aware Pixel-Shuffle Down-Sampling (MPD) 下采样
来源 简介:这个代码实现了一个带有掩码感知的像素重排下采样模块,主要用于图像处理任务(如图像修复或分割)。 论文题目:HINT: High-quality INpainting Transformer with Mask-Aware Encoding and Enhanced Attentio…...

本贴会成为记录贴
这几天有些心力交瘁了 一方面带着对互联网下行的伤心,一方面是对未来的担忧 一转眼好像就是20 21那个 可以在宿舍肆意玩手机 大学生活 可是我不小了 是个26岁的人了 时间很快 快的就好像和自己开了一个玩笑 我以为可以找到一个自己足够喜欢的 可爱的人 可是我没有 …...
)
redis数据结构-04 (HINCRBY、HDEL、HKEYS、HVALS)
哈希操作:HINCRBY、HDEL、HKEYS、HVALS Redis 中的哈希功能极其丰富,让您能够以类似于编程语言中对象的方式存储和检索数据。本课将深入探讨具体的哈希操作,这些操作为操作以下结构中的数据提供了强大的工具: HINCRBY 、 HDEL 、…...

python 写一个工作 简单 番茄钟
1、图 2、需求 番茄钟(Pomodoro Technique)是一种时间管理方法,由弗朗西斯科西里洛(Francesco Cirillo)在 20 世纪 80 年代创立。“Pomodoro”在意大利语中意为“番茄”,这个名字来源于西里洛最初使用的一个…...
)
复现MAET的环境问题(自用)
我的配置是3090,CUDA Version: 12.4 配置环境时总有冲突,解决好的环境如下 如果你的配置也是CUDA12.4,可以把下面的配置信息保存成 environment.yml 文件 然后执行下面的代码创建环境即可 conda env export > environment.yml name:…...

PDF2zh插件在zotero中安装并使用
1、首先根据PDF2zh说明文档,安装PDF2zh https://github.com/guaguastandup/zotero-pdf2zh/tree/v2.4.0 我没有使用conda,直接使用pip安装pdf2zh (Python版本要求3.10 < version <3.12) pip install pdf2zh1.9.6 flask pypd…...
)
第二十三节:图像金字塔- 图像金字塔应用 (图像融合)
一、引言:视觉信息的层次化表达 在数字图像处理领域,图像金字塔(Image Pyramid)作为一种多尺度表示方法,自20世纪80年代提出以来,始终在计算机视觉领域扮演着关键角色。这种将图像分解为不同分辨率层次的结构化表示方法,完美地模拟了人类视觉系统对场景的多尺度感知特性…...

一种混沌驱动的后门攻击检测指标
摘要 人工智能(AI)模型在各个领域的进步和应用已经改变了我们与技术互动的方式。然而,必须认识到,虽然人工智能模型带来了显著的进步,但它们也存在固有的挑战,例如容易受到对抗性攻击。目前的工作提出了一…...

LeetCode 高频题实战:如何优雅地序列化和反序列化字符串数组?
文章目录 摘要描述题解答案题解代码分析编码方法解码方法 示例测试及结果时间复杂度空间复杂度总结 摘要 在分布式系统中,数据的序列化与反序列化是常见的需求,尤其是在网络传输、数据存储等场景中。LeetCode 第 271 题“字符串的编码与解码”要求我们设…...

leetcode 15. 三数之和
题目描述 代码: class Solution { public:vector<vector<int>> threeSum(vector<int>& nums) {sort(nums.begin(),nums.end());int len nums.size();int left 0;int right 0;vector<vector<int>> res;for(int i 0;i <len…...

HTML难点小记:一些简单标签的使用逻辑和实用化
HTML难点小记:一些简单标签的使用逻辑和实用化 jarringslee 文章目录 HTML难点小记:一些简单标签的使用逻辑和实用化简单只是你的表象标签不是随便用的<div> 滥用 vs 语义化标签的本质嵌套规则的隐藏逻辑SEO 与可访问性的隐形关联 暗藏玄机的表单…...

Linux : 31个普通信号含义
Linux : 31个普通信号 信号含义特殊的两个信号 信号含义 信号编号信号名信号含义1SIGHUP如果终端接口检测到一个连接断开,则会将此信号发送给与该终端相关的控制进程,该信号的默认处理动作是终止进程。2SIGINT当用户按组合键(一般…...

软件测试都有什么???
文章目录 一、白盒测试(结构测试)二、黑盒测试(功能测试)三、灰盒测试四、其他测试类型五、覆盖准则对比六、应用场景 软件测试主要根据测试目标、技术手段和覆盖准则进行分类。分为白盒测试、黑盒测试、灰盒测试及其他补充类型 一…...

LangGraph框架中针对MCP协议的变更-20250510
MCP(Model Context Protocol)的出现为AI Agent与外部工具及数据源的集成提供了标准化接口,而LangGraph作为基于LangChain的智能体开发框架,在MCP协议的影响下也进行了适配性调整,主要体现在工具调用、异步交互和多步推…...
V23.4 LTS 正式发布)
YashanDB(崖山数据库)V23.4 LTS 正式发布
2024年回顾 2024年11月我们受邀去深圳参与了2024国产数据库创新生态大会。在大会上崖山官方发布了23.3。这个也是和Oracle一样采用的事编年体命名。 那次大会官方希望我们这些在一直从事在一线的KOL帮助产品提一些改进建议。对于这样的想法,我们都是非常乐于合作…...
二、transformers基础组件之Tokenizer
在使用神经网络处理自然语言处理任务时,我们首先需要对数据进行预处理,将数据从字符串转换为神经网络可以接受的格式,一般会分为如下几步: - Step1 分词:使用分词器对文本数据进行分词(字、字词);- Step2 构建词典:根据数据集分词的结果,构建…...

git 报错:错误:RPC 失败。curl 28 Failed to connect to github.com port 443 after 75000
错误:RPC 失败。curl 28 Failed to connect to github.com port 443 after 75000 ms: Couldnt connect to server致命错误:在引用列表之后应该有一个 flush 包 方法一: 直接换一个域名:把 git clone https://github.com/zx59530…...
)
软考 系统架构设计师系列知识点之杂项集萃(56)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(55) 第91题 商业智能关注如何从业务数据中提取有用的信息,然后采用这些信息指导企业的业务开展。商业智能系统主要包括数据预处理、建立()、数据分…...

数据库的脱敏策略
数据库的脱敏策略:就是屏蔽敏感的数据 脱敏策略三要求: (1)表对象 (2)生效条件(脱敏列、脱敏函数) (3)二元组 常见的脱敏策略规则: 替换、重排、…...

Lora原理及实现浅析
Lora 什么是Lora Lora的原始论文为《LoRA: Low-Rank Adaptation of Large Language Models》,翻译为中文为“大语言模型的低秩自适应”。最初是为了解决大型语言模在进行任务特定微调时消耗大量资源的问题;随后也用在了Diffusion等领域,用于…...

力扣热题100之合并两个有序链表
题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 代码 方法一:新建一个链表 这里就先随便新建一个节点作为一个链表的头节点,然后每次遍历都将小的那个节点放入这个链表,遍历完一…...

Linux511SSH连接 禁止root登录 服务任务解决方案 scp Vmware三种模式回顾
创造一个临时文件 引用 scp -p 3712 atthistime.txt code11.1.1.100:/at ssh connect to host 11.1.1.100 port 22:No route to host lost connection 对方虚拟机是[rootlocalhost caozx26]# ll -d /at drwxr-xr-x. 2 root root 6 5月 11 11:10 /at sshd_config文件修改了port为…...