python打卡day21
知识点回顾:
- LDA线性判别
- PCA主成分分析
- t-sne降维
之前学了特征降维的两个思路,特征筛选(如树模型重要性、方差筛选)和特征组合(如SVD/PCA)。
现在引入特征降维的另一种分类:无/有监督降维。无监督降维只需要特征数据本身,在降维过程中不使用任何关于数据样本的标签信息(比如类别标签、目标值等),仅仅根据数据点本身的分布、方差、相关性、局部结构等特性来寻找低维表示,典型算法是PCA、t-SNE等
相应的,降维时使用标签信息的有监督降维,典型算法就是LDA(特征筛选可以是无监督或有监督,取决于是否使用标签,比如之前特征筛选的学习中除了方差筛选其他都是有监督降维)
1.PCA(主成分分析)
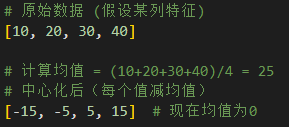
PCA这种无监督降维方法的目标是保留数据的最大方差(即主成分),将数据投影到由这些最重要的主成分构成的新的、维度更低子空间上,这些方差大的方向不一定是对分类最有用的方向。PCA本质上就是在SVD之前对数据进行了均值中心化,均值中心化就是把每个特征"挪到原点附近"的操作,比如:
都提到了最大方差,那PCA和方差筛选有什么不一样呢?假设有两个高度相关的特征:
- 方差筛选可能只保留其中一个,每个特征来计算独立的方差
- PCA会生成一个融合两者的主成分,操作对象是特征的线性组合
所以PCA是一种线性降维,对于数据结构高度非线性(例如“瑞士卷”、“S型曲线”),PCA会将其投影到一个线性子空间,这可能会丢失关键的非线性关系,在这种情况下,非线性降维技术(如 t-SNE, UMAP, LLE, Isomap, 核PCA, 自编码器)会是更好的选择
降维维度可以根据解释方差来选择:
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np # 确保numpy导入# 假设 X_train, X_test, y_train, y_test 已经准备好了# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: PCA降维
pca_expl = PCA(random_state=42) # 创建PCA对象(暂不指定降维维度)
pca_expl.fit(X_train_scaled_pca) # 在标准化后的数据上拟合PCA模型
cumsum_variance = np.cumsum(pca_expl.explained_variance_ratio_) # 计算累计解释方差比例
n_components_to_keep_95_var = np.argmax(cumsum_variance >= 0.95) + 1 # 找到第一个使累计解释方差≥95%的维度
print(f"为了保留95%的方差,需要的主成分数量: {n_components_to_keep_95_var}")# ----------- 打印结果 -----------
为了保留95%的方差,需要的主成分数量: 26也可以自己手动指定降维维度,这里以降到10个特征为例:
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np # 确保numpy导入# 假设 X_train, X_test, y_train, y_test 已经准备好了# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: PCA降维
n_components_pca = 10
pca_manual = PCA(n_components=n_components_pca, random_state=42) # 现在创建PCA对象时,指定降维维度为10X_train_pca = pca_manual.fit_transform(X_train_scaled_pca)
X_test_pca = pca_manual.transform(X_test_scaled_pca) # 使用在训练集上fit的pcaprint(f"PCA降维后,训练集形状: {X_train_pca.shape}, 测试集形状: {X_test_pca.shape}")
start_time_pca_manual = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_pca = RandomForestClassifier(random_state=42)
rf_model_pca.fit(X_train_pca, y_train)# 步骤 4: 在测试集上预测
rf_pred_pca_manual = rf_model_pca.predict(X_test_pca)
end_time_pca_manual = time.time()print(f"手动PCA降维后,训练与预测耗时: {end_time_pca_manual - start_time_pca_manual:.4f} 秒")print("\n手动 PCA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_pca_manual))
print("手动 PCA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_pca_manual))
2.t-SNE(t-分布随机邻域嵌入)
PCA 的目标是保留数据的全局方差,而 t-SNE 的核心目标是在高维空间中相似的数据点,在降维后的低维空间中也应该保持相似(即彼此靠近),而不相似的点则应该相距较远。特别擅长于将高维数据集投影到二维或三维空间进行可视化,从而揭示数据中的簇结构或流形结构
总的来说,t-SNE是一种适合非线性数据可视化的降维算法,而非数据处理中普适的降维;同时PCA同样适合聚类前的可视化,但PCA更适合一般数据预处理

- Perplexity (困惑度):这个参数对结果影响较大。常见的取值范围是 5 到 50。较小的困惑度关注非常局部的结构,较大的困惑度则考虑更广泛的邻域。通常需要尝试不同的值
- n_iter (迭代次数):需要足够的迭代次数让算法收敛。默认值通常是1000。如果可视化结果看起来还不稳定,可以尝试增加迭代次数
- learning_rate (学习率):也可能影响收敛
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
import matplotlib.pyplot as plt # 用于可选的可视化
import seaborn as sns # 用于可选的可视化# 步骤 1: 特征缩放
scaler_tsne = StandardScaler()
X_train_scaled_tsne = scaler_tsne.fit_transform(X_train)
X_test_scaled_tsne = scaler_tsne.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: t-SNE 降维
n_components_tsne = 2 # 更典型的t-SNE用于分类的维度,如果想快速看到结果# 如果你想严格对比PCA的10维,可以将这里改为10,但会很慢
# 对训练集进行 fit_transform
tsne_model_train = TSNE(n_components=n_components_tsne,perplexity=30, # 常用的困惑度值n_iter=1000, # 足够的迭代次数init='pca', # 使用PCA初始化,通常更稳定learning_rate='auto', # 自动学习率 (sklearn >= 1.2)random_state=42, # 保证结果可复现n_jobs=-1) # 使用所有CPU核心
print("正在对训练集进行 t-SNE fit_transform...")
start_tsne_fit_train = time.time()
X_train_tsne = tsne_model_train.fit_transform(X_train_scaled_tsne)
end_tsne_fit_train = time.time()
print(f"训练集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_train - start_tsne_fit_train:.2f} 秒")# 对测试集进行 fit_transform
# 再次强调:这是独立于训练集的变换
tsne_model_test = TSNE(n_components=n_components_tsne,perplexity=30,n_iter=1000,init='pca',learning_rate='auto',random_state=42, # 保持参数一致,但数据不同,结果也不同n_jobs=-1)
print("正在对测试集进行 t-SNE fit_transform...")
start_tsne_fit_test = time.time()
X_test_tsne = tsne_model_test.fit_transform(X_test_scaled_tsne) # 注意这里是 X_test_scaled_tsne
end_tsne_fit_test = time.time()
print(f"测试集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_test - start_tsne_fit_test:.2f} 秒")print(f"t-SNE降维后,训练集形状: {X_train_tsne.shape}, 测试集形状: {X_test_tsne.shape}")start_time_tsne_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_tsne = RandomForestClassifier(random_state=42)
rf_model_tsne.fit(X_train_tsne, y_train)# 步骤 4: 在测试集上预测
rf_pred_tsne_manual = rf_model_tsne.predict(X_test_tsne)
end_time_tsne_rf = time.time()print(f"t-SNE降维数据上,随机森林训练与预测耗时: {end_time_tsne_rf - start_time_tsne_rf:.4f} 秒")
total_tsne_time = (end_tsne_fit_train - start_tsne_fit_train) + \(end_tsne_fit_test - start_tsne_fit_test) + \(end_time_tsne_rf - start_time_tsne_rf)
print(f"t-SNE 总耗时 (包括两次fit_transform和RF): {total_tsne_time:.2f} 秒")print("\n手动 t-SNE + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_tsne_manual))
print("手动 t-SNE + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_tsne_manual))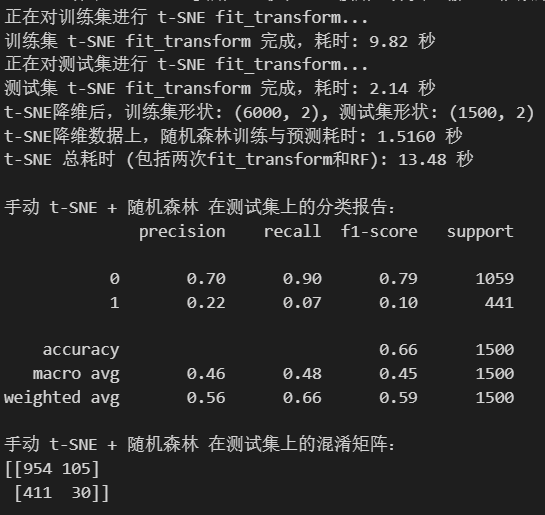
3.LDA(线性判别)
在分类任务中,LDA通常比PCA更直接有效,会更注重类别信息,不像PCA选择方差大的方向,而是会选择能让不同类别的点尽量分开的方向,即使这个方向数据整体方差不是最大的
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 如果需要3D绘图
import seaborn as sns# 步骤 1: 特征缩放
scaler_lda = StandardScaler()
X_train_scaled_lda = scaler_lda.fit_transform(X_train)
X_test_scaled_lda = scaler_lda.transform(X_test) # 使用在训练集上fit的scaler# 步骤 2: LDA 降维
n_features = X_train_scaled_lda.shape[1]
if hasattr(y_train, 'nunique'):n_classes = y_train.nunique()
elif isinstance(y_train, np.ndarray):n_classes = len(np.unique(y_train))
else:n_classes = len(set(y_train))max_lda_components = min(n_features, n_classes - 1)# 设置目标降维维度
n_components_lda_target = 10if max_lda_components < 1:print(f"LDA 不适用,因为类别数 ({n_classes})太少,无法产生至少1个判别组件。")X_train_lda = X_train_scaled_lda.copy() # 使用缩放后的原始特征X_test_lda = X_test_scaled_lda.copy() # 使用缩放后的原始特征actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")
else:# 实际使用的组件数不能超过LDA的上限,也不能超过我们的目标(如果目标更小)actual_n_components_lda = min(n_components_lda_target, max_lda_components)if actual_n_components_lda < 1: # 这种情况理论上不会发生,因为上面已经检查了 max_lda_components < 1print(f"计算得到的实际LDA组件数 ({actual_n_components_lda}) 小于1,LDA不适用。")X_train_lda = X_train_scaled_lda.copy()X_test_lda = X_test_scaled_lda.copy()actual_n_components_lda = n_featuresprint("将使用缩放后的原始特征进行后续操作。")else:print(f"原始特征数: {n_features}, 类别数: {n_classes}")print(f"LDA 最多可降至 {max_lda_components} 维。")print(f"目标降维维度: {n_components_lda_target} 维。")print(f"本次 LDA 将实际降至 {actual_n_components_lda} 维。")lda_manual = LinearDiscriminantAnalysis(n_components=actual_n_components_lda, solver='svd')X_train_lda = lda_manual.fit_transform(X_train_scaled_lda, y_train)X_test_lda = lda_manual.transform(X_test_scaled_lda)print(f"LDA降维后,训练集形状: {X_train_lda.shape}, 测试集形状: {X_test_lda.shape}")start_time_lda_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_lda = RandomForestClassifier(random_state=42)
rf_model_lda.fit(X_train_lda, y_train)# 步骤 4: 在测试集上预测
rf_pred_lda_manual = rf_model_lda.predict(X_test_lda)
end_time_lda_rf = time.time()print(f"LDA降维数据上,随机森林训练与预测耗时: {end_time_lda_rf - start_time_lda_rf:.4f} 秒")print("\n手动 LDA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lda_manual))
print("手动 LDA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lda_manual))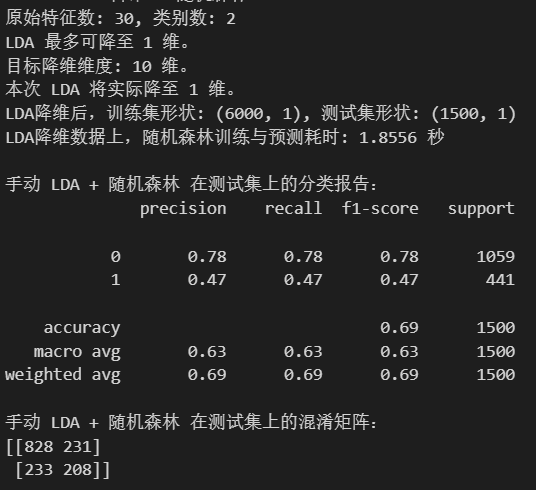
收获心得:
讲实话关于特征降维这一两节内容学的有点麻,以后再认真看看
@浙大疏锦行
相关文章:

python打卡day21
常见的降维算法 知识点回顾: LDA线性判别PCA主成分分析t-sne降维 之前学了特征降维的两个思路,特征筛选(如树模型重要性、方差筛选)和特征组合(如SVD/PCA)。 现在引入特征降维的另一种分类:无/有…...
投稿经验分享)
KNOWLEDGE-BASED SYSTEMS(KBS期刊)投稿经验分享
期刊介绍: KBS是计算机一区,CCF-c期刊,(只看大类分区,小类不用看,速度很快,桌拒比较多,能送审就机会很大!) 具体时间流程: 7月初投稿…...

vue使用rules实现表单校验——校验用户名和密码
编写校验规则 常规校验 const rules {username: [{ required: true, message: 请输入用户名, trigger: blur },{ min: 5, max: 16, message: 长度在 5 到 16 个字符, trigger: blur }],password: [{ required: true, message: 请输入密码, trigger: blur },{ min: 5, max: 1…...

[CANN] 安装软件依赖
环境 昊算平台910b NPUdocker容器 安装步骤 安装依赖-安装CANN(物理机场景)-软件安装-开发文档-昇腾社区 apt安装miniconda安装 Apt 首先进行换源,参考昇腾NPU容器内 apt 换源 Miniconda 安装miniconda mkdir -p ~/miniconda3 wget …...

代码随想录算法训练营第三十七天
LeetCode题目: 300. 最长递增子序列674. 最长连续递增序列718. 最长重复子数组2918. 数组的最小相等和(每日一题) 其他: 今日总结 往期打卡 300. 最长递增子序列 跳转: 300. 最长递增子序列 学习: 代码随想录公开讲解 问题: 给你一个整数数组 nums ,找到其中最长…...
)
Qt开发经验 --- 避坑指南(11)
文章目录 [toc]1 QtCreator同时运行多个程序2 刚安装的Qt编译报错cannot find -lGL: No such file or directory3 ubuntu下Qt无法输入中文4 Qt版本发行说明5 Qt6.6 VS2022报cdb.exe无法定位dbghelp.dll输入点6 Qt Creator13.0对msvc-qmake-jom.exe支持有问题7 银河麒麟系统中ud…...

vue 组件函数式调用实战:以身份验证弹窗为例
通常我们在 Vue 中使用组件,是像这样在模板中写标签: <MyComponent :prop"value" event"handleEvent" />而函数式调用,则是让我们像调用一个普通 JavaScript 函数一样来使用这个组件,例如:…...
)
青藏高原东北部祁连山地区250m分辨率多年冻土空间分带指数图(2023)
时间分辨率:10年 < x < 100年空间分辨率:100m - 1km共享方式:开放获取数据大小:24.38 MB数据时间范围:近50年来元数据更新时间:2023-10-08 数据集摘要 多年冻土目前正在经历大规模的退化,…...
)
[6-2] 定时器定时中断定时器外部时钟 江协科技学习笔记(41个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 V 30 31 32 33 34 35 36 37 38 39 40 41...

抖音视频去水印怎么操作
在抖音上保存或分享视频时,水印通常会自动添加。如果想去除水印,可以尝试以下方法,但请注意尊重原创作者的版权,仅限个人合理使用。 方法 1:使用第三方去水印工具(手机/电脑均可) 复制视频链接 …...

Java并发编程
Java并发编程的核心挑战 线程安全与数据竞争 线程安全的概念及其重要性数据竞争的产生原因及常见场景如何通过同步机制(如锁、原子类)避免数据竞争 // 示例:使用synchronized关键字实现线程安全 public class Counter {private int count …...

【ospf综合实验】
拓扑图:...

NVMe控制器之仿真平台搭建
本设计采用Verilog HDL语言进行实现并编写测试激励,仿真工具使用Mentor公司的QuestaSim 10.6c软件完成对关键模块的仿真验证工作,由于是基于Xilinx公司的Kintex UltraScale系列FPGA器件实现的,因此使用Xilinx公司的Vivado2019.1设计套件工具进…...

深入探究 InnoDB 的写失效问题
在 MySQL 数据库的世界中,InnoDB 存储引擎凭借其卓越的性能和可靠性,成为众多应用的首选。然而,如同任何复杂的系统一样,InnoDB 也面临着一些挑战,其中写失效问题便是一个值得深入探讨的关键议题。本文将带您全面了解 …...

边缘计算从专家到小白
“云-边-端”架构 “云” :传统云计算的中心节点,是边缘计算的管控端。汇集所有边缘的感知数据、业务数据以及互联网数据,完成对行业以及跨行业的态势感知和分析。 “边” :云计算的边缘侧,分为基础设施边缘和设备边缘…...

智能商品推荐系统技术路线图
智能商品推荐系统技术路线图 系统架构图 --------------------------------------------------------------------------------------------------------------- | 用户交互层 (Presentation Layer) …...

SpringMVC面试内容
SpringMVC运行流程 SpringMVC的运行流程SpringBoot Vue交互流程HTTP 的 GET 和 POST 区别跨域请求是什么?有什么问题?怎么解决?浏览器访问资源没有响应,怎么排查Cookie的理解Session的理解 Cookie和Session的区别 SpringMVC的运行流程 1、域名解析…...

Python 核心概念速查清单
本文大纲 1. 变量与字符串 (Variables and Strings) 变量 (Variables): 用于存储值。字符串 (String): 由单引号或双引号包围的字符序列。 示例:打印 “Hello world!” print("Hello world!")使用变量打印: msg = "Hello world!" print(msg)字符串拼接…...

Unity.UGUI DrawCall合批笔记
前言 昨天在通过FrameDebug查看DrawCall时,发现批次结果与理解中的不一致,又去补充了一下这方面知识,笔记记录下,只关乎UGUI。 基础场景 首先列一下无法合批的一些基础场景 1.图片无图集或图集不同,图片是运行时生成的…...

高精度加减
1、高精度加法 主要有以下几步: 输入处理:使用字符串来存储大整数,避免数值范围限制。对齐数字:确保两个数字的数位对齐(前面补零)。逐位相加:从最低位开始,逐位相加并处理进位。最…...

day21python打卡
知识点回顾: LDA线性判别PCA主成分分析t-sne降维 还有一些其他的降维方式,也就是最重要的词向量的加工,我们未来再说 作业: 自由作业:探索下什么时候用到降维?降维的主要应用?或者让ai给你出题&…...

DataBinding与Kotlin优化视图绑定
在 Android 开发中,DataBinding 与 Kotlin 的结合可以显著提升代码的简洁性和可维护性,彻底摆脱传统 findViewById 的繁琐操作。以下是如何通过 DataBinding 优化视图绑定的完整指南: 一、为何要告别 findViewById? 模板代码冗余…...

CDGP主观题题库与范例解答
本文共8400字,涉及数据建模、数据安全、主数据、数据架构等主观题解答范例 数据建模题目 初次访问网购网站的访客,如试图在网站上购物,则需要申请会员。申请会员时需要填写会员姓名、性别、身份证号码、联系电话、会员ID、密码等信息。会员申请成功后,通过会员ID和密码便…...

2.商户查询缓存
2.0 问题记录 2.0.1 为什么要给缓存 TTL 1. 防止内存泄漏:如果不设置过期时间,缓存数据会永久存在于 Redis 中,随着时间推移可能导致 Redis 内存耗尽。2. 数据一致性:设置合理的过期时间可以确保缓存不会长期存储过时数据&#…...

vs python“““标记注释报错,vs使用自带环境安装 python第三方库
文章目录 vs python"""标记注释报错vs使用自带环境安装 python第三方库 vs python"""标记注释报错 解决方法: 切换编码 文件-高级保存选项-编码处选择下拉菜单中的“Unicode(UTF-8带签名)-代码页65001”-确定 这里更详细:…...

区块链技术中的Java SE实战:从企业级应用到5大核心问题解析
区块链技术中的Java SE实战:从企业级应用到5大核心问题解析 问题1:如何在Java SE中实现区块链的基本数据结构? 回答1: 区块链的核心数据结构是链式区块,每个区块包含数据、哈希值以及前一个区块的哈希值。以下是一个…...
)
数据结构—(概述)
目录 一 数据结构,相关概念 1. 数据结构: 2. 数据(Data): 3. 数据元素(Data Element): 4. 数据项: 5. 数据对象(Data Object): 6. 容器(container): 7. 结点(Node)ÿ…...

UE5 PCG学习笔记
https://www.bilibili.com/video/BV1onUdY2Ei3/?spm_id_from333.337.search-card.all.click&vd_source707ec8983cc32e6e065d5496a7f79ee6 一、安装PCG 插件里选择以下进行安装 移动目录后,可以使用 Update Redirector References,更新下࿰…...

Harness: 全流程 DevOps 解决方案,让持续集成如吃饭般简单
引言 在当今快速发展的软件开发世界中,高效的 DevOps 工具变得越来越重要。Harness 作为一个开源的运维平台,为开发和运维团队提供了从代码托管到 CI/CD 的全流程解决方案,同时实现自动化的开发环境和制品管理。这种集中化的工具可以显著减少运维难度,提高团队效率,真正解…...

Windows:Powershell的使用
文章目录 零、格式化输出命令1、Format-List(别名:fl) 一、服务管理SC命令二、软件管理命令三、权限管理命令1、Get-Acl2、Set-Acl 总结 零、格式化输出命令 1、Format-List(别名:fl) 可通过管道符传递对象…...

AIGC时代大模型幻觉问题深度治理:技术体系、工程实践与未来演进
文章目录 一、幻觉问题的多维度透视与产业冲击1.1 幻觉现象的本质特征与量化评估1.2 产业级影响案例分析 二、幻觉问题的根源性技术解剖2.1 数据污染的复合效应2.1.1 噪声数据类型学分析2.1.2 数据清洗技术实现 2.2 模型架构的先天缺陷2.2.1 注意力机制的局限性2.2.2 解码策略的…...
 协议发送和接收 Protocol Buffers (Proto) 消息)
JMeter 中通过 WebSocket (WS) 协议发送和接收 Protocol Buffers (Proto) 消息
在 JMeter 中通过 WebSocket (WS) 协议发送和接收 Protocol Buffers (Proto) 消息,需要使用 JMeter WebSocket 插件,并结合 JSR223 脚本处理 Proto 的序列化和反序列化。以下是完整步骤: 1. 准备工作 1.1 安装 WebSocket 插件 下载插件&…...

PyQt5基础:QWidget类的全面解析与应用实践
在Python的GUI编程领域,PyQt5是一个强大且广泛应用的库。其中,QWidget类作为所有用户界面对象的基类,是构建丰富多样用户界面的基础。今天,我们就来深入了解QWidget类及其相关应用。 QWidget类概述 QWidget类是PyQt中所有窗口和…...

DA14585墨水屏学习
一、do_min_word void do_min_work(void) {timer_used_min app_easy_timer(APP_PERIPHERAL_CTRL_TIMER_DELAY_MINUTES, do_min_work);current_unix_time time_offset;time_offset 60;// if (isconnected 1)// {// GPIO_SetActive(GPIO_LED_PORT, GPIO_LED_PIN);// …...

AI日报 · 2025年5月10日|OpenAI“Stargate”超级数据中心项目掀起美国各州争夺战
1、OpenAI“Stargate”超级数据中心项目掀起美国各州争夺战 《华盛顿邮报》披露,OpenAI 与 Oracle、SoftBank 合作推进的“Stargate”项目(首期投资 1000 亿美元,四年内总投资 5000 亿美元)已收到超过 250 份选址提案ÿ…...

浅谈装饰模式
一、前言 hello大家好,本次打算简单聊一下装饰者模式,其实写有关设计模式的内容还是蛮有挑战性的,首先呢就是小永哥实力有限担心说不明白,其次设计模式是为了解决某些问题场景,在当前技术生态圈如此完善的情况下&#…...

《Python星球日记》 第54天:卷积神经网络进阶
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、深度CNN架构解析1. LeNet-5(1998)2. AlexNet&#x…...

R 语言科研绘图 --- 桑基图-汇总
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

JDBC工具类
目录 引言 一、JDBC连接数据库步骤 1. 加载驱动 2. 获取连接(URL 用户名 密码) 3. 编写sql 4. 获取执行sql的stmt的对象 5. 执行sql 拿到结果集 6. 遍历结果集 7. 关闭资源(先开的后关 后开的先关) 二、JDBC工具类 版…...

【深度学习-Day 8】让数据说话:Python 可视化双雄 Matplotlib 与 Seaborn 教程
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

InnoDB结构与表空间文件页的详解
目录 1.InnoDB的概览 表空间文件在哪里? 为什么要设计成内存结构和磁盘结构? 表空间与表空间文件关系? 用户数据如何在表空间文件存储? 2.页 如何设置页的大小? 页的结构及在表空间的位置? 页头包…...

计算机网络基础科普
IP地址是计算机网络中标识设备的唯一地址 IPv4(32位)IPv6(128位) 1.IPv4(32位) 简介:IPv4(Internet Protocol version 4)是互联网协议(IP)的…...

PostgreSQL 的 pg_advisory_lock_shared 函数
PostgreSQL 的 pg_advisory_lock_shared 函数详解 pg_advisory_lock_shared 是 PostgreSQL 提供的共享咨询锁函数,允许多个会话同时获取相同键值的共享锁,但排斥排他锁。 共享咨询锁 vs 排他咨询锁 锁类型共享锁 (pg_advisory_lock_shared)排他锁 (pg…...

Win11安装APK方法详解
1、官方win11系统 预览版 开发版 正式版 都行 2、同时你还需要开启主板 BIOS 虚拟化选项(具体名称不同主板略有不同) 这一步自行百度 开始:先去确定有没有开启虚拟化 任务管理器检查—— 虚拟化是否已经开启,如果没有自己去BIO…...

kafka的安装及简单使用
kafka 1、什么是kafka kafka是一个分布式事件流平台,核心功能有发布/订阅消息系统、实时处理数据流等,Kafka非常适合超大数据量场景。 2、kafka安装 (1)下载 在kafka官网下载二进制压缩包 (2)解压安…...

圆角边框 盒子阴影 文字阴影
一.圆角边框 在css3中,新增了圆角边框样式,这样我们的盒子就可以变成圆角了 1.border-radius border-radius属性用于设置元素的外边框圆角 border-radius:length; radius半径(圆的半径)原理:椭圆与矩形边框的交集形…...

LRU CPP实现
缓存结构: 使用一个双向链表(std::list<int>)保存缓存中的页面编号,越靠前的是最近访问的,越靠后的是最久未访问的。 使用一个哈希表(std::unordered_map<int, list<int>::iterator>&am…...

C/C++复习-- C语言初始基础
C语言初始基础 本文结合代码实例与理论解析,系统讲解C语言的核心知识点,涵盖数据类型、控制结构、函数、指针、结构体等核心内容,并辅以常见错误分析与进阶技巧。通过对比文件一代码与文件二理论,帮助初学者构建完整的C语言知识框…...

小刚说C语言刷题—1078求恰好使s=1+1/2+1/3+…+1/n的值大于X时n的值
1.题目描述 求恰好使 s11/21/3⋯1/n 的值大于 X 时 n 的值。( 2≤x≤10 ) 输入 输入只有一行,包括 1个整数 X 。 输出 输出只有一行(这意味着末尾有一个回车符号),包括 1 个整数。 样例 输入 2 输出 4 2.参考代码(C语言…...

深度学习篇---MediaPipe 及其人体姿态估计模型详解
文章目录 前言一、MediaPipe 核心特点跨平台支持实时性能模块化设计预训练模型 二、MediaPipe 人体姿态估计模型1. MediaPipe Pose (BlazePose)模型特点实时性能两种变体LiteHeavy 关键点定义技术细节检测器关键点预测器支持3D姿态估计 2. MediaPipe Holistic模型特点更全面的检…...