《Python星球日记》 第54天:卷积神经网络进阶
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
目录
- 一、深度CNN架构解析
- 1. LeNet-5(1998)
- 2. AlexNet(2012)
- 3. VGG(2014)
- 4. ResNet(2015)
- 5. CNN架构演化与对比
- 二、数据增强技术
- 1. 数据增强的核心原理
- 2. 常见的数据增强技术
- 几何变换
- 颜色和强度变换
- 3. 使用Keras实现数据增强
- 4. 数据增强的最佳实践
- 三、Dropout与Batch Normalization
- 1. Dropout技术
- 工作原理
- Dropout的优势
- 使用建议
- 2. Batch Normalization
- 工作原理
- Batch Normalization的优势
- 使用建议
- 3. Dropout与BN的结合使用
- 四、CIFAR-10图像分类实战
- 1. 数据集介绍
- 2. 数据预处理
- 3. 构建ResNet模型
- 4. 模型训练与评估
- 5. 结果可视化
- 6. 可视化特征图
- 五、总结与展望
- 学习资源
- 下一步学习方向
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第53天:卷积神经网络(CNN)入门
欢迎来到Python星球的第54天!🪐
昨天我们学习了卷积神经网络的基础知识,今天我们将深入探索更高级的CNN架构和技术,这些知识将帮助你构建更强大、更准确的图像识别模型。
一、深度CNN架构解析
随着深度学习的发展,卷积神经网络的架构也变得越来越复杂和强大。让我们来了解几个里程碑式的CNN架构。
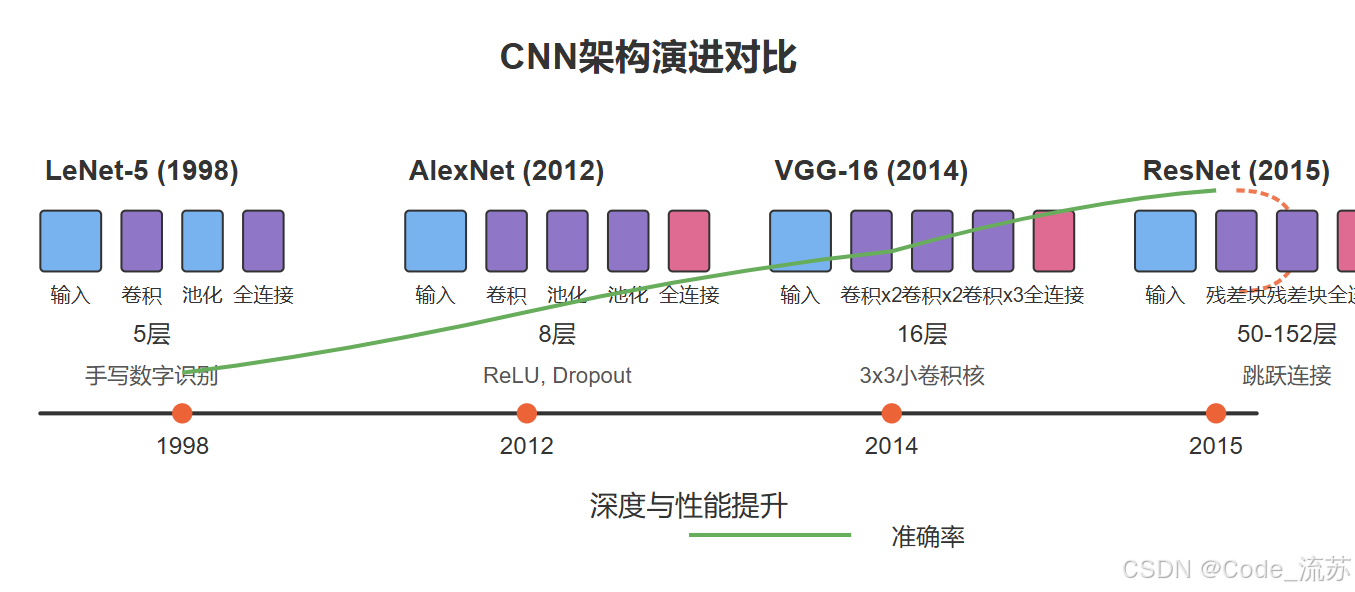
1. LeNet-5(1998)
LeNet-5是由Yann LeCun开发的最早的CNN架构之一,主要用于手写数字识别。
LeNet-5 虽然结构简单,但奠定了现代CNN的基础,包含了卷积层、池化层和全连接层的组合。它的设计思想是通过卷积提取特征,通过池化减少参数,最后通过全连接层进行分类。
2. AlexNet(2012)
AlexNet是深度学习复兴的标志性架构,在2012年的ImageNet竞赛中以显著优势获胜。
AlexNet的主要创新点:
- 使用ReLU激活函数替代传统的Sigmoid,减缓了梯度消失问题
- 引入Dropout来防止过拟合
- 使用GPU加速训练,这使得更深的网络成为可能
- 数据增强技术的广泛应用
3. VGG(2014)
VGG网络由牛津大学Visual Geometry Group提出,以其简洁统一的结构著称。
VGG的主要特点:
- 使用小尺寸卷积核(3×3)替代大尺寸卷积核,通过叠加多层实现更大的感受野
- 网络结构统一,易于理解和扩展
- 具有多个变体(VGG-16, VGG-19等),深度不同
- 参数量大,需要更多的计算资源
4. ResNet(2015)
残差网络(ResNet)解决了深度网络训练中的梯度消失/爆炸问题,使得训练超过100层的网络成为可能。
ResNet的核心创新是引入了残差块(Residual Block),它通过添加跳跃连接(Skip Connection),允许信息直接从前层传递到后层,大大缓解了梯度消失问题。
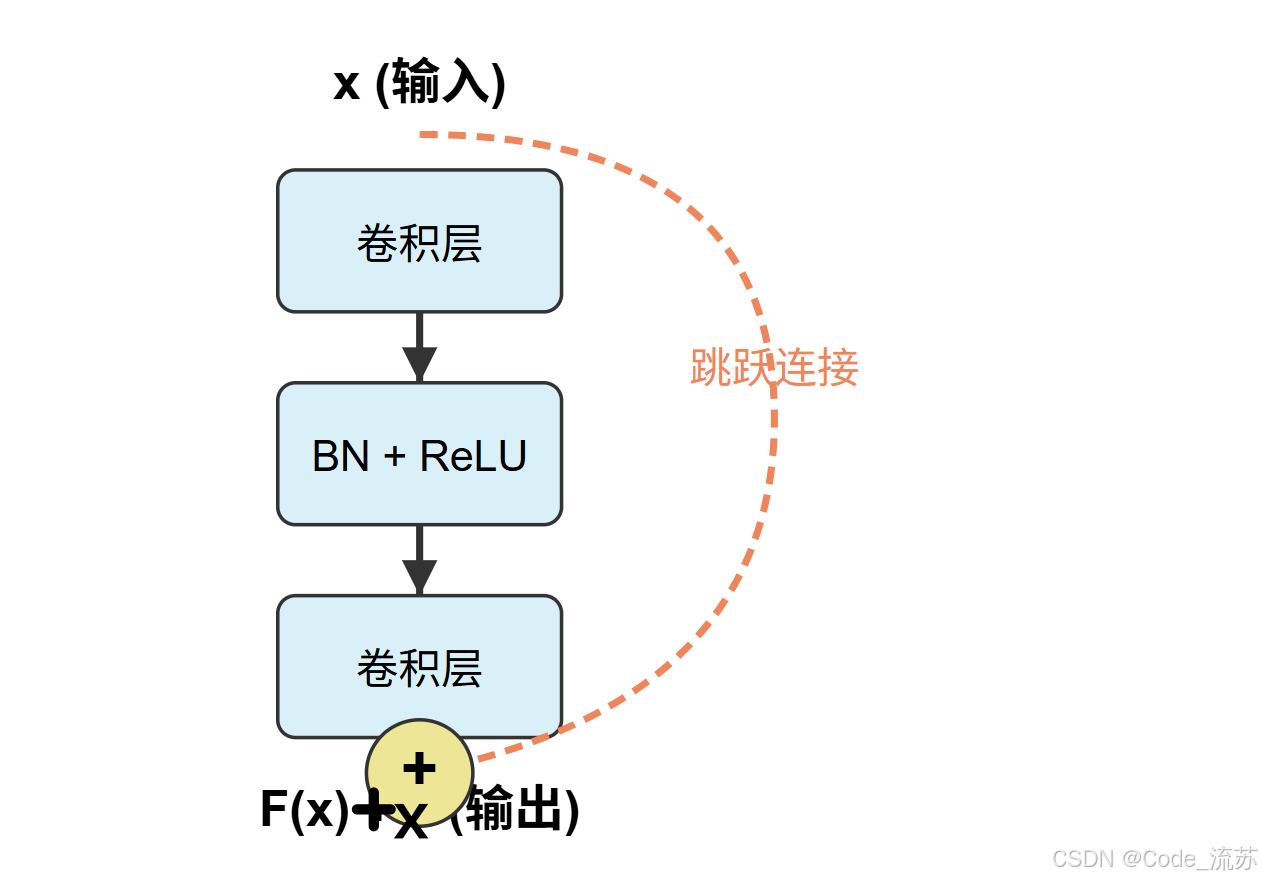
残差块的数学表达式为: F(x) + x,其中F(x)是需要学习的残差映射,x是输入特征。这种简单而优雅的设计使网络能够学习残差而非完整映射,大大简化了训练过程。
5. CNN架构演化与对比
随着时间的推移,CNN架构变得越来越深,性能也越来越强:
| 网络名称 | 年份 | 层数 | 参数量 | Top-5错误率(ImageNet) | 主要创新点 |
|---|---|---|---|---|---|
| LeNet-5 | 1998 | 5 | 60K | - | 基础CNN结构 |
| AlexNet | 2012 | 8 | 62M | 15.3% | ReLU, Dropout, 数据增强 |
| VGG-16 | 2014 | 16 | 138M | 7.3% | 小卷积核堆叠, 统一结构 |
| ResNet-50 | 2015 | 50 | 25.6M | 3.6% | 残差连接 |
| ResNet-152 | 2015 | 152 | 60M | 3.57% | 超深网络 |
我们可以看到,深度增加的同时,现代网络通过特殊设计(如残差连接)实现了参数量的相对控制。
二、数据增强技术
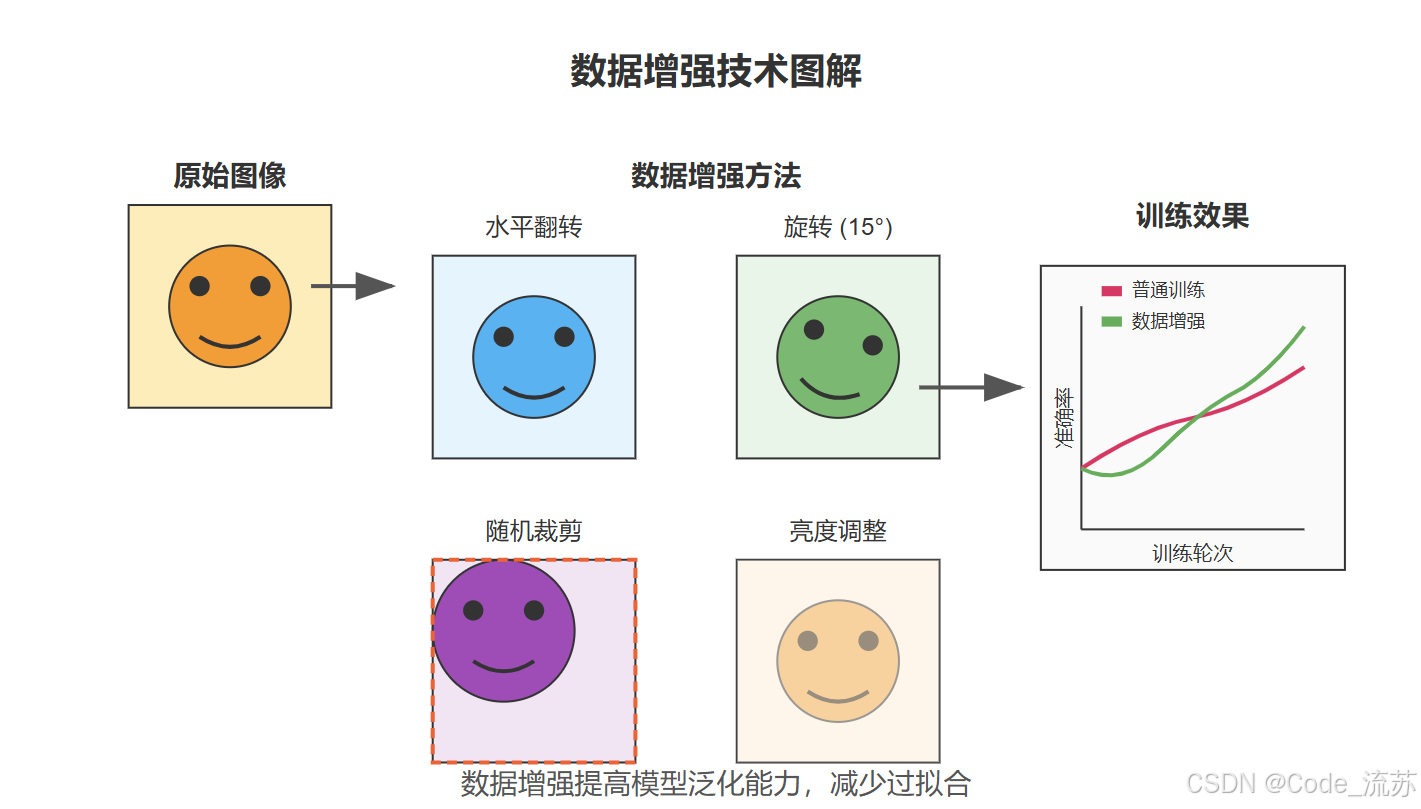
数据增强是解决过拟合和提高模型泛化能力的重要技术,尤其在训练数据有限的情况下。
1. 数据增强的核心原理
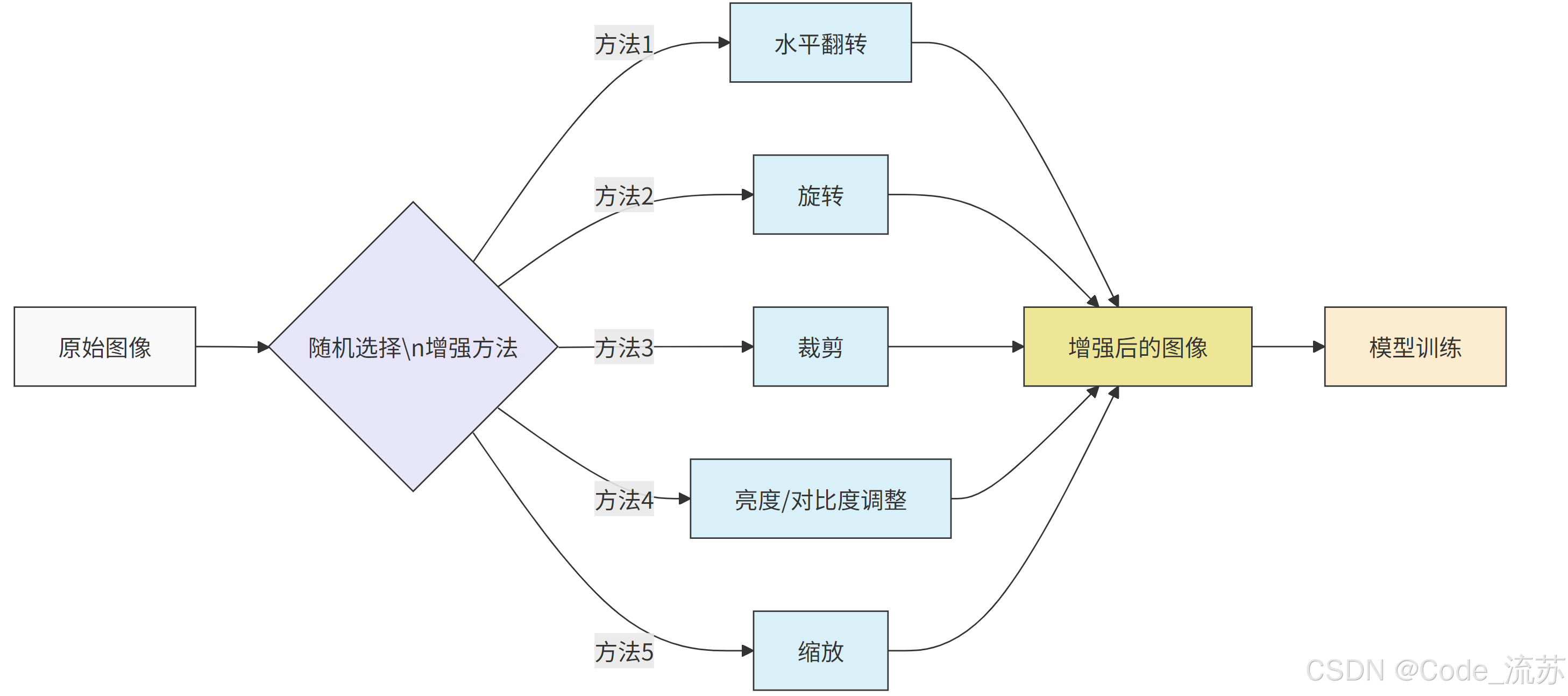
数据增强通过对原始图像进行各种变换,生成新的训练样本,从而:
- 扩大训练集规模
- 增加数据多样性
- 提高模型对各种变化的鲁棒性
- 减少过拟合
2. 常见的数据增强技术
几何变换
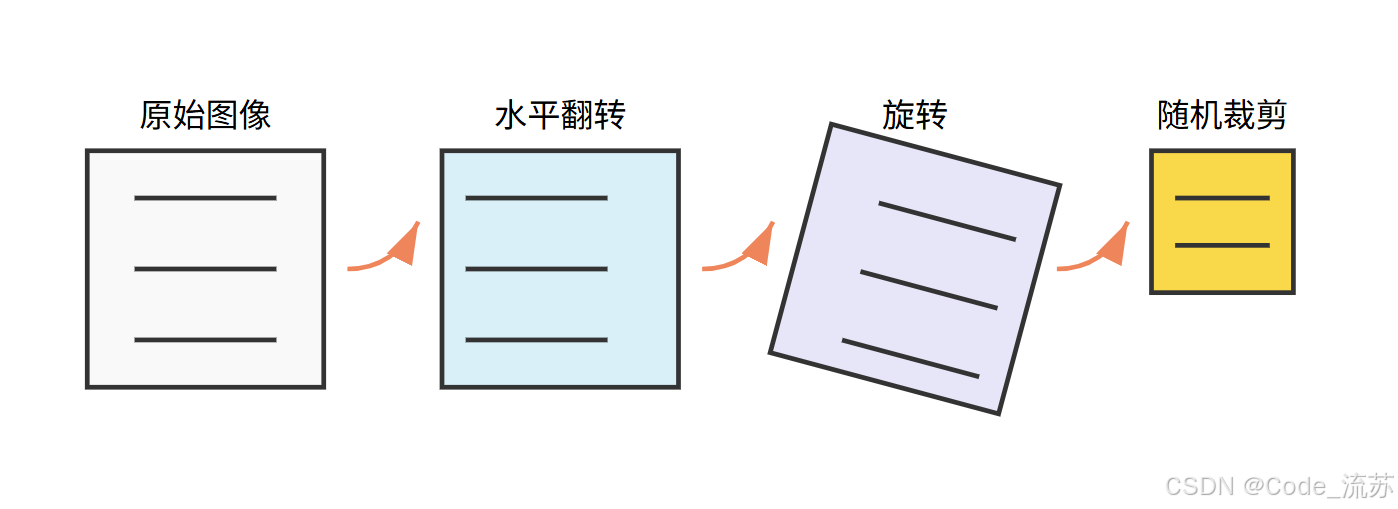
-
水平翻转(Horizontal Flip)
- 将图像左右翻转
- 特别适合对称物体,如人脸、车辆等
- 代码实现:
tf.image.flip_left_right(image)
-
旋转(Rotation)
- 将图像按一定角度旋转
- 通常使用较小的角度(如±15°)避免信息丢失
- 代码实现:
tf.image.rot90(image, k=1)(旋转90度)
-
随机裁剪(Random Crop)
- 从原图中随机裁剪一部分作为训练样本
- 能够强制模型关注图像的不同部分
- 代码实现:
tf.image.random_crop(image, [height, width, 3])
颜色和强度变换
-
亮度和对比度调整
- 随机改变图像的亮度和对比度
- 提高模型对不同光照条件的适应能力
- 代码实现:
# 随机调整亮度 image = tf.image.random_brightness(image, max_delta=0.2) # 随机调整对比度 image = tf.image.random_contrast(image, lower=0.8, upper=1.2)
-
色调和饱和度调整
- 改变图像的色调和饱和度
- 增强模型对颜色变化的鲁棒性
- 代码实现:
# 随机调整色调 image = tf.image.random_hue(image, max_delta=0.2) # 随机调整饱和度 image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
3. 使用Keras实现数据增强
Keras提供了便捷的ImageDataGenerator类来实现数据增强:
from tensorflow.keras.preprocessing.image import ImageDataGenerator# 创建数据增强器
data_augmentation = ImageDataGenerator(rotation_range=15, # 旋转范围(0-180)width_shift_range=0.1, # 水平平移范围height_shift_range=0.1, # 垂直平移范围horizontal_flip=True, # 水平翻转zoom_range=0.1, # 缩放范围shear_range=0.1, # 剪切变换范围brightness_range=[0.8, 1.2], # 亮度调整范围fill_mode='nearest' # 填充模式
)# 应用到训练数据
train_generator = data_augmentation.flow(x_train, y_train,batch_size=32
)# 训练模型
model.fit(train_generator,steps_per_epoch=len(x_train) // 32,epochs=50
)
4. 数据增强的最佳实践
- 保持标签一致性:确保增强后的图像仍然与原来的标签相符
- 适度使用:过度增强可能引入不必要的噪声
- 领域相关:根据特定任务选择合适的增强方法(例如医学图像可能不适合颜色变换)
- 实时增强:在训练过程中动态生成增强图像,而不是预先生成
- 验证集不增强:只对训练集应用数据增强,验证集保持原样以准确评估模型性能
三、Dropout与Batch Normalization
在深度神经网络中,Dropout和Batch Normalization是两种重要的正则化和优化技术。
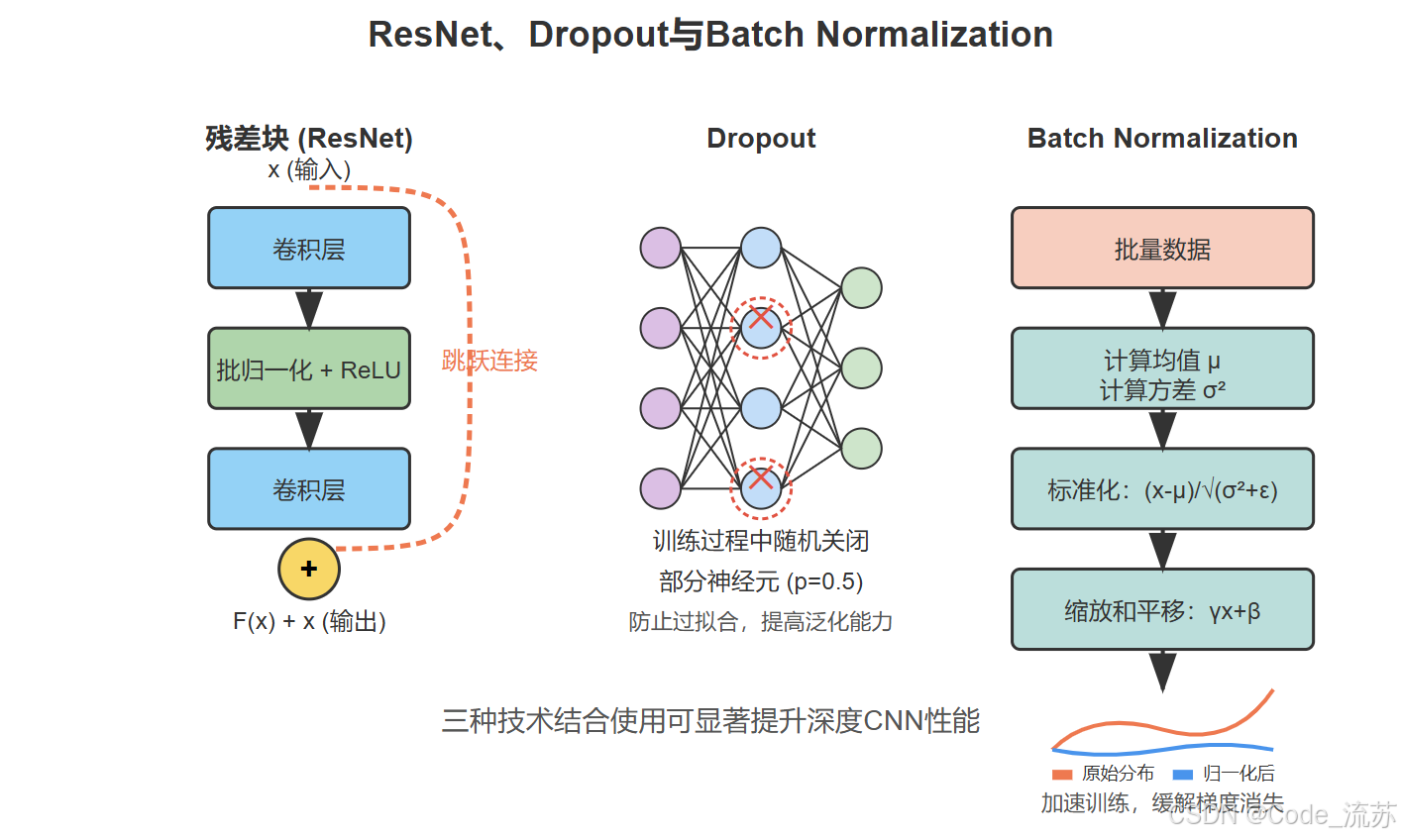
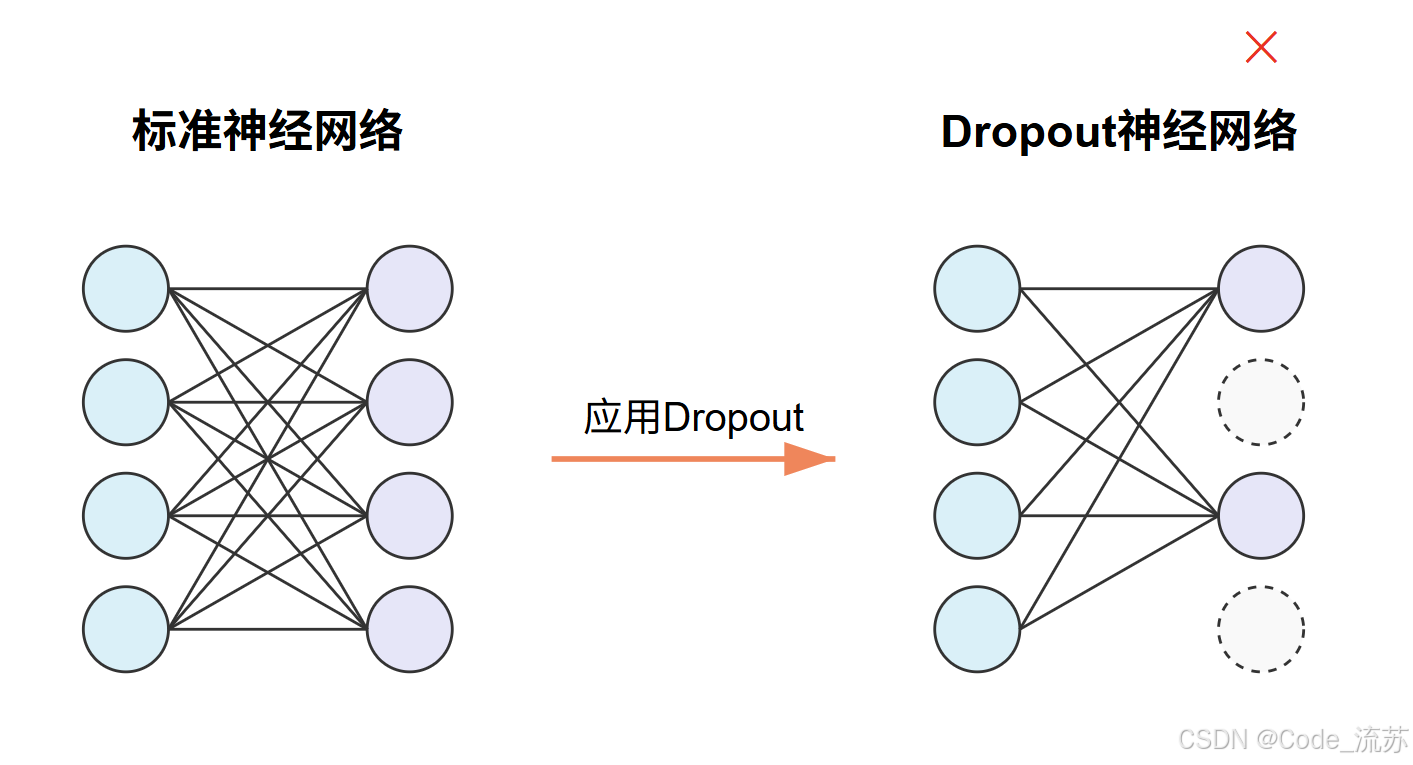
1. Dropout技术
Dropout是一种简单而有效的正则化技术,主要用于防止神经网络过拟合。
工作原理
Dropout在训练过程中随机关闭(设置为0)一定比例的神经元,强制网络学习更加鲁棒的特征表示。具体来说:
-
训练阶段:以概率p随机断开神经元连接
# Dropout层,p=0.5表示有50%的神经元会被随机关闭 model.add(Dropout(0.5)) -
测试阶段:所有神经元都参与计算,但输出会乘以(1-p)进行缩放,以补偿训练时丢弃的神经元
Dropout的优势
- 防止过拟合:通过随机丢弃神经元,避免网络对训练数据的过度记忆
- 提高鲁棒性:迫使网络学习多样化的特征,不依赖于特定的神经元组合
- 实现了集成学习:相当于同时训练多个不同的子网络,并在测试时进行平均
- 降低神经元间的共适应性:防止神经元之间形成强依赖关系
使用建议
- 合适的丢弃率:通常设置为0.2-0.5,较大的网络可以使用较高的丢弃率
- 放置位置:一般放在全连接层之后,卷积层之后较少使用
- 不在测试时使用:测试阶段应关闭Dropout功能
2. Batch Normalization
Batch Normalization (BN)是一种网络层,用于标准化每一层的输入,从而加速训练过程并提高模型性能。
工作原理
Batch Normalization通过以下步骤对每个mini-batch的特征进行标准化:
- 计算批次均值:μᵦ = (1/m) Σᵢ₌₁ᵐ xᵢ
- 计算批次方差:σ²ᵦ = (1/m) Σᵢ₌₁ᵐ (xᵢ - μᵦ)²
- 标准化:x̂ᵢ = (xᵢ - μᵦ) / √(σ²ᵦ + ε),其中ε是一个小常数,防止除零
- 缩放和偏移:yᵢ = γ · x̂ᵢ + β,其中γ和β是可学习的参数
在Keras中的实现:
from tensorflow.keras.layers import BatchNormalizationmodel.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
Batch Normalization的优势
- 加速训练:通过标准化每层的输入,减少了内部协变量偏移,使得优化过程更加稳定
- 允许更高的学习率:归一化后的数据不容易产生梯度爆炸或消失
- 减少过拟合:具有一定的正则化效果,因为每个mini-batch的统计量有微小波动
- 降低对初始化的敏感性:减轻了权重初始化对模型训练的影响
- 减少对Dropout的依赖:在某些情况下,BN可以部分替代Dropout的功能
使用建议
- 放置位置:一般放在卷积层或全连接层之后,激活函数之前
- 与激活函数的关系:
# 推荐方式:Conv -> BN -> ReLU model.add(Conv2D(64, (3, 3))) model.add(BatchNormalization()) model.add(Activation('relu')) - 小批量大小:BN对较小的批量大小效果不佳,建议使用>=32的批量大小
- 推理阶段:测试时使用整个训练集的均值和方差,而不是批次统计量
3. Dropout与BN的结合使用
Dropout和Batch Normalization通常可以结合使用,但需要注意顺序:
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.3)) # 在激活函数之后应用Dropout
研究表明,将BN放在激活函数前,将Dropout放在激活函数后效果最佳。
四、CIFAR-10图像分类实战
CIFAR-10是一个包含60,000张32×32彩色图像的数据集,分为10个类别,每类6,000张图像。这是一个很好的CNN进阶练习数据集。
1. 数据集介绍
CIFAR-10的10个类别包括:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。
# 加载CIFAR-10数据集
from tensorflow.keras.datasets import cifar10(x_train, y_train), (x_test, y_test) = cifar10.load_data()# 查看数据集形状
print(f"训练集: {x_train.shape}, {y_train.shape}")
print(f"测试集: {x_test.shape}, {y_test.shape}")
2. 数据预处理
import numpy as np
from tensorflow.keras.utils import to_categorical# 数据归一化
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0# 对标签进行one-hot编码
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)# 创建数据增强器
from tensorflow.keras.preprocessing.image import ImageDataGeneratordatagen = ImageDataGenerator(rotation_range=15,width_shift_range=0.1,height_shift_range=0.1,horizontal_flip=True,zoom_range=0.1
)# 将数据增强器应用于训练数据
datagen.fit(x_train)
3. 构建ResNet模型
让我们实现一个基于ResNet的深度CNN模型来分类CIFAR-10图像:
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Activation
from tensorflow.keras.layers import MaxPooling2D, AveragePooling2D, Flatten, Dense, add, Dropoutdef residual_block(x, filters, kernel_size=3, stride=1, conv_shortcut=False):"""残差块的实现"""shortcut = xif conv_shortcut:shortcut = Conv2D(filters, 1, strides=stride)(shortcut)shortcut = BatchNormalization()(shortcut)# 第一个卷积块x = Conv2D(filters, kernel_size, strides=stride, padding='same')(x)x = BatchNormalization()(x)x = Activation('relu')(x)# 第二个卷积块x = Conv2D(filters, kernel_size, padding='same')(x)x = BatchNormalization()(x)# 添加跳跃连接x = add([x, shortcut])x = Activation('relu')(x)return xdef build_resnet_model(input_shape, num_classes):"""构建ResNet模型"""inputs = Input(shape=input_shape)# 初始卷积层x = Conv2D(32, 3, padding='same')(inputs)x = BatchNormalization()(x)x = Activation('relu')(x)# 残差块x = residual_block(x, 32)x = residual_block(x, 32)x = residual_block(x, 64, stride=2, conv_shortcut=True)x = residual_block(x, 64)x = residual_block(x, 128, stride=2, conv_shortcut=True)x = residual_block(x, 128)# 全局平均池化x = AveragePooling2D(pool_size=4)(x)x = Flatten()(x)x = Dense(256)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = Dropout(0.5)(x)# 输出层outputs = Dense(num_classes, activation='softmax')(x)model = Model(inputs=inputs, outputs=outputs)return model# 构建模型
model = build_resnet_model((32, 32, 3), 10)# 编译模型
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy']
)# 打印模型结构
model.summary()
4. 模型训练与评估
from tensorflow.keras.callbacks import ModelCheckpoint, LearningRateScheduler, ReduceLROnPlateau# 学习率调度器
def lr_schedule(epoch):lr = 0.001if epoch > 75:lr *= 0.1if epoch > 100:lr *= 0.1return lrlr_scheduler = LearningRateScheduler(lr_schedule)# 学习率自动调整
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.00001
)# 模型保存
checkpoint = ModelCheckpoint('best_resnet_cifar10.h5',monitor='val_accuracy',save_best_only=True,mode='max'
)# 训练模型
batch_size = 64
epochs = 120history = model.fit(datagen.flow(x_train, y_train, batch_size=batch_size),steps_per_epoch=len(x_train) // batch_size,epochs=epochs,validation_data=(x_test, y_test),callbacks=[lr_scheduler, reduce_lr, checkpoint]
)# 加载最佳模型
from tensorflow.keras.models import load_model
best_model = load_model('best_resnet_cifar10.h5')# 评估模型
score = best_model.evaluate(x_test, y_test)
print(f"测试集准确率: {score[1]*100:.2f}%")
5. 结果可视化
import matplotlib.pyplot as plt# 绘制训练历史
plt.figure(figsize=(12, 4))# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='训练准确率')
plt.plot(history.history['val_accuracy'], label='验证准确率')
plt.title('模型准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率')
plt.legend()# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.title('模型损失')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()plt.tight_layout()
plt.show()# 混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns# 预测测试集
y_pred = best_model.predict(x_test)
y_pred_classes = np.argmax(y_pred, axis=1)
y_true = np.argmax(y_test, axis=1)# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred_classes)# 绘制混淆矩阵
plt.figure(figsize=(10, 8))
class_names = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=class_names, yticklabels=class_names)
plt.title('混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
6. 可视化特征图
查看卷积层提取的特征,帮助我们理解CNN的工作原理:
import tensorflow as tf# 创建一个模型,用于提取中间层特征
layer_outputs = [layer.output for layer in model.layers if isinstance(layer, tf.keras.layers.Conv2D)]
activation_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs)# 选择一张测试图像
img_index = 12
test_img = x_test[img_index:img_index+1]# 获取特征图
activations = activation_model.predict(test_img)# 显示原始图像
plt.figure(figsize=(6, 6))
plt.imshow(x_test[img_index])
plt.title(f"原始图像: {class_names[y_true[img_index]]}")
plt.axis('off')
plt.show()# 可视化前两个卷积层的特征图
plt.figure(figsize=(15, 8))
for i in range(2):feature_maps = activations[i]n_features = min(16, feature_maps.shape[-1]) # 最多显示16个特征图for j in range(n_features):plt.subplot(2, 8, i*8+j+1)plt.imshow(feature_maps[0, :, :, j], cmap='viridis')plt.axis('off')if j == 0:plt.title(f"卷积层 {i+1}")plt.tight_layout()
plt.show()
五、总结与展望
在本文中,我们深入探讨了卷积神经网络的进阶内容。我们学习了从LeNet到ResNet的经典CNN架构演化,了解了数据增强的重要性和实现方法,掌握了Dropout和Batch Normalization的工作原理,并通过CIFAR-10图像分类任务进行了实践。
这些进阶知识将帮助你构建更强大、更准确的卷积神经网络模型。随着深度学习的不断发展,CNN架构也在不断创新,如MobileNet(轻量级网络)、EfficientNet(自动缩放网络)等,这些都是值得进一步探索的方向。
学习资源
-
论文:
- Deep Residual Learning for Image Recognition (ResNet)
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
-
课程:
- 吴恩达的深度学习课程(Coursera)
- CS231n: Convolutional Neural Networks for Visual Recognition(斯坦福)
-
书籍:
- 《Deep Learning》by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
下一步学习方向
- 迁移学习:利用预训练模型加速新任务的学习
- 目标检测:YOLO、SSD、Faster R-CNN等算法
- 语义分割:U-Net、DeepLab等架构
- 生成对抗网络(GANs):用于图像生成和风格迁移
希望本文对你理解卷积神经网络的进阶内容有所帮助。在下一篇文章中,我们将探索更多深度学习的前沿技术!
祝你学习愉快,Python星球的探索者!👨🚀🌠
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!
相关文章:

《Python星球日记》 第54天:卷积神经网络进阶
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、深度CNN架构解析1. LeNet-5(1998)2. AlexNet&#x…...

R 语言科研绘图 --- 桑基图-汇总
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

JDBC工具类
目录 引言 一、JDBC连接数据库步骤 1. 加载驱动 2. 获取连接(URL 用户名 密码) 3. 编写sql 4. 获取执行sql的stmt的对象 5. 执行sql 拿到结果集 6. 遍历结果集 7. 关闭资源(先开的后关 后开的先关) 二、JDBC工具类 版…...

【深度学习-Day 8】让数据说话:Python 可视化双雄 Matplotlib 与 Seaborn 教程
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

InnoDB结构与表空间文件页的详解
目录 1.InnoDB的概览 表空间文件在哪里? 为什么要设计成内存结构和磁盘结构? 表空间与表空间文件关系? 用户数据如何在表空间文件存储? 2.页 如何设置页的大小? 页的结构及在表空间的位置? 页头包…...

计算机网络基础科普
IP地址是计算机网络中标识设备的唯一地址 IPv4(32位)IPv6(128位) 1.IPv4(32位) 简介:IPv4(Internet Protocol version 4)是互联网协议(IP)的…...

PostgreSQL 的 pg_advisory_lock_shared 函数
PostgreSQL 的 pg_advisory_lock_shared 函数详解 pg_advisory_lock_shared 是 PostgreSQL 提供的共享咨询锁函数,允许多个会话同时获取相同键值的共享锁,但排斥排他锁。 共享咨询锁 vs 排他咨询锁 锁类型共享锁 (pg_advisory_lock_shared)排他锁 (pg…...

Win11安装APK方法详解
1、官方win11系统 预览版 开发版 正式版 都行 2、同时你还需要开启主板 BIOS 虚拟化选项(具体名称不同主板略有不同) 这一步自行百度 开始:先去确定有没有开启虚拟化 任务管理器检查—— 虚拟化是否已经开启,如果没有自己去BIO…...

kafka的安装及简单使用
kafka 1、什么是kafka kafka是一个分布式事件流平台,核心功能有发布/订阅消息系统、实时处理数据流等,Kafka非常适合超大数据量场景。 2、kafka安装 (1)下载 在kafka官网下载二进制压缩包 (2)解压安…...

圆角边框 盒子阴影 文字阴影
一.圆角边框 在css3中,新增了圆角边框样式,这样我们的盒子就可以变成圆角了 1.border-radius border-radius属性用于设置元素的外边框圆角 border-radius:length; radius半径(圆的半径)原理:椭圆与矩形边框的交集形…...

LRU CPP实现
缓存结构: 使用一个双向链表(std::list<int>)保存缓存中的页面编号,越靠前的是最近访问的,越靠后的是最久未访问的。 使用一个哈希表(std::unordered_map<int, list<int>::iterator>&am…...

C/C++复习-- C语言初始基础
C语言初始基础 本文结合代码实例与理论解析,系统讲解C语言的核心知识点,涵盖数据类型、控制结构、函数、指针、结构体等核心内容,并辅以常见错误分析与进阶技巧。通过对比文件一代码与文件二理论,帮助初学者构建完整的C语言知识框…...

小刚说C语言刷题—1078求恰好使s=1+1/2+1/3+…+1/n的值大于X时n的值
1.题目描述 求恰好使 s11/21/3⋯1/n 的值大于 X 时 n 的值。( 2≤x≤10 ) 输入 输入只有一行,包括 1个整数 X 。 输出 输出只有一行(这意味着末尾有一个回车符号),包括 1 个整数。 样例 输入 2 输出 4 2.参考代码(C语言…...

深度学习篇---MediaPipe 及其人体姿态估计模型详解
文章目录 前言一、MediaPipe 核心特点跨平台支持实时性能模块化设计预训练模型 二、MediaPipe 人体姿态估计模型1. MediaPipe Pose (BlazePose)模型特点实时性能两种变体LiteHeavy 关键点定义技术细节检测器关键点预测器支持3D姿态估计 2. MediaPipe Holistic模型特点更全面的检…...

Embedding 的数学特性与可视化解析
一、向量空间的可视化解码 1.1 GloVe 词向量实例 取词向量维度 d 50 d50 d50 的 GloVe 嵌入示例: king_vec [[0.50451, 0.68607, -0.59517, -0.022801, 0.60046, -0.13498, -0.08813, 0.47377, -0.61798, -0.31012, -0.076666, 1.493, -0.034189, -0.98173, 0…...

“睿思 BI” 系统介绍
“睿思 BI” 商业智能系统是由成都睿思商智科技有限公司自主研发的企业数据分析系统,以下是对该系统的详细介绍: 功能模块 : • 数据集成与准备 :支持数据导入、数据填报、数据 ETL 等功能,可抽取企业在经营过程中产生…...

[ctfshow web入门] web69
信息收集 使用cinclude("php://filter/convert.base64-encode/resourceindex.php");读取的index.php if(isset($_POST[c])){$c $_POST[c];eval($c); }else{highlight_file(__FILE__); }解题 查目录 百度了一下有哪些打印函数,var_export能用 var_exp…...
)
AI赋能研究工作:我的深度学习助手使用体验(DeepResearch)
在过去一年多的时间里,AI工具在国内经历了数次大规模普及与质量波动。作为一名研究工作者,我一直在寻找稳定高效的AI解决方案来辅助日常工作。今天想分享一个让我受益良多的平台——GPTYOU.com 为什么它值得一试? 和市面上众多同类产品相比…...
_监视属性、深度监视、监视的简写形式)
Vue基础(8)_监视属性、深度监视、监视的简写形式
监视属性(watch): 1.当被监视的属性变化时,回调函数(handler)自动调用,进行相关操作。 2.监视的属性必须存在,才能进行监视!! 3.监视的两种写法: (1).new Vue时传入watch配置 (2).通过vm.$watc…...

STM32硬件I2C驱动OLED屏幕
本文基于STM32硬件I2C驱动SSD1306 OLED屏幕,提供完整的代码实现及关键注意事项,适用于128x32或128x64分辨率屏幕。代码通过模块化设计,支持显示字符、数字、汉字及位图,并优化了显存刷新机制。 零、完整代码 完整代码: 1&#x…...

2021-11-16 C++歌手去掉2最高2最低均分
缘由大学一年级c编程题目-编程语言-CSDN问答 void 歌手去掉2最高2最低均分() {//缘由https://ask.csdn.net/questions/7551893?spm1005.2025.3001.5141int n 0, h 0, j 0, qd[6]{0}, fs[50]{0};scanf_s("%d", &n); j n; qd[2] qd[3] INT_MAX; qd[0] qd[…...
详解)
Vue插槽(Slots)详解
文章目录 1. 插槽简介1.1 什么是插槽?1.2 为什么需要插槽?1.3 插槽的基本语法 2. 默认插槽2.1 什么是默认插槽?2.2 默认插槽语法2.3 插槽默认内容2.4 默认插槽实例:创建一个卡片组件2.5 Vue 3中的默认插槽2.6 默认插槽的应用场景 …...
)
[虚幻官方教程学习笔记]深入理解实时渲染(An In-Depth Look at Real-Time Rendering)
原英文教程地址深入理解实时渲染(An In-Depth Look at Real-Time Rendering) 文章目录 1.Intro to An In-Depth Look at Real-Time RenderingCPU VS GPUDeferred VS Forward 2. Before Rendering and OcclusionCulling计算的步骤使用console command:fre…...

【bibtex4word】在Word中高效转换bib参考文献,Texlive环境安装bibtex4word插件
前言 现已退出科研界,本人水货一个。希望帮到有缘人 本篇关于如何将latex环境中的参考文献bib文件转化为word,和一些踩坑记录。 可以看下面的资料进行配置,后面的文字是这些资料的补充说明。 参考文章:https://blog.csdn.net/g…...

torch.nn 下的常用深度学习函数
1. 层(Layers) 这些函数用于定义神经网络中的各种层,是构建模型的基础模块。 torch.nn.Linear 用途:全连接层(也称为线性层)。用于将输入数据从一个维度映射到另一个维度,常用于神经网络的隐藏…...
图文解锁RAG从原理到实操)
(2025)图文解锁RAG从原理到实操
什么是RAG RAG(检索增强生成)是一种将语言模型与可搜索知识库结合的方法,主要包含以下关键步骤: 数据预处理 加载:从不同格式(PDF、Markdown等)中提取文本分块:将长文本分割成短序列(通常100-500个标记),作为检索单元…...

PXE_Kickstart_无人值守自动化安装系统
文章目录 1. PXE2. 配置服务参数2.1 tftp服务配置2.2 dhcp服务配置2.3 http服务配置 3. 配置PXE环境3.1 网络引导文件pxelinux.03.2 挂载镜像文件3.3 创建配置文件default3.4 复制镜像文件和驱动文件3.5 修改default文件3.6 配置ks.cfg文件 4. PXE客户端4.1 创建虚拟机…...

Redis经典面试题
本篇文章简单介绍一些 Redis 常见的面试题。 Redis 是什么? Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库&…...

Vite Proxy配置详解:从入门到实战应用
Vite Proxy配置详解:从入门到实战应用 一、什么是Proxy代理? Proxy(代理)是开发中常用的解决跨域问题的方案。Vite内置了基于http-proxy的代理功能,可以轻松配置API请求转发。 二、基础配置 在vite.config.js中配置…...

用AI写简历是否可行?
让AI批量写简历然后投简历是绝对不行的!!! 为什么不行,按照 "招聘经理" 工作经历举例: ai提示词:请帮我写一份招聘经理的工作经历内容: 招聘经理 | XXX科技有限公司 | 2020年…...

投影显示技术全解析:主流方案对比与雷克赛恩 CyberPro1 的核心优势
目录 一、主流投影显示技术深度解析 (一)LCD 投影技术 (二)DP 投影技术 (三)3LCD 技术 (四)FSHD 技术 FSHD 技术优势 二、雷克赛恩 CyberPro1 核心优势对比分析 (…...

Skyvern:用 AI+视觉驱动浏览器自动化
Skyvern:用 AI视觉驱动浏览器自动化 一、前言二、项目概览2.1 Skyvern 项目简介2.2 代码结构与模块划分 三、环境搭建与快速上手3.1 环境准备3.1.1 系统与依赖3.1.2 克隆项目3.1.3 安装 Python 依赖3.1.4 配置环境变量3.1.5 启动服务 3.2 验证安装 四、核心功能与实…...

101alpha第九
alpha ((rank(ts_arg_max((vwap - close), 3)) * rank(ts_delta(volume, 3))) 今天我们来学下这个 这个是两个rank操作符相加,然后和另外一个操作符相乘,我们来看实现了什么 vwap - close:这部分先计算成交量加权平均价(vwap&am…...

蓝牙身份证阅读器使用Uniapp调用二次开发demo
<template> <view class"content"> <view class"search" :loading"searchingstatus" click"searchbluetooth"> {{searchingstatus?"搜索中":"搜索蓝牙阅读器"}} </view> …...

好用的shell终端工具
FinalShell SSH工具,服务器管理 FinalShell SSH工具,服务器管理,远程桌面加速软件,支持Windows,macOS,Linux,版本4.5.12,更新日期2024.10.30 - FinalShell官网...

OSPF不规则区域划分
1、建立一条虚链路 vlink 可以被视为是⻣⼲区域的⼀段延伸。 这⼀条虚拟的链路,只能够跨域⼀个⾮⻣⼲区域。 [r2-ospf-1-area-0.0.0.1]vlink-peer 3.3.3.3 [r3-ospf-1-area-0.0.0.1]vlink-peer 2.2.2.2 在没有建立虚链路之前,r1是不能ping r4的。vlink建⽴的邻居关…...

复习javascript
1.修改元素内的内容 <div>zsgh</div> <script> const box1document.querySelector("div") box1.innerText"ppp" box1.innerHtml<h1>修改</h1> </script> 2.随机点名练习 <!DOCTYPE html> <html lang…...

海盗王64位服务端+32位客户端3.0版本
经过多天的尝试,终于把海盗王3.0的服务端改成了64位的,包括AccountServer GroupServer GameServer GateServer。 客户端则保留了32位。 服务端改成64位的好处是GameServer可以只启动一个就开全部地图,大概6G内存左右,直接将跳…...

【从零实现JsonRpc框架#2】Muduo库介绍
1.基本概念 Muduo 由陈硕大佬开发,是一个基于非阻塞IO和事件驱动的C高并发TCP网络编程库。它是一款基于主从Reactor模型的网络库,其使用的线程模型是 one loop per thread。 1.1 主从 Reactor 模型 主 Reactor(MainReactor,通常…...

如何创建伪服务器,伪接口
创建伪接口一般是用于模拟真实接口的行为,以便在开发和测试过程中进行使用,以下是一些常见的创建伪接口的方法: 使用 Web 框架搭建: Python 和 Flask:Flask 是一个轻量级的 Python Web 框架。示例代码如下:…...

NX949NX952美光科技闪存NX961NX964
NX949NX952美光科技闪存NX961NX964 在半导体存储领域,美光科技始终扮演着技术引领者的角色。其NX系列闪存产品线凭借卓越的性能与创新设计,成为数据中心、人工智能、高端消费电子等场景的核心组件。本文将围绕NX949、NX952、NX961及NX964四款代表性产品…...

vue配置代理解决前端跨域的问题
文章目录 一、概述二、报错现象三、通过配置代理来解决修改request.js中的baseURL为/api在vite.config.js中增加代理配置 四、参考资料 一、概述 跨域是指由于浏览器的同源策略限制,向不同源(不同协议、不同域名、不同端口)发送ajax请求会失败 二、报错现象 三、…...

深入解析Vue3中ref与reactive的区别及源码实现
深入解析Vue3中ref与reactive的区别及源码实现 前言 Vue3带来了全新的响应式系统,其中ref和reactive是最常用的两个API。本文将从基础使用、核心区别到源码实现,由浅入深地分析这两个API。 一、基础使用 1. ref import { ref } from vueconst count…...

Java Bean容器详解:核心功能与最佳使用实践
在Java企业级开发中,Bean容器是框架的核心组件之一,它通过管理对象(Bean)的生命周期、依赖关系等,显著提升了代码的可维护性和扩展性。主流的框架如Spring、Jakarta EE(原Java EE)均提供了成熟的…...

Xilinx Kintex-7 XC7K325T-2FFG676I 赛灵思 FPGA
XC7K325T-2FFG676I 属于 Kintex-7 FPGA ,低功耗与合理成本的应用市场,可提供比前代产品两倍的性价比提升和卓越的系统集成能力。该器件于 28 nm 工艺节点制造,速度等级为 -2,适合对时序要求严格但预算有限的系统设计。 产品架构与…...
AI 的 6 大核心方向 + 学习阶段路径)
AI实战笔记(1)AI 的 6 大核心方向 + 学习阶段路径
一、机器学习(ML) 目标:用数据“训练”模型,完成分类、回归、聚类等任务。 学习阶段: (1)基础数学:线性代数、概率统计、微积分(适度) (2…...

Ceph集群故障处理 - PG不一致修复
Ceph集群故障处理 - PG不一致修复 目录故障现象故障分析故障定位修复过程磁盘状态检查OSD存储结构检查修复分析故障总结问题原因修复方法后续建议经验教训最佳实践 参考资料 # ceph -v ceph version 14.2.22目录 故障现象故障分析故障定位修复过程磁盘状态检查OSD存储结构检查…...

【前端】每日一道面试题3:如何实现一个基于CSS Grid的12列自适应布局?
要实现一个基于CSS Grid的12列自适应布局,关键在于利用网格系统的灵活性和响应式设计能力。以下是具体实现步骤及核心代码示例: 一、基础网格容器定义 创建网格容器 使用display: grid将父元素定义为网格容器: .container {display: grid;gr…...

leetcode 349. Intersection of Two Arrays
题目描述 题目限制0 < nums1[i], nums2[i] < 1000,所以可以开辟一个1001个元素的数组来做哈希表。 class Solution { public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {vector<int> table(1001,0…...

机器学习 day01
文章目录 前言一、机器学习的基本概念二、数据集的加载1.玩具数据集2.联网数据集3.本地数据集 三、数据集的划分四、特征提取1.稀疏矩阵与稠密矩阵2.字典列表特征提取3.文本特征提取 前言 目前我开始学习机器学习部分的相关知识,通过今天的学习,我掌握了…...