数据分析2
五、文件
CSV
Comma-Separated Value,逗号分割值。CSV文件以纯文本形式存储表格数据(数字和文本)。
CSV记录间以某种换行符分隔,每条记录由字段组成,字段间以其他字符或字符串分割,最常用逗号或制表符。
CSV文件第一行为表头,数据之间用逗号分割。
读取
import csv
import sys
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data2.csv'
with open(input_file, 'r', newline='') as filereader:with open(output_file, 'w', newline='') as filewriter:header = filereader.readline()header = header.strip()header_list = header.split(',')print(header_list)filewriter.write(','.join(map(str, header_list))+'\n')for row in filereader:row = row.strip()row_list = row.split(',')print(row_list)filewriter.write(','.join(map(str, row_list))+'\n')筛选特定行
import csv
import sys
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data2.csv'
with open(input_file, 'r', newline='') as csv_in_file:with open(output_file, 'w', newline='') as csv_out_file:filereader = csv.reader(csv_in_file)filewriter = csv.writer(csv_out_file)header = next(filereader)filewriter.writerow(header)for row_list in filereader:year = int(str(row_list[0]).strip())cost = int(str(row_list[-1]).strip('$').replace(',',''))if year > 2020 and cost < 5000:filewriter.writerow(row_list)
筛选特定行
import csv
import sys
import re
input_file = 'D:/pythoncode/aiSelf/supplier_data.csv'
output_file = 'D:/pythoncode/aiSelf/supplier_data3.csv'
pattern = re.compile(r'(a2.*)')
with open(input_file, 'r', newline='', encoding='utf-8') as csv_in_file:with open(output_file, 'w', newline='', encoding='utf-8') as csv_out_file:filereader = csv.reader(csv_in_file)filewriter = csv.writer(csv_out_file)header = next(filereader)filewriter.writerow(header)for row_list in filereader:invoice_number = row_list[2]if pattern.search(invoice_number):filewriter.writerow(row_list)统计文件数与文件中行列数
import csv
import glob
import os
import string
import sys
pa = 'D:/pythoncode/aiSelf'
file_counter = 0
for input_file in glob.glob(os.path.join(pa,'p11*')):row_counter = 1with open(input_file,'r',newline='',encoding='utf-8') as csvfile:filereader = csv.reader(csvfile)header = next(filereader)for row in filereader:row_counter += 1print('{0:s}:\t{1:d} rows \t {2:d} columns'.format(\os.path.basename(input_file),row_counter,len(header)))file_counter += 1
print('文件数量:{0:d}'.format(file_counter))
CSV文件数据统计
import csv
import glob
import os
import string
import sys
input_path = 'D:/pythoncode/aiSelf'
output_path = 'D:/pythoncode/aiSelf/output.txt'
output_header_list = ['file_name','total_sales','average_sales']
csv_out_file = open(output_path, 'a', newline='')
filewriter = csv.writer(csv_out_file)
filewriter.writerow(output_header_list)
for input_file in glob.glob(os.path.join(input_path, 'instruments*.csv')):with open(input_file, 'r', newline='', encoding='utf-8') as csv_in_file:filereader = csv.reader(csv_in_file)output_list = []output_list.append(os.path.basename(input_file))header = next(filereader)total_sales = 0.0number_of_sales = 0.0for row in filereader:sale_amount = row[4]total_sales += float(str(sale_amount).strip('$').replace(',',''))number_of_sales += 1.0average_sales = '{0:.2f}'.format(total_sales/number_of_sales)output_list.append(total_sales)output_list.append(average_sales)filewriter.writerow(output_list)
csv_out_file.close()
Excel文件
Python处理Excel需导入xlrd和xlwt两个扩展包。
查看工作簿信息
import sys
from xlrd import open_workbook
input_file = 'D:/pythoncode/aiSelf/instruments_1.xls'
workbook = open_workbook(input_file)
print('工作簿数量:',workbook.nsheets)
for worksheet in workbook.sheets():print('工作簿名字:', worksheet.name, '\tRows:', worksheet.nrows, '\tColumns:', worksheet.ncols)
筛选满足一定条件的行
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = 'D:/pythoncode/aiSelf/instruments_2.xls'
output_file = 'D:/pythoncode/aiSelf/p128shujufenxi356.xls'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('Sheet1')
sale_amount_column_index = 3
with open_workbook(input_file) as workbook:worksheet = workbook.sheet_by_name('instruments_2')data = []header = worksheet.row_values(0)data.append(header)for row_index in range(1, worksheet.nrows):row_list = []sale_amount = worksheet.cell_value(row_index,sale_amount_column_index)if sale_amount > 1500.0 and sale_amount < 4500.0:for column_index in range(worksheet.ncols):cell_value = worksheet.cell_value(row_index,column_index)cell_type = worksheet.cell_type(row_index,column_index)if cell_type == 3:date_cell = xldate_as_tuple(cell_value, workbook.datemode)date_cell = date(*date_cell[0:3]).strftime('%Y/%m/%d')row_list.append(date_cell)else:row_list.append(cell_value)if row_list:data.append(row_list)for list_index, output_list in enumerate(data):for element_index, element in enumerate(output_list):output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)一组工作表的处理
import sys
from datetime import date
from xlrd import open_workbook, xldate_as_tuple
from xlwt import Workbook
input_file = 'D:/pythoncode/aiSelf/instruments_2.xls'
output_file = 'D:/pythoncode/aiSelf/p129shujufenxi357.xls'
output_workbook = Workbook()
output_worksheet = output_workbook.add_sheet('Sheet1')
my_sheets = [0,1]
threshold = 3000.0
sales_column_index = 3
first_worksheet = True
with open_workbook(input_file) as workbook:data = []for sheet_index in range(workbook.nsheets):if sheet_index in my_sheets:worksheet = workbook.sheet_by_index(sheet_index)if first_worksheet:header_row = worksheet.row_values(0)data.append(header_row)first_worksheet = Falsefor row_index in range(1,worksheet.nrows):row_list = []sale_amount = worksheet.cell_value(row_index, sales_column_index)if sale_amount > threshold:for column_index in range(worksheet.ncols):cell_value = worksheet.cell_value(row_index, column_index)cell_type = worksheet.cell_type(row_index, column_index)if cell_type == 3:date_cell = xldate_as_tuple(cell_value, workbook.datemode)date_cell = date(*date_cell[0:3].strftime('%Y%m%d'))row_list.append(date_cell)else:row_list.append(cell_value)if row_list:data.append(row_list)for list_index, output_list in enumerate(data):for element_index, element in enumerate(output_list):output_worksheet.write(list_index, element_index, element)
output_workbook.save(output_file)多个工作簿的处理
六、Python标准库
数据处理的Numpy、Pandas和数据可视化的Matplotlib详见数据分析1。
datetime模块
| 常用类 | 说明 |
| date | 日期类。包括year、month、day属性 |
| time | 时间类。包括hour、minute、second、microsecond属性 |
| datetime | 时间日期类。 |
| timedelta | 时间间隔类。表示两个date、time、datetime实例之间的时间间隔 |
| tzinfo | 时区类。 |
from datetime import date
date类
date类包含对日期数据进行操作和格式化的方法。
格式化日期
| 方法 | 功能 |
| isoformat() | 返回符合ISO8601标准的YYYY-MM-DD |
| isocalender() | 返回包括三个值的元组,年份year,本年的第几周week number,weekday周一为1,周日为7 |
| isoweekday() | 返回ISO标准日期所在的星期几,周一为1,周日为7 |
| weekday() | 返回指定日期星期几,周一为0,周日为6 |
日期比较方法
| 方法 | 功能 |
| x.__eq__(y) | x是否等于y |
| x.__lt__(y) | x是否小于y |
| x.__le__(y) | x是否小于等于y |
| x.__gt__(y) | x是否大于y |
| x.__ge__(y) | x是否大于等于y |
| x.__ne__(y) | x是否不等于y |
计算日期差
| 方法 | 功能 |
| x.__sub__(y) | 计算x和y两个日期的差 |
| x.__rsub__(y) | 计算y和x两个日期的差 |
其他
| 方法 | 功能 |
| today() | 获取当前日期 |
| fromtimestamp() | 将时间戳转换为日期 |
datetime类
可以看作date类和time类的综合。它有一些专有方法。
| 方法 | 功能 |
| now() | 返回当前日期和时间 |
| date() | 返回当前日期和时间的日期部分 |
| time() | 返回当前日期和时间的时间部分 |
| combine(date对象,time对象) | 将date对象和time对象合并为datetime对象 |
时间转化与格式设置
时间对象转化为字符串用isoformat()方法。
字符串转化为时间对象用strptime()方法。
time对象
| 格式控制字符 | 说明 |
| %H | 24小时制小时数0-23 |
| %I | 12小时制小时数01-12 |
| %M | 分钟数00-59 |
| %S | 秒数00-59 |
| %p | 设置显示AM上午,PM下午 |
date对象和datetime对象
| 格式控制字符 | 说明 |
| %Y | 四位数年份0001-9999 |
| %y | 两位数年份01-99 |
| %m | 月份01-12 |
| %d | 日期01-31 |
from datetime import date
date1 = date(2025,5,1)
print(date1)
print(date1.year)
print(date1.month)
print(date1.day)from datetime import date
from datetime import datetime
date2 = date.today()
print(date2.strftime("%Y-%m-%d"))
datetime3 = datetime.now()
print(datetime3.strftime("%Y-%m-%d %H:%M:%S %p"))

math模块
数学常量:
| math.pi | 3.14159.. |
| math.e | 2.718.. |
| math.inf | 浮点正无穷大 |
| math.nan | 浮点非数字NaN值 |
数学函数:
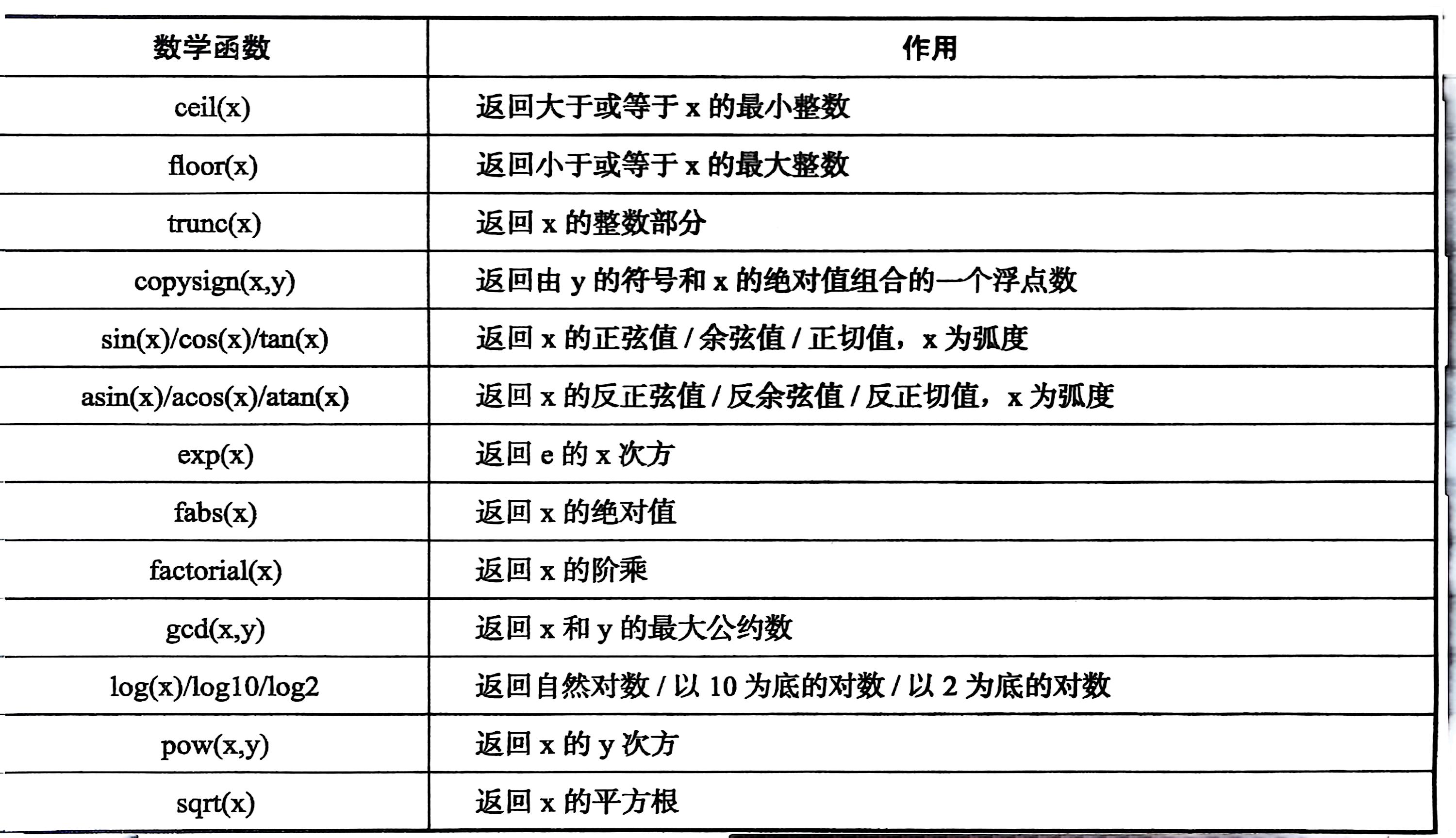
import math
print(math.ceil(3.5))
print(math.floor(3.5))
print(math.trunc(3.5))
print(math.log(math.e))random模块
import random
print('输出各种随机数')
print(random.random())
print(random.uniform(10,100))
print(random.randint(10,100))
print(random.randrange(10,100))
print(random.randrange(4,100,4))
print('返回序列中随机元素')
print(random.choice('wolf is very handsome'))
print(random.choice(['wolf', 'is', 'very', 'handsome']))
print(random.choice(('wolf', 'is', 'very', 'handsome')))
print('改变List中元素顺序')
list = ['wolf', 'is', 'very', 'handsome']
random.shuffle(list)
print(list)
print('随机种子')
random.seed(1)
print(random.random())
print(random.uniform(10,100))
print(random.randint(10,100))
print(random.randrange(10,100))
print(random.randrange(4,100,4))
如果指定种子,会使每次随机的结果相同
os模块
| os.name | 判断正在使用的平台 |
| os.environ | 查看系统环境变量 |
| os.listdir() | 指定所有目录中所有的文件名称和目录名称 |
| os.remove() | 删除指定文件 |
| os.rmdir() | 删除指定目录 |
| os.mkdir() | 创建目录 |
| os.path.isdir() | 判断指定对象是否为目录 |
| os.path.isfile() | 判断指定对象是否为文件 |
import os
if os.name == 'nt':print('当前使用windows')
if os.name == 'posix':print('当前使用Linux')print('系统使用环境变量为', os.environ)
print(os.environ['HOMEPATH'])path = '/pythoncode/'
for i in os.listdir(path):print(i)os.remove('D:/pythoncode/analyse/text804.txt')
print('文件删除完毕')# os.removedirs('文件名')
# os.mkdir('一层的路径')
# os.path.isdir()用来判定对象是否为目录
# os.path.isfile()用来判定指定对象是否为文件
七、正则表达式
元字符
元字符是预先定义好的特殊字符,是用来描述其他字符的。
主要元字符
| \ | 转义符,表示转义 |
| . | 表示任意一个字符 |
| + | 表示重复1次或多次 |
| * | 表示重复0次或多次 |
| ? | 表示重复0次或1次 |
| | | 选择符号,或 |
| {} | 定义量词 |
| [] | 定义字符类 |
| () | 定义分组 |
| ^ | 表示取反,或匹配一行的开始 |
| $ | 匹配一行的结束 |
预定义字符
用于转义
| \n | 匹配换行符 |
| \r | 匹配回车符 |
| \f | 匹配一个换页符 |
| \t | 匹配一个水平制表符 |
| \v | 匹配一个垂直制表符 |
| \s | 匹配一个空格符,等价于[\t\n\r\f\v] |
| \S | 匹配一个非空格符,等价于[^\s] |
| \d | 匹配一个数字字符,等价于[0-9] |
| \D | 匹配一个非数字字符,等价于[^0-9] |
| \b | 匹配单词的开始或结束,单词的分布符为空格、标点符号或换行 |
| \w | 匹配任意语言的字符、数字或下划线等内容。若正则表达式标志设置为ASCII,则只匹配[a-zA-Z0-9] |
| \W | 等价于[^\w] |
例如匹配一个8位数字的电话号码,可以使用
\d\d\d\d\d\d\d\d
该方法还是比较繁琐的,可以使用下面这个正则表达式代替。
\d{8}
标记开始与结束
$结束,^开始
\w+@163.com$ 以163.com结尾
^\w+@163.com 以163.com开头
匹配一组字符
正则表达式中可以用字符类定义一组字符,其中任意一个字符出现在输入字符串中即匹配成功。需注意,每次只能匹配一个字符。
定义一组字符
需要中括号[]基本元字符
想要匹配python和Python
[pP]ython
对一组字符取反
^取反
想要匹配不是阿拉伯数字
[^1234567890]
使用区间简化一组字符的定义
-
想要匹配不是阿拉伯数字
[^0-9]
所有英文字母和数字
[A-Za-z0-9]
下面这个正则表达式是0-3和6-8,不是0-36
[0-36-8]
使用量词多次匹配
元字符只能匹配显示一次字符或字符串,想要匹配多次字符或字符串,应使用量词
常用量词
| ? | 出现0次或1次 |
| * | 出现0次或多次 |
| + | 出现1次或多次 |
| {n} | 出现n次 |
| {n,m} | 至少出现n次,但不超过m次 |
| {n,} | 至少出现n次 |
匹配八位数字的电话号码,不要再用8个\d了
\d{8}
颜色有color和colour
colou?r
贪婪和非贪婪匹配
关于重复的操作,需要注意正则表达式默认使用贪婪匹配方式。
贪婪匹配是只要符合条件就会尽可能多的匹配。
转换成非贪婪匹配只要在量词后加上?
\d{5,9}
\d{5,9}?
分组
在前面的例子中,量词只能重复显示一个字符,如果想让一个字符串作为整体使用量词对其进行重复匹配,可以使用圆括号(),分组。
(123){3}匹配123123123
123{3}只会对字符3重复匹配
使用re模块处理正则表达式
Python的re模块具有正则表达式的匹配功能。使用re模块前先导入
import rePython正则表达式的语法
Python中的正则表达式是作为模式字符串使用的,也就是两侧加单引号。
例如[^a-zA-Z]应写为
'[^a-zA-Z]'部分特殊含义字母应使用反斜杠\
或在模式字符串前加上大小写字母R或r,表示原生字符串
例如\bd\w*\b应写为
r'\bd\w*\b'
# 或
'\\bd\w*\\b'匹配字符串
re模块中的match()方法、search()方法、findall()方法用于字符串匹配
match()方法从字符串开始位置匹配,在开始位置匹配成功返回Match对象,否则返回None。
re.match(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
import re
mystr = ['streetwolf', 'silverwolf', 'Streetsheep', 'streetcat', 'StreetMouse', 'streetfish']
p = r'street\w+'
for i in range(len(mystr)):m = re.match(p, mystr[i], re.I)if m:print(mystr[i], '开始位置', m.start(), ',结束位置', m.end(), ',跨度', m.span(), ',匹配内容', m.string)else:print(mystr[i], '不匹配')with open('telephonenumber.txt', 'r', encoding='utf-8') as f:lst = f.readlines()
number = 0for i in range(len(lst)):p = re.match(r'17[01]\d{8}|000',lst[i])if p:number = number + 1
print(number)search()方法可以在整个字符串中查找,并返回第一个匹配内容,若找到一个则匹配对象,否则匹配None。
re.search(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,匹配成功以列表形式返回,否则返回空列表。
re.findall(pattern模式字符串, string要匹配的字符串, [flags]可选可不选标志位用于控制匹配方式如是否区分字母大小写等)
替换字符串
sub()方法实现字符串替换
re.sub(pattern模式字符串,repl替换的字符串,string原始字符串,count模式匹配后替换的最大次数默认0替换所有匹配,flags表示位控制匹配方式)
分割字符串
split()方法分割字符串,返回列表,与字符串对象的split()方法类似
re.split(pattern,string,[maxsplit]最大拆分次数,[flags])
相关文章:

数据分析2
五、文件 CSV Comma-Separated Value,逗号分割值。CSV文件以纯文本形式存储表格数据(数字和文本)。 CSV记录间以某种换行符分隔,每条记录由字段组成,字段间以其他字符或字符串分割,最常用逗号或制表符。…...

每日一题:两个仓库的最低配送费用问题
文章目录 两个仓库的最低配送费用问题一、问题描述二、解题思路(一)初始假设(二)差值定义(三)选择最优(四)计算答案 三、代码实现四、代码分析(一)输入处理&a…...

SemanticSplitterNodeParser 和 Sentence-BERT 的区别和联系是什么
这涉及到文本切分(chunking)与语义向量(embedding)之间的关系。我们来详细对比: ✅ 1. SemanticSplitterNodeParser 是什么? SemanticSplitterNodeParser 是 llama-index 提供的一种 语义感知的文本切分工…...

Fabric系列 - SoftHSM 软件模拟HSM
在 fabric-ca-server 上使用软件模拟的 HSM(密码卡) 功能 安装 SoftHSMv2 教程 SoftHSMv2 默认的配置文件 /etc/softhsm2.conf默认的token目录 /var/lib/softhsm/tokens/ 初始化和启动fabric-ca-server,需要设置一个管理员用户的名称和密码 初始化令牌 # 初始…...

简易图片编辑工具,支持抠图和替换背景
软件介绍 Photo Retouch是一款由微软官方商店推出的免费图片处理软件,具有抠图、换背景、修复等功能,操作便捷且效率极高,非常值得尝试。 功能详解 这款软件提供五大功能,包括删除物体、快速修复、一键抠图、背景调整和裁剪…...

CountDownLatch 并发编程中的同步利器
CountDownLatch 并发编程中的同步利器 文章目录 CountDownLatch 并发编程中的同步利器一、CountDownLatch 基础概念1.1 什么是 CountDownLatch?1.2 CountDownLatch 的核心方法1.3 基本使用示例 二、CountDownLatch 实战应用2.1 应用场景一:并行任务协调2…...

C++GO语言微服务之用户信息处理
目录 01 01-微服务实现用户注册-微服务端-上 02 02-微服务实现用户注册-微服务端-下 03 03-微服务实现用户注册-web端 04 04-微服务实现用户注册-web端-流程小结 05 05-获取地域信息-读MySQL写Redis入 06 06-获取地域信息-先查redis-没有读MySQL写入 01 07-Cookie简介 0…...

互联网大厂Java求职面试实战:Spring Boot微服务与数据库优化详解
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通 😁 2. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。 ❤️ 3. Python爬虫专栏…...
)
Linux基本指令(一)
目录 基本指令 pwd指令 cd指令 cd ..编辑 cd ~ ls指令 ls -l ls -a ls -d touch指令 mkdir指令 rmdir指令 && rm 指令 操作系统是什么呢?一个好的操作系统要具备什么条件呢? 简单来说,操作系统是是一款做软硬件管理的软…...

Java—— 集合 List
List集合的特点 有序:存和取的元素顺序一致 有索引:可以通过索引操作元素 可重复:存储的元素可以重复 List集合的方法 Collection的方法List都继承了,可以使用Collection中的方法 此外,List集合因为有索引,…...

使用谱聚类将相似度矩阵分为2类
使用谱聚类将相似度矩阵分为2类的步骤如下: 构建相似度矩阵:提供的1717矩阵已满足对称性且对角线为1。 计算度矩阵:对每一行求和得到各节点的度,形成对角矩阵。 计算归一化拉普拉斯矩阵:采用对称归一化形式 LsymI−D…...
高级用法(二))
【Bootstrap V4系列】学习入门教程之 组件-表单(Forms)高级用法(二)
Bootstrap V4系列 学习入门教程之 组件-表单(Forms)高级用法(二) 表单(Forms)高级用法(二)一、Help text 帮助文本二、Disabled forms 禁用表单三、Validation 验证3.1 How it works…...

【许可证】Open Source Licenses
长期更新 扩展:shield.io装饰 开源许可证(Open Source Licenses)有很多种,每种都有不同的授权和限制,适用于不同目的。 默认的ISC🟰MIT License是否可商用是否要求开源衍生项目是否必须署名是否有专利授权…...

RT-Thread 深入系列 Part 7:RT-Thread vs 其他 RTOS 对比与选型指南
摘要 本文对比 RT-Thread、FreeRTOS、Zephyr、uC/OS、Mbed OS 等主流嵌入式操作系统,从功能特性、社区生态、学习成本、商业支持、安全性和典型应用场景六个维度进行详尽对比,并给出不同项目类型下的选型建议,帮助你为下一个嵌入式项目做出最合适的决策。 目录 功能特性对比…...

每天五分钟机器学习:KTT条件
本文重点 在前面的课程中,我们学习了拉格朗日乘数法求解等式约束下函数极值,如果约束不是等式而是不等式呢?此时就需要KTT条件出手了,KTT条件是拉格朗日乘数法的推广。KTT条件不仅统一了等式约束与不等式约束的优化问题求解范式,KTT条件给出了这类问题取得极值的一阶必要…...

金融学知识笔记
金融学知识笔记 一、引言 金融学它结合了数学、概率论、统计学、经济学和计算机科学等多学科的知识,用于解决金融领域中的各种问题,如金融衍生品定价、投资组合优化、风险管理和固定收益证券分析等。通过对金融学的学习,我们可以更好地理解…...

Web3 实战项目项目部署到 GitHub 和上线预览的完整指南
目录 🚀 一、部署到 GitHub ✅ 前置准备 🧱 部署步骤: 1. 创建一个 GitHub 仓库 2. 上传项目文件 方法一:使用 Git 命令行 方法二:直接上传 🌐 二、通过 GitHub Pages 免费上线 DApp(前端…...
)
嵌入式开发学习(阶段二 C语言基础)
C语言:第05天笔记 内容提要 分支结构 条件判断用if语句实现分支结构用switch语句实现分支结构 分支结构 条件判断 条件判断:根据某个条件成立与否,决定是否执行指定的操作。 条件判断的结果是逻辑值,也就是布尔类型值&#…...

【沉浸式求职学习day35】【Tomcat安装、配置】【Http简述】
😩😩😩,真的每天忙死,感觉自己精神上压力真的很大,希望我的努力能够激励到你们~ 沉浸式求职学习 Tomcat1.安装2.Tomcat启动和配置3.配置高难度面试题 4.发布一个web网站5.Http1.什么是HTTP2.两个时代3.Htt…...

基于大模型的新型隐球菌脑膜炎智能诊疗全流程系统设计与实现的技术方案文档
目录 一、术前风险预测系统1. 多模态融合模型架构2. 风险预测流程图(Mermaid)二、麻醉剂量预测系统1. 靶控输注(TCI)模型2. 麻醉方案优化流程图(Mermaid)三、术后并发症预测模型1. 时序预测模型(LSTM)2. 并发症预测流程图(Mermaid)四、健康教育管理模块1. 移动健康(…...

如何实现PLC远程编程
1. 什么是PLC编程 PLC编程是指为可编程逻辑控制器(Programmable Logic Controller,PLC)编写控制逻辑的过程。PLC是一种工业自动化控制设备,广泛应用于制造业、机械控制、流水线、电力系统等领域,用于替代传统的继电器…...

Go基于plugin的热更新初体验
背景 对于一个部署在生产环境的项目来说,我们希望当代码出现bug的时候,可以不用重启进程而达到动态修改代码的目的—— 这就是代码热部署! 使用java做游戏服务器,最大的好处是,当代码出现bug,可以直接热…...

【STM32 学习笔记】I2C通信协议
注:通信协议的设计背景 3:00~10:13 I2C 通讯协议(Inter-Integrated Circuit)是由Phiilps公司开发的,由于它引脚少,硬件实现简单,可扩展性强, 不需要USART、CAN等通讯协议的外部收发设备,现在被广…...

RAG与语义搜索:让大模型成为测试工程师的智能助手
引言 AI大模型风头正劲,自动生成和理解文本的能力让无数行业焕发新生。测试工程师也不例外——谁不想让AI自动“看懂需求、理解接口、生成用例”?然而,很多人发现:直接丢问题给大模型,答案貌似“懂行”,细…...

Nakama:让游戏与应用更具互动性和即时性
在现代游戏和应用程序开发中,实现社交互动和实时功能已成为用户体验的核心需求。为满足这种需求,许多开发者正转向分布式服务器技术,在这些技术中,Nakama 构建起了一座桥梁。Nakama 是一个开源的分布式服务器,专门为社…...

[Spring AOP 7] 动态通知调用
动态通知调用 本笔记基于黑马程序员 Spring高级源码解读 更美观清晰的版本在:Github 注意:阅读本章内容之前,建议先熟悉静态通知调用的内容 在静态通知调用一节中,我们还有一个悬而未决的问题。 我们谈到了调用链MethodInvocation…...

Redis 集群
集群基本介绍 广义的集群,只要是多个机器构成了分布式系统,都可以称为是一个“集群”(主从模式,哨兵模式) 狭义的集群,Redis 提供的集群模式,在这个模式下主要解决的是存储空间不足的问题&…...

【Redis】基础命令数据结构
文章目录 基础命令keysexistsdelexpirettltype 数据结构和内部编码 在介绍数据类型前先介绍一下 Redis 的基础命令,方便理解 基础命令 keys 返回所有满足样式(pattern)的 key keys pattern 当前有如下 key PS:实际开发环境和生…...
:逻辑运算符)
C++(6):逻辑运算符
目录 1. 代码示例 示例 1:基础用法 示例 2:条件判断 2. 短路求值(Short-Circuit Evaluation) 代码示例 3. 实际应用场景 场景 1:输入合法性验证 场景 2:游戏状态判断 4. 注意事项 逻辑运算符用于组…...

项目管理从专家到小白
敏捷开发 Scrum 符合敏捷开发原则的一种典型且在全球使用最为广泛的框架。 三个角色 产品负责人Product Ower:专注于了解业务、客户和市场要求,然后相应地确定工程团队需要完成的工作的优先顺序。 敏捷教练Scrum Master:确保 Scrum 流程顺…...

AI绘画灵感觉醒指南:从灵感源泉到创意输出
目录 一、引言 二、灵感来源 2.1 现实生活 2.2 其他艺术作品 2.3 文学作品 三、灵感转化为输入提示 3.1 明确主题与核心元素 3.2 细化描述 3.3 使用修饰词与专业术语 3.4 组合与优化提示词 四、案例分析 4.1 从现实生活获取灵感 4.2 从其他艺术作品获取灵感 4.3 …...
)
【Java学习】枚举(匿名类详解)
目录 一、匿名类 1.形式 2.性质 2.1匿名性 2.1.1同步性 使用场景 2.1.2复用性 2.1.3向上转型 2.2实现性 3.传参 3.1构造传全参 3.1.1过程 3.1.2效果 2.1.4原子类构造无参 4.权限 二、枚举类 1.枚举常量 2.性质 2.1多态性 2.2单例性 2.2.1private保护 2.2…...

力扣题解:2、两数相加
个人认为,该题目可以看作合并两个链表的变种题,本题与21题不同的是,再处理两个结点时,对比的不是两者的大小,而是两者和是否大于10,加法计算中大于10要进位,所以我们需要声明一个用来标记是否进…...

PyTorch API 9 - masked, nested, 稀疏, 存储
文章目录 torch.randomtorch.masked简介动机什么是 MaskedTensor? 支持的运算符一元运算符二元运算符归约操作查看与选择函数 torch.nested简介构造方法数据布局与形状支持的操作查看嵌套张量的组成元素填充张量的相互转换形状操作注意力机制 与 torch.compile 的配…...

linux测试硬盘读写速度
#!/bin/bash # 文件名: disk_rate.sh # linux测试硬盘读写速度 TEST_FILE"disk_speed_test.tmp" TEST_SIZE"1024M" echo "开始测试磁盘写入速度..." WRITE_RESULT$(dd if/dev/zero of$TEST_FILE bs$TEST_SIZE count1 oflagdirect 2…...
)
单片机系统设计不同开发方式的优缺点(面包板,洞洞板,PCB板)
目录 快速验证代码逻辑 涉及具体电路较多 涉及高频电路 快速验证代码逻辑 面包板,无焊接,适合快速搭建临时电路。优点应该是使用方便,不需要焊接,可以随时更换元件。但缺点可能是不稳定,接触不良,不适合高…...
)
数字信号处理|| 快速傅里叶变换(FFT)
一、实验目的 (1)加深对快速傅里叶变换(FFT)基本理论的理解。 (2)了解使用快速傅里叶变换(FFT)计算有限长序列和无限长序列信号频谱的方法。 (3)掌握用MATLA…...

基于CNN卷积神经网络的带频偏QPSK调制信号检测识别算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 (完整程序运行后无水印) 2.算法运行软件版本 matlab2024b 3.部分核心程序 (完整版代码包含详细中文注释和操作步骤视频)…...

数据库索引详解:原理 · 类型 · 使用 · 优化
在关系型数据库中,索引(Index)是提高查询性能的利器。合理设计和使用索引,可以极大地减少 IO 操作,提升查询效率;但滥用或误用索引,却可能带来维护开销和性能瓶颈。我将从以下几个方面ÿ…...

Java大数据可视化在城市空气质量监测与污染溯源中的应用:GIS与实时数据流的技术融合
随着城市化进程加速,空气质量监测与污染溯源成为智慧城市建设的核心议题。传统监测手段受限于数据离散性、分析滞后性及可视化能力不足,难以支撑实时决策。2025年4月27日发布的《Java大数据可视化在城市空气质量监测与污染溯源中的应用》一文,…...

【基于 LangChain 的异步天气查询3】OpenWeather实现实时天气查询
目录 一、项目功能概述 1、城市识别(GeoNames API) 2、天气数据获取(OpenWeather API) 3、AI 分析天气(deepseek-r1) 4、异步运行支持 5、配置文件隔离(.env) 二、注册 OpenW…...
)
.Net HttpClient 管理客户端(初始化与生命周期管理)
HttpClient 初始化与生命周期管理 HttpClient 旨在实例化一次,并在应用程序的整个生命周期内重复使用。 为实现复用,HttpClient类库默认使用连接池和请求管道,可以手动管理(连接池、配置管道、使用Polly); 结合IoC容器、工厂模式(提供了IHt…...
no cameras available,完美解决)
树莓派4的v4l2摄像头(csi)no cameras available,完美解决
根据2025年最新技术文档和树莓派官方支持建议,no cameras available错误通常由驱动配置冲突或硬件连接问题导致。以下是系统化解决方案: 一、核心修复步骤 强制禁用传统驱动 sudo nano /boot/firmware/config.txt确保包含以下配置(2025年新版…...

VBA将PDF文档内容逐行写入Excel
VBA是无法直接读取PDF文档的,但结合上期我给大家介绍了PDF转换工具xpdf-tools-4.05,先利用它将PDF文档转换为TXT文档,然后再将TXT的内容写入Excel,这样就间接实现了将PDF文档的内容导入Excel的操作。下面的代码将向大家演示如何实…...

【STM32 学习笔记】USART串口
注意:在串口助手的接收模式中有文本模式和HEX模式两种模式,那么它们有什么区别? 文本模式和Hex模式是两种不同的文件编辑或浏览模式,不是完全相同的概念。文本模式通常是指以ASCII编码格式表示文本文件的编辑或浏览模式。在文…...

位图布隆过滤器
1.位图 所谓位图,就是用每一位来存放某种状态,适用于海量数据,整数,数据无重复的场景。通常是用来判 断某个数据存不存在的。 如上例子,10个整数本应该存放需要40个字节,此时用位图只需要3个字节。 下面代…...

【Web】使用Vue3开发鸿蒙的HelloWorld!
文章目录 1、简介2、效果3、环境3.1、开发环境3.2、运行环境 4、实现4.1、在VSCode上使用Vue开发HelloWorld4.1.1、通过 Vite 快速创建项目4.1.2、修改 src/App.vue4.1.3、模拟Web浏览器运行 4.2、使用DevEco完成手机App端移植4.2.1、构建Vue 3项目为静态文件4.2.2、创建Harmon…...
)
cv_area_center()
主题 用opencv实现了halcon中area_center算子的功能, 返回region的面积,中心的行坐标和中心的列坐标 代码很简单 def cv_area_center(region):area[]row []col []for re in region:retval cv2.moments(re)area.append(retval[m00])row.append(int(r…...

Python+OpenCV实现手势识别与动作捕捉:技术解析与应用探索
引言:人机交互的新维度 在人工智能与计算机视觉技术飞速发展的今天,手势识别与动作捕捉技术正逐步从实验室走向大众生活。通过Python的OpenCV库及MediaPipe等工具,开发者能够以较低门槛实现精准的手部动作识别,为虚拟现实、智能家…...

【llama-factory】Lora微调和DPO训练
微调参考 DPO参考 llama-factory官网 LoRA微调 数据集处理 数据集格式和注册 Alpaca数据集格式: [{"instruction": "人类指令(必填)","input": "人类输入(选填)","…...