利用大型语言模型有效识别网络威胁情报报告中的攻击技术
摘要
本研究评估了网络威胁情报(CTI)提取方法在识别来自网络威胁报告中的攻击技术方面的性能,这些报告可从网络上获取,并使用了 MITRE ATT&CK 框架。我们分析了四种配置,这些配置利用了最先进的工具,包括威胁报告 ATT&CK 映射器(TRAM)和开源大型语言模型(LLM),例如 Llama2。我们的研究结果揭示了重大挑战,包括类别不平衡、过拟合和特定领域的复杂性,这些都阻碍了准确的技术提取。为了缓解这些问题,我们提出了一种新颖的两步流程:首先,LLM 总结报告;其次,重新训练的 SciBERT 模型处理使用 LLM 生成的数据增强的重新平衡数据集。与基线模型相比,这种方法实现了 F1 分数的提高,其中几种攻击技术的 F1 分数超过 0.90。我们的贡献提高了基于 Web 的 CTI 系统的效率,并支持互联数字环境中的协作网络安全运营,为未来研究集成人机协作平台铺平了道路。
网络威胁情报、大型语言模型、文本摘要、网络安全、MITRE ATT&CK 技术、网络报告
1 引言
在当今快速发展的数字化环境中,网络安全已成为全球组织机构关注的关键问题。安全运营中心(SOC)通过利用人工智能和机器学习等先进技术[8],在防御日益复杂的网络威胁方面发挥着关键作用。这些技术增强了实时检测、分析和响应威胁的能力,从而提高了数字基础设施的弹性。此外,人机协作和协同的整合正日益受到关注,并成为提高不同领域效率和效力的策略[7, 13, 16],包括网络安全运营[1, 5, 19, 20]。通过将人类专家的分析优势与人工智能的快速处理能力相结合,安全运营中心可以更有效地管理他们每天遇到的庞大而复杂的数据流。网络安全分析师通常依赖于网络威胁情报(CTI)报告,以随时了解不断演变的威胁态势。
网络威胁情报报告是综合性文档,可为组织机构提供有关当前和新兴网络威胁的宝贵见解。这些报告通常由网络安全分析师或专门机构编写,旨在帮助企业和政府实体了解威胁形势,并采取积极措施来保护其数字资产[15]。网络威胁情报报告的关键组成部分包括:(i) 各种网络威胁的详细描述,例如恶意软件、勒索软件、网络钓鱼攻击和高级持续性威胁 (APT);(ii) 威胁行为者的概况,包括其动机、策略、技术和程序 (TTP);(iii) 入侵指标 (IOC),例如指示潜在违规行为的 IP 地址、恶意软件哈希或域名;以及 (iv) 旨在应对这些威胁的建议缓解策略。
然而,由于CTI报告通常是非结构化的且冗长的,因此对其进行手动分析带来了重大挑战。此类报告可能长达数十页,使得SOC分析师难以迅速提取关键信息[17]。这种低效率加剧了警报疲劳这一更广泛的问题,研究表明,高达70%的SOC分析师对警报数量感到不知所措,导致43%的人禁用警报作为一种应对机制[18,22]。鉴于现代网络安全运营在很大程度上依赖于实时的、基于网络的协作和决策,解决这些低效率问题对于维持有效的威胁防御至关重要。
为了缓解这些挑战,已经开发了自动化的CTI提取方法,从而有助于从大量网络来源的报告中识别IOC和TTP [4, 9]。尽管人工智能和自然语言处理(NLP)取得了进展,但在自动化CTI分析方面仍然存在一些障碍:(i)领域复杂性:CTI报告通常包含与标准英语不同的专业术语,阻碍了通用NLP工具的准确提取;(ii)冗长性:关于网络攻击的相关信息通常埋藏在冗长的文档中。例如,一份42页的报告[6]可能只用几个段落来描述实际的攻击细节;以及(iii)关系提取:准确捕获实体之间的关系,例如攻击者、工具和受害者,对于理解TTP至关重要,但当前的NLP系统难以处理这项复杂的任务[10]。
本研究旨在通过探索创新方法来应对这些挑战,这些方法可以增强CTI报告的自动提取和利用,最终使SOC能够在面对不断演变的 cyber 威胁时做出更明智和及时的决策。鉴于这些挑战,本研究探讨以下研究问题:
RQ1:独立的原始大型语言模型(LLM)在CTI提取中的效果如何?
RQ2:基于LLM的增强能否提高自动化CTI提取方法的性能?
为了回答这些研究问题,我们做出了以下贡献:
综合评估:我们使用四种配置评估CTI提取方法,如图1所示。我们的评估突出了每种配置的优点和缺点,其中表现最佳的基线(即,使用原始SciBert的TRAM)由于过度拟合和类别不平衡,仅实现了略高于0.4的F1分数。
新型提取流程:受到LLM最新进展的启发,我们提出了一个两步流程:(i)使用GPT-3.5进行CTI报告摘要:减少报告的冗长性,专注于关键威胁信息;以及(ii)重新训练的SciBERT模型:使用在重新平衡的数据集上训练的SciBERT模型[2],以解决类别不平衡问题并提高分类准确率,从而在识别几种攻击技术时,F1值超过0.90。
本文余下部分的组织结构如下:第2节回顾了CTI提取方面的当前进展和局限性。第3节详细介绍了评估方法和提出的方法。第4节介绍了评估结果。第5节总结了这项工作,并概述了局限性和未来的研究方向1。
2 背景与相关工作
本节概述了网络威胁情报(CTI)、其提取和共享过程,以及现有CTI提取方法的当前局限性,强调了改进方法论的必要性。
2.1 网络威胁情报
网络威胁情报(CTI)作为一种预防网络攻击的防御机制。根据美国国家标准与技术研究院(NIST)的定义,CTI 被定义为“经过聚合、转换、分析、解释或丰富,从而为决策过程提供必要背景信息的威胁信息”[11]。
评估网络威胁情报(CTI)的首要标准是其可操作性。根据 Pawlinski 等人 [14] 的观点,可操作的网络威胁情报必须具备以下特征:(i)相关性:适用于接收者的责任范围;(ii)时效性:信息必须足够新近才能有效;延迟可能导致网络威胁情报过时;(iii)准确性:信息应经过验证且无错误;(iv)完整性:提供充分的背景信息以理解过去的网络攻击;以及(v)可摄取性:以接收者系统可以处理的格式共享。
2.2 CTI提取与共享
现代CTI提取方法通常遵循一个标准化的流程,包括以下步骤:(i)识别来源:选择相关的威胁报告进行分析;(ii)报告爬取:自动从各种存储库收集报告;(iii)文本处理和标注:提取和注释相关实体,例如入侵指标(IOC)和战术、技术和程序(TTP);(iv)文本摘要:使用基于学习的方法减少冗长性,同时保留关键信息;(v)处理输出:将提取的数据转换为适合下游应用程序的格式,例如知识图谱。已经开发了诸如AttackG [9]和TRAM [4]之类的方法来自动化CTI提取。这些方法利用NLP技术来识别基于MITRE ATT&CK框架的攻击技术。
CTI提取方法当前的局限性[NT0]。尽管取得了进展,CTI提取方法仍面临着阻碍其有效性的重大挑战:(i)领域复杂性:CTI报告包含特定于网络安全的术语,这些术语与标准英语不同,使得通用NLP模型难以准确处理。(ii)冗长性:许多CTI报告篇幅很长,但只有一小部分包含可操作的威胁信息。例如,一份42页的报告可能只包含几句话详细描述实际攻击[6]。(iii)关系提取:提取实体(例如,攻击者、工具、受害者)之间的关系至关重要,但对于现有的NLP系统来说仍然具有挑战性[10]。(iv)类别不平衡:许多提取方法都存在类别不平衡的问题,某些技术过度表示,而其他技术则表示不足。(v)复制不一致性:由于条件和数据集的不同,研究论文中的性能声明通常无法在不同的数据集上复制。
这些挑战导致了低精确率、召回率和 F1 分数,突显了对更有效的 CTI 提取方法的需求。我们的工作试图通过对多种 CTI 提取方法进行全面评估,并引入一种新的提取流程,来解决现有 CTI 提取方法的一些局限性。
3 方法论
我们的评估方法包括五个关键组成部分:提取方法选择、数据集准备、实验设计和评估指标。
3.1 提取方法选择
为了回答研究问题RQ1,我们选择了vanilla Llama2的三个变体[21],即7B、13B和70B,在零样本提示下进行。为了回答研究问题RQ2,我们选择了TRAM,一种基于SciBERT的方法,旨在将句子分类到MITRE ATT&CK框架中最常见的50种技术中[4],作为基础模型,并使用有和没有基于LLM的增强的不同配置进行评估。
3.2 真实数据集
使用了两个带注释的数据集作为评估的真值来源:
对抗模拟库(AEL):该数据集包含关于攻击活动(例如,APT29、Carbanak、FIN6)的简明报告,并标注了MITRE ATT&CK技术ID
攻击技术数据集(ATD):该数据集包含更长的报告(例如,OceanLotus、Sowbug、MuddyWater),并标注了详细的技术信息[12]
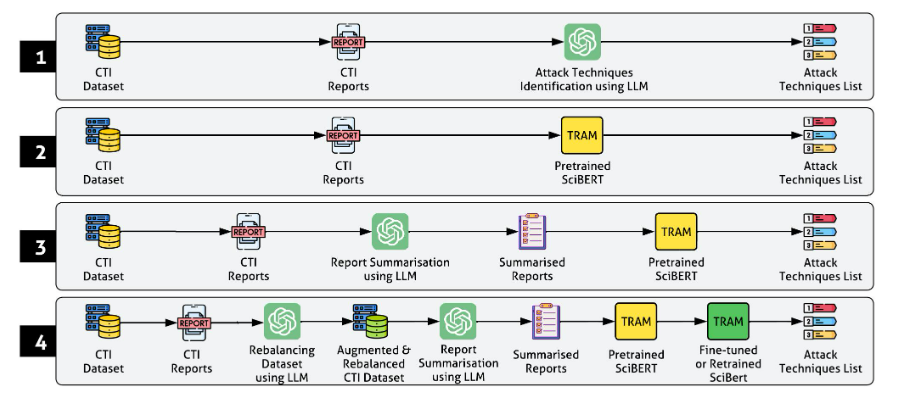
图1:我们的评估方法使用四种配置。
报告经过预处理,移除了技术ID、超链接和无关内容,以确保评估的公正性。为了与TRAM的训练数据保持一致,排除了MITRE ATT&CK框架中最常见的50种技术之外的技术。
3.3 实验设计
如图1所示,我们使用四种实验设置来评估和比较CTI提取方法:
用于CTI提取的独立LLM:评估了开源LLM(Llama2)的零样本提示能力。计算了精确率、召回率和F1分数,以及真阳性、假阳性和假阴性的计数。
原始TRAM配置:TRAM的性能评估使用了预训练的SciBERT模型,置信度阈值分别为25%和80%。我们将其表示为原始SciBERT。
采用基于LLM的总结的TRAM:此配置使用由LLM(GPT-3.5)生成的总结性CTI报告,然后进行SciBERT分类,置信水平分别为25%和75%。我们将其表示为aCTIon。注意:此选择基于最佳性能设置。
基于LLM的总结、重平衡和再训练的TRAM:在此配置中,我们使用GPT-3.5增强代表性不足的技术,并对代表性过高的技术进行降采样。CTI报告使用GPT-3.5进行总结,以减少冗长性并保留与攻击技术相关的相关内容。然后,总结后的报告由在重新平衡的数据集上重新训练的SciBERT模型处理。我们使用了三种训练设置,即再训练、微调和再训练与重交叉验证,最终得到9种配置用于评估TRAM。

表1:Llama2模型在AEL数据集上的假阳性和假阴性比较。“-”号表示假阴性,“+”号表示假阳性。
评估指标[NT0]。每个提取方法的性能均使用标准分类指标进行评估:精确率、召回率和 F1 分数。注:由于篇幅限制,本文仅报告 F1 分数。其他分析包括真阳性、假阳性和假阴性的计数。对于 AttackG 和 LLM,如果提取的技术名称或 ID 与真实情况相符,则认为结果正确。对于 TRAM,需要技术名称和 ID 完全匹配。
4 结果
本节介绍用于 CTI 提取的独立开源 LLM 的评估结果,然后对不同的 TRAM 配置进行比较分析,重点介绍模型改进和数据集重新平衡对性能的影响。
4.1 独立开源LLM的评估
为了解决研究问题1(RQ1),我们使用AEL数据集中的六份报告评估了LLama2的性能,每份报告少于500字。这确保了可控的处理时间,并减轻了依赖爆炸问题。表 1 比较了各种版本的LLama2(7B、13B和70B)的假阳性和假阴性数量。值得注意的是,较大的70B LLama2模型在某些情况下往往会产生更多的假阳性。例如,在FIN6的案例中,LLama2-7B和LLama2-13B分别产生了7个和8个假阳性,而LLama2-70B产生了19个假阳性,是LLama2-13B的两倍多。未来的工作应该探讨微调LLama2模型是否可以减少假阳性和假阴性的数量。
表2: Llama2模型的真阳性结果。
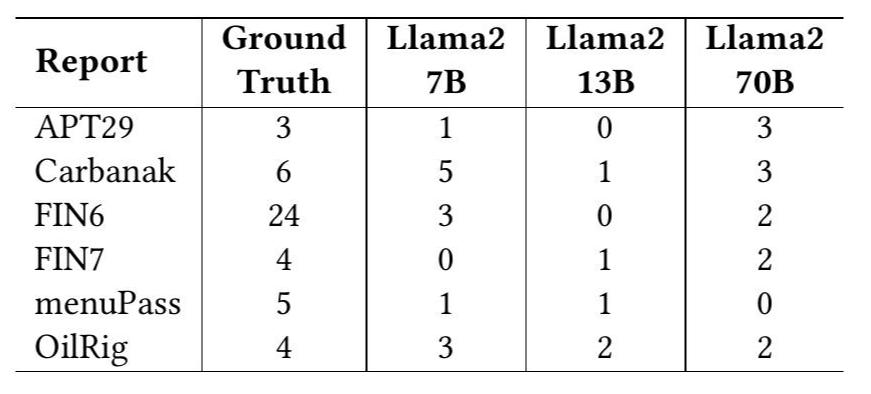
表3: Llama2模型的平均性能。
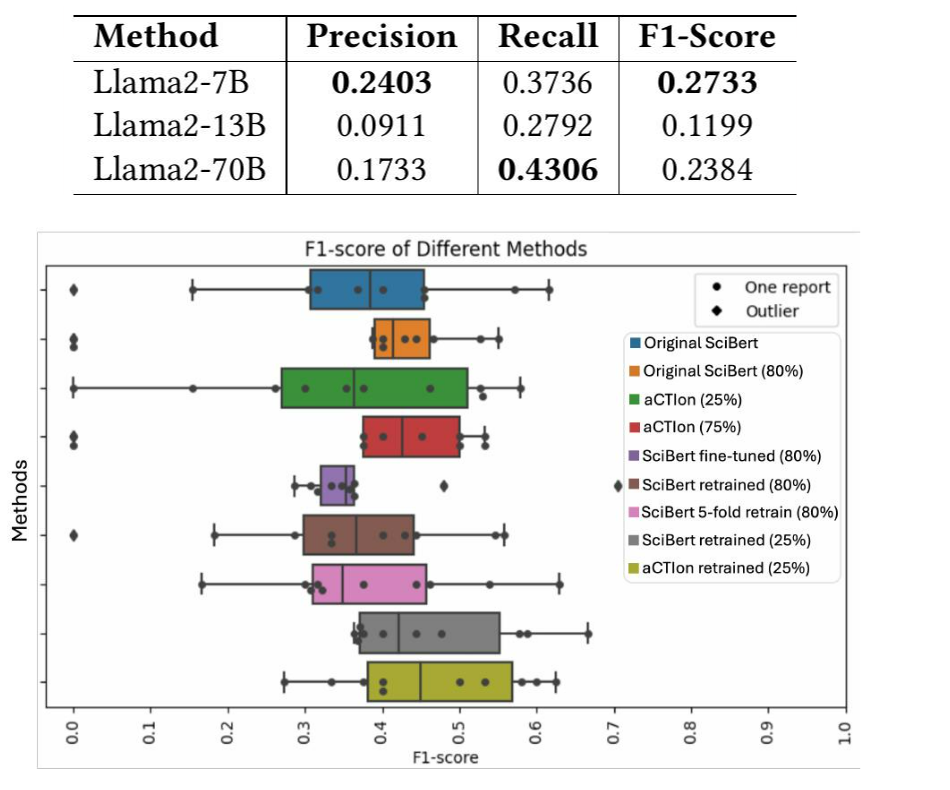
图2:TRAM在使用我们在ATD数据集上提出的不同配置时的性能。
表2展示了每个模型检测到的真正例数量,表3总结了每种方法的总体精确率、召回率和F1分数。如表2和3所示,所有模型的表现都很差,在许多情况下仅检测到一小部分真正例。尽管LLama2 70B模型检测到的真正例最多,但由于LLama2 70B产生的假正例数量较多,LLama2 7B的总体性能略好。这种低性能突显了任务的复杂性以及对CTI提取专用方法的需求。我们的下一个研究问题旨在探索这个方向。
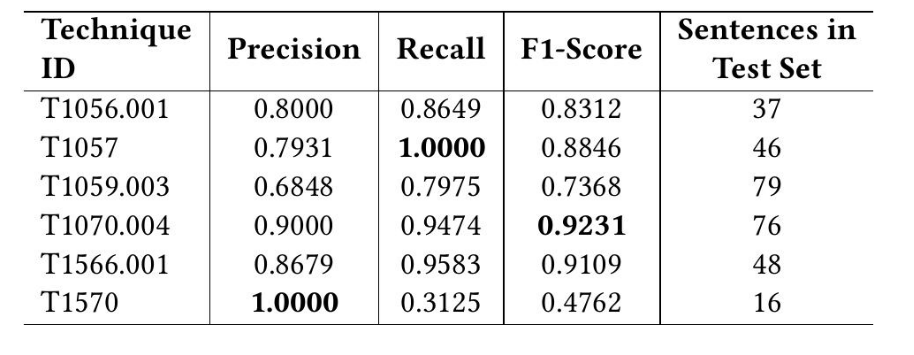
表 4:使用在 ATD 数据集上重新训练的 SciBERT 模型对所选技术进行分类的结果。
4.2 TRAM配置的比较
为了解决研究问题RQ2,我们评估了TRAM在不同配置和置信水平(25%和80%)下的表现。结果如图2所示,突出了配置更改的影响。我们可以观察到,首先使用GPT-3.5总结报告,然后使用SciBERT进行分类,其性能略优于SciBERT的默认设置。
为了解决TRAM中的类别不平衡和过拟合问题,我们使用重新平衡的数据集重新训练了SciBERT模型。如图2所示,与基线模型相比,这种方法使F1-score的中位数提高了约七个百分点。表4展示了使用性能最佳的重新训练的SciBERT模型对一些选定技术的分类结果。我们观察到,该模型在MITRE ATT&CK框架中最常见的50种技术中的许多技术上表现良好,F1-score高达0.92。
5 结论
本研究评估了最先进的网络威胁情报提取方法,强调了诸如类别不平衡、过拟合以及网络安全文本的复杂性等关键挑战。为了解决这些问题,我们提出了一种新颖的流程,该流程结合了用于报告总结的GPT-3.5和一个经过重新训练的SciBERT模型,以提高分类准确率,该模型使用由LLM增强的重新平衡的数据。与基线模型相比,这种方法使F1分数提高了七个百分点,并且对于几种攻击技术,F1分数达到了0.90以上。尽管取得了这些改进,但在对代表性不足的技术进行分类和减少误报方面仍然存在挑战。未来的工作应侧重于整合人机协作以提高提取准确率,并探索微调的LLM以进行更有效的CTI分析。这些贡献为更可靠的自动化CTI系统奠定了基础,以支持网络安全运营。
相关文章:

利用大型语言模型有效识别网络威胁情报报告中的攻击技术
摘要 本研究评估了网络威胁情报(CTI)提取方法在识别来自网络威胁报告中的攻击技术方面的性能,这些报告可从网络上获取,并使用了 MITRE ATT&CK 框架。我们分析了四种配置,这些配置利用了最先进的工具,包…...

笔试模拟 day4
观前提醒: 笔试所有系列文章均是记录本人的笔试题思路与代码,从中得到的启发和从别人题解的学习到的地方,所以关于题目的解答,只是以本人能读懂为目标,如果大家觉得看不懂,那是正常的。如果对本文的某些知…...

TCP的连接管理
三次握手 什么是三次握手? 1. 第一次握手(客户端 → 服务器) 客户端发送一个 SYN 报文,请求建立连接。 报文中包含一个初始序列号 SEQ x。 表示:我想和你建立连接,我的序列号是 x。 2. 第二次握手&a…...

ffmpeg 写入avpacket时候,即av_interleaved_write_frame方法是如何不需要 业务层释放avpacket的 逻辑分析
我们在通过 av_interleaved_write_frame方法 写入 avpacket的时候,通常不需要关心 avpacket的生命周期。 本文分析一下内部实现的部分。 ----> 代表一个内部实现。 A(){ B(); C(); } B(){ D(); } 表示为: A ---->B(); ---->D(); ---->C(); int…...

【MyBatis-7】深入理解MyBatis二级缓存:提升应用性能的利器
在现代应用开发中,数据库访问往往是性能瓶颈之一。作为Java生态中广泛使用的ORM框架,MyBatis提供了一级缓存和二级缓存机制来优化数据库访问性能。本文将深入探讨MyBatis二级缓存的工作原理、配置方式、使用场景以及最佳实践,帮助开发者充分利…...

扫雷革命:矩阵拓扑与安全扩散的数学之美
目录 扫雷革命:矩阵拓扑与安全扩散的数学之美引言第一章 雷区生成算法1.1 组合概率模型1.2 矩阵编码体系第二章 数字计算系统2.1 卷积核运算2.2 边缘处理第三章 安全扩散机制3.1 广度优先扩散3.2 记忆化加速第四章 玩家推理模型4.1 线性方程组构建4.2 概率决策模型第五章 高级…...

通俗的桥接模式
桥接模式(Bridge Pattern) 就像一座桥,把两个原本独立变化的东西连接起来,让它们可以各自自由变化,互不干扰。简单来说,就是 “把抽象和实现分开,用组合代替继承”。 一句话理解桥接模式 假设你…...

金丝猴食品:智能中枢AI-COP构建全链路数智化运营体系
“金丝猴奶糖”,这个曾藏在无数人童年口袋里的甜蜜符号,如今正经历一场数智焕新。当传统糖果遇上数字浪潮,这家承载着几代人味蕾记忆的企业,选择以数智化协同运营平台为“新配方”,将童年味道酿成智慧管理的醇香——让…...

基于定制开发开源AI智能名片S2B2C商城小程序的公私域流量融合运营策略研究
摘要:本文以定制开发开源AI智能名片S2B2C商城小程序为技术载体,系统探讨公域流量向私域流量沉淀的数字化路径。研究通过分析平台流量(公域流量)与私域流量的共生关系,提出"公域引流-私域沉淀-数据反哺"的闭环…...

一、数据仓库基石:核心理论、分层艺术与 ETL/ELT 之辨
随着企业数据的爆炸式增长,如何有效地存储、管理和分析这些数据,从中提炼价值,成为现代企业的核心竞争力之一。数据仓库 (Data Warehouse, DW) 正是为此而生的关键技术。理解其基础理论对于构建高效的数据驱动决策体系至关重要。 一、数据库…...
)
智慧能源大数据平台建设方案(PPT)
1、建设背景 2、建设思路 3、建设架构 4、应用场景 5、展望 软件开发全方位管理资料包清单概览: 任务部署指令书,可行性研究报告全集,项目启动审批文件,产品需求规格详尽说明书,需求调研策略规划,用户调研问…...
)
递归函数(斐波那契数列0,1,1,2,3,5,8,13,21,34,55...)
目录 一、斐波那契数列(兔子问题) 二、迭代法(用while循环推下一项 ) 三、递归函数 (函数的定义中调用函数自身的一种函数定义方式) 四、递归函数的底层逻辑推理 (二叉树推倒最左下节点回退法) 一、斐波那契数列(兔子问题&…...

Python 从 SQLite 数据库中批量提取图像数据
Python 从 SQLite 数据库中批量提取图像数据 flyfish 实现了一个可扩展的 SQLite 图像导出工具,能够自动检测图像格式、处理数据前缀,并将数据库中的二进制图像数据导出为文件系统中的标准图像文件 import os import sqlite3 from typing import Dict…...

rust-candle学习笔记12-实现因果注意力
参考:about-pytorch 定义结构体: struct CausalAttention {w_qkv: Linear,dropout: Dropout, d_model: Tensor,mask: Tensor,device: Device, } 定义new方法: impl CausalAttention {fn new(vb: VarBuilder, embedding_dim: usize, ou…...

vue3使用tailwindcss报错问题
npm create vitelatestnpm install -D tailwindcss postcss autoprefixernpx tailwindcss init 4. 不过执行 npx tailwindcss init 的时候控制台就报错了PS E:\vite-demo> npx tailwindcss init npm ERR! cb.apply is not a function npm ERR! A complete log of this run c…...
 查询优化详解!)
MySQL COUNT(*) 查询优化详解!
目录 前言1. COUNT(*) 为什么慢?—— InnoDB 的“计数烦恼” 🤔2. MySQL 执行 COUNT(*) 的方式 (InnoDB)3. COUNT(*) 优化策略:快!准!狠!策略一:利用索引优化带 WHERE 子句的 COUNT(*) (最常见且…...

5.Redission
5.1 前文锁问题 基于 setnx 实现的分布式锁存在下面的问题: 重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如 HashTable 这样的代码中,他的方法都是使用 sync…...

RAG 赋能客服机器人:多轮对话与精准回复
一、引言 在人工智能技术飞速发展的今天,客服机器人已成为企业提升服务效率的重要工具。然而,传统客服系统在多轮对话连贯性和精准回复能力上存在明显短板。检索增强生成(Retrieval-Augmented Generation, RAG)技术通过结合大语言…...

rust-candle学习笔记13-实现多头注意力
参考:about-pytorch 定义结构体: use core::f32;use candle_core::{DType, Device, Result, Tensor}; use candle_nn::{embedding, linear_no_bias, linear, ops, Dropout, Linear, Module, VarBuilder, VarMap};struct MultiHeadAttention {w_qkv: Li…...

PyTorch API 5 - 全分片数据并行、流水线并行、概率分布
文章目录 全分片数据并行 (FullyShardedDataParallel)torch.distributed.fsdp.fully_shardPyTorch FSDP2 (fully_shard) Tensor Parallelism - torch.distributed.tensor.parallel分布式优化器流水线并行为什么需要流水线并行?什么是 torch.distributed.pipelining&…...

STL-list
一、 list的介绍 std::list 是 C 标准模板库(STL)中的一种双向链表容器。每个元素包含指向前后节点的指针,支持高效插入和删除操作,但随机访问性能较差。 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器&#x…...

WPF中如何自定义控件
WPF自定义控件简化版:账户菜单按钮(AccountButton) 我们以**“账户菜单按钮”为例,用更清晰的架构实现一个支持标题显示、渐变背景、选中状态高亮**的自定义控件。以下是分步拆解: 一、控件核心功能 我们要做一个类似…...

华为云Git使用与GitCode操作指南
案例介绍 本文档带领开发者学习如何在云主机上基于GitCode来使用Git来管理自己的项目代码,并使用一些常用的Git命令来进行Git环境的设置。 案例内容 1 概述 1.1 背景介绍 Git 是一个快速、可扩展的分布式版本控制系统,它拥有异常丰富的命令集,可以提供高级操作和对内部…...

UniRepLknet助力YOLOv8:高效特征提取与目标检测性能优化
文章目录 一、引言二、UniRepLknet 的框架原理(一)架构概述(二)架构优势 三、UniRepLknet 在 YOLOv8 中的集成(一)集成方法(二)代码实例 四、实验与对比(一)对…...

【软件工程】基于频谱的缺陷定位
基于频谱的缺陷定位(Spectrum-Based Fault Localization, SBFL)是一种通过分析程序执行覆盖信息(频谱数据)来定位代码中缺陷的方法。其核心思想是:通过测试用例的执行结果(成功/失败)和代码覆盖…...

stm32之IIC
目录 1.I2C1.1 简介1.2 硬件电路1.3 时序基本单元1.4 时序实例1.4.1 指定地址写1.4.2 当前地址读1.4.3 指定地址读 2.MPU60502.1 简介2.2 参数2.3 硬件电路2.4 框图2.5 文档 3.软件操作MPU60504.I2C通信外设4.1 简介4.2 I2C框图4.3 基本结构4.4 主机发送/接收4.5 软件/硬件波形…...

阿里云购买ECS 安装redis mysql nginx jdk 部署jar 部署web
阿里云服务维护 1.安装JDK 查询要安装jdk的版本,命令:yum -y list java* 命令:yum install -y java-1.8.0-openjdk.x86_64 yum install -y java-17-openjdk.x86_64 2.安装nginx 启用 EPEL 仓库 sudo yum install epel-release 安装 Nginx sudo yum …...

记录 ubuntu 安装中文语言出现 software database is broken
搜索出来的结果是 sudo apt-get install language-pack-zh-han* 然而,无效,最后手动安装如下 apt install language-pack-zh-hans apt install language-pack-zh-hans-base apt install language-pack-gnome-zh-hans apt install fonts-arphic-uming apt install libreoffic…...

质数和约数
一、知识和经验 把质数和约数放在一起就是因为他们有非常多的联系,为了验证这个观点我们可以先学习唯一分解定理:一个大于 1 的自然数一定能被唯一分解为有限个质数的乘积。 而且一个数不仅能被质数分解,原本也应该被自己的约数分解…...
详解)
OSPF的四种特殊区域(Stub、Totally Stub、NSSA、Totally NSSA)详解
OSPF的四种特殊区域(Stub、Totally Stub、NSSA、Totally NSSA)通过限制LSA的传播来优化网络性能,减少路由表规模。以下是它们的核心区别: 1. Stub 区域(末梢区域) 允许的LSA类型:Type 1-3&#…...

Docker中运行的Chrome崩溃问题解决
问题 各位看官是否在 Docker 容器中的 Linux 桌面环境(如Xfce)上启动Chrome ,遇到了令人沮丧的频繁崩溃问题?尤其是在打开包含图片、视频的网页,或者进行一些稍复杂的操作时,窗口突然消失?如果…...

【从零实现JsonRpc框架#3】线程模型与性能优化
1.Muduo 的线程模型 Muduo 基于 Reactor 模式 ,采用 单线程 Reactor 和 多线程 Reactor 相结合的方式,通过事件驱动和线程池实现高并发。 1. 单线程模型 核心思想 :所有 I/O 操作(accept、read、write)和业务逻辑均…...

Kubernetes资源管理之Request与Limit配置黄金法则
一、从"酒店订房"看K8s资源管理 想象你经营一家云上酒店(K8s集群),每个房间(Node节点)都有固定数量的床位(CPU)和储物柜(内存)。当客人(Pod&#…...

Windows 上使用 WSL 2 后端的 Docker Desktop
执行命令 docker pull hello-world 执行命令 docker run hello-world 执行命令 wsl -d Ubuntu...

OpenLayers根据任意数量控制点绘制贝塞尔曲线
以下是使用OpenLayers根据任意数量控制点绘制贝塞尔曲线的完整实现方案。该方案支持三个及以上控制点,使用递归算法计算高阶贝塞尔曲线。 实现思路 贝塞尔曲线原理:使用德卡斯特里奥算法(De Casteljau’s Algorithm)递归计算任意…...

使用 Jackson 在 Java 中解析和生成 JSON
JSON(JavaScript Object Notation)是一种轻量级、跨语言的数据交换格式,因其简单易读和高效解析而广泛应用于 Web 开发、API 通信和数据存储。在 Java 中,处理 JSON 是许多应用程序的核心需求,尤其是在与 RESTful 服务交互或管理配置文件时。Jackson 是一个功能强大且广受…...

Qt中在子线程中刷新UI的方法
Qt中在子线程中刷新UI的方法 在Qt中UI界面并不是线程安全的,意味着在子线程中不能随意操作UI界面组件(比如按钮、标签)等,如果强行操作这些组件有可能会导致程序崩溃。那么在Qt中如何在子线程中刷新UI控件呢? 两种方…...

封装 RabbitMQ 消息代理交互的功能
封装了与 RabbitMQ 消息代理交互的功能,包括发送和接收消息,以及管理连接和通道。 主要组件 依赖项: 代码使用了多个命名空间,包括 Microsoft.Extensions.Configuration(用于配置管理)、RabbitMQ.Client&a…...

关于ffmpeg的简介和使用总结
主要参考: 全网最全FFmpeg教程,从新手到高手的蜕变指南 - 知乎 (zhihu.com) FFmpeg入门教程(非常详细)从零基础入门到精通,看完这一篇就够了。-CSDN博客 FFmpeg教程(超级详细版) - 个人文章 - S…...
(第2版)学习笔记 08.阴影)
计算机图形学编程(使用OpenGL和C++)(第2版)学习笔记 08.阴影
阴影 没有阴影的渲染效果如下,看起来不真实: 有阴影的渲染效果如下,看起来真实: 显示阴影有两种方式,一种是原书中的方式,另一种是采用光线追踪技术,该技术可以参考ShaderToy学习笔记 08.阴…...
低速接口篇)
[面试]SoC验证工程师面试常见问题(七)低速接口篇
SoC验证工程师面试常见问题(七)低速接口篇 摘要:低速接口是嵌入式系统和 SoC (System on Chip) 中常用的通信接口,主要用于设备间的短距离、低带宽数据传输。相比高速接口(如 PCIe、USB 3.0),低速接口的传输速率较低(通常在 kbps 到几 Mbps 范围),但具有简单…...

算法训练营第十三天|226.翻转二叉树、101. 对称二叉树、 104.二叉树的最大深度、111.二叉树的最小深度
递归 递归三部曲: 1.确定参数和返回值2.确定终止条件3.确定单层逻辑 226.翻转二叉树 题目 思路与解法 第一想法: 递归,对每个结点进行反转 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, le…...

电子电器架构 --- 车载网关的设计
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 钝感力的“钝”,不是木讷、迟钝,而是直面困境的韧劲和耐力,是面对外界…...

`C_PiperInterface` 类接口功能列表
C_PiperInterface 类接口功能列表 C_PiperInterface 提供了全面的接口,用于控制 Piper 机械臂的运动、查询状态、设置参数以及管理 SDK 限制。 官仓链接 以下是 C_PiperInterface 类中所有接口的功能总结: 1. 初始化与连接相关接口 __new__: 实现单例…...
】)
D. Apple Tree Traversing 【Codeforces Round 1023 (Div. 2)】
D. Apple Tree Traversing 题目大意 有一个包含 n n n 个节点的苹果树,初始时每个节点上有一个苹果。你有一张纸,初始时纸上没有任何内容。 你需要通过以下操作遍历苹果树,直到所有苹果都被移除: • 选择一个苹果路径 ( u , v…...

Docker镜像搬运工:save与load命令的实战指南
在日常的容器化开发中,镜像的搬运和部署是每个开发者必须掌握的技能。今天我们将深入探讨Docker的"save"和"load"这对黄金搭档,揭秘它们在镜像管理中的妙用。 一、基础认知:镜像的打包与解包 docker save 和 docker loa…...

查看Electron 应用的调试端口
以下是一些可以知道已发布第三方 Electron 应用调试端口的方法: * **通过命令行参数查看** : * 如果该 Electron 应用在启动时添加了类似 --remote-debugging-portxxxx 或 --inspectxxxx 的参数,那么其调试端口就是该参数指定的端口号。比…...

各种环境测试
加载测试专用属性 当在测试时想要加入某些配置且对其他测试类不产生影响是可以用Import注释添加配置 测试类中启动web环境 默认为none不开启...

腾讯云低代码实战:零基础搭建家政维修平台
目录 1. 欢迎与项目概览1.1 教程目的与受众1.2 项目愿景与目标:我们要搭建一个怎样的平台?1.3 平台核心构成与架构解析1.4 技术栈选择与考量1.5 如何高效阅读本教程 欢迎来到“腾讯云云开发低代码实战:从零搭建家政维修服务平台”开发教程&am…...

居然智家亮相全零售AI火花大会 AI大模型赋能家居新零售的进阶之路
当人工智能技术以摧枯拉朽之势重构商业世界时,零售业正在经历一场静默而深刻的革命。在这场变革中,居然智家作为新零售领域的创新标杆,凭借其在AI技术应用上的超前布局和持续深耕,已悄然构建起从消费场景到产业生态的智能化闭环。…...