【人工智能学习之动作识别TSM训练与部署】
【人工智能学习之动作识别TSM训练与部署】
- 基于MMAction2动作识别项目的开发
- 一、MMAction2的安装
- 二、数据集制作
- 三、模型训练
- 1. 配置文件准备
- 2. 关键参数修改
- 3. 启动训练
- 4. 启动成功
- ONNX模型部署方案
- 一、环境准备
- 二、执行转换命令
基于MMAction2动作识别项目的开发
一、MMAction2的安装
MMAction2 适用于 Linux、Windows 和 MacOS。
需要 Python 3.7+,CUDA 10.2+ 和 PyTorch 1.8+。
——————————————华丽的分割线—————————————————
第一步:从官方网站下载并安装 Miniconda。
第二步: 创建一个 conda 环境并激活它。
conda create --name openmmlab python=3.8 -y
conda activate openmmlab
第三步: 安装 PyTorch,按照官方说明进行操作。
第四步: 使用 MIM 安装依赖(其中MMDetection和 MMPose是可选的,非必须安装),注意MMCV需要根据前几步的版本进行选择安装版本。版本选择
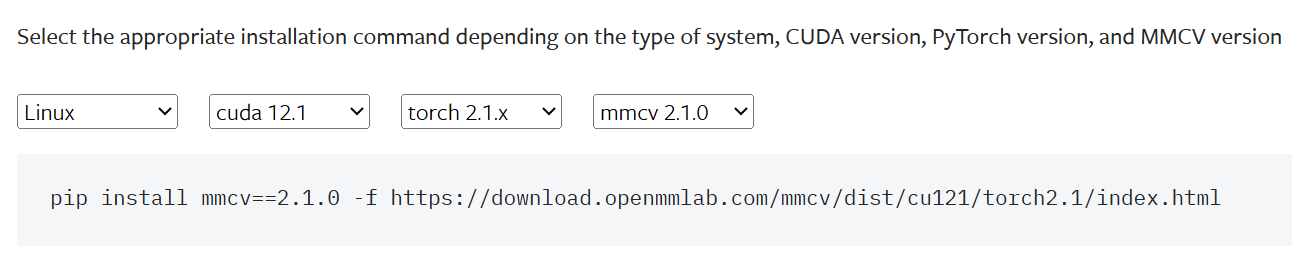
pip install -U openmim
mim install mmengine
mim install mmcv
mim install mmdet
mim install mmpose
第五步:从源代码构建 MMAction2。
git clone https://github.com/open-mmlab/mmaction2.git
cd mmaction2
pip install -v -e .
# "-v" 表示输出更多安装相关的信息
# "-e" 表示以可编辑形式安装,这样可以在不重新安装的情况下,让本地修改直接生效。
第六步:验证 MMAction2 是否安装正确。
1.下载配置文件和权重文件
mim download mmaction2 --config tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb --dest .
2.验证推理演示
# demo.mp4 和 label_map_k400.txt 都来自于 Kinetics-400
python demo/demo.py tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb.py \tsn_imagenet-pretrained-r50_8xb32-1x1x8-100e_kinetics400-rgb_20220906-2692d16c.pth \demo/demo.mp4 tools/data/kinetics/label_map_k400.txt
如果在终端看到前5个标签及其对应的分数则已经安装成功。
二、数据集制作
-
RawFrameDataset格式的原始帧注释
-
数据目录结构:
dataset_root/ ├── rawframes/ │ ├── train/ │ │ ├── video1/ │ │ │ ├── img_00001.jpg │ │ │ └── ... │ └── val/ ├── annotations/ │ ├── train.txt │ └── val.txt -
标注文件格式示例:
video1 150 0 video2 180 1原始帧数据集的注释是一个包含多行的文本文件,每一行表示一个视频的 frame_directory(相对路径)、视频的 total_frames 和视频的 label,用空格分隔。以上是一个示例。
这里分享我的俩个脚本,用于抽帧和标注:
抽帧脚本:import os import cv2def extract_frames(video_path, output_dir):cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")returnframe_count = 0while True:ret, frame = cap.read()if not ret:breakframe_name = f"img_{frame_count + 1:05d}.jpg"frame_path = os.path.join(output_dir, frame_name)cv2.imwrite(frame_path, frame)frame_count += 1cap.release()def process_videos(root_dir):for sub_dir in os.listdir(root_dir):sub_dir_path = os.path.join(root_dir, sub_dir)if os.path.isdir(sub_dir_path):for video_file in os.listdir(sub_dir_path):if video_file.endswith('.mp4'):video_path = os.path.join(sub_dir_path, video_file)video_name = os.path.splitext(video_file)[0]output_dir = os.path.join(sub_dir_path, video_name)if not os.path.exists(output_dir):os.makedirs(output_dir)extract_frames(video_path, output_dir)if __name__ == "__main__":root_directory = r'C:\WorkFiles\company_server_SSH\fight\TSM\dataset\dataset' # 这里可以修改为你的一级目录路径process_videos(root_directory)标注脚本:
import osdef count_images_and_save(root_dir, output_file):results = []for root, dirs, files in os.walk(root_dir):# 若当前目录没有子目录,就认定为末级目录if not dirs:jpg_files = [f for f in files if f.lower().endswith('.jpg')]image_count = len(jpg_files)# 把上级目录名当作标签label = os.path.basename(os.path.dirname(root))# 仅保留从 train 开始的相对路径relative_path = os.path.relpath(root, start=os.path.dirname(root_dir))results.append(f"{relative_path} {image_count} {label}")with open(output_file, 'w') as f:for line in results:f.write(line + '\n')if __name__ == "__main__":root_directory = r'C:\WorkFiles\company_server_SSH\fight\TSM\dataset\dataset\images\val' # 替换成你的根目录output_txt_file = 'val_videofolder.txt' # 替换成你想要的输出文件名count_images_and_save(root_directory, output_txt_file)print(f"结果已保存到 {output_txt_file}")
-
-
VideoDataset格式的视频注释
-
数据目录结构:
dataset_root/ ├── videos/ │ ├── video1.mp4 │ └── video2.avi ├── annotations/ │ ├── train.txt │ └── val.txt -
执行格式转换:
python tools/data/build_rawframes.py [原始视频路径] [输出路径] --ext mp4 -
标注文件格式示例:
some/path/000.mp4 1 some/path/001.mp4 1 some/path/002.mp4 2视频数据集的注释是一个包含多行的文本文件,每一行表示一个样本视频,包括 filepath(相对路径)和 label,用空格分隔。以上是一个示例。
通常,我会将相同分类的视频放在同一个文件夹中,并将分类序号作为文件夹名称,通过脚本直接生成标注文件。
具体操作如下:
脚本如下:import osdef generate_video_labels(root_dir, output_file):with open(output_file, 'w') as f:for root, dirs, files in os.walk(root_dir):for file in files:if file.lower().endswith(('.mp4', '.avi', '.mov', '.mkv')):label = os.path.basename(root)file_path = os.path.join(root, file)relative_path = os.path.relpath(file_path, root_dir)f.write(f"{relative_path} {label}\n")if __name__ == "__main__":root_directory = r'C:\WorkFiles\dataset\fight\dataset'output_txt = 'video_labels.txt'generate_video_labels(root_directory, output_txt)
-
三、模型训练
1. 配置文件准备
本项目选择的是TSM模型,读者可以根据自己的需求选择其他模型。
先复制一份构建模型训练的配置文件,并将其重命名。这里我们复制到configs目录下以免后面找不到。
cp mmaction2/configs/recognition/tsm/tsm_r50_1x1x8_50e_kinetics400_rgb.py configs/my_tsm.py
2. 关键参数修改
打开我们的配置文件,首先需要修改我们的数据集配置:
# 数据集配置
# dataset settingsdata_root = '/home/OpenMMLAB/mmaction2/fight/dataset/'data_root_val = '/home/OpenMMLAB/mmaction2/fight/dataset/'ann_file_train = '/home/OpenMMLAB/mmaction2/fight/dataset/video_labels_train.txt'ann_file_val = '/home/OpenMMLAB/mmaction2/fight/dataset/video_labels_val.txt'
其次,我们还需要对模型进行修改分类输出:
# model settingsmodel = dict(cls_head=dict(type='TSMHead',num_classes=6 # 将 400 修改为 101))
其他的训练策略看个人情况,我没有做训练器等其他方面的修改。
3. 启动训练
接下来通过命令启动训练:
python tools/train.py configs/my_tsm.py \--seed=0 \--deterministic \--validate \--work-dir work_dirs/my_tsm
脚本完整用法:
python tools/train.py ${CONFIG_FILE} [ARGS]
| 参数 | 描述 |
|---|---|
| CONFIG_FILE | 配置文件的路径。 |
| –work-dir WORK_DIR | 保存日志和权重的目标文件夹。默认为与配置文件相同名称的文件夹,位于 ./work_dirs 下。 |
| –resume [RESUME] | 恢复训练。如果指定了路径,则从该路径恢复,如果未指定,则尝试从最新的权重自动恢复。 |
| –amp | 启用自动混合精度训练。 |
| –no-validate | 不建议使用。在训练期间禁用权重评估。 |
| –auto-scale-lr | 根据实际批次大小和原始批次大小自动缩放学习率。 |
| –seed | 随机种子。 |
| –diff-rank-seed | 是否为不同的 rank 设置不同的种子。 |
| –deterministic | 是否为 CUDNN 后端设置确定性选项。 |
| –cfg-options CFG_OPTIONS | 覆盖使用的配置中的某些设置,xxx=yyy 格式的键值对将合并到配置文件中。如果要覆盖的值是一个列表,则应采用 key=“[a,b]” 或 key=a,b 的形式。该参数还允许嵌套的列表/元组值,例如 key=“[(a,b),(c,d)]”。请注意,引号是必需的,且不允许有空格。 |
| –launcher {none,pytorch,slurm,mpi} | 作业启动器的选项。默认为 none。 |
注意:默认情况下,MMAction2 更倾向于使用 GPU 而不是 CPU 进行训练。如果您想在 CPU 上训练模型,请清空 CUDA_VISIBLE_DEVICES 或将其设置为 -1 以使 GPU 对程序不可见。
CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
当然,也可以使用多卡训练,官方提供了一个 shell 脚本使用torch.distributed.launch 来启动多个 GPU 的训练任务。
bash tools/dist_train.sh ${CONFIG} ${GPUS} [PY_ARGS]
| 参数 | 描述 |
|---|---|
| CONFIG_FILE | 配置文件的路径。 |
| GPUS | 要使用的 GPU 数量。 |
| [PYARGS] | tools/train.py 的其他可选参数。 |
4. 启动成功
开始输出loss则标志模型开始训练了。
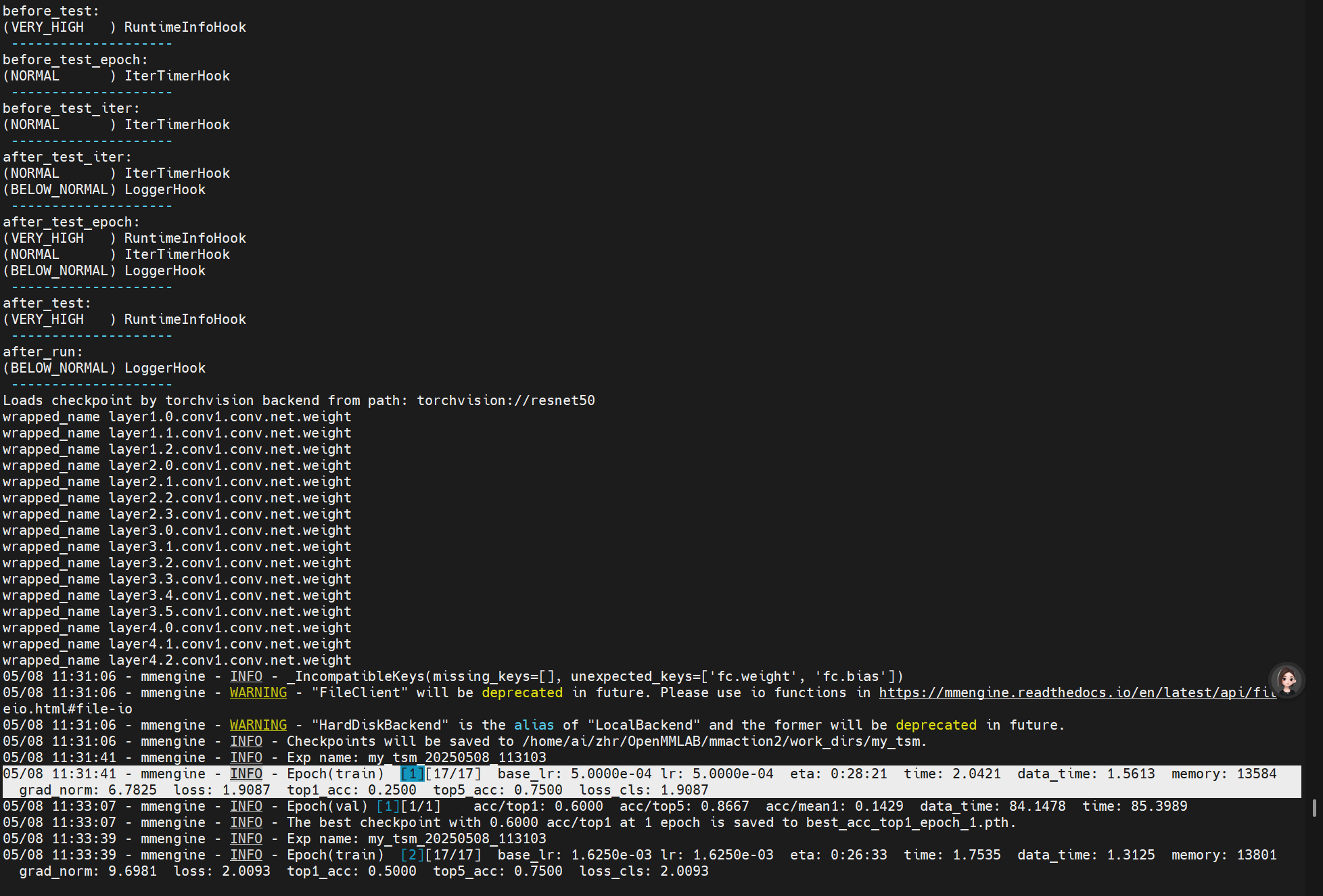
最后训练完成会得到:
top1达到best并不意味着top5也是best。
我们根据自己的需求选择其中表现最好的即可。
ONNX模型部署方案
一、环境准备
先决条件
为了进行端到端的模型部署,MMDeploy 需要 Python 3.6+ 和 PyTorch 1.8+。
——————————————华丽的分割线—————————————————
第一步:从官方网站下载并安装 Miniconda。
第二步:创建 conda 环境并激活它,也可以直接使用我们之前创建的openmmlab
第三步:按照官方说明安装 PyTorch(如果没装的话)
第四步:安装mmcv和mmengine,如果是之前创建的环境在已有mmengine和mmcv的基础上,我们只需要安装mmdeploy即可。
第五步:下载Github最新版MMDeploy
git clone https://github.com/open-mmlab/mmdeploy.git --recursive
cd mmdeploy第六步:根据需求安装对应依赖,engine或onnx,这里我安装的onnx部署环境
# 1. install MMDeploy model converter
pip install mmdeploy==1.3.1# 2. install MMDeploy sdk inference
# you can install one to install according whether you need gpu inference
# 2.1 support onnxruntime
pip install mmdeploy-runtime==1.3.1
# 2.2 support onnxruntime-gpu, tensorrt
pip install mmdeploy-runtime-gpu==1.3.1# 3. install inference engine
# 3.1 install TensorRT
# !!! If you want to convert a tensorrt model or inference with tensorrt,
# download TensorRT-8.2.3.0 CUDA 11.x tar package from NVIDIA, and extract it to the current directory
pip install TensorRT-8.2.3.0/python/tensorrt-8.2.3.0-cp38-none-linux_x86_64.whl
pip install pycuda
export TENSORRT_DIR=$(pwd)/TensorRT-8.2.3.0
export LD_LIBRARY_PATH=${TENSORRT_DIR}/lib:$LD_LIBRARY_PATH
# !!! Moreover, download cuDNN 8.2.1 CUDA 11.x tar package from NVIDIA, and extract it to the current directory
export CUDNN_DIR=$(pwd)/cuda
export LD_LIBRARY_PATH=$CUDNN_DIR/lib64:$LD_LIBRARY_PATH# 3.2 install ONNX Runtime
# you can install one to install according whether you need gpu inference
# 3.2.1 onnxruntime
wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-1.8.1.tgz
tar -zxvf onnxruntime-linux-x64-1.8.1.tgz
export ONNXRUNTIME_DIR=$(pwd)/onnxruntime-linux-x64-1.8.1
export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH
# 3.2.2 onnxruntime-gpu
pip install onnxruntime-gpu==1.8.1
wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-gpu-1.8.1.tgz
tar -zxvf onnxruntime-linux-x64-gpu-1.8.1.tgz
export ONNXRUNTIME_DIR=$(pwd)/onnxruntime-linux-x64-gpu-1.8.1
export LD_LIBRARY_PATH=$ONNXRUNTIME_DIR/lib:$LD_LIBRARY_PATH
二、执行转换命令
通过命令我们就得到了着四个文件,分别为onnx和三个json:
相关文章:

【人工智能学习之动作识别TSM训练与部署】
【人工智能学习之动作识别TSM训练与部署】 基于MMAction2动作识别项目的开发一、MMAction2的安装二、数据集制作三、模型训练1. 配置文件准备2. 关键参数修改3. 启动训练4. 启动成功 ONNX模型部署方案一、环境准备二、执行转换命令 基于MMAction2动作识别项目的开发 一、MMAct…...

PostgreSQL冻结过程
1.冻结过程 冻结过程有两种模式,依特定条件而择其一执行。为方便起见,将这两种模式分别称为惰性模式(lazy mode)和迫切模式(eager mode)。 并发清理(Concurrent VACUUM)通常在内部…...
SSHv2公钥认证示例-Paramiko复用 Transport 连接
在 Paramiko 中复用 Transport 连接时,若要通过 公钥认证(而非密码)建立连接,需手动加载私钥并与 Transport 关联。以下是详细操作步骤及完整代码示例: 步骤 1:加载私钥文件 使用 RSAKey 或 Ed25519Key 类…...

华为5.7机考-最小代价相遇的路径规划Java题解
题目内容 输入描述 输出描述 示例: 输入: 2 1 2 2 1 输出: 3 思路: Dijkstra 算法实现 dijkstra(int sx, int sy, int[][] dirs) 方法: 参数:起点坐标 (sx, sy) 和允许的移动方向 初始化࿱…...

element-ui分页的使用及修改样式
1.安装 npm install element-ui -S 2.在main.js中引入,这里是全部引入,也可以按需引入 import ElementUI from element-ui import element-ui/lib/theme-chalk/index.css Vue.use(ElementUI) 3.使用 layout"prev, pager, next, jumper" :jumpe…...

[Unity]-[UI]-[Image] 关于UI精灵图资源导入设置的详细解释
Unity UI Sprite UI资源导入详解图片导入项目Texture TypeTexture ShapeAdvanced Setting 高级设置 图片设置案例常见细节问题 知识点详解来源 UI资源导入详解 Unity中的UI资源有图片、矢量图、字体、预制体、图集、动画等等资源。 这其中图片是最重要以及最基础的资源组成&a…...

MLX-Audio:高效音频合成的新时代利器
MLX-Audio:高效音频合成的新时代利器 现代社会的快节奏生活中,对语音技术的需求越来越高。无论是个性化语音助手,还是内容创作者所需的高效音频生成工具,语音技术都发挥着不可或缺的作用。今天,我们将介绍一个创新的开…...

操作系统导论——第27章 插叙:线程API
关键问题:如何创建和控制线程? 操作系统应该提供哪些创建和控制线程的接口?这些接口如何设计得易用和实用? 一、线程创建 编写多线程程序的第一步就是创建新线程,因此必须存在某种线程创建接口。在 POSIX 中࿱…...

代采系统:定义、优势与未来趋势
一、代采系统的定义 代采系统是一种基于互联网的集中采购平台,它通过整合供应链资源,为中小企业或个人提供采购代理服务。商家可以在没有自己库存的情况下销售产品,当客户下单时,订单信息会自动或手动发送给供应商,由…...
(c++))
后缀表达式+栈(详解)(c++)
前言 很抱歉,上一期没有介绍栈stack的用法,今天简要介绍一下,再讲讲后缀表达式,用stack栈做一些后缀表达式的练习。 栈 栈stack是c中系统给出的栈,有了它,就不用自己创建栈啦! 头文件 栈sta…...

Kaggle图像分类竞赛实战总结详细代码解读
前言 我是跟着李沐的动手学深度学习v2视频学习深度学习的,光看不做假把式,所以在学习完第七章-现代卷积神经网络之后,参加了一次李沐发布的Kaggle竞赛。自己动手,从组织数据集开始,到训练,再到推理&#x…...

开源AI对比--dify、n8n
原文网址:开源AI对比--dify、n8n-CSDN博客 简介 本文介绍开源AI工作流工具的选型。 对比 项difyn8n占优者学习难度简单中等dify核心理念用LLM构建应用。“连接一切”。以工作流自动化连接各系统。平手工作模式 Chatflow:对话。支持用户意图识别、上下…...

【SQL系列】多表关联更新
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
)
软件设计师教程——第一章 计算机系统知识(下)
前言 在竞争激烈的就业市场中,证书是大学生求职的重要加分项。中级软件设计师证书专业性强、认可度高,是计算机相关专业学生考证的热门选择,既能检验专业知识,又有助于职业发展。本教程将聚焦核心重点,以点带面构建知…...
系统软件部署全攻略:Redis、RabbitMQ、MySQL 等集群搭建指南)
华为银河麒麟 V10(ARM)系统软件部署全攻略:Redis、RabbitMQ、MySQL 等集群搭建指南
一、Redis 集群部署(主从 哨兵模式) 1. 环境准备 系统:华为银河麒麟 V10(ARM64)节点:3 台服务器(1 主 2 从 3 哨兵) 2. 安装包下载 bash # 华为镜像站 wget https://update.c…...

World of Warcraft [CLASSIC][80][Deluyia] [Fragment of Val‘anyr]
瓦兰奈尔的碎片 [Fragment of Valanyr] 有时候下个班打个游戏,没想到套路也这么多,唉,何况现实生活,这一个片版本末期才1000G,30个,也就30000G,时光徽章等同月卡15000G,折合一下也就…...

C++:求分数序列和
【描述】 有一个分数序列 2/1,3/2,5/3,8/5,13/8,21/13,.... 求这个分数序列的前n项之和。 输入 输入有一行:正整数n。 输出 输出有一行:分数序列的和(浮点数,精确到小数点后4位)。 【样例输入】 99 【样例输出】 160.4…...

支付宝沙盒模式商家转账经常出现 响应异常: 解包错误
2025年5月9日16:27:08 php8.3 laravel11 octane swoole加速 测试时不时就出现 响应异常: 解包错误 错误信息: Yansongda\Artful\Exception\InvalidResponseException: 响应异常: 解包错误 in /opt/www/vendor/yansongda/artful/src/Direction/CollectionDirect…...

第04章—技术突击篇:如何根据求职意向进行快速提升与复盘
经过上一讲的内容阐述后,咱们定好了一个与自身最匹配的期望薪资,接着又该如何准备呢? 很多人在准备时,通常会选择背面试八股文,这种做法效率的确很高,毕竟能在“八股文”上出现的题,也绝对是面…...

数据统计的意义:钱包余额变动
钱包余额变动统计的核心意义在于通过数据可视化实现资金流动的透明化管理,其价值主要体现在以下五个维度: 一、财务健康诊断() 资金流动可视化 通过期初/期末余额对比,可快速识别异常波动(如连续3个月余额…...
)
单调栈模版型题目(3)
单调栈型题目贡献法 基本模版 这是数组a中的 首先我们要明白什么叫做贡献,在一个数组b{1,3,5}中,连续包含1的连续子数组为{1},{1,3},{1,3,5},一共有三个,这三个数一共能组成6个连续子数组,而其…...

PostgreSQL 的 pg_advisory_lock 函数
PostgreSQL 的 pg_advisory_lock 函数 pg_advisory_lock 是 PostgreSQL 提供的一种应用级锁机制,它不锁定具体的数据库对象(如表或行),而是通过数字键值来协调应用间的并发控制。 锁的基本概念 PostgreSQL 提供两种咨询锁(advi…...

NLP基础
1. 基本概念 自然语言处理(Natural Language Processing,简称NLP)是人工智能和语言学领域的一个分支,它涉及到计算机和人类(自然)语言之间的相互作用。它的主要目标是让计算机能够理解、解释和生成人类语言…...

[AI Tools] Dify 工具插件上传指南:如何将插件发布到官方市场
Dify 作为开源的 LLM 应用开发平台,不仅支持本地化插件开发,也提供了插件市场机制,让开发者能够将自己构建的插件发布并供他人使用。本文将详细介绍如何将你开发的 Dify Tools 插件上传至官方插件市场,包括 README 编写、插件打包、仓库 PR 等核心步骤。 一、准备 README 文…...

Qt读写XML文档
XML 结构与概念简介 XML(可扩展标记语言) 是一种用于存储和传输结构化数据的标记语言。其核心特性包括: 1、树状结构:XML 数据以层次化的树形结构组织,包含一个根元素(Root Element)ÿ…...

htmlUnit和Selenium的区别以及使用BrowserMobProxy捕获网络请求
1. Selenium:浏览器自动化之王 核心定位: 跨平台、跨语言的浏览器操控框架,通过驱动真实浏览器实现像素级用户行为模拟。 技术架构: 核心特性: 支持所有主流浏览器(含移动端模拟) 精…...
)
C#黑魔法:鸭子类型(Duck Typing)
C#黑魔法:鸭子类型(Duck Typing) 如果它走起路来像鸭子,叫起来像鸭子,那么它就是鸭子。 鸭子类型,主要应用于动态语言类型,比如JS、Python等,核心理念为:关注对象的行为(方法或属性…...

2025 年数维杯数学建模B题完整论文代码模型
《2025 年数维杯数学建模B题完整论文代码模型》 B题完整论文 一、赛事背景与题目总览 2025 年第十届数维杯大学生数学建模挑战赛的 B 题聚焦于“马拉松经济的高质量发展思路探索”。近年来,我国马拉松赛事如同一颗颗璀璨的星星,在城市的天空中闪耀&am…...

C++23 中的 views::chunk:深入探索与应用
文章目录 一、views::chunk 的背景与动机二、views::chunk 的基本用法语法与参数示例代码 三、views::chunk 的高级用法处理不完整块与 views::drop 和 views::take 结合 四、性能分析五、应用场景1. 批量处理数据2. 分页显示3. 并行处理 六、与其他范围适配器的组合1. 与 view…...

库室指静脉人脸门禁机 LK-BM-S10C/JR
1、采用大于等于四核处理器,主频大于1G; 2、内存≥4G DDR3;存储≥8G 3、核心模块采用国产工业级处理芯片和嵌入式Android实时多任务系统,采用模块化设计,模块间通过标准接口相连; 4、大于等于10英寸电容屏…...

低成本自动化改造的18个技术锚点深度解析
执行摘要 本文旨在深入剖析四项关键的低成本自动化技术,这些技术为工业转型提供了显著的运营和经济效益。文章将提供实用且深入的指导,涵盖老旧设备联网、AGV车队优化、空压机系统智能能耗管控以及此类项目投资回报率(ROI)的严谨…...

线程中常用的方法
知识点详细说明 Java线程的核心方法集中在Thread类和Object类中,以下是新增整合后的常用方法分类解析: 1. 线程生命周期控制 方法作用注意事项start()启动新线程,JVM调用run()方法多次调用会抛出IllegalThreadStateException(线程状态不可逆)。run()线程的任务逻辑直接调…...

运维体系架构规划
运维体系架构规划是一个系统性工程,旨在构建高效、稳定、安全的运维体系,保障业务系统的持续运行。下面从规划目标、核心模块、实施步骤等方面进行详细阐述: 一、规划目标 高可用性:确保业务系统 724 小时不间断运行,…...

C++结构体介绍
结构体的定义 在C中,结构体(struct)是一种用户定义的数据类型,允许将不同类型的数据组合在一起。结构体的定义使用struct关键字,后跟结构体名称和一对花括号{},花括号内包含成员变量的声明。 struct Pers…...

RoPE长度外推:外插内插
RoPE:假定 α \alpha α是定值 其中一半位置是用cos表示的 cos ( k α − 2 i d ) \cos(k\alpha^{-\frac{2i}{d}}) cos(kα−d2i)(另一半是sin)(d是词嵌入维度) 当太长如何解决: 1 直接不管—外插 缺点:超过一定长度性能急剧下降。(较大时,对应的很多位置编码…...

牛客练习赛138-题解
牛客练习赛138-题解 https://ac.nowcoder.com/acm/contest/109081#question A-小s的签到题 题目描述 给定一个比赛榜单: 第一行是 n 个不同的大写字母,代表题号第二行是 n 个形如a/b的字符串,表示每道题的通过人数和提交人数 找到通过人…...

MySQL高可用方案全攻略:选型指南与AI运维实践
MySQL高可用方案全攻略:选型指南与AI运维实践 引言:当数据库成为业务生命线 在数字化时代,数据库就是企业的"心脏"。一次数据库宕机可能导致: 电商网站每秒损失上万元订单游戏公司遭遇玩家大规模流失金融系统引发连锁反应本文将为你揭秘: MySQL主流高可用方案…...
、包(Package)和模块(Module)解析】)
【库(Library)、包(Package)和模块(Module)解析】
在Python中,**库(Library)、包(Package)和模块(Module)**是代码组织的不同层级,而import语句的导入行为与它们密切相关。以下是详细对比和解释: 📦 1. 核心概…...

记录一次使用thinkphp使用PhpSpreadsheet扩展导出数据,解决身份证号码等信息科学计数法问题处理
PhpSpreadsheet官网 PhpSpreadsheet安装 composer require phpoffice/phpspreadsheet使用composer安装时一定要下载php对应的版本,下载之前使用php -v检查当前php版本 简单使用 <?php require vendor/autoload.php;use PhpOffice\PhpSpreadsheet\Spreadshee…...

为什么业务总是被攻击?使用游戏盾解决方案
业务频繁遭受攻击的核心原因在于攻防资源不对等,攻击者利用技术漏洞、利益驱动及企业防护短板发起攻击,而游戏盾通过针对性架构设计实现高效防御。以下是具体分析与解决方案: 一、业务被攻击的根源 利益驱动攻击 勒索与数…...

4.1【LLaMA-Factory 实战】医疗领域大模型:从数据到部署的全流程实践
【LLaMA-Factory实战】医疗领域大模型:从数据到部署的全流程实践 一、引言 在医疗AI领域,构建专业的疾病诊断助手需要解决数据稀缺、知识专业性强、安全合规等多重挑战。本文基于LLaMA-Factory框架,详细介绍如何从0到1打造一个垂直领域的医…...

二维旋转矩阵:让图形动起来的数学魔法 ✨
大家好!今天我们要聊一个超酷的数学工具——旋转矩阵。它就像数学中的"旋转魔法",能让图形在平面上优雅地转圈圈。别被"矩阵"这个词吓到,其实它就是一个数字表格,但功能超级强大! 一、什么是旋转…...

go语言封装、继承与多态:
1.封装: 封装是通过将数据和操作数据的方法绑定在一起来实现的。在Go语言中,封装通过结构体(struct)和方法(method)来实现。结构体的字段可以通过大小写来控制访问权限。 package stutype Person struct …...

golang -- 如何获取变量类型
目录 前言获取变量类型一、fmt.Printf二、类型断言三、类型选择四、反射 reflect.TypeOf五、reflect.Value的Type()方法 前言 在学习反射的时候,对reflect包中获取变量类型的函数很迷惑 比如下面这个 用Type获取变量类型的方法(在下面提到) …...
)
Missashe考研日记-day36(改版说明)
Missashe考研日记-day36 改版说明 经过一天的思考、纠结和尝试,博主决定对更新内容进行改版,如下:1.不再每天都发一篇日记,改为一周发一篇包含一周七天学习进度的周记,但为了标题和以前相同(强迫症&#…...

opencv中的图像特征提取
图像的特征,一般是指图像所表达出的该图像的特有属性,其实就是事物的图像特征,由于图像获得的多样性(拍摄器材、角度等),事物的图像特征有时并不特别突出或与无关物体混杂在一起,因此图像的特征…...

一文了解氨基酸的分类、代谢和应用
氨基酸(Amino acids)是在分子中含有氨基和羧基的一类化合物。氨基酸是生命的基石,人类所有的疾病与健康状况都与氨基酸有直接或间接的关系。氨基酸失衡可引起肝硬化、神经系统感染性疾病、糖尿病、免疫性疾病、心血管疾病、肾病、肿瘤等各类疾…...

Linux 系统安装Minio详细教程
一、🔍 MinIO 简介 MinIO 是一个高性能的对象存储服务,兼容 Amazon S3 接口,适用于大数据、AI、云原生等场景,支持分布式部署和高可用性,可作为轻量级的私有云对象存储解决方案。 二、📦 安装准备 ✅ 系…...

排序算法-归并排序
归并排序是一种分治算法(Divide and Conquer)。对于给定的一组数据,利用递归与分治技术将数据序列划分成为越来越小的半子表,在对半子表排序后,再用递归方法将排好序的半子表合并成为越来越大的有序序列。 核心思想 分…...
相同,为某个对象设置disabled属性)
js 两个数组中的指定参数(id)相同,为某个对象设置disabled属性
在JavaScript中,如果想要比较两个数组并根据它们的id属性来设置某个对象的disabled属性为true,你可以使用几种不同的方法。这里我将介绍几种常用的方法: 方法1:使用循环和条件判断 const array1 [{ id: 1, name: Item 1 },{ id…...