第J7周:ResNeXt解析
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架: Tensorflow
(二)具体步骤
1. 代码
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.models import Model
from tensorflow.keras.layers import ( Input, Conv2D, BatchNormalization, ReLU, Add, MaxPooling2D, GlobalAveragePooling2D, Dense, Concatenate, Lambda
)
from tensorflow.keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping, TensorBoard
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
from datetime import datetime
import time # 设置GPU内存增长
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus: try: for gpu in gpus: tf.config.experimental.set_memory_growth(gpu, True) print(f"找到 {len(gpus)} 个GPU,已设置内存增长") except RuntimeError as e: print(f"设置GPU内存增长时出错: {e}") # 设置中文字体支持
def set_chinese_font(): """配置Matplotlib中文字体支持""" import platform if platform.system() == 'Windows': plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'SimSun'] else: # Linux/Mac plt.rcParams['font.sans-serif'] = ['WenQuanYi Micro Hei', 'Arial Unicode MS', 'Heiti TC'] plt.rcParams['axes.unicode_minus'] = False # 分组卷积块实现
def grouped_convolution_block(inputs, filters, strides, groups, prefix=None): """ 实现分组卷积 参数: - inputs: 输入张量 - filters: 过滤器数量 - strides: 步长 - groups: 分组数量 - prefix: 层名称前缀,用于避免命名冲突 返回: - 输出张量 """ # 确保过滤器数量可以被分组数整除 assert filters % groups == 0, "过滤器数量必须能被分组数整除" # 计算每组的过滤器数量 group_filters = filters // groups # 初始化保存分组卷积结果的列表 group_convs = [] # 对每个组执行卷积 for group_idx in range(groups): name = f'{prefix}_group_conv_{group_idx}' if prefix else None group_conv = Conv2D( group_filters, kernel_size=(3, 3), strides=strides, padding='same', use_bias=False, name=name )(inputs) group_convs.append(group_conv) # 合并所有组的卷积结果 if len(group_convs) > 1: name = f'{prefix}_concat' if prefix else None output = Concatenate(name=name)(group_convs) else: output = group_convs[0] return output # ResNeXt残差块
def block(x, filters, strides=1, groups=32, conv_shortcut=True, block_id=None): """ ResNeXt残差单元 参数: - x: 输入张量 - filters: 过滤器数量(最终输出将是filters*2) - strides: 步长 - groups: 分组数量 - conv_shortcut: 是否使用卷积快捷连接 - block_id: 块ID,用于唯一命名 返回: - 输出张量 """ prefix = f'block{block_id}' if block_id is not None else None # 快捷连接 if conv_shortcut: shortcut_name = f'{prefix}_shortcut_conv' if prefix else None shortcut = Conv2D(filters * 2, kernel_size=(1, 1), strides=strides, padding='same', use_bias=False, name=shortcut_name)(x) shortcut_bn_name = f'{prefix}_shortcut_bn' if prefix else None shortcut = BatchNormalization(epsilon=1.001e-5, name=shortcut_bn_name)(shortcut) else: shortcut = x # 三层卷积 # 第一层: 1x1卷积降维 conv1_name = f'{prefix}_conv1' if prefix else None x = Conv2D(filters=filters, kernel_size=(1, 1), strides=1, padding='same', use_bias=False, name=conv1_name)(x) bn1_name = f'{prefix}_bn1' if prefix else None x = BatchNormalization(epsilon=1.001e-5, name=bn1_name)(x) relu1_name = f'{prefix}_relu1' if prefix else None x = ReLU(name=relu1_name)(x) # 第二层: 分组3x3卷积 x = grouped_convolution_block(x, filters, strides, groups, prefix=prefix) bn2_name = f'{prefix}_bn2' if prefix else None x = BatchNormalization(epsilon=1.001e-5, name=bn2_name)(x) relu2_name = f'{prefix}_relu2' if prefix else None x = ReLU(name=relu2_name)(x) # 第三层: 1x1卷积升维 conv3_name = f'{prefix}_conv3' if prefix else None x = Conv2D(filters=filters * 2, kernel_size=(1, 1), strides=1, padding='same', use_bias=False, name=conv3_name)(x) bn3_name = f'{prefix}_bn3' if prefix else None x = BatchNormalization(epsilon=1.001e-5, name=bn3_name)(x) # 添加残差连接 add_name = f'{prefix}_add' if prefix else None x = Add(name=add_name)([x, shortcut]) relu3_name = f'{prefix}_relu3' if prefix else None x = ReLU(name=relu3_name)(x) return x # 堆叠残差块
def stack(x, filters, blocks, strides=1, groups=32, stack_id=None): """ 堆叠多个残差单元 参数: - x: 输入张量 - filters: 过滤器数量 - blocks: 残差单元数量 - strides: 第一个残差单元的步长 - groups: 分组数量 - stack_id: 堆栈ID,用于唯一命名 返回: - 输出张量 """ # 第一个残差单元可能会改变通道数和特征图大小 block_prefix = f'{stack_id}_0' if stack_id is not None else None x = block(x, filters, strides=strides, groups=groups, block_id=block_prefix) # 堆叠剩余的残差单元 for i in range(1, blocks): block_prefix = f'{stack_id}_{i}' if stack_id is not None else None x = block(x, filters, groups=groups, conv_shortcut=False, block_id=block_prefix) return x # 构建ResNeXt50模型
def ResNeXt50(input_shape=(224, 224, 3), num_classes=1000, groups=32): """ 构建ResNeXt-50模型 参数: - input_shape: 输入图像形状 - num_classes: 分类数量 - groups: 基数(分组数量) 返回: - Keras模型 """ # 定义输入 input_tensor = Input(shape=input_shape) # 初始卷积层 x = Conv2D(64, kernel_size=(7, 7), strides=2, padding='same', use_bias=False, name='conv1')(input_tensor) x = BatchNormalization(epsilon=1.001e-5, name='bn1')(x) x = ReLU(name='relu1')(x) # 最大池化 x = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same', name='max_pool')(x) # 四个阶段的残差块堆叠 # Stage 1 x = stack(x, 128, 3, strides=1, groups=groups, stack_id='stage1') # Stage 2 x = stack(x, 256, 4, strides=2, groups=groups, stack_id='stage2') # Stage 3 x = stack(x, 512, 6, strides=2, groups=groups, stack_id='stage3') # Stage 4 x = stack(x, 1024, 3, strides=2, groups=groups, stack_id='stage4') # 全局平均池化 x = GlobalAveragePooling2D(name='avg_pool')(x) # 全连接分类层 x = Dense(num_classes, activation='softmax', name='fc')(x) # 创建模型 model = Model(inputs=input_tensor, outputs=x, name='resnext50') return model # 创建数据生成器
def create_data_generators(data_dir, img_size=(224, 224), batch_size=32): """ 创建训练、验证和测试数据生成器 参数: - data_dir: 数据集根目录 - img_size: 图像大小 - batch_size: 批次大小 返回: - train_generator: 训练数据生成器 - validation_generator: 验证数据生成器 - test_generator: 测试数据生成器 - num_classes: 类别数量 """ # 数据增强设置 - 训练集 train_datagen = ImageDataGenerator( rescale=1. / 255, rotation_range=20, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest' ) # 仅进行缩放 - 验证集和测试集 valid_datagen = ImageDataGenerator( rescale=1. / 255 ) # 路径设置 train_dir = os.path.join(data_dir, 'train') valid_dir = os.path.join(data_dir, 'val') test_dir = os.path.join(data_dir, 'test') # 检查目录是否存在 if not os.path.exists(train_dir): raise FileNotFoundError(f"训练集目录不存在: {train_dir}") if not os.path.exists(valid_dir): raise FileNotFoundError(f"验证集目录不存在: {valid_dir}") # 创建生成器 train_generator = train_datagen.flow_from_directory( train_dir, target_size=img_size, batch_size=batch_size, class_mode='categorical', shuffle=True ) validation_generator = valid_datagen.flow_from_directory( valid_dir, target_size=img_size, batch_size=batch_size, class_mode='categorical', shuffle=False ) # 检查测试集 test_generator = None if os.path.exists(test_dir): test_generator = valid_datagen.flow_from_directory( test_dir, target_size=img_size, batch_size=batch_size, class_mode='categorical', shuffle=False ) print(f"测试集已加载: {test_generator.samples} 张图像") num_classes = len(train_generator.class_indices) print(f"类别数量: {num_classes}") print(f"类别映射: {train_generator.class_indices}") return train_generator, validation_generator, test_generator, num_classes # 训练模型
def train_model(model, train_generator, validation_generator, epochs=20, initial_epoch=0): """ 训练模型 参数: - model: Keras模型 - train_generator: 训练数据生成器 - validation_generator: 验证数据生成器 - epochs: 总训练轮数 - initial_epoch: 初始轮数(用于断点续训) 返回: - history: 训练历史 """ # 创建保存目录 os.makedirs('models', exist_ok=True) os.makedirs('logs', exist_ok=True) # 设置回调函数 callbacks = [ # 保存最佳模型 ModelCheckpoint( filepath='models/resnext50_best.h5', monitor='val_accuracy', save_best_only=True, verbose=1 ), # 学习率调度器 ReduceLROnPlateau( monitor='val_loss', factor=0.5, patience=3, verbose=1, min_delta=0.0001, min_lr=1e-6 ), # 早停 EarlyStopping( monitor='val_loss', patience=8, verbose=1, restore_best_weights=True ), # TensorBoard日志 TensorBoard( log_dir=f'logs/resnext50_{datetime.now().strftime("%Y%m%d-%H%M%S")}', histogram_freq=1 ) ] # 编译模型 model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=['accuracy'] ) # 设置训练步数 steps_per_epoch = train_generator.samples // train_generator.batch_size validation_steps = validation_generator.samples // validation_generator.batch_size # 确保至少有一个步骤 steps_per_epoch = max(1, steps_per_epoch) validation_steps = max(1, validation_steps) print(f"开始训练模型,共 {epochs} 轮...") print(f"训练步数: {steps_per_epoch}, 验证步数: {validation_steps}") # 训练模型 history = model.fit( train_generator, steps_per_epoch=steps_per_epoch, epochs=epochs, initial_epoch=initial_epoch, validation_data=validation_generator, validation_steps=validation_steps, callbacks=callbacks, verbose=1 ) # 保存最终模型 model.save('models/resnext50_final.h5') print("训练完成,模型已保存为 'models/resnext50_final.h5'") return history # 评估模型
def evaluate_model(model, generator, set_name="测试集"): """ 评估模型 参数: - model: Keras模型 - generator: 数据生成器 - set_name: 数据集名称(用于打印) 返回: - results: 评估结果 """ if generator is None: print(f"{set_name}不存在,跳过评估") return None print(f"评估模型在{set_name}上的性能...") steps = generator.samples // generator.batch_size steps = max(1, steps) # 确保至少有一个步骤 results = model.evaluate(generator, steps=steps, verbose=1) print(f"{set_name}损失: {results[0]:.4f}") print(f"{set_name}准确率: {results[1]:.4f}") return results # 绘制训练历史
def plot_training_history(history): """ 绘制训练历史曲线 参数: - history: 训练历史 """ set_chinese_font() # 创建图表 fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5)) # 绘制准确率曲线 ax1.plot(history.history['accuracy'], label='训练准确率', linewidth=2) ax1.plot(history.history['val_accuracy'], label='验证准确率', linewidth=2) ax1.set_title('模型准确率', fontsize=14) ax1.set_ylabel('准确率', fontsize=12) ax1.set_xlabel('轮次', fontsize=12) ax1.grid(True, linestyle='--', alpha=0.7) ax1.legend(loc='lower right', fontsize=10) # 绘制损失曲线 ax2.plot(history.history['loss'], label='训练损失', linewidth=2) ax2.plot(history.history['val_loss'], label='验证损失', linewidth=2) ax2.set_title('模型损失', fontsize=14) ax2.set_ylabel('损失', fontsize=12) ax2.set_xlabel('轮次', fontsize=12) ax2.grid(True, linestyle='--', alpha=0.7) ax2.legend(loc='upper right', fontsize=10) plt.tight_layout() plt.savefig('training_history.png', dpi=120) plt.show() # 可视化预测结果
def visualize_predictions(model, generator, num_images=5): """ 可视化模型预测结果 参数: - model: Keras模型 - generator: 数据生成器 - num_images: 要显示的图像数量 """ set_chinese_font() # 获取类别标签 class_indices = generator.class_indices class_names = {v: k for k, v in class_indices.items()} # 获取一批图像 x, y_true = next(generator) # 仅使用前num_images张图像 x = x[:num_images] y_true = y_true[:num_images] # 预测 y_pred = model.predict(x) # 创建图表 fig = plt.figure(figsize=(15, 10)) for i in range(num_images): # 获取图像 img = x[i] # 获取真实标签和预测标签 true_label = np.argmax(y_true[i]) pred_label = np.argmax(y_pred[i]) pred_prob = y_pred[i][pred_label] # 获取类别名称 true_class_name = class_names[true_label] pred_class_name = class_names[pred_label] # 创建子图 plt.subplot(1, num_images, i + 1) # 显示图像 plt.imshow(img) # 设置标题 title_color = 'green' if true_label == pred_label else 'red' plt.title(f"真实: {true_class_name}\n预测: {pred_class_name}\n概率: {pred_prob:.2f}", color=title_color, fontsize=10) plt.axis('off') plt.tight_layout() plt.savefig('prediction_results.png', dpi=120) plt.show() # 测试单张图像
def predict_image(model, image_path, class_names, img_size=(224, 224)): """ 预测单张图像 参数: - model: Keras模型 - image_path: 图像路径 - class_names: 类别名称字典 - img_size: 图像大小 返回: - pred_class: 预测的类别 - confidence: 置信度 """ from tensorflow.keras.preprocessing import image # 加载图像 img = image.load_img(image_path, target_size=img_size) # 转换为数组 x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = x / 255.0 # 归一化 # 预测 preds = model.predict(x) # 获取最高置信度的类别 pred_class_idx = np.argmax(preds[0]) confidence = preds[0][pred_class_idx] # 获取类别名称 pred_class = class_names[pred_class_idx] return pred_class, confidence # 打印模型架构并显示中间特征图尺寸
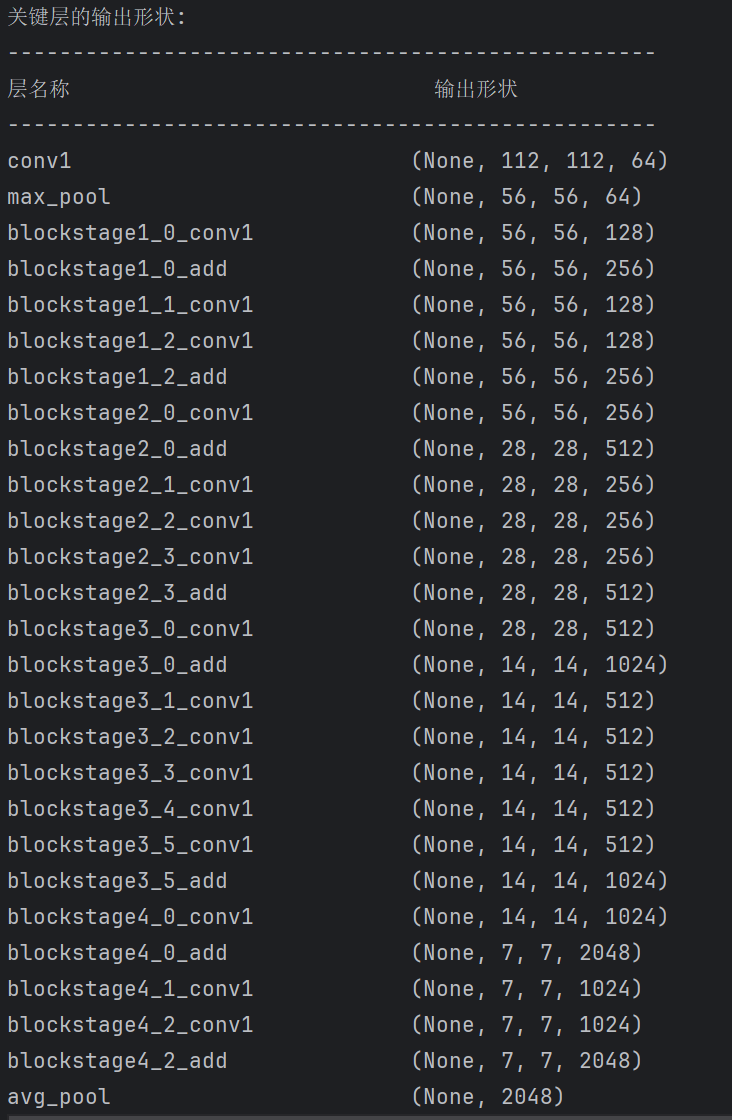
def print_model_architecture(model): """ 打印模型架构信息,包括每层输出形状 参数: - model: Keras模型 """ # 打印模型摘要 model.summary() # 显示每个块的输出形状 layer_outputs = [] layer_names = [] # 选择要显示的关键层 target_layers = [ 'conv1', 'max_pool', 'stage1_0_add', 'stage1_2_add', 'stage2_0_add', 'stage2_3_add', 'stage3_0_add', 'stage3_5_add', 'stage4_0_add', 'stage4_2_add', 'avg_pool' ] print("\n关键层的输出形状:") print("-" * 50) print(f"{'层名称':<30} {'输出形状':<20}") print("-" * 50) for layer in model.layers: if any(target_name in layer.name for target_name in target_layers): print(f"{layer.name:<30} {str(layer.output_shape):<20}") # 主函数
def main(): """主函数""" # 设置参数 DATA_DIR = './data' IMG_SIZE = (224, 224) BATCH_SIZE = 32 EPOCHS = 20 CARDINALITY = 32 # 获取当前设备信息 print(f"TensorFlow版本: {tf.__version__}") print(f"使用设备: {'GPU' if tf.config.list_physical_devices('GPU') else 'CPU'}") try: # 创建数据生成器 print("加载数据集...") train_generator, validation_generator, test_generator, num_classes = create_data_generators( DATA_DIR, IMG_SIZE, BATCH_SIZE ) # 创建模型 print(f"创建ResNeXt-50模型 (基数={CARDINALITY})...") model = ResNeXt50( input_shape=(IMG_SIZE[0], IMG_SIZE[1], 3), num_classes=num_classes, groups=CARDINALITY ) # 显示模型架构 print_model_architecture(model) # 计算模型参数量 trainable_params = np.sum([np.prod(v.get_shape()) for v in model.trainable_weights]) non_trainable_params = np.sum([np.prod(v.get_shape()) for v in model.non_trainable_weights]) total_params = trainable_params + non_trainable_params print(f"模型参数数量: {total_params:,}") print(f"可训练参数: {trainable_params:,}") print(f"不可训练参数: {non_trainable_params:,}") # 检查是否有已保存的模型,实现断点续训 initial_epoch = 0 if os.path.exists('models/resnext50_final.h5'): print("找到已保存的模型,询问是否继续训练...") choice = input("是否继续训练已保存的模型?(y/n): ") if choice.lower() == 'y': print("加载已保存的模型...") model = tf.keras.models.load_model('models/resnext50_final.h5') initial_epoch = int(input("请输入起始轮数: ")) else: print("从头开始训练新模型...") # 训练模型 print("开始训练模型...") start_time = time.time() history = train_model(model, train_generator, validation_generator, EPOCHS, initial_epoch) training_time = time.time() - start_time print(f"训练完成,耗时: {training_time:.2f} 秒") # 绘制训练历史 plot_training_history(history) # 评估验证集 evaluate_model(model, validation_generator, "验证集") # 评估测试集 evaluate_model(model, test_generator, "测试集") # 可视化预测结果 print("可视化预测结果...") visualize_predictions(model, validation_generator) # 找一张测试图像进行单独预测 if test_generator: print("查找测试图像进行单独预测...") # 获取测试集中的一张图像路径 test_dir = os.path.join(DATA_DIR, 'test') class_dirs = [d for d in os.listdir(test_dir) if os.path.isdir(os.path.join(test_dir, d))] if class_dirs: # 选择第一个类别目录 class_dir = class_dirs[0] class_path = os.path.join(test_dir, class_dir) # 获取目录中的图像 images = [f for f in os.listdir(class_path) if f.endswith(('.jpg', '.jpeg', '.png'))] if images: # 选择第一张图像 image_path = os.path.join(class_path, images[0]) # 获取类别名称 class_indices = test_generator.class_indices class_names = {v: k for k, v in class_indices.items()} # 预测图像 pred_class, confidence = predict_image(model, image_path, class_names, IMG_SIZE) print(f"测试图像路径: {image_path}") print(f"真实类别: {class_dir}") print(f"预测类别: {pred_class}") print(f"预测置信度: {confidence:.4f}") print("所有操作完成!") except Exception as e: print(f"发生错误: {e}") import traceback traceback.print_exc() if __name__ == "__main__": main()
2. 关于快捷链接
残差连接是ResNet和ResNeXt架构的核心创新之一,它允许信息直接从一层"跳过"到另一层,绕过中间的卷积操作。这解决了深层网络中的梯度消失问题,使得非常深的网络也能有效训练。
# 快捷连接
if conv_shortcut: shortcut_name = f'{prefix}_shortcut_conv' if prefix else None shortcut = Conv2D(filters * 2, kernel_size=(1, 1), strides=strides, padding='same', use_bias=False, name=shortcut_name)(x) shortcut_bn_name = f'{prefix}_shortcut_bn' if prefix else None shortcut = BatchNormalization(epsilon=1.001e-5, name=shortcut_bn_name)(shortcut)
else: shortcut = x
当conv_shortcut=True:当输入和输出的尺寸或通道数不匹配时,需要使用卷积型快捷连接,使用kernel_size=(1, 1)的卷积进行通道转换,将输入通道数转换为filters*2,然后使用批量归一批标准化卷积输出。
当conv_shortcut=False: 当输入和输出的尺寸和通道数完全匹配时,使用恒等型快捷连接,也就是不做任何的变换。确实这里可能会出现一个问题那就是通道数不匹配的问题,但是我们的代码是可以正常执行的,为什么呢?按我的理解:通道数不一致肯定不行。看一下残差堆叠的代码:
# 堆叠残差块
def stack(x, filters, blocks, strides=1, groups=32, stack_id=None): """ 堆叠多个残差单元 参数: - x: 输入张量 - filters: 过滤器数量 - blocks: 残差单元数量 - strides: 第一个残差单元的步长 - groups: 分组数量 - stack_id: 堆栈ID,用于唯一命名 返回: - 输出张量 """ # 第一个残差单元可能会改变通道数和特征图大小 block_prefix = f'{stack_id}_0' if stack_id is not None else None x = block(x, filters, strides=strides, groups=groups, block_id=block_prefix) # 堆叠剩余的残差单元 for i in range(1, blocks): block_prefix = f'{stack_id}_{i}' if stack_id is not None else None x = block(x, filters, groups=groups, conv_shortcut=False, block_id=block_prefix) return x
在for之前,第一个残差单元是确定的:x = block(x, filters, strides=strides, groups=groups, block_id=block_prefix) 这是通道数已经完成了转换,而后续的残差单元是通过for在生成的,它并没有改变通道数,而是使用了第一个残差单元的通道数。那么最后输出肯定也是一致的通道数。
因此我们总结:
- 第一个残差单元总是默认conv_shortcut=True,完成了通道数的转换。
- 前一个block的返回值成为下一个block的输入,这样保证了通道数一致。
相关文章:

第J7周:ResNeXt解析
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标 具体实现 (一)环境 语言环境:Python 3.10 编 译 器: PyCharm 框 架: Tensorflow (二)具体…...
)
机器学习-无量纲化与特征降维(一)
一.无量纲化-预处理 无量纲,即没有单位的数据 无量纲化包括"归一化"和"标准化",这样做有什么用呢?假设用欧式距离计算一个公司员工之间的差距,有身高(m)、体重(kg&#x…...
:JWT介绍)
Shiro(八):JWT介绍
1、什么是JWT? JWT(JSON Web Token,JSON Web令牌)是一种开放标准(RFC 7519),用于在网络应 用环境间安全地传递声明(claims)作为JSON对象;JWT会按指定的加密算…...

linux0.11内核源码修仙传第十六章——获取硬盘信息
🚀 前言 书接第十四章:linux0.11内核源码修仙传第十四章——进程调度之fork函数,在这一节博客中已经通过fork进程创建了一个新的进程1,并且可以被调度,接下来接着主线继续走下去。希望各位给个三连,拜托啦&…...

画家沈燕的山水实验:在传统皴法里植入时代密码
导语:当宋代山水遇上AI算法,当青绿颜料邂逅生态数据,沈燕在宣纸与人工智能的交界处,开启了一场关于水墨基因的“基因突变”实验。她的画笔既似考古学家的洛阳铲,又似未来学家的扫描仪,在古今对话中重构山水…...

聊聊四种实时通信技术:短轮询、长轮询、WebSocket 和 SSE
这篇文章,我们聊聊 四种实时通信技术:短轮询、长轮询、WebSocket 和 SSE 。 1 短轮询 浏览器 定时(如每秒)向服务器发送 HTTP 请求,服务器立即返回当前数据(无论是否有更新)。 优点࿱…...

国联股份卫多多与北京经纬智诚签署战略合作协议
5月9日,北京经纬智诚电子商务有限公司(以下简称“经纬智诚”)总经理王学文一行到访国联股份卫多多,同卫多多/纸多多副总裁、产发部总经理段任飞,卫多多机器人产业链总经理郭碧波展开深入交流,双方就未来合作…...

在 Envoy 的配置文件中出现的 “@type“ 字段
在 Envoy 的配置文件中出现的 "type" 字段是 Protocol Buffers(Protobuf)的 JSON/YAML 编码规范的一部分,属于 Typed Struct 的表示方式。它的作用是明确指定当前配置对象的 Protobuf 类型,以便 Envoy 正确解析配置。以…...

编译原理实验 之 语法分析程序自动生成工具Yacc实验
文章目录 实验环境准备复现实验例子分析总的文件架构实验任务 什么是Yacc Yacc(Yet Another Compiler Compiler)是一个语法分析程序自动生成工具,Yacc实验通常是在编译原理相关课程中进行的实践项目,旨在让学生深入理解编译器的语法分析阶段以及掌握Yac…...
)
【大模型】LLM概念相关问题(上)
1.主流的大语言模型 截至2025年,主流的大型语言模型(LLM)体系涵盖了多个国家和机构的成果,具有多样的架构设计、参数规模和应用场景。以下是一些具有代表性的开源和闭源 LLM 体系: 🇺🇸 OpenA…...

AWS IoT Core与MSK集成实战:打造高可靠实时IoT数据管道
在物联网快速发展的今天,如何高效、安全地处理海量设备数据成为企业面临的一大挑战。本文将带您深入探索AWS IoT Core与Amazon MSK(Managed Streaming for Apache Kafka)的集成方案,手把手教您搭建一个可靠、可扩展的实时IoT数据处理管道。无论您是IoT开发者、大数据工程师还是…...

智慧交通-车门开关状态检测数据集VOC+YOLO格式1006张2类
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1006 标注数量(xml文件个数):1006 标注数量(txt文件个数):1006 …...

【传感器】代码——DHT11温湿度传感器
目录 一、代码流程 二、模块.c代码 三、模块.h代码 四、主函数代码 一、代码流程 1.模块复位:主机发送开始通信时序,从机做出响应(需检测是否有响应) 2.MCU读取1Bit数据 3.MCU读取1Byte数据 4.MCU读取8Byte数据组成完整Dat…...
MySQL 的事务(Transaction)
1. 什么是事务? 事务是一组原子性的数据库操作序列,这些操作要么全部执行成功,要么全部失败回滚。事务的目的是确保数据库从一个一致状态转换到另一个一致状态,即使在执行过程中发生错误或中断。 …...

vue知识点总结 依赖注入 动态组件 异步加载
一 依赖注入 使用场景:当需要多层组件需要传值 如 祖宗-》父亲-》儿子-》孙子如祖宗的数据需要直接传给孙子 在祖宗组件中写: data(){return {}} provide(){ return {shujukey:数据值 } }在孙子组件中接收,模板代码中直接使用{{shujukey}}获取数据 dat…...

【软件设计师:存储】16.计算机存储系统
一、主存储器 存储器是计算机系统中的记忆设备,用来存放程序和数据。 计算机中全部信息,包括输入的原始数据、计算机程序、中间运 行结果和最终运行结果都保存在存储器中。 存储器分为: 寄存器Cache(高速缓冲存储器)主存储器辅存储器一、存储器的存取方式 二、存储器的性…...

快速开发-基于gin的中间件web项目开发
一、概述 在 Gin 框架中,中间件(Middleware)是一种在处理 HTTP 请求之前或之后执行的函数。使用中间件可以方便地实现诸如身份验证(Auth)、日志记录、请求限流等功能。 二、编写中间件 // 中间件 func StartCost1(c …...

耀圣-气动带刮刀硬密封法兰球阀:攻克颗粒高粘度介质的自清洁 “利器”
气动带刮刀硬密封法兰球阀:攻克颗粒高粘度介质的自清洁 “利器” 在化工、矿业、食品加工等行业中,带颗粒高粘度介质、料浆及高腐蚀性介质的输送与控制一直是行业难题。普通阀门极易因介质附着、颗粒堆积导致卡阻失效,密封面磨损加剧&#x…...

MySQL + Elasticsearch:为什么要使用ES,使用场景与架构设计详解
MySQL Elasticsearch:为什么要使用ES,使用场景与架构设计详解 前言一、MySQL Elasticsearch的背景与需求1.1 为什么要使用Elasticsearch(ES)?1.2 为什么MySQL在某些场景下不足以满足需求?1.3 MySQL Elas…...
)
【C语言】--指针超详解(三)
目录 一.数组名的理解 二.使用指针访问数组 三.一维数组传参的本质 四.冒泡排序 五.二级指针 六.指针数组 6.1--指针数组的定义 6.2--指针数组模拟二维数组 🔥个人主页:草莓熊Lotso的个人主页 🎬作者简介:C方向学习者 &…...

污水处理厂逆袭:Ethernet/IP 转 CANopen 开启“智净”时代
在我们的日常生活中,污水处理厂发挥着至关重要的作用,它们处理着城市污水,确保我们的水源安全。然而,这些关键设施的运行和管理并非易事,尤其是在数字化转型的大潮中。现在,我们有了一款创新的解决方案——…...

ROS导航局部路径规划算法
在导航功能包中,局部路径规划器的位置如图红框所示。它接受全局路径规划器生成的全局路径以及里程计信息和局部代价地图,最后输出速度控制信息 一、DWA(Dynamic Window Approach) 原理介绍 DWA 是一种基于动态窗口采样的局部路…...

《深挖Java中的对象生命周期与垃圾回收机制》
大家好呀!👋 今天我们要聊一个Java中超级重要的话题——对象的生命周期和垃圾回收机制。 一、先来认识Java世界的"居民"——对象 👶 在Java世界里,一切皆对象。就像现实世界中的人一样,每个Java对象也有自…...

Java——包装类
目录 3.5 包装类 3.5 包装类 有时需要把基本类型转换为对象。所有基本类型都有一个与之对应的类。这些类称为包装器/类。这些类是不可变类,即一旦构造了包装器/类,就不允许改变包装在其中的值。其次包装类还是final,不用可以被继承。 为什么要…...

【谭浩强】第七章第14题
实验结果:当M1时输出的结果 实验总结:用define定义要频繁使用的值可以节省时间;求完一门课平均成绩之后要让sum重新等于0;求最高分对应的学生和对应的课程要循环完一遍覆盖一遍r和c的值; 程序代码 #include <stdi…...

Linux 内核中的 security_sk_free:安全模块与 Socket 释放机制解析
引言 在 Linux 内核中,网络通信和进程间交互(IPC)的核心数据结构之一是 struct sock(即 socket)。其生命周期管理涉及复杂的资源分配与释放逻辑。本文聚焦于 security_sk_free 这一函数,探讨其作用、调用场景以及与安全模块的交互机制,并解答一个常见疑问:在单机间 TC…...
)
学习笔记:黑马程序员JavaWeb开发教程(2025.4.1)
11.10 案例-配置文件-yml配置文件 Yml语法: 数据格式: 11.11 案例-配置文件-ConfigurationProperties 配置项自动注入,需要保持KEY的属性名一样,需要在文件中加上Data注解,要将这个类交给IOC容器管理,使其成…...

深度学习-161-Dify工具之对比使用工作流和聊天流生成图表可视化的html文件
文章目录 1 任务背景2 使用chatflow聊天流2.1 开始节点2.2 文档提取器2.3 LLM2.4 参数提取器2.5 代码执行2.6 直接回复2.7 应用展示3 生成html文件可视化图表3.1 使用workflow工作流3.1.1 LLM3.1.2 效果展示3.2 使用chatflow聊天流3.2.1 LLM3.2.2 效果展示4 参考附录分别使用聊…...

关于VScode的调试
调试代码要有这么几个工具:源代码、带调试符号的程序、MAP表,调试器。 在启动调试器之前,要首先编译带有符号表的程序,生成对应map。然后启动调试器。 不同的语言有不同的特性,比如解释型语言不需要编译成可执行程序…...
 ^ 3 − x ^ 2 * y ^ 3 = 1)
(x ^ 2 + 2y − 1) ^ 3 − x ^ 2 * y ^ 3 = 1
二元高次方程 EquationSolver20250509.java package math;import org.apache.commons.math3.analysis.MultivariateFunction; import org.apache.commons.math3.optim.InitialGuess; import org.apache.commons.math3.optim.MaxEval; import org.apache.commons.math3.optim.P…...

弹窗表单的使用,基于element-ui二次封装
el-dialog-form 介绍 基于element-ui封装的弹窗式表单组件 示例 git地址 https://gitee.com/chenfency/el-dialog-form.git 更新日志 2021-8-12 版本1.0.0 2021-8-17 优化组件,兼容element原组件所有Attributes及Events 2021-9-9 新增tip提示 安装教程 npm install …...

关系模式-无损连接和保持函数依赖的判断
1、怎样判断一个关系模式的分解是否是无损连接? 方法一:公式定理法 关系模式R<U,F>的一个分解具有无损连接的充分必要条件是: 或 方法二:表格法(常用与分解成3个及以上关系模式) a. 通过立一张j…...

Vmware 最新下载教程和安装教程,外带免下载文件
一、VMware 的简介 VMware 是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发、测试 、部署新的应用程序的最佳解决方案。VMware可在一部实体机器上模拟完整的网络环境,以及可便于携带的虚拟机…...

开平机:从原理到实践的全面技术剖析
一、开平机核心模块技术解析 1. 校平辊系的力学建模与辊型设计 校平机精度核心在于辊系设计,需通过弹塑性力学模型计算变形量。典型校平辊配置参数: 辊径比:校平辊直径(D)与板材厚度(t)需满足…...

Edu教育邮箱申请2025年5月
各位好,这里是aigc创意人竹相左边 如你所见,这里是第3部分 现在是选择大学的学科专业 选专业的时候记得考虑一下当前的时间日期。 比如现在是夏天,所以你选秋天入学是合理的。...

文本框碰撞测试
1.核心代码: // 初始化舞台和变量 var stage, textField, bounds, velocity;function init() {// 创建舞台stage = new createjs.Stage("canvas");// 设置矩形边界bounds = {x: 50, y: 50, width: 400, height: 300};// 绘制边界矩形var border = new createjs.Shap…...
——visualize_dataset_html.py/visualize_dataset.py)
LeRobot 项目部署运行逻辑(六)——visualize_dataset_html.py/visualize_dataset.py
可视化脚本包括了两个方法:远程下载 huggingface 上的数据集和使用本地数据集 脚本主要使用两个: 目前来说,ACT 采集训练用的是统一时间长度的数据集,此外,这两个脚本最大的问题在于不能裁剪,这也是比较好…...

Python函数:从基础到进阶的完整指南
在Python编程中,函数是构建高效、可维护代码的核心工具。无论是开发Web应用、数据分析还是人工智能模型,函数都能将复杂逻辑模块化,提升代码复用率与团队协作效率。本文将从函数基础语法出发,深入探讨参数传递机制、高阶特性及最佳…...

图灵爬虫练习平台第七题千山鸟飞绝js逆向
题目七:千山鸟飞绝 还是先进入开发者模式,一进来还是一个无限debugger,直接右键点击一律不在此处停留 然后点击下一页,复制curl进行代码生成,然后就会发现加密内容是headers中的m,ts,还有参数中的x…...

使用Python和OpenCV实现实时人脸检测与识别
前言 在计算机视觉领域,人脸检测与识别是两个非常重要的任务。人脸检测是指在图像中定位人脸的位置,而人脸识别则是进一步识别出人脸的身份。随着深度学习的发展,这些任务的准确性和效率都有了显著提升。OpenCV是一个开源的计算机视觉库&…...

Excel实现单元格内容拼接
一、应用场景: 场景A:将多个单元格拼接,比如写测试用例时,将多个模块拼接,中间用“-”隔开 场景B:将某单元格内容插入另一单元格固定位置(例如在B1中添加A1的内容) 二、实际应用&a…...

C语言实现:打印素数、最大公约数
本片博客起源于作者在经历了学校的测试之后猛然发现自己居然忘记了一些比较基础的代码,因此写了本片博客加强记忆 以下算法仅供参考 打印素数 打印:0到200之间所有的素数 #define _CRT_SECURE_NO_WARNINGS#include<stdio.h> #include<math.h&…...

TDengine 在智慧油田领域的应用
简介 智慧油田,亦称为数字油田或智能油田,是一种采用尖端信息技术与先进装备的现代油田开发模式。该模式通过实时更新油气田层析图及动态生产数据,显著提高了油气田的开发效率与经济价值。 信息技术在此领域发挥着至关重要的作用࿰…...

将 iconfont 图标转换成element-plus也能使用的图标组件
在做项目时发现,element-plus的图标组件,不能像文档示例中那样使用 iconfont 的图标。经过研究发现,element-plus的图标封装成了vue组件,组件内容是一个svg,然后以组件的方式引入和调用图标。根据这个思路,…...

使用程序绘制中文字体——中文字体的参数化设计方案初探
目录 写在前面基本设计思路笔画骨架参数设计笔画风格参数设计起笔风格转角风格字重变化弯曲程度 字形的“组装拟合”基于骨架的结构调整笔画绘制二三事撇的两侧轮廓绘制——不是两条贝塞尔曲线那么简单转角的处理,怎样能显得不突兀?笔画骨架关键点的拖拽…...

高频数据结构面试题总结
基础数据结构 1. 数组(Array) 特点:连续内存、固定大小、随机访问O(1)常见问题: 两数之和/三数之和合并两个有序数组删除排序数组中的重复项旋转数组最大子数组和(Kadane算法) 2. 链表(Linked List) 类型:单链表、双链表、循环链表常见问…...

工业设计破局密码:3D 可视化技术点燃产业升级引擎
3D可视化是一种将数据、信息或抽象概念以三维图形、模型和动画的形式呈现出来的技术。3D可视化技术通过构建三维数字孪生体,将设计思维转化为可交互的虚拟原型,不仅打破了传统二维设计的空间局限,更在效率、精度与用户体验层面开创了全新维度…...

【动态导通电阻】p-GaN HEMTs正向和反向导通下的动态导通电阻
2024 年,浙江大学的 Zonglun Xie 等人基于多组双脉冲测试方法,研究了两种不同技术的商用 p-GaN 栅极 HEMTs 在正向和反向导通模式以及硬开关和软开关条件下的动态导通电阻(RON)特性。实验结果表明,对于肖特基型 p-GaN 栅极 HEMTs,反向导通时动态 RON 比正向导通高 3%-5%;…...

Python代码编程基础
字符串 str.[]实现根据下标定位实现对元素的截取 for 循环可以实现遍历 while 循环可以在实现遍历的同时实现对某一下标数值的修改 字符串前加 r 可以实现对字符串的完整内容输出 字符串前加 f 可以实现对字符串内{}中包裹内容的格式化输出,仅在 v3.6 之后可用…...

基于RAG+MCP开发【企文小智】企业智能体
一、业务场景描述 1.1、背景介绍 几乎每家企业都积累了大量关于规章制度的文档资料,例如薪酬福利、绩效考核、保密协议、考勤管理、采购制度、资产管理制度等。这些文档大多以 Word、PDF 等非结构化格式存在。传统方式下,员工在查询某项具体规则时&…...