LeRobot 项目部署运行逻辑(六)——visualize_dataset_html.py/visualize_dataset.py
可视化脚本包括了两个方法:远程下载 huggingface 上的数据集和使用本地数据集
脚本主要使用两个:
![]()
目前来说,ACT 采集训练用的是统一时间长度的数据集,此外,这两个脚本最大的问题在于不能裁剪,这也是比较好的升级方向;
目录
1 可视化运行
1.1 远程 html
1.2 本地数据集
2 代码详解 visualize_dataset_html.py
2.1 综述
2.2 流程概览
2.3 库引用
2.4 mian() 函数
2.5 关键函数
2.5.1 run_server() —— Flask 应用核心
2.5.2 get_ep_csv_fname(episode_id)
2.5.3 get_episode_data()
2.5.4 get_episode_video_paths
2.5.5 get_episode_language_instruction
2.5.6 get_dataset_info(repo_id)
2.5.7 visualize_dataset_html
3 代码详解 visualize_dataset.py
3.1 综述
3.2 流程概览
3.3 库引用
3.4 mian() 函数
3.5 关键函数
3.5.1 采样器(EpisodeSampler)
3.5.2 图像转换(to_hwc_uint8_numpy)
3.5.3 核心可视化函数(visualize_dataset())
1 可视化运行
1.1 远程 html
对于开源数据集,只需要在 huggingface 上查看 id,比如 aloha_static_coffee 这个:
![]()
点进去选择 use this dataset,可以看到id
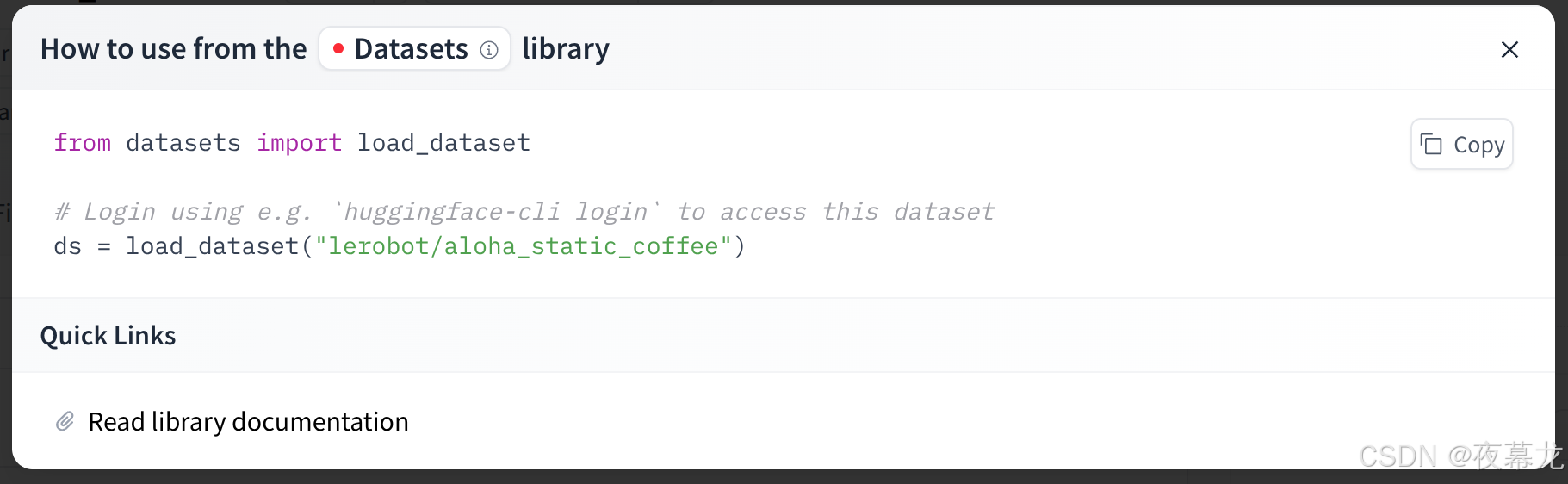
然后运行脚本:
python lerobot/scripts/visualize_dataset_html.py \--repo-id lerobot/aloha_static_coffee下载数据集后生成 web browser:http://127.0.0.1:9090

可以看到采集的各类信息:
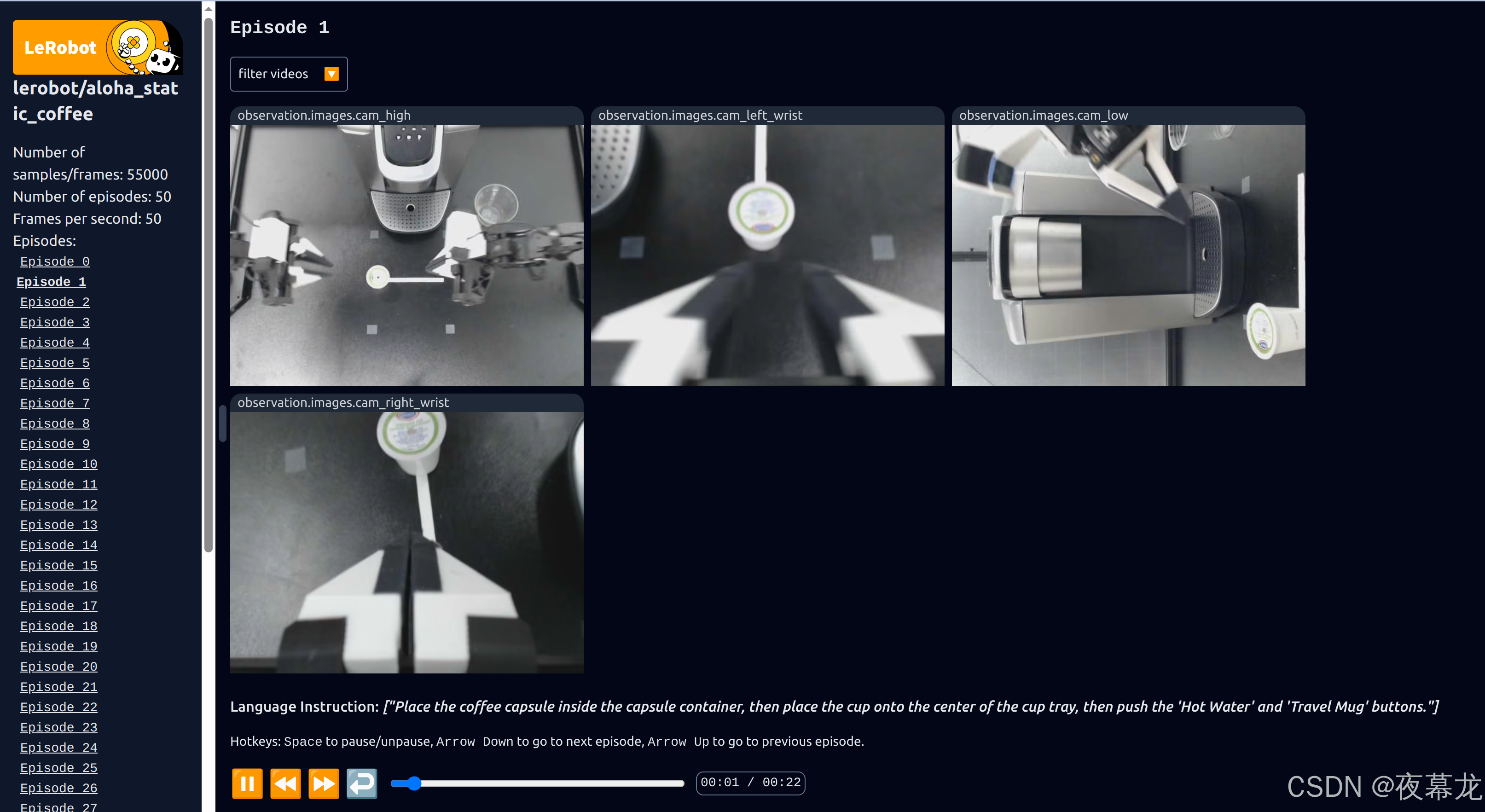
可以看到结果保存地址:

其中,下载的数据集默认存储在了 /home/yejiangchen/.cache/huggingface/lerobot/lerobot

下次再运行会直接调用无需下载
此外,如果想运行本地数据集,则需要指定 --root:
python lerobot/scripts/visualize_dataset_html.py \--root /home/yejiangchen/.cache/huggingface/lerobot/lerobot/aloha_static_coffee \--repo-id lerobot/aloha_static_coffee即可正常运行:

1.2 本地数据集
本地的话可以直接使用 visualize_dataset.py 脚本,测试一下之前下载的数据
python lerobot/scripts/visualize_dataset.py \--repo-id lerobot/aloha_static_coffee \--episode-index 0
2 代码详解 visualize_dataset_html.py
2.1 综述
此脚本将 LeRobotDataset 中的视频+时序传感数据(动作、状态等)渲染成交互式网页,方便快速浏览与排查
-
视频:在浏览器原生 <video> 标签播放
-
时序数值:转成 CSV 字符串,交给前端 Dygraphs JavaScript 库即刻绘制折线图
-
语言任务描述:展示在同一页面
-
部署:内置 Flask 服务器(默认 127.0.0.1:9090)即可本地或经 SSH‑tunnel 远程查看
2.2 流程概览
main() -> visualize_dataset_html() ->(配置、软链接)-> run_server() ->(HTTP 请求)-> get_dataset_info()、get_episode_data()、get_episode_language_instruction() 等
main()└─ 解析 CLI 参数└─ (可选)加载本地/远程数据集 → LeRobotDataset 或 IterableNamespace└─ visualize_dataset_html()├─ 创建/复用输出目录(含模板与静态文件)├─ (本地数据集)软链接视频到 static/videos└─ run_server() ←– 关键:注册所有 Flask 路由├─ "/" : 首页 / 数据集选择页├─ "/<ns>/<name>" : 自动跳到 episode_0└─ "/<ns>/<name>/episode_<id>" : 主可视化页面2.3 库引用
import argparse # 用于解析命令行参数
import csv # 用于生成 CSV 格式字符串
import json # 用于解析和生成 JSON 数据
import logging # 用于日志记录
import re # 用于正则表达式处理
import shutil # 用于文件和目录操作,如复制、删除
import tempfile # 用于创建临时目录
from io import StringIO # 用于将字符串当作文件读写
from pathlib import Path # 用于跨平台路径操作import numpy as np # 数值计算库
import pandas as pd # 数据处理库
import requests # 用于发起 HTTP 请求
from flask import Flask, redirect, render_template, request, url_for # Flask Web 框架核心组件from lerobot import available_datasets # 导入可用数据集列表
from lerobot.common.datasets.lerobot_dataset import LeRobotDataset # LeRobotDataset 类
from lerobot.common.datasets.utils import IterableNamespace # 简单 namespace 类型
from lerobot.common.utils.utils import init_logging # 初始化日志设置2.4 mian() 函数
作为脚本入口,负责解析所有命令行参数并据此准备数据集实例,最后调用 visualize_dataset_html() 启动可视化流程
核心流程:
- 用 argparse 定义并读取参数(如 --repo-id、--root、--episodes、--serve 等)
- 根据 --load-from-hf-hub 决定是实例化完整的 LeRobotDataset(加载本地/缓存数据与视频),还是只拉取元信息 (get_dataset_info)
- 将解析好的 dataset 对象与其它参数传入 visualize_dataset_html()
| 参数 | 作用 | 典型值 |
|---|---|---|
--repo-id | HF Hub 上的数据集 namespace/name | lerobot/pusht |
--root | 本地数据集根目录 | ./data |
--load-from-hf-hub | 整数;为 1 时只下拉 meta / parquet / mp4,不构造完整 LeRobotDataset | 0/1 |
--episodes | 想看的 episode 索引列表 | 0 3 5 |
--host, --port | Flask 服务地址 | 默认 127.0.0.1:9090 |
--tolerance-s | 时间戳容差,保证 fps 一致性 | 1e-4 |
def main():# 入口:解析命令行并调用可视化函数parser = argparse.ArgumentParser()parser.add_argument("--repo-id",type=str,default=None,help="Name of hugging face repositery containing a LeRobotDataset dataset (e.g. `lerobot/pusht`).",)parser.add_argument("--root",type=Path,default=None,help="Root directory for a dataset stored locally (e.g. `--root data`).",)parser.add_argument("--load-from-hf-hub",type=int,default=0,help="Load videos and parquet files from HF Hub rather than local system.",)parser.add_argument("--episodes",type=int,nargs="*",default=None,help="Episode indices to visualize (e.g. `0 1 5 6`).",)parser.add_argument("--output-dir",type=Path,default=None,help="Directory path to write html files and kickoff a web server.",)parser.add_argument("--serve",type=int,default=1,help="Launch web server.",)parser.add_argument("--host",type=str,default="127.0.0.1",help="Web host used by the http server.",)parser.add_argument("--port",type=int,default=9090,help="Web port used by the http server.",)parser.add_argument("--force-override",type=int,default=0,help="Delete the output directory if it exists already.",)parser.add_argument("--tolerance-s",type=float,default=1e-4,help=("Tolerance in seconds used to ensure data timestamps respect the dataset fps value""If not given, defaults to 1e-4."),)args = parser.parse_args() # 解析命令行参数kwargs = vars(args)repo_id = kwargs.pop("repo-id") # 获取 repo-id 并从 kwargs 删除load_from_hf_hub = kwargs.pop("load_from_hf_hub")root = kwargs.pop("root")tolerance_s = kwargs.pop("tolerance_s")dataset = Noneif repo_id:# 根据 load_from_hf_hub 决定实例化 LeRobotDataset 还是只读 metadataset = (LeRobotDataset(repo_id, root=root, tolerance_s=tolerance_s)if not load_from_hf_hubelse get_dataset_info(repo_id))visualize_dataset_html(dataset, **vars(args)) # 调用主可视化入口if __name__ == "__main__":# 脚本直接运行时进入 mainmain()2.5 关键函数
2.5.1 run_server() —— Flask 应用核心
全局配置:app.config["SEND_FILE_MAX_AGE_DEFAULT"] = 0 # 每次刷新都拉最新资源
路由配置:
| 路由 | 功能 |
|---|---|
/ | • 如果脚本在**“单数据集模式”**(已传 dataset),立刻重定向到 episode 0• 否则渲染首页,列出推荐 ( featured_datasets) + 全部可用数据集 (lerobot_datasets) |
/<ns>/<name> | 纯跳转:把 <dataset>/episode_0 作为入口 |
/<ns>/<name>/episode_<id> | 主工作函数: 1.若脚本启动时没载数据,就动态 get_dataset_info()2.检查数据集版本 <2 则拒绝(旧格式) 3.调用 get_episode_data() → CSV + 列信息;拼装 Video‑URL / Tasks‑Text4.把所有信息喂给 visualize_dataset_template.html 渲染 |
def run_server(dataset: LeRobotDataset | IterableNamespace | None,episodes: list[int] | None,host: str,port: str,static_folder: Path,template_folder: Path,
):"""启动 Flask HTTP 服务,渲染可视化页面。参数:- dataset: 已加载的数据集实例或 None- episodes: 要展示的 episode 列表或 None- host, port: 服务监听地址与端口- static_folder: 静态文件目录(视频、JS、CSS)- template_folder: Jinja2 模板目录"""app = Flask(__name__,static_folder=static_folder.resolve(), # 静态资源路径template_folder=template_folder.resolve() # 模板文件路径)app.config["SEND_FILE_MAX_AGE_DEFAULT"] = 0 # 禁用浏览器缓存,确保每次都拉最新的资源@app.route("/")def hommepage(dataset=dataset):"""应用根路由:根据有无 dataset 参数决定重定向或渲染选择页"""if dataset:# 如果在脚本启动时传入 dataset,直接跳转到第 0 集dataset_namespace, dataset_name = dataset.repo_id.split("/")return redirect(url_for("show_episode",dataset_namespace=dataset_namespace,dataset_name=dataset_name,episode_id=0,))# 否则尝试从 query 参数读取 dataset & episode 再跳转dataset_param, episode_param = None, Noneall_params = request.argsif "dataset" in all_params:dataset_param = all_params["dataset"]if "episode" in all_params:episode_param = int(all_params["episode"])if dataset_param:dataset_namespace, dataset_name = dataset_param.split("/")return redirect(url_for("show_episode",dataset_namespace=dataset_namespace,dataset_name=dataset_name,episode_id=episode_param if episode_param is not None else 0,))# 默认渲染首页,列出 featured + 全部 available datasetsfeatured_datasets = ["lerobot/aloha_static_cups_open","lerobot/columbia_cairlab_pusht_real","lerobot/taco_play",]return render_template("visualize_dataset_homepage.html",featured_datasets=featured_datasets,lerobot_datasets=available_datasets,)@app.route("/<string:dataset_namespace>/<string:dataset_name>")2.5.2 get_ep_csv_fname(episode_id)
简单工具,按约定返回某集 CSV 文件名 episode_{id}.csv
def get_ep_csv_fname(episode_id: int):# 根据 episode 索引构造 CSV 文件名ep_csv_fname = f"episode_{episode_id}.csv"return ep_csv_fname2.5.3 get_episode_data()
把单个 episode 的多通道数值数据 -> 二维列表 -> CSV 字符串(返给前端 JS)
1. 列挑选
selected = [col for col, ft in ds.features.items()if ft["dtype"] in ["float32", "int32"]]
selected.remove("timestamp")
2. 过滤高维张量:shape 维度 > 1 的列记入 ignored_columns,避免动态图崩溃
3. 列名展开:如果在 meta 里有 names 用定义好的;否则按 col_0 … col_n 生成
4. 取数据:本地 LeRobotDataset 利用 .episode_data_index 截取 parquet;Hub‑Only 直接 pd.read_parquet(url)
5. 转换为 CSV string(StringIO + csv.writer)
def get_episode_data(dataset: LeRobotDataset | IterableNamespace, episode_index):"""获取 episode 的时序数据,并将其转换为 CSV 字符串返回。Returns:- csv_string: CSV 格式的整个 episode 数据- columns: [{key: 原始列名, value: 展开后子列名列表}, ...]- ignored_columns: 被忽略的高维列名称列表"""columns = [] # 存储展开后列的信息# 选出所有 dtype 为 float32/int32 的数值列selected_columns = [col for col, ft in dataset.features.items() if ft["dtype"] in ["float32", "int32"]]selected_columns.remove("timestamp") # timestamp 先单独处理ignored_columns = [] # 高维列名称for column_name in selected_columns:shape = dataset.features[column_name]["shape"] # 列的原始 shapeshape_dim = len(shape)if shape_dim > 1:# 如果维度 >1,则忽略,不支持 Dygraph 绘多维张量selected_columns.remove(column_name)ignored_columns.append(column_name)# CSV header: timestamp + 各子列名header = ["timestamp"]# 遍历每个一维列,展开成多列子名称for column_name in selected_columns:dim_state = (dataset.meta.shapes[column_name][0]if isinstance(dataset, LeRobotDataset)else dataset.features[column_name].shape[0])if "names" in dataset.features[column_name] and dataset.features[column_name]["names"]:# 如果 meta 中定义了 names,则使用自定义子列名column_names = dataset.features[column_name]["names"]while not isinstance(column_names, list):column_names = list(column_names.values())[0]else:# 否则按 col_0...col_n 展开column_names = [f"{column_name}_{i}" for i in range(dim_state)]columns.append({"key": column_name, "value": column_names})header += column_names # 累加到 CSV header# timestamp 放回最前selected_columns.insert(0, "timestamp")if isinstance(dataset, LeRobotDataset):# 本地模式:根据 index 范围 select pandas DataFramefrom_idx = dataset.episode_data_index["from"][episode_index]to_idx = dataset.episode_data_index["to"][episode_index]data = (dataset.hf_dataset.select(range(from_idx, to_idx)).select_columns(selected_columns).with_format("pandas"))else:# 远程模式:通过 HTTP 拉取 parquet,然后筛列repo_id = dataset.repo_idurl = (f"https://huggingface.co/datasets/{repo_id}/resolve/main/"+ dataset.data_path.format(episode_chunk=int(episode_index) // dataset.chunks_size,episode_index=episode_index))df = pd.read_parquet(url)data = df[selected_columns]# 构造 numpy 二维数组:首列 timestamp,其余为各子列值rows = np.hstack((np.expand_dims(data["timestamp"], axis=1),*[np.vstack(data[col]) for col in selected_columns[1:]],)).tolist()# 写 CSV 到内存字符串csv_buffer = StringIO()csv_writer = csv.writer(csv_buffer)csv_writer.writerow(header)csv_writer.writerows(rows)csv_string = csv_buffer.getvalue()return csv_string, columns, ignored_columns2.5.4 get_episode_video_paths
仅在本地 LeRobotDataset 场景下,获取指定 episode 在底层 HF 数据集中的视频文件路径列表(内部没用到,备用)
- 找到该集第一帧在整表中的行索引
- 针对每个 dataset.meta.video_keys,在对应列读取 ["path"] 字段
def get_episode_video_paths(dataset: LeRobotDataset, ep_index: int) -> list[str]:# hack: 取该 episode 第一帧索引以定位 video pathfirst_frame_idx = dataset.episode_data_index["from"][ep_index].item()return [dataset.hf_dataset.select_columns(key)[first_frame_idx][key]["path"]for key in dataset.meta.video_keys]2.5.5 get_episode_language_instruction
仅在数据集包含 language_instruction 特征时调用,从对应行抽取并清洗掉 Tensor 的包装字符串,返回指令文本
- 判断 dataset.features 是否存在 language_instruction
- 取该集第一帧索引,读取字段,去掉前后缀冗余信息
def get_episode_language_instruction(dataset: LeRobotDataset, ep_index: int) -> list[str]:# 如果数据集含 language_instruction 特征,则提取并清洗字符串if "language_instruction" not in dataset.features:return Nonefirst_frame_idx = dataset.episode_data_index["from"][ep_index].item()language_instruction = dataset.hf_dataset[first_frame_idx]["language_instruction"]# 去除 Tensor 格式冗余包装return language_instruction.removeprefix("tf.Tensor(b'").removesuffix("', shape=(), dtype=string)")2.5.6 get_dataset_info(repo_id)
远程数据辅助:拉 meta/info.json 并包成 IterableNamespace
额外用 episodes.jsonl 找每一集的 tasks 列表
def get_dataset_info(repo_id: str) -> IterableNamespace:# 远程拉取 meta/info.json 并转为 IterableNamespaceresponse = requests.get(f"https://huggingface.co/datasets/{repo_id}/resolve/main/meta/info.json",timeout=5)response.raise_for_status()dataset_info = response.json()dataset_info["repo_id"] = repo_idreturn IterableNamespace(dataset_info)2.5.7 visualize_dataset_html
搭建静态目录结构(HTML 模板 + 静态资源),并根据是否已有数据集对象决定是否创建视频软链接,最后根据 serve 标志调用 run_server()
- 调用 init_logging() 初始化日志设置
- 计算模板目录 templates,创建或清空(若 force_override)输出目录以及 static 子目录
- 若传入本地 LeRobotDataset,在 static/videos 下打软链接指向数据集的 videos 文件夹
- 若 serve 为真,调用 run_server() 启动 Flask 服务
def visualize_dataset_html(dataset: LeRobotDataset | None,episodes: list[int] | None = None,output_dir: Path | None = None,serve: bool = True,host: str = "127.0.0.1",port: int = 9090,force_override: bool = False,
) -> Path | None:# 主函数:准备静态目录 & 启动服务器init_logging() # 配置根日志级别等template_dir = Path(__file__).resolve().parent.parent / "templates"if output_dir is None:# 未指定输出目录时,创建临时目录output_dir = tempfile.mkdtemp(prefix="lerobot_visualize_dataset_")output_dir = Path(output_dir)if output_dir.exists():if force_override:shutil.rmtree(output_dir) # 强制覆盖时先删掉else:logging.info(f"Output directory already exists. Loading from it: '{output_dir}'")output_dir.mkdir(parents=True, exist_ok=True)static_dir = output_dir / "static"static_dir.mkdir(parents=True, exist_ok=True)if dataset is None:# 仅在无本地 dataset 且 serve=True 时进入 run_serverif serve:run_server(dataset=None,episodes=None,host=host,port=port,static_folder=static_dir,template_folder=template_dir,)else:# 本地数据集:在 static/videos 创建软链接到 dataset.root/videosif isinstance(dataset, LeRobotDataset):ln_videos_dir = static_dir / "videos"if not ln_videos_dir.exists():ln_videos_dir.symlink_to((dataset.root / "videos").resolve())# 启动服务器if serve:run_server(dataset, episodes, host, port, static_dir, template_dir)3 代码详解 visualize_dataset.py
3.1 综述
此脚本基于 Rerun SDK,实现对 LeRobotDataset 中单个 episode 进行可视化或记录,主要有三种模式:
- 本地交互模式(mode="local") 直接在当前机器弹出可视化窗口,用于快速调试与观测
- 远端服务模式(mode="distant") 在数据存放的远端机器上启动 WebSocket+HTTP 服务,本地通过 rerun ws://… 连接浏览
- 离线保存模式(--save 1) 将整次会话记录到一个 .rrd 文件,后续可通过 rerun path/to/file.rrd 离线回放
其中,脚本既能实时显示视频帧,也能同步绘制动作、状态、奖励等时序数值
3.2 流程概览
main()├─ 解析 CLI 参数├─ LeRobotDataset(repo_id, root, tolerance_s)└─ visualize_dataset(...)├─ EpisodeSampler(dataset, episode_index)├─ DataLoader(dataset, sampler, batch_size, num_workers)├─ rr.init(namespace, spawn=local_viewer?)├─ gc.collect() # 避免多 worker 卡死├─ (mode=="distant")? rr.serve(web_port, ws_port)├─ for batch in DataLoader:│ ├─ for each frame in batch:│ │ ├─ rr.set_time_sequence/frame_index│ │ ├─ rr.set_time_seconds/timestamp│ │ ├─ rr.log(Image) for each camera│ │ └─ rr.log(Scalar) for each numeric field└─ 会话结束├─ local+save → rr.save(.rrd)└─ distant → 阻塞等待 Ctrl–C3.3 库引用
import argparse # 解析命令行参数模块
import gc # 垃圾回收模块,用于手动触发回收
import logging # 日志记录模块
import time # 时间相关函数模块
from pathlib import Path # 跨平台路径操作
from typing import Iterator # 类型提示:迭代器import numpy as np # 数值计算库
import rerun as rr # Rerun SDK,用于实时可视化
import torch # PyTorch 深度学习库
import torch.utils.data # PyTorch 数据加载工具
import tqdm # 进度条库from lerobot.common.datasets.lerobot_dataset import LeRobotDataset # 自定义 LeRobotDataset 数据集类3.4 mian() 函数
- 强制要求:--repo-id(数据集标识)和 --episode-index(要可视化的集号)
- 可选:数据集根目录、DataLoader 配置(--batch-size、--num-workers)、模式切换(--mode、--save、--output-dir、--web-port、--ws-port)等
- 最终实例化 LeRobotDataset 并调用 visualize_dataset()
def main():# 脚本入口:解析参数并调用可视化函数parser = argparse.ArgumentParser()parser.add_argument("--repo-id",type=str,required=True,help="HF Hub 上数据集标识,例如 `lerobot/pusht`。",)parser.add_argument("--episode-index",type=int,required=True,help="要可视化的 episode 索引。",)parser.add_argument("--root",type=Path,default=None,help="本地数据集根目录,例如 `--root data`。默认使用 HuggingFace 缓存。",)parser.add_argument("--output-dir",type=Path,default=None,help="保存 .rrd 文件的目录,当 `--save 1` 时生效。",)parser.add_argument("--batch-size",type=int,default=32,help="DataLoader 的 batch 大小。",)parser.add_argument("--num-workers",type=int,default=4,help="DataLoader 的并行工作进程数。",)parser.add_argument("--mode",type=str,default="local",help=("可视化模式:'local' 或 'distant'。`"local` 会本地弹出 viewer;`"distant` 则启动服务供远程浏览。"),)parser.add_argument("--web-port",type=int,default=9090,help="`--mode distant` 时的 HTTP 服务端口。",)parser.add_argument("--ws-port",type=int,default=9087,help="`--mode distant` 时的 WebSocket 服务端口。",)parser.add_argument("--save",type=int,default=0,help=("是否保存为 .rrd 文件,启用后会禁用弹窗。""使用 `--output-dir path` 指定目录。"),)parser.add_argument("--tolerance-s",type=float,default=1e-4,help=("时间戳容差,保证与 fps 一致。""传入 LeRobotDataset 构造参数。"),)args = parser.parse_args() # 解析命令行kwargs = vars(args)repo_id = kwargs.pop("repo_id") # 提取 repo_idroot = kwargs.pop("root") # 提取 roottolerance_s = kwargs.pop("tolerance_s") # 提取容差参数logging.info("Loading dataset") # 日志:开始加载数据集dataset = LeRobotDataset(repo_id, root=root, tolerance_s=tolerance_s) # 构造数据集visualize_dataset(dataset, **vars(args)) # 调用可视化主函数if __name__ == "__main__":# 如果脚本被直接执行,则运行 main()main()3.5 关键函数
3.5.1 采样器(EpisodeSampler)
只遍历指定 episode 在底层数据表(Parquet)中的帧索引范围,供 PyTorch DataLoader 使用
class EpisodeSampler(torch.utils.data.Sampler):# 自定义数据采样器,仅遍历指定 episode 的帧索引def __init__(self, dataset: LeRobotDataset, episode_index: int):# 根据 episode_index 从 dataset 中获取起始和结束的全局帧索引from_idx = dataset.episode_data_index["from"][episode_index].item()to_idx = dataset.episode_data_index["to"][episode_index].item()# 保存帧索引范围,用于 DataLoader 的 samplerself.frame_ids = range(from_idx, to_idx)def __iter__(self) -> Iterator:# 返回一个针对帧索引的迭代器return iter(self.frame_ids)def __len__(self) -> int:# 返回此 sampler 的总采样数量(即帧数)return len(self.frame_ids)3.5.2 图像转换(to_hwc_uint8_numpy)
把 PyTorch 的 C×H×W 浮点图像张量(float32, 值域 [0,1])转换为 NumPy 的 H×W×C uint8 数组(值域 [0,255]),以便 Rerun 显示
def to_hwc_uint8_numpy(chw_float32_torch: torch.Tensor) -> np.ndarray:# 将 C×H×W 的 float32 Torch 张量转换为 H×W×C 的 uint8 NumPy 数组assert chw_float32_torch.dtype == torch.float32 # 确保数据类型为 float32assert chw_float32_torch.ndim == 3 # 确保是 3 维c, h, w = chw_float32_torch.shape # 解包通道、高度、宽度assert c < h and c < w, f"expect channel first images, but instead {chw_float32_torch.shape}"# 先乘 255,再转 uint8,然后 permute 到 HWC,最后转换为 NumPyhwc_uint8_numpy = (chw_float32_torch * 255).type(torch.uint8).permute(1, 2, 0).numpy()return hwc_uint8_numpy # 返回处理后的图像数组3.5.3 核心可视化函数(visualize_dataset())
1. 初始化
- 构造 DataLoader(dataset, sampler=EpisodeSampler, batch_size, num_workers)
- 调用 rr.init() 启动 Rerun 会话
- 在远端模式下额外执行 rr.serve() 开启 WebSocket+HTTP 服务
2. 数据记录
- 遍历每个 batch、每帧
- 用 rr.set_time_sequence/rr.set_time_seconds 标注时间信息
- 对所有摄像头键(camera_keys)逐帧 rr.log(Image)
- 逐维 rr.log(Scalar) 记录 action、observation.state、next.reward、next.done、next.success 等数值
3. 会话收尾
- 本地保存模式:rr.save() 写出 .rrd 文件并返回路径
- 远端服务模式:进入阻塞循环以保持 WebSocket 连接,直至 Ctrl–C 退出
def visualize_dataset(dataset: LeRobotDataset,episode_index: int,batch_size: int = 32,num_workers: int = 0,mode: str = "local",web_port: int = 9090,ws_port: int = 9087,save: bool = False,output_dir: Path | None = None,
) -> Path | None:# 主可视化函数,根据模式(Local/Distant)实时或离线记录并展示数据if save:# 如果要保存为 .rrd 文件,必须传入 output_dirassert output_dir is not None, ("Set an output directory where to write .rrd files with `--output-dir path/to/directory`.")repo_id = dataset.repo_id # 获取数据集唯一标识logging.info("Loading dataloader") # 日志:开始加载 DataLoaderepisode_sampler = EpisodeSampler(dataset, episode_index) # 创建只遍历指定 episode 的 samplerdataloader = torch.utils.data.DataLoader(dataset, # 数据集num_workers=num_workers, # 并行加载进程数batch_size=batch_size, # 每个 batch 的帧数sampler=episode_sampler, # 自定义 sampler)logging.info("Starting Rerun") # 日志:启动 Rerun 会话if mode not in ["local", "distant"]:# 不支持其它模式时抛错raise ValueError(mode)# 本地模式且不保存时,自动 spawn viewer;否则不弹出spawn_local_viewer = mode == "local" and not saverr.init(f"{repo_id}/episode_{episode_index}", spawn=spawn_local_viewer)# Rerun v0.16 前的 workaround:触发垃圾回收,避免多进程 DataLoader 卡住gc.collect()if mode == "distant":# 远端模式:启动 WebSocket + HTTP 服务,不自动打开浏览器rr.serve(open_browser=False, web_port=web_port, ws_port=ws_port)logging.info("Logging to Rerun") # 日志:开始写入 Rerun 数据for batch in tqdm.tqdm(dataloader, total=len(dataloader)):# 遍历每个 batch,显示进度条for i in range(len(batch["index"])):# 记录时间序列:帧索引与时间戳rr.set_time_sequence("frame_index", batch["frame_index"][i].item())rr.set_time_seconds("timestamp", batch["timestamp"][i].item())# 遍历所有 camera key,记录图像for key in dataset.meta.camera_keys:rr.log(key, rr.Image(to_hwc_uint8_numpy(batch[key][i])))# 如果存在 action 字段,则按维度记录每个动作值if "action" in batch:for dim_idx, val in enumerate(batch["action"][i]):rr.log(f"action/{dim_idx}", rr.Scalar(val.item()))# 如果存在 observation.state,则按维度记录状态值if "observation.state" in batch:for dim_idx, val in enumerate(batch["observation.state"][i]):rr.log(f"state/{dim_idx}", rr.Scalar(val.item()))# 可选字段:next.done, next.reward, next.successif "next.done" in batch:rr.log("next.done", rr.Scalar(batch["next.done"][i].item()))if "next.reward" in batch:rr.log("next.reward", rr.Scalar(batch["next.reward"][i].item()))if "next.success" in batch:rr.log("next.success", rr.Scalar(batch["next.success"][i].item()))if mode == "local" and save:# 本地保存模式:写入 .rrd 文件并返回路径output_dir = Path(output_dir)output_dir.mkdir(parents=True, exist_ok=True)repo_id_str = repo_id.replace("/", "_")rrd_path = output_dir / f"{repo_id_str}_episode_{episode_index}.rrd"rr.save(rrd_path)return rrd_pathelif mode == "distant":# 远端模式:阻塞当前进程,直到手动按 Ctrl-Ctry:while True:time.sleep(1)except KeyboardInterrupt:print("Ctrl-C received. Exiting.")4 本地数据集效果
python lerobot/scripts/visualize_dataset.py --repo-id loacalhost/square_into_box --root=./collections/square_into_box/ --episode-index 0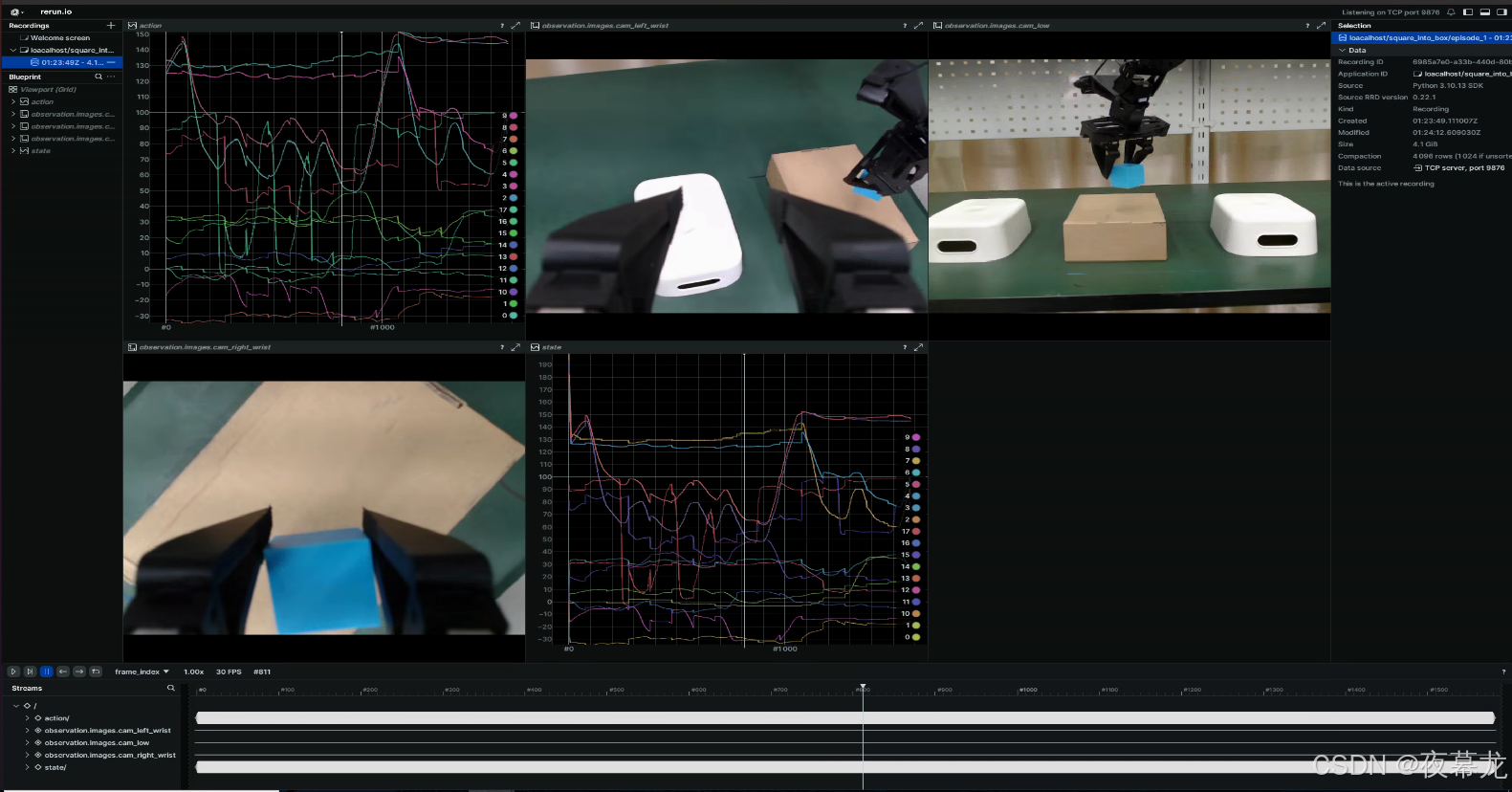
相关文章:
——visualize_dataset_html.py/visualize_dataset.py)
LeRobot 项目部署运行逻辑(六)——visualize_dataset_html.py/visualize_dataset.py
可视化脚本包括了两个方法:远程下载 huggingface 上的数据集和使用本地数据集 脚本主要使用两个: 目前来说,ACT 采集训练用的是统一时间长度的数据集,此外,这两个脚本最大的问题在于不能裁剪,这也是比较好…...

Python函数:从基础到进阶的完整指南
在Python编程中,函数是构建高效、可维护代码的核心工具。无论是开发Web应用、数据分析还是人工智能模型,函数都能将复杂逻辑模块化,提升代码复用率与团队协作效率。本文将从函数基础语法出发,深入探讨参数传递机制、高阶特性及最佳…...

图灵爬虫练习平台第七题千山鸟飞绝js逆向
题目七:千山鸟飞绝 还是先进入开发者模式,一进来还是一个无限debugger,直接右键点击一律不在此处停留 然后点击下一页,复制curl进行代码生成,然后就会发现加密内容是headers中的m,ts,还有参数中的x…...

使用Python和OpenCV实现实时人脸检测与识别
前言 在计算机视觉领域,人脸检测与识别是两个非常重要的任务。人脸检测是指在图像中定位人脸的位置,而人脸识别则是进一步识别出人脸的身份。随着深度学习的发展,这些任务的准确性和效率都有了显著提升。OpenCV是一个开源的计算机视觉库&…...

Excel实现单元格内容拼接
一、应用场景: 场景A:将多个单元格拼接,比如写测试用例时,将多个模块拼接,中间用“-”隔开 场景B:将某单元格内容插入另一单元格固定位置(例如在B1中添加A1的内容) 二、实际应用&a…...

C语言实现:打印素数、最大公约数
本片博客起源于作者在经历了学校的测试之后猛然发现自己居然忘记了一些比较基础的代码,因此写了本片博客加强记忆 以下算法仅供参考 打印素数 打印:0到200之间所有的素数 #define _CRT_SECURE_NO_WARNINGS#include<stdio.h> #include<math.h&…...

TDengine 在智慧油田领域的应用
简介 智慧油田,亦称为数字油田或智能油田,是一种采用尖端信息技术与先进装备的现代油田开发模式。该模式通过实时更新油气田层析图及动态生产数据,显著提高了油气田的开发效率与经济价值。 信息技术在此领域发挥着至关重要的作用࿰…...

将 iconfont 图标转换成element-plus也能使用的图标组件
在做项目时发现,element-plus的图标组件,不能像文档示例中那样使用 iconfont 的图标。经过研究发现,element-plus的图标封装成了vue组件,组件内容是一个svg,然后以组件的方式引入和调用图标。根据这个思路,…...

使用程序绘制中文字体——中文字体的参数化设计方案初探
目录 写在前面基本设计思路笔画骨架参数设计笔画风格参数设计起笔风格转角风格字重变化弯曲程度 字形的“组装拟合”基于骨架的结构调整笔画绘制二三事撇的两侧轮廓绘制——不是两条贝塞尔曲线那么简单转角的处理,怎样能显得不突兀?笔画骨架关键点的拖拽…...

高频数据结构面试题总结
基础数据结构 1. 数组(Array) 特点:连续内存、固定大小、随机访问O(1)常见问题: 两数之和/三数之和合并两个有序数组删除排序数组中的重复项旋转数组最大子数组和(Kadane算法) 2. 链表(Linked List) 类型:单链表、双链表、循环链表常见问…...

工业设计破局密码:3D 可视化技术点燃产业升级引擎
3D可视化是一种将数据、信息或抽象概念以三维图形、模型和动画的形式呈现出来的技术。3D可视化技术通过构建三维数字孪生体,将设计思维转化为可交互的虚拟原型,不仅打破了传统二维设计的空间局限,更在效率、精度与用户体验层面开创了全新维度…...

【动态导通电阻】p-GaN HEMTs正向和反向导通下的动态导通电阻
2024 年,浙江大学的 Zonglun Xie 等人基于多组双脉冲测试方法,研究了两种不同技术的商用 p-GaN 栅极 HEMTs 在正向和反向导通模式以及硬开关和软开关条件下的动态导通电阻(RON)特性。实验结果表明,对于肖特基型 p-GaN 栅极 HEMTs,反向导通时动态 RON 比正向导通高 3%-5%;…...

Python代码编程基础
字符串 str.[]实现根据下标定位实现对元素的截取 for 循环可以实现遍历 while 循环可以在实现遍历的同时实现对某一下标数值的修改 字符串前加 r 可以实现对字符串的完整内容输出 字符串前加 f 可以实现对字符串内{}中包裹内容的格式化输出,仅在 v3.6 之后可用…...

基于RAG+MCP开发【企文小智】企业智能体
一、业务场景描述 1.1、背景介绍 几乎每家企业都积累了大量关于规章制度的文档资料,例如薪酬福利、绩效考核、保密协议、考勤管理、采购制度、资产管理制度等。这些文档大多以 Word、PDF 等非结构化格式存在。传统方式下,员工在查询某项具体规则时&…...

【软件测试】测试用例的设计方法
目录 一、基于需求进行测试用例的设计 1.1 功能需求测试分析 二、黑盒测试用例设计方法 2.1 等价类划分法(解决穷举) 2.1.1 等价类设计步骤 2.1.2 等价类划分法案例 2.1.2.1 验证 QQ 账号的合法性 2.1.2.2 验证某城市电话号码的正确性 2.1.3 适用场景 2.2 边界值分析…...
——3.5高速以太网)
计算机网络笔记(十八)——3.5高速以太网
3.5.1 100BASE-T以太网 1. 基本概念 标准规范:IEEE 802.3u,是快速以太网的典型代表,运行速率100Mbps。物理介质:使用双绞线(UTP或STP),支持最大传输距离100米(Cat5/5e及以上&#…...

海外广告账号资源解析:如何选择适合业务的广告账户?
在全球化数字营销的浪潮下,海外广告投放已成为企业拓展市场的核心手段。然而,不同平台的广告账号类型复杂多样,如何选择适合自身业务的资源?本文将深度解析 Facebook、Google、TikTok 三大平台的广告账号类型,助您精准…...

Java设计模式之建造者模式:从入门到精通
1. 建造者模式概述 1.1 定义与核心概念 **建造者模式(Builder Pattern)**是一种创建型设计模式,它将复杂对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表示。 专业术语解释表: 术语解释产品(Product)最终要构建的复杂对象建造者(Builder)定义创建产品各个…...

Faiss 索引深度解析:从基础到实战
在处理高维数据的相似性搜索时,Faiss(Facebook AI Similarity Search)无疑是一款强大且高效的工具。它为我们提供了多种索引类型,适用于不同规模和需求的数据场景。本文将结合代码实例,深入剖析 Faiss 中常见索引的原理…...
 dapper sqlite)
Error parsing column 10 (YingShou=-99.5 - Double) dapper sqlite
在使用sqlite 调取 dapper的时候出现这个问题提示: 原因是 在 sqlite表中设定的字段类型是 decimel而在C#的字段属性也是decimel,结果解析F负数 小数的时候出现这个错误提示: 解决办法:使用默认的sqlite的字段类型来填入 REAL描述…...

星云智控:物联网时代的设备守护者——卓伊凡详解物联网监控革命-优雅草卓伊凡
星云智控:物联网时代的设备守护者——卓伊凡详解物联网监控革命-优雅草卓伊凡 一、物联网的本质解析 1.1 什么是物联网? 当卓伊凡被问及”星云智控物联网是干嘛的”这个问题时,他首先给出了一个技术定义:物联网(Int…...
——intelrealsense.py/configs.py)
LeRobot 项目部署运行逻辑(五)——intelrealsense.py/configs.py
在运行 control_robot.py 的时候会启用相机拍摄,lerobot 中封装好了两种相机类型:realsense 和 opencv realsense 直接使用他们的脚本就可以,但需要在 lerobot/robot_devices/robots/configs.py 中修改相机 serial_number 由于我们设备采用的…...
)
从0开始学linux韦东山教程第一三章问题小结(1)
本人从0开始学习linux,使用的是韦东山的教程,在跟着课程学习的情况下的所遇到的问题的总结,理论虽枯燥但是是基础。 摘要关键词:VMware、Ubuntu、网络网口 视频链接:【【韦东山】韦东山手把手教你嵌入式Linux快速入门到精通 | Lin…...

解决 MySQL 数据库无法远程连接的问题
在使用 MySQL 数据库时,遇到这样的问题: 本地可以连接 MySQL,但远程机器连接时,总是报错 Host ... is not allowed to connect to this MySQL server。 这通常是因为 MySQL 的用户权限或配置限制了远程访问。 1. 登录 MySQL 数据…...

分享一款开源的图片去重软件 ImageContrastTools,基于Electron和hash算法
最近发现个挺实在的图片查重软件,叫ImageContrastTools。电脑手机都能用,特别适合整理乱七八糟的相册。直接去这里下载就能用: https://github.com/html365/ImageContrastTools 功能说明: 1️⃣ 选个文件夹就能自动扫重复图&…...
)
软件测试——用例篇(2)
目录 一、基于需求的设计方法 1.1设计账号注册、账号登录的测试用例 1.1.1功能测试 1.1.2界面测试 1.1.3性能测试 1.1.4兼容性测试 1.1.5易用性测试 1.1.6安全测试 一、基于需求的设计方法 根据参考需求文档/产品规格说明书来设计测试用例 测试人员接到需求之后、对需求…...

图像匹配导航定位技术 第 11 章
第 11 章 基 于 改 进 SIFT 的 SAR 与 可 见光 图 像 匹 配 控 制 点 定 位 算 法 HOG 描述子也只是对整幅图像的特征向量进行匹配,但是仍然存在局部匹配误差。而局部不变特征(如 SIFT,Harris 等)是对特征点局部邻域的特征进行描述来构造局部…...

安装jdk步骤
将Linux安装jdk的步骤放入shell脚本中 #!/bin/bash # 阿里云服务器专用 - 全自动安装 OpenJDK 1.8(无交互) # 仅支持 yum 系系统(CentOS/RHEL/Alibaba Cloud Linux)# 检查 root 权限 if [ "$(id -u)" -ne 0 ]; thenech…...

理解 `.sln` 和 `.csproj`:从项目结构到构建发布的一次梳理
理解 .sln 和 .csproj:从项目结构到构建发布的一次梳理 在初学 .NET 项目开发时,很多人都会对 .sln(解决方案)和 .csproj(项目)文件感到疑惑。随着开发经验的积累,我逐渐理解了这些层级的设计意…...

高频算法面试题总结
高频算法面试题总结 排序算法 1. 基础排序算法 快速排序: public void quickSort(int[] arr, int low, int high) {if (low < high) {int pivot = partition(arr, low, high);quickSort(arr, low, pivot - 1);quickSort(arr, pivot + 1, high);} }平均时间复杂度:O(n lo…...

SQL进阶:如何把字段中的键值对转为JSON格式?
JSON 一、问题描述二、ORACLE<一>、键值对拆分(REGEXP_SUBSTR)<二>、转为JSON<三>、不足 三、MYSQL<一>、键值对拆分(RECURSIVE)<二>、转为JSON 一、问题描述 假如某张表的某列是键值对数据,如何把这个键值对转为json格式,数据如下所示 dynast…...

vue3:十二、图形看板- echart图表-柱状图、饼图
一、效果 如图展示增加了饼图和柱状图,并且优化了浏览器窗口大小更改,图表随着改变 二、 饼图 1、新建组件文件 新增组件EchartsExaminePie.vue,用于存储审核饼图的图表 2、写入组件信息 (1)视图层 写入一个div,写入变量chart和图表宽高 <template><div ref…...

nacos-server-2.2.2.tar及使用方式
下载链接 nacos-server-2.2.2.tar包及使用资源-CSDN文库 下载与安装 下载地址:可从 Nacos 官网版本下载页面 或 Nacos GitHub Releases 获取 nacos-server-2.2.2.tar.gz 安装包。 环境准备:Nacos 依赖 Java 环境运行,需确保安装了 64 位 J…...

el-form的label星号位置如何修改
默认情况 修改后 实现代码 .el-form {.el-form-item {.el-form-item__label {padding: 0;&::before {float: none;position: relative;}}} }...

小刚说C语言刷题—1004阶乘问题
1.题目描述 编程求 123⋯n 。 输入 输入一行,只有一个整数 n(1≤n≤10); 输出 输出只有一行(这意味着末尾有一个回车符号),包括 1 个整数。 样例 输入 5 输出 120 2.参考代码(C语言版) #include <stdio…...

Java 集合体系深度解析面试篇
一、Java 集合体系核心架构与高频考点 1. 集合体系架构图(大厂必问) Java集合框架 ├─ Collection(单列集合) │ ├─ List(有序、可重复) │ │ ├─ ArrayList(动态数组,随机…...

websocketd 10秒教程
websocketd 参考地址:joewalnes/websocketd 官网地址:websocketd websocketd简述 websocketd是一个简单的websocket服务Server,运行在命令行方式下,可以通过websocketd和已经有程序进行交互。 现在,可以非常容易地构…...

PCA降维
主成分分析(Principal Component Analysis,PCA)降维是一种广泛使用的无监督机器学习技术,主要用于数据预处理阶段,其目的是在尽量保留数据重要信息的前提下,减少数据的维度。 PCA 的原理 PCA 的核心思想…...

【计算机视觉】OpenCV实战项目: opencv-text-deskew:实时文本图像校正
opencv-text-deskew:基于OpenCV的实时文本图像校正 一、项目概述与技术背景1.1 核心功能与创新点1.2 技术指标对比1.3 技术演进路线 二、环境配置与算法原理2.1 硬件要求2.2 软件部署2.3 核心算法流程 三、核心算法解析3.1 文本区域定位3.2 角度检测优化3.3 仿射变换…...

具身智能时代的机器人导航和操作仿真器综述
系列文章目录 前言 导航和操作是具身智能的核心能力,然而在现实世界中训练具有这些能力的智能体却面临着高成本和时间复杂性。因此,从模拟到现实的转移已成为一种关键方法,但模拟到现实的差距依然存在。本调查通过分析以往调查中忽略的物理模…...

Go语言Stdio传输MCP Server示例【Cline、Roo Code】
Go语言 Stdio 传输 MCP Server 示例 AI 应用开发正处于加速发展阶段,新技术和新方法不断涌现。Model Context Protocol (MCP) 作为一个开放标准,正在改变 AI 应用与数据源和工具集成的方式。 Go-MCP 是一个 MCP 协议的 GO 实现&…...

Xcode16.3配置越狱开发环境
首先先在https://developer.apple.com/xcode/resources/ 这里面登陆Apple账号,然后访问url下载 https://download.developer.apple.com/Developer_Tools/Xcode_16.3/Xcode_16.3.xip 1、安装theos https://theos.dev/docs/installation-macos 会安装到默认位置~/th…...

AWS IoT Core与MSK跨账号集成:突破边界的IoT数据处理方案
随着企业规模的扩大和业务的复杂化,跨账号资源访问成为云架构中的一个常见需求。本文将深入探讨如何实现AWS IoT Core与Amazon MSK(Managed Streaming for Apache Kafka)的跨账号集成,为您的IoT数据处理方案开辟新的可能性。无论您是正在构建多账号架构,还是需要整合不同部门的…...
】)
【Python 列表(List)】
Python 中的列表(List)是最常用、最灵活的有序数据集合,支持动态增删改查操作。以下是列表的核心知识点: 一、基础特性 有序性:元素按插入顺序存储可变性:支持增删改操作允许重复:可存储重复元…...

在另一个省发布抖音作品,IP属地会随之变化吗?
你是否曾有过这样的疑惑:出差旅游时在外地发布了一条抖音视频,评论区突然冒出“IP怎么显示xx省了?”的提问?随着各大社交平台上线“IP属地”功能,用户的地理位置标识成为公开信息,而属地显示的“灵敏性”也…...

在线工具源码_字典查询_汉语词典_成语查询_择吉黄历等255个工具数百万数据 养站神器,安装教程
在线工具源码_字典查询_汉语词典_成语查询_择吉黄历等255个工具数百万数据 养站神器,安装教程 资源宝分享:https://www.httple.net/154301.html 一次性打包涵盖200个常用工具!无论是日常的图片处理、文件格式转换,还是实用的时间…...

D720201 PCIE 转USB HUB
1. 启动时出现了下面错误 [ 4.682595] pcieport 0004:00:00.0: Signaling PME through PCIe PME interrupt [ 4.684939] pci 0004:01:00.0: Signaling PME through PCIe PME interrupt [ 4.691287] pci 0004:01:00.0: enabling device (0000 -> 0002) [ 5.2962…...
)
QT事件介绍及实现字体放大缩小(滚轮)
使用update是为了回调paintEvent这个事件函数 pic.load是加载一张图片 setfixedsize(pic.siez())是为了把按键的矩形区域变成和pic一样大 painter.drawPixmap(rec(),pic)就是在按键的矩形区域画一个pic emit clicked();是用来发送clicked信号的,当然你也可以在事…...

p2p虚拟服务器
ZeroTier Central ✅ 推荐工具:ZeroTier(免费、稳定、跨平台) ZeroTier 可以帮你把多台设备(无论是否跨网)加入一个虚拟局域网,彼此间可以像在同一个 LAN 中通信,UDP 视频、文件传输、SSH 等都…...

高尔夫基本知识及规则·棒球1号位
高尔夫与棒球的结合看似跨界,但两者在规则、策略和运动哲学上存在有趣的关联性。以下从五个角度进行对比分析,揭示它们的异同与潜在联系: 一、核心目标的对比性结合 高尔夫:以最少击球次数完成18洞(标准杆72杆左右&am…...