Ascend的aclgraph(2)_npu_backend中还有些什么秘密?
1 _npu_backend
文章还是从代码开始
import torch_npu, torchair
config = torchair.CompilerConfig()
# 设置图下沉执行模式
config.mode = "reduce-overhead"
npu_backend = torchair.get_npu_backend(compiler_config=config)
opt_model = torch.compile(model, backend=npu_backend)
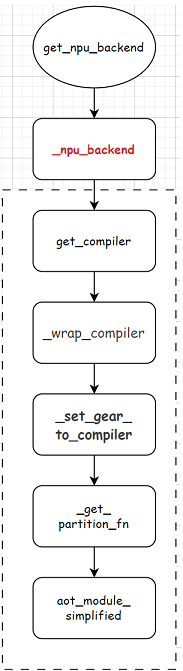
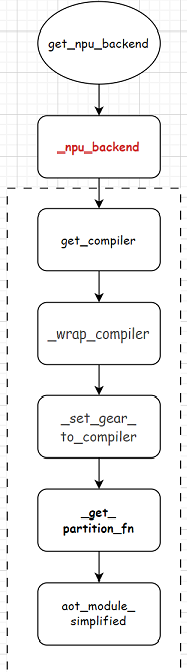
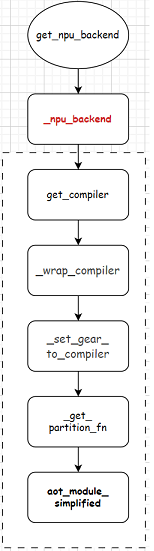
get_npu_backend调用的是_npu_backend函数。整体流程图如下:
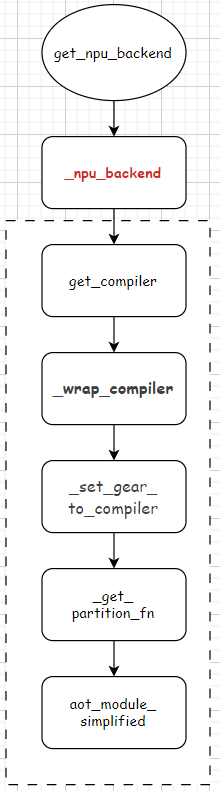
上文Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?对get_compiler函数进行了分析。本章接着分析剩余的部分。
1.1 _wrap_compiler
_wrap_compiler是一个装饰器
def _wrap_compiler(compiler: Callable, compiler_config: CompilerConfig):@functools.wraps(compiler)def wrapped_compiler(gm: torch.fx.GraphModule,example_inputs: List[torch.Tensor],is_inference: bool):if is_inference and compiler_config.experimental_config.npu_fx_pass:_npu_joint_graph_passes(gm)return compiler(gm, example_inputs)@functools.wraps(compiler)def joint_compiler(gm: torch.fx.GraphModule,example_inputs: List[torch.Tensor]):if compiler_config.experimental_config.npu_fx_pass:_npu_joint_graph_passes(gm)return compiler(gm, example_inputs)fw_compiler = functools.partial(wrapped_compiler, is_inference=False)inference_compiler = functools.partial(wrapped_compiler, is_inference=True)return fw_compiler, inference_compiler, joint_compiler
依旧使用了python的偏函数的功能:functools.partial。
- 对
wrapped_compiler函数进行了2次封装,区别在于is_inference参数。从代码上推测,_npu_joint_graph_passes在推理的时候,对图进行了进一步的优化。在is_inference = True的时候,返回inference_compiler。 - 另外根据
compiler_config.experimental_config.npu_fx_pass参数,专门返回了一个joint_compiler函数。
通过该装饰器,总共返回3个compile执行函数。
return fw_compiler, inference_compiler, joint_compiler
1.2 _set_gear_to_compiler
接着看_set_gear_to_compiler函数。
该函数依旧是个装饰器。重点关注函数中的guard_gears_shape。该函数是对图输入的情况进行判断,输入的tensor的shape需要在指定的范围内变化,也就说,torchair当前使用torch.compile支持有限个shape是变化的场景。如果超过了指定的范围,程序就会就会报错推出。
def _set_gear_to_compiler(compiler: Callable, compiler_config: CompilerConfig, input_dim_gears: Dict[int, List[int]]):@functools.wraps(compiler)def gear_compiler(gm: torch.fx.GraphModule,example_inputs: List[torch.Tensor],):for i, dim_gears in input_dim_gears.items():set_dim_gears(example_inputs[i], dim_gears)guard_gears_shape(example_inputs)return compiler(gm, example_inputs)return gear_compiler
注意,这里对分别对上述的fw_compiler和inference_compiler调用了_set_gear_to_compiler函数。
fw_compiler = _set_gear_to_compiler(fw_compiler, compiler_config, input_dim_gears)
inference_compiler = _set_gear_to_compiler(inference_compiler, compiler_config, input_dim_gears)
1.3 _get_partition_fn
接着看_get_partition_fn函数。
def _get_partition_fn(compiler_config: CompilerConfig):def partition_fn(graph: torch.fx.GraphModule, joint_inputs, **kwargs):_npu_joint_graph_passes(graph)return default_partition(graph, joint_inputs, **kwargs)if compiler_config.experimental_config.npu_fx_pass:return partition_fnreturn default_partition
default_partition是torch._functorch.partitioners中的函数。_get_partition_fn返回的partition函数类型与compiler_config.experimental_config.npu_fx_pass参数相关。在配置compiler_config.experimental_config.npu_fx_pass情况下,返回与输入参数joint_inputs相关的partition函数。
return default_partition(graph, joint_inputs, **kwargs)
1.4 aot_module_simplified
aot_module_simplified是_npu_backend中的最后一个调用函数。
return aot_module_simplified(gm, example_inputs, fw_compiler=fw_compiler, bw_compiler=compiler,decompositions=decompositions, partition_fn=partition_fn,keep_inference_input_mutations=keep_inference_input_mutations,inference_compiler=inference_compiler)
aot_module_simplified是torch._functorch.aot_autograd中的函数,看如下注释。
aot_module_simplified
是 PyTorch 中与 Ahead-of-Time (AOT) 编译相关的函数,特别是在使用 TorchInductor 后端时。AOT 编译是指在模型运行之前预先编译模型的计算图,以期达到加速执行和优化资源使用的目的。
在 PyTorch 中,TorchInductor 是 torch.compile 的一个后端,它旨在为 GPU 和 CPU 生成高度优化的代码。aot_module_simplified 函数通常用于简化将一个 PyTorch 模型准备好进行 AOT 编译的过程。其主要作用包括:
- 准备模型进行AOT编译:该函数帮助用户方便地指定需要进行 AOT 编译的模型部分。通过处理模型的输入输出、设置必要的编译参数等,使得模型可以直接进入编译流程。
- 优化计算图:在编译阶段,aot_module_simplified 可能会应用一系列优化措施,如算子融合、内存优化等,目的是提高最终编译产物的执行效率。
- 简化流程:正如其名“simplified”所暗示的,这个函数简化了 AOT 编译的准备工作,允许用户以较少的代码实现模型的编译和优化,而不需要深入了解编译过程中的复杂细节。
- 跨设备支持:它可能还提供对不同硬件平台的支持,确保编译后的模型可以在指定的目标设备(如GPU或CPU)上高效运行。
总的来说,aot_module_simplified 提供了一种简化的方式,让开发者可以更容易地利用 PyTorch 的 AOT 编译功能来优化他们的模型性能,尤其是在使用 TorchInductor 后端时。这有助于降低高性能模型部署的门槛,使得更多开发者能够从先进的编译技术和硬件优化中受益。需要注意的是,具体的实现细节可能会随着 PyTorch 版本的更新而有所变化。
2 torch.compile
回到例子中,可以看到传入到torch.compile中的backend是get_npu_backend返回的,也就是
npu_backend = torchair.get_npu_backend(compiler_config=config)
opt_model = torch.compile(model, backend=npu_backend)
既然提到了torch.compile,由于其内容比较复杂,小编认知有限,这里只对其做一个简单介绍,了解它的工作原理即可,主要是看backend是怎么起作用的。
2.1 torch.compile背景
参考:https://zhuanlan.zhihu.com/p/9418379234
为了改善模型训练推理性能,Pytorch推出torch.compile,并从torch 1.xx更为torch 2.xx,改变并增强了Pytorch在编译器级别的运行方式,同时开始将pytorch的部分代码从C++迁移回python,主要有以下特点:
- 将动态的 PyTorch 模型转换为静态的、优化过的执行图,从而减少运行时的开销,提高计算效率。
- 用户无需手动修改模型代码或选择特定的优化策略,torch.compile可以自动识别和应用最佳的优化路径,使得模型加速更加便捷。
- 支持广泛的 PyTorch API 和操作,确保大部分现有模型在使用 torch.compile后无需进行大的调整即可获益于性能提升。
说白了就是,torch.eager模式性能基本优化到头了,从python->c++->cuda(npu),流程上已经没有可以优化的空间。而如果将模型整形成一张图,却大有可为,可能有的小伙伴会问:tensorflow的图模式不是已经很好了吗?tensorflow为什么会日落西山了
这里允许小编胡诌一下。
1、tensorflow在小模型时代,或者说模型输入如果保持不变的话,那么使用tensorflow成图的性能依旧不输torch的eager模式;
2、时代成就英雄。tensorflow以图模式(性能)起家,torch以eager模式(易用性)起家,而时代的浪潮是:模型的输入需要支持动态shape。图模式的性能来源于:模型结构不变(也即是没有if,else等能改变图结构)、输入shape不变(显存效率)等。这样的情况下,模型能做各种算子融合、ir融合的pass,内存利用率也能达到极致。而在动态shape下,图模式的这些优势荡然无存,反而因为图的反复编译,造成的性能的劣化。而torch以eager模式不存在图编译的概念,每次都是单算子下发,时代的浪潮并没有掀翻它,反而是在给它助力。
说着说着,不免想起了mindspore(昇思),起步也是从图模式开始,导致发展机会错失,现在还在时代浪潮中被拉扯,而pytorch已经已然成为了AI框架的基础设施。
留个问题:大模型时代,模型的输入也是变化的,那么图模式的收益安歇来自于哪里呢?
想想看,哪些地方的输入shape是不变的。回答留在后面的文章中。
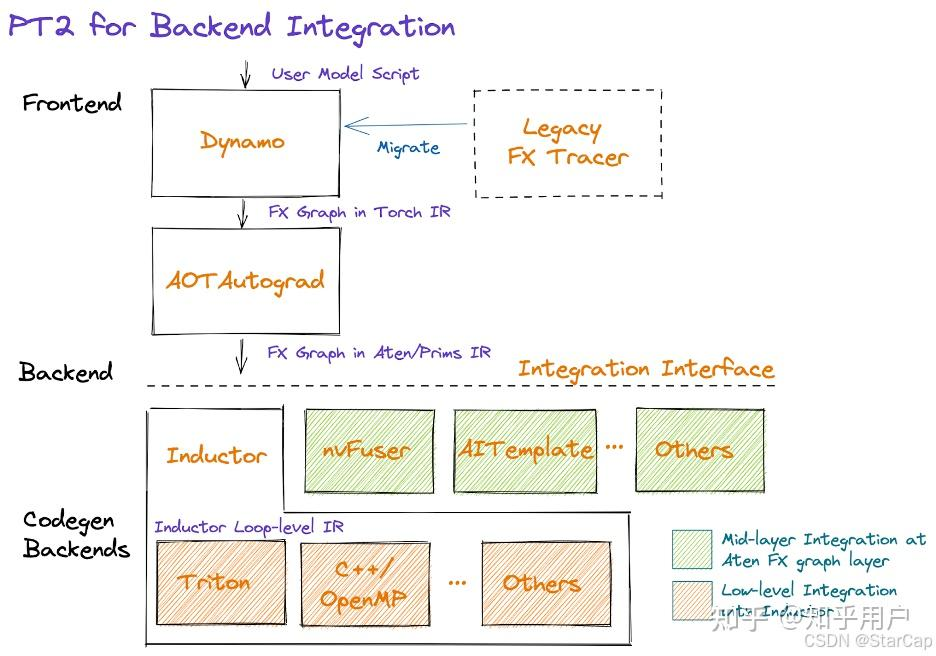
2.2 torch.compile的组成
torch.compile主要包含四个基础组件:
- TorchDynamo:从python bytecode中解析构建计算图,是一个动态的、Python级别的编译器,旨在捕捉 PyTorch 模型的动态执行路径,将其转换为优化代码,实现bytecode-to-bytecode编译。
- AOTAutograd:是 PyTorch 引入的一种自动求导机制,旨在在模型执行之前预先生成梯度计算的代码。这种方法通过静态分析模型的前向计算图,提前生成反向传播所需的梯度计算逻辑,从而减少运行时的开销,提升训练效率。
- PrimTorch:将2000+ Pytorch op规范化为约250个原始op封闭集合,是 PyTorch 的一个中间表示(Intermediate Representation, IR)层,负责将高层的 PyTorch 操作转换为更低层次的、适合进一步优化和编译的基础操作。它通过简化和标准化操作,提高编译器和后端优化器处理计算图的效率。
- TorchInductor:深度学习编译器,可为多种加速器和后端生成代码,生成OpenAI Triton(Nvidia/AMD GPU)和OpenMP/C++(CPU)代码,它利用多种优化技术,包括内存优化、并行化和低层次的代码生成,以最大化计算性能。
以上四个组件都是用Python编写的,支持动态形状(即能够发送不同大小的张量而无需重新编译),实现灵活并减低开发人员和供应商开发门槛的效果。
2.3 torch.compile支持的后端
当前支持的后端有:
>>> import torch
>>> import torch._dynamo as dynamo
>>> dynamo.list_backends()
['cudagraphs', 'inductor', 'onnxrt', 'openxla', 'tvm']
一般默认的是inductor,使用的方式是:
import torch
import torchvision.models as modelsmodel = models.resnet18().cuda(
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model, backend="inductor") # 通过backend参数指定后端,默认为inductor
# compiled_model = torch._dynamo.optimize("inductor")(fn) # 也可以通过torch._dynamo.optmize函数进行编译x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
接着分析下,npu的后端是如何在torch.compile中起作用的。请注意代码中注释的部分:
compiled_model = torch.compile(model, backend="inductor") # 通过backend参数指定后端,默认为inductor
# compiled_model = torch._dynamo.optimize("inductor")(fn) # 也可以通过torch._dynamo.optmize函数进行编译
也就是说torch._dynamo.optimize("inductor")(fn)和torch.compile(model, backend="inductor")是等价调用的。
2.3.1 torch.compile调用
torch.compile函数解析:torch.compile只是对torch._dynamo.optmize函数的简单封装
def compile(model: Optional[Callable] = None, *, # Module/function to optimizefullgraph: builtins.bool = False, #If False (default), torch.compile attempts to discover compileable regions in the function that it will optimize. If True, then we require that the entire function be capturable into a single graph. If this is not possible (that is, if there are graph breaks), then this will raise an error.dynamic: Optional[builtins.bool] = None, # dynamic shapebackend: Union[str, Callable] = "inductor", # backend to be usedmode: Union[str, None] = None, # Can be either "default", "reduce-overhead", "max-autotune" or "max-autotune-no-cudagraphs"options: Optional[Dict[str, Union[str, builtins.int, builtins.bool]]] = None, # A dictionary of options to pass to the backend. Some notable ones to try out aredisable: builtins.bool = False) # Turn torch.compile() into a no-op for testing-> Callable:# 中间代码省略... return torch._dynamo.optimize(backend=backend, nopython=fullgraph, dynamic=dynamic, disable=disable)(model)
torch._dynamo.optimize函数解析:进一步分析torch._dynamo.optimize的函数调用栈,会发现torch._dynamo.optimize只是通过_optimize_catch_errors函数返回了一个OptimizeContext对象。
因此,经过torch.compile装饰过的函数/模型成为一个OptimizeContext,其中convert_frame.catch_errors_wrapper成为了OptimizeContext中的一个回调函数 (callback),而这个回调函数包含编译函数入口,如inductor或自定义编译函数。由此可见,torch.compile并没有进行实际的编译,只是做一些简单的初始化工作,只有第一次正式执行代码前才会进行编译。
def _optimize(rebuild_ctx: Callable[[], Union[OptimizeContext, _NullDecorator]],backend="inductor",*,nopython=False,guard_export_fn=None,guard_fail_fn=None,disable=False,dynamic=None,
) -> Union[OptimizeContext, _NullDecorator]:# 中间代码省略...return _optimize_catch_errors(convert_frame.convert_frame(backend, hooks=hooks), // backendhooks,backend_ctx_ctor,dynamic=dynamic,compiler_config=backend.get_compiler_config()if hasattr(backend, "get_compiler_config")else None,rebuild_ctx=rebuild_ctx,)# ---------------------------------------------------------------------------------------------------------------------------------------
def _optimize_catch_errors(compile_fn,hooks: Hooks,backend_ctx_ctor=null_context,export=False,dynamic=None,compiler_config=None,rebuild_ctx=None,
):return OptimizeContext(convert_frame.catch_errors_wrapper(compile_fn, hooks),backend_ctx_ctor=backend_ctx_ctor,first_ctx=True,export=export,dynamic=dynamic,compiler_config=compiler_config,rebuild_ctx=rebuild_ctx,)
torch.compile优化流程:基于TorchDynamo和AOTAutograd构建Pytorch的前向和反向计算图,通过PrimTorch将op拆解转化为更低层次的、适合进一步优化和编译的基础op,最后Inductor进行算子融合等图优化并针对特定硬件生成triton(GPU)或OpenMP/C++(CPU)优化代码。
2.3.2 实现自定义的backend后端
从如上TorchInductor的定义:深度学习编译器,可为多种加速器和后端生成代码,生成OpenAI Triton(Nvidia/AMD GPU)和OpenMP/C++(CPU)代码。也就是说,这种后端的作用,是为了生成能够执行的代码。那是否可以自己自定义后端实现?来来来,试一下。
import torch
from typing import List
import torch._dynamo as dynamodef my_compiler(gm: torch.fx.GraphModule, example_inputs_: List[torch.Tensor]):print("===============my compiler=================")gm.graph.print_tabular() # 格式化输出FX Graphprint("code is:",gm.code) # 对应的python代码return gm# 调用torch._dynamo.optimize函数
def my_func(x, y):if x.sum() > y.sum():loss = torch.cos(torch.cos(x))else:loss = torch.cos(torch.cos(y))return lossdef test():func = dynamo.optimize(my_compiler)(my_func) // my_compiler就是自定义的后端,my_func就是模型x, y = torch.randn(10,requires_grad=True), torch.randn(10,requires_grad=True)func(x,y)test()
看到这里也就明白了。_npu_backend的后端也是自定义的,生成的代码是能在npu上执行的代码。
原谅小编想到哪里,就写到哪里。要看明白aclgraph的图是如基于torch.compile起作用的,看来还是要看对TorchDynamo做个一个简单的了解,下一篇见。
相关文章:
_npu_backend中还有些什么秘密?)
Ascend的aclgraph(2)_npu_backend中还有些什么秘密?
1 _npu_backend 文章还是从代码开始 import torch_npu, torchair config torchair.CompilerConfig() # 设置图下沉执行模式 config.mode "reduce-overhead" npu_backend torchair.get_npu_backend(compiler_configconfig) opt_model torch.compile(model, back…...

免布线视频桩:智慧城市停车降本增效的破局利器
在智慧城市建设的进程中,传统停车管理面临成本高、效率低、施工复杂等难题。而视频桩作为创新解决方案,以“免布线、智能化”为核心,正逐步改变这一局面。视频桩通过融合物联网与AI技术,实现自动化监测与数据实时管理,…...

Vulfocus靶场-文件上传-2
monstra 文件上传 (CVE-2020-13384) Monstra 是一个现代化的轻量级内容管理系统。它易于安装、升级和使用。 Monstra CMS 3.0.4版本中存在着一处安全漏洞,该漏洞源于程序没有正确验证文件扩展名。攻击者可以上传特殊后缀的文件执行任意PHP代…...

nvidia-smi 和 nvcc -V 作用分别是什么?
命令1:nvidia-smi 可以查看当前显卡的驱动版本,以及该驱动支持的CUDA版本。 命令2:nvcc -V 可以看到实际安装的CUDA工具包版本为 12.8 更详细的介绍,可以参考如下链接...
)
力扣刷题(第二十一天)
灵感来源 - 保持更新,努力学习 - python脚本学习 二叉树的最大深度 解题思路 这道题要求计算二叉树的最大深度,即从根节点到最远叶子节点的最长路径上的节点数。可以使用递归或迭代方法解决: 递归法(推荐)&#…...

AIOps 工具介绍
AIOps(智能运维)是通过人工智能技术优化IT运维流程的实践,其核心在于利用机器学习、大数据分析等技术实现运维自动化与智能化。以下从定义、核心价值、技术架构及工具等方面展开说明: 一、AIOps的定义与核心价值 AIOps࿰…...

4.3【LLaMA-Factory实战】教育大模型:个性化学习路径生成系统全解析
【LLaMA-Factory实战】教育大模型:个性化学习路径生成系统全解析 一、引言 在教育领域,传统"一刀切"的教学模式难以满足学生的个性化需求。本文基于LLaMA-Factory框架,详细介绍如何构建一个个性化学习路径生成系统,包…...

如何构建容器镜像并将其推送到极狐GitLab容器镜像库?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 构建容器镜像并将其推送到容器镜像库 (BASIC ALL) 在构建和推送容器镜像之前,您必须通过容器镜像库的身份验证。 …...

雷赛伺服L7-EC
1电子齿轮比: 电机圈脉冲1万 (pa11的值 x 4倍频) 2电机刚性: pa003 或者 0x2003 // 立即生效的 3LED显示: PA5.28 1 电机速度 4精度: PA14 //默认30,超过3圈er18…...

爬虫学习————开始
🌿自动化的思想 任何领域的发展原因————“不断追求生产方式的改革,即使得付出与耗费精力越来愈少,而收获最大化”。由此,创造出方法和设备来提升效率。 如新闻的5W原则直接让思考过程规范化、流程化。或者前端框架/后端轮子的…...

Shell 脚本编程详细指南:第五章 - 函数与参数传递
Shell 脚本编程详细指南:第五章 - 函数与参数传递 引言:函数在脚本工程化中的核心价值 函数是Shell脚本实现模块化编程的基石。本章将深入解析函数编程的各个方面,从基础定义到高级应用,助您构建可维护、可重用的脚本架构。我们…...

使用 docker 安装 nacos3.x
一、安装 nacos 1.拉取镜像 使用如下指令拉取镜像 docker pull nacos/nacos-server 拉取完成后,可以使用以下命令查看是否拉取到对应的镜像,默认拉取最新镜像 docker images 2.新建挂载文件目录 mkdir -p /home/ubuntu/nacos/conf/mkdir -p /home/…...

Docker的基础操作
docker是一个用Go语言实现的开源项目,可以让我们方便的创建和使用容器,docker将程序以及程序所有的依赖都打包到docker container,这样你的程序可以在任何环境都会有一致的表现,这里程序运行的依赖也就是容器就好比集装箱…...

权限控制模型全解析:RBAC、ACL、ABAC 与现代混合方案
权限控制模型全解析:RBAC、ACL、ABAC 与现代混合方案 在企业信息系统、SaaS 应用、安全平台中,权限控制模型是确保用户访问安全和功能隔离的基础架构设计之一。本文将系统性梳理常见的权限控制模型,包括 RBAC、ACL、ABAC、DAC、MAC、ReBAC 等…...

内存安全革命:工具、AI 与政策驱动的 C 语言转型之路
引言 在 CVE-2025-21298 等高危漏洞频发的背景下,内存安全已成为全球软件产业的核心议题。根据 CISA 最新数据,2024 年全球 72% 的网络攻击源于内存安全漏洞,而 C/C 代码贡献了其中 89% 的风险。这一严峻现实催生了技术革新的三重浪潮&#…...

电厂数据库未来趋势:时序数据库 + AI 驱动的自优化系统
在电力行业加速数字化与智能化转型的进程中,电厂数据库作为数据管理与应用的核心枢纽,正经历着深刻变革。时序数据库与 AI 技术的融合,正催生一种全新的自优化系统,为电厂设备全生命周期管理带来前所未有的效能提升与创新机遇。这…...

stm32 debug卡在0x1FFFxxxx
自己画的一个四轴飞机电路板,之前还能debug,改了一下mos管两端的电阻,还能正常下载,蓝牙接收也正常,但是debug出问题了,刚下载就自动运行,然后程序就在0x1FFFxxxx附近循环运行,这一块…...

什么是AI写作
一、AI写作简介 AI 写作正在成为未来 10 年最炙手可热的超级技能。已经有越来越多的人通过 AI 写作,在自媒体、公文写作、商业策划等领域实现了提效,甚至产生了变现收益。 掌握 AI 写作技能,不仅能提高个人生产力,还可能在未来的 …...

港大今年开源了哪些SLAM算法?
过去的5个月,香港大学 MaRS 实验室陆续开源了四套面向无人机的在线 SLAM 框架:**FAST-LIVO2 、Point-LIO(grid-map 分支) 、Voxel-SLAM 、Swarm-LIO2 **。这四套框架覆盖了单机三传感器融合、高带宽高速机动、长时间多级地图优化以…...

PostgreSQL 表空间占用分析与执行计划详解
PostgreSQL 表空间占用分析与执行计划详解 引言 在数据库管理和优化中,了解表占用的空间大小以及查询的执行计划是至关重要的。本文将详细介绍如何在 PostgreSQL 中查看普通表和分区表的空间占用情况,以及如何分析和解读执行计划。 一、查看表空间占用 …...

robotframe启动ride.py
我的双击ride.py会自动用pycharm打开,变成代码文件 解决方法:定位到ride.py所在文件夹(在anaconda的scripts里面),文件夹上方输入cmd 再输入该命令即可...

通过Linux系统服务管理IoTDB集群的高效方法
IoTDB是一款专为工业物联网领域设计的高性能时间序列数据库。在生产环境中,确保IoTDB集群的稳定运行至关重要。本文将介绍如何利用Linux系统服务来管理IoTDB集群,以实现高效的启动、监控和自动重启。 一、基本配置与环境需求 为了解决传统IoTDB启动方式…...

机器学习-数据集划分和特征工程
一.数据集划分 API函数: sklearn.model_selection.train_test_split(*arrays,**options) 参数: - arrays:多个数组,可以是列表,numpy数组,也可以是dataframe数据框等 - options:&…...

LDO与DCDC总结
目录 1. 工作原理 2. 性能对比 3. 选型关键因素 4. 典型应用 总结 1. 工作原理 LDO LDO通过线性调节方式实现降压,输入电压需略高于输出电压(压差通常为0.2-2V),利用内部PMOS管或PNP三极管调整压差以稳定输出电压。其结构简单…...

5 种距离算法总结!!
大家好!我是 我不是小upper~ 今天,咱们聚焦一个在机器学习领域极为关键、在实际项目中也高频使用的主题 ——距离算法。在机器学习的世界里,距离算法就像是一把 “度量尺”,专门用来衡量数据点之间的相似性或差异性。…...

【leetcode100】最长重复子数组
1、题目描述 给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长的子数组的长度 。 示例 1: 输入:nums1 [1,2,3,2,1], nums2 [3,2,1,4,7] 输出:3 解释:长度最长的公共子数组是 [3,2,1] 。示例 2&…...

独立自主的网络浏览器——Ladybird
独立自主的网络浏览器——Ladybird 随着互联网技术的飞速发展,浏览器作为人们探索网络世界的窗口,其技术创新和安全措施至关重要。然而,市场上绝大多数浏览器都是基于现有的成熟引擎进行开发,如何创新突破,成为一个独…...

强化学习三大基本方法-DP、MC、TD
强化学习进阶 本文主要讲解 动态规划法(Dynamic Programming DP)蒙特卡洛法(Monte Carlo MC)时序差分法(Temporal Difference TD) 1. 动态规划法 1.1 动态规划概念 动态规划核心思想: 其核心…...

【数据结构】1. 时间/空间复杂度
- 第 95 篇 - Date: 2025 - 05 - 09 Author: 郑龙浩/仟墨 【数据结构 】 文章目录 数据结构 - 1 -了解数据结构与算法1 什么是数据结构2 什么是算法3 数据结构的重要性? 一 时间复杂度_空间复杂度1 时间复杂度① 表示方法② 推导大 O 的规则:③ **代码示例 ** 2 空…...

k8s存储类型:emptyDir、hostPath、nfs、pvc及存储类storageclass的静态/动态创建pv
Kubernetes存储类型详解 Kubernetes(K8s)提供了多种存储类型,满足不同的存储需求。这些存储类型包括 emptyDir、hostPath、nfs、PersistentVolumeClaim(PVC)以及存储类(StorageClass)的静态和动…...

TRAE 配置blender MCP AI自动3D建模
BlenderMCP - Blender模型上下文协议集成 BlenderMCP通过模型上下文协议(MCP)将Blender连接到Claude AI,允许Claude直接与Blender交互并控制Blender。这种集成实现了即时辅助的3D建模、场景创建和操纵。 1.第一步下载 MCP插件(addon.py):Blender插件,在…...

不拆机查看电脑硬盘型号的常用方法
要比较两个硬件的参数,首先要知道的是硬件准确的型号。不过,如硬盘这类硬件,一般都藏在电脑“肚子里”,拆下看费时又费力。那么,不拆机电脑硬盘型号怎么看呢?接下来,我们就来分享几种方法。 使…...

抖音 “碰一碰” 发视频:短视频社交的新玩法
在短视频社交的广阔天地里,抖音始终站在创新的前沿。2023 年,抖音重磅推出 “碰一碰” 功能,借助近距离通信技术,实现设备间视频的闪电分享,为短视频社交注入全新活力。本文将深入剖析这一功能背后的技术奥秘、丰富应用…...

learning ray之ray核心设计和架构
我们每天都在处理海量、多样且高速生成的数据,这对计算能力提出了前所未有的挑战。传统的单机计算模式在面对日益复杂的机器学习模型和大规模数据集时,往往显得力不从心。更重要的是,数据科学家们本应专注于模型训练、特征工程、超参数调优这…...

深入理解 JavaScript 对象与属性控制
ECMA-262将对象定义为一组属性的无序集合,严格来说,这意味着对象就是一组没有特定顺序的值,对象的每个属性或方法都由一个名称来标识,这个名称映射到一个值. 可以把js的对象想象成一张散列表,其中的内容就是一组名/值对,值可以是数据或者函数 1. 理解对象 创建自定义对象的…...
)
深入理解 Linux 虚拟文件系统(VFS)
在 Linux 操作系统的世界里,虚拟文件系统(Virtual File System,VFS)扮演着极为关键的角色。它就像是一座桥梁,连接着各种不同类型的物理文件系统与操作系统以及应用程序,使得我们在使用 Linux 时能够以统一…...

AI云防护真的可以防攻击?你的服务器用群联AI云防护吗?
1. 传统防御方案的局限性 静态规则缺陷:无法应对新型攻击模式(如HTTP慢速攻击)资源浪费:固定带宽采购导致非攻击期资源闲置 2. AI云防护技术实现 动态流量调度算法: # 智能节点选择伪代码(参考群联防护…...

计算机视觉——MedSAM2医学影像一键实现3D与视频分割的高效解决方案
引言 在乡村医院的傍晚高峰时段,扫描室内传来阵阵低沉的嗡鸣声,仿佛一台老旧冰箱的运转声。一位疲惫的医生正全神贯注地检查着当天的最后一位患者——一位不幸从拖拉机上摔下的农民,此刻正呼吸急促。CT 机器飞速旋转,生成了超过一…...

软件工程之软件项目管理深度解析
前文基础: 1.软件工程学概述:软件工程学概述-CSDN博客 2.软件过程深度解析:软件过程深度解析-CSDN博客 3.软件工程之需求分析涉及的图与工具:软件工程之需求分析涉及的图与工具-CSDN博客 4.软件工程之形式化说明技术深度解…...

40. 组合总和 II
题目 给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的每个数字在每个组合中只能使用 一次 。 注意:解集不能包含重复的组合。 示例 1: 输入: candidates [10,1…...

java-多态
一、多态的来历 我们先来了解一个业务场景:请设计一个系统,描述主人喂养宠物的场景,首先在这个场景当中应该有”宠物对象“,“宠物对象”应该有一个吃的行为,另外还需要一个“主人对象”,主人应该有一个喂的…...

重构 cluster-db 选择器,新增限制字段 showDb 不影响原功能前提实现查询功能增量拓展
1.为DbSelect组件新添加showDb字段 :show-db"false"时只显示集群不显示数据库信息 重构 cluster-db 选择器,新增限制字段 showDb 不影响原功能前提实现查询功能增量拓展,。保证组件**高可用性,减少冗余方法的编写,提高整体代码复用性和维护性**。 <!-…...
)
Modbus RTU 详解 + FreeMODBUS移植(附项目源码)
文章目录 前言一、Modbus RTU1.1 通信方式1.2 模式特点1.3 数据模型1.4 常用功能码说明1.5 异常响应码1.6 通信帧格式1.6.1 示例一:读取保持寄存器(功能码 0x03)1.6.2 示例二:写单个线圈(功能码 0x05)1.6.3…...

新闻发稿筛选媒体核心标准:影响力、适配性与合规性
1. 评估媒体影响力 权威性与公信力:优先选择央级媒体,其报道常被其他平台转载,传播链条长,加分权重高。 传播数据:参考定海区融媒体中心的赋分办法,关注媒体的阅读量、视频播放量等指标,如阅读…...

豆包:基于多模态交互的智能心理咨询机器人系统设计与效果评估——情感计算框架下的对话机制创新
豆包:基于多模态交互的智能心理咨询机器人系统设计与效果评估——情感计算框架下的对话机制创新 摘要 随着人工智能在心理健康领域的应用深化,本文提出一种融合情感计算与动态对话管理的智能心理咨询机器人系统架构。通过构建“用户状态-情感响应-策略生成”三层模型,结合…...

坐席业绩可视化分析工具
这个交互式的坐席业绩分析工具具有以下特点: 数据导入功能:支持上传 CSV 文件,自动解析并展示数据多维度分析:可按日 / 周 / 月分析业绩数据,支持切换不同业绩指标(接通时长 / 外呼次数 / 接通次数&#x…...

MATLAB制作柱状图与条图:数据可视化的基础利器
一、什么是柱状图与条图? 柱状图和条图都是用来表示分类数据的常见图表形式,它们的核心目的是通过矩形的长度来比较各类别的数值大小。条图其实就是“横着的柱状图”,它们的本质是一样的:用矩形的长度表示数值大小,不同…...

com.fasterxml.jackson.dataformat.xml.XmlMapper把对象转换xml格式,属性放到标签<>里边
之前从没用过xml和对象相互转换,最近项目接了政府相关的。需要用xml格式数据进行相互转换。有些小问题,困扰了我一下下。 1.有些属性需要放到标签里边,有的需要放到标签子集。 2.xml需要加<?xml version"1.0" encoding"…...

在js中大量接口调用并发批量请求处理器
并发批量请求处理器 ✨ 设计目标 该类用于批量异步请求处理,支持: 自定义并发数请求节拍控制(延时)失败重试机制进度回调通知 🔧 构造函数参数 new BulkRequestHandler({dataList, // 要处理的数据列表r…...

Azure资源创建与部署指南
本文将指导您如何在Azure平台上创建和配置必要的资源,以部署基于OpenAI的应用程序。 资源组创建 资源组是管理和组织Azure资源的逻辑容器。 在Azure门户顶端的查询框中输入"Resource groups"(英文环境)或"资源组"(中文环境)在搜索结果中点击"资…...