5 种距离算法总结!!
大家好!我是 我不是小upper~
今天,咱们聚焦一个在机器学习领域极为关键、在实际项目中也高频使用的主题 ——距离算法。在机器学习的世界里,距离算法就像是一把 “度量尺”,专门用来衡量数据点之间的相似性或差异性。它的应用场景十分广泛,每一个场景都对算法的性能和效果起着至关重要的作用:
- 聚类分析:在聚类分析任务中,距离算法堪称核心工具。以 K 均值聚类为例,算法首先随机初始化 K 个聚类中心,随后通过不断计算每个数据点与这些聚类中心的距离,将数据点分配到距离最近的聚类簇中,并更新聚类中心的位置。这个迭代过程不断重复,直到聚类结果稳定。而层次聚类则是基于数据点之间的距离,通过计算簇与簇之间的距离,将距离近的簇逐步合并,构建出树形的聚类结构,最终根据需求确定合适的聚类层次。
- 最近邻分类:最近邻分类是一种直观且实用的基于距离的分类算法。其中,K 最近邻(KNN)算法的原理最为典型。当遇到一个待分类样本时,KNN 算法会计算该样本与训练集中所有样本的距离,然后找出距离最近的 K 个邻居样本。根据这 K 个邻居样本中出现频率最高的类别,来决定待分类样本的类别。例如,在手写数字识别任务中,通过计算待识别数字图像与训练集中图像的距离,找到最相似的 K 个数字图像,进而判断待识别数字的类别。
- 特征选择:在特征选择环节,距离算法能帮助我们评估特征之间的关联程度。我们可以通过计算特征向量之间的距离,来衡量特征之间的相关性或互信息。距离较近的特征,往往具有较高的相关性,可能存在信息冗余;而与目标变量距离较近的特征,则意味着它们与目标变量的关联更为紧密,对模型的贡献更大。通过筛选出与目标变量高度相关的特征,我们可以减少特征空间的维度,降低模型的复杂度,同时提升模型的性能和泛化能力。
- 异常检测:距离算法也是异常检测的重要手段。基于距离的异常检测方法,会将每个数据点与其邻近点之间的距离作为判断依据。当某个数据点与其他数据点的距离超出预先设定的阈值时,就会被认定为异常点或离群点。比如在银行交易数据中,如果某笔交易记录与其他正常交易记录的距离过大,就可能存在异常交易行为,需要进一步关注和审查。
- 降维:在处理高维数据集时,数据的复杂性和计算成本会显著增加。距离算法可以帮助我们在降低数据维度的同时,尽可能保留数据的重要结构信息。通过计算数据点之间的距离或相似性,我们可以将高维数据映射到一个较低维度的空间中。例如,主成分分析(PCA)就是一种常用的降维方法,它通过寻找数据的主要成分方向,将数据投影到这些方向上,从而实现降维。在这个过程中,距离算法用于衡量数据点在不同维度上的分布和差异,确保降维后的数据集能够最大程度地保留原始数据的特征和信息。
接下来,我将详细地去介绍5 种经典的距离算法,不仅会深入讲解算法的原理和适用场景,还会提供完整的 Python 代码,让大家能够轻松理解并应用这些算法到实际项目中!
欧几里德距离(Euclidean Distance):
在度量空间中,欧几里德距离(Euclidean Distance)作为经典的距离度量方法,通过计算两点之间直线段的长度,精准刻画数据点间的空间差异,在数据挖掘、机器学习、图像处理等领域扮演着举足轻重的角色。
常见使用场景
- 数据挖掘领域:在海量数据处理中,欧几里德距离能够量化不同数据样本的相似程度。以聚类分析为例,算法依据数据点间的欧氏距离,将距离相近的样本聚为一类,从而挖掘数据内在的分布模式;在推荐系统中,通过计算用户行为数据或商品特征向量间的欧氏距离,找出相似用户或商品,实现精准推荐。
- 机器学习领域:在 K 近邻(KNN)等分类算法中,欧几里德距离是衡量特征相似性的核心工具。当新样本需要分类时,算法计算其与训练集中所有样本的欧氏距离,找出距离最近的 K 个邻居,依据邻居类别投票确定新样本归属,直观地将空间距离转化为分类决策依据。
- 图像处理领域:在图像匹配和检索任务中,欧几里德距离用于量化图像特征向量的差异。通过提取图像的颜色、纹理等特征,计算特征向量间的欧氏距离,距离越小则图像相似度越高,从而实现快速的图像检索与匹配。
下面是一个使用 Python 代码计算欧几里德距离:
import mathdef euclidean_distance(point1, point2):"""计算两个点之间的欧几里德距离输入参数:point1: 第一个点的坐标,格式为 (x1, y1)point2: 第二个点的坐标,格式为 (x2, y2)返回值:两个点之间的欧几里德距离"""x1, y1 = point1x2, y2 = point2distance = math.sqrt((x2 - x1)**2 + (y2 - y1)**2)return distance# 示例使用
point_1 = (2, 3)
point_2 = (5, 7)
distance = euclidean_distance(point_1, point_2)
print("两点之间的欧几里德距离:", distance)
上述代码定义了euclidean_distance函数,接收两个二维坐标点point1和point2作为参数。通过解包操作提取坐标值,依据欧几里德距离公式
,
利用math.sqrt函数计算并返回两点间的直线距离。以点(2, 3)和(5, 7)为例,经计算可得欧氏距离为5。
可视化演示
为了更直观地理解欧几里德距离,我们借助matplotlib库将两点及其距离可视化:
import matplotlib.pyplot as pltpoint1 = (2, 3)
point2 = (5, 7)# 计算欧几里德距离
distance = ((point2[0] - point1[0])**2 + (point2[1] - point1[1])**2)**0.5# 创建一个新的图形
fig, ax = plt.subplots()# 网格
ax.grid(True, linestyle='--', linewidth=0.5, color='gray')# 两个点
ax.plot(point1[0], point1[1], 'ro', label='A')
ax.plot(point2[0], point2[1], 'bo', label='B')# 连线
ax.plot([point1[0], point2[0]], [point1[1], point2[1]], 'k-', label='Distance')# 欧几里德距离标签
ax.annotate(f'Euclidean Distance: {distance:.2f}', xy=(3.5, 5), xytext=(3.5, 5))# 添加每个点的标签
ax.annotate('A', xy=point1, xytext=(point1[0]-0.8, point1[1]+0.3))
ax.annotate('B', xy=point2, xytext=(point2[0]-0.8, point2[1]+0.3))
ax.annotate(f'{distance:.2f}', xy=((point1[0]+point2[0])/2, (point1[1]+point2[1])/2),xytext=((point1[0]+point2[0])/2-0.5, (point1[1]+point2[1])/2+0.4))# 设置坐标轴范围
ax.set_xlim(0, 6)
ax.set_ylim(0, 8)# 添加图例
ax.legend()plt.show()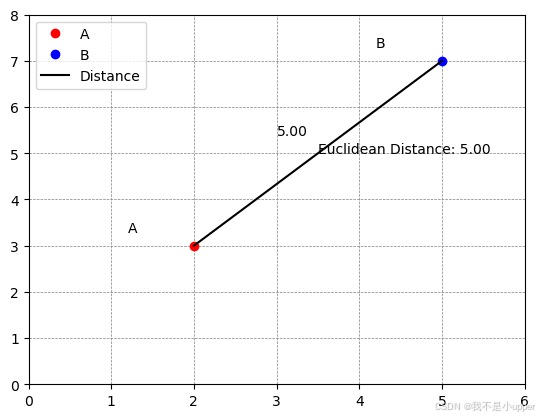
运行代码后,将生成一个带有灰色网格的二维坐标系。其中,红点A代表坐标(2, 3),蓝点B代表坐标(5, 7),黑色线段连接两点直观呈现欧几里德距离。图中还添加了清晰的标注,包括点的标签、距离数值标签,以及图例说明,可以帮助我们更直观地理解欧氏距离在二维空间中的几何意义 。
曼哈顿距离(Manhattan Distance):
曼哈顿距离,又被称作城市街区距离或 L1 距离,是一种独特的距离度量方式。它与欧几里德距离直接计算两点间直线长度不同,曼哈顿距离更像是在城市网格状的街区中,从一个地点到另一个地点沿着街道横竖行走的总路程,通过计算两点在各个坐标轴上差值的绝对值之和,来衡量它们之间的距离。
常见使用场景
- 路径规划:在网格地图场景中,如城市道路规划、游戏地图导航等,曼哈顿距离是计算最短路径的得力助手。由于现实中的道路往往呈网格状布局,两点间无法直接直线通行,而曼哈顿距离恰好能模拟行人或车辆在街道上横向、纵向移动的实际路程,帮助规划出符合实际道路规则的最短路线。
- 物流管理:在物流配送环节,仓库与各个配送目的地通常分布在城市的不同区域,道路网络也多为网格状。曼哈顿距离可以精准计算货物从仓库到目的地的最短配送路径,考虑到实际交通规则和道路布局,为物流调度提供合理的参考,优化配送路线,减少运输成本和时间。
- 特征选择:在数据分析与机器学习领域,曼哈顿距离可用于评估特征之间的相关性。通过计算不同特征向量在各个维度上的差异绝对值之和,来衡量特征之间的相似程度或关联程度。以此为依据,能够筛选出与目标变量相关性高的特征,剔除冗余或无关特征,实现特征选择和降维,提高模型的效率和性能。
下面使用Python代码计算曼哈顿距离:
def manhattan_distance(point1, point2):"""计算两个点之间的曼哈顿距离输入参数:point1: 第一个点的坐标,格式为 (x1, y1)point2: 第二个点的坐标,格式为 (x2, y2)返回值:两个点之间的曼哈顿距离"""x1, y1 = point1x2, y2 = point2distance = abs(x2 - x1) + abs(y2 - y1)return distance# 示例使用
point_1 = (2, 3)
point_2 = (5, 7)
distance = manhattan_distance(point_1, point_2)
print("两点之间的曼哈顿距离:", distance)对于示例中的点(2, 3)和(5, 7),计算结果为下图:
![]()
网上特别流行的一张图:
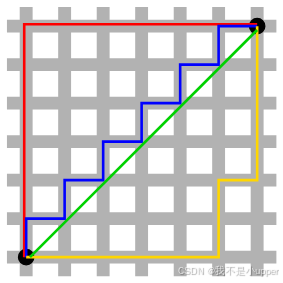
该图形展示了二维平面上两个点A和B之间的曼哈顿距离。曼哈顿距离是通过在坐标轴上的横向和纵向移动来测量的,即将水平方向和垂直方向的距离相加。
切比雪夫距离(Chebyshev Distance):
在度量空间中,切比雪夫距离是一种独特且实用的距离度量方式,专门用于刻画两个向量之间的差异程度。它的核心定义为:两个向量在各个维度上元素差值的最大值,这个 “最大差值” 就代表了两个向量间的切比雪夫距离。从数学公式来看,若有两个向量和
,它们之间的切比雪夫距离
表示为:
其中,n为向量的维度,计算的是两个向量在第i个维度上元素的差值绝对值,而整个公式就是在所有维度的差值绝对值中取最大值。
常见使用场景
- 图像处理领域:在图像分类、对象识别和图像匹配等任务中,切比雪夫距离发挥着重要作用。例如,在对图像特征进行分析时,可将图像的某些特征抽象为向量,通过计算不同图像特征向量间的切比雪夫距离,判断图像的相似性。若两张图像特征向量在某一关键维度上差异过大(即切比雪夫距离的那个 “最大差值” 过大),则说明这两张图像在该特征上有明显区别,有助于快速筛选出符合特定条件的图像。
- 机器学习领域:在聚类算法,如 K - means 算法中,切比雪夫距离可作为衡量数据点间相似性的度量标准。传统 K - means 算法常用欧几里得距离,但在某些场景下,数据点在某些维度上的差异对聚类结果影响更大,此时使用切比雪夫距离,以 “最大维度差距” 来划分数据点,能更好地反映数据间的内在结构,得到更符合需求的聚类结果。
- 异常检测领域:切比雪夫距离常用于识别异常数据点。在一组数据中,每个数据可看作高维空间中的一个向量,当某个数据向量与其他正常数据向量在某一维度上的差异显著超出正常范围(即与其他向量的切比雪夫距离过大),就可将其判定为异常数据,帮助人们及时发现数据集中的异常情况,以便进一步分析处理。
下面使用 Python 计算切比雪夫距离:
def chebyshev_distance(x, y):assert len(x) == len(y), "Vectors must have the same length"return max(abs(a - b) for a, b in zip(x, y))# 例子:计算两个向量的切比雪夫距离
vector1 = [1, 2, 3]
vector2 = [4, 5, 6]
distance = chebyshev_distance(vector1, vector2)
print("切比雪夫距离:", distance)
上述代码定义了chebyshev_distance函数,专门用于计算两个向量之间的切比雪夫距离。函数接收两个向量参数x和y,首先通过assert len(x) == len(y)语句进行条件判断,确保输入的两个向量长度一致。因为只有维度相同的向量,计算它们在各维度上的差值才有意义,若向量长度不同,就无法准确计算切比雪夫距离,此时程序会抛出异常提示 “Vectors must have the same length”。
在确认向量长度一致后,函数使用了一个精妙的生成器表达式abs(a - b) for a, b in zip(x, y)。这里的zip(x, y)函数将两个向量x和y中对应位置的元素一一配对,例如x的第一个元素与y的第一个元素组成一对,第二个元素与第二个元素组成一对,以此类推。然后,abs(a - b)计算每一对元素的差值绝对值,最后通过max()函数从所有这些差值绝对值中找出最大值,这个最大值就是两个向量之间的切比雪夫距离,并将其返回。
以向量vector1 = [1, 2, 3]和vector2 = [4, 5, 6]为例,它们对应元素的差值绝对值分别为abs(1 - 4)=3、abs(2 - 5)=3、abs(3 - 6)=3,通过max()函数选取最大值,最终得到切比雪夫距离为3,程序输出 “切比雪夫距离: 3” 。
闵可夫斯基距离(Minkowski Distance):
在向量空间的度量体系中,闵可夫斯基距离堪称一座 “桥梁”,它将多种经典距离度量方法统一在一个公式框架之下,是切比雪夫距离、欧几里得距离和曼哈顿距离的通用化表达。通过调整关键参数,闵可夫斯基距离能够灵活切换,适配不同场景下的距离计算需求。
从数学定义来看,对于两个向量 和
,闵可夫斯基距离
的计算公式为:
其中,n 表示向量的维度, 计算的是两个向量在第 i 个维度上元素的差值绝对值,p 是一个大于 0 的实数参数,它决定了距离度量的特性和类型。
特殊情况解析
- 当 p = 1 时:闵可夫斯基距离退化为曼哈顿距离(Manhattan Distance),也被称为城市街区距离或 L1 距离。此时的计算公式变为:
在二维平面中,若向量 A 的坐标为
,向量 B 的坐标为 (
),则曼哈顿距离表示从点 A 到点 B 在网格状路径(只能沿水平或垂直方向移动)上的最短行走距离,就像在城市街区中从一个路口到另一个路口的路程计算方式。
- 当 p = 2 时:闵可夫斯基距离转化为欧几里得距离(Euclidean Distance),是最直观的直线距离度量。计算公式如下:
在二维空间中,它代表两点之间直线段的长度;在高维向量空间里,同样用于计算两点间的 “直线” 距离,广泛应用于几何学、机器学习等领域。
- 当
时:闵可夫斯基距离趋近于切比雪夫距离(Chebyshev Distance),其本质是取两个向量在各个维度上元素差的最大值,即:
由此可见,参数 p 就像一个 “调控开关”,改变 p 的取值,就能调整距离计算中各个维度的权重分布,实现从不同角度衡量向量间的差异 。
常见使用场景
- 数据挖掘领域:在聚类、分类和异常检测等任务中,闵可夫斯基距离为数据间的相似性度量提供了灵活的选择。例如,在聚类分析时,通过调整 p 值,可以根据数据特点选择合适的距离度量方式,使聚类结果更贴合数据内在结构;在异常检测中,也能通过它精准识别与其他数据点差异较大的异常点。
- 图像处理领域:在图像匹配、对象识别和图像检索等场景中,闵可夫斯基距离可用于量化图像特征向量之间的差异。比如,将图像的颜色、纹理等特征转换为向量后,根据不同的任务需求选择合适的 p 值计算距离,从而快速找到相似图像。
- 文本挖掘领域:在文本分类、信息检索和自然语言处理等任务里,闵可夫斯基距离能够度量文本向量之间的相似度。将文本表示为向量形式后,利用它可以计算不同文本间的距离,进而实现文本分类、检索相关文档等功能。
下面使用 Python 计算闵可夫斯基距离:
import mathdef minkowski_distance(x, y, p):assert len(x) == len(y), "Vectors must have the same length"return math.pow(sum(math.pow(abs(a - b), p) for a, b in zip(x, y)), 1/p)# 例子:计算两个向量的闵可夫斯基距离
vector1 = [1, 2, 3]
vector2 = [4, 5, 6]
distance = minkowski_distance(vector1, vector2, 3)
print("闵可夫斯基距离:", distance)![]()
上述代码定义了 minkowski_distance 函数,专门用于计算两个向量之间的闵可夫斯基距离。函数接收三个参数:向量 x、向量 y 以及参数 p。首先,通过 assert len(x) == len(y) 语句确保输入的两个向量长度一致,因为只有维度相同的向量,才能依据公式准确计算闵可夫斯基距离,若长度不同,程序会抛出异常提示 “Vectors must have the same length”。
接下来,函数使用了一个嵌套的生成器表达式 math.pow(abs(a - b), p) for a, b in zip(x, y)。其中,zip(x, y) 将两个向量中对应位置的元素一一配对,abs(a - b) 计算每一对元素的差值绝对值,math.pow(abs(a - b), p) 对差值绝对值进行 p 次幂运算。sum() 函数将所有维度上计算得到的 p 次幂结果求和,最后通过 math.pow(..., 1/p) 对求和结果进行 \(\frac{1}{p}\) 次幂运算,也就是开 p 次方,得到的最终结果就是两个向量之间的闵可夫斯基距离,并将其返回。
以向量 vector1 = [1, 2, 3] 和 vector2 = [4, 5, 6] 为例,当 p = 3 时,经过函数的一系列计算,最终得到闵可夫斯基距离为 4.326748710922225,程序输出 “闵可夫斯基距离: 4.326748710922225” 。
余弦相似度(Cosine Similarity):
在机器学习和数据挖掘领域,余弦相似度是一种应用极为广泛的相似性度量方法,它专注于衡量两个向量在方向上的相似程度,通过计算两个向量夹角的余弦值,巧妙地揭示数据之间的内在关联。与传统距离度量方法(如欧几里得距离)不同,余弦相似度更关注向量的方向一致性,而非向量的长度差异,这使得它在处理高维数据时展现出独特的优势。
核心公式解析
余弦相似度的计算公式如下:
其中, 和
是待比较的两个向量;
表示向量
和
的点积,它等于对应元素乘积的总和;
和
分别是向量
和
的模(长度),通过对各元素平方和开方计算得到。从几何角度来看,该公式计算的就是两个向量夹角的余弦值,余弦值越接近 1,说明两个向量的方向越相近,数据的相似性越高;余弦值越接近 -1,则表示两个向量方向相反;当余弦值为 0 时,意味着两个向量相互垂直,即数据之间不存在相似性。
常见使用场景
- 文本相似度计算:在自然语言处理领域,文本通常被转化为高维向量(如词向量、TF-IDF 向量)进行表示。余弦相似度可以高效地计算不同文本向量之间的相似程度,广泛应用于文本分类、信息检索、文本查重等任务。例如,在搜索引擎中,通过计算用户查询文本与文档库中文档的余弦相似度,能够快速筛选出与查询内容最相关的文档;在文本分类任务中,根据待分类文本与各类别样本的余弦相似度,判断其所属类别。
- 推荐系统:推荐系统中,用户和商品的特征往往被抽象为向量形式。通过计算用户特征向量与商品特征向量的余弦相似度,可以找到与用户兴趣最匹配的商品,为用户提供个性化推荐。比如,电商平台根据用户的历史购买记录、浏览行为等生成用户特征向量,同时将商品的属性、类别等信息转化为商品特征向量,利用余弦相似度计算两者的相似性,进而向用户推荐相似性较高的商品。
- 图像处理:在图像处理任务中,图像的特征(如颜色直方图、局部特征描述子等)可以用向量表示。余弦相似度用于衡量不同图像向量之间的相似性,在图像匹配、图像检索、图像聚类等方面发挥重要作用。例如,在图片搜索应用中,用户上传一张图片,系统将其特征向量与数据库中图片的特征向量进行余弦相似度计算,返回相似性高的图片作为搜索结果。
对于直观理解余弦相似度的计算过程,我们用Python代码再来表示:
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity# 定义两个向量 A 和 B
A = np.array([1, 2, 3])
B = np.array([4, 5, 6])# 将向量转换为行向量
A = A.reshape(1, -1)
B = B.reshape(1, -1)# 计算余弦相似度
similarity = cosine_similarity(A, B)[0][0]print("余弦相似度:", similarity)上述代码借助 numpy 库和 sklearn 库中的 cosine_similarity 函数,实现了余弦相似度的快速计算。首先,使用 np.array 定义了两个向量 A 和 B。由于 cosine_similarity 函数期望输入的是二维数组(每一行代表一个向量),因此通过 reshape(1, -1) 将一维向量转换为只有一行的二维行向量。最后,调用 cosine_similarity 函数传入两个行向量,函数返回一个二维数组,其中 [0][0] 表示第一个向量(即 A)与第二个向量(即 B)之间的余弦相似度,将结果打印输出。
可视化理解
为了更直观地理解余弦相似度的计算原理,我们通过以下代码进行可视化展示:
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.patches import Arc# 定义两个向量 A 和 B
A = np.array([1, 2])
B = np.array([2, 3])# 计算向量 A 和 B 的模
norm_a = np.linalg.norm(A)
norm_b = np.linalg.norm(B)# 计算夹角余弦值
cos_theta = np.dot(A, B) / (norm_a * norm_b)# 绘制向量 A 和 B
plt.quiver(0, 0, A[0], A[1], angles='xy', scale_units='xy', scale=1, color='r')
plt.quiver(0, 0, B[0], B[1], angles='xy', scale_units='xy', scale=1, color='b')# 绘制夹角
theta = np.arccos(cos_theta)
arc = Arc((0,0), 0.5, 0.5, angle=0, theta1=0, theta2=np.degrees(theta))
plt.gca().add_patch(arc)# 设置坐标轴范围
plt.xlim(-1, 3)
plt.ylim(-1, 4)# 添加标签和标题
plt.text(1, 2.5, 'A', fontsize=12)
plt.text(2, 3.5, 'B', fontsize=12)
plt.title('Cosine Similarity')# 显示图形
plt.grid()
plt.show()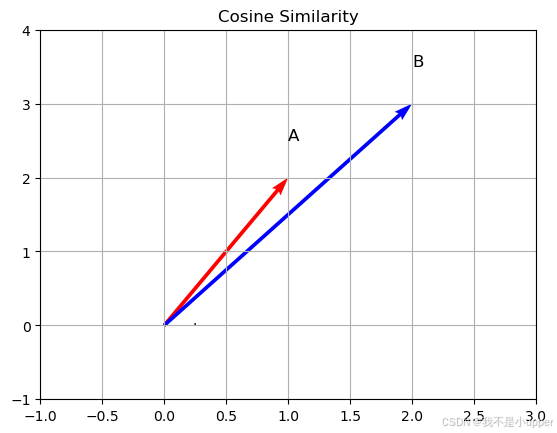
这段代码使用 matplotlib 库绘制了二维平面上的两个向量 A 和 B,并直观呈现了它们之间的夹角。首先,定义向量 A 和 B 后,通过 np.linalg.norm 函数计算向量的模,利用 np.dot 函数计算点积,进而得到夹角的余弦值 cos_theta。接着,使用 plt.quiver 函数以箭头形式绘制出向量 A 和 B,箭头起点为坐标原点 (0, 0),箭头方向和长度对应向量的方向和模。然后,通过 np.arccos 函数将余弦值转换为弧度制的夹角 theta,使用 Arc 类绘制表示夹角的圆弧,并添加到图形中。最后,设置坐标轴范围、添加向量标签和图形标题,并通过 plt.show() 显示可视化图形,帮助我们更清晰地理解余弦相似度与向量夹角之间的关系。
相关文章:

5 种距离算法总结!!
大家好!我是 我不是小upper~ 今天,咱们聚焦一个在机器学习领域极为关键、在实际项目中也高频使用的主题 ——距离算法。在机器学习的世界里,距离算法就像是一把 “度量尺”,专门用来衡量数据点之间的相似性或差异性。…...

【leetcode100】最长重复子数组
1、题目描述 给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长的子数组的长度 。 示例 1: 输入:nums1 [1,2,3,2,1], nums2 [3,2,1,4,7] 输出:3 解释:长度最长的公共子数组是 [3,2,1] 。示例 2&…...

独立自主的网络浏览器——Ladybird
独立自主的网络浏览器——Ladybird 随着互联网技术的飞速发展,浏览器作为人们探索网络世界的窗口,其技术创新和安全措施至关重要。然而,市场上绝大多数浏览器都是基于现有的成熟引擎进行开发,如何创新突破,成为一个独…...

强化学习三大基本方法-DP、MC、TD
强化学习进阶 本文主要讲解 动态规划法(Dynamic Programming DP)蒙特卡洛法(Monte Carlo MC)时序差分法(Temporal Difference TD) 1. 动态规划法 1.1 动态规划概念 动态规划核心思想: 其核心…...

【数据结构】1. 时间/空间复杂度
- 第 95 篇 - Date: 2025 - 05 - 09 Author: 郑龙浩/仟墨 【数据结构 】 文章目录 数据结构 - 1 -了解数据结构与算法1 什么是数据结构2 什么是算法3 数据结构的重要性? 一 时间复杂度_空间复杂度1 时间复杂度① 表示方法② 推导大 O 的规则:③ **代码示例 ** 2 空…...

k8s存储类型:emptyDir、hostPath、nfs、pvc及存储类storageclass的静态/动态创建pv
Kubernetes存储类型详解 Kubernetes(K8s)提供了多种存储类型,满足不同的存储需求。这些存储类型包括 emptyDir、hostPath、nfs、PersistentVolumeClaim(PVC)以及存储类(StorageClass)的静态和动…...

TRAE 配置blender MCP AI自动3D建模
BlenderMCP - Blender模型上下文协议集成 BlenderMCP通过模型上下文协议(MCP)将Blender连接到Claude AI,允许Claude直接与Blender交互并控制Blender。这种集成实现了即时辅助的3D建模、场景创建和操纵。 1.第一步下载 MCP插件(addon.py):Blender插件,在…...

不拆机查看电脑硬盘型号的常用方法
要比较两个硬件的参数,首先要知道的是硬件准确的型号。不过,如硬盘这类硬件,一般都藏在电脑“肚子里”,拆下看费时又费力。那么,不拆机电脑硬盘型号怎么看呢?接下来,我们就来分享几种方法。 使…...

抖音 “碰一碰” 发视频:短视频社交的新玩法
在短视频社交的广阔天地里,抖音始终站在创新的前沿。2023 年,抖音重磅推出 “碰一碰” 功能,借助近距离通信技术,实现设备间视频的闪电分享,为短视频社交注入全新活力。本文将深入剖析这一功能背后的技术奥秘、丰富应用…...

learning ray之ray核心设计和架构
我们每天都在处理海量、多样且高速生成的数据,这对计算能力提出了前所未有的挑战。传统的单机计算模式在面对日益复杂的机器学习模型和大规模数据集时,往往显得力不从心。更重要的是,数据科学家们本应专注于模型训练、特征工程、超参数调优这…...

深入理解 JavaScript 对象与属性控制
ECMA-262将对象定义为一组属性的无序集合,严格来说,这意味着对象就是一组没有特定顺序的值,对象的每个属性或方法都由一个名称来标识,这个名称映射到一个值. 可以把js的对象想象成一张散列表,其中的内容就是一组名/值对,值可以是数据或者函数 1. 理解对象 创建自定义对象的…...
)
深入理解 Linux 虚拟文件系统(VFS)
在 Linux 操作系统的世界里,虚拟文件系统(Virtual File System,VFS)扮演着极为关键的角色。它就像是一座桥梁,连接着各种不同类型的物理文件系统与操作系统以及应用程序,使得我们在使用 Linux 时能够以统一…...

AI云防护真的可以防攻击?你的服务器用群联AI云防护吗?
1. 传统防御方案的局限性 静态规则缺陷:无法应对新型攻击模式(如HTTP慢速攻击)资源浪费:固定带宽采购导致非攻击期资源闲置 2. AI云防护技术实现 动态流量调度算法: # 智能节点选择伪代码(参考群联防护…...

计算机视觉——MedSAM2医学影像一键实现3D与视频分割的高效解决方案
引言 在乡村医院的傍晚高峰时段,扫描室内传来阵阵低沉的嗡鸣声,仿佛一台老旧冰箱的运转声。一位疲惫的医生正全神贯注地检查着当天的最后一位患者——一位不幸从拖拉机上摔下的农民,此刻正呼吸急促。CT 机器飞速旋转,生成了超过一…...

软件工程之软件项目管理深度解析
前文基础: 1.软件工程学概述:软件工程学概述-CSDN博客 2.软件过程深度解析:软件过程深度解析-CSDN博客 3.软件工程之需求分析涉及的图与工具:软件工程之需求分析涉及的图与工具-CSDN博客 4.软件工程之形式化说明技术深度解…...

40. 组合总和 II
题目 给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。 candidates 中的每个数字在每个组合中只能使用 一次 。 注意:解集不能包含重复的组合。 示例 1: 输入: candidates [10,1…...

java-多态
一、多态的来历 我们先来了解一个业务场景:请设计一个系统,描述主人喂养宠物的场景,首先在这个场景当中应该有”宠物对象“,“宠物对象”应该有一个吃的行为,另外还需要一个“主人对象”,主人应该有一个喂的…...

重构 cluster-db 选择器,新增限制字段 showDb 不影响原功能前提实现查询功能增量拓展
1.为DbSelect组件新添加showDb字段 :show-db"false"时只显示集群不显示数据库信息 重构 cluster-db 选择器,新增限制字段 showDb 不影响原功能前提实现查询功能增量拓展,。保证组件**高可用性,减少冗余方法的编写,提高整体代码复用性和维护性**。 <!-…...
)
Modbus RTU 详解 + FreeMODBUS移植(附项目源码)
文章目录 前言一、Modbus RTU1.1 通信方式1.2 模式特点1.3 数据模型1.4 常用功能码说明1.5 异常响应码1.6 通信帧格式1.6.1 示例一:读取保持寄存器(功能码 0x03)1.6.2 示例二:写单个线圈(功能码 0x05)1.6.3…...

新闻发稿筛选媒体核心标准:影响力、适配性与合规性
1. 评估媒体影响力 权威性与公信力:优先选择央级媒体,其报道常被其他平台转载,传播链条长,加分权重高。 传播数据:参考定海区融媒体中心的赋分办法,关注媒体的阅读量、视频播放量等指标,如阅读…...

豆包:基于多模态交互的智能心理咨询机器人系统设计与效果评估——情感计算框架下的对话机制创新
豆包:基于多模态交互的智能心理咨询机器人系统设计与效果评估——情感计算框架下的对话机制创新 摘要 随着人工智能在心理健康领域的应用深化,本文提出一种融合情感计算与动态对话管理的智能心理咨询机器人系统架构。通过构建“用户状态-情感响应-策略生成”三层模型,结合…...

坐席业绩可视化分析工具
这个交互式的坐席业绩分析工具具有以下特点: 数据导入功能:支持上传 CSV 文件,自动解析并展示数据多维度分析:可按日 / 周 / 月分析业绩数据,支持切换不同业绩指标(接通时长 / 外呼次数 / 接通次数&#x…...

MATLAB制作柱状图与条图:数据可视化的基础利器
一、什么是柱状图与条图? 柱状图和条图都是用来表示分类数据的常见图表形式,它们的核心目的是通过矩形的长度来比较各类别的数值大小。条图其实就是“横着的柱状图”,它们的本质是一样的:用矩形的长度表示数值大小,不同…...

com.fasterxml.jackson.dataformat.xml.XmlMapper把对象转换xml格式,属性放到标签<>里边
之前从没用过xml和对象相互转换,最近项目接了政府相关的。需要用xml格式数据进行相互转换。有些小问题,困扰了我一下下。 1.有些属性需要放到标签里边,有的需要放到标签子集。 2.xml需要加<?xml version"1.0" encoding"…...

在js中大量接口调用并发批量请求处理器
并发批量请求处理器 ✨ 设计目标 该类用于批量异步请求处理,支持: 自定义并发数请求节拍控制(延时)失败重试机制进度回调通知 🔧 构造函数参数 new BulkRequestHandler({dataList, // 要处理的数据列表r…...

Azure资源创建与部署指南
本文将指导您如何在Azure平台上创建和配置必要的资源,以部署基于OpenAI的应用程序。 资源组创建 资源组是管理和组织Azure资源的逻辑容器。 在Azure门户顶端的查询框中输入"Resource groups"(英文环境)或"资源组"(中文环境)在搜索结果中点击"资…...

图解gpt之神经概率语言模型与循环神经网络
上节课我们聊了词向量表示,像Word2Vec这样的模型,它确实能捕捉到词语之间的语义关系,但问题在于,它本质上还是在孤立地看待每个词。英文的“Apple”,可以指苹果公司,也可以指水果。这种一词多义的特性&…...

Jenkins linux安装
jenkins启动 service jenkins start 重启 service jenkins restart 停止 service jenkins stop jenkins安装 命令切换到自己的下载目录 直接用命令下载 wget http://pkg.jenkins-ci.org/redhat-stable/jenkins-2.190.3-1.1.noarch.rpm 下载直接安装 rpm -ivh jenkins-2.190.3-…...

android 修改单GPS,单北斗,单伽利略等
从hal层入手,代码如下: 各个类型如下: typedef enum {MTK_CONFIG_GPS_GLONASS 0,MTK_CONFIG_GPS_BEIDOU,MTK_CONFIG_GPS_GLONASS_BEIDOU,MTK_CONFIG_GPS_ONLY,MTK_CONFIG_BEIDOU_ONLY,MTK_CONFIG_GLONASS_ONLY,MTK_CONFIG_GPS_GLONASS_BEIDO…...

CNG汽车加气站操作工岗位职责
CNG(压缩天然气)汽车加气站操作工是负责天然气加气设备操作、维护及安全管理的重要岗位。以下是该岗位的职责、技能要求、安全注意事项及职业发展方向的详细说明: *主要职责 加气操作 按照规程为车辆加注CNG,检查车辆气瓶合格证…...

纯Java实现反向传播算法:零依赖神经网络实战
在深度学习框架泛滥的今天,理解算法底层实现变得愈发重要。反向传播(Backpropagation)作为神经网络训练的基石算法,其实现往往被各种框架封装。本文将突破常规,仅用Java标准库实现完整BP算法,帮助开发者: 1) 深入理解…...

springboot3 + mybatis-plus3 创建web项目实现表增删改查
Idea创建项目 环境配置说明 在现代化的企业级应用开发中,合适的开发环境配置能够极大提升开发效率和应用性能。本文介绍的环境配置为: 操作系统:Windows 11JDK:JDK 21Maven:Maven 3.9.xIDE:IntelliJ IDEA…...
)
多模型协同预测在风机故障预测的应用(demo)
数据加载和预处理的真实性: 下面的代码中,DummyDataset 和数据加载部分仍然是高度简化和占位的。为了让这个训练循环真正有效,您必须用您自己的数据加载逻辑替换它。这意味着您需要创建一个 torch.utils.data.Dataset 的子类,它能…...

韩媒聚焦Lazarus攻击手段升级,CertiK联创顾荣辉详解应对之道
近日,韩国知名科技媒体《韩国IT时报》(Korea IT Times)刊文引述了CertiK联合创始人兼CEO顾荣辉教授的专业见解,聚焦黑客组织Lazarus在Web3.0领域攻击手段的持续升级,分析这一威胁的严峻性,并探讨了提升行业…...

5.9-selcct_poll_epoll 和 reactor 的模拟实现
5.9-select_poll_epoll 本文演示 select 等 io 多路复用函数的应用方法,函数具体介绍可以参考我过去写的博客。 先绑定监听的文件描述符 int sockfd socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in serveraddr; memset(&serveraddr, 0, sizeof(struc…...

图上思维:基于知识图的大型语言模型的深层可靠推理
摘要 尽管大型语言模型(LLM)在各种任务中取得了巨大的成功,但它们经常与幻觉问题作斗争,特别是在需要深入和负责任的推理的场景中。这些问题可以通过在LLM推理中引入外部知识图(KG)来部分解决。在本文中&am…...
)
37-智慧医疗服务平台(在线接诊/问诊)
系统功能特点: 技术栈: springBootVueMysql 功能点: 医生端 用户端 管理员端 医生端: 科室信息管理、在线挂号管理、预约体检管理、体检报告管理、药品信息管理、处方信息管理、缴费信息管理、病历信息管理、智能导诊管理、在线接诊患者功能 (和患者1V1沟通) 用户…...

【新品发布】VXI可重构信号处理系统模块系列
VXI可重构信号处理系统模块概述 VXI可重构信号处理系统模块包括了 GPU 模块,CPU 模块,射频模块、IO 模块、DSP模块、高速存储模块、交换模块,采集处理模块、回放处理模块等,全套组件为单体3U VPX架构,可自由组合到多槽…...

React 第三十八节 Router 中useRoutes 的使用详解及注意事项
前言 useRoutes 是 React Router v6 引入的一个钩子函数,允许通过 JavaScript 对象(而非传统的 JSX 语法)定义路由配置。这种方式更适合复杂路由结构,且代码更简洁易维护。 一、基础使用 1.1、useRoutes路由配置对象 useRoute…...

Redhat 系统详解
Red Hat 系统深度解析:从企业级架构到核心组件 一、Red Hat 概述:企业级 Linux 的标杆 Red Hat 是全球领先的开源解决方案供应商,其核心产品 Red Hat Enterprise Linux(RHEL) 是企业级 Linux 的黄金标准。RHEL 以 稳…...

docker常用命令总结
常用命令含义docker info查看docker 服务的信息-------------------------镜像篇docker pull XXX从官网上拉取名为XXX的镜像docker login -u name登录自己的dockerhub账号docker push XXX将XXX镜像上传到自己的dockerhub账户中(XXX的命名必须是用户名/镜像名&#x…...

【el-admin】el-admin关联数据字典
数据字典使用 一、新增数据字典1、新增【图书状态】和【图书类型】数据字典2、编辑字典值 二、代码生成配置1、表单设置2、关联字典3、验证关联数据字典 三、查询操作1、模糊查询2、按类别查询(下拉框) 四、数据校验 一、新增数据字典 1、新增【图书状态…...

component :is是什么?
问: component :is是什么? 是组件? 那我们是不是就不需要自己创建组件了?还是什么意思?component :is和什么功能是类似的,同时和类似功能相比对什么时候用component :is…...

适老化洗浴辅具产业:在技术迭代与需求升级中重塑银发经济新生态
随着中国人口老龄化程度的不断加深,老年群体对于适老化产品的需求日益增长。 适老化洗浴辅具作为保障老年人洗浴安全与舒适的关键产品,其发展状况备受关注。 深入剖析中国适老化洗浴辅具的发展现状,并探寻助力产业发展的有效路径࿰…...

『Python学习笔记』ubuntu解决matplotlit中文乱码的问题!
ubuntu解决matplotlit中文乱码的问题! 文章目录 simhei.ttf字体下载链接:http://xiazaiziti.com/210356.html将字体放到合适的地方 sudo cp SimHei.ttf /usr/share/fonts/(base) zkfzkf:~$ fc-list | grep -i "SimHei" /usr/local/share/font…...

从AI到新能源:猎板PCB的HDI技术如何定义高端制造新标准?
2025年,随着AI服务器、新能源汽车、折叠屏设备等新兴领域的爆发式增长,高密度互连(HDI)电路板成为电子制造业的“必争之地”。HDI板凭借微孔、细线宽和高层间对位精度,能够实现电子设备的高集成化与微型化,…...

汽车制造行业的数字化转型
嘿,大家好!今天来和大家聊聊汽车制造行业的数字化转型,这可是当下非常热门的话题哦! 随着科技的飞速发展,传统的汽车制造行业正经历着一场深刻的变革。数字化技术已经不再是“锦上添花”,而是车企能否在未…...

Redis 常见数据类型
Redis 常见数据类型 一、基本全局命令详解与实操 1. KEYS 命令 功能:按模式匹配返回所有符合条件的键(生产环境慎用,可能导致阻塞)。 语法: KEYS pattern 模式规则: h?llo:匹配 hello, ha…...

【计算机网络-传输层】传输层协议-TCP核心机制与可靠性保障
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:传输层协议-UDP 下篇文章: 网络层 我们的讲解顺序是&…...

对golang中CSP的理解
概念: CSP模型,即通信顺序进程模型,是由英国计算机科学家C.A.R. Hoare于1978年提出的。该模型强调进程之间通过通道(channel)进行通信,并通过消息传递来协调并发执行的进程。CSP模型的核心思想是“不要通过…...