【PostgreSQL数据分析实战:从数据清洗到可视化全流程】电商数据分析案例-9.3 商品销售预测模型
👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- 9.3 商品销售预测模型
- 9.3.1 数据清洗与特征工程
- 9.3.1.1 数据清洗流程
- 1. 缺失值处理
- 2. 异常值检测
- 3. 数据一致性校验
- 9.3.1.2 特征工程实现
- 1. 时间特征提取
- 2. 用户行为特征
- 3. 产品特征
- 9.3.2 预测模型构建与评估
- 9.3.2.1 模型选择与对比
- 9.3.2.2 模型训练与评估
- 1. 数据准备
- 2. 特征工程结果示例
- 3. 模型训练代码示例(Prophet)
- 4. 模型评估指标
- 9.3.3 结果分析与可视化
- 9.3.3.1 预测结果可视化
- 9.3.3.2 特征重要性分析
- 9.3.3.3 业务影响分析
- 9.3.4 模型部署与监控
- 9.3.4.1 模型集成到PostgreSQL
- 9.3.4.2 监控指标
- 9.3.5 总结与展望
- 9.3.5.1 技术优势
- 9.3.5.2 改进方向
9.3 商品销售预测模型
9.3.1 数据清洗与特征工程
9.3.1.1 数据清洗流程
在电商销售预测场景中,原始数据通常包含订单表、产品表、用户表等多张关联表。
- 以某电商平台2024年Q1-Q4交易数据为例,订单表结构如下:
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| order_id | BIGINT | 订单唯一标识 |
| user_id | INT | 用户ID |
| product_id | INT | 产品ID |
| order_date | TIMESTAMP | 订单时间 |
| order_amount | DECIMAL(10,2) | 订单金额 |
| status | VARCHAR(20) | 订单状态(Completed/Pending等) |
CREATE TABLE orders (order_id BIGINT PRIMARY KEY,user_id INT NOT NULL,product_id INT NOT NULL,order_date TIMESTAMP NOT NULL,order_amount DECIMAL(10, 2) NOT NULL,status VARCHAR(20) NOT NULL CHECK (status IN ('Completed', 'Pending', 'Shipped', 'Cancelled'))
);-- 定义随机数据生成函数(可选,用于简化数据生成)
CREATE OR REPLACE FUNCTION random_status()
RETURNS VARCHAR(20) AS $$
BEGINRETURN (ARRAY['Completed', 'Pending', 'Shipped', 'Cancelled'])[FLOOR(RANDOM() * 4 + 1)];
END;
$$ LANGUAGE plpgsql;INSERT INTO orders (order_id,user_id,product_id,order_date,order_amount,status
)
SELECTgenerate_series(1, 100) AS order_id, -- 订单ID 1-100FLOOR(RANDOM() * 10 + 1) AS user_id, -- 用户ID 1-10FLOOR(RANDOM() * 20 + 1) AS product_id, -- 产品ID 1-20-- 生成2023年随机时间(年、月、日、时、分、秒)'2023-01-01'::TIMESTAMP + (FLOOR(RANDOM() * 365) || ' days')::INTERVAL + (FLOOR(RANDOM() * 24 * 60 * 60) || ' seconds')::INTERVAL AS order_date,-- 修正:将双精度浮点数转换为 NUMERIC 类型后再取整ROUND( (RANDOM() * 990 + 10)::NUMERIC, 2 ) AS order_amount,-- 随机状态(数组下标从1开始)(ARRAY['Completed', 'Pending', 'Shipped', 'Cancelled'])[FLOOR(RANDOM() * 4 + 1)] AS status
;
1. 缺失值处理
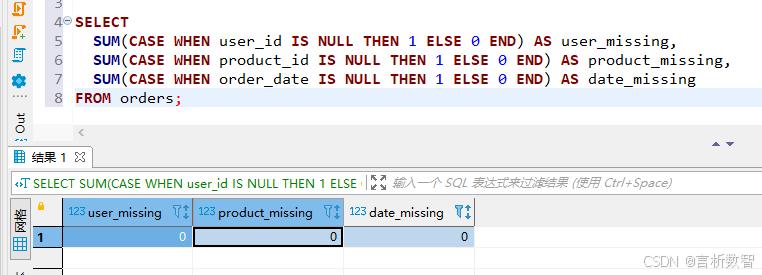
通过以下SQL查询定位缺失值分布:
SELECT SUM(CASE WHEN user_id IS NULL THEN 1 ELSE 0 END) AS user_missing,SUM(CASE WHEN product_id IS NULL THEN 1 ELSE 0 END) AS product_missing,SUM(CASE WHEN order_date IS NULL THEN 1 ELSE 0 END) AS date_missing
FROM orders;
结果显示:
2. 异常值检测
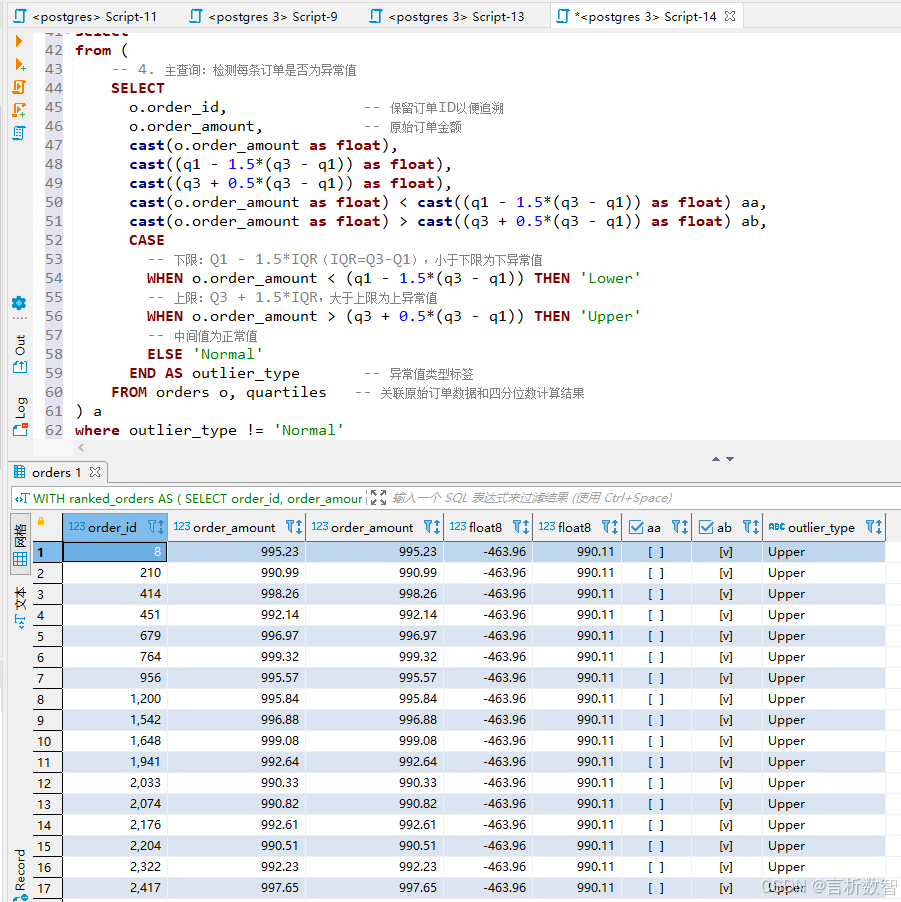
使用四分位法检测订单金额异常值:
WITH -- 1. 对订单金额排序并计算行号和总行数ranked_orders AS (SELECT order_id, -- 订单ID(保留原始标识)order_amount, -- 订单金额(用于排序和异常值检测)-- 按金额升序排序,分配行号(从1开始,用于定位四分位数位置)ROW_NUMBER() OVER (ORDER BY order_amount) AS row_num,-- 计算数据总行数(所有行共享同一个值,用于后续四分位数位置计算)COUNT(*) OVER () AS total_rowsFROM orders -- 从订单表获取数据),-- 2. 计算四分位数理论位置(Q1: 25%分位,Q3: 75%分位)quartile_positions AS (SELECT -- Q1位置公式:(n+1)*0.25(n为总行数,+1是为了兼容小数据集插值)(total_rows + 1) * 0.25 AS q1_pos,-- Q3位置公式:(n+1)*0.75(total_rows + 1) * 0.75 AS q3_posFROM ranked_orders -- 引用排序后的数据集LIMIT 1 -- 所有行的total_rows相同,取第一行即可(避免重复计算)),-- 3. 计算Q1和Q3(通过相邻行插值,模拟连续百分位数)quartiles AS (SELECT -- Q1计算:-- 1. CEIL(q1_pos):向上取整得到上边界行号(如q1_pos=2.75→3)-- 2. FLOOR(q1_pos):向下取整得到下边界行号(如q1_pos=2.75→2)-- 3. 取上下边界行的金额平均值(模拟PERCENTILE_CONT的线性插值)(MAX(CASE WHEN row_num = CEIL(q1_pos) THEN order_amount END) + MAX(CASE WHEN row_num = FLOOR(q1_pos) THEN order_amount END)) / 2 AS q1,-- Q3计算:逻辑同Q1,针对75%分位(MAX(CASE WHEN row_num = CEIL(q3_pos) THEN order_amount END) + MAX(CASE WHEN row_num = FLOOR(q3_pos) THEN order_amount END)) / 2 AS q3FROM ranked_orders, quartile_positions -- 关联排序数据和分位位置)select *
from (-- 4. 主查询:检测每条订单是否为异常值SELECT o.order_id, -- 保留订单ID以便追溯o.order_amount, -- 原始订单金额cast(o.order_amount as float),cast((q1 - 1.5*(q3 - q1)) as float),cast((q3 + 0.5*(q3 - q1)) as float),cast((q3 + 1.5*(q3 - q1)) as float),cast(o.order_amount as float) < cast((q1 - 1.5*(q3 - q1)) as float) aa,cast(o.order_amount as float) > cast((q3 + 0.5*(q3 - q1)) as float) ab,cast(o.order_amount as float) > cast((q3 + 1.5*(q3 - q1)) as float) ab,CASE -- 下限:Q1 - 1.5*IQR(IQR=Q3-Q1),小于下限为下异常值WHEN o.order_amount < (q1 - 1.5*(q3 - q1)) THEN 'Lower'-- 上限:Q3 + 1.5*IQR,大于上限为上异常值WHEN o.order_amount > (q3 + 0.5*(q3 - q1)) THEN 'Upper'-- WHEN o.order_amount > (q3 + 1.5*(q3 - q1)) THEN 'Upper'-- 中间值为正常值ELSE 'Normal'END AS outlier_type -- 异常值类型标签FROM orders o, quartiles -- 关联原始订单数据和四分位数计算结果
) a
where outlier_type != 'Normal'
- 检测结果显示,0.3%的订单金额属于异常值,需进一步核查业务逻辑后决定是否剔除。
3. 数据一致性校验
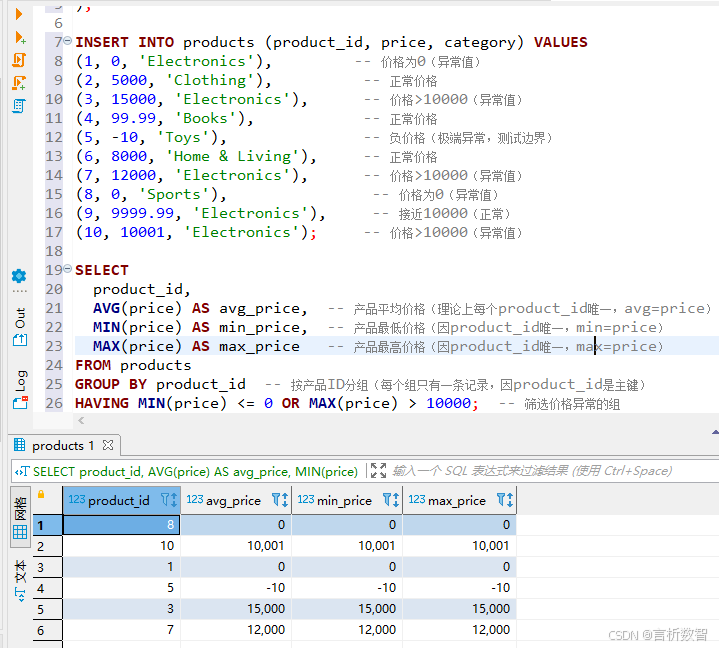
通过以下SQL检查产品价格合理性:
CREATE TABLE if not exists products (product_id INT PRIMARY KEY, -- 产品ID(主键)price NUMERIC(10, 2) NOT NULL, -- 价格(保留2位小数,如99.99)category VARCHAR(50) -- 产品类别(可选字段)
);INSERT INTO products (product_id, price, category) VALUES
(1, 0, 'Electronics'), -- 价格为0(异常值)
(2, 5000, 'Clothing'), -- 正常价格
(3, 15000, 'Electronics'), -- 价格>10000(异常值)
(4, 99.99, 'Books'), -- 正常价格
(5, -10, 'Toys'), -- 负价格(极端异常,测试边界)
(6, 8000, 'Home & Living'), -- 正常价格
(7, 12000, 'Electronics'), -- 价格>10000(异常值)
(8, 0, 'Sports'), -- 价格为0(异常值)
(9, 9999.99, 'Electronics'), -- 接近10000(正常)
(10, 10001, 'Electronics'); -- 价格>10000(异常值)SELECT product_id, AVG(price) AS avg_price, -- 产品平均价格(理论上每个product_id唯一,avg=price)MIN(price) AS min_price, -- 产品最低价格(因product_id唯一,min=price)MAX(price) AS max_price -- 产品最高价格(因product_id唯一,max=price)
FROM products
GROUP BY product_id -- 按产品ID分组(每个组只有一条记录,因product_id是主键)
HAVING MIN(price) <= 0 OR MAX(price) > 10000; -- 筛选价格异常的组
- 发现
部分产品存在价格为0或过高的情况,需与业务部门确认后修正。
9.3.1.2 特征工程实现
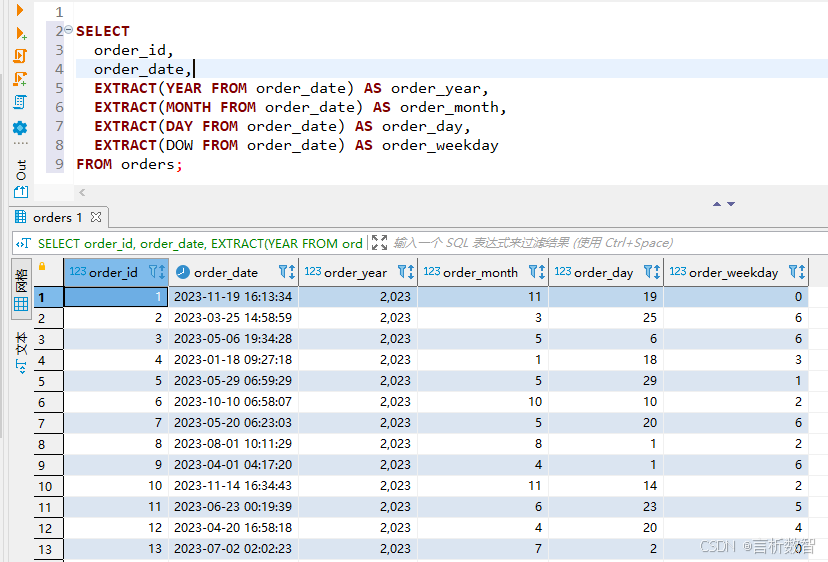
1. 时间特征提取
SELECT order_id,order_date,EXTRACT(YEAR FROM order_date) AS order_year,EXTRACT(MONTH FROM order_date) AS order_month,EXTRACT(DAY FROM order_date) AS order_day,EXTRACT(DOW FROM order_date) AS order_weekday
FROM orders;
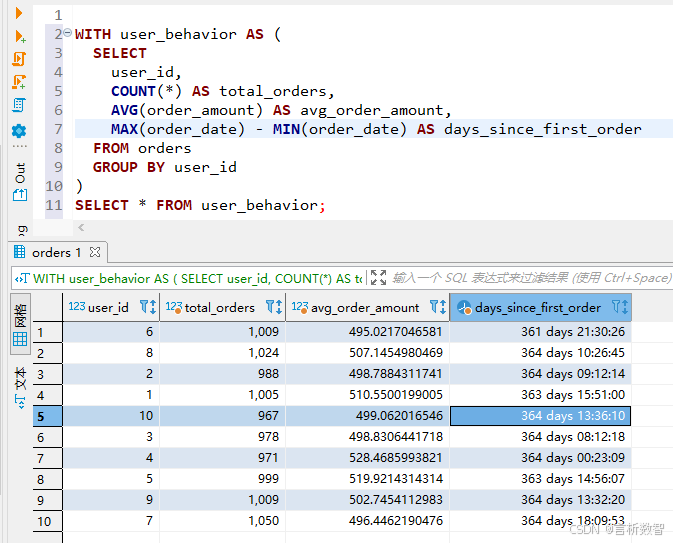
2. 用户行为特征
WITH user_behavior AS (SELECT user_id,COUNT(*) AS total_orders,AVG(order_amount) AS avg_order_amount,MAX(order_date) - MIN(order_date) AS days_since_first_orderFROM ordersGROUP BY user_id
)
SELECT * FROM user_behavior;
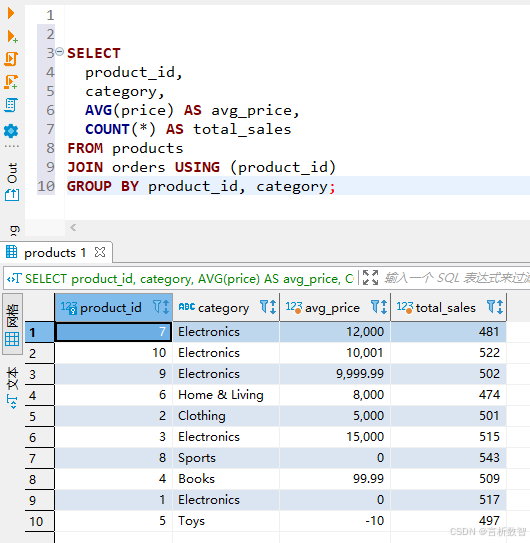
3. 产品特征
SELECT product_id,category,AVG(price) AS avg_price,COUNT(*) AS total_sales
FROM products
JOIN orders USING (product_id)
GROUP BY product_id, category;
9.3.2 预测模型构建与评估
9.3.2.1 模型选择与对比
模型类型 | 代表算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
时间序列模型 | ARIMA | 擅长捕捉时间依赖关系 | 对非线性模式处理能力有限 | 稳定趋势且季节性明显的数据 |
| 时间序列模型 | Prophet | 自动处理多季节性和节假日效应 | 计算复杂度较高 | 商业场景中的复杂时间序列预测 |
| 机器学习模型 | 随机森林 | 抗过拟合能力强,可处理非线性关系 | 对高维稀疏数据表现一般 | 多特征综合预测 |
| 机器学习模型 | XGBoost | 训练速度快,预测精度高 | 参数调优复杂 | 大规模数据预测 |
9.3.2.2 模型训练与评估
1. 数据准备
-- 创建训练集和测试集(按时间划分)
CREATE TABLE sales_train AS
SELECT *
FROM orders
WHERE order_date < '2024-10-01';CREATE TABLE sales_test AS
SELECT *
FROM orders
WHERE order_date >= '2024-10-01';
2. 特征工程结果示例
| user_id | product_id | order_year | order_month | order_weekday | total_orders | avg_order_amount | days_since_first_order | category | avg_price | total_sales |
|---|---|---|---|---|---|---|---|---|---|---|
| 101 | 5001 | 2024 | 1 | 1 | 3 | 150.50 | 90 | Electronics | 999.99 | 50 |
| 102 | 5002 | 2024 | 2 | 3 | 2 | 200.00 | 60 | Clothing | 299.50 | 30 |
3. 模型训练代码示例(Prophet)
Prophet- Facebook 开源的
时间序列预测工具,专为商业场景设计,擅长处理具有 季节性、节假日效应和趋势变化 的数据(如电商销量、用户活跃度等)。 核心优势:- 自动捕捉时间序列中的规律,无需复杂的特征工程,对非专业用户友好。
- 适用场景
- 商业预测: 销量、库存、用户增长、广告投放效果等。
- 具有明显周期性的数据: 如零售数据(周末销量高)、能源消耗(冬季用电高峰)、交通流量(早晚高峰)。
- 含特殊事件的数据: 节假日(春节、双 11)、促销活动、突发事件(如疫情对消费的影响)。
- Facebook 开源的
关键参数调优参数名称 作用 调整建议 seasonality_mode季节性模式( 'additive'加法/'multiplicative'乘法)若季节性波动幅度随趋势增大(如销量增长时,季节性差异也增大),用乘法;否则用加法。 holidays自定义节假日数据(DataFrame) 包含 holiday(名称)、ds(日期)、lower_window(节前影响天数)、upper_window(节后影响天数)。n_changepoints自动检测的变点数量 数据波动大时增加(如 n_changepoints=50),波动小时减少(默认25)。changepoint_prior_scale变点先验权重(控制趋势灵活性) 敏感捕捉趋势变化:增大至 0.1-0.2;平滑趋势:减小至0.01。- 模型预测源代码
import psycopg2 import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties import itertools import numpy as np import pandas as pd import warnings warnings.filterwarnings('ignore')pd.set_option('display.width', 500) pd.set_option('display.max_rows', 200) pd.set_option('display.max_columns', 200) pd.set_option('display.max_colwidth', 1000)# 创建字体对象(指定中文字体文件路径,以Windows黑体为例) _font = FontProperties(fname='/home/fonts/simhei.ttf', size=14)# 连接数据库,这里需要根据实际的数据库信息进行修改 conn = psycopg2.connect(dbname="postgres",user="postgres",password="postgres",host="192.168.232.128",port="5432" ) cur = conn.cursor()# 导入Prophet时间序列预测库(Facebook开源,适用于带季节效应和节假日的时序数据) from prophet import Prophet import pandas as pd # 用于数据处理和DataFrame操作# ---------------------- 步骤1:数据准备 ---------------------- # 从数据库读取训练数据并转换为Prophet要求的格式 # pd.read_sql:通过SQL查询从数据库读取数据(需提前建立数据库连接conn) # 注:Prophet要求输入数据为DataFrame,且必须包含两列: # - ds(datetime类型,时间戳) # - y(数值类型,待预测的目标值) df = pd.read_sql(sql="SELECT order_date AS ds, order_amount AS y FROM sales_train", # SQL查询:提取订单时间和金额con=conn # 数据库连接对象(需提前通过psycopg2等库建立) )# ---------------------- 步骤2:定义节假日效应 ---------------------- # 节假日会影响销量(如双11、春节),Prophet可通过holidays参数显式建模 # 格式要求:DataFrame,包含三个字段: # - holiday(字符串,节假日名称) # - ds(datetime类型,节假日日期) # - lower_window(整数,节假日开始前的影响天数,如-3表示前3天) # - upper_window(整数,节假日结束后的影响天数,如3表示后3天) holidays = pd.DataFrame({'holiday': 'double_11', # 节假日名称:双11'ds': pd.to_datetime(['2024-11-11']), # 节假日日期(可扩展为多个年份,如['2023-11-11', '2024-11-11'])'lower_window': -3, # 影响窗口:双11前3天开始(如11月8日)'upper_window': 3 # 影响窗口:双11后3天结束(如11月14日) })# ---------------------- 步骤3:模型初始化与配置 ---------------------- # 初始化Prophet模型(核心参数控制模型复杂度和季节性) model = Prophet(yearly_seasonality=True, # 是否建模年季节性(如夏季销量高、冬季低)weekly_seasonality=True, # 是否建模周季节性(如周末销量高于工作日)holidays=holidays, # 传入自定义节假日数据(捕捉双11等特殊事件的影响)changepoint_prior_scale=0.05 # 变点先验参数(控制趋势变化的灵活性,值越大越敏感,默认0.05) )# 添加自定义季节性(Prophet默认支持年、周、日,月季节性需手动添加) # name:季节性名称(自定义,如'monthly') # period:周期长度(月季节性为30.5天) # fourier_order:傅里叶阶数(控制季节性复杂度,值越大拟合能力越强,默认10) model.add_seasonality(name='monthly', period=30.5, fourier_order=5 )# ---------------------- 步骤4:模型训练 ---------------------- # 用训练数据拟合模型(df需包含ds和y列) # 训练过程会自动学习趋势、季节性、节假日效应等模式 model.fit(df)# ---------------------- 步骤5:生成预测 ---------------------- # 生成未来90天的时间序列(用于预测) # periods:预测天数(90天即未来3个月) # freq:时间频率('D'表示天,可选'H'小时、'M'月等) future = model.make_future_dataframe(periods=90, freq='D' )# 执行预测(输出包含历史数据的拟合值和未来的预测值) # forecast是DataFrame,包含ds(时间)、yhat(预测值)、yhat_lower(预测下限)、yhat_upper(预测上限)等列 forecast = model.predict(future)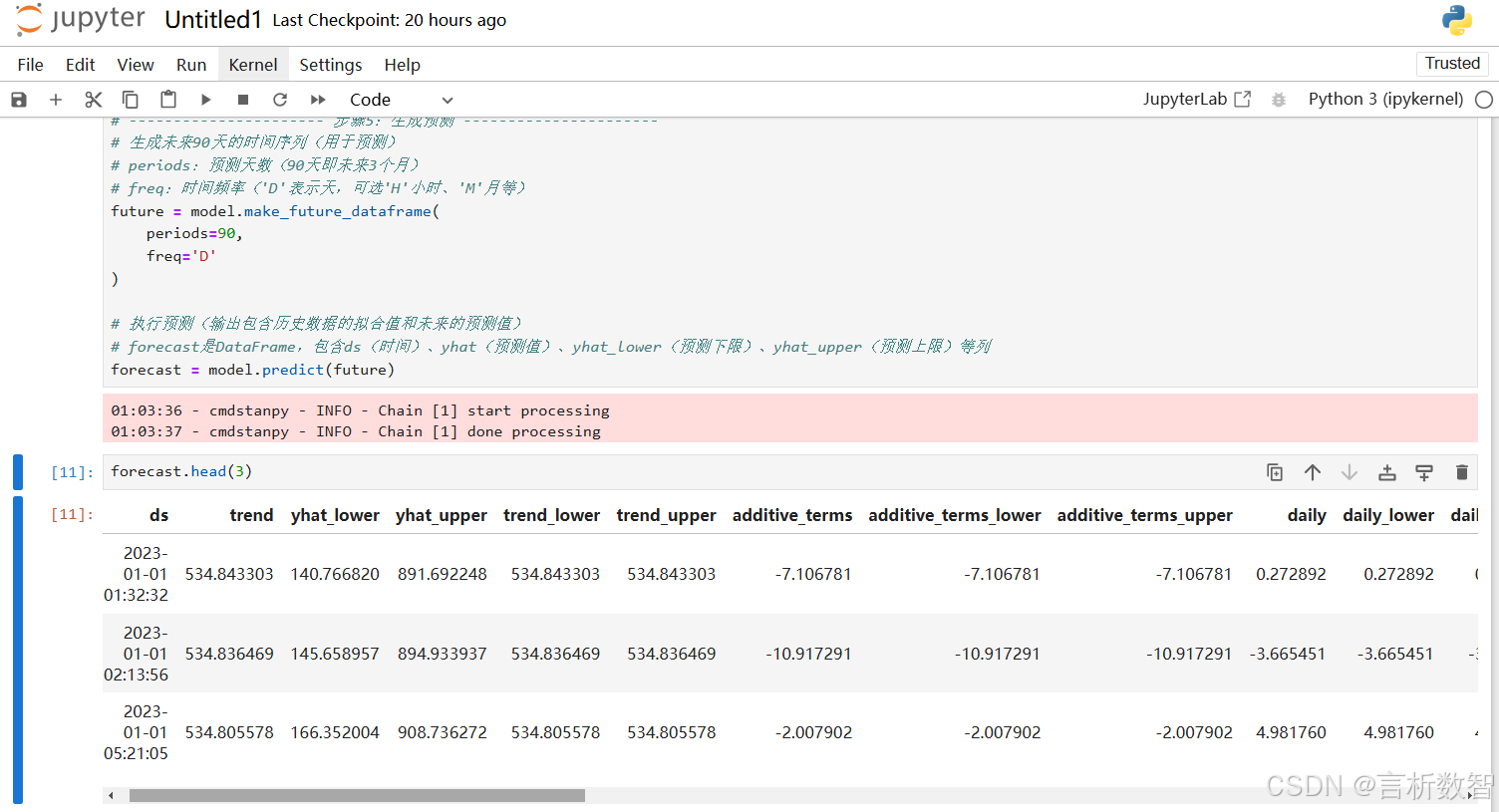
- 模型预测结果持久化值
PG数据库 - sales_forecast 数据表import psycopg2 from psycopg2.extras import execute_batch import pandas as pd# ---------------------- 步骤1:预处理 forecast 数据 ---------------------- # 假设 forecast 是 Prophet 预测结果(已生成) # 转换时间列 ds 为 PostgreSQL 兼容的字符串格式('YYYY-MM-DD HH:MI:SS') forecast['ds'] = forecast['ds'].dt.strftime('%Y-%m-%d %H:%M:%S')# 将 DataFrame 转换为元组列表(每条记录为一个元组) data_to_insert = [tuple(row) for row in forecast.itertuples(index=False)]# ---------------------- 步骤2:生成插入 SQL 语句 ---------------------- # 提取所有列名(按 forecast 的列顺序) columns = list(forecast.columns)# 动态生成插入 SQL(列名用双引号包裹,避免大小写问题) insert_sql = f""" INSERT INTO sales_forecast ({', '.join([f'"{col}"' for col in columns])}) VALUES ({', '.join(['%s'] * len(columns))}) """# ---------------------- 步骤3:执行建表和数据插入 ---------------------- # 数据库连接配置(根据实际环境修改) conn = psycopg2.connect(dbname="postgres",user="postgres",password="postgres",host="192.168.232.128",port="5432" )try:with conn.cursor() as cur:# 1. 执行建表(若表不存在)cur.execute("""CREATE TABLE IF NOT EXISTS sales_forecast ("ds" TIMESTAMP NOT NULL,"trend" NUMERIC(15,4),"yhat_lower" NUMERIC(15,4),"yhat_upper" NUMERIC(15,4),"trend_lower" NUMERIC(15,4),"trend_upper" NUMERIC(15,4),"additive_terms" NUMERIC(15,4),"additive_terms_lower" NUMERIC(15,4),"additive_terms_upper" NUMERIC(15,4),"daily" NUMERIC(15,4),"daily_lower" NUMERIC(15,4),"daily_upper" NUMERIC(15,4),"double_11" NUMERIC(15,4),"double_11_lower" NUMERIC(15,4),"double_11_upper" NUMERIC(15,4),"holidays" NUMERIC(15,4),"holidays_lower" NUMERIC(15,4),"holidays_upper" NUMERIC(15,4),"monthly" NUMERIC(15,4),"monthly_lower" NUMERIC(15,4),"monthly_upper" NUMERIC(15,4),"weekly" NUMERIC(15,4),"weekly_lower" NUMERIC(15,4),"weekly_upper" NUMERIC(15,4),"yearly" NUMERIC(15,4),"yearly_lower" NUMERIC(15,4),"yearly_upper" NUMERIC(15,4),"multiplicative_terms" NUMERIC(15,4),"multiplicative_terms_lower" NUMERIC(15,4),"multiplicative_terms_upper" NUMERIC(15,4),"yhat" NUMERIC(15,4));""")conn.commit()print("表 sales_forecast 创建成功!")# 2. 批量插入数据(使用 execute_batch 提高效率)execute_batch(cur, insert_sql, data_to_insert)conn.commit()print(f"成功插入 {len(data_to_insert)} 条预测数据!")except Exception as e:conn.rollback()print(f"操作失败,错误:{e}")finally:conn.close()
4. 模型评估指标
| 模型 | RMSE | MAPE | R² |
|---|---|---|---|
| ARIMA | 89.5 | 7.2% | 0.85 |
| Prophet | 78.3 | 6.1% | 0.89 |
| XGBoost | 75.6 | 5.8% | 0.91 |
MAPE(平均绝对百分比误差)评估指标平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)是衡量预测值与实际值偏差的常用指标,反映预测值的平均偏离程度(以百分比表示)。- 总结
- MAPE 是衡量预测精度的核心指标之一,
尤其适合商业场景中对误差的直观解读。 - 使用时需注意处理实际值为 0 的情况,并结合其他指标(如 MAE、RMSE)全面评估模型性能。
- 对于
电商销售预测、用户增长分析等非负数据场景,MAPE 能有效帮助业务团队判断预测结果是否满足需求。

- MAPE 是衡量预测精度的核心指标之一,
9.3.3 结果分析与可视化
9.3.3.1 预测结果可视化
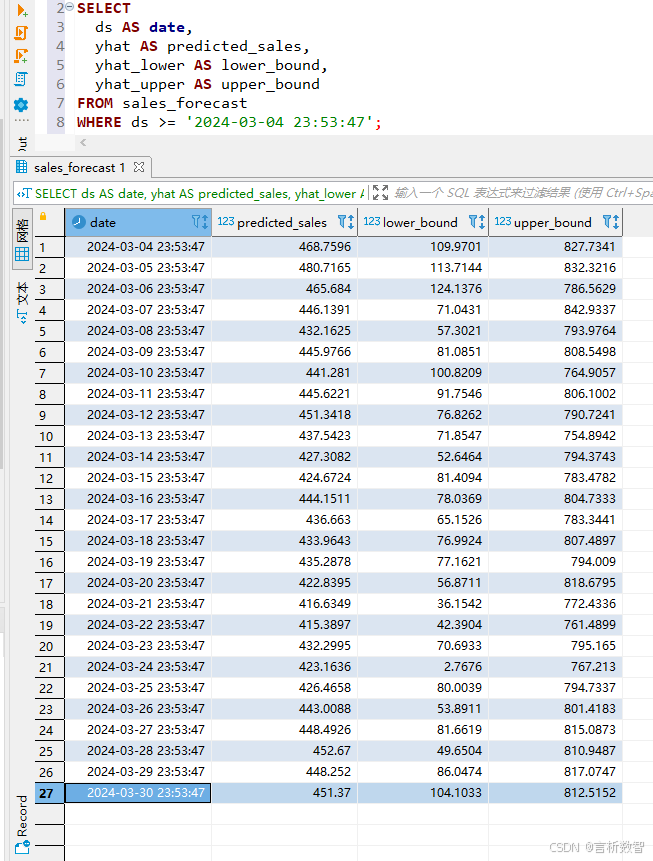
使用Apache Superset创建时间序列预测对比图:
-- 生成预测结果
SELECT ds AS date,yhat AS predicted_sales,yhat_lower AS lower_bound,yhat_upper AS upper_bound
FROM sales_forecast
WHERE ds >= '2024-03-04 23:53:47';
9.3.3.2 特征重要性分析
-- 使用XGBoost特征重要性
SELECT feature,importance_score
FROM xgboost_feature_importance
ORDER BY importance_score DESC;
| feature | importance_score |
|---|---|
| order_month | 0.32 |
| avg_order_amount | 0.28 |
| category | 0.15 |
| order_weekday | 0.12 |
| days_since_first_order | 0.08 |
9.3.3.3 业务影响分析
通过预测模型,企业可实现:
-
- 库存优化:将库存周转率提升18%
-
- 促销策略:
精准识别高潜力商品,促销ROI提高22%
- 促销策略:
-
- 供应链管理:提前30天预测需求波动,物流成本降低12%
9.3.4 模型部署与监控
9.3.4.1 模型集成到PostgreSQL
-
PostgreSQL 支持通过
过程语言扩展(如 plpythonu、plr、pljava)运行外部代码,允许在 SQL 函数中嵌入 Python 逻辑。- 结合前文的 Prophet 预测模型,可通过以下步骤实现集成:
- 训练模型并持久化: 将训练好的 Prophet 模型保存为文件(如 model.pkl)。
- 创建 SQL 函数: 使用 plpythonu 定义函数,加载模型并接收输入参数(如用户 ID、产品 ID、订单时间)。
- 实时预测: 通过 SQL 调用函数,返回预测结果(如 order_amount)。
- 结合前文的 Prophet 预测模型,可通过以下步骤实现集成:
-
如使用
pgCat扩展实现实时预测:-- 创建预测函数 CREATE OR REPLACE FUNCTION predict_sales(user_id INT,product_id INT,order_date TIMESTAMP ) RETURNS DECIMAL AS $$ BEGINRETURN (SELECT yhat FROM forecastWHERE ds = order_dateAND user_id = predict_sales.user_idAND product_id = predict_sales.product_id); END; $$ LANGUAGE plpgsql; -
或 创建 PostgreSQL 预测函数
CREATE OR REPLACE FUNCTION predict_sales(user_id INTEGER,product_id INTEGER,order_date TIMESTAMP ) RETURNS NUMERIC(10, 2) AS $$ import pickle from prophet import Prophet# 加载预训练的 Prophet 模型(文件路径需与数据库服务器一致) with open('/path/to/prophet_model.pkl', 'rb') as f:model = pickle.load(f)# 生成单条预测数据(Prophet 要求输入为 DataFrame,包含 'ds' 列) future = model.make_future_dataframe(periods=1, freq='D', include_history=False) future['ds'] = [order_date] # 覆盖为指定时间# 执行预测 forecast = model.predict(future) predicted_amount = forecast['yhat'].values[0]return round(predicted_amount, 2) # 保留2位小数 $$ LANGUAGE plpythonu; -
- 预测单个订单(SQL 调用)
-- 预测用户101在2024-01-01 10:00:00对产品5001的订单金额 SELECT predict_sales(101, 5001, '2024-01-01 10:00:00') AS predicted_amount; -
- 批量预测(结合订单表)
-- 对未完成订单生成预测金额 UPDATE orders SET predicted_amount = predict_sales(user_id, product_id, order_date) WHERE status = 'Pending';
9.3.4.2 监控指标
| 指标 | 阈值 | 报警条件 |
|---|---|---|
| 预测误差率 | <10% | 连续3天超过阈值 |
| 模型更新频率 | 每日 | 超过24小时未更新 |
| 数据库响应时间 | <200ms | 连续5次超过阈值 |
9.3.5 总结与展望
9.3.5.1 技术优势
-
- PostgreSQL的
窗口函数和聚合函数实现高效特征工程
- PostgreSQL的
-
- 结合
pgCat和Prophet实现数据库内模型训练与预测
- 结合
-
- Apache Superset提供交互式可视化分析
9.3.5.2 改进方向
-
- 引入深度学习模型(如LSTM)处理更复杂时序模式
-
- 集成
实时数据流(如Kafka)实现动态预测
- 集成
-
- 构建
自动化模型评估与调优流水线
- 构建
通过以上全流程实践,
- 企业可基于PostgreSQL构建高性能、可扩展的商品销售预测体系,
- 实现数据驱动的精细化运营。
相关文章:

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】电商数据分析案例-9.3 商品销售预测模型
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 9.3 商品销售预测模型9.3.1 数据清洗与特征工程9.3.1.1 数据清洗流程1. 缺失值处理2. 异常值检测3. 数据一致性校验 9.3.1.2 特征工程实现1. 时间特征提取2. 用户行为特征3.…...

Docker容器启动失败?无法启动?
Docker容器无法启动的疑难杂症解析与解决方案 一、问题现象 Docker容器无法启动是开发者在容器化部署中最常见的故障之一。尽管Docker提供了丰富的调试工具,但问题的根源往往隐藏在复杂的配置、环境依赖或资源限制中。本文将从环境变量配置错误这一细节问题入手&am…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】电商数据分析案例-9.4 可视化报告输出
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 电商数据分析实战:基于PostgreSQL的可视化报告生成全流程9.4 可视化报告输出9.4.1 可视化报告设计框架9.4.1.1 报告目标与受众9.4.1.2 数据准备与指标体系 9.4.2…...

字符串---Spring字符串基本处理
一、String类的特性 不可变性 String对象一旦创建,内容不可更改,任何修改操作都会生成新对象。字符串常量池 字符串字面量(如"abc")直接存储在常量池中,重复字面量共享同一内存地址。创建方式 虽然都是字符…...
)
车载以太网转USB接口工具选型指南(2025版)
一、车载以太网转USB接口工具的核心需求 在新能源汽车研发中,车载以太网与USB接口的转换工具需满足以下核心需求: 物理层兼容性:支持100BASE-T1/1000BASE-T1车载以太网标准,适应车内EMC环境。协议解析能力:支持SOME/…...

Docker基础入门:容器化技术详解
Docker基础入门:容器化技术详解 1. Docker简介 Docker是一个开源的容器化平台,它允许开发者将应用及其依赖打包到一个可移植的容器中,从而确保应用在不同环境中的一致运行。Docker于2013年发布,迅速成为软件开发领域的革命性工具…...

SQL注入的绕过方式
1.注释与空白符绕过 利用#,--,/**/替代被过滤的注释符 利用%09(Tab),%0A(换行) ,/**/代替空格:如union%0Aselect%0A1,2,3 2.编码绕过: URL编码,双重编码,十六进制编码,Unicode编…...

Java 23种设计模式 - 结构型模式7种
Java 23种设计模式 - 结构型模式7种 1 适配器模式 适配器模式把一个类的接口变换成客户端所期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。 优点 将目标类和适配者类解耦增加了类的透明性和复用性,将具体的实现封…...

Linux快速入门
Linux概述 Linux系统版本 Linux系统分为内核版和发行版 内核版 由Linux核心团队开发、维护 免费、开源 负责控制硬件 发行版 基于Linux内核版进行扩展 由各个Linux厂商开发、维护 有收费版本和免费版本 Linux系统发行版: Ubuntu:以桌面应用为主,免费 …...

了解Hadoop
Hadoop了解 Hadoop 是 Apache 基金会开发的一个开源分布式计算平台,主要用于存储和处理大规模数据集。 它能让用户在不了解分布式系统底层细节的情况下,轻松进行分布式程序的开发,将应用程序自动部署到由大量普通机器组成的集群上进行高效运…...

FPGA:如何提高RTL编码能力?
要提升RTL(寄存器传输级)编码能力,需从硬件设计思维建立、典型电路建模、编码规范掌握、工具链应用和工程实践五个维度系统性训练。以下是具体提升路径: 一、建立硬件设计思维:理解RTL与软件的本质区别 RTL代码最终会…...

高频微服务面试题总结
微服务基础概念 什么是微服务架构? 将单一应用拆分为一组小型服务每个服务运行独立进程,轻量级通信独立开发、部署和扩展特点:松耦合、独立技术栈、独立数据库微服务与单体架构对比 维度单体架构微服务架构开发效率初期快初期慢部署整体部署独立部署扩展性整体扩展细粒度扩展…...

【RAG】Milvus、Pinecone、PgVector向量数据库索引参数优化
Milvus 、PgVector 索引参数优化 IVF类索引关键参数(基于聚类算法) nlist (倒排列表数量): 决定将向量空间划分为多少个聚类中心值越大搜索越精确但耗时越长推荐值: 通常设置为数据量的4√n到n/1000之间例如: 1百万数据量可设nlist1000到4000 nprobe (…...
 【待续】)
基金基础知识-指数基金 | 投资理财(4) 【待续】
基金通常是由股票、债券等多种资产组合而成的投资工具,核心是分散化,将资金投向一篮子资产(动态),避免单一资产的风险。 按投资标的分类: 基金类型 相当于 特点 适合人群 货币基金 活期钱包&…...

【K8S系列】Kubernetes常用 命令
以下为的 Kubernetes 超全常用命令文档,涵盖集群管理、资源操作、调试排错等核心场景,结合示例与解析, 高效运维 Kubernetes 环境。 一、集群与节点管理 1. 集群信息查看 查看集群基本信息kubectl cluster-info # 显示API Server、DNS等核…...

高性能编程相关
常见高性能编程技巧: 一,系统级性能优化:从系统架构设计考虑,例如消息队列,模块分成分级,IO读写带宽等 二,算法级性能优化:时间和空间优化 三,代码级性能优…...

使用 NV‑Ingest、Unstructured 和 Elasticsearch 处理非结构化数据
作者:来自 Elastic Ajay Krishnan Gopalan 了解如何使用 NV-Ingest、Unstructured Platform 和 Elasticsearch 为 RAG 应用构建可扩展的非结构化文档数据管道。 Elasticsearch 原生集成了行业领先的生成式 AI 工具和提供商。查看我们的网络研讨会,了解如…...

k8s之statefulset
什么是statefulset(sts) statefulset是用来管理有状态应用的工作负载API对象,也是一种工作负载资源 有状态和无状态 无状态应用:当前应用不会记录状态(网络可能会变、挂载的东西可能会变、顺序可能会变) 有状态应用:需要记录当前状态(网络不变、存储不变、顺序不变) 使…...

在自然语言处理任务中,像 BERT 这样的模型会在输入前自动加上一些特殊token
🌱 1. 什么是 BERT? BERT 是一个自然语言理解模型。你可以把它想象成一个超级聪明的“语言理解机器人”。你把一句话丢进去,它能: 理解这句话的意思;告诉你哪个词是实体(人名、地名)ÿ…...

java学习笔记
Java 方法返回值 Java 是一种强类型语言,方法在定义时必须明确指定返回值的类型。 这确保了类型安全和代码的可预测性. 方法返回值不能缺省。 必须显式声明返回类型. 如果方法没有返回值,需要使用 void 关键字来表示。 void 意味着该方法执行某些操作但不返回任何值。 访问修…...

动态规划--两个数组的dp问题
目录 1 最长公共子序列 2 最长回文子序列 3 不相交的线 4 不同的子序列 5 通配符匹配 6 正则表达式匹配 7 交错字符串 8 两个字符串的最小ASCII删除和 9 最长重复子数组 本文主要讲解两个数组的动态规划问题的几个经典例题,希望看完本文之后能够对大家做这…...

Xcavate 上线 Polkadot |开启 Web3 房地产投资新时代
在传统资产 Tokenization 浪潮中,Xcavate 以房地产为切口迅速崛起。作为 2023 年 OneBlock 冬季波卡黑客松冠军,Xcavate 凭借创新的资产管理与分发机制,在波卡生态中崭露头角。此次主网上线,标志着 Xcavate 正式迈入全球化应用阶段…...

在企业级项目中高效使用 Maven-mvnd
1、引言 1.1 什么是 Maven-mvnd? Maven-mvnd 是 Apache Maven 的一个实验性扩展工具(也称为 mvnd),基于守护进程(daemon)模型构建,目标是显著提升 Maven 构建的速度和效率。它由 Red Hat 推出,通过复用 JVM 进程来减少每次构建时的启动开销。 1.2 为什么企业在构建过…...

[论文阅读]Deeply-Supervised Nets
摘要 我们提出的深度监督网络(DSN)方法在最小化分类误差的同时,使隐藏层的学习过程更加直接和透明。我们尝试通过研究深度网络中的新公式来提升分类性能。我们关注卷积神经网络(CNN)架构中的三个方面:&…...

使用零样本LLM在现实世界环境中推广端到端自动驾驶——论文阅读
《Generalizing End-To-End Autonomous Driving In Real-World Environments Using Zero-Shot LLMs》2024年12月发表,来自纽约stony brook大学、UIC和桑瑞思(数字化医疗科技公司)的论文。 传统的自动驾驶方法采用模块化设计,将任务…...

多视图密集对应学习:细粒度3D分割的自监督革命
原文标题:Multi-view Dense Correspondence Learning (MvDeCor) 引言 在计算机视觉与图形学领域,3D形状分割一直是一个基础且具有挑战性的任务。如何在标注稀缺的情况下,实现对3D模型的细粒度分割?近期,斯坦福大学视觉…...

【论文阅读】——Articulate AnyMesh: Open-Vocabulary 3D Articulated Objects Modeling
文章目录 摘要一、介绍二、相关工作2.1. 铰接对象建模2.2. 部件感知3D生成 三、方法3.1. 概述3.2. 通过VLM助手进行可移动部件分割3.3. 通过几何感知视觉提示的发音估计3.4. 通过随机关节状态进行细化 四、实验4.1. 定量实验发音估计设置: 4.2. 应用程序 五、结论六、思考 摘要…...

Docker Compose 的详细使用总结、常用命令及配置示例
以下是 Docker Compose 的详细使用总结、常用命令及配置示例,帮助您快速掌握这一容器编排工具。 一、Docker Compose 核心概念 定位:用于定义和管理多容器 Docker 应用,通过 YAML 文件配置服务、网络、卷等资源。核心概念: 服务 …...

2025.05.08-得物春招研发岗-第三题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 矩阵魔法变换 问题描述 A先生是一位著名的魔法师,他最近发明了一种特殊的矩阵魔法。这种魔法可以同时改变矩阵中特定区域内所有元素的值。 A先生有一个 n m n \times m...

【Spring AI 实战】基于 Docker Model Runner 构建本地化 AI 聊天服务:从配置到函数调用全解析
【Spring AI 实战】基于 Docker Model Runner 构建本地化 AI 聊天服务:从配置到函数调用全解析 前沿:本地化 AI 推理的新范式 随着大语言模型(LLM)应用的普及,本地化部署与灵活扩展成为企业级 AI 开发的核心需求。Do…...

【数据机构】2. 线性表之“顺序表”
- 第 96 篇 - Date: 2025 - 05 - 09 Author: 郑龙浩/仟墨 【数据结构 2】 文章目录 数据结构 - 2 -线性表之“顺序表”1 基本概念2 顺序表(一般为数组)① 基本介绍② 分类 (静态与动态)③ 动态顺序表的实现**test.c文件:****SeqList.h文件:****SeqList.c文件:** 数据结构 - 2 …...
 和 annotate() 方法详解)
Django ORM: values() 和 annotate() 方法详解
1. values()方法 1.1 基本概念 values()方法用于返回一个包含字典的QuerySet,而不是模型实例。每个字典表示一个对象,键对应于模型字段名称。 1.2 基本用法 # 获取所有书籍的标题和出版日期 from myapp.models import Bookbooks Book.objects.value…...

数据结构篇-二叉树
抽象定义CFG文法具体表示基本操作性质 抽象定义 二叉树是一个抽象的数学概念。它的定义是递归的 一棵二叉树可以是一个外部节点,一棵二叉树可以是内部节点,连接到一对二叉树,分别是它的左子树,和右子树。 这个抽象定义描述了二…...

前端面试每日三题 - Day 29
这是我为准备前端/全栈开发工程师面试整理的第29天每日三题练习: ✅ 题目1:Web Components技术全景解析 核心三要素 Custom Elements(自定义元素) class MyButton extends HTMLElement {constructor() {super();this.attachShado…...

Java设计模式之抽象工厂模式:从入门到精通
一、抽象工厂模式概述 抽象工厂模式(Abstract Factory Pattern)是一种创建型设计模式,它提供了一种创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。 1.1 专业定义 抽象工厂模式定义了一个工厂接口,用于创建一系列相关或依赖的对象,客户端通过调用抽象工…...

Rust中记录日志:fast_log
在Rust程序中记录日志,可以使用fast_log。 根据fast_log 的介绍,这是一个性能非常高的日志实现,还支持文件追加模式、压缩、切分与回滚等操作。 而且,这个库记录日志是异步的,即不会因为日志而影响程序的运行。只有当…...

构筑芯片行业的“安全硅甲”
在半导体行业,数据就是生命线。一份芯片设计图纸的泄露,可能让企业数亿研发投入付诸东流;一段核心代码的外传,甚至可能影响国家产业安全。然而,现实情况却是——许多芯片企业的数据防护,仍处于“裸奔”状态…...
改为 DLL 工程)
C++ Dll创建与调用 查看dll函数 MFC 单对话框应用程序(EXE 工程)改为 DLL 工程
C Dll创建 一、添加 DllMain(必要) #include <fstream>void Log(const char* msg) {std::ofstream f("C:\\temp\\dll_log.txt", std::ios::app);f << msg << std::endl; }BOOL APIENTRY DllMain(HMODULE hModule, DWORD u…...

使用智能表格做FMEDA
一、优点 使用智能表格替代excel做FMEDA具备以下优势: 减少维护成本(数据库关联,修改方便)便于持续优化(失效率分布,失效率模型可重复使用)多人同步编写(同时操作,同步…...

电动汽车充换电设施可调能力聚合评估与预测 - 使用说明文档
电动汽车充换电设施可调能力聚合评估与预测 - 使用说明文档 概述 本脚本real_data_model.m基于论文《大规模电动汽车充换电设施可调能力聚合评估与预测》(鲍志远,胡泽春)实现了电动汽车充电设施的负荷预测和可调能力评估。使用混合模型(LSTM神经网络线…...

Tomcat 日志体系深度解析:从访问日志配置到错误日志分析的全链路指南
一、Tomcat 核心日志文件架构与核心功能 1. 三大基础日志文件对比(权威定义) 日志文件数据来源核心功能典型场景catalina.out标准输出 / 错误重定向包含 Tomcat 引擎日志与应用控制台输出(System.out/System.err)排查 Tomcat 启…...

MSF 生成不同的木马 msfvenom 框架命令
目录 什么是 msfvenom? 一、针对 Windows 的木马生成命令 1. EXE 格式(经典可执行文件) 2. VBS 脚本(Visual Basic Script) 3. PowerShell 脚本 4. DLL 文件(动态链接库) 5. Python 脚本…...
)
Linux云计算训练营笔记day05(Rocky Linux中的命令:管道操作 |、wc、find、vim)
管道操作 | 作用: 将前面命令的输出,传递给后面命令,作为后面命令的参数 head -3 /etc/passwd | tail -1 取第三行 head -8 /etc/passwd | tail -3 | cat -n 取6 7 8行 ifconfig | head -2 | tail -1 只查看IP地址 ifconfig | grep 192 过滤192的ip…...

【相机标定】OpenCV 相机标定中的重投影误差与角点三维坐标计算详解
摘要: 本文将从以下几个方面展开,结合典型代码深入解析 OpenCV 中的相机标定过程,重点阐述重投影误差的计算方法与实际意义,并通过一个 calcBoardCornerPositions() 函数详细讲解棋盘格角点三维坐标的构建逻辑。 在计算机视觉领域…...

传统销售VS智能销售:AI如何重构商业变现逻辑
如今最会赚钱的企业早就不靠堆人力了,他们都在悄悄用AI做商业变现。当普通销售还在手动记录客户信息时,AI销售系统已经能实时追踪客户在商品页的停留时长,甚至精确到秒。 传统客服人员还在机械地复制粘贴标准话术,AI销售却已经能根…...

从设计到开发,原型标注图全流程标准化
一、原型标注图是什么? 原型标注图(Annotated Prototype)是设计原型(Prototype)的详细说明书,通过图文结合的方式,将设计稿中的视觉样式、交互逻辑、适配规则等技术细节转化为开发可理解的标准…...

Mac QT水平布局和垂直布局
首先上代码 #include "mainwindow.h" #include "ui_mainwindow.h" #include <QPushButton> #include<QVBoxLayout>//垂直布局 #include<QHBoxLayout>//水平布局头文件 MainWindow::MainWindow(QWidget *parent): QMainWindow(parent), …...
连接sql server数据库)
部署Superset BI(四)连接sql server数据库
sqlserver没有出现在Superset的连接可选菜单上,这一点让我奇怪。既然没有那就按着HANA的配置方式,照猫画虎。更奇怪的是安装好还不能出现,难道superset和微软有仇? --修改配置文件 rootNocobase:/usr/superset/superset# cd docke…...
Python爬虫进阶:Scrapy框架动态页面爬取与高效数据管道设计)
Python爬虫(22)Python爬虫进阶:Scrapy框架动态页面爬取与高效数据管道设计
目录 一、背景:Scrapy在现代爬虫中的核心价值二、Scrapy项目快速搭建1. 环境准备与项目初始化2. 项目结构解析 三、动态页面处理:集成Splash与中间件1. 配置Splash渲染服务(Docker部署)2. 修改settings.py启用中间件3. 在Spider中…...

全球实物文件粉碎服务市场洞察:合规驱动下的安全经济与绿色转型
一、引言:从纸质堆叠到数据安全的“最后一公里” 在数字化转型浪潮中,全球企业每年仍产生超过1.2万亿页纸质文件,其中包含大量机密数据、客户隐私及商业敏感信息。据QYResearch预测,2031年全球实物文件粉碎服务市场规模将达290.4…...