Off-Policy策略演员评论家算法SAC详解:python从零实现
引言
软演员评论家(SAC)是一种最先进的Off-Policy策略演员评论家算法,专为连续动作空间设计。它在 DDPG、TD3 的基础上进行了显著改进,并引入了最大熵强化学习的原则。其目标是学习一种策略,不仅最大化预期累积奖励,还要最大化策略的熵。这种添加鼓励了探索,提高了对噪声的鲁棒性,通常与之前的 DDPG 和 TD3 方法相比,能够实现更快、更稳定的学习。
SAC 是什么?
SAC 学习三个主要组件(通常使用五个网络实现):
- 演员( π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ)):一个随机策略网络,将状态映射到动作上的概率分布(在连续控制中通常为高斯分布)。由 θ \theta θ 参数化。
- 评论家(双 Q 网络 Q ( s , a ; ϕ 1 ) , Q ( s , a ; ϕ 2 ) Q(s, a; \phi_1), Q(s, a; \phi_2) Q(s,a;ϕ1),Q(s,a;ϕ2)):两个独立的 Q 值网络,估计软动作值(预期回报加上熵)。使用两个评论家有助于减少 Q 值高估。由 ϕ 1 , ϕ 2 \phi_1, \phi_2 ϕ1,ϕ2 参数化。
- 熵温度( α \alpha α):一个正系数,用于权衡目标中熵项的重要性。这可以是固定的超参数,也可以自动调整。
与 DDPG 类似,它采用:
- 回放缓冲区:用于离策略学习和样本效率。
- 目标网络:维护评论家的缓慢更新目标网络,以稳定 Q 学习目标。
- 软更新:对目标网络使用缓慢、平滑的更新。
关键思想:最大熵强化学习
标准强化学习旨在最大化预期折扣奖励总和: E [ ∑ t γ t R ( s t , a t ) ] \mathbb{E}[\sum_t \gamma^t R(s_t, a_t)] E[∑tγtR(st,at)]。最大熵强化学习修改了这一目标,在每一步加入策略的熵:
J ( π ) = E τ ∼ π [ ∑ t = 0 T γ t ( R ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ) ] J(\pi) = \mathbb{E}_{\tau \sim \pi} \left[ \sum_{t=0}^T \gamma^t \left( R(s_t, a_t) + \alpha H(\pi(\cdot|s_t)) \right) \right] J(π)=Eτ∼π[t=0∑Tγt(R(st,at)+αH(π(⋅∣st)))]
其中 H ( π ( ⋅ ∣ s t ) ) H(\pi(\cdot|s_t)) H(π(⋅∣st)) 是状态 s t s_t st 下策略分布的熵,而 α \alpha α 是控制奖励最大化和熵最大化之间权衡的温度参数。
最大化熵的好处:
- 更好的探索:代理被激励去探索更多样化的动作,可能更快地发现更好的解决方案,避免过早收敛。
- 鲁棒性:高熵策略对环境或执行中的扰动和噪声更具鲁棒性。
- 组合性:通过最大熵强化学习学习的策略有时可以更轻松地组合用于层次化任务。
SAC 的应用场景和方法
SAC 是连续控制任务中的领先算法,广泛应用于:
- 机器人学:特别适用于在模拟(MuJoCo、PyBullet)和现实世界中学习复杂的运动和操作技能。
- 连续控制基准测试:在标准基准测试(如摆动、跳跃、行走、模拟人类等)中常常取得顶级性能。
- 自主系统:需要平滑、连续控制动作的领域。
当满足以下条件时,SAC 是合适的选择:
- 动作空间是连续的。
- 需要高样本效率(离策略)。
- 探索和鲁棒性很重要。
- 稳定的学习优先于可能更快但更脆弱的方法。
SAC 的数学基础
最大熵目标
如前所述,目标是找到一个策略 π \pi π,最大化:
J ( π ) = ∑ t = 0 T E ( s t , a t ) ∼ ρ π [ γ t ( R ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ) ] J(\pi) = \sum_{t=0}^T \mathbb{E}_{(s_t, a_t) \sim \rho_\pi} [\gamma^t (R(s_t, a_t) + \alpha H(\pi(\cdot|s_t)))] J(π)=t=0∑TE(st,at)∼ρπ[γt(R(st,at)+αH(π(⋅∣st)))]
软状态值函数( V s o f t V_{soft} Vsoft)
在这个框架中,值函数也被修改(“软化”)以考虑预期的未来熵。软状态值函数通过 Bellman 方程隐式定义:
V s o f t π ( s ) = E a ∼ π ( ⋅ ∣ s ) [ Q s o f t π ( s , a ) − α log π ( a ∣ s ) ] V_{soft}^{\pi}(s) = \mathbb{E}_{a \sim \pi(\cdot|s)} [ Q_{soft}^{\pi}(s,a) - \alpha \log \pi(a|s) ] Vsoftπ(s)=Ea∼π(⋅∣s)[Qsoftπ(s,a)−αlogπ(a∣s)]
它表示从状态 s s s 开始的预期回报加上预期未来熵。
软动作值函数( Q s o f t Q_{soft} Qsoft)
软动作值函数满足软 Bellman 方程:
Q s o f t π ( s , a ) = R ( s , a ) + γ E s ′ ∼ P [ V s o f t π ( s ′ ) ] Q_{soft}^{\pi}(s,a) = R(s,a) + \gamma \mathbb{E}_{s' \sim P} [ V_{soft}^{\pi}(s') ] Qsoftπ(s,a)=R(s,a)+γEs′∼P[Vsoftπ(s′)]
将 V s o f t π ( s ′ ) V_{soft}^{\pi}(s') Vsoftπ(s′) 的定义代入 Q s o f t π Q_{soft}^{\pi} Qsoftπ 方程中,得到训练评论家时使用的 Bellman 备份算符:
Q s o f t π ( s , a ) ≈ R ( s , a ) + γ E s ′ ∼ P , a ′ ∼ π ( ⋅ ∣ s ′ ) [ Q s o f t π ( s ′ , a ′ ) − α log π ( a ′ ∣ s ′ ) ] Q_{soft}^{\pi}(s,a) \approx R(s,a) + \gamma \mathbb{E}_{s' \sim P, a' \sim \pi(\cdot|s')} [ Q_{soft}^{\pi}(s', a') - \alpha \log \pi(a'|s') ] Qsoftπ(s,a)≈R(s,a)+γEs′∼P,a′∼π(⋅∣s′)[Qsoftπ(s′,a′)−αlogπ(a′∣s′)]
软 Bellman 备份(评论家更新)
评论家网络( Q ϕ 1 , Q ϕ 2 Q_{\phi_1}, Q_{\phi_2} Qϕ1,Qϕ2)通过最小化软 Bellman 残差进行训练,使用从回放缓冲区 D \mathcal{D} D 采样的样本 ( s , a , r , s ′ , d ) (s, a, r, s', d) (s,a,r,s′,d)。目标值 y ( r , s ′ , d ) y(r, s', d) y(r,s′,d) 为:
y ( r , s ′ , d ) = r + γ ( 1 − d ) ( min i = 1 , 2 Q ϕ i ′ ′ ( s ′ , a ′ ) − α log π h e t a ( a ′ ∣ s ′ ) ) , 其中 a ′ ∼ π h e t a ( ⋅ ∣ s ′ ) y(r, s', d) = r + \gamma (1-d) \left( \min_{i=1,2} Q'_{\phi'_i}(s', a') - \alpha \log \pi_ heta(a'|s') \right), \quad \text{其中 } a' \sim \pi_ heta(\cdot|s') y(r,s′,d)=r+γ(1−d)(i=1,2minQϕi′′(s′,a′)−αlogπheta(a′∣s′)),其中 a′∼πheta(⋅∣s′)
注意:
- Q ϕ i ′ ′ Q'_{\phi'_i} Qϕi′′ 是目标评论家网络。
- a ′ a' a′ 从当前策略网络 π h e t a \pi_ heta πheta 采样(使用重参数化技巧)。
- 取两个目标 Q 值的最小值(剪辑双 Q 学习)。
- α \alpha α 是当前的熵温度。
每个评论家 i = 1 , 2 i=1,2 i=1,2 的损失为:
L ( ϕ i ) = E ( s , a , r , s ′ , d ) ∼ D [ ( Q ϕ i ( s , a ) − y ( r , s ′ , d ) ) 2 ] L(\phi_i) = \mathbb{E}_{(s,a,r,s',d) \sim \mathcal{D}} [ (Q_{\phi_i}(s,a) - y(r, s', d))^2 ] L(ϕi)=E(s,a,r,s′,d)∼D[(Qϕi(s,a)−y(r,s′,d))2]
策略改进(演员更新)
演员 π h e t a \pi_ heta πheta 被更新以最大化预期的软值,这相当于最小化以下损失:
L ( h e t a ) = E s ∼ D , a ∼ π h e t a ( ⋅ ∣ s ) [ α log π h e t a ( a ∣ s ) − min i = 1 , 2 Q ϕ i ( s , a ) ] L( heta) = \mathbb{E}_{s \sim \mathcal{D}, a \sim \pi_ heta(\cdot|s)} [ \alpha \log \pi_ heta(a|s) - \min_{i=1,2} Q_{\phi_i}(s, a) ] L(heta)=Es∼D,a∼πheta(⋅∣s)[αlogπheta(a∣s)−i=1,2minQϕi(s,a)]
这鼓励策略输出具有高软 Q 值和高熵(低负对数概率)的动作 a a a。
重参数化技巧
为使评论家的 Q 值估计的梯度能够回流到演员网络参数 θ \theta θ,当最小化 L ( θ ) L(\theta) L(θ) 时,采样过程 a ∼ π h e t a ( ⋅ ∣ s ) a \sim \pi_ heta(\cdot|s) a∼πheta(⋅∣s) 通过重参数化技巧变得可微分。对于高斯策略 π h e t a ( ⋅ ∣ s ) = N ( μ h e t a ( s ) , σ h e t a ( s ) ) \pi_ heta(\cdot|s) = \mathcal{N}(\mu_ heta(s), \sigma_ heta(s)) πheta(⋅∣s)=N(μheta(s),σheta(s)),动作采样为:
a = a n h ( μ h e t a ( s ) + σ h e t a ( s ) ⋅ ξ ) , ξ ∼ N ( 0 , I ) a = anh(\mu_ heta(s) + \sigma_ heta(s) \cdot \xi), \quad \xi \sim \mathcal{N}(0, I) a=anh(μheta(s)+σheta(s)⋅ξ),ξ∼N(0,I)
演员网络输出 μ h e t a ( s ) \mu_ heta(s) μheta(s) 和 log σ h e t a ( s ) \log \sigma_ heta(s) logσheta(s)。$ anh$ 函数将输出压缩到有界范围(例如,[-1, 1]),在计算用于演员和评论家目标更新的对数概率 log π h e t a ( a ∣ s ) \log \pi_ heta(a|s) logπheta(a∣s) 时需要一个校正项。
熵温度( α \alpha α)调整
而不是固定 α \alpha α,可以通过定义目标熵 H ˉ \bar{H} Hˉ(通常启发式设置,例如 − dim ( A ) -\text{dim}(\mathcal{A}) −dim(A))并优化 α \alpha α 使其匹配策略的平均熵来自动调整。 α \alpha α 的损失(通过其对数 log α \log \alpha logα 优化)为:
L ( log α ) = E a t ∼ π h e t a [ − log α ( log π h e t a ( a t ∣ s t ) + H ˉ ) 分离 ] L(\log \alpha) = \mathbb{E}_{a_t \sim \pi_ heta} [ -\log \alpha ( \log \pi_ heta(a_t|s_t) + \bar{H} )^{\text{分离}} ] L(logα)=Eat∼πheta[−logα(logπheta(at∣st)+Hˉ)分离]
通过梯度下降最小化该损失会调整 α \alpha α:如果熵太低, α \alpha α 增加;如果熵太高, α \alpha α 减少。
双 Q 学习和目标网络
- 双 Q 学习:使用两个评论家网络( Q 1 , Q 2 Q_1, Q_2 Q1,Q2)并取其目标值的最小值,有助于减少 Q 学习中常见的高估偏差。
- 目标网络:使用单独的目标网络( Q 1 ′ , Q 2 ′ Q'_1, Q'_2 Q1′,Q2′)计算 Bellman 目标 y y y。它们通过软更新( τ \tau τ)缓慢地向主评论家网络更新。
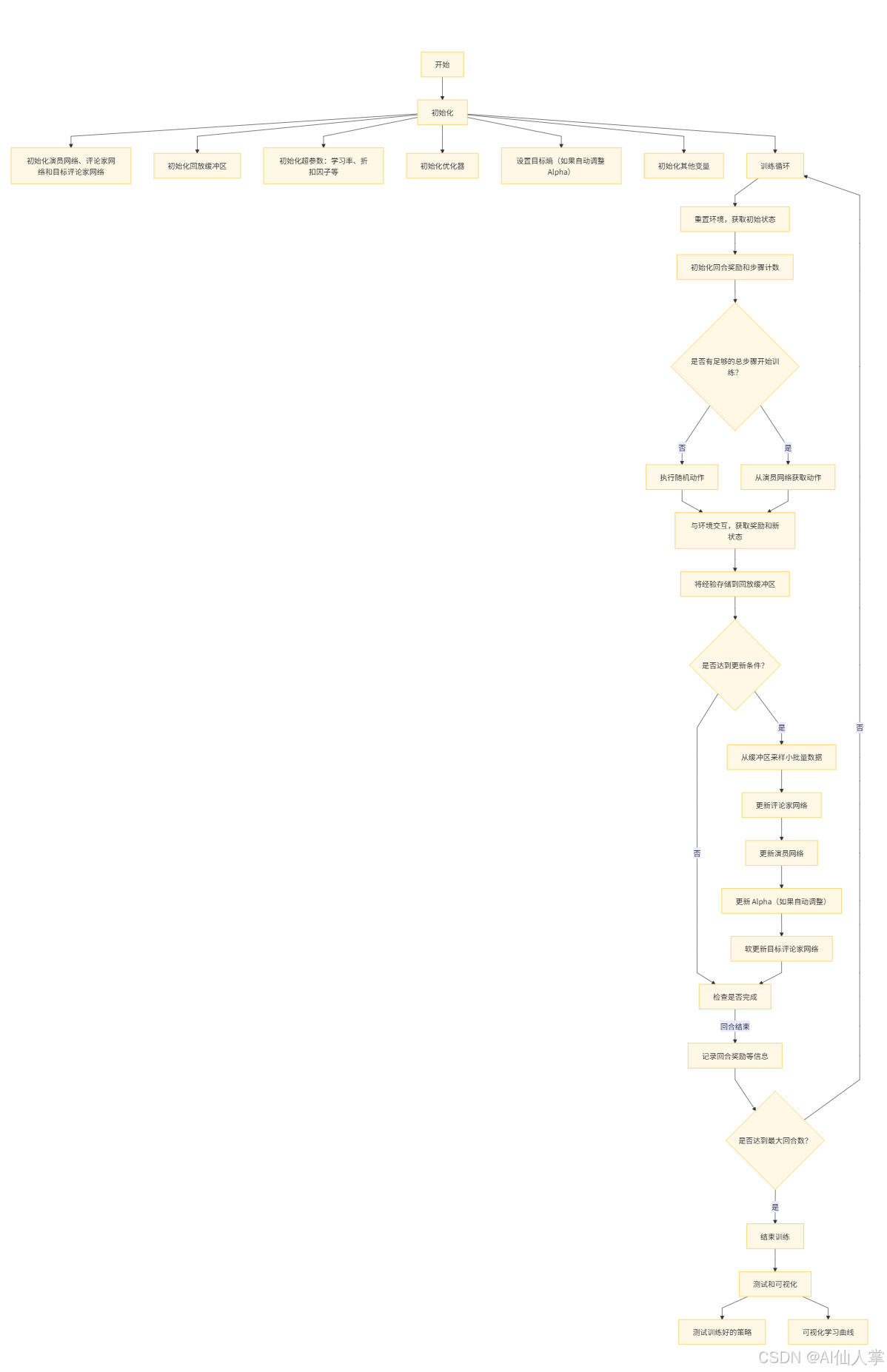
SAC 的逐步解释
- 初始化:演员网络 π h e t a \pi_ heta πheta,两个评论家网络 Q ϕ 1 , Q ϕ 2 Q_{\phi_1}, Q_{\phi_2} Qϕ1,Qϕ2。
- 初始化:两个目标评论家网络 Q ϕ 1 ′ ′ , Q ϕ 2 ′ ′ Q'_{\phi'_1}, Q'_{\phi'_2} Qϕ1′′,Qϕ2′′,其中 ϕ 1 ′ ← ϕ 1 \phi'_1 \leftarrow \phi_1 ϕ1′←ϕ1, ϕ 2 ′ ← ϕ 2 \phi'_2 \leftarrow \phi_2 ϕ2′←ϕ2。
- 初始化:回放缓冲区 D \mathcal{D} D。
- 初始化:熵温度 α \alpha α(可以固定或通过 log α \log \alpha logα 自动调整);如果是自动调整,初始化目标熵 H ˉ \bar{H} Hˉ 和 log α \log \alpha logα 优化器。
- 初始化:演员和评论家优化器。
- 对于每个回合:
a. 重置环境,获取初始状态 s 0 s_0 s0。
b. 对于每一步 t t t:
i. 从 π h e t a ( ⋅ ∣ s t ) \pi_ heta(\cdot|s_t) πheta(⋅∣st) 采样动作 a t a_t at(使用重参数化技巧,如果需要只添加噪声——随机策略进行探索)。
ii. 执行 a t a_t at,观察奖励 r t r_t rt,下一个状态 s t + 1 s_{t+1} st+1,完成标志 d t d_t dt。
iii. 将过渡 ( s t , a t , r t , s t + 1 , d t ) (s_t, a_t, r_t, s_{t+1}, d_t) (st,at,rt,st+1,dt) 存储到 D \mathcal{D} D 中。
iv. 更新步骤(在收集足够数据后,例如每一步或每隔几步):
1. 从 D \mathcal{D} D 中采样一个大小为 N N N 的小批量过渡。
2. 更新评论家:
- 使用目标评论家、当前演员和 α \alpha α 计算目标值 y j y_j yj。
- 通过梯度下降最小化均方误差损失 L ( ϕ 1 ) L(\phi_1) L(ϕ1) 和 L ( ϕ 2 ) L(\phi_2) L(ϕ2)。
3. 更新演员:
- 使用当前评论家和当前演员计算演员损失 L ( θ ) L(\theta) L(θ)。
- 通过梯度下降最小化 L ( θ ) L(\theta) L(θ)。
4. 更新 Alpha(如果调整):
- 计算 alpha 损失 L ( log α ) L(\log \alpha) L(logα)。
- 通过梯度下降最小化 L ( log α ) L(\log \alpha) L(logα)。
5. 更新目标评论家:执行软更新:
ϕ i ′ ← τ ϕ i + ( 1 − τ ) ϕ i ′ \phi'_i \leftarrow \tau \phi_i + (1 - \tau) \phi'_i ϕi′←τϕi+(1−τ)ϕi′ 对于 i = 1 , 2 i=1,2 i=1,2。
v. s t ← s t + 1 s_t \leftarrow s_{t+1} st←st+1。
vi. 如果 d t d_t dt,则中断回合。 - 重复:直到收敛或达到最大回合数/步骤数。
SAC 的关键组件
随机演员网络(策略)
- 将状态 s s s 映射到动作 a a a 的分布参数(例如,均值、对数标准差)。
- 被训练以最大化软 Q 值和熵。
- 使用重参数化技巧实现可微分性。
评论家网络(双 Q 网络)
- 两个网络( Q 1 , Q 2 Q_1, Q_2 Q1,Q2)估计软动作值 Q s o f t ( s , a ) Q_{soft}(s,a) Qsoft(s,a)。
- 使用软 Bellman 目标进行训练。
目标评论家网络
- 缓慢更新的副本( Q 1 ′ , Q 2 ′ Q'_1, Q'_2 Q1′,Q2′),用于计算稳定的 Bellman 目标。
熵温度( α \alpha α)
- 平衡奖励和熵最大化。可以固定或自动调整。
回放缓冲区
- 标准离策略缓冲区,用于存储转换。
软目标更新
- 缓慢将主评论家参数混合到目标评论家参数中( τ \tau τ)。
超参数
- 缓冲区大小、批量大小、学习率(演员、评论家、alpha)。
- 目标更新率( τ \tau τ)、折扣( γ \gamma γ)。
- 初始 α \alpha α 和目标熵 H ˉ \bar{H} Hˉ(如果调整 α \alpha α)。
- 网络架构。
实践示例:摆动环境
我们使用 Gymnasium 中的 Pendulum-v1 来演示 SAC 在连续动作空间中的应用。需要 gymnasium。
为什么选择摆动环境?(连续动作和探索)
SAC 非常适合具有连续动作空间的环境,如 Pendulum-v1。虽然网格世界提供离散动作(上、下、左、右),但 SAC 在需要学习精细控制时表现出色。Pendulum-v1 环境是一个标准基准测试,非常适合演示 SAC 的能力,因为它:
-
连续状态:[cos(theta), sin(theta), theta_dot] 表示摆的角度和角速度。
-
连续动作:施加在摆关节上的扭矩。这是一个通常在 [-2.0, 2.0] 范围内的单个连续值。
-
探索的强调:SAC 通过将熵最大化与奖励相结合,固有地鼓励探索。这对于
Pendulum-v1环境特别有用,因为找到最优控制策略通常需要尝试不同的扭矩级别并观察结果动态。连续动作空间为代理提供了广泛的可能行为以进行探索。
使用此环境可以正确演示 SAC 对连续动作的处理及其探索策略。需要 gymnasium 库,与参考 DQN 笔记本中“仅基本库”约束略有不同,因为 SAC 本质上是为连续动作空间设计的,探索是关键。
设置环境
导入库,包括 gymnasium。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import random
import math
from collections import namedtuple, deque
from itertools import count
from typing import List, Tuple, Dict, Optional, Callable, Any
import copy# 导入 PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.distributions import Normal # 使用正态分布处理连续动作torch.set_default_tensor_type(torch.FloatTensor) # 设置默认为 float32# 导入 Gymnasium
try:import gymnasium as gym
except ImportError:print("未找到 Gymnasium。请使用 'pip install gymnasium' 或 'pip install gym[classic_control]' 安装。")gym = None# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}")# 设置随机种子
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():torch.cuda.manual_seed_all(seed)%matplotlib inline
使用设备:cpuc:\Users\faree\Desktop\all-rl-algorithms\.venv-all-rl-algos\lib\site-packages\torch\__init__.py:1236: UserWarning: torch.set_default_tensor_type() 自 PyTorch 2.1 起已弃用,请改用 torch.set_default_dtype() 和 torch.set_default_device()。 (在 C:\actions-runner\_work\pytorch\pytorch\pytorch\torch\csrc\tensor\python_tensor.cpp:436 触发内部)_C._set_default_tensor_type(t)
创建连续环境(Gymnasium)
实例化摆动环境。
# 实例化摆动环境
if gym is not None:try:env = gym.make('Pendulum-v1')env.reset(seed=seed)env.action_space.seed(seed)n_observations_sac = env.observation_space.shape[0]n_actions_sac = env.action_space.shape[0]action_low_sac = env.action_space.low[0]action_high_sac = env.action_space.high[0]print(f"摆动环境:")print(f"状态维度:{n_observations_sac}")print(f"动作维度:{n_actions_sac}")print(f"动作下限:{action_low_sac}")print(f"动作上限:{action_high_sac}")except Exception as e:print(f"创建 Gymnasium 环境时出错:{e}")n_observations_sac = 3n_actions_sac = 1action_low_sac = -2.0action_high_sac = 2.0env = None
else:print("Gymnasium 不可用。无法创建摆动环境。")n_observations_sac = 3n_actions_sac = 1action_low_sac = -2.0action_high_sac = 2.0env = None
摆动环境:
状态维度:3
动作维度:1
动作下限:-2.0
动作上限:2.0
实现 SAC 算法
定义 SAC 组件:演员、评论家、回放缓冲区、更新逻辑。
定义演员网络(高斯策略)
输出均值和对数标准差,用于高斯分布。动作通过 tanh 压缩,并修正对数概率。
LOG_STD_MAX = 2
LOG_STD_MIN = -20
EPSILON = 1e-6 # 用于数值稳定的小数class ActorNetworkSAC(nn.Module):""" SAC 的随机高斯演员网络 """def __init__(self, n_observations: int, n_actions: int, action_high_bound: float):super(ActorNetworkSAC, self).__init__()self.action_high_bound = action_high_bound# 架构(根据需要调整复杂度)self.layer1 = nn.Linear(n_observations, 256)self.layer2 = nn.Linear(256, 256)self.mean_layer = nn.Linear(256, n_actions) # 输出均值self.log_std_layer = nn.Linear(256, n_actions) # 输出对数标准差def forward(self, state: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:"""输出动作及其对数概率,使用重参数化和 tanh 压缩。参数:- state (torch.Tensor):输入状态。返回:- Tuple[torch.Tensor, torch.Tensor]:- action: 从策略中采样的压缩动作。- log_prob: 压缩动作的对数概率。"""# 检查状态是否为单个样本并添加批量维度(如果需要)add_batch_dim = Falseif state.dim() == 1:state = state.unsqueeze(0) # 添加批量维度add_batch_dim = Truex = F.relu(self.layer1(state))x = F.relu(self.layer2(x))mean = self.mean_layer(x)log_std = self.log_std_layer(x)# 为稳定性限制 log_stdlog_std = torch.clamp(log_std, LOG_STD_MIN, LOG_STD_MAX)std = torch.exp(log_std)# 创建高斯分布normal_dist = Normal(mean, std)# 重参数化技巧:采样预压缩动作# 使用 rsample() 进行可微分采样z = normal_dist.rsample()# 应用 tanh 压缩以获得有界动作action = torch.tanh(z)# 计算对数概率并修正 tanh 压缩# log_prob = log_normal(z) - log(1 - tanh(z)^2)log_prob = normal_dist.log_prob(z) - torch.log(1 - action.pow(2) + EPSILON)# 沿动作维度求和(正确处理维度)if log_prob.dim() > 1:log_prob = log_prob.sum(dim=1, keepdim=True)else:log_prob = log_prob.sum(keepdim=True)# 将动作缩放到环境范围action = action * self.action_high_bound# 移除添加的批量维度(如果添加了)if add_batch_dim:action = action.squeeze(0)log_prob = log_prob.squeeze(0)return action, log_prob
定义评论家网络(双 Q)
包含两个内部 Q 网络。
class CriticNetworkSAC(nn.Module):""" SAC 的双 Q 值评论家网络 """def __init__(self, n_observations: int, n_actions: int):super(CriticNetworkSAC, self).__init__()# Q1 架构self.q1_layer1 = nn.Linear(n_observations + n_actions, 256)self.q1_layer2 = nn.Linear(256, 256)self.q1_output = nn.Linear(256, 1)# Q2 架构self.q2_layer1 = nn.Linear(n_observations + n_actions, 256)self.q2_layer2 = nn.Linear(256, 256)self.q2_output = nn.Linear(256, 1)def forward(self, state: torch.Tensor, action: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:"""输出两个内部评论家的 Q 值。参数:- state (torch.Tensor):输入状态张量。- action (torch.Tensor):输入动作张量。返回:- Tuple[torch.Tensor, torch.Tensor]:Q1(s, a) 和 Q2(s, a)。"""sa = torch.cat([state, action], dim=1) # 连接状态和动作# Q1 前向传播q1 = F.relu(self.q1_layer1(sa))q1 = F.relu(self.q1_layer2(q1))q1 = self.q1_output(q1)# Q2 前向传播q2 = F.relu(self.q2_layer1(sa))q2 = F.relu(self.q2_layer2(q2))q2 = self.q2_output(q2)return q1, q2
定义回放缓冲区
标准缓冲区,与 DDPG/DQN 版本相同。
# 定义存储转换的结构
# 使用与 DDPG/DQN 相同的 Transition 命名元组
Transition = namedtuple('Transition',('state', 'action', 'reward', 'next_state', 'done'))# 定义回放缓冲区类(与 DDPG/DQN 版本相同)
class ReplayMemory(object):def __init__(self, capacity: int):self.memory = deque([], maxlen=capacity)def push(self, *args: Any) -> None:processed_args = []for arg in args:if isinstance(arg, torch.Tensor):# 确保张量为 float32 且在 CPU 上processed_args.append(arg.to(torch.float32).cpu())elif isinstance(arg, np.ndarray):# 将 numpy 数组转换为 float32 张量processed_args.append(torch.from_numpy(arg).to(torch.float32).cpu())elif isinstance(arg, (bool, float, int)):# 将标量值存储为 float32 张量processed_args.append(torch.tensor([arg], dtype=torch.float32))else:processed_args.append(arg)self.memory.append(Transition(*processed_args))def sample(self, batch_size: int) -> List[Transition]:return random.sample(self.memory, batch_size)def __len__(self) -> int:return len(self.memory)
软更新函数
重用软更新函数。
def soft_update(target_net: nn.Module, main_net: nn.Module, tau: float) -> None:""" 对目标网络参数执行软更新。(相同) """for target_param, main_param in zip(target_net.parameters(), main_net.parameters()):target_param.data.copy_(tau * main_param.data + (1.0 - tau) * target_param.data)
SAC 更新步骤
执行评论家、演员和(可选)alpha 更新。
def update_sac(memory: ReplayMemory,batch_size: int,actor: ActorNetworkSAC,critic: CriticNetworkSAC,target_critic: CriticNetworkSAC,actor_optimizer: optim.Optimizer,critic_optimizer: optim.Optimizer,log_alpha: torch.Tensor,alpha_optimizer: optim.Optimizer,target_entropy: float,gamma: float,tau: float) -> Tuple[float, float, float, float]:"""执行一个 SAC 更新步骤(评论家、演员、alpha)。"""# 确保内存中有足够的样本if len(memory) < batch_size:return 0.0, 0.0, 0.0, torch.exp(log_alpha.detach()).item()# 从内存中采样一批转换transitions = memory.sample(batch_size)batch = Transition(*zip(*transitions))# 解包并移至适当设备,显式指定 dtype=float32state_batch = torch.cat([s.view(1, -1).float() for s in batch.state]).to(device)action_batch = torch.cat([a.view(1, -1).float() for a in batch.action]).to(device)reward_batch = torch.cat([r.view(1, -1).float() for r in batch.reward]).to(device)next_state_batch = torch.cat([s.view(1, -1).float() for s in batch.next_state]).to(device)done_batch = torch.cat([d.view(1, -1).float() for d in batch.done]).to(device)# --- 评论家更新 ---with torch.no_grad():# 从当前策略获取下一个动作和对数概率next_action, next_log_prob = actor(next_state_batch)# 从目标评论家获取目标 Q 值q1_target_next, q2_target_next = target_critic(next_state_batch, next_action)q_target_next = torch.min(q1_target_next, q2_target_next) # 取两个 Q 值的最小值# 计算软目标:# soft_target = Q_target_next - α * log_probalpha = torch.exp(log_alpha.detach()).float()soft_target = q_target_next - alpha * next_log_prob# 计算 Bellman 方程的目标值:# y = reward + γ * (1 - done) * soft_targety = reward_batch + gamma * (1.0 - done_batch) * soft_target# 获取评论家的当前 Q 估计q1_current, q2_current = critic(state_batch, action_batch)# 计算评论家损失(均方误差):# critic_loss = MSE(Q1_current, y) + MSE(Q2_current, y)critic1_loss = F.mse_loss(q1_current, y)critic2_loss = F.mse_loss(q2_current, y)critic_loss = critic1_loss + critic2_loss# 优化评论家网络critic_optimizer.zero_grad()critic_loss.backward()critic_optimizer.step()# --- 演员更新 ---# 冻结评论家梯度以避免在演员优化期间更新它们for p in critic.parameters():p.requires_grad = False# 从演员获取当前状态下的动作和对数概率pi_action, pi_log_prob = actor(state_batch)# 从评论家获取这些动作的 Q 值q1_pi, q2_pi = critic(state_batch, pi_action)min_q_pi = torch.min(q1_pi, q2_pi) # 取两个 Q 值的最小值# 计算演员损失:# actor_loss = E[α * log_prob - Q_min]actor_loss = (alpha * pi_log_prob - min_q_pi).mean()# 优化演员网络actor_optimizer.zero_grad()actor_loss.backward()actor_optimizer.step()# 解冻评论家梯度for p in critic.parameters():p.requires_grad = True# --- Alpha(熵温度)更新 ---# 计算 alpha 损失:# alpha_loss = -E[log_alpha * (log_prob + target_entropy)]target_entropy_tensor = torch.tensor(target_entropy, dtype=torch.float32, device=device)alpha_loss = -(log_alpha * (pi_log_prob.detach().float() + target_entropy_tensor)).mean()# 优化 alpha(如果启用了自动调整)if alpha_optimizer is not None:alpha_optimizer.zero_grad()alpha_loss.backward()alpha_optimizer.step()# 获取 alpha 的当前值current_alpha = torch.exp(log_alpha.detach()).item()# --- 更新目标网络 ---# 对目标评论家网络执行软更新:# θ_target = τ * θ_main + (1 - τ) * θ_targetsoft_update(target_critic, critic, tau)# 返回损失和当前 alpha 值return critic_loss.item(), actor_loss.item(), alpha_loss.item(), current_alpha
运行 SAC 算法
设置超参数,初始化所有内容,并运行 SAC 训练循环。
超参数设置
为摆动定义 SAC 超参数。
# SAC 在摆动上的超参数
BUFFER_SIZE_SAC = int(1e6) # 回放缓冲区容量
BATCH_SIZE_SAC = 256 # 小批量大小
GAMMA_SAC = 0.99 # 折扣因子
TAU_SAC = 5e-3 # 软更新因子
LR_SAC = 3e-4 # 演员、评论家和 alpha 的学习率
INITIAL_ALPHA = 0.2 # 初始熵温度(或如果未调整则为固定值)
AUTO_TUNE_ALPHA = True # 是否自动调整 alpha
TARGET_ENTROPY = -float(n_actions_sac) # 启发式目标熵:-|动作空间维度|NUM_EPISODES_SAC = 100 # 训练回合数
MAX_STEPS_PER_EPISODE_SAC = 200 # 摆动通常使用 200 步
START_STEPS = 1000 # 初始随机步骤数,之后开始训练
UPDATE_EVERY_SAC = 1 # 每个环境步骤后执行更新
初始化
初始化所有网络、目标网络、优化器、alpha 和缓冲区。
if env is None:raise RuntimeError("无法创建 Gymnasium 环境 'Pendulum-v1'。")# 初始化网络
actor_sac = ActorNetworkSAC(n_observations_sac, n_actions_sac, action_high_sac).to(device)
critic_sac = CriticNetworkSAC(n_observations_sac, n_actions_sac).to(device)
target_critic_sac = CriticNetworkSAC(n_observations_sac, n_actions_sac).to(device)
target_critic_sac.load_state_dict(critic_sac.state_dict())
# 冻结目标评论家参数
for p in target_critic_sac.parameters():p.requires_grad = False# 初始化优化器
actor_optimizer_sac = optim.Adam(actor_sac.parameters(), lr=LR_SAC)
critic_optimizer_sac = optim.Adam(critic_sac.parameters(), lr=LR_SAC)# 初始化 Alpha(熵温度)
# 初始化 Alpha(熵温度)并显式设置为 float32
if AUTO_TUNE_ALPHA:# 学习 log_alpha 以提高稳定性log_alpha_sac = torch.tensor(np.log(INITIAL_ALPHA), dtype=torch.float32, requires_grad=True, device=device)alpha_optimizer_sac = optim.Adam([log_alpha_sac], lr=LR_SAC)
else:log_alpha_sac = torch.tensor(np.log(INITIAL_ALPHA), dtype=torch.float32, requires_grad=False, device=device)alpha_optimizer_sac = None # 如果 alpha 固定则不需要优化器# 确保目标熵也是 float32
TARGET_ENTROPY_TENSOR = torch.tensor(-float(n_actions_sac), dtype=torch.float32, device=device)# 初始化回放缓冲区
memory_sac = ReplayMemory(BUFFER_SIZE_SAC)# 用于绘图的列表
sac_episode_rewards = []
sac_episode_critic_losses = []
sac_episode_actor_losses = []
sac_episode_alpha_losses = []
sac_episode_alphas = []
训练循环
SAC 训练循环,包括初始随机探索。
print("开始在摆动上训练 SAC...")# --- SAC 训练循环 ---
total_steps_sac = 0
for i_episode in range(1, NUM_EPISODES_SAC + 1):state_np, info = env.reset()state = torch.from_numpy(state_np).float().to(device)episode_reward = 0episode_critic_loss = 0episode_actor_loss = 0episode_alpha_loss = 0num_updates = 0for t in range(MAX_STEPS_PER_EPISODE_SAC):# --- 动作选择 --- if total_steps_sac < START_STEPS:# 初始探索使用随机动作action = env.action_space.sample() # 从环境的动作空间采样action_tensor = torch.from_numpy(action).float().to(device)else:# 从随机策略采样动作actor_sac.eval() # 设置为评估模式以进行一致采样with torch.no_grad():action_tensor, _ = actor_sac(state)actor_sac.train() # 恢复训练模式action = action_tensor.cpu().numpy() # 转换为 numpy 用于 env.step# 动作已由网络缩放# 如果网络输出 + 噪声略微超出范围,仍需裁剪action = np.clip(action, action_low_sac, action_high_sac)# --- 环境交互 --- next_state_np, reward, terminated, truncated, _ = env.step(action)done = terminated or truncated# --- 存储经验 --- # 确保存储的动作是张量action_store_tensor = torch.from_numpy(action if isinstance(action, np.ndarray) else np.array([action])).float()memory_sac.push(state, action_store_tensor, reward, next_state_np, done)state_np = next_state_npstate = torch.from_numpy(state_np).float().to(device)episode_reward += rewardtotal_steps_sac += 1# --- 更新网络(如果收集了足够的步骤且缓冲区足够) --- if total_steps_sac >= START_STEPS and total_steps_sac % UPDATE_EVERY_SAC == 0:if len(memory_sac) > BATCH_SIZE_SAC:c_loss, a_loss, alpha_loss, _ = update_sac(memory_sac, BATCH_SIZE_SAC, actor_sac, critic_sac, target_critic_sac,actor_optimizer_sac, critic_optimizer_sac,log_alpha_sac, alpha_optimizer_sac if AUTO_TUNE_ALPHA else None, TARGET_ENTROPY if AUTO_TUNE_ALPHA else 0.0,GAMMA_SAC, TAU_SAC)episode_critic_loss += c_lossepisode_actor_loss += a_lossepisode_alpha_loss += alpha_lossnum_updates += 1if done:break# --- 回合结束 --- sac_episode_rewards.append(episode_reward)sac_episode_critic_losses.append(episode_critic_loss / num_updates if num_updates > 0 else 0)sac_episode_actor_losses.append(episode_actor_loss / num_updates if num_updates > 0 else 0)sac_episode_alpha_losses.append(episode_alpha_loss / num_updates if num_updates > 0 else 0)sac_episode_alphas.append(torch.exp(log_alpha_sac.detach()).item())# 打印进度if i_episode % 10 == 0:avg_reward = np.mean(sac_episode_rewards[-10:])avg_closs = np.mean(sac_episode_critic_losses[-10:])avg_aloss = np.mean(sac_episode_actor_losses[-10:])current_alpha = sac_episode_alphas[-1]print(f"回合 {i_episode}/{NUM_EPISODES_SAC} | 步骤:{total_steps_sac} | 平均奖励:{avg_reward:.2f} | 评论家损失:{avg_closs:.4f} | 演员损失:{avg_aloss:.4f} | Alpha:{current_alpha:.4f}")print("摆动训练完成(SAC)。")
开始在摆动上训练 SAC...
回合 10/100 | 步骤:2000 | 平均奖励:-1413.71 | 评论家损失:13.7941 | 演员损失:9.2109 | Alpha:0.1522
回合 20/100 | 步骤:4000 | 平均奖励:-1133.37 | 评论家损失:34.4909 | 演员损失:61.2778 | Alpha:0.1203
回合 30/100 | 步骤:6000 | 平均奖励:-783.47 | 评论家损失:89.4786 | 演员损失:95.3463 | Alpha:0.1385
回合 40/100 | 步骤:8000 | 平均奖励:-201.32 | 评论家损失:133.6666 | 演员损失:109.4018 | Alpha:0.2055
回合 50/100 | 步骤:10000 | 平均奖励:-208.57 | 评论家损失:147.7181 | 演员损失:109.8792 | Alpha:0.2450
回合 60/100 | 步骤:12000 | 平均奖励:-137.20 | 评论家损失:162.6894 | 演员损失:102.9486 | Alpha:0.2321
回合 70/100 | 步骤:14000 | 平均奖励:-183.97 | 评论家损失:150.2266 | 演员损失:93.0447 | Alpha:0.2226
回合 80/100 | 步骤:16000 | 平均奖励:-168.13 | 评论家损失:132.5991 | 演员损失:82.4845 | Alpha:0.1889
回合 90/100 | 步骤:18000 | 平均奖励:-127.96 | 评论家损失:120.6159 | 演员损失:71.2044 | Alpha:0.1632
回合 100/100 | 步骤:20000 | 平均奖励:-155.37 | 评论家损失:113.2320 | 演员损失:61.8330 | Alpha:0.1420
摆动训练完成(SAC)。
可视化学习过程
绘制集数奖励、损失和学习的 alpha 值。
# 绘制摆动上的 SAC 结果
plt.figure(figsize=(20, 8))# 集数奖励
plt.subplot(2, 3, 1)
plt.plot(sac_episode_rewards)
plt.title('SAC 摆动:集数奖励')
plt.xlabel('集数')
plt.ylabel('总奖励')
plt.grid(True)
if len(sac_episode_rewards) >= 10:rewards_ma_sac = np.convolve(sac_episode_rewards, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(rewards_ma_sac)) + 9, rewards_ma_sac, label='10 集数移动平均', color='橙色')plt.legend()# 评论家损失
plt.subplot(2, 3, 2)
plt.plot(sac_episode_critic_losses)
plt.title('SAC 摆动:每集平均评论家损失')
plt.xlabel('集数')
plt.ylabel('平均均方误差损失')
plt.grid(True)
if len(sac_episode_critic_losses) >= 10:closs_ma_sac = np.convolve(sac_episode_critic_losses, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(closs_ma_sac)) + 9, closs_ma_sac, label='10 集数移动平均', color='橙色')plt.legend()# 演员损失
plt.subplot(2, 3, 3)
plt.plot(sac_episode_actor_losses)
plt.title('SAC 摆动:每集平均演员损失')
plt.xlabel('集数')
plt.ylabel('平均损失(alpha*log_pi - Q)')
plt.grid(True)
if len(sac_episode_actor_losses) >= 10:aloss_ma_sac = np.convolve(sac_episode_actor_losses, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(aloss_ma_sac)) + 9, aloss_ma_sac, label='10 集数移动平均', color='橙色')plt.legend()# Alpha 值
plt.subplot(2, 3, 4)
plt.plot(sac_episode_alphas)
plt.title('SAC 摆动:每集 Alpha(熵温度)')
plt.xlabel('集数')
plt.ylabel('Alpha')
plt.grid(True)# Alpha 损失(如果自动调整)
if AUTO_TUNE_ALPHA:plt.subplot(2, 3, 5)plt.plot(sac_episode_alpha_losses)plt.title('SAC 摆动:每集平均 Alpha 损失')plt.xlabel('集数')plt.ylabel('平均损失')plt.grid(True)if len(sac_episode_alpha_losses) >= 10:alphloss_ma_sac = np.convolve(sac_episode_alpha_losses, np.ones(10)/10, mode='valid')plt.plot(np.arange(len(alphloss_ma_sac)) + 9, alphloss_ma_sac, label='10 集数移动平均', color='橙色')plt.legend()plt.tight_layout()
plt.show()
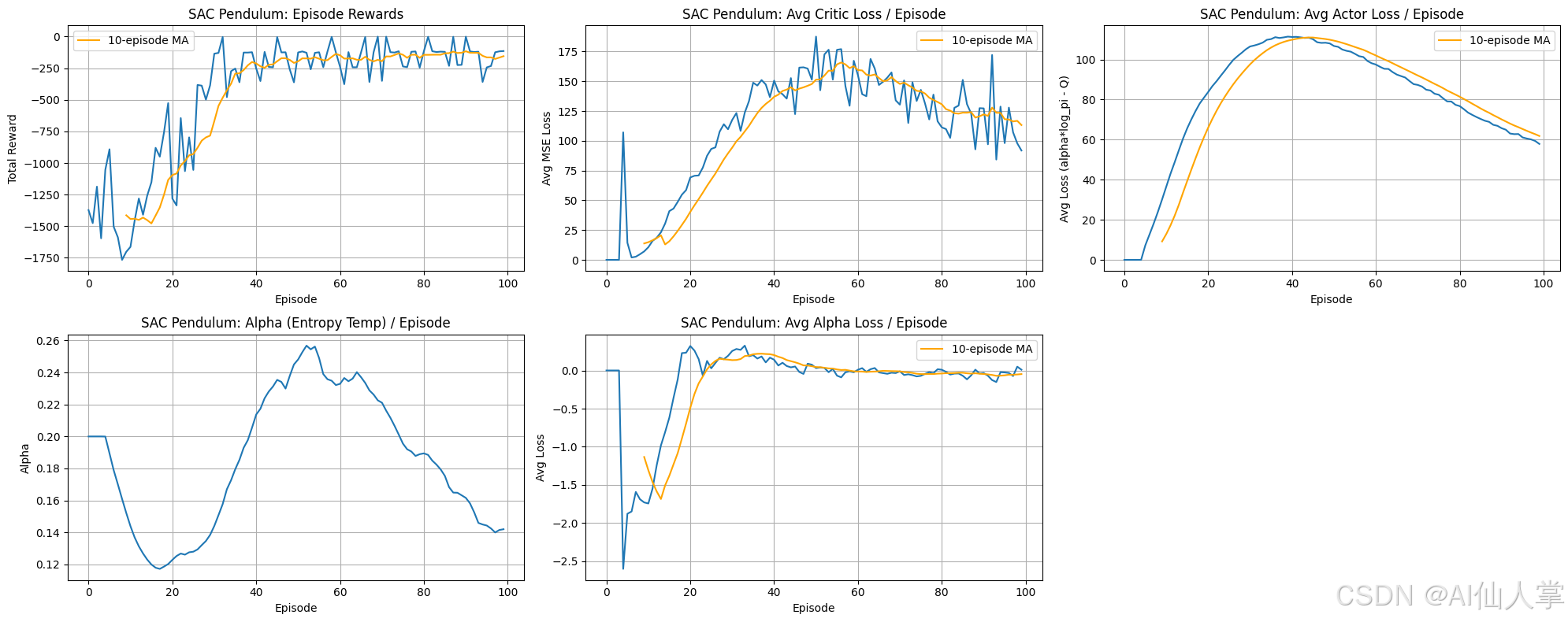
SAC 学习曲线分析(摆动):
-
集数奖励:
代理表现出清晰且相对稳定的学习,在前 40-50 个回合中,10 集数移动平均奖励从大约 -1500 显著增加到约 -200,表示策略的优化成功。奖励在较高水平上趋于稳定,表明探索策略有效。与 DDPG 相比,方差似乎更低,这可能是由于 SAC 的熵正则化促进了更平滑的策略变化。 -
每集平均评论家损失:
与 DDPG 类似,评论家的均方误差损失在训练期间显著增加。这反映了评论家正在适应改进的策略和更高的目标 Q 值(与更好的性能相关的更少负奖励)。尽管上升的损失有时可能表明不稳定性,但在此处它可能对应于该任务中 Q 值规模的增加,而稳定的奖励表明评论家学习是有效的。 -
每集平均演员损失:
演员损失(代表alpha*log_pi - Q)最初增加,在约第 40 个回合达到峰值后逐渐减少。由于 SAC 的复杂目标旨在同时最大化预期回报(高 Q)和策略熵(高 log_pi),因此损失(最小化即目标最大化)的峰值后下降表明重点已转向最大化 Q 值。 -
Alpha(熵温度)/ 集数:
自动调整的熵温度参数 alpha 表现出有趣的行为。它最初下降,表明代理迅速变得更加确定(降低熵),然后在约第 55 个回合显著增加,表明需要更多探索以逃离局部最优或适应更高价值的状态,最后随着策略收敛和变得更加确定而再次下降。这种动态调整是 SAC 探索与利用平衡的关键。 -
每集平均 Alpha 损失:
与调整 alpha 相关的损失显示初始负尖峰,随后上升并稳定接近零。该损失旨在驱动 alpha 使得策略熵匹配目标值。其稳定接近零表明自动调整机制已收敛,成功平衡策略的熵。
总体结论:
SAC 在连续动作的摆动任务上表现出有效且相对稳定的学习,实现的奖励与 DDPG 相当但可能方差更低。自动调整的熵温度(alpha)积极调整整个训练过程中的探索水平,为稳健学习做出了贡献。评论家和演员的损失显示出与摆动环境动态和 SAC 最大熵目标一致的趋势。
分析学习的策略(测试)
通过在环境中确定性地(使用策略分布的均值)运行训练好的 SAC 代理来可视化其性能。
def test_sac_agent(actor_net: ActorNetworkSAC, env_instance: gym.Env, num_episodes: int = 5, render: bool = False, seed_offset: int = 2000) -> None:"""使用均值动作(确定性)测试训练好的 SAC 代理。"""if env_instance is None:print("无法进行测试,环境不可用。")returnactor_net.eval() # 设置演员为评估模式print(f"\n--- 测试 SAC 代理({num_episodes} 个回合,确定性) ---")all_rewards = []for i in range(num_episodes):state_np, info = env_instance.reset(seed=seed + seed_offset + i)state = torch.from_numpy(state_np).float().to(device)episode_reward = 0done = Falset = 0while not done:if render:try:env_instance.render()time.sleep(0.01)except Exception as e:print(f"渲染失败:{e}。禁用渲染。")render = Falsewith torch.no_grad():# --- 获取确定性动作(均值) --- # 前向传播以获取均值,忽略采样动作和对数概率x = F.relu(actor_net.layer1(state))x = F.relu(actor_net.layer2(x))mean = actor_net.mean_layer(x)action_deterministic = torch.tanh(mean) * actor_net.action_high_bound# -----------------------------------------action = action_deterministic.cpu().numpy()# 仅在必要时裁剪action_clipped = np.clip(action, env_instance.action_space.low, env_instance.action_space.high)next_state_np, reward, terminated, truncated, _ = env_instance.step(action_clipped)done = terminated or truncatedstate = torch.from_numpy(next_state_np).float().to(device)episode_reward += rewardt += 1print(f"测试回合 {i+1}:奖励 = {episode_reward:.2f},长度 = {t}")all_rewards.append(episode_reward)if render:env_instance.close()print(f"--- 测试完成。平均奖励:{np.mean(all_rewards):.2f} ---")# 运行测试回合
test_sac_agent(actor_sac, env, num_episodes=3, render=False) # 如需要,可设置 render=True
--- 测试 SAC 代理(3 个回合,确定性) ---
测试回合 1:奖励 = -0.47,长度 = 200
测试回合 2:奖励 = -123.35,长度 = 200
测试回合 3:奖励 = -0.76,长度 = 200
--- 测试完成。平均奖励:-41.53 ---
SAC 的常见挑战和解决方案
挑战:超参数敏感性(尤其是 α \alpha α)
-
问题:性能对学习率、 τ \tau τ、批量大小和特别是熵温度 α \alpha α 非常敏感。固定的 α \alpha α 可能过高(过度探索,收敛缓慢)或过低(探索不足,策略次优)。
-
解决方案:
- 自动调整 Alpha:实现基于目标熵的自动调整 α \alpha α(如本笔记本中所做)通常可以提高稳定性和性能。
- 仔细手动调整:如果不使用自动调整, α \alpha α 需要仔细的手动调整,通常需要实验。
- 使用标准默认值:从常见值开始(例如,LR=3e-4, τ \tau τ=5e-3,批量=256)。
挑战:目标熵 H ˉ \bar{H} Hˉ 的选择
-
问题:在自动调整 α \alpha α 时,目标熵 H ˉ \bar{H} Hˉ 的选择可以影响策略的探索水平。常用的启发式方法 H ˉ = − dim ( A ) \bar{H} = -\text{dim}(\mathcal{A}) Hˉ=−dim(A) 并不总是最优的。
-
解决方案:
- 使用启发式方法:从 H ˉ = − dim ( A ) \bar{H} = -\text{dim}(\mathcal{A}) Hˉ=−dim(A) 开始。
- 实验:如果性能不满意,尝试略微不同的 H ˉ \bar{H} Hˉ 值。
挑战:实现细节(压缩校正)
- 问题:忘记应用由于
tanh压缩函数导致的对数概率校正项是常见的实现错误,严重影响性能。
解决方案:确保对数概率计算正确减去 log ( 1 − tanh ( z ) 2 ) \log(1 - \tanh(z)^2) log(1−tanh(z)2),沿动作维度求和。
挑战:非常复杂任务的样本效率
- 问题:尽管由于离策略学习而具有很高的样本效率,但极其复杂的环境可能仍然需要大量的数据。
解决方案:
* 分布式训练:使用多个并行收集数据的代理(例如,RLLib 框架)。
* 基于模型的强化学习:结合学习的环境动力学模型以生成额外的模拟数据。
* 离线强化学习:如果有足够的预收集数据,可以使用离线强化学习变体。
结论
软演员评论家(SAC)是一种强大的Off-Policy策略演员评论家算法,在连续控制任务中表现出色,通过结合最大熵框架。通过优化奖励和策略熵,SAC 鼓励稳健的探索,并通常实现最先进的性能,具有高样本效率和稳定性。
关键特性包括随机策略与重参数化、双 Q 评论家与软目标更新,以及通常自动调整的熵温度( α \alpha α),使其成为现代强化学习中具有吸引力的选择,适用于具有挑战性的连续控制问题。
相关文章:

Off-Policy策略演员评论家算法SAC详解:python从零实现
引言 软演员评论家(SAC)是一种最先进的Off-Policy策略演员评论家算法,专为连续动作空间设计。它在 DDPG、TD3 的基础上进行了显著改进,并引入了最大熵强化学习的原则。其目标是学习一种策略,不仅最大化预期累积奖励&a…...

基于大模型的计划性剖宫产全流程预测与方案优化研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 二、大模型在计划性剖宫产中的应用原理 2.1 大模型介绍 2.2 数据收集与处理 2.3 模型训练与优化 三、术前预测与准备 3.1 风险因素评估 3.2 大模型术前预测 3.3 术前准备方案 四、术中预测与应对 4.1 术中…...

在Lua中使用轻量级userdata在C/C++之间传递数据和调用函数
在Lua中使用轻量级userdata在C/C之间传递数据和调用函数 轻量级userdata是Lua中一种高效的数据传递机制,它允许你在C/C和Lua之间传递指针而不创建完整的userdata对象。下面是如何使用轻量级userdata的详细说明: 基本概念 轻量级userdata:只…...

总线通信篇:I2C、SPI、CAN 的底层结构与多机通信设计
本文为嵌入式通信协议系列第三章,深入剖析 MCU 世界中的三大总线协议 —— I2C、SPI 和 CAN。 这些总线协议广泛应用于传感器数据采集、Flash 存储、外设扩展、汽车电子、工业设备控制等领域,是嵌入式开发不可或缺的通信骨架。 📜 一、总线通信的基本概念 1.1 什么是总线?…...
 和 Ping/Echo 策略)
心跳策略(Heartbeat) 和 Ping/Echo 策略
一、心跳策略(Heartbeat) 原理:客户端定期向服务端发送心跳包,服务端监控客户端存活状态,超时未收到心跳则判定客户端离线 服务端代码 using System; using System.Net; using System.Net.Sockets; using System.Coll…...

探索网络设备安全:Shodan 的原理与合法应用
在数字化时代,网络摄像头因其便捷性和高效性被广泛应用于家庭、商业和工业领域。然而,这些设备的安全性问题也日益受到关注。Shodan,这个被称为“设备搜索引擎”的工具,能够帮助我们发现和分析网络摄像头的分布和安全性。本文将深…...
 学习笔记)
Java JWT 配置类 (JwtProperties) 学习笔记
1. 核心作用: 此类 (JwtProperties) 作为一个集中的“配置信息持有者”,专门用来存储项目中与 JWT(JSON Web Token,一种用于身份验证的令牌)相关的配置参数。 2. 关键注解说明: Component: 含义ÿ…...

沃伦森电容器支路阻抗特性监控系统 电容器组智能健康管理专家
行业现状与挑战 在现代电力系统中,电容器组作为无功补偿的核心设备,对保障电网稳定运行和提升电能质量至关重要。然而,长期运行中面临的谐波干扰、过电压/过电流冲击等问题,极易导致电容值衰减、介质老化甚至爆炸等严重故障&#…...

macOS Arduino IDE离线安装ESP8266支持包
其实吧,本来用platformio也是可以的,不过有时候用Arduino IDE可能更快一些,因为以前一直是Arduino.app和Arduino IDE.app共存了一段时间,后来下决心删掉Arduino.app并升级到最新的Arduino IDE.app。删除了旧的支持板级支持包之后就…...

在Fiddler中添加自定义HTTP方法列并高亮显示
在Fiddler中添加自定义HTTP方法列并高亮显示 Fiddler 是一款强大的 Web 调试代理工具,允许开发者检查和操作 HTTP 流量。一个常见需求是自定义 Web Sessions 列表,添加显示 HTTP 方法(GET、POST 等)的列,并通过颜色区…...

HTTP学习
HTTP知识 01. 经典五层模型 应用层 为应用软件提供了很多服务,构建于协议之上。 传输层 数据的传输都是在这层定义的,数据过大分包,分片。 网络层 为数据在节点之间传输创建逻辑链路 数据链路层 通讯实体间建立数据链路连接 物理层 主要作用…...

正态分布和幂律分布
1. 背景与引入 正态分布 历史来源:18世纪由高斯(Gauss)在研究测量误差时提出,后被广泛应用于自然现象和社会科学的数据建模。重要性:被称为“钟形曲线”,是统计学中最核心的分布之一,支撑中心极…...

网络安全赛题解析
扫描之后发现目标靶机 上开启了 ftp ssh http mysql等服务 第一题 第一题需要获取文件 首先尝试 ftp 匿名用户 从这里可以发现 hint.txt 文件的大小为 127b 或 127bytes 提交127b 第二题 通过hint.txt 文件可以发现目标主机 上有用户 Jay 密码为五位字符串 其中三位不知道 利…...

Android单例模式知识总结
六种核心实现方式对比 1. 饿汉式单例(Eager Initialization) 原理:利用类加载时静态变量初始化的特性,天然线程安全。 代码: public class EagerSingleton {private static final EagerSingleton INSTANCE new Eag…...

何不乘东风?利用mcp实现小红书自动发布
1.准备环境 conda create -n mcpo python3.11 conda activate mcpo pip install mcpo pip install uvnpx puppeteer/browsers install chromedriver134.0.6998.166pip install xhs-mcp-server 2.进行登陆 env phoneYOUR_PHONE_NUMBER json_pathPATH_TO_STORE_YOUR_COOKIES u…...

DeepSeek多尺度数据:无监督与原则性诊断方案全解析
DeepSeek 多尺度数据诊断方案的重要性 在当今的 IT 领域,数据如同石油,是驱动各类智能应用发展的核心资源。随着技术的飞速发展,数据的规模和复杂性呈爆炸式增长,多尺度数据处理成为了众多领域面临的关键挑战。以计算机视觉为例,在目标检测任务中,小目标可能只有几个像素…...

【开源】Python打造高效剪贴板历史管理器:实现跨平台生产力工具
📋【开源】Python打造高效剪贴板历史管理器:实现跨平台生产力工具 🌈 个人主页:创客白泽 - CSDN博客 🔥 系列专栏:🐍《Python开源项目实战》 💡 热爱不止于代码,热情源自…...

Day 14 训练
Day 14 训练 SHAP(SHapley Additive exPlanations)1.创建解释器2.将特征贡献可视化第一部分:绘制SHAP特征重要性条形图第二部分:绘制SHAP特征重要性蜂巢图 SHAP(SHapley Additive exPlanations) 旨在解释复…...

V型球阀材质性能深度解析:专攻颗粒、料浆与高腐蚀介质的工业利器-耀圣
V型球阀材质性能深度解析:专攻颗粒、料浆与高腐蚀介质的工业利器 在工业流体控制领域,V型球阀凭借其独特的V型切口设计与多元化材质适配能力,成为含颗粒、纤维、料浆及强腐蚀性介质的“终极克星”。本文从材质性能与驱动适配性两大维度切入&…...

缓存套餐-01.Spring Cache入门案例
一.导入案例代码 application.yml server:port: 8888 spring:datasource:druid:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/spring_cache_demo?serverTimezoneAsia/Shanghai&useUnicodetrue&characterEncodingutf-8&zeroDat…...

2025年APP安全攻防指南:抵御DDoS与CC攻击的实战策略
2025年,随着AI技术与物联网设备的深度渗透,DDoS与CC攻击的复杂性和破坏性显著升级。攻击者通过伪造用户行为、劫持智能设备、利用协议漏洞等手段,对APP发起精准打击,导致服务瘫痪、用户流失甚至数据泄露。面对这一挑战,…...

力扣:多数元素
题目 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 示例 1: 输入:nums [3,2,3] 输出ÿ…...

2025年小程序DDoS与CC攻击防御全指南:构建智能安全生态
2025年,小程序已成为企业数字化转型的核心载体,但随之而来的DDoS与CC攻击也愈发复杂化、智能化。攻击者利用AI伪造用户行为、劫持物联网设备发起T级流量冲击,甚至通过漏洞窃取敏感数据。如何在高并发业务场景下保障小程序的稳定与安全&#x…...
)
【Python】PDF文件处理(PyPDF2、borb、fitz)
Python提供了多种方法和库用于处理PDF文件,这些工具可以帮助开发者实现诸如读取、写入、合并、拆分以及压缩等功能。以下是几个常用的Python PDF操作库及其基本用法(PyPDF2、borb、fitz)。 1. PyPDF2 PyPDF2 是一个功能强大的库࿰…...

Web 架构之前后端分离
文章目录 思维导图一、引言二、前后端分离的概念代码示例(简单的前后端分离交互)后端(使用 Python Flask 框架)前端(使用 JavaScript 和 jQuery) 三、前后端分离的优势3.1 提高开发效率3.2 代码可维护性增强…...

Pycharm安装后打开提示:此应用无法在你的电脑上运行,若要找到合适于你的电脑的版本,请咨询发布者
问题描述 今天下载安装好社区版的pycharm之后双击运行出现提示:此应用无法在你的电脑上运行,若要找到合适于你的电脑的版本,请咨询发布者。 首先我们需要查看Windows如何查看系统是ARM64还是X64架构 在 cmd 命令窗中输入 systeminfo 即可&a…...

正则表达式实战指南:原理、口诀与高频场景案例
正则表达式实战指南:原理、口诀与高频场景案例 正则表达式(Regular Expression)是程序员处理文本的瑞士军刀,被广泛应用于数据验证、日志分析、爬虫开发等领域。本文将从原理讲解、口诀速查到高频实战案例,带你系统掌…...

Spark缓存--persist方法
1. 功能本质 persist:这是一个通用的持久化方法,能够指定多种不同的存储级别。存储级别决定了数据的存储位置(如内存、磁盘)以及存储形式(如是否序列化)。 2. 存储级别指定 persist:可以通过传入…...

【LeetCode 热题 100】二叉树 系列
📁 104. 二叉树的最大深度 深度就是树的高度,即只要左右子树其中有一个不为空,就继续往下递归,知道节点为空,向上返回。 int maxDepth(TreeNode* root) {if(root nullptr)return 0;return max(maxDepth(root->lef…...

CTF之常见的文件头和文件尾
1、图片 JPEG 文件头:FF D8 FF 文件尾:FF D9TGA 未压缩的前4字节 00 00 02 00 RLE压缩的前5字节 00 00 10 00 00PNG 文件头:89 50 4E 47 0D 0A 1A 0A 文件尾:AE 42 60 82GIF 文件头:47 49 46 38 39(37) 61 文件尾&…...
)
软件设计师教程——第一章 计算机系统知识(上)
前言 在竞争激烈的就业市场中,证书是大学生求职的重要加分项。中级软件设计师证书专业性强、认可度高,是计算机相关专业学生考证的热门选择,既能检验专业知识,又有助于职业发展。本教程将聚焦核心重点,以点带面构建知…...
 集群配置指南(超简单,脱离 ZooKeeper 集群)还包含了简化测试指令的脚本!!!)
KRaft (Kafka 4.0) 集群配置指南(超简单,脱离 ZooKeeper 集群)还包含了简化测试指令的脚本!!!
docker-compose方式部署kafka集群 Kafka 4.0 引入了 KRaft 模式(Kafka Raft Metadata Mode),它使 Kafka 集群不再依赖 ZooKeeper 进行元数据管理。KRaft 模式简化了 Kafka 部署和管理,不需要额外配置 ZooKeeper 服务,…...

安全月演讲比赛活动讲话稿
同志们:在公司上下万众一心创建“无违章企业”的大形势下,由公司工会、团委举办的“安全与我”演讲比赛,经过紧张激烈的预赛,今天进行正式决赛。 从预赛的38名选手中脱颖而出的10名选手,今天将再次登台献技,…...

实时操作系统:航空电子系统的安全基石还是创新枷锁?
引言:航空电子系统的进化论 在航空电子技术的漫长发展历程中,飞行器控制系统实现从机械仪表到数字计算机的跨越,这一进步具有深远意义。现代战机以超过 2 马赫的速度突破音障,无人机群在复杂电磁环境下完成自主编队,这…...

windows 部署 Kafka3.x KRaft 模式 不依赖 ZooKeeper
1.下载 https://archive.apache.org/dist/kafka/3.9.0/kafka_2.12-3.9.0.tgz2.配置使用 KRaft 模式 2.1 修改 Kafka 的配置文件 cd D:\data\bigdata\kafka_2.12-3.9.0\config\kraft 修改 server.properties # 设置 Kafka 数据日志存储目录 log.dirsD:\\data\\bigdata\\kaf…...
-(一))
SEMI E40-0200 STANDARD FOR PROCESSING MANAGEMENT(加工管理标准)-(一)
1 目的 物料(例如晶圆)加工在设备中的自动化管理与控制是实现工厂自动化的关键要素。本标准针对半导体制造环境中与设备内部物料处理相关的通信需求进行了规范。本标准规定了在加工单元接收到的指定材料所应适用的加工方法(例如Etch腔室需要Run哪支Recipe)。它阐述了物料加工的…...

Web 架构之高可用基础
文章目录 引言一、无状态服务设计(Session 托管至 Redis 集群)1. 概念与原理2. 代码示例(Python Flask 应用)3. 常见问题及解决办法 二、数据库读写分离(MySQL 主从 ProxySQL 流量分发)1. 概念与原理2. 配…...
)
巧用python之--模仿PLC(PLC模拟器)
工作中用到了VM(VisionMaster4.3)有时候需要和PLC打交道,但是PLC毕竟是别人的,不方便修改别人的程序,这时候需要一个灵活的PLC模拟器是多么好呀! 先说背景: PLC型号 汇川Easy521: Modbus TCP 192.168.1.10:502 在汇川Easy521中Modbus保持寄存器D寄存器 ,在modbus协议中 0-4区…...

Nginx +Nginx-http-flv-module 推流拉流
这两天为了利用云服务器实现 Nginx 进行OBS Rtmp推流,Flv拉流时发生了诸多情况,记录实现过程。 环境 OS:阿里云CentOS 7.9 64位Nginx:nginx-1.28.0Nginx-http-flv-module:nginx-http-flv-module-1.2.12 安装Nginx编…...

DRF+Vue项目线上部署:腾讯云+Centos7.6
1.服务器选购和配置 1.1.服务器选购 1.2.防火墙/安全组配置 80是HTTP的端口,443是HTTPS的端口,22是远程连接的端口,3306是mysql的端口。 1.3.远程连接软件(tabby)配置 下载:https://github.com/Eugeny/ta…...
拉流至电脑,实现直播)
大疆无人机(全系列,包括mini)拉流至电脑,实现直播
参考视频 【保姆级教程】大疆无人机rtmp推流直播教程_哔哩哔哩_bilibili VLC使用教程: VLC工具使用指南-CSDN博客 目录 实现效果: 电脑端 编辑 编辑 无人机端 VLC拉流 分析 实现效果: (实验机型:大疆mini4kRC-N2遥控器、大…...

Spring普通配置类 vs 自动配置类-笔记
1.简要版 Configuration和Bean,既可以用于普通配置类,也可以用于自动配置类。二者的区别和联系是什么呢? 区别: Configuration和Bean是Spring框架本身的注解,用于定义配置类和生成Bean。而自动配置通常是Spring Boo…...

解决Ceph 14.2.22 Nautilus版本监视器慢操作问题的实践指南
解决Ceph Nautilus版本监视器慢操作问题的实践指南 问题背景问题现象问题分析1. 确认监视器状态2. 检查慢操作详情3. 深入分析操作状态 问题原因解决方案立即解决方法 总结 在生产环境中执行任何操作前,请确保已备份重要数据,并在测试环境中验证解决方案…...

Go使用Gin写一个对MySQL的增删改查服务
首先用SQL创建一个包含id、name属性的users表 create table users (id int auto_incrementprimary key,name varchar(255) null );查询所有用户信息: func queryData(db *sql.DB, w http.ResponseWriter) {rows, err : db.Query("SELECT * FROM users"…...

数字孪生医疗:构建患者特异性数字孪生体路径探析
引言 数字孪生技术正逐渐成为医疗健康领域的一场革命性力量,它通过创建人体器官和系统的数字复制品,为疾病预测、诊断和个性化治疗开辟了前所未有的可能性。在心血管疾病领域,数字孪生技术的应用尤为引人注目,特别是对于扩张型心肌病(Dilated Cardiomyopathy,DCM)这一常…...

rust程序静态编译的两种方法总结
1. 概述 经过我的探索,总结了两种rust程序静态编译的方法,理论上两种方法都适用于windows、mac os和linux(mac os未验证),实测方法一性能比方法二好,现总结如下,希望能够帮到你. 2.方法一 2.1 添加配置文件 在项目的同级文件夹下新…...

threejs 添加css3d标签 vue3
如图所示,给收费站标注标签。步骤如下: 一、引入 import {CSS3DRenderer,CSS3DObject, } from "three/examples/jsm/renderers/CSS3DRenderer"; 二、 //一、申明css3渲染器 const label3DRenderer ref()//二、创建css3d渲染器--将渲染器加…...

【git】git fsmonitor
git fsmonitor 是 Git 提供的一个特性,用于提高 Git 的性能,尤其是在处理文件状态检查(git status)时。它通过文件系统监控服务(如 Windows 上的 FileSystemWatcher 或 Linux 上的 inotify)来跟踪文件系统的…...

开源照片管理系统PhotoPrism的容器化部署与远程管理配置
文章目录 前言1.关于PhotoPrism2.本地部署PhotoPrism3.PhotoPrism简单使用4. 安装内网穿透5.配置PhotoPrism公网地址6. 配置固定公网地址 前言 你是不是用手机拍照片的时候无所谓拍了多少张,但在整理的时候却要占用超多时间?别怕,今天给大家…...

macOS Python 环境配置指南
1. 检查现有 Python 环境 python3 --version # 检查 Python 3 版本 pip3 --version # 检查 pip 版本 2. 安装 pyenv(Python 版本管理工具) # 使用 Homebrew 安装 pyenvbrew install pyenv# 配置 pyenv 环境变量(添加到 ~/.zshrc&#…...