数据结构*二叉树
树
树是一种非线性数据结构。
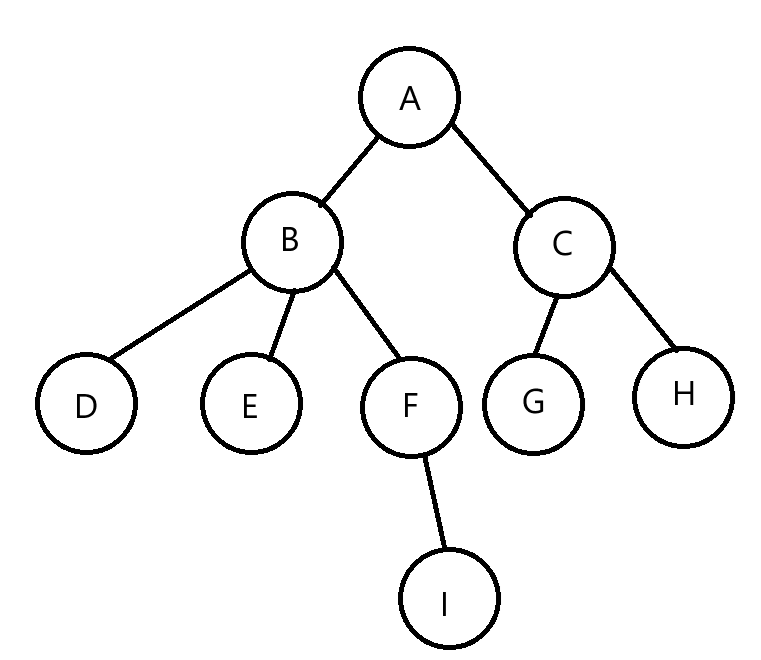
这就是抽象的树的结构。
对于一棵树来说,有N个结点,就有N-1条边
其中有许多概念:
根结点:对于上图来说就是A
子树:就是结点下面分开的部分。例如:A的子树就是以B为根结点的树和以C为根结点的树。
结点的度:就是这个节点含有子树的个数称为该节点的度。
树的度:就是这棵树所有节点的度的最大值。上图的树的度为3
叶子结点或终端结点:度为0的结点。例如:D、E、I、G、H
层次:根节点为第一层。
树的高度或深度:树的最大层次。例如:上图就是4
当然还有许多概念,可以自行查找
树的表示方法
对于树的表示方法有很多种,如:双亲表示法,孩子表示法、孩子双亲表示法、孩子兄弟表示法等等。下面是孩子兄弟表示法。
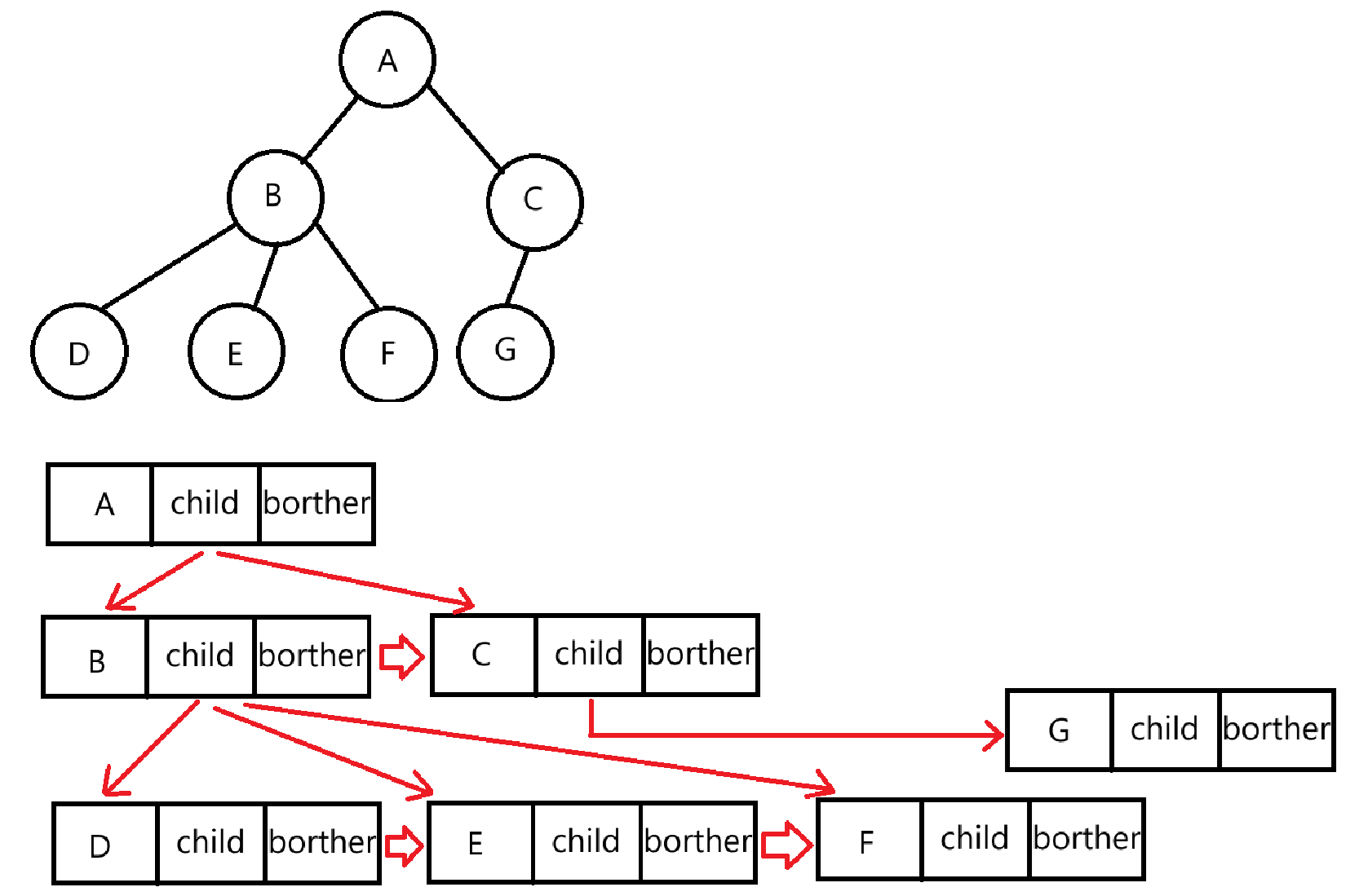
二叉树
什么是二叉树
二叉树就是特殊的一种树,其每个结点最多有两棵子树 ,即结点的度最大为 2 。对于二叉树来说,左子树和右子树有严格顺序之分,次序不能颠倒 。如下图所示:
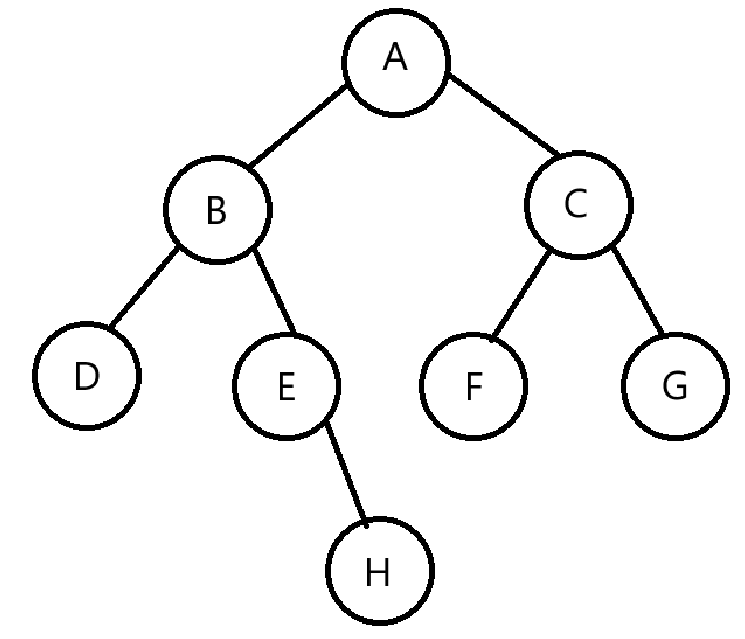
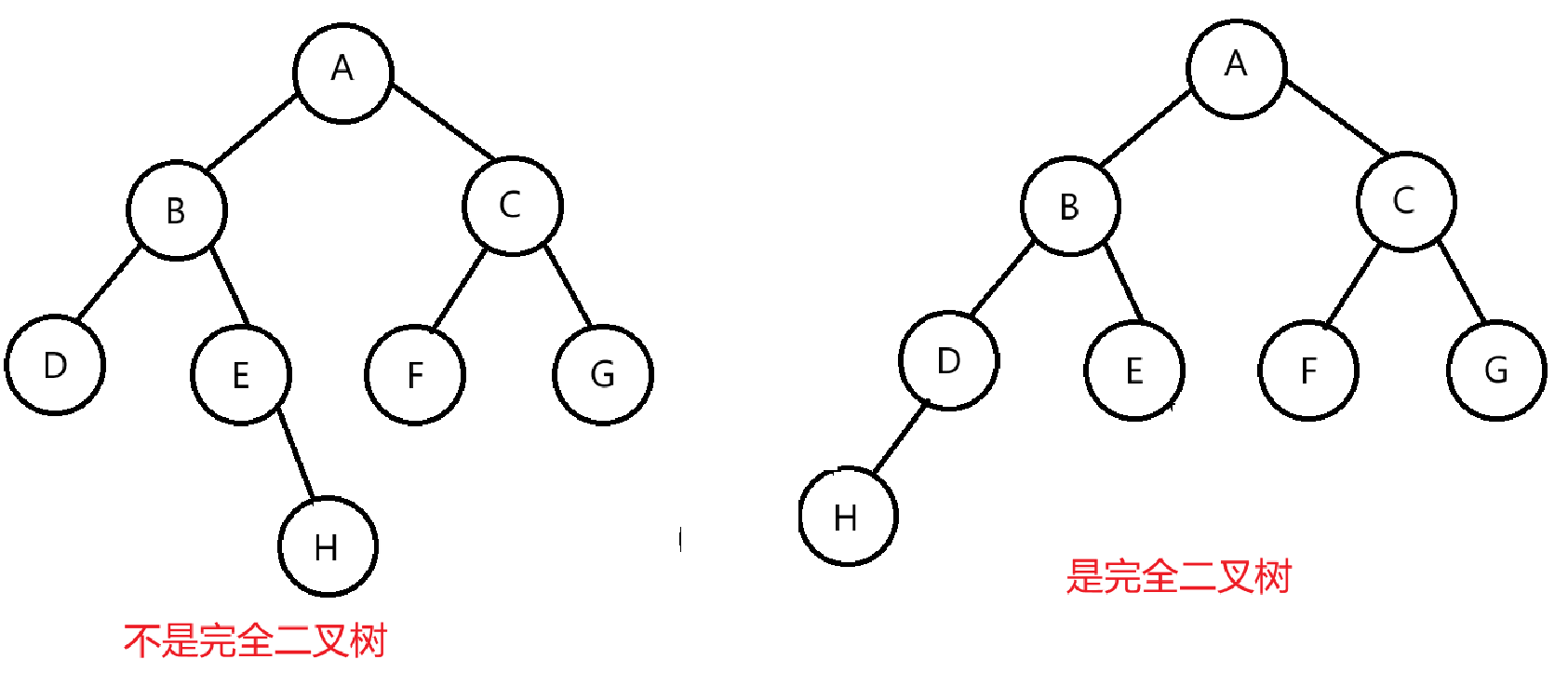
当然还有一些特殊的二叉树:满二叉树、完全二叉树。
满二叉树通俗来讲就是每一层的结点都是满的二叉树,如下图所示:
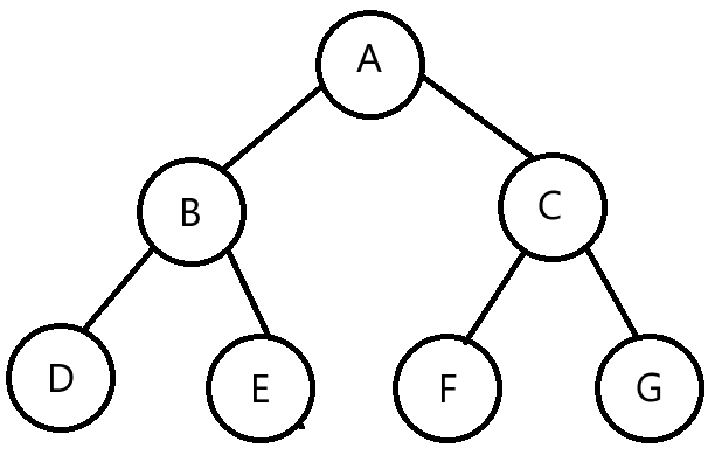
完全二叉树通俗来讲就是只有最后一层不是满的,其余层都是满的。但是最后一层的节点都是从最左边开始排,不会在中间空着 。如下图所示:
二叉树的一些性质
1、 一颗非空二叉树的第i层上最多有2^(i-1)个结点。
2、 一颗深度为k的二叉树,其树的最大结点为2^k-1
3、 由第二条性质推出,具有n个结点的完全二叉树的深度k = log(n+1) [以2为底的log] 向上取整。
4、 对于任意一颗二叉树,其叶子结点为n0(结点度为0),度为2的结点个数为n2,则n0 = n2 + 1。
5、 对于具有n个结点的完全二叉树,按照从上到下、从左到右的顺序从0开始编号,则对于序号i的结点:
左孩子结点下标为2i + 1,当2i + 1 > n 时,就不存在左孩子结点。
右孩子结点下标为2i + 2,当2i + 2 > n 时,就不存在右孩子结点。
其父亲结点的下标为(i - 1) / 2。i == 0时,其结点为根节点,没有父亲结点。
二叉树的存储
二叉树的存储方式主要有两种,分别是顺序存储和链式存储。顺序存储是把二叉树的节点按照层次依次存于数组中。链式存储是通过节点类来构建二叉树。
下面是用孩子表示法来构建二叉树
static class TreeNode{public char val;public TreeNode left;public TreeNode right;public TreeNode(char val) {this.val = val;}
}
二叉树的遍历
对于二叉树的遍历有四种:前序遍历、中序遍历、后序遍历、层序遍历。
下面遍历一这棵二叉树为例:
层序遍历
1、层序遍历就是从上到下从左到右开始访问结点。
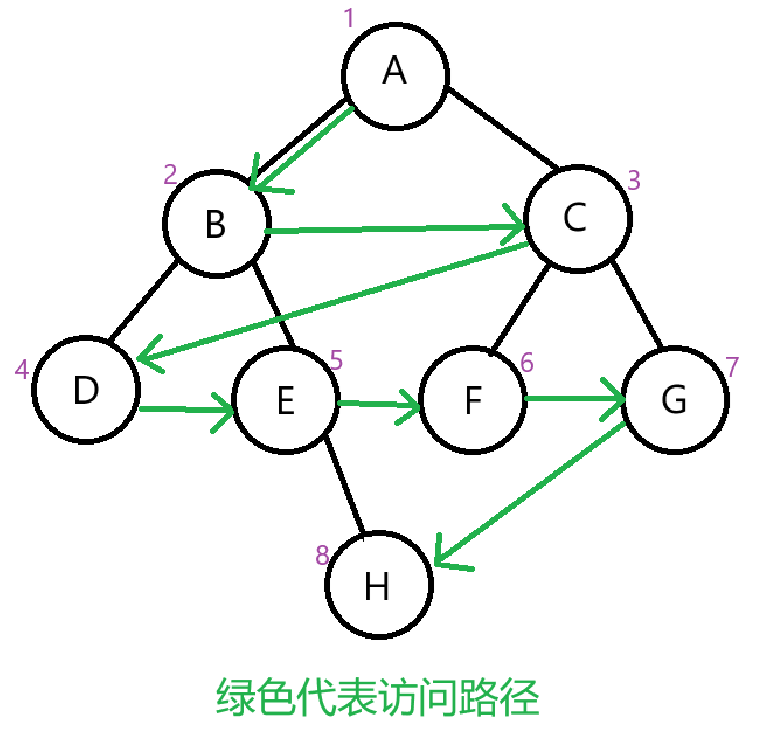
输出为:A B C D E F G H
下面我们重点来说明前中后序遍历! 对于这三种遍历的过程就好像递归一样,始终重复完成某一操作。
前序遍历
2、前序遍历就是按照先访问根,再访问左子树,最后访问右子树。在访问根的时候输出。
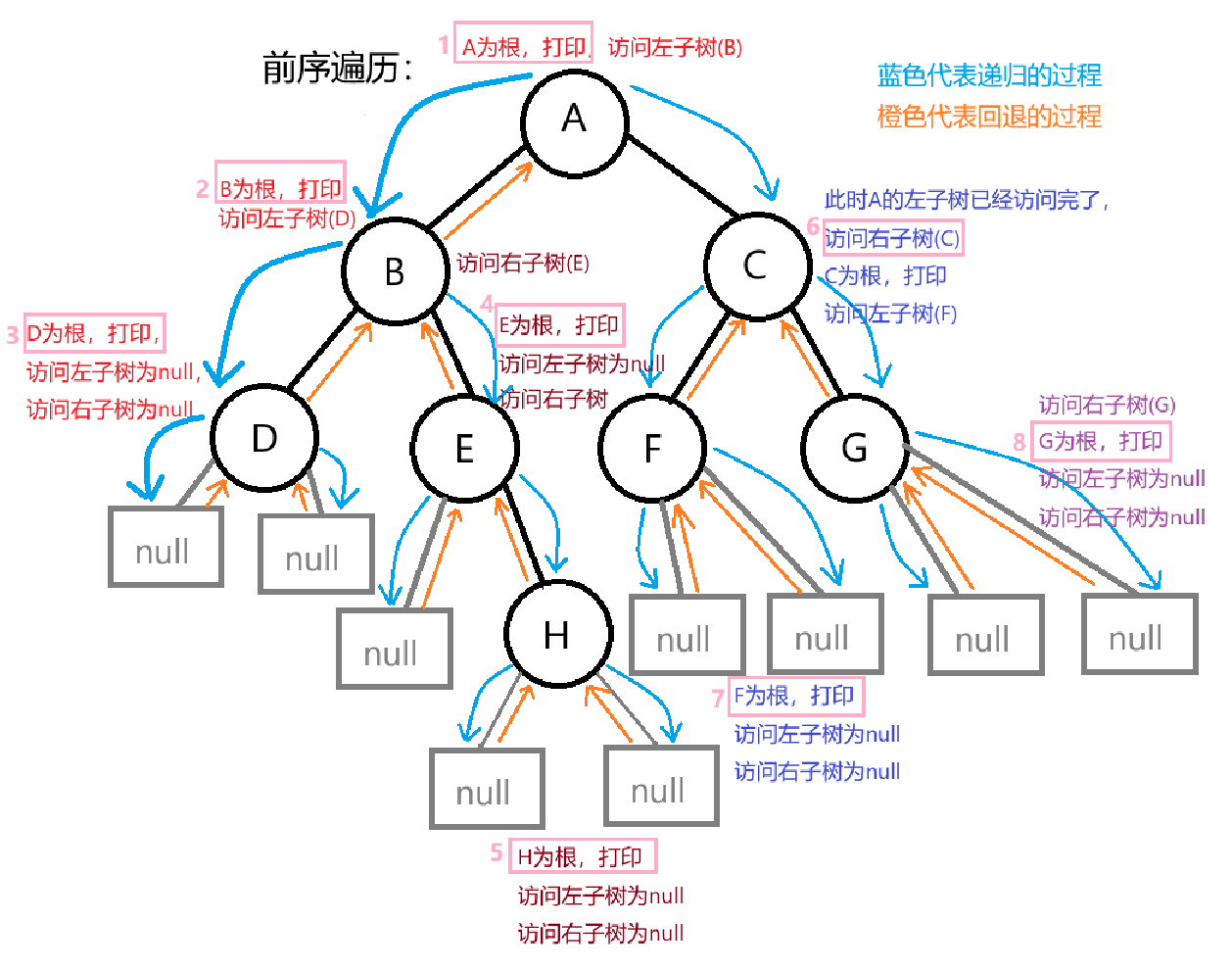
对应的流程如上图所示:按照根 -> 左子树 -> 右子树的访问顺序
输出为:A B D E H C F G
代码展示:
public void preOrder(TreeNode root) {if(root == null) {return;}System.out.print(root.val + " ");preOrder(root.left);preOrder(root.right);
}
代码解释:
代码采用递归的方式,将问题化成子问题,就是访问根,打印根,访问左树(root.left),访问右树(root.right)。结束条件就是当root为空时,直接返回,说明已经访问到底了(这颗树已经访问完了)。
中序遍历
3、中序遍历就是按照先访问左子树,再访问根,最后访问右子树。在访问根的时候输出。
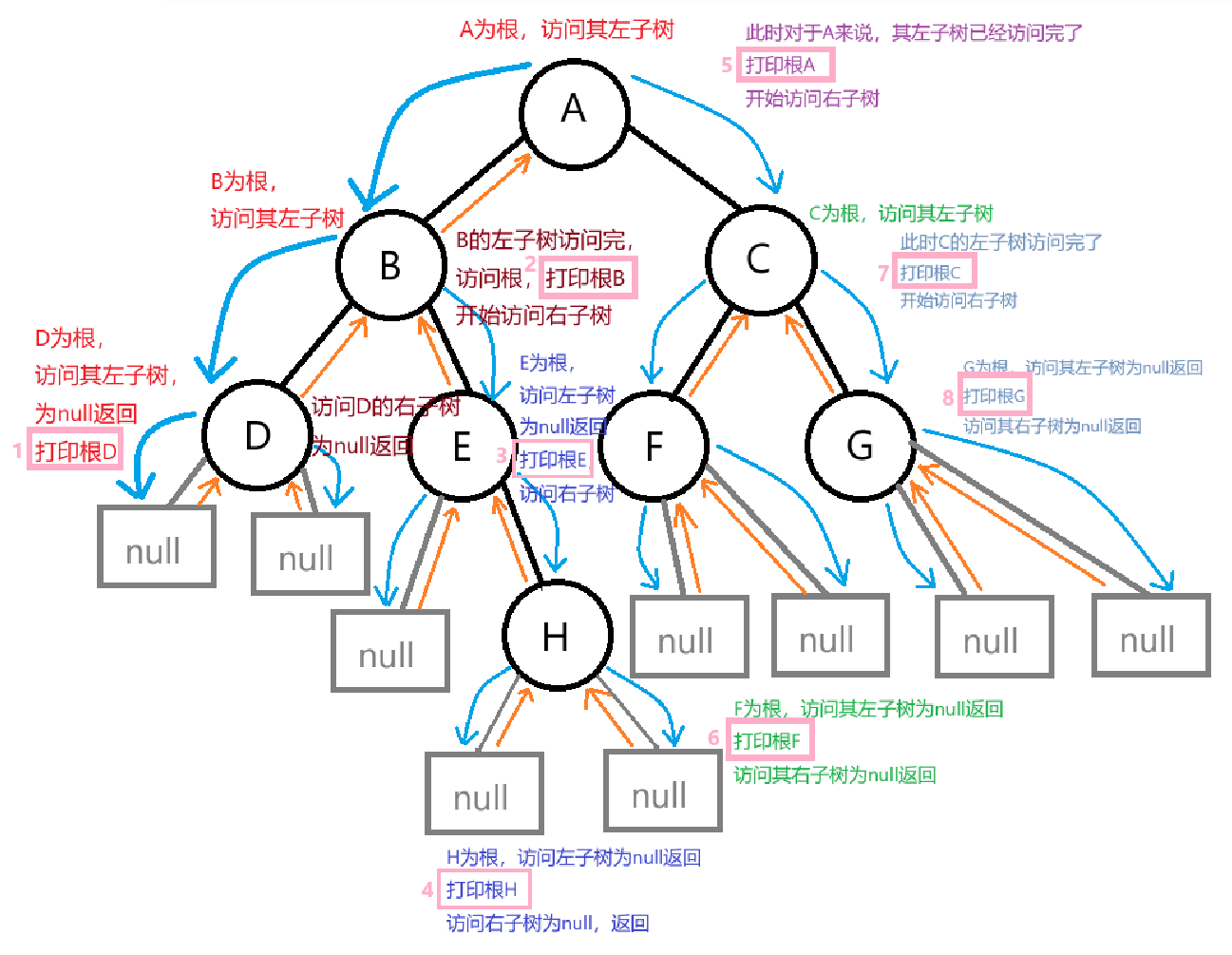
对应的流程如上图所示:按照左子树 -> 根 -> 右子树的访问顺序
输出为:D B E H A F C G
代码展示:
public void inOrder(TreeNode root){if(root == null) {return;}inOrder(root.left);System.out.print(root.val + " ");inOrder(root.right);
}
代码解释:
代码采用递归的方式,将问题化成子问题,就是访问左树(root.left),访问根,打印根,访问右树(root.right)。结束条件就是当root为空时,直接返回,说明已经访问到底了(这颗树已经访问完了)。
后序遍历
4、后序遍历就是按照先访问左子树,再访问右子树,最后访问根。在访问根的时候输出。
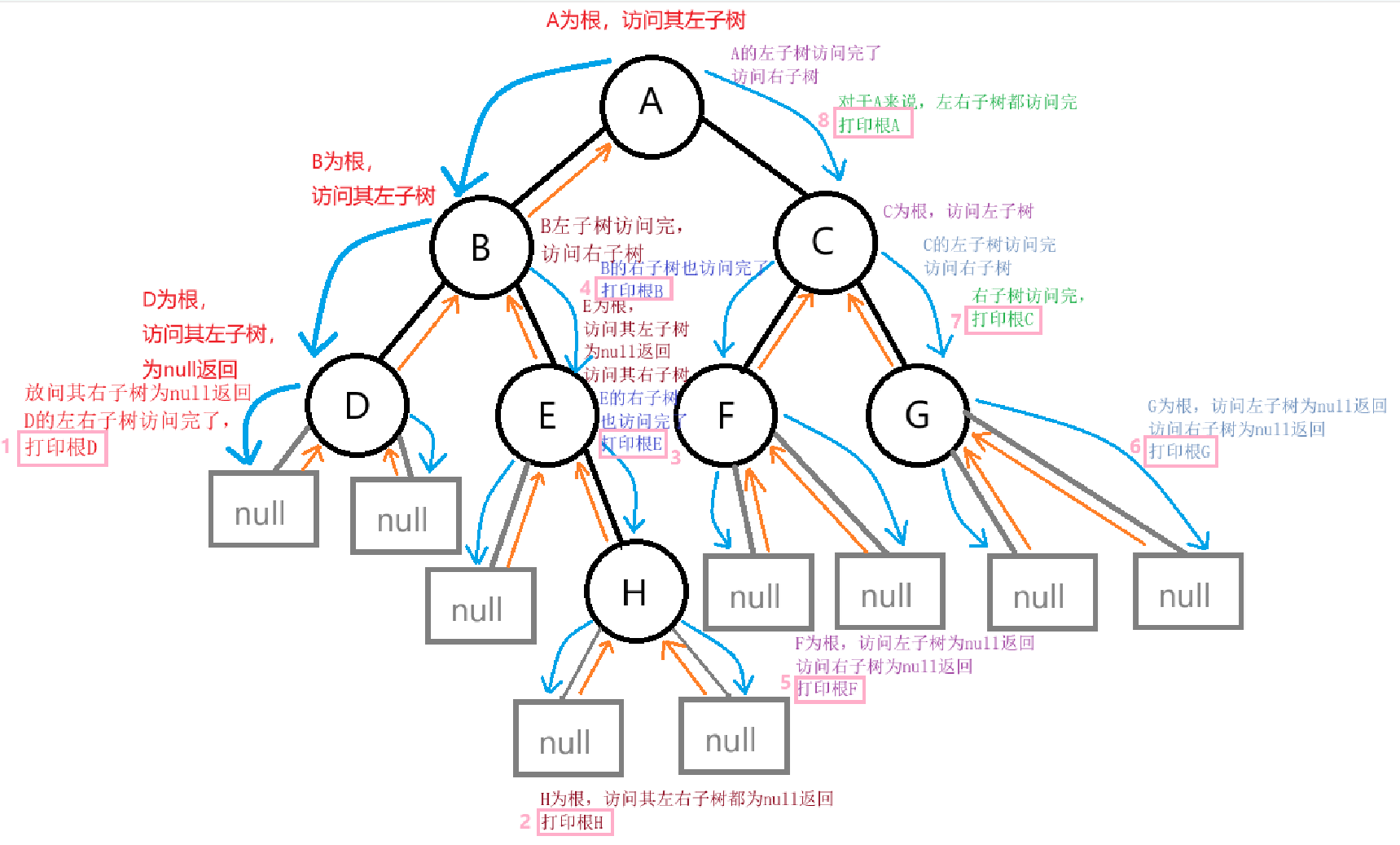
对应的流程如上图所示:按照左子树 -> 右子树 -> 根的访问顺序
输出为:D H E B F G C A
代码展示:
public void postOrder(TreeNode root){if(root == null) {return;}postOrder(root.left);postOrder(root.right);System.out.print(root.val + " ");
}
代码解释:
代码采用递归的方式,将问题化成子问题,就是访问左树(root.left),访问右树(root.right),访问根,打印根。结束条件就是当root为空时,直接返回,说明已经访问到底了(这颗树已经访问完了)。
二叉树的一些简单操作
求结点个数
代码展示:
// 获取树中节点的个数
private static int size= 0;
public int size1(TreeNode root) {//用计数的方式 -> 遍历if(root == null) {return 0;}size++;size1(root.left);size1(root.right);return size;
}
public int size(TreeNode root) {//子问题 -> 树的结点 = 左子树的结点 + 右子树的结点 + 1(root)if(root == null) {return 0;}return size(root.left) + size(root.right) + 1;
}
代码解释:
有两种思路:
1、用遍历思路,访问一个结点就size++
2、子问题思路:利用递归,将问题变成了“树的结点 = 左子树的结点 + 右子树的结点 + 1”
求叶子结点个数
代码展示:
// 获取叶⼦节点的个数
private static int count = 0;
public int getLeafNodeCount1(TreeNode root){//遍历思路 -> 左右子树都为nullif(root == null) {return 0;}if(root.left == null && root.right == null) {count++;}getLeafNodeCount1(root.left);getLeafNodeCount1(root.right);return count;
}
public int getLeafNodeCount(TreeNode root){//子问题 -> 树的叶子结点 = 左子树的叶子节点 + 右子树的叶子节点if(root == null) {return 0;}if(root.left == null && root.right == null) {return 1;}return getLeafNodeCount(root.left) + getLeafNodeCount(root.right);
}
代码解释:
有两种思路:
1、用遍历思路,访问一个结点当满足条件是就count++。当root == null时,也就说明了这棵树为空,没有结点。
2、子问题思路:利用递归,将问题变成了“树的叶子结点 = 左子树的叶子节点 + 右子树的叶子节点”,当满足条件时就说明是一个叶子结点。
求第K层节点的个数
代码展示:
public int getKLevelNodeCount(TreeNode root,int k){//当root为null时,说明这棵树提前走完了,还没有到第k层,也就没有第k层的结点if(root == null) {return 0;}//递归结束条件,当k==1时,说明已经走到了第k层if(k == 1) {return 1;}return getKLevelNodeCount(root.left,k - 1) + getKLevelNodeCount(root.right,k - 1);
}
代码解释:
将问题转换为左子树第k层的个数+右子树第k层的个数。此时层数逐次递减(k-1)。遍历到第k层就结束遍历了。
求二叉树的高度
代码展示:
public int getHeight(TreeNode root){//子问题 -> 左子树与右子树深度的最大值 + 1(root)if(root == null) {return 0;}return Math.max(getHeight(root.left),getHeight(root.right)) + 1;
}
代码解释:
将问题转换为“左子树与右子树深度的最大值 + 1(根结点本身高度1)”
检测值为val的元素是否存在
代码展示:
public TreeNode find(TreeNode root, int val){//当root为null时,也就没有val,返回nullif(root == null) {return null;}//当匹配成功,就返回当前结点if(root.val == val) {return root;}//到这里说明没有匹配成功,访问左子树有没有TreeNode ret = find(root.left,val);//如果没有匹配成功,则ret为null//ret不为null,则返回找到的结点if(ret != null) {return ret;}//到这里说明左子树也都没有匹配成功ret = find(root.right,val);//开始在右子树找return ret;//找到了ret就是匹配的结点,没有就是null
}
代码解释:
也是利用递归,将问题换成“左子树找,再在右子树找”。
层序遍历
代码展示:
1、使用队列
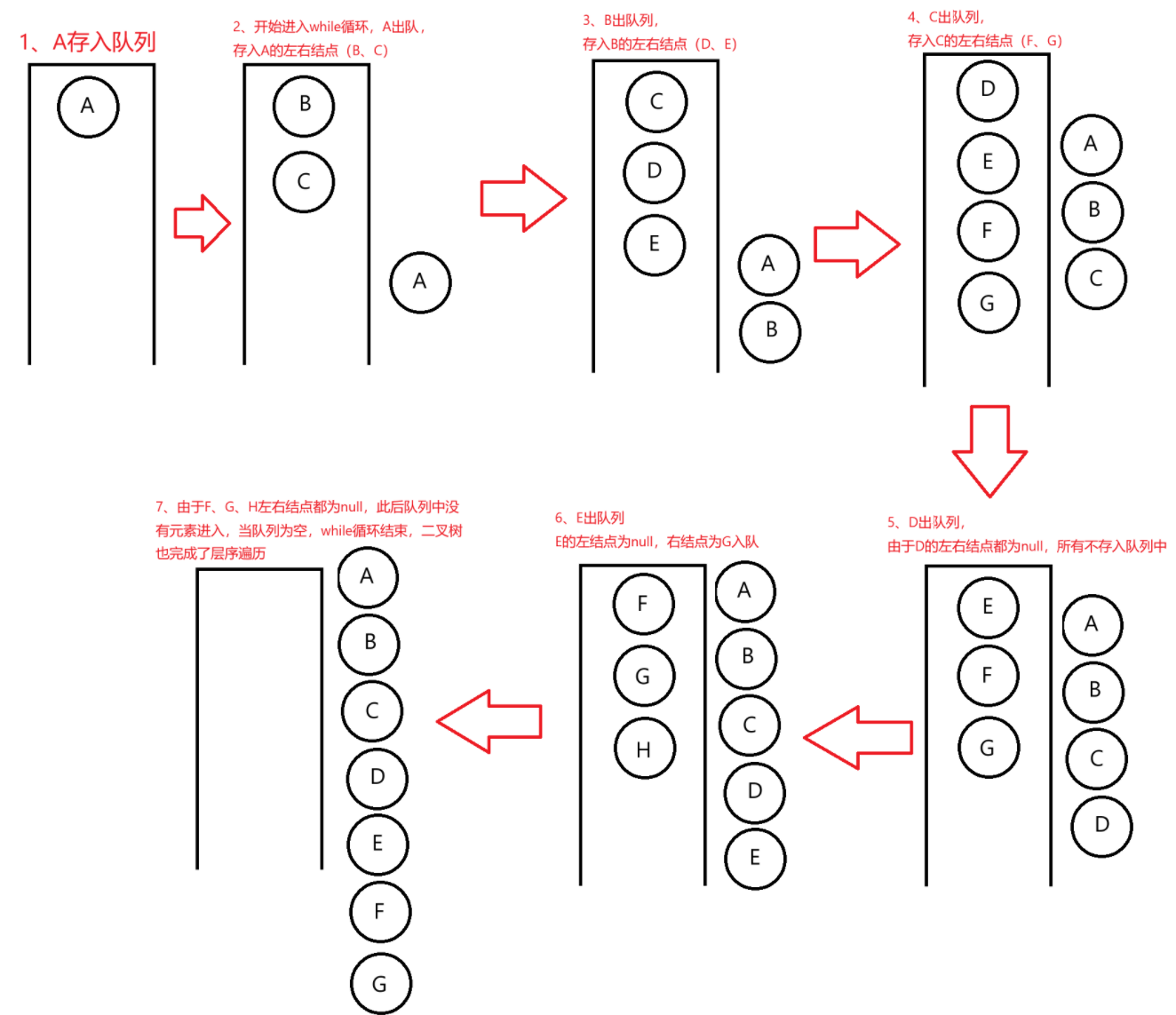
public void levelOrder(TreeNode root){//当root为null时,就没有结点,直接返回if(root == null) {return;}Queue<TreeNode> queue = new LinkedList<>();//创建队列,将结点存储到队列中//从父亲结点开始,放入队列中queue.offer(root);while (!queue.isEmpty()) {//当将二叉树中的元素全部pop,此时queue为空,层序遍历完了TreeNode cur = queue.poll();//将队列中最上面的元素取出System.out.print(cur.val+" ");//打印//将其输出的左边的结点存入队列中(不为空)if(cur.left != null){queue.offer(cur.left);}//将其输出的右边的结点存入队列中(不为空)if(cur.right != null){queue.offer(cur.right);}//最后再通过循环将所有的结点的左右依次存入队列中,输出。//A -> B C(A的左右) -> D E(B的左右) F G(C的左右) -> H(E的右)}
}
2、使用嵌套列表+队列
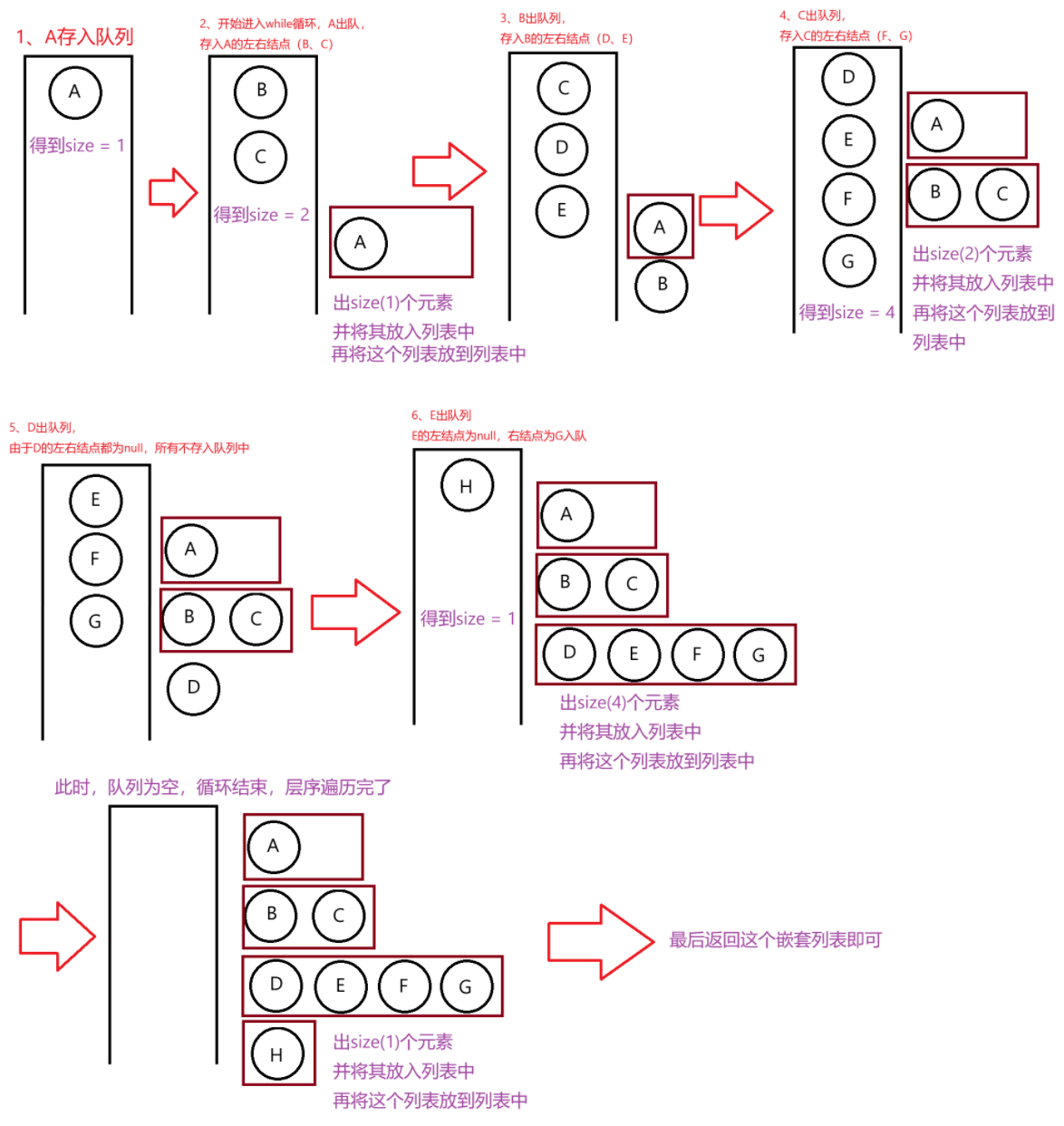
public List<List<Character>> levelOrderPlus(TreeNode root) {List<List<Character>> ret = new ArrayList<>();if(root == null) {return ret;}Queue<TreeNode> queue = new LinkedList<>();queue.offer(root);while (!queue.isEmpty()) {//当将二叉树中的元素全部pop,此时queue为空,层序遍历完了List<Character> curRow = new ArrayList<>();//每层创建一个新的列表//用来判断每层的个数。从父亲结点A一个 -> 经过while(size != 0)循环,列表中存入B D两个元素,列表中个数也就是2 -> 同理依次类推int size = queue.size();//进行分行处理,while (size != 0){TreeNode cur = queue.poll();//将队列中最上面的元素取出curRow.add(cur.val);//将这一层的元素存入当前列表中//将其输出的左边的结点存入队列中(不为空)if(cur.left != null){queue.offer(cur.left);}//将其输出的右边的结点存入队列中(不为空)if(cur.right != null){queue.offer(cur.right);}size--;}ret.add(curRow);//将这一层的列表存入列表中}return ret;//返回这个二维列表
}
代码解释:
方法一是使用队列,利用队列先进先出的特点,先将父亲结点放进去,然后就开始向队列存放元素。(具体过程:首先从队列出元素并打印,存放出来元素的左结点和右结点)如下图所示:
方法二是多使用了嵌套列表,是为了更好的区分每层的元素。利用每次队列中的size,来创建列表,再存入列表中。如下图所示:
判断是否为完全二叉树
完全二叉树和层序遍历有关,思路和层序遍历差不多,但使用队列时候,是需要存入null值的,这样好判断在中间是不是空着的。
代码展示:
public boolean isCompleteTree(TreeNode root){if(root == null) {return true;}Queue<TreeNode> queue = new LinkedList<>();queue.offer(root);while (!queue.isEmpty()) {TreeNode cur = queue.poll();if(cur == null){break;}else {queue.offer(cur.left);queue.offer(cur.right);}}while (!queue.isEmpty()) {if(queue.poll() != null) {return false;}}return true;
}
代码解释:
这里不需要判断cur的左右是否为空,直接进队列即可。当出队列的为null,说明层序遍历到了null。如果这是一棵完全二叉树,则剩下的结点都为null,也就是队列中的元素全为null;当不是一棵完全二叉树,队列中的元素中必然有结点。后面的while循环就是用来判断队列中是否全为null。
相关文章:

数据结构*二叉树
树 树是一种非线性数据结构。 这就是抽象的树的结构。 对于一棵树来说,有N个结点,就有N-1条边 其中有许多概念: 根结点:对于上图来说就是A 子树:就是结点下面分开的部分。例如:A的子树就是以B为根结点的…...

RESTful
一:简介 定义 (1)访问网络资源的格式 (2)优点 (3)区分操作 (4)注意事项...

人工智能的自动驾驶新纪元:端到端智能系统挑战与前沿探索方案
一、引言:从模块化到端到端的范式革命 (一)自动驾驶技术演进的三个时代 自动驾驶技术自诞生以来,经历了从机械化辅助到智能化决策的漫长演进。早期,以定速巡航为代表的 1.0 时代,仅实现了简单的速度控制,车辆仍需驾驶员全程主导操控。随着传感器与算法发展,进入 2.0 时…...

第四章 OpenCV篇—图像梯度与边缘检测—Python
目录 一.Sobel算子 二.Scharr算子与laplacian算子 三.Canny边缘检测 1.高斯滤波器 2.梯度和方向 3.非极大值抑制 4.双阈值检测 此章节主要讲解图像梯度计算方法和边缘检测算法,分别主要是:sobel算子、scharr与lapkacian算子、canny边缘检测流程。…...

幂等的几种解决方案以及实践
目录 什么是幂等? 解决幂等的常见解决方案: 唯一标识符案例 数据库唯一约束 案例 乐观锁案例 分布式锁(Distributed Locking) 实践精选方案 首先 为什么不直接使用分布式锁呢? 自定义实现幂等组件!…...

拥塞控制 流量控制 区别
对比项拥塞控制流量控制关注对象整个网络 是否过载接收方主机 是否处理不过来控制目标避免网络路由器、链路拥塞避免发送方发太快,接收方来不及处理发生原因网络中有太多数据包,引起排队、丢包接收方缓存能力有限实现方式基于网络状态动态调整发送速率基…...

AWS VPC架构师指南:从零设计企业级云网络隔离方案
一、VPC核心概念解析 1.1 核心组件 VPC:逻辑隔离的虚拟网络,可自定义IPv4/IPv6地址范围(CIDR块) 子网(Subnet): 公有子网:绑定Internet Gateway(IGW)&#…...
)
[逆向工程]什么是DLL注入(二十二)
[逆向工程]什么是DLL注入(二十二) 引言 DLL注入(DLL Injection) 是Windows系统下一种重要的进程控制技术,广泛应用于软件调试、功能扩展、安全检测等领域。然而,它也是一把“双刃剑”——恶意软件常借此实…...

极简远程革命:节点小宝 — 无公网IP的极速内网穿透远程解决方案
极简远程革命:节点小宝,让家庭与职场无缝互联 ——打破公网桎梏,重塑数字生活新体验 关键词:节点小宝|内网穿透|P2P直连|家庭网络|企业协作|智能组网节点小宝࿵…...

Vue生命周期脚手架工程Element-UI
一 Vue2.x生命周期 每个vue实例再被创建时都要经过一系列的初始化过程: 创建实例 装载模板 渲染模板等等 vue为生命周期中的每个状态都设置了钩子函数(监听函数)。每个vue实例处于不同的生命周期时,对应的函数就会触发调用 https:…...

LeetCode[226] 翻转二叉树
思路: 使用递归,归根结底还是左右节点互相倒,那么肯定需要一个temp节点在中间传递,最后就是递归,没什么说的 代码: /*** Definition for a binary tree node.* public class TreeNode {* int …...

ConcurrentHashMap解析
ConcurrentHashMap解析 以下是对 Java 8 及以后版本 ConcurrentHashMap 源码的深入解析,涵盖其底层数据结构、并发控制机制、核心操作流程、扩容与迁移、树化/退化策略,以及性能特性。总体来说,ConcurrentHashMap 在 JDK 8 中摒弃了原有的 S…...

windows10 系统显示mov文件格式缩略图
最近做视频剪辑,有些mov格式文件,但是尝试用各种播放器默认播放,都没有缩略图可看, 很影响查看。 遂选择了个插件,来在windows10系统显示mov文件的缩略图。 1.下载安装 K-Lite Codec Pack (安装时一路Ne…...
力扣.跳跃游戏II(还是思想)力扣.分发糖果力扣151.反转字符串中的单词力扣.轮转数组)
力扣智慧思想小题,目录力扣.跳跃游戏(思想很重要)力扣.跳跃游戏II(还是思想)力扣.分发糖果力扣151.反转字符串中的单词力扣.轮转数组
目录 力扣.跳跃游戏(思想很重要) 力扣.跳跃游戏II(还是思想) 力扣.分发糖果 力扣151.反转字符串中的单词 力扣.轮转数组 字符 a97 A65; JRE:Java运行时候的环境 JDK: JAVA开发套件(工具包) java原本是.java文件,编译成.class字节码文件 八种基本数据…...

【LangChain基础系列】深入全面掌握文本分类
文本分类是自然语言处理领域中的一个重要任务,旨在将文本数据自动归类到预定义的类别中。它是实现信息检索、智能推荐、情感分析等应用的基础技术之一。 应用场景 1. 垃圾邮件过滤 :自动识别并过滤垃圾邮件。 2. 情感分析 :分析用户评论或社交媒体内容…...

AI赋能高频PCB信号完整性优化
在5G通信、自动驾驶、卫星导航等高频技术快速迭代的今天,**信号完整性(SI)**已成为高频PCB设计的核心挑战。如何在高密度布线、复杂电磁环境中实现信号的精准传输?猎板PCB通过**AI驱动设计优化**、**材料与工艺创新**以及**智能化…...

如何从播放器构造角度研究 Media3 源码
Jetpack Media3 是 Android 提供的现代化媒体播放库。 Media3 的核心组件包括: ExoPlayer:播放器核心,负责协调媒体播放。MediaSource:定义媒体来源(如 DASH、HLS、Progressive)。TrackSelectorÿ…...

大模型深度思考与ReAct思维方式对比
大模型的「深度思考」与「ReAct思维方式」虽然都涉及复杂推理过程,但并非完全等同的概念。它们在目标、机制和应用场景上存在显著差异,以下是具体分析: 一、概念本质差异 深度思考(Deep Reasoning) 定义:泛…...

视频编解码学习六之视频采集和存储
视频采集的核心原理是用光学元件(如摄像头)将光信号转换为电信号进行传输和存储。 摄像头的主要功能是将光学图像转换为电信号(模拟或数字),核心流程如下: 1. 光学成像 镜头组:聚焦光线到感光…...

Linux开发工具【中】
目录 一、vim 1.1 插入模式 1.2 底行模式 1)set nu 2)set nonu 3) /XXX n 4)!command 5)vs other 1.3 补充 1) 批量化操作 2)批量化替换 : 3)快速定位&am…...

Django之账号登录及权限管理
账号登录及权限管理 目录 1.登录功能 2.退出登录 3.权限管理 4.代码展示合集 这篇文章, 会讲到如何实现账号登录。账号就是我们上一篇文章写的账号管理功能, 就使用那里面已经创建好的账号。这一次登录, 我们分为三种角色, 分别是员工, 领导, 管理员。不同的角色, 登录进去…...

深度学习Y7周:YOLOv8训练自己数据集
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 一、配置环境 1.官网下载源码 2.安装需要环境 二、准备好自己的数据 目录结构: 主目录 data images(存放图片) annotati…...
(题目+回答))
2025年渗透测试面试题总结-某服面试经验分享(附回答)(题目+回答)
网络安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 1. 协议类型 2. OSI七层模型 3. 网络层协议 4. HTTP请求头 5. 常见端口 6. 中间件解析漏洞 7. CS…...

手写Promise的静态方法
最近对promise原理的理解,手写下其中的静态方法。 手写Promise的静态方法 1. Promise.resolve2. Promise.reject3. Promise.all4. Promise.any5. Promise.race6. Promise.allSettled 1. Promise.resolve 首先就是resolve方法,它会接收一个值࿰…...

Python Cookbook-7.8 使用 Berkeley DB 数据库
任务 你想将一些数据做持久化处理,而且也想体验一下BerkeleyDB数据库的简洁和高效。 解决方案 如果以前在你的计算机中安装过 BerkeleyDB,Python标准库附带的bsddb包(以及可选的 bsddb3,用于访间Berkeley DBrelease 3.2数据库)可以被用来作…...

云手机虚拟地址技术的运营场景
云手机虚拟地址技术通过模拟地理位置(GPS/IP地址)与设备指纹,结合云端虚拟化能力,在多个商业场景中实现突破性应用。以下是其核心运营场景及技术实现路径的深度解析: 一、跨境电商与区域化运营 本地化合规与流量突破 目…...
)
操作符详解(2)
目录 9 结构成员访问操作符 9.1.2 结构体变量的定义和初始化 9.2 结构体成员的直接访问 10 操作符的属性:优先级、结合性 10.1 优先级 11 表达式求值 11.1 整型提升 11.2 算术转换 11.3 问题表达式解析 11.3.1 表达式1 11.3.2 表达式2 11.3.3 表达式3 1…...

责任链设计模式
一、核心接口定义 MyAbstractChainHandler<T> 接口继承自 Ordered 接口,用于实现链式处理逻辑。 import org.springframework.core.Ordered;public interface MyAbstractChainHandler<T> extends Ordered {void handle(T requestParam);String getCha…...

【银河麒麟高级服务器操作系统】服务器外挂存储ioerror分析及处理分享
更多银河麒麟操作系统产品及技术讨论,欢迎加入银河麒麟操作系统官方论坛 forum.kylinos.cn 了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:product.kylinos.cn 开发者专区:developer.kylinos.cn 文档中心&a…...

麒麟信安举办特种行业核心代理商中级技术认证培训班
近日,麒麟信安举办为期一周的特种行业核心代理商中级技术认证培训班,吸引了众多来自各地代理商公司的技术骨干踊跃参与。 此次培训班旨在赋能合作伙伴,助力其深入理解并熟练运用麒麟信安产品的核心优势,进一步提升在特种行业中的业…...

非对称加密:为什么RSA让“公开传密”成为可能
在1977年之前,加密世界遵循一个铁律:想要安全通信,必须先秘密交换密钥。无论是凯撒密码还是二战时的恩尼格玛机,都依赖发送方和接收方预先共享同一把“钥匙”。但RSA算法的出现颠覆了这一规则——它让陌生人可以在完全公开的环境下…...

阿里云ddos云防护服务器有哪些功能?ddos防御手段有哪些??
阿里云ddos云防护服务器有哪些功能?ddos防御手段有哪些?? DDoS(分布式拒绝服务)云防护服务器通过多种技术和策略来抵御大规模网络攻击,确保服务的高可用性。以下是其主要功能和防御手段的详细说明: 一、D…...

如何防止域名DNS被劫持?
防止域名DNS被劫持需要综合技术手段和管理措施,以下是一份详细的防护方案: --- ### **一、基础防护措施** 1. **选择可靠的域名注册商和DNS服务商** - 优先选择支持DNSSEC、提供多因素认证(MFA)的知名服务商(如Cl…...

桥隧坡灾害监测报警:用科技筑起生命安全的“智能防线”
.2024年,梅大高速茶阳路段高边坡塌方事件造成重大伤亡,举国痛心。这场悲剧再次敲响警钟:桥梁、隧道、边坡等高风险区域的实时监测与精准报警,已成为交通安全的生命线。如何用技术手段在灾害发生前“抢跑”,第一时间阻断…...

K8S常见问题汇总
一、 驱逐 master 节点上的所有 Pod 这会“清空”一个节点(包括 master)上的所有可驱逐的 Pod: kubectl drain <master-node-name> --ignore-daemonsets --delete-emptydir-data--ignore-daemonsets:保留 DaemonSet 类型的…...
)
ideal创建Springboot项目(Maven,yml)
以下是使用 IntelliJ IDEA 创建基于 Maven 的 Spring Boot 项目并使用 YAML 配置文件的详细步骤: 一、创建 Spring Boot 项目 启动项目创建向导 打开 IntelliJ IDEA,点击“File”->“New”->“Project”。 在弹出的“New Project”窗口中&#…...
)
解决:‘java‘ 不是内部或外部命令,也不是可运行的程序-Java环境变量配置(含JDK8、JDK21安装包一站式配置)
在使用命令行运行 .jar 文件时,很多用户会遇到如下错误提示: java 不是内部或外部命令,也不是可运行的程序或批处理文件。 这个报错表明系统无法识别 java 命令,通常是由于 Java 没有正确安装,或是系统环境变量没有配…...

android.app.Fragment和androidx.fragment:fragment的区别
android.app.Fragment 与 androidx.fragment.app.Fragment 的区别 这两个 Fragment 实现代表了 Android 碎片化开发的两个时代,以下是它们的核心区别: 一、起源与演变 android.app.Fragmentandroidx.fragment.app.Fragment引入时间Android 3.0 (API 1…...
3 - 串口)
OrangePi Zero 3学习笔记(Android篇)3 - 串口
目录 1. 找到串口号 2. 修改串口权限 3. 串口类 3.1 serialport.hpp 3.2 serialport.cpp 3.2.1 构造函数 3.2.2 Open函数 3.2.3 Close函数 3.2.4 Write函数 3.2.5 Read函数 3.2.6 SetFlowCtrl函数 4. 测试程序 5. 编译 6. 运行验证 除了默认的UART用于shell&…...

Node.js 技术原理分析系列9——Node.js addon一文通
Node.js 是一个开源的、跨平台的JavaScript运行时环境,它允许开发者在服务器端运行JavaScript代码。Node.js 是基于Chrome V8引擎构建的,专为高性能、高并发的网络应用而设计,广泛应用于构建服务器端应用程序、网络应用、命令行工具等。 本系…...

HBuilderX安卓真机运行安装失败解决汇总
前置方案 1. 确认USB调试和连接模式 (1)开启USB调试:进入手机设置 > 开发者选项 > 确保USB调试已开启(如无开发者选项,连续点击“版本号”激活)。 (2)连接模式:将…...

TensorFlow 2.x入门实战:从零基础到图像分类项目
TensorFlow 2.x入门实战:从零基础到图像分类项目 前言 TensorFlow是Google开发的开源机器学习框架,已成为深度学习领域的重要工具。TensorFlow 2.x版本相比1.x有了重大改进,更加易用且功能强大。本文将带你从零开始学习TensorFlow 2.x&…...

SpringBoot+Dubbo+Zookeeper实现分布式系统步骤
SpringBootDubboZookeeper实现分布式系统 一、分布式系统通俗解释二、环境准备(详细版)1. 软件版本2. 安装Zookeeper(单机模式) 三、完整项目结构(带详细注释)四、手把手代码实现步骤1:创建父工…...

数据中台-常用工具组件:DataX、Flink、Dolphin Scheduler、TensorFlow和PyTorch等
数据实施服务工具组件概览 数据中台的数据实施服务涵盖 数据采集、处理、调度、分析与应用 全流程,以下为关键工具组件及其作用: 工具类型核心功能典型应用场景DataX离线数据采集多源异构数据批量同步数据仓库ODS层数据导入Apache Flink实时计算引擎流…...

【PostgreSQL数据分析实战:从数据清洗到可视化全流程】电商数据分析案例-9.2 流量转化漏斗分析
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 9.2 流量转化漏斗分析:从数据清洗到可视化全流程实战一、背景与目标二、数据准备与清洗2.1 数据来源与字段说明2.2 数据清洗步骤2.2.1 去除无效数据2.2.2 处理时…...

结合Splash与Scrapy:高效爬取动态JavaScript网站
在当今的Web开发中,JavaScript的广泛应用使得许多网站的内容无法通过传统的请求-响应模式直接获取。为了解决这个问题,Scrapy开发者经常需要集成像Splash这样的JavaScript渲染引擎。本文将详细介绍Splash JS引擎的工作原理,并探讨如何将其与S…...

[计算机科学#10]:早期的计算机编程方式
【核知坊】:释放青春想象,码动全新视野。 我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!! 内容摘要:1804年,为了在织布机上编织出丰富多彩的…...

JAVA:Spring Boot 集成 Lua 的技术博客
1、简述 在现代开发中,Lua 以其轻量级、高性能以及易嵌入的特点广泛用于脚本扩展、游戏开发以及配置处理场景。将 Lua 与 Spring Boot 集成,可以在 Java 项目中实现动态脚本功能,增强项目的灵活性和动态配置能力。 样例代码: https://gitee.com/lhdxhl/springboot-example…...

代码随想录算法训练营 Day40 动态规划Ⅷ 股票问题
动态规划 题目 121. 买卖股票的最佳时机 - 力扣(LeetCode) 使用二维 dp 数组表示 1. dp[i][0] 表示持有股票的最大金额,dp[i][1] 表示不持有股票的最大金额,表示盈利结果 2. 递推公式由前一天持有金额和是否买股票决定 决定是否…...

【已解决】WORD域相关问题;错误 未找到引用源;复制域出错;交叉引用域到底是个啥
(微软赶紧倒闭 所有交叉引用域,有两个状态:1.锁定。2.手动。可通过编辑->链接查看。 “锁定”状态域的能力: 1. 导出PDF格式稳定(【已解决】WORD导出PDF时,参考文献上标自动被取消/变为正常文本_word…...