网易游戏 Flink 云原生实践
摘要:本文整理自网易游戏实时计算&数据湖平台负责人林小铂老师和网易游戏大数据开发工程师陈宇智老师,在Flink Forward Asia 2024 云原生专场的分享。主要分为四个部分:
1、背景
2、架构演进
3、实践挑战
4、总结和展望
01.背景
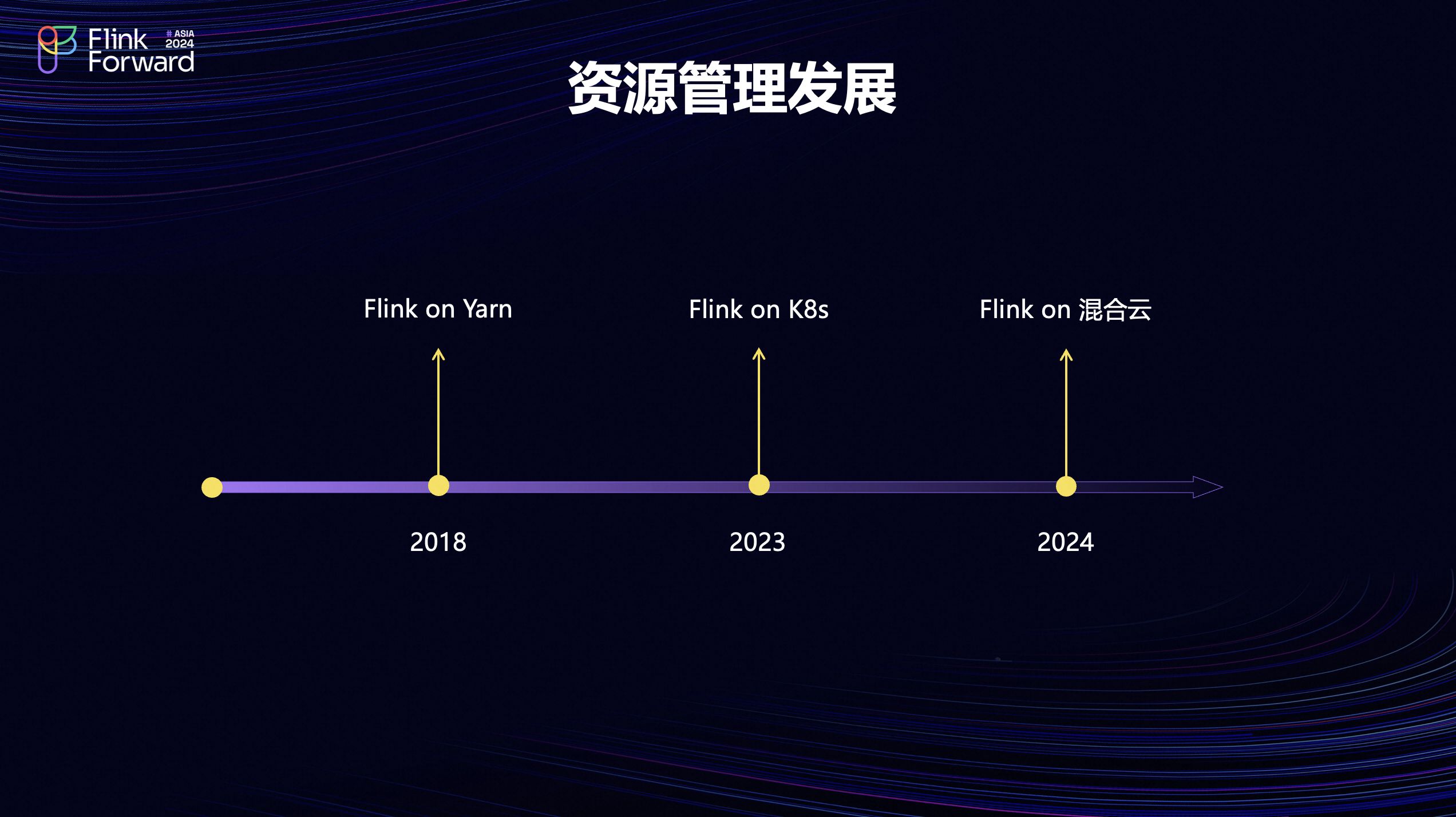
Flink 在网易游戏的资源管理发展主要分为以下三个阶段。第一阶段是在2018年的时候;最开始是使用 Yarn 作为 Flink 作业的资源管理和调度。这个阶段主要是希望能够利用 Yarn 直接复用现有的一些资源,帮助业务快速完成 Flink 作业的部署上线。第二个阶段是在2023年开始了 Flink on K8s 云原生的支持;这个阶段主要是希望能够通过 K8s 接入私有云的弹性资源,同时提高 Flink 作业的资源隔离能力。第三个阶段是在2024年,开始接入公有云的资源,形成了混合云的资源管理体系;这个阶段主要希望在已有的私有云基础上接入公有云资源,满足游戏流量高峰时候突增的资源需求。

早期使用 Yarn 做 Flink 作业的资源管理和调度时,有比较明显的优势和劣势。先看一下它的优势,第一可以复用现有离线资源帮助业务快速的上线。第二它可以做资源的统一管理和调度,因为 Yarn 的所有节点资源,比如 CPU 和 Memory 都会被抽象为 Container ,Flink 在运行任务的时候只需要按需去跟 Yarn 的 Resource Manager 申请对应的 Container 就好了。同时 Yarn 也提供了比较多的调度策略,比如说 Fair 和 Capacity 策略满足不同的调度需求。第三是 Yarn 的容错性也比较好,比如 Flink 作业经常会有偶发的异常退出,在 Yarn 集群里面,基于 Application Master Attempt重试机制可以比较好地帮助 Flink 做快速的 Failover 恢复。
但在使用 Yarn 的过程中也有一些比较明显的劣势和痛点,第一是它的资源粒度比较粗,异构资源调度灵活性低。因为在 Yarn 里,它的最小的资源粒度是 1 core ,有一些小作业是用不满这个资源的。另外如果作业使用 RocksDB StateBackend,需要把作业专门调度到挂载有SSD 的机器上,对 Yarn 集群来说实现比较麻烦。第二个是它的资源隔离能力比较差,在做实时/离线作业混部的时候发现离线作业有一个特点,它启动的时候网络流量特别大,导致机器上其他的 Flink 作业会出现网络异常而退出。第三个是 Yarn 集群环境依赖管理特别复杂,运维成本比较高。比如用户的 PyFlink 作业往往有很多第三方 Python 依赖,这个时候需要管理员帮用户提前把这些依赖部署在节点 Pyenv 环境上帮助用户加速作业的启动。当节点数比较多的时候,运维成本相当高。
所以基于上述 Yarn 的痛点和问题,我们进行了 Flink on K8s 云原生的支持。
02.架构演进
接下来分享一下这个阶段在架构上的演进。

Flink on K8s 首先要考虑的是怎么把 Flink 作业在K8s上面部署起来。
社区主要提供了3种模式。第一种是 Standalone 模式,这种模式需要在外部提前创建管理 Flink 的资源,为了避免资源不足往往会从峰值流量去考虑创建比较大的集群,这个时候它的资源利用率是比较低的。同时,这个作业运行完成之后,作业的资源也要自己进行回收,这种方式管理比较复杂,扩展性也比较差。第2种模式是 Native 模式,相比第一种模式,这种模式可以做到让作业按需申请计算资源,但是在这个作业异常或需要升级的时候还是要人工进行处理。第3种模式是 Flink Operator 模式,这种模式可以做到自动管理 Flink 作业以及它的生命周期,作业的启停和升级等。另外 Flink Operator和 Flink 以及 K8s 都做了深度的集成,可以给 Flink 提供比较高级的特性,比如说健康检查以及优化等。这种模式也是社区比较推荐的部署模式,所以最后采用了这种部署模式。

决定了用 Flink Operator 部署模式之后, Flink on K8s 的架构和流程如上图所示。上层是用户的 Flink Streaming、Flink Batch 和 Flink SQL 作业。中间第二层是作业管理,包含有平台的 Lambda 调度器、 Flink Operator服务。第三层,是 K8s 的调度层,同时我们会使用 ZooKeeper 作为高可用服务。因为之前发现在 Flink 作业大规模使用 ConfigMap作为 HA 的时候,它会对 K8s etcd 造成压力从而影响到API service 对外的服务,所以就把这一块单独分离出来使用 ZooKeeper 作为 HA 。第四层是存储层,包括有存储状态数据的 HDFS ,还有存储镜像的镜像仓库以及存储日志的 CubeFS ,最底层的是机器资源池。整体流程如下,Flink 作业在平台启动之后,调度器会收到启动请求,对作业进行编排,也就是 FlinkDeployment CRD的编排。在编码完成之后会提交给 K8s API Server ,由 K8s 的 API Server 把 CRD 信息同步给 Flink Operator 。然后由Flink Operator 基于 Native 的 K8s SDK 去为作业申请创建对应的 Pod 以及其他的 Service、ConfigMap 资源。
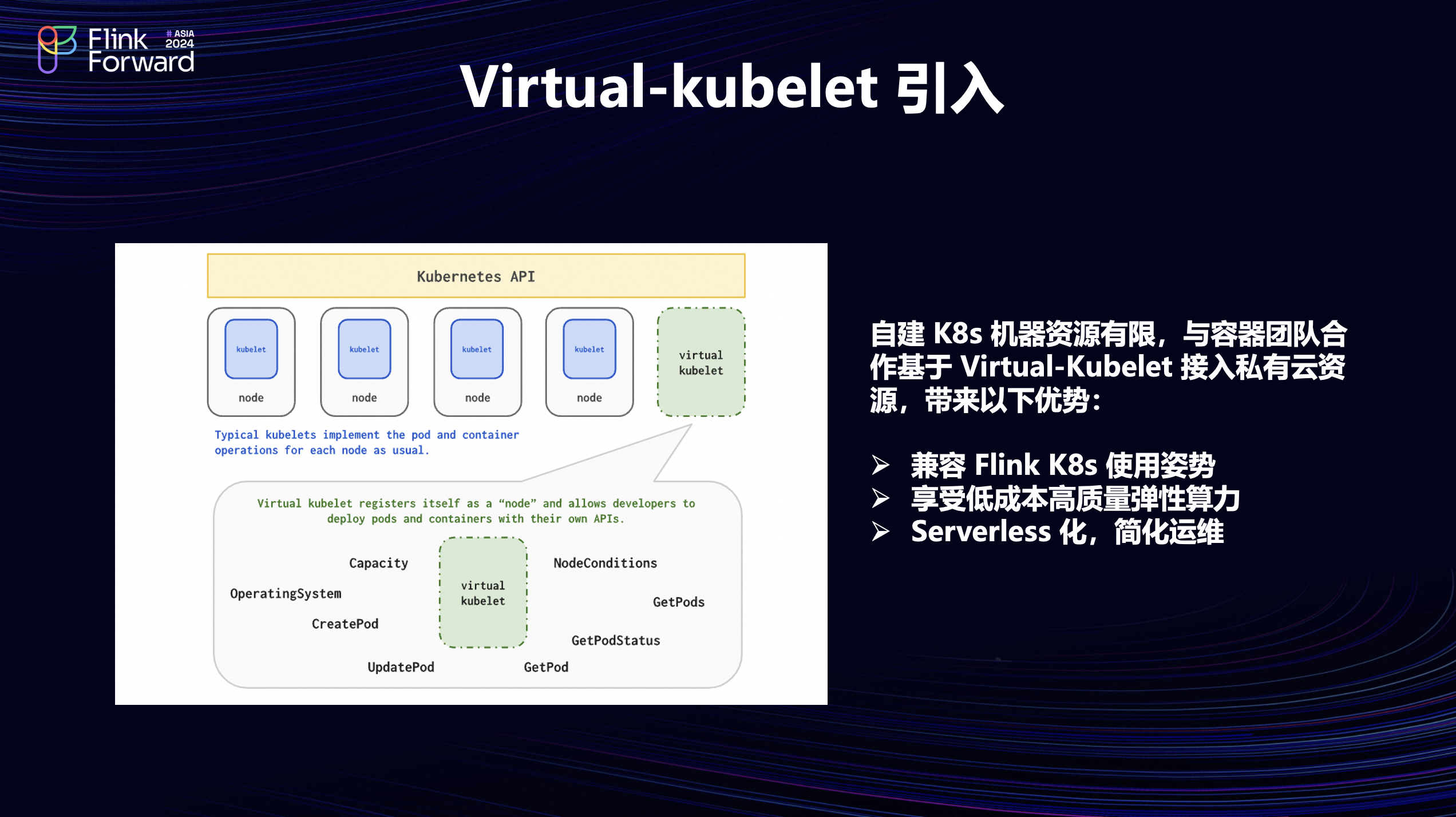
在上述 Flink on K8s 架构里,作业其实都是运行在内部的机器资源池上面。但是这部分资源相对来说还是比较有限的,所以和内部的容器团队合作希望接入更多的资源,基于 Virtual Kubelet 去接入了私有云的容器弹性资源。Virtual Kubelet 可以把我们私有云的 K8s 集群作为虚拟节点加入到自己维护的 K8s 控制面上。这样做可以带来以下一些好处;第一是可以兼容原来的 Flink K8s 使用姿势。因为之前在平台上面已经对 Flink 做了 K8s适配,而 Virtual Kubelet 本身又兼容原生的 K8s 接口,所以适配成本比较低;第二是可以享受到低成本高质量的弹性算力;第三是 Serverless 化简化运维, 整个集群里面的计算节点其实只有一个,可以大大减少机器相关的操作,降低运维的压力。
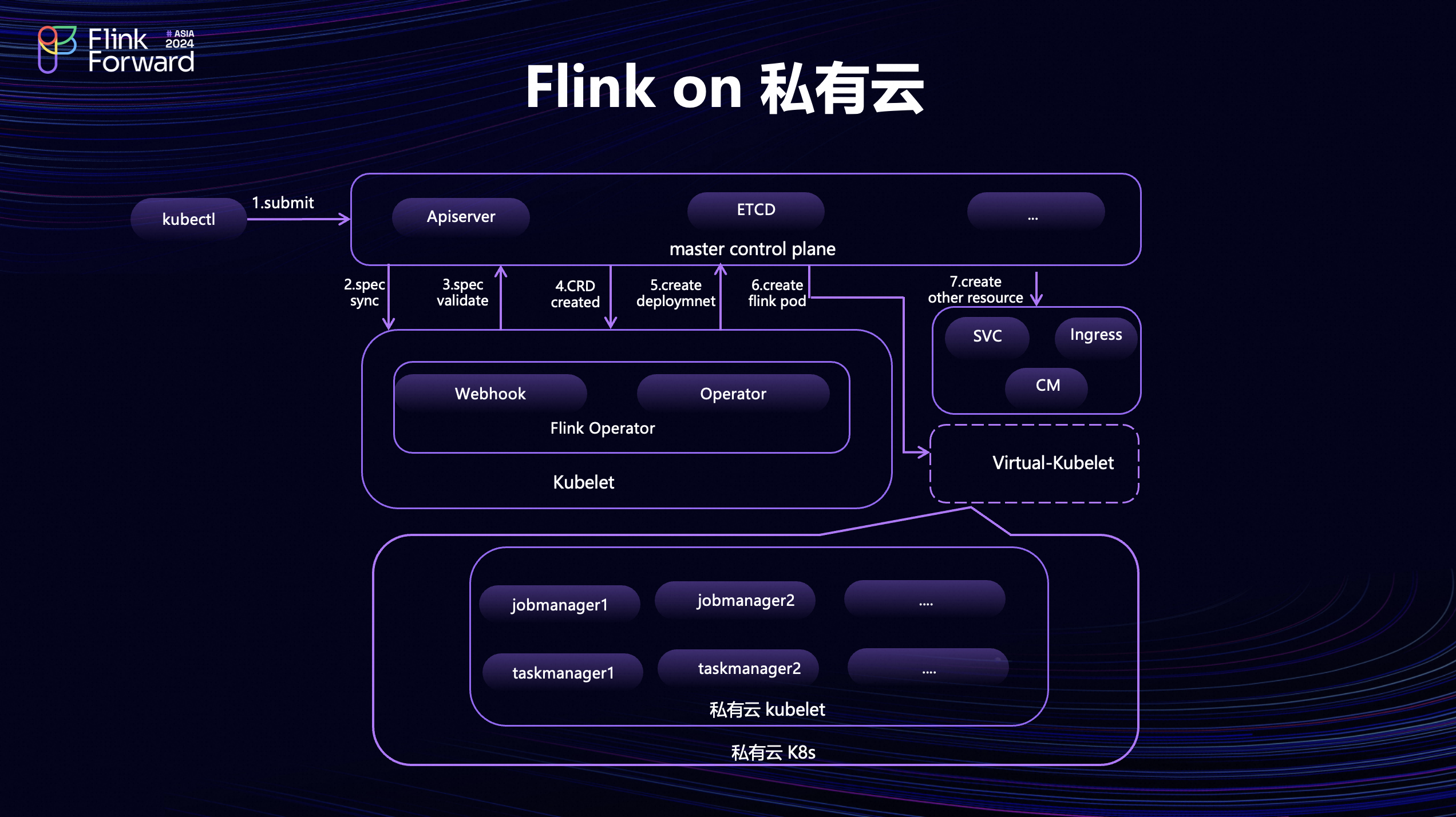
引用了 Virtual Kubelet 之后, Flink 作业的部署架构和流程就发生了一些变化。从图可以看到上层是主控制面,下层是私有云的 K8s 控制面。整体流程会先通过 kubectl去往主控制面提交 FlinkDeployment CRD ,这个时候会被 Flink Operator 服务的 Web hook进行拦截,进行校验的一些操作;没有问题之后会同步回主控制面,主控制面会进行 CRD 资源创建的同时通知到 Operator 服务这边,然后 Operator 继续为 Flink 作业去主控制面申请创建对应的 Deployment、Service、Ingress等。主控制面在为 Deployment 去申请创建对应的 Pod 时会根据平台设置的节点亲和性,把 Pod 调度到 Virtual Kubelet 节点上去。在架构里面可以看到只有 Flink Operator Pod 是运行在主控制面上, Flink 作业的所有 Pod都运行在私有云的 K8s 集群上。

在完成了私有云的接入之后,最后还接入了公有云的资源,形成混合云的资源管理体系。
之所以这样做,其实综合考虑了私有云和公有云的优缺点,私有云的优点比较明显,第一它有比较强的控制权,比如管理员对机器的权限都是比较高,各种操作都很方便。第二是安全性比较高,私有云的机器一般在内网里面,有防火墙还有安全组的安全扫描保护。第三是成本稳定可以预测,在私有云里面资源单价比较固定的,所以计算成本也是能够预测得到。第四是灵活性比较好,可以根据业务的需求做一些定制和优化,但这部分的资源相对来说还是有限的,有赖于 IDC 提供的机器资源,维护成本也比较高。
公有云的优点是理论上它是有无限的弹性资源;其次可以做到按需计费,随用随停;另外就是高效可靠,因为公有云厂商提供的技术支持和运维服务比较高效专业。但如果所有的 Flink 作业都运行在公有云上会涉及到数据安全的问题。所以希望结合两者的优缺点去进行混合云的建设,可以获得以下的优势和能力。第一是弹性伸缩,基于公有云弹性伸缩能力可以把一部分临时的负载弹到公有云上。第二是基于私有云成本稳定可预测以及公有云按时计费的特性做到比较好的成本控制。第三是稳定高效,保证已有作业稳定运行的同时,能够快速满足业务增长对资源的需求。第四是安全敏捷,处理重要敏感的 Flink 作业就可以跑在私有云上去,保障安全,其他作业可以放在公共云上。

接入公有云之后,就形成了混合云的架构。最上层是应用层,还是会有业务的 Flink streaming、 Flink Batch、Flink SQL 这些作业。第二层是作业管理,作业管理包含平台的 Lambda 调度器和 Flink Operator服务;同时会有集群管理,包含有虚拟集群和容量管理,虚拟集群主要是用来满足用户对不同集群以及 Flink 版本的定制化需求和配置。容量管理是对不同项目的配额管理。第三层是容器编排层,现在已经接入了自建 K8s 以及私有云和公有云的 ACK 作为编排调度引擎。用户可以根据业务形态以及它的资源需求选择不同的引擎,比如说业务的上游流量是在阿里云上,他就可以选择 ACK 作为他的编排调度引擎。第四层是共享存储,有 HDFS 以及 OSS,在自建的 K8s 和私有云的环境上,会使用HDFS作为状态存储,在 ACK 环境下会使用 OSS 作为状态的共享存储。最底层的是基础设施,包括网络、计算、存储相关基础设施。同样还会有其他的周边配套服务,包含有不同环境的日志采集、指标上报、告警服务。
03.实践挑战
接下来分享一下在演进过程中的实践和挑战。
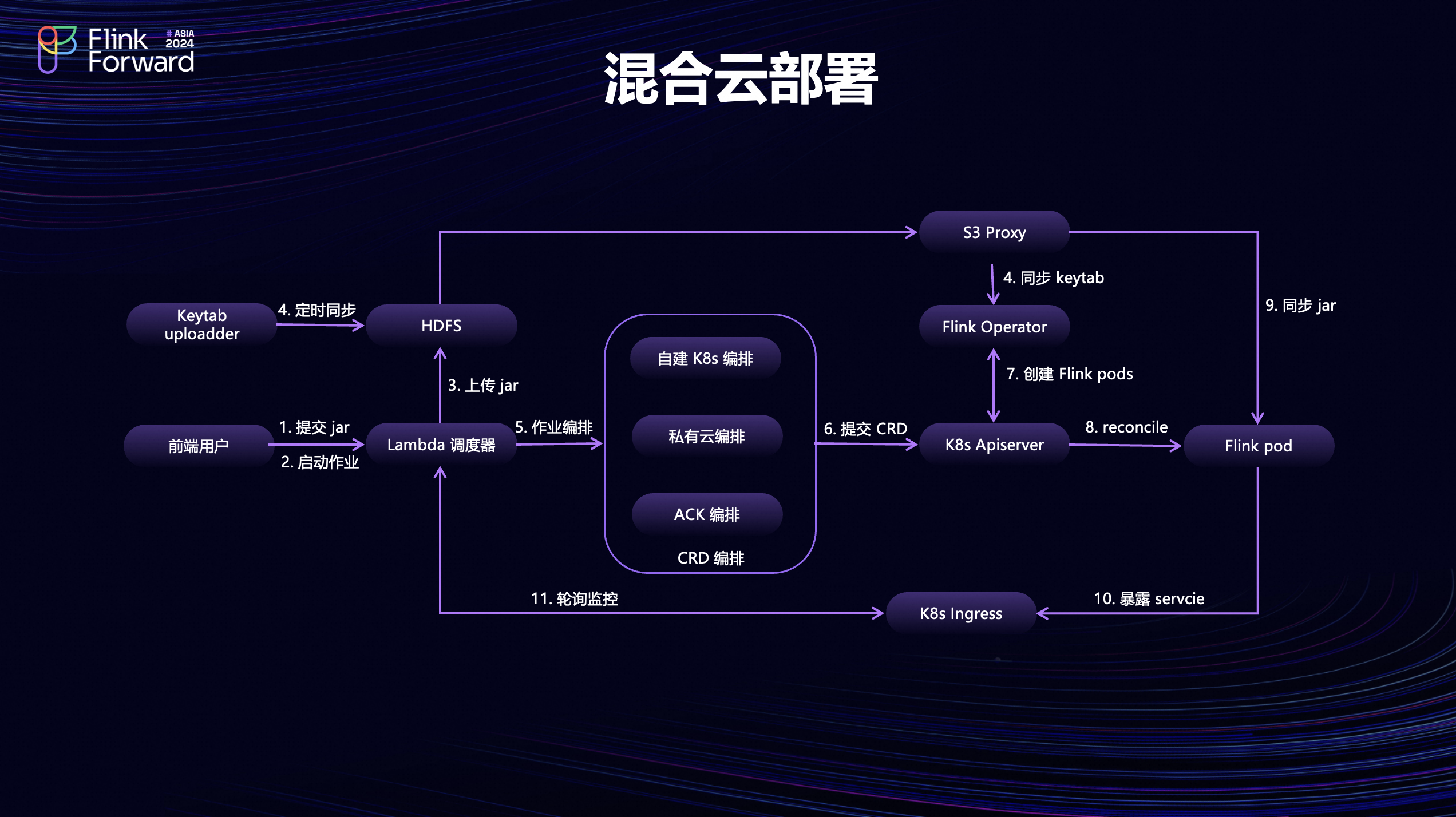
首先介绍一下在混合云场景下怎么把 Flink 作业给部署起来。前端用户首先要在平台提交作业Jar,然后选择虚拟集群进行启动。 Lambda调度器这时会收到启动请求,把用户提交的作业 Jar上传到 HDFS,同时外部会有定时任务把 Kerberos 的keytab文件同步到 HDFS ,用于后面 Flink Operator 启动作业的时候使用。当 Lambda 调度器在上传完作业Jar之后,就会对作业进行编排,也就是 Flink Deployment 的编排。在这里编排的时候,如果作业选择的是自建 K8s 或者私有云的集群就会在编排里面指定使用 HDFS 作为状态的共享存储,如果是 ACK 的集群就可以选择 OSS 作为存储。 CRD 编排完成后会提交给 K8s 的 API Server 。然后 API Server 把 CRD 的信息同步给 Flink Operator服务,后续就由 Flink Operator服务作为 CRD 的 Controller 为 Flink 作业申请创建对应的Jobmanager Pod, Jobmanager Pod初始化的时候就会通过S3 Proxy 访问到刚刚上传到 HDFS 的作业Jar进行下载和同步。 Jobmanager 启动完成之后会和 API Server 通信去创建作业所需要的 TaskManager Pod ,最后就是通过定时轮询 Flink Rest Service 的方式去跟踪作业的状态。通过这个流程就可以把 Flink 作业统一高效的部署到不同K8s环境上。

Flink 作业在混合云支持之后主要有以下三个应用场景。第一是游戏的 CBT 测试,因为新游戏上线之前,往往要经过比较多轮的 CBT 测试。这些测试数据有流量大周期短的特点,但是都需要用 Flink 作业进行消费,所以每次测试的时候,都需要为这些短期的测试流量,准备较多的计算资源。但在测试完成之后这部分流量又没了,准备的资源就会被闲置,造成浪费。所以有了混合云的支持之后,就可以把这部分的测试流量弹到公有云上,基于公有云的弹性资源去满足测试产生的大量的计算资源的需求,测试完成之后主动释放公有云的资源,减少资源的浪费和机器的成本。 第二个是流量高峰的负载转移,因为游戏流量有比较明显的潮汐现象的,一般是在晚上还有周末的时候流量比较高,其他时候流量比较低。在 Flink 集群水位比较高的时候,如果遇到了游戏搞活动,流量上涨,Flink 作业很有可能会因为资源不够或者资源碎片的问题出现扩容失败,有了混合云的支持之后,我们就可以把高峰时候的一部分负载转移到公有云上,避免 Flink 作业因为资源不足而扩容失败。第三是异地容灾,因为私有云和公有云的机房在不同的地方,当其中一个集群出现比较大规模故障的时候就可以做异地的迁移。
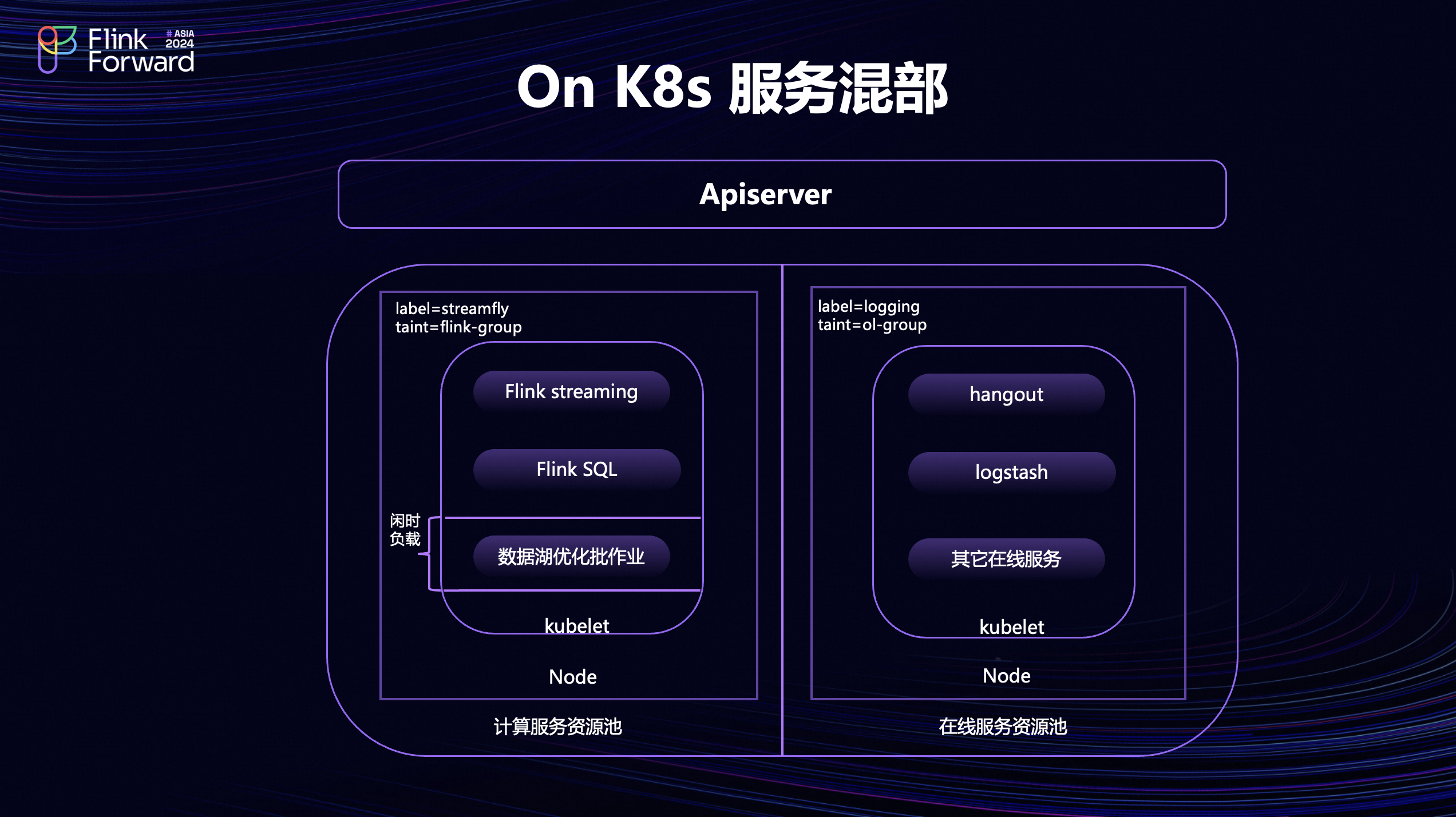
K8s相比于 Yarn,在资源隔离上做得比较好,使得它在服务方面比较有优势。首先介绍一下On K8s 的服务混部。如图所示,我们会对集群上的节点打上不同的标签和污点来划分不同的资源池,比如说这里会划分为计算服务资源池、在线服务资源池。通过 K8s 的节点亲和性、反节点亲和性把 Flink 作业调度到计算服务资源池上。其他的服务,比如说 Hangout 或者 Logstash 就会运行在在线服务资源池上。这样的好处是不同的服务可以共用一套控制面,但是它运行在不同的节点上,资源隔离程度比较高,也有利于 SLA 比较高的在线服务稳定运行。而在计算服务资源池里,在它资源负载比较低的时候,会把一些批作业调度上去。比如说数据湖的优化批作业。充分利用闲时资源,提高资源利用率。
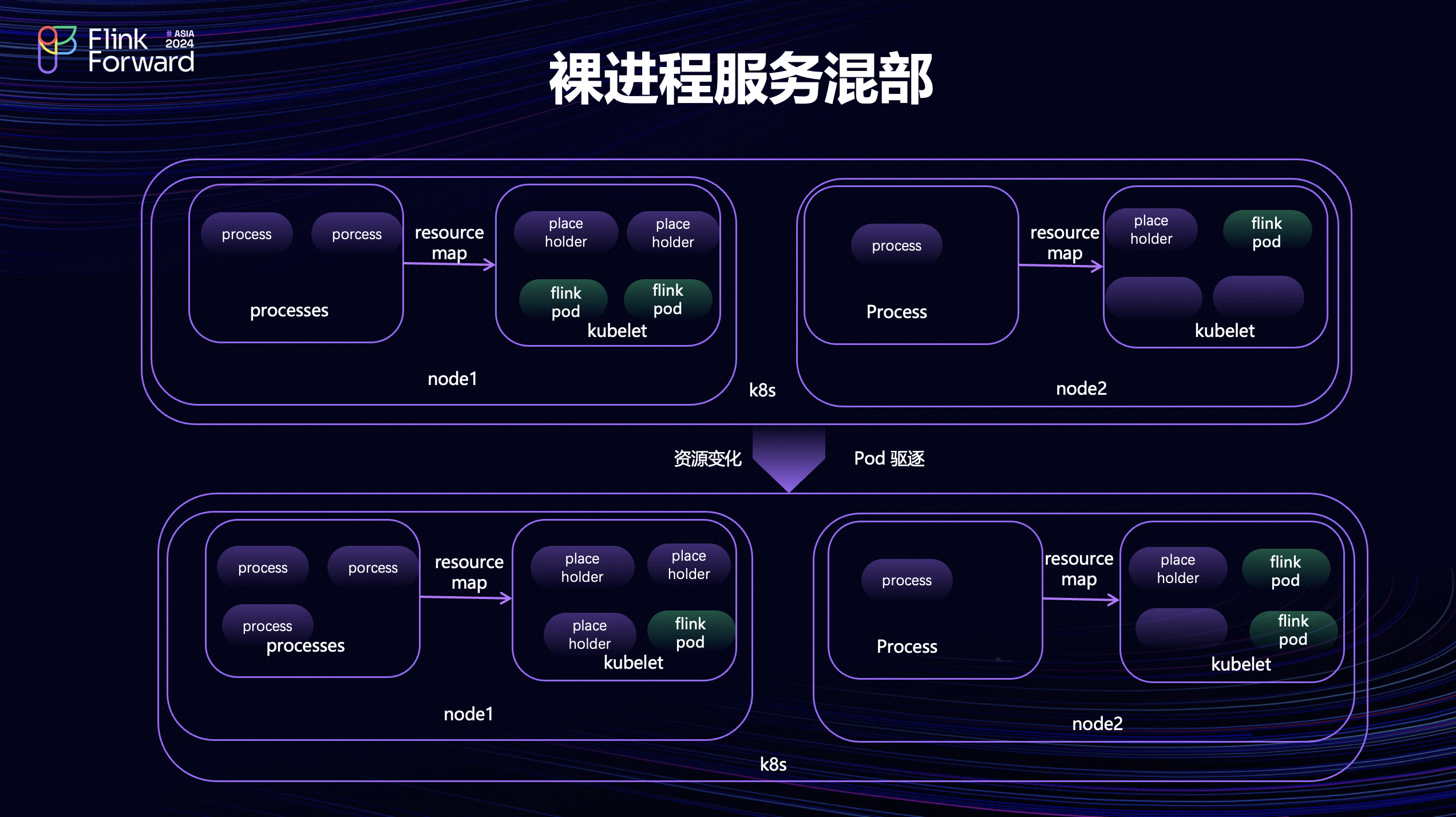
On K8s服务分布只能对运行在 K8s 上的服务进行分布。但还有很多的服务由于各种原因没有运行在 K8s上,比如很多服务没有做容器化的改造,是以进程的方式运行在物理机上。基于裸进程服务混部就可以把这部分资源也利用上。以上图为例子,左上角的节点1,它本身就运行了两个进程服务,把它所消耗的资源,比如说 CPU 、Memory 会映射为同节点上两个优先级比较高的 PlaceHolder Pod,节点上也会运行有其他的 Flink Pod。节点2也是同样道理,在这里可以看到节点1的资源水位比较高,节点2资源水位相对空闲一些,当节点1的进程资源消耗变化的时候,对应的 Placeholder 资源占用也会发生变化,并且触发重新部署。此时K8s 会根据设置的优先级保证高优先级的PlaceHolder Pod的资源得到满足,在资源不足的时候会把低优先级的 Flink Pod 驱逐调度给到其它节点。这里就会把节点1上的 Flink Pod 驱逐到相对比较空闲的节点2上,基于 Flink 内部的 Failover 机制完成作业的恢复。基于进程的 PlaceHolder 映射、K8s 优先级和抢占机制可以实现裸进程服务和Flink作业的混部。
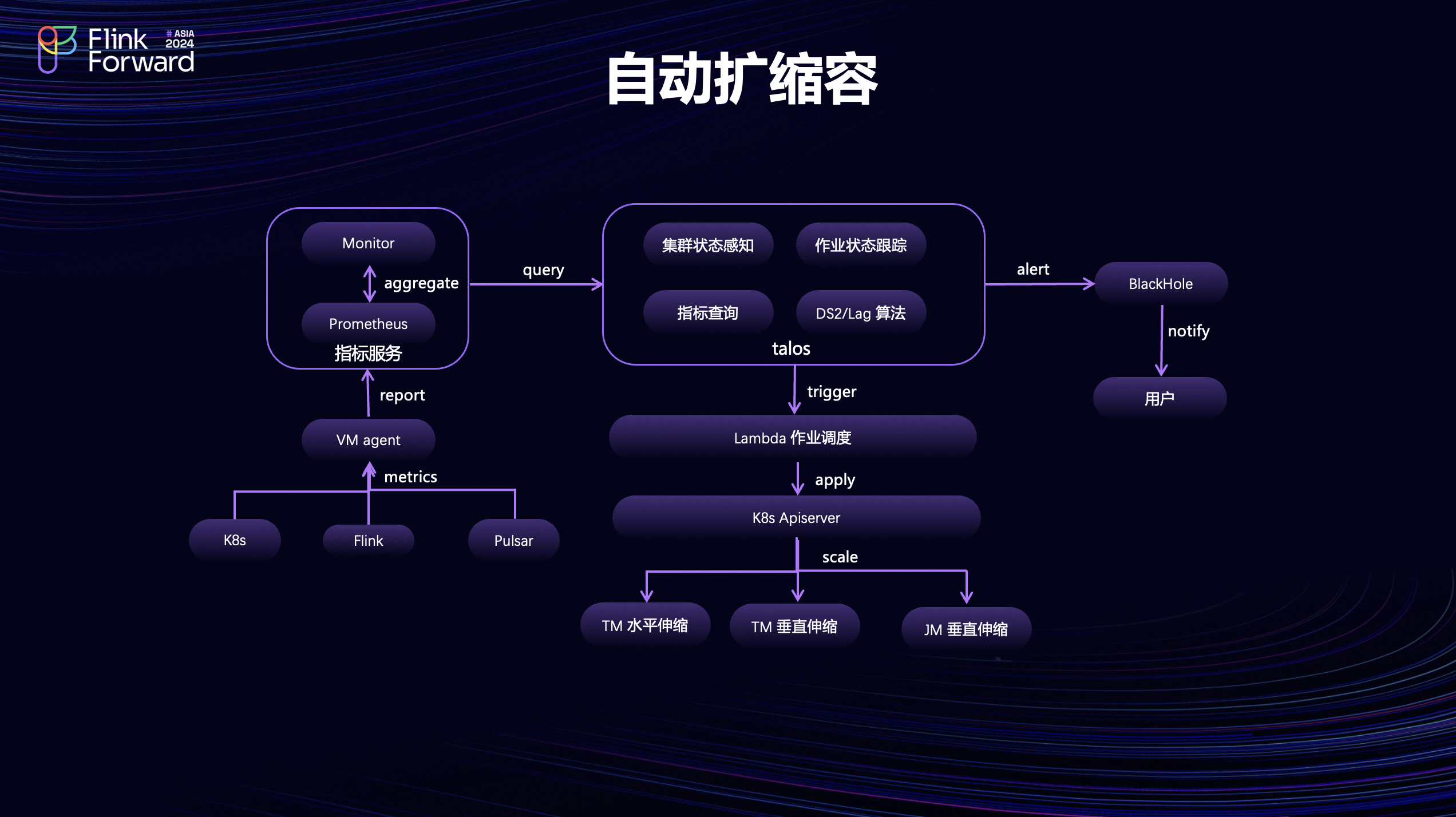
为了更好的利用 K8s 的弹性伸缩能力,平台为 Flink 作业提供了自动扩缩容的功能。如上图所示,我们会把 K8s 还有 Flink 以及 Pulsar的指标通过 VM agent 去采集上报到Prometheus服务,同时还会在内部的 Monitor 指标管理平台设置一些清洗、关联的规则。比如说 Pulsar的 Lag 指标默认没有暴露到 Client 端,这里就可以对它进行清洗转换并和 Flink 指标关联;中间会有名为 Talos 的扩缩容服务去指标服务里面查询需要的指标,结合作业设置的扩缩容算法,比如说 DS 2 或者 Lag 算法;同时感知集群的状态感知,去为作业计算最新的资源配置和选择合适的集群。当作业的资源配置发生变化的时候,会向 Lambda 调度器发起扩缩容请求,并发送最新的资源配置。Lambda 调度器会把最新的资源配置提交给K8s的API Server 去完成 Flink 作业的资源伸缩。目前已经支持了 Task Manager 水平和垂直的伸缩,同时也支持了 JobManager 的垂直伸缩。Talos 扩缩容服务还会对作业扩缩容之后的状态进行跟踪,保证它在扩缩容之后最少能够完成一次checkpoint。如果中间出现了问题,会通过内部的 BlackHole 告警平台去通知到用户或者管理员进行处理。
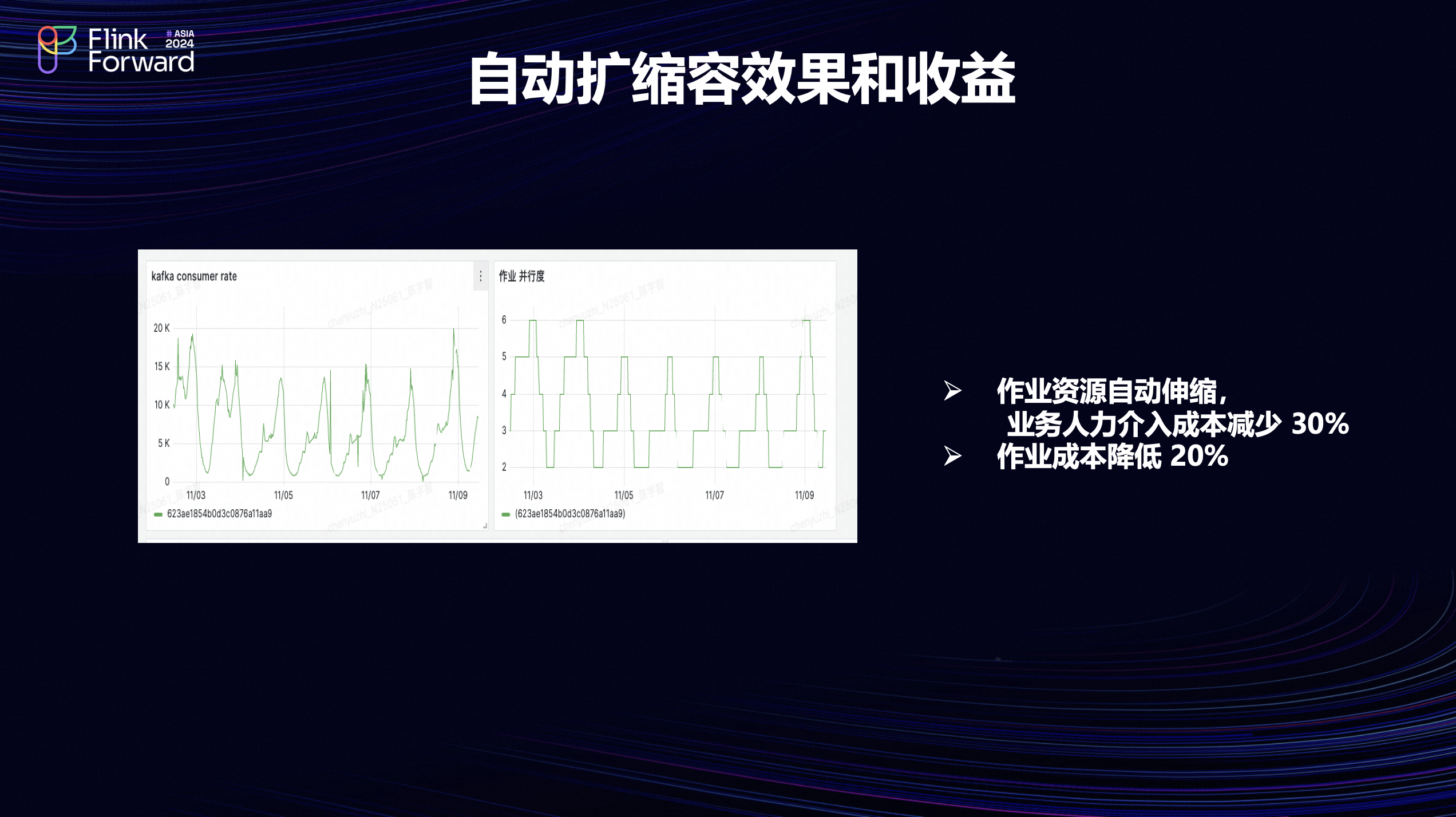
从这张图可以看出,作业开启了自动扩缩容之后,作业资源是会跟着流量变化而变化的。在流量上涨的时候,会自动去扩容申请更多的资源提高消费能力。在流量下来的时候也会自动的释放一些资源,这样给业务带来的好处是可以减少因为数据延迟而需要人力介入的情况。这部分的人力成本大概可以减少30%。
同时,作业在开启了自动扩缩容之后,它的资源利用率也会有所提高,计算成本也会发生下降,这部分成本大概降低20%。
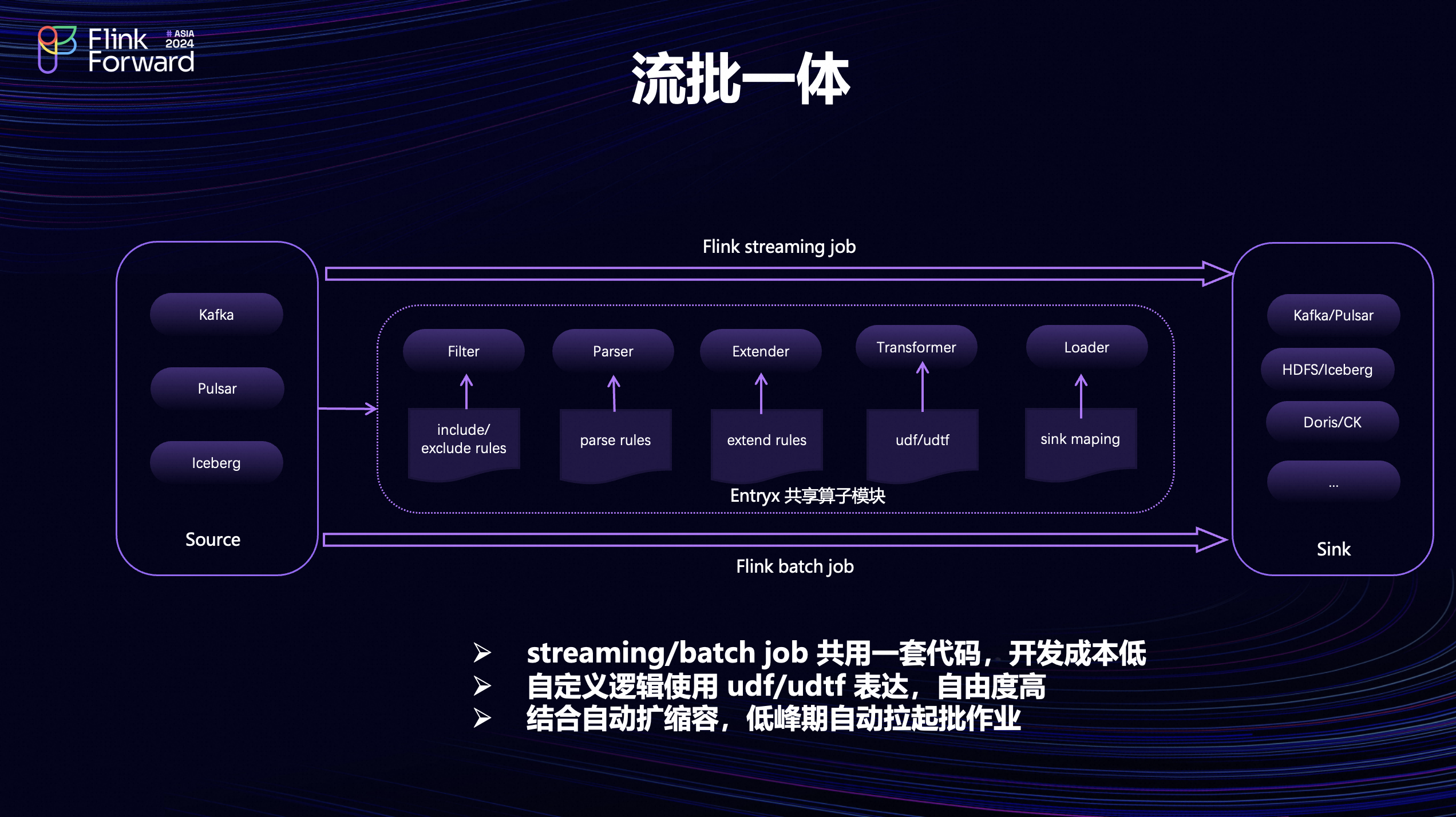
刚才说到会在 K8s上面混部一些批作业,其中有一部分批作业是来自于数据集成服务的共享算子模块,这些算子都是运行在 Flink 作业里,它既能以流模式来运行,也能以批模式来运行。共享算子主要是应用在数据集成上,所以它整体的流程和设计体现了ETL中数据抽取、清洗转换和输出的过程。
如图所示,Source算子可以通过 connector 去连接上游的Kafka、Pulsar或者Iceberg数据源;之后数据会经过 Filter 算子根据自定义的规则进行过滤;然后基于 Parser 和 Extender算子可以对数据进行结构化以及扩展;随后经过 Transform算子的时候会调用业务编写的UDF/UDTF进行数据处理,最后经过 Loader 算子的时候会输出到下游的各个系统。基于这样一个流程,业务的实时流作业和历史批作业就可以共用一套代码和规则,业务的开发和管理的成本明显降低的,对用户来说也不太容易出错。而业务的自定义逻辑,可以使用 UDF/UDTF 来表达,自由度比较高。同时结合自动扩缩容可以在低峰的时候会拉起一部分批作业去运行。
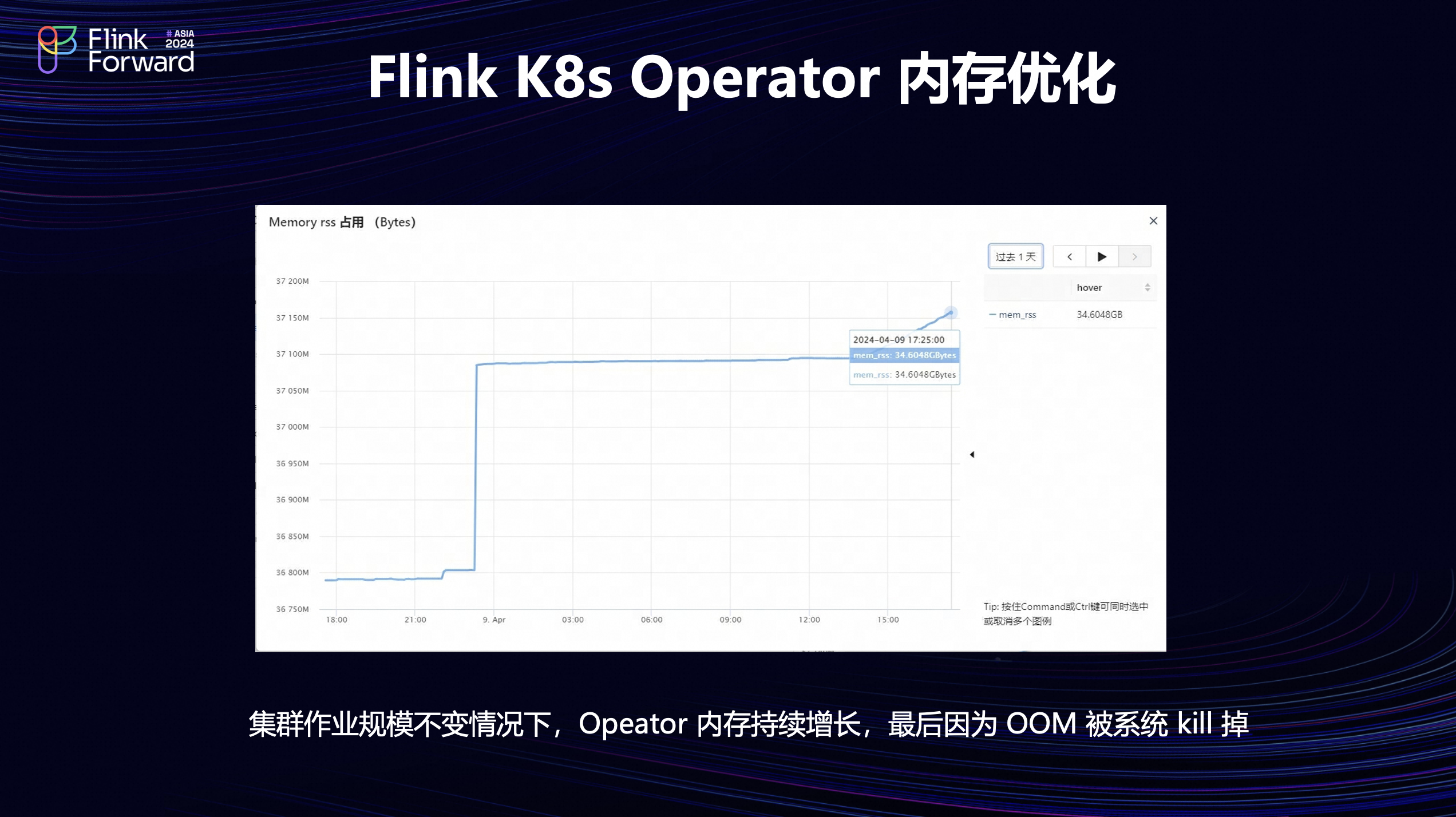
在K8s集群中,Flink Operator 服务的稳定性、可用性对于 Flink 作业起着重要的作用。在实际生产中我们对此也做了一些优化,首先看一下内存方面的优化。
当时的背景是在集群作业规模不变的情况下, Operator 的内存持续的增长,最后出现 OOM Kill的情况。从图中可以看到内存增长到了35G。但是当时集群作业规模比较小,只有1000个左右,这么大的内存使用明显是不合理的。
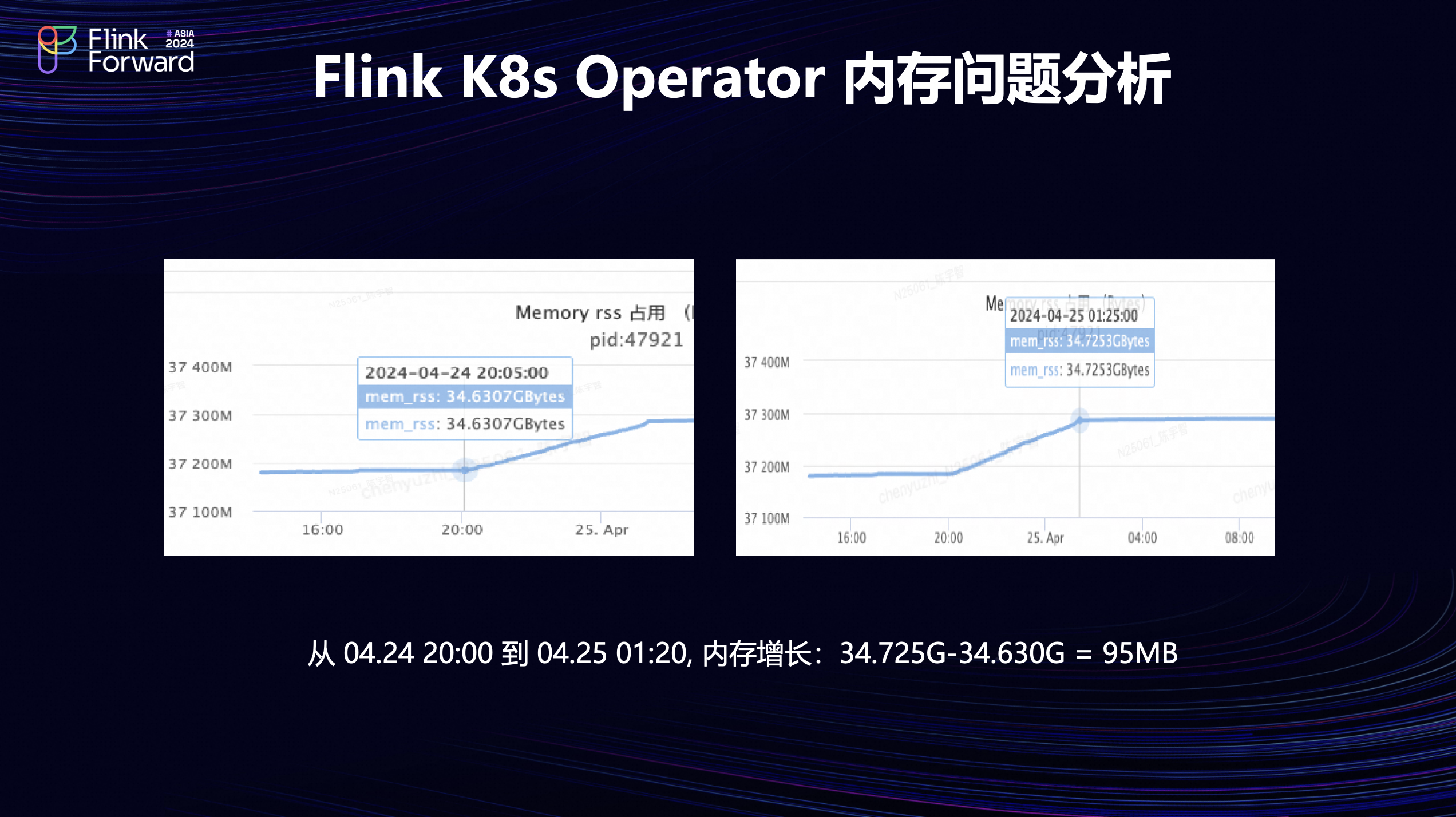
经过进一步Heap dump 和 GC 分析,发现堆内存使用正常。
怀疑此前内存增长应该是来自堆外内存,尝试对这部分内存进行分析。从当时监控可以看到,服务的总内存在4小时里增长了95MB左右。

后面我们使用pmap做了内存分析,发现内存增长主要来源于前面栈内存地址段,从74MB到165MB,增长了大概91MB,说明前面95MB的增长大部分都来自于这一块区域。而且它有很多64MB的内存段,这部分很符合线程Arena内存块的大小,后续结合CPU profile 的分析,发现内存增长确实是发生在线程创建的内存分配阶段。而Operator 默认使用 glibc2.3 做内存分配,基本上可以确认是glibc在多线程场景下的内存碎片问题,所以后续升级为 Jemalloc 去优化这一块内存的使用。
对 Operator 除了内存方面的优化,还做了一些其他优化,比如Kerberos keytab 文件的同步优化。之前一般是把keytab文件同步到宿主机再挂载到 Operator 容器里,在作业启动的时候使用。但在混合云场景下要把文件同步到外部宿主存在很多限制,也有安全风险,所以基于 HDFS + S3 Proxy + Sidecar Container的方式做了优化。
具体的做法会先把 keytab 文件同步到内部的HDFS,通过 S3 proxy 可以被Operator的 Sidecar Container 以 S3A 协议的方式进行下载。另外一个优化是Operator在为Flink作业设置Ingress路由规则的时候,发现它只能路由到ClusterIP 类型的Service上。而在私有云场景下,其实是优先使用 HeadLess Service 类型。所以在这一块也进行了优化,让Operator 设置Ingress规则的时候,支持路由到HeadLess/ClusterIP Service类型。
04.总结和展望
最后是我们的总结和展望。

先总结下目前生产的现状以及上云的情况,现在生产上面大概是有1万+的作业,资源规模大概是十万+的CPU core,目前已经完成了50%作业的上云的迁移,每天处理的数据量,大概是十万亿。

目前 Flink 上云带来的收益,主要分为以下三个方面。第一个是基于服务混部和自动扩缩容可以大幅提高集群的资源利用率,使得机器资源大概减少30%;另外基于 K8s 的细粒度资源管理,很多小作业在上云之后就可以设置比较小的CU,所以大部分的小作业计算成本是40%的下降,平均也有20%的下降;而 Flink 上云之后带来了更多廉价的弹性资源,满足了业务增长对计算资源的需求。

未来工作主要分为以下三个方面来开展,第一是性能和规模的提升,继续提升上云的规模,满足大规模算力场景下对调度性能和吞吐能力的要求;第二个是 Flink 流批一体能力的推广;第三个是结合机器学习为用户提供智能运维的能力,减少人力介入的成本。
相关文章:

网易游戏 Flink 云原生实践
摘要:本文整理自网易游戏实时计算&数据湖平台负责人林小铂老师和网易游戏大数据开发工程师陈宇智老师,在Flink Forward Asia 2024 云原生专场的分享。主要分为四个部分: 1、背景 2、架构演进 3、实践挑战 4、总结和展望 01.背景 Flink 在…...

使用迁移学习的自动驾驶汽车信息物理系统安全策略
信息物理系统 (CPS) 是一种新兴系统,它通过信息通信基础设施,实现控制系统、传感器、执行器和周围环境等物理组件之间有效的实时通信与协作 (C&C)。自动驾驶汽车 (AV) 是大量采用 CPS 方法的领域之一,旨在通过降低能源消耗和空气污染来改善智慧城市中的人们生活。因此,…...
》阅读笔记:p11-p13)
《算法导论(第4版)》阅读笔记:p11-p13
《算法导论(第4版)》学习第 8 天,p11-p13 总结,总计 3 页。 一、技术总结 无。 二、英语总结(生词:2) 1.precious (1)precious: pretium(“value, worth, price”) adj. of great value(宝贵,珍贵)。 (2)示例 Computing t…...

Qt 编译 sqldrivers之psql
编译postgres pgsql驱动 下载驱动源码修改配置文件编译 下载驱动源码 // 源代码下载 https://download.qt.io/archive/qt/5.15/5.15.2/submodules/驱动目录:qtbase-everywhere-src-5.15.2\src\plugins\sqldrivers 修改配置文件 打开pro文件 右键点击添加库 此处的为debu…...

查看单元测试覆盖率
文章目录 1、POM文件配置2、编写单元测试3、执行单元测试4、查看单元测试覆盖率 1、POM文件配置 pom文件配置jacoco插件 <!-- 生成JaCoCo覆盖率数据插件 --> <plugin><groupId>org.jacoco</groupId><artifactId>jacoco-maven-plugin</artif…...

ASP.NET Core 中实现 Markdown 渲染中间件
文章目录 前言一、核心功能二、实现步骤1)安装依赖包2)创建中间件类3)中间件扩展方法4)在Program.cs配置5)模板文件示例6)*.md文件示例7)缓存优化8)使用示例 三、注意事项总结 前言 …...

AI学习路径
一、AI入门与系统课程 (1)《开启AI革命:7天从小白到大神》 简介:保姆级教学,覆盖AI基础知识、机器学习、深度学习、自然语言处理(NLP)、大语言模型(LLM)等,…...
)
基于Kubernetes的Apache Pulsar云原生架构解析与集群部署指南(下)
文章目录 k8s安装部署Pulsar集群前期准备版本要求 安装 Pulsar Helm chart管理pulsarClustersBrokersTopic k8s安装部署Pulsar集群 前期准备 版本要求 Kubernetes 集群,版本 1.14 或更高版本Helm v3(3.0.2 或更高版本)数据持久化ÿ…...

B站搜索关键词全攻略:掌握B站搜索关键词的运作机制
在拥有超过7亿月活用户的B站,每天都有海量视频涌入平台。无论是普通用户还是内容创作者,掌握B站搜索关键词的运作机制,都能极大提升平台体验和内容价值。本文将从用户和创作者双重视角,深入解析B站搜索关键词的应用技巧和优化策略…...

Windows系统安装Cursor与远程调用本地模型QWQ32B实现AI辅助开发
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

DBeaver查询PostgreSQL的只读模式
问题 DBeaver查询PostgreSQL数据表时,注意到经常会出现“Detect unique identifiers" 这个阶段,几乎需要花费10s时间,想着挺浪费时间的。 问题解决办法 把”读取数据表元数据(唯一键)"这个复选框选项去掉,再进行查询…...

C++内存管理与模板初阶详解:从原理到实践
目录: 一、C/C内存管理1. 内存区域划分2. 动态内存管理3. 底层原理:operator new/delete4.new和delete的实现原理5. 定位new(了解即可) 二、模板初阶1. 泛型编程2. 函数模板实例化隐式实例化:编译器自动推导类型显式实…...

02-GBase 8s 事务型数据库 客户端工具dbaccess
dbaccess概述 数据库产品通常会提供一个命令行客户端工具。 数据库厂商 命令行客户端 Oracle sqlplus MySQL mysql Marladb mysql GBase 8s dbaccess Kingbase ES ksql DM8 disql dbaccess 是 GBase 8s 数…...

【kubernetes】通过Sealos 命令行工具一键部署k8s集群
一、前言 1、sealos安装k8s集群官网:K8s > Quick-start > Deploy-kubernetes | Sealos Docs 2、本文安装的k8s版本为v1.28.9 3、以下是一些基本的安装要求: 每个集群节点应该有不同的主机名。主机名不要带下划线。所有节点的时间需要同步。需要…...

【Pandas】pandas DataFrame abs
Pandas2.2 DataFrame Computations descriptive stats 方法描述DataFrame.abs()用于返回 DataFrame 中每个元素的绝对值 pandas.DataFrame.abs() pandas.DataFrame.abs() 方法用于返回 DataFrame 中每个元素的绝对值。该方法适用于包含数值型数据的 DataFrame,对…...

如何在 C# 和 .NET 中打印 DataGrid
DataGrid 是 .NET 架构中一个功能极其丰富的组件,或许也是最复杂的组件之一。写这篇文章是为了回答“我到底该如何打印 DataGrid 及其内容”这个问题。最初即兴的建议是使用我的屏幕截图文章来截取表单,但这当然无法解决打印 DataGrid 中虚拟显示的无数行…...

使用DEEPSEEK快速修改QT创建的GUI
QT的GUI,本质上是使用XML进行描述的,在QT CREATOR的界面编辑处,按CTRL2 切换到代码视图,CTRL3切换到编辑器视图。 CTRL2 切换到代码视图 CTRL3 切换到编辑器视图 鼠标左键点击代码视图中,按CTRLA → CTRLC复制XML代码…...

前端面试宝典---JavaScript import 与 Node.js require 的区别
import 和 require 来自不同的规范: import 是 ES6(ECMAScript 2015)模块系统的一部分,是 JavaScript 语言的标准语法 require 是 CommonJS 规范的一部分,最初为 Node.js 环境设计 加载方式: require() …...

C++入门小馆 :多态
嘿,各位技术潮人!好久不见甚是想念。生活就像一场奇妙冒险,而编程就是那把超酷的万能钥匙。此刻,阳光洒在键盘上,灵感在指尖跳跃,让我们抛开一切束缚,给平淡日子加点料,注入满满的pa…...

极简远程革命:打破公网桎梏,重塑数字生活新体验
简远程革命:节点小宝,让家庭与职场无缝互联 ——打破公网桎梏,重塑数字生活新体验 引言:当公网IP成为过去式 在2025年的今天,80%的家庭仍因缺乏公网IP而深陷远程访问困境。NAS玩家为端口映射焦头烂额,家长…...

Linux 网络管理 的实战代码示例
涵盖网络接口配置、连接测试、防火墙管理、数据包捕获、服务监控等核心场景。每个示例均附带详细注释和操作说明,帮助您深入理解 Linux 网络管理的实战技巧。 1. 网络接口配置与管理 1.1 使用 ip 命令管理网络接口 ip 是现代 Linux 系统中管理网络的主要工具,功能比 ifcon…...

OPCUA,OPCDA与MODBUS学习笔记
MODBUS与OPC之间的关系是什么? 前言 OPC协议(OLE for Process Control,即过程控制的OLE)是一种标准化的通信协议,旨在帮助不同厂商的设备、控制系统和软件之间进行数据交换。OPC协议的目标是提供一种统一的接口&…...

千星计划小程序开发方案
千星计划小程序开发方案 (基于2025年行业实践与系统需求) 一、核心功能架构 1.用户管理模块 用户分层管理:普通用户、达人、合伙人三级身份体系,支持身份升级审核与权限配置 实名认证与资质审核:对接公安系统…...

【RAG技术全景解读】从原理到工业级应用实践
目录 🌟 前言🏗️ 技术背景与价值🚨 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🔍 一、技术原理剖析📐 核心概念图解💡 核心作用讲解⚙️ 关键技术模块说明⚖️ 技术选型对比 &…...

20250508在WIN10下使用移远的4G模块EC200A-CN直接上网
1、在WIN10/11下安装驱动程序:Quectel_Windows_USB_DriverA_Customer_V1.1.13.zip 2、使用移远的专用串口工具:QCOM_V1.8.2.7z QCOM_V1.8.2_win64.exe 3、配置串口UART42/COM42【移远会自动生成连续三个串口,最小的那一个】 AT命令…...

室内无人机自主巡检解决方案-自主方案
室内无人机自主巡检解决方案-自主方案 AIBOX-基于离线地图的LIO室内3D空间位置服务...

SpringCloud服务拆分:Nacos服务注册中心 + LoadBalancer服务负载均衡使用
SpringCloud中Nacos服务注册中心 LoadBalancer服务负载均衡使用 前言Nacos工作流程nacos安装docker安装window安装 运行nacos微服务集成nacos高级特性1.服务集群配置方法效果图模拟服务实例宕机 2.权重配置3.环境隔离 如何启动集群节点本地启动多个节点方法 LoadBalancer集成L…...

视频编解码学习9之照相机历史
照相机的发展历史可以追溯到19世纪初,至今已有200多年。以下是照相机技术演进的主要阶段和里程碑: 1. 早期探索阶段(1820s-1880s) 1826年:法国人尼埃普斯(Nicphore Nipce)用沥青感光法拍摄《窗…...

物流无人机自动化装卸技术解析!
一、自动化装卸技术模块的技术难点 1. 货物多样性适配 物流场景中货物包装类型、尺寸、材质差异大,如农产品、医疗物资、工业设备等,要求装卸模块具备高度柔性化设计。例如,单元货物需视觉识别系统进行单个抓取,而整托货物需大…...

图形渲染+事件处理最终版
基于之前做的项目图形移动处理-CSDN博客添加了相机,透视投影,鼠标控制图形旋转。虽然个人感觉这个项目用的是一个二维的三角形,给他加透视投影和相机意义不大,因为透视投影是近大远小,我这个程序设置了放大缩小的限制&…...

前端三大件---CSS
目录 一、CSS 概述 二、引入 CSS 的三种方式 2.1 内联样式 2.2 内部样式表 2.3 外部样式表 三、CSS 选择器 3.1 ID 选择器 3.2 class 选择器 3.3 标签选择器 3.4 通配选择器 3.5 分组选择器 3.6 层级选择器 3.7 属性选择器 3.8 伪类选择器 3.9 同辈选择器 四、…...

蓝桥杯FPGA赛道第二次模拟题代码
一、顶层文件 module test( input wire sys_clk, input wire sys_rst, input wire [3:0]key_in, output reg [7:0]led,output wire scl, inout wire sda,//i2c的信号output wire [7:0]sel, output wire [7:0]seg//数码管的驱动 );wire [23:0] data ; reg [31:0] dsp_dat…...

keep the pipe Just full But no fuller - BBR 与尘封 40 年的求索
推荐一部短视频 Keep the pipe just full, but no fuller,作者就是大名鼎鼎的 L. Kleinrock,现代分组交换网的奠基人,这里有关于他这个人的介绍: https://www.lk.cs.ucla.edu/index.html https://en.wikipedia.org/wiki/Leonard…...

《React Native热更新实战:用Pushy打造无缝升级体验》
《React Native热更新实战:用Pushy打造应用“空中加油”,实现无缝升级体验》 写在前面:当你的APP需要"空中加油"时… 想象一下这样的场景:凌晨2点,你的React Native应用刚上线就爆出重大BUG,用户差评如潮水般涌来,应用商店审核至少需要3天…此刻你多么希望能…...

【开源解析】基于Python的智能文件备份工具开发实战:从定时备份到托盘监控
📁【开源解析】基于Python的智能文件备份工具开发实战:从定时备份到托盘监控 🌈 个人主页:创客白泽 - CSDN博客 🔥 系列专栏:🐍《Python开源项目实战》 💡 热爱不止于代码࿰…...

第四章:基于langchain构造一个完整RAG系统
文章目录 引言一、RAG的基本原理1.1 什么是RAG?1.2 RAG的应用场景 二、RAG系统的构建步骤2.1 环境准备2.2 加载和处理文档2.2.1 文档加载2.2.2 文本分割 2.3 构建嵌入模型2.4 创建向量存储与检索器2.5 检索与生成2.5.1 检索相关文档2.5.2 生成答案 三、完整代码示例…...
)
uniapp|实现多终端视频弹幕组件、内容轮询、信息表情发送(自定义全屏半屏切换、弹幕启用)
基于UniApp框架实现跨终端视频弹幕组件的开发,结合CSS3动画与setInterval轮询机制,完成弹幕从右向左的动态滚动效果,针对交互需求,设计弹幕启用开关、全屏/半屏模式切换功能,并利用cover-view组件解决原生层级覆盖问题。 目录 引言视频弹幕的交互价值与多终端适配需求Un…...
——栈的应用—数制转换)
数据结构(四)——栈的应用—数制转换
利用栈进行数制转换: 十进制转换八进制:先将十进制数除以八得到余数,余数入栈,然后将得到的商继续除以八,直到商为零 #include <stdio.h> #include <stdlib.h>#define MAXSIZE 100//数制转换//定义链表节…...

flinksql bug : Max aggregate function does not support type: CHAR
这个问题是flink中 CHAR 存在语义歧义,主要涉及到位数的关系,这里不做多讨论。 这个问题已经有人提了pr,新版本可以关注是否有解决 这个报错发生在 max(测试字段) ,这个测试字段如果是char 就会报错不支持 解决办法:…...

解决社区录音应用横屏状态下,录音后无法播放的bug
最近看到社区有小伙伴反映,社区录音应用横屏时,录音后无法播放的问题。现分享解决办法。 社区录音应用的来源:https://gitee.com/openharmony/applications_app_samples/tree/OpenHarmony-5.0.2-Release/code/SystemFeature/Media/Recorder …...

【MySQL】存储引擎 - InnoDB详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! &…...

软件工程之形式化说明技术深度解析
按照形式化的程度,可以把软件工程使用的方法划分成非形式化、半形式化和形式化3种。用自然语言描述需求规格说明书,是典型的非形式化方法。用数据流图或实体-联系图建立模型,是典型的半形式化方法。 所谓形式化方法,是描述系统性…...

Nacos源码—6.Nacos升级gRPC分析一
大纲 1.Nacos 2.x版本的一些变化 2.客户端升级gRPC发起服务注册 3.服务端进行服务注册时的处理 4.客户端服务发现和服务端处理服务订阅的源码分析 1.Nacos 2.x版本的一些变化 变化一:客户端和服务端的交互方式由HTTP升级为gRPC Nacos 1.x服务端会提供一系列的…...

使用 React 实现语音识别并转换功能
在现代 Web 开发中,语音识别技术的应用越来越广泛。它为用户提供了更加便捷、自然的交互方式,例如语音输入、语音指令等。本文将介绍如何使用 React 实现一个简单的语音识别并转换的功能。 功能概述 我们要实现的功能是一个语音识别测试页面࿰…...

2.5 点云数据存储格式——大型点云传输格式
通常,进行大型点云数据传输时,一般采用一种后缀为bin的文...
)
Windows系统下使用Kafka和Zookeeper,Python运行kafka(一)
下载和安装见Linux系统下使用Kafka和Zookeeper 配置 Zookeeper Zookeeper 是 Kafka 所依赖的分布式协调服务。在 Kafka 解压目录下,有一个 Zookeeper 的配置文件模板config/zookeeper.properties,你可以直接使用默认配置。 启动 Zookeeper 打开命令提示符(CMD),进入 K…...
——栈和队列)
数据结构(三)——栈和队列
一、栈和队列的定义和特点 栈:受约束的线性表,只允许栈顶元素入栈和出栈 对栈来说,表尾端称为栈顶,表头端称为栈底,不含元素的空表称为空栈 先进后出,后进先出 队列:受约束的线性表࿰…...

零基础入门Hadoop:IntelliJ IDEA远程连接服务器中Hadoop运行WordCount
今天我们来聊一聊大数据,作为一个Hadoop的新手,我也并不敢深入探讨复杂的底层原理。因此,这篇文章的重点更多是从实际操作和入门实践的角度出发,带领大家一起了解大数据应用的基本过程。我们将通过一个经典的案例——WordCounter&…...

在Postman中高效生成测试接口:从API文档到可执行测试的完整指南
引言 在API开发与测试流程中,Postman是一款高效的工具,能将API文档快速转化为可执行的测试用例。本文以《DBC协议管理接口文档》为例,详细讲解如何通过Postman实现接口的创建、配置、批量生成及自动化测试,帮助开发者和测试人员提升效率,确保接口质量。 一、准备工作:理…...

飞云分仓操盘副图指标操作技术图文分解
如上图,副图指标-飞云分仓操盘指标,指标三条线蓝色“首峰线”,红色“引力1”,青色“引力2”,多头行情时“首峰线”和“引力1”之间显示为红色,“引力1”和“引力2”多头是区间颜色显示为紫色。 如上图图标信…...