零基础入门Hadoop:IntelliJ IDEA远程连接服务器中Hadoop运行WordCount
今天我们来聊一聊大数据,作为一个Hadoop的新手,我也并不敢深入探讨复杂的底层原理。因此,这篇文章的重点更多是从实际操作和入门实践的角度出发,带领大家一起了解大数据应用的基本过程。我们将通过一个经典的案例——WordCounter,来帮助大家入门。简单来说,这个案例的目标是从一个文本文件中读取每一行,统计其中单词出现的频率,最后生成一个统计结果。表面上看,这个任务似乎不难,毕竟我们在本地用Java程序就可以很轻松地实现。
然而,实际情况并非如此简单。虽然我们能够在一台计算机上通过简单的Java程序完成类似的任务,但在大数据的场景下,数据量远远超过一台机器能够处理的能力。此时,单纯依赖一台机器的计算资源就无法应对庞大的数据量,这正是分布式计算和存储技术的重要性所在。分布式计算将任务拆分为多个子任务,并利用多台机器协同工作,从而实现高效处理海量数据,而分布式存储则可以将数据切分并存储在多个节点上,解决数据存储和访问的瓶颈。

因此,通过今天的介绍,我希望能够带大家从一个简单的例子出发,逐步理解大数据处理中如何借助Hadoop这样的分布式框架,来高效地进行数据计算和存储。
环境准备
Hadoop安装
这里我不太喜欢在本地 Windows 系统上进行安装,因为本地环境中通常会积累很多不必要的文件和配置,可能会影响系统的干净与流畅度。因此,演示的重点将放在以 Linux 服务器为主的环境上,通过 Docker 实现快速部署。
我们将利用宝塔面板进行一键式安装,只需通过简单的操作即可完成整个部署过程,免去手动敲命令的麻烦,让安装变得更加便捷和快速。
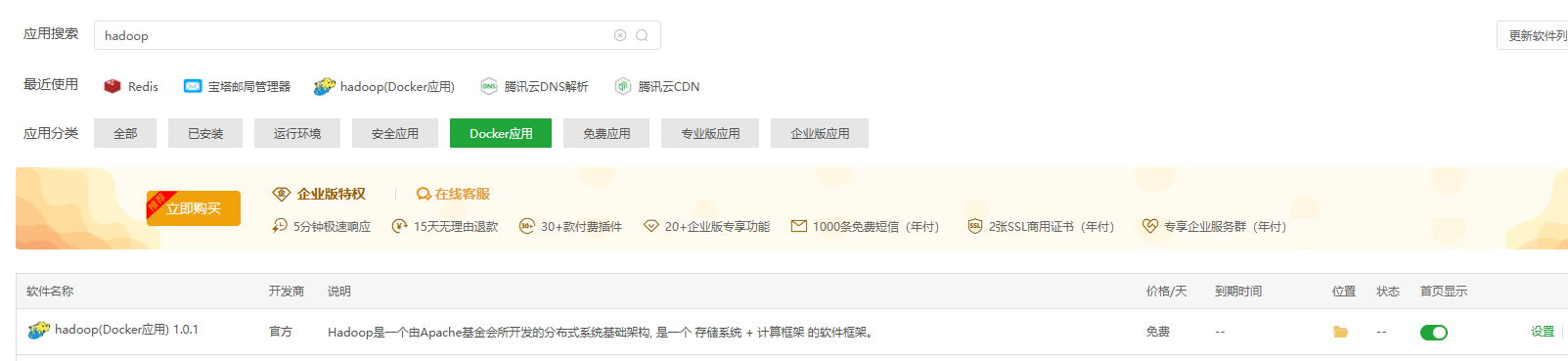
开放端口
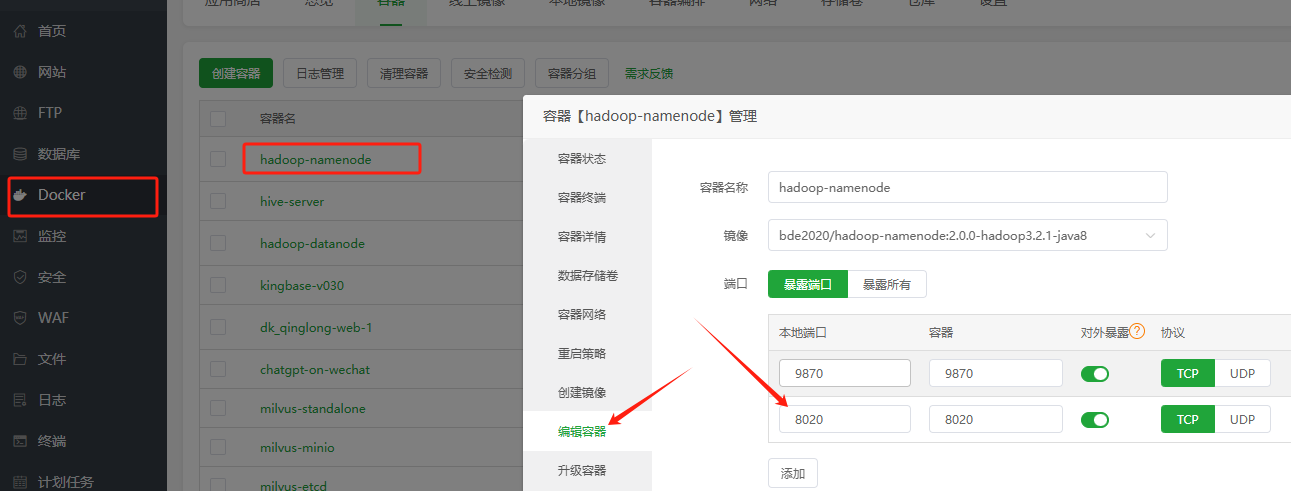
这里,系统本身已经对外开放了部分端口,例如 9870 用于访问 Web UI 界面,但有一个重要的端口 8020 并没有开放。这个端口是我们需要通过本地的 IntelliJ IDEA 进行连接和使用的,因此必须手动进行额外的配置,确保该端口能够正常访问。具体操作可以参考以下示意图进行设置,以便顺利完成连接。
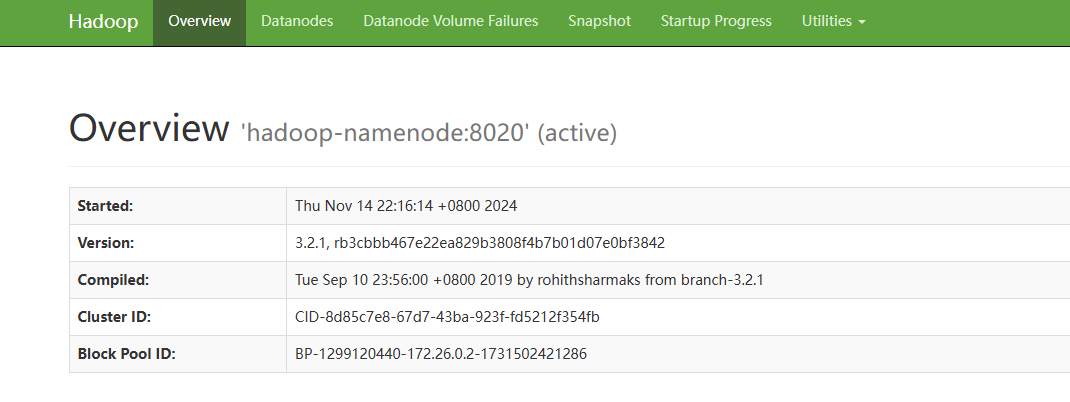
如果你已经成功启动并完成配置,那么此时你应该能够顺利访问并查看 Web 页面。如图所示:
项目开发
创建项目
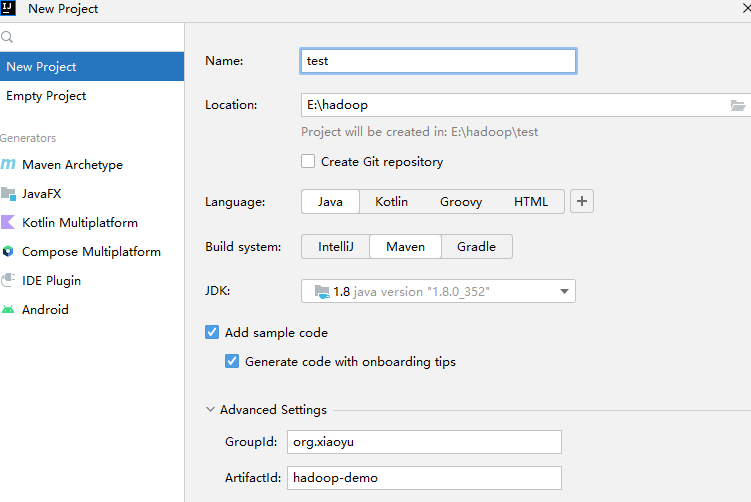
我们可以直接创建一个新的项目,并根据项目需求手动配置相关的项目信息,例如 groupId、artifactId、version 等基本配置。为了确保兼容性和稳定性,我们选择使用 JDK 8 作为开发环境版本。
首先,让我们先来查看一下项目的文件目录结构,以便对整个项目的组织形式和文件分布有一个清晰的了解。
tree /f 可以直接生成
├─input
│ test.txt
├─output
├─src
│ ├─main
│ │ ├─java
│ │ │ └─org
│ │ │ └─xiaoyu
│ │ │ InputCountMapper.java
│ │ │ Main.java
│ │ │ WordsCounterReducer.java
│ │ │
│ │ └─resources
│ │ core-site.xml
│ │ log4j.xml
接下来,我们将实现大数据中的经典示例——“Hello, World!” 程序,也就是我们通常所说的 WordCounter。为了实现这个功能,首先,我们需要编写 MapReduce 程序。在 Map 阶段,主要的任务是将输入的文件进行解析,将数据分解并转化成有规律的格式(例如,单词和其出现次数的键值对)。接着,在 Reduce 阶段,我们会对 Map 阶段输出的数据进行汇总和统计,最终得到我们想要的统计结果,比如每个单词的出现次数。
此外,我们还需要编写一个启动类——Job 类,用来配置和启动 MapReduce 任务,确保 Map 和 Reduce 阶段的流程能够顺利进行。通过这整套流程的实现,我们就完成了一个基本的 WordCounter 程序,从而理解了 MapReduce 的核心思想与应用。
pom依赖
这里没有什么好说的,直接添加相关依赖即可:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.2.0</version>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.2.0</version>
</dependency>
<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.2.0</version>
</dependency><!--mapreduce-->
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.2.0</version>
</dependency>
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>3.2.0</version>
</dependency>
core-site.xml
这里配置的我们远程Hadoop连接配置信息:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://你自己的ip:8020</value></property>
</configuration>
test.txt
我们此次主要以演示为主,因此并不需要处理非常大的文件。为了简化演示过程,我在此仅提供了一部分数据。
xiaoyu xiaoyu
cuicui ntfgh
hanhan dfb
yy yy
asd dfg
123 43g
nmao awriojd
InputCountMapper
先来构建一下InputCountMapper类。代码如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class InputCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString().trim();for (int i = 0; i < line.split(" ").length; i++) {word.set(line.split(" ")[i]);context.write(word, one);}}
}
在Hadoop的MapReduce编程中,写法其实是相对简单的,关键在于正确理解和定义泛型。你需要集成一个Mapper类,并根据任务的需求为其定义四个泛型类型。在这个过程中,每两个泛型组成一对,形成K-V(键值对)结构。以上面的例子来说,输入数据的K-V类型是LongWritable-Text,输出数据的K-V类型定义为Text-IntWritable。这里的LongWritable、Text、IntWritable等都是Hadoop自定义的数据类型,它们代表了不同的数据格式和类型。除了String在Hadoop中被替换成Text,其他的数据类型通常是在后面加上Writable后缀。
接下来,对于Mapper类的输出格式,我们已经在代码中定义了格式类型。然而,需要注意的是,我们重写的map方法并没有直接返回值。相反,Mapper类会通过Context上下文对象来传递最终结果。
因此,我们只需要确保在map方法中将格式化后的数据存入Context,然后交给Reducer处理即可。
WordsCounterReducer
这一步的代码如下:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordsCounterReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}context.write(key, new IntWritable(sum));}
}
在Hadoop的MapReduce编程中,Reduce阶段的写法也遵循固定模式。首先,我们需要集成Reducer类,并定义好四个泛型参数,类似于Mapper阶段。这四个泛型包括输入键值对类型、输入值类型、输出键值对类型、以及输出值类型。
在Reduce阶段,输入数据的格式会有所变化,尤其是在值的部分,通常会变成Iterable类型的集合。这个变化的原因是,Mapper阶段处理时,我们通常将每个单词的出现次数(或其他统计信息)作为1存入Context。比如,假设在Mapper阶段遇到单词“xiaoyu”时,我们每次都会输出一个(xiaoyu, 1)的键值对。结果,如果单词“xiaoyu”在输入数据中出现多次,Context会把这些键值对合并成一个Iterable集合,像是(xiaoyu, [1, 1]),表示该单词出现了两次。
在这个例子中,Reduce阶段的操作非常简单,只需要对每个Iterable集合中的值进行累加即可。比如,对于xiaoyu的输入集合(xiaoyu, [1, 1]),我们只需要将其所有的1值累加起来,得出最终的结果2。
Main
最后我们需要生成一个Job,代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class Main {static {try {System.load("E:\\hadoop.dll");//建议采用绝对地址,bin目录下的hadoop.dll文件路径} catch (UnsatisfiedLinkError e) {System.err.println("Native code library failed to load.\n" + e);System.exit(1);}}public static void main(String[] args) throws Exception{Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "wordCounter"); job.setJarByClass(Main.class);job.setMapperClass(InputCountMapper.class);job.setReducerClass(WordsCounterReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path("file:///E:/hadoop/test/input"));FileOutputFormat.setOutputPath(job, new Path("file:///E:/hadoop/test/output"));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
好的,这里所展示的是一种完全固定的写法,但在实际操作过程中,需要特别注意的是,我们必须通过 Windows 环境来连接远程的 Hadoop 集群进行相关操作。这个过程中会遇到很多潜在的问题和坑,尤其是在配置、连接、权限等方面。
接下来,我将逐一解析并解决这些常见的难题,希望能为大家提供一些实际的参考和指导,帮助大家更顺利地完成操作。
疑难解答
目录不存在
如果你并不是以本地 Windows 目录为主,而是以远程服务器上的目录为主进行操作,那么你可能会采用类似以下的写法:
FileInputFormat.addInputPath(job, new Path("/input"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
那么,在这种情况下,我们必须先创建与操作相关的输入目录(input),但需要特别注意的是,切勿提前创建输出目录(output),因为 Hadoop 在运行作业时会自动创建该目录,如果该目录已存在,会导致作业执行失败。因此,只需要进入 Docker 环境并直接执行以下命令即可顺利开始操作。
hdfs dfs -mkdir /input
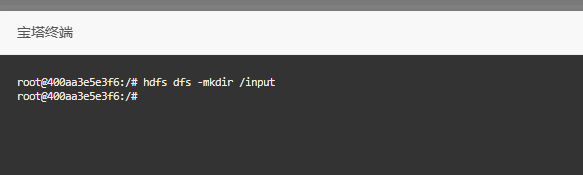
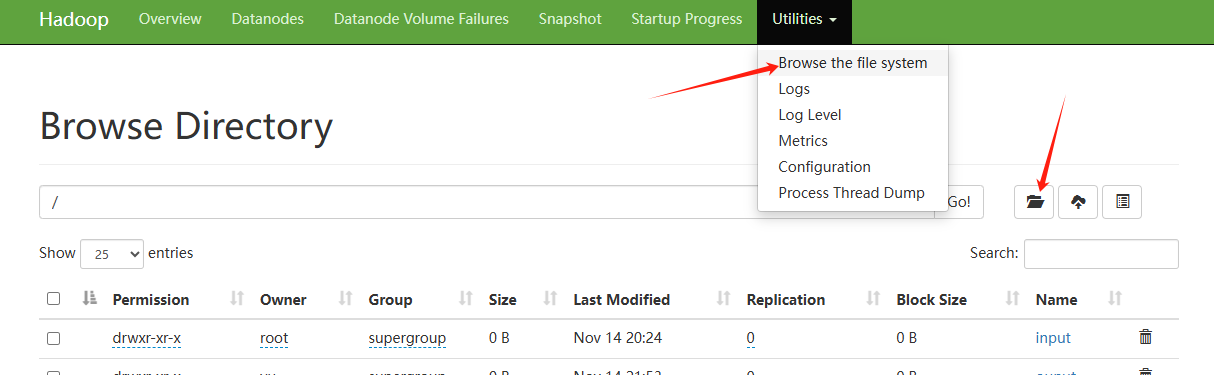
当然,还有一种更简单的方式,就是直接通过图形界面在页面上创建相关目录或资源。具体操作可以参考以下步骤,如图所示:
Permission denied
接下来,当你在运行 Job 任务时,系统会在最后一步尝试创建输出目录(output)。然而,由于当前用户并没有足够的权限来进行此操作,因此会出现类似于以下的权限错误提示:Permission denied: user=yu, access=WRITE, inode="/":root:supergroup:drwxr-xr-x。该错误意味着当前用户(yu)试图在根目录下创建目录或文件,但由于该目录的权限设置为只有管理员(root)才能写入,普通用户无法进行写操作,从而导致作业执行失败。
所以你仍需要进入docker容器,执行以下命令:
hadoop fs -chmod 777 /
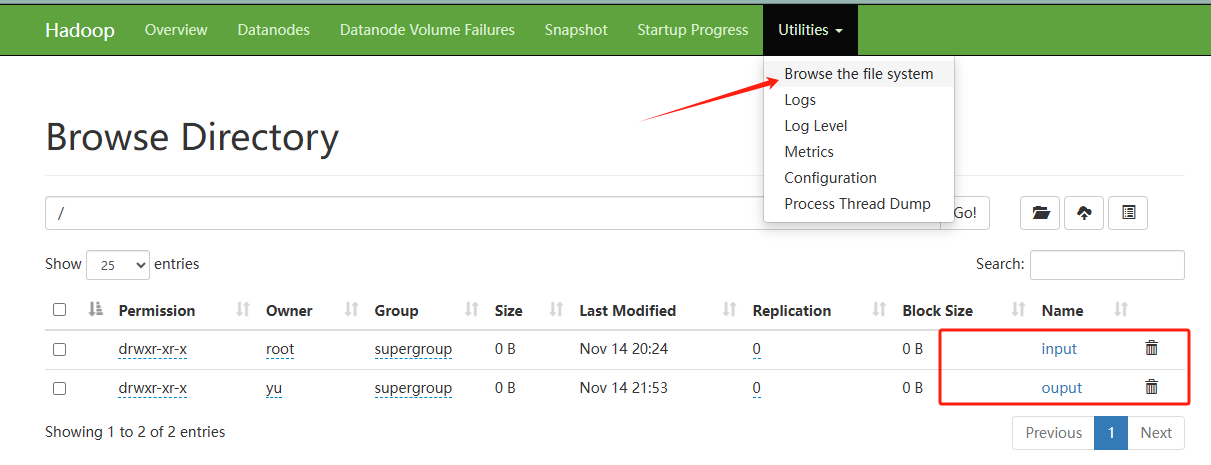
这样基本上就可以顺利完成任务了。接下来,你可以直接点击进入查看 output 目录下的文件内容。不过需要注意的是,由于我们没有配置具体的 IP 地址,因此在进行文件下载时,你需要手动将文件中的 IP 地址替换为你自己真实的 IP 地址,才能确保下载过程能够顺利进行并成功获取所需的文件。
报错:org.apache.hadoop.io.nativeio.NativeIO$Windows
这种问题通常是由于缺少 hadoop.dll 文件导致的。在 Windows 系统上运行 Hadoop 时,hadoop.dll 或者 winutils.exe 是必需的依赖文件,因为它们提供了 Hadoop 在 Windows 上所需的本地代码支持和执行环境。
为了确保顺利运行,你需要下载对应版本的 hadoop.dll 或者 winutils.exe 文件。已经为你准备好了多个 Hadoop 版本对应的这些文件,所有的文件都可以从以下链接下载:https://github.com/cdarlint/winutils
我们这里只下载一个hadoop.dll,为了不重启电脑,直接在代码里面写死:
static {try {System.load("E:\\hadoop.dll");//建议采用绝对地址,bin目录下的hadoop.dll文件路径} catch (UnsatisfiedLinkError e) {System.err.println("Native code library failed to load.\n" + e);System.exit(1);}
}
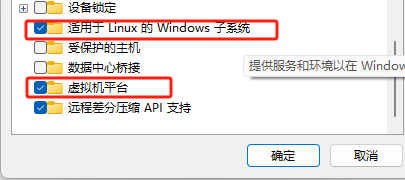
如果仍然有问题,那就配置下windows下的wsl子系统:
使用Windows + R快捷键打开「运行」对话框,执行OptionalFeatures打开「Windows 功能」。
勾选「适用于 Linux 的 Windows 子系统」和「虚拟机平台」,然后点击「确定」。
最终效果
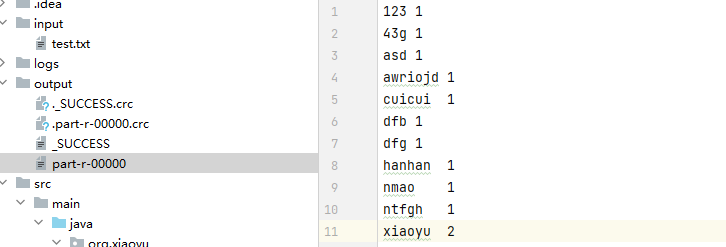
终于成功跑出结果了!在这个过程中,输出的结果是按照默认的顺序进行排序的,当然这个排序方式是可以根据需要进行自定义的。如果你对如何控制排序有兴趣,实际上可以深入了解并调整排序机制。
总结
通过今天的分享,我们简单地了解了大数据处理中一个经典的应用——WordCounter,并通过Hadoop框架的实践,展示了如何使用MapReduce进行分布式计算。虽然表面上看,WordCounter是一个相对简单的程序,但它却揭示了大数据处理中的核心思想。
从安装配置到编写代码,我们一步步走过了Hadoop集群的搭建过程,希望通过这篇文章,你能对大数据应用开发,特别是Hadoop框架下的MapReduce编程,获得一些启发和帮助。大数据的世界庞大而复杂,但每一次小小的实践,都会带你离真正掌握这门技术更近一步。
我是努力的小雨,一名 Java 服务端码农,潜心研究着 AI 技术的奥秘。我热爱技术交流与分享,对开源社区充满热情。同时也是一位腾讯云创作之星、阿里云专家博主、华为云云享专家、掘金优秀作者。
💡 我将不吝分享我在技术道路上的个人探索与经验,希望能为你的学习与成长带来一些启发与帮助。
🌟 欢迎关注努力的小雨!🌟
相关文章:

零基础入门Hadoop:IntelliJ IDEA远程连接服务器中Hadoop运行WordCount
今天我们来聊一聊大数据,作为一个Hadoop的新手,我也并不敢深入探讨复杂的底层原理。因此,这篇文章的重点更多是从实际操作和入门实践的角度出发,带领大家一起了解大数据应用的基本过程。我们将通过一个经典的案例——WordCounter&…...

在Postman中高效生成测试接口:从API文档到可执行测试的完整指南
引言 在API开发与测试流程中,Postman是一款高效的工具,能将API文档快速转化为可执行的测试用例。本文以《DBC协议管理接口文档》为例,详细讲解如何通过Postman实现接口的创建、配置、批量生成及自动化测试,帮助开发者和测试人员提升效率,确保接口质量。 一、准备工作:理…...

飞云分仓操盘副图指标操作技术图文分解
如上图,副图指标-飞云分仓操盘指标,指标三条线蓝色“首峰线”,红色“引力1”,青色“引力2”,多头行情时“首峰线”和“引力1”之间显示为红色,“引力1”和“引力2”多头是区间颜色显示为紫色。 如上图图标信…...

K8s中的containerPort与port、targetPort、nodePort的关系:
pod中的containerPort与service中的port、targetPort、nodePort的关系: 1、containerPort为pod的配置,对应pod内部服务监听的具体端口,例如nginx服务默认监听80端口,那么nginx的pod的containerPort应该配置为80,例如m…...

jquery+ajax+SpringBoot实现前后端分离技术
一、前端方面: 第1步,在前端HTML页面的头部引入jquery <head><meta http-equiv"Content-Type" content"text/html;charsetUTF-8"><title>XXX</title><link rel"stylesheet" type"text/…...
)
阀门产业发展方向报告(石油化工阀门应用技术交流大会)
本文大部分内容来自中国通用机械工业协会副会长张宗列在“2024全国石油化工阀门应用技术交流大会”上发表的报告。 一、国外阀门产业发展 从全球阀门市场分布看,亚洲是最大的工业阀门市场,美洲是全球第二大工业阀门市场,欧洲位列第三。 从国…...

华为云Astro后端开发中对象、事件、脚本、服务编排、触发器、工作流等模块的逻辑关系如何?以iotDA数据传输过程举例演示元素工作过程
目录 🏭 类比总览:低代码平台就像一座自动化工厂 🧱 1. 对象(Object) = 工厂里的“原材料仓库” 🧱 2. 结构体(Structure) = 自定义的“装配模具” 🔔 3. 事件(Event) = 触发的“感应器” ✍️ 4. 脚本(Script) = 后台的“逻辑处理代码” ⚙️ 5. 服务编…...

面向小型企业顶点项目的网络安全咨询人机协作框架
1. 简介 1.1. 背景和动机 由于小型企业无法访问结构化系统,且缺乏大型组织通常拥有的专用资源,它们经常面临巨大的网络安全挑战 [ [1 ]。为大型企业设计的网络安全框架通常对小型企业来说过于复杂且不切实际,导致它们容易受到复杂的网络威胁 2 ]。这种复杂性可能导致小型…...

RSAC 2025观察:零信任+AI=网络安全新范式
2025年4月28日~5月1日,全球最具影响力的网络安全盛会RSAC 2025在美国旧金山举办,吸引了全球44,000名网络安全从业者参与。大会以“Many Voices. One Community.”为主题,聚焦AI安全、供应链风险、零信任等核心议题。其中,AI Agent…...

ruoyi-flowable-plus 前端框架启动报错修复
版本 1. ruoyi-flowable-plus 前端框架启动报错修复 启动时设置环境变量 "scripts": {"dev": "SET NODE_OPTIONS--openssl-legacy-provider && vue-cli-service serve","build:prod": "vue-cli-service build",&qu…...

安全可控·高效响应|北峰智能互通矿业通信系统解决方案
项目概况 随着矿业行业工作环境日益复杂,涵盖地下开采、露天挖掘、矿物运输及深加工等多个环节,作业区域呈现广阔且分散的特点,往往存在诸多安全风险。当面临突发事故,由于应急救援体系不完善,救援通信系统相对落后&a…...

ubuntu查看安装的软件包的位置
在 Ubuntu 中,libcli11-dev 是一个 头文件库(header-only),因此它不会像动态库(.so 文件)那样有明确的下载路径。但你可以通过以下方法查看它的安装位置: 1. 查看 libcli11-dev 安装的文件 使用…...

【金仓数据库征文】金仓数据库 KES 助力企业数据库迁移的实践路径
在企业数字化转型浪潮的强力推动下,数据库迁移已成为企业升级 IT 架构、提升数据管理能力的关键环节。从 MySQL 到金仓数据库 KingbaseES(KES)的迁移方案,为企业提供了一条高效、可靠的数据库升级路径。 一、迁移挑战与金仓数据…...

Nginx1.26.2安装包编译安装并配置stream模块
准备nginx安装文件:nginx-1.26.2.tar.gz cd /usr/local wget http://nginx.org/download/nginx-1.26.2.tar.gz tar -zxvf nginx-1.26.2.tar.gz && cd nginx-1.26.2 1.创建安装目录 mkdir nginx 2.解压安装文件nginx-1.26.2.tar.gz tar -zxvf nginx-1.26…...

kotlin @JvmStatic注解的作用和使用场景
1. JvmStatic 的作用 JvmStatic 是 Kotlin 提供的一个注解,用于在 JVM 上将伴生对象(companion object)中的方法或属性暴露为 Java 静态方法或字段。 作用对象:只能用在 companion object 中的函数或属性。效果: 在 …...

Blind SSRF with Shellshock exploitation过关
Blind SSRF with Shellshock exploitation 生活就像一杯咖啡,苦与甜都是必需的,关键是要学会享受每一口。 先说通关方法: 1.首先在bp的扩展商店安装插件 Collaborator Everywhere 2.进入靶场首页 复制url https://0af600d3048daad080e6…...

2025-05-08 Unity 网络基础9——FTP通信
文章目录 1 FTP1.1 工作原理1.2 传输模式 2 搭建 FTP 服务器2.1 启用服务2.2 配置站点2.3 设置防火墙2.4 指定用户登录 3 常用 API3.1 NetworkCredential3.2 FtpWebRequest3.3 FtpWebResponse 4 实战操作4.1 上传文件4.2 下载文件4.3 删除文件4.4 获取文件大小4.5 创建文件夹4.…...
)
3.2.3 掌握RDD转换算子 - 5. 合并算子 - union()
在本节课中,我们学习了Spark RDD的union()算子,它能够将两个数据类型一致的RDD合并为一个新的RDD,主要用于整合不同数据源。通过案例演示,我们成功将两个简单的数字RDD合并,直观地看到合并结果是按原顺序纵向拼接&…...

数据来源合法性尽职调查:保障权益的关键防线
首席数据官高鹏律师团队 在当今数字化时代,数据已成为企业和个人最为宝贵的资产之一。然而,伴随着数据的广泛应用与流通,其来源的合法性问题愈发凸显,犹如隐藏在暗处的礁石,稍不留神就可能让涉事主体陷入法律的漩涡。…...

sui在windows虚拟化子系统Ubuntu和纯windows下的安装和使用
一、sui在windows虚拟化子系统Ubuntu下的安装使用(WindowsWsl2Ubuntu24.04) 前言:解释一下WSL、Ubuntu的关系 WSL(Windows Subsystem for Linux)是微软推出的一项功能,允许用户在 Windows 系统中原生运行…...

springmvc的入门案例
springmvc的概述 SpringMVC的概述 是一种基于Java实现的MVC设计模型的请求驱动类型的轻量级WEB框架。Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面。Spring 框架提供了构建 Web 应用程序的全功能 MVC 模块。使用 Spring 可插入的 MVC 架…...

【MCP】为什么使用Streamable HTTP: 相比SSE的优势与实践指南
在现代Web开发中,实时通信已经成为许多应用的核心需求。从聊天应用到股票市场更新,从游戏服务器到AI模型通信,各种技术应运而生以满足这些需求。最近,Model Context Protocol (MCP) 引入了一种新的传输机制 —— Streamable HTTP&…...
的使用)
CentOS的防火墙工具(firewalld和iptables)的使用
CentOS的防火墙工具因版本不同而异,以下是具体操作步骤: 一、firewalld(CentOS 7及以上默认工具) 1、安装与启动: 安装:sudo yum install firewalld 启动服务:sudo systemctl start fir…...

解析小米大模型MiMo:解锁语言模型推理潜力
一、基本介绍 1.1 项目背景 在大型语言模型快速发展的背景下,小米AI团队推出MiMo系列模型,突破性地在7B参数规模上实现卓越推理能力。传统观点认为32B以上模型才能胜任复杂推理任务,而MiMo通过创新的训练范式证明:精心设计的预训练和强化学习策略,可使小模型迸发巨大推理…...

web 自动化之 Selenium 元素定位和浏览器操作
文章目录 一、元素定位的八大方法1、基于 id/name/class/tag_name 定位2、基于 a 标签元素的链接文本定位3、基于xpath定位4、css定位 二、浏览器操作1、信息获取2、 浏览器关闭3、 浏览器控制 一、元素定位的八大方法 web 自动化测试就是通过代码对网页进行测试,在…...

vscode如何使用 GitHub Copilot
1.在vscode中扩展工具栏搜索“copilot”,选择GitHub Copilot安装。 2.使用快捷键CtrlAltI 打开聊天界面,输入问题后回车即可使用。 注意: 使用copilot需要使用GitHub账号先登录,如果打不开登录页面,需要修改host文件&a…...

AWS之存储服务
存储术语 分类 接口/技术类型 应用场景特点 关系及区别 机械硬盘接口 IDE(Integrated Drive Electronics) 早期用于个人电脑,现已逐渐淘汰 机械硬盘接口、固态硬盘接口是硬盘与主机或其他设备连接的物理和协议规范; FC - …...

安装 Docker
一、CentOS 系统安装 Docker 1. 卸载旧版本(如有) sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine 2. 安装依赖工具 sudo yum install -y…...

代理协议解析:如何根据需求选择HTTP、HTTPS或SOCKS5?
在现代网络中,代理服务器是一种常见的工具,用于提高安全性、匿名性和访问速度。常见的代理协议包括HTTP、HTTPS和SOCKS5。本文将详细解析这三种代理协议,并帮助您根据具体需求选择最合适的代理协议。 一、HTTP代理 1.1 特点 用途广泛&…...

用于构建安全AI代理的开源防护系统
大家读完觉得有帮助记得及时关注!!! 大型语言模型(LLMs)已经从简单的聊天机器人演变为能够执行复杂任务的自主代理,例如编辑生产代码、编排工作流程以及基于不受信任的输入(如网页和电子邮件&am…...

CTF-DAY10
[SWPUCTF 2021 新生赛]zipbomb 题目描述: 请注意,不要以任何方式尝试完全解压该文件,运存被塞满后果自负。请尝试分析该文件。 使用WinRAR解压打开 CTFSHOW刷题 crypto11 密文:a8db1d82db78ed452ba0882fb9554fc 提交 flag{明…...
 vs swr 请求)
WHAT - react-query(TanStack Query) vs swr 请求
文章目录 react-query什么是 TanStack Query(原 React Query)核心特性 TanStack Query vs SWR 对比具体特性对比哪个更适合你 总结 react-query react-query(现已更名为 TanStack Query)和 SWR 一样,都是专注于 远程数…...

WebFlux与HttpStreamable关系解析
1-Streamable 1-WebFlux与HttpStreamable关系解析2-MCP协议Streamable HTTP 2-参考网址 MCP协议Streamable HTTPMCP协议重大升级,Spring AI Alibaba联合Higress发布业界首个Streamable HTTP实现方案 3-WebFlux与HttpStreamable关系解析 WebFlux 和 HttpStreamabl…...

深度学习工程化:基于TensorFlow的模型部署全流程详解
深度学习工程化:基于TensorFlow的模型部署全流程详解 引言 在深度学习项目中,模型训练只是第一步,将模型成功部署到生产环境才是真正创造价值的关键。本文将全面介绍TensorFlow模型从训练到部署的完整工程化流程,涵盖多种部署场…...

RAG技术在测试用例生成中的应用
测试用例中的 RAG 通常指 Retrieval-Augmented Generation(检索增强生成) 在测试领域的应用,是一种结合检索与生成的技术方法,用于自动化生成或优化测试用例。 核心概念 RAG 技术背景: • RAG 最初由 Meta 提出…...
)
uniapp + vue3 + 京东Nut动作面板组件:实现登录弹框组件(含代码、案例、小程序截图)
uniapp + vue3 + 京东Nut动作面板组件:实现登录弹框组件(含代码、案例、小程序截图) 代码示下,不再赘述。 动作面板组件:https://nutui-uniapp.netlify.app/components/feedback/actionsheet.html 项目背景 业务需求 描述: uniapp + vue3 + 京东Nut框架:实现登录弹框组…...

在登录页面上添加验证码
这是一个简单的登录页面,里面必须通过验证码通过之后才能够进入页面 创建一个servlet(验证码的) package qcby.util;import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.annotation.WebServlet; im…...

人协同的自动化需求分析
多人协同的自动化需求分析是指通过技术工具和协作流程,让多个参与者(如产品经理、开发人员、测试人员等)在需求分析阶段高效协作,并借助自动化手段提升需求收集、整理、验证和管理的效率与质量。以下是其核心要点: 1. …...

C++使用PoDoFo库处理PDF文件
📚 PoDoFo 简介 PoDoFo 是一个用 C 编写的自由开源库,专用于 读取、写入和操作 PDF 文件。它适用于需要程序化处理 PDF 文件的应用程序,比如批量生成、修改、合并、提取元数据、绘图等。 🌟 核心特点 特性说明📄 P…...

18.Java 序列化与反序列化
18.Java 序列化与反序列化 概述 在Java中,序列化是将对象的状态信息转换为可以存储或传输的格式的过程,而反序列化则是将这种格式转换回Java对象的过程。 序列化 要使一个对象支持序列化,该对象必须实现java.io.Serializable接口。这个接…...
大语言模型主流架构解析:从 Transformer 到 GPT、BERT
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4-turbo模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...

flow-matching 之学习matcha-tts cosyvoice
文章目录 matcha 实现cosyvoice 实现chunk_fmchunk_maskcache_attn stream token2wav 关于flow-matching 很好的原理性解释文章, 值得仔细读,多读几遍,关于文章Flow Straight and Fast: Learning to Generate and Transfer Data with Rectifi…...

聊聊自动化办公未来趋势
1. 自动化办公未来趋势 1.1 智能化与AI融合加深 随着人工智能技术的不断成熟,其在自动化办公中的应用将更加广泛和深入。未来,办公软件将具备更强的智能交互能力,能够理解自然语言指令,自动完成复杂的任务,如文档编辑…...

软件工程之需求分析涉及的图与工具
需求分析与规格说明书是一项十分艰巨复杂的工作。用户与分析员之间需要沟通的内容非常的多,在双方交流信息的过程中很容易出现误解或遗漏,也可能存在二义性。如何才能更加准确的表达双方的意思,且清楚明了,绘制各类图形就显得非常…...

火影bug,未保证短时间数据一致性,拿这个例子讲一下Redis
本文只拿这个游戏的bug来举例Redis,如果有不妥的地方,联系我进行删除 描述:今天在高速上打火影(有隧道,有时候会卡),发现了个bug,我点了两次-1000的忍玉(大概用了1千七百…...

机器人领域和心理学领域 恐怖谷 是什么
机器人领域和心理学领域 恐怖谷 是什么 恐怖谷是一个在机器人领域和心理学领域备受关注的概念,由日本机器人专家森政弘于1970年提出。 含义 当机器人与人类的相似度达到一定程度时,人类对它们的情感反应会突然从积极变为消极,产生一种毛骨悚然、厌恶恐惧的感觉。这种情感…...

Hadoop MapReduce 图文代码讲解
一、MapReduce原理 首先要了解一下MapReduce的几个过程,每个数据集中需要编写的逻辑会有所不同,但是大致是差不多的 1、MapReduce大致为这几个过程: 1、读取数据集并根据文件大小128MB拆分成多个map同时进行下面步骤 2、Map: 匹配和数据筛…...

【Rust】结构体
目录 结构体结构体的定义和实例化结构体使用场景方法定义方法多参数方法关联函数多个 impl 块 结构体 结构体,是一个自定义数据类型,允许包装和命名多个相关的值,从而形成一个有意义的组合,类似于 C语言中的结构体或者 Java 中的…...

青少年编程与数学 02-019 Rust 编程基础 01课题、环境准备
青少年编程与数学 02-019 Rust 编程基础 01课题、环境准备 一、Rust核心特性应用场景开发工具社区与生态 二、Rust 和 Python 比较1. **内存安全与并发编程**2. **性能**3. **零成本抽象**4. **跨平台支持**5. **社区与生态系统**6. **错误处理**7. **安全性**适用场景总结 三、…...
:从原理到实战(上))
深入理解Embedding Models(嵌入模型):从原理到实战(上)
🐇明明跟你说过:个人主页 🏅个人专栏:《深度探秘:AI界的007》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、嵌入模型是什么 2、在NLP、推荐系统、知识图谱等领域…...