适合java程序员的Kafka消息中间件实战
创作的初心:
我们在学习kafka时,都是基于大数据的开发而进行的讲解,这篇文章为java程序员为核心,助力大家掌握kafka实现。
什么是kafka:
历史:
- 诞生与开源(2010 - 2011 年)
- 2010 年,Kafka 由 LinkedIn 公司的工程师团队开发,用于处理公司内部的大规模实时数据,如用户活动、系统日志等。
- 2011 年,Kafka 开源并成为 Apache 软件基金会的孵化项目,吸引了社区的广泛关注和参与。
- 成为顶级项目(2012 - 2013 年)
- 2012 年,Kafka 从 Apache 孵化项目毕业,成为 Apache 顶级项目,标志着它在开源社区中获得了广泛认可。
- 这一时期,Kafka 的功能不断丰富,性能也得到了进一步提升,逐渐被越来越多的公司用于构建实时数据处理系统。
- 蓬勃发展(2014 - 2017 年)
- 2014 年,Confluent 公司成立,专注于 Kafka 的商业化推广和技术支持,为 Kafka 的发展提供了强大的商业推动力量。
- 随着大数据和云计算技术的兴起,Kafka 作为高性能的消息队列和流处理平台,在数据处理领域的应用越来越广泛,许多公司开始将 Kafka 作为其数据基础设施的重要组成部分。
- 2017 年,Kafka 发布了 0.11.0 版本,引入了幂等性和事务支持,进一步提升了 Kafka 在处理精确一次语义(Exactly - once Semantics)场景下的能力,使其更适合用于对数据一致性要求较高的业务场景。
- 持续创新(2018 - 2022 年)
- 2018 年,Kafka 发布了 2.0.0 版本,对 Kafka 的架构进行了一些重大改进,如引入了 Kafka Connect 用于数据集成,Kafka Streams 用于流处理等,使 Kafka 不仅仅是一个消息队列,还成为了一个功能强大的流计算平台。
- 2020 年,Kafka 发布了 2.8.0 版本,开始引入 KIP - 500,即 Kafka Raft(KRaft),逐步实现不依赖 Zookeeper 的目标,开启了 Kafka 架构的重大变革。
- 2022 年,Kafka 持续推进 KRaft 的发展,不断完善其功能和性能,为 Kafka 的未来发展奠定了坚实的基础。
- 成熟与拓展(2023 年 - 至今)
- 2023 年,Kafka 在 KRaft 模式下不断成熟,社区继续致力于提升 Kafka 的性能、稳定性和安全性,同时拓展其在更多领域的应用,如物联网、金融科技等。
- 随着技术的不断发展,Kafka 将继续适应新的业务需求和技术趋势,不断演进和完善,保持其在分布式消息队列和流处理领域的领先地位。
总结:Kafka 是一个分布式的、高吞吐量的消息队列系统,由 Apache 软件基金会开发,最初是由 LinkedIn 公司开发并开源。
核心特点
- 高吞吐量:Kafka 能够处理大量的消息,每秒可以处理数千甚至数百万条消息,这得益于其分布式架构和高效的存储机制。它采用了顺序读写磁盘、零拷贝等技术,大大提高了数据的读写速度。
- 可扩展性:Kafka 集群可以很容易地扩展,通过添加新的节点(broker)可以线性地增加集群的处理能力和存储容量。同时,它支持自动的负载均衡,能够将数据和请求均匀地分布在各个节点上。
- 持久性和可靠性:Kafka 将消息持久化到磁盘上,并通过副本机制来保证数据的可靠性。每个消息在多个节点上有副本,当某个节点出现故障时,其他副本可以继续提供服务,确保数据不会丢失。
- 高并发:它能够支持大量的生产者和消费者同时并发地读写消息,通过分区和多副本机制,可以实现对消息的并行处理,提高系统的整体性能。
主要组件
- 生产者(Producer):负责将消息发送到 Kafka 集群。生产者可以将消息发送到指定的主题(Topic),并可以指定消息的键(Key)和值(Value)。根据消息的键,Kafka 可以将消息分区,以便更好地进行数据的存储和处理。
- 消费者(Consumer):从 Kafka 集群中读取消息进行消费。消费者属于一个消费者组(Consumer Group),每个消费者组可以有多个消费者实例。同一消费者组中的消费者会均衡地消费主题中的各个分区,不同消费者组之间相互独立,每个消费者组都会独立地从 Kafka 中获取消息。
- 主题(Topic):是 Kafka 中消息的逻辑分类,类似于数据库中的表。每个主题可以分为多个分区(Partition),每个分区是一个有序的、不可变的消息序列。消息在分区中按照顺序进行存储,并且每个消息都有一个唯一的偏移量(Offset)来标识其在分区中的位置。
- 代理(Broker):Kafka 集群中的服务器节点称为代理。每个代理负责处理一部分主题的分区,并将消息持久化到本地磁盘。代理之间通过网络进行通信,共同组成一个分布式的集群,实现数据的复制、备份和负载均衡等功能。
下载Kafka及命令行使用:
下载地址:
大家可以自行在官网下载:Apache Kafka
启动的方式:
kafka本身是不区分操作系统的,他的目录中我们可以发现它提供了Windows下的启动方式,
小编的版本是kafka_2.13-3.3.1
依赖 ZooKeeper(Kafka 2.8 之前)
1. 启动 ZooKeeper
ZooKeeper 是一个分布式协调服务,Kafka 依赖它来存储元数据。
在 Kafka 安装目录下,使用命令行工具执行以下命令启动 ZooKeeper:
# Windows 系统
.\bin\windows\zookeeper-server-start.bat ../../config/zookeeper.properties
# Linux 或 macOS 系统
bin/zookeeper-server-start.sh config/zookeeper.properties
2. 启动 Kafka 服务
在 ZooKeeper 成功启动后,你可以启动 Kafka 服务。同样在 Kafka 安装目录下,使用以下命令启动:
# Windows 系统
.\bin\windows\kafka-server-start.bat ../../config/server.properties
# Linux 或 macOS 系统
bin/kafka-server-start.sh config/server.properties
不依赖 ZooKeeper(Kafka 2.8 及之后)
在 Kafka 2.8 及更高版本中,可以不依赖 ZooKeeper 启动 Kafka,使用 KRaft 模式。步骤如下:
但是这种方式在windows上不好用,产生错误,没有官方的解决方式(但是有一位大神写了一个补丁版本的kafka,大家可以搜索着下载一下)。还是使用Linux操作系统吧。
1. 生成集群 ID
# Windows 系统
.\bin\windows\kafka-storage.bat random-uuid
# Linux 或 macOS 系统
./kafka-storage.sh random-uuid
执行上述命令后,会生成一个随机的 UUID,你需要记住这个 UUID,后续步骤会用到。
2. 格式化存储目录
使用上一步生成的 UUID 来格式化存储目录,在命令行中执行以下命令:
# Windows 系统
D:\soft_setup\kafka_2.13-3.3.1\bin\windows>kafka-storage.bat format -t ZlDD6NrNQk2fiMxF4-iB8w -c ../../config/kraft/server.properties
# Linux 或 macOS 系统
./kafka-storage.sh format -t svPXC5N-SIiymvhRKPwZ3g -c ../config/kraft/server.properties
请将 <your-uuid> 替换为第一步中生成的实际 UUID。
3. 启动 Kafka 服务
格式化完成后,就可以启动 Kafka 服务了:
# Windows 系统
.\bin\windows\kafka-server-start.bat .\config\kraft\server.properties
# Linux 或 macOS 系统
./kafka-server-start.sh ../config/kraft/server.properties4.关闭kafka
# Windows 系统
# Linux 或 macOS 系统./kafka-server-stop.sh ../config/kraft/server.properties早期版本的kafka和zookeeper的关系:
- Kafka 依赖 Zookeeper 进行元数据管理
- Kafka 的集群信息、主题信息、分区信息以及消费者组的偏移量等元数据都存储在 Zookeeper 中。例如,当创建一个新的主题时,相关的主题配置和分区分配信息会被写入 Zookeeper。
- Zookeeper 以树形结构存储这些元数据,使得 Kafka 能够方便地进行查询和更新操作,从而让 Kafka broker 可以快速获取到所需的元数据信息来处理客户端的请求。
- Zookeeper 为 Kafka 提供集群管理功能
- Kafka 集群中的 broker 节点会在 Zookeeper 上进行注册,通过 Zookeeper 的节点创建和观察机制,Kafka 可以实时感知到集群中 broker 节点的动态变化,如节点的加入或退出。
- 当有新的 broker 节点加入集群时,它会向 Zookeeper 注册自己的信息,其他 broker 节点通过监听 Zookeeper 上的相关节点变化,就能及时发现新节点的加入,并进行相应的协调和数据分配操作。
- Zookeeper 协助 Kafka 进行分区 leader 选举
- 在 Kafka 中,每个分区都有一个 leader 副本和多个 follower 副本。当 leader 副本所在的 broker 节点出现故障时,需要选举出一个新的 leader。
- Zookeeper 通过其选举机制,能够快速确定哪个 follower 副本可以成为新的 leader,确保分区的读写操作能够尽快恢复,保证了 Kafka 集群的高可用性和数据的一致性。
- Zookeeper 帮助 Kafka 实现消费者组管理
- 消费者组的成员信息、消费偏移量以及消费者组的协调等工作都依赖于 Zookeeper。消费者在启动时会向 Zookeeper 注册自己所属的消费者组和相关信息。
- Zookeeper 会监控消费者组中各个消费者的状态,当有消费者加入或离开组时,会触发重新平衡操作,确保每个分区能够被合理地分配给消费者组中的消费者进行消费,从而实现了消费者组对主题分区的负载均衡消费
发展进程:
Kafka 从 2.8.0 版本开始引入 KIP-500,实现了 Raft 分布式一致性机制,开启了不依赖 Zookeeper 的进程1。但在 2.8.0 版本中,Zookeeper - less Kafka 还属于早期版本,并不完善1。
到 3.3 版本时,Kafka Raft(KRaft)被标记为生产就绪,具备了生产环境使用的条件3。3.4 版本提供了从 Zookeeper 模式到 KRaft 模式的早期访问迁移功能,3.5 版本中迁移脚本正式生产就绪,同时弃用了 Zookeeper 支持。
直至 4.0 版本,Zookeeper 被彻底移除,所有版本完全基于 KRaft 模式运行,Kafka 不再依赖 Zookeeper,这标志着 Kafka 在摆脱 Zookeeper 依赖方面的工作基本完成。
注意:下面小编的操作是基于Linux系统
kafka的主题Topic和事件Event
主题(Topic)
定义:
主题是 Kafka 中消息的逻辑分类,类似于数据库中的表或者文件系统中的文件夹,用于对消息进行归类和管理。每个主题可以有多个生产者向其发送消息,也可以有多个消费者从其读取消息。
特点
可分区:一个主题可以被划分为多个分区(Partition),每个分区是一个有序的、不可变的消息序列。分区可以分布在不同的服务器上,从而实现数据的分布式存储和并行处理,提高系统的吞吐量和可扩展性。
多副本:为了保证数据的可靠性和高可用性,每个分区可以有多个副本(Replica),这些副本分布在不同的 Broker 上。其中一个副本被指定为领导者(Leader),负责处理读写请求,其他副本作为追随者(Follower),与领导者保持数据同步。
消息持久化:Kafka 将消息持久化到磁盘上,即使服务器重启,消息也不会丢失。消息会根据一定的保留策略在磁盘上保留一段时间,过期的消息将被自动删除,以释放磁盘空间。
创建主题:
通过kafka-topics.sh脚本语言创建主题,直接运行这个脚本就会告诉你如何使用这个脚本。
命令:
//使用脚本创建主题
./kafka-topics.sh --create --topic hello --bootstrap-server localhost:9092
//-creat 创建一个主题
//--topic 后面的hello是我们的topic的名字
// bootstrap-server localhost:9092 这个是必须的后面指定的是我们当前节点的主机地址
查找主题:
./kafka-topics.sh --list --bootstrap-server localhost:9092
删除主题
./kafka-topics.sh --delete --topic hello --bootstrap-server localhost:9092
显示主题详细信息:
./kafka-topics.sh --describe --topic hello --bootstrap-server localhost:9092
修改分区数:
./kafka-topics.sh --alter --topic hello --partitions 5 --bootstrap-server localhost:9092
事件(Event)
- 定义:在 Kafka 的语境中,事件通常指的是生产者发送到主题中的一条具体的消息(Message)。它是 Kafka 中数据传输和处理的基本单元,包含了消息的内容、键(Key)、时间戳等元数据。
- 特点
- 不可变性:一旦事件被发布到 Kafka 主题中,它就是不可变的,不能被修改或删除。这确保了消息的一致性和可追溯性。
- 有序性:在同一个分区内,事件是按照它们被生产的顺序进行存储和消费的,保证了消息的顺序性。但不同分区之间的事件顺序是不确定的。
- 灵活性:事件的内容可以是任何格式的数据,如 JSON、XML、二进制数据等,生产者和消费者可以根据自己的需求对消息进行编码和解码。
事件的发送和接收:
事件的发送:
时间发送的命令
./kafka-console-producer.sh --topic hello --bootstrap-server localhost:9092
在之后的每次换行就是一条消息
![]()
事件读取:
从头开始读:
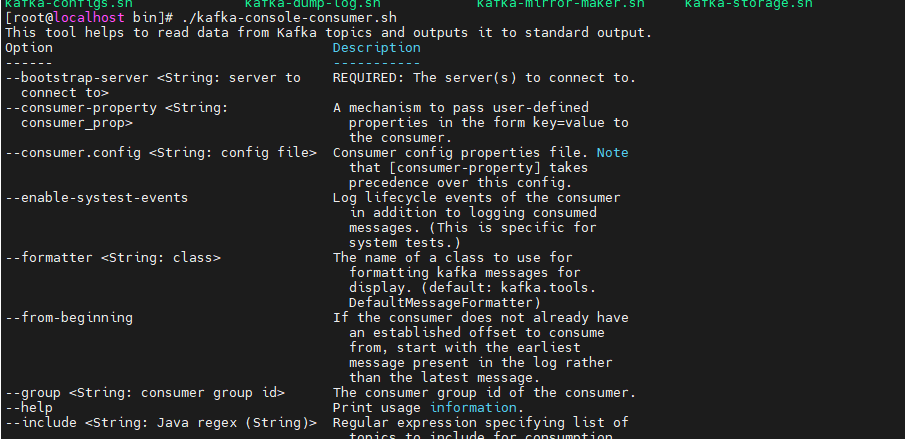
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello --from-beginning
--from-beginning 添加这个参数就是在日志文件中的第一个消息开始读,如果不添加这个就是监听当前消息,之后生产者发送消息,消费者才会监听。
小技巧:我们在学习时,总是依靠记忆是不对的,因为总会忘记的,最好的方式就是依靠我们的管官方文档和开发手册,对于kafka的命令,我们还是依靠他的帮助来实现。
kafka的远程连接:
下载kafka插件:
插件是:
 免费插件
免费插件
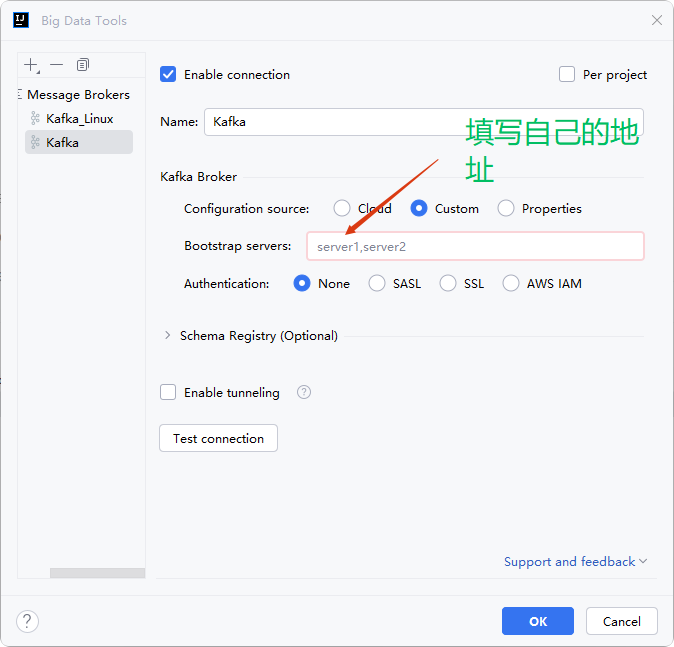
连接kafka:
解决无法远程连接问题:
课程地址:042 Docker容器Kafka配置文件修改_哔哩哔哩_bilibili
视频中演示的是docker的配置,但是实际上那种方式都是这种修改方式
我们在远程连接kafka是,按着默认的配置文件是无法远程连接的,但是我们可以通过修改配置文件的方式达到远程连接的要求。
配置文件修改的位置是:
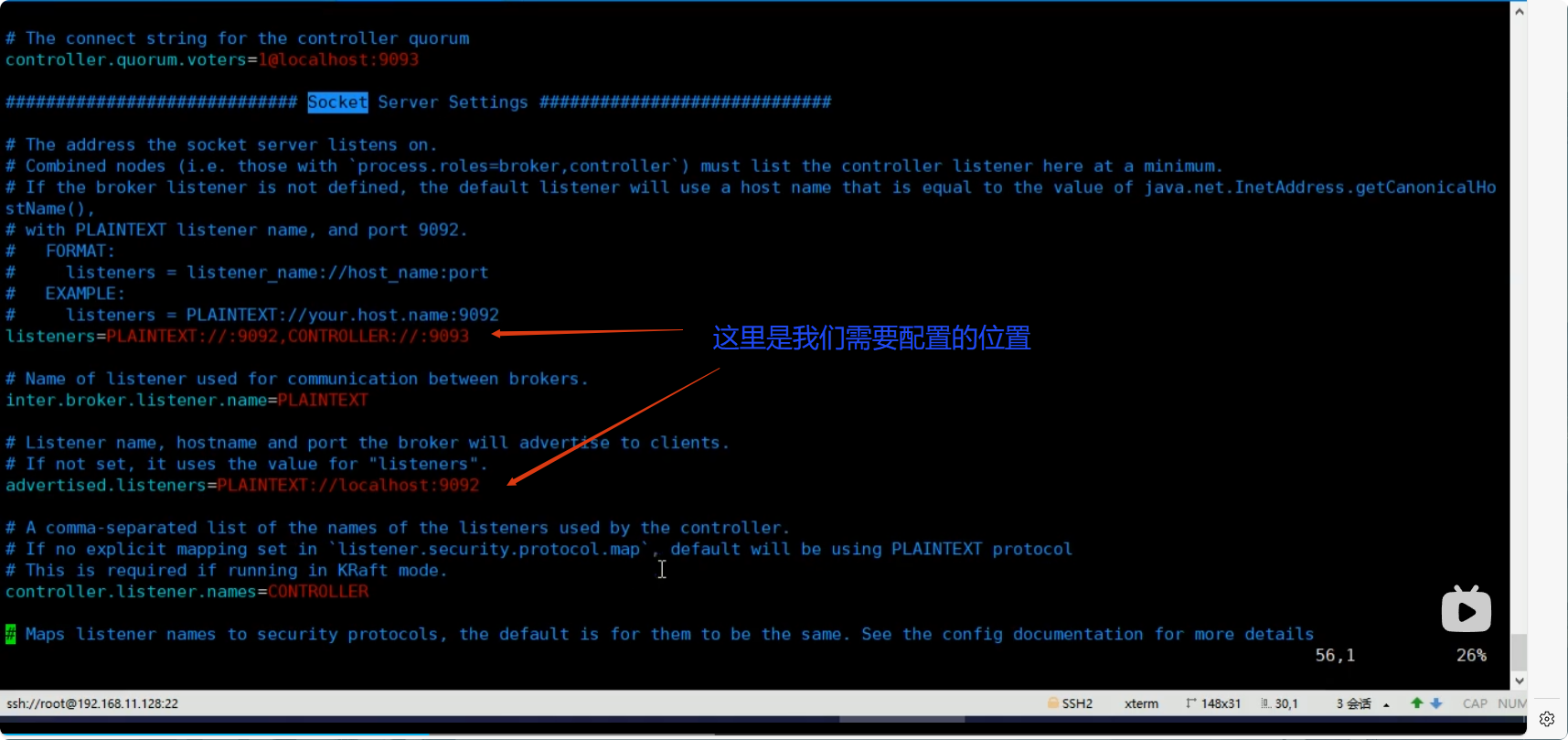
我们需要将配置文件修改为:
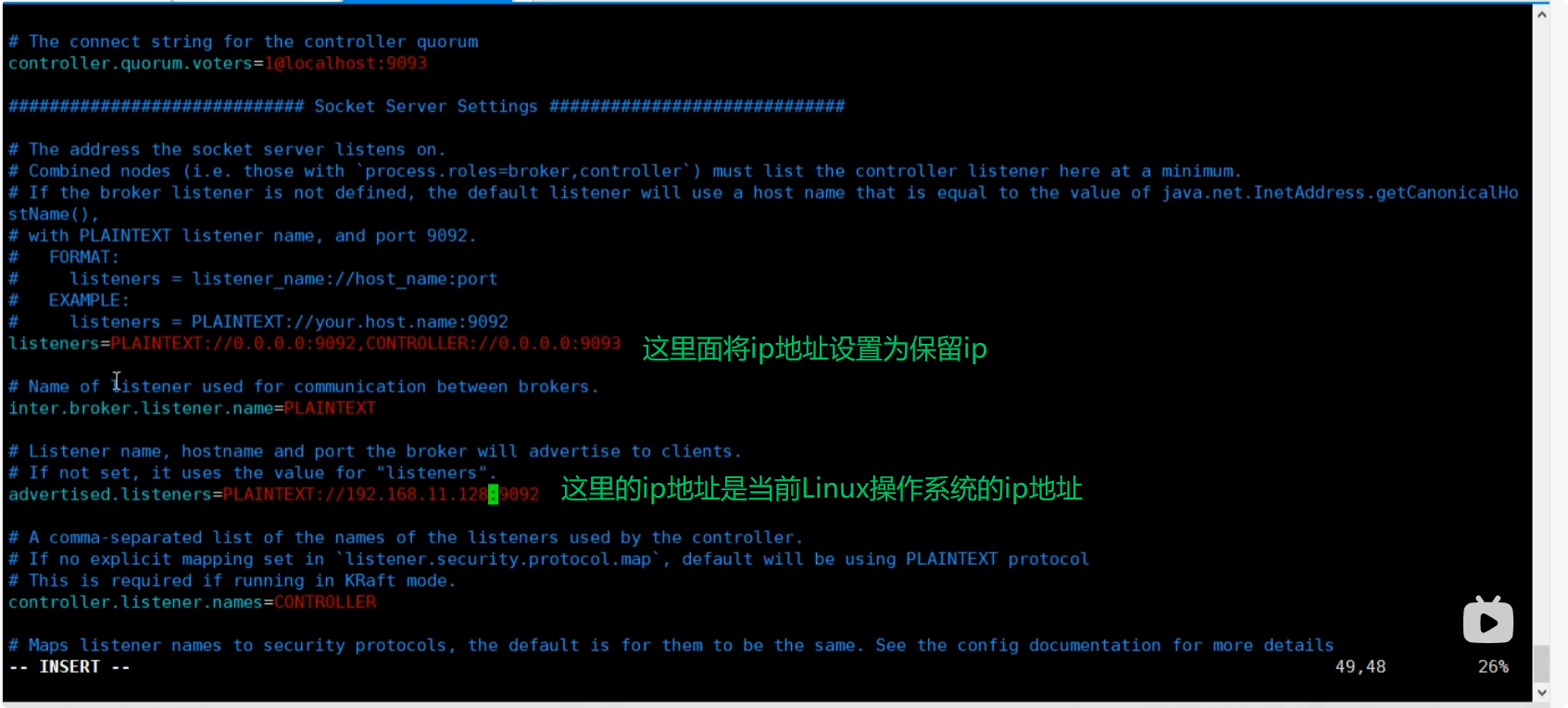
修改之后我们可以远程连接kafka.

显示我们的topic,证明连接成功。
Spring-boot集成Kafka
快速开始
导入的依赖:
//他的版本是2.8.10 原因是因为我的jdk版本是1.8,如果是3.X的kafka,集成的boot版本是3.X,JDK版本是17,小编不再升级JDK版本了,所以直接使用2.8.10 <dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId> </dependency>
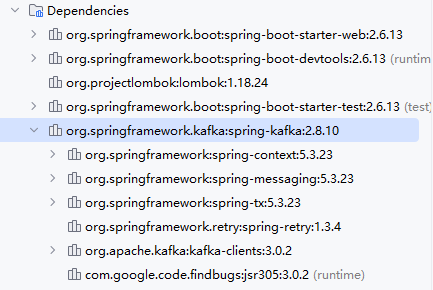
编写配置文件:
对于我们所有的MQ产品,配置文件几乎都是三个部分构成,服务器连接配置,生产者配置,消费之配置。三个部分生成。
对于我们现在常见的三个中间件分别是:RabbitMQ,RocketMQ,kafka.如果大家想学习其他的中间件的话,可以看小编的其他文章。为大家带来了详细的消息中间件实战。
两小时拿下RocketMQ实战_rocketmq使用案例-CSDN博客
快速上手RabbitMQ_逸Y 仙X的博客-CSDN博客
spring:kafka:#kafka连接地址bootstrap-servers: 192.168.0.169:9092#配置生产者 (24个配置,我们在这个基础班的base中全部使用默认配置)#producer:#配置消费者,27个配置#consumer:编写生产者:
@Component
public class EventProduce {//加入spring-kafka依赖之后,自动配置好了kafkaTemplate@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;public void sentEvent(){ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send("hello", "这是使用java发送的第一条消息");}}//使用test进行测试的代码
@SpringBootTest
public class EventProduceTest {@Autowiredprivate EventProduce eventProduce;@Testpublic void produceEventTest(){eventProduce.sentEvent();}
}编写消费者:
注意点:使用@KafkaListener注解监听时,必须雨哦的两个参数是 topics 和 groupId
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/4/29 20:36*/
@Component
public class EventConsumer {//监听的方式@KafkaListener(topics = "hello",groupId ="hello-group" )//必须有的两个参数是topics 和 groupIdpublic void eventConsumer(String event){//默认是知识监听最新的消息System.out.println("读取的事件是"+event);}
}展示结果:
详细解释配置文件:
consumer中的配置:auto-offset-reset: earliest
当前配置是可以读取更早的信息,也就是读取以签的信息 ,但是如果当前的消费组id已经消费过的话,kafka会记住偏移量,配置就不会生效,Kafka只会在中不到偏移量时,使用配置,可以手动重置偏移量,或者是使用新的id
spring:kafka:#kafka连接地址bootstrap-servers: 192.168.0.169:9092#配置生产者 (24个配置,我们在这个基础班的base中全部使用默认配置)#producer:#配置消费者,27个配置consumer:#当前配置是可以读取更早的信息,也就是读取以签的信息#但是如果当前的消费组id已经消费过的话,kafka会记住偏移量,配置就不会生效,Kafka只会在中不到偏移量时,使用配置,可以手动重置偏移量,或者是使用新的idauto-offset-reset: earliest
使用 新的id让配置生效:
@Component
public class EventConsumer {//监听的方式@KafkaListener(topics = "hello",groupId ="hello-group-02" )//必须有的两个参数是topics 和 groupIdpublic void eventConsumer(String event){//默认是知识监听最新的消息System.out.println("读取的事件是"+event);}
}
结果展示:

方式二:重置偏移量:
命令:
将偏移量设置为最早开始位置
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --topic hello --group hello-group-02 --reset-offsets --to-earliest --execute
//设置为最后的偏移量位置
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --topic hello --group hello-group-02 --reset-offsets --to-latest --execute

发送消息:
发送Message消息:
/*** 发送Message消息*/public void sentMessgeEvent(){//todo 使用这种方式创建时,将topic的名字放在header中,这个方式的来与时在KafkaOperations这个类中Message<String> message = MessageBuilder.withPayload("使用message发送消息到hello topic").setHeader(KafkaHeaders.TOPIC,"hello-Message").build();kafkaTemplate.send(message);System.out.println("消息发送成功");}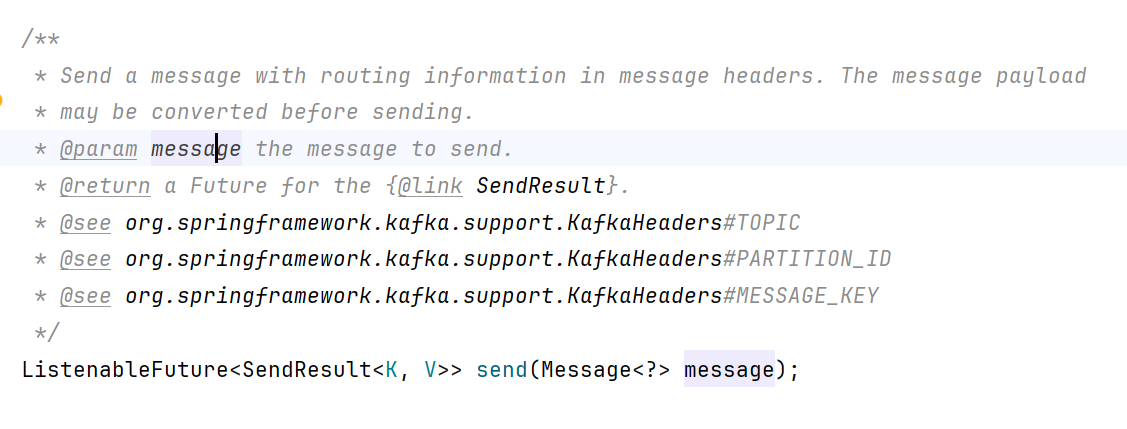
发送ProducerRecord消息
/*** 发送ProducerRecord对象*/public void sendProducerRecord(){//使用headers,传递数据,消费者可以获得我们传输的数据Headers header = new RecordHeaders();header.add("phone","11111111111".getBytes(StandardCharsets.UTF_8));//public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)ProducerRecord<String,String> producerRecord = new ProducerRecord<>("hello",0, Instant.now().toEpochMilli(),"key1" ,"kafka value1",header);ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send(producerRecord);System.out.println("发送成功");}sent的重载方式:
/*** sent的重载方式*/public void sentLong(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", 0, Instant.now().toEpochMilli(), "key2", "value2");}sendDefault方式:
他是一种通过配置文件,省略我们在发送是指定topic的返送方式,对于我们每次只是发送到相同的topic中可以采用的方式
/*** 测试sendDefault方式*/public void sentDefault(){//大家可以看一下,这里面是不是没有指定我们的topic,如果直接发送的话就会出现错误//需要配置配置文件ListenableFuture<SendResult<String, String>> sendResultListenableFuture = kafkaTemplate.sendDefault( 0, Instant.now().toEpochMilli(), "key2", "value2");System.out.println("消息发送成功");}配置文件:
spring:kafka:template:#配置模板的默认的主题,使用sendDefault时,直接发送到hello中default-topic: hello
发送对象:
通过序列化的方式发送对象:
spring:kafka:#kafka连接地址bootstrap-servers: 192.168.0.169:9092#配置生产者 (24个配置,我们在这个基础班的base中全部使用默认配置)#producer:#配置消费者,27个配置producer:value-serializer: org.springframework.kafka.support.serializer.JsonSerializer#key-serializer: 键序列化,默认是StringSerializer
/*** 发送对象* 直接序列化的时候出现异常,异常是StringSerializer,需要配置序列化方式*/public void sendObj(){//其实如果是发送对象的话,就是将对象进行序列化User user = User.builder().id(1).name("lihua").phone("13464299018").build();//如果分区是null,kafka自己选择放置到那个分区中template.send("hello",null,Instant.now().toEpochMilli(),"key3",user);}发送状态接受:
同步方式:
/*** 发送之后获取结果,阻塞的方式获取结果*/public void resultSent(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "这是使用java发送的第一条消息");try {//这个方法是阻塞的SendResult<String, String> sendResult = result.get();//RecordMetadata 如果是空就是没有接受到消息if(sendResult.getRecordMetadata()!=null){//kafka接受消息成功System.out.println("kafka接受消息成功");ProducerRecord<String, String> producerRecord = sendResult.getProducerRecord();String value = producerRecord.value();System.out.println("value = "+value);}} catch (InterruptedException e) {throw new RuntimeException(e);} catch (ExecutionException e) {throw new RuntimeException(e);}}异步方式:
spring-kafka 2.X
/*** 发送之后使用异步的方式获取结果* 使用回调函数在ListenableFuture(kafka2.X),* 使用thenAccept() thenApply() thenRun() 等方式来注册回调函数, CompletableFuture(kafka3.X)完成时执行*/public void sendAsynchronous(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "这是使用java发送的第一条消息");result.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {@Overridepublic void onFailure(Throwable ex) {System.out.println(ex.getMessage());}@Overridepublic void onSuccess(SendResult<String, String> result) {if(result.getRecordMetadata()!=null){//kafka接受消息成功System.out.println("kafka接受消息成功");ProducerRecord<String, String> producerRecord = result.getProducerRecord();String value = producerRecord.value();System.out.println("value = "+value);}}});}/*** 当前操作时将我们的返回值转化为CompletableFuture类型进行操作 结合了我们的3.X的方式实现* 发送之后使用异步的方式获取结果* 使用回调函数在ListenableFuture(kafka2.X),* 使用thenAccept() thenApply() thenRun() 等方式来注册回调函数, CompletableFuture(kafka3.X)完成时执行*/public void sendAsynchronous2(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "这是使用java发送的第一条消息");CompletableFuture<SendResult<String, String>> completable = result.completable();try{completable.thenAccept((sendResult)->{if(sendResult.getRecordMetadata()!=null){//kafka接受消息成功System.out.println("kafka接受消息成功");ProducerRecord<String, String> producerRecord = sendResult.getProducerRecord();String value = producerRecord.value();System.out.println("value = "+value);}}).exceptionally((ex)->{ex.printStackTrace();//如果失败,进行处理return null;});}catch (RuntimeException e){throw new RuntimeException();}}spring-kafka 3.X
下面是一个案例代码,我们的上面2.X中的代码第二种方式,删除转化的部分,3.X可以直接使用。
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;import java.util.concurrent.CompletableFuture;public class KafkaSender3x {private final KafkaTemplate<String, String> kafkaTemplate;public KafkaSender3x(KafkaTemplate<String, String> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}/*** 发送之后使用异步的方式获取结果* 使用 CompletableFuture 的 thenAccept 方法来处理结果*/public void sendAsynchronous() {CompletableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "这是使用java发送的第一条消息");result.thenAccept(sendResult -> {System.out.println("消息发送成功,分区: " + sendResult.getRecordMetadata().partition() +", 偏移量: " + sendResult.getRecordMetadata().offset());}).exceptionally(ex -> {System.err.println("消息发送失败: " + ex.getMessage());return null;});}
} Spring-boot创建主题指定分区和副本:
分区(Partition)和副本(Replica)概念讲解:
- 分区(Partition)
- 定义:可以将其看作是一个主题(Topic)的物理细分。如果把主题类比为一个文件夹,那么分区就像是文件夹中的不同子文件夹。每个分区都是一个独立的、有序的消息序列,消息在分区内按照顺序进行存储和处理。
- 作用:通过分区,可以实现数据的并行处理和存储,提高系统的吞吐量和可扩展性。不同的分区可以分布在不同的服务器上,这样多个消费者可以同时从不同的分区读取消息进行处理,从而加快消息处理的速度。例如,在一个处理大量订单消息的系统中,将订单主题分为多个分区,每个分区可以由不同的消费者组进行处理,从而提高订单处理的整体效率。
- 副本(Replica)
- 定义:是分区的一个拷贝,它包含了与原始分区相同的消息数据。副本可以存在于不同的服务器上,用于提供数据的冗余和容错能力。
- 作用:当某个分区所在的服务器出现故障时,副本可以替代故障分区继续提供服务,保证数据的可用性和系统的稳定性。例如,在一个分布式消息队列系统中,如果一个分区的主副本所在服务器崩溃了,那么系统可以自动切换到该分区的其他副本所在服务器上,继续处理消息,而不会导致数据丢失或服务中断。同时,副本也可以用于负载均衡,多个副本可以分担读取请求的压力,提高系统的整体性能。
-
细节点:replica:副本 他是为了放置我们partition数据不丢失,且kafka可以继续工作,kafka的每个节点可以有1个或者是多个副本 .副本分为Leader Replica 和 Follower Replica副本。 副本最少是1个,最多不能超果节点数(kafka服务器数),否则将不能创建Topic。 我们主副本可读可写,从副本只能读不能写
-
命令行方式创建副本:
-
./kafka-topics.sh --create --topic mytopic --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092

我们当前是单节点的kafka,创建两个副本的话,就会出现错误,现实的错误信息是: only 1 broker(s) are registered.
使用spring-kafka创建主题分区和副本
如果我们直接使用kafkaTemplate的send(String topic,String event);这种方式的话,就是创建了以topic,但是他只有一个分区和一个副本(主副本,可读可写);
通过编写配置文件设置分区个数和副本个数:
package com.hdk.springbootkafkabase01.config;import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaResourceFactory;
import org.springframework.kafka.core.KafkaTemplate;import java.util.Optional;/*** @Author HanDK* @CreateTime: 2025/5/1 09:18*/
@Configuration
public class KafkaConfig {/*** 我们再次启动时,当前的消息不会丢失,也不会将我们以签有的topic覆盖掉* 也就是如果存在的话就不会创建,只有不存在才会创建* @return*/@Beanpublic NewTopic newTopic(){
// 构造函数
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//创建一个topic 5个分区 1个副本NewTopic newTopic = new NewTopic("myTopic",5,(short)1 );return newTopic;}//但是现在将我们的myTopic的分区改为9个分区//在创建时如果有一摸一样的topic,不会创建。但是如果有改变的话,就会修改@Beanpublic NewTopic updateNewTopic(){
// 构造函数
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//创建一个topic 5个分区 1个副本NewTopic newTopic = new NewTopic("myTopic",9,(short)1 );return newTopic;}}
消息发送策略:
我们的一个topic中有很多的分区,但是我们在发送时使用的是什么策略呢?
默认的随机策略:
指定key:使用key生成hash值,之后在计算获取我们的partition的分区数值。如果我们的key值是不变的,他就会一直放置在一个分区中。
没有key:但是如果在发送消息时没有指定key值,他会随机发送到那个partition中。使用随机数算法获取随机的分区数。
轮询分配策略:
kafka的类:RoundRobinPartitioner implements Partitioner
如何使用轮询策略:(代码的方式获取)
我们发现直接使用配置文件的形式是不可以配置轮询策略的,使用代码的方式将策略设置为轮询策略。
编写配置文件:
@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.producer.value-serializer}")private String valueSerializer;@Beanpublic Map<String,Object> producerConfigs(){//使用map的形式填写配置文件Map<String,Object> props = new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,valueSerializer);props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);return props;}@Beanpublic ProducerFactory<String,Object> producerFactory(){//创建生产者工厂return new DefaultKafkaProducerFactory<>(producerConfigs());}//@Beanpublic KafkaTemplate<String,Object> kafkaTemplate(){KafkaTemplate<String, Object> kafkaTemplate = new KafkaTemplate<>(producerFactory());return kafkaTemplate;}当前我们的每个分区都没有事件,现在我发送9条消息,展示是不是轮询策略。
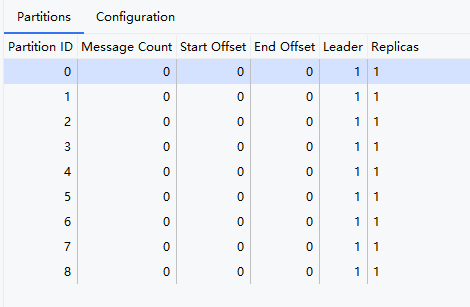
我们可以看到他确实时进入了轮询的策略,大家可以使用这个代码去Debug
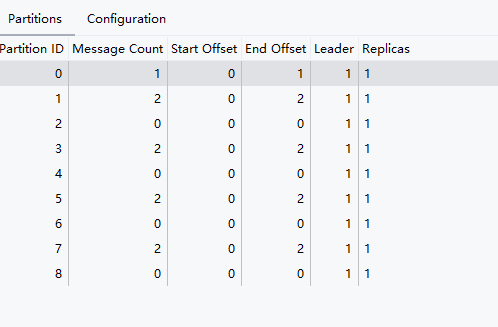
我们对于partition方法调用两次,他的放置文件时就是间隔一份放置。
自定义分配策略:
按着上面的思路,我们可以知道,其实如果自定一分区策略的话,自己去实现我们的Partitioner接口,实现分区策略就可以了。
生产者消息发送的流程:
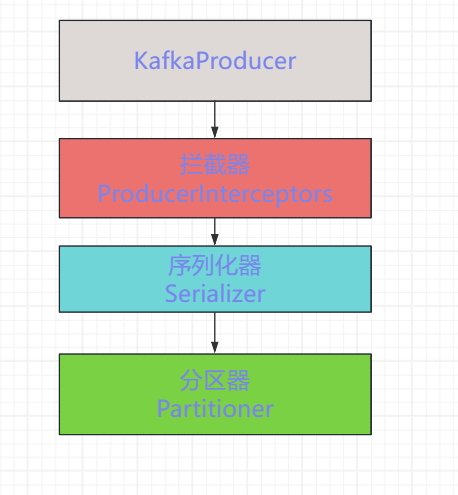
编写拦截器:
package com.hdk.springbootkafkabase01.config;import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;import java.util.Map;/*** @Author H* @CreateTime: 2025/5/1 17:04*/
public class CustomerProducerInterceptor implements ProducerInterceptor<String,Object> {/*** 发送消息是,对于消息进行拦截* @param record the record from client or the record returned by the previous interceptor in the chain of interceptors.* @return*/@Overridepublic ProducerRecord<String, Object> onSend(ProducerRecord<String, Object> record) {System.out.println("获取到内容是:"+record.value());return record;}/*** 消息确认机制* @param metadata The metadata for the record that was sent (i.e. the partition and offset).* If an error occurred, metadata will contain only valid topic and maybe* partition. If partition is not given in ProducerRecord and an error occurs* before partition gets assigned, then partition will be set to RecordMetadata.NO_PARTITION.* The metadata may be null if the client passed null record to* {@link org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord)}.* @param exception The exception thrown during processing of this record. Null if no error occurred.*/@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {if(metadata!=null){System.out.println("发送成功");}else{System.out.println("出现异常");exception.printStackTrace();}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
配置拦截器
直接在配置文件中还是不能直接获取到配置项,使用编码实现
package com.hdk.springbootkafkabase01.config;import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.RoundRobinPartitioner;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaResourceFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;import java.util.HashMap;
import java.util.Map;
import java.util.Optional;/*** @Author HanDK* @CreateTime: 2025/5/1 09:18*/
@Configuration
public class KafkaConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.producer.value-serializer}")private String valueSerializer;@Beanpublic Map<String,Object> producerConfigs(){//使用map的形式填写配置文件Map<String,Object> props = new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,valueSerializer);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class);props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);//配置拦截器,默认是没有拦截器的props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomerProducerInterceptor.class.getName());return props;}@Beanpublic ProducerFactory<String,?> producerFactory(){//创建生产者工厂return new DefaultKafkaProducerFactory<>(producerConfigs());}//@Beanpublic KafkaTemplate<String,?> kafkaTemplate(){KafkaTemplate<String,?> kafkaTemplate = new KafkaTemplate<>(producerFactory());return kafkaTemplate;}/*** 我们再次启动时,当前的消息不会丢失,也不会将我们以签有的topic覆盖掉* 也就是如果存在的话就不会创建,只有不存在才会创建* @return*/@Beanpublic NewTopic newTopic(){
// 构造函数
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//创建一个topic 5个分区 1个副本NewTopic newTopic = new NewTopic("myTopic",5,(short)1 );return newTopic;}//但是现在将我们的myTopic的分区改为9个分区//在创建时如果有一摸一样的topic,不会创建。但是如果有改变的话,就会修改@Beanpublic NewTopic updateNewTopic(){
// 构造函数
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//创建一个topic 5个分区 1个副本NewTopic newTopic = new NewTopic("myTopic",9,(short)1 );return newTopic;}}
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomerProducerInterceptor.class.getName());//这里不可以直接.class
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,该配置项期望的值是一个包含拦截器类全限定名(Fully Qualified Class Name)的字符串或者字符串列表。这是因为 Kafka 在启动时需要根据这些类名,通过 Java 的反射机制来实例化对应的拦截器类。不能直接传输Class对象。
消息消费细节:
@Payload注解
他修饰的变量是发送的内容
@Hearder注解
他标注请求头的信息。但是需要指明获取的是头信息中的那个键值信息
ConsumerRecord<String,String> record 使用他接受消息的全信息
package com.hdk.springbootkafkabase02.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/5/1 17:37*/
@Component
public class EventConsumer {//@Payload 这个注解证明他修饰的变量就是消息体的内容//@Header 这个注解接收请求头的信息@KafkaListener(topics = {"helloTopic"},groupId="group1")public void listenerEvent(@Payload String message, @Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,ConsumerRecord<String,String> record){System.out.println("接收的信息是"+message);System.out.println("接收的topic是"+topic);System.out.println("record中获取value:"+record.value());System.out.println("record中获取偏移量:"+record.offset());System.out.println("打印record的所有信息"+record);}/*** ConsumerRecord<String,String> record 使用他接受消息*/
}
接收的信息是hello topic
接收的topic是helloTopic
record中获取value:hello topic
record中获取偏移量:2
打印record的所有信息ConsumerRecord(topic = helloTopic, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1746152401289, serialized key size = -1, serialized value size = 11, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello topic)
消费对象信息:
在消费对象消息式,我们可以使用序列化和反序列化的方式,首先是想通过框架直接序列化和反序列化,但是出现了不信任的问题,所以我们将序列化和反序列化的工作交给我们程序员,编写Json工具类,手动实现
#producer:#value-serializer: org.springframework.kafka.support.serializer.JsonSerializer#consumer:#这是需要jackson依赖,导入我们的spring-boot-stater-json 依赖#错误点二:如果需要反序列化的话。当前报必须是可信赖的,需要将这个类设置为可信赖#The class 'com.hdk.springbootkafkabase02.entity.User' is not in the trusted packages: [java.util, java.lang].#If you believe this class is safe to deserialize, please provide its name.#If the serialization is only done by a trusted source, you can also enable trust all (*).#value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
序列化工具类:
package com.hdk.springbootkafkabase02.util;import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;/*** @CreateTime: 2025/5/2 11:25* 这里的序列化方式大家可以选择自己习惯的序列化方式*/
public class JsonUtils {//使用jackson方式序列化private static final ObjectMapper OBJECTJSON = new ObjectMapper();/*** 将自定义类型序列化* @param obj* @return*/public static String toJson(Object obj) {String ans = null;try {ans = OBJECTJSON.writeValueAsString(obj);} catch (JsonProcessingException e){e.printStackTrace();}return ans;}/*** json转对象* @param json* @param clazz* @return* @param <T>*/public static <T> T toBean(String json,Class<T> clazz){T obj = null;try {obj = OBJECTJSON.readValue(json, clazz);} catch (JsonProcessingException e) {throw new RuntimeException(e);}return obj;}
}
生产者代码:
public void sendObj(){/*** #这是需要jackson依赖,导入我们的spring-boot-stater-json 依赖* #错误点二:如果需要反序列化的话。当前报必须是可信赖的,需要将这个类设置为可信赖* #The class 'com.hdk.springbootkafkabase02.entity.User' is not in the trusted packages: [java.util, java.lang].* #If you believe this class is safe to deserialize, please provide its name.* #If the serialization is only done by a trusted source, you can also enable trust all (*).* 因为上面的原因,将我们的User类型转化为Json字符串*/User user = new User("lihua", 15, "11155551111");/*** 这种方式不需要值的序列化,也不需要反序列化*/String userJson = JsonUtils.toJson(user);kafkaTemplate.send("helloTopic",userJson);}消费者代码:
//接收对象消息@KafkaListener(topics = {"helloTopic"},groupId="group1")public void listenerObj(@Payload String userJson){System.out.println(userJson);//再自行进行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);}将监听信息写道配置文件中:
上面的消费者的topics,groupId写死在我们的代码中,这种方式的编码修改不方便
可以采用${}的方式在配置文件中读取
配置文件:
#自定义配置文件 kafka:topic:name: helloTopicconsumer:groupId: group1
代码:
//接收对象消息@KafkaListener(topics = {"${kafka.topic.name}"},groupId="${kafka.consumer.groupId}")public void listenerObj2(@Payload String userJson){System.out.println(userJson);//再自行进行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);}kafka消费手动确认:
kafka默认是自动确认,首先在配置文件中设置为手动确认
spring:kafka:bootstrap-servers: 192.168.0.168:9092#配置监听器listener:ack-mode: manual
之后在接受参数是,添加上参数`` ``,代码展示如下:
//手动确认下的消费者代码@KafkaListener(topics = {"${kafka.topic.name}"},groupId="${kafka.consumer.groupId}")public void listenerManual(@Payload String userJson, Acknowledgment acknowledgment){System.out.println(userJson);//再自行进行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);acknowledgment.acknowledge();}但是如果我们没有手动进行确认的化,会发生什么呢:
如果没有确认消费的话,我们的偏移量不会更新,我们在重启时,还会再之前的偏移量的位置开始消费。
我们再业务中可以这样写代码:
//手动确认下的消费者代码@KafkaListener(topics = {"${kafka.topic.name}"},groupId="${kafka.consumer.groupId}")public void listenerManual(@Payload String userJson, Acknowledgment acknowledgment){try {System.out.println(userJson);//再自行进行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);//没有问题时,直接确认acknowledgment.acknowledge();} catch (Exception e) {//出现问题,没有消费成功,抛出异常throw new RuntimeException(e);}}细化消费:如何指定消费的分区,偏移量
//细化消费,指定分区和偏移量@KafkaListener(groupId="${kafka.consumer.groupId}",topicPartitions = {@TopicPartition(topic ="${kafka.topic.name}",partitions = {"0","1","2"}, // 0 1 2 分区所有的数据都读partitionOffsets = {//分区3 4 只是读3之后的数据@PartitionOffset(partition = "3",initialOffset = "3"),@PartitionOffset(partition = "4",initialOffset = "1")})})public void consumerPartition(@Payload String jsonUser,Acknowledgment acknowledgment){System.out.println("获取到的数据是"+jsonUser);acknowledgment.acknowledge();}偏移量细节:
1. Kafka 偏移量机制
Kafka 的偏移量是一个单调递增的数字,用来标记消息在分区中的位置。当你指定一个初始偏移量时,Kafka 会尝试从这个偏移量开始为你提供消息。要是指定的偏移量超过了分区中当前最大的偏移量,Kafka 会按照消费策略(例如从最早或者最新的消息开始消费)来处理。
2. 消费策略的影响
在 Kafka 里,当指定的偏移量超出了分区的范围,就会依据 auto.offset.reset 配置项来决定从哪里开始消费。这个配置项有两个常用的值:
earliest:从分区的最早消息开始消费。latest:从分区的最新消息开始消费。
所以,当分区中的消息数小于你设定的初始偏移量时,Kafka 会依据 auto.offset.reset 的值来决定起始消费位置,而不是从你指定的偏移量开始。
批量消费消息:
配置文件:
spring:kafka:bootstrap-servers: 192.168.0.168:9092listener:# 默认是single(单一的),这是消费方式是批量type: batchconsumer:#为消费之设置消费数量max-poll-records: 20
消费者代码:
package com.hdk.springbootkafkabase03.consumer;import com.hdk.springbootkafkabase03.entity.User;
import com.hdk.springbootkafkabase03.utils.JsonUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;import java.util.List;/*** @CreateTime: 2025/5/3 08:28*/
@Component
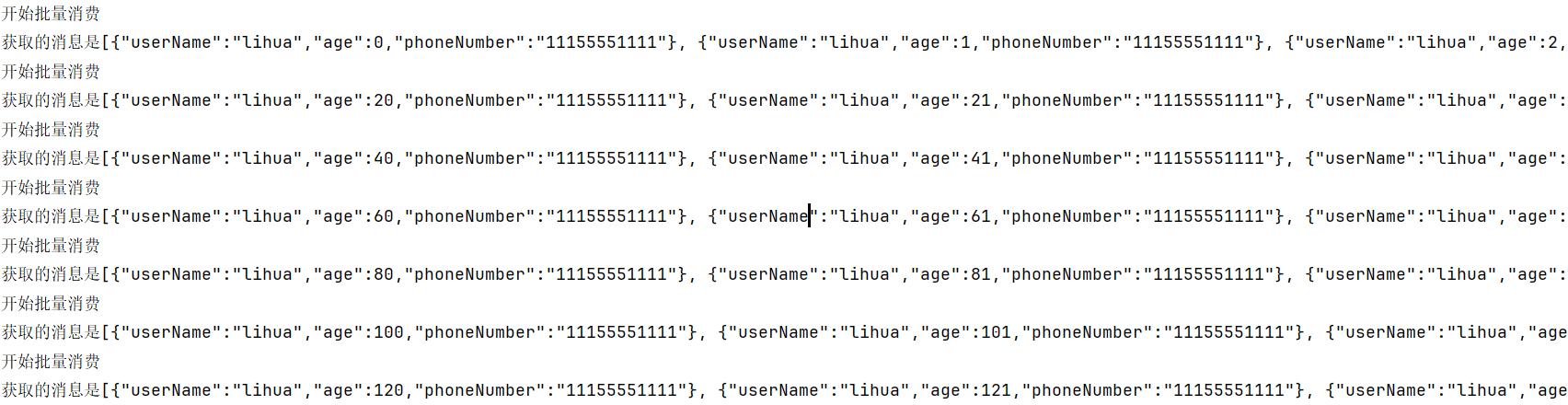
public class EventConsumer {/*** 对于批量的消费,接收时必须是集合形式接收* @param jsonUser* @param records*/@KafkaListener(groupId ="${kafka.consumer.group}",topics = "batchTopic")public void consumerBatchEvent(@Payload List<String> jsonUser, List<ConsumerRecord<String,String>> records){System.out.println("开始批量消费");System.out.println("获取的消息是"+jsonUser);}
}
运行截图:
消息拦截:
在消息消费之前,我们可以设置拦截器,对消息进行一些符合业务的操作。例如记录日志,修改消息内容或者执行一些安全检查。
实现方式:
实现接口ConsumerIntercepter
package com.hdk.springbootkafkabase03.interceptor;import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;import java.time.LocalDateTime;
import java.util.Map;/*** 自定义消息拦截器* @CreateTime: 2025/5/3 09:12*/public class CustomConsumerInterceptor implements ConsumerInterceptor<String,String> {//在消息消费之前@Overridepublic ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {//记录日志System.out.println("开始消费"+ LocalDateTime.now());return records; //返回的数据继续执行}/*** 消费消费之后,提交offset之前的方法* @param offsets A map of offsets by partition with associated metadata*/@Overridepublic void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {System.out.println("提交offset"+offsets);}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
将过滤器配置到项目中:
配置消费者工厂,配置监听器容器工厂
package com.hdk.springbootkafkabase03.config;import com.hdk.springbootkafkabase03.interceptor.CustomConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;import java.util.HashMap;
import java.util.Map;/*** @CreateTime: 2025/5/3 08:37*/
@Configuration
public class KafkaConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.consumer.key-deserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")private String valueDeserializer;public Map<String,Object> consumerConfig(){Map<String,Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,keyDeserializer);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,valueDeserializer);//添加一个消费者拦截器props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());return props;}/*** 配置消费者工厂* @return*/@Beanpublic ConsumerFactory<String,String> consumerFactory(){DefaultKafkaConsumerFactory defaultKafkaConsumerFactory = new DefaultKafkaConsumerFactory(consumerConfig());return defaultKafkaConsumerFactory;}/*** 创建消费者监听期容器工厂*/@Beanpublic KafkaListenerContainerFactory kafkaListenerContainerFactory(){ConcurrentKafkaListenerContainerFactory concurrentKafkaListenerContainerFactory = new ConcurrentKafkaListenerContainerFactory();concurrentKafkaListenerContainerFactory.setConsumerFactory(consumerFactory());return concurrentKafkaListenerContainerFactory;}}
消费者代码:
/*** 对于批量的消费,接收时必须是集合形式接收* @param jsonUser* @param records* containerFactory 注意这个配置,指定一下*/@KafkaListener(groupId ="${kafka.consumer.group}",topics = "batchTopic",containerFactory = "kafkaListenerContainerFactory")public void consumerBatchEvent(@Payload List<String> jsonUser, List<ConsumerRecord<String,String>> records){System.out.println("开始批量消费");System.out.println("获取的消息是"+jsonUser);}消息转发:
情景模拟:
我们监听TopicA的消息,经过处理之后发送给TopicB,使用业务b监听TopicB的消息。实现了我们雄消息的转发。
package com.hdk.springbootkafkabase05.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.messaging.handler.annotation.SendTo;
import org.springframework.stereotype.Component;/*** 消息转发* @CreateTime: 2025/5/3 15:54*/
@Component
public class EventConsumer {/*** @param record 消息的信息* @return 将要转发到topicB的信息*/@KafkaListener(topics = "topicA",groupId = "group1")@SendTo("topicB")public String consumerAndSendMessage(ConsumerRecord<String,String> record){System.out.println("当前的消息信息是:"+record.value());return record.value()+"forward-message";}@KafkaListener(topics = "topicB",groupId = "group1")public void consumerTopicB(ConsumerRecord<String,String> record){System.out.println("当前的消息信息是:"+record.value());}}
发送者代码:
@Component
public class EventProducer {@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;public void sendToTopicA(){kafkaTemplate.send("topicA","消息发送到kafkaA");}
}消息消费时的分区策略:
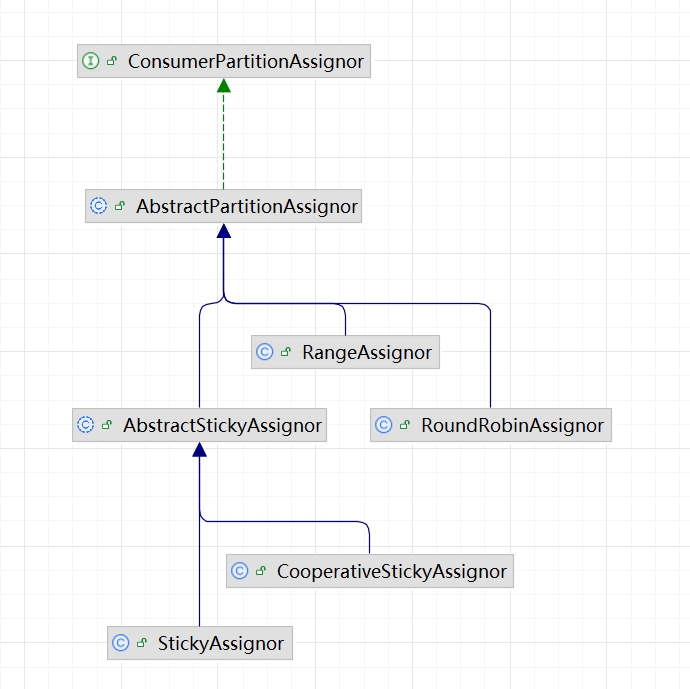
默认消费策略rangeAssignor:
我们debug启动时,可以发现直接进入了我们的类:
package org.apache.kafka.clients.consumer 中的RangeAssignor
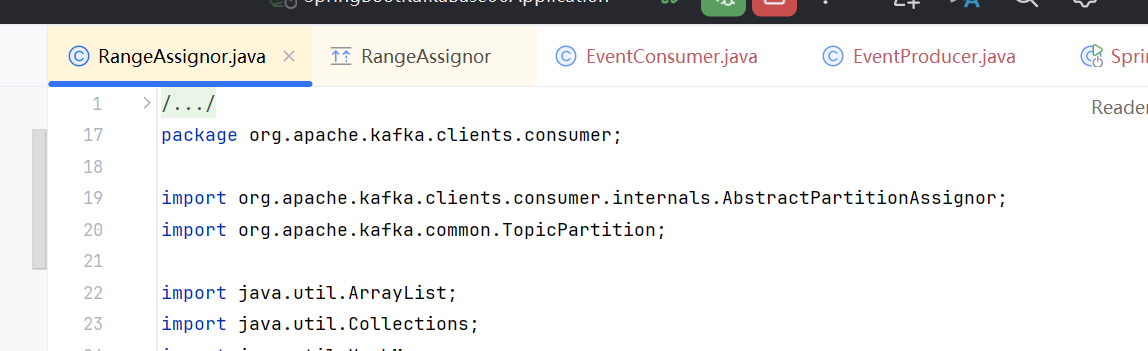
按着范围分区:
假设我们的myTopic主题中有10个分区,一个消费组中有三个消费者consumer1 ,consumer2,consunmer3。
他的分配策略是:
1.计算每个消费者应得的分区数:
分区总数/消费者数=3.......1;
但是有一个余数是1.这时第一个消费者会获取到4个分区。consumer1的分区数是4;
2.具体分配是:
consumer1:0 1 2 3
consumer2:4 5 6
consumer3:7 8 9
使用代码测试一下:
消费者代码:
package com.hdk.springbootkafkabase06.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/5/5 18:26*/
@Component
public class EventConsumer {/*** 默认策略RangeAssignor的结果:* org.springframework.kafka.KafkaListenerEndpointContainer#0-2-C-1 线程消费的消息内容是发送消息,结合分区策略* org.springframework.kafka.KafkaListenerEndpointContainer#0-1-C-1 线程消费的消息内容是发送消息,结合分区策略* org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1 线程消费的消息内容是发送消息,结合分区策略* 发现是三个线程名在消费* 使用这个concurrency,后面的配置证明他的一个消费组中,有几个消费者* 其实就是开启了那几个线程消费消息* 下面的代码表示一个消费组中有三个消费者* @param record*/@KafkaListener(topics = "myTopic",groupId = "myGroup",concurrency ="3" )public void listener(ConsumerRecord<String,String> record){String value = record.value();//借助线程名查看不同的消费者消费消息System.out.println(Thread.currentThread().getName()+"线程消费的消息内容是"+value);}
}
生产者代码:
package com.hdk.springbootkafkabase06.producer;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;/*** @Author HanDK* @CreateTime: 2025/5/5 18:29*/
@Component
public class EventProducer {@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;public void sendString(){for(int i=0;i<100;i++){String index=String.valueOf(i);ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send("myTopic", index,"发送消息,结合分区策略");send.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {@Overridepublic void onFailure(Throwable ex) {System.out.println("消息发送失败,开始写入数据库");try {Thread.sleep(2000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("写如数据库成功");}@Overridepublic void onSuccess(SendResult<String, String> result) {System.out.println("发送消息成功");}});}}
}
创建主题和分区代码:
package com.hdk.springbootkafkabase06.config;import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/5/5 19:58*/
@Configuration
public class KafkaConfig {/*** 创建一个主题,里面有10个分区* @return*/@Beanpublic NewTopic newTopic(){return new NewTopic("myTopic",10,(short) 1);}
}
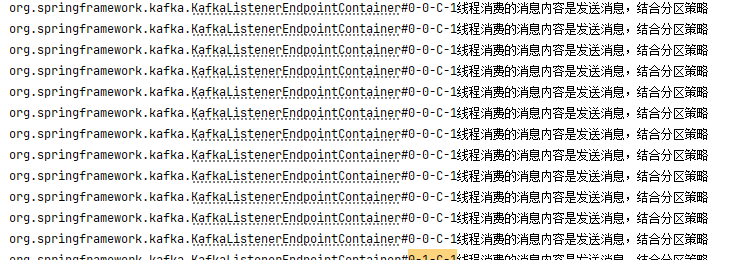
轮询策略RoundRobinAssignor:
在配置文件中我们发现是无法直接通过配置文件的方式配置的,所以只能是代码的形式编写配置文件。
在轮询的策略下,我们的消费的具体分配是:
consumer1:0 3 6 9
consumer2:1 4 7
consumer3:2 5 8
配置文件的编写:
package com.hdk.springbootkafkabase06.config;import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.RoundRobinAssignor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.stereotype.Component;import java.util.HashMap;
import java.util.Map;import static org.apache.kafka.clients.consumer.RoundRobinAssignor.ROUNDROBIN_ASSIGNOR_NAME;/*** @Author HanDK* @CreateTime: 2025/5/5 19:58*/
@Configuration
public class KafkaConfig {/*** 创建一个主题,里面有10个分区* @return*/@Beanpublic NewTopic newTopic(){return new NewTopic("myTopic",10,(short) 1);}@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.consumer.auto-offset-reset}")private String autoOffsetReset;@Value("${spring.kafka.consumer.key-deserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")private String valueDeserializer;/*** 自定义配置,返回Map类型的配置文件* @return*/@Beanpublic Map<String,Object> consumerConfig(){Map<String,Object> props = new HashMap<>();//设置主机和端口号props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);//设置序列化方式props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,keyDeserializer);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,valueDeserializer);//设置消费策略props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,autoOffsetReset);//设置消费分区策略为轮询策略props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName() );return props;}/*** 创建消费者工厂* @return*/@Beanpublic ConsumerFactory consumerFactory(){ConsumerFactory<String, String> consumerFactory = new DefaultKafkaConsumerFactory<>(consumerConfig());return consumerFactory;}/*** 创建监听器容器工厂* @return*/@Beanpublic KafkaListenerContainerFactory ourKafkaListenerContainerFactory(){ConcurrentKafkaListenerContainerFactory listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory();listenerContainerFactory.setConsumerFactory(consumerFactory());return listenerContainerFactory;}
}
消费者代码:
/*** 沦胥策略监听* containerFactory = "ourKafkaListenerContainerFactory" 使用这个注解表明我们使用的监听器容器工厂是哪个* 但是需要注意的是我们改变消费者的分区策略时,我们的消费组是不能有offset的* 我们将上面的myGroup改变为myGroup1* @param record*/@KafkaListener(topics = "myTopic",groupId = "myGroup1",concurrency ="3",containerFactory = "ourKafkaListenerContainerFactory")public void listenerRoundRobin(ConsumerRecord<String,String> record){System.out.println(Thread.currentThread().getName()+record);//借助线程名查看不同的消费者消费消息}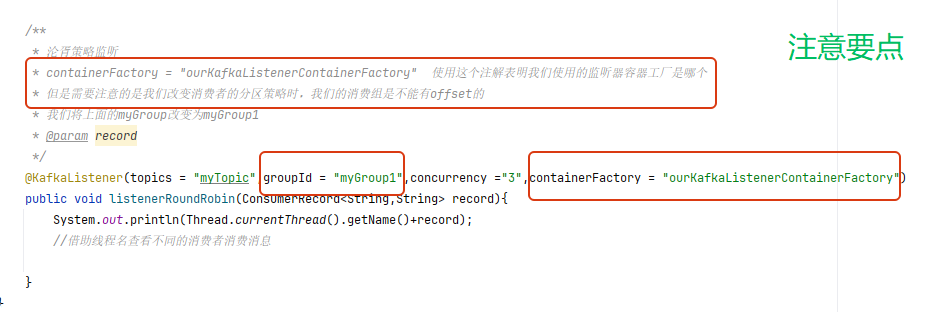
StickyAssignor:
尽可能的保持当前的消费者和分区的关系不变,即使我们的消费者的成员发生变话,也要减少不必要的分配。
仅仅只是对新的消费者或离开的消费者进行分区调整,大多数消费者还是继续保持他的消费分区不变。只是少数的消费者处理额外的分区。是一种粘性的分配
CooperativeStickyAssignor:
与StickyAssignor类似,但增加了对协作式重新分配的支持,消费者在他离开消费者之前通知协调器,以便协调器可以预先计划分区迁移,而不是在消费者突然离开时进行分配。
Kafka事件(消息,数据)存储:
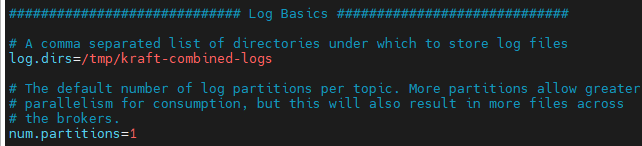
kafka的所有的事件消息都是以日志的形式保存的。他的配置方式是log.dir=****
kafka一般是海量的日志数据,避免日志文件过大,日志文件被放在多个目录下,日志文件的命名规则是<topic_name>--<partition_id>;


Kafka的__consumer_offsets的主题:
这个主题记录的每次消费完成之后,会保存当前消费到的最近的一个offset.,--consumer-offsets他保存了consumer_group某一时刻提交的offset信息。这个主题的默认有50个分区。

生产者的offset:
生产者发送一条消息到topic下的partition,kafka内部会为每条消息分配一个唯一的offset,该offset就是该消息在partition中的位置。
消费者的offset:
消费者的offset是消费者需要知道自己已经读取到的位置,接下来需要从哪个位置开始读取。
每个消费组中的消费者都会独立的维护自己的offset,当消费者从某个partition读取消息时,他会记录当前读到的offset,这样即使是消费者宕机或重启,也不会出现数据的丢失。(之后消息确认才会提交offset)
相关文章:

适合java程序员的Kafka消息中间件实战
创作的初心: 我们在学习kafka时,都是基于大数据的开发而进行的讲解,这篇文章为java程序员为核心,助力大家掌握kafka实现。 什么是kafka: 历史: 诞生与开源(2010 - 2011 年) 2010 年…...

当体育数据API遇上WebSocket:一场技术互补的「攻防战」
在世界杯决赛的最后一分钟,你正通过手机观看直播。突然,解说员大喊“球进了!”,但你的屏幕却卡在对方半场的回放画面——这种「延迟乌龙」的尴尬,正是实时体育应用面临的终极挑战。 在体育数字化浪潮下,用…...
)
1:点云处理—三种显示方法(自建点云)
1.彩色显示 *读取三维点云 dev_get_window(WindowHandle)dev_open_window(0, 0, 512, 512, black, WindowHandle1) read_object_model_3d(./19-12-26/t.ply, m, [], [], ObjectModel3D, Status)Instructions[0] : Rotate: Left button Instructions[1] : Zoom: Shift left…...

SCADA|KingSCADA运行报错:加载实时库服务失败
哈喽,你好啊,我是雷工! 最近在绵阳出差,在现场调试时遇到报错问题,翻了下以往记录没有该错误的相关笔记。 于是将问题过程及处理办法记录下来。 01 问题描述 昨天还好好的,可以正常运行的程序今天再次运行时报错: “加载 实时库服务 失败” 查看日志中错误信息如下: …...

k8s | Kubernetes 服务暴露:NodePort、Ingress 与 YAML 配置详解
CodingTechWork 引言 在 Kubernetes 集群中,服务暴露是将集群内部的服务对外部网络提供访问的关键环节。NodePort 和 Ingress 是两种常用的服务暴露方式,它们各有特点和适用场景。本文将详细介绍这两种方式的原理、配置方法以及如何通过 YAML 文件实现服…...

upload-labs靶场通关详解:第一关
一、一句话木马准备 新建一个文本文档,写入php代码,修改文件后缀名为php,保存。 phpinfo() 是 PHP 里的一个内置函数,其功能是输出关于当前 PHP 环境的详细信息。这些信息涵盖 PHP 版本、服务器配置、编译选项、PHP 扩展、环境变…...

SSA-CNN+NSGAII+熵权TOPSIS,附相关气泡图!
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 经典麻雀搜索算法深度学习多目标优化多属性决策!SSA-CNNNSGAII熵权TOPSIS,附相关气泡图!本文旨在通过优化卷积神经网络(CNN)以及采用NSGAII多目标优化与熵权…...

数据结构之栈与队列
一,栈和队列的区别 1、核心定义与特性 特性栈(Stack)队列(Queue)定义仅允许在栈顶(表尾)进行插入和删除的线性表,遵循 后进先出(LIFO)。允许在队尾插入、队…...
详解)
SSHv2 密钥交换(Key Exchange)详解
1. 算法协商 在密钥交换开始前,客户端和服务端会协商确定本次会话使用的算法组合。具体过程如下: 交换算法列表 客户端和服务端各自发送支持的算法列表,包括: 密钥交换算法(如 diffie-hellman-group14-sha256…...
:一文详解three.js中的纹理映射UV)
从零开始学习three.js(15):一文详解three.js中的纹理映射UV
1. UV 映射基础概念 1.1 什么是 UV 坐标? 在三维计算机图形学中,UV 坐标是将二维纹理映射到三维模型表面的坐标系统。UV 中的 U 和 V 分别代表2D纹理空间的水平(X)和垂直(Y)坐标轴,与三维空间…...

解锁 Postgres 扩展日!与瀚高共探 C/Java 跨语言扩展技术的边界与未来
2025 年 5 月 13 日至 16 日(蒙特利尔时间),一年一度的 PostgreSQL 开发者大会 PGConf.dev(原 PGCON 会议)将在加拿大蒙特利尔盛大举行。同去年一样,在本次大会开幕的前一天同样会举办另外一个专场活动——…...

【Hive入门】Hive增量数据导入:基于Sqoop的关系型数据库同步方案深度解析
目录 引言 1 增量数据导入概述 1.1 增量同步与全量同步对比 1.2 增量同步技术选型矩阵 2 Sqoop增量导入原理剖析 2.1 Sqoop架构设计 2.2 增量同步核心机制 3 Sqoop增量模式详解 3.1 append模式(基于自增ID) 3.2 lastmodified模式(基…...

✍️【TS类型体操进阶】挑战类型极限,成为类型魔法师!♂️✨
哈喽类型战士们!今天我们要玩转TS类型体操,让你的类型系统像体操运动员一样灵活优雅~ 学会这些绝招,保准你的代码类型稳如老狗!(文末附类型体操段位表)🚀 一、什么是类型体操? &…...
)
部署Prometheus+Grafana简介、监控及设置告警(一)
部署PrometheusGrafana简介、监控及设置告警 一. 环境准备 服务器类型IP地址组件 Prometheus服务器、agent服务器、Grafana服务器192.168.213.7Prometheus 、node_expprter,Grafanaagent服务器192.168.213.8node_exporter 如果有防火请记得开启9090&am…...

k8s部署OpenELB
k8s部署OpenELB k8s部署OpenELB配置示例: layer2模式 k8s部署OpenELB 部署OpenELB至K8s集群 # k8s部署OpenELB kubectl apply -f https://raw.githubusercontent.com/openelb/openelb/refs/heads/master/deploy/openelb.yaml# 查看openelb的pod状态 kubectl get pods -n open…...

python打卡day18
聚类后的分析:推断簇的类型 知识点回顾: 推断簇含义的2个思路:先选特征和后选特征通过可视化图形借助ai定义簇的含义科研逻辑闭环:通过精度判断特征工程价值 作业:参考示例代码对心脏病数据集采取类似操作,并且评估特征…...

新品发布 | 96MHz主频 M0+内核低功耗单片机CW32L011产品介绍
CW32L011是基于 eflash 的单芯片低功耗微控制器,集成了主频高达 96MHz的 ARMCortex-M0内核、高速嵌入式存储器(多至 64K字节 FLASH 和多至 6K 字节 SRAM)以及一系列全面的增强型外设和 I/O 口。 所有型号都提供全套的通信接口(3路 UART、1路 SPI和1路12C)、12位高速…...

【面试 · 二】JS个别重点整理
目录 数组方法 字符串方法 遍历 es6 构造函数及原型 原型链 this指向 修改 vue事件循环Event Loop FormData 数组方法 改变原数组:push、pop、shift、unshift、sort、splice、reverse不改变原属组:concat、join、map、forEach、filter、slice …...

【详细教程】ROC曲线的计算方式与绘制方法详细介绍
《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【…...

【神经网络与深度学习】VAE 在解码前进行重参数化
在 VAE 中,解码之前进行重参数化主要有以下几个重要原因: 可微分性 在深度学习里,模型是通过反向传播算法来学习的,而这需要计算梯度。若直接从潜在变量的分布 (q_{\theta}(z|x))(由编码器输出的均值 (\mu) 和方差 (…...
开发 python3基础11: java 调用python waitfor卡死,导致深入理解操作系统进程模型和IPC机制)
ai agent(智能体)开发 python3基础11: java 调用python waitfor卡死,导致深入理解操作系统进程模型和IPC机制
java 调用python waitfor 卡死 导致浏览器无法自动关闭,java ,python双发无限等待 根源在于还是没有理解 进程之间标准输入输出到底是什么含义 系统进程与跨语言调用的核心机制 在跨语言调用(如Java调用Python)时,理…...

大模型赋能:2D 写实数字人开启实时交互新时代
在数字化浪潮席卷全球的当下,人工智能技术不断突破创新,其中大模型驱动的 2D 写实数字人正成为实时交互领域的一颗新星,引领着行业变革,为人们带来前所未有的交互体验。 一、2D 写实数字人概述 2D 写实数字人是通过计算机图形学…...
)
CATIA高效工作指南——零件建模篇(二)
一、PowerCopy特征复用技术 1.1 智能特征封装 通过几何图形集(Geometrical Set)构建参数化特征组,将关联的草图、曲面、实体等元素进行逻辑封装。操作流程如下: 创建新几何图形集并完成特征建模激活PowerCopy命令,选择目标几何集定…...

QT人工智能篇-opencv
第一章 认识opencv 1. 简单概述 OpenCV是一个跨平台的开源的计算机视觉库,主要用于实时图像处理和计算机视觉应用。它提供了丰富的函数和算法,用于图像和视频的采集、处理、分析和显示。OpenCV支持多种编程语言,包括C、Python、Java等&…...

java实现一个操作日志模块功能,怎么设计
为了设计一个高效、可靠且可扩展的操作日志模块,可以结合 AOP(面向切面编程)、异步处理(多线程或MQ)以及合理的存储策略,具体方案如下: 1. 技术选型与架构设计 (1) AOP 实现非侵…...

音频相关基础知识
主要参考: 音频基本概念_音频和音调的关系-CSDN博客 音频相关基础知识(采样率、位深度、通道数、PCM、AAC)_音频2通道和8ch的区别-CSDN博客 概述 声音的本质 声音的本质是波在介质中的传播现象,声波的本质是一种波,是一…...

【Agent】使用 Python 结合 OpenAI 的 API 实现一个支持 Function Call 的程序,修改本机的 txt 文件
使用 Python 结合 OpenAI 的 API 来实现一个支持 Function Call 的程序,修改本机的 txt 文件。需要注意,在运行代码前,要确保已经安装了 openai 库,并且拥有有效的 OpenAI API Key。 import openai import os# 设置你的 OpenAI A…...

mint系统详解详细解释
Linux Mint是一款基于Ubuntu的开源桌面操作系统,以用户友好、稳定性强、功能全面著称,尤其适合从Windows迁移的新手和追求高效办公的用户。以下从技术架构、版本演进、生态体系、核心功能、应用场景等维度进行深度解析: 一、技术架构&#x…...
:WordPress网站优化)
WordPress个人博客搭建(三):WordPress网站优化
前言 在之前的WordPress个人博客搭建(一)与WordPress个人博客搭建(二)文章中,我们已经在自己的非凡云云服务器上成功搭建了WordPress个人博客。现在让我们继续这场数字世界的耕耘,通过插件与主题的巧妙搭配…...

力扣1812题解
记录 2025.5.7 题目: 思路: 从左下角开始,棋盘的行数和列数(均从 1 开始计数)之和如果为奇数,则为白色格子,如果和为偶数,则为黑色格子。 代码: class Solution {pu…...
学习笔记(三))
深入理解XGBoost(何龙 著)学习笔记(三)
原创 化心为海 微阅读札记https://mp.weixin.qq.com/s/vBE3fu9AZDjRFd5niJU0lg 2025年05月06日 18:17 北京 第三章 机器学习算法基础 摘要:本章首先介绍了基础的机器学习算法的实现原理和应用;然后对决策树模型做了详细介绍;最后࿰…...

一篇文章解析 H.264/AVC 视频编解码标准框架
古人有云: “不积跬步, 无以至千里; 不积小流, 无以成江海。” 本文给小伙伴们删繁就简介绍 H.264/AVC 视频编解码标准框架。 H.264/AVC框架 H.264/AVC 作为视频编码领域的里程碑标准,仍然沿用混合编码框架,但其通过模块化技术创新显著提升了压缩效率和网络适应性。H.264/AV…...

Sat2Density论文详解——卫星-地面图像生成
“Sat2Density: Faithful Density Learning from Satellite-Ground Image Pairs”,即从卫星-地面图像对中学习忠实的密度表示。论文的主要目标是开发一种能够准确表示卫星图像三维几何结构的方法,特别关注从卫星图像中合成具有3D意识的地面视图图像的挑战…...
架构)
【计算机架构】RISC(精简指令集计算机)架构
一、引言 在计算机科学技术飞速发展的长河中,计算机架构犹如一艘艘领航的巨轮,不断引领着计算技术朝着更高性能、更低功耗、更智能化的方向前行。RISC(精简指令集计算机)架构便是其中一艘极为独特且极具影响力的“巨轮”。从早期计…...

智算中心基础设施0-1建设全流程及投产后的运维
0 - 1 建设全流程 规划与设计 需求分析:与相关部门和用户沟通,了解智算中心的业务需求,包括计算能力、存储容量、网络带宽、应用场景等,为后续的设计提供依据。选址规划:考虑电力供应、网络接入、环境条件、安全因素等…...
)
用3D slicer 去掉影像中的干扰体素而还原干净影像(脱敏切脸处理同)
今天遇到一个特殊的影像,扫描被试的头颅被很多干扰阴影快给遮盖住了,3D 建模出来的头颅有很多干扰,非常影响处理和视觉体验,正好解锁一个3D slicer 的功能吧。 背景:有一个被试数据头顶有很多干扰,直接覆盖…...

滚动条样式
title: 滚动条样式 date: 2025-05-07 19:59:31 tags:css 滚动条样式完整定义 HTML 示例 以下是一个包含所有主流浏览器滚动条样式属性的完整HTML文件,涵盖了WebKit内核浏览器和Firefox的滚动条定制: <!DOCTYPE html> <html lang"zh-CN&…...
工程师,“跟AI聊天”)
Prompt(提示词)工程师,“跟AI聊天”
提示词工程师这活儿早就不只是“跟AI聊天”那么简单了,特别是现在MetaGPT、LangChain这些框架出来后,整个赛道都升级成“AI指挥官”的较量了。 第一层:基础能力得打牢 AI语言学家的功底 别笑,真得像学外语一样研究大模型。比如GP…...
)
Java版ERP管理系统源码(springboot+VUE+Uniapp)
ERP系统是企业资源计划(Enterprise Resource Planning)系统的缩写,它是一种集成的软件解决方案,用于协调和管理企业内各种关键业务流程和功能,如财务、供应链、生产、人力资源等。它的目标是帮助企业实现资源的高效利用…...

金融小知识
📉 一、“做空”是啥? 通俗说法:押“它会跌”,赚钱! ✅ 举个例子: 有一天老王的包子涨价到 10 块一个,张三觉得这价格肯定撑不住,未来会跌到 5 块。于是他: 向朋友借了…...

高组装导轨的特点
高组装导轨通常是四列式单圆弧齿形接触直线导轨,具有整合化的结构设计,适用于重负荷和精密应用。与其它直线导轨高组装导轨提升了负荷与刚性能力,具备四方向等负载特色和自动调心功能,能够吸收安装面的装配误差,达到高…...
)
PE文件结构(导入表)
导入表 什么是导入表? 导入表就是pe文件需要依赖哪些模块以及依赖这些模块中的哪些函数 回想我们导出表的内容,导出表的位置和大小是保存在扩展pe头最后一个结构体数组当中的 IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES]第…...

AI 实践探索:辅助生成测试用例
背景 目前我们的测试用例主要依赖人工生成和维护,AI时代的来临,我们也在思考“AI如何赋能业务”,提出了如下命题: “探索通过AI辅助生成测试用例,完成从需求到测试用例生成的穿刺”。 目标 找全测试路径辅助生成测…...

2025年链游行业DDoS与CC攻击防御全解析:高带宽时代的攻防博弈
2025年,链游行业在元宇宙与Web3.0技术的推动下迎来爆发式增长,但随之而来的DDoS与CC攻击也愈发猖獗。攻击者瞄准链游的高频交易接口、NFT拍卖系统及区块链节点,通过混合型攻击(如HTTP FloodUDP反射)瘫痪服务࿰…...

LeetCode热题100--73.矩阵置零--中等
1. 题目 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]] 输出:[[1,0,1],[0,0,0],[1,0,1]] 示例 2ÿ…...

51camera将参加第九届沥青路面论坛暨新技术新成果展示会
51camera志强视觉 51camera即将参加第九届沥青路面论坛暨新技术新成果展示会,届时会有相关动态应用展示,欢迎广大客户朋友莅临参观。 会议时间:2025 年5月16日-18日 会议地点:长沙国际会议中心一层多功能厅1-6厅(长…...

python 闭包获取循环数据经典 bug
问题代码 def create_functions():functions []for i in range(3):# 创建一个函数,期望捕获当前循环的i值functions.append(lambda: print(f"My value is: {i}"))return functions# 创建三个函数 f0, f1, f2 create_functions()# 调用这些函数 f0() # 期望输出 &…...

Java的HashMap面试题
目录 1. 说一下HashMap的工作原理?(1.7和1.8都是) 2. 了解的哈希冲突解决方法有哪些 3. JAVA8的 HashMap做了哪些优化 4. HashMap的数组长度必须是 2 的 n 次方 5. HashMap什么时候引发扩容 5.1 数组容量小于64的情况: 5.2…...

spring4.x详解介绍
一、核心特性与架构改进 全面支持Java 8与Java EE 7 Spring 4.x首次实现对Java 8的完整支持,包括: Lambda表达式与Stream API:简化代码编写,提升函数式编程能力; 新的时间日期API(如LocalDate、LocalTime&…...

从图灵机到量子计算:逻辑可视化的终极进化
一、图灵机:离散符号系统的奠基者 1.1 计算理论的数学根基 1936 年,艾伦・图灵在《论可计算数及其在判定问题中的应用》中提出的图灵机模型,本质上是一个由七元组\( M (Q, \Sigma, \Gamma, \delta, q_0, q_{accept}, q_{reject}) \)构成的…...