Java的HashMap面试题
目录
1. 说一下HashMap的工作原理?(1.7和1.8都是)
2. 了解的哈希冲突解决方法有哪些
3. JAVA8的 HashMap做了哪些优化
4. HashMap的数组长度必须是 2 的 n 次方
5. HashMap什么时候引发扩容
5.1 数组容量小于64的情况:
5.2 链表转红黑树的条件是什么
6. 默认扩容的负载因子为什么是0.75 设太大和太小有什么问题
7. Java 8 中 HashMap 链表转红黑树和红黑树转链表的阈值为什么分别是 8 和 6
一、为什么链表转换为红黑树的阈值是 8?
二、还会从红黑树变回链表吗?会的。
流程核心问题(⭐️💗💗)流程核心问题(⭐️💗💗)
8. JDK1.7的HashMap的扩容流程
参考面试回答:
9. JDK 1.8的HashMap 的 扩容流程
参考面试回答:
10. JDK1.7的put 方法的流程
参考面试回答:
11. JDK 1.8 Put流程
参考面试回答:
12. HashMap key可以为null吗
13. HashMap 和 HashTable 有什么区别
14. HashMap为什么不是线程安全的
JDK 1.7 中 HashMap 的线程不安全表现:
JDK1.8:
15. ConcurrentHashMap在JDK 1.7中实现原理
参考面试回答:
16. ConcurrentHashMap在JDK 1.8中实现原理
参考面试回答:
17. ConcurrentHashMap1.7和1.8的区别
18. ConcurrentHashMap 和 Hashtable 的区别 分别说1.7 和1.8与Hashtable 的区别
19. ConcurrentHashMap的key、value是否可以为null?
1. 说一下HashMap的工作原理?(1.7和1.8都是)
分析: 这个问题笼统回答即可
参考回答:
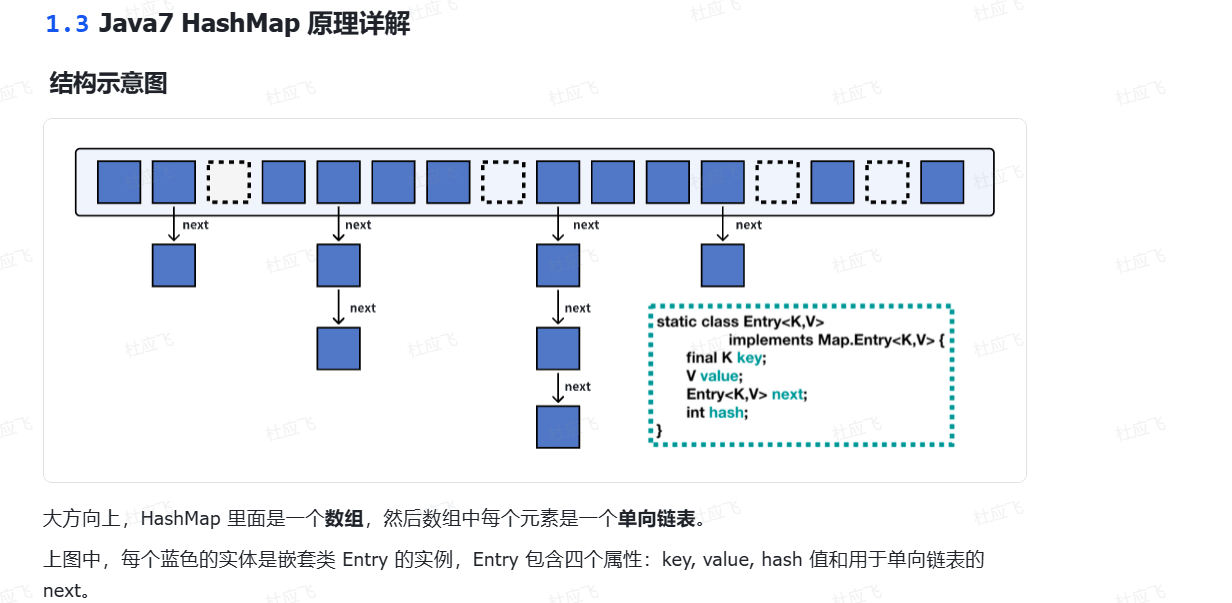
HashMap的工作原理基于哈希表、是使用哈希函数将键映射到存储位置的数据结构。哈希表通过计算键的哈希值、并将其转化为索引数组、从而快速定位键值对的存储位置。
-
HashMap的底层是一个数组,每个数组元素称为一个 bucket。通过哈希函数将键(key)映射到数组(称为table或buckets)的某个索引位置。 -
在理想情况下、哈希函数能将键均匀分布到哈希表中、以最小化哈希冲突。然而当多个键哈希到同一位置时、就需要解决哈希冲突。
-
顺便说一下了解的哈希冲突解决方法有哪些:链地址法、开放地址法、再哈希法
-
在Java 1.7中、HashMap主要使用链表来解决哈希冲突、将具有相同哈希值的键值对链接在一起。
-
但在Java 1.8中、为了进一步提高性能、当链表长度和数组长度超过一定阈值时、链表会转换为红黑树。
-
-
所以总结HashMap结合了哈希表、链表和红黑树的优点,实现了高效的键值对存储和查找功能。
2. 了解的哈希冲突解决方法有哪些
参考回答:链地址法、开放地址法、再哈希法
-
链地址法:
-
每个哈希桶存放一个链表(或其他数据结构,如红黑树)、所有映射到同一哈希槽的键值对都存放在这个链表中。
-
优点:实现简单、在负载因子较低时性能较好、链表长度动态增长。
-
缺点:当碰撞严重时、链表会变长、查找效率可能退化到 O(n)(但可以通过转换为红黑树等方式优化)
-
-
开放地址法:
-
所有元素都存放在哈希表本身中、当发生冲突时、通过探测寻找下一个空槽。
-
常见探测策略:
-
线性探测(Linear Probing):依次检查下一个位置。
-
二次探测(Quadratic Probing):探测位置与步长的平方有关,减少聚集问题。
-
双重哈希(Double Hashing):采用第二个哈希函数确定探测步长,更均匀分布。
-
-
优点:节省内存,不需要额外的链表结构。
-
缺点:在负载因子较高时容易产生堆积现象、性能下降、删除操作较为复杂。
-
-
再哈希法:
-
当哈希冲突严重或负载因子达到一定阈值时、重新构造哈希表并计算新的哈希槽。
-
优点:可以均衡哈希分布、降低冲突概率。
-
缺点:重建哈希表会带来较大的开销、尤其在数据量大时性能影响明显。
-
3. JAVA8的 HashMap做了哪些优化
- 1.7的数组+链表 改成了 1.8的数组+链表或红黑树
- 1.7的链表的插入方式从头插法 改成了 尾插法
- 扩容的时候:
- 1.7 需要对原数组中的元素进行重新
hash定位在新数组的位置 - 1.8采用更简单的判断逻辑位置不变或索引+旧容量大小
- Java 7 是先扩容后插入新值、而 Java 8 是先插入新值再判断是否要扩容。
- 1.7 需要对原数组中的元素进行重新
4. HashMap的数组长度必须是 2 的 n 次方
参考回答:
HashMap的长度选择为 2的幂次方、主要是为了提高哈希表的性能。
在 HashMap 中、键值对的存储位置是通过哈希值和数组长度计算得出的。一开始是通过取模运算
但是取模运算(%)的性能较低 尤其是在高频率操作(如 put 和 get)中、会影响 HashMap 的整体性能。
所以
-
用位与运算(
&)替代取模运算(%) 因为位与运算的性能更高。 -
但位与运算替代取模运算需要满足一个条件:
-
也就是
hash % length == hash & (length - 1) -
这个等式只有当
length是 2 的 n 次方时才成立。
其次
-
当 HashMap 的键值对数量达到数组长度的75%时、会触发数组扩容操作。
-
而扩容时利用2的幂次方的长度、可以非常快速地将原有的节点重新分配到新的数组位置上。
5. HashMap什么时候引发扩容
参考面试回答:
HashMap进行扩容取决于以下两个元素:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子、默认值0.75
- 当Map中的元素个数超过了16*0.75=12之后开始扩容
- 通常是扩容为原来的两倍长度
扩容的时候:
-
JDK 1.7: 在扩容时、需要遍历旧数组中的每一个元素、重新计算其哈希值(因为哈希函数可能依赖于数组长度、或者说重新计算在新表中的索引)、然后将其定位到新数组(容量通常是旧数组的两倍)的相应位置。这个过程涉及到所有元素的重新散列。
-
JDK 1.8: 扩容机制得到了优化。由于新容量是旧容量的两倍、元素在新数组中的位置要么保持不变、要么是 原索引 + 旧容量。这个判断只需要根据元素哈希值的某一个特定位(hash & oldCap)是0还是1来决定、避免了对所有元素进行完整的重新哈希计算、效率更高
5.1 数组容量小于64的情况:
-
如果当前链表长度小于8并且数组的长度小于 64、HashMap 会选择扩容、而不是将链表转换为红黑树。
-
HashMap会优先选择扩容整个哈希表。这是因为:-
如果数组容量本身就很小(小于64)、出现长链表很可能是因为容量不足导致哈希冲突过于频繁。此时扩大数组容量、让元素能更均匀地散布到更多的桶中、是更合理的解决方案、通常能有效缩短链表长度。
-
如果扩容后该链表(或者其他链表)依然达到了长度8、并且此时数组容量已经大于等于64了、那么才会进行树化
-
5.2 链表转红黑树的条件是什么
-
当链表长度达到 8 且 数组长度大于等于64的时候 才会转换为红黑树
-
当某个桶(bucket)中的链表长度达到 TREEIFY_THRESHOLD(默认为8)
-
并且 HashMap 当前的数组容量(table.length)必须大于等于 MIN_TREEIFY_CAPACITY(默认为64)。
-
只有同时满足这两个条件、该桶中的链表才会转换为红黑树。
-
6. 默认扩容的负载因子为什么是0.75 设太大和太小有什么问题
参考面试回答:
-
是空间与时间的权衡:
-
对于使用链表法的哈希表、查找一个元素的平均时间复杂度为 O(1+n)、其中 n 是链表的长度。
-
加载因子越大、空间利用率越高、但链表长度越长、查找效率越低。
-
加载因子越小、空间利用率越低、链表长度越短、查找效率越高。
-
-
默认值 0.75 的合理性:
-
0.75 是一个经验值、能够在空间利用率和查找效率之间取得较好的平衡。
-
如果加载因子太大(如 1.0)、链表长度会增加、查找效率下降。
-
如果加载因子太小(如 0.5)、太小可能会影响扩容频繁、影响性能。空间利用率低、造成内存浪费。
-
7. Java 8 中 HashMap 链表转红黑树和红黑树转链表的阈值为什么分别是 8 和 6
分析:
链表转换为红黑树的阈值是 8、而红黑树转换回链表的阈值是 6。
参考面试回答:
-
在 Java 的 HashMap 中、当发生哈希碰撞、同一个桶内的节点最初会以链表形式组织。
-
如果链表长度较短(小于 8)、遍历链表的性能是可以接受的
-
而当链表长度达到 8 时、意味着碰撞的可能性非常高、查找效率可能会退化到 O(n)的水平。
-
为了避免这种情况、HashMap 会将链表转换成红黑树、这样查找、插入和删除操作的时间复杂度就能降到 O(logn)O(log n)。
选择 8 作为转换的阈值有三个主要原因:
一、为什么链表转换为红黑树的阈值是 8?
选择 8 作为链表转换为红黑树的阈值,主要是基于以下几点考虑:
1. 性能与时间复杂度的权衡:
- 当哈希冲突发生、同一个桶(bucket)中的元素会以链表形式存储。如果链表长度很短、遍历链表的查询效率(O(N))是可以接受的。
- 但是当链表长度持续增长、查询性能会急剧下降。为了避免在极端情况下(例如大量哈希冲突导致某个桶的链表非常长)性能退化、
HashMap引入了红黑树。红黑树的查找、插入和删除操作的时间复杂度都能稳定在 O(log N)。 - 阈值 8 就是一个在链表查询效率尚可和红黑树结构优势开始显现之间的一个平衡点
2. 概率统计与经验数据:
- 在理想的哈希函数和负载因子下、一个桶中链表长度达到 8 的概率是非常低的。根据泊松分布、理想情况下,哈希冲突导致链表长度达到 8 的概率大约是千万分之六 (0.00000006)。这意味着正常情况下很少会触发树化。
- 这个阈值是基于大量实验和统计分析得出的。选择 8 能够在绝大多数情况下保持链表的简单高效、同时在极少数极端哈希冲突发生时,通过转换为红黑树来保证性能下限。
3. 空间开销的考虑:
- 红黑树的节点(
TreeNode)比普通链表的节点(Node)要占用更多的内存空间、因为它需要存储颜色、父节点、左子节点和右子节点的引用。 - 如果链表长度很短就进行树化、那么这种额外的空间开销可能就不太划算。因此只有当链表确实比较长、性能提升能够抵消空间开销时、转换才有意义。
二、还会从红黑树变回链表吗?会的。
为了避免在链表和红黑树之间因为元素数量的微小波动而频繁地进行结构转换(这本身也是有开销的)
因为只有当链表确实比较长、性能提升能够抵消空间开销时、转换才有意义。
设计者引入了一个回退策略
-
去树化阈值: 当红黑树中的节点数量因为删除操作而减少到一定程度时、它会转换回链表。这个阈值通常是 6(
UNTREEIFY_THRESHOLD)。 -
滞后性(Hysteresis): 您可以看到、树化的阈值是 8、而去树化的阈值是 6。这两个阈值之间存在一个差值(7 这个临界点)。这种设计被称为滞后性或迟滞现象。
-
它的目的是防止频繁转换。如果树化和去树化的阈值是同一个值(比如都是7)、那么当一个桶的元素数量在7和8之间波动时、就会频繁地进行链表和红黑树之间的转换、这会带来不必要的性能开销。
-
通过设置不同的阈值(8用于树化、6用于去树化)、可以确保只有当元素数量发生较大变化时、才会进行结构转换、从而提高了整体的稳定性与效率
-
总结:
HashMap在链表长度达到 8 时会转换为红黑树以优化查询性能- 当红黑树节点数减少到 6 时、会转换回链表以减少空间开销并避免在临界点频繁转换结构。
流程核心问题(⭐️💗💗)流程核心问题(⭐️💗💗)
8. JDK1.7的HashMap的扩容流程
参考面试回答:
JDK 1.7 HashMap 的扩容是一个在达到特定条件时、通过创建一个两倍于原容量的新数组、并将旧数组中的所有元素通过头插法 然后重新计算索引并迁移到新数组的过程。这个过程是单线程的、并且由于头插法的特性、在并发环境下(如果外部不加锁)进行扩容操作时存在产生环形链表(死循环)的风险。
关于 JDK 1.7 中 HashMap 的扩容流程、它主要分为以下几个核心步骤:
1. 触发扩容
- 当向
HashMap中添加元素,并且HashMap当前的元素数量 (size) 达到了预设的阈值 - 这个阈值通常是
当前容量 * 加载因子也就是16*0.75。就会触发扩容操作。
2. 创建新数组
- 首先
HashMap会创建一个新的Entry数组、这个新数组的容量通常是旧数组容量的两倍
3. 数据迁移
- 这是扩容过程中最核心也最复杂的部分、由
transfer方法执行。 - 遍历旧表:
transfer方法会遍历旧Entry数组中的每一个桶(bucket)。 - 遍历桶内链表: 对于每个桶中存在的链表(如果该桶非空),它会依次处理链表中的每一个
Entry对象。 - 重新计算索引: 对于从旧表中取出的每一个
Entry、需要根据其键的哈希值和新数组的容量来重新计算它在新数组中的索引位置。计算方式通常是hash & (newCapacity - 1)。 - 头插法迁移: 这是 JDK 1.7 扩容的一个关键特点。当将一个
Entry迁移到新数组的某个桶时、它会采用头插法。也就是说这个被迁移的Entry会成为新桶中链表的新的头部、其next指针会指向原先该桶中的旧头节点。这个头插法是导致并发扩容时可能产生死循环的根源、因为它会反转原链表中元素的顺序。4.
4. 最后更新内部引用和属性:
- 当所有元素都从旧表成功迁移到新表后:
HashMap内部的table引用会从指向旧数组改为指向新创建的、容量更大的数组。threshold(下一次扩容的阈值)会根据新的容量和加载因子重新计算并更新。
9. JDK 1.8的HashMap 的 扩容流程
参考面试回答:
10. JDK1.7的put 方法的流程
参考面试回答:
首先会判断 table 容器是否为空:
-
如果
table为空、表示HashMap尚未初始化 需要先初始化 table 数组。 -
如果
table未初始化 调用initialize方法进行初始化。
然后判断 key 是否为空:
-
如果
key为null则调用特殊方法处理null键(哈希值固定为 0 存储在table[0]的位置)。 -
如果
key不为null则调用hash(key)方法 根据key计算哈希值。
然后计算数组索引:
-
根据哈希值和数组长度计算键值对在
table数组中的存储位置 -
如果该位置不为空 说明存在哈希冲突 需要进一步处理。
解析哈希冲突遍历链表(或红黑树):
-
JDK 7:
-
遍历链表、查找是否存在相同的
key。 -
如果找到相同的
key、则直接替换对应的value。 -
如果未找到相同的
key、则将新的键值对插入到链表的头部(头插法)。
-
处理扩容:
-
如果当前元素数量超过阈值 则调用
resize()方法进行扩容。 -
扩容后 数组长度变为原来的 2 倍 并重新计算所有键值对的存储位置
插入新元素:
-
调用
addEntry方法、将新的键值对插入到链表或红黑树中。
结束:put 方法执行完毕。
11. JDK 1.8 Put流程
参考面试回答:
总结来说,JDK 1.8 的 put 流程是:
- 先定位桶、如果桶为空则直接插入
- 如果不为空、则根据桶是链表还是红黑树进行相应的查找、更新或插入(链表尾插)操作、并在必要时进行链表到红黑树的转换。
- 最后更新
size并检查是否需要扩容。
分析:表初始化检查:首先会检查内部的 数组是否为null或者是空的。如果是会调用 resize() 方法进行初始化
-
计算哈希与定位桶
-
计算传入
key的哈希值。根据计算出的哈希值和当前table的长度、确定该键值对应该存储在table数组中的哪个索引位置(即哪个桶)。 -
计算方式通常是
hash & (table.length - 1)。
-
-
处理桶内情况
-
空桶 (Empty Bucket): 如果目标桶当前是空的(即
table[i] == null)、则直接创建一个新的Node(包含键、值、哈希和next指针为null)、并将其放置在该桶中。 -
非空桶: 如果目标桶中已经有节点了、说明发生了哈希冲突、此时会:
-
检查头节点: 首先检查桶的头节点(
p = table[i])。如果头节点的哈希值与当前key的哈希值相同,并且它们的key也相同(通过==或equals()判断),则说明找到了相同的键。此时会用新的value覆盖旧的value、并返回旧value。 -
检查节点类型并遍历: 如果头节点不是要找的键、则需要进一步判断该桶的结构:
-
红黑树 如果桶的头节点是
TreeNode类型说、明这个桶已经被树化了。此时会调用红黑树的插入方法 (p.putTreeVal(this, tab, hash, key, value)) 来添加或更新节点。 -
链表 如果桶是链表结构、则会遍历链表中的每一个节点:
-
在遍历过程中、如果找到了与当前
key相同的节点(哈希相同且keyequals)、则用新value覆盖旧value、并返回旧value。 -
如果遍历到链表末尾仍未找到相同的
key、则创建一个新的Node、并将其追加到链表的尾部(尾插法)。 -
树化检查
-
-
-
-
-
更新计数与检查扩容
-
如果成功插入了一个新的键值对(而不是更新已存在的键),
modCount(修改计数器)会增加、并且HashMap的实际元素数量size会加1。 -
在
size增加后、会检查size是否超过了当前的扩容阈值 (threshold)。如果超过了、则会调用resize()方法进行扩容。
-
-
返回
-
如果
put操作是更新了已存在键的值、则返回旧的value。 -
如果
put操作是插入了一个新的键值对、则返回null
-
12. HashMap key可以为null吗
答: HashMap 允许键(key)为 null。
-
hashMap的key和value都可以null、但是null作为key只能有一个。 即
HashMap中最多只能有一个null键。因为hashMap中、如果key值一样、那么put操作会覆盖相同key值对应value、所以key为null只能有一个。 -
但是null作为value可以有多个
-
当Key为null时 当键为
null时 HashMap 会将其哈希值特殊处理为 0。 -
也就是将
null键对应的键值对存储到哈希表(table数组)的第一个位置(即索引为 0 的桶)
-
13. HashMap 和 HashTable 有什么区别
-
HashMap 是线程不安全的、HashTable 是线程安全的。HashTable 的方法通过
synchronized关键字实现同步、保证了线程安全、但性能较低 -
HashMap 只允许一条记录的键为 null、允许多条记录的值为 null
-
HashTable:不允许键或值为
null、否则会抛出NullPointerException
初始容量:
-
HashMap:默认初始容量为 16、扩容时容量变为原来的 2 倍
-
HashTable:默认初始容量为 11、扩容时容量变为原来的 2 倍加 1
哈希值计算:
-
HashMap对hashCode进行额外处理 会重新计算键的哈希值、以减少哈希冲突。
-
HashTable:直接使用对象的
hashCode不进行额外的哈希
14. HashMap为什么不是线程安全的
分为JDK1.7和1.8回答
JDK 1.7 中 HashMap 的线程不安全表现:
- 在 JDK 1.7 中,
HashMap的线程不安全主要体现在以下几个方面: -
并发
put操作导致数据覆盖或丢失:-
当多个线程同时向同一个桶(bucket)或者对
HashMap进行插入操作时、由于put操作(特别是addEntry方法中的步骤不是原子的、一个线程的写入操作可能会被另一个线程的写入操作覆盖、导致数据丢失。 -
并发的
put、remove或resize操作也可能因为没有正确的同步而导致某些元素丢失、或者size属性不准确、出现数据丢失或不一致的情况。
-
-
并发
resize(扩容) 导致死循环:-
这是 JDK 1.7
HashMap在并发场景下最著名的问题。 -
死循环产生过程简述:
-
假设有两个线程(T1、 T2)同时检测到需要扩容并执行
resize。 -
它们可能同时操作旧表中的同一个链表(例如
e -> nextE)。 -
T1 执行一部分、比如处理了
e、将e移到新表、此时在新表中e的next可能指向了某个节点(或者为 null)。 -
T2 也开始处理、它看到的
e和nextE可能还是旧表中的状态。 -
由于头插法和并发执行的交错、可能导致
e.next指向了nextE、同时nextE.next又意外地指向了e、从而形成一个环形链表。当后续get操作遍历到这个环形链表时,就会陷入死循环,导致 CPU 飙升
-
-
-
ConcurrentModificationException异常:-
当一个线程通过迭代器遍历
HashMap时、如果另一个线程同时对HashMap的结构进行了修改(如添加或删除元素)、那么迭代器在下一次操作时会检测到modCount的变化 -
并抛出
ConcurrentModificationException。
-
JDK1.8:
-
JDK1.8的HashMap 通过在扩容时采用尾插法、成功解决了 JDK 1.7 版本中因并发扩容(头插法)可能导致的链表死循环问题。这是一个重要的改进。
-
然而尽管解决了死循环的问题、JDK 1.8 的 HashMap 仍然不是线程安全的。在没有外部同步的情况下、多个线程并发地对 HashMap 进行修改操作(如 put、remove、resize)时、依旧会产生问题、主要是数据丢失、数据覆盖或内部结构损坏(尽管不一定是死循环)它的核心操作都不是原子性的、也没有内置的锁机制来保护共享状态。
-
因此在多线程环境下、直接并发写 HashMap 是不安全的、会导致数据不一致、丢失或覆盖。对于并发场景应该选择 ConcurrentHashMap。
15. ConcurrentHashMap在JDK 1.7中实现原理
参考面试回答:
-
原理
-
JDK 1.7 的 ConcurrentHashMap 的核心思想是将整个 HashMap 分割成多个独立的段 (Segment)
-
而每个
Segment元素、即每个分段则类似于一个Hashtable,它有自己的锁(ReentrantLock)。
-
-
数据结构
-
它的数据结构就是
ConcurrentHashMap内部维护一个Segment数组。 -
Segment 的数量在初始化时确定、并且之后不能改变、默认是16。也就是说默认可以同时支持16个线程并发写-
每个
Segment继承自ReentrantLock、这意味着每个 Segment 都是一个独立的锁。 -
每个
Segment内部包含一个HashEntry数组(HashEntry<K,V>[] table)。HashEntry 用于存储键值对、并且当发生哈希冲突时、这些 HashEntry 会以链表的形式组织起来 -
当对HashEntry数组的数据进行修改时、必须首先获得对应的Segment的锁。也就是说对同一Segment的并发写入会被阻塞、不同Segment的写入是可以并发执行的。
-
-
16. ConcurrentHashMap在JDK 1.8中实现原理
参考面试回答:
相比于 JDK 1.7、JDK 1.8 的 ConcurrentHashMap 做了较大的改动,摒弃了分段锁(Segment)的设计。采用了更为细粒度的锁机制、主要是 CAS (Compare-And-Swap) 操作 和 synchronized 关键字
-
核心设计思想与数据结构变化:
-
去 Segment 化: JDK 1.8 不再使用
Segment数组、而是回归到类似于HashMap的结构、即一个Node 数组(Node<K,V>[] table)。Node是存储键值对的基本单元。 -
锁的粒度更细: 锁的粒度从原先的
Segment级别降低到了每个数组桶(bin)的头节点级别。这意味着只有当多个线程尝试修改同一个桶中的数据时、才会发生锁竞争。 -
引入红黑树: 当某个桶中的链表长度过长(默认超过阈值 8、并且数组长度大于等于64)时为了提高查询效率(从 O(N) 降低到 O(logN))、链表会转换为红黑树(
TreeNode)
-
-
并发控制机制:
-
CAS 操作: 对于 Node 数组的初始化、向空桶中放置第一个节点等操作、会优先尝试使用 CAS 操作来原子性地更新。如果 CAS 成功、则避免了加锁的开销。
-
如果当 CAS 操作失败、或者需要修改某个桶中已存在的链表或红黑树时(例如添加新节点、删除节点、更新节点值)、会使用
synchronized关键字锁住该桶的头节点(链表的第一个节点或红黑树的根节点)。 -
选择
synchronized而不是ReentrantLock,一方面是因为 JDK 1.6 以后synchronized的性能得到了极大的优化(如锁膨胀机制)、另一方面是synchronized在某些情况下可以减少内存开销
-
17. ConcurrentHashMap1.7和1.8的区别
ConcurrentHashMap 分为JDK1.7 和JDK1.8 来回答
-
JDK 1.7 版本:
-
1.7是将整个 HashMap 分割成多个独立的段 (Segment)而每个
Segment元素、即每个分段则类似于一个Hashtable,每个 Segment 继承自 ReentrantLock、这意味着每个 Segment 都是一个独立的锁。每个数组段内部用链表来解决哈希冲突。 -
在 JDK 1.7 中、通过分段锁(Segment)机制、每个段拥有独立的锁、不同段之间的操作可以并发执行、大大提升了并发性能。
-
-
JDK 1.8 版本:
-
ConcurrentHashMap进行了优化、底层数据结构变为 Node 数组+CAS+synchronized、结合链表和红黑树。当某个桶中的链表长度过长(默认链表长度超过阈值 8、并且数组长度大于等于64)时为了提高查询效率(从 O(N) 降低到 O(logN))、链表会转换为红黑树(TreeNode) -
并发控制机制:
-
CAS 操作: 对于 Node 数组的初始化、向空桶中放置第一个节点等操作、会优先尝试使用 CAS 操作来原子性地更新。如果 CAS 成功、则避免了加锁的开销。
-
如果当 CAS 操作失败、或者需要修改某个桶中已存在的链表或红黑树时(例如添加新节点、删除节点、更新节点值)、会使用
synchronized关键字锁住该桶的头节点(链表的第一个节点或红黑树的根节点)。 -
选择
synchronized而不是ReentrantLock,主要是JDK 1.6 以后synchronized的性能得到了极大的优化(如锁膨胀机制)
-
-
18. ConcurrentHashMap 和 Hashtable 的区别 分别说1.7 和1.8与Hashtable 的区别
1. 底层数据结构:
-
JDK 1.7 版本:
-
1.7是将整个 HashMap 分割成多个独立的段 (Segment)而每个
Segment元素、即每个分段则类似于一个Hashtable,每个 Segment 继承自 ReentrantLock、这意味着每个 Segment 都是一个独立的锁。每个数组段内部用链表来解决哈希冲突。 -
Hashtable采用数组+链表的结构、数组作为主要存储结构、链表用于解决冲突。与1.7的Segment有不同
-
-
JDK 1.8 版本:
-
ConcurrentHashMap进行了优化、底层数据结构变为 Node 数组+CAS+synchronized、结合链表和红黑树。当某个桶中的链表长度过长(默认链表长度超过阈值 8、并且数组长度大于等于64)时为了提高查询效率(从 O(N) 降低到 O(logN))、链表会转换为红黑树(TreeNode) -
Hashtable 的数据结构依然保持数组+链表的方式
-
2. 线程安全实现方式:
-
ConcurrentHashMap:
-
在 JDK 1.7 中、通过分段锁(Segment)机制、每个段拥有独立的锁。
-
在 JDK 1.8 中、摒弃了
Segment的概念、改为对每个桶使用 synchronized 和 CAS(进行细粒度控制、仅在冲突时对单个桶加锁、进一步提高了并发度和性能。
-
-
Hashtable:
-
采用单一的锁机制(即在所有公共方法上都使用 synchronized)、导致任何一个线程操作时都会阻塞其他线程、无论是读还是写、都存在严重的锁竞争、性能明显低于 ConcurrentHashMap。
-
-
✅ 3. 是否支持 null 键值
-
Hashtable:
-
不允许 null 键和 null 值、调用会抛 NullPointerException。
-
-
ConcurrentHashMap:-
也不允许 null 键或 null 值(为了避免在并发场景中、无法判断返回值是 key 不存在还是 value 为 null)。
-
相比之下、
HashMap 是允许一个 null key 和多个 null value 的
-
19. ConcurrentHashMap的key、value是否可以为null?
参考回答:
-
答:不行。如果key或者value为null会抛出空指针异常。
-
(原因是因为没办法解决get返回值为null时的二义性问题、即没办法确定是存储的值本身为null、还是说值不存在)
-
注意:HashMap允许使用null作为值和键。
-
(因为HashMap只能单线程下使用、所以hashmap可以用
containsKey来二次判断、排除二义性问题)
相关文章:

Java的HashMap面试题
目录 1. 说一下HashMap的工作原理?(1.7和1.8都是) 2. 了解的哈希冲突解决方法有哪些 3. JAVA8的 HashMap做了哪些优化 4. HashMap的数组长度必须是 2 的 n 次方 5. HashMap什么时候引发扩容 5.1 数组容量小于64的情况: 5.2…...

spring4.x详解介绍
一、核心特性与架构改进 全面支持Java 8与Java EE 7 Spring 4.x首次实现对Java 8的完整支持,包括: Lambda表达式与Stream API:简化代码编写,提升函数式编程能力; 新的时间日期API(如LocalDate、LocalTime&…...

从图灵机到量子计算:逻辑可视化的终极进化
一、图灵机:离散符号系统的奠基者 1.1 计算理论的数学根基 1936 年,艾伦・图灵在《论可计算数及其在判定问题中的应用》中提出的图灵机模型,本质上是一个由七元组\( M (Q, \Sigma, \Gamma, \delta, q_0, q_{accept}, q_{reject}) \)构成的…...
)
Python初学者笔记第九期 -- (列表相关操作及列表编程练习题)
第17节课 列表相关操作 无论是内置函数、对象函数,用起来确实很方便,但是作为初学者,你必须懂得它们背后的运行逻辑! 1 常规操作 (1)遍历 arr [1,2,3,4] # 以索引遍历:可以在遍历期间修改元素 for ind…...

设备指纹破解企业面临的隐私与安全双重危机
在数字经济高速发展的今天,黑灰产攻击如影随形,个人隐私泄露、金融欺诈、电商刷单等风险事件频发。芯盾时代 “觅迹” 设备指纹全新升级,以跨渠道识别能力打破行业壁垒,为金融、电商、游戏等多场景构筑安全屏障。 黑灰产肆虐隐私…...

多功能气体检测报警系统,精准监测,守护安全
在化学品生产、石油化工、矿山、消防、环保、实验室等领域,有毒有害气体泄漏风险严重威胁工作人员和环境安全。化工企业生产中易产生大量可燃有毒气体,泄漏达一定浓度易引发爆炸、中毒等重大事故;矿井下瓦斯、一氧化碳等有害气体的浓度实时监…...

【HarmonyOS 5】鸿蒙中常见的标题栏布局方案
【HarmonyOS 5】鸿蒙中常见的标题栏布局方案 一、问题背景: 鸿蒙中常见的标题栏:矩形区域,左边是返回按钮,右边是问号帮助按钮,中间是标题文字。 那有几种布局方式,分别怎么布局呢?常见的思维…...

登顶中国:基于 Trae AI与 EdgeOne MCP 的全国各省最高峰攀登攻略博客构建实践
一、背景与目标 随着户外运动和登山活动的日益流行,越来越多的人希望挑战自然,体验登顶的乐趣。中国幅员辽阔,34个省级行政区(包括23个省、5个自治区、4个直辖市和2个特别行政区)拥有众多壮丽的山峰,其…...

iOS蓝牙技术实现及优化
以下是针对2025年iOS蓝牙技术实现的核心技术要点的深度解析,结合当前iOS 18(推测版本)的最新特性与开发实践,分模块结构化呈现: 一、硬件与协议层适配 BLE 5.3 支持 iOS 18默认支持蓝牙5.3协议,需注意&…...

STC单片机--仿真调试
目录 一、仿真介绍二、仿真步骤 一、仿真介绍 通常单片机的仿真有ST-Link、JTAG等,连接好线路之后,在keil的debug选项设置好就可以仿真了。但是,STC需要在STC-ISP软件上的仿真界面进行配置,然后才能在keil里正常仿真 二、仿真步骤…...

SecureCRT SFTP命令详解与实战
在日常的开发工作中,安全地进行文件传输是一个常见的需求。无论是部署应用到远程服务器,还是从生产环境下载日志文件分析问题,一个可靠的工具可以大大提高工作效率。今天,我们就来详细介绍如何使用SecureCRT内置的SFTP功能&#x…...

Unity Gizmos
简介 Gizmos 是Unity编辑器中的一种可视化调试工具,用于在场景视图(Scene View)中绘制辅助图形、图标或文本,帮助开发者直观理解游戏对象的位置、范围、逻辑关系等信息 核心功能 1. 辅助可视化调试 在场景视图中显示碰撞体、触…...

EEG设备的「减法哲学」:Mentalab Explore如何用8通道重构高质量脑电信号?
在脑电图(EEG)研究领域,选择适配的工具是推动研究进展的重要步骤。Mentalab Explore 以其便捷性和高效性,成为该领域的一项创新性解决方案。研究者仅用较少的 EEG 通道即可完成实验,并且能够确保数据的高质量。其搭载的…...

PDF文档压缩攻略
前言:早上花了一点时间网上搜索了一下压缩pdf文档大小的方法,发现大部分是利用第三方在线网页,上传文件付费压缩,同时缺乏文件保密性。 经实践,利用浏览器或者wps(不付费)即可轻松处理。 一、…...

vllm命令行启动方式并发性能实测
设备V100双卡,测试模型qwen2.5-7b,并发度为100。 表现如下: 单卡959.48token/s 双卡 使用 --pipeline-parallel-size 2 939.78token/s双卡 使用 --tensor-parallel-size 21084.82token/s双卡,两张卡分别跑一个接口,形成两个接口…...

医疗AI存在 9 类系统性漏洞
医疗AI存在9类系统性漏洞 理解1. 从整体目的入手2. 关键术语:什么是“红队测试”(Red Teaming)?3. 红队测试的对象:LLM(大模型)4. 红队测试的切入点:为什么要让“临床专家”来做?5. 什么叫做“脆…...
)
怎么有效管理项目路径(避免使用绝对路径)
怎么有效管理项目路径(避免使用绝对路径) import os 使用 os.path 方法会自动处理不同操作系统的路径分隔符(如 \ 和 /) 1.**current_dir os.path.dirname(os.path.abspath(\__file__)) ** __file__ 获取当前脚本的文件路径&…...

MySQL的行级锁锁的到底是什么?
大家好,我是锋哥。今天分享关于【MySQL的行级锁锁的到底是什么?】面试题。希望对大家有帮助; MySQL的行级锁锁的到底是什么? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 MySQL的行级锁是数据库管理系统(DBMS)的一…...

多账号管理、反追踪与自动化测试:我的浏览器实战笔记
作为一名在自动化测试和数据采集方面“踩坑”无数的开发者,我想聊聊自己在浏览器工具选择上的一些经验,也许能帮到同样在“账号风控”“浏览器指纹”“隐私追踪”这些问题上挣扎的朋友们。 一、从最初的Chrome开始:万能但不够隐蔽 起初做Se…...

如何应对客户在验收后提出新需求?
应对客户在验收后提出新需求的方法包括:明确新需求的范围与影响、与客户积极沟通、进行影响评估、合理协商费用与时间调整。其中,明确新需求的范围与影响最为关键。明确新需求的范围意味着迅速界定新需求的边界,分析它对现有项目进度、成本和…...

Android Studio根目录下创建多个可运行的模块
右键选中根目录,选择New -> Module 接着选中Phone & Tablet, 填写项目名和包名 选择一个模板,选择Next 然后可以看到app对应一开始创建的app模块,刚创建的customcomponent对应的,这样就可以在一个根目录下有多个可以安装运…...

【Linux】Linux环境基础开发工具
前言 本篇博客我们来了解Linux环境下一些基础开发工具 💓 个人主页:zkf& ⏩ 文章专栏:Linux 若有问题 评论区见📝 🎉欢迎大家点赞👍收藏⭐文章 目录 1.Linux 软件包管理器 yum 2.Linux开发工具 2.1…...

五子棋html
<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8" /> <meta name"viewport" content"widthdevice-width, initial-scale1" /> <title>五子棋游戏</title> <style>bo…...

分布式-基于数据库排他锁
原理: 除了可以通过增删操作数据表中的记录以外,其实还可以借助数据库中自带的锁来实现分布式的锁。 我们还用刚刚创建的那张数据库表。可以通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引 擎,可以使用以下方法来实现加锁操作&…...

docker host模式问题
为什么乌班图得docker 我装什么都必须要host 而-p映射不管用 在 Ubuntu 上使用 Docker 时,如果你发现只有 --network host 模式能正常工作,而端口映射(-p)不管用,可能有以下几种原因: 1. Docker 网络模式…...

分布式-Redis分布式锁
Redis实现分布式锁优点 (1)Redis有很高的性能; (2)Redis命令对此支持较好,实现起来比较方便 实现思路 (1)获取锁的时候,使用setnx加锁,并使用expire命令为锁…...

【Python爬虫电商数据采集+数据分析】采集电商平台数据信息,并做可视化演示
前言 随着电商平台的兴起,越来越多的人开始在网上购物。而对于电商平台来说,商品信息、价格、评论等数据是非常重要的。因此,抓取电商平台的商品信息、价格、评论等数据成为了一项非常有价值的工作。本文将介绍如何使用Python编写爬虫程序&a…...

大数据应用开发和项目实战-电商双11美妆数据分析2
数据可视化 使用seaborn库绘制复杂图表,展示各品牌和品类的销售情况。 绘制嵌套柱形图,分别按主类别和子类别进行对比。 通过饼图展示男士专用产品的销售偏好,发现男士主要关注清洁和补水类产品。 用seaborn包给出每个店铺各个大类以及各个…...

GSENSE2020BSI sCMOS科学级相机主要参数及应用场景
GSENSE2020BSI sCMOS科学级相机是一款面向宽光谱成像需求的高性能科学成像设备,结合了背照式(Back-Side Illuminated, BSI)CMOS技术与先进信号处理算法,适用于天文观测、生物医学成像、工业检测等领域。以下是其核心特点及技术细节…...

基于深度学习的交通标志识别系统
基于深度学习的交通标志识别系统 项目简介 本项目实现了一个基于深度学习的交通标志识别系统,使用卷积神经网络(CNN)对交通标志图像进行分类识别。系统包含数据预处理、模型训练与评估、结果可视化和用户交互界面等模块。 数据集 项目使用德国交通标志识别基准数…...

Golang的linux运行环境的安装与配置
很多新手在学go时,linux下的配置环境一头雾水,总结下,可供参考! --------------------------------------Golang的运行环境的安装与配置-------------------------------------- 将压缩包放在/home/tools/下 解压 tar -zxvf g…...
)
时间序列数据集增强构造方案(时空网络建模)
时间序列数据集增强构造方案(时空网络建模) 时间序列数据集TimeSeriesDataset 时间序列数据集增强EnhancedTimeSeriesDataset 一、方案背景与动机 1.1 背景分析 传统时间序列预测方法(如ARIMA、Prophet等)以及很多深度学习方法…...

实验六 基于Python的数字图像压缩算法
一、实验目的 掌握图像压缩的必要性; 掌握常见的图像压缩标准; 掌握常见的图像压缩方法分类; 掌握常见的图像压缩方法原理与实现(包括哈夫曼编码、算术编码、行程编码方法等); 了解我国音视…...

Vue 3 中的 nextTick 使用详解与实战案例
Vue 3 中的 nextTick 使用详解与实战案例 在 Vue 3 的日常开发中,我们经常需要在数据变化后等待 DOM 更新完成再执行某些操作。此时,nextTick 就成了一个不可或缺的工具。本文将介绍 nextTick 的基本用法,并通过三个实战案例,展示…...

Docker + Watchtower 实现容器自动更新:高效运维的终极方案
文章目录 前言一、Watchtower 简介二、Watchtower 安装与基本使用1. 快速安装 Watchtower2. 监控特定容器 三、Watchtower 高级配置1. 设置检查间隔2. 配置更新策略3. 清理旧镜像4. 通知设置 四、生产环境最佳实践1. 使用标签控制更新2. 更新前执行健康检查3. 结合CI/CD流水线 …...
的一个类cv::bgsegm::BackgroundSubtractorGSOC)
OpenCV 中用于背景分割(背景建模)的一个类cv::bgsegm::BackgroundSubtractorGSOC
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::bgsegm::BackgroundSubtractorGSOC 是 OpenCV 中用于背景分割(背景建模)的一个类,它是基于 GMMÿ…...

AI恶魔之眼使用说明书
AI恶魔之眼使用说明书 产品简介 1.1 产品介绍 AI恶魔之眼是一款具备动态视觉效果与仿生眼睛模拟功能的智能显示产品,可实现以下特性: 真实人眼模拟:支持虹膜样式变换、眨眼动画、瞳孔缩放等动态特效,仿真度高自定义内容上传&am…...

PBR材质-Unity/Blender/UE
目录 前言: 一、Unity: 二、Blender: 三、UE: 四、全家福: 五、后记: 前言: PBR流程作为表达物理效果的经典方式,很值得一学。纹理贴图使用的是上一期的Textures | cgbookcas…...

C++复习
线程库(类) 在C11之前,涉及到多线程问题,都是和平台相关的,比如Windows和Linux下各有自己的接口,这使得代码的可移植性比较差。C11中最重要的特性就是对线程进行了支持,使得C在并行编程时不需要依赖第三方…...

如何使用docker配置ros-noetic环境并使用rviz,gazebo
参考链接:【Ubuntu】Docker中配置ROS并可视化Rviz及Gazebo_docker ros-CSDN博客 前言: 其实这个东西是相当必要的,因为我们有时候需要在一台电脑上跑好几个项目,每个项目都有不同的依赖,这些依赖冲突搞得人头皮发麻&…...

计算机网络中相比于RIP,路由器动态路由协议OSPF有什么优势?
好的!以下是关于路由信息协议(RIP,Routing Information Protocol)的技术原理详解,以及其与OSPF(Open Shortest Path First)的对比分析。内容分为技术原理、对比优势和不足两部分。 一、RIP技术原理深度解析 1. 基本概念 协议类型:RIP属于距离向量路由协议(Distance-V…...

相似命令对比
awk 命令用法表格 场景命令示例说明示例输入文件内容 (input.txt)输出结果1. 基础字段提取awk -F: {print $1} /etc/passwd按分隔符提取第1列(如用户名)。root:x:0:0:root:/root:/bin/bashroot2. 多字段组合输出awk -F: {print $1, $3, $7} /etc/passwd…...

Vuerouter 的底层实现原理
文章目录 前言🧩 Vue Router 底层实现核心原理🧠 执行流程图(简化版)🔍 核心模块源码原理(简要)① 路由注册与匹配(createRouterMatcher)② 历史模式管理器(c…...
)
按拼音首字母进行排序组成新的数组(vue)
数据按首字母相同的组成新的数组,使用拼音(Pinyin)转换 比如想要的效果: 下载 npm install pinyin代码: import pinyin from "pinyin"; let studentAllList [{onLine: true,points: undefined…...

在IPv6头部中,Next Header字段
在IPv6头部中,Next Header字段 在IPv6头部中,Next Header字段是一个8位的字段,它的作用是指示下一个头部扩展的类型或者最终的传输层协议类型。这个字段的值决定了数据包中紧随IPv6头部之后的头部扩展的类型,或者是直接指向传输层…...

vue项目部署后部分子页面刷新后403
经过我的仔细分析;终于找到了是刷新后路径后面自动拼接了 / ;如 66.66.66.66/aPage 刷新后变成了 66.66.66.66/aPage/ 导致403 方法一: 修改路由为hash模式 // router/index.jsimport { createRouter, createWebHistory, createWebHashHist…...

C# NX二次开发:曲线和点位相关UFUN函数详解
大家好,今天要介绍查询曲线上点位和返回沿着曲线偏移一定距离的UFUN函数。 (1)UF_MODL_ask_curve_points:这个函数的定义为按照给定条件查询曲线上的点位。 Defined in: uf_modl_curves.h Overview Returns an array of 3D …...

服务器数据恢复—硬盘坏道导致EqualLogic存储不可用的数据恢复
服务器存储数据恢复环境&故障: 一台EqualLogic某型号存储中有一组由16块SAS硬盘组建的RAID5阵列。上层采用VMFS文件系统,存放虚拟机文件,上层一共分了4个卷。 磁盘故障导致存储不可用,且设备已经过保。 服务器存储数据恢复过程…...

【2019 CWE/SANS 25 大编程错误清单】12越界写入
案例1: void tonly_aw21036_led_drv_pwm_init(tonly_gpio_pin_t gpio_pin, uint8_t pwm) {uint8_t pin gpio_pin - AW21036_GPIO_PIN_START;if (pin < AW21036_LED_MAX_CHANNEL){aw21036_ctx.pwm[pin] pwm; /* 有效通道号: 0-35 */}else{TONLY_LED_LOG_E(&qu…...

redis bitmap数据类型调研
一、bitmap是什么? redis原文: Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type . This means that bitmaps can be used with string commands, and most importantly with SET and GET. 翻…...