Linux:认识基础IO
1.理解"⽂件"
1.1狭义理解
- ⽂件在磁盘⾥
- 磁盘是永久性存储介质,因此⽂件在磁盘上的存储是永久性的
- 磁盘是外设(即是输出设备也是输⼊设备)
- 磁盘上的⽂件 本质是对⽂件的所有操作,都是对外设的输⼊和输出 简称 IO
1.2广义理解
Linux 下⼀切皆⽂件(键盘、显⽰器、⽹卡、磁盘…… 这些都是抽象化的过程)
1.3⽂件操作的归类认知
- 对于 0KB 的空⽂件是占⽤磁盘空间的
- ⽂件是⽂件属性(元数据)和⽂件内容的集合(⽂件 = 属性(元数据)+ 内容)
- 所有的⽂件操作本质是⽂件内容操作和⽂件属性操作
1.4系统角度
- 对⽂件的操作本质是进程对⽂件的操作
- 磁盘的管理者是操作系统
- ⽂件的读写本质不是通过 C 语⾔ / C++ 的库函数来操作的(这些库函数只是为⽤⼾提供⽅便),⽽是通过⽂件相关的系统调⽤接⼝来实现的
2.C文件接口
fopen():打开文件
#include <stdio.h>//FILE *fopen(const char *path, const char *mode);
int main()
{FILE* fp = fopen("myfile", "w");if (!fp) {printf("fopen error!\n");}while (1);fclose(fp);return 0;
}
path:文件路径。mode:打开模式(见下表)。- 成功:返回
FILE*流指针。- 失败:返回
NULL,并设置errno。
文件打开模式
| 模式 | 说明 | 文件不存在时 | 文件存在时 |
|---|---|---|---|
"r" | 只读 | 失败 | 打开 |
"w" | 只写(清空文件) | 创建 | 清空 |
"a" | 追加(写入文件末尾) | 创建 | 保留内容,追加 |
"r+" | 读写(从文件头开始) | 失败 | 打开 |
"w+" | 读写(清空文件) | 创建 | 清空 |
"a+" | 读写(追加到文件末尾) | 创建 | 保留内容,可读写 |
fwrite():写入文件
#include <stdio.h>
#include <string.h>//size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
int main()
{FILE* fp = fopen("myfile", "w");if (!fp) {printf("fopen error!\n");}const char* msg = "hello bit!\n";int count = 5;while (count--) {fwrite(msg, strlen(msg), 1, fp);//fwrite(msg, 1, strlen(msg), fp);}fclose(fp);return 0;
}
ptr:要写入的数据指针。size:每个数据项的字节数(如sizeof(int))。nmemb:要写入的数据项数量。stream:FILE*流。- 成功:返回实际写入的数据项数量(可能小于
nmemb)。- 失败:返回
0或EOF(需检查ferror(fp))
差异
| 写法 | 参数解释 | 返回值意义 |
|---|---|---|
fwrite(msg, strlen(msg), 1, fp) | 将 msg 视为 1 个数据块,每个块大小为 strlen(msg) 字节 | 成功时返回 1(写入 1 个块) |
fwrite(msg, 1, strlen(msg), fp) | 将 msg 视为 strlen(msg) 个数据项,每个项大小为 1 字节(即逐字节) | 成功时返回 strlen(msg) |
区别
| 特性 | fwrite(msg, strlen(msg), 1, fp) | fwrite(msg, 1, strlen(msg), fp) |
|---|---|---|
| 写入粒度 | 整个字符串作为 1 个块 | 逐字节写入 |
| 返回值 | 1(成功)或 0(失败) | 实际写入的字节数(可能部分成功) |
| 错误处理 | 全或无(要么全部成功,要么完全失败) | 可检测部分写入 |
| 适用场景 | 必须完整写入的敏感数据(如配置文件) | 流式数据或允许部分写入(如日志、网络) |
fread():读取文件
#include <stdio.h>
#include <string.h>//size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
int main()
{FILE* fp = fopen("myfile", "r");if (!fp) {printf("fopen error!\n");return 1;}char buf[1024];const char* msg = "hello bit!\n";while (1) {//注意返回值和参数ssize_t s = fread(buf, 1, strlen(msg), fp);if (s > 0) {buf[s] = 0;printf("%s", buf);}if (feof(fp)) {break;}}fclose(fp);return 0;
}
ptr:存储读取数据的缓冲区。size:每个数据项的字节数。nmemb:要读取的数据项数量。stream:FILE*流。- 成功:返回实际读取的数据项数量(可能小于
nmemb)。- EOF:返回
0(需用feof(fp)检查是否到达文件末尾)。- 失败:返回
0或EOF(检查ferror(fp))。
stdin & stdout & stderr
- C默认会打开三个输⼊输出流,分别是stdin, stdout, stderr
- 仔细观察发现,这三个流的类型都是FILE*, fopen返回值类型,⽂件指针
#include <stdio.h>
extern FILE *stdin;
extern FILE *stdout;
extern FILE *stderr;3.系统⽂件I/O
3.1⼀种传递标志位的⽅法
#include <stdio.h>
#define ONE 0001 //0000 0001
#define TWO 0002 //0000 0010
#define THREE 0004 //0000 0100
void func(int flags) {if (flags & ONE) printf("flags has ONE! ");if (flags & TWO) printf("flags has TWO! ");if (flags & THREE) printf("flags has THREE! ");printf("\n");
}
int main() {func(ONE);func(THREE);func(ONE | TWO);func(ONE | THREE | TWO);return 0;
}3.2系统接口
open():打开文件
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>//int open(const char *pathname, int flags, mode_t mode);int fd = open("data.txt", O_RDWR | O_CREAT, 0644); // 读写模式,不存在则创建
if (fd == -1) {perror("open failed");exit(1);
}
pathname:文件路径(如"./test.txt")。flags:打开方式(见下表)。mode(可选):文件权限(仅在O_CREAT时有效,如0644)。- 成功:返回文件描述符。
- 失败:返回
-1,并设置errno。
| 标志 | 说明 |
|---|---|
O_RDONLY | 只读 |
O_WRONLY | 只写 |
O_RDWR | 读写 |
O_CREAT | 文件不存在时创建(需指定 mode) |
O_TRUNC | 若文件存在,清空内容 |
O_APPEND | 追加写入(避免并发写入冲突) |
read():读取文件
#include <unistd.h>
//ssize_t read(int fd, void *buf, size_t count);char buf[1024];
ssize_t bytes_read = read(fd, buf, sizeof(buf));
if (bytes_read == -1) {perror("read failed");
} else if (bytes_read == 0) {printf("EOF reached\n");
} else {printf("Read %zd bytes: %.*s\n", bytes_read, (int)bytes_read, buf);
}
fd:文件描述符(由open()返回)。buf:存储读取数据的缓冲区。count:要读取的最大字节数。- 成功:返回实际读取的字节数(可能小于
count)。- 文件结束(EOF):返回
0。- 失败:返回
-1,并设置errno。
write():写入文件
#include <unistd.h>//ssize_t write(int fd, const void *buf, size_t count);const char *msg = "Hello, world!\n";
ssize_t bytes_written = write(fd, msg, strlen(msg));
if (bytes_written == -1) {perror("write failed");
} else if (bytes_written < strlen(msg)) {printf("Partial write: %zd/%zu bytes\n", bytes_written, strlen(msg));
}
fd:文件描述符。buf:要写入的数据指针。count:要写入的字节数。- 成功:返回实际写入的字节数(可能小于
count)。- 失败:返回
-1,并设置errno。
关键注意事项
(1) 文件描述符 vs FILE*
open()返回int文件描述符,需用read()/write()操作。fopen()返回FILE*,需用fread()/fwrite()操作。- 不要混用:例如用
write()写入fopen()打开的文件。
(2) 缓冲区别
write():无缓冲,数据直接进入内核缓冲区(但不一定立即落盘)。fwrite():带缓冲,数据先存到stdio缓冲区,满后才调用write()。
3.3先来认识⼀下两个概念: 系统调⽤ 和 库函数
- 上⾯的 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数(libc)。
- ⽽ open close read write lseek 都属于系统提供的接⼝,称之为系统调⽤接⼝。
3.4⽂件描述符fd
通过对open函数的学习,我们知道了⽂件描述符就是⼀个⼩整数
3.4.1 0 & 1 & 2
- Linux进程默认情况下会有3个缺省打开的⽂件描述符,分别是标准输⼊0, 标准输出1, 标准错误2.
- 0,1,2对应的物理设备⼀般是:键盘,显⽰器,显⽰器
所以输⼊输出还可以采⽤如下⽅式:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>
int main()
{char buf[1024];ssize_t s = read(0, buf, sizeof(buf));if (s > 0) {buf[s] = 0;write(1, buf, strlen(buf));write(2, buf, strlen(buf));}return 0;
}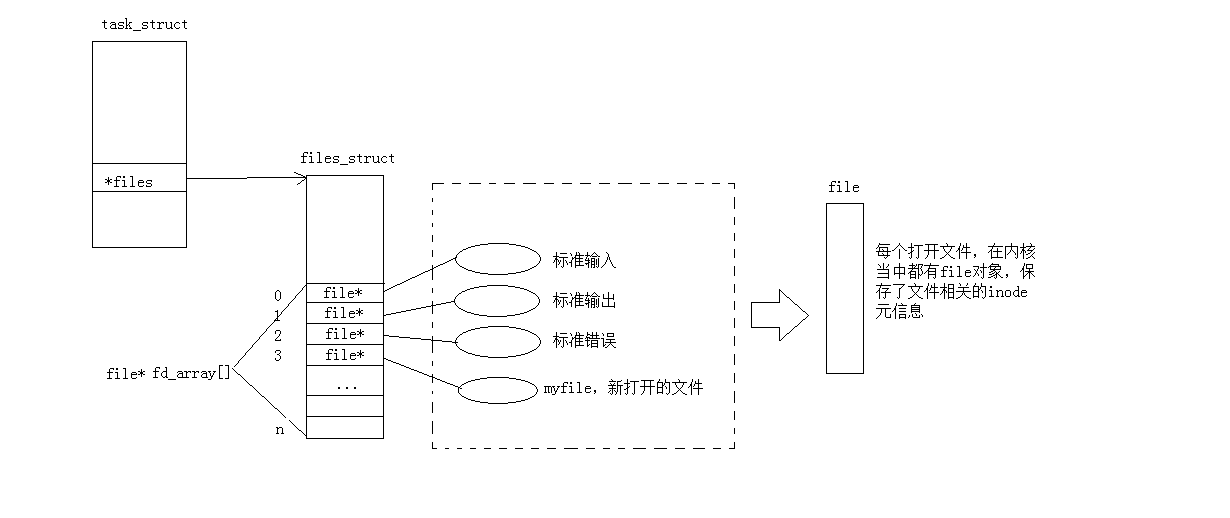
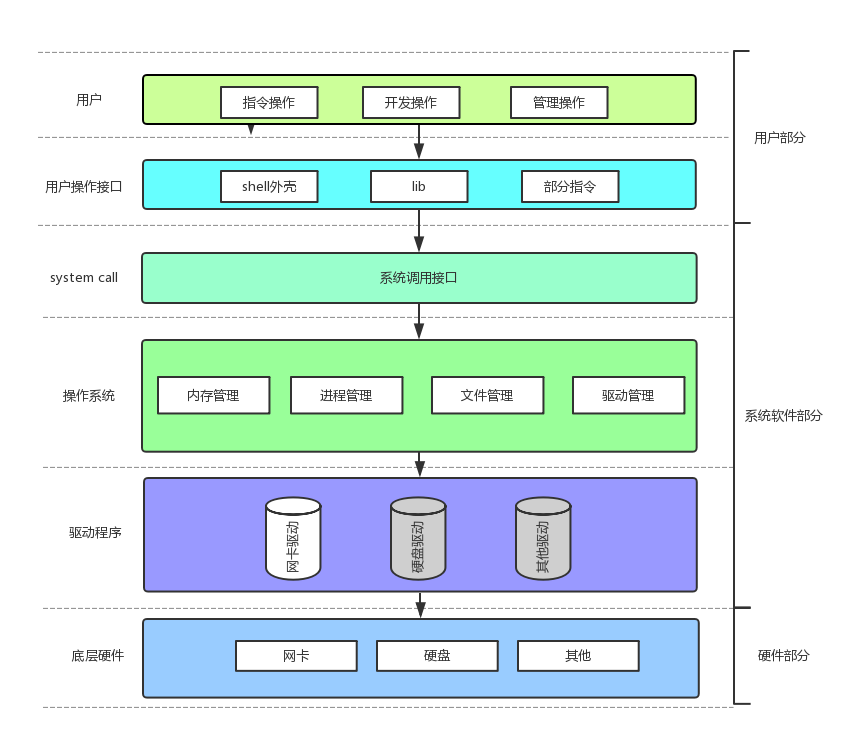
现在知道,⽂件描述符就是从0开始的⼩整数。当我们打开⽂件时,操作系统在内存中要创建相应的数据结构来描述⽬标⽂件。于是就有了file结构体。表⽰⼀个已经打开的⽂件对象。⽽进程执⾏open系统调⽤,所以必须让进程和⽂件关联起来。每个进程都有⼀个指针*files, 指向⼀张表files_struct,该表最重要的部分就是包含⼀个指针数组,每个元素都是⼀个指向打开⽂件的指针!所以,本质上,⽂件描述符就是该数组的下标。所以,只要拿着⽂件描述符,就可以找到对应的⽂件。
3.4.2文件描述符的分配规则
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{int fd = open("myfile", O_RDONLY);if (fd < 0) {perror("open");return 1;}printf("fd: %d\n", fd);close(fd);return 0;
}输出发现是 fd: 3
关闭0或者2,在看
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{close(0);//close(2);int fd = open("myfile", O_RDONLY);if (fd < 0) {perror("open");return 1;}printf("fd: %d\n", fd);close(fd);return 0;
}发现是结果是: fd: 0 或者 fd 2 ,可⻅,⽂件描述符的分配规则:在files_struct数组当中,找到当前没有被使⽤的最⼩的⼀个下标,作为新的⽂件描述符。
3.4.3重定向
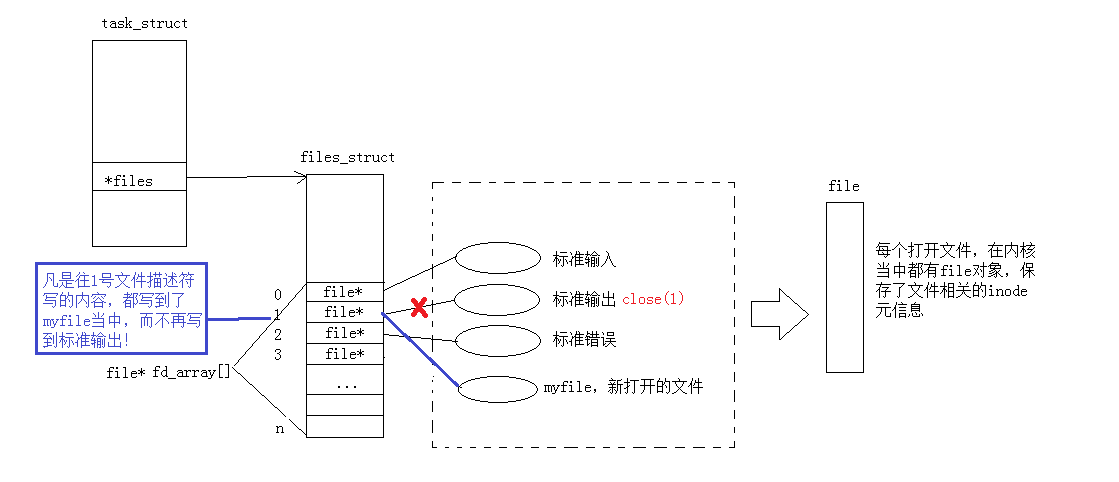
那如果关闭1呢?看代码:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{close(1);int fd = open("myfile", O_WRONLY | O_CREAT, 00644);if (fd < 0) {perror("open");return 1;}printf("fd: %d\n", fd);fflush(stdout);close(fd);exit(0);
} 3.4.4使⽤ dup2 系统调⽤
3.4.4使⽤ dup2 系统调⽤
函数原型
#include <unistd.h>
int dup2(int oldfd, int newfd);示例
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main() {int fd = open("./log", O_CREAT | O_RDWR);if (fd < 0) {perror("open");return 1;}close(1);dup2(fd, 1);for (;;) {char buf[1024] = { 0 };ssize_t read_size = read(0, buf, sizeof(buf) - 1);if (read_size < 0) {perror("read");break;}printf("%s", buf);fflush(stdout);}return 0;
}printf是C库当中的IO函数,⼀般往 stdout 中输出,但是stdout底层访问⽂件的时候,找的还是fd:1, 但此时,fd:1下标所表⽰内容,已经变成了myfifile的地址,不再是显⽰器⽂件的地址,所以,输出的任何消息都会往⽂件中写⼊,进⽽完成输出重定向。
4.缓冲区
4.1什么是缓冲区
4.2为什么要引⼊缓冲区机制
读写⽂件时,如果不会开辟对⽂件操作的缓冲区,直接通过系统调⽤对磁盘进⾏操作(读、写等),那么每次对⽂件进⾏⼀次读写操作时,都需要使⽤读写系统调⽤来处理此操作,即需要执⾏⼀次系统调⽤,执⾏⼀次系统调⽤将涉及到CPU状态的切换,即从⽤⼾空间切换到内核空间,实现进程上下⽂的切换,这将损耗⼀定的CPU时间,频繁的磁盘访问对程序的执⾏效率造成很⼤的影响。
为了减少使⽤系统调⽤的次数,提⾼效率,我们就可以采⽤缓冲机制。⽐如我们从磁盘⾥取信息,可以在磁盘⽂件进⾏操作时,可以⼀次从⽂件中读出⼤量的数据到缓冲区中,以后对这部分的访问就不需要再使⽤系统调⽤了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作⼤ 快于对磁盘的操作,故应⽤缓冲区可⼤ 提⾼计算机的运⾏速度。
4.3缓冲类型
标准I/O提供了3种类型的缓冲区
- 全缓冲区:这种缓冲⽅式要求填满整个缓冲区后才进⾏I/O系统调⽤操作。对于磁盘⽂件的操作通常使⽤全缓冲的⽅式访问。
- ⾏缓冲区:在⾏缓冲情况下,当在输⼊和输出中遇到换⾏符时,标准I/O库函数将会执⾏系统调⽤操作。当所操作的流涉及⼀个终端时(例如标准输⼊和标准输出),使⽤⾏缓冲⽅式。因为标准I/O库每⾏的缓冲区⻓度是固定的,所以只要填满了缓冲区,即使还没有遇到换⾏符,也会执⾏I/O系统调⽤操作,默认⾏缓冲区的⼤⼩为1024。
- ⽆缓冲区:⽆缓冲区是指标准I/O库不对字符进⾏缓存,直接调⽤系统调⽤。
- 缓冲区满时;
- 执⾏flush语句;
4.4FILE
#include <stdio.h>
#include <string.h>
int main()
{const char* msg0 = "hello printf\n";const char* msg1 = "hello fwrite\n";const char* msg2 = "hello write\n";printf("%s", msg0);fwrite(msg1, strlen(msg0), 1, stdout);write(1, msg2, strlen(msg2));fork();return 0;
}hello printf
hello fwrite
hello writehello write
hello printf
hello fwrite
hello printf
hello fwrite- ⼀般C库函数写⼊⽂件时是全缓冲的,⽽写⼊显⽰器是⾏缓冲。
- printf fwrite 库函数+会⾃带缓冲区,当发⽣重定向到普通⽂件时,数据的缓冲⽅式由⾏缓冲变成了全缓冲。
- ⽽我们放在缓冲区中的数据,就不会被⽴即刷新,甚⾄fork之后
- 但是进程退出之后,会统⼀刷新,写⼊⽂件当中。
- 但是fork的时候,⽗⼦数据会发⽣写时拷⻉,所以当你⽗进程准备刷新的时候,⼦进程也就有了同样的⼀份数据,随即产⽣两份数据。
- write 没有变化,说明没有所谓的缓冲。
相关文章:

Linux:认识基础IO
1.理解"⽂件" 1.1狭义理解 ⽂件在磁盘⾥ 磁盘是永久性存储介质,因此⽂件在磁盘上的存储是永久性的 磁盘是外设(即是输出设备也是输⼊设备) 磁盘上的⽂件 本质是对⽂件的所有操作,都是对外设的输⼊和输出 简称 IO 1.2广…...

SimpleMindMap:一个支持AI的思维导图软件
SimpleMindMap(思绪思维导图)是一款开源、跨平台且功能丰富的思维导图工具,支持 Web 端及多平台客户端(Windows、macOS、Linux)。 SimpleMindMap 提供的主要功能如下: 插件化设计,除了核心功能…...

数据库故障排查指南:MySQL 解决常见问题解决
数据库是现代 IT 系统的核心引擎,承载着企业最重要的数据资产。数据库的稳定、高效运行直接关系到业务的生死存亡。然而,由于软硬件、配置、应用访问等多种因素的影响,数据库故障难以完全避免。当故障发生时,能够迅速定位、分析并解决问题,同时确保数据安全不受影响,是每…...
)
2025年特种作业操作证考试题库及答案(登高架设作业)
一、单选题 202.带电跨越架羊角撑杆高度( )m。 A.1 B.1.1 C.1.2 答案:B 203.跨越架拉线地锚埋深必须按( )及架体设计要求进行。 A.现场情况决定 B.土质情况 C.地锚设计分坑图 答案:C 204.单排脚手架洞口处&#…...

Open CASCADE学习|ApplicationFramework 框架使用指南
在现代 CAD(计算机辅助设计)应用开发中,构建一个高效、可扩展且用户友好的应用程序框架是至关重要的。Open CASCADE(简称 OCC)提供了一个功能强大的 ApplicationFramework(应用程序框架)&#x…...
)
hadoop中的序列化和反序列化(3)
3. Java的序列化 Java提供了内置的序列化机制,通过java.io.Serializable接口实现。 3.1 如何实现Java序列化 让类实现Serializable接口。 使用ObjectOutputStream进行序列化。 使用ObjectInputStream进行反序列化。 示例代码 序列化 java 复制 import jav…...

PostgreSQL给新用户授权select角色
✅ 切换到你的数据库并以超级用户登录(例如 postgres): admin#localhost: ~$ psql -U postgres -d lily✅ 创建登录的账号机密吗 lily> CREATE USER readonly_user WITH PASSWORD xxxxxxxxxxx; ✅ 确认你授予了这个表的读取权限…...
英文题库(1-10))
MySQL 8.0 OCP(1Z0-908)英文题库(1-10)
目录 第1题题目解析正确答案 第2题题目解析正确答案 第3题题目解析正确答案 第4题题目解析正确答案 第5题题目解析正确答案 第6题题目解析正确答案 第7题题目解析正确答案 第8题题目解析正确答案 第9题题目解析正确答案 第10题题目解析正确答案: 第1题 Your MySQL …...

南京市出台工作方案深化“智改数转网联”,物联网集成商从“困局”到“蓝海”!
为落实《江苏省深化制造业智能化改造数字化转型网络化联接三年行动计划(2025-2027年)》,南京市近日出台“工作方案”,部署五大行动17项重点任务,进一步深化全市制造业智能化改造、数字化转型、网络化联接(以…...

系统思考:教育焦虑恶性循环分析
今天和团队的小伙伴一起拆解了一个父母教育焦虑与报班行为之间的系统环路图,报班越多 ➡ 孩子自由时间越少 ➡ 情绪调节力下降 ➡ 学习效率更低 ➡ 成绩不理想 ➡ 家长更焦虑 ➡ 继续加码报班…… 一圈一圈,像是陷入了“焦虑的恶性循环”。 这也是我一直…...
完美解决C盘拓展卷是灰色的无法扩容的问题以及如何正确地在WINDOS上从一个盘扩容到C盘)
(已完结)完美解决C盘拓展卷是灰色的无法扩容的问题以及如何正确地在WINDOS上从一个盘扩容到C盘
众所周知,window系统在“计算机”管理中自带了一个磁盘管理系统 但是在使用过程中会出现各种各样无法扩容的毛病。 第一:首先排查,大多数人在扩容之前忽视了一点就是,我们现代的很多新机器都是默认开启BitLocker加密的ÿ…...
)
优选算法系列(8.多源BFS)
简介: 01 矩阵(medium): 题目链接:542. 01 矩阵 - 力扣(LeetCode) 算法: 对于求的最终结果,我们有两种方式: 第⼀种方式:从每⼀个 1 开始&#…...

迈向AI辅助数据分析代码生成的透明性与知识共享
李升伟 摘译 生成式人工智能(AI)及尤其大型语言模型(LLMs)正在改变我们进行数据科学研究的方式. 最显著的例子包括科学家使用该技术与科学数据交互, 回答数据分析问题, 生成数据分析代码以及(重新)撰写科研手稿. 然而遗憾的是&am…...

autojs和冰狐智能辅助该怎么选择?
最近打算做自动化脚本,在autojs和冰狐智能辅助中做选择,不知道该怎么选。没办法只能花费大量时间仔细研究了autojs和冰狐智能辅助,综合考虑功能需求、开发复杂度、编程经验及项目规模等因素。以下是两者的核心对比及选择建议,仅供…...

小数的二进制表示
相信很多人都知道整数的二进制表示方法,但是小数的二进制就不一定了。 想来简单说一下整数的,就是不断的除以2取余数, 大致这样 从下往上取,这里42的结果就是101010 而且每个整数都有他对应的二进制数,但是小数转二…...
2025最新(十))
信息系统项目管理师-软考高级(软考高项)2025最新(十)
个人笔记整理---仅供参考 第十章项目进度管理 10.1管理基础 10.2项目进度管理过程 10.3规划进度管理 10.4定义活动 选C 10.5排列活动顺序 10.6估算活动持续时间 10.7制订进度计划 制订进度计划4个步骤(背,案例可能会考!) 10.8控制…...

Linux内核初始化机制全解析:从pure_initcall到late_initcall
引言 Linux内核的启动过程是一个高度有序的初始化流程,涉及数百个模块和子系统的协同工作。为了确保依赖关系正确、硬件资源按需分配,内核通过一系列初始化宏(如pure_initcall、subsys_initcall、late_initcall等)将函数划分为不同的优先级,按严格顺序执行。本文将深入探…...

pcie协议复位
pcie协议复位共有4中情况;cold reset;warm reset;hot reset;function level reset; 分类: 依据spec 6.6: Conventional reset(传统复位):cold,…...

boost笔记: Cannot open include file: ‘boost/mpl/aux_/preprocessed/plain/.hpp‘
1. 问题描述 因为一下库定义了宏and,导致boost的文件包含and.hpp展开成&.hpp,所以出现以下错误 Cannot open include file: ‘boost/mpl/aux_/preprocessed/plain/&.hpp’ 2. 解决方案 在定义宏之前包含boost文件,但这种方案的缺点…...

Xilinx XCKU11P-2FFVA1156I 赛灵思 FPGA AMD Kintex UltraScale+
XCKU11P-2FFVA1156I 属于 AMD Kintex UltraScale™ FPGA 家族,采用 TSMC 20 nm FinFET 工艺,兼顾高性能与功耗效率,提供约 653 100 个逻辑单元、2 928 个 DSP 切片、21.1 Mb Block RAM 和 22.5 Mb UltraRAM,可广泛应用于网络加速、…...
)
hadoop中的序列化和反序列化(4)
4. Hadoop的序列化 Hadoop提供了自己的序列化机制,用于高效地处理分布式计算中的数据传输。Hadoop的序列化机制比Java的序列化更高效,更适合大规模数据处理。 4.1 Hadoop序列化的特点 高效:Hadoop的序列化格式紧凑,适合大规模数…...

实现引用计数线程安全的shared_ptr
c11引入了三个智能指针,用来自动管理内存,使用智能指针可以有效地减少内存泄漏。 其中,shared_ptr是共享智能指针,可以被多次拷贝,拷贝时其内部的引用计数1,被销毁时引用计数-1,如果引用计数为…...

今日行情明日机会——20250507
指数今天放量上涨,政策层面也释放出重大利好消息~ 上证缺口已补,大盘股表现总体较好 深证60分钟缺口依然未补,等待后续走势~ 2025年5月7日涨停股主要行业方向分析 一、核心主线方向 军工(政策催化地缘驱动) • 涨停…...

配置Hadoop集群-测试使用
(一)上传小文件 上传文件的时候,我们传一个大一点的(>128M),再传一个小一点的。对于大一点的文件,我们要去看看它是否会按128M为单位去拆分这个大文件,而拆分成大文件之后&#…...

MEGA3:分子进化遗传学分析和序列比对集成软件
李升伟 摘译 摘要 在分子进化和群体遗传学的理论基础稳固确立后,比较DNA和蛋白质序列分析在重建物种和多基因家族的进化历史、估计分子进化速率以及推断塑造基因和基因组进化的性质和程度方面发挥了核心作用。随着高通量测序技术和新颖的统计及计算方法的发展&…...

21. LangChain金融领域:合同审查与风险预警自动化
引言:当AI成为24小时不眠的法律顾问 2025年某商业银行的智能合同系统,将百万级合同审查时间从平均3周缩短至9分钟,风险条款识别准确率达98.7%。本文将基于LangChain的金融法律框架,详解如何构建合规、精准、可追溯的智能风控体系…...

7D-AI系列:模型微调之mlx-lm
大模型的出现,导致信息量太大,只有静心动手操作,才能得到真理。 文章目录 环境要求安装示例mlx-lm微调工具参数准备数据集下载模型微调模型合并模型验证结果验证微调前的模型验证微调后的模型 环境要求 macbook pro m系列芯片mlx环境已安装 …...
)
数据可视化:php+echarts实现数据可视化(包含echart安装引入)
一、实现效果 实现动态时间,多列柱状图,单列柱状图,普通表格,表格动画等效果 二、实现 1、动态时间显示 通过php获取当前时间 设置计时器来动态显示时间秒数 <!-- 时间动画 --> <script>// 动态更新时间中的秒数function updateTime() {const now = new D…...

《Python星球日记》 第47天:聚类与KMeans
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏:《Python星球日记》,限时特价订阅中ing 目录 一、聚类与…...
联网情况下部署)
linux(centos)联网情况下部署
nginx部署 1.linux(centos)联网情况下部署 1.下载nginx所需依赖 # 安装开发工具组(若未安装) sudo yum groupinstall "Development Tools"# 安装 OpenSSL 开发包 sudo yum install openssl-devel# 安装 PCRE 开发包 sudo yum install pcre-…...

Kubernetes生产级资源管理实战:从QoS策略到OOM防御体系
一、资源限制的本质:不是成本控制,而是稳定性保障 当集群中某个节点的内存耗尽时,Kubernetes会像冷酷的交通警察一样,根据Pod的"优先级证件"(QoS类别)决定哪些Pod需要被驱逐。这种机制直接关系到…...

gcc的使用
gcc 是 GNU Compiler Collection(GNU 编译器套件)的缩写,是 GNU 项目开发的编程语言编译器集合,支持多种编程语言(如 C、C、Objective-C、Fortran、Ada 等)。以下是关于 gcc 的核心信息: 1. 主要…...

聊一聊Qwen3思考模式实现以及背后原理探讨
Qwen3思考模式切换实现 硬开关 我们先通过官方的示例代码来体验一下,如何实现在思考模式和非思考模式之间切换 通过tokenizer.apply_chat_template的enable_thinking参数来实现 默认情况下,Qwen3 启用了思考功能,类似于 QwQ-32B。这意味着…...

spark行动算子
在 Apache Spark 中,行动算子(Action)用于触发对 RDD 的实际计算,并将结果返回给驱动程序(Driver)或保存到外部存储系统中。与转换算子(Transformation)不同,行动算子会立…...
)
电商双十一美妆数据分析(代码)
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import jieba # 数据读取 df pd.read_csv(双十一_淘宝美妆数据.csv) # 数据清洗 # 处理重复值 data df.drop_duplicates(inplaceFalse) data data.reset_index(in…...

STM32裸机开发问题汇总
一、代码编写 1. keil中某个文件无法修改 keil中某个文件无法修改,不能输入_keil5 h文件无法修改-CSDN博客 2.编译报错declaration may not appear after executable statement in block STM32常见错误error: #268: declaration may not appear after executabl…...

C语言复习笔记--自定义类型
今天我们来复习一下自定义类型.自定义类型大概分为结构体,枚举,联合体,数组这几种.数组在之前就介绍过.今天我们来看下其他三种. 结构体 首先来看结构体. 结构体类型的声明 之前在操作符的地方简单认识过结构体.下面我们回顾一下. 结构体回顾 结构是⼀些值的集合,这…...

做 iOS 调试时,我尝试了 5 款抓包工具
日常做开发的人,特别是和客户端接口打交道的同学,应该对“抓包”这件事不陌生。 调试登录流程、分析接口格式、排查错误返回、分析网络性能、甚至研究第三方 App 的数据通信……说到底,都绕不开“抓 HTTPS 包”这一步。 而这一步࿰…...
附源码)
html css js网页制作成品——HTML+CSS珠海网页设计网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

FID和IS的区别
📊 生成模型评估:你选 IS 还是 FID? 在评估 GAN、Diffusion 等图像生成模型时,两个最常被提到的指标是: 🔹IS (Inception Score) 🔹FID (Frchet Inception Distance) 🧠 Inception…...

前端三大件--HTML
引言 在互联网的世界里,每一个绚丽多彩的网页背后,都离不开 HTML 的支撑。HTML(Hyper Text Markup Language,超文本标记语言)作为网页开发的基础语言,就像是搭建高楼大厦的砖块,是所有 Web 开发…...

Node.js 的 child_process 模块详解
Node.js 的 child_process 模块提供了创建子进程的能力,使 Node.js 应用能够执行系统命令、运行其他程序或脚本。这个模块非常强大,可以帮助我们实现很多复杂的功能。 1. exec - 执行 shell 命令 exec 方法用于执行 shell 命令,并缓冲任何产生的输出。 特点 创建 shell 来…...
)
日常知识点之随手问题整理(虚函数 虚函数表 继承的使用场景)
新来的同事提到一个虚函数解耦头文件的问题,就想起来对虚函数进行一些回顾。 他的问题是,通过纯虚函数,如何实现不包含头文件即可真正调用到子类的实际接口。 》这里肯定是不合理的,需要一个中间管理类,对纯虚函数和相…...
)
【软件设计师:数据结构】2.数据结构基础(二)
一、树 树是n(n≥0)个结点的有限集合,n=0时称为空树,在任一非空树中 ● 有且仅有一个称为根的结点。 ● 其余的结点可分为m(m≥0)个互不相交的子集T1,T2…,Tm,其中每个子集本身又是一棵树,并称其为根结点的子树。 1、树的基本概念 ● 双亲和孩子 ● 兄弟:具有相同双…...
)
Python训练营打卡——DAY18(2025.5.7)
目录 一、基于聚类进一步推断类型 1. 聚类分析 2. 簇的总结与定义 二、作业 1. 聚类分析 2. 簇的总结与定义 3. 模型效果提升 一、基于聚类进一步推断类型 选用昨天kmeans得到的效果进行聚类,进而推断出每个簇的实际含义。 1. 聚类分析 # 先运行之前预处理…...

初学Python爬虫
文章目录 前言一、 爬虫的初识1.1 什么是爬虫1.2 爬虫的核心1.3 爬虫的用途1.4 爬虫分类1.5 爬虫带来的风险1.6. 反爬手段1.7 爬虫网络请求1.8 爬虫基本流程 二、urllib库初识2.1 http和https协议2.2 编码解码的使用2.3 urllib的基本使用2.4 一个类型六个方法2.5 下载网页数据2…...

【CSS】Grid 的 auto-fill 和 auto-fit 内容自适应
CSS Grid 的 auto-fill 和 auto-fit /* 父元素 */ .grid {display: grid;/* 定义「网格容器」里有多少列,以及每列的宽度 *//* repeat 是个「重复函数」,表示后面的模式会被重复多次 *//* auto-fit 是一个特殊值,自动根据容器宽度ÿ…...

绕线机的制作与研究
绕线机的制作与研究 摘要 本文详细阐述了绕线机的制作过程,涵盖从设计规划到实际制作的各个环节。通过对绕线机工作原理的深入分析,确定了关键技术参数,并依此完成机械结构与控制系统的设计。在制作阶段,运用多种加工工艺完成零件制造与设备组装。经测试,自制绕线机性能…...

引用的使用
引用的语法 作用:起别名 引用的本质是指针常量 数据类型 &别名原名; 引用必须要初始化 引用一旦初始化,不能修改 不能返回局部变量的引用 引用做形参 #include<iostream> #include<string> using namespace std; //通过引用…...

css animation 动画属性
animation // 要绑定的关键帧规则名称 animation-name: slidein;// 定义动画完成一个周期所需的时间,秒或毫秒 animation-duration: 3s;// 定义动画速度曲线 animation-timing-function: ease;// 定义动画开始前的延迟时间 animation-delay: 1s;// 定义动画播放次数…...